







原文:System Design Interview – An Insider’s Guide
译者:飞龙
零、序言
我们很高兴你决定加入我们学习系统设计面试。系统设计面试问题是所有技术面试中最难解决的。这些问题要求受访者为一个软件系统设计一个架构,这个软件系统可以是新闻提要、谷歌搜索、聊天系统等。这些问题令人生畏,没有一定的模式可循。这些问题通常范围很广,也很模糊。这些过程是开放式的,没有标准或正确的答案是不清楚的。
公司广泛采用系统设计面试,因为这些面试中测试的沟通和解决问题的技能与软件工程师日常工作所需的技能相似。受访者的评估基于她如何分析一个模糊的问题,以及她如何一步一步地解决问题。测试的能力还包括她如何解释想法,与他人讨论,以及评估和优化系统。在英语中,使用“她”比使用“他或她”或在两者之间跳跃更流畅。为了便于阅读,我们在整本书中使用了阴性代词。没有不尊重男性工程师的意思。
系统设计问题是开放式的。就像在现实世界中一样,系统中存在许多差异和变化。期望的结果是提出一个架构来实现系统设计目标。根据面试官的不同,讨论可能会以不同的方式进行。有的面试官可能会选择高层架构,涵盖方方面面;而有些人可能会选择一个或多个领域来关注。典型地,系统需求、限制和瓶颈应该被很好地理解以塑造访问者和被访问者的方向。
本书的目的是提供一个解决系统设计问题的可靠策略。正确的策略和知识对面试的成功至关重要。
这本书提供了构建可扩展系统的坚实知识。阅读这本书获得的知识越多,你就越有能力解决系统设计问题。
这本书也提供了一个逐步解决系统设计问题的框架。它提供了许多例子来说明系统化的方法以及您可以遵循的详细步骤。通过不断的练习, 你将有能力应对系统设计面试问题。
一、从零扩展到数百万用户
设计一个支持数百万用户的系统极具挑战性,这是一个需要不断改进和完善的旅程。在这一章中,我们构建了一个支持单个用户的系统,并逐步将其扩展到服务数百万用户。读完这一章,你将掌握一些技巧,帮助你解决系统设计面试问题。
单服务器设置
千里之行始于足下,构建一个复杂的系统也不例外。从简单的开始,一切都运行在一台服务器上。图 1-1 展示了一个单一的服务器设置,所有的东西都在一个服务器上运行:web 应用程序、数据库、缓存等等。
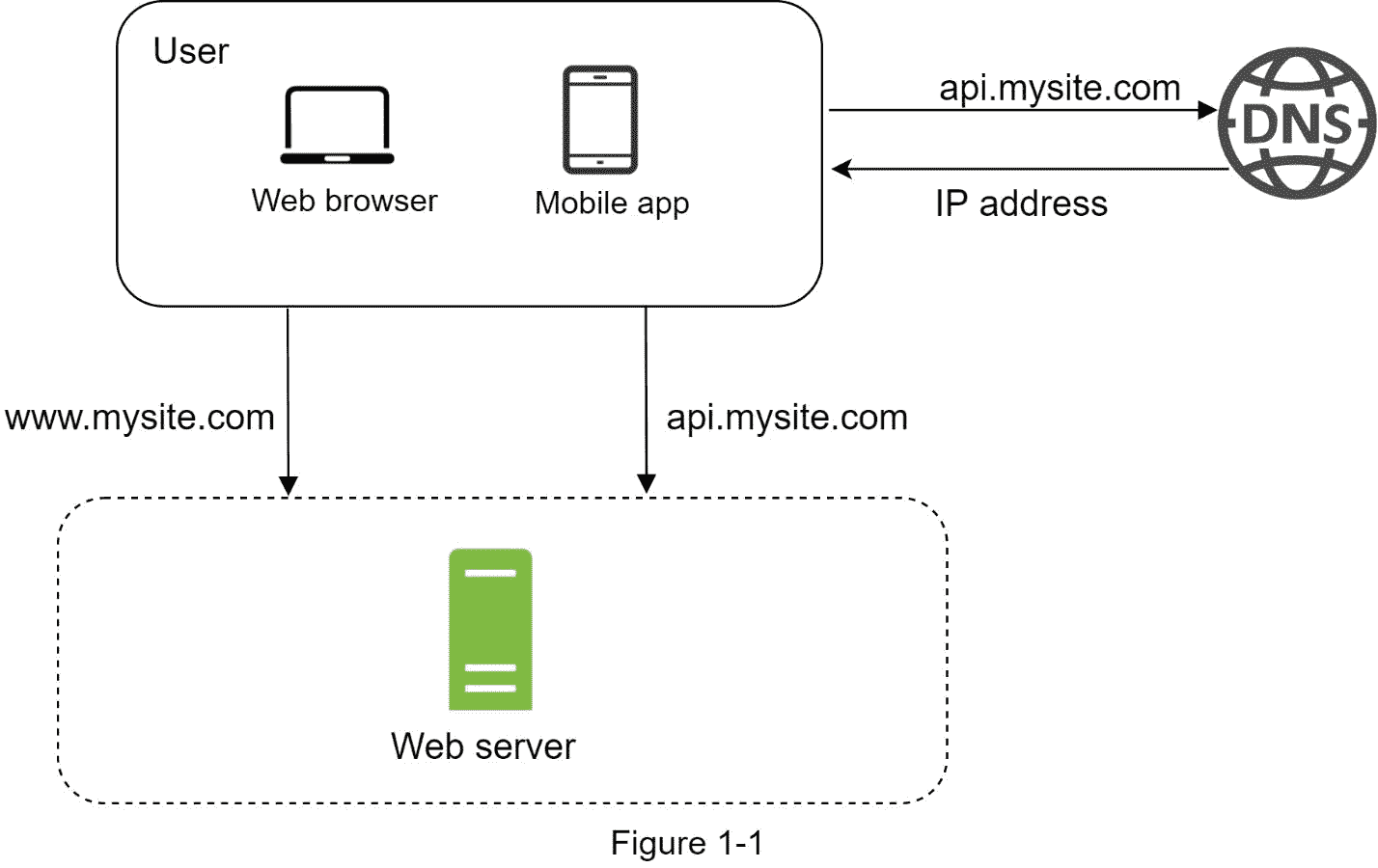
为了理解这种设置,研究请求流和流量源是有帮助的。让我们首先看看请求流程(图 1-2)。
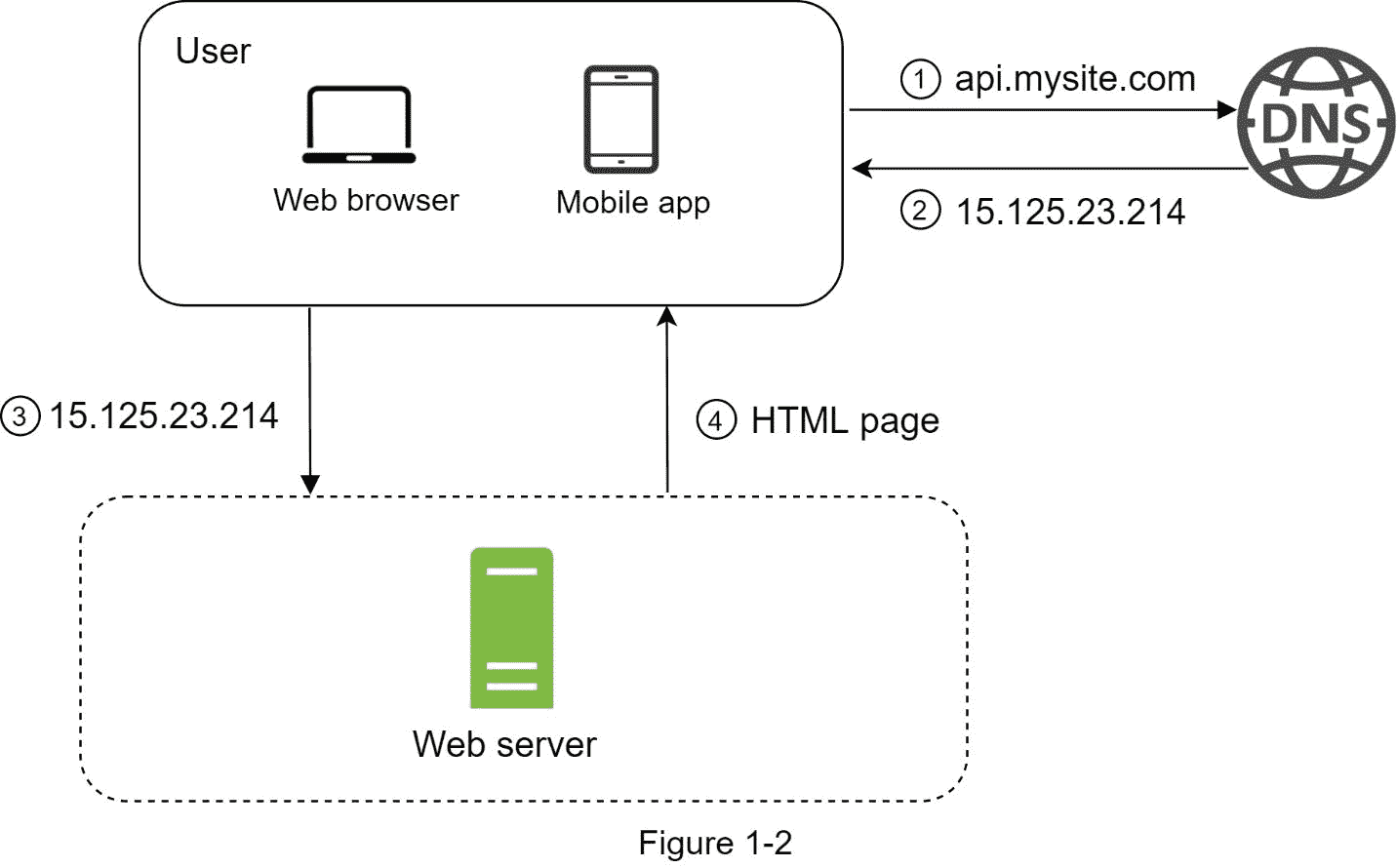
1。用户通过域名访问网站,如 api.mysite.com。通常,域名系统(DNS)是由第三方提供的付费服务,而不是由我们的服务器托管。
2。互联网协议(IP)地址返回给浏览器或移动应用程序。在本例中,返回了 IP 地址 15.125.23.214。
3。一旦获得 IP 地址,超文本传输协议(HTTP) [1]请求就直接发送到您的 web 服务器。
4。web 服务器返回 HTML 页面或 JSON 响应进行呈现。
接下来,我们来考察一下流量来源。web 服务器的流量来自两个来源:web 应用程序和移动应用程序。
Web 应用:使用服务器端语言的组合(Java、Python 等。)来处理业务逻辑、存储等。,以及用于表示的客户端语言(HTML 和 JavaScript)。
手机应用:HTTP 协议是手机 app 与 web 服务器之间的通信协议。JavaScript Object Notation (JSON)因其简单性而成为传输数据的常用 API 响应格式。JSON 格式的 API 响应示例如下所示:
GET/users/12–检索 id = 12 的用户对象

数据库
随着用户群的增长,一台服务器是不够的,我们需要多台服务器:一台用于 web/移动流量,另一台用于数据库(图 1-3)。将 web/移动流量(web 层)和数据库(数据层)服务器分开,可以使它们独立扩展。
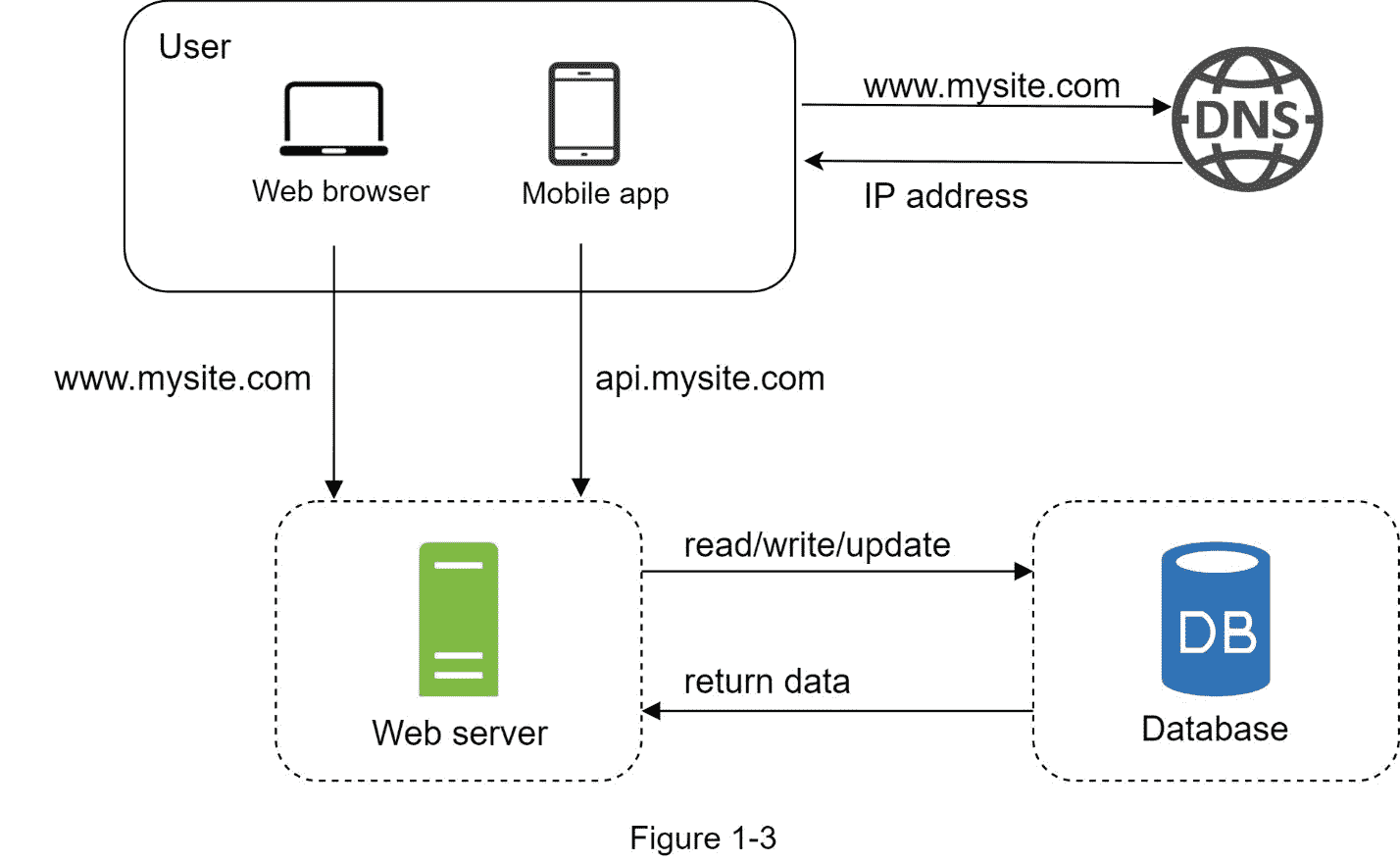
使用哪些数据库?
您可以在传统的关系数据库和非关系数据库之间进行选择。让我们来看看他们的不同之处。
关系数据库也称为关系数据库管理系统(RDBMS)或 SQL 数据库。最受欢迎的有 MySQL、Oracle 数据库、PostgreSQL 等。关系数据库在表和行中表示和存储数据。您可以使用 SQL 跨不同的数据库表执行连接操作。
非关系数据库也称为 NoSQL 数据库。比较流行的有 CouchDB,Neo4j,Cassandra,HBase,Amazon DynamoDB 等。[2].这些数据库分为四类:键值存储、图形存储、列存储和文档存储。非关系数据库中通常不支持连接操作。
对于大多数开发人员来说,关系数据库是最好的选择,因为它们已经存在了 40 多年,而且从历史上看,它们工作得很好。但是,如果关系数据库不适合您的特定用例,那么探索关系数据库之外的内容是至关重要的。非关系数据库可能是正确的选择,如果:
您的应用需要超低延迟。
您的数据是非结构化的,或者您没有任何关系数据。
你只需要序列化和反序列化数据(JSON、XML、YAML 等)。).
你需要存储海量的数据。
垂直缩放与水平缩放
垂直扩展,简称“纵向扩展”,是指增加更多功能(CPU、RAM 等)的过程。)到您的服务器。水平扩展,也称为“横向扩展”,允许您通过向资源池中添加更多服务器来进行扩展。
当流量较低时,垂直扩展是一个很好的选择,垂直扩展的简单性是其主要优势。不幸的是,它有严重的局限性。
垂直缩放有硬限制。不可能给单个服务器添加无限的 CPU 和内存。
垂直扩展不具备故障转移和冗余。如果一台服务器宕机,网站/应用程序也会随之完全宕机。
由于垂直缩放的局限性,水平缩放更适合大规模应用。
在以前的设计中,用户是直接连接到 web 服务器的。如果 web 服务器离线,用户将无法访问网站。在另一种情况下,如果许多用户同时访问 web 服务器,并且达到了 web 服务器的负载极限,用户通常会经历较慢的响应或无法连接到服务器。负载平衡器是解决这些问题的最佳技术。
负载均衡器
负载平衡器在负载平衡集中定义的 web 服务器之间均匀地分配传入流量。图 1-4 显示了负载均衡器是如何工作的。
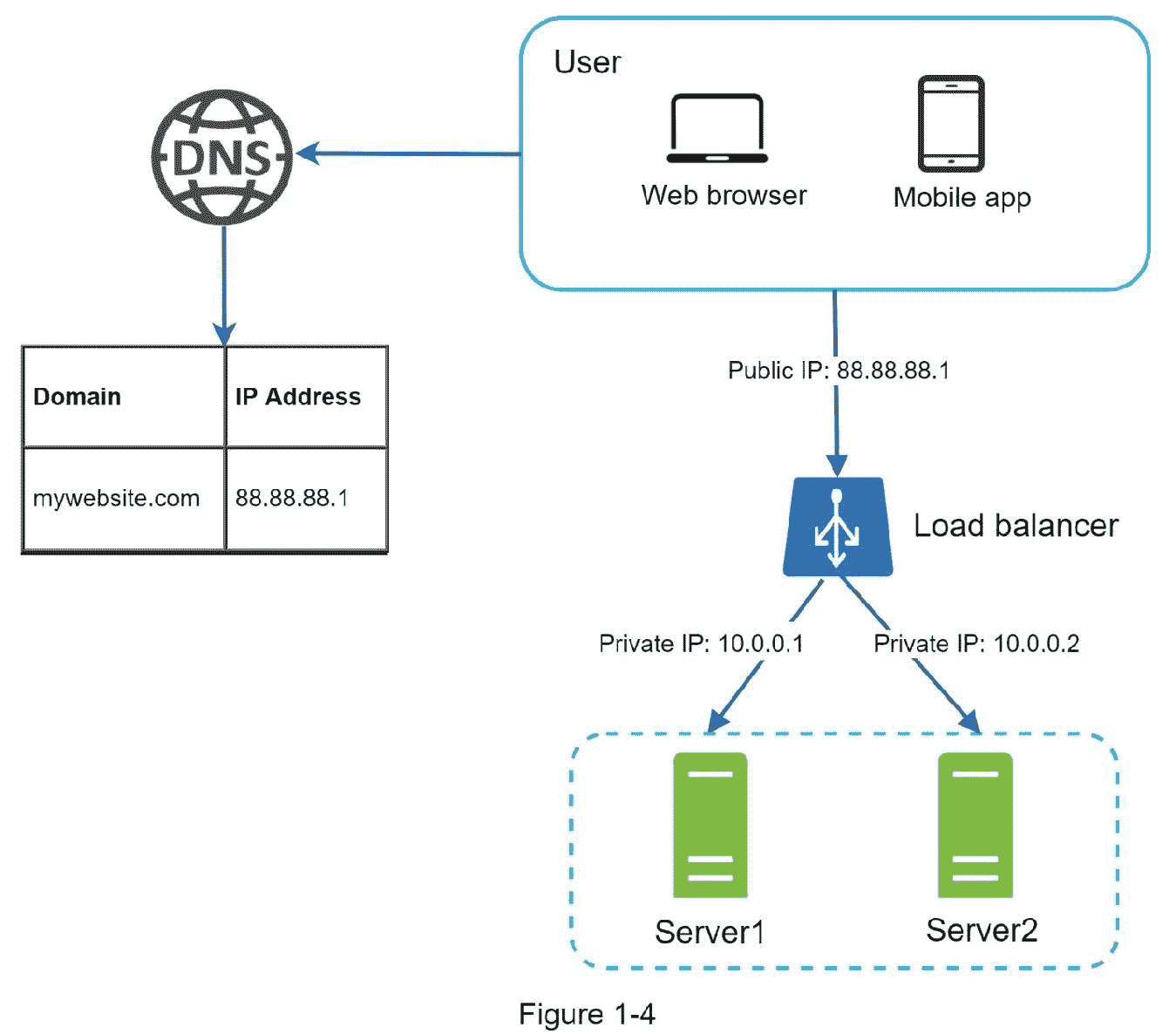
如图 1-4 所示,用户直接连接到负载均衡器的公共 IP。有了这个设置,客户端就不能直接访问 web 服务器了。为了更好的安全性,私有 IP 用于服务器之间的通信。专用 IP 是只能在同一网络中的服务器之间到达的 IP 地址;但是,它无法通过互联网访问。负载平衡器通过私有 IP 与 web 服务器通信。
在图 1-4 中,在添加了负载平衡器和第二台 web 服务器后,我们成功地解决了无故障转移问题,并提高了 web 层的可用性。详细解释如下:
如果服务器 1 离线,所有流量将被路由到服务器 2。这可以防止网站脱机。我们还将在服务器池中添加一个新的健康的 web 服务器来平衡负载。
如果网站流量快速增长,两台服务器不足以处理流量,负载均衡器可以优雅地处理这个问题。您只需要向 web 服务器池中添加更多的服务器,负载平衡器就会自动开始向它们发送请求。
现在 web 层看起来不错,那么数据层呢?当前设计只有一个数据库,因此不支持故障转移和冗余。数据库复制是解决这些问题的常用技术。让我们来看看。
数据库复制
引自维基百科:“数据库复制可以用在很多数据库管理系统中,通常在原件(主)和副本(从)之间存在主/从关系”[3]。
主数据库通常只支持写操作。从数据库从主数据库获取数据的副本,并且只支持读操作。所有数据修改命令,如插入、删除或更新,都必须发送到主数据库。大多数应用程序需要更高的读写比率;因此,系统中从数据库的数量通常大于主数据库的数量。图 1-5 显示了一个主数据库和多个从数据库。
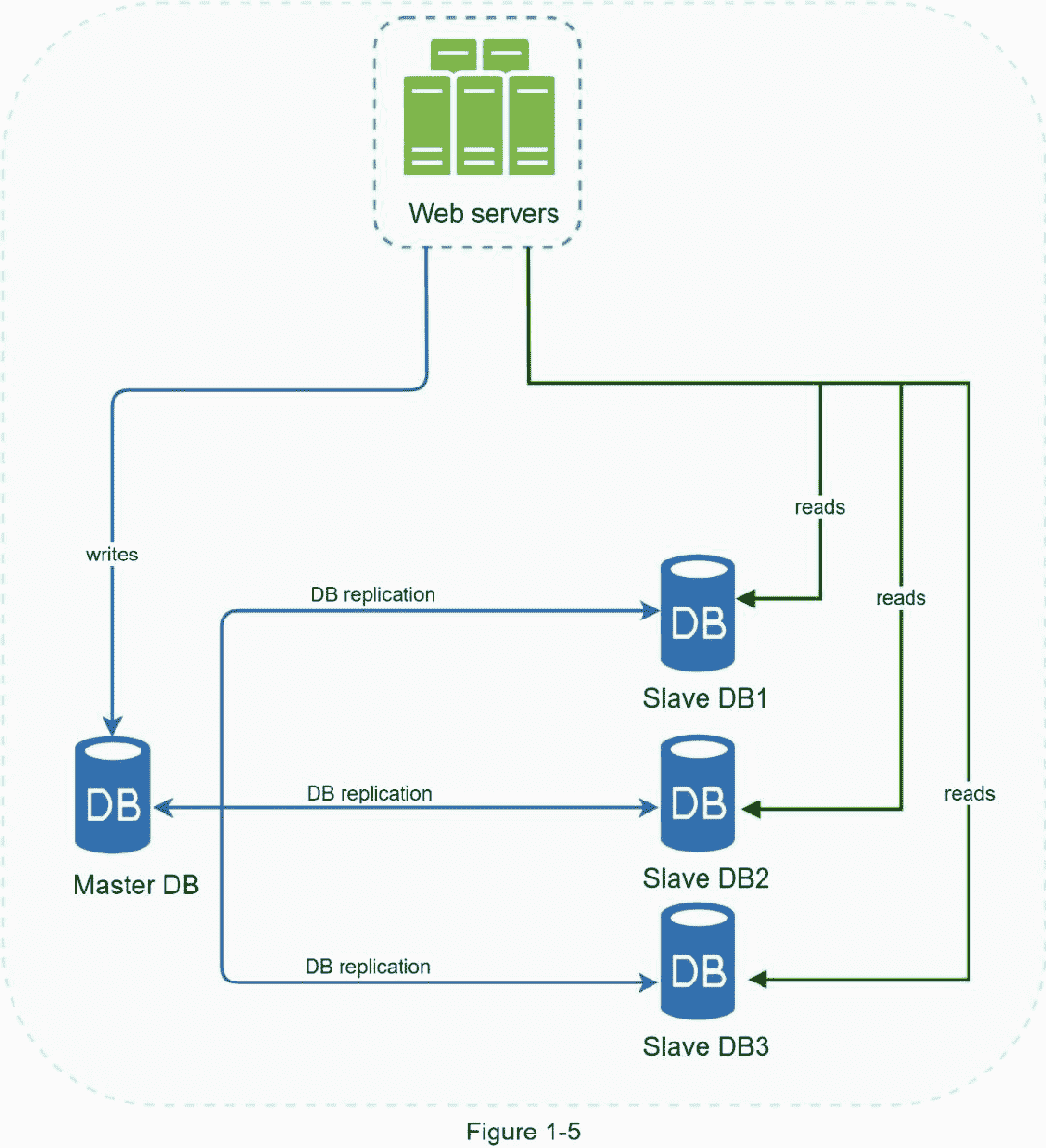
数据库复制的优势:
更好的性能:在主从模式下,所有的写入和更新都发生在主节点;而读取操作分布在从节点上。该模型提高了性能,因为它允许并行处理更多的查询。
可靠性:如果你的一个数据库服务器被自然灾害摧毁,比如台风或地震,数据仍然保存。您不必担心数据丢失,因为数据是跨多个位置复制的。
高可用性:通过跨不同位置复制数据,即使一个数据库离线,您的网站也能保持运行,因为您可以访问存储在另一个数据库服务器中的数据。
在上一节中,我们讨论了负载平衡器如何帮助提高系统可用性。我们在这里问同样的问题:如果其中一个数据库离线了怎么办?图 1-5 中讨论的架构设计可以处理这种情况:
如果只有一个从数据库可用,并且它脱机,读取操作将临时定向到主数据库。一旦发现问题,新的从数据库将替换旧的从数据库。如果有多个从数据库可用,读取操作将被重定向到其他健康的从数据库。新的数据库服务器将取代旧的。
如果主数据库离线,从数据库将升级为新的主数据库。所有数据库操作都将临时在新的主数据库上执行。一个新的从属数据库将立即替换旧的数据库进行数据复制。在生产系统中,提升新的主数据库更加复杂,因为从数据库中的数据可能不是最新的。需要通过运行数据恢复脚本来更新丢失的数据。虽然其他一些复制方法,如多母盘和循环复制可能会有所帮助,但这些设置更复杂;他们的讨论超出了本书的范围。感兴趣的读者应该参考列出的参考资料[4] [5]。
图 1-6 显示了添加负载均衡器和数据库复制后的系统设计。
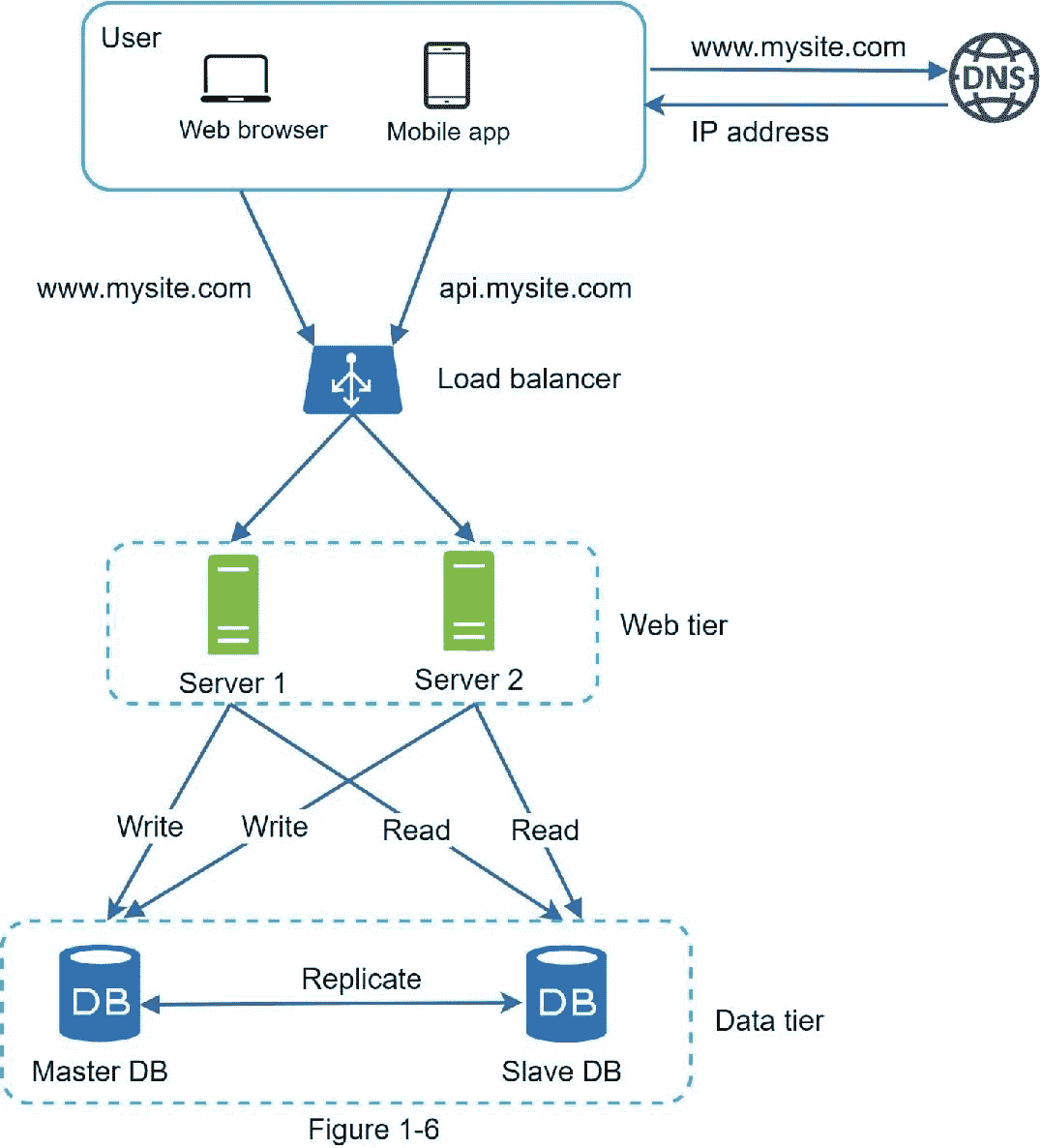
让我们来看看设计:
用户从 DNS 获取负载均衡器的 IP 地址。
用户使用此 IP 地址连接负载平衡器。
HTTP 请求被路由到服务器 1 或服务器 2。
web 服务器从从数据库读取用户数据。
网络服务器将任何数据修改操作路由到主数据库。这包括写入、更新和删除操作。
现在,您已经对 web 和数据层有了深入的了解,是时候改善加载/响应时间了。这可以通过添加缓存层并将静态内容(JavaScript/CSS/图像/视频文件)转移到内容交付网络(CDN)来实现。
缓存
缓存是一个临时存储区域,它将昂贵的响应结果或频繁访问的数据存储在内存中,以便更快地处理后续请求。如图 1-6 所示,每次加载新的网页时,都会执行一个或多个数据库调用来获取数据。重复调用数据库会极大地影响应用程序的性能。缓存可以缓解这个问题。
缓存层
缓存层是一个临时数据存储层,比数据库快得多。拥有单独的缓存层的好处包括更好的系统性能、减少数据库工作负载的能力以及独立扩展缓存层的能力。图 1-7 显示了一个缓存服务器的可能设置:

web 服务器收到请求后,首先检查缓存是否有可用的响应。如果有,它会将数据发送回客户端。如果没有,它查询数据库,将响应存储在缓存中,并将其发送回客户端。这种缓存策略称为通读缓存。根据数据类型、大小和访问模式,还可以使用其他缓存策略。之前的一项研究解释了不同的缓存策略是如何工作的[6]。
与缓存服务器交互很简单,因为大多数缓存服务器都提供了通用编程语言的 API。下面的代码片段展示了典型的 Memcached API:

