







原文:Design Patterns and Best Practices in Java
译者:飞龙
本文来自【ApacheCN Java 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。
六、让我们开始反应式吧
这一章将描述反应式编程范式,以及为什么它能很好地适用于带有函数元素的语言。读者将熟悉反应式编程背后的概念。我们将介绍在创建反应式应用时从观察者模式和迭代器模式中使用的元素。这些示例将使用反应式框架和名为 RxJava(版本 2.0)的 Java 实现。
我们将讨论以下主题:
- 什么是反应式编程?
- RxJava 简介
- 安装 RxJava
- 可观察对象、可流动对象、观察者和订阅
- 创建可观察对象
- 变换可观察对象
- 过滤可观察对象
- 组合可观察对象
- 错误处理
- 调度者
- 主题
- 示例项目
什么是反应式编程?
根据《反应宣言》,无功系统具有以下属性:
- 响应:系统以一致的、可预测的方式及时响应。
- 恢复:系统对故障有弹性,能快速恢复。
- 弹性:系统通过增加或减少分配的资源,在不同的工作负载下保持其响应能力。这是通过动态查找和修复瓶颈来实现的。这不能与可伸缩性混淆。弹性系统需要根据需要上下伸缩——见这个页面。
- 消息驱动:依赖异步消息传递,确保松耦合、隔离、位置透明和容错。
需求是真实的。如今,无响应系统被认为是有缺陷的,用户将避免使用。根据这个页面的说法,一个没有回应的网站在搜索引擎中的排名很低:
“响应式设计是谷歌的推荐设计模式”
反应式系统是一种使用元素构成复杂系统的架构风格,有些元素是用反应式编程技术构建的。
反应式编程是一种依赖于异步数据流的范例。它是异步编程的事件驱动子集。相反,反应式系统是消息驱动的,这意味着接收器是预先知道的,而对于事件,接收器可以是任何观察者。
反应式编程不仅仅是基于事件的编程,因为它利用了数据流,它强调数据流而不是控制流。以前,诸如鼠标或键盘事件之类的事件,或者诸如服务器上的新套接字连接之类的后端事件,都是在线程事件循环(thread of execution)中处理的。现在一切都可以用来创建一个数据流;假设来自某个后端端点的 JSON REST 响应成为一个数据流,它可以被等待、过滤,或者与来自不同端点的其他响应合并。这种方法通过消除开发人员显式创建在多核和多 CPU 环境中处理异步调用的所有样板代码的需要,提供了很大的灵活性。
一个最好的也是最被过度使用的反应式编程示例是电子表格示例。定义流(flow)类似于声明 Excel 的 C1 单元格的值等于 B1 单元格和 A1 单元格的内容。每当 A1 或 B1 单元更新时,就会观察到变化并对其作出反应,其副作用是 C1 值得到更新。现在假设 C2 到 Cn 单元格等于 A2 到 An 加上 B2 到 Bn 的内容;同样的规则适用于所有单元格。
反应式编程使用以下一些编程抽象,有些抽象取自函数式编程世界:
Optional/Promise:这些提供了一种手段,可以对不久的将来某个地方将要提供的值采取行动。- 流:它提供了数据管道,就像列车轨道一样,为列车运行提供了基础设施。
- 数据流变量:这些是应用于流函数的输入变量的函数的结果,就像电子表格单元格一样,通过对两个给定的输入参数应用加号数学函数来设置。
- 节流:该机制用于实时处理环境,包括数字信号处理器(DSP)等硬件,通过丢弃元件来调节输入处理的速度,以赶上输入速度;用作背压策略。
- 推送机制:这与好莱坞原理相似,因为它反转了调用方向。一旦数据可用,就调用流中的相关观察者来处理数据;相反,拉机制以同步方式获取信息。
有许多 Java 库和框架允许程序员编写反应式代码,如 Reactor、Ratpack、RxJava、Spring Framework 5 和 Vert.x。通过添加 JDK9 Flow API,开发人员可以使用反应式编程,而无需安装其他 API。
RxJava 简介
RxJava 是从 Microsoft.NET 世界移植的反应式扩展(一个库,用于使用可观察序列编写异步和基于事件的程序)的实现。2012 年,Netflix 意识到他们需要一个范式的转变,因为他们的架构无法应对庞大的客户群,所以他们决定通过将无功扩展的力量引入 JVM 世界来实现无功扩展;RxJava 就是这样诞生的。除了 RxJava 之外,还有其他 JVM 实现,比如 RxAndroid、RxJavaFX、RxKotlin 和 RxScale。这种方法给了他们想要的动力,通过公开,它也为我们提供了使用它的机会。
RxJavaJar 是根据 Apache 软件许可证 2.0 版获得许可的,可以在中央 Maven 存储库中获得。
有几个外部库使用 RxJava:
hystrix:一个延迟和容错库,用于隔离远程系统的访问点rxjava-http-tail:一个 HTTP 日志跟踪库,可用方式与tail -f相同rxjava-jdbc:使用 RxJava 和到ResultSets流的 JDBC 连接
安装 RxJava 框架
在本节中,我们将介绍 Maven 的 RxJava 安装(Gradle、SBT、Ivy、Grape、Leiningen 或 Buildr 步骤类似)以及 Java9 的 replJShell 的用法。
Maven 安装
安装 RxJava 框架很容易。JAR 文件和依赖的项目反应流在 Maven 下的这个页面中可用。
为了使用它,在您的pom.xml文件中包括这个 Maven 依赖项:
<project xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.packt.java9</groupId>
<artifactId>chapter6_client</artifactId>
<version>0.0.1-SNAPSHOT</version>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<!-- https://mvnrepository.com/artifact/io.reactivex.
rxjava2/rxjava -->
<dependency>
<groupId>io.reactivex.rxjava2</groupId>
<artifactId>rxjava</artifactId>
<version>2.1.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.
reactivestreams/reactive-streams -->
<dependency>
<groupId>org.reactivestreams</groupId>
<artifactId>reactive-streams</artifactId>
<version>1.0.1</version>
</dependency>
</dependencies>
</project>
安装在 Gradle、SBT、Ivy、Grape、Leiningen 或 Buildr 中类似;查看这个页面了解需要添加到configuration文件的更多信息。
JShell 安装
我们将在第 9 章“Java 最佳实践”中详细讨论 JShell,现在让我们从 RxJava 的角度来看一下。在 JShell 中安装 RxJava 框架是通过将 classpath 设置为 RxJava 和 reactive streams JAR 文件来完成的。请注意,Linux 上使用冒号,Windows 上使用分号作为文件路径分隔符:
"c:Program FilesJavajdk-9binjshell" --class-path D:Kitsrxjavarxjava-2.1.3.jar;D:Kitsrxjavareactive-streams-1.0.1.jar
屏幕上将显示以下错误:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hTvpKigH-1681378425553)(https://gitcode.net/apachecn/apachecn-java-zh/-/raw/master/docs/design-pattern-best-prac-java/img/081f90ec-4fec-4cf3-bfe5-4793220a018d.png)]
前面的错误是因为我们忘记导入相关的 Java 类。
以下代码处理此错误:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JQZ8FggD-1681378425554)(https://gitcode.net/apachecn/apachecn-java-zh/-/raw/master/docs/design-pattern-best-prac-java/img/fd64466a-2b93-43ce-9fe2-a4fc81f8dd59.png)]
现在我们已经成功地创建了我们的第一个可观察对象。在下面的部分中,我们将学习它的功能以及如何使用它。
可观察对象、可流动对象、观察者和订阅者
在 ReactiveX 中,观察者订阅一个可观察的对象。当观察者发射数据时,观察者通过消耗或转换数据做出反应。这种模式便于并发操作,因为它不需要在等待可观察对象发出对象时阻塞。相反,它以观察者的形式创建了一个哨兵,随时准备在以观察者的形式出现新数据时做出适当的反应。这个模型被称为反应堆模式。下图取自这个页面,解释了可观测数据流:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZC7HQYSC-1681378425554)(https://gitcode.net/apachecn/apachecn-java-zh/-/raw/master/docs/design-pattern-best-prac-java/img/b33888d8-4408-4fd5-9215-3a609f5cea79.png)]
反应式的可观察性与祈使式的可观察性相似。它解决了相同的问题,但策略不同。一旦可用,Observable通过异步推送更改来工作,而Iterable则以同步方式拉送更改机制。处理错误的方法也不同;一种使用错误回调,而另一种使用副作用,例如抛出异常。下表显示了差异:
| 事件 | 可迭代对象 | 可观察对象 |
| — | — |
| 获取数据 | T next() | onNext(T) |
| 错误 | throw new Exception | onError(Exception) |
| 完成 | Return | onCompleted() |
使用订阅(onNextAction、onErrorAction、onCompletedAction)方法将观察者连接到被观察者。观察者实现以下方法的一些子集(只有onNext是必需的):
onNext:每当被观察对象发出一个项目时调用,方法以被观察对象发出的项目作为参数onError:调用它是为了表示它没有生成预期的数据或遇到了其他错误,并将异常/错误作为它的参数onCompleted:当没有更多的数据要发出时调用
从设计的角度来看,反应式可观测对象通过使用onError和onCompleted回调来增加在完成和错误时发出信号的能力,从而增强了四人帮的观察者模式。
有两种类型的反应式观察结果:
- 热:即使没有连接用户,也会尽快开始发送。
- 冷:在开始发送数据之前,等待至少一个订户连接,因此至少一个订户可以从一开始就看到序列。它们被称为“可连接的”可观察对象,RxJava 拥有能够创建此类可观察对象的操作符。
RxJava2.0 引入了一种新的可观察类型,称为Flowable。新的io.reactivex.Flowable是一个支持背压的基本反应类,而可观察的不再是。背压是一组策略,用于处理当可观察对象发出订户可以处理的更多数据时的情况。
RxJava Observable应用于小数据集(最长不超过 1000 个元素),以防止OutOfMemoryError或用于 GUI 事件,例如鼠标移动或小频率(1000 Hz 或以下)的触摸事件。
在处理超过 10000 个元素、从磁盘读取(解析)文件(这在背压下很好地工作)、通过 JDBC 从数据库读取数据或执行基于块和/或拉的数据读取时,将使用Flowable。
创建可观察对象
以下操作符用于从现有对象、其他数据结构的数组或序列或计时器中从头开始创建可观察对象。
创建操作符
可以通过调用以下io.reactivex.Observable方法之一(操作符)从头开始创建可观察对象:
- 创建
- 生成
- 不安全创建
下面的示例演示如何从头开始构造一个可观察的。调用onNext()直到观察者没有被释放,onComplete()和onError()以编程方式获得 1 到 4 的数字范围:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EeVHU7Ah-1681378425555)(https://gitcode.net/apachecn/apachecn-java-zh/-/raw/master/docs/design-pattern-best-prac-java/img/5d7d884e-4933-47c8-822e-433252cffe4d.png)]
正如我们在前面的屏幕截图中所看到的,输出与预期一样,范围从 1 到 4,序列在使用后会被处理掉。
延迟运算符
一旦观察者连接,可以通过调用defer方法为每个观察者创建一个新的观察者。以下代码显示了defer在我们提供号码时的用法:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZCiT8dLC-1681378425555)(https://gitcode.net/apachecn/apachecn-java-zh/-/raw/master/docs/design-pattern-best-prac-java/img/d13e22a4-5612-4842-8604-45131c8b57e5.png)]
控制台println方法输出 123,这是可观察的整数。
空运算符
可以通过调用empty()或never() io.reactivex.Observable方法来创建从不发送的空项目。
from运算符
通过调用以下方法之一,可以从数组、Future或其他对象和数据结构进行转换:
fromArray:将数组转换为可观察数组fromCallable:将提供值的Callable转换为ObservablefromFuture:将Future提供的值转换为可观察的值fromIterable:将Iterable转换为ObservablefromPublisher:将反应发布者流转换为可观察发布者流just:将给定对象转换为可观察对象
下面的示例从字母列表(abc)中创建一个Observable:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lI4vMH5i-1681378425556)(https://gitcode.net/apachecn/apachecn-java-zh/-/raw/master/docs/design-pattern-best-prac-java/img/3827aba1-f52f-4a66-a1ed-1c62e1f65eda.png)]
a、b和c的整个数组被消耗,并通过System.out.println方法打印到控制台。
区间运算符
通过使用interval方法,可以创建一个可观察的对象,该对象发出一个由特定时间间隔间隔隔开的整数序列。下面的示例从不停止;它每秒钟连续打印一次记号号:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dfpRRXTK-1681378425556)(https://gitcode.net/apachecn/apachecn-java-zh/-/raw/master/docs/design-pattern-best-prac-java/img/fb9d71db-f693-4721-be43-73004eac1fa4.png)]
尝试停止计时器也无济于事(即使是Ctrl + C,只要关闭窗口),它会继续按指令每隔一秒向控制台打印递增的数字。
定时器运算符
通过使用计时器方法,可以在给定的延迟之后发出单个项目。
范围运算符
可以使用以下方法创建序列号范围:
intervalRange:发出一系列长值的信号,第一个在一些初始延迟之后,接下来是周期性的range:发出指定范围内的整数序列
重复运算符
为了重复特定的项目或特定的顺序,请使用:
repeat:重复给定可观测源发射的项目序列多次或永远(取决于输入)repeatUntil:重复可观测源发出的项目序列,直到提供的stop函数返回truerepeatWhen:除了onComplete之外,发出与初始可观察对象相同的值
以下代码重复给定的a值,直到满足条件:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cCMIVaix-1681378425556)(https://gitcode.net/apachecn/apachecn-java-zh/-/raw/master/docs/design-pattern-best-prac-java/img/417d530b-771a-41b7-b2b6-b8fa3283219f.png)]
它向控制台重复三次a,直到x的值 3 大于 2。作为练习,将x++替换为++x并检查控制台。
转换可观测对象
这些运算符转换由可观察对象发出的项。
订阅操作符
这些是订户用来消耗来自可观察对象的发射和通知的方法,例如onNext、onError和onCompleted。用于订阅的可观察方法有:
blockingForEach:消耗此可观察对象发出的每个项目,并阻塞直到可观察对象完成。blockingSubscribe:订阅当前线程上的可观察事件并消耗事件。forEachWhile:订阅Observable并接收每个元素的通知,直到onNext谓词返回false。forEach:订阅可观察到的元素并接收每个元素的通知。subscribe:将给定的观察者订阅到该可观察对象。观察器可以作为回调、观察器实现或抽象io.reactivex.subscribers.DefaultSubscriber<T>类的子类型提供。
缓冲区运算符
buffer方法用于创建给定大小的包,然后将它们打包为列表。下面的代码显示了如何在 10 个数字中创建两个bundle,一个有 6 个,另一个有其余 4 个:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6etwOVNf-1681378425557)(https://gitcode.net/apachecn/apachecn-java-zh/-/raw/master/docs/design-pattern-best-prac-java/img/c4292f4c-a67d-44da-99b9-07359a89daa5.png)]
展开映射操作符
通过使用以下操作符之一,可以通过到达顺序(flatMap)、保持最后发射的顺序(switchMap)或通过保持原始顺序(concatMap)将给定的可观察对象转换为单个可观察对象:concatMap、concatMapDelayError、concatMapEager、concatMapEagerDelayError、concatMapIterable、flatMap、flatMapIterable、switchMap,或switchMapDelayError。下面的示例演示了如何通过随机选择可观察对象的顺序来更改输出的内容。(flatMap、concatMap、switchMap:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8DBt45Y9-1681378425557)(https://gitcode.net/apachecn/apachecn-java-zh/-/raw/master/docs/design-pattern-best-prac-java/img/c3fdb310-ec85-4469-86b6-329586a071bd.png)]
concatMap实现将c字符串附加到给定的a、b和c字符串中的每一个,因此,输出是ac、bc和cc。
flatMap实现将f字符串附加到给定的a、b和c字符串中的每一个,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eEi9aQAp-1681378425557)(https://gitcode.net/apachecn/apachecn-java-zh/-/raw/master/docs/design-pattern-best-prac-java/img/96750fcd-8d66-48dc-b62d-dea37238d9bf.png)]
由于随机延迟,顺序与预期的af、bf、cf不同,运行几次就会输出预期的顺序。
下面的代码段显示了不同的输出。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Y0nxkwzV-1681378425558)(https://gitcode.net/apachecn/apachecn-java-zh/-/raw/master/docs/design-pattern-best-prac-java/img/98226dc4-761c-43f3-a4cf-d70b57c77f86.png)]
switchMap实现将s字符串附加到给定的a、b和c字符串列表中的最后一个元素。
注意advanceTimeBy的用法。没有这个电话,什么都不会打印,因为发射被推迟了。
分组运算符
groupBy用于将一个可观察对象划分为一组可观察对象,每个可观察对象发出一组不同的项目。下面的代码按起始字母对字符串进行分组,然后打印键和特定键的组数据。请注意,这些组是可观察的,可用于构造其他数据流。
以下输出按第一个字母显示组作为一个组,并显示组键(即第一个字母):
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sMjw5sIj-1681378425558)(https://gitcode.net/apachecn/apachecn-java-zh/-/raw/master/docs/design-pattern-best-prac-java/img/44c6e7ea-5442-4bf8-bea1-6c8f0e77e773.png)]
映射运算符
为每个项目应用一个函数来转换可观察对象可以通过以下方法实现:
cast:将结果强制转换为给定类型map:对每个发出的项目应用指定的函数
扫描运算符
利用积累的转换可以用scan方法来完成。以下代码通过发出元素的当前和来使用它:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NPFIjfXw-1681378425558)(https://gitcode.net/apachecn/apachecn-java-zh/-/raw/master/docs/design-pattern-best-prac-java/img/2430126e-d52b-4730-b9bb-a70032b24ff7.png)]
窗口操作符
window方法用于周期性地将项目从一个可观察窗口细分为可观察窗口,并突发发射这些窗口。下面的代码显示,使用一个元素的窗口不起任何作用,同时使用三个元素输出它们的总和:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-S2jATBVa-1681378425558)(https://gitcode.net/apachecn/apachecn-java-zh/-/raw/master/docs/design-pattern-best-prac-java/img/4d1158a4-c0ab-495a-a14c-f298825df7e3.png)]
过滤可观察对象
这些操作符根据给定的条件/约束从给定的可观察对象选择性地发射项。
去抖动算符
只能在经过特定时间跨度后发射,可以使用以下方法:
debounce:镜像最初的可观察项,除了它删除源发出的项,然后在一段时间内删除另一项throttleWithTimeout:仅发射那些在指定时间窗口内没有后跟另一个发射项的项
在下面的示例中,我们将删除在 100 毫秒的去抖动时间跨度过去之前触发的项;在我们的示例中,它只是最后一个管理的值。同样,通过使用测试调度器,我们提前了时间:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nogG5oIK-1681378425559)(https://gitcode.net/apachecn/apachecn-java-zh/-/raw/master/docs/design-pattern-best-prac-java/img/14796180-af89-486d-b2c6-af30de36f343.png)]
去重运算符
这将使用以下方法删除可观察对象发出的不同项:
distinct:只发射不同的元素distinctUntilChanged:仅发射与其直接前辈不同的元素
在下面的代码中,我们将看到如何使用distinct方法从给定序列中删除重复项:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AAG29dWm-1681378425559)(https://gitcode.net/apachecn/apachecn-java-zh/-/raw/master/docs/design-pattern-best-prac-java/img/04062498-1881-48c2-a36b-cafb2aa80c50.png)]
我们可以看到重复的aaa字符串已经从输出中删除。
获取元素运算符
为了通过索引获得元素,使用elementAt方法。以下代码打印列表中的第三个元素:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kXNVrixX-1681378425559)(https://gitcode.net/apachecn/apachecn-java-zh/-/raw/master/docs/design-pattern-best-prac-java/img/0d1cf753-0142-4ac3-bdb3-f27485bfaebc.png)]
过滤运算符
在以下方法上使用只允许从通过测试(谓词/类型测试)的可观察对象中发出那些项:
filter:只发出满足指定谓词的元素ofType:只发出指定类型的元素
