







1、typedef和#define的区别
1、typedef:
typedef常用来定义一个标识符及关键字的别名,它是语言编译过程的一部分,但它并不实际分配内存空间。
可以增强程序的可读性,以及标识符的灵活性。
2、#define:
#define为宏定义语句,是预处理指令。通常用来定义常量(包括无参量与带参量)。它本身并不在编译过程中进行,而是在这之前(预处理过程)就已经完成了,但也因此难以发现潜在的错误及其它代码维护问题。
3、区别:
(1)typedef在编译阶段有效,由于是在编译阶段,因此typedef有类型检查的功能。#define则是宏定义,发生在预处理阶段,也就是编译之前,它只进行简单而机械的字符串替换,而不进行任何检查。
(2)宏定义只是简单的字符串代换(原地扩展),而typedef则不是原地扩展,它的新名字具有一定的封装性,以致于新命名的标识符具有更易定义变量的功能。在连续几个变量的声明中,用typedef定义的类型能保证声明中所有的变量均为同一种类型,而用#define定义的类型无法保证。如下所示:
typedef int* pINT;
#define pINT2 int*效果完全不同!
pINT a,b;的效果与int *a; int *b;相同,表示定义了两个整型指针变量。而pINT2 a,b;的效果与int *a, b;相同,表示定义了一个整型指针变量a和整型变量b。
因此,typedef可以用作同时声明指针型的多个对象,形式直观。
(3)作用域不同。#define没有作用域的限制,只要是之前预定义过的宏,在以后的程序中都可以使用。而typedef有自己的作用域。
Effective C++一书中有关于#define的分析:
(1)对于单纯常亮,最好以const对象或enums替换#define。
(2)对于形似函数的宏,最好改用inline函数替换#define。
2、数组和指针并不相同
1、定义和声明
(1)定义:只能出现在一个地方; 确定对象的类型并分配内存,用于创建新的对象。如:int my_array[100];
(2)声明:可以多次出现; 描述对象的类型,用于指代其他地方定义的对象。如:extern int my_array[];
C语言中的对象必须有且只有一个定义,但它可以有多个extern声明。
2、指针和数组是如何访问的
(1)对数组的访问:对内存直接的引用。每个符号的地址在编译时可知。所以,如果编译器需要一个地址(可能还需要加上偏移量)来执行某种操作,它就可以直接进行操作,并不需要增加指令首先取得具体的地址。
这也说明了为什么extern char a[]与extern char a[100]等价。这两个声明都指明 a 是一个数组,也就是一个内存地址。编译器并不知道数组有多长,因为它只产生偏离其实地址的偏移地址。从数组提取一个字符,只要简单地从符号表显示的 a 的地址加上下标,需要的字符就位于这个地址中。
(2)对指针的引用:对内存间接的引用。必须首先在运行时取得它的当前值,然后才能对它进行解除引用操作(作为以后进行查找的步骤之一)。
也就是说,如果声明 extern char *p,它告诉编译器 p 是一个指针,它指向的对象是一个字符。为了取得这个字符,必须得到地址 p 的内容,把它作为字符的地址并从这个地址中取得这个字符。指针的访问需要增加一次额外的提取。
3、当你“定义为指针,但以数组方式引用”时会发生什么
例如:
char *p="abcdefgh";
c=p[i];(本来针对数组)需要对内存进行直接的引用,但是编译器所执行的却是对内存进行间接引用(因为定义的是指针)。实质是指针和数组两种访问方式的组合,编译器执行的过程:
(1)取得符号表中p的地址,提取存储于此处的指针。
(2)把下标所表示的偏移量与指针的值(内容为字符串的地址)相加,产生一个地址。
(3)访问上面这个地址,取得字符。
3、段
就目标文件而言,段(segments)是二进制文件中简单的区域,里面保存了和某种特定类型(如符号表条目)相关的所有信息。一个段一般包含几个section。
一个可执行文件一般包含三个段:文本段、数据段、BSS段(由符号开始的块)。
(1)文本段是最容易受优化措施影响的段。