使用缓存的注意事项
这里有一些使用缓存系统的注意事项:
决定何时使用缓存。当数据经常被读取但很少被修改时,可以考虑使用缓存。由于缓存数据存储在易失性内存中,缓存服务器并不适合持久化数据。例如,如果缓存服务器重新启动,内存中的所有数据都会丢失。因此,重要的数据应该保存在持久数据存储中。
到期政策。实现过期策略是一个很好的做法。缓存的数据一旦过期,就会从缓存中删除。如果没有过期策略,缓存的数据将永久存储在内存中。建议不要将到期日期设置得太短,因为这会导致系统过于频繁地从数据库中重新加载数据。同时,建议不要让到期日期太长,因为数据可能会变得陈旧。
一致性:这涉及到保持数据存储和缓存同步。由于数据存储和缓存上的数据修改操作不在单个事务中,因此可能会发生不一致。当跨多个区域扩展时,维护数据存储和缓存之间的一致性是一项挑战。要了解更多细节,请参考脸书发表的题为“在脸书扩展 Memcache”的论文[7]。
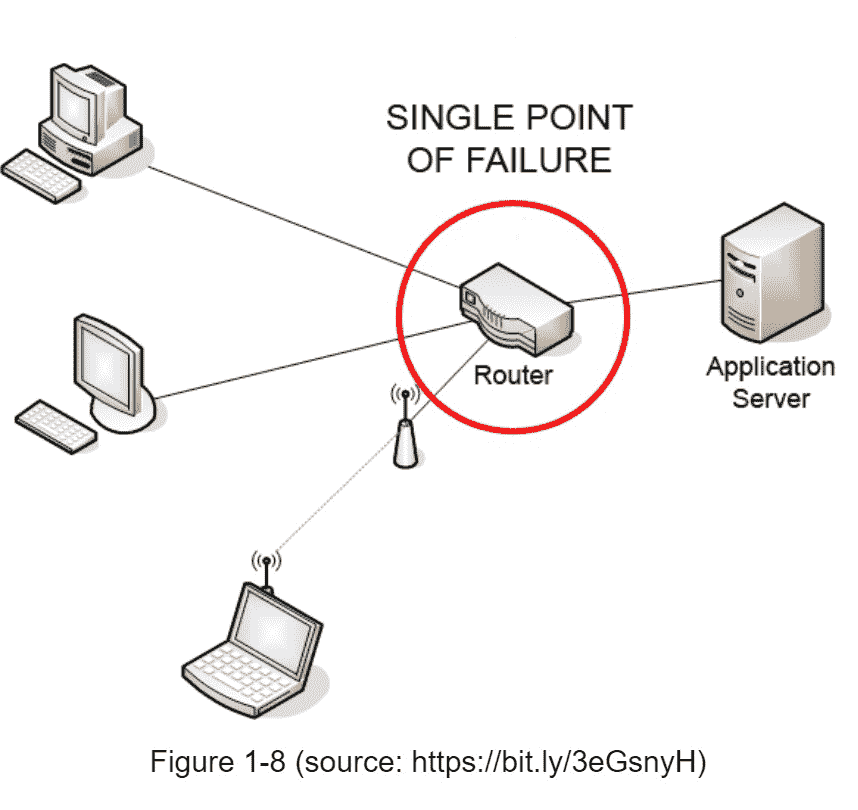
减轻故障:单个缓存服务器代表潜在的单点故障(SPOF),在维基百科中定义如下:“单点故障(SPOF)是系统的一部分,如果它发生故障,将停止整个系统的工作”[8]。因此,建议跨不同数据中心的多个缓存服务器来避免 SPOF。另一个推荐的方法是按照一定的百分比过度配置所需的内存。这在内存使用增加时提供了一个缓冲。
驱逐策略: 一旦高速缓存已满,任何向高速缓存添加项目的请求都可能导致现有项目被移除。这被称为缓存回收。最近最少使用(LRU)是最流行的缓存回收策略。可以采用其他驱逐策略,如最不常用(LFU)或先进先出(FIFO),以满足不同的使用情况。
【内容交付网络(CDN)
CDN 是地理上分散的服务器网络,用于交付静态内容。CDN 服务器缓存静态内容,如图像、视频、CSS、JavaScript 文件等。
动态内容缓存是一个相对较新的概念,超出了本书的范围。它支持基于请求路径、查询字符串、cookies 和请求头的 HTML 页面的缓存。有关这方面的更多信息,请参考参考资料[9]中提到的文章。本书重点讲述如何使用 CDN 缓存静态内容。
下面是 CDN 在高层的工作方式:当用户访问一个网站时,离用户最近的 CDN 服务器将提供静态内容。直觉上,用户离 CDN 服务器越远,网站加载越慢。例如,如果 CDN 服务器在旧金山,洛杉矶的用户将比欧洲的用户更快地获得内容。图 1-9 是一个很好的例子,展示了 CDN 如何改善加载时间。
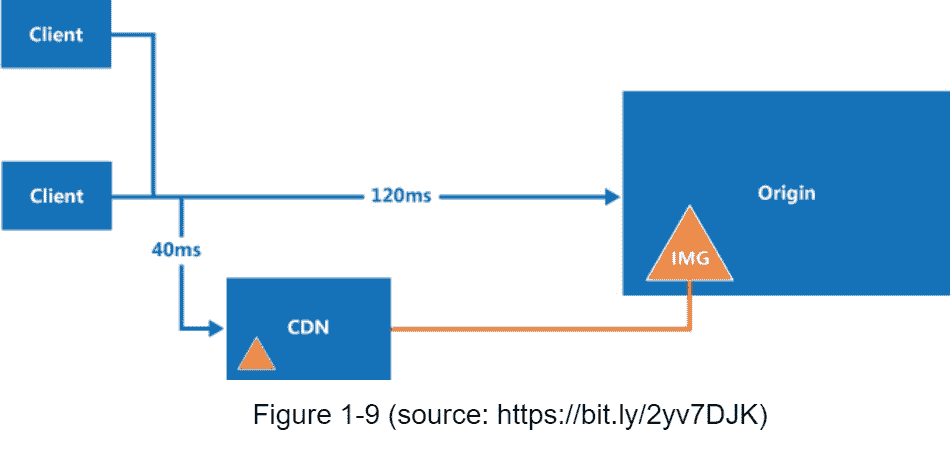
图 1-10 演示了 CDN
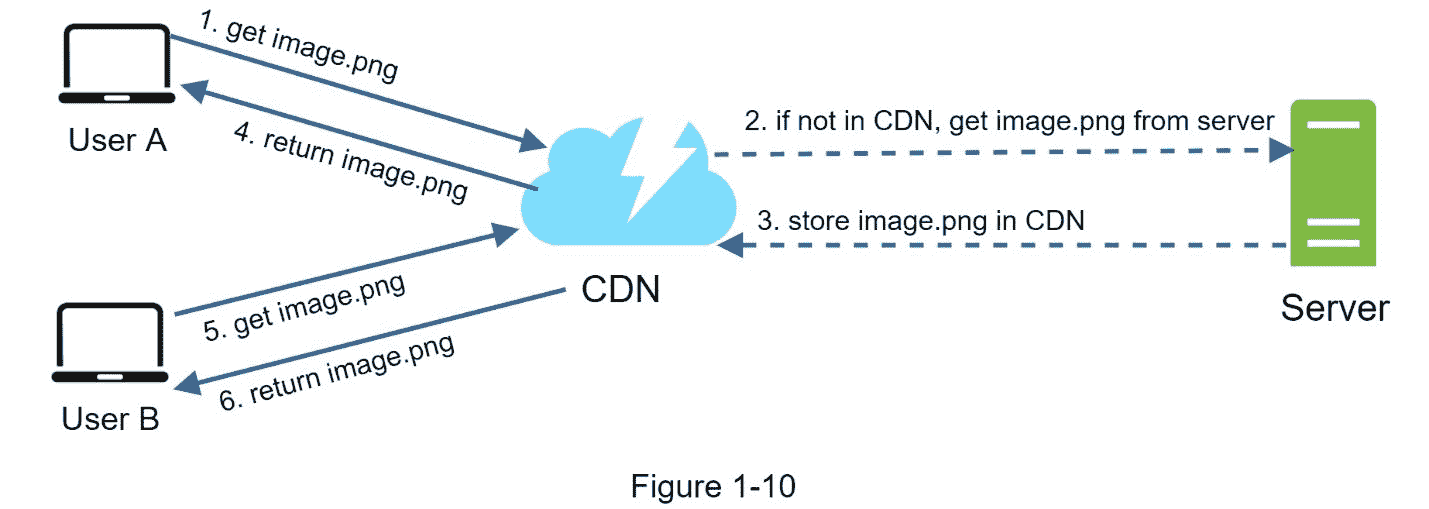
1。用户 A 试图通过使用图像 URL 来获取 image.png。URL 的域由 CDN 提供商提供。下面两个图片 URL 是用来演示亚马逊和 Akamai CDNs 上的图片 URL 是什么样子的示例:
https://mysite.cloudfront.net/logo.jpg
2。如果 CDN 服务器的缓存中没有image.png,CDN 服务器会从源服务器请求文件,源服务器可以是 web 服务器或在线存储,如亚马逊S3。
3。原点将image.png 返回给 CDN 服务器,其中包括可选的 HTTP 报头生存时间(TTL ),它描述了图像被缓存的时间。
4。CDN 缓存图像并将其返回给用户 a。图像会一直缓存在 CDN 中,直到 TTL 过期。
5。用户 B 发送一个请求来获得相同的图像。
6。只要 TTL 没有过期,就会从缓存中返回图像。
使用 CDN 的考虑事项
费用:CDN 由第三方提供商运营,进出 CDN 的数据传输向您收费。缓存不经常使用的资产不会带来显著的好处,因此您应该考虑将它们移出 CDN。
设置适当的缓存过期时间:对于时间敏感的内容,设置缓存过期时间很重要。 缓存到期时间不能太长也不能太短。如果太长,内容可能不再新鲜。如果太短,可能会导致内容从源服务器重复加载到 CDN。
CDN 回退:你应该考虑你的网站/应用如何应对 CDN 故障。如果有一个临时的 CDN 中断,客户端应该能够检测到问题,并从源请求资源。
使文件失效:您可以通过执行以下操作之一,在文件到期前将其从 CDN 中删除:
使用 CDN 厂商提供的 API 使 CDN 对象失效。
使用对象版本化来服务对象的不同版本。要对对象进行版本控制,可以向 URL 添加一个参数,如版本号。例如,版本号 2 被添加到查询字符串:image.png?v=2。
图 1-11 显示了添加 CDN 和缓存后的设计。
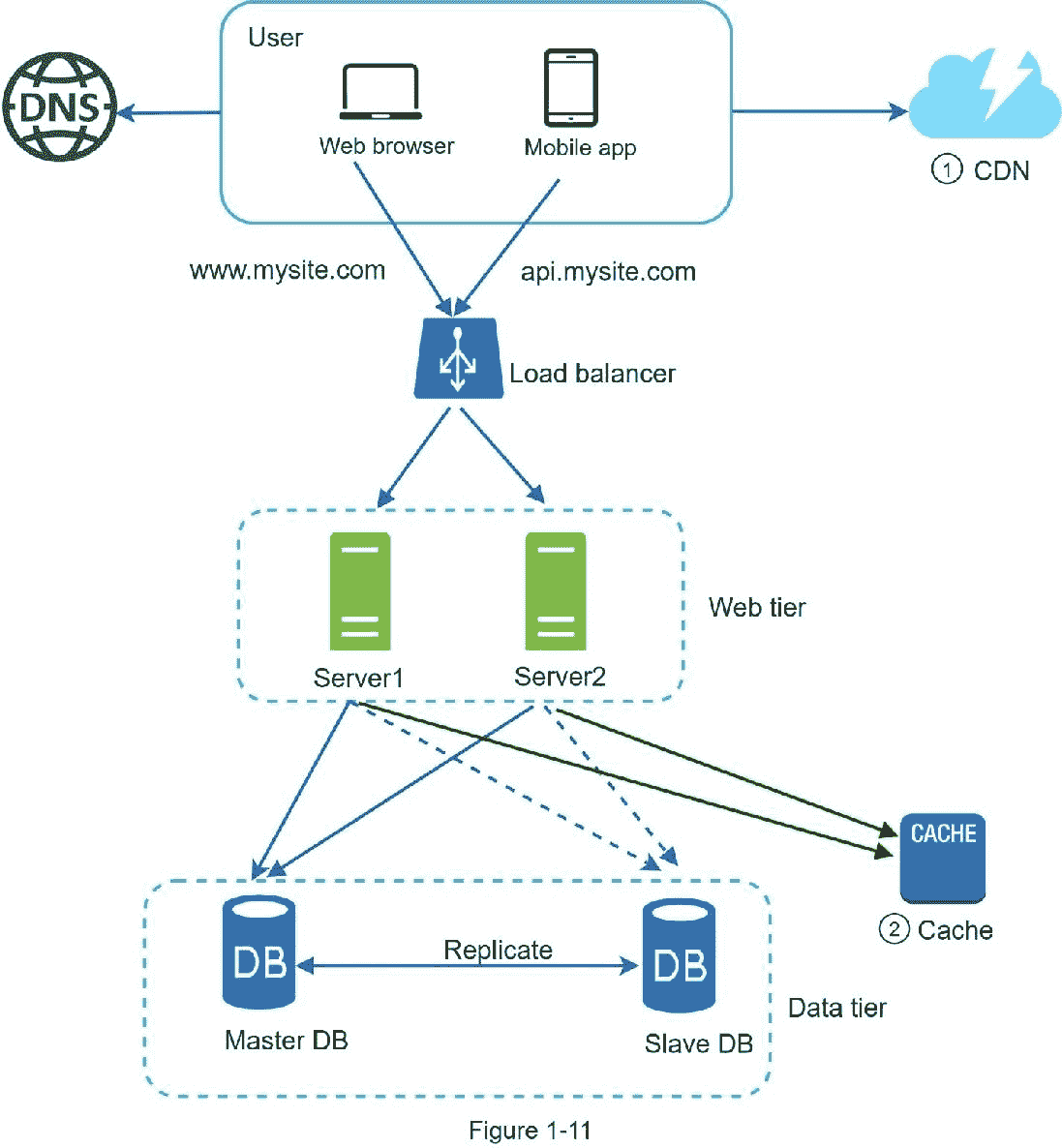
1。静态资产(JS、CSS、图片等。,)不再由 web 服务器提供服务。为了更好的性能,它们从 CDN 中取出。
2。通过缓存数据减轻了数据库负载。
无状态 web 层
现在是时候考虑横向扩展 web 层了。 为此,我们需要将状态(例如用户会话数据)移出 web 层。一个好的做法是将会话数据存储在持久存储中,如关系数据库或 NoSQL。群集中的每个 web 服务器都可以访问数据库中的状态数据。这被称为无状态 web 层。
有状态架构
有状态服务器和无状态服务器有一些关键的区别。有状态服务器从一个请求到下一个请求记住客户机数据(状态)。无状态服务器不保存状态信息。
图 1-12 显示了一个有状态架构的例子。
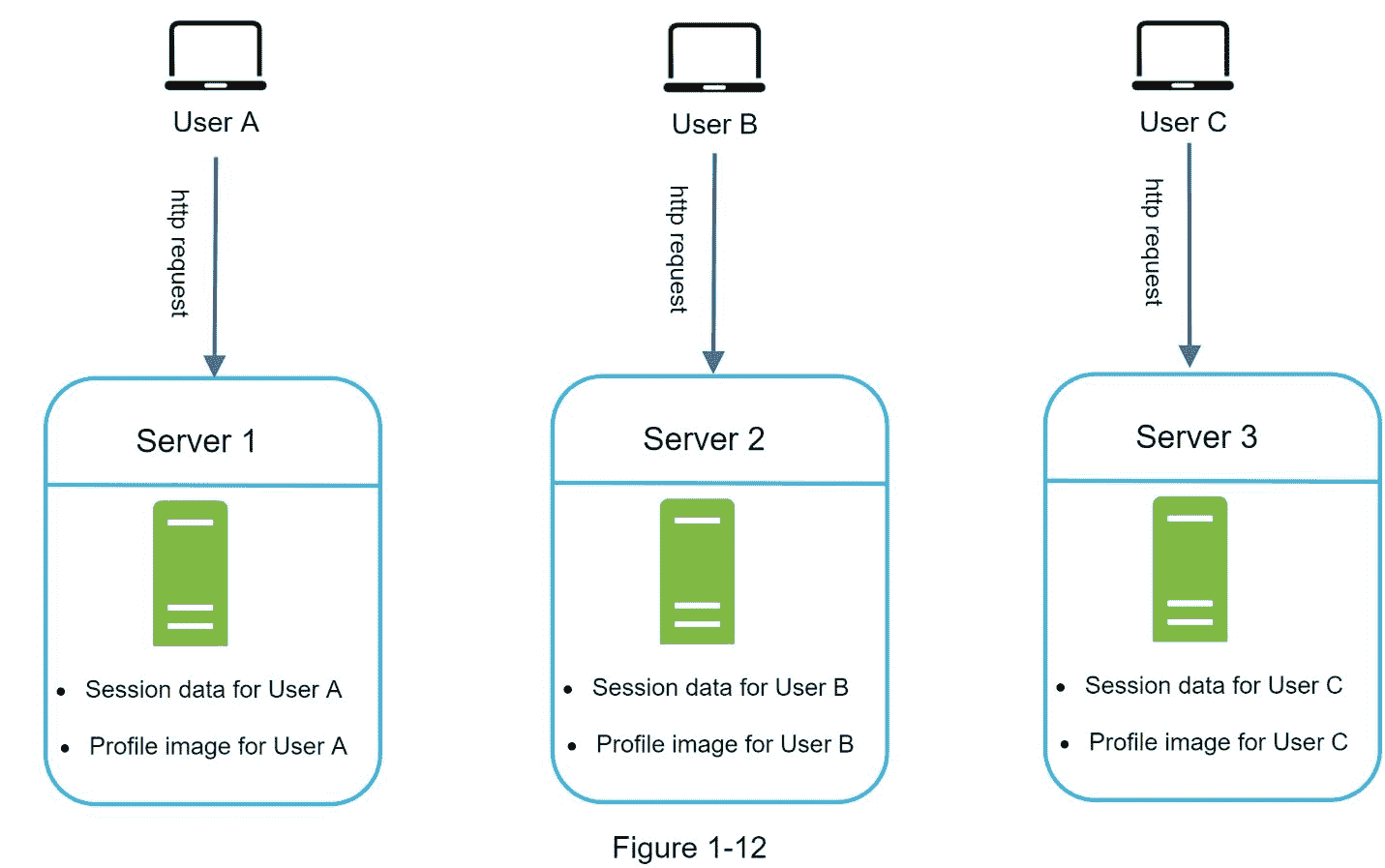
在图 1-12 中,用户 A 的会话数据和个人资料图像存储在服务器 1 中。要对用户 A 进行身份验证,HTTP 请求必须路由到服务器 1。如果请求被发送到其他服务器,如服务器 2,身份验证将失败,因为服务器 2 不包含用户 A 的会话数据。类似地,来自用户 B 的所有 HTTP 请求都必须路由到服务器 2;来自用户 C 的所有请求都必须发送到服务器 3。
问题是来自同一个客户端的每个请求都必须被路由到同一个服务器。这可以通过大多数负载平衡器中的粘性会话来实现[10];然而,这增加了开销。使用这种方法添加或删除服务器要困难得多。处理服务器故障也是一项挑战。
无状态架构
图 1-13 显示了无状态架构。
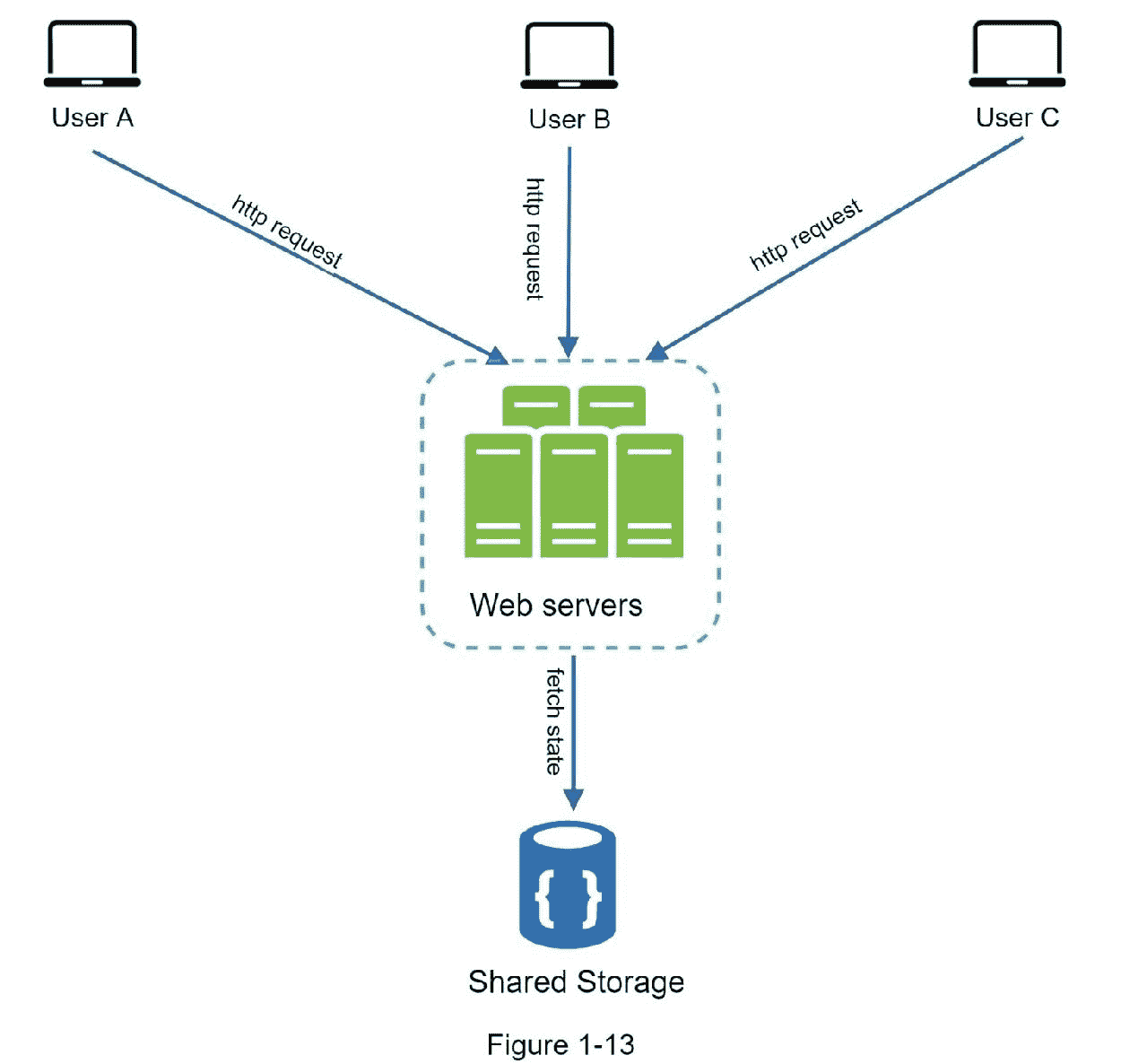
在这种无状态架构中,来自用户的 HTTP 请求可以发送到任何 web 服务器,这些服务器从共享数据存储中获取状态数据。状态数据存储在一个共享数据存储中,并远离 web 服务器。无状态系统更简单、更健壮、可伸缩。
图 1-14 显示了无状态 web 层的更新设计。
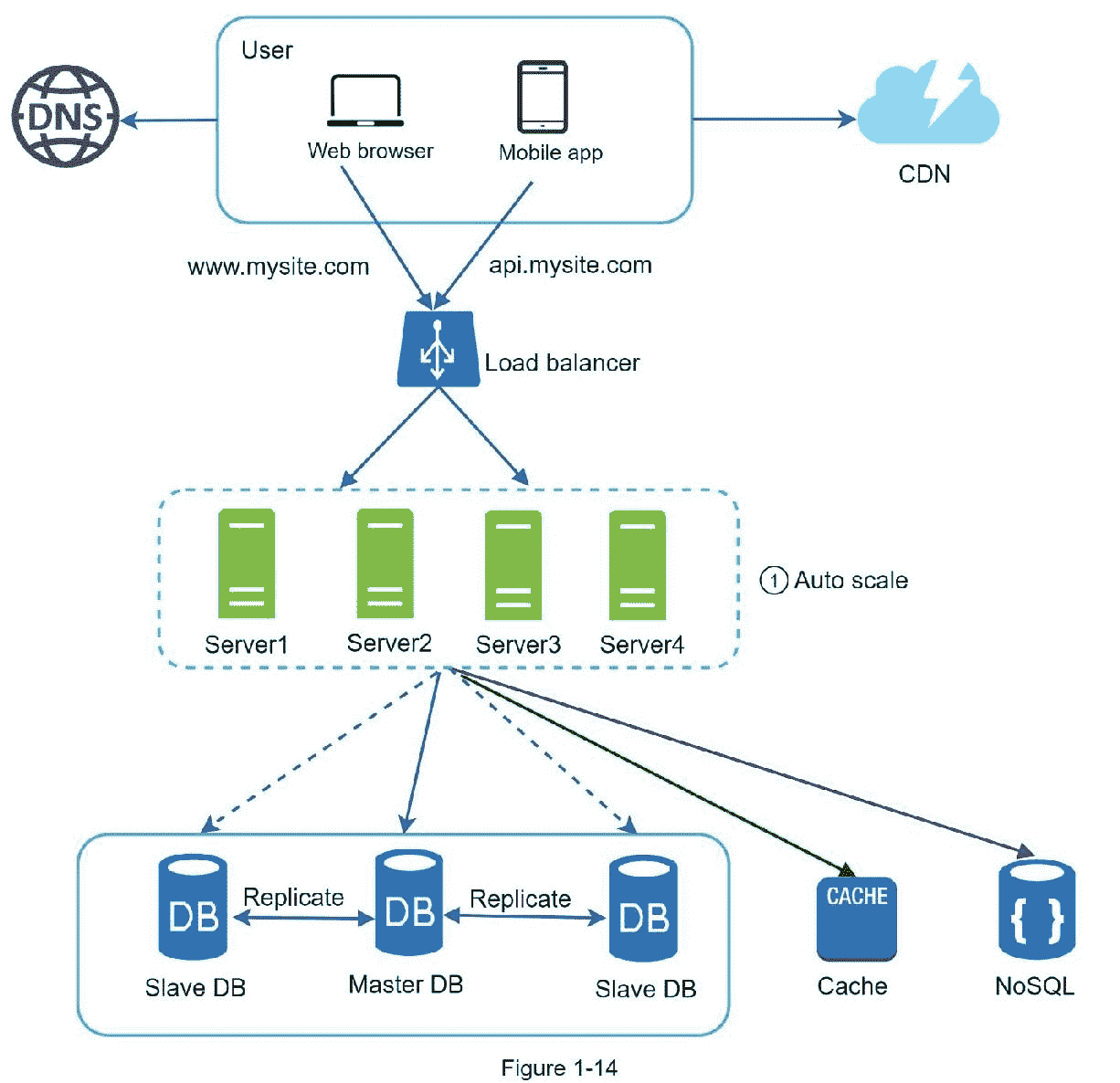
在图 1-14 中,我们将会话数据移出 web 层,并将它们存储在持久数据存储中。共享数据存储可以是关系数据库、Memcached/Redis、NoSQL 等。选择 NoSQL 数据存储是因为它易于扩展。自动缩放意味着根据流量负载自动添加或删除 web 服务器。从 web 服务器中删除状态数据后,可以根据流量负载添加或删除服务器,从而轻松实现 web 层的自动伸缩。
你的网站发展迅速,吸引了大量国际用户。为了提高可用性并在更广泛的地理区域提供更好的用户体验,支持多个数据中心至关重要。
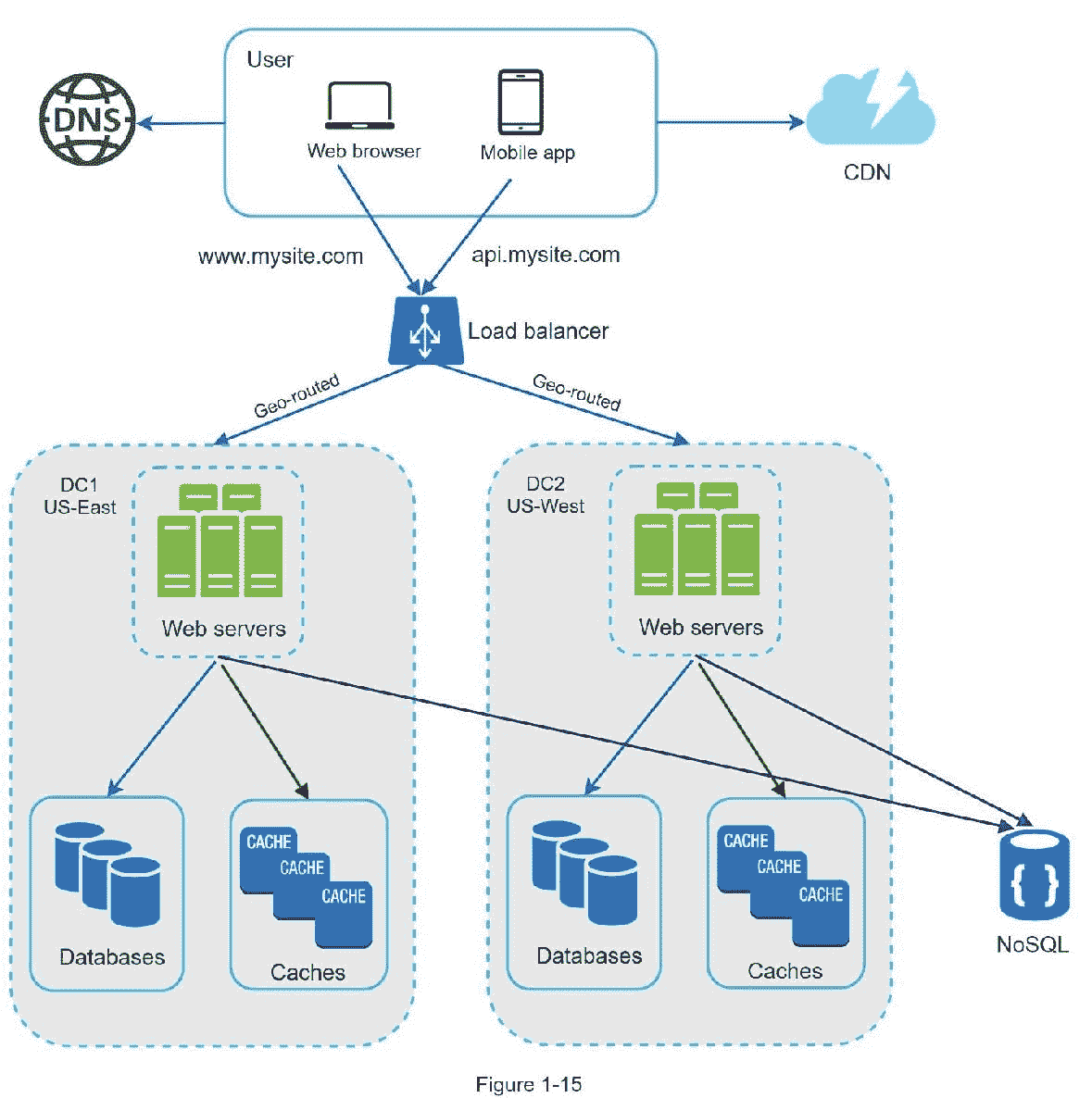
数据中心
图 1-15 显示了两个数据中心的设置示例。在正常操作中,用户通过 geoDNS 路由(也称为地理路由)到达最近的数据中心,分流流量为美国东部的(100–x)%。geoDNS 是一种 DNS 服务,允许根据用户的位置将域名解析为 IP 地址。
如果发生任何重大数据中心故障,我们会将所有流量导向健康的数据中心。在图 1-16 中,数据中心 2(美国西部)离线,100%的流量被路由到数据中心 1(美国东部)。
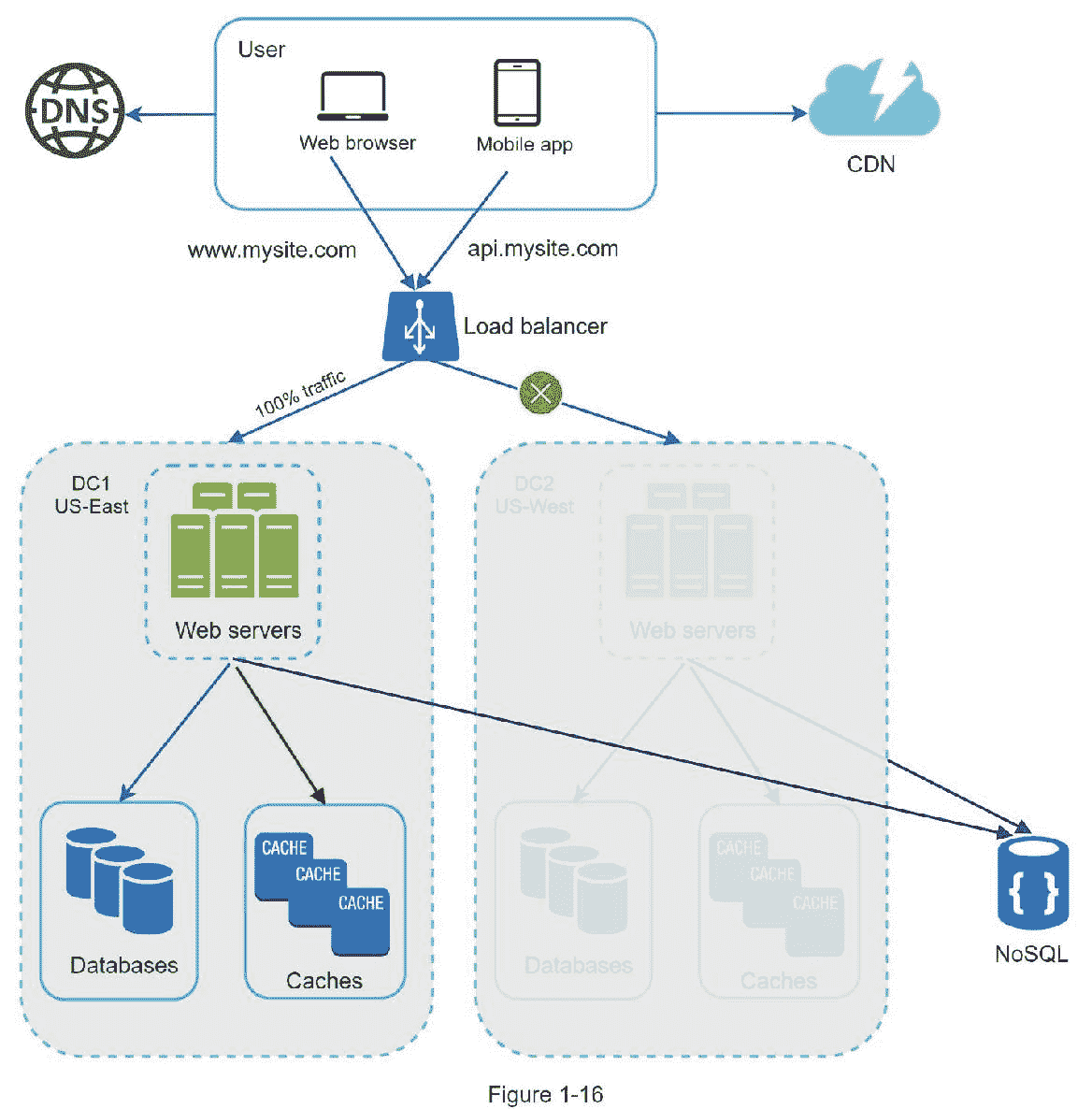
要实现多数据中心设置,必须解决几个技术难题:
流量重定向:需要有效的工具将流量定向到正确的数据中心。根据用户所在的位置,GeoDNS 可用于将流量导向最近的数据中心。
数据同步:不同地区的用户可以使用不同的本地数据库或缓存。在故障转移的情况下,流量可能会被路由到数据不可用的数据中心。一种常见的策略是跨多个数据中心复制数据。之前的一项研究展示了网飞如何实施异步多数据中心复制[11]。
测试和部署:对于多数据中心设置,在不同位置测试您的网站/应用程序非常重要。自动化部署工具对于保持所有数据中心的服务一致性至关重要[11]。
为了进一步扩展我们的系统,我们需要分离系统的不同组件,以便它们可以独立扩展。消息队列是许多现实世界的分布式系统用来解决这个问题的关键策略。
消息队列
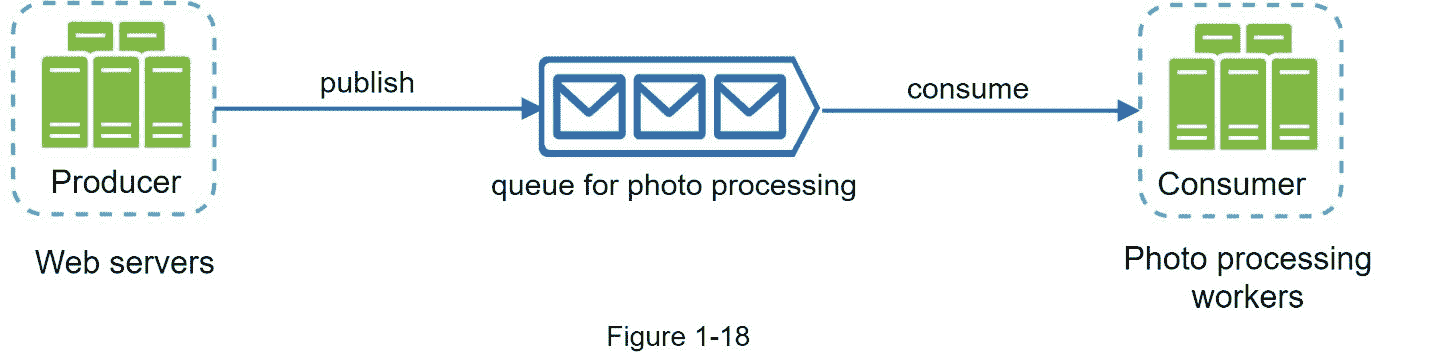
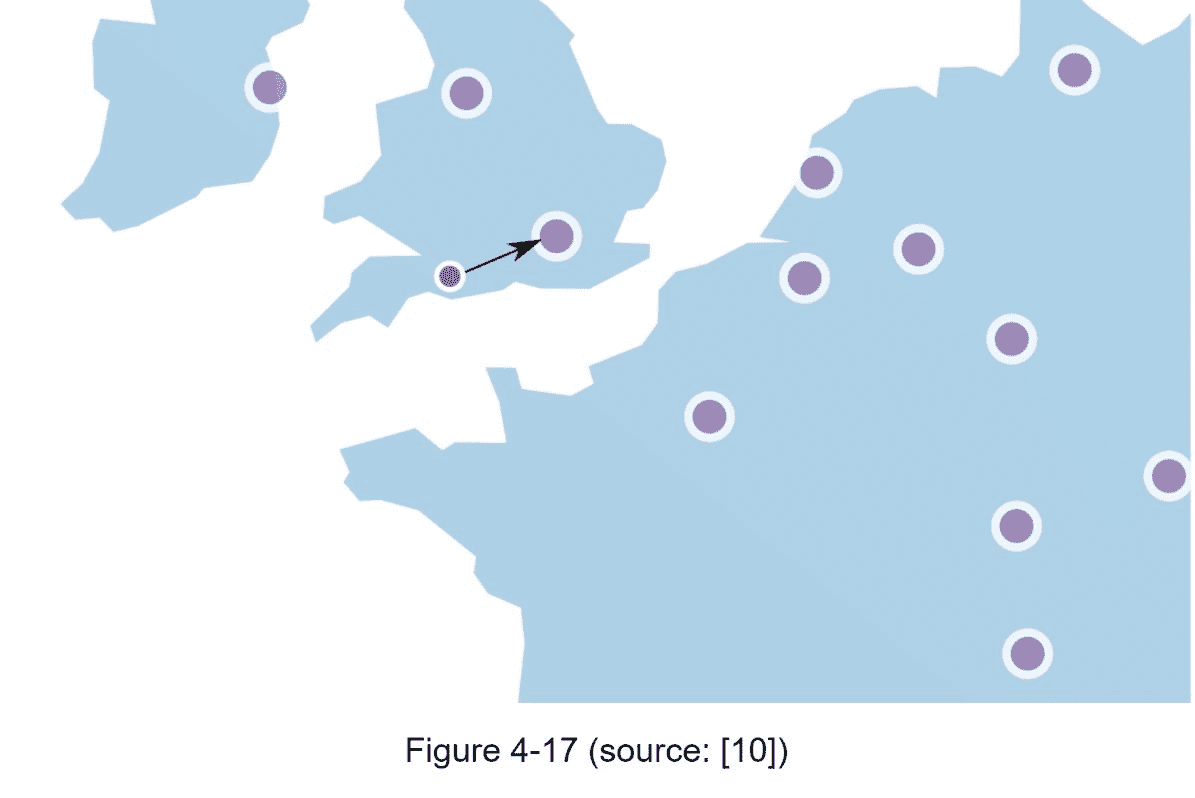
消息队列是一个持久的组件,存储在内存中,支持异步通信。它充当缓冲区并分发异步请求。消息队列的基本架构很简单。称为生产者/发布者的输入服务创建消息,并将它们发布到消息队列。其他服务或服务器(称为消费者/订户)连接到队列,并执行消息定义的操作。该模型如图 1-17 所示。