以下代码显示了filter方法的用法,用于过滤掉不以字母a开头的元素:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bVsOgqq9-1681378425560)(https://gitcode.net/apachecn/apachecn-java-zh/-/raw/master/docs/design-pattern-best-prac-java/img/b231376c-4dd4-4c41-a306-c5c36fdb8475.png)]
第一个/最后一个运算符
这些方法用于根据给定条件返回项目的第一个和最后一个匹配项。也有阻塞版本可用。可用的io.reactivex.Observable methods是:
blockingFirst:返回可观察对象发出的第一项blockingSingle:返回可观察对象发出的第一个Single项first:返回可观察对象发出的第一项firstElement:返回仅发射第一个项目的Maybesingle:返回仅发射第一个项目的SinglesingleElement:返回一个只发出第一个单曲的MaybeblockingLast:返回可观察对象发出的最后一项last:返回可观察对象发出的最后一项lastElement:返回只发出最后一个单曲的Maybe
示例运算符
使用此运算符可发射特定项目(由采样时间段或节气门持续时间指定)。io.reactivex.Observable提供以下方法:
sample:在给定的时间段内发出最近发出的项目(如果有)throttleFirst:仅发射给定连续时间窗口内发射的第一个项目throttleLast:仅发射给定连续时间窗口内发射的最后一项
跳过运算符
从可观察的输出中删除第n个倒数第n个元素。以下代码显示了如何跳过给定输入的前三个元素:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZOeOAVsX-1681378425560)(https://gitcode.net/apachecn/apachecn-java-zh/-/raw/master/docs/design-pattern-best-prac-java/img/97de704a-97d6-44a5-9d1d-d5c670cc354c.png)]
调用skipLast方法将只输出 1 和 2。
选取运算符
它只从给定的可见光发送第n个倒数第n个元素。以下示例显示如何仅从可观察的数值范围中获取前三个元素:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jjcsfc7i-1681378425560)(https://gitcode.net/apachecn/apachecn-java-zh/-/raw/master/docs/design-pattern-best-prac-java/img/e8d8122d-3c2c-4d1e-bc61-ae5c9313715c.png)]
使用具有相同参数的takeLast方法将输出 3、4 和 5。
组合可观察对象
这些运算符用于组合多个可观察对象。
联合运算符
通过调用以下方法之一,组合来自两个或多个可观测对象的最新发射值:
combineLatest:发出聚合每个源的最新值的项withLatestFrom:将给定的可观察对象合并到当前实例中
下面的示例(永远运行)显示了组合两个具有不同时间跨度的间隔可观察对象的结果—第一个每 6 毫秒发射一次,另一个每 10 毫秒发射一次:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5vkKbrIx-1681378425560)(https://gitcode.net/apachecn/apachecn-java-zh/-/raw/master/docs/design-pattern-best-prac-java/img/5c5081da-a559-42b7-b9fe-33696c536ca3.png)]
前面代码的执行需要通过按Ctrl + C停止,因为它创建了一个无限列表。输出与预期一样,它包含基于创建时间戳的两个序列的组合值。
连接运算符
通过调用以下方法之一,可以基于给定窗口组合两个可观察对象:
join:使用聚合函数,根据重叠的持续时间,将两个可观察对象发出的项目连接起来groupJoin:使用聚合函数,根据重叠的持续时间,将两个可观察对象发出的项目加入到组中
下面的示例使用join组合两个可观察对象,一个每 100 毫秒触发一次,另一个每 160 毫秒触发一次,并每 55 毫秒从第一个值中获取一个值,每 85 毫秒从第二个值中获取一个值:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qgxylr5M-1681378425565)(https://gitcode.net/apachecn/apachecn-java-zh/-/raw/master/docs/design-pattern-best-prac-java/img/55cdf0f8-ce56-4452-a25d-5b04eaf29dc7.png)]
前面的代码永远执行,需要手动停止。
合并运算符
将多个可观察对象合并为一个可观察对象,所有给定的发射都可以通过调用:
merge:将多个输入源展开为一个可观察源,无需任何转换mergeArray:将作为数组给出的多个输入源展开为一个可观察源,而不进行任何转换mergeArrayDelayError:将作为数组给出的多个输入源展开为一个可观察源,没有任何转换,也没有被错误打断mergeDelayError:将多个输入源展开为一个可观察源,没有任何转换,也没有被错误打断mergeWith:将这个和给定的源展开为一个可观察的,没有任何转换
在下面的示例中,我们将合并原始 1 到 5 范围的部分,合并方式是它包含所有条目,但顺序不同:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PDu5cOFR-1681378425566)(https://gitcode.net/apachecn/apachecn-java-zh/-/raw/master/docs/design-pattern-best-prac-java/img/6e6af107-c6bc-4a15-be00-3023a00ad305.png)]
压缩运算符
基于组合器函数将多个可观察项组合成单个可观察项可以通过调用:
zip:将指定的组合器函数的结果应用于给定可观测项所发射的多个项目的组合zipIterable:发出一个指定的组合器函数的结果,该函数应用于给定的可观测项发出的多个项的组合zipWith:发出一个指定的组合器函数的结果,该组合器函数应用于这个和给定的可观察对象的组合
下面的代码显示了如何基于字符串连接组合器将zip应用于从 1 到 5 到 10 到 16(更多元素)的范围发出的元素。请注意,由于没有要应用的对应项,因此不会应用额外的发射(编号 16):
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ji0HhhUS-1681378425566)(https://gitcode.net/apachecn/apachecn-java-zh/-/raw/master/docs/design-pattern-best-prac-java/img/eb0fc961-36a5-4e0b-a200-3ac7f2b45424.png)]
错误处理
Observable包含几个操作符,这些操作符允许错误处理、吞咽异常、转换异常、调用finally块、重试失败的序列以及即使发生错误也可以处理资源。
捕获运算符
这些运算符可以通过继续执行以下顺序从错误中恢复:
onErrorResumeNext:指示一个可观察对象将控制权传递给供应器提供的另一个可观察对象,而不是在出现问题时调用onErroronErrorReturn:指示可观察对象发出函数提供的默认值,以防出现错误onErrorReturnItem:指示可观察对象发出提供的缺省值,以防出现错误onExceptionResumeNext:指示一个可观察对象将控制传递给另一个可观察对象,而不是在出现问题时调用onError
下面的示例演示如何使用onErrorReturnItem方法;不使用flatMap技巧调用它将停止流并在最后输出Default。通过延迟对异常抛出代码的调用并对其应用onErrorReturnItem,我们可以继续序列并使用提供的默认值:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Tm0lwStu-1681378425566)(https://gitcode.net/apachecn/apachecn-java-zh/-/raw/master/docs/design-pattern-best-prac-java/img/672adc55-ebf3-4bb3-89de-850771d01fd4.png)]
do运算符
这些用于注册对特定生命周期事件采取的操作。我们可以使用它们来模拟final语句行为,释放分配给上游的资源,进行性能度量,或者执行不依赖于当前调用成功与否的其他任务。RxJava Observable通过提供以下方法来实现这一点:
doFinally:注册当前可观察对象调用onComplete或onError或被释放时要调用的动作doAfterTerminate:在当前可观察对象调用onComplete或onError之后注册要调用的动作doOnDispose:注册一个动作,在处理序列时调用doOnLifecycle:根据序列的生命周期事件(订阅、取消、请求),为相应的onXXX方法注册回调doOnTerminate:注册当前可观察对象调用onComplete或onError时要调用的动作
以下代码段显示了前面提到的命令的用法:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-U7mxhVVD-1681378425567)(https://gitcode.net/apachecn/apachecn-java-zh/-/raw/master/docs/design-pattern-best-prac-java/img/56ecf8ec-7db3-4947-85b0-5801ba97a7b5.png)]
在前面的示例中,我们可以看到生命周期事件的顺序是:订阅、终止、完成或错误,最后通过在每个事件上注册控制台打印操作。
using运算符
using操作符在 Java 中有一个对应的操作符,名为资源尝试。它基本上也是这样做的,即创建一个在给定时间(当可观察对象被释放时)被释放的可支配资源。RxJava2.0 方法using实现了这个行为。
重试运算符
这些是在发生可恢复的故障(例如服务暂时关闭)时要使用的操作符。他们通过重新订阅来工作,希望这次能顺利完成。可用的 RxJava 方法如下:
retry:错误时永远重放同一流程,直到成功retryUntil:重试,直到给定的stop函数返回trueretryWhen:基于接收错误/异常的重试逻辑函数,在错误情况下永远重放相同的流,直到成功为止
在下面的示例中,我们使用只包含两个值的zip来创建重试逻辑,该逻辑在一个时间段后重试两次以运行失败的序列,或者用 500 乘以重试计数。当连接到无响应的 Web 服务时,尤其是从每次重试都会消耗设备电池的移动设备时,可以使用此方法:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-arNEODeT-1681378425567)(https://gitcode.net/apachecn/apachecn-java-zh/-/raw/master/docs/design-pattern-best-prac-java/img/70d6545a-2809-4a40-8d32-b37e6e937ae9.png)]
调度器
在线程调度方面,可观测是不可知的——在多线程环境中,这是调度器的工作。一些操作符提供了可以将调度器作为参数的变体。有一些特定的调用允许从下游(使用操作符的点,这是observeOn的情况)或不考虑调用位置(调用位置无关紧要,因为这是subscribeOn方法的情况)观察流。在下面的示例中,我们将从上游和下游打印当前线程。注意,在subscribeOn的情况下,线程总是相同的:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UdbJqDYc-1681378425567)(https://gitcode.net/apachecn/apachecn-java-zh/-/raw/master/docs/design-pattern-best-prac-java/img/4acf684b-55fd-4938-845d-b40f900a1022.png)]
注意map方法中的线程主要用法:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-W50VAzAF-1681378425568)(https://gitcode.net/apachecn/apachecn-java-zh/-/raw/master/docs/design-pattern-best-prac-java/img/027fbe82-d16e-4588-99b5-8abae35211b6.png)]
请注意,map方法不再使用线程main。
RxJava2.0 提供了更多来自io.reactivex.schedulers.Schedulers工厂的调度器,每个调度器都有特定的用途:
computation():返回用于计算工作的Scheduler实例io():返回一个用于 I/O 工作的Scheduler实例single():对于需要在同一后台线程上强顺序执行的工作,返回Scheduler实例trampoline():返回一个Scheduler实例,该实例在一个参与线程上以 FIFO 方式执行给定的工作newThread():返回一个Scheduler实例,该实例为每个工作单元创建一个新线程from(Executor executor):将Executor转换成新的Scheduler实例,并将工作委托给它
有一个只用于特殊测试目的的Scheduler,称为io.reactivex.schedulers.TestScheduler。我们已经使用了它,因为它允许手动推进虚拟时间,因此非常适合于测试依赖于时间的流,而不必等待时间通过(例如,单元测试)。
主体
主体是可观察的和订户的混合体,因为它们都接收和发射事件。RxJava2.0 提供了五个主题:
AsyncSubject:仅发射源可观测到的最后一个值,后跟一个完成BehaviorSubject:发射最近发射的值,然后是可观测源发射的任何值PublishSubject:仅向订阅方发送订阅时间之后源发送的项目ReplaySubject:向任何订户发送源发出的所有项目,即使没有订阅UnicastSubject:只允许单个用户在其生存期内订阅
示例项目
在下面的示例中,我们将展示 RxJava 在实时处理从多个传感器接收到的温度中的用法。传感器数据由 Spring 引导服务器提供(随机生成)。服务器配置为接受传感器名称作为配置,以便我们可以为每个实例更改它。我们将启动五个实例,并在客户端显示警告,如果其中一个传感器输出超过 80 摄氏度。
使用以下命令可以从 bash 轻松启动多个传感器:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SMDwsCLg-1681378425568)(https://gitcode.net/apachecn/apachecn-java-zh/-/raw/master/docs/design-pattern-best-prac-java/img/2570a499-f35d-448f-92a0-e008531b9272.png)]
服务器端代码很简单,我们只配置了一个 REST 控制器,将传感器数据输出为 JSON,如下代码所示:
@RestController
publicclass SensorController
{
@Value("${sensor.name}")
private String sensorName;
@RequestMapping(value="/sensor", method=RequestMethod.GET,
produces=MediaType.APPLICATION_JSON_VALUE)
public ResponseEntity<SensorData> sensor() throws Exception
{
SensorData data = new SensorData(sensorName);
HttpHeaders headers = new HttpHeaders();
headers.set(HttpHeaders.CONTENT_LENGTH, String.valueOf(new
ObjectMapper().writeValueAsString(data).length()));
returnnew ResponseEntity<SensorData>(data, headers,
HttpStatus.CREATED);
}
}
传感器数据是在SensorData构造器中随机生成的(注意 Lombock 库的使用,以摆脱获取设置器代码):
@Data
publicclass SensorData
{
@JsonProperty
Double humidity;
@JsonProperty
Double temperature;
@JsonProperty
String sensorName;
public SensorData(String sensorName)
{
this.sensorName = sensorName;
humidity = Double.valueOf(20 + 80 * Math.random());
temperature = Double.valueOf(80 + 20 * Math.random());
}
}
现在我们已经启动了服务器,我们可以从支持 RxJava 的客户端连接到它。
客户端代码使用 rxapache http 库:
publicclass Main
{
@JsonIgnoreProperties(ignoreUnknown = true)
staticclass SensorTemperature
{
Double temperature;
String sensorName;
public Double getTemperature()
{
return temperature;
}
publicvoid setTemperature(Double temperature)
{
this.temperature = temperature;
}
public String getSensorName()
{
return sensorName;
}
publicvoid setSensorName(String sensorName)
{
this.sensorName = sensorName;
}
@Override
public String toString()
{
return sensorName + " temperature=" + temperature;
}
}
}
SensorTemperature是我们的客户资料。它是服务器可以提供的内容的快照。其余信息将被 Jackson 数据绑定器忽略:
publicstaticvoid main(String[] args) throws Exception
{
final RequestConfig requestConfig = RequestConfig.custom()
.setSocketTimeout(3000)
.setConnectTimeout(500).build();
final CloseableHttpAsyncClient httpClient = HttpAsyncClients.custom()
.setDefaultRequestConfig(requestConfig)
.setMaxConnPerRoute(20)
.setMaxConnTotal(50)
.build();
httpClient.start();
在前面的代码中,我们通过设置 TCP/IP 超时和允许的连接数来设置并启动 HTTP 客户端:
Observable.range(1, 5).map(x ->
Try.withCatch(() -> new URI("http", null, "127.0.0.1", 8080 + x, "/sensor", null, null), URISyntaxException.class).orElse(null))
.flatMap(address -> ObservableHttp.createRequest(HttpAsyncMethods.createGet(address), httpClient)
.toObservable())
.flatMap(response -> response.getContent().map(bytes -> new String(bytes)))
.onErrorReturn(error -> "{"temperature":0,"sensorName":""}")
.map(json ->
Try.withCatch(() -> new ObjectMapper().readValue(json, SensorTemperature.class), Exception.class)
.orElse(new SensorTemperature()))
.repeatWhen(observable -> observable.delay(500, TimeUnit.MILLISECONDS))
.subscribeOn(Schedulers.io())
.subscribe(x -> {
if (x.getTemperature() > 90) {
System.out.println("Temperature warning for " + x.getSensorName());
} else {
System.out.println(x.toString());
}
}, Throwable::printStackTrace);
}
}
前面的代码基于范围创建 URL 列表,将其转换为响应列表,将响应字节展开为字符串,将字符串转换为 JSON,并将结果打印到控制台。如果温度超过 90 度,它将打印一条警告信息。它通过在 I/O 调度器中运行来完成所有这些,每 500 毫秒重复一次,如果出现错误,它将返回默认值。请注意Try单子的用法,因为选中的异常是由 Lambda 代码引发的,因此需要通过转换为可由 RxJava 在onError中处理的未选中表达式或在 Lambda 块中本地处理来处理。
由于客户端永远旋转,部分输出如下:
NuclearCell2 temperature=83.92902289170053
Temperature warning for NuclearCell1
Temperature warning for NuclearCell3
Temperature warning for NuclearCell4
NuclearCell5 temperature=84.23921169948811
Temperature warning for NuclearCell1
NuclearCell2 temperature=83.16267124851476
Temperature warning for NuclearCell3
NuclearCell4 temperature=81.34379085987851
Temperature warning for NuclearCell5
NuclearCell2 temperature=88.4133065761349
总结
在本章中,我们学习了反应式编程,然后重点介绍了可用的最常用的反应式库之一——RxJava。我们学习了反应式编程抽象及其在 RxJava 中的实现。我们通过了解可观察对象、调度器和订阅是如何工作的、最常用的方法以及它们是如何使用的,从而通过具体的示例迈出了进入 RxJava 世界的第一步。
在下一章中,我们将学习最常用的反应式编程模式,以及如何在代码中应用它们。
七、反应式设计模式
在最后一章中,我们讨论了反应式编程风格,并强调了进行反应式编程的重要性。在本章中,我们将逐一回顾反应式编程的四大支柱,即响应性、弹性、弹性和消息驱动,并了解实现这些支柱的各种模式。本章将介绍以下主题:
- 响应模式
- 恢复模式
- 弹性模式
- 消息驱动的通信模式
响应模式
响应性意味着应用的交互性。它是否及时与用户交互?点击一个按钮能做它应该做的吗?界面是否在需要更新时得到更新?其思想是应用不应该让用户不必要地等待,应该提供即时反馈。
让我们看看帮助我们在应用中实现响应性的一些核心模式。
请求-响应模式
我们将从最简单的设计模式开始,请求-响应模式,它解决了反应式编程的响应性支柱。这是我们在几乎所有应用中使用的核心模式之一。是我们的服务接收请求并返回响应。许多其他模式都直接或间接地依赖于此,因此值得花几分钟来理解此模式。
下图显示了一个简单的请求-响应通信:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oSjfRLTK-1681378425568)(https://gitcode.net/apachecn/apachecn-java-zh/-/raw/master/docs/design-pattern-best-prac-java/img/0919b0eb-e256-4666-a18f-da09af8fed7d.png)]
请求-响应关系有两个参与方。一个实体发出请求,第二个实体完成请求。请求者可以是从服务器请求详细信息的浏览器,也可以是从其他服务请求数据的服务。双方需要就请求和响应格式达成一致。这些可以是 XML、HTML、字符串、JSON 等形式;只要两个实体都理解通信,就可以使用任何格式。
我们将从一个简单的基于 Servlet 的示例开始。您可能不会在实际项目中使用基于 Servlet 的实现,除非您使用的是遗留应用,但是了解基础知识非常重要,因为它们是我们使用的大多数现代框架的起点。
我们将在这里创建一个雇员服务,它将处理GET和POST请求:
/**
*
* This class is responsible for handling Employee Entity
related requests.
