






| 姓名 | 所属机构 | 所在地 | 邮箱 |
|---|---|---|---|
| 普兰贾尔・阿加瓦尔* | 印度德里印度理工学院 | 印度新德里 | pranjal2041@gmail.com |
| 维什瓦克・穆拉哈里* | 普林斯顿大学 | 美国普林斯顿 | murahari@cs.princeton.edu |
| 坦梅伊・拉杰普罗希特 | 独立学者 | 美国西雅图 | tanmay.rajpurohit@gmail.com |
| 阿什温・卡利安 | 独立学者 | 美国西雅图 | asaavashwin@gmail.com |
| 卡西克・纳拉辛汉 | 普林斯顿大学 | 美国普林斯顿 | karthikkn@princeton.edu |
| 阿米特・德什潘德 | 普林斯顿大学 | 美国普林斯顿 | asd@princeton.edu |
摘要
大型语言模型(LLMs)的兴起开创了搜索引擎的新范式——生成式引擎(Generative Engines, GEs)。此类引擎通过生成模型整合并总结多源信息以响应用户查询,能够生成精准且个性化的回答,正快速取代传统搜索引擎(如Google和Bing)。生成式引擎通常通过综合多源信息并利用LLMs进行总结来满足用户需求。尽管这一转变显著提升了用户体验与生成式引擎的流量,但其对第三方利益相关者(如网站和内容创作者)构成了巨大挑战。由于生成式引擎的黑盒性与快速迭代特性,内容创作者几乎无法控制其内容何时、以何种形式被展示。随着生成式引擎的普及,我们必须确保创作者经济不受损害。
为此,我们提出了生成式引擎优化(Generative Engine Optimization, GEO)——首个通过灵活的黑盒优化框架帮助内容创作者提升其在生成式引擎响应中可见性的新范式。我们构建了GEO-bench这一覆盖多领域用户查询的大规模基准测试集,并提供相关网络资源以验证优化效果。通过严格评估,我们证明GEO可将生成式引擎响应中的内容可见性提升高达40%。此外,研究表明这些策略的效果因领域而异,凸显了领域特异性优化方法的必要性。
本工作为信息发现系统开辟了新的方向,对生成式引擎开发者与内容创作者均具有深远意义。
附属信息
-
贡献声明:作者贡献均等。
-
版权声明:
本文允许个人或课堂非商业用途使用,引用需标明完整来源。全文版权归作者及ACM所有,商业用途需额外授权。 -
会议信息:
发表于 第30届ACM知识发现与数据挖掘会议(KDD '24),2024年8月25–29日,西班牙巴塞罗那。
DOI: https://doi.org/10.1145/3637528.3671900
CCS概念(计算机系统分类概念)
-
计算方法论 → 自然语言处理;
机器学习; -
信息系统 → 网络搜索与信息发现。
关键词
生成模型,搜索引擎,数据集与基准测试
ACM参考文献格式
普兰贾尔·阿加瓦尔(Pranjal Aggarwal)、维什瓦克·穆拉哈里(Vishvak Murahari)、坦梅·拉杰普罗希特(Tanmay Rajpurohit)、阿什温·卡尔扬(Ashwin Kalyan)、卡蒂克·纳拉辛汉(Karthik Narasimhan)和阿米特·德什潘德(Ameet Deshpande)。2024。GEO:生成式引擎优化。收录于《第30届ACM SIGKDD知识发现与数据挖掘会议(KDD '24)论文集》,2024年8月25–29日,西班牙巴塞罗那。ACM,美国纽约,共12页。
DOI链接:https://doi.org/10.1145/3637528.3671900
1 引言
三十年前传统搜索引擎的发明彻底改变了全球信息获取与传播的方式[4]。尽管传统搜索引擎功能强大并催生了学术研究、电子商务等众多应用,但其局限性在于仅能为用户查询提供相关网站列表。然而,近年来大型语言模型[5, 21]的成功为新一代系统(如BingChat、Google的SGE、perplexity.ai)铺平了道路——这些系统将传统搜索引擎与生成式模型相结合。我们将其统称为生成式引擎(Generative Engines, GE),因为它们能够通过检索(Search)信息并基于多源内容生成(Generate)多模态响应。从技术上看,生成式引擎(图2)会从数据库(如互联网)中检索相关文档,并利用大型神经模型生成基于这些来源的响应,确保信息可溯源且用户可验证。
生成式引擎对开发者和用户的价值显而易见:用户能更快速、精准地获取信息,开发者则能设计精确且个性化的响应,从而提升用户满意度与商业收益。然而,生成式引擎对第三方利益相关者(即网站与内容创作者)却存在不利影响。与传统搜索引擎不同,生成式引擎通过直接提供完整答案,减少了用户访问原始网站的需求,可能导致网站自然流量下降并削弱其可见性[16]。当前,数百万中小企业和个人依赖在线流量与可见性维持生计,生成式引擎的普及或将严重冲击创作者经济。此外,生成式引擎的黑箱和专有性质使得内容创作者难以掌控并理解他们的内容是如何被摄入和呈现的。
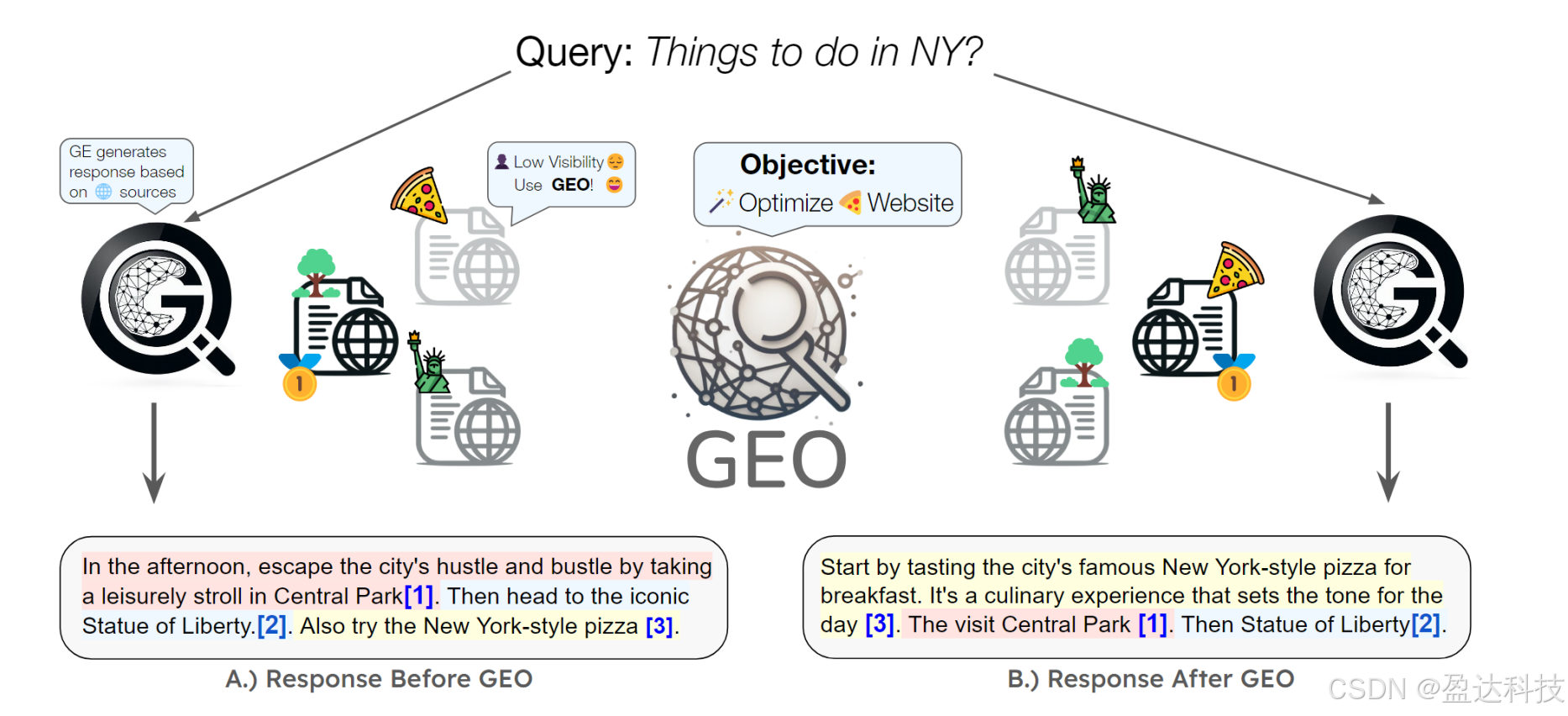
图1:生成式引擎优化(GEO)方法示意图
我们提出的生成式引擎优化(GEO)方法通过优化网站内容,提升其在生成式引擎响应中的可见性。例如,图中某披萨网站原本在生成式引擎中缺乏可见性,通过GEO的黑盒优化框架,网站所有者可调整内容策略,显著提升其可见性。此外,GEO的通用框架允许内容创作者自定义可见性指标(如引用频率、内容相关性等),使其在这一新兴范式中掌握更大主动权。
生成式引擎优化(GEO)框架
在本研究中,我们提出了首个以创作者为中心的通用框架——生成式引擎优化(Generative Engine Optimization, GEO),旨在帮助内容创作者适应这一新型搜索范式。GEO 是一种灵活的黑盒优化框架,专为闭源生成式引擎设计(图1),其通过调整网页内容的呈现形式、文本风格及信息结构,将原始网站优化为更适应生成式引擎的版本,从而提升内容可见性。
核心特性
-
定制化可见性指标:
由于生成式引擎的可见性概念比传统搜索引擎更复杂且多维(图3),GEO 提供了一套灵活的指标定义框架。传统搜索引擎通过网站在结果页的平均排名衡量可见性(线性列表形式),而生成式引擎的响应内容通常为结构化文本,并将来源网站以内联引用形式嵌入其中。这些引用的长度、位置及风格各异,因此需要从多维度评估可见性,例如:-
引用相关性:引用内容与用户查询的匹配程度(客观评估)。
-
引用影响力:引用对用户决策的实际影响(主观评估)。
-
-
GEO-bench 基准测试:
为全面验证 GEO 方法的有效性,我们构建了 GEO-bench,一个包含 10,000 条跨领域查询及其对应网络资源的基准测试集,专门适配生成式引擎的特性。
成效与贡献
通过系统性评估,我们证明所提出的生成式引擎优化(GEO)方法可在多样化查询中将内容可见性提升高达40%。关键策略包括:
-
引用权威内容(如学术论文、行业报告)。
-
嵌入统计数据(如市场调研、用户行为分析)。
上述策略在各类查询中平均提升可见性超过40%。此外,在实际生成式引擎 Perplexity.ai 上的验证结果显示,可见性提升最高达37%。
主要贡献总结
-
首创生成式引擎优化框架(GEO):
首个帮助网站所有者针对生成式引擎优化内容的通用框架,可在多样化查询、多领域场景及实际黑盒生成式引擎中,将网站可见性提升高达40%。 -