解耦使得消息队列成为构建可伸缩且可靠的应用程序的首选架构。使用消息队列,生产者可以在消费者无法处理消息时将消息发送到队列。即使生产者不可用,消费者也可以从队列中读取消息。
考虑以下用例:你的应用支持照片定制,包括裁剪、锐化、模糊等。这些定制任务需要时间来完成。在图 1-18 中,web 服务器将照片处理作业发布到消息队列中。照片处理人员从消息队列中选取作业,并异步执行照片定制任务。生产者和消费者可以独立伸缩。当队列变大时,会添加更多的工人来减少处理时间。但是,如果队列大部分时间都是空的,那么可以减少工人的数量。
日志记录、指标、自动化
当处理一个运行在几台服务器上的小型网站时,日志、指标和自动化支持是很好的实践,但不是必须的。然而,现在你的网站已经成长为一个大企业服务,投资这些工具是必不可少的。
日志记录:监控错误日志很重要,因为它有助于识别系统中的错误和问题。您可以在每个服务器级别监控错误日志,或者使用工具将它们聚合到一个集中的服务中,以便于搜索和查看。
度量:收集不同类型的度量有助于我们获得业务洞察力并了解系统的健康状态。以下一些指标是有用的:
主机级指标:CPU、内存、磁盘 I/O 等。
聚合级指标:例如,整个数据库层、缓存层等的性能。
关键业务指标:日活跃用户、留存、收入等。
自动化:当一个系统变得庞大而复杂时,我们需要构建或利用自动化工具来提高生产率。持续集成是一个很好的实践,其中每个代码签入都通过自动化来验证,允许团队尽早发现问题。此外,自动化您的构建、测试、部署过程等。可以显著提高开发人员的工作效率。
添加消息队列和不同的工具
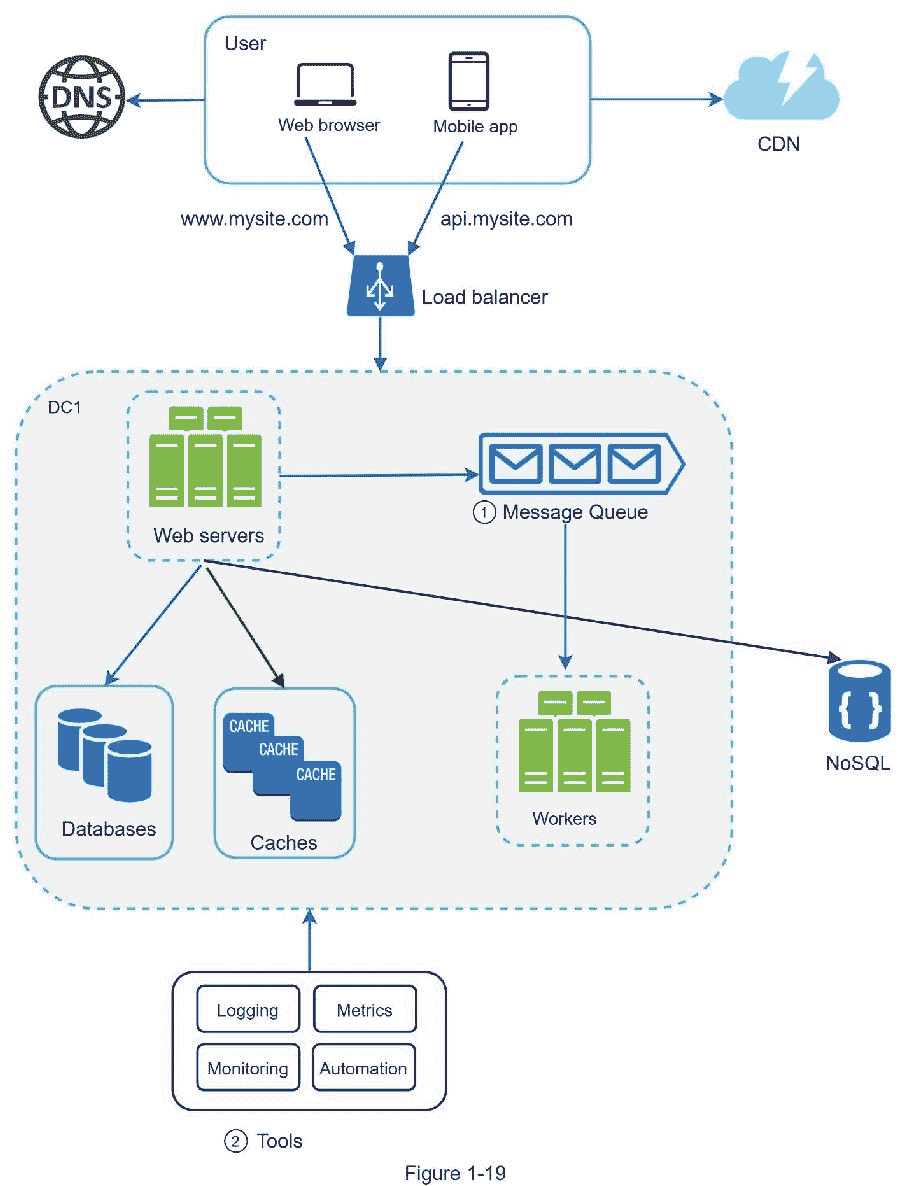
图 1-19 显示了更新后的设计。由于空间限制,图中仅显示了一个数据中心。
1。该设计包括一个消息队列,这有助于使系统更加松散耦合和具有故障恢复能力。
2。包括日志记录、监控、指标和自动化工具。
随着数据每天的增长,您的数据库变得更加超载。是时候扩展数据层了。
数据库缩放
数据库扩展有两种主要方法:垂直扩展和水平扩展。
垂直缩放
垂直扩展,也称为纵向扩展,是通过增加更多能力(CPU、RAM、磁盘等)来进行的扩展。)到现有的机器上。有一些强大的数据库服务器。根据亚马逊关系数据库服务(RDS) [12],你可以得到一个 24 TB 内存的数据库服务器。这种功能强大的数据库服务器可以存储和处理大量数据。例如,stackoverflow.com 在 2013 年每月有超过 1000 万的独立访问者,但它只有一个主数据库[13]。然而,垂直缩放有一些严重的缺点:
可以添加更多的 CPU、RAM 等。到您的数据库服务器,但有硬件限制。如果您有大量用户,单个服务器是不够的。
更大的单点故障风险。
纵向扩展的整体成本很高。功能强大的服务器要贵得多。
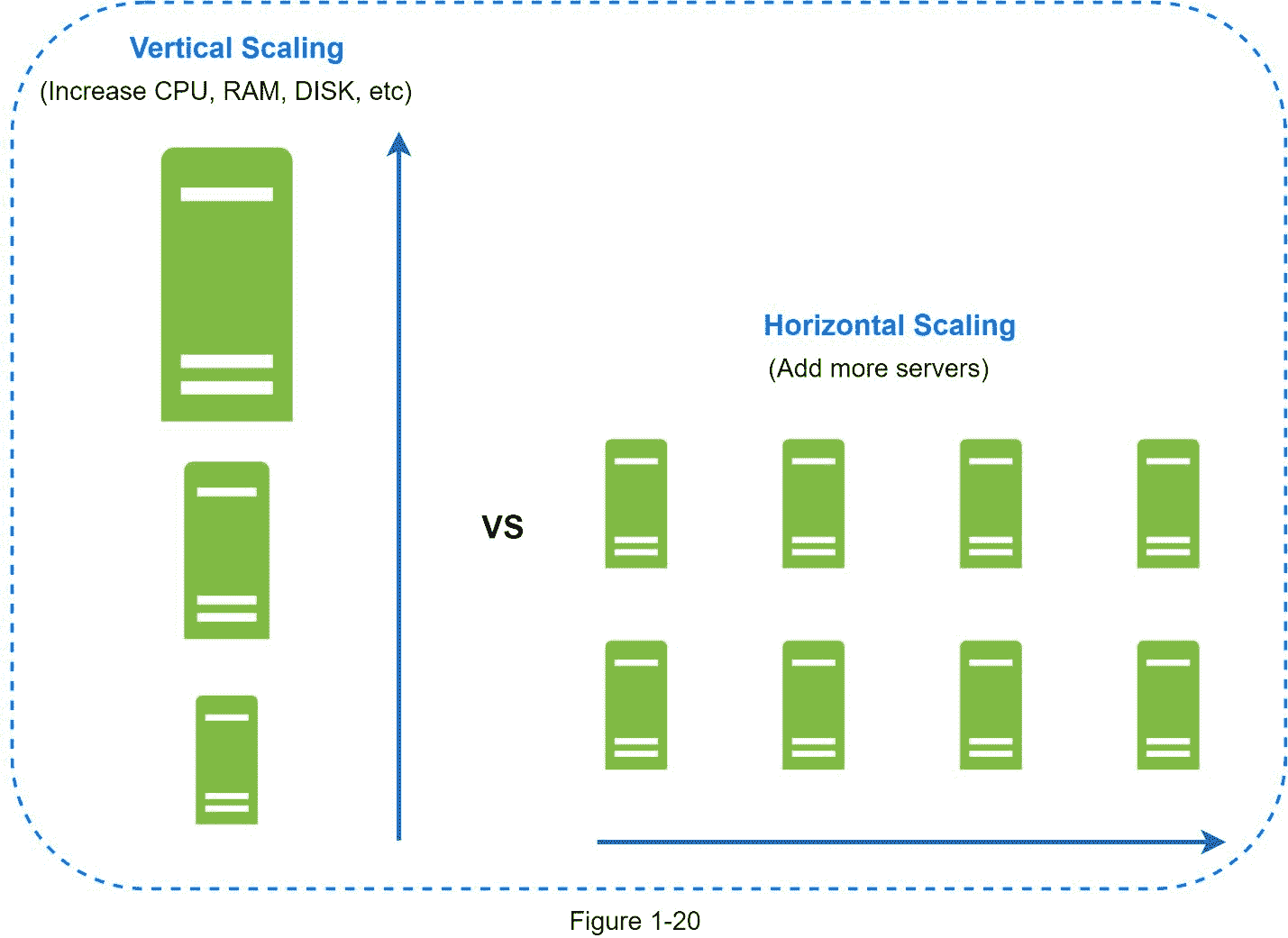
水平缩放
水平扩展,也称为分片,是添加更多服务器的实践。图 1-20 比较了垂直缩放和水平缩放。
分片将大型数据库分成更小、更容易管理的部分,称为分片。每个分片共享相同的模式,尽管每个分片上的实际数据对于该分片是唯一的。
图 1-21 显示了一个分片数据库的例子。用户数据根据用户 id 分配给数据库服务器。每当您访问数据时,都会使用哈希函数来查找相应的碎片。在我们的例子中, user_id % 4 被用作哈希函数。如果结果等于 0,碎片 0 用于存储和获取数据。如果结果等于 1,则使用碎片 1。同样的逻辑也适用于其他碎片。
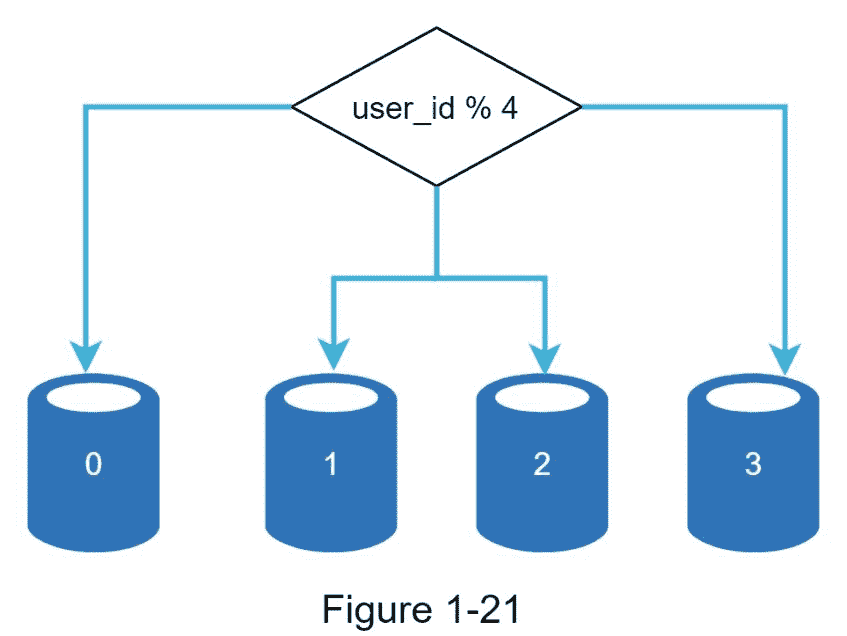
图 1-22 显示了分片数据库中的用户表。
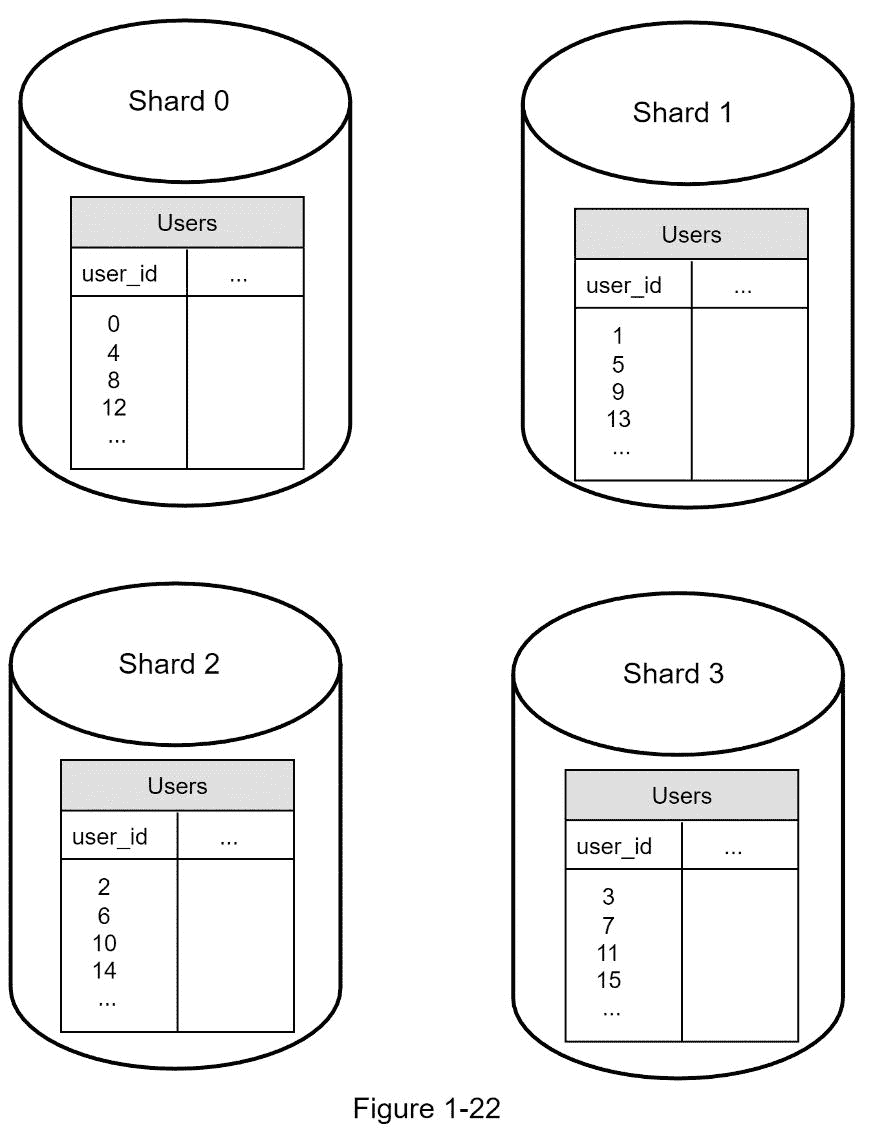
在实施分片策略时,要考虑的最重要的因素是分片密钥的选择。分片键(也称为分区键)由一列或多列组成,这些列决定了数据的分布方式。如图 1-22 所示, 【用户 id】是分片键。通过将数据库查询路由到正确的数据库,分片键允许您高效地检索和修改数据。在选择分片密钥时,最重要的标准之一是选择一个可以均匀分布数据的密钥。
分片是扩展数据库的一项伟大技术,但它远非完美的解决方案。它给系统带来了复杂性和新的挑战:
重新共享数据 :当 1)由于快速增长,单个碎片无法再容纳更多数据时,需要重新共享数据。2)由于数据分布不均匀,某些碎片可能比其他碎片更快耗尽。当分片耗尽时,需要更新分片函数并四处移动数据。将在第五章讨论的一致哈希法是解决这个问题的常用技术。
名人问题 :这也叫热点关键问题。对特定碎片的过度访问可能会导致服务器过载。想象一下凯蒂·佩里、贾斯汀比伯和 Lady Gaga 的数据都出现在同一个碎片上。对于社交应用来说,这个碎片将会被读操作淹没。为了解决这个问题,我们可能需要为每个名人分配一个碎片。每个碎片甚至可能需要进一步的划分。
连接和解规范化 :一旦一个数据库被分割到多个服务器上,就很难执行跨数据库分片的连接操作。一种常见的解决方法是对数据库进行反规范化,以便可以在单个表中执行查询。
在图 1-23 中,我们共享数据库来支持快速增长的数据流量。与此同时,一些非关系功能被转移到 NoSQL 数据库,以减少数据库负荷。这里有一篇文章涵盖了 NoSQL 的许多用例[14]。
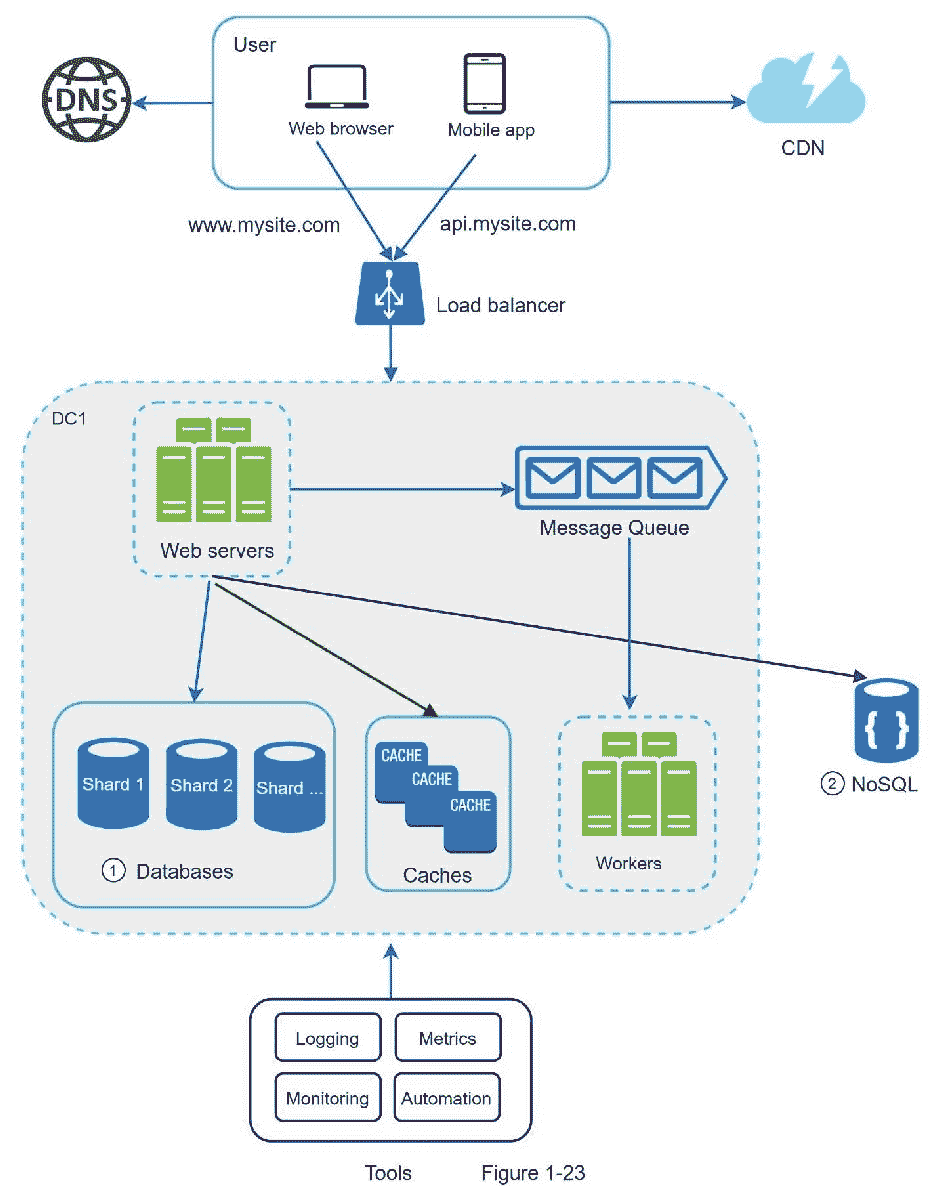
百万用户及以上
扩展系统是一个迭代的过程。重复我们在这一章学到的东西可以让我们走得更远。要超越数百万用户,需要更多的微调和新策略。例如,您可能需要优化您的系统并将系统解耦到更小的服务。本章学习的所有技术应该为应对新的挑战提供一个良好的基础。在本章的结尾,我们总结了如何扩展我们的系统来支持数百万用户:
保持 web 层无状态
在每一层建立冗余
尽可能多地缓存数据
支持多个数据中心
在 CDN 中托管静态资产
通过分片扩展您的数据层
将层级划分为单独的服务
监控您的系统并使用自动化工具
祝贺你走到这一步!现在给自己一个鼓励。干得好!
参考资料
[1] Hypertext Transfer Protocol: https://en.wikipedia.org/wiki/Hypertext_Transfer_Protocol
[2] Should you go Beyond Relational Databases?:
https://blog.teamtreehouse.com/should-you-go-beyond-relational-databases
[3] Replication: https://en.wikipedia.org/wiki/Replication_(computing)
[4] Multi-master replication:
https://en.wikipedia.org/wiki/Multi-master_replication
[5] NDB Cluster Replication: Multi-Master and Circular Replication: https://dev.mysql.com/doc/refman/5.7/en/mysql-cluster-replication-multi-master.html
[6] Caching Strategies and How to Choose the Right One:
https://codeahoy.com/2017/08/11/caching-strategies-and-how-to-choose-the-right-one/
[7] R. Nishtala, "Facebook, Scaling Memcache at," 10th USENIX Symposium on Networked Systems Design and Implementation (NSDI ’13).
[8] Single point of failure: https://en.wikipedia.org/wiki/Single_point_of_failure
[9] Amazon CloudFront Dynamic Content Delivery:
https://aws.amazon.com/cloudfront/dynamic-content/
[10] Configure Sticky Sessions for Your Classic Load Balancer:
https://docs.aws.amazon.com/elasticloadbalancing/latest/classic/elb-sticky-sessions.html
[11] Active-Active for Multi-Regional Resiliency:
https://netflixtechblog.com/active-active-for-multi-regional-resiliency-c47719f6685b
[12] Amazon EC2 High Memory Instances:
https://aws.amazon.com/ec2/instance-types/high-memory/
[13] What it takes to run Stack Overflow:
http://nickcraver.com/blog/2013/11/22/what-it-takes-to-run-stack-overflow
[14] What The Heck Are You Actually Using NoSQL For:
http://highscalability.com/blog/2010/12/6/what-the-heck-are-you-actually-using-nosql-for.html
二、信封背面估计
在系统设计面试中,有时你会被要求使用粗略估计来估计系统容量或性能需求。根据谷歌高级研究员 Jeff Dean 的说法,“信封背面的计算是你使用思维实验和常见性能数字的组合来创建的估计,以获得满足你要求的设计的良好感觉”[1]。
您需要对可伸缩性基础有一个很好的认识,以便有效地进行预估。应该很好地理解以下概念:2 的幂,每个程序员都应该知道的延迟数字,以及可用性数字。
二的幂
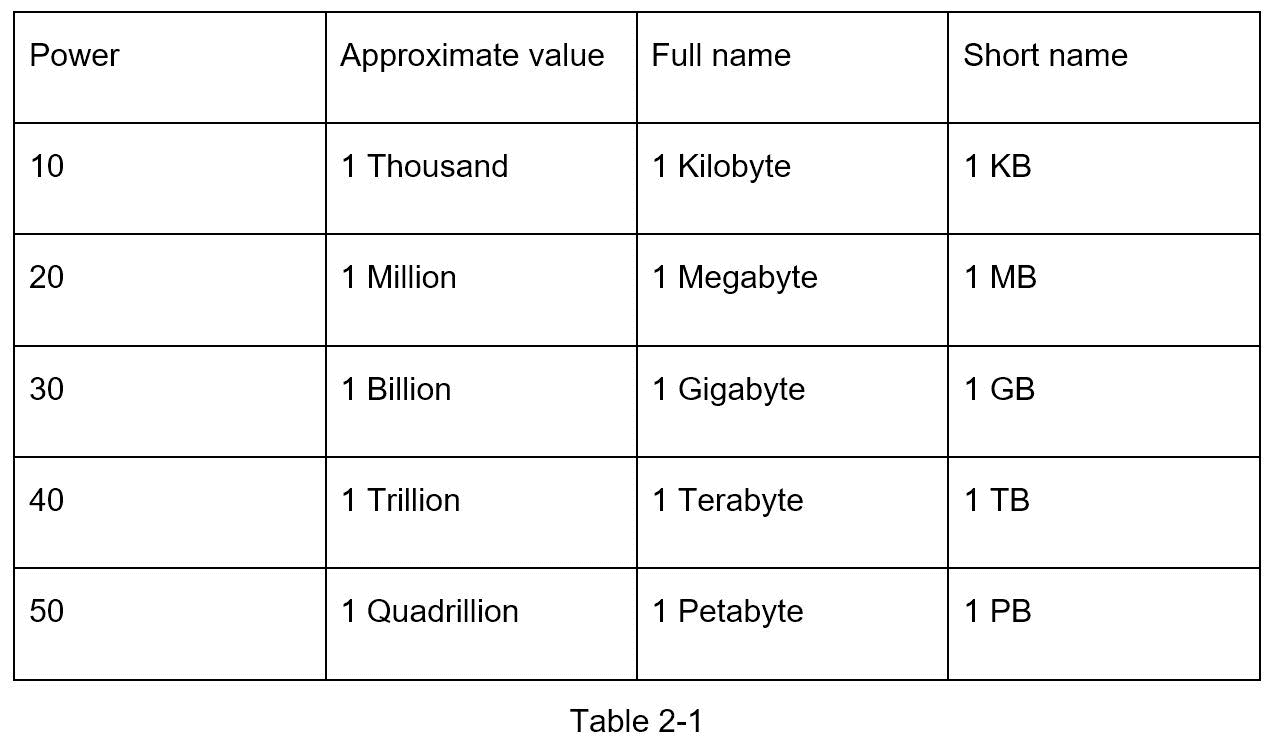
虽然在处理分布式系统时,数据量会变得巨大,但计算都归结为基础。为了获得正确的计算结果,使用 2 的幂知道数据量单位是非常重要的。一个字节是 8 位的序列。一个 ASCII 字符使用一个字节的内存(8 位)。下表解释了数据量单位(表 2-1)。
每个程序员都应该知道的延迟数字
来自谷歌的迪恩博士揭示了 2010 年典型计算机操作的长度[1]。随着计算机变得更快更强大,一些数字已经过时了。然而,这些数字应该仍然能够让我们了解不同计算机操作的快慢。
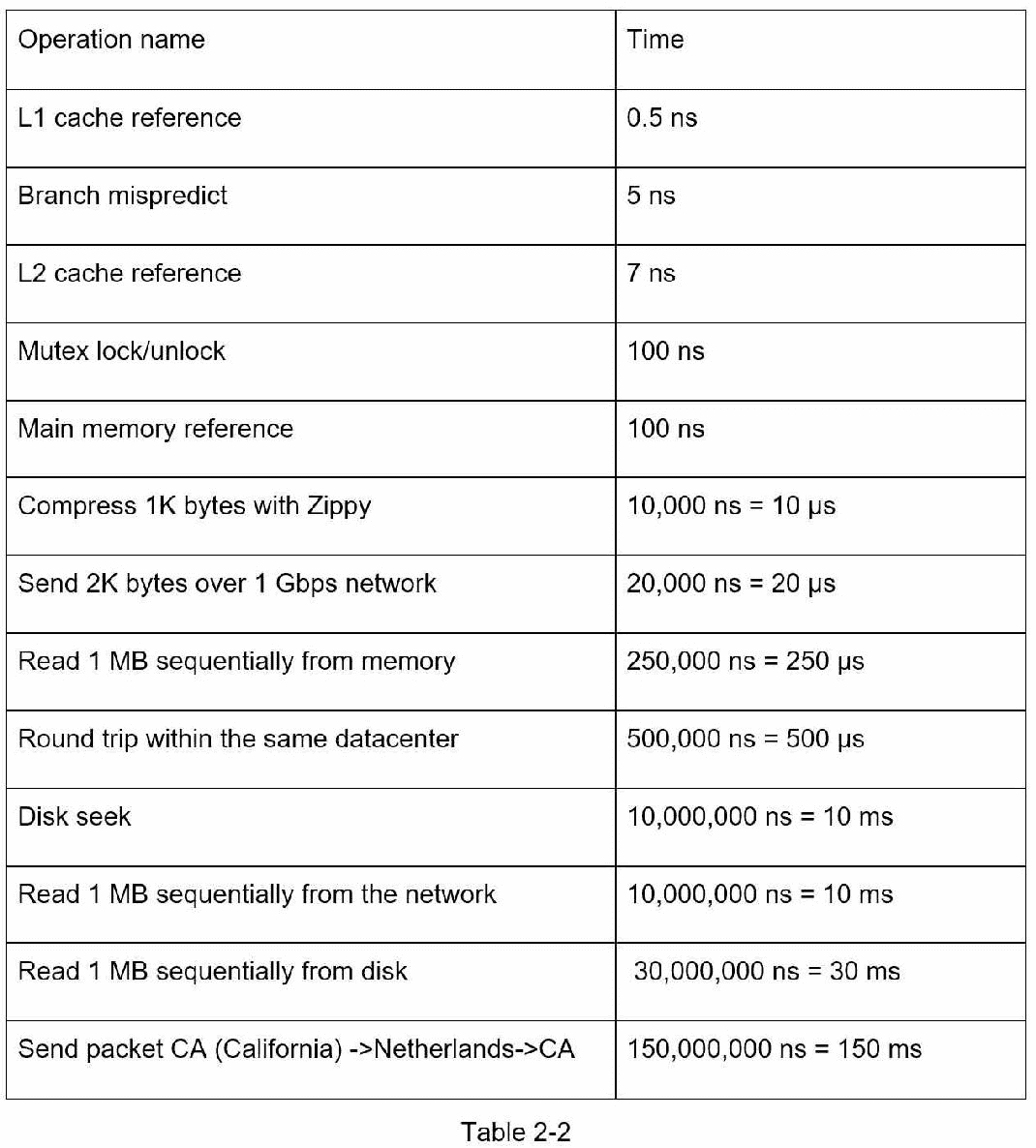
注释
ns = 纳秒,s = 微秒,ms = 毫秒
1 纳秒 = 10^-9 秒
1 秒 = 10^-6 秒 = 1000 纳秒
1 毫秒 = 10^-3 秒 = 1000 秒 = 1000000 纳秒
一名谷歌软件工程师开发了一个工具来可视化迪安博士的数据。该工具还考虑了时间因素。图 2-1 显示了截至 2020 年的可视化延迟数字(图片来源:参考资料[3])。

通过分析图 2-1 中的数字,我们得到以下结论:
内存快但磁盘慢。
尽可能避免磁盘寻道。
简单压缩算法速度快。
如果可能的话,在通过互联网发送数据之前对其进行压缩。
数据中心通常在不同的区域,它们之间发送数据需要时间。
可用性数字
高可用性是指系统在期望的长时间内持续运行的能力。高可用性以百分比来衡量,100%意味着服务没有停机时间。大多数服务介于 99%和 100%之间。
服务水平协议(SLA)是服务提供商常用的术语。这是您(服务提供商)和您的客户之间的协议,该协议正式定义了您的服务将提供的正常运行时间水平。云提供商亚马逊[4]、谷歌[5]和微软[6]将其 SLA 设定为 99.9%或以上。正常运行时间传统上是以 9 来衡量的。九越多越好。如表 2-3 所示,9 的数量与预期的系统停机时间相关。