*
*/
public class EmployeeWebService extends HttpServlet
{
public void init() throws ServletException
{
// Do required initialization
}
public void doGet(HttpServletRequest request,
HttpServletResponse response) throws ServletException,
IOException
{
// Set response content type
response.setContentType("application/json");
PrintWriter out = response.getWriter();
/*
* This is a dummy example where we are simply returning
static employee details.
* This is just to give an idea how simple request response
works. In real world you might want to
* fetch the data from data base and return employee list
or an employee object based on employee id
* sent by request. Well in real world you migth not want
to use servlet at all.
*/
JSONObject jsonObject = new JSONObject();
jsonObject.put("EmployeeName", "Dave");
jsonObject.put("EmployeeId", "1234");
out.print(jsonObject);
out.flush();
}
public void doPost(HttpServletRequest request,
HttpServletResponse response) throws ServletException,
IOException
{
// Similar to doGet, you might want to implement do post.
where we will read Employee values and add to database.
}
public void destroy()
{
// Handle any object cleanup or connection closures here.
}
}
前面的代码应该让您了解一个简单的请求-响应模式是如何工作的。GET和POST是两种最重要的通信方式。顾名思义,GET用于从服务器获取任何数据、信息、工件,而POST则向服务器添加新数据。大约 10-12 年前,您也会看到 Servlet 中嵌入了 HTML。但是,最近,情况已经转向更好、更易于维护的设计。为了保持关注点的分离和松散耦合,我们尝试保持表示层或前端代码独立于服务器端代码。这使我们可以自由地创建应用编程接口(API),以满足各种各样的客户,无论是桌面应用、移动应用还是第三方服务调用应用。
让我们更进一步,讨论一下维护 API 的 RESTful 服务。REST 代表表述性状态转移。最常见的 REST 实现是通过 HTTP,通过实现GET、POST、PUT和DELETE来实现,即处理 CRUD 操作。
我们来看看这四个核心业务:
-
GET:作为列表或单个实体获取数据。假设我们有一个雇员实体:<url>/employees/将返回系统中所有雇员的列表。<url>/employees/{id}/将返回特定的员工记录。 -
POST:新增实体数据。<url>/employees/将向系统中添加新的员工记录。 -
PUT:更新实体的数据。<url>/employees/{id}将更新系统中现有的员工记录。 -
DELETE:删除已有的实体记录。<url>/employees/{id}将从系统中删除现有员工记录。
如前所述,您几乎不会编写直接处理请求和响应的显式代码。有许多框架,如 Struts、Spring 等,可以帮助我们避免编写所有样板代码,并将重点放在核心业务逻辑上。
下面是一个基于 Spring 的快速示例;正如您将看到的,我们可以避免很多样板代码:
@RestController
@RequestMapping("/employees")
/**
* This class implements GET and POST methods for Employee Entity
*/
publicclass EmployeeWebService
{
EmployeeDAO empDAO = new EmployeeDAO();
/**
* This method returns List of all the employees in the system.
*
* @return Employee List
* @throws ServletException
* @throws IOException
*/
@RequestMapping(method = RequestMethod.GET)
public List<Employee> EmployeeListService() throws
ServletException, IOException
{
// fetch employee list and return
List<Employee> empList = empDAO.getEmployeeList();
return empList;
}
/**
* This method returns details of a specific Employee.
*
* @return Employee
* @throws ServletException
* @throws IOException
*/
@RequestMapping(method = RequestMethod.GET, value = "/{id}")
public Employee EmployeeDataService(@PathVariable("id")
String id) throws ServletException, IOException
{
// fetch employee details and return
Employee emp = empDAO.getEmployee(id);
return emp;
}
/**
* This method returns Adds an Employee to the system
*
* @return Employee List
* @throws ServletException
* @throws IOException
*/
@RequestMapping(method = RequestMethod.POST)
public String EmployeeAddService(@RequestBody Employee emp) throws
ServletException, IOException
{
// add employee and return id
String empId= empDAO.addEmployee(emp);
return empId;
}
}
如您所见,我们正在使用一个普通的旧 Java 对象(POJO)类,并让它处理我们所有的 REST 调用。不需要扩展HttpServlet或管理init或destroy方法。
如果您了解 springmvc,就可以进入下一个模式。对于那些不熟悉 Spring 框架的人来说,花几分钟时间来理解前一个示例背后的工作原理是值得的。
当您使用 Spring 框架时,您需要告诉它您的服务器。因此,在你的web.xml中,添加以下内容:
<servlet>
<servlet-name>springapp</servlet-name>
<servlet-class>org.springframework.web.servlet.
DispatcherServlet</servlet-class>
<init-param>
<param-name>contextClass</param-name>
<param-value>org.springframework.web.context.support.
AnnotationConfigWebApplicationContext </param-value>
</init-param>
<init-param>
<param-name>contextConfigLocation</param-name>
<param-value>com.employee.config.EmployeeConfig</param-value>
</init-param>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>springapp</servlet-name>
<url-pattern>/service/*</url-pattern>
</servlet-mapping>
这里我们已经告诉web.xml我们正在使用 Spring 的DispatcherServlet,对模式/服务的任何请求都应该转发到 Spring 代码。除了前面的代码行之外,我们还需要为 spring 提供配置。这可以在基于 Java 类或基于 XML 的配置中完成。我们已经告诉web.xml在com.employee.config.EmployeeConfig中寻找配置。
下面是一个基于类的配置示例:
package com.employee.config;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.servlet.config.annotation.EnableWebMvc;
@EnableWebMvc
@Configuration
@ComponentScan(basePackages = "com.employee.*")
public class EmployeeConfig
{
}
如您所见,这是一个非常基本的配置文件。您还可以添加数据库配置、安全特性等。关于 springmvc 的任何进一步讨论都超出了本书的范围。
要运行前面的代码,我们需要为 spring 和其他依赖项包含某些 JAR 文件。可以用不同的方式管理这些依赖关系;例如,人们可能更喜欢将 Jar 添加到存储库,或者使用 Maven、Gradle 等等。同样,对这些工具的讨论超出了本书的范围。以下是可以添加到 Maven 中的依赖项:
<dependencies>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-webmvc</artifactId>
<version>4.3.9.RELEASE</version>
</dependency>
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>servlet-api</artifactId>
<version>2.5</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.5.0</version>
</dependency>
</dependencies>
异步通信模式
当我们讨论反应式编程的响应支柱时,需要考虑的另一个重要模式是异步通信模式。虽然请求-响应模式确保所有请求都获得成功响应,但它没有考虑到某些请求可能需要花费大量时间来响应这一事实。异步通信模式有助于我们的应用保持响应,即使我们正在执行批量任务。我们实现响应或快速响应的方法是使核心任务执行异步。可以将其视为您的代码请求服务执行特定任务,例如更新数据库中的数据;服务接收数据并立即响应它已接收到数据。请注意,对数据库的实际写入尚未完成,但会向调用方法返回一条成功消息。
一个更相关的例子是,当一个服务被要求执行一项复杂的任务时,比如通过计算每个雇员的纳税义务来生成一个 Excel 报表,这个纳税义务需要根据每个雇员提供的工资和税务详细信息进行动态计算。因此,当税务报告服务收到生成此类报告的请求时,它只会返回一个确认收到请求的响应,并且 UI 将显示一条消息,在几分钟后刷新页面以查看更新的报告链接。这样,我们就不会阻塞最终用户,他/她可以在后台生成报告的同时执行其他任务。
异步通信是在多个层次上处理的;例如,当浏览器调用服务器时,我们的 JavaScript 框架(如 ReactJS 或 AngularJS)会根据接收到的数据量智能地呈现屏幕,并异步等待挂起的数据。但是,在这里,我们将更多地关注 Java 诱导的异步通信。在 Java 中处理异步任务的最简单方法是通过线程。
举个例子。我们有一个场景,在这个场景中,我们希望在 UI 上显示一个员工列表,同时,编译一个包含一些复杂计算的报告并将其发送给管理员。
以下代码显示了使用同步类型的方法调用时代码的外观:
/**
* This method generates Employee data report and emails it to admin. This also
* returns number of employees in the system currently.
*
* @return EmployeeCount
* @throws ServletException
* @throws IOException
*/
@RequestMapping(method = RequestMethod.GET, value = "/report")
public List<Employee> EmployeeReport() throws ServletException, IOException
{
// Lets say this method gets all EmployeeDetails First
List<Employee> empList = new EmployeeService().getEmployees();
// Say there is a ReportUtil which takes the list data, does
some calculations
// and dumps the report at a specific location
String reportPath = ReportUtil.generateReport();
// Finally say we have an email service which picks the report
and send to admin.
EmailUtil.sendReport(reportPath);
// Finally return the employee's count
return empList;
}
假设获取数据需要一秒钟,生成报告需要四秒钟,通过电子邮件发送报告需要两秒钟。我们正在让用户等待 7 秒钟以获取他/她的数据。我们可以使报告异步化,以加快通信速度:
/**
* This method generates Employee data report and emails it to admin. This also
* returns number of employees in the system currently.
*
* @return EmployeeCount
* @throws ServletException
* @throws IOException
*/
@RequestMapping(method = RequestMethod.GET, value = "/report")
public List<Employee> EmployeeReport() throws ServletException, IOException
{
// Lets say this method gets all EmployeeDetails First
List<Employee> empList = new EmployeeService().getEmployees();
Runnable myrunLambda = ()->
{
// Say there is a ReportUtil which takes the list data, does
some calculations
// and dumps the report at a specific location
String reportPath = ReportUtil.generateReport();
// Finally say we have an email service which picks the report
and send to admin.
EmailUtil.sendReport(reportPath);
};
new Thread(myrunLambda).start();
// Finally return the employee's count
return null;
}
我们已经将报表生成和电子邮件发送部分移出了关键路径,现在主线程在获取记录后立即返回。报告功能是在一个单独的线程中实现的。除了线程之外,实现异步通信的另一个重要方法是使用消息队列和消息驱动 bean。
缓存模式
另一种可以用来确保应用响应的模式是实现缓存。缓存将确保通过缓存结果以更快的方式处理类似类型的请求。我们可以在不同的层次上实现缓存,比如控制器层、服务层、数据层等等。我们还可以在请求命中代码之前实现缓存;也就是说,在服务器或负载平衡器级别。
在本章中,让我们以一个非常简单的示例来了解缓存如何帮助我们提高性能。让我们看一个简单的 Web 服务,它为员工返回数据:
/**
* This method fetches a particular employee data.
* @param id
* @return
* @throws ServletException
* @throws IOException
*/
@RequestMapping(method = RequestMethod.GET, value = "/{id}")
public Employee EmployeeDataService(@PathVariable("id") String id) throws ServletException, IOException
{
/*
* Again, to keep it simple, returning a dummy record.
*/
EmployeeService employeeService = new EmployeeService();
Employee emp = employeeService.getEmployee(id);
return emp;
}
此方法从数据库获取数据并将其返回给最终用户。
Java 中有许多缓存实现。在本例中,我们创建一个非常简单的缓存机制:
/**
* A simple cache class holding data for Employees
*
*/
class EmployeeCache
{
static Map<String,Employee> cache = new HashMap<String,Employee>();
/**
* get Employee from cache
* @param id
* @return Employee
*/
public static Employee getData(String id)
{
return cache.get(id);
}
/**
* Set employee data to cache
* @param id
* @param employee
*/
public static void putData(String id, Employee employee)
{
cache.put(id, employee);
}
}
现在让我们更新我们的方法以利用缓存:
/**
* This method fetches a particular employee data.
* @param id
* @return
* @throws ServletException
* @throws IOException
*/
@RequestMapping(method = RequestMethod.GET, value = "/{id}")
public Employee EmployeeDataService(@PathVariable("id") String id) throws ServletException, IOException
{
/*
* Lets check of the data is available in cache.
* If not available, we will get the data from database and
add to cache for future usage.
*/
Employee emp = EmployeeCache.getData(id);
if(emp==null)
{
EmployeeService employeeService = new EmployeeService();
emp = employeeService.getEmployee(id);
EmployeeCache.putData(id, emp);
}
return emp;
}
我们可以看到,第一次查找员工的详细信息时,缓存中将找不到这些信息,并且将执行从数据库获取数据的正常流程。同时,这些数据被添加到缓存中。因此,为同一员工获取数据的任何后续请求都不需要访问数据库。
扇出和最快的回复模式
在某些应用中,速度非常重要,尤其是在处理实时数据的情况下,例如在投注网站上,根据现场事件计算赔率非常重要。在最后五分钟内的进球,对于一场平局的比赛来说,会极大地改变胜算,有利于一支球队,你希望在人们开始增加赌注之前,这一点能在几秒钟内反映在网站上。
在这种情况下,请求处理的速度很重要,我们希望服务的多个实例来处理请求。我们将接受最先响应的服务的响应,并放弃其他服务请求。正如您所看到的,这种方法确实保证了速度,但它是有代价的。
快速失效模式
快速失败模式指出,如果服务必须失败,它应该快速失败并尽快响应调用实体。想想这个场景:你点击了一个链接,它显示了一个加载器。它会让您等待三到四分钟,然后显示一条错误消息,服务不可用,请在 10 分钟后重试。好吧,服务不可用是一回事,但是为什么要让某人等着告诉他们服务现在不可用呢。简言之,如果一个服务不得不失败,它至少应该尽快做到这一点,以保持良好的用户体验。
快速失败实现的一个例子是,如果您的服务依赖于另一个服务,那么您应该有一个快速机制来检查第三方服务是否启动。这可以通过简单的 ping 服务来实现。因此,在发送实际请求并等待响应之前,我们会对服务进行健康检查。如果我们的服务依赖于多个服务,这一点更为重要。在我们开始实际处理之前,检查所有服务的运行状况是很好的。如果任何服务不可用,我们的服务将立即发送等待响应,而不是部分处理请求然后发送失败。
恢复模式
在考虑应用的弹性时,我们应该尝试回答以下问题:应用能否处理失败条件?如果应用的一个组件出现故障,是否会导致整个应用宕机?应用中是否存在单点故障?