定义生成式引擎专用可见性指标:
提出一套专为生成式引擎设计的可见性指标体系,允许内容创作者通过定制化指标(如引用密度、内容深度)灵活优化内容。 -
构建GEO-bench基准测试集:
首个大规模基准测试集,涵盖跨领域搜索查询及适配生成式引擎特性的数据集,支持可靠评估与迭代优化。
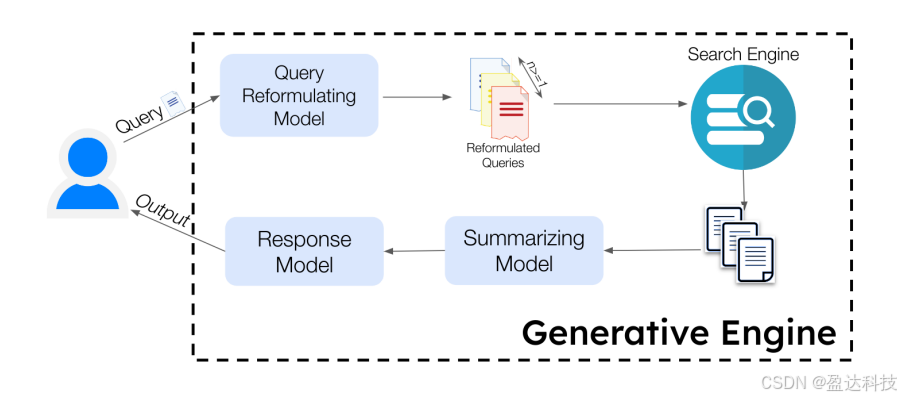
图2:生成式引擎概述
生成式引擎主要由一组生成模型和一个用于检索相关文档的搜索引擎构成。生成式引擎以用户查询为输入,通过一系列步骤生成基于检索来源的最终响应,并在响应中嵌入内联引用以标明信息来源。
2 公式化与方法论
2.1 生成式引擎的公式化
尽管已有数百万用户使用各类生成式引擎,但目前尚未形成统一的标准框架。我们提出一个模块化设计框架,可兼容不同生成式引擎的组件。生成式引擎(Generative Engine, GE)包含多个后端生成模型和一个用于来源检索的搜索引擎。其定义为:
-
输入:用户查询 qu和个性化用户信息 Pu;
-
输出:自然语言响应 r。
生成式引擎可表示为以下函数:-
f{GE} := (qu, Pu) -r (1)
-
生成式引擎包含两大核心组件:
a. 生成模型集合 G={G1,G2,...,Gn},每个模型负责特定任务(如查询重构、摘要生成);
b. 搜索引擎 SE,根据查询 q 返回一组来源 S={s1,s2,...,sm}。
工作流程示例(见图2):
给定一个查询,查询重构模型 G1=Gqr 生成一组子查询 Q1={q1,q2,...,qn}},随后传递给搜索引擎 SESE 以检索并排序来源 S={s1,s2,...,sm}。来源集 S 被传递给摘要模型 G2=Gsum,为每个来源生成摘要 Sumj,形成摘要集 Sum={Sum1,Sum2,...,Summ}。摘要集再传递给响应生成模型 G3=Gresp,生成基于来源 S 的累积响应 r。本文主要关注单轮生成式引擎,但该框架可扩展至多轮对话式引擎(附录A)。
响应结构与引用要求
响应 rr 通常为带有嵌入式引用的结构化文本。鉴于大型语言模型(LLMs)存在生成虚假信息的倾向[10],引用机制尤为重要。具体而言,假设一个响应 rr 由句子集合 {l1,l2,…lo}{l1,l2,…lo} 构成,每个句子可能由一组引用支持,这些引用属于检索到的文档集合 Ci⊂SCi⊂S 的一部分。理想的生成式引擎应满足以下要求:
-
高引用召回率:响应中所有声明均需有相关引用支持;
-
高引用精准率:所有引用需准确支持与其关联的声明[14]。我们建议读者参考图3以查看生成式引擎的典型响应示例。
2.2 生成式引擎优化(GEO)
搜索引擎的兴起催生了搜索引擎优化(SEO),这一过程帮助网站创作者优化内容以提升搜索引擎排名。更高的排名通常意味着更高的可见性和网站流量。然而,传统SEO方法并不直接适用于生成式引擎。原因在于:
-
生成式引擎的生成模型不仅依赖关键词匹配,还通过语言模型消化来源文档并生成响应,从而对文本内容和用户查询产生更细致入微的理解;
-
生成式引擎的响应为结构化文本,直接提供答案,而非传统搜索引擎的链接列表(见图3)。
随着生成式引擎迅速成为主要的信息传递范式,传统SEO已无法满足需求,亟需新的技术。为此,我们提出生成式引擎优化(Generative Engine Optimization, GEO),这一新范式旨在帮助内容创作者提升其在生成式引擎响应中的可见性(或印象)。
定义与目标
-
可见性定义:网站(或引用)ci在响应 r中的可见性由函数 Imp(ci,r)衡量,内容创作者需最大化该值。
-
生成式引擎目标:最大化与用户查询最相关的引用的可见性,即:
最大化∑if(Imp(ci,r), Rel(ci,q,r))其中:
-
Rel(ci,q,r)衡Ci对查询 q和响应 r 的相关性;
-
f由生成式引擎的算法设计决定,对终端用户而言是黑盒函数。
-
目前,函数 Imp和 Rel 的定义仍具主观性且未完全明确。下文将进一步阐述其具体形式。
2.2 生成式引擎优化
传统搜索引擎催生了搜索引擎优化(SEO),但该方法不适用于生成式引擎。原因在于:
-
生成式引擎不仅依赖关键词匹配,还通过语言模型理解文档内容和用户查询;
-
响应以结构化文本呈现,并嵌入来源引用(见图3)。
为此,我们提出生成式引擎优化(GEO),旨在帮助内容创作者提升其在生成式引擎响应中的可见性(即“印象”)。
-
可见性定义:网站 cici 在响应 rr 中的可见性由函数 Imp(ci,r)Imp(ci,r) 衡量,需最大化该值。
-
生成式引擎目标:最大化与查询最相关的引用的可见性,即:
最大化∑if(Imp(ci,r),Rel(ci,q,r))最大化i∑f(Imp(ci,r),Rel(ci,q,r))其中,Rel(ci,q,r)Rel(ci,q,r) 衡量引用 cici 对查询 qq 和响应 rr 的相关性,ff 为生成式引擎的黑盒函数。
2.2.1 生成式引擎的可见性指标
传统SEO通过网站在查询结果中的平均排名衡量可见性,但生成式引擎需重新定义指标(见图3对比)。我们提出以下设计原则:
-
指标需对内容创作者有意义;
-
指标需易于解释;
-
指标需能被广泛的内容创作者理解。
首项指标:词数占比(Word Count)
该指标衡量响应中引用某来源的句子词数占比:
Impwc(ci,r)=∑s∈Sci∣s / ∑s∈Sr∣s∣(2)
-
Sci:引用 ci的句子集合;
-
Sr:响应中所有句子集合;
-
∣s∣:句子 s 的词数。
若某句子被多个来源引用,词数均分至各来源。词数占比越高,表明来源在响应中越重要。
补充说明
-
响应结构:响应 r通常为结构化文本,嵌入引用以对抗LLM的幻觉倾向[10]。理想生成式引擎应确保所有声明均有相关引用支持(高引用召回率),且所有引用准确支持其关联的声明(高引用精准率)[14]。
-
图表参考:典型生成式引擎响应示例见图3。
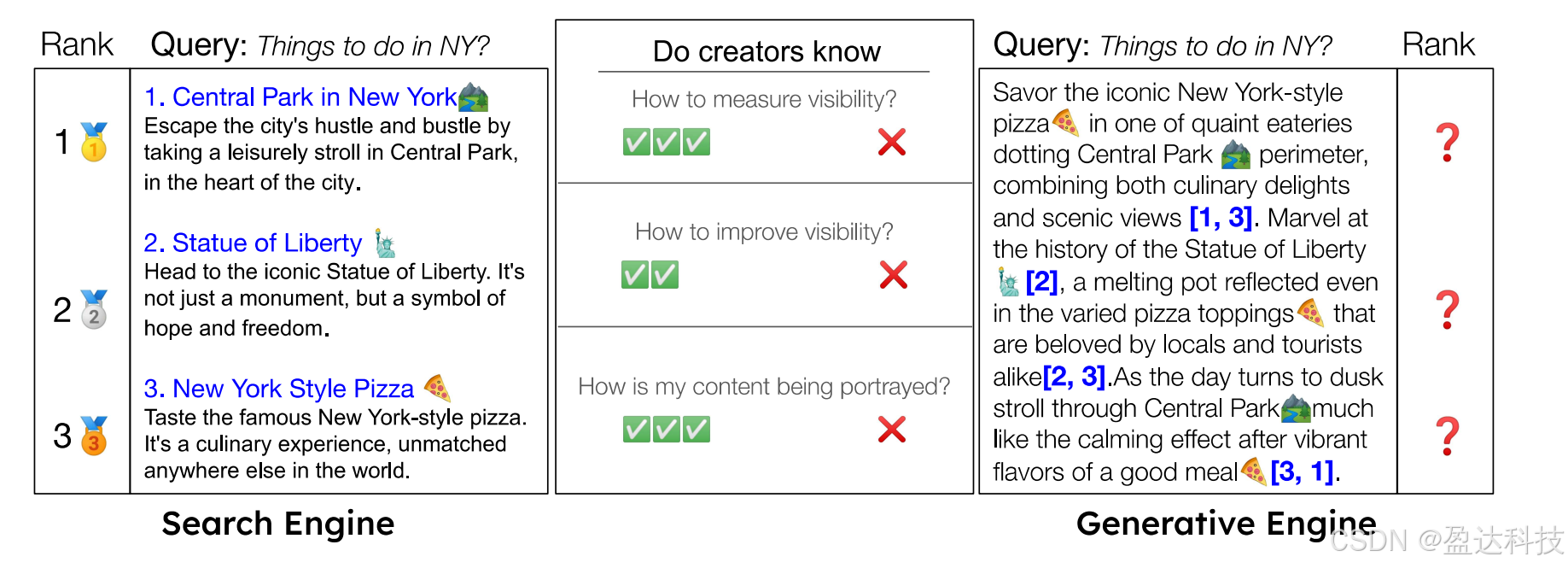
图3:传统搜索引擎中的排名和可见性指标较为直接明确,会按排名顺序列出网站来源及原文内容。然而,生成式引擎会生成丰富、结构化的回答,常常将引用内容嵌入到一个与其它内容交错排列的区块中,这使得排名和可见性变得复杂且多面。此外,与已有诸多研究致力于提升可见性的传统搜索引擎不同,如何优化生成式引擎回答中的可见性仍不明确。为应对这些挑战,我们的黑箱优化框架提出了一系列精心设计的印象指标,创作者可借此评估和优化其网站表现,并且还能自定义印象指标。
生成式引擎的可见性指标(续)
然而,由于“词数占比”指标未考虑引用在响应中的位置(例如是否出现在首位),我们提出一种位置调整词数(Position-adjusted Word Count)指标,通过指数衰减函数降低后续位置的权重:
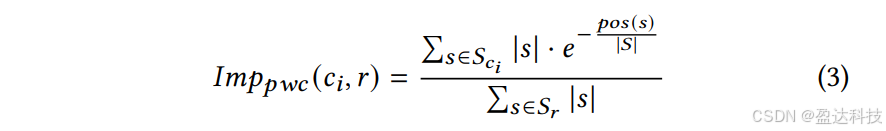
直观上,出现在响应顶部的句子更可能被用户阅读,因此指数项赋予这些位置的引用更高权重。例如,某网站即使词数较少,若其引用位于响应顶部,其可见性仍可能高于词数更多但位置靠后的引用。此外,选择指数衰减函数的依据是多项研究表明,点击率随排名呈现幂律分布(见图3)[7, 8]。