示例:估计 Twitter QPS 和存储需求
请注意,以下数字仅用于本练习,因为它们不是来自 Twitter 的真实数字。
假设:
3 亿月活跃用户。
50%的用户每天都使用 Twitter。
用户平均每天发布 2 条推文。
10%的推文包含媒体。
数据保存 5 年。
估计:
每秒查询(QPS)估计:
日活跃用户(DAU) = 3 亿 * 50% = 1.5 亿
推文 QPS = 1.5 亿 * 2 推文 / 24 小时 / 3600 秒 = ~3500
峰值 QPS = 2 * QPS = ~7000
我们在这里只估计媒体存储量。
平均推文大小:
推特 ID 64 字节
文本 140 字节
媒体 1 MB
媒体存储: 每天 1.5 亿 * 2 * 10% * 1mb = 30tb
5 年介质存储: 30 TB * 365 * 5 = ~55 PB
提示
信封背面的评估是关于整个过程的。解决问题比获得结果更重要。面试官可能会测试你解决问题的能力。以下是一些可以遵循的提示:
舍入和近似。面试时很难进行复杂的数学运算。比如99987 / 9.1是什么结果?没必要花宝贵的时间去解复杂的数学题。不期望精度。使用对你有利的整数和近似值。除法问题可以简化为:10 万 / 10。
写下你的假设。写下你的假设供以后参考是个好主意。
给你的单位贴上标签。你写下“5”,是指 5 KB 还是 5 MB?你可能会对此感到困惑。写下单位,因为“5 MB”有助于消除歧义。
常见的粗略估计:QPS、峰值 QPS、存储、缓存、服务器数量等。准备面试的时候可以练习一下这些计算。熟能生巧。
祝贺你走到这一步!现在给自己一个鼓励。干得好!
参考资料
[1] J. Dean.Google Pro Tip: Use Back-Of-The-Envelope-Calculations To Choose The Best Design:
http://highscalability.com/blog/2011/1/26/google-pro-tip-use-back-of-the-envelope-calculations-to-choo.html
[2] System design primer: https://github.com/donnemartin/system-design-primer
[3] Latency Numbers Every Programmer Should Know:
https://colin-scott.github.io/personal_website/research/interactive_latency.html
[4] Amazon Compute Service Level Agreement:
https://aws.amazon.com/compute/sla/
[5] Compute Engine Service Level Agreement (SLA):
https://cloud.google.com/compute/sla
[6] SLA summary for Azure services: https://azure.microsoft.com/en-us/support/legal/sla/summary/
三、系统设计面试的框架
你刚刚获得了梦寐以求的理想公司的现场面试机会。招聘协调员会给你发一份当天的日程表。浏览列表,你会感觉很好,直到你的目光落在这个面试环节——系统设计面试。
系统设计面试通常令人生畏。它可以像“设计一个知名产品 X?”。这些问题模棱两可,而且似乎过于宽泛。你的疲倦是可以理解的。毕竟,怎么可能有人在一个小时内设计出一款流行的产品,而这需要数百甚至数千名工程师来完成?
好消息是没人期望你这么做。现实世界的系统设计极其复杂。例如,谷歌搜索看似简单;然而,支撑这种简单性的技术数量确实令人吃惊。如果没有人期望你在一个小时内设计出一个真实世界的系统,那么系统设计面试有什么好处呢?
系统设计面试模拟现实生活中的问题解决,两名员工合作解决一个模糊的问题,并提出一个符合他们目标的解决方案。这个问题是开放式的,没有完美的答案。与你在设计过程中所做的工作相比,最终的设计没有那么重要。这允许你展示你的设计技巧,捍卫你的设计选择,并以建设性的方式回应反馈。
让我们把桌子翻过来,想想面试官走进会议室见你时脑子里在想什么。面试官的首要目标是准确评估你的能力。她最不希望的就是给出一个不确定的评价,因为会议进行得很糟糕,没有足够的信号。在系统设计面试中,面试官想要的是什么?
许多人认为系统设计面试是关于一个人的技术设计技能。远不止如此。一次有效的系统设计面试会给出一个人的合作能力、在压力下工作的能力以及建设性地解决歧义的能力的强烈信号。问出好问题的能力也是一项必备技能,许多面试官专门寻找这项技能。
一个好的面试官也会寻找危险信号。过度工程是许多工程师的真正疾病,因为他们喜欢设计的纯粹性,而忽视权衡。他们常常意识不到过度设计系统的复合成本,许多公司为这种无知付出了高昂的代价。你肯定不希望在系统设计面试中表现出这种倾向。其他危险信号包括心胸狭窄、固执等。
在本章中,我们将复习一些有用的技巧,并介绍一个简单有效的框架来解决系统设计面试问题。
有效系统设计面试的 4 步流程
每个系统设计面试都不一样。伟大的系统设计面试是开放式的,没有放之四海而皆准的解决方案。然而,每个系统设计面试都有一些步骤和共同点。
第一步——了解问题并确定设计范围
“老虎为什么要吼叫?”
教室后面突然伸出一只手。
“是的,吉米?”,老师回应道。
“因为他饿了”。
“非常好的吉米。”
在童年时代,吉米总是第一个回答班上的问题。每当老师提问时,教室里总有一个孩子爱试着回答这个问题,不管他是否知道答案。那是吉米。
吉米是个优等生。他以很快知道所有答案而自豪。在考试中,他通常是第一个做完题目的人。他是教师参加任何学术竞赛的首选。
不要像吉米一样。
在系统设计面试中,不假思索地快速给出答案不会给你加分。没有完全理解要求的回答是一个巨大的危险信号,因为面试不是一个琐事竞赛。没有正确的答案。
因此,不要马上给出解决方案。慢点。深入思考,提出问题,明确需求和假设。这是极其重要的。
作为工程师,我们喜欢解决难题,一头扎进最终的设计中;然而,这种方法很可能会导致您设计错误的系统。作为一名工程师,最重要的技能之一是提出正确的问题,做出适当的假设,并收集构建系统所需的所有信息。所以,不要害怕提问。
当你提问时,面试官要么直接回答你的问题,要么让你做出假设。如果是后者,在白板或纸上写下你的假设。你以后可能需要它们。
问什么样的问题?提出问题,了解确切的要求。这里有一个帮助你开始的问题列表:
我们要构建什么样的特性?
产品有多少用户?
公司预计扩大规模的速度有多快?3 个月、6 个月和一年后的预期规模是多少?
公司的技术栈是什么?您可以利用哪些现有服务来简化设计?
例子
如果你被要求设计一个新闻订阅系统,你会问一些有助于你阐明需求的问题。你和面试官之间的对话可能是这样的:
考生 :这是手机 app 吗?还是一个 web app?还是两者都有?
面试官 :都有。
候选人 :产品最重要的特点是什么?
面试官 :发帖和查看好友动态的能力。
候选人 : 新闻提要是按时间倒序排序还是按特定顺序排序?这种特殊的顺序意味着每个帖子被赋予不同的权重。例如,来自你亲密朋友的帖子比来自一个团体的帖子更重要。
面试官 : 为了简单起见,我们假设提要是按时间倒序排序的。
候选人 : 一个用户可以有多少好友?
面试官 : 5000
候选人 :车流量是多少?
面试官 :日活跃用户 1000 万(DAU)
候选:feed 可以包含图片、视频,或者只是文字?
面试官 :可以包含媒体文件,包括图片和视频。
以上是你可以问面试官的一些问题。理解需求和澄清歧义很重要
第二步——提出高水平的设计并获得认同
在这一步,我们的目标是开发一个高层次的设计,并与面试官就设计达成一致。在面试过程中与面试官合作是个好主意。
拿出最初的设计蓝图。寻求反馈。把你的面试官当成队友,一起努力。许多优秀的面试官喜欢交谈和参与。
在白板或纸上画出关键部件的方框图。这可能包括客户端(移动/web)、API、web 服务器、数据存储、缓存、CDN、消息队列等。
进行粗略计算,评估你的蓝图是否符合规模限制。大声思考。在深入调查之前,如果有必要的话,和面试官交流一下。
如果可能的话,浏览几个具体的用例。这将帮助您构建高层次的设计。用例也有可能帮助您发现您还没有考虑的边缘用例。
我们应该在这里包括 API 端点和数据库模式吗?这个要看问题。对于“设计谷歌搜索引擎”这样的大型设计问题来说,这有点太低级了。对于像为多人扑克游戏设计后端这样的问题,这是一个公平的游戏。与你的面试官交流。
例子
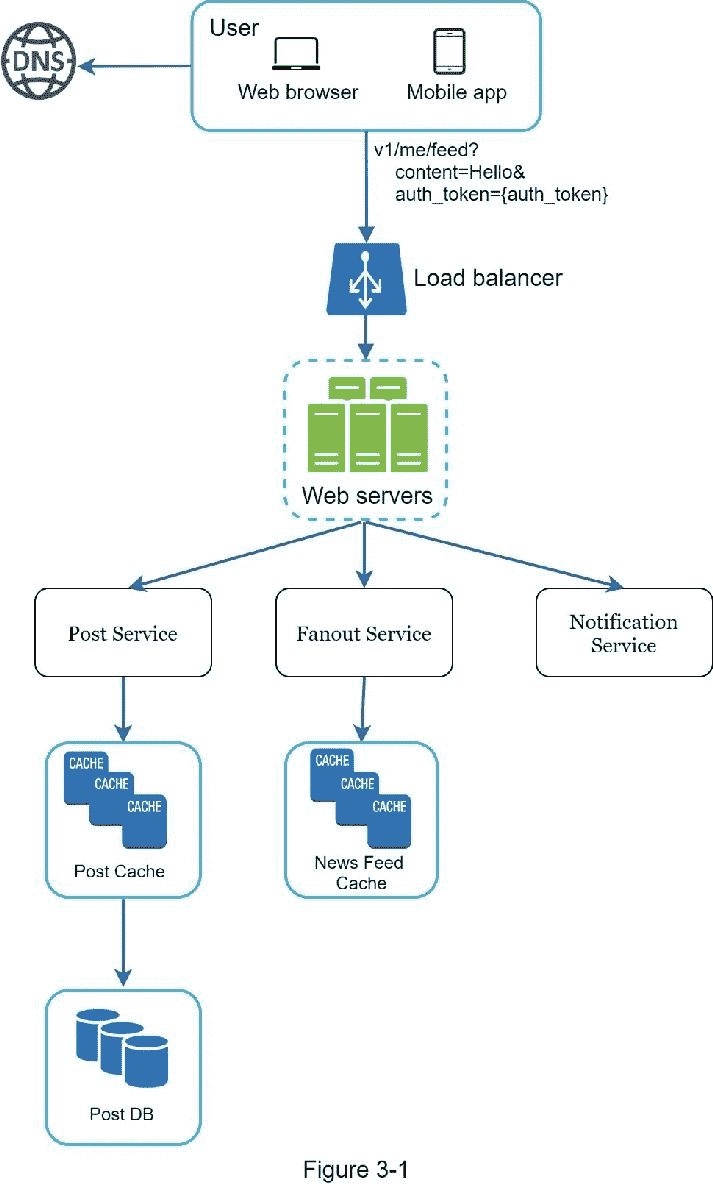
让我们用“设计一个新闻反馈系统”来演示如何进行高级设计。在这里 你不需要了解系统实际上是如何工作的。所有细节将在第十一章解释。
在高层次上,设计分为两个流程:提要发布和新闻提要构建。
Feed 发布:当用户发布帖子时,相应的数据被写入缓存/数据库,该帖子将被填充到好友的新闻 Feed 中。
新闻提要构建:新闻提要是通过按时间倒序聚合朋友的帖子来构建的。
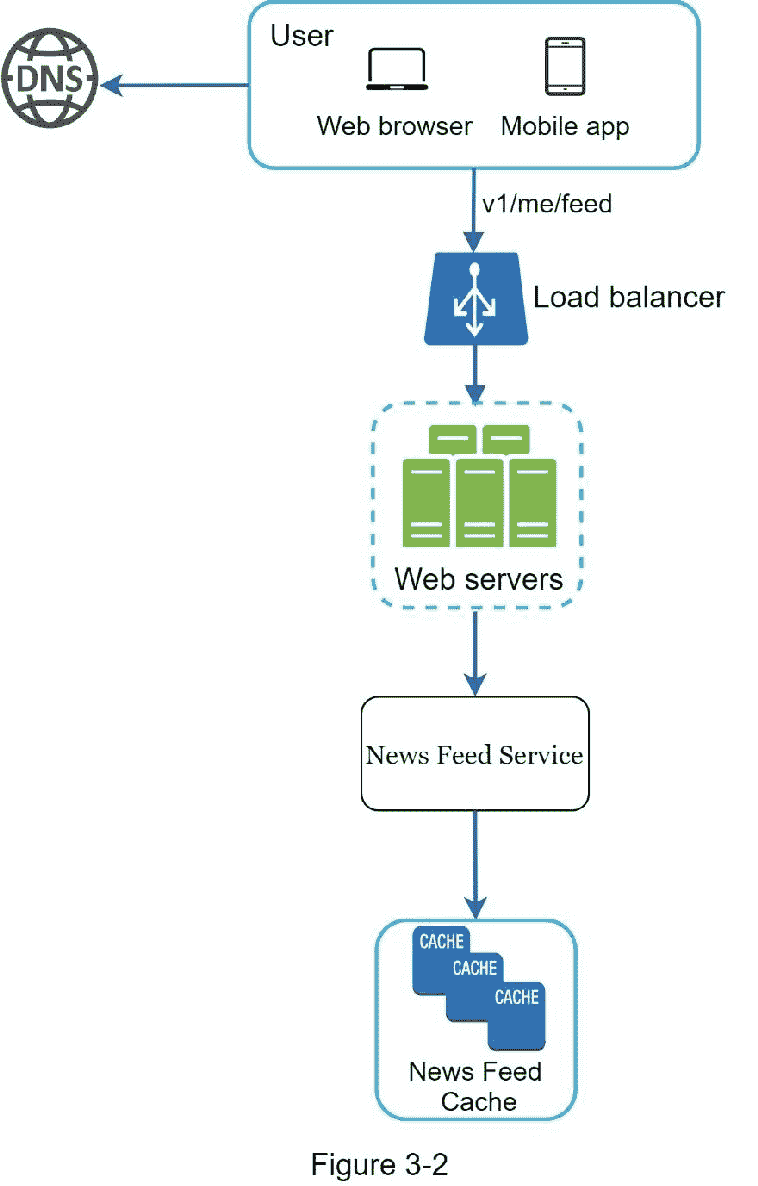
图 3-1 和图 3-2 分别展示了提要发布和新闻提要构建流程的高级设计。
第三步——设计深潜
在这一步,你和你的面试官应该已经达到了以下目标:
商定总体目标和功能范围
勾画出总体设计的高层次蓝图
从你的面试官那里获得了关于高层设计的反馈
根据她的反馈,对深度探索中需要关注的领域有了一些初步想法
你应该和面试官一起确定架构中组件的优先级。值得强调的是,每次面试都是不同的。有时候,面试官可能会暗示她喜欢关注高层次的设计。有时,对于高级候选人面试,讨论可能是关于系统性能特征,可能集中在瓶颈和资源估计上。在大多数情况下,面试官可能希望你深入了解一些系统组件的细节。对于 URL shortener,深入研究将长 URL 转换成短 URL 的哈希函数设计是很有趣的。对于一个聊天系统来说,如何减少延迟和如何支持在线/离线状态是两个有趣的话题。
时间管理是必不可少的,因为人们很容易被无法展示你能力的微小细节冲昏头脑。你必须准备好向面试官展示的信号。尽量不要陷入不必要的细节。例如,在系统设计面试中详细讨论脸书 feed 排名的 EdgeRank 算法是不理想的,因为这会花费很多宝贵的时间,并且不能证明你设计可扩展系统的能力。
例子
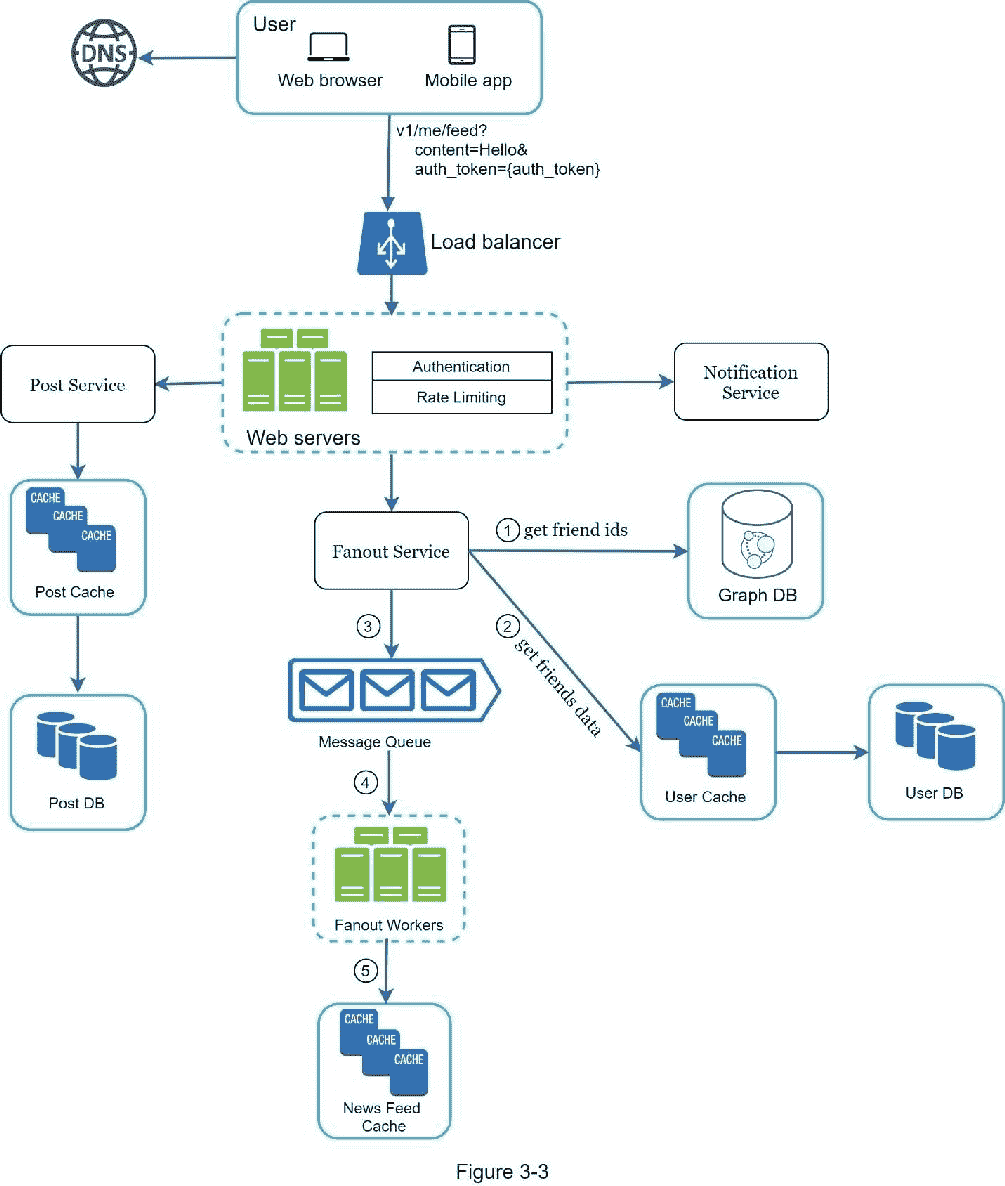
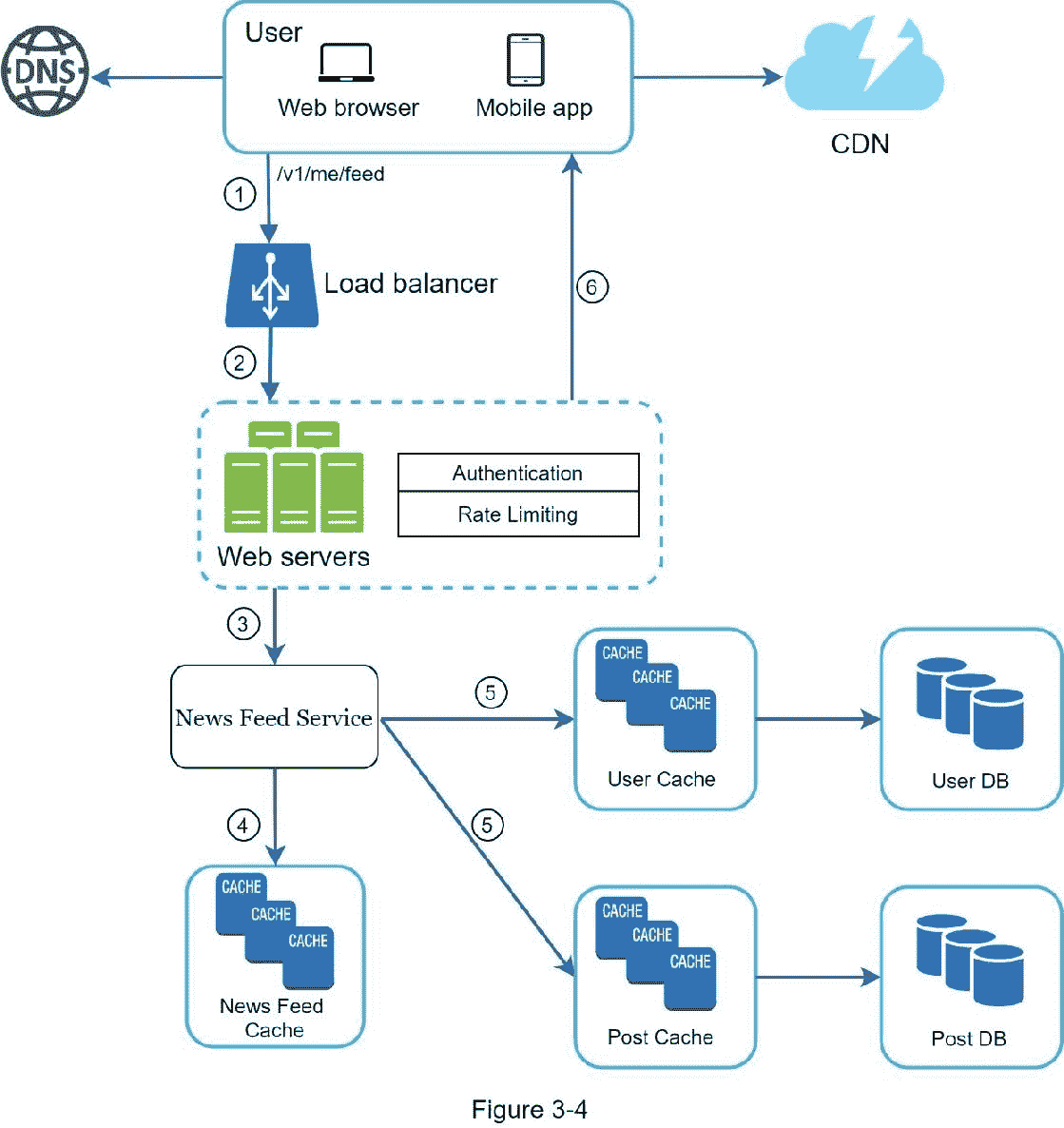
至此,我们已经讨论了新闻订阅系统的高级设计,面试官对你的提议很满意。接下来,我们将研究两个最重要的用例:
1。订阅源发布
2。新闻提要检索
图 3-3 和图 3-4 显示了两个用例的详细设计,这将在第十一章中详细解释。
第四步——总结
在这最后一步,面试官可能会问你几个后续问题,或者给你讨论其他要点的自由。这里有几个方向可以遵循:
面试官可能希望你找出系统的瓶颈并讨论潜在的改进。永远不要说你的设计是完美的,没有什么可以改进的。总有需要改进的地方。这是一个展示你批判性思维并留下好的最终印象的好机会。
给面试官回顾一下你的设计可能会有帮助。如果你提出了一些解决方案,这一点尤为重要。在长时间的谈话后,刷新面试官的记忆会很有帮助。
错误案例(服务器故障、网络丢失等。)都是很有意思的话题。
运营问题值得一提。如何监控指标和错误日志?如何铺开系统?
如何处理下一个比例曲线也是一个有趣的话题。例如,如果您当前的设计支持 100 万用户,您需要做哪些更改来支持 1000 万用户?
如果你有更多的时间,提出你需要的其他改进。
作为总结,我们总结了一系列该做和不该做的事情。
Dos
总是要求澄清。不要假设你的假设是正确的。
理解问题的要求。
没有正确的答案,也没有最好的答案。旨在解决年轻初创公司问题的解决方案不同于拥有数百万用户的老牌公司。确保你理解这些要求。
让面试官知道你在想什么。和你的面试沟通。
如有可能,建议多种方法。
一旦你和面试官就蓝图达成一致,就要详细讨论每一部分。首先设计最关键的部件。
向面试官反映想法。一个好的面试官像队友一样和你一起工作。
永不放弃。
不要做
不要对典型的面试问题毫无准备。
在没有明确需求和假设的情况下,不要急于找到解决方案。
不要一开始就对单个组件进行过多的细节描述。首先给出概要设计,然后再向下钻取。
如果你卡住了,不要犹豫,寻求提示。
再次沟通。不要在沉默中思考。
不要以为一旦你给出了设计,你的面试就结束了。直到你的面试官说你结束了,你才算结束。尽早并经常寻求反馈。
每一步上的时间分配
系统设计面试问题通常非常宽泛,45 分钟或者一个小时都不足以涵盖整个设计。时间管理至关重要。每一步应该花多少时间?以下是在 45 分钟的面试中分配时间的粗略指南。请记住这是一个粗略的估计,实际的时间分布取决于问题的范围和面试官的要求。
第一步了解问题并确定设计范围:3 - 10 分钟
第二步提出高级设计并获得认同:10 - 15 分钟
第三步设计深潜:10 - 25 分钟
第四步包装:3 - 5 分钟
四、设计速率限制器
在网络系统中,速率限制器用于控制客户端或服务发送流量的速率。在 HTTP 世界中,速率限制器限制了在特定时间段内允许发送的客户端请求的数量。如果 API 请求计数超过速率限制器定义的阈值,所有超出的调用都会被阻塞。下面举几个例子:
一个用户每秒最多只能写 2 篇文章。
您每天最多可以从同一个 IP 地址创建 10 个账户。
同一台设备每周可申领奖励不超过 5 次。
本章要求你设计一个限速器。在开始设计之前,我们首先来看看使用 API 速率限制器的好处:
防止拒绝服务(DoS)攻击造成的资源饥饿[1]。几乎所有大型科技公司发布的 API 都实施了某种形式的速率限制。例如,Twitter 将推文数量限制为每 3 小时 300 条[2]。Google docs APIs 有如下默认限制:每用户每 60 秒 300 个读取请求[3]。速率限制器通过阻止过量呼叫来防止有意或无意的 DoS 攻击。
降低成本。限制过多的请求意味着更少的服务器和分配更多的资源给高优先级的 API。速率限制对于使用付费第三方 API 的公司来说极其重要。例如,您需要为以下外部 API 的每次调用付费:检查信用、付款、检索健康记录等。限制通话次数对降低成本至关重要。
防止服务器过载。为了减少服务器负载,速率限制器用于过滤掉由机器人或用户不当行为引起的过量请求。
第一步——了解问题并确定设计范围
速率限制可以使用不同的算法来实现,每种算法都有其优缺点。面试官和候选人之间的互动有助于澄清我们试图建立的限速器的类型。
候选 : 我们要设计什么样的限速器?是客户端速率限制器还是服务器端 API 速率限制器?
采访者 :好问题。我们关注服务器端 API 速率限制器。
候选人 : 速率限制器是否基于 IP、用户 ID 或其他属性来限制 API 请求?
采访者 :限速器应该足够灵活,以支持不同的节流规则。
候选 : 系统的规模是多少?是为创业公司打造,还是为用户基数大的大公司打造?
面试官 :系统必须能够处理大量的请求。
候选 : 系统会在分布式环境下工作吗?
面试官 :是的。
候选 : 速率限制器是一个独立的服务还是应该在应用程序代码中实现?
采访者 :这是你的设计决定。
候选 : 我们需要通知被节流的用户吗?
面试官 :是的。
要求
以下是对系统要求的总结:
准确限制过分的要求。
低潜伏期。速率限制器不应该减慢 HTTP 响应时间。
尽量少用内存。
分布式限速。速率限制器可以在多个服务器或进程之间共享。
异常处理。当用户的请求被限制时,向用户显示明确的异常。
容错性高。如果速率限制器出现任何问题(例如,缓存服务器离线),不会影响整个系统。
第二步——提出高水平的设计并获得认同
让我们保持简单,使用基本的客户端和服务器模型进行通信。
限速器放哪里?
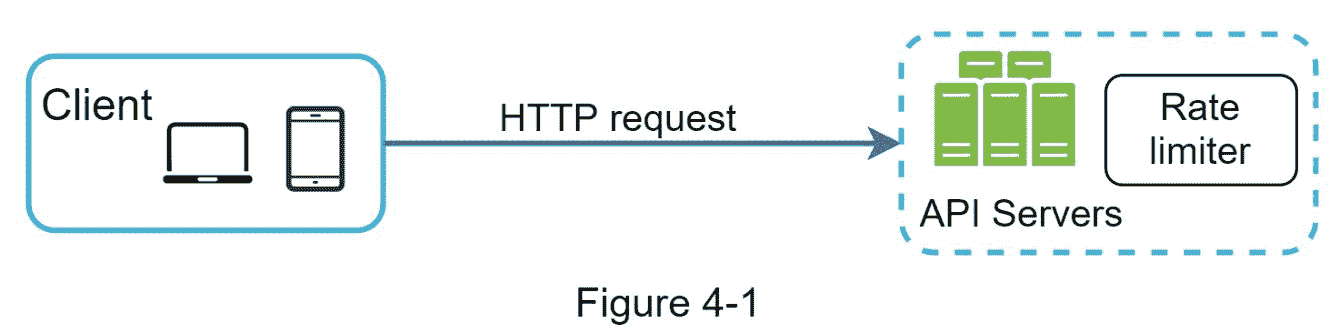
直观地说,你可以在客户端或服务器端实现速率限制器。
客户端实现。一般来说,客户端是一个不可靠的实施速率限制的地方,因为客户端请求很容易被恶意参与者伪造。此外,我们可能无法控制客户端的实现。
服务器端实现。图 4-1 显示了放置在服务器端的速率限制器。
除了客户端和服务器端的实现,还有另一种方法。我们没有在 API 服务器上设置速率限制器,而是创建了一个速率限制器中间件,来抑制对 API 的请求,如图 4-2 所示。
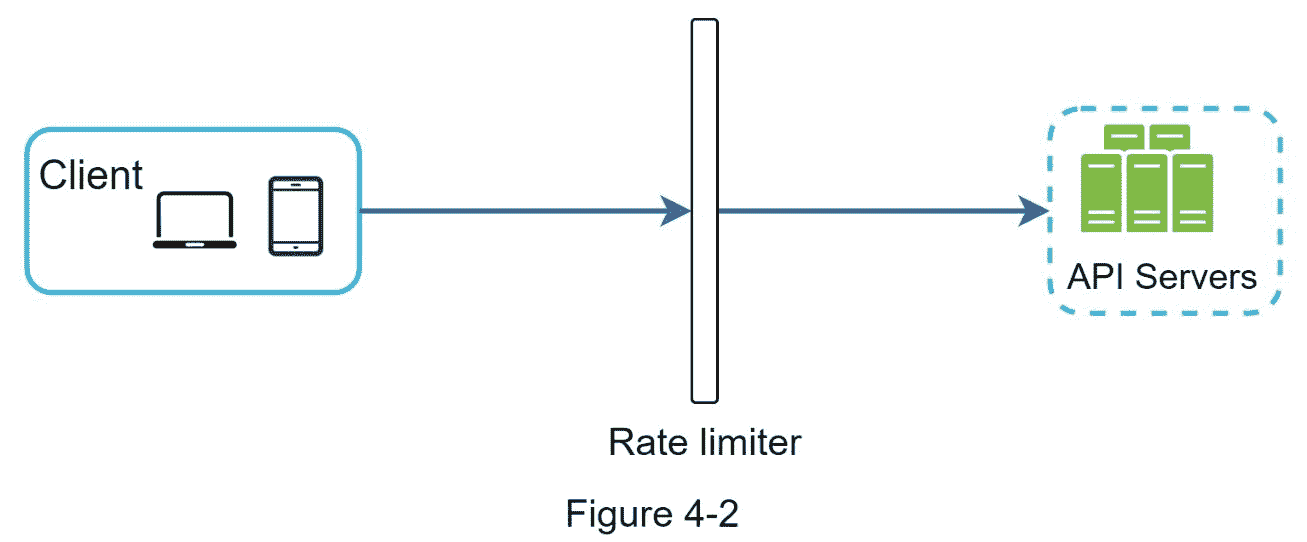
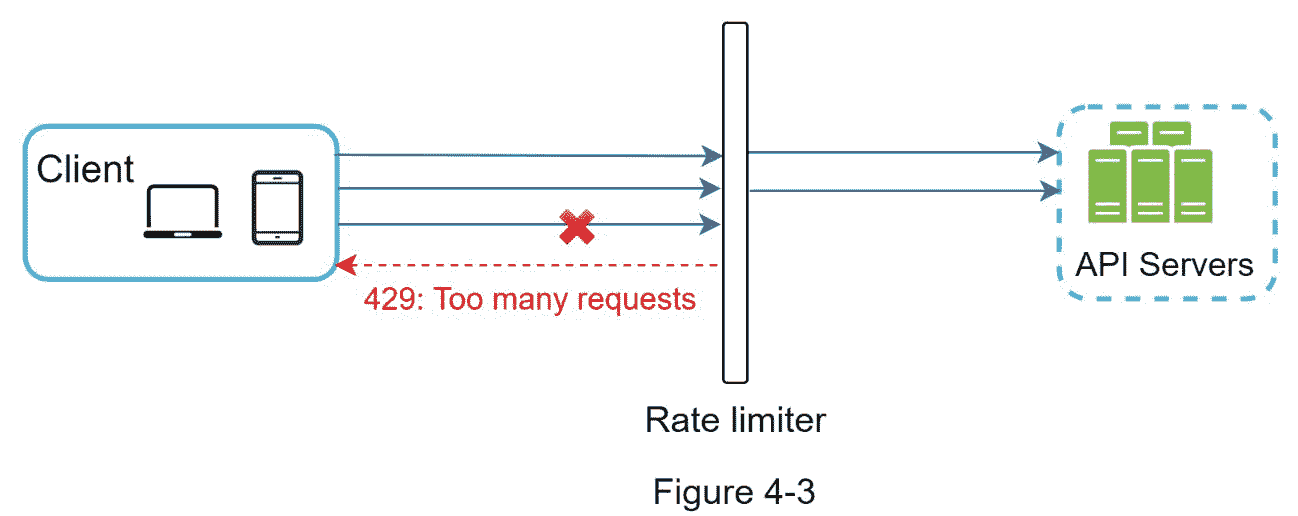
让我们用图 4-3 中的例子来说明速率限制在这个设计中是如何工作的。假设我们的 API 允许每秒 2 个请求,一个客户机在一秒钟内向服务器发送 3 个请求。前两个请求被路由到 API 服务器。然而,速率限制器中间件抑制了第三个请求,并返回一个 HTTP 状态代码 429。HTTP 429 响应状态代码表示用户发送了太多请求。
云微服务[4]已经变得非常流行,速率限制通常在一个名为 API gateway 的组件中实现。API gateway 是一种完全托管的服务,支持速率限制、SSL 终止、身份验证、IP 白名单、静态内容服务等。现在,我们只需要知道 API 网关是一个支持速率限制的中间件。
在设计速率限制器时,我们要问自己的一个重要问题是:应该在哪里实现速率限制器,在服务器端还是在网关中?没有绝对的答案。这取决于您公司当前的技术堆栈、工程资源、优先级、目标等。这里有几个通用的准则:
评估你目前的技术栈,比如编程语言、缓存服务等。确保您当前的编程语言能够有效地在服务器端实现速率限制。
确定适合您业务需求的速率限制算法。当你在服务器端实现一切时,你就完全控制了算法。但是,如果您使用第三方网关,您的选择可能会受到限制。
如果你已经使用了微服务架构,并且在设计中包含了 API 网关来执行认证、IP 白名单等。,您可以向 API 网关添加速率限制器。
自建费率 限制服务需要时间。如果您没有足够的工程资源来实现速率限制器,商业 API 网关是一个更好的选择。
限速算法
速率限制可以使用不同的算法来实现,每种算法都有明显的优缺点。尽管本章并不关注算法,但从高层次理解它们有助于选择合适的算法或算法组合来适应我们的用例。下面是流行算法的列表:
令牌桶
漏桶
固定窗口计数器
滑动窗口日志
推拉窗计数器
令牌桶算法
令牌桶算法广泛用于速率限制。简单易懂,互联网公司常用。Amazon [5]和 Stripe [6]都使用这种算法来抑制他们的 API 请求。
令牌桶算法工作如下:
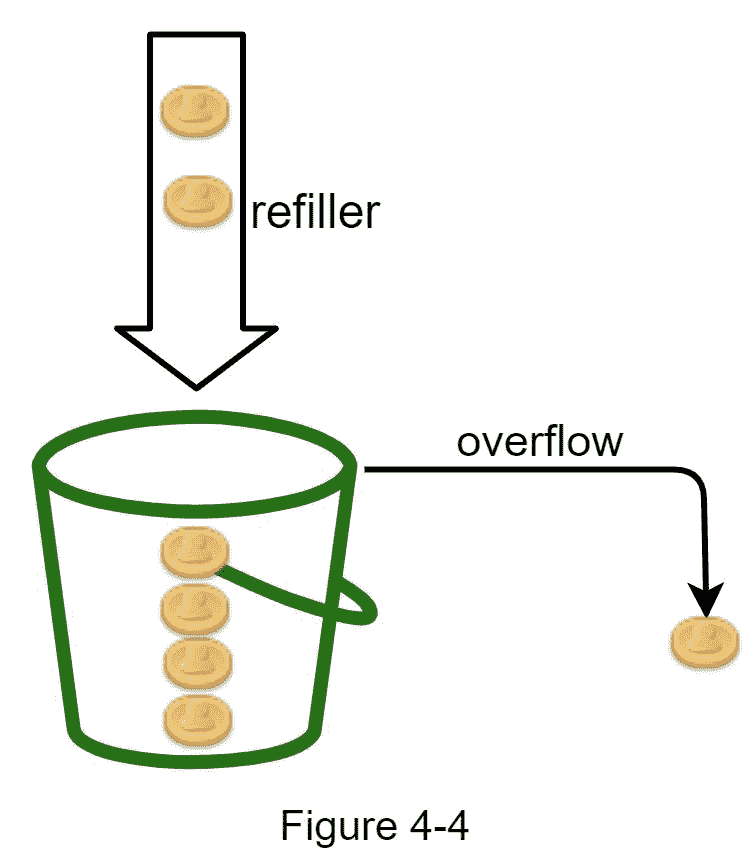
令牌桶是具有预定义容量的容器。令牌以预设的速率定期放入桶中。一旦桶满了,就不再添加令牌。如图 4-4 所示,令牌桶容量为 4。加油员每秒钟往桶里放 2 个代币。一旦桶满了,额外的代币就会溢出。
每个请求消耗一个令牌。当请求到达时,我们检查桶中是否有足够的令牌。图 4-5 解释了它是如何工作的。
如果有足够的令牌,我们为每个请求取出一个令牌,请求通过。
如果没有足够的令牌,请求被丢弃。
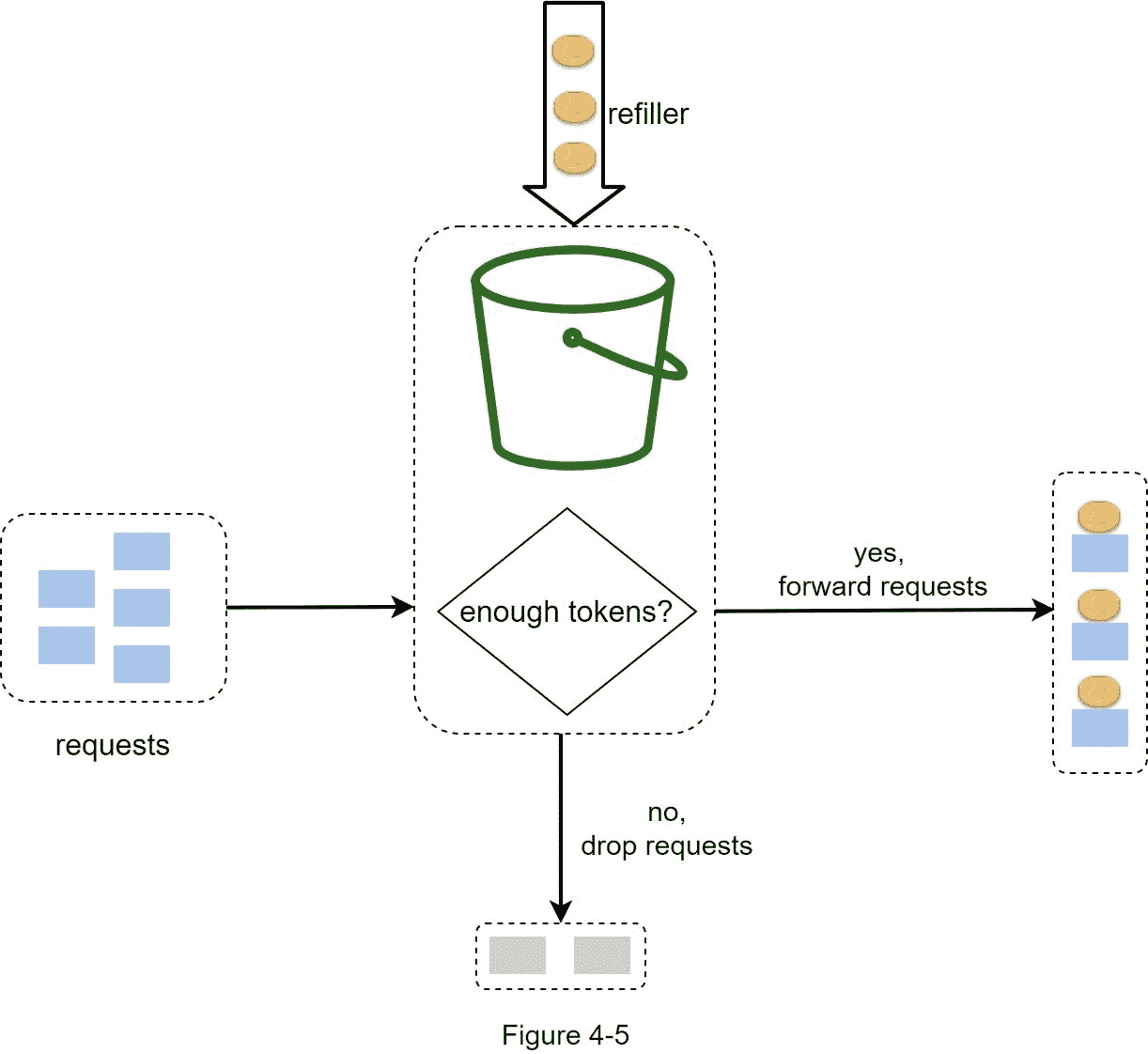
图 4-6 说明了代币消费、 、 和速率限制逻辑是如何工作的。在此示例中,令牌桶大小为 4,再填充速率为每 1 分钟 4 次。