让我们看看一些模式,它们将帮助我们使应用具有弹性。
断路器型式
这是在系统中实现弹性和响应性的重要模式。通常,当一个服务在系统中失败时,它也会影响其他服务。例如,服务 X 调用系统中的服务 Y 来获取或更新一些数据。如果服务 Y 由于某种原因没有响应,我们的服务 X 将调用服务 Y,等待它超时,然后自己失败。设想一个场景,其中服务 X 本身被另一个服务 P 调用,以此类推。我们看到的是一个级联故障,最终会导致整个系统崩溃。
受电路启发的断路器模式表明,我们应该将故障限制在单个服务级别,而不是让故障传播;也就是说,我们需要一种机制让服务 X 了解服务 Y 是不健康的,并处理这种情况。处理这种情况的一种方法是服务 X 调用服务 Y,如果它观察到服务 Y 在 N 次重试后没有响应,它会认为服务不正常并将其报告给监视系统。同时,它在一段固定的时间内停止对服务 Y 的调用(例如,我们设置了一个 10 分钟的阈值)。
服务 X 将根据服务 Y 执行的操作的重要性来优雅地处理此故障。例如,如果服务 Y 负责更新帐户详细信息,服务 X 将向调用服务报告故障,或者对于 Y 正在执行的记录事务详细信息的所有服务,服务 X 将添加日志详细信息到回退队列,当服务 Y 备份时,它可以被清除。
这里的重要因素是不要让一次服务故障导致整个系统瘫痪。调用服务应该找出哪些是不健康的服务,并管理备用方法。
故障处理模式
在系统中保持弹性的另一个重要方面是问这样一个问题:如果一个或多个组件或服务宕机,我的系统还能正常工作吗?例如,以一个电子商务网站为例。有许多服务和功能协同工作以保持网站正常运行,例如产品搜索、产品目录、推荐引擎、评论组件、购物车、支付网关等等。如果其中一项服务(如搜索组件)由于负载或硬件故障而宕机,是否会影响最终用户下订单的能力?理想情况下,这两个服务应该独立创建和维护。因此,如果搜索服务不可用,用户仍然可以在购物车中订购商品或直接从目录中选择商品并购买。
处理失败的第二个方面是优雅地处理对失败组件的任何请求。对于上一个示例,如果用户尝试使用搜索功能(例如,用户界面上的搜索框仍然可用),我们不应该向用户显示空白页或让他/她永远等待。我们可以向他/她显示缓存的结果,或者显示一条消息,说明服务将在接下来的几分钟内使用推荐的目录启动。
有界队列模式
这种模式有助于我们保持系统的弹性和响应能力。此模式表示我们应该控制服务可以处理的请求数。大多数现代服务器都提供了一个请求队列,可以将其配置为在请求被丢弃和服务器繁忙消息被发送回调用实体之前让它知道应该排队的请求数。我们正在将这种方法扩展到服务级别。每个服务都应该基于一个队列,该队列将容纳要服务的请求。
队列应该有一个固定的大小,即服务在特定时间(例如一分钟)内可以处理的量。例如,如果我们知道服务 X 可以在一分钟内处理 500 个请求,那么我们应该将队列大小设置为 500,并且任何其他请求都将被发送一条关于服务正忙的消息。基本上,我们不希望调用实体等待很长时间,从而影响整个系统的性能。
监测模式
为了保持系统的弹性,我们需要监控服务性能和可用性的方法。我们可以向应用和服务添加多种类型的监视;例如,对于响应性,我们可以向应用添加周期性 ping,并验证响应需要多长时间,或者我们可以检查系统的 CPU 和 RAM 使用情况。如果您使用的是第三方云,例如 Amazon Web Services(AWS),那么您就获得了对这种监视的内置支持;否则您可以编写简单的脚本来检查当前的健康状态。日志监视用于检查应用中是否抛出错误或异常,以及这些错误或异常的严重程度。
监控到位后,我们可以在系统中添加警报和自动错误处理。警报可能意味着根据问题的严重程度发送电子邮件或文本消息。还可以内置升级机制;例如,如果问题在 X 时间内没有得到解决,则会向下一级升级点发送一条消息。通过使用自动错误处理,我们可以在需要创建其他服务实例、需要重新启动服务等情况下进行调用。
舱壁模式
舱壁是从货船上借来的术语。在货船中,舱壁是建造在不同货物段之间的一堵墙,它确保一段中的火灾或洪水仅限于该段,而其他段不受影响。您肯定已经猜到了我们的意图:一个服务或一组服务中的故障不应该导致整个应用崩溃。
为了实现隔板模式,我们需要确保我们的所有服务彼此独立地工作,并且一个服务中的故障不会导致另一个服务中的故障。维护单一责任模式、异步通信模式或快速故障和故障处理模式等技术有助于我们实现阻止一个故障在整个应用中传播的目标。
弹性模式
应用必须对可变负载条件作出反应。如果负载增加或减少,应用不应受到影响,并且应该能够处理任何负载级别而不影响性能。弹性的一个未提及的方面是应用不应该使用不必要的资源。例如,如果您希望您的服务器每分钟处理 1000 个用户,那么您将不会设置一个基础结构来处理 10000 个用户,因为您将支付所需成本的 10 倍。同时,您需要确保如果负载增加,应用不会阻塞。
让我们来看看帮助我们保持系统弹性的一些重要模式。
单一责任模式
也被称为简单组件模式或微服务模式,单责任模式是 OOP 单责任原则的一种扩展。在本书的最初几章中,我们已经讨论了单一责任原则。在基本层次上,当应用于面向对象编程时,单一责任原则规定一个类应该只有一个改变的理由。将此定义进一步扩展到架构级别,我们将此原则的范围扩展到组件或服务。因此,现在我们将单一责任模式定义为一个组件或服务应该只负责一个任务。
需要将应用划分为更小的组件或服务,其中每个组件只负责一个任务。将服务划分为更小的服务将产生更易于维护、扩展和增强的微服务。
为了进一步说明这一点,假设我们有一个名为updateEmployeeSalaryAndTax的服务。此服务获取基本工资并使用它计算总工资,包括可变和固定部分,最后计算税金:
public void updateEmployeeSalaryAndTax(String employeeId, float baseSalary)
{
/*
* 1\. Fetches Employee Data
* 2\. Fetches Employee Department Data
* 3\. Fetches Employee Salary Data
* 4\. Applies check like base salary cannot be less than existing
* 5\. Calculates House Rent Allowance, Grade pay, Bonus component
based on Employees
* position, department, year of experience etc.
* 6\. Updates Final salary Data
* 7\. Gets Tax slabs based on country
* 8\. Get state specific tax
* 9\. Get Employee Deductions
* 10\. Update Employee Tax details
*/
}
虽然在工资更新时计算这个似乎是合乎逻辑的,但是如果我们只需要计算税呢?比如说,一个员工更新了节税细节,为什么我们需要再次计算所有的工资细节,而不仅仅是更新税务数据。复杂的服务不仅通过添加不必要的计算来增加执行时间,而且还阻碍了可伸缩性和可维护性。假设我们需要更新税务公式,我们最终也会更新包含薪资计算细节的代码。总体回归范围面积增大。此外,假设我们知道薪资更新并不常见,但每次节税细节更新都会更新税务计算,而且税务计算本质上很复杂。对我们来说,将SalaryUpdateService保存在容量较小的服务器上,将TaxCalculationService保存在单独的、更大的机器上,或者保存多个TaxCalculationService实例可能更容易。
检查您的服务是否只执行一项任务的经验法则是,尝试用简单的英语解释并查找单词and,例如,如果我们说此服务更新工资明细and计算税款,或者此服务修改数据格式and将其上传到存储。当我们在对服务的解释中看到and时,我们知道这可以进一步细分。
无状态服务模式
为了确保我们的服务是可伸缩的,我们需要确保以无状态的方式构建它们。所谓无状态,我们的意思是服务不保留以前调用的任何状态,并将每个请求视为新的请求。这种方法的优点是,我们可以轻松地创建同一服务的副本,并确保哪个服务实例处理请求并不重要。
例如,假设我们有 10 个EmployeeDetails服务实例,负责为我<url>/employees/id提供服务,并返回特定员工的数据。不管哪个实例为请求提供服务,用户最终都会得到相同的数据。这有助于我们保持系统的弹性,因为我们可以随时启动任意数量的实例,并根据服务在该时间点上的负载将它们关闭。
让我们看一个反例;假设我们正在尝试使用会话或 Cookie 来维护用户操作的状态。这里,在EmployeeDetails服务上执行操作:
状态 1:John 成功登录。
状态 2:John 要求提供戴夫的雇员详细资料。
状态 3:John 请求 Dave 的详细信息页面上的薪资详细信息,系统返回 Dave 的薪资。
在这种情况下,状态 3请求没有任何意义,除非我们有来自前一状态的信息。我们得到一个请求<url>/salary-details,然后我们查看会话以了解谁在请求细节以及请求是为谁提出的。嗯,维护状态不是个坏主意,但是它会阻碍可伸缩性。
假设我们看到EmployeeDetail服务的负载在增加,并计划向集群中添加第二台服务器。挑战在于,假设前两个请求进入方框 1,第三个请求进入方框 2。现在,方框 2 不知道是谁在询问工资细节,是为谁。有一些解决方案,如维护粘性会话或跨框复制会话,或将信息保存在公共数据库中。但是这些都需要额外的工作来完成,这就破坏了快速自动缩放的目的。
如果我们认为每个请求都是独立的,也就是说,在提供所请求的信息、由谁提供、用户的当前状态等方面是自给自足的,那么我们就不必再担心维护用户的状态了。
例如,从/salary-details to /employees/{id}/salary-details开始的请求调用中的一个简单更改现在提供了关于请求谁的详细信息的信息。关于谁在询问详细信息,即用户的认证,我们可以使用基于令牌的认证或通过请求发送用户令牌等技术。
让我们看看基于 JWT 的认证。JWT 代表 JSON Web 令牌。JWT 只不过是嵌入在令牌或字符串中的 JSON。
我们先来看看如何创建 JWT 令牌:
/**
* This method takes a user object and returns a token.
* @param user
* @param secret
* @return
*/
public String createAccessJwtToken(User user, String secret)
{
Date date = new Date();
Calendar c = Calendar.getInstance();
c.setTime(date);
c.add(Calendar.DATE, 1);
// Setting expiration for 1 day
Date expiration = c.getTime();
Claims claims = Jwts.claims().setSubject(user.getName())
.setId(user.getId())
.setIssuedAt(date)
.setExpiration(expiration);
// Setting custom role field
claims.put("ROLE",user.getRole());
return Jwts.builder().setClaims(claims).signWith
(SignatureAlgorithm.HS512, secret).compact();
}
类似地,我们将编写一个方法来获取令牌并从令牌中获取详细信息:
/**
* This method takes a token and returns User Object.
* @param token
* @param secret
* @return
*/
public User parseJwtToken(String token, String secret)
{
Jws<Claims> jwsClaims ;
jwsClaims = Jwts.parser()
.setSigningKey(secret)
.parseClaimsJws(token);
String role = jwsClaims.getBody().get("ROLE", String.class);
User user = new User();
user.setId(jwsClaims.getBody().getId());
user.setName(jwsClaims.getBody().getSubject());
user.setRole(role);
return user;
}
关于 JWT 的完整讨论超出了本书的范围,但是前面的代码应该可以帮助我们理解 JWT 的基本概念。其思想是在令牌中添加关于请求实体的任何关键信息,这样我们就不需要显式地维护状态。令牌可以作为参数或头部的一部分发送到请求中,服务实体将解析令牌以确定请求是否确实来自有效方。
自动缩放模式
这更像是一种部署模式而不是开发模式。但理解这一点很重要,因为它将影响我们的开发实践。自动缩放与应用的弹性特性直接相关。服务可以通过两种方式放大或缩小以处理更高或更低数量的请求:垂直缩放和水平缩放。垂直扩展通常是指为同一台机器添加更多的电源,而水平扩展是指添加更多可以负载共享的实例。由于垂直缩放通常是昂贵的和有限制的,当我们谈到自动缩放时,我们通常指的是水平缩放。
自动缩放是通过监视实例容量使用情况并在此基础上进行调用来实现的。例如,我们可以设置一个规则,当托管服务的实例集群的平均 CPU 使用率超过 75% 时,应该引导一个新实例以减少其他实例的负载。类似地,我们可以有一个规则,每当平均负载降低到 40% 以下时,就会杀死一个实例以节省成本。大多数云服务提供商(如 Amazon)都提供了对自动缩放的内置支持。
自包含模式
简单地说,自包含意味着应用或服务应该是自给自足的,或者能够作为独立实体工作,而不依赖于任何其他实体。假设我们有一个针对EmployeeData的服务,处理一般员工数据处理,还有一个针对EmployeeSalary的服务。假设我们负责维护到EmployeeData服务的数据库连接。因此,每当EmployeeSalary服务需要处理数据库时,它都会调用EmplyeeData服务的getDatabaseHandle方法。这增加了一个不需要的依赖项,这意味着除非EmployeeData服务正常运行,否则我们的EmployeeSalary服务将无法正常工作。因此,EmployeeSalary服务应该维护自己的数据库连接池,并以自主的方式运行,这是合乎逻辑的。
消息驱动实现的模式
如果我们依赖基于消息的通信,我们可以避免紧耦合,增强弹性,因为组件可以增长或收缩而不必担心其他组件,并处理故障情况,因为一个组件的问题不会传播到其他组件。
以下是使用反应式应用编程时需要注意的主要设计模式。
事件驱动的沟通模式
事件驱动通信是指两个或多个组件基于某个事件相互传递消息。事件可以是添加新数据、更新数据状态或删除数据。例如,在系统中添加新员工记录时,需要向经理发送电子邮件。因此,负责管理员工记录的服务或组件将在添加新记录时向负责电子邮件功能的组件发送消息。处理这种通信有多种方法,但最常用的方法是通过消息队列。事件触发组件向队列中添加一条消息,接收方读取该消息并执行其部分操作:在本例中,向管理器发送一封电子邮件。
事件驱动模式背后的思想是,这两个组件彼此独立,但同时可以相互通信并采取所需的操作。在前面的示例中,电子邮件组件独立于添加记录的组件。如果电子邮件组件无法立即处理请求,则不会影响记录的添加。电子邮件组件可能已加载或由于某种原因已关闭。当电子邮件组件准备好处理消息时,它将从队列中读取并执行它需要执行的操作。
发布-订阅服务器模式
通常称为发布-订阅模式,这可以看作是事件驱动通信的扩展。在事件驱动通信中,一个动作触发一个事件,另一个组件需要在此基础上执行一些动作。如果多个组件对监听消息感兴趣怎么办?如果同一个组件对监听多种类型的消息感兴趣呢?利用主题的概念来解决问题。更广泛地说,我们可以把一个事件看作一个话题。
让我们重温一个示例,在这个示例中,雇员记录添加事件需要触发一封给经理的电子邮件。假设还有其他组件,例如运输系统、薪资管理系统等,它们还需要根据添加新员工记录的事件执行一些操作。此外,假设 EmailingTheManager 组件还对更新员工记录和删除员工记录等事件感兴趣;在这些情况下,也应该触发发送给经理的电子邮件。
所以,我们有一个主题叫做 Employee Added,另一个主题叫做 Employee Updated,还有一个主题叫做 Employee Deleted。负责管理员工数据的组件将所有这些事件发布到队列,因此称为发布者。对其中一个或多个主题感兴趣的组件将订阅这些主题,并称为订阅者。订阅者将听取他们感兴趣的主题,并根据收到的消息采取行动。
Pub-Sub 模式帮助我们实现组件之间的松散耦合,因为订阅者不需要知道发布者是谁,反之亦然。
幂等模式
当我们瞄准消息驱动和异步通信时,它会带来一些挑战。例如,如果系统中添加了重复的消息,是否会破坏状态?假设我们有一个银行帐户更新服务,我们发送一条消息,向帐户中添加 1000 美元。如果我们有重复的消息怎么办?系统将如何确保它不会仅仅因为收到重复的消息就两次添加钱?此外,该系统将如何区分重复消息和新消息?
有各种技术可以用来处理这个问题。最常见的方法是为每条消息添加一个消息编号或 ID,这样系统就可以确保每个具有唯一 ID 的消息只处理一次。另一种方法是保持消息中的前一个状态和新状态,即旧余额为 X,新余额为 Y,系统负责应用验证,以确保消息中提到的状态(旧余额)与系统状态匹配。
底线是,无论何时构建系统,我们都需要确保我们的应用能够处理这样一种情况:重复发送的消息得到了优雅的处理,并且不会破坏系统的状态。
总结
在本章中,我们讨论了帮助我们保持应用的反应式的模式,或者换句话说,帮助我们实现反应式编程的四大支柱,即响应性、弹性、弹性和消息驱动的通信。
在下一章中,我们将继续我们的旅程,探索一个架构良好的应用的一些当代方面。
八、应用架构的发展趋势
每当我们开始开发一个应用时,我们首先需要确定的是我们将要使用的设计或架构。随着软件行业在过去几十年的成熟,我们用来设计系统的方式也发生了变化。在本章中,我们将讨论我们在最近的过去看到的一些重要的架构趋势,这些趋势至今仍然相关。我们将尝试分析这些架构模式的好、坏和丑,并找出哪种模式能够解决哪种类型的问题。本章将介绍以下主题:
- 什么是应用架构?
- 分层架构
- 模型-视图-控制器架构
- 面向服务的架构
- 基于微服务的架构
- 无服务器架构
什么是应用架构?
