







 AlexNet是2012年由Hinton等人提出的深度学习模型,它在ImageNet数据集上取得优异表现,降低了图像识别错误率。模型包含5个卷积层和3个全连接层,使用ReLU激活函数、GPU加速训练、数据增强、Dropout等技术防止过拟合。论文证明了深度网络在大规模图像识别中的潜力。
AlexNet是2012年由Hinton等人提出的深度学习模型,它在ImageNet数据集上取得优异表现,降低了图像识别错误率。模型包含5个卷积层和3个全连接层,使用ReLU激活函数、GPU加速训练、数据增强、Dropout等技术防止过拟合。论文证明了深度网络在大规模图像识别中的潜力。
论文发表于2012年,由深度学习之父Hinton和他的学生发表。Alex Krizhevshy, Ilya Sutskever Geoffre E.Hinton。Hinton在深度学习领域的地位不用多说,神级别的人物,本人只能跪拜了。
摘要
论文训练一个非常大,深的卷积神经网络,针对120w的高分辨率图像(来自ImageNet LSVRC-2010)进行1000类进行识别。在测试集中,top1和top5的错误率分别达到了37.5%和17.0%,较之前的任何结果都要好。这个网络模型包括600w的参数和650,000个神经元,其中包括5个卷积层,某些卷积层紧跟着max-pooling层操作,3个全链接层紧跟着一个1000维的softmax输出。为了使得网络训练更快,论文采用了非饱和性质的神经元(应该是之非饱和性质的激活函数)和GPU执行卷积操作。为了减少过拟合, 本文利用了当时比较流行且有效的方法’drop-out’。最后论文页在ILSVRC-2012上进行了测试,达到了15.3%的top5的错误率,相较于第二名的26.2%有了很大的提升。
简介
论文在简介中重点介绍了几点:
- 2012年以前,数据集相对较小,从而作者收集了大量的数据集用来训练模型
- 对于小的数据集,当时的任务已经能够很好的解决了,例如MNIST数字识别数据集,识别错误了已经达到了0.3%,人类的识别水平。
- 由于物体识别的巨大复杂性,仅用ImageNet的数据是不够的,所以论文利用了很多先验知识作为补充;
- 论文指出了CNN的优点:很少的链接和参数使得其更容易训练
- 尽管CNN的优点很多,但是对于高分辨率的图像的计算代价很高,从而论文是采用GPU加速
- 受到GPU的显存限制,作者采用了2块GTX 580 3GB GPUs,并指出,随着GPU的速度越来越快,训练更大的数据集将变成可能, 作者当时就已经意识到GPU的发展将给深度学习带来很大的帮助
- 最后,重点介绍了一下论文的贡献:
- 论文训练了一个非常大的卷积神经网络,并在ImageNet ILSVRC-2010和ILSVRC-2012比赛中取得了当时最好的成绩
- 作者编写了GPU版本的2D卷积操作
- 论文采用了很多不常见的小技巧:ReLU, Multiple GPUs, Local Response Normalization, Overlapping Pooling, overall Architecture
- 采用了一些技巧防止过拟合(overfitting): Data Augmentation, Dropout
- 作者指出,即使每一层的卷机只占所有参数的不到1%,但去掉任何一层卷积网络,最终的预测效果都会导致性能的下降
数据集
ImageNet数据集,包含超过1500w的高分辨率图像,并且含有22000个类别标签。2010年选取了其中的1000类作为一个ImageNet Large-Scale Visual Recognition Challenge(ILSVC)比赛用。其中包含120w的训练数据,50,000张验证数据,150,000测试数据。
图像尺寸:论文在训练模型的时候,将图像固定到256x256大小。
- 首先给定一张图像,将图像的最小边缩放到256
- 然后在图像的中心位置裁剪出256x256大小的图像
颜色变换:减去整个数据集的均值
网络结构
这部分是本文的重点。
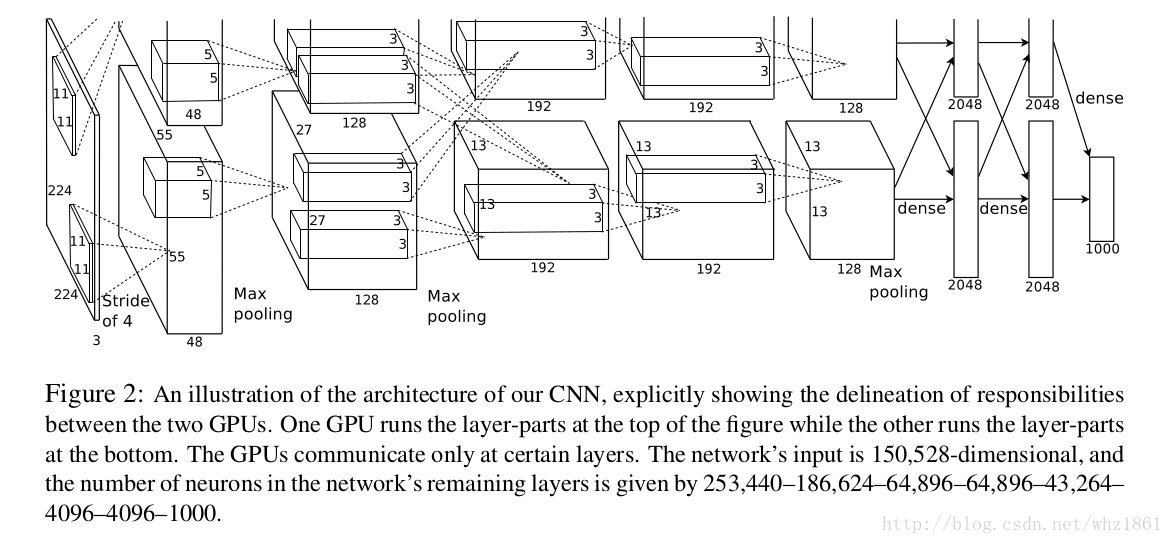
ReLU Nonlinearity
以前的标准做法都是采用sigmoid或者tanh非线性函数对网络输出进行非线性处理。
f(x)=11+e−xtanh(x)=ex−e−xex+
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 631
631

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