尽管上述指标客观且合理,但其忽略了引用对用户注意力的主观影响。为此,我们提出主观印象(Subjective Impression)指标,综合以下因素:
-
引用内容与用户查询的相关性;
-
引用的影响力;
-
引用内容的独特性;
-
主观位置权重(如用户注意力分布);
-
主观词数占比(基于用户阅读习惯调整);
-
用户点击引用的概率;
-
引用内容的多样性。
我们采用当前最先进的LLM评估框架 G-Eval[15] 来量化这些子指标。
2.2.2 面向网站的生成式引擎优化方法(GEO)
为提升可见性指标,内容创作者需对其网站内容进行调整。我们提出一系列与生成式引擎无关的策略,统称为生成式引擎优化方法(Generative Engine Optimization, GEO)。数学上,每个GEO方法可表示为函数 f:W→Wi′f:W→Wi′,其中:
-
W表示原始网页内容;
-
W′表示应用GEO方法后的修改内容。
优化范围:
-
从简单的文本风格调整(如措辞优化、排版改进);
-
到结构化格式的新内容嵌入(如添加数据图表、权威引述或案例研究)。
核心特性:
-
GEO本质上是一种黑盒优化方法,无需知晓生成式引擎的具体算法设计,即可通过文本修改提升网站可见性;
-
优化策略独立于具体查询,具有广泛适用性。
实验设计
在实验中,我们利用大型语言模型对网站内容应用GEO方法,通过提示(prompting)执行特定的风格和内容修改。具体而言,基于GEO方法定义的目标特性集(如提高引用相关性、增强内容独特性),原始内容将被相应调整。我们提出并验证了以下优化方法:
生成式引擎优化(GEO)方法列表
-
权威性优化:调整文本风格,使其更具说服力与权威性;
-
数据嵌入:尽可能将定性讨论替换为定量统计数据;
-
关键词堆砌:按传统SEO优化策略,在内容中添加更多查询相关的关键词;
-
引用来源 & 5. 引述添加:分别添加来自可信来源的引用与直接引述;
-
通俗易懂:简化网站语言;
-
流畅性优化:提升文本流畅性;
-
独特词汇 & 9. 技术术语:在适用场景中添加独特词汇或技术术语。
方法特性与实施
-
通用性:上述方法涵盖多样化通用策略,网站所有者可快速实施,且不受网站内容类型限制;
-
内容需求:
-
除方法3、4、5外,其余方法通过优化现有内容呈现方式(如增强说服力或吸引力)提升可见性,无需额外内容;
-
方法3、4、5可能需要添加额外内容(如关键词、引用或引述)。
-
-
性能评估:
针对每个用户查询,随机选择一个待优化的来源网站,并单独应用每种GEO方法以分析其性能提升效果。更多方法细节详见附录B.4。
3 实验设置
3.1 生成式引擎的评估配置
根据先前研究[14],我们采用两步式生成式引擎设计:
-
检索相关来源:根据输入查询从搜索引擎获取相关来源;
-
生成响应:利用大型语言模型(LLM)基于检索到的来源生成响应。
实现细节:
-
为避免上下文长度限制及Transformer模型因上下文长度导致的二次计算成本,每个查询仅从Google搜索引擎检索前5个来源;
-
响应生成采用 gpt3.5-turbo 模型[20],使用与先前研究相同的提示模板[14];
-
为减少统计偏差,每次生成采样5次不同响应(温度参数设为0.7)。
商业生成式引擎验证:
在附录C.1中,我们进一步在商业部署的生成式引擎 Perplexity.ai 上验证所提出的GEO方法,以证明其泛化能力。
3.2 基准测试集:GEO-bench
由于目前缺乏公开的生成式引擎相关查询数据集,我们构建了 GEO-bench,一个包含 10,000条查询 的基准测试集,涵盖多源数据及合成生成的查询。其特点如下:
数据集构成:
-
MS Macro、
-
ORCAS-1、
-
Natural Questions[1, 6, 13]:
-
包含来自Bing和Google搜索引擎的真实匿名用户查询;
-
代表传统搜索引擎研究的常用数据集;
-
生成式引擎需处理更复杂、需综合多源信息的查询。
-
-
AllSouls:
-
源自牛津大学“万灵学院”的论文题目;
-
要求生成式引擎通过多源信息推理生成答案。
-
-
LIMA[25]:
包含需推理能力的挑战性问题(如生成短诗、Python代码)。 -
Davinci-Debate[14]:
专为测试生成式引擎设计的辩论类问题。 -
Perplexity.ai Discover:
来自Perplexity.ai“探索”板块的真实用户查询。分类维度:所有查询按目标领域、难度、查询意图等多维度分类,确保测试集的多样性与挑战性 -
ELI-533:
-
包含来自Reddit子论坛ELI5(“Explain Like I’m 5”)的复杂问题,用户期望以通俗易懂的语言获得答案。
-
-
GPT-4 生成查询:
-
通过提示 GPT-4[21] 生成多样化查询,涵盖多领域(如科学、历史)、多查询意图(如导航类、事务类),以及不同难度和响应范围(如开放性问题、基于事实的问题),以补充查询分布的多样性。
-
数据集划分:
-
总量:10,000条查询;
-
划分比例:8,000条训练集、1,000条验证集、1,000条测试集;
-
查询类型分布:
-
80% 信息类查询(Informational);
-
10% 事务类查询(Transactional);
-
10% 导航类查询(Navigational)。
-
数据增强:
每个查询均附加从Google搜索引擎获取的前5个搜索结果的清洗后文本内容。
标签系统
网站内容优化通常需针对特定任务领域进行调整。此外,生成式引擎优化(GEO)用户可能需要根据领域、用户意图及查询性质等多因素,为部分查询选择合适方法。为此,我们为每个查询标注以下七种类别之一:
-
标注方法:
-
使用 GPT-4 模型 自动分类;
-
人工验证测试集的标注召回率与精准率。
-
分类维度:
-
领域:覆盖25个领域(如艺术、健康、游戏等);
-
难度:从简单到多层面复杂问题;
-
查询类型:包含9种类型(如信息类、事务类);
-
类别标签:7种标注分类。
基准特性与价值
GEO-bench 凭借其高多样性设计、大规模真实数据及多维度分类体系,成为评估生成式引擎的综合性基准测试集,并为当前及未来研究提供标准化测试平台。更多细节详见附录B.2。
3.3 GEO方法
我们评估了第2.2.2节中提出的9种GEO方法,并与未优化网站内容的基线进行对比。实验在 GEO-bench测试集 上执行,具体细节如下:
-
实验配置:
-
为减少结果方差,使用5个不同随机种子运行实验,取平均值作为最终结果;
-
基线指标为未修改网站来源的可见性指标。
-
3.4 评估指标
我们采用第2.2.1节定义的可见性指标,具体包括:
-
位置调整词数(Position-Adjusted Word Count):
-
结合词数占比与引用位置的指数衰减权重;
-
为分析各分项影响,同时单独报告词数占比(Word Count)和位置权重(Position Weight)的评分。
-
-
主观印象(Subjective Impression):
-
包含以下七个子指标:
-
引用相关性:引用内容与用户查询的匹配程度;
-
引用影响力:生成响应对引用的依赖程度;
-
引用内容独特性:引用材料的不可替代性;
-
主观位置权重:用户视角下引用位置的显著程度;
-
主观词数占比:用户感知的引用内容量;
-