当我们开始构建一个应用时,我们有一组需求,我们试图设计一个我们认为能够满足所有需求的解决方案。这种设计被称为应用架构。需要考虑的一个重要因素是,您的架构不仅应该考虑当前的需求,还应该预测预期的未来变化并将其考虑在内。通常,有一些未指定的需求,称为非功能性需求,您需要处理。功能需求将作为需求文档的一部分给出,但是架构师或高级开发人员需要自己解决非功能需求。性能需求、可伸缩性需求、安全性需求、可维护性、可增强性、应用的可用性等等,是在设计解决方案时需要考虑的一些重要的非功能性需求。
使应用架构的技巧既有趣又富有挑战性的事实是,没有固定的规则集。适用于一个应用的架构或设计可能不适用于另一个应用;例如,银行解决方案架构可能看起来与电子商务解决方案架构不同。另外,在一个解决方案中,不同的组件可能需要遵循不同的设计方法。例如,您可能希望其中一个组件支持基于 HTTP-REST 的通信,而对于另一个组件,您可以使用消息队列进行通信。这样做的目的是找出解决当前问题的最佳可行方法。
在下面的部分中,我们将讨论 JEE 应用中最常见和最有效的架构样式。
分层架构
我们尝试将代码和实现划分为不同的层,每一层都有固定的职责。没有一套固定的层次结构可以应用于所有的项目,因此您可能需要考虑什么样的层次结构将适用于手头的项目。
下图显示了一个常见的分层架构,在考虑典型的 Web 应用时,这是一个很好的起点:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4H1t5Z5B-1681378425569)(https://gitcode.net/apachecn/apachecn-java-zh/-/raw/master/docs/design-pattern-best-prac-java/img/07ecc040-ee16-482f-9117-f371920cd4ea.png)]
设计有以下几层:
- 表示层
- 控制器/Web 服务层
- 服务层
- 业务层
- 数据访问层
表示层是保存 UI 的层,即 HTML/JavaScript/JSP 等。这是最终用户可以直接与之交互的层。
控制器/ Web 服务层是第三方请求的入口点。此请求可以来自表示层(主要)或其他服务;例如,移动或桌面应用。因为这是任何请求的入口点,所以这一层将应用于任何初始级别的检查、数据清理、验证、安全需求,例如认证和授权等。一旦这个层得到满足,请求就被接受和处理。
服务层又称应用层,负责提供不同的服务,如添加记录、发送邮件、下载文件、生成报告等。在小型应用中,我们可以将服务层与 Web 服务层合并,特别是当我们知道服务层只处理来自 Web 的请求时。如果当前服务也可以从其他服务调用,那么最好将服务与 Web 服务或控制器分开。
业务层保存所有与业务相关的逻辑。例如,在员工数据管理服务中,如果系统试图将某个员工提升为经理,则该层负责应用所有业务检查,包括该员工是否具有相关经验、是否已担任副经理、去年的考核等级是否与目标相匹配必需的规则,等等。有时,如果所讨论的应用或服务没有一组强大的业务规则,那么业务层将与应用层合并。另一方面,您可能希望进一步将业务层划分为子层,以防应用需要强大的业务规则实现。同样,在实现分层设计时,不需要遵循固定的指导原则,而且实现可以根据应用或服务的需要进行更改。
数据访问层负责管理所有与数据相关的操作,如获取数据、以所需格式表示数据、清理数据、存储数据、更新数据等。在创建这个层时,我们可以使用一个对象关系映射(ORM)框架或者创建我们自己的处理器。这里的想法是让其他层不必担心数据处理,也就是数据的存储方式。它是来自另一个第三方服务还是存储在本地?这些和类似的问题仅由该层负责。
横切关注点是每一层需要处理的关注点,例如,每一层负责检查请求是否来自正确的通道,没有未经授权的请求得到服务。每个层可能希望通过记录每条消息来记录请求的进入和退出。这些问题可以通过跨层使用和分布的公共工具来处理,也可以由每个层独立处理。通常,使用诸如面向切面编程(AOP)之类的技术,使这些关注点独立于核心业务或应用逻辑是一个好主意。
分层架构及其应用实例
为了进一步理解分层架构风格,让我们看一下代码和设计示例。让我们做一个非常简单的需求,我们需要从数据库中获取员工列表。
首先,让我们通过查看此图,尝试从层的角度来可视化需求:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-b4E2CTci-1681378425569)(https://gitcode.net/apachecn/apachecn-java-zh/-/raw/master/docs/design-pattern-best-prac-java/img/fae785fd-7c32-4a0b-a983-0d911cdaded0.png)]
在本例中,我们创建了四个层。表示层可以看作是一个简单的带有 JavaScript 的 HTML。您可能希望使用复杂的框架(如 ReactJS 或 AngularJS)来保持表示层的组织,但是在本例中,我们有一个简单的表示层,例如,单击“Show Employee List”按钮时,会对控制器层进行 AJAX 调用,并获取员工数据。
下面是一个简单的 JavaScript 函数,用于获取员工的数据并将其显示在 UI 上:
function getEmployeeData()
{
var xhttp = new XMLHttpRequest();
xhttp.onreadystatechange = function()
{
if (this.readyState == 4 && this.status == 200)
{
document.getElementById("demo").innerHTML = this.responseText;
}
};
xhttp.open("GET", "/LayeredEmployeeExample/service/employees/", true);
xhttp.send();
}
您可以看到,表示层并不知道下一层的实现;它所知道的只是一个 API,该 API 应该为它提供所需的数据。
接下来,我们转到 Web 服务或控制器层。这一层的职责是确保请求以正确的格式来自正确的源。Java 中有很多可用的框架,比如 SpringSecurity 和 JavaWebToken,它们帮助我们实现每个请求的授权和认证。另外,我们可以为此创建拦截器。为了简化本章,我们将重点介绍核心功能,即从下一层获取数据并将其返回给调用函数。请看下面的代码:
/**
* This method returns List of all the employees in the system.
*
* @return Employee List
* @throws ServletException
* @throws IOException
*/
@RequestMapping(method = RequestMethod.GET, value = "/")
public List<Employee> EmployeeListService() throws ServletException, IOException
{
List<Employee> empList = new ArrayList<Employee>();
// Let's call Employee service which will return employee list
EmployeeService empService = new EmployeeService();
empList = empService.getEmployeeList();
return empList;
}
同样,我们可以看到当前层不知道谁在调用它,也不知道下一层的实现。
类似地,我们有一个服务层:
/**
* This methods returns list of Employees
* @return EmployeeList
*/
public List<Employee> getEmployeeList()
{
// This method calls EmployeeDAL and gets employee List
EmployeeDAL empDAL = new EmployeeDAL();
return empDAL.getEmployeeList();
}
为了这个例子,我们将这个层保持得非常简单。你可能会问,为什么我们需要一个额外的层而不从控制器本身调用数据访问层(DAL)?如果您确定获取员工数据的唯一方法是通过控制器,则可以这样做。但是我们建议使用服务层,因为在某些情况下其他服务需要调用我们的服务,因此我们不需要重复的业务或 DAL 调用。
如果你仔细看,我们已经跳过了业务层。这个想法是,你不需要所有的层只是为了它。同时,您可以根据手头的需求将一个层分解为多个层或引入新层。在本例中,我们没有任何要实现的业务规则,因此省略了层。另一方面,如果我们想要实现一些业务规则,比如一些员工记录应该对某些特定角色隐藏,或者应该在向最终用户显示之前进行修改,那么我们将实现一个业务层。
让我们转到最后一层,数据访问层。在我们的示例中,我们的 DAL 负责获取数据并返回到调用层。请看下面的代码:
/**
* This methods fetches employee list and returns to the caller.
* @return EmployeeList
*/
public List<Employee> getEmployeeList()
{
List<Employee> empList = new ArrayList<Employee>();
// One will need to create a DB connection and fetch Employees
// Or we can use ORM like hibernate or frameworks like mybatis
...
return empList;
}
分层与分层
在现实世界中,层和层可以互换使用。例如,您一定听说过术语表示层或表示层指的是同一组代码。尽管在引用一组代码时交换术语并没有什么坏处,但您需要了解,当我们根据物理部署需求划分代码时,使用术语层,而层更关心逻辑隔离。
分层架构能保证什么?
分层架构为我们提供了以下保障:
- 代码组织:分层架构帮助我们实现代码,每个代码层都是独立实现的。代码更具可读性;例如,如果您想查看如何从数据库访问特定数据,可以直接查看 DAL 而忽略其他层。
- 易开发性:由于代码是在不同的层中实现的,我们可以用类似的方式组织我们的团队,一个团队在表示层工作,另一个团队在 DAL 上工作。
分层架构面临哪些挑战?
分层架构的挑战如下:
- 部署:由于代码仍然是紧密耦合的,我们不能保证我们可以独立地部署每一层。我们最终可能还是会进行整体部署。
- 可伸缩性:由于我们仍将整个应用视为一个整体部署,因此我们无法独立地伸缩组件。
模型-视图-控制器架构
另一个广泛使用的组织代码的标准是遵循模型视图控制器(MVC)架构设计模式。顾名思义,我们正在考虑将应用组织为三个部分,即模型、视图和控制器。遵循 MVC 有助于我们保持关注点的分离,并允许我们更好地组织代码。请看以下内容:
- 模型:模型是数据的表示。数据是任何应用的关键部分。模型层负责组织和实现逻辑,以便正确地管理和修改数据。它负责处理在某些数据被修改时需要发生的任何事件。总之,该模型具有核心业务实现。
- 视图:任何应用的另一个重要部分是视图,即最终用户与之交互的部分。视图负责向最终用户显示信息并获取用户的输入。该层需要确保最终用户能够获得预期的功能。
- 控制器:顾名思义,控制器控制流量。当视图上发生某些操作时,它会让控制器知道,然后控制器会调用来确定此操作是影响模型还是视图。
由于 MVC 是一个古老的模式,架构师和开发人员以不同的方式解释和使用它,您可能会发现 MVC 模式的不同实现可用。我们将从一个非常简化的实现开始,然后转向特定于 Java 的实现。
下图为我们提供了 MVC 流程的基本理解:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sSPsvkU6-1681378425569)(https://gitcode.net/apachecn/apachecn-java-zh/-/raw/master/docs/design-pattern-best-prac-java/img/be5ecc24-ba51-45ec-a2f7-99b6b9519285.png)]
如我们所见,最终用户通过一个动作与控制器交互,比如表单提交或按钮点击。控制器接受此请求并更新模型中的数据。最后,视图组件根据模型上发生的操作获取更新。更新后的视图将呈现给用户以供查看和执行进一步操作。
如前所述,MVC 是一种旧模式,最初用于桌面和静态应用。许多 Web 框架对该模式的解释和实现都有所不同。在 Java 中,也有许多框架提供了 Webmvc 实现。springmvc 是最常用的框架之一,因此值得一看。
下图从较高的层次解释了 Spring MVC 中的控制流:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3F7CmGui-1681378425569)(https://gitcode.net/apachecn/apachecn-java-zh/-/raw/master/docs/design-pattern-best-prac-java/img/b039db08-47a0-4a03-a5ce-3d658a023171.png)]
让我们仔细看看流程:
1:Spring MVC 遵循前置控制器模式,这意味着所有请求最初都必须通过一个点,在本例中是一个分发 Servlet2:然后,前端控制器将请求委托给要处理特定请求的控制器3:控制器根据给定的请求操作或更新模型,并返回最终用户请求的模型4:然后框架选择要处理当前请求的视图,并将模型传递给它5:视图通常是 JSP,根据提供的模型呈现数据6:最后的响应通常是 HTML,发送回调用代理或浏览器
MVC 架构及其应用实例
为了进一步澄清问题,让我们看一个示例实现。首先,我们将在web.xml中添加以下内容:
<servlet>
<servlet-name>springmvc</servlet-name>
<servlet-class>org.springframework.web.servlet.
DispatcherServlet</servlet-class>
<init-param>
<param-name>contextClass</param-name>
<param-value>org.springframework.web.context.support.
AnnotationConfigWebApplicationContext</param-value>
</init-param>
<init-param>
<param-name>contextConfigLocation</param-name>
<param-value>com.employee.config.EmployeeConfig</param-value>
</init-param>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>springmvc</servlet-name>
<url-pattern>/mvc/*</url-pattern>
</servlet-mapping>
我们已经告诉我们的web.xml,所有具有/mvc/模式的请求都应该重定向到我们的前端控制器,即 Spring MVC 的DispatcherServlet。我们还提到了配置类文件的位置。这是我们的配置文件:
@EnableWebMvc
@Configuration
@ComponentScan(basePackages = "com.employee.*")
/**
* The main Configuration class file.
*/
public class EmployeeConfig
{
@Bean
/**
* Configuration for view resolver
*/
public ViewResolver viewResolver()
{
InternalResourceViewResolver viewResolver = new
InternalResourceViewResolver();
viewResolver.setViewClass(JstlView.class);
viewResolver.setPrefix("/WEB-INF/pages/");
viewResolver.setSuffix(".jsp");
return viewResolver;
}
}
我们已经告诉我们的应用,我们将使用 WebMVC 框架和组件的位置。此外,我们通过视图解析器让应用知道视图的位置和格式。
下面是一个示例控制器类:
@Controller
@RequestMapping("/employees")
/**
* This class implements controller for Employee Entity
*/
public class EmployeeController
{
/**
* This method returns view to display all the employees in the system.
*
* @return Employee List
* @throws ServletException
* @throws IOException
*/
@RequestMapping(method = RequestMethod.GET, value = "/")
public ModelAndView getEmployeeList(ModelAndView modelView) throws
ServletException, IOException
{
List<Employee> empList = new ArrayList<Employee>();
EmployeeDAL empDAL = new EmployeeDAL();
empList = empDAL.getEmployeeList();
modelView.addObject("employeeList", empList);
modelView.setViewName("employees");
return modelView;
}
}
我们可以看到,这个控制器以模型的形式获取数据,并让应用知道响应当前请求的适当视图。返回一个ModelAndView对象,其中包含有关视图和模型的信息。
控制器被传递给视图,在本例中是员工.jsp:
<%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding="UTF-8" %>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<meta http-equiv="Content-Type" content= text/html; charset=UTF-8">
<title>Welcome to Spring</title>
<%@ taglib uri="http://java.sun.com/jsp/jstl/core" prefix="c" %>
</head>
<body>
<table>
<th>Name</th>
<th>Email</th>
<th>Address</th>
<th>Telephone</th>
<th>Action</th>
<c:forEach var="employee" items="${employeeList}">
<tr>
<td>${employee.id}</td>
<td>${employee.name}</td>
<td>${employee.designation}</td>
</tr>
</c:forEach>
</table>
</body>
</html>
如我们所见,JSP 所做的所有这些视图都是创建一个以表格形式显示员工详细信息的 HTML。
springmvc 更像是实现 MVC 的一种经典方式。在最近一段时间里,我们试图摆脱 jsp,以保持关注点的分离。在现代应用中,视图通常独立于服务器端代码,并使用 ReactJS、AngularJS 等 JavaScript 框架在前端完全呈现。尽管 MVC 的核心原则仍然成立,但是通信可能看起来不同。
更现代的 MVC 实现
对于富互联网应用,MVC 实现可能更像下图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7hrBbMRO-1681378425570)(https://gitcode.net/apachecn/apachecn-java-zh/-/raw/master/docs/design-pattern-best-prac-java/img/889ec2d7-470c-4395-b045-dbde8d8ff9ab.png)]
其核心思想是模型和视图是完全独立的。控制器接收来自视图和模型的通信,并根据触发的操作更新它们。例如,当用户单击 SubmitNewEmployeeRecord 上的一个按钮时,控制器接收到这个请求,并更新模型。类似地,当模型更新时,它会通知控制器,然后控制器会更新视图以反映正确的模型状态。
MVC 架构保证了什么?
MVC 架构保证了以下几点:
- 关注点分离:与分层架构类似,MVC 保证了关注点的分离,即视图、模型和控制器可以看作是需要独立开发和维护的不同组件。
- 易部署性:应用有不同的方面,即模型、视图和控制器可以由不同的团队独立开发。尽管您需要集成这些组件才能获得完整的图像。
MVC 架构有哪些挑战?
MVC 架构的挑战如下:
- 可扩展性:由于我们仍然需要将整个应用作为一个单元来部署,MVC 不能保证可扩展性。由于我们不能仅扩展与性能相关的部分,因此应用需要作为一个整体进行扩展。
- 可测试性:应用的可测试性在 MVC 中并不简单。虽然我们可以独立地测试一个组件,但是在我们可以端到端地测试一个功能之前,我们需要集成所有的部分。
面向服务的架构
当我们谈论面向服务架构(SOA)方法时,我们谈论的是各种服务或可重用单元的应用。例如,让我们来看一个电子商务购物系统,比如 Amazon。可以将其视为多个服务的组合,而不是单个应用。我们可以考虑一个负责实现产品搜索的搜索服务,一个将实现购物车维护的购物车服务,一个独立处理支付的支付处理服务,等等。这样做的目的是将您的应用分解为可以独立开发、部署和维护的服务。
为了理解面向服务的架构方法的优势,让我们考虑这样一种情况:我们能够将应用划分为 10 个独立的服务。因此,我们将架构的复杂性降低了 10 倍。我们能够将团队分成 10 个部分,我们知道维持较小的团队更容易。此外,它还为我们提供了独立构建、实现、部署和维护每个服务的自由。如果我们知道一个特定的服务可以用一种语言或框架更好地实现,而另一个服务可以用一种完全不同的语言或框架实现,那么我们可以很容易地做到这一点。通过独立部署,我们可以根据每个服务的使用情况独立地扩展它们。此外,我们可以确保,如果一个服务出现故障或遇到任何问题,其他服务仍然能够响应而不出现任何问题。例如,如果由于某种原因,在电子商务系统中,我们有一个无响应的搜索服务,它不应该影响正常的购物车和购买功能。
面向服务的架构及其应用实例
假设我们正在创建一个员工管理系统,该系统负责创建、编辑和删除记录,并管理员工文档、休假计划、评估、运输等。从这个单一的定义开始,让我们开始将它划分为不同的服务。我们最终将拥有一个核心的EmployeeRecordManagement服务,一个LeaveManagement服务,一个DocumentManagement服务,等等。这种拆分成更小的服务的第一个好处是,我们现在可以独立设计和开发这些服务了。因此,50 人的大型团队可以分成 8-10 个规模较小、易于管理的团队,每个团队拥有自己的服务。我们有松散耦合的服务,这意味着进行更改也更容易,因为更改休假规则并不意味着您需要更新整个代码。如果需要,这种 SOA 方法还可以帮助我们分阶段交付;例如,如果我现在不想实现休假管理服务,可以等到第二个版本。
下面的图表应该直观地解释 SOA 设计对于前面的示例的期望:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DEaS8II7-1681378425570)(https://gitcode.net/apachecn/apachecn-java-zh/-/raw/master/docs/design-pattern-best-prac-java/img/f0bc9b89-f803-49ed-b3cd-cb672523e19f.png)]
我们可以看到每个服务都有一个独立的标识。但如果需要,服务可以相互交互。此外,服务共享资源(如数据库和存储)也很常见。
对于每项服务,我们都需要了解三个核心组件:
- 服务提供者:提供服务的组件。服务提供者向服务目录注册服务。
- 服务使用者:使用服务的组件。服务使用者可以在 services 目录中查找服务。
- 服务目录:服务目录包含服务列表。它与提供者和使用者交互以更新和共享服务数据。
Web 服务
顾名思义,Web 服务是通过 Web 或互联网提供的服务。Web 服务有助于普及面向服务的架构,因为它们使人们很容易从互联网上公开的服务的角度来考虑应用。在因特网上公开服务的方式有很多种,简单对象访问协议(SOAP)和 REST 是最常见的两种实现方式。
SOAP 和 REST
SOAP 和 REST 都有助于在互联网上公开服务,但它们的性质截然不同。
SOAP 数据包是基于 XML 的,需要采用非常特定的格式。以下是 SOAP 数据包的主要组件:
- 信封:将 XML 包标识为 SOAP 消息
- 头部:提供头信息的可选元素
- 正文:包含对服务的请求和响应
- 故障:表示状态和错误的可选元素
这就是 SOAP 数据包的外观:
<?xml version="1.0"?>
<soap:Envelope
xmlns:soap="http://www.w3.org/2003/05/soap-envelope/"
soap:encodingStyle="http://www.w3.org/2003/05/soap-encoding">
<soap:Header>
...
</soap:Header>
<soap:Body>
...
<soap:Fault>
...
</soap:Fault>
</soap:Body>
</soap:Envelope>
REST 没有那么多规则和格式。REST 服务可以通过 HTTP 支持GET、POST、PUT和DELETE中的一个或多个方法来实现。
POST请求的示例 JSON REST 负载如下所示:
{
"employeeId":"1",
"employeeName":"Dave",
"department":"sales",
...
