







GRN(Graph Recurrent Network)
循环图神经网络
-
与GCN相比
-
GRN在不同层之间使用相同的参数,这使得参数能够逐步收敛
-
GCN在不同层之间使用不同的参数,从而能够提取不同尺度的特征
-
GGNN(Gated Graph Neural Network)
Paper : Gated graph sequence neural networks
门控图神经网络(使用了GRU)
a v t = A v T [ h 1 t − 1 . . . h N t − 1 ] T + b \bm{ a_v^t = A_v^T[h_1^{t-1}...h_N^{t-1}]^T + b } avt=AvT[h1t−1...hNt−1]T+b
z v t = σ ( W z a v t + U z h v t − 1 ) \bm{ z_v^t = σ(W^za_v^t + U^zh_v^{t-1}) } zvt=σ(Wzavt+Uzhvt−1)
r v t = σ ( W r a v t + U r h v t − 1 ) \bm{ r_v^t = σ(W^ra_v^t + U^rh_v^{t-1}) } rvt=σ(Wravt+Urhvt−1)
h ~ v t = t a n h ( W a v t + U ( r v t ⊙ h v t − 1 ) ) \bm{ \tilde{h}_v^t = tanh(Wa_v^t + U(r_v^t ⊙ h_v^{t-1})) } h~vt=tanh(Wavt+U(rvt⊙hvt−1))
h v t = ( 1 − z v t ) ⊙ h v t − 1 + z v t ⊙ h ~ v t \bm{ h_v^t = (1 - z_v^t) ⊙ h_v^{t-1} + z_v^t ⊙ \tilde{h}_v^t } hvt=(1−zvt)⊙hvt−1+zvt⊙h~vt
-
节点 v v v首先聚合其相邻节点的信息,其中 A v A_v Av是图邻接矩阵A的子矩阵,表示节点 v v v与相邻节点的连接情况。类似GRU的更新函数使用来自每个节点的领域信息以及上一个时间步的信息更新节点的隐状态。向量 a a a聚合节点 v v v的领域信息, z z z和 r r r分别是更新门和重置门, ⊙ ⊙ ⊙是阿达马积
-
在GGNN的基础上进一步提出了GGS-NN
-
使用多个GGNN来输出序列 o ( 1 ) . . . o ( K ) o^{(1)}...o^{(K)} o(1)...o(K)
-
在第K个输出步,节点特征矩阵记为X^{(k)}

-
上图架构使用了两个GGNN
-
F o ( k ) F_o^{(k)} Fo(k)用于从 X ( k ) X^{(k)} X(k)中预测 o ( k ) o^{(k)} o(k)
-
F x ( k ) F_x^{(k)} Fx(k)用于从 X ( k ) X^{(k)} X(k)中预测 X ( k + 1 ) X^{(k+1)} X(k+1)
-
-
我们使用 H ( k , t ) H^{(k, t)} H(k,t)表示第k输出步的第t轮传播的隐状态。在每个输出步中, H ( k , 1 ) H^{(k, 1)} H(k,1)都会用 X ( k ) X^{(k)} X(k)来初始化。 F o ( k ) F_o^{(k)} Fo(k)和 F x ( k ) F_x^{(k)} Fx(k)既可以是不同的模型,也可以共享权重参数
-
-
GGNN模型被用于bAbI(Towards AI-Complete Question Answering: A Set of Prerequisite Toy Tasks)任务,以及程序验证任务
Tree-LSTM
Tree-LSTM
-
Tree-LSTM分为两类
-
Child-Sum Tree-LSTM
-
N-ary Tree-LSTM
-
-
与标准LSTM单元一样,每个Tree-LSTM(由 v v v索引)都包含输入门 i v i_v iv、输出门 o v o_v ov、存储单元 c v c_v cv和隐状态 h v h_v hv。标准LSTM单元使用单个遗忘门,Tree-LSTM单元则具有多个遗忘门,对每个子节点 k k k使用遗忘门 f v k f_{vk} fvk,从而使节点 v v v能够聚合来自其子节点的信息。Child-Sum Tree-LSTM的传播公式如下:
h ~ v t − 1 = ∑ k ∈ N v h k t − 1 \bm{ \tilde{h}_v^{t-1} = \sum\limits_{k \in N_v}{h_k^{t-1}} } h~vt−1=k∈Nv∑hkt−1
i v t = σ ( W i x v t + U i h ~ v t − 1 + b i ) \bm{ i_v^t = σ(W^ix_v^t + U^i\tilde{h}_v^{t-1} + b^i) } ivt=σ(Wixvt+Uih~vt−1+bi)
f v k t = σ ( W f x v t + U f h ~ k t − 1 + b f ) \bm{ f_{vk}^t = σ(W^fx_v^t + U^f\tilde{h}_k^{t-1} + b^f) } fvkt=σ(Wfxvt+Ufh~kt−1+bf)
o v t = σ ( W o x v t + U o h ~ v t − 1 + b o ) \bm{ o_v^t = σ(W^ox_v^t + U^o\tilde{h}_v^{t-1} + b^o) } ovt=σ(Woxvt+Uoh~vt−1+bo)
u v t = t a n h ( W u x v t + U u h ~ v t − 1 + b u ) \bm{ u_v^t = tanh(W^ux_v^t + U^u\tilde{h}_v^{t-1} + b^u) } uvt=tanh(Wuxvt+Uuh~vt−1+bu)
c v t = i v t ⊙ u v t + ∑ k ∈ N v f v k t ⊙ c k t − 1 \bm{ c_v^t = i_v^t ⊙ u_v^t + \sum\limits_{k \in N_v}{f_{vk}^t ⊙ c_k^{t-1}} } cvt=ivt⊙uvt+k∈Nv∑fvkt⊙ckt−1
h
v
t
=
o
v
t
⊙
t
a
n
h
(
c
v
t
)
\bm{ h_v^t = o_v^t ⊙ tanh(c_v^t) }
hvt=ovt⊙tanh(cvt)
其中,
x
v
t
x_v^t
xvt是在标准的LSTM设置下t时间步的输入向量
- 如果树中每个节点的子节点数最多为K,并且这些子节点可以排序,则可以应用N-ary Tree-LSTM。对于节点 v v v, h v k t h_{vk}^t hvkt和 c v k t c_{vk}^t cvkt分别表示其在时间t的第k个子节点的隐状态和存储单元,转换方程如下:
i v t = σ ( W i x v t + ∑ l = 1 K U l i h v l t − 1 + b i ) \bm{ i_v^t = σ(W^ix_v^t + \sum\limits_{l=1}^K{U_l^ih_{vl}^{t-1}} + b^i) } ivt=σ(Wixvt+l=1∑KUlihvlt−1+bi)
f v k t = σ ( W f x v t + ∑ l = 1 K U k l f h v l t − 1 + b f ) \bm{ f_{vk}^t = σ(W^fx_v^t + \sum\limits_{l=1}^K{U_{kl}^fh_{vl}^{t-1}} + b^f) } fvkt=σ(Wfxvt+l=1∑KUklfhvlt−1+bf)
o v t = σ ( W o x v t + ∑ l = 1 K U l o h v l t − 1 + b o ) \bm{ o_v^t = σ(W^ox_v^t + \sum\limits_{l=1}^K{U_{l}^oh_{vl}^{t-1}} + b^o) } ovt=σ(Woxvt+l=1∑KUlohvlt−1+bo)
u v t = t a n h ( W u x v t + ∑ l = 1 K U l u h v l t − 1 + b u ) \bm{ u_v^t = tanh(W^ux_v^t + \sum\limits_{l=1}^K{U_{l}^uh_{vl}^{t-1}} + b^u) } uvt=tanh(Wuxvt+l=1∑KUluhvlt−1+bu)