令牌桶算法采用两个参数:
桶大小:桶中允许的最大令牌数
充值率:每秒钟投入桶中的代币数量
我们需要多少桶?这是不同的,它取决于限速规则。这里有几个例子。
对于不同的 API 端点,通常需要有不同的桶。例如,如果允许用户每秒发 1 篇帖子,每天添加 150 个朋友,每秒 5 篇帖子,则每个用户需要 3 个桶。
如果我们需要根据 IP 地址限制请求,每个 IP 地址都需要一个桶。
如果系统允许每秒最多 10,000 个请求,那么让所有请求共享一个全局桶是有意义的。
优点:
该算法易于实现。
记忆高效。
令牌桶允许短时间的流量爆发。只要还有令牌,请求就可以通过。
缺点:
算法中的两个参数是桶大小和令牌再填充率。然而,对它们进行适当的调优可能是一个挑战。
漏桶算法
泄漏桶算法类似于令牌桶,只是请求以固定速率处理。它通常用先进先出(FIFO)队列来实现。算法工作如下:
当请求到达时,系统检查队列是否已满。如果未满,请求将被添加到队列中。
否则,请求被放弃。
请求被从队列中取出并定期处理。
图 4-7 解释了算法的工作原理。
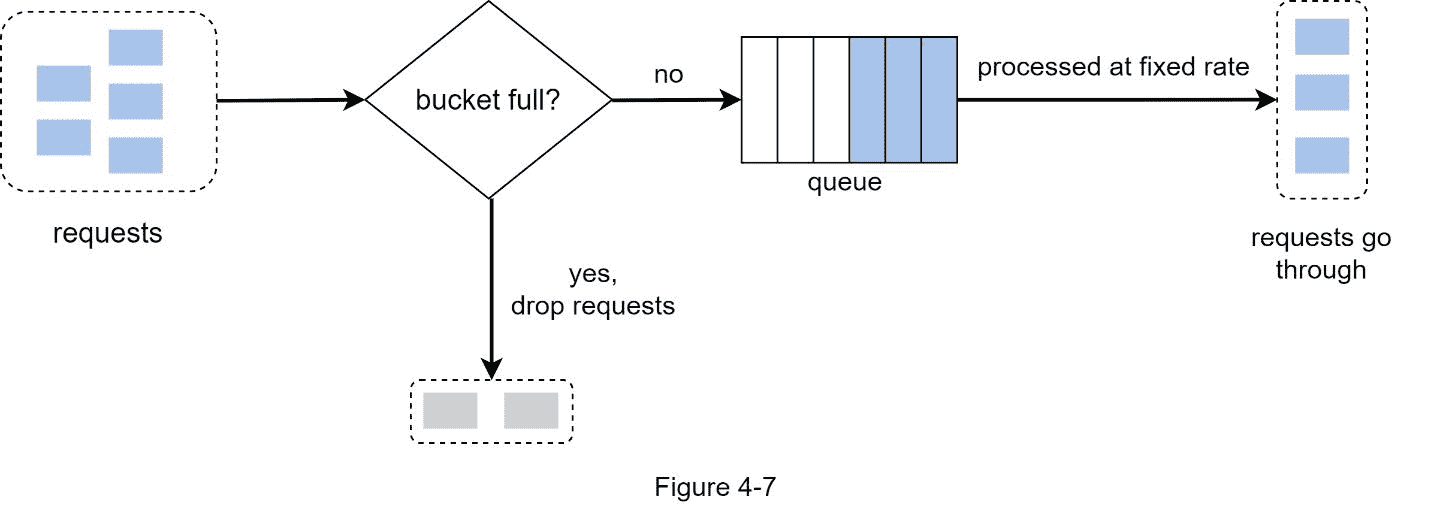
漏桶算法取以下两个参数:
桶大小:等于队列大小。该队列以固定的速率保存要处理的请求。
流出率:它定义了以固定的速率可以处理多少个请求,通常以秒为单位。
电子商务公司 Shopify 使用漏桶进行限速[7]。
优点:
给定有限队列大小的内存效率。
请求以固定速率处理,因此适用于需要稳定流出速率的用例。
缺点:
突发流量用旧请求填满队列,如果不及时处理,最近的请求将受到速率限制。
算法中有两个参数。正确地调整它们可能不容易。
固定窗口计数器算法
固定窗口计数器算法工作如下:
该算法将时间轴分为固定大小的时间窗口,并为每个窗口分配一个计数器。
每个请求都使计数器加 1。
一旦计数器达到预定义的阈值,新的请求就会被丢弃,直到新的时间窗口开始。
让我们用一个具体的例子来看看它是如何工作的。在图 4-8 中,时间单位是 1 秒,系统允许每秒最多 3 次请求。在每个第二个窗口中,如果收到 3 个以上的请求,多余的请求将被丢弃,如图 4-8 所示。
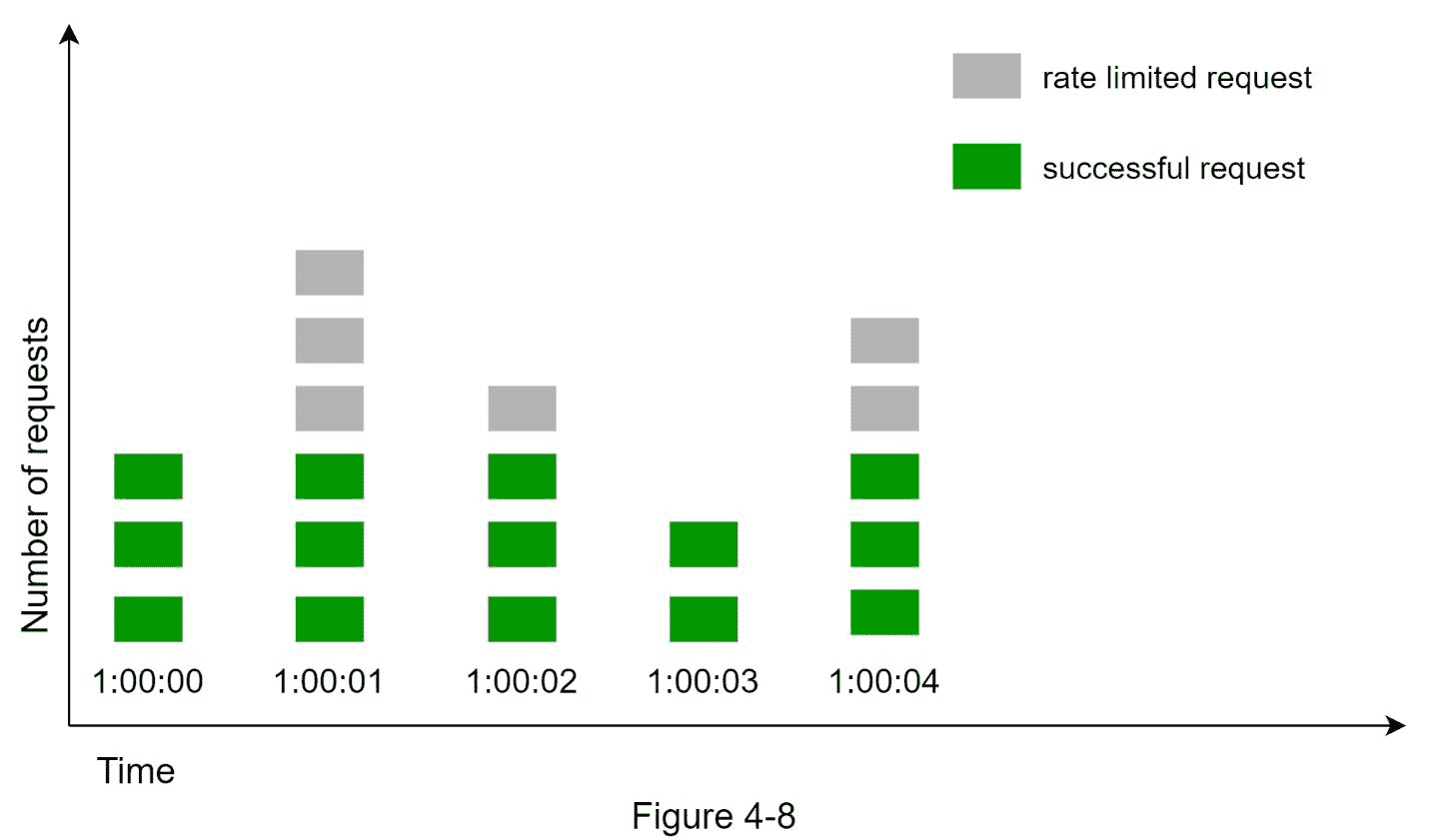
此算法的一个主要问题是,时间窗口边缘的流量突发可能会导致超过允许配额的请求通过。考虑以下情况:

在图 4-9 中,系统允许每分钟最多 5 个请求,可用配额在人性化的整数分钟重置。如图所示,在 2:00:00 和 2:01:00 之间有五个请求,在 2:01:00 和 2:02:00 之间还有五个请求。对于 2:00:30 到 2:01:30 之间的一分钟窗口,有 10 个请求通过。这是允许请求的两倍。
优点:
记忆高效。
通俗易懂。
在单位时间窗口结束时重置可用配额适合某些用例。
缺点:
窗口边缘的流量峰值可能会导致超过允许配额的请求通过。
滑动窗口日志算法
如前所述,固定窗口计数器算法有一个主要问题:它允许更多的请求在窗口边缘通过。滑动窗口日志算法解决了这个问题。其工作原理如下:
该算法跟踪请求时间戳。时间戳数据通常保存在缓存中,例如 Redis 的排序集[8]。
当一个新的请求进来时,删除所有过时的时间戳。过时的时间戳被定义为比当前时间窗口的开始时间更早的时间戳。
将新请求的时间戳添加到日志中。
如果日志大小等于或小于允许的计数,则接受请求。否则,它被拒绝。
我们用一个如图 4-10 所示的例子来解释这个算法。
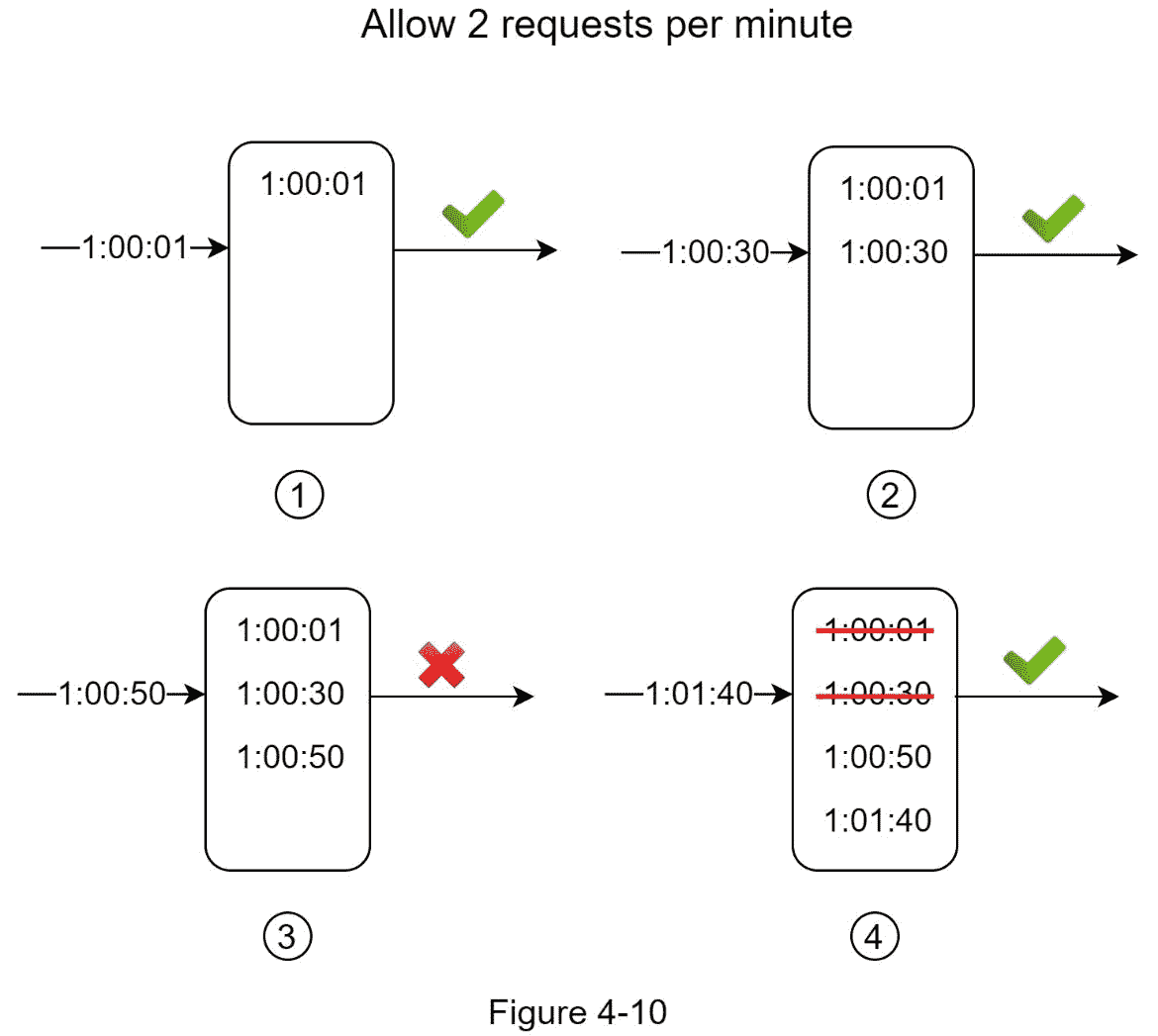
在本例中,速率限制器允许每分钟 2 个请求。通常,Linux 时间戳存储在日志中。然而,为了更好的可读性,在我们的例子中使用了人类可读的时间表示。
新请求在 1:00:01 到达时,日志为空。因此,请求被允许。
一个新请求在 1:00:30 到达,时间戳 1:00:30 被插入到日志中。插入后,日志大小为 2,不超过允许的计数。因此,请求被允许。
一个新请求在 1:00:50 到达,时间戳被插入到日志中。插入后,日志大小为 3,大于允许的大小 2。因此,即使时间戳保留在日志中,该请求也会被拒绝。
一个新的请求到达 1:01:40。范围[1:00:40, 1:01:40]内的请求在最新的时间范围内,但是在 1:00:40 之前发送的请求已经过时。从日志中删除了两个过期的时间戳:1:00:01 和 1:00:30。删除操作之后,日志大小变为 2;因此,请求被接受。
优点:
该算法实现的速率限制非常精确。在任何滚动窗口中,请求都不会超过速率限制。
缺点:
该算法消耗大量内存,因为即使请求被拒绝,其时间戳仍可能存储在内存中。
滑动窗口计数器算法
滑动窗口计数器算法是一种结合了固定窗口计数器和滑动窗口日志的混合方法。该算法可以通过两种不同的方法来实现。我们将在本节中解释一个实现,并在本节的最后为另一个实现提供参考。图 4-11 说明了这种算法是如何工作的。
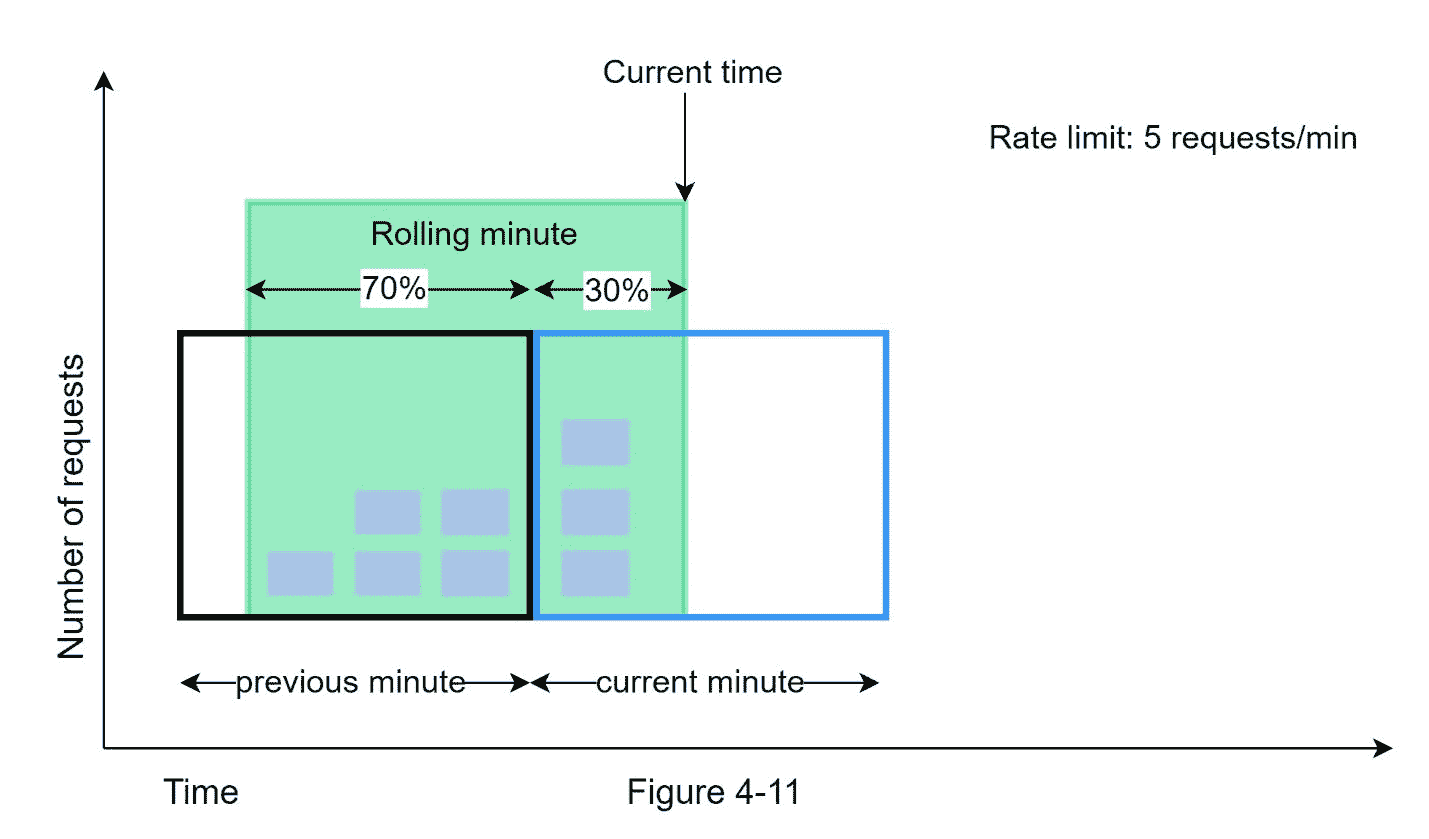
假设速率限制器每分钟最多允许 7 个请求,前一分钟有 5 个请求,当前分钟有 3 个请求。对于在当前分钟到达 30%位置的新请求,使用以下公式计算滚动窗口中的请求数:
请求当前窗口 + 请求前一窗口 * 滚动窗口与前一窗口的重叠百分比
利用这个公式,我们得到 3 + 5 * 0.7% = 6.5 的请求。根据使用情况,该数字可以向上或向下取整。在我们的例子中,它被向下舍入到 6。
由于速率限制器允许每分钟最多 7 个请求,当前请求可以通过。但是,在再收到一个请求后,将达到限制。
由于篇幅限制,我们在这里不讨论其他实现。感兴趣的读者应该参考参考资料[9]。这个算法并不完美。它有利有弊。
优点
它平滑流量峰值,因为速率是基于前一窗口的平均速率。
记忆高效。
缺点
只对不那么严格的回望窗有效。这是实际速率的近似值,因为它假设前一个窗口中的请求是均匀分布的。然而,这个问题可能没有看起来那么糟糕。根据 Cloudflare [10]所做的实验,在 4 亿个请求中,只有 0.003%的请求被错误地允许或速率受限。
高层建筑
速率限制算法的基本思想很简单。在高层,我们需要一个计数器来跟踪从同一个用户、IP 地址等发出了多少请求。如果计数器大于限制值,则不允许请求。
我们应该把柜台放在哪里?由于磁盘访问缓慢,使用数据库不是一个好主意。选择内存缓存是因为它速度快,并且支持基于时间的过期策略。例如,Redis [11]是实现利率限制的一个流行选项。它是一个内存存储,提供两个命令:INCR 和过期。
INCR:存储的计数器加 1。
到期:设置计数器超时。如果超时,计数器将自动删除。
图 4-12 显示了速率限制的高级架构,其工作原理如下:
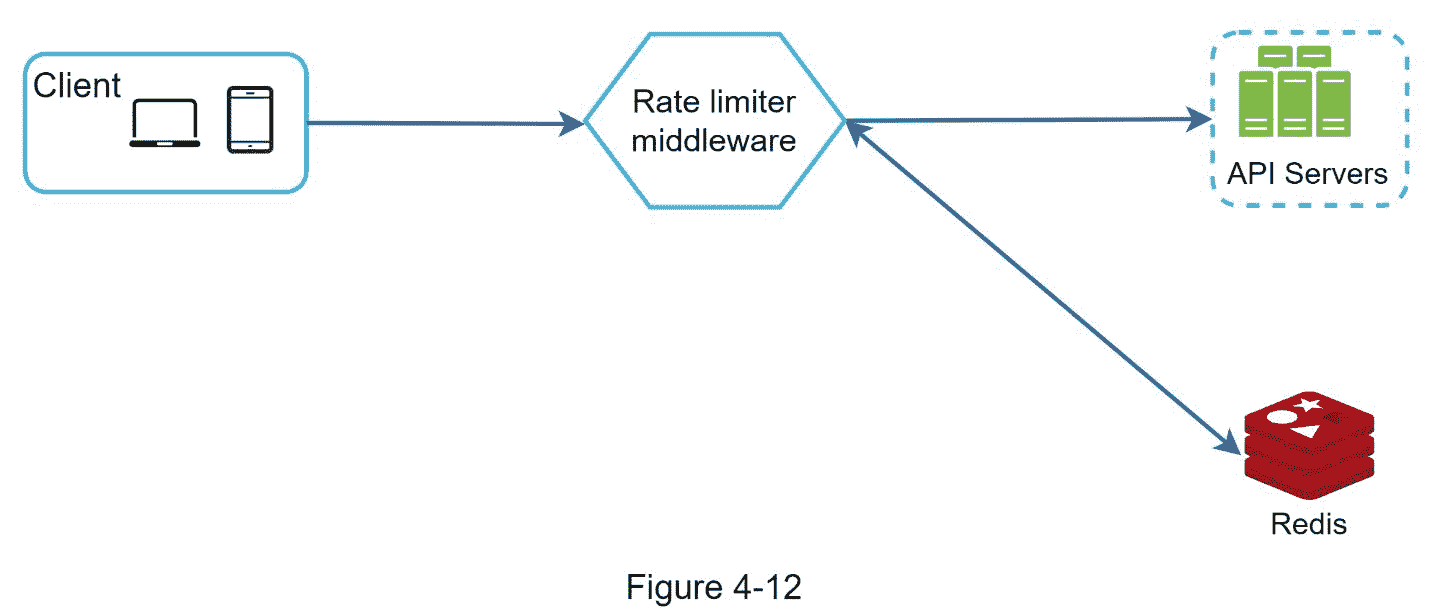
客户端向限速中间件发送请求。
限速中间件从 Redis 中相应的桶中取出计数器,检查是否达到限额。
如果达到限制,请求被拒绝。
如果没有达到限制,请求被发送到 API 服务器。同时,系统递增计数器并将其保存回 Redis。
第三步——设计深潜
图 4-12 中的高层设计没有回答以下问题:
限速规则是如何创建的?规则存储在哪里?
如何处理速率受限的请求?
在本节中,我们将首先回答有关速率限制规则的问题,然后讨论处理速率限制请求的策略。最后,我们将讨论分布式环境中的速率限制、详细设计、性能优化和监控。
限速规则
Lyft 开源了他们的限速组件[12]。我们将查看组件内部,并查看一些速率限制规则的示例:
域 : 消息传递
描述符 :
–按键-:-消息 _ 类型
价值 :营销
利率 _ 限额 :
单位 : 日
请求 _ 每单位 : 5
在上述示例中,系统被配置为每天最多允许 5 条营销消息。下面是另一个例子:
域名 : 认证
描述符 :
–键-:-auth _ type
值 :登录
利率 _ 限额 :
单位 :分钟
请求 _ 每单位 : 5
该规则显示,客户端不允许在 1 分钟内登录 5 次以上。规则通常写在配置文件中并保存在磁盘上。
超过速率限制
如果请求是速率受限的,API 会向客户端返回一个 HTTP 响应代码 429(请求太多)。根据用例的不同,我们可能会将速率受限的请求排入队列,以便稍后处理。例如,如果一些订单由于系统过载而受到费率限制,我们可能会将这些订单留待以后处理。
限速器标题
客户端如何知道它是否被节流?客户端如何知道在被节流之前允许的剩余请求的数量?答案就在 HTTP 响应头中。速率限制器向客户端返回以下 HTTP 报头:
X-Ratelimit-Remaining:窗口内允许请求的剩余数量。
X-Ratelimit-Limit: 表示客户在每个时间窗口内可以拨打多少个电话。
X-Ratelimit-Retry-After:等待的秒数,直到可以再次发出请求而不被限制。
当用户发送过多请求时,向客户端返回 429 过多请求错误和X-RateLimit-Retry-After报头。
详细设计
图 4-13 展示了系统的详细设计。
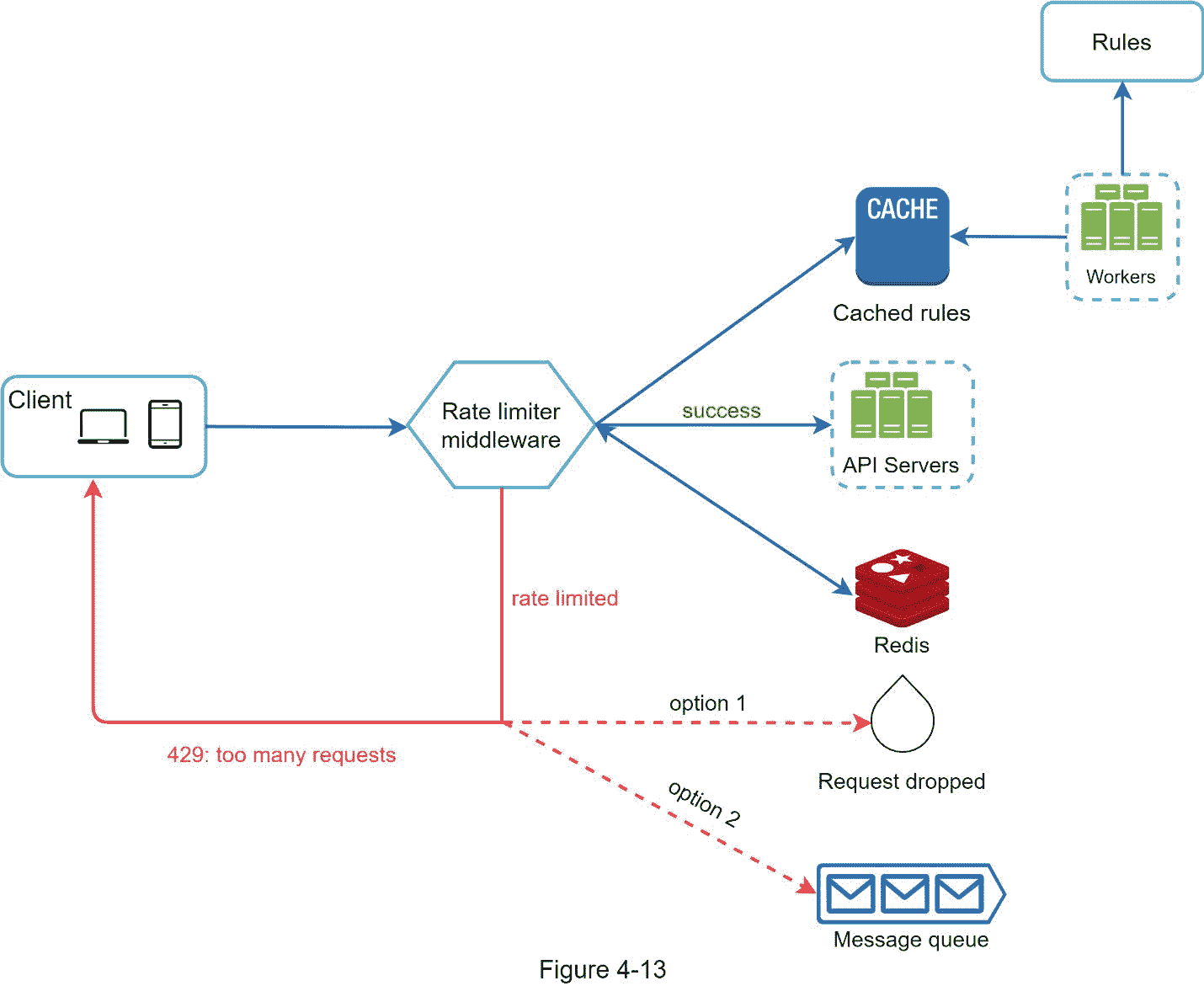
规则存储在磁盘上。工作人员经常从磁盘中提取规则,并将它们存储在缓存中。
当客户端向服务器发送请求时,请求首先被发送到限速器中间件。
限速器中间件从缓存中加载规则。它从 Redis 缓存中获取计数器和上次请求时间戳。基于该响应,速率限制器决定:
如果请求没有速率限制,则转发给 API 服务器。
如果请求是速率受限的,速率限制器向客户端返回 429 过多请求错误。与此同时,请求要么被丢弃,要么被转发到队列。
分布式环境中的限速器
构建一个在单一服务器环境中工作的速率限制器并不困难。然而,扩展系统以支持多个服务器和并发线程是另一回事。有两个挑战:
比赛条件
同步发布
比赛状态
如前所述,速率限制器在高层工作如下:
从 Redis 中读取 计数器 的值。
检查 ( 计数器+1)是否超过阈值。
如果不是,Redis 中的计数器值加 1。
如图 4-14 所示,竞争条件可能发生在高度并发的环境中。