}
如我们所见,没有开销,比如定义一个合适的包结构,比如 SOAP。由于其简单性,基于 REST 的 Web 服务在过去几年中变得很流行。
企业服务总线
在我们讨论面向服务的架构时,理解企业服务总线(ESB)在改善通信方面所起的作用是很重要的。在为您的组织开发不同的应用时,您可能会创建几个不同的服务。在某些级别上,这些服务需要与其他服务交互。这会增加很多并发症。例如,一个服务理解基于 XML 的通信,而另一个服务期望所有通信都使用 JSON,而另一个服务期望基于 FTP 的输入。此外,我们还需要添加诸如安全性、请求排队、数据清理、格式化等特性。ESB 是我们所有问题的解决方案。
下图显示了不同的服务如何独立地与 ESB 通信:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-eXrE9hTj-1681378425570)(https://gitcode.net/apachecn/apachecn-java-zh/-/raw/master/docs/design-pattern-best-prac-java/img/5a01d1f5-7b03-4257-b7fd-5eef0c9c2764.png)]
我们可以看到任何数量的服务都在与 ESB 交互。一个服务可以用 Java 编写,另一个用.Net 编写,其他的用其他语言编写。类似地,一个服务可能需要基于 JSON 的数据包,而另一个服务可能需要 XML。ESB 的职责是确保这些服务能够顺利地相互交互。ESB 还有助于服务编排,即我们可以控制排序和流。
面向服务的架构能保证什么?
面向服务的架构保证了以下几点:
- 易开发性:由于我们可以将应用划分为不同的服务,因此团队可以在不影响彼此工作的情况下轻松处理不同的服务。
- 松耦合:每个服务都是相互独立的,所以如果我们改变一个服务实现,保持 API 请求和响应相同,用户就不需要知道发生了什么变化。例如,在前面,一个服务正在从数据库中获取数据,但是我们引入了缓存并进行了更改,以便该服务首先从缓存中获取数据。调用方服务甚至不需要知道服务中是否发生了更改。
- 可测试性:每个服务都可以独立测试。因此,要测试一个服务,不需要等待完整的代码准备就绪。
面向服务的架构面临哪些挑战?
面向服务架构的挑战如下:
- 部署:虽然我们是从服务的角度来考虑的,但是我们还是在逻辑层面进行架构,没有考虑这些服务的独立部署。最后,我们可能会处理难以增强和维护的单片应用的部署。
- 可伸缩性:可伸缩性仍然是 SOA 的主要挑战。我们仍在处理更大的服务,而且大部分服务分离是在逻辑级别,而不是在物理级别。因此,扩展单个服务或服务的一部分是困难的。最重要的是,如果我们使用的是 ESB(ESB 本身是部署的一大块),那么扩展它可能是一场噩梦。
基于微服务的架构
顾名思义,基于微服务的架构建议将服务划分为细粒度级别。当提到微服务时,有不同的思想流派;有些人会认为它只是面向服务架构的一个别致的名字。我们当然可以将微服务视为面向服务架构的扩展,但是有许多特性使微服务与众不同。
微服务将面向服务的架构提升到了一个新的层次。SOA 将服务考虑在功能级别,而微服务将其考虑到任务级别。例如,如果我们有一个用于发送和接收电子邮件的电子邮件服务,我们就可以有诸如拼写检查、垃圾邮件过滤器等微服务,每个微服务都处理一个专门的任务。
相对于 SOA,微服务概念带来的一个重要区别因素是,每个微服务都应该是可独立测试和可部署的。尽管这些特性在 SOA 中是可取的,但在基于微服务的架构中它们是必需的。
微服务架构及其应用实例
让我们看一个简单的例子来了解微服务是如何帮助我们的。假设我们需要在一个电子商务网站上建立一个功能,在那里你可以上传产品的图片。当上传一个产品的图片时,服务需要保存图片并创建一个缩放版本(假设我们希望所有的产品图片保持1280×720的标准分辨率)。此外,我们还需要创建图像的缩略图版本。简而言之,我们尝试在单个服务中执行以下任务。
图像上传服务可帮助您执行以下操作:
- 接收产品图像。
- 将图像上传到存储器。
- 用相关信息更新数据库。
- 将图像缩放到标准分辨率(
1280*720)。 - 将缩放后的图像上传到存储器。
- 生成图像的缩略图版本。
- 将缩略图上传到存储器。
- 返回成功。
好吧,上面提到的所有任务对于上传产品图片来说都很重要,但是对于服务来说这看起来太多了。微服务架构可以帮助我们解决这种情况。例如,我们可以将服务重新考虑为以下微服务。
图像上传服务可帮助您执行以下操作:
- 接收产品图像。
- 将图像上传到存储器。
- 用相关信息更新数据库。
- 返回成功。
缩放图像服务可帮助您执行以下操作:
- 将图像缩放到标准分辨率(
1280*720)。 - 将缩放后的图像上传到存储器。
缩略图服务可帮助您执行以下操作:
- 生成图像的缩略图版本。
- 将缩略图上传到存储器。
您仍然可以继续独立地创建一个 UploadToStore 服务。因此,您希望服务的细粒度如何取决于您的系统。找到合适的粒度级别是非常重要的,也是一项棘手的任务。如果您不将更大的服务正确地分解为微服务,您将无法实现微服务的优势,例如可伸缩性、易部署性、可测试性等等。另一方面,如果您的微服务粒度太细,您将不必要地维护太多的服务,这也意味着要努力使这些服务相互通信并处理性能问题。
服务间通信
在前面的例子中,一个显而易见的问题是:如何触发缩放图像服务和缩略图服务?嗯,有很多选择。最常见的是基于 REST 的通信,其中上传服务可以对其他两个服务进行 REST 调用,或者基于消息队列的通信,其中上传服务将向队列中添加可由其他服务处理的消息,或者基于状态的工作流,其中上传服务将在数据库中设置一个状态(例如,准备好缩放),该状态将被其他服务读取和处理。
根据应用的需要,您可以调用哪个通信方法是首选的。
基于微服务的架构能保证什么?
基于微服务的架构保证了以下几点:
- 可伸缩性:我们在之前所有架构中面临的一个主要挑战是可伸缩性。微服务帮助我们实现分布式架构,从而支持松散耦合。更容易扩展这些松散耦合的服务,因为每个服务都可以独立部署和扩展。
- 持续交付:在业务快速发展的今天,持续交付是应用需求的一个重要方面。由于我们处理的是许多服务,而不是单一的单一应用,因此根据需求修改和部署服务要容易得多。简而言之,将更改推送到生产环境很容易,因为不需要部署整个应用。
- 易部署:微服务可以独立开发和部署。因此,我们不需要对整个应用进行 bing-bang 部署;只能部署受影响的服务。
- 可测试性:每个服务都可以独立测试。如果我们正确地定义了每个服务的请求和响应结构,我们就可以将服务作为一个独立的实体进行测试,而不用担心其他服务。
基于微服务的架构面临哪些挑战?
基于微服务架构的挑战如下:
- 依赖 devops:由于我们需要维护多个通过消息相互作用的服务,因此我们需要确保所有服务都可用并受到适当的监控。
- 保持平衡:维持适量的微服务本身就是一个挑战。如果我们有太细粒度的服务,我们就会面临部署和维护太多服务等挑战。另一方面,如果我们拥有的大型服务太少,我们最终会失去微服务所提供的优势。
- 重复代码:由于我们所有的服务都是独立开发和部署的,一些常用的工具需要复制到不同的服务中。
无服务器架构
到目前为止,在我们讨论的所有架构样式中,有一个共同的因素:对基础结构的依赖性。每当我们为一个应用设计时,我们都需要考虑一些重要的因素,例如:系统将如何放大或缩小?如何满足系统的性能需求?这些服务将如何部署?我们需要多少实例和服务器?他们的能力是什么?等等。
这些问题很重要,同时也很难回答。我们已经从专用硬件转向基于云的部署,这使得我们的部署更加轻松,但我们仍然需要规划基础设施需求,并回答前面提到的所有问题。一旦获得了硬件,无论是在云端还是其他地方,我们都需要维护它的健康,并确保服务能够根据需求进行扩展,这就需要 devops 的大量参与。另一个重要问题是基础设施的使用不足或过度使用。如果你有一个简单的网站,在那里你不希望有太多的流量,你仍然需要提供一些基础设施的能力来处理请求。如果您知道一天中只有几个小时的时间会有很高的流量,那么您需要智能地管理您的基础结构,以便进行上下扩展。
为了解决上述问题,出现了一种全新的思维方式,即所谓的无服务器部署,也就是说,将功能作为服务提供。其想法是开发团队应该只关心代码,云服务提供商将负责基础设施需求,包括功能的扩展。
如果你能只为你使用的计算能力付费呢?如果不需要预先提供任何基础设施容量,该怎么办?如果服务提供商自己负责扩展所需的计算能力,自行管理每小时是否有一个请求或每秒是否有一百万个请求呢?
无服务器架构及其应用实例
如果我们已经引起你的注意,让我们举一个非常简单的例子来说明这一点。我们将尝试创建一个简单的问候语示例,其中作为服务实现的函数将问候用户。我们将在本例中使用 AWS Lambda 函数。
让我们用一个示例问候语函数来创建我们的类:
/**
* Class to implement simple hello world example
*
*/
public class LambdaMethodHandler implements RequestStreamHandler
{
public void handleRequest(InputStream inputStream, OutputStream
outputStream, Context context) throws IOException
{
BufferedReader reader = new BufferedReader(new InputStreamReader
(inputStream));
JSONObject responseJson = new JSONObject();
String name = "Guest";
String responseCode = "200";
try
{
// First parse the request
JSONParser parser = new JSONParser();
JSONObject event = (JSONObject)parser.parse(reader);
if (event.get("queryStringParameters") != null)
{
JSONObject queryStringParameters = (JSONObject)event.get
("queryStringParameters");
if ( queryStringParameters.get("name") != null)
{
name = (String)queryStringParameters.get("name");
}
}
// Prepare the response. If name was provided use that
else use default.
String greeting = "Hello "+ name;
JSONObject responseBody = new JSONObject();
responseBody.put("message", greeting);
JSONObject headerJson = new JSONObject();
responseJson.put("isBase64Encoded", false);
responseJson.put("statusCode", responseCode);
responseJson.put("headers", headerJson);
responseJson.put("body", responseBody.toString());
}
catch(ParseException parseException)
{
responseJson.put("statusCode", "400");
responseJson.put("exception", parseException);
}
OutputStreamWriter writer = new OutputStreamWriter
(outputStream, "UTF-8");
writer.write(responseJson.toJSONString());
writer.close();
}
}
这个简单的函数从查询字符串中读取输入参数并创建一条问候语消息,该消息嵌入到 JSON 的message标记中并返回给调用者。我们需要从中创建一个 JAR 文件。如果您使用的是 Maven,那么只需使用一个 shade 包,比如mvn clean package shade:shade。
一旦准备好 JAR 文件,下一步就是创建 Lambda 函数并上传 JAR。转到您的 AWS 帐户,选择“Lambda service | Create function | Author from scratch”,并提供所需的值。看看这个截图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7wTKFE5S-1681378425571)(https://gitcode.net/apachecn/apachecn-java-zh/-/raw/master/docs/design-pattern-best-prac-java/img/0d636b2c-05a5-414e-b3bf-38fedb32ec95.png)]
您需要提供名称和运行时环境。根据 Lambda 函数应该执行的操作,您将授予它权限。例如,您可能正在读取存储、访问队列或数据库等。
接下来,我们上传 JAR 文件并将其保存到 Lambda 函数,如下面的屏幕截图所示。为处理函数提供完全限定的路径-com.test.LambdaMethodHandler::handleRequest:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ypSqngvm-1681378425571)(https://gitcode.net/apachecn/apachecn-java-zh/-/raw/master/docs/design-pattern-best-prac-java/img/467d227a-59dc-4548-a1f6-9957d6ef8eef.png)]
现在,我们通过设置一个测试事件来测试我们的函数。看看这个截图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SNZ3kyUN-1681378425571)(https://gitcode.net/apachecn/apachecn-java-zh/-/raw/master/docs/design-pattern-best-prac-java/img/4bec5194-18b3-4df9-8a14-4bd67a9a8145.png)]
最后,单击“Test”按钮将显示如下响应:
{
"isBase64Encoded": false,
"headers": {},
"body": "{"message":"Hello Guest"}",
"statusCode": "200"
}
我们已经创建了一个成功的 Lambda 函数,但是我们需要了解如何调用它。让我们创建一个 API 来调用这个函数。Amazon 为此向我们提供了 API 网关。在 Designer 的“Add triggers”下,选择“API Gateway”,如下屏幕截图所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZjpmpbEV-1681378425572)(https://gitcode.net/apachecn/apachecn-java-zh/-/raw/master/docs/design-pattern-best-prac-java/img/208089e8-276a-4b36-aea6-1982207b5d60.png)]
最后,添加 API 网关配置。看看这个截图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gbpSr52Q-1681378425572)(https://gitcode.net/apachecn/apachecn-java-zh/-/raw/master/docs/design-pattern-best-prac-java/img/371926cf-d2c0-4cdd-9ca0-1763e0bc61ce.png)]
添加配置后,系统将为您提供一个 API 链接,点击该链接后,将打印所需的 JSON:
{"message":"Hello Guest"}
或者,如果提供名称查询参数,则打印Hello {name}。
基础设施规划独立
整个练习的一个重要核心思想是认识到我们创建了一个 API,而没有设置任何机器或服务器。我们只是创建了一个 JAR 文件并上传到 Amazon 上。我们不再担心负载或性能。我们不考虑是否使用 Tomcat、Jboss 或任何其他服务器。我们并没有考虑这个 API 在一天内会得到一次点击还是一百万次点击。我们将只支付请求的数量和使用的计算能力。
请注意,我们使用 API 调用函数并返回了一条简单的消息。更复杂的实现很容易得到支持。例如,可以从消息队列、数据库更改或存储触发功能,并且类似地,可以访问其他云提供商服务,例如数据库、存储、消息、电子邮件等,以及第三方服务。
尽管我们在本书中使用了 amazonLambda 示例,但我们不推荐任何特定的供应商。这个想法只是解释无服务器架构的用法。所有主要的云玩家,如微软、谷歌、IBM 等,都提供了自己的无服务器功能实现作为服务部署。建议读者根据自己的需要和使用情况,在比较所选供应商后进行选择。
无服务器架构能保证什么?
无服务器架构保证了以下几点:
- 从基础设施规划中解放出来:好吧,如果不是完全的话,在很大程度上,无服务器架构帮助我们关注代码,让服务提供商来管理基础设施。您不必考虑上下扩展服务和添加自动扩展或负载平衡逻辑。
- 成本效益:由于您只为实际使用或实际流量付费,因此您不必担心维护最低的基础设施级别。如果你的网站没有受到任何影响,你就不会为基础设施支付任何费用(基于你的云服务提供商的条件)。
- 微服务的下一步:如果您已经实现了基于微服务的架构,那么将很容易发展到无服务器架构。使用基于函数的无服务器实现,部署以函数形式实现的服务更容易。
- 持续交付:与微服务一样,我们可以通过无服务器架构实现持续交付,因为一次功能更新不会影响整个应用。
无服务器架构面临哪些挑战?