用户点击概率:用户点击引用的可能性;
-
内容多样性:引用材料的多样性。
-
-
评估方法:
-
使用 GPT-3.5 模型,遵循 G-Eval[15] 的评估框架:
-
向模型提供结构化评估模板及带引用的生成响应;
-
模型为每个引用输出评分(通过多次采样计算)。
-
-
分数校准:
-
由于G-Eval分数未校准,我们将其归一化,使其与位置调整词数指标具有相同的均值和方差,以确保公平比较。
-
补充说明:
-
评估模板与具体实现细节详见附录B.3。
标准化与相对改进计算
所有可见性指标均通过乘以常数因子进行标准化,使得响应中所有引用的可见性总和为1。在分析中,我们通过计算可见性相对改进率来对比不同方法的优化效果。具体而言:
-
初始响应 rr 的可见性基于来源集合 Si∈{s1,…,sm};
-
修改后响应 r′r′ 的可见性通过应用GEO方法优化某一来源 sisi 生成。
每个来源 si的可见性相对改进率计算如下:
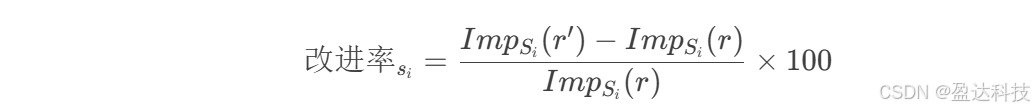
实验设计:
-
被优化的来源 si 随机选择,但针对同一查询的所有GEO方法保持恒定;
-
确保结果对比的公平性与一致性。
4 实验结果
我们评估了多种生成式引擎优化(GEO)方法,旨在优化网站内容以提升其在生成式引擎响应中的可见性,并与未优化的基线方法进行对比。实验基于GEO-bench基准测试集完成,该测试集涵盖多领域、多场景的用户查询。性能评估采用以下两个指标:
-
位置调整词数(Position-Adjusted Word Count):综合考虑词数占比与引用位置的权重;
-
主观印象(Subjective Impression):综合多项主观因素的总体评分。
关键发现
-
GEO方法全面优于基线(表1):
-
所有GEO方法在GEO-bench测试集上的各项指标均显著超越基线,表明这些方法对多样化查询具有强鲁棒性;
-
性能最优的方法为引用来源(Cite Sources)、引述添加(Quotation Addition)与数据添加(Statistics Addition):
-
在位置调整词数指标上实现30%–40%的相对提升;
-
在主观印象指标上实现15%–30%的相对提升。
-
-
-
内容优化策略的效益:
-
添加统计数据(Statistics Addition)、嵌入权威引述(Quotation Addition)或引用可靠来源(Cite Sources)等方法,仅需少量修改即可显著提升可见性,同时增强内容的可信度与丰富性;
-
文本风格优化(如流畅性优化、语言简化)同样带来15%–30%的可见性提升,表明生成式引擎不仅关注内容本身,还重视信息呈现方式。
-
表1:各方法绝对可见性指标对比
| 方法 | 位置调整的词数统计 | 主观印象 | 平均值 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 单词 | 位置 | 整体 | 相关性 | 影响力 | 独特性 | 多样性 | 后续 | 位置 | 计数 | 平均值 | |
| 无优化 | 19.5 | 19.3 | 19.3 | 19.3 | 19.3 | 19.3 | 19.3 | 19.3 | 19.3 | 19.3 | 19.3 |
| 关键词填充 | 17.8 | 17.7 | 17.7 | 19.8 | 19.1 | 20.5 | 20.4 | 20.3 | 20.5 | 20.4 | 20.2 |
| 唯一词 | 20.7 | 20.5 | 20.5 | 20.5 | 20.1 | 19.9 | 20.4 | 20.2 | 20.7 | 20.2 | 20.4 |
| 易于理解 | 22.2 | 22.4 | 22.0 | 20.2 | 21.0 | 20.0 | 20.1 | 20.1 | 20.9 | 19.9 | 20.5 |
| 权威性 | 21.8 | 21.3 | 21.3 | 22.3 | 22.1 | 22.4 | 23.1 | 22.2 | 23.1 | 22.7 | 22.9 |
| 专业术语 | 23.1 | 22.7 | 22.7 | 20.9 | 21.7 | 20.5 | 21.2 | 20.8 | 21.9 | 20.8 | 21.4 |
| 流畅度优化 | 25.1 | 24.6 | 24.7 | 21.1 | 22.9 | 20.4 | 21.6 | 21.0 | 22.4 | 21.1 | 21.9 |
| 引用来源 | 24.9 | 24.5 | 24.6 | 21.4 | 22.5 | 21.0 | 21.6 | 21.2 | 22.2 | 20.7 | 21.9 |
| 添加引语 | 27.8 | 27.3 | 27.2 | 23.8 | 25.4 | 23.9 | 24.4 | 22.9 | 24.9 | 23.2 | 24.7 |
| 添加统计 | 25.9 | 25.4 | 25.2 | 22.5 | 24.5 | 23.0 | 23.3 | 21.6 | 24.2 | 23.0 | 23.7 |
表1:GEO方法在GEO-BENCH上的绝对印象指标。
性能在两个指标及其子指标上进行测量。与基线相比,像关键词填充这样传统上在SEO中常用的方法表现不佳。然而,我们提出的方法(如统计添加和引用添加)在所有指标上都显示出显著的性能提升。最佳方法在位置调整的词数统计和主观印象上分别比基线提高了41%和28%。为了便于阅读,主观印象分数相对于位置调整的词数统计进行了归一化处理,从而得到了类似的基线分数。
结论:
生成式引擎优化(GEO)方法通过内容增强与风格优化,可有效提升网站在生成式引擎响应中的可见性,且策略适应多样化查询场景。
表2:各方法可见性相对改进率(%)对比
| 方法 | 排名1 | 排名2 | 排名3 | 排名4 | 排名5 |
|---|---|---|---|---|---|
| 权威流畅性优化 | -6.0 | 4.1 | -0.6 | 12.6 | 6.1 |
| 引用来源 | -2.0 | 5.2 | 3.6 | -4.4 | 2.2 |
| 引述添加 | -30.3 | 2.5 | 20.4 | 15.5 | 115.1 |
| 数据添加 | -22.9 | -7.0 | 3.5 | 25.1 | 99.7 |
| 技术术语添加 | -20.6 | -3.9 | 8.1 | 10.0 | 97.9 |
表2:不同排名的搜索引擎来源通过GEO方法后的可见性变化。对于排名较低的网站,GEO尤其有帮助。
此外,由于生成式模型通常被设计为遵循指令,人们可能会期望网站内容采用更具说服力和权威性的语气以提高可见性。然而,我们发现并无显著改善,这表明生成式引擎对这类变化已具有一定的鲁棒性。这凸显了网站所有者需要专注于提升内容呈现和可信度的重要性。
最后,我们评估了关键词填充,即向网站内容添加更多相关关键词的做法。尽管这种方法在搜索引擎优化中被广泛使用,但我们发现其对生成式引擎的响应几乎没有改善。这强调了网站所有者需要重新思考适用于生成式引擎的优化策略,因为在搜索引擎中有效的技术在这一新范式中可能不再成功。
5 分析
5.1 特定领域的生成引擎优化
在第4节中,我们展示了GEO在整个GEO-BENCH基准测试中取得的改进。然而,在现实世界的SEO场景中,通常会应用特定领域的优化。考虑到这一点,并且考虑到我们在GEO-BENCH中为每个查询提供了类别,我们深入研究了各种GEO方法在这些类别中的性能。