假设 Redis 中的 计数器 的值为 3。如果两个请求同时读取 计数器 的值,在它们中的任何一个写回该值之前,每个请求都将把 计数器 加 1,并写回该值,而不检查另一个线程。两个请求(线程)都认为它们拥有正确的 计数器 值 4。然而,正确的 计数器的 值应该是 5。
锁是解决竞争状况的最明显的解决方案。但是,锁会显著降低系统速度。有两种策略常用来解决这个问题:Lua 脚本[13]和 Redis 中的有序集数据结构[8]。对这些策略感兴趣的读者,可以参考相应的参考资料[8] [13]。
同步发布
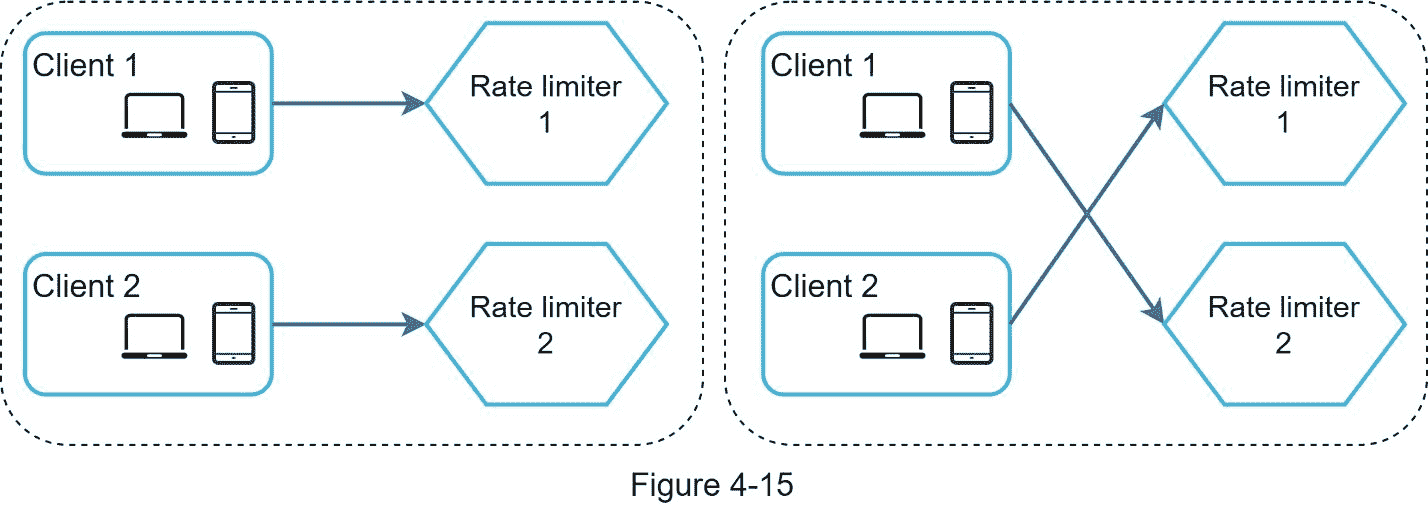
同步是分布式环境中需要考虑的另一个重要因素。为了支持数百万用户,一台限速服务器可能不足以处理流量。当使用多个速率限制器服务器时,需要同步。例如,在图 4-15 的左侧,客户端 1 向速率限制器 1 发送请求,客户端 2 向速率限制器 2 发送请求。由于 web 层是无状态的,客户端可以向不同的速率限制器发送请求,如图 4-15 右侧所示。如果没有同步发生,速率限制器 1 不包含关于客户端 2 的任何数据。因此,限速器不能正常工作。
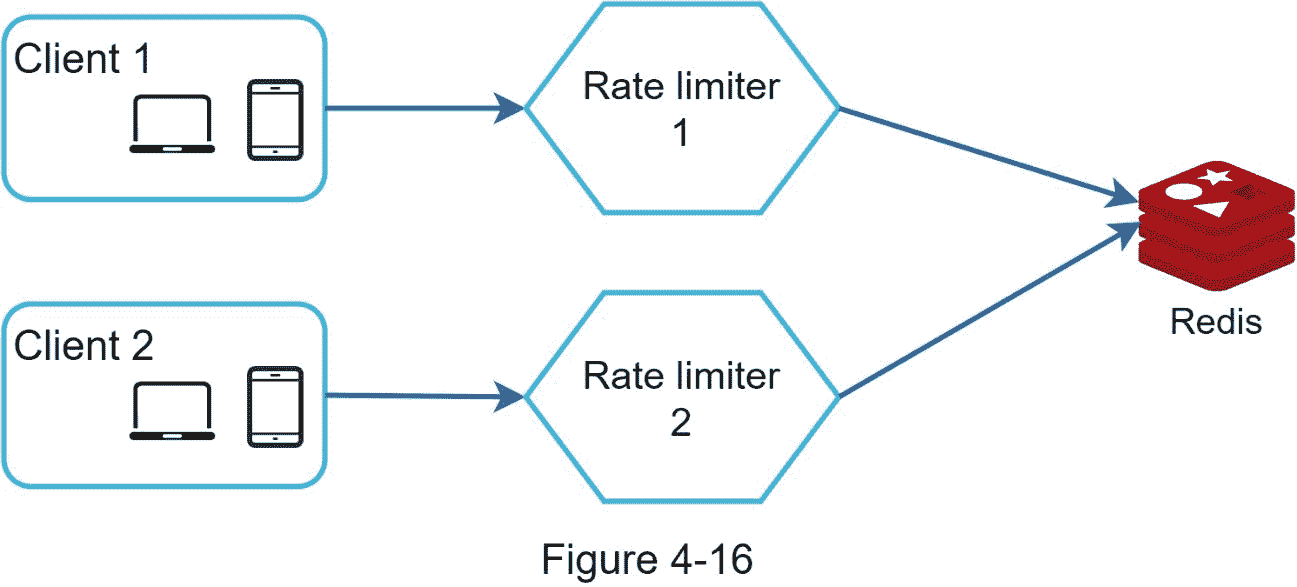
一种可能的解决方案是使用粘性会话,允许客户端向同一个速率限制器发送流量。这种解决方案是不可取的,因为它既不可伸缩也不灵活。更好的方法是使用像 Redis 这样的集中式数据存储。设计如图 4-16 所示。
性能优化
性能优化是系统设计面试中的常见话题。我们将从两个方面进行改进。
首先,多数据中心设置对于速率限制器至关重要,因为对于远离数据中心的用户来说,延迟很高。大多数云服务提供商在世界各地建立了许多边缘服务器。例如,截至 20 20 年 5 月 20 日,Cloudflare 拥有 194 台地理位置分散的边缘服务器[14]。流量被自动路由到最近的边缘服务器,以减少延迟。
第二,用最终的一致性模型同步数据。如果您不清楚最终的一致性模型,请参考“第六章:设计键值存储”中的“一致性”一节
监控
实施限速器后,收集分析数据以检查限速器是否有效非常重要。首先,我们要确保:
限速算法有效。
限速规则有效。
例如,如果速率限制规则太严格,许多有效请求会被丢弃。在这种情况下,我们希望稍微放宽一些规则。在另一个例子中,我们注意到当流量突然增加时,如闪购,我们的限速器变得无效。在这种情况下,我们可以替换算法来支持突发流量。令牌桶很适合这里。
第四步——总结
在本章中,我们讨论了不同的速率限制算法及其优缺点。讨论的算法包括:
令牌桶
漏桶
固定窗口
滑动窗口日志
推拉窗计数器
然后,我们讨论了系统架构、分布式环境中的速率限制器、性能优化和监控。与任何系统设计面试问题类似,如果时间允许,您还可以提及其他话题:
硬 vs 软限速。
硬:请求数量不能超过阈值。
软:请求可以在短时间内超过阈值。
分级限速。在本章中,我们只讨论了应用层(HTTP:第 7 层)的速率限制。有可能在其他层应用速率限制。例如,您可以使用 Iptables [15] (IP:第 3 层)通过 IP 地址应用速率限制。注:开放系统互连模型(OSI 模型)有 7 层[16]:第 1 层:物理层,第 2 层:数据链路层,第 3 层:网络层,第 4 层:传输层,第 5 层:会话层,第 6 层:表示层,第 7 层:应用层。
避免被费率限制。用最佳实践设计您的客户端:
使用客户端缓存避免频繁的 API 调用。
了解限制,不要在短时间内发送太多请求。
包含捕捉异常或错误的代码,以便您的客户端能够从容地从异常中恢复。
添加足够的回退时间以重试逻辑。
祝贺你走到这一步!现在给自己一个鼓励。干得好!
参考资料
[1] Rate-limiting strategies and techniques: https://cloud.google.com/solutions/rate-limiting-strategies-techniques
[2] Twitter rate limits: https://developer.twitter.com/en/docs/basics/rate-limits
[3] Google docs usage limits: https://developers.google.com/docs/api/limits
[4] IBM microservices: https://www.ibm.com/cloud/learn/microservices
[5] Throttle API requests for better throughput:
https://docs.aws.amazon.com/apigateway/latest/developerguide/api-gateway-request-throttling.html
[6] Stripe rate limiters: https://stripe.com/blog/rate-limiters
[7] Shopify REST Admin API rate limits: https://help.shopify.com/en/api/reference/rest-admin-api-rate-limits
[8] Better Rate Limiting With Redis Sorted Sets: https://engineering.classdojo.com/blog/2015/02/06/rolling-rate-limiter/
[9] System Design — Rate limiter and Data modelling: https://medium.com/@saisandeepmopuri/system-design-rate-limiter-and-data-modelling-9304b0d18250
[10] How we built rate limiting capable of scaling to millions of domains: https://blog.cloudflare.com/counting-things-a-lot-of-different-things/
[11] Redis website: https://redis.io/
[12] Lyft rate limiting: https://github.com/lyft/ratelimit
[13] Scaling your API with rate limiters: https://gist.github.com/ptarjan/e38f45f2dfe601419ca3af937fff574d#request-rate-limiter
[14] What is edge computing: https://www.cloudflare.com/learning/serverless/glossary/what-is-edge-computing/
[15] Rate Limit Requests with Iptables: https://blog.programster.org/rate-limit-requests-with-iptables
[16] OSI model: https://en.wikipedia.org/wiki/O
五、设计一致哈希
为了实现水平扩展,在服务器之间高效、均匀地分配请求/数据非常重要。一致哈希是实现这一目标的常用技术。但首先,让我们深入研究一下这个问题。
老调重弹问题
如果你有 n 个缓存服务器,平衡负载的一个常用方法是使用下面的哈希方法:
server index = hash(key)% N,其中 N 是服务器池的大小。
让我们用一个例子来说明它是如何工作的。如表 5-1 所示,我们有 4 台服务器和 8 个带哈希的字符串键。
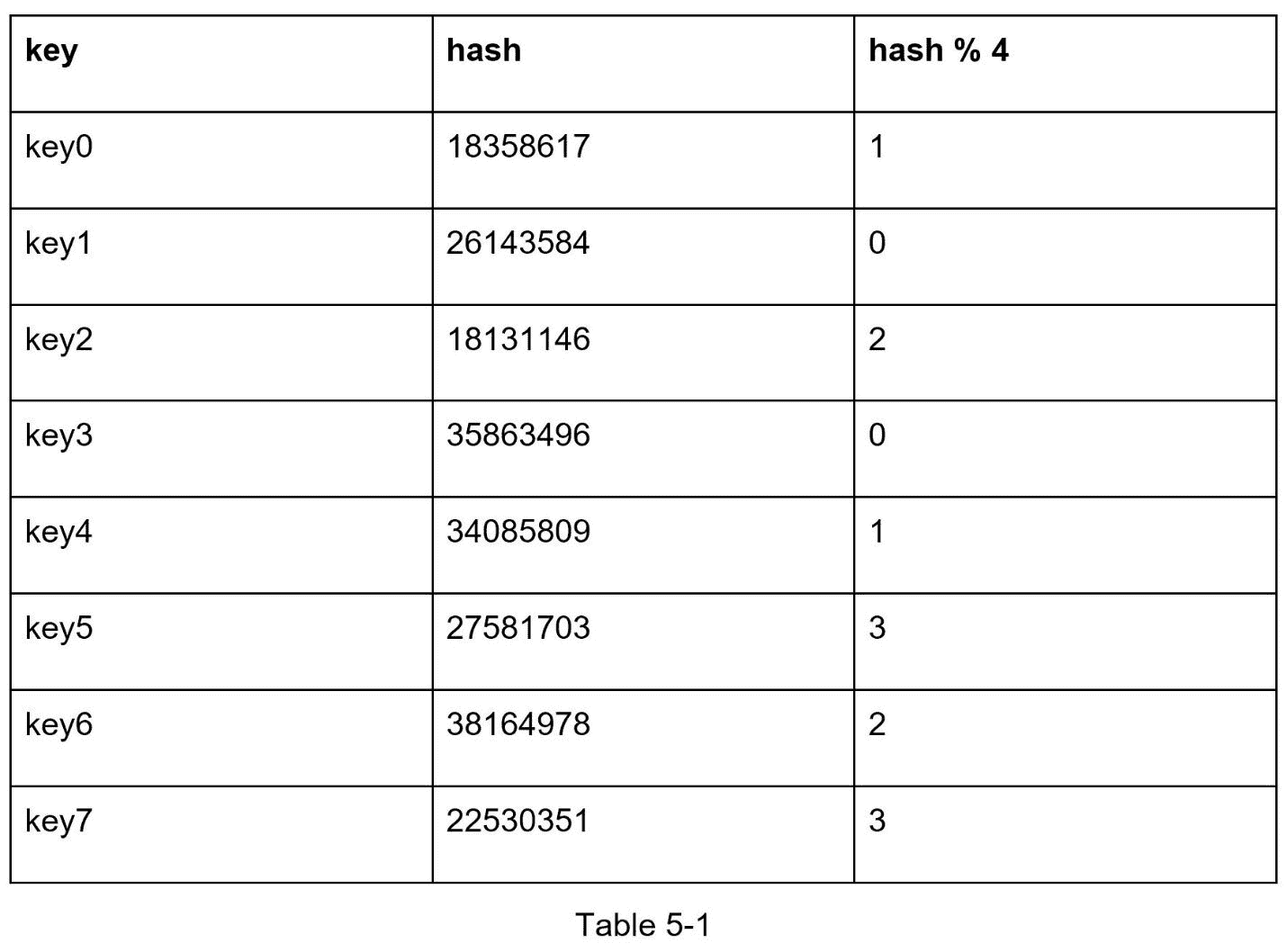
为了获取存储密钥的服务器,我们执行模块化操作 f(key) % 4 。例如, hash(key0) % 4 = 1 表示客户端必须联系服务器 1 来获取缓存的数据。图 5-1 显示了基于表 5-1 的键的分布。

当服务器池的大小固定且数据分布均匀时,这种方法非常有效。然而,当添加新的服务器或者移除现有的服务器时,问题 出现 。例如,如果服务器 1 脱机,服务器池的大小将变为 3。 使用相同的哈希函数,我们得到一个键的相同哈希值。但是应用模运算给了我们不同的服务器索引,因为服务器的数量减少了 1。 我们应用 hash % 3 : 得到如表 5-2 所示的结果
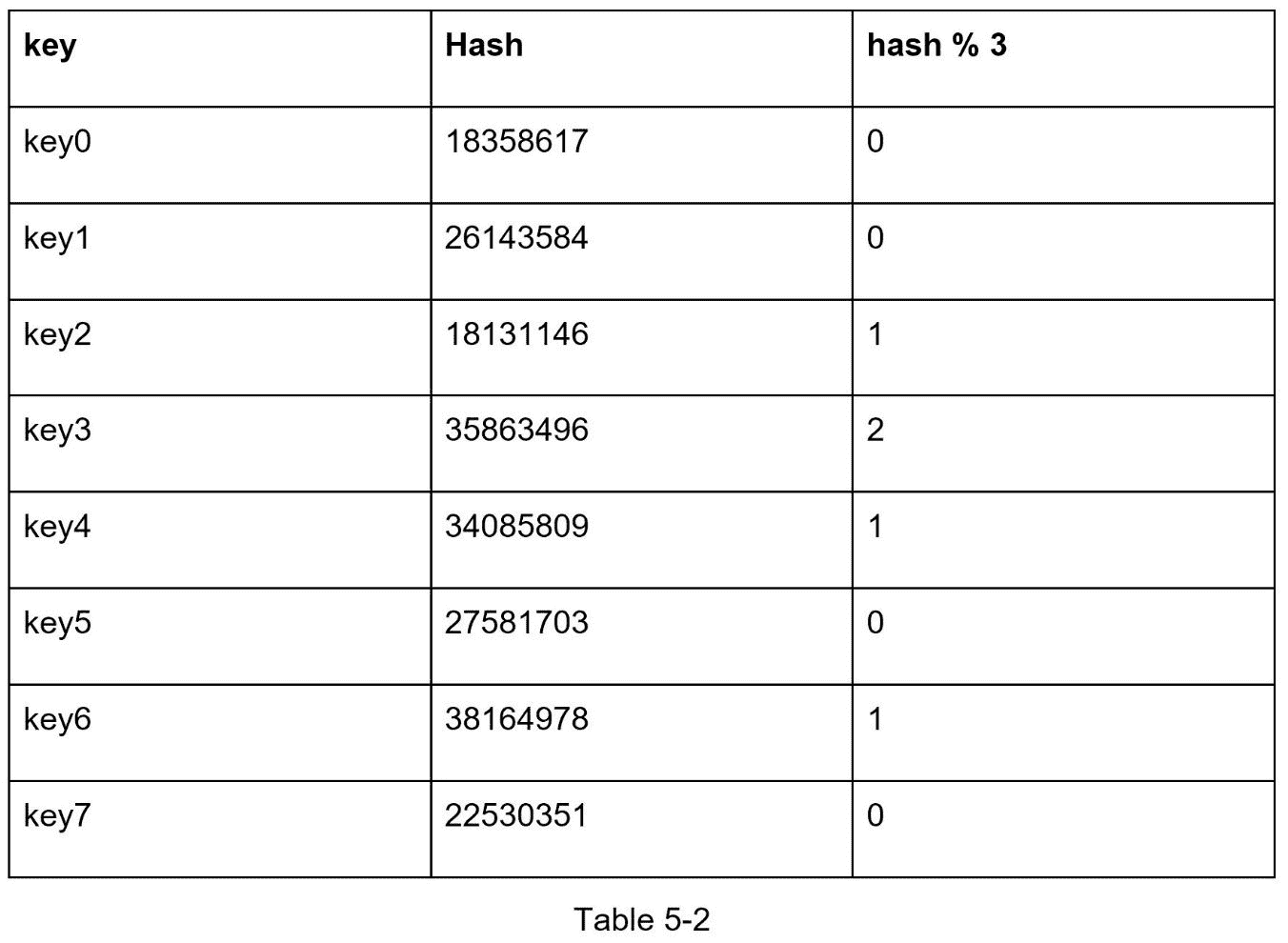
图 5-2 显示了基于表 5-2 的新的密钥分布。
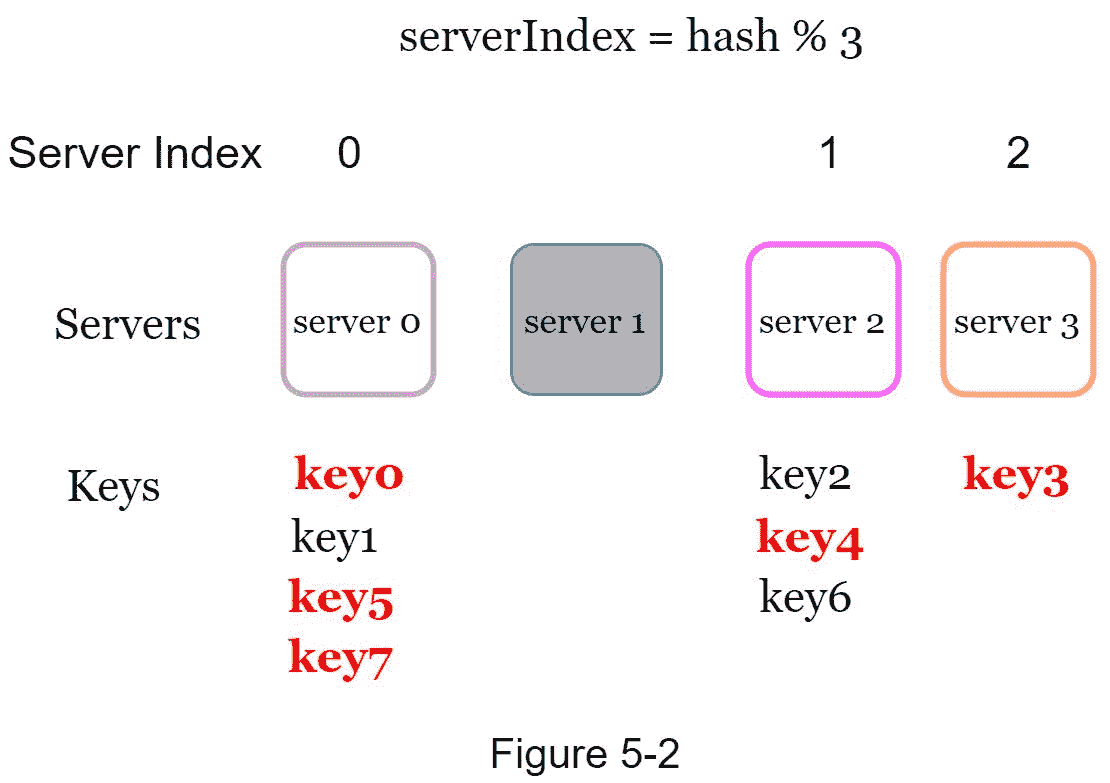
如图 5-2 所示,大部分的键都是重新分配的,而不仅仅是原来存储在离线服务器(服务器 1)中的那些。 这意味着当服务器 1 离线时,大多数缓存客户端将连接到错误的服务器来获取数据。这导致了高速缓存未命中的风暴。一致哈希是缓解这一问题的有效技术。
一致哈希
引自维基百科:“一致哈希是一种特殊的哈希,当哈希表重新调整大小并使用一致哈希时,平均只有 k/n 个键需要重新映射,其中 k 是键的数量,n 是槽的数量。相反,在大多数传统哈希表中,数组槽数量的变化会导致几乎所有的键被重新映射[1]”。
哈希空间和哈希环
现在我们了解了一致性哈希的定义,让我们看看它是如何工作的。假设 SHA-1 作为哈希函数 f, 哈希函数的输出 范围为 : x0, x1, x2, x3, …, xn 。在密码学中,SHA-1 的哈希空间从 0 到 2¹⁶⁰ - 1。这意味着 x0 对应于 0, xn 对应于2¹⁶⁰ - 1,中间的所有其他哈希值落在 0 和 2¹⁶⁰-1 之间。图 5-3 显示了哈希空间。

