







 本文提出了一种名为SEP-Nets的深度学习模型压缩方法,通过二值化kxk(k>1)卷积而不处理1x1卷积,以及引入Pattern Residual Block,减少了模型参数量。实验表明,在保持性能的同时,模型参数显著减少。
本文提出了一种名为SEP-Nets的深度学习模型压缩方法,通过二值化kxk(k>1)卷积而不处理1x1卷积,以及引入Pattern Residual Block,减少了模型参数量。实验表明,在保持性能的同时,模型参数显著减少。
Albeit there are already intensive studies on compressing the size of CNNs, the considerable drop of performance is still a key concern in many designs. This paper addresses this concern with several new contributions.
First, we propose a simple ye powerful method for compressing the size of deep CNNs based on parameter binarization. The striking difference from most previous work on parameter binarization/quantization lies at different treatments of 1x1 convolutions and kxk convolutions(K>1), where we only binarize k x k convolutions into binary patterns.
Second, in light of the different functionalities of 1x1 (data projection/transformation) and kxk convolutions(pattern extraction), we propose a new Blok structure codenamed the pattern residual block that adds transformed feature maps generated by kxk convolutions, based on which we design a small network with ~1 million parameters.
思想
深度学习有两个问题:
- 创新网络结构,不断提高网络的表达能力【关注模型的表达效果】
- 在相同表达能力的情况下,不断缩小模型大小【关注模型参数的多少】
本文关注的是第二个问题,怎么保证模型表达效果的前提下,不断缩小模型的参数量。在此基础上,作者也提出了一个新的网络结构。
目前模型压缩的方法有:
- quantization
- binarization
- sharing
- pruning
- hashing
- Huffman coding
论文考虑了减少模型参数的方法:
- binarizatin【二值化】:但论文只考虑kxk(k>1)的卷积核的二值化,对1x1卷积核不做处理
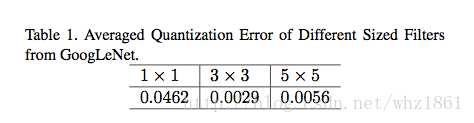
- 相对于3x3,5x5的卷积,1x1的卷积对网络结构的作用更加重要
- 作者提出了一种新的卷积模块,包含几层卷积操作和残差连接
模型结构
Pattern Binarization
- 说明:
- step 1: 正常训练一个卷积神经网络,比如GoogLeNet
- step 2: 将kxk(k>1)的卷积进行二值化
- step 3: 给二值化的kxk卷积增加一个尺度因子 α ,然后fine-tune这个尺度因子 α 和1x1的卷积【该1x1的卷积是float数据类型】 ,即,优化下面问题:
minα∈R,B∈{ 1
- 说明:

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 234
234

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