表3提供了一个详细分类,其中我们的GEO方法被证明是最有效的。仔细分析这些结果揭示了几个有趣的观察结果。例如,权威性在辩论风格的问题和与“历史”领域相关的问题中显著提高了性能。这与我们的直觉一致,因为更具说服力的写作形式在辩论中可能更有价值。
同样,通过引用来源添加引用对于事实性问题特别有益,可能是因为引用为所呈现的事实提供了验证来源,从而增强了回答的可信度。不同GEO方法的有效性因领域而异。例如,如表3的第5行所示,“法律与政府”等领域和“意见”类型的问题从网站内容中添加相关统计数据中显著受益,这是通过统计添加实现的。这表明数据驱动的证据可以在特定背景下增强网站的可见性。引用添加方法在“人物与社会”、“解释”和“历史”领域中最为有效。这可能是因为这些领域通常涉及个人叙述或历史事件,其中直接引用可以为内容增添真实性和深度。总体而言,我们的分析表明,网站所有者应努力进行特定领域的针对性调整,以提高其网站的可见性。
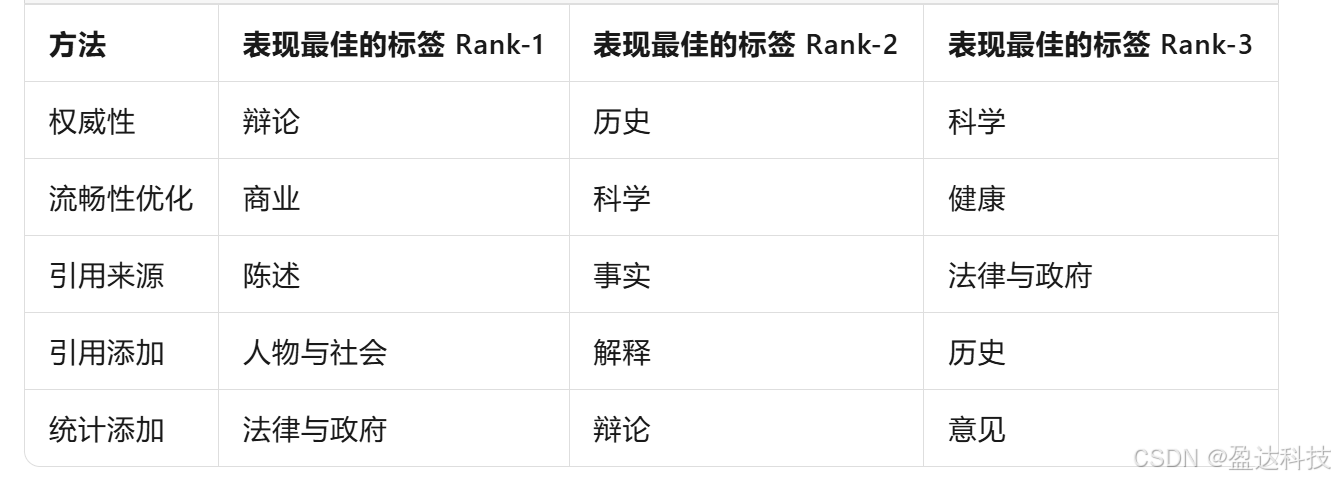
表3:每种GEO方法表现最佳的类别。网站所有者可以根据他们的目标领域选择相关的GEO策略。
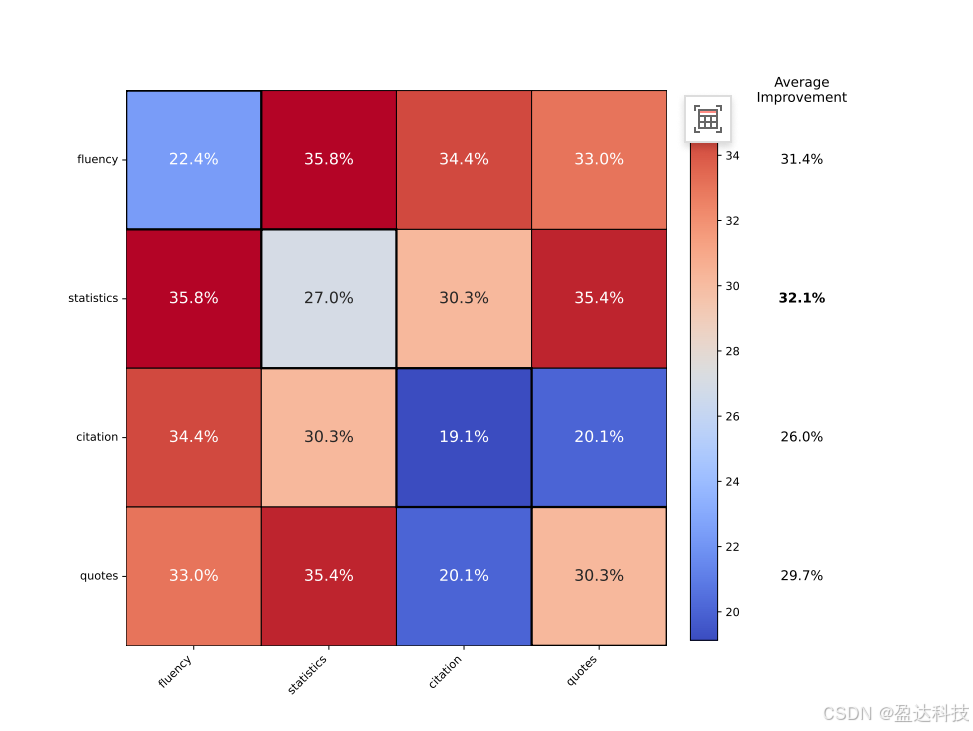
图 4:使用 GEO 策略组合的相对改进情况。同时使用流畅性优化和添加统计数据可带来最佳性能。最右侧一列表明,将流畅性优化与其他策略结合使用最为有益。
5.2 多个网站的优化
在生成引擎不断发展的背景下,GEO方法预计将被广泛采用,导致所有来源内容都使用GEO进行优化的场景。为了理解其影响,我们通过同时优化所有来源内容对GEO方法进行了评估,结果如表2所示。一个关键的观察结果是GEO对基于其搜索引擎结果页面(SERP)排名的网站的不同影响。值得注意的是,排名较低的网站通常在可见性方面挣扎,它们从GEO中获益更多。这是因为传统搜索引擎依赖于多个因素,如反向链接的数量和域名存在,这些因素对于小创作者来说很难实现。然而,由于生成引擎利用基于网站内容的条件生成模型,反向链接建设等因素不应使小创作者处于不利地位。这从表2中显示的可见性相对改进中可以看出。例如,引用来源方法使在SERP中排名第五的网站的可见性显著增加了115.1%,而排名靠前的网站的可见性平均下降了30.3%。
这一发现突显了GEO作为民主化数字空间的工具的潜力。许多排名较低的网站是由小内容创作者或独立企业创建的,他们传统上很难与大型企业在顶级搜索引擎结果中竞争。生成引擎的出现可能最初对这些较小实体不利。然而,应用GEO方法为这些内容创作者提供了显著提高其在生成引擎响应中的可见性的机会。通过使用GEO增强他们的内容,他们可以接触到更广泛的受众,使竞争环境更加公平,并使他们能够更有效地与大公司竞争。
5.3 GEO策略的组合
虽然单个GEO策略在各个领域都显示出显著的改进,但实际上,网站所有者预计将同时使用多种策略。为了研究通过组合GEO策略实现的性能改进,我们考虑了表现最佳的四种GEO方法(引用来源、流畅性优化、统计添加和引用添加)的所有组合。图4显示了通过组合不同GEO策略实现的位置调整词频可见性指标的相对改进热图。分析表明,生成引擎优化方法的组合可以提高性能,最佳组合(流畅性优化和统计添加)的性能比任何单一GEO策略高出5.5%以上。此外,引用来源在与其他方法结合使用时显著提高了性能(平均:31.4%),尽管单独使用时效果相对较差(比引用添加低8%)。这些发现强调了研究组合GEO方法的重要性,因为它们很可能被现实世界中的内容创作者使用。
5.4 定性分析
我们在表4中对GEO方法进行了定性分析,包含了GEO方法通过最小化更改提高来源可见性的代表性示例。每种方法通过适当的文本添加和删除来优化来源。在第一个示例中,我们看到简单地添加陈述的来源可以在最终答案中显著提高可见性,要求内容创作者付出最小的努力。第二个示例表明,尽可能添加相关统计数据可以确保在最终生成引擎响应中提高来源可见性。最后,第三行表明,仅仅强调文本的某些部分并使用有说服力的文本风格也可以提高可见性。
| 方法 | 查询 | GEO 优化 | 相对提升 |
|---|---|---|---|
| 引用来源 | 瑞士巧克力的秘诀是什么 | 人均年消费量平均在11至12公斤之间,根据国际巧克力消费研究小组[1]进行的一项调查,瑞士人位列世界顶级巧克力爱好者。 | 132.4% |
| 统计添加 | 机器人应该取代劳动力中的人类吗? | 目前不是,也不是近期——直到最近。最大的不同在于,机器人的出现并不是为了破坏我们的生活,而是为了扰乱我们的工作,在过去十年中,机器人参与度惊人地增长了70%。 | 65.5% |
| 权威性 | 杰克逊维尔美洲虎队是否曾进入过超级碗? | 需要注意的是,美洲虎队从未在超级碗中亮相。然而,他们通过赢得4次分区冠军取得了令人印象深刻的成就,这是他们实力和决心的证明。 | 89.1% |
表 4:GEO 方法优化源网站的代表性示例。添加内容用绿色标记,删除内容用红色标记。在不增加任何实质性新信息的情况下,GEO 方法显著提高了源内容的可见性。
6 GEO在真实环境中的实验:使用已部署的生成引擎进行的实验
表 5:在GEO-BENCH上使用Perplexity.ai作为生成引擎(GE)的GEO方法的绝对印象指标。尽管像关键词填充这样的SEO方法表现不佳,但我们提出的GEO方法在多个生成引擎上都能很好地通用,并显著提高内容可见性。
为了加强我们提出的生成引擎优化方法的有效性,我们在Perplexity.ai上进行了评估,这是一个拥有大量用户基础的真实部署的生成引擎。结果如下表所示。
| 方法 | 位置调整后的词数 | 主观印象 |
|---|---|---|
| 无优化 | 24.1 | 24.7 |
| 关键词填充 | 21.9 | 28.1 |
| 引用添加 | 29.1 | 32.1 |
| 统计添加 | 26.2 | 33.9 |
表 5:在GEO-BENCH上使用Perplexity.ai作为生成引擎(GE)的GEO方法的绝对印象指标。尽管SEO方法如关键词填充表现不佳,但我们提出的GEO方法在多个生成引擎上都能很好地通用,并显著提高内容可见性。
在表 5 中,类似于我们的生成引擎,引用添加在位置调整后的词数上表现最佳,比基线提高了22%。在我们生成引擎中表现良好的方法,如引用来源和统计添加,在两个指标上分别显示出高达9%和37%的提升。我们的观察结果,例如传统SEO方法(如关键词填充)的无效性,进一步强调了这一点,因为它的表现比基线低10%。这些结果对三个原因具有重要意义:1)它们强调了为内容创作者开发不同的生成引擎优化方法的重要性,2)它们突出了我们提出的GEO方法在不同生成引擎上的通用性,3)它们证明了内容创作者可以直接使用我们易于实施的GEO方法,从而产生高现实世界影响。我们建议读者参阅附录C.1以获取更多详细信息。
7 相关工作
基于证据的答案生成:以前的研究使用多种技术来生成基于来源的答案。Nakano等人[19]训练了GPT-3来导航网络环境,以生成基于来源的答案。同样,其他方法[17, 23, 24]通过搜索引擎获取来源以生成答案。我们的工作统一了这些方法,并为未来改进这些系统提供了一个共同的基准。在最近的一篇工作草稿中,Kumar和Lakkaraju[11]表明,策略性文本序列可以操纵大型语言模型(LLM)的推荐,以增强生成引擎中产品的可见性。虽然他们的方法侧重于通过对抗性文本提高产品可见性,但我们的方法引入了非对抗性策略来优化任何网站内容,以提高生成引擎搜索结果中的可见性。