无服务器架构的挑战如下:
- 基于供应商的限制:不同供应商在提供功能作为服务时可能会受到限制。例如,对于 Amazon,服务器可以执行的最大持续时间是 5 分钟。因此,如果您需要创建一个正在进行繁重处理的函数,并且可能需要比所施加的限制更多的时间,Lambda 函数可能不适合您。
- 管理分布式架构:维护大量功能可能会变得棘手。您需要跟踪所有实现的函数,并确保一个函数 API 中的升级不会破坏其他调用函数。
总结
在本章中,我们讨论了各种架构风格,从分层架构、MVC 架构、面向服务架构、微服务开始,最后是无服务器架构。我想到的一个明显的问题是:在这些设计应用的风格中,哪一种是最好的。这个问题的答案也很明显,这取决于手头的问题。好吧,如果有一个架构可以应用于所有的问题,每个人都会使用它,我们只会讨论那个特定的架构风格。
这里需要注意的一点是,这些架构风格并不是相互排斥的;事实上,它们是相辅相成的。因此,大多数时候,您可能会使用这些架构风格的混合体。例如,如果我们正在进行基于面向服务架构的设计,我们可能会看到这些服务的内部实现可能是基于分层或 MVC 架构的。此外,我们可能最终将一些服务分解为微服务,而在这些微服务中,一些可能以无服务器的方式实现为函数。关键是,您必须根据当前要解决的问题选择设计或架构。
在下一章中,我们将重点介绍最近 Java 版本升级中的一些最新趋势和更新。
九、Java 最佳实践
在本章中,我们将讨论 Java9 和 Java10 中的最佳实践。Java 从 1995 年发布的版本 1.0 到最近的版本 Java10 已经有了很大的发展。我们将快速了解 Java 从一开始到今天的发展历程,但我们将更多地关注 Java9 和 Java10 带来的最新变化。
在本章中,我们将介绍以下主题:
- Java 简史
- Java9 的最佳实践和新特性
- Java10 的最佳实践和新特性
Java 简史
Java1 最初于 1995 年推出,其企业版(JavaEE)于 1999 年与 Java2 一起推出。考虑到 Java 已经存在了 20 多年的事实,毫无疑问,在构建复杂的企业应用时,Java 具备成为首选语言的条件。
让我们看看让 Java 一炮走红的特性:
- 面向对象:面向对象语言很容易学习,因为它们更接近真实世界。对于已经使用面向对象语言(如 C++)的开发人员来说,将其转换为 Java 更容易,这使得它成为一种流行的选择。
- 平台无关:“编写一次,随处(
DEBUG)执行”是 Java 的口头禅。由于 Java 代码被编译成字节码(由 JVM 解释),所以在何处编写代码和在何处执行代码没有限制。我们可以在 Linux 机器上开发一个 Java 程序,并在 Windows 或 MacOS 机器上运行它,而没有任何问题。 - 安全:当 Java 代码被转换成字节码,字节码在 Java 虚拟机(JVM)内运行时,它被认为是安全的,因为它不能访问 JVM 之外的任何内存。另外,Java 不支持指针,内存管理完全由 JVM 负责,这使得语言安全。
除了核心 Java 之外,将该语言进一步普及的是 J2EE 中 Servlet 等概念的引入。随着互联网的普及,Java 提供的易用性和安全性使其成为 Web 应用开发中的一种重要语言。进一步的概念,如多线程,有助于实现更好的性能和资源管理。
Java1.2 之所以被称为 Java2,是因为它以企业版的形式带来了重大变化。Java2 非常流行,以至于接下来的两个版本,1.3 和 1.4,通常只被称为 Java2 版本。后来出现了 Java5,它带来了一些重要的特性,并被赋予了一个独立的身份。
Java5 的特点
Java5 引入了泛型。在泛型之前,许多数据结构(如列表和映射)都不是类型安全的。也就是说,您可以将一个人和一辆车添加到同一个列表中,然后尝试执行可能导致错误的操作。
Java5 带来的另一个重要特性是自动装箱,它有助于原始类型类和相应的包装类之间的转换。枚举也在 Java5 中获得了新的生命。它们不仅可以保持常量值,还可以保持数据和行为。
方法采用可变参数。如果元素属于同一类型,则不再强制您提供元素的确切数目。例如,您可以简单地编写stringMethod(String... str)并将任意数量的字符串传递给此方法。Java5 还引入了注解,这些注解在以后的版本中得到了增强,并成为许多框架的一个组成部分。
Java5 中还有许多其他增强功能,这使得该版本成为 Java 历史上的一个重要时刻。
在 Java5 之后,Java6 和 Java7 是其他重要的版本,但是 Java8 带来了重大的变化。
Java8 的特点
Java8 是 Java 历史上另一个重要的里程碑版本。除了许多其他特性(如首次打开接口以允许静态和默认方法定义)之外,还引入了optional和forEach;两个核心添加是流和 Lambda 表达式。
流可以被认为是数据管道,在其中我们可以执行两种类型的操作:中间操作和终端操作。中间操作是应用于流上转换数据的操作,但结果仍然是流;例如,map和filter。例如,在整数数据流中,使用apply函数(如过滤掉所有偶数或为每个数加 N)可以得到一个结果流。然而,终端操作会产生具体的输出。例如,整数数据流上的sum函数将返回一个最终数字作为输出。
对于 Lambda 表达式,Java 首次遇到函数式编程。Lambda 帮助我们实现函数式接口,这些接口只有一个未实现的方法。与以前的版本不同,我们必须创建类或匿名类,现在可以创建 Lambda 函数来实现函数式接口。一个典型的例子是可以运行来实现多线程。请看下面的代码:
Runnable myrunnable = new Runnable()
{
@Override
public void run()
{
// implement code here
}
};
new Thread(myrunnable).start();
But with Lambdas, we can do this:
Runnable myrunnableLambda = ()->
{
// implement code here
};
new Thread(myrunnableLambda).start();
我们已经在第 5 章、”函数式模式“中介绍了流和 Lambda 的一些细节。
当前支持的 Java 版本
在编写本书时,Oracle Java 正式支持两个版本。它们是 Java8 和 Java10。Java8 是长期支持版本,Java10 是快速发布版本。Java9 是另一个快速发布版本,于 2017 年 9 月发布,从 2018 年 1 月起停止接收更新。Java8 于 2014 年 3 月发布,预计将在 2019 年 1 月之前提供商业支持,在 2020 年 12 月之前提供非商业支持。Java10 于 2018 年 3 月发布,预计将于 2018 年 9 月结束。同时,当 Java10 失去支持时,我们希望 Java11 能够发布,这将是另一个长期支持的版本,比如 Java8。
如我们所见,Java9 和 Java10 是较新的版本,因此了解它们引入的所有新特性以及使用这些新版本时的一些最佳实践是有意义的。
Java9 的最佳实践和新特性
Java9 带来的最重要和最大的变化是 Jigsaw 项目或 Java 平台模块系统的实现。在此更改之前,您需要将完整的 Java 运行时环境(JRE)作为一个整体加载到服务器或机器上以运行 Java 应用。使用 ProjectJigsaw,您可以决定应用需要加载哪些库。除了模块系统之外,Java9 还将 JShell 添加到 Java 的武库中,这对于那些使用过 RubyonRails、Python 等语言的人来说是一个福音。这与类似的功能。我们将详细讨论模块和 Jshell,以及 Java9 带来的一些其他重要变化,这些变化会影响我们如何用 Java 编写代码。
Java 平台模块系统
如果说 Java8 帮助我们改变了编码方式,那么 Java9 更多的是关于在应用运行时如何加载文件和模块。
首先,让我们看看 Java9 是如何将整个应用划分为模块的。您只需运行以下代码:
java --list-modules
您将看到与以下屏幕截图中的模块列表类似的模块列表:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aCEL2ffK-1681378425572)(https://gitcode.net/apachecn/apachecn-java-zh/-/raw/master/docs/design-pattern-best-prac-java/img/ef36f6d4-79ad-43cb-82eb-1882ca54ce70.png)]
我们现在的优势是可以选择应用将使用哪些模块,而不是默认添加所有模块。
为了理解模块的功能,让我们看一个例子。让我们尝试创建一个非常简单的计算器应用,它只提供add和subtract方法,以保持简单。
让我们在provider/com.example/com/example/calc中创建类:
package com.example.calc;
/**
* This class implements calculating functions on integers.
*/
public class Calculator
{
/**
* This method adds two numbers.
*/
public int add(int num1, int num2)
{
return num1+num2;
}
/**
* This method returns difference between two numbers.
*/
public int diff(int num1, int num2)
{
return num1-num2;
}
}
现在我们创建一个模块-provider/com.example中的info.java:
module com.example
{
requires java.base;
exports com.example.calc;
}
我们不需要明确提供requires java.base。默认添加,因为所有模块都默认需要java.base。但我们保留它只是为了明确。
现在编译类:
javac -d output/classes provider/com.example/module-info.java provider/com.example/com/example/calc/Calculator.java
最后,创建 JAR:
jar cvf output/lib/example.jar -C output/classes/
所以,我们有一个模块,可以提供加法和减法功能。我们来看看如何在user/com.example.user/com/example/user中创建一个用户类来使用这个模块:
package com.example.user;
import com.example.calc.*;
/**
* This classes uses calculator module
*/
public class User
{
public static void main(String s[])
{
Calculator calculator = new Calculator();
System.out.println(calculator.add(1,2));
}
}
同样,我们需要在user/com.example.user中创建模块-info.java:
module com.example.user
{
requires com.example;
}
让我们把这些方法编译成output/userclasses:
javac --module-path output/lib -d output/userclasses user/com.example.user/module-info.java user/com.example.user/com/example/user/User.java
创建user.jar,如下图:
jar cvf output/lib/user.jar -C output/userclasses/
最后,运行类:
java --module-path output/lib -m com.example.user/com.example.user.User
前面的代码解释了模块如何在 Java9 中工作。在继续下一个主题之前,让我们先看看 jlink,它为 Java 模块化增加了功能:
jlink --module-path output/lib --add-modules com.example,com.example.user --output calculaterjre
请注意,您需要将java.base.mod添加到/output/lib,因为我们的com.example依赖于java.base模块。创建自定义 JRE 后,可以按以下方式运行它:
./calculaterjre/bin/java -m com.example.user/com.example.user.User
你可以看到,我们能够创建自己的小 JRE。为了了解我们的小可执行文件有多紧凑和轻量级,让我们再次运行--list-modules:
calculaterjre/bin/java --list-modules w
这将返回以下内容:
com.example
com.example.user
java.base@9.0.4
将它与我们最初列出的缺省情况下随 Java9 提供的模块进行比较。我们可以了解我们新的可部署单元有多轻。
JShell
我们在本书前面已经给出了一些 JShell 用法的例子。在这里,我们将对 JShell 进行更具描述性的描述。如果您使用过 Python 或 Ruby-on-Rails 等语言,您一定注意到了很酷的 Shell 特性或读取求值打印循环(REPL)工具。这样做的目的是在开始真正的实现之前,先试用和试验这种语言。是时候让 Java 向它添加一个类似的特性了。
JShell 是开始使用 Java 的一种简单方法。您可以编写代码片段,查看它们是如何工作的,查看不同类和方法的行为,而不必实际编写完整的代码,还可以使用 Java。让我们仔细看看,以便更好地理解。
让我们先开始贝壳吧。注意 Java9 是一个先决条件,jdk-9/bin/应该已经添加到您的系统路径中。
只需键入jshell,它将带您进入 JShell 提示符,并显示一条欢迎消息:
$ jshell
| Welcome to JShell -- Version 9.0.4
| For an introduction type: /help intro
jshell>
让我们尝试几个简单的命令开始:
jshell> System.out.println("Hello World")
Hello World
一个简单的Hello World。无需编写、编译或运行类:
jshell> 1+2
$1 ==> 3
jshell> $1
$1 ==> 3
当我们在 Shell 中输入1+2时,我们在一个变量中得到结果:$1。请注意,我们可以在以后的命令中使用此变量:
jshell> int num1=10
num1 ==> 1
jshell> int num2=20
num2 ==> 2
jshell> int num3=num1+num2
num3 ==> 30
在前面的命令中,我们创建了几个变量,并在以后使用这些变量。
假设我想尝试一段代码,看看它在实际应用中是如何工作的。我可以用贝壳做。假设我想编写一个方法并进行试验,以评估它是否返回了预期的结果,以及在某些情况下是否会失败。我可以在 Shell 中完成以下操作:
jshell> public int sum(int a, int b){
...> return a+b;
...> }
| created method sum(int,int)
jshell> sum(3,4)
$2 ==> 7
jshell> sum("str1",6)
| Error:
| incompatible types: java.lang.String cannot be converted to int
| sum("str1",6)
| ^----^
我创建了一个方法,并了解了它在不同输入下的行为。
您还可以使用 JShell 作为教程,学习对象可用的所有函数。
例如,假设我有一个String str,我想知道所有可用于此的方法。我只需要写下str,然后按Enter键:
jshell> String str = "hello"
str ==> "hello"
jshell> str.
输出如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dXkHD9xx-1681378425573)(https://gitcode.net/apachecn/apachecn-java-zh/-/raw/master/docs/design-pattern-best-prac-java/img/548e8a0c-fd2e-49e0-85c1-70e337fc7362.png)]
JShell 还提供了其他帮助命令。第一个你可能想用的是/help给你所有的命令。另一个有用的命令是/import检查所有已经导入的包:
jshell> /import
|
import java.io.*
|
import java.math.*
|
import java.net.*
|
import java.nio.file.*
|
import java.util.*
|
import java.util.concurrent.*
|
import java.util.function.*
|
import java.util.prefs.*
|
import java.util.regex.*
|
import java.util.stream.*
您可以将其他包和类导入 Shell 并使用它们。
最后,/exit将让您关闭外壳:
jshell> /exit
| Goodbye
接口中的私有方法
Java8 允许我们向接口添加默认方法和静态方法,在接口中只需要实现未实现的方法。现在,当我们被允许添加默认实现时,我们可能希望将代码分解为模块,或者在一个可以被其他函数使用的方法中提取公共代码。但我们不想公开这种常用方法。为了解决这个问题,Java9 允许在接口中使用私有方法。
下面的代码显示了 Java9 中接口的完全有效的实现,它有一个默认方法使用的辅助私有方法:
package com.example;
/**
* An Interface to showcase that private methods are allowed
*
*/
public interface InterfaceExample
{
/**
* Private method which sums up 2 numbers
* @param a
* @param b
* @return
*/
private int sum(int a, int b)
{
return a+b;
}
/**
* Default public implementation uses private method
* @param num1
* @param num2
* @return
*/
default public int getSum(int num1, int num2)
{
return sum(num1, num2);
}
/**
* Unimplemented method to be implemented by class which
implements this interface
*/
public void unimplementedMethod();
}
流中的增强功能
Java8 为我们带来了流的奇妙特性,它帮助我们非常轻松高效地对列表和数据集进行操作。Java9 进一步增强了流的使用,使它们更加有用。这里我们将讨论流中的重要增强:
takeWhile():Java8 给了我们一个过滤器,它可以根据过滤条件检查每个元素。例如,假设从一个流中我们需要所有小于 20 的数字。可能有这样一种情况:在满足条件之前,我们需要所有数字的列表,而忽略其余的输入。也就是说,当第一次违反过滤条件时,忽略其余的输入,然后执行诸如返回或退出命令之类的操作。
下面的代码展示了返回所有数字的情况,除非满足数字小于 20 的条件。条件满足一次后的所有数据被忽略:
jshell> List<Integer> numList = Arrays.asList(10, 13, 14, 19, 22, 19, 12, 13)
numList ==> [10, 13, 14, 19, 22, 19, 12, 13]
jshell> numList.stream().takeWhile(num -> num < 20).forEach(System.out::println)
输出如下:
10
13
14
19
dropWhile():这几乎是takewhile()的反转。dropWhile确保删除所有输入,除非满足给定的条件,并且在条件满足一次之后,所有数据都报告为输出。
让我们以takewhile为例来说明问题:
jshell> List<Integer> numList = Arrays.asList(10, 13, 14, 19, 22, 19, 12, 13)
numList ==> [10, 13, 14, 19, 22, 19, 12, 13]
jshell> numList.stream().dropWhile(num -> num < 20).forEach(System.out::println)
输出如下:
22
19
12
13
iterate():Java8 已经支持Stream.iterate,但是 Java9 可以添加一个谓词条件,使它更接近一个带有终止条件的循环。
下面的代码显示了循环条件的替换,该循环条件将变量初始化为 0,递增 2,并打印到数字小于 10 为止:
jshell> IntStream.iterate(0, num -> num<10, num -> num+2).forEach(System.out::println)
输出如下:
0
2
4
6
8
创建不可变集合
Java9 为我们提供了创建不可变集合的工厂方法。例如,要创建一个不可变列表,我们使用列表:
jshell> List immutableList = List.of("This", "is", "a", "List")
immutableList ==> [This, is, a, List]
jshell> immutableList.add("something")
| Warning:
| unchecked call to add(E) as a member of the raw type java.util.List
| immutableList.add("something")
| ^----------------------------^
| java.lang.UnsupportedOperationException thrown:
| at ImmutableCollections.uoe (ImmutableCollections.java:71)
| at ImmutableCollections$AbstractImmutableList.add (ImmutableCollections.java:77)
| at (#6:1)
类似地,我们有Set.of、Map.of和Map.ofEntries。我们来看看用法:
jshell> Set immutableSet = Set.of(1,2,3,4,5);
immutableSet ==> [1, 5, 4, 3, 2]
jshell> Map immutableMap = Map.of(1,"Val1",2,"Val2",3,"Val3")
immutableMap ==> {3=Val3, 2=Val2, 1=Val1}
jshell> Map immutableMap = Map.ofEntries(new AbstractMap.SimpleEntry<>(1,"Val1"), new AbstractMap.SimpleEntry<>(2,"Val2"))
immutableMap ==> {2=Val2, 1=Val1}
数组中的附加功能
到目前为止,我们已经讨论了流和集合。数组中还有一些附加功能:
mismatch():尝试匹配两个数组,并返回数组不匹配的第一个元素的索引。如果两个数组相同,则返回-1:
jshell> int[] arr1={1,2,3,4}
arr1 ==> int[4] { 1, 2, 3, 4 }
jshell> Arrays.mismatch(arr1, new int[]{1,2})
$14 ==> 2
jshell> Arrays.mismatch(arr1, new int[]{1,2,3,4})
$15 ==> -1
我们创建了一个整数数组。第一个比较显示数组在索引 2 处不匹配。第二个比较显示两个数组是相同的。
compare():按字典顺序比较两个数组。还可以指定开始索引和结束索引,这是一个可选参数:
jshell> int[] arr1={1,2,3,4}
arr1 ==> int[4] { 1, 2, 3, 4 }
jshell> int[] arr2={1,2,5,6}
arr2 ==> int[4] { 1, 2, 5, 6 }
jshell> Arrays.compare(arr1,arr2)
$18 ==> -1
jshell> Arrays.compare(arr2,arr1)
$19 ==> 1
jshell> Arrays.compare(arr2,0,1,arr1,0,1)
$20 ==> 0
我们创建了两个数组并进行了比较。当两个数组相等时,我们将得到 0 输出。如果第一个词的词法较大,则得到1,否则得到-1。在最后一次比较中,我们提供了要比较的数组的开始索引和结束索引。因此,两个数组只比较前两个元素,这两个元素相等,因此 0 是输出。
equals():顾名思义,equals方法检查两个数组是否相等。同样,您可以提供开始索引和结束索引:
jshell> int[] arr1={1,2,3,4}
arr1 ==> int[4] { 1, 2, 3, 4 }
jshell> int[] arr2={1,2,5,6}
arr2 ==> int[4] { 1, 2, 5, 6 }
jshell> Arrays.equals(arr1, arr2)
$23 ==> false
jshell> Arrays.equals(arr1,0,1, arr2,0,1)
$24 ==> true
Optional类的附加功能
Java8 给了我们java.util.Optional类来处理空值和空指针异常。Java9 又添加了一些方法:
ifPresentOrElse:如果存在Optional值,则方法void ifPresentOrElse(Consumer<? super T> action, Runnable emptyAction)执行给定动作;否则执行emptyAction。我们来看几个例子:
//Example 1
jshell> Optional<String> opt1= Optional.ofNullable("Val")
opt1 ==> Optional[Val]
//Example 2
jshell> Optional<String> opt2= Optional.ofNullable(null)
opt2 ==> Optional.empty
//Example 3
jshell> opt1.ifPresentOrElse(v->System.out.println("found:"+v),
()->System.out.println("no"))
found:Val
//Example 4
jshell> opt2.ifPresentOrElse(v->System.out.println("found:"+v),
()->System.out.println("not found"))
not found
ofNullable():由于可选对象可以有值,也可以为null,所以当您需要返回当前可选对象,如果它有某个合法值返回,否则返回其他可选对象时,or函数会有所帮助。
我们来看几个例子:
//Example 1
jshell> Optional<String> opt1 = Optional.ofNullable("Val")
opt1 ==> Optional[Val]
//Example 2
jshell> Optional<String> opt2 = Optional.ofNullable(null)
opt2 ==> Optional.empty
//Example 3
jshell> Optional<String> opt3 = Optional.ofNullable("AnotherVal")
opt3 ==> Optional[AnotherVal]
//Example 4
jshell> opt1.or(()->opt3)
$41 ==> Optional[Val]
//Example 5
jshell> opt2.or(()->opt3)
$42 ==> Optional[AnotherVal]
由于opt1不为空,与或一起使用时返回;而opt2为空,因此返回opt3。
stream():流在 Java8 之后开始流行,Java9 为我们提供了一种将可选对象转换为流的方法。我们来看几个例子:
//Example 1
jshell> Optional<List> optList = Optional.of(Arrays.asList(1,2,3,4))
optList ==> Optional[[1, 2, 3, 4]]
//Example 2
jshell> optList.stream().forEach(i->System.out.println(i))
[1, 2, 3, 4]
新的 HTTP 客户端
Java9 带来了一个新的光滑的 HTTP 客户端 API,支持 HTTP/2。让我们通过在 JShell 中运行一个示例来进一步了解一下。
要使用httpclient,我们需要用jdk.incubator.httpclient模块启动 JShell。以下命令告诉 JShell 添加所需的模块:
jshell -v --add-modules jdk.incubator.httpclient
现在让我们导入 API:
jshell> import jdk.incubator.http.*;
使用以下代码创建一个HttpClient对象:
jshell> HttpClient httpClient = HttpClient.newHttpClient();
httpClient ==> jdk.incubator.http.HttpClientImpl@6385cb26
| created variable httpClient : HttpClient
让我们为 URL 创建一个请求对象:
jshell> HttpRequest httpRequest = HttpRequest.newBuilder().uri(new URI("https://www.packtpub.com/")).GET().build();
httpRequest ==> https://www.packtpub.com/ GET
| created variable httpRequest : HttpRequest
最后,调用 URL。结果将存储在HttpResponse对象中:
jshell> HttpResponse<String> httpResponse = httpClient.send(httpRequest, HttpResponse.BodyHandler.asString());
httpResponse ==> jdk.incubator.http.HttpResponseImpl@70325e14
| created variable httpResponse : HttpResponse<String>
我们可以检查响应状态码,甚至打印正文:
jshell> System.out.println(httpResponse.statusCode());
200
jshell> System.out.println(httpResponse.body());
我们可以看到它的易用性,并且没有必要为 HTTP 客户端包含大量的第三方库。
对 Java9 的更多补充
到目前为止,我们已经讨论了 Java9 的核心添加内容,它们将影响您的日常编码生活。让我们看看更多的功能添加,这些功能可能没有那么大的影响,但仍然值得了解:
-
Javadocs 的改进:Java9 带来了 Javadocs 的改进,比如支持 HTML5,增加了搜索功能,在现有 Javadocs 功能的基础上增加了模块信息。
-
多版本 JAR:假设一个类有不同的版本,应该在不同的 Java 版本上运行。例如,Java 有两个不同的版本,一个支持 Java8,另一个支持 Java9。您将创建这两个类文件,并在创建 JAR 文件时包含它们。将根据与 Java7 或 Java9 一起使用的 JAR 选择文件的正确版本。
-
进程 API 改进:Java5 为我们提供了进程构建器 API,它有助于生成新进程。Java9 引入了
java.lang.ProcessHandle和java.lang.ProcessHandle.InfoAPI,以便更好地控制和收集有关进程的更多信息。 -
try-with-resource改进:Java7 引入了一个特性,您可以使用Try块来管理资源并帮助删除大量样板代码。Java9 进一步改进了它,这样就不需要在try块中引入新的变量来使用资源尝试。
让我们看一个小例子来理解我们的意思。以下是在 Java9 之前编写的代码:
jshell> void beforeJava9() throws IOException{
...> BufferedReader reader1 = new BufferedReader(new FileReader("/Users/kamalmeetsingh/test.txt"));
...> try (BufferedReader reader2 = reader1) {
...> System.out.println(reader2.readLine());
...> }
...> }
| created method beforeJava9()
Java9 之后的代码如下:
jshell> void afterJava9() throws IOException{
...> BufferedReader reader1 = new BufferedReader(new FileReader("/Users/kamalmeetsingh/test.txt"));
...> try (reader1) {
...> System.out.println(reader1.readLine());
...> }
...> }
| created method afterJava9()
- 匿名类菱形运算符:在 Java8 之前,您不可能将菱形运算符用于内部类。Java9 中删除了这个限制。
我们已经介绍了 Java9 的大部分重要特性,这些特性将影响您在 Java 中编写代码的方式。使用上述实践将帮助我们充分利用 Java 的功能。但是我们知道 Java10 带来了额外的变化,所以在下一节中我们将进一步讨论影响代码的一些重要特性。
Java10 的最佳实践和新特性
Java10 是 Java 的最新版本。与以前的版本一样,这也为语言添加了一些有趣的特性。在编写代码时,我们可以直接与一些功能进行交互,但也有一些在幕后起作用的改进,例如改进的垃圾收集,它可以改善用户的总体体验。在本节中,我们将讨论 Java10 添加的一些重要特性。
局部变量类型推断
这可能是 Java10 中最大的改变,它将影响您过去的编码方式。Java 一直被称为严格类型语言。好吧,它仍然是,但是在 Java10 中,您可以在声明局部变量时自由地使用var,而不是提供适当的类型。
举个例子:
public static void main(String s[])
{
var num = 10;
var str = "This is a String";
var dbl = 10.01;
var lst = new ArrayList<Integer>();
System.out.println("num:"+num);
System.out.println("str:"+str);
System.out.println("dbl:"+dbl);
System.out.println("lst:"+lst);
}
我们可以定义和使用变量,而无需指定类型。但这项功能并非没有它的一系列限制。
不能将类作用域变量声明为var。例如,以下代码将显示编译器错误:
public class VarExample {
// not allowed
// var classnum=10;
}
即使在局部范围内,只有当编译器可以从表达式的右侧推断变量的类型时,才可以使用var。例如,以下情况很好:
int[] arr = {1,2,3};
但是,这并不好:
var arr = {1,2,3};
但是,您可以始终使用以下选项:
var arr = new int[]{1,2,3};
还有其他情况不能使用var。例如,不能使用var定义方法返回类型或方法参数。
不允许出现以下情况:
public var sum(int num1, int num2)
{
return num1+num2;
}
这也不允许:
public int sum(var num1, var num2)
{
return num1+num2;
}
尽管可以使用var来声明变量,但还是需要注意一点。您需要注意如何声明变量以保持代码的可读性。例如,您可能会在代码中遇到以下行:
var sample = sample();
你能看懂这个变化多端的样品吗?是字符串还是整数?您可能会认为,我们可以在命名变量(如strSample或intSample)时提供适当的命名约定。但是如果你的类型有点复杂呢?看看这个:
public static HashMap<Integer, HashMap<String, String>> sample()
{
return new HashMap<Integer, HashMap<String, String>>();
}
在这种情况下,您可能需要确保使用了正确的基于类型的声明,以避免代码可读性问题。
在声明集合时需要小心的另一个领域是ArrayLists。例如,这在 Java 中是合法的:
var list = new ArrayList<>();
list.add(1);
list.add("str");
你很清楚这里的问题。编译器已推断出包含对象的前面列表,而您的代码可能正在查找整数列表。因此,我们预计在这种情况下会出现一些严重的运行时错误。所以,在这种情况下,最好始终明确。
因此,简而言之,var是 Java 的一个很好的补充,可以帮助我们更快地编写代码,但我们在使用它时需要小心,以避免代码可读性和维护问题。
集合的copyOf方法
引入了copyOf方法来创建集合的不可修改副本。例如,假设您有一个列表,并且您需要一个不可变或不可修改的副本,您可以使用copyOf函数。如果您使用过集合,您可能想知道它与Collections.unmodifiableCollection有何不同,后者承诺做同样的事情,即创建集合的不可修改副本。虽然这两种方法都提供了一个不可修改的副本,但是当我们在集合(比如列表)上使用copyOf时,它会返回一个不能进一步修改的列表,加上对原始列表的任何更改都不会影响复制的列表。另一方面,在上述情况下,Collections.unmodifiableCollection确实返回了一个不可修改的列表,但是这个列表仍然会反映原始列表中的任何修改。
让我们仔细看看,让事情更清楚:
public static void main(String args[]) {
List<Integer> list = new ArrayList<Integer>();
list.add(1);
list.add(2);
list.add(3);
System.out.println(list);
var list2 = List.copyOf(list);
System.out.println(list2);
var list3 = Collections.unmodifiableCollection(list);
System.out.println(list3);
// this will give an error
// list2.add(4);
// but this is fine
list.add(4);
System.out.println(list);
// Print original list i.e. 1, 2, 3, 4
System.out.println(list2);
// Does not show added 4 and prints 1, 2, 3
System.out.println(list3);
// Does show added 4 and prints 1, 2, 3, 4
}
类似地,我们可以对集合、哈希映射等使用copyOf函数来创建对象的不可修改副本。
完全垃圾收集的并行化
在 C 语言和 C++ 语言中,分配和分配内存是开发者的责任。这可能很棘手,因为如果开发人员犯了一个错误,比如忘记释放分配的内存,就会导致内存不足的问题。Java 通过提供垃圾收集来处理这个问题。分配和释放内存的责任从开发人员转移到了 Java。
Java 使用两种机制来维护它的内存:栈和堆。您一定看到了两个不同的错误,即StackOverFlowError和OutOfMemoryError,表示某个内存区域已满。栈中的内存仅对当前线程可见。因此,清理是直接的;也就是说,当线程离开当前方法时,栈上的内存就会释放。堆中的内存更难管理,因为它可以在整个应用中使用;因此,需要专门的垃圾收集。
多年来,Java 对垃圾收集(GC)算法进行了改进,使其越来越有效。其核心思想是,如果分配给对象的内存空间不再被引用,则可以释放该空间。大多数 GC 算法将分配的内存分为新生代和老年代。从使用情况来看,Java 能够标记大多数对象在 GC 早期或初始 GC 周期期间成为符合 GC 条件的对象。例如,方法中定义的对象只有在方法处于活动状态之前是活动的,并且一旦返回响应,局部范围变量就可以进行 GC。
G1 收集器或垃圾第一垃圾收集器最早是在 Java7 中引入的,在 Java7 中是默认的。垃圾收集主要分为两个阶段。在第一阶段,垃圾收集器标记可以删除或清理的元素;也就是说,它们不再被引用。第二阶段实际上是清理内存。此外,这些阶段在分配了不同代内存的不同单元上独立运行。G1 收集器可以在后台并发执行大多数活动,而无需停止应用,但完全垃圾收集除外。当通常清理新生代内存的部分 gc 没有充分清理空间时,需要进行完全的垃圾收集。
在 Java10 中,完全的垃圾收集可以通过并行线程完成。这是早些时候在单线程模式下完成的。当涉及到完整 GC 时,这将提高整体 GC 性能。
对 Java10 的更多补充
我们已经介绍了 Java10 的大多数重要特性添加,但还有一些值得在这里讨论:
- 基于时间的版本控制:这并不完全是一个新特性,但更多的是 Java 推荐的未来版本的版本控制方式。如果您长期使用 Java,那么了解 Java 版本是如何发布的是值得的。
版本号的格式如下:$FEATURE.$INTERIM.$UPDATE.$PATCH
Java 决定每六个月发布一个新的特性版本。记住这一点,Java11 的发布定于 2018 年 9 月,也就是 Java11 发布六个月之后。这个想法是每六个月不断更新一次。有两种思想流派;一种支持这种安排,因为用户将经常得到更改,但另一种则表示,这将减少开发人员习惯发布的时间。
因此,如果您查看版本号 10.0.2.1,就会知道这属于功能版本 10,没有临时版本、更新版本 2 和修补程序 1。
-
通用编译器:编译器是以代码为输入,将代码转换为机器语言的计算机程序。Java 的 JIT 编译器将代码转换成字节码,然后由 JVM 将字节码转换成机器语言。使用 Java10,您可以在 Linux 机器上使用实验性的 Graal 编译器。需要注意的是,这仍处于试验阶段,不建议用于生产。
-
应用类数据共享:这是 Java 的又一个内部更新,所以您在编写代码时可能不会注意到,但是了解它是件好事。这样做的目的是减少 Java 应用的启动时间。JVM 在应用启动时加载类。如果不更新文件,早期的 JVM 仍然会重新加载所有类。使用 Java10,JVM 将只创建一次数据并将其添加到存档中,如果下次不更新类,则无需重新加载数据。另外,如果多个 jvm 正在运行,那么这些数据可以在它们之间共享。同样,此更新不是一个可见的更新,但将提高应用的整体性能。
到目前为止,我们已经介绍了 Java10 的大部分重要特性。在结束本章之前,让我们先看看 Java 未来的发展趋势;也就是说,Java11 有什么可以期待的,它计划什么时候发布?
在 Java11 中应该期望什么?
Java11 预计将于 2018 年 9 月左右发布。值得一看 Java11 中的一些重要特性:
-
Lambda 表达式的局部变量语法:Java10 引入了一个特性,可以在声明局部变量时使用
var,但是现在不允许与 Lambda 表达式一起使用。这个限制应该随着 Java11 而消失。 -
Epsilon 低开销垃圾收集器:这个 JEP 或 JDK 增强方案讨论了实现一个无操作垃圾收集器。换句话说,这个垃圾收集器应该主要关注内存分配,而不是实现任何内存回收机制。可能很难想象一个应用不需要任何垃圾收集,但这是针对一组不分配太多堆内存或重用分配的对象的应用的,在某种意义上,没有太多的对象成为不可访问或短暂的作业。对于无操作垃圾收集器的有用性有不同的看法,但它将是 Java 的一个有趣的补充。
-
动态类文件常量:此 JEP 或 JDK 增强方案扩展了当前 Java 类文件格式,以支持新的常量池形式
CONSTANT_Dynamic。这里的想法是减少创建新形式的可物化类文件常量的成本和中断。
除了上面提到的添加,Java11 还建议删除一些模块,比如 JavaEE 和 CORBA。这些模块在 Java9 中已经被弃用,在 JavaSDK11 中应该被完全删除。
另外,Java11 应该是长期支持(LTS)的版本。这意味着,与 Java9 和 Java10 不同,Java9 和 Java10 对 JDK 的支持仅限于几个月,Java11 将支持 2 到 3 年。Java 决定每三年发布一次 LTS 版本,因此如果我们预计 Java11 将在 2018 年 9 月发布,那么下一个 LTS 版本将在 2021 年发布。
总结
在本章中,我们讨论了 Java 的一些重要特性和最佳实践。我们从 Java 发行版的一开始就开始了我们的旅程,并触及了 Java 的一些重要里程碑。我们讨论了一些重要的 Java 版本,比如 Java5 和 Java8,它们通过引入泛型、自动装箱、Lambda 表达式、流等特性,在某种程度上改变了我们在 Java 中编写代码的方式。
然后我们详细介绍了更现代的版本,即 Java9 和 Java10。Java9 给了我们模块化。我们现在可以根据不同的模块来考虑 Java 代码,并选择应用所需的模块。Java9 还将 JShell 添加到了它的库中,这有助于我们在不实际编写和编译类的情况下尝试和实验这种语言。Java9 增加了在接口中定义私有方法的功能。此外,我们还使用 Java9 在流、集合、数组等方面获得了新特性。
Java10 为我们提供了使用var关键字声明变量的灵活性,而无需显式地提及对象类型。我们讨论了使用var的局限性,以及为什么在使用var声明对象时需要小心,以避免损害代码的可读性和可维护性。我们还讨论了创建集合的不可变副本的方法以及 Java10 中的垃圾收集改进。
最后,我们讨论了在 Java11 中可以预期的内容,例如添加到垃圾收集中以及将var与 Lambda 一起使用。与 Java9 和 Java10 不同,Java11 预计是一个长期版本。而且,根据 Oracles 的 3 年政策,下一个长期版本预计将在 2021 年 Java11 之后的某个时候发布。
Java 自诞生以来已经走过了很长的一段路,它一次又一次地重新发明自己。将来还会有更多的东西,看看 Java 未来的发展会很有趣。














 2391
2391











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










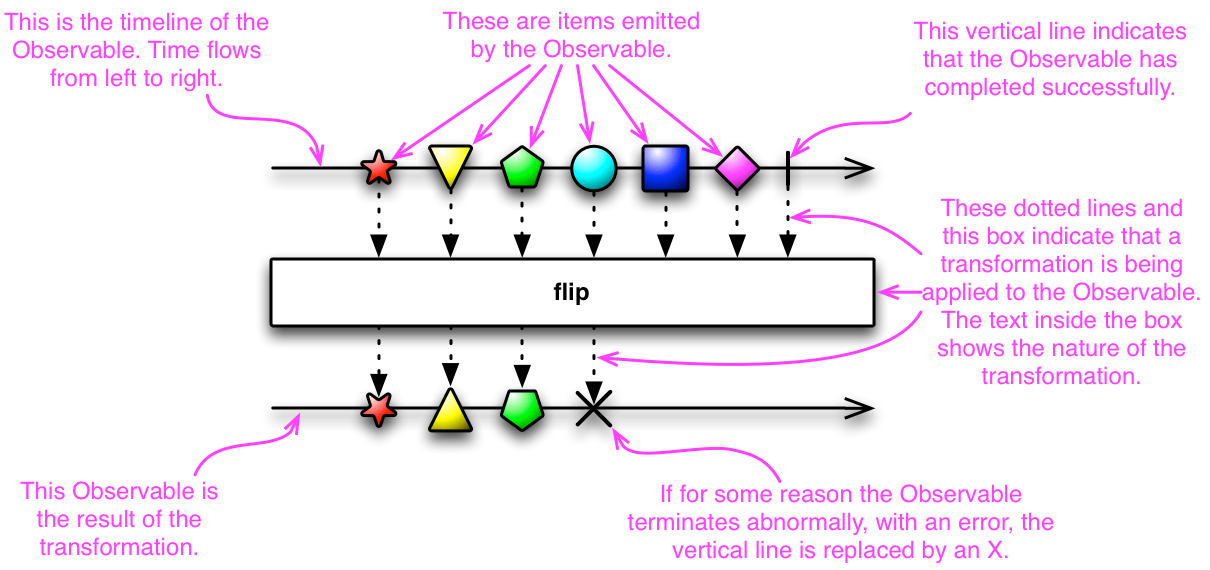{kind=link}