(2)BSS段只保存没有值的变量,所以事实上它并不需要保存这些变量的映像。运行时需要的BSS段的大小记录在目标文件中,但BSS段(不像其他段)并不占据目标文件的任何空间。
(3)数据段保存在目标文件中。
(4)a.out的大小受调试状态下编译的影响,但段不受影响。
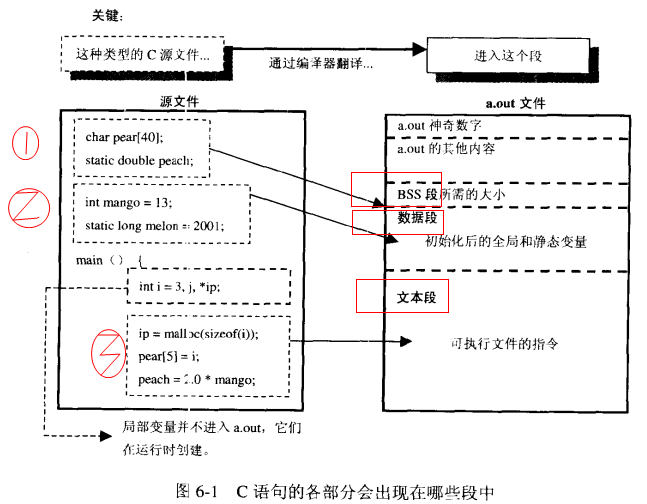
由上图可知:
(1)未初始化的全局和静态变量放在BSS段。BSS段的大小从可执行文件中得到,然后连接器得到这个大小的内存块,紧跟在数据段之后。
(2)数据段包含经过初始化的全局和静态变量以及它们的值;
(3)文本段包含程序的指令。局部变量不进入a.out,他们在运行时创建。
包含数据段和BSS段的整个区段通常统称为数据区。这是因为在操作系统的内存管理术语中,段就是一片连续的虚拟地址,所以相邻的段被结合。一般情况下,在任何进程中数据段是最大的段。
堆栈段用于保存局部变量、临时数据、传递到函数中的参数等。
运行时的数据结构包括:堆栈、活动记录、数据、堆等。
堆栈段有三个主要的用途,其中两个跟函数有关,另一个跟表达式计算有关:
(1)、为函数内部声明的局部变量提供存储空间。
(2)、进行函数调用时,堆栈存储与此有关的一些维护性信息。这些信息被称为堆栈结构,另外一个更常用的名字是过程活动记录。它包括函数调用地址(即当调用的函数结束后调回的地方)、任何不适合装入寄存器的参数以及一些寄存器值的保存。
(3)、堆栈也可以被用作暂时存储区。比如计算表达式,存储中间结果。
除了递归调用之外,堆栈并非必须。因为在编译时可以知道局部变量、参数和返回地址所需空间的固定大小,并可以将它们分配于BSS段。
在绝大多数处理器中,堆栈是向下增长的,也就是朝着低地址方向生长。
4、当函数被调用时发生了什么:过程活动记录
过程活动记录解决的问题:跟踪调用链,即哪些函数调用了哪些函数,当下一个return语句执行后,控制将返回何处等。
也就是说,过程活动记录可以告诉你函数被调用时发生了什么。
当每个函数被调用时,都会产生一个过程活动记录。过程活动记录是一种数据结构,用于支持过程调用,并记录调用结束以后返回调用点所需要的全部信息。
在X86架构中,运行时系统维护一个指针(常位于寄存器中),通常称为fp,用于提示活动堆栈结构。它的值是最靠近堆栈顶部的过程活动记录的地址。
下图表示出程序执行在不同点时堆栈中活动记录的情况:
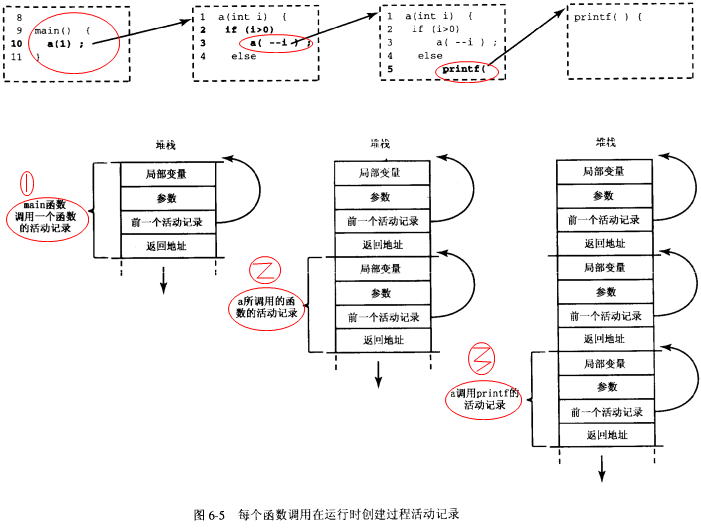
当控制从一个函数转到另一个函数时,堆栈的新状态显示在下面。程序从main函数开始执行,堆栈向下生长。
每次调用函数时,就会将一个项压入栈中。这个项称为栈帧(stack frame)或活动记录,它包含被调用函数返回到调用函数时所需的返回地址。如果被调函数返回,则会弹出这个函数调用的帧栈,且控制会转移到被弹出的帧栈所包含的返回地址。
调用栈的亮点在于每个被调函数都能够在调用栈的顶部找到返回到它的调用者时所需要的信息。而且,如果一个函数调用了另一个函数,则这个新函数的栈帧也会被简单地压入调用栈。因此,新的被调函数返回到它的调用者所需要的返回地址,就位于栈的顶部。
帧栈还有另外一个重要责任。大多数函数都有自动变量,包括参数及他说声明的所有局部变量。自动变量需要在函数执行时存在。如果函数调用了其他函数,则他们仍然需要保持活动状态。但是当被调函数返回到他的调用者后,它的自动变量需要“消失”。被调函数的帧栈是保存它的自动变量的理想场所。只要被调函数处于活动状态,它的帧栈就会存在。当函数返回时(此时不在需要它的局部自动变量),它的帧栈就从栈弹出,而这些局部变量不再为程序所知。
补充:
尽管通常说“将过程活动记录压倒堆栈中”,但过程活动记录并不一定要存在于堆栈中。事实上,尽可能地把过程活动记录的内容放到寄存器中会使函数调用的速度更快,效果更好。
不能从函数中返回一个指向该函数局部自动变量的指针。因为当进入该函数时,自动变量在堆栈中分配。当函数结束后,变量不复存在,它所占用的堆栈空间被收回,可能在任何时候被覆盖。如果想返回一个指向在函数内部定义的变量的指针时,要把那个变量声明为static。















 2801
2801

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









