






学习主成分分析前,先回顾一些数学知识
• 方差:是各个样本和样本均值的差的平方和的均值,用来度量一组
数据的分散程度。
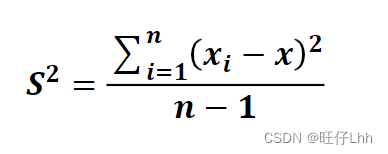
• 协方差:用于度量两个变量之间的线性相关性程度,若两个变量的
协方差为0,则可认为二者线性无关。协方差矩阵则是由变量的协方差值
构成的矩阵(对称阵)。
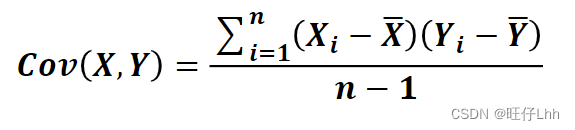
• 特征向量和特征值:矩阵的特征向量是描述数据集结构的非零向量,并满足
如下公式:
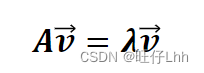
主成分分析原理
原理:矩阵的主成分就是其协方差矩阵对应的特征向量,按照对应
的特征值大小进行排序,最大的特征值就是第一主成分,其次是第二主
成分,以此类推。
主成分分析(Principal Component Analysis,PCA)是最常用的
一种降维方法,通常用于高维数据集的探索与可视化,还可以用作数
据压缩和预处理等。
PCA可以把具有相关性的高维变量合成为线性无关的低维变量,称为
主成分。主成分能够尽可能保留原始数据的信息。
主成分分析-算法过程
 实例-鸢尾花数据集主成分分析
实例-鸢尾花数据集主成分分析
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
data = load_iris()
y = data.target
x = data.data
pca =PCA(n_components=2) #n_components指主成分的个数,即降维后数据的维度
reduced_x = pca.fit_transform(x) #对数据进行降维
#print(reduced_x)
red_x,red_y = [],[]
blue_x,blue_y = [],[]
green_x,green_y = [],[]
for i in range(len(reduced_x)):
if y[i]==0:
red_x.append(reduced_x[i][0])
red_y.append(reduced_x[i][1])
elif y[i]==1:
blue_x.append(reduced_x[i][0])
blue_y.append(reduced_x[i][1])
else:
green_x.append(reduced_x[i][0])
green_y.append(reduced_x[i][1])
#可视化
plt.scatter(red_x,red_y,c='r',marker='o')
plt.scatter(blue_x,blue_y,c='b',marker='*')
plt.scatter(green_x,green_y,c='g',marker='^')
plt.show()运行结果
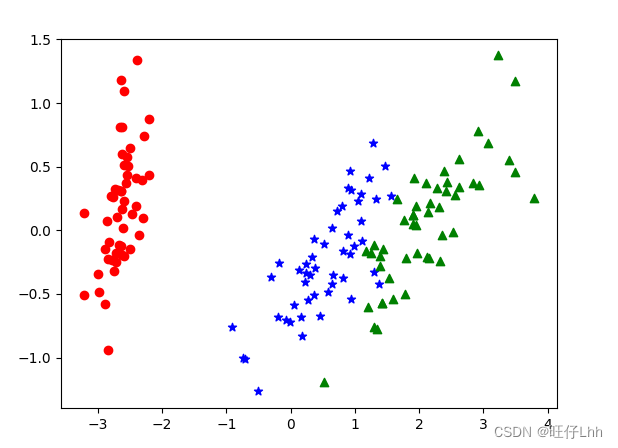
从运行结果可以看出降维后的数据仍能够清晰地分成三类。这样不仅能削减数据的维度,降低分类任务的工作量,还能保证分类的质量。















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