检索增强语言模型:最近的几项研究通过从知识库中获取相关来源来解决语言模型内存有限的问题,以完成任务[3, 9, 18]。然而,生成引擎需要生成答案并在整个答案中提供归属。此外,生成引擎不仅限于单一文本模态,无论是输入还是输出。此外,生成引擎的框架不仅限于获取相关来源,而是包括多项任务,如查询重构、来源选择以及决定如何和何时执行这些任务。
搜索引擎优化:在过去25年中,广泛的研究已经优化了搜索引擎的网页内容[2, 12, 22]。这些方法包括页面内SEO,通过改善内容和用户体验,以及页面外SEO,通过链接建设来提升网站权威。相比之下,GEO处理的是一个更复杂的环境,涉及多模态、对话设置。由于GEO是针对生成模型进行优化的,而不仅仅是简单的关键词匹配,传统的SEO策略不会适用于生成引擎设置,这突显了GEO的必要性。
8 结论
在这项工作中,我们提出了增强了生成模型的搜索引擎,我们称之为生成引擎。我们提出了生成引擎优化(GEO)来赋能内容创作者,以优化他们在生成引擎下的内容。我们定义了生成引擎的印象度量,并提出并发布了GEO-BENCH:一个包含来自多个领域和设置的多样化用户查询的基准,以及回答这些查询所需的相关来源。我们提出了几种优化生成引擎内容的方法,并证明这些方法可以将生成引擎响应中的来源可见性提高多达40%。在其他发现中,我们表明包含引用、相关来源的引用和统计数据可以显著提高来源可见性。此外,我们发现GEO方法的有效性取决于查询领域,并且结合多种GEO策略的潜力。我们在一个拥有数百万活跃用户的商业部署的生成引擎上展示了有希望的结果,展示了我们工作的实际影响。总之,我们的工作是首次正式提出重要且及时的GEO范式,发布算法和基础设施(基准、数据集和度量),以促进社区在生成引擎方面的快速进展。这作为理解生成引擎对数字空间影响以及GEO在搜索引擎新范式中作用的第一步。
9 局限性
虽然我们在两个生成引擎上严格测试了我们提出的方法,包括一个公开可用的引擎,但随着生成引擎的演变,这些方法可能需要随着时间的推移进行调整,以反映SEO的演变。此外,尽管我们努力确保GEO-BENCH中的查询与现实世界的查询密切相关,但查询的性质可能会随着时间的推移而改变,需要持续更新。此外,由于搜索引擎算法的黑箱性质,我们没有评估GEO方法如何影响搜索排名。然而,我们注意到GEO方法所做的更改是针对文本内容的特定更改,与SEO方法有些相似,同时不影响其他元数据,如域名、反向链接等,因此不太可能影响搜索引擎排名。此外,随着语言模型中更大的上下文长度变得普遍,预计未来的生成模型将能够摄取更多来源,从而减少搜索排名的影响。最后,虽然我们提出的GEO-BENCH中的每个查询都经过标记和手动检查,但由于主观解释或标记错误,可能存在差异。
10 致谢
本材料基于国家科学基金会资助的工作,资助编号为2107048。本材料中表达的任何意见、发现和结论或建议仅代表作者的观点,不一定反映国家科学基金会的观点。
文献列表
-
Daria Alexander, Wojciech Kusa, and Arjen P. de Vries. 2022. ORCAS-I: Queries Annotated with Intent using Weak Supervision. Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval (2022). https://api.semanticscholar.org/CorpusID:248495926
-
Prashant Ankalkoti. 2017. Survey on Search Engine Optimization Tools & Techniques. Imperial journal of interdisciplinary research 3 (2017). https://api.semanticscholar.org/CorpusID:116487363
-
Akari Asai, Xinyan Velocity Yu, Jungo Kasai, and Hannaneh Hajishirzi. 2021. One Question Answering Model for Many Languages with Cross-lingual Dense Passage Retrieval. In Neural Information Processing Systems. https://api.semanticscholar.org/CorpusID:236428949
-
Sergey Brin and Lawrence Page. 1998. The Anatomy of a Large-Scale Hypertextual Web Search Engine. Comput. Networks 30 (1998), 107–117. https://api.semanticscholar.org/CorpusID:7587743
-
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language Models are Few-Shot Learners. In Advances in Neural Information Processing Systems, H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin (Eds.), Vol. 33. Curran Associates, Inc., 1877–1901. https://proceedings.neurips.cc/paper/2020/file/1457c0d6bfc49b67418bfb8ac142164a-Paper.pdf
-
Nick Craswell, Bhaskar Mitra, Emine Yilmaz, Daniel Fernando Campos, and Jimmy J. Lin. 2021. MS MARCO: Benchmarking Ranking Models in the Large-Data Regime. Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval (2021). https://api.semanticscholar.org/CorpusID:233346491
-
Brian Dean. 2023. We Analyzed 4 Million Google Search Results. Here’s What We Learned About Organic Click Through Rate. We Analyzed 4 Million Google Search Results. Here's What We Learned About Organic CTR Accessed: 2024-06-08.