c v t = i v t ⊙ u v t + ∑ l = 1 K f v l t ⊙ c v l t − 1 \bm{ c_v^t = i_v^t ⊙ u_v^t + \sum\limits_{l=1}^K{f_{vl}^t ⊙ c_{vl}^{t-1}} } cvt=ivt⊙uvt+l=1∑Kfvlt⊙cvlt−1
h v t = o v t ⊙ t a n h ( c v t ) \bm{ h_v^t = o_v^t ⊙ tanh(c_v^t) } hvt=ovt⊙tanh(cvt)
- 与Child-Sum Tree-LSTM不同,N-ary Tree-LSTM为每个子节点引入了单独的参数矩阵,这使模型能够基于每个节点的子节点信息,为每个节点得到更细粒度的表示
Graph-LSTM
Graph-LSTM(这部分模型变体较多,详见Google)
i v t = σ ( W i x v t + ∑ k ∈ N v U m ( v , k ) i h k t − 1 + b i ) \bm{ i_v^t = σ(W^ix_v^t + \sum\limits_{k \in N_v}{U_{m(v,k)}^ih_k^{t-1}} + b^i) } ivt=σ(Wixvt+k∈Nv∑Um(v,k)ihkt−1+bi)
f v k t = σ ( W f x v t + U m ( v , k ) f h k t − 1 + b f ) \bm{ f_{vk}^t = σ(W^fx_v^t + U_{m(v,k)}^fh_k^{t-1} + b^f) } fvkt=σ(Wfxvt+Um(v,k)fhkt−1+bf)
o v t = σ ( W o x v t + ∑ k ∈ N v U m ( v , k ) o h k t − 1 + b o ) \bm{ o_v^t = σ(W^ox_v^t + \sum\limits_{k \in N_v}{U_{m(v,k)}^oh_k^{t-1}} + b^o) } ovt=σ(Woxvt+k∈Nv∑Um(v,k)ohkt−1+bo)
u v t = t a n h ( W u x v t + ∑ k ∈ N v U m ( v , k ) u h k t − 1 + b u ) \bm{ u_v^t = tanh(W^ux_v^t + \sum\limits_{k \in N_v}{U_{m(v,k)}^uh_k^{t-1}} + b^u) } uvt=tanh(Wuxvt+k∈Nv∑Um(v,k)uhkt−1+bu)
c v t = i v t ⊙ u v t + ∑ k ∈ N v f v k t ⊙ c k t − 1 \bm{ c_v^t = i_v^t ⊙ u_v^t + \sum\limits_{k \in N_v}{f_{vk}^t ⊙ c_{k}^{t-1}} } cvt=ivt⊙uvt+k∈Nv∑fvkt⊙ckt−1
h
v
t
=
o
v
t
⊙
t
a
n
h
(
c
v
t
)
\bm{ h_v^t = o_v^t ⊙ tanh(c_v^t) }
hvt=ovt⊙tanh(cvt)
其中
m
(
v
,
k
)
m(v,k)
m(v,k)表示节点
v
v
v和
k
k
k之间的边的标签
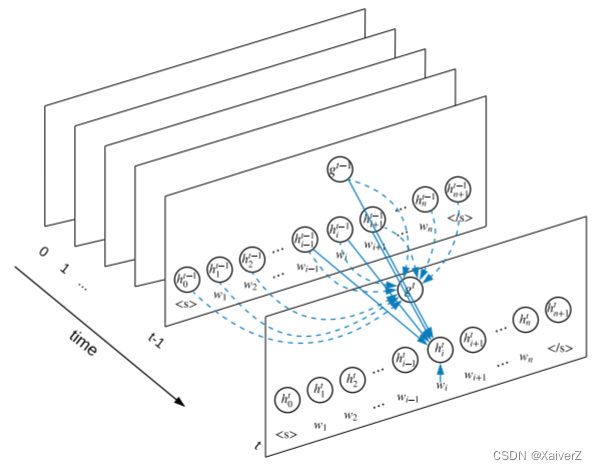
S-LSTM(Sentence-LSTM)
Paper : Sentence-State LSTM for Text Representation
S-LSTM
-
用于解决NLP相关任务,讲文本转换为图结构,并用LSTM学习相应表示
-
S-LSTM将每个单词视为图中的一个节点,并添加了一个超节点。对于每一层,单词节点可以聚合来自其相邻单词以及超节点的信息。超节点可以聚合它自身的信息以及来自所有单词节点的信息。
-
超节点可以提供全局信息解决长距离依赖问题,单词节点则可以根据其相邻单词建模上下文信息。这样一来,每个单词都可以获取足够的信息并对局部信息和全局信息进行建模
-
S-LSTM可用于许多NLP任务。单词节点的隐状态可以解决Token-Level的问题,而超节点的隐状态可以解决Sentence-Level的问题
-
S-LSTM胜过了Transformer
-














 4424
4424











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