-
Danny Goodwin. 2011. Top Google Result Gets 36.4% of Clicks [Study]. https://www.searchenginewatch.com/2011/04/21/top-google-result-gets-36-4-of-clicks-study/
-
Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Ming-Wei Chang. 2020. REALM: Retrieval-Augmented Language Model Pre-Training. ArXiv abs/2002.08909 (2020). https://api.semanticscholar.org/CorpusID:211204736
-
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. 2023. Survey of hallucination in natural language generation. Comput. Surveys 55, 12 (2023), 1–38.
-
Aounon Kumar and Himabindu Lakkaraju. 2024. Manipulating Large Language Models to Increase Product Visibility. arXiv:2404.07981 [cs.IR]
-
R.Anil Kumar, Zaiduddin Shaik, and Mohammed Furqan. 2019. A Survey on Search Engine Optimization Techniques. International Journal of P2P Network Trends and Technology (2019). https://doi.org/10.14445/2249261
-
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur P. Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc V. Le, and Slav Petrov. 2019. Natural Questions: A Benchmark for Question Answering Research. Transactions of the Association for Computational Linguistics 7 (2019), 453–466. https://api.semanticscholar.org/CorpusID:68611921
-
Nelson F. Liu, Tianyi Zhang, and Percy Liang. 2023. Evaluating Verifiability in Generative Search Engines. ArXiv abs/2304.09848 (2023). https://api.semanticscholar.org/CorpusID:258212854
-
Yang Liu, Dan Iter, Yichong Xu, Shuo Wang, Ruochen Xu, and Chenguang Zhu. 2023. G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment. ArXiv abs/2303.16634 (2023). https://api.semanticscholar.org/CorpusID:257804696
-
G. D. Maayan. 2023. How Google SGE will impact your traffic – and 3 SGE recovery case studies. Search Engine Land (5 Sep 2023). https://searchengineland.com/how-google-sge-will-impact-your-traffic-and-3-sge-recovery-case-studies-431430
-
Jacob Menick, Maja Trębacz, Vladimir Mikulik, John Aslanides, Francis Song, Martin Chadwick, Mia Glaese, Susannah Young, Lucy Campbell-Gillingham, Geoffrey Irving, and Nathan McAleese. 2022. Teaching language models to support answers with verified quotes. ArXiv abs/2203.11147 (2022). https://api.semanticscholar.org/CorpusID:247594830
-
Grégoire Mialon, Roberto Dessì, Maria Lomelì, Christoforos Nalmpantis, Ramakanth Pasunuru, Roberta Raileanu, Baptiste Rozière, Timo Schick, Jane Dwivedi-Yu, Asli Celikyilmaz, Edouard Graess, Yann LeCun, and Thomas Scialom. 2023. Augmented Language Models: A Survey. ArXiv abs/2302.07842 (2023). https://api.semanticscholar.org/CorpusID:256868474
-
Reichiro Nakano, Jacob Hilton, S. Arun Balaji, Jeff Wu, Ouyang Long, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, Xu Jiang, Karl Cobbe, Tyna Eloundou, Gretchen Krueger, Kevin Button, Matthew Knight, Benjamin Chess, and John Schulman. 2021. WebGPT: Browser-assisted question-answering with human feedback. ArXiv abs/2112.09332 (2021). https://api.semanticscholar.org/CorpusID:245329531
-
OpenAI. 2022. Introducing ChatGPT. https://openai.com/index/chatgpt/
-
OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Alman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkhat, Red Avila, Igor Babuschkin, Suchir Balaji, Valerie Bafti, Ankur P. Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc V. Le, and Slav Petrov. 2019. Natural Questions: A Benchmark for Question Answering Research. Transactions of the Association for Computational Linguistics 7 (2019), 453–466. https://api.semanticscholar.org/CorpusID:68611921
-
A. Shahzad, Deden Witarsyah Jacob, Nazir M. Nawi, Hairulnizam Bin Mahdin, and Marheni Eka Saputra. 2020. The new trend for search engine optimization, tools and techniques. Indonesian Journal of Electrical Engineering and Computer Science 18 (2020), 1568. https://api.semanticscholar.org/CorpusID:213123106
-
Kurt Shuster, Jing Xu, Mojtaba Komelii, Da Ju, Eric Michael Smith, Stephen Roller, Megan Ung, Moya Chen, Kushal Arora, Joshua Lane, Morteza Behrooz, W.K.F. Ngan, Spencer Poff, Naman Goyal, Arthur Szlam, Y-Lan Boureau, Melanie Kambadur, and Jason Weston. 2022. BlenderBot 3: a deployed conversational agent that continually learns to responsibly engage. ArXiv abs/2208.03188 (2022). https://api.semanticscholar.org/CorpusID:251371589
-
Romal Thoppilan, Daniel De Freitas, Jamie Hall, Noam Shazeer, Apoorv Kulshrestha, Heng-Tze Cheng, Alicia Jin, Taylor Bos, Leslie Baker, Yu Du, YaGuang Li, Hongrae Lee, Huaixiu Steven Zheng, Amin Ghafouri, Marcelo Menegal, Yanping Huang, Maxim Krikun, Dmitry Lepikhin, James Qin, Dehao Chen, Yuanzhong Xu, Zhifeng Chen, Adam Roberts, Maarten Bosma, Vincent Zhao, Yangyi Zhou, Chung-Ching Chang, Igor Krivokon, Will Rush, Marc Pickett, Pranesh Srinivasan, Laichee Man, Kathleen Meier-Hellstern, Meredith Ringel Morris, Tulsee Doshi, Renelio Delos Santos, Toju Duke, Johnny Soraker, Ben Zevenbergen, Vinodkumar Prabhakaran, Mark Diaz, Ben Hutchinson, Kristen Olson, Alejandra Molina, Erin Hoffman-John, Josh Lee, Lora Aroyo, Ravi Rajakumar, Alena Butryna, Matthew Lamm, Viktoriya Kuzmina, Joe Fenton, Aaron Cohen, Rachel Bernstein, Ray Kurzweil, Blaise Aguera-Arcas, Claire Cui, Marian Croak, Ed Chi, and Quoc Le. 2022. LaMDA: Language Models for Dialog Applications. ArXiv:2201.08239 [cs.CL]
-
Chunting Zhou, Pengfei Liu, Puxin Xu, Srinivas Iyer, Jiao Sun, Yuning Mao, Xuezhe Ma, Avia Efrat, Ping Yu, L. Yu, Susan Zhang, Gargi Ghosh, Mike Lewis, Luke Zettlemoyer, and Omer Levy. 2023. LIMA: Less Is More for Alignment. ArXiv abs/2305.11206 (2023). https://api.semanticscholar.org/CorpusID:258822910
A 会话生成引擎
在第2.1节中,我们讨论了一个单轮生成引擎,它根据用户查询输出单个响应。然而,即将到来的生成引擎的优势之一将是它们能够进行积极的来回对话。对话允许用户对他们的查询或生成引擎响应进行澄清并提出后续问题。具体来说,在公式1中,输入不是单个查询 qu,而是建模为对话历史 H=(qut,rt) 对。然后定义响应 rt+1 为:
GE:=fLE(H,PU)→rt+1
其中 t 是轮次编号。
此外,为了在对话中吸引用户,一个单独的大型语言模型(LLM),Lfollow 或 Lresp,可能会基于 H、PU 和 rt+1 生成建议的后续查询。建议的后续查询通常旨在最大化用户参与的可能性。这不仅通过增加用户互动来使生成引擎提供者受益,而且还通过提高他们的可见性来使网站所有者受益。此外,这些后续查询可以通过获取更详细的信息来帮助用户。
B 实验设置
B.1 评估生成引擎
所使用的确切提示如列表1所示。
B.2 基准测试
GEO-BENCH包含来自九个数据集的查询。每个数据集的代表性查询如图2所示。此外,我们根据7个不同类别的池为每个查询打标签。对于标签,我们使用GPT-4模型,并手动确认高召回率和精确度。然而,由于这样一个自动化系统,标签可能会有噪音,不应被仔细考虑。有关这些查询的详细信息如下:
-
难度等级:查询的复杂性,从简单到复杂。
-
查询性质:查询所寻求的信息类型,如事实、意见或比较。
-
类型:查询的类别或领域,如艺术和娱乐、金融或科学。
-
具体主题:查询的具体主题,如物理、经济学或计算机科学。
-
敏感性:查询是否涉及敏感话题。
-
用户意图:用户查询背后的目的,如研究、购买或娱乐。
-
答案类型:查询所寻求的答案格式,如事实、意见或列表。
B.3 评估指标
我们使用了7种不同的主观印象度量,其提示在我们的公共存储库中展示:https://github.com/GEO-optim/GEO。
B.4 GEO方法
我们提出了9种不同的生成引擎优化方法来优化生成引擎的网站内容。我们在完整的GEO-BENCH测试集上评估这些方法。此外,为了减少结果中的方差,我们在五个不同的随机种子上运行我们的实验,并报告平均值。
B.5 GEO方法的提示
我们在公共存储库中展示了所有提示:https://github.com/GEO-optim/GEO。所有实验均使用GPT-3.5 turbo。
C 结果
我们在五个随机种子上进行实验,并在表6中展示结果,带有统计偏差。
C.1 真实环境下的GEO:使用已部署的生成引擎进行实验
我们还在真实环境中部署的生成引擎Perplexity.ai上评估了我们提出的生成引擎优化(GEO)方法。由于Perplexity.ai不允许用户指定来源URL,我们改为将来源文本作为文件上传到Perplexity.ai,确保所有答案仅使用提供的文件来源生成。我们在测试集的一个子集上评估了我们所有的方法,即200个样本。使用Perplexity.ai的结果如表7所示。
| 方法 | 位置调整后的词数 | 主观印象 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 词 | 位置 | 总体 | 相关性 | 信息量 | 独特性 | 多样性 | 后续 | 位置 | 计数 | 平均值 | |
| 无优化 | 19.7 (±0.7) | 19.6 (±0.5) | 19.8 (±0.6) | 19.8 (±0.9) | 19.8 (±1.6) | 19.8 (±0.6) | 19.8 (±1.1) | 19.8 (±1.0) | 19.8 (±1.0) | 19.8 (±1.0) | 19.8 (±0.9) |
| 关键词填充 | 19.6 (±0.5) | 19.5 (±0.6) | 19.8 (±0.5) | 20.8 (±0.8) | 19.8 (±1.0) | 20.4 (±0.5) | 20.6 (±0.9) | 19.9 (±0.9) | 21.1 (±1.0) | 21.0 (±0.9) | 20.6 (±0.7) |
| 独特词 | 20.6 (±0.6) | 20.5 (±0.7) | 20.7 (±0.5) | 20.8 (±0.7) | 20.3 (±1.3) | 20.5 (±0.3) | 20.9 (±0.3) | 20.4 (±0.7) | 21.5 (±0.6) | 21.2 (±0.4) | 20.9 (±0.4) |
表 6:GEO-BENCH上GEO方法的绝对印象指标。与传统SEO中表现不佳的简单方法(如关键词填充)相比,我们提出的方法(如统计添加和引用添加)在所有指标上都显示出显著的改进。最佳方法在位置调整后的词数和主观印象上分别比基线提高了41%和28%。
| 高性能生成引擎优化方法 | 位置调整后的词数 | 主观印象 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 易于理解 | 21.5 (±0.7) | 22.0 (±0.8) | 21.5 (±0.6) | 21.0 (±1.1) | 21.1 (±1.8) | 21.2 (±0.9) | 20.9 (±1.1) | 20.6 (±1.0) | 21.9 (±1.1) | 21.4 (±0.9) | 21.3 (±1.0) |
| 权威性 | 21.3 (±0.7) | 21.2 (±0.9) | 21.1 (±0.8) | 22.3 (±0.8) | 22.9 (±0.8) | 22.1 (±0.9) | 23.2 (±0.7) | 21.9 (±0.6) | 23.9 (±1.1) | 23.0 (±1.2) | 23.1 (±0.7) |
| 技术术语 | 22.5 (±0.6) | 22.4 (±0.6) | 22.5 (±0.6) | 21.2 (±0.7) | 21.8 (±0.8) | 20.5 (±0.5) | 21.1 (±0.6) | 20.5 (±0.6) | 22.1 (±0.6) | 21.2 (±0.2) | 21.4 (±0.4) |
| 流畅性优化 | 24.4 (±0.8) | 24.4 (±0.6) | 24.4 (±0.8) | 21.3 (±0.9) | 23.2 (±1.5) | 21.2 (±1.0) | 21.4 (±1.4) | 20.8 (±1.3) | 23.2 (±1.8) | 21.5 (±1.3) | 22.1 (±1.2) |
| 引用来源 | 25.5 (±0.7) | 25.3 (±0.6) | 25.3 (±0.6) | 22.8 (±0.9) | 24.2 (±0.7) | 21.7 (±0.3) | 22.3 (±0.8) | 21.3 (±0.6) | 23.5 (±0.4) | 21.7 (±0.6) | 22.9 (±0.5) |
| 引用添加 | 27.5 (±0.8) | 27.6 (±0.8) | 27.1 (±0.6) | 24.4 (±1.0) | 26.7 (±1.1) | 24.6 (±0.6) | 24.9 (±0.9) | 23.2 (±0.9) | 26.4 (±1.0) | 24.1 (±1.2) | 25.5 (±0.9) |
| 统计添加 | 25.8 (±1.2) | 26.0 (±0.8) | 25.5 (±1.2) | 23.1 (±1.4) | 26.1 (±0.9) | 23.6 (±0.9) | 24.5 (±1.2) | 22.4 (±1.2) | 26.1 (±1.2) | 23.8 (±1.2) | 24.8 (±1.1) |
| 方法 | 位置调整后的词数 | 主观印象 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 词 | 位置 | 总体 | 相关性 | 信息量 | 独特性 | 多样性 | 后续 | 位置 | 计数 | 平均值 | |
| 无优化 | 24.0 | 24.4 | 24.1 | 24.7 | 24.7 | 24.7 | 24.7 | 24.7 | 24.7 | 24.7 | 24.7 |
| 关键词填充 | 21.9 | 21.4 | 21.9 | 26.3 | 27.2 | 27.2 | 30.2 | 27.9 | 28.2 | 26.9 | 28.1 |
| 独特词 | 24.0 | 23.7 | 23.6 | 24.9 | 25.1 | 24.7 | 24.4 | 23.0 | 23.6 | 23.9 | 24.1 |
| 高性能生成引擎优化方法 | 位置调整后的词数 | 主观印象 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 权威性 | 25.6 | 25.7 | 25.9 | 28.9 | 30.9 | 31.2 | 31.7 | 31.5 | 26.9 | 29.5 | 30.6 |
| 流畅性优化 | 25.8 | 26.2 | 26.0 | 28.9 | 29.4 | 29.8 | 30.6 | 30.1 | 29.6 | 29.6 | 30.0 |
| 引用来源 | 26.6 | 26.9 | 26.8 | 19.8 | 20.7 | 19.5 | 18.9 | 20.0 | 18.5 | 18.9 | 19.0 |
| 引用添加 | 28.8 | 28.7 | 29.1 | 31.4 | 31.9 | 31.9 | 32.3 | 31.4 | 31.7 | 30.9 | 32.1 |
| 统计添加 | 25.8 | 26.6 | 26.2 | 31.6 | 33.4 | 33.7 | 34.0 | 33.3 | 33.1 | 33.9 | 33.9 |
表 7:在GEO-BENCH上使用Perplexity.ai作为生成引擎的GEO方法的性能提升。与传统SEO中常用的简单方法(如关键词填充)相比,我们提出的方法(如统计添加和引用添加)在所有指标上都显示出显著的性能提升。最佳方法在位置调整后的词数和主观印象上分别比基线提高了22%和37%。

















 1229
1229

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