通过连接两端,我们得到一个哈希环如图 图 5-4 :
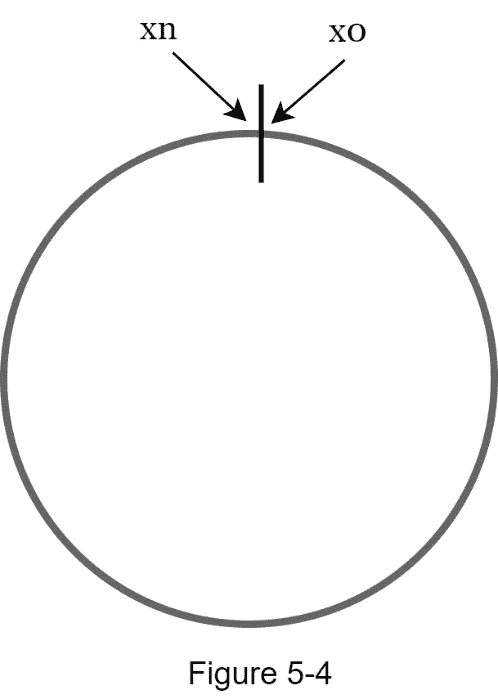
哈希服务器
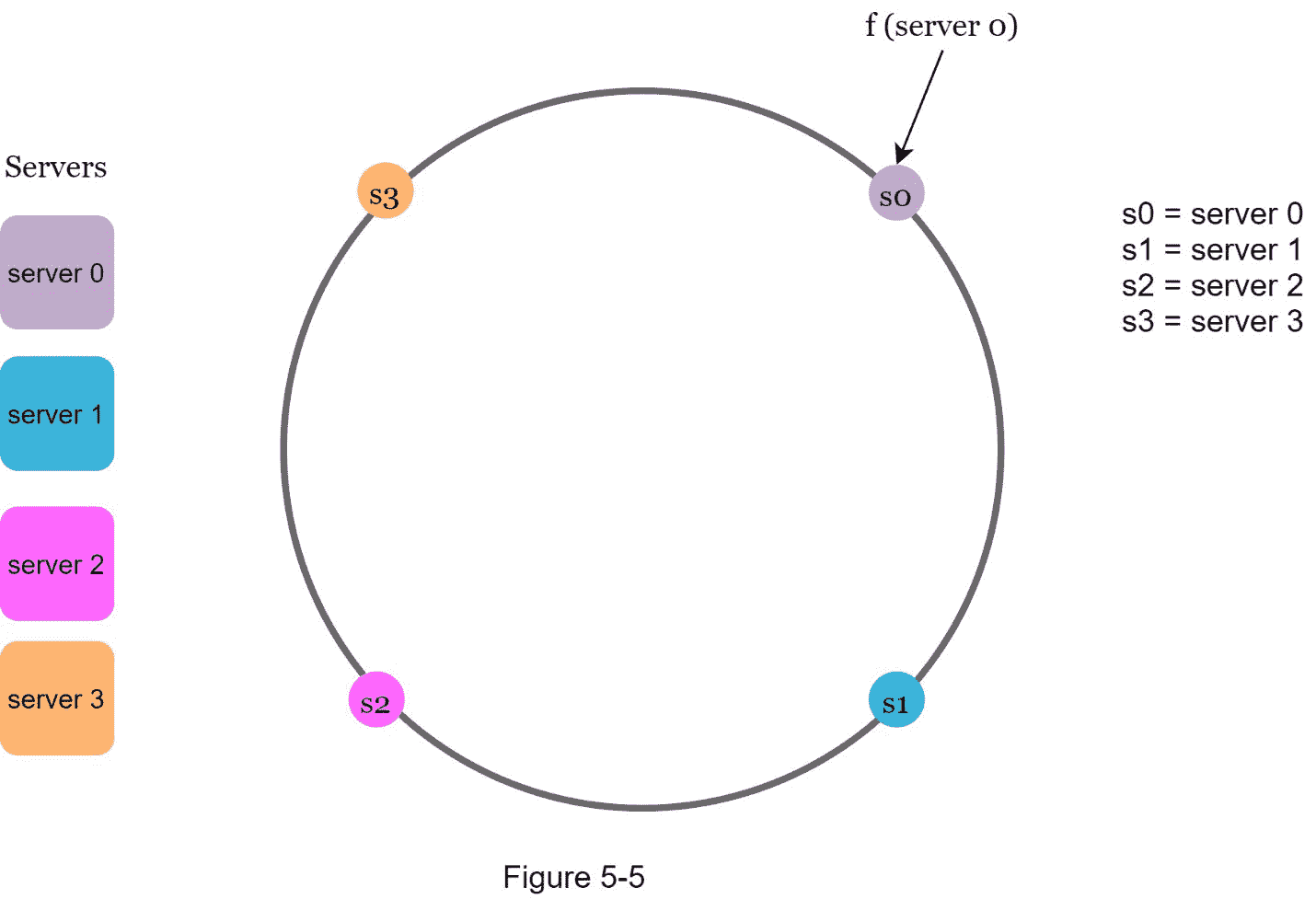
使用相同的哈希函数 f ,我们基于服务器 IP 或名称将服务器映射到环上。图 5-5 显示了 4 个服务器被映射到哈希环上。
哈希键
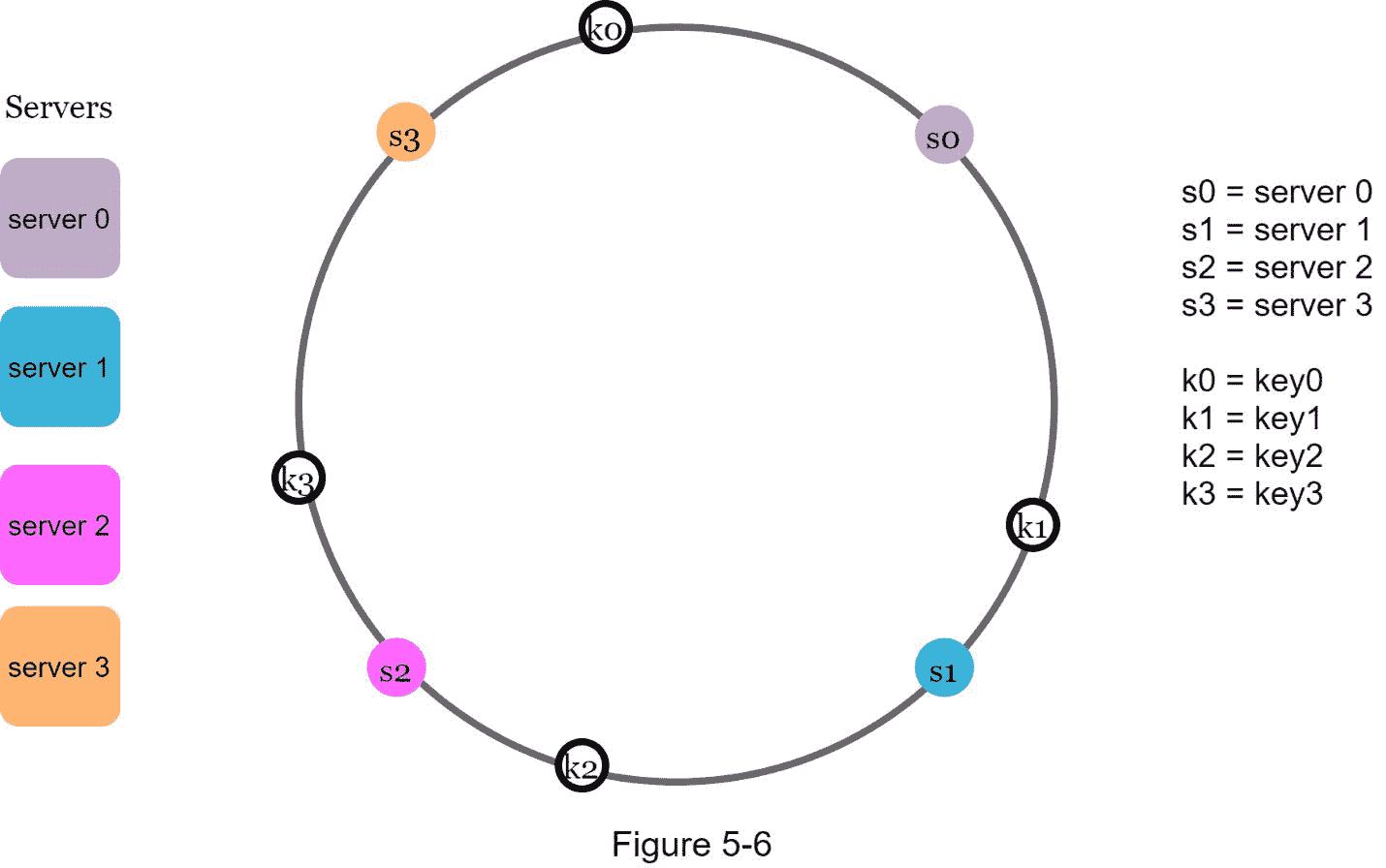
值得一提的是,这里使用的哈希函数与“重哈希问题”中的不同,没有模运算。如图 5-6 所示,4 个缓存键(key0、key1、key1和 key3)被哈希到哈希环上
服务器查找
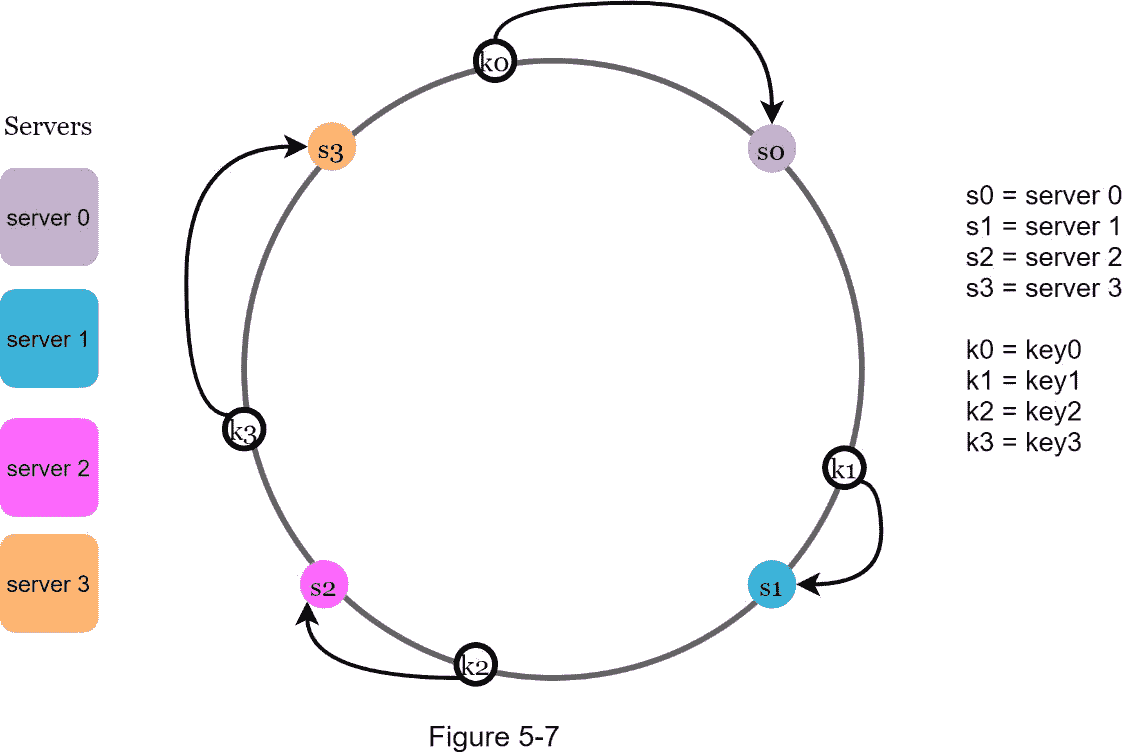
为了确定一个密钥存储在哪个服务器上,我们从环上的密钥位置开始顺时针旋转,直到找到一个服务器。 图 5-7 解释了这个过程。顺时针转动 , 键 0 存储在 服务器 0 上;key1存储在 服务器 1 上;key1存储在 服务器 2 和key1存储在 服务器 3 。
添加服务器
使用上述逻辑,添加新的服务器将只需要重新分发一小部分密钥。
在图 5-8 中,增加了一个新的 服务器 4 后,只有key0需要重新分配。k1、k1、 和k1保持在相同的服务器上。让我们仔细看看其中的逻辑。在添加 服务器 4 之前,key0存储在 服务器 0 上。现在,key0将被存储在服务器 4 上,因为服务器 4 是它从key0在环上的位置顺时针方向遇到的第一个服务器。其他密钥不会基于一致的哈希算法进行重新分配。
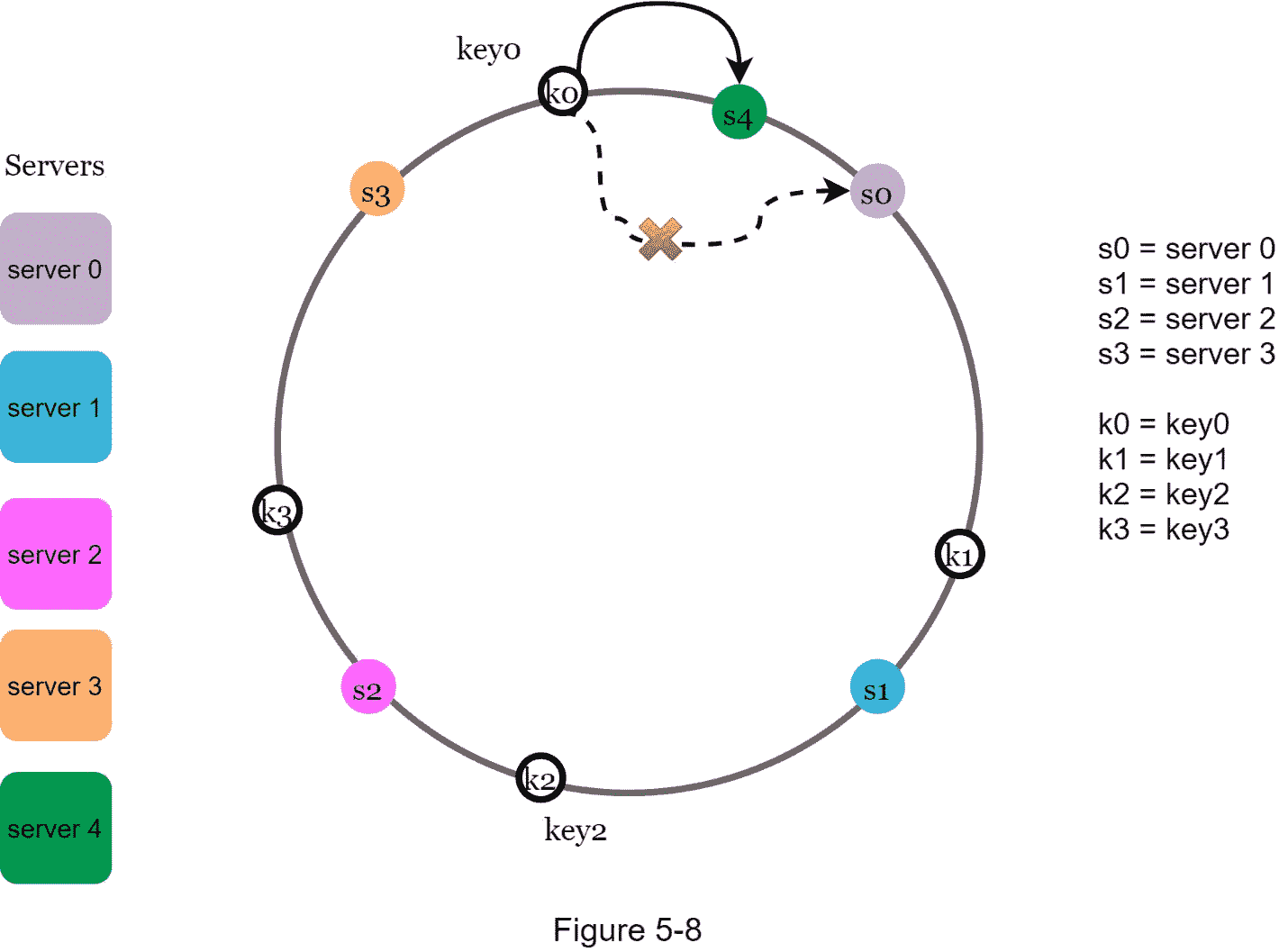
移除一个服务器
当服务器被移除时,只有一小部分密钥需要用一致的哈希法重新分配。在图 5-9 中,当 服务器 1 被移除后,只有key1必须重新映射到 服务器 2 。其余的键不受影响。
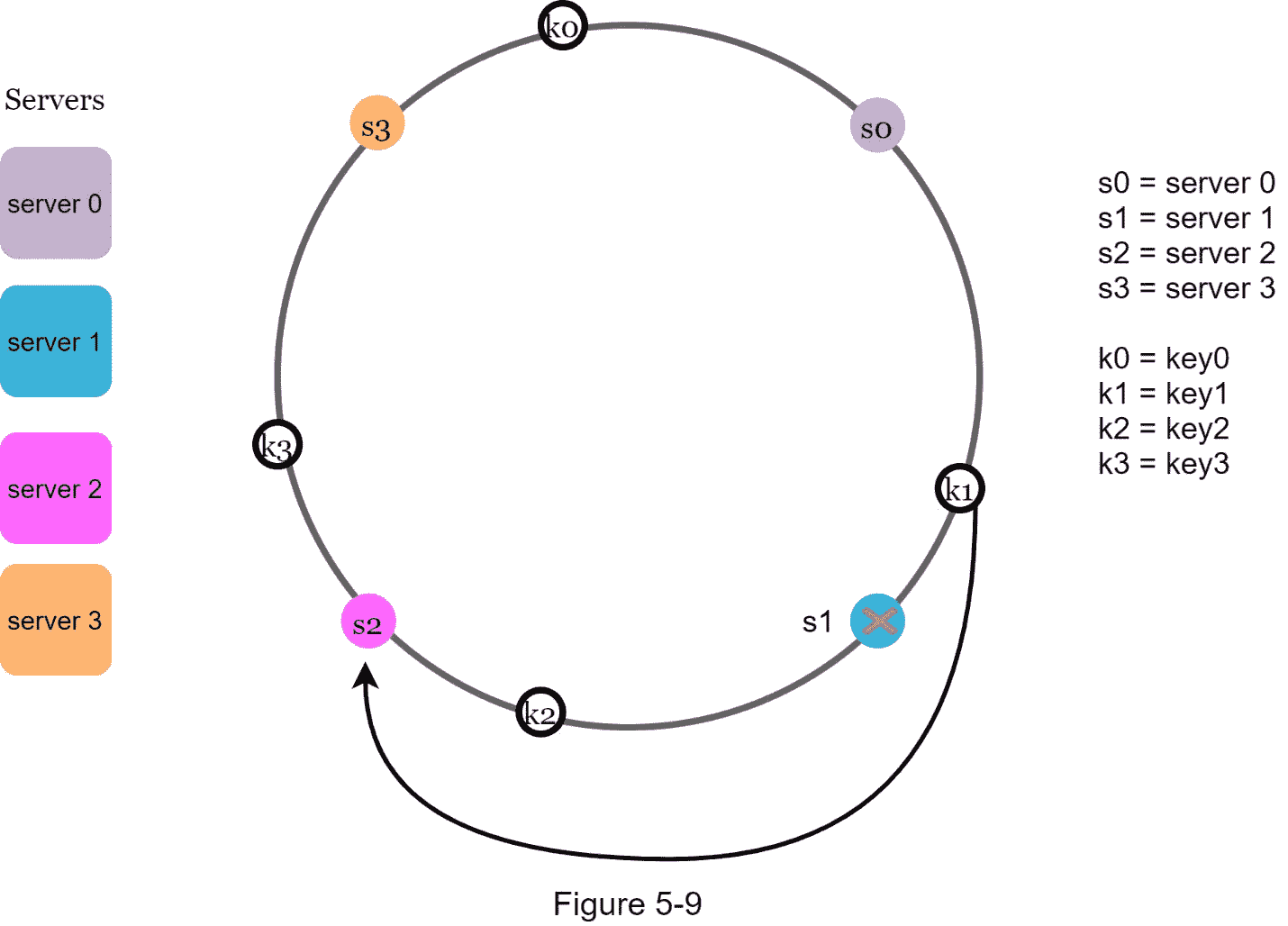
两个问题的基本处理方法
一致性哈希算法是由 Karger 等人在麻省理工学院提出的[1]。基本步骤是:
使用均匀分布的哈希函数将服务器和密钥映射到环上。
要找出一个密钥映射到哪个服务器,从密钥位置开始顺时针方向走,直到找到环上的第一个服务器。
这种方法发现了两个问题。首先,考虑到可以添加或移除服务器,不可能为环上的所有服务器保持相同大小的分区。分区是相邻服务器之间的哈希空间。分配给每个服务器的环上的分区的大小可能非常小或相当大。在图 5-10 中,如果去掉s1,s1的 分区(用双向箭头突出显示)是s1和s1的 分区的两倍。
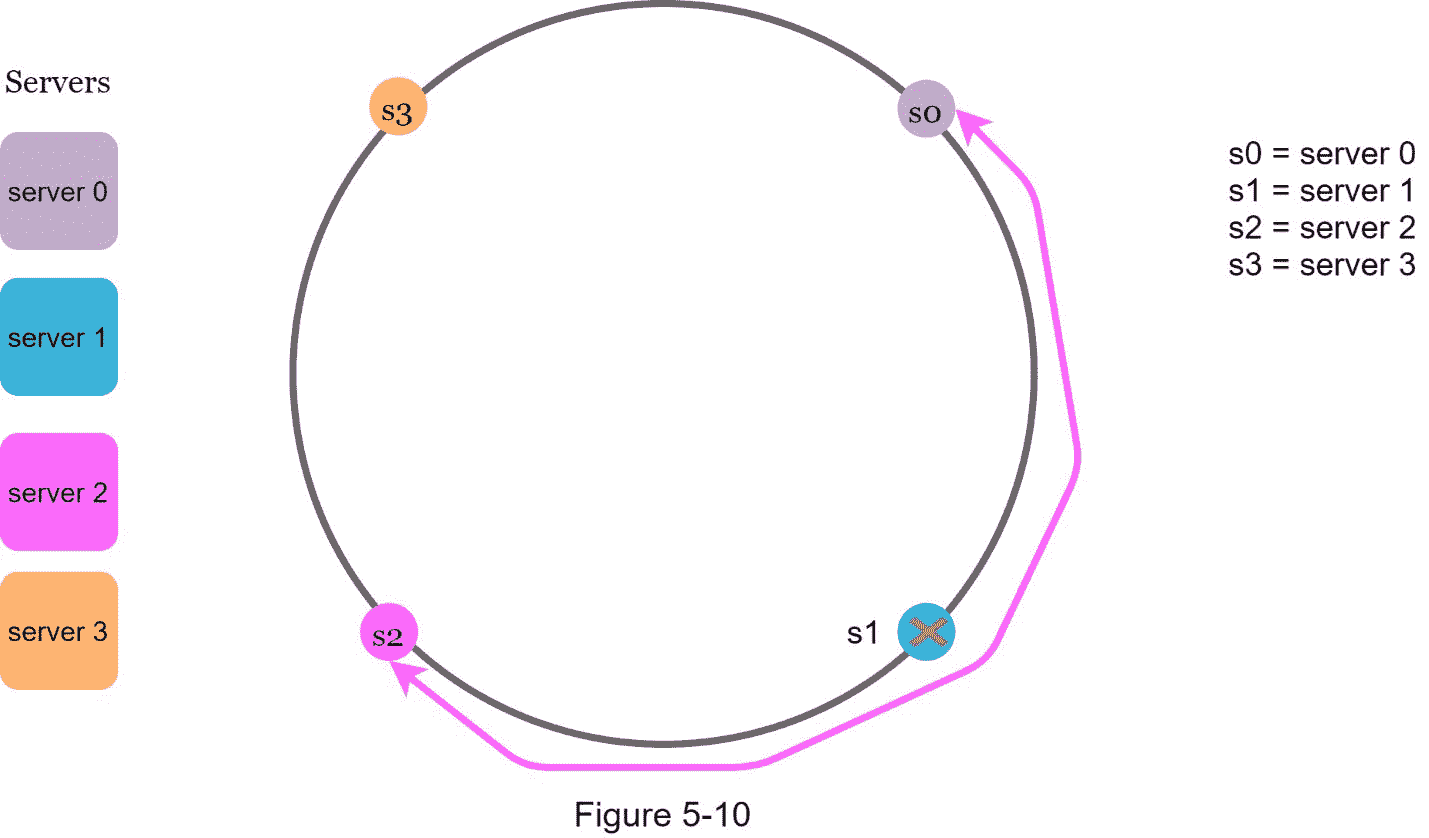
第二,环上可能有不均匀的密钥分布。例如,如果服务器被映射到图 5-11 中列出的位置,那么大部分密钥都存储在 服务器 2 上。但是 服务器 1 服务器 3 没有数据。
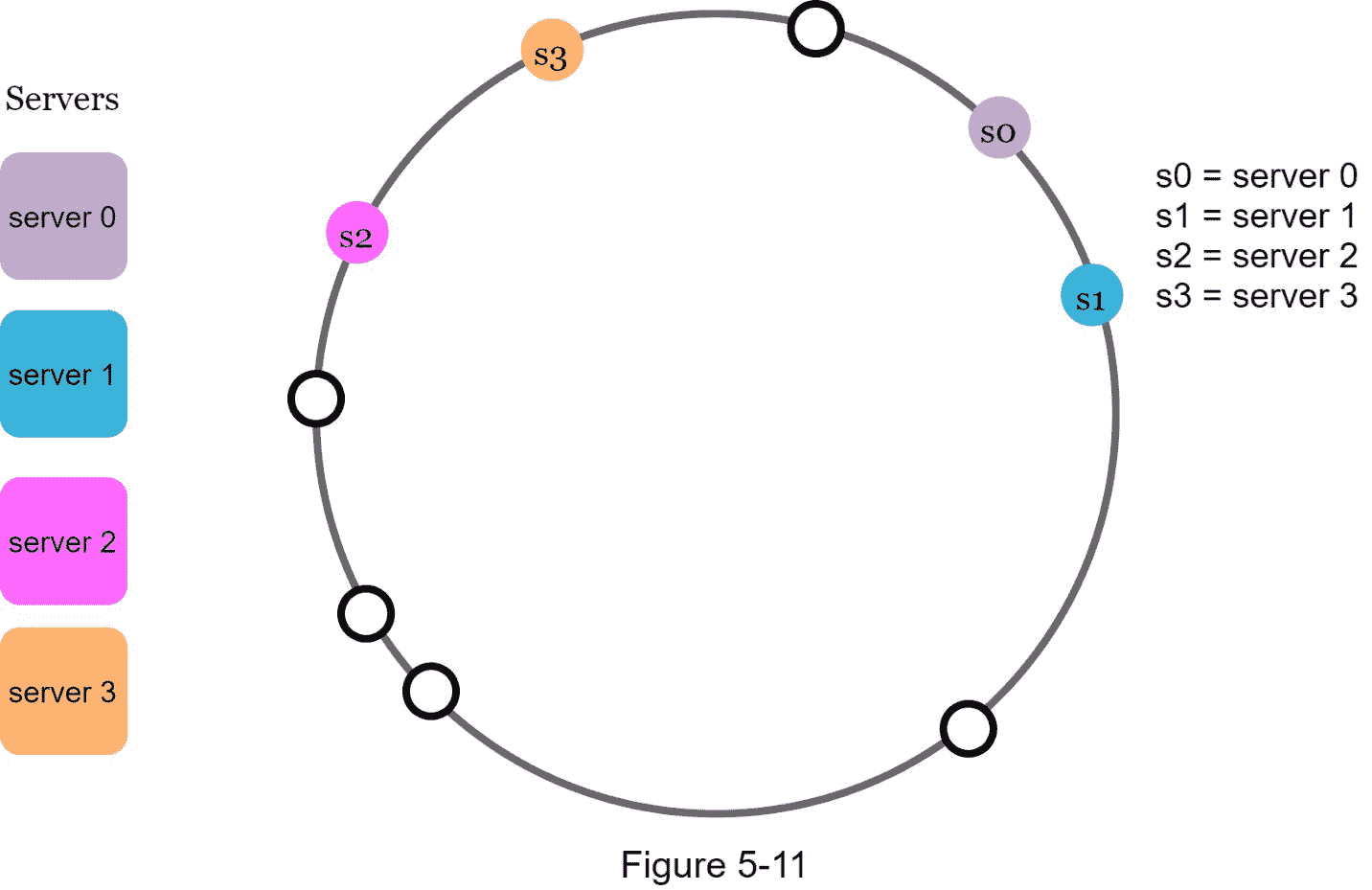
一种叫做虚拟节点或副本的技术被用来解决这些问题。
虚拟节点
虚拟节点是指真实节点,每个服务器由环上的多个虚拟节点表示。在图 5-12 中, 服务器 0 和 服务器 1 都有 3 个虚拟节点。3 是任意选择的;而在现实世界的系统中,虚拟节点的数量要大得多。我们没有用 s0 ,而是用 s0_0,s0_1 ,s0_2 来代表环上的 服务器 0 。同样, s1_0,s1_1 ,和 s1_2 代表环上的服务器 1。对于虚拟节点,每台服务器负责多个分区。标签为s0的分区(边缘)由服务器 0 管理。另一方面,标签为 s1 的分区由 服务器 1 管理。
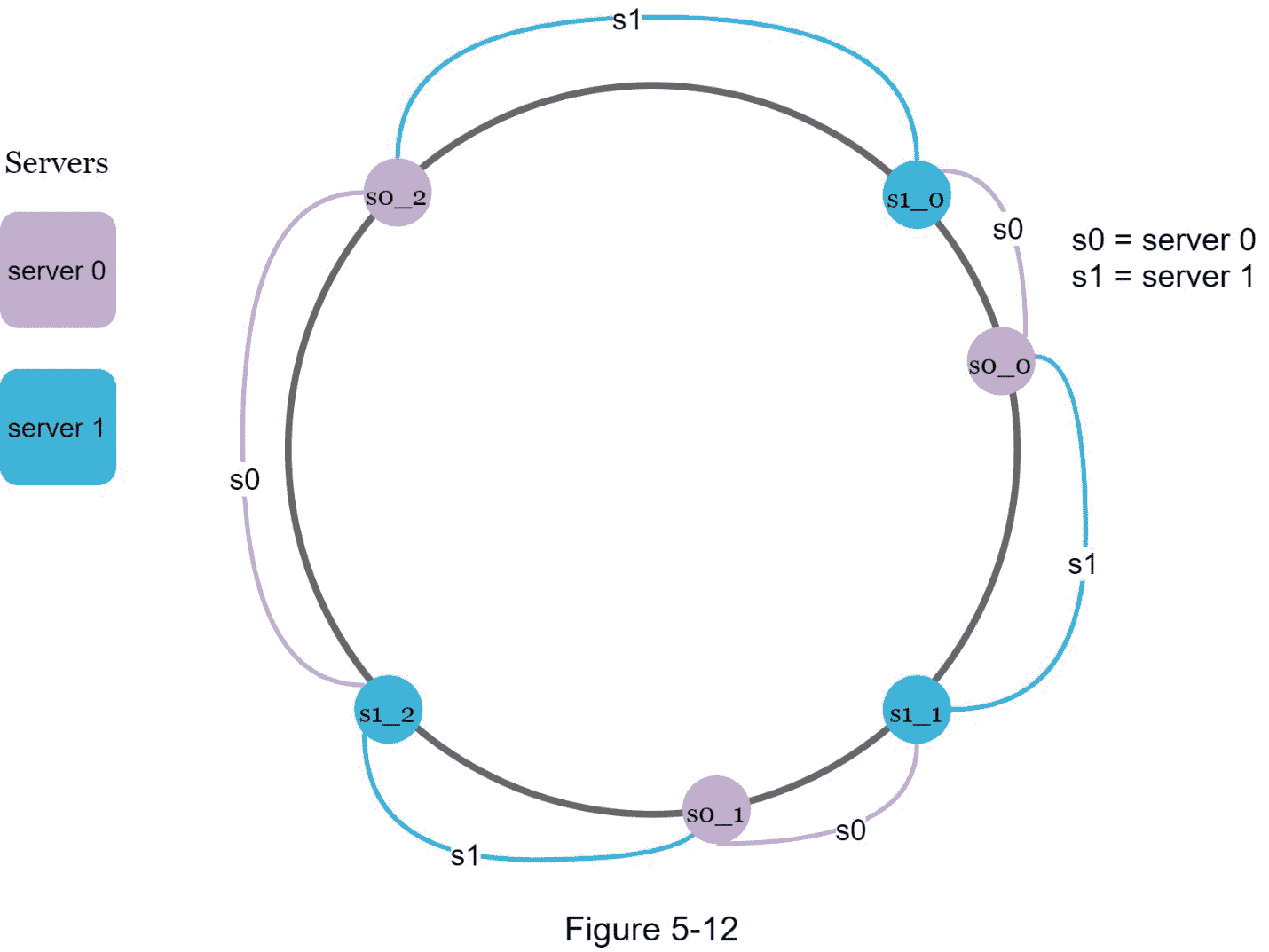
为了找到一个密钥存储在哪个服务器上,我们从密钥的位置开始顺时针方向,找到环上遇到的第一个虚拟节点。在图 5-13 中,为了找出k0存储在哪个服务器上,我们从k0的位置顺时针方向,找到虚拟节点 s1_1 ,它指的是 服务器 1 。

随着虚拟节点数量的增加,键的分布变得更加均衡。这是因为虚拟节点越多,标准偏差就越小,从而导致平衡的数据分布。标准差衡量数据是如何分布的。在线研究 [2]进行的实验结果显示,对于一个或两百个虚拟节点,标准偏差在平均值的 5% (200 个虚拟节点)和 10% (100 个虚拟节点)之间。当我们增加虚拟节点的数量时,标准偏差会更小。然而,需要更多的空间来存储关于虚拟节点的数据。这是一种权衡,我们可以调整虚拟节点的数量来适应我们的系统需求。
找到受影响的按键
当添加或删除服务器时,需要重新分配一小部分数据。如何找到受影响的范围来重新分配密钥?
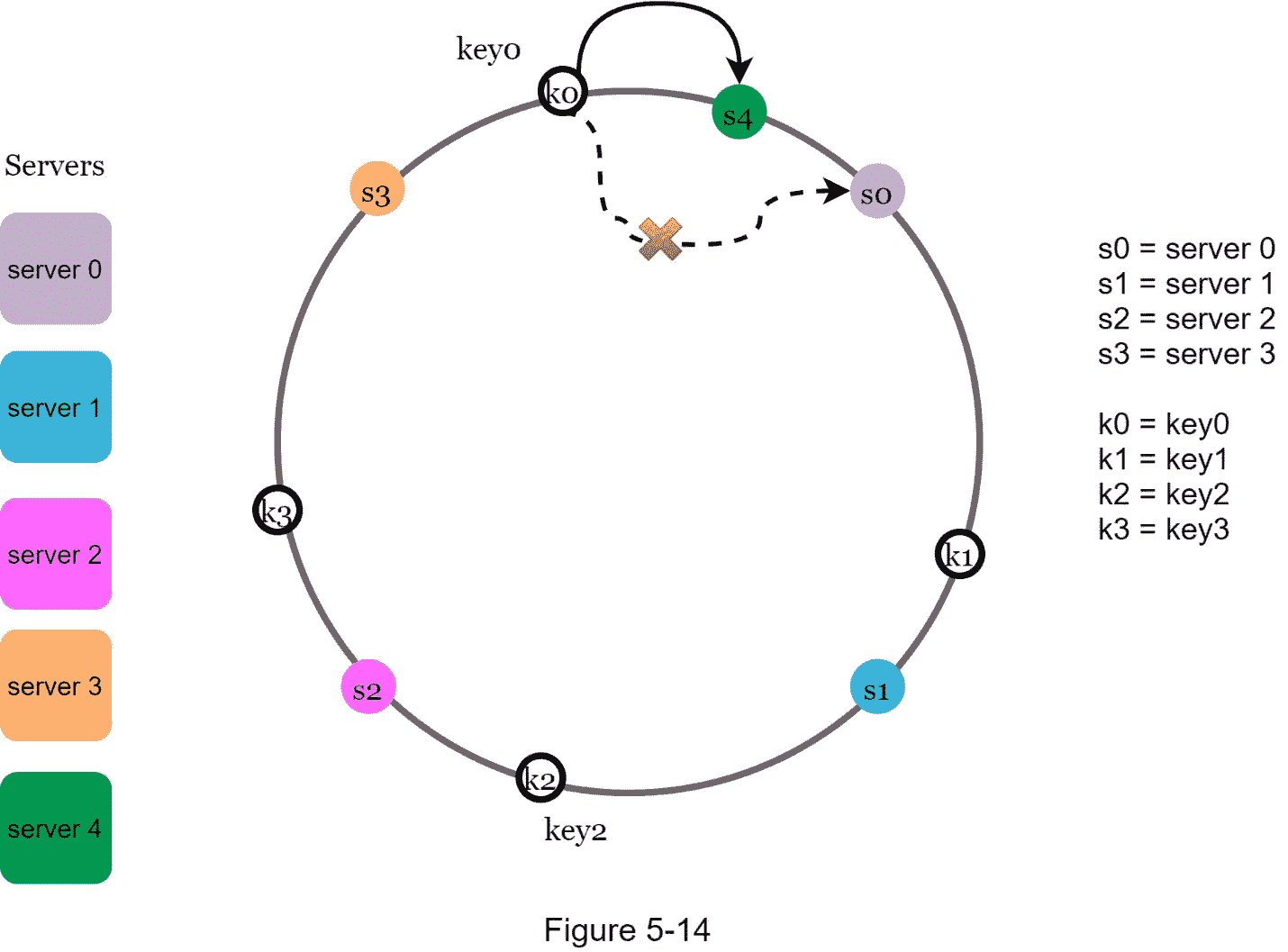
在图 5-14 中, 服务器 4 被添加到环上。受影响的范围从 s4 (新增节点)开始,绕环逆时针移动,直到找到一个服务器( s3 )。因此,位于s3和s3之间的键需要重新分配给s3。
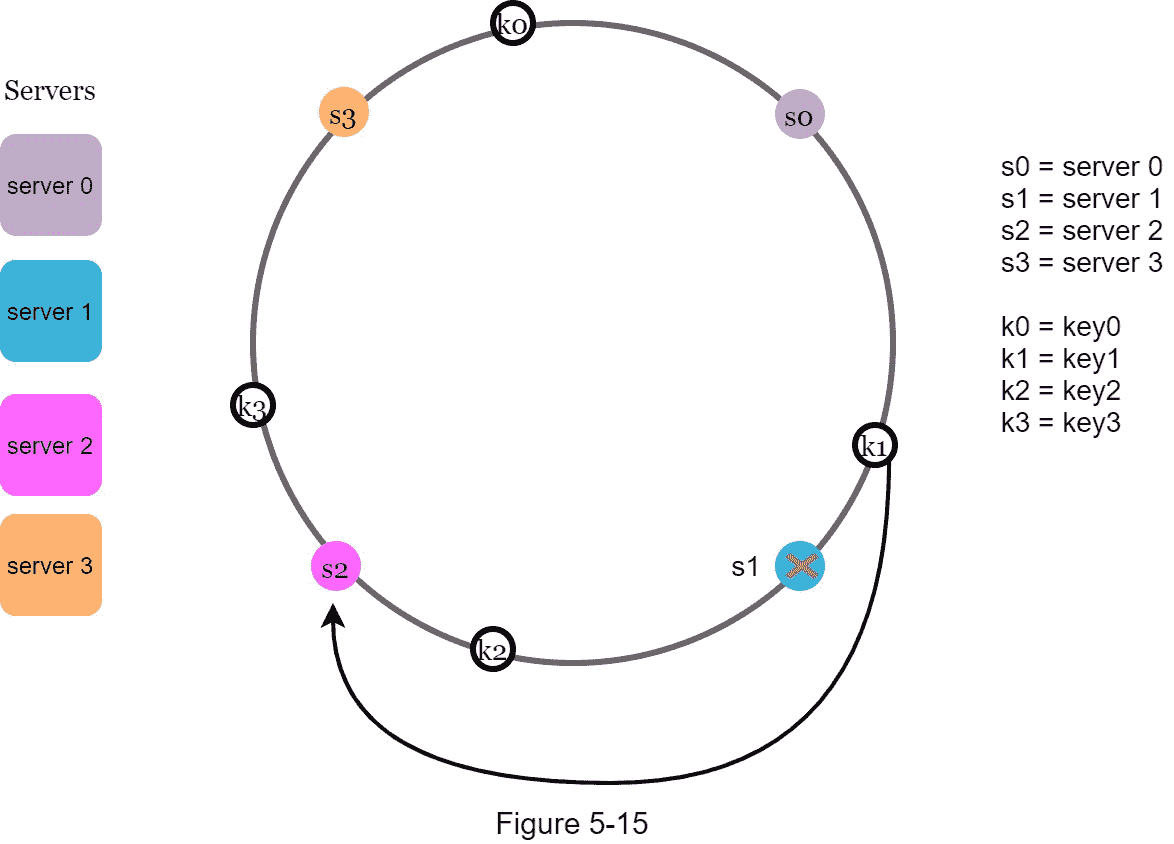
当一个服务器( s1 )被移除时,如图 5-15 所示,受影响的范围从 s1 (被移除的节点)开始,绕环逆时针移动,直到找到一个服务器( s0 )。因此,位于s0和s0之间的键必须重新分配给s0。
总结起来
在本章中,我们深入讨论了一致性哈希,包括为什么需要它以及它是如何工作的。一致哈希的好处包括:
添加或删除服务器时,最小化的密钥会重新分配。
因为数据分布更均匀,所以水平缩放更容易。
缓解热点关键问题。对特定碎片的过度访问可能会导致服务器过载。想象一下凯蒂·佩里、贾斯汀比伯和 Lady Gaga 的数据都在同一个碎片上。一致哈希通过更均匀地分布数据来帮助缓解这个问题。
一致性哈希在现实世界的系统中被广泛使用,包括一些著名的:
亚马逊迪纳摩数据库分区组件【3】
Apache Cassandra[4]中跨集群的数据分区
不和谐聊天应用【5】
Akamai 内容交付网络【6】
磁悬浮网络负载均衡器【7】
祝贺你走到这一步!现在给自己一个鼓励。干得好!
参考资料
[1] Consistent hashing: https://en.wikipedia.org/wiki/Consistent_hashing
[2] Consistent Hashing:
https://tom-e-white.com/2007/11/consistent-hashing.html
[3] Dynamo: Amazon’s Highly Available Key-value Store: https://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf
[4] Cassandra - A Decentralized Structured Storage System:
http://www.cs.cornell.edu/Projects/ladis2009/papers/Lakshman-ladis2009.PDF
[5] How Discord Scaled Elixir to 5,000,000 Concurrent Users: https://blog.discord.com/scaling-elixir-f9b8e1e7c29b
[6] CS168: The Modern Algorithmic Toolbox Lecture #1: Introduction and Consistent Hashing: http://theory.stanford.edu/~tim/s16/l/l1.pdf
[7] Maglev: A Fast and Reliable Software Network Load Balancer: https://static.googleusercontent.c
六、设计键值存储
键值存储,也称为键值数据库,是一种非关系数据库。每个唯一标识符都存储为一个键及其相关值。这种数据配对被称为“键-值”对。
在键-值对中,键必须是唯一的,与键相关联的值可以通过键来访问。键可以是纯文本或哈希值。出于性能原因,短键效果更好。钥匙长什么样?下面举几个例子:
纯文本密钥:“上次登录时间”
哈希键:253 dec 4
键值对中的值可以是字符串、列表、对象等。在键值存储中,值通常被视为不透明的对象,如 Amazon dynamo [1]、Memcached [2]、Redis [3]等。
下面是键值存储中的一个数据片段:

在本章中,要求你设计一个支持以下操作的键值存储:
-
put(key,value):插入与key关联的value -
get(key):获取与key关联的value
了解问题并建立设计范围
没有完美的设计。每种设计都在读取、写入和内存使用之间取得了特定的平衡。另一个需要权衡的是一致性和可用性。在这一章中,我们设计了一个键值存储,它包括以下特征:
键-值对的大小很小:小于 10 KB。
存储大数据的能力。
高可用性:即使在故障期间,系统也能快速响应。
高可扩展性:系统可以扩展以支持大数据集。
自动伸缩:服务器的添加/删除应根据流量自动进行。
可调一致性。
低潜伏期。
单服务器键值存储
开发驻留在单个服务器上的键值存储很容易。一种直观的方法是将键值对存储在哈希表中,将所有内容保存在内存中。尽管内存访问速度很快,但由于空间限制,将所有内容都放入内存可能是不可能的。可以进行两种优化,以便在单个服务器中容纳更多数据:
数据压缩
仅将常用数据存储在内存中,其余数据存储在磁盘上
即使进行了这些优化,单台服务器也能很快达到其容量。支持大数据需要分布式键值存储。
分布式键值存储
分布式键值存储也称为分布式哈希表,它将键值对分布在许多服务器上。在设计分布式系统时,理解 CAP ( C 一致性, A 可用性, P 分区容差)定理是很重要的。
上限定理
CAP 定理指出,分布式系统不可能同时提供三个保证中的两个以上:一致性、可用性和分区容差。让我们建立几个定义。
一致性 :一致性是指所有客户端同时看到相同的数据,无论它们连接到哪个节点。
可用性: 可用性意味着任何请求数据的客户端都可以得到响应,即使某些节点出现故障。
分区容错: 一个分区表示两个节点之间的通信中断。分区容差意味着尽管存在网络分区,系统仍能继续运行。
CAP 定理指出,必须牺牲三个属性中的一个来支持三个属性中的两个,如图 6-1 所示。
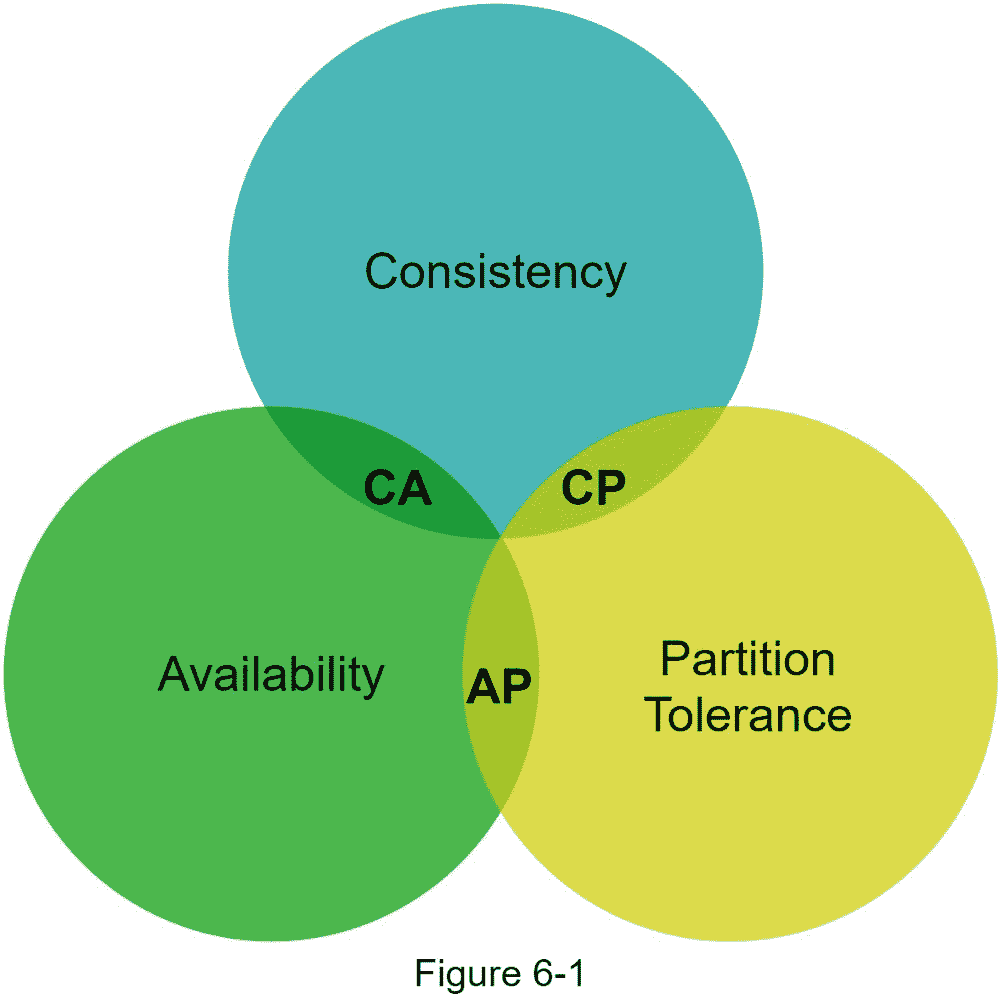
现在,键值存储是根据它们支持的两个 CAP 特征来分类的:
CP(一致性和分区容差)系统:CP 键值存储支持一致性和分区容差,但牺牲了可用性。
AP(可用性和分区容差)系统:AP 键值存储支持可用性和分区容差,但牺牲了一致性。
CA(一致性和可用性)系统:CA 键值存储支持一致性和可用性,同时牺牲分区容差。由于网络故障不可避免,分布式系统必须容忍网络分区。因此,CA 系统不能存在于现实世界的应用程序中。
你上面读到的大多是定义部分。为了更容易理解,让我们看一些具体的例子。在分布式系统中,数据通常被复制多次。假设数据复制在三个副本节点上,n1,n1和n1如图 6-2 所示。
理想情况
在理想世界中,网络分区永远不会发生。写入n1的数据自动复制到n1和n1。实现了一致性和可用性。

现实世界的分布式系统
在分布式系统中,分区是不可避免的,当出现分区时,我们必须在一致性和可用性之间做出选择。图 6-3 中,n3下行,无法与n3和n3通信。如果客户端向n3或n3写入数据,数据无法传播到n3。如果数据被写入到【n3】但是没有被传播到n3和n3,n3和n3就会有陈旧数据。
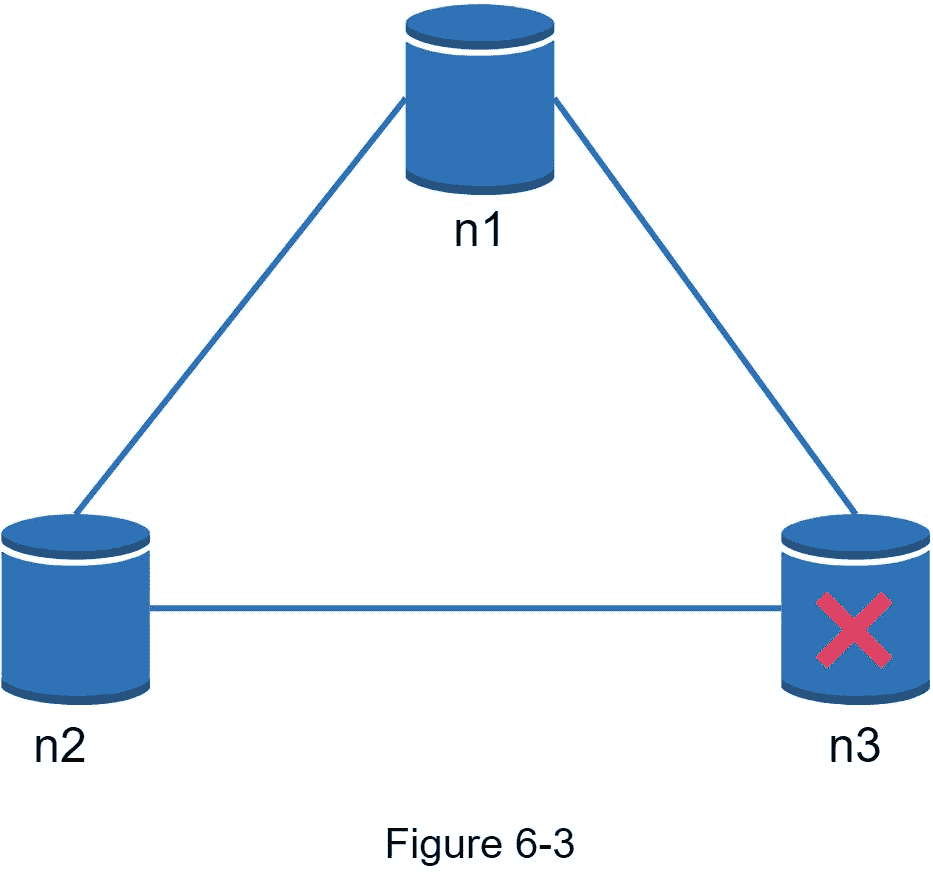
如果我们选择一致性而不是可用性(CP 系统),我们必须阻止对n1和n1的所有写操作,以避免这三个服务器之间的数据不一致,从而导致系统不可用。银行系统通常有极高的一致性要求。例如,对于银行系统来说,显示最新的余额信息至关重要。如果由于网络分区而出现不一致,银行系统会在解决不一致之前返回一个错误。
然而,如果我们选择可用性而不是一致性(AP 系统),系统会继续接受读取,即使它可能会返回过时的数据。对于写入,n1和n1将继续接受写入,并且当网络分区被解析时,数据将被同步到n1。
选择适合您的用例的正确 CAP 担保是构建分布式键值存储的重要一步。你可以和你的面试官讨论这个问题,并据此设计系统。
系统组件
在本节中,我们将讨论以下用于构建键值存储的核心组件和技术:
数据分区
数据复制
一致性
不一致性解决
处理故障
系统架构图
写路径
读取路径
下面的内容主要基于三个流行的键值存储系统:Dynamo [4]、Cassandra [5]和 BigTable [6]。
数据分区
对于大型应用程序,将完整的数据集放在一台服务器上是不可行的。实现这一点的最简单方法是将数据分割成更小的分区,并将它们存储在多个服务器中。对数据进行分区时有两个挑战:
将数据均匀分布在多台服务器上。
添加或删除节点时,尽量减少数据移动。
第五章中讨论的一致哈希法是解决这些问题的一个很好的技术。让我们从高层次上重新审视一下一致性哈希是如何工作的。
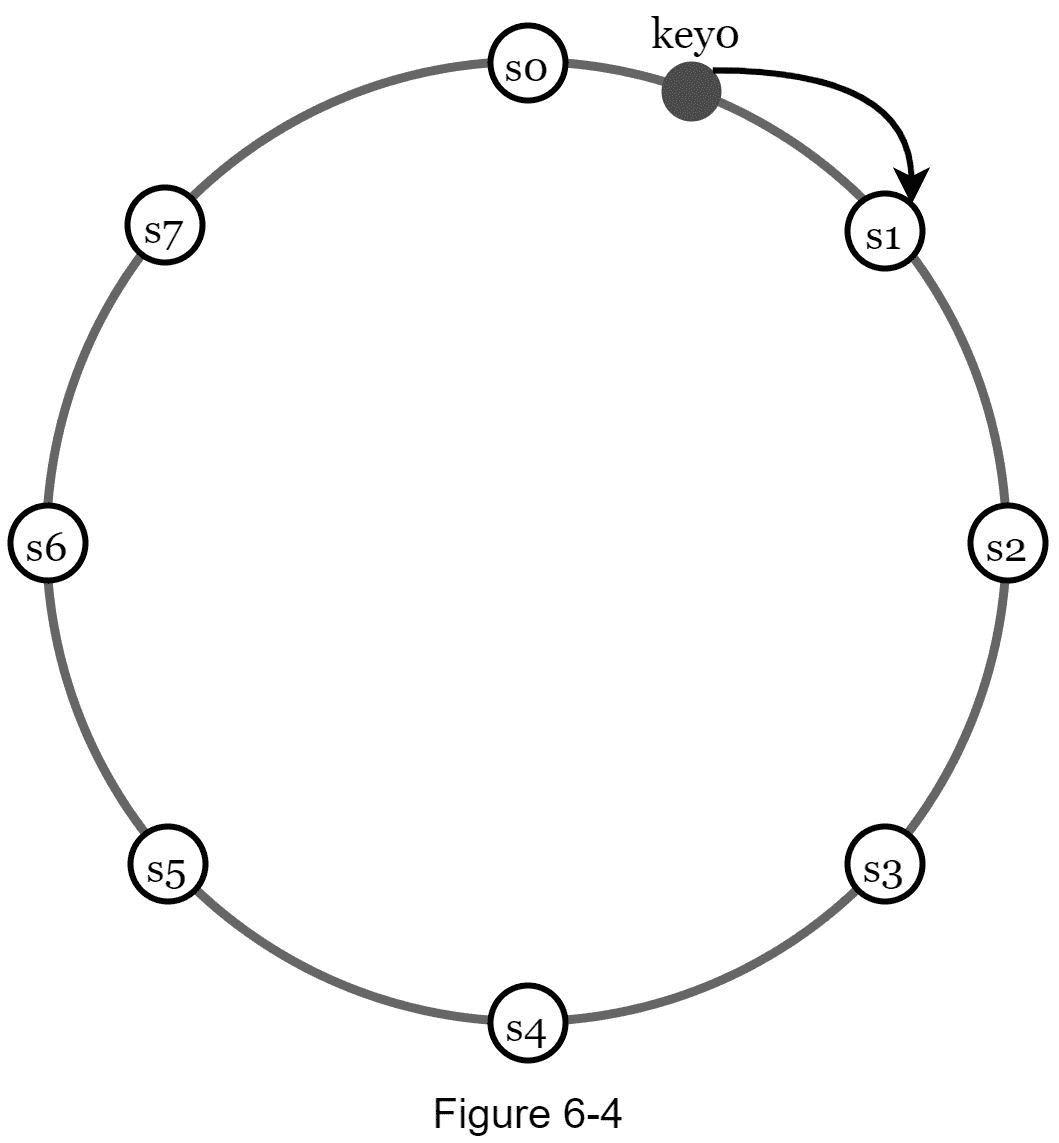
首先,服务器被放置在一个哈希环上。在图 6-4 中,八个服务器,分别用s0,s0,…,s0表示,放置在哈希环上。
接下来,一个密钥被哈希到同一个环上,并存储在顺时针方向移动时遇到的第一个服务器上。例如,key0使用此逻辑存储在s1中。
使用一致哈希对数据进行分区有以下优点:
自动扩展: 可以根据负载自动添加和删除服务器。
异构: 一台服务器的虚拟节点数量与服务器容量成正比。例如,为容量较高的服务器分配更多的虚拟节点。
数据复制
为了实现高可用性和可靠性,数据必须通过 N 服务器异步复制,其中 N 是一个可配置的参数。使用以下逻辑选择这些 N 服务器:在将一个键映射到哈希环上的一个位置之后,从该位置顺时针行走,选择环上的第一个 N 服务器来存储数据副本。在图 6-5 中( N = 3 ),key0被复制在s1、 和s1。
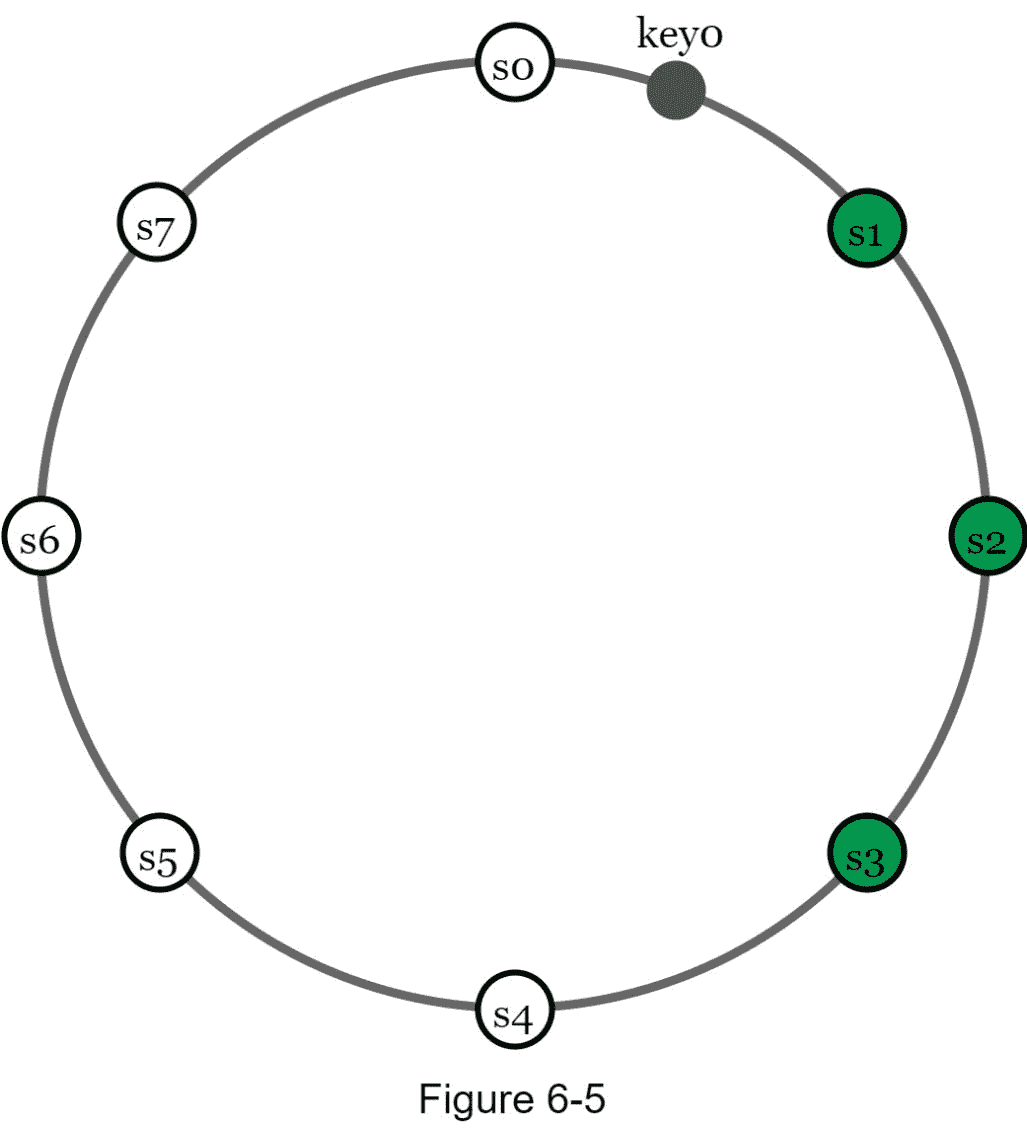
有了虚拟节点,环上的第一个 N 个 节点可能归少于 N 个 物理服务器所有。为了避免这个问题,我们在执行顺时针遍历逻辑时只选择唯一的服务器。
由于停电、网络问题、自然灾害等原因,同一数据中心的节点经常同时发生故障。为了更好的可靠性,副本被放置在不同的数据中心,并且数据中心通过高速网络连接。
一致性
由于数据在多个节点上复制,因此必须跨副本进行同步。仲裁共识可以保证读写操作的一致性。让我们先确立几个定义。
N = 副本数量
W = 一写法定人数 W 。为了使写入操作被认为是成功的,必须从 W 副本确认写入操作。
R = 一读法定人数大小 R 。为了使读取操作被认为是成功的,读取操作必须等待来自至少 R 个副本的响应。
考虑下面图 6-6 所示的例子,其中 N = 3 。
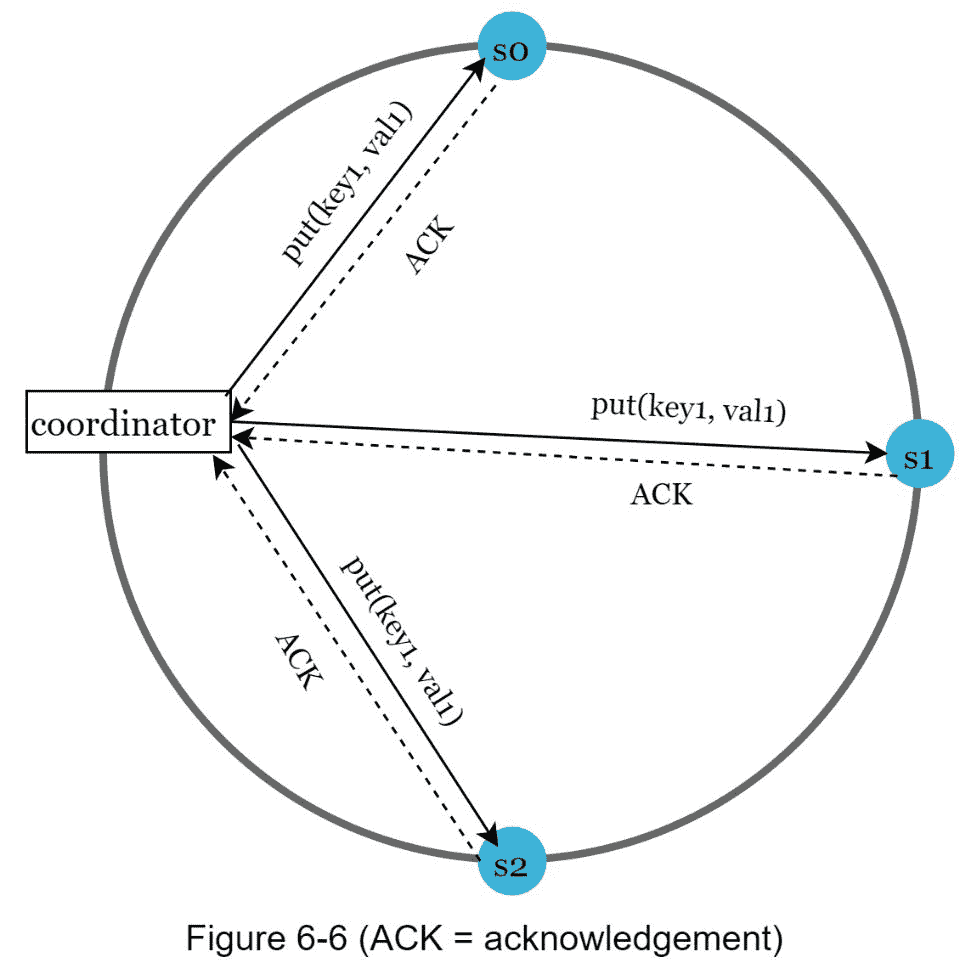
W = 1 并不意味着数据写在一台服务器上。例如,在图 6-6 的配置中,数据在s0、s0、 和s0被复制。 W = 1 表示在写入操作被认为成功之前,协调器必须收到至少一个确认。例如,如果我们从s0得到确认,我们就不再需要等待来自s0和s0的确认。协调器充当客户端和节点之间的代理。
W,RN 的配置是典型的延迟和一致性的权衡。如果 W = 1 或 R = 1 ,操作会快速返回,因为协调器只需等待来自任何副本的响应。如果 W 或 R > 1 ,系统提供更好的一致性;但是,查询会比较慢,因为协调器必须等待最慢的副本的响应。
如果W + R > N 强一致性得到保证,因为必须至少有一个重叠节点具有最新数据以确保一致性。
如何配置 N,W ,以及 R 来适应我们的用例?以下是一些可能的设置:
如果 R = 1 且 W = N ,则系统为快速读取而优化。
如果 W = 1 且 R = N ,则系统针对快速写入进行优化。
如果 W + R > N ,则保证强一致性(通常 N = 3,W = R = 2 )。
如果 W + R < = N ,强一致性得不到保证。
根据需求,我们可以调整 W,R,N 的值,以达到所需的一致性水平。
一致性模型
一致性模型是设计键值存储时要考虑的另一个重要因素。一致性模型定义了数据一致性的程度,并且存在多种可能的一致性模型:
强一致性:任何读操作都返回一个与最近更新的写数据项的结果对应的值。客户端永远不会看到过时的数据。
弱一致性:后续的读操作可能看不到最新的值。
最终一致性:这是弱一致性的一种具体形式。如果有足够的时间,所有更新都会传播,并且所有副本都是一致的。
强一致性通常通过强制副本不接受新的读/写操作来实现,直到每个副本都同意当前的写操作。这种方法对于高可用性系统并不理想,因为它可能会阻塞新的操作。Dynamo 和 Cassandra 采用最终一致性,这是我们为键值存储推荐的一致性模型。对于并发写入,最终一致性允许不一致的值进入系统,并迫使客户端读取这些值进行协调。下一节解释了协调如何与版本控制一起工作。
不一致解决方案:版本控制
复制提供了高可用性,但会导致副本之间的不一致。版本控制和向量时钟用于解决不一致性问题。版本化意味着将每个数据修改视为数据的一个新的不可变版本。在我们谈论版本控制之前,让我们用一个例子来解释不一致是如何发生的:
如图 6-7 所示,两个副本节点n1和n1具有相同的值。让我们称这个值为原来的 值。服务器 1 和 服务器 2 对name操作获取相同的值。
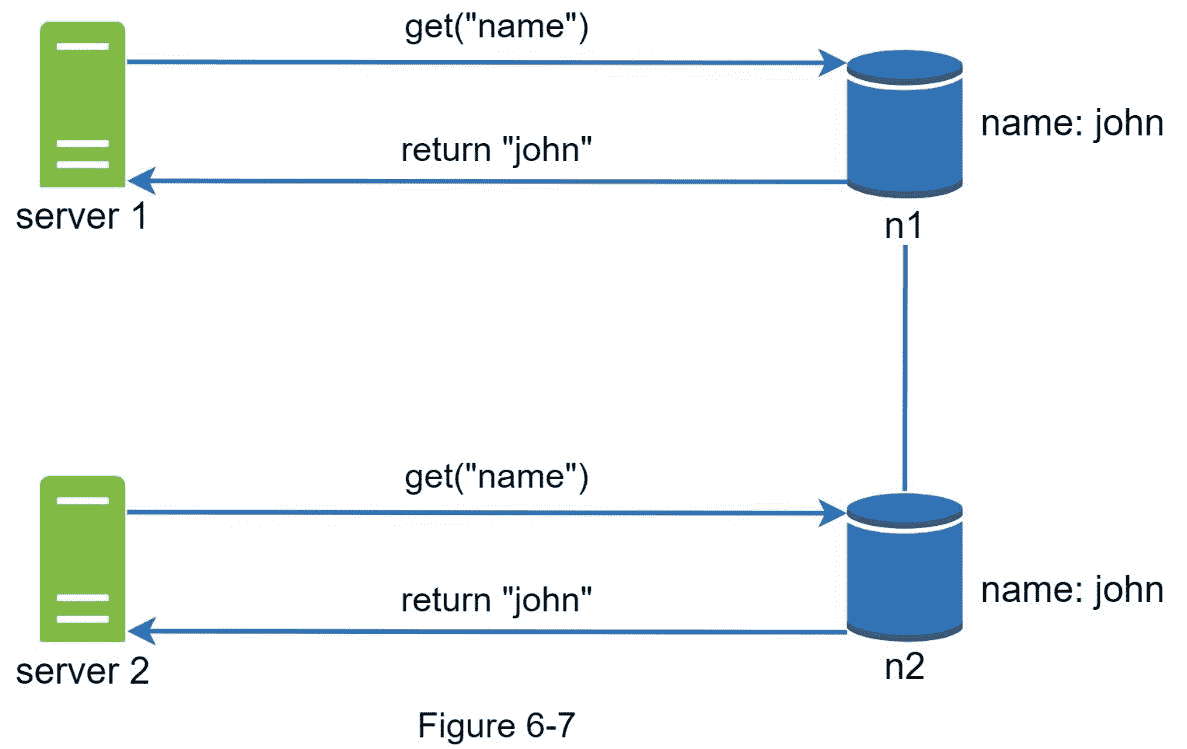
接下来, 服务器 1 将名称改为johnSanFrancisco, 服务器 2 将名称改为johnNewYork,如图 6-8 所示。这两种变化是同时进行的。现在,我们有相互冲突的值,叫做版本 v1 和 v2 。
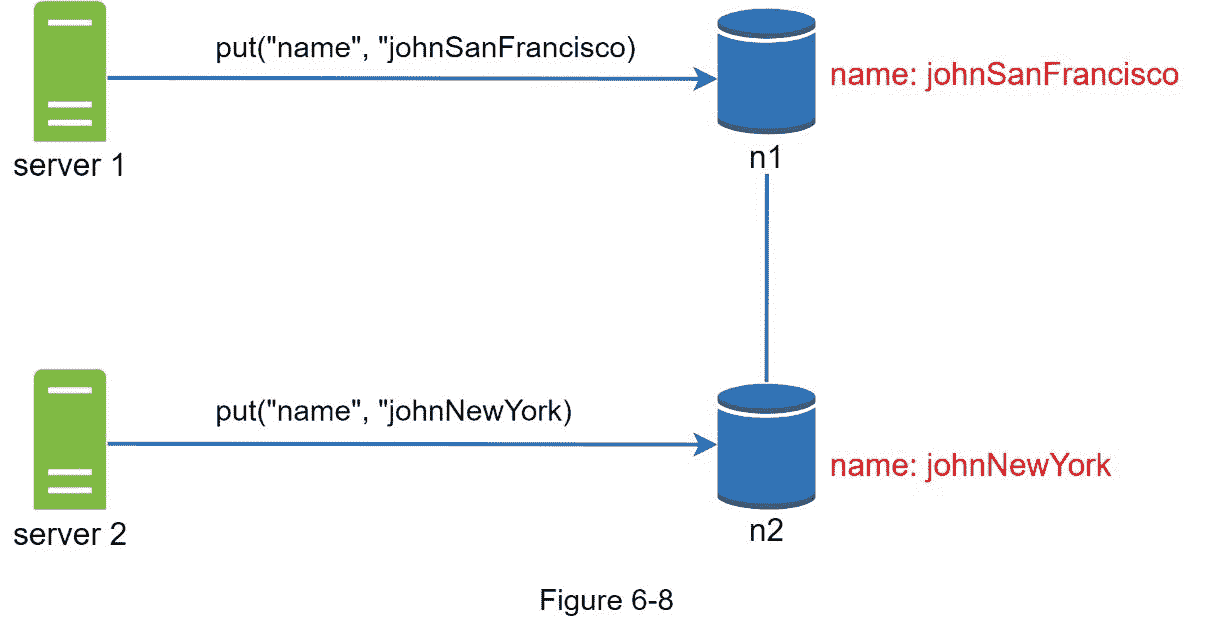
在这个例子中,原始值可以被忽略,因为修改是基于它的。但是,没有明确的方法来解决后两个版本的冲突。为了解决这个问题,我们需要一个能够检测冲突并协调冲突的版本控制系统。矢量时钟是解决这一问题的常用技术。让我们来看看矢量时钟是如何工作的。
向量时钟是与数据项相关联的 【服务器,版本】 对。它可用于检查一个版本是否领先、成功或与其他版本冲突。
假设一个矢量时钟用D([S1, v1], [S1, v2], …, [Sn, VN])表示,其中 D 为数据项, v1 为版本计数器,S1为服务器号等。如果数据项 D 被写入服务器 Si ,系统必须执行以下任务之一。
增量 vi 如果[Si, vi]存在。
否则,新建一个条目[Si, 1]。
以上抽象的逻辑用一个具体的例子来说明,如图 6-9 所示。
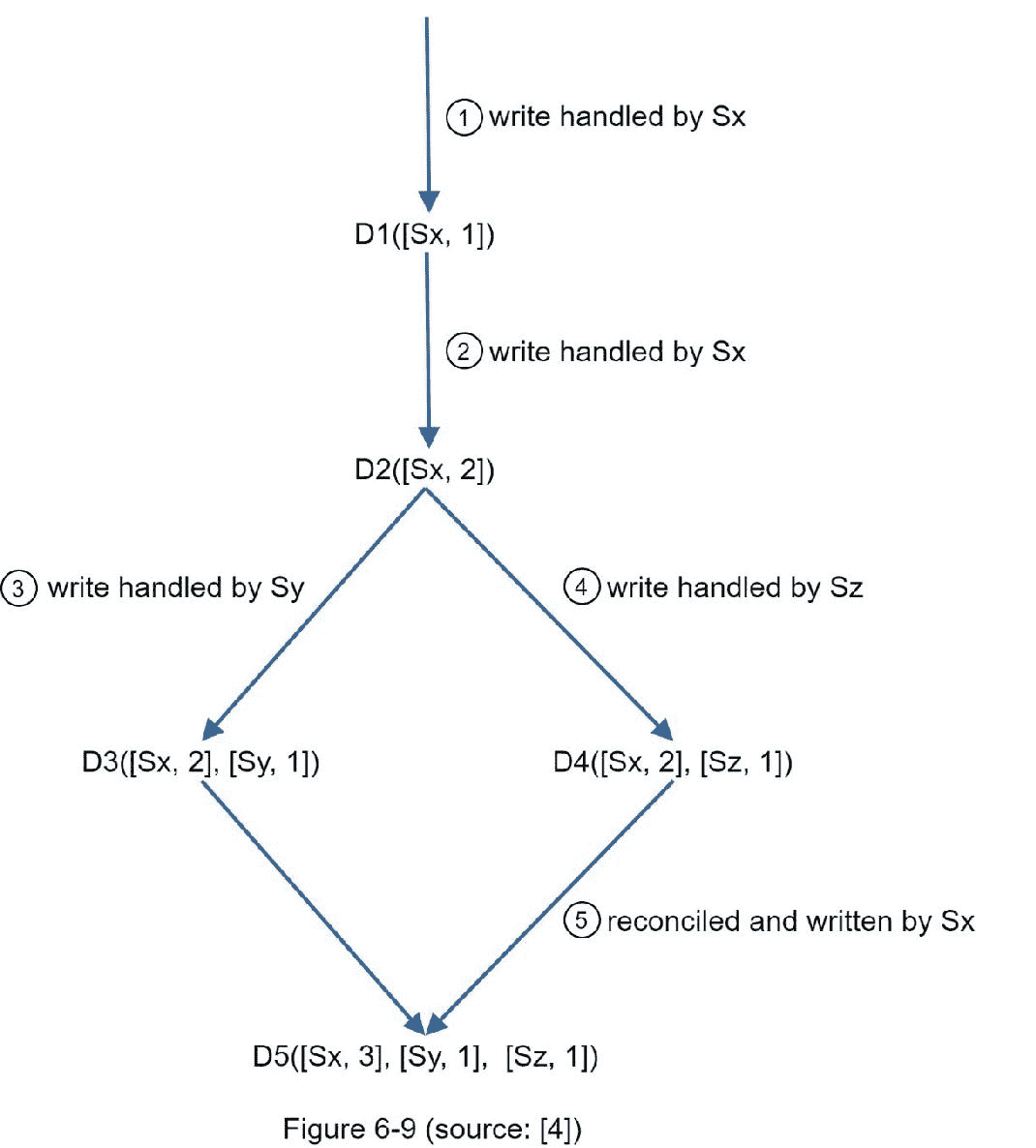
1。一个客户端向系统写一个数据项,这个写由服务器 Sx 处理,它现在有了向量时钟D1[Sx, 1]。
2。另一个客户端读取最新的 D1 ,更新为 D2 ,并写回。 D2 是 D1 的后代,所以它覆盖了 D1 。假设写操作由同一个服务器Sx处理,该服务器现在有向量时钟D2(Sx, 2)。
3。另一个客户端读取最新的,更新为 D3 ,并写回。假设写操作由服务器Sy处理,它现在有向量时钟 D3([Sx,2],[Sy,1])。
4。另一个客户端读取最新的 D2 ,更新为 D4 ,并写回。假设写操作由服务器处理,它现在有D4([Sx, 2], [Sz, 1])。
5。当另一个客户端读取 D3 和 D4 时,发现一个冲突,这个冲突是由于数据项D2被和 Sz 同时修改引起的。客户端解决冲突,并将更新的数据发送到服务器。假设写的是由Sx处理的,这里面现在有D5([Sx, 3], [Sy, 1], [Sz, 1])。我们将很快解释如何检测冲突。
使用矢量时钟,很容易判断出一个 版本 X 是一个 Y 版本的祖先(即没有冲突),如果 版本的计数器对于的矢量时钟中的每个参与者都大于或等于版本 X 中的计数器。比如向量时钟 D([s0, 1], [s0, 1])就是 D([s0, 1], [s0, 2]) 的一个祖先。因此,不会记录冲突。
同样,如果 Y 的向量时钟中有任何参与者的计数器小于其在 X 中对应的计数器,则可以看出版本 X 是 Y 的兄弟(即存在冲突)。比如下面两个向量时钟表示有冲突: D([s0, 1], [s0, 2]) 和 D([s0, 2], [s0, 1])。
尽管矢量时钟可以解决冲突,但也有两个明显的缺点。首先,向量时钟增加了客户端的复杂性,因为它需要实现冲突解决逻辑。
第二, 【服务器:版本】 成对出现在向量时钟中的可能迅速增长。为了解决这个问题,我们为长度设置了一个阈值,如果它超过了限制,最早的对将被删除。这可能导致协调效率低下,因为后代关系无法准确确定。但是基于迪纳摩纸业[4],亚马逊在生产中还没有遇到这个问题;所以,对于大多数公司来说,大概是可以接受的解决方案。
处理故障
正如任何大规模的大型系统一样,故障不仅不可避免,而且很常见。处理故障场景非常重要。在本节中,我们首先介绍检测故障的技术。然后,我们回顾常见的故障解决策略。
故障检测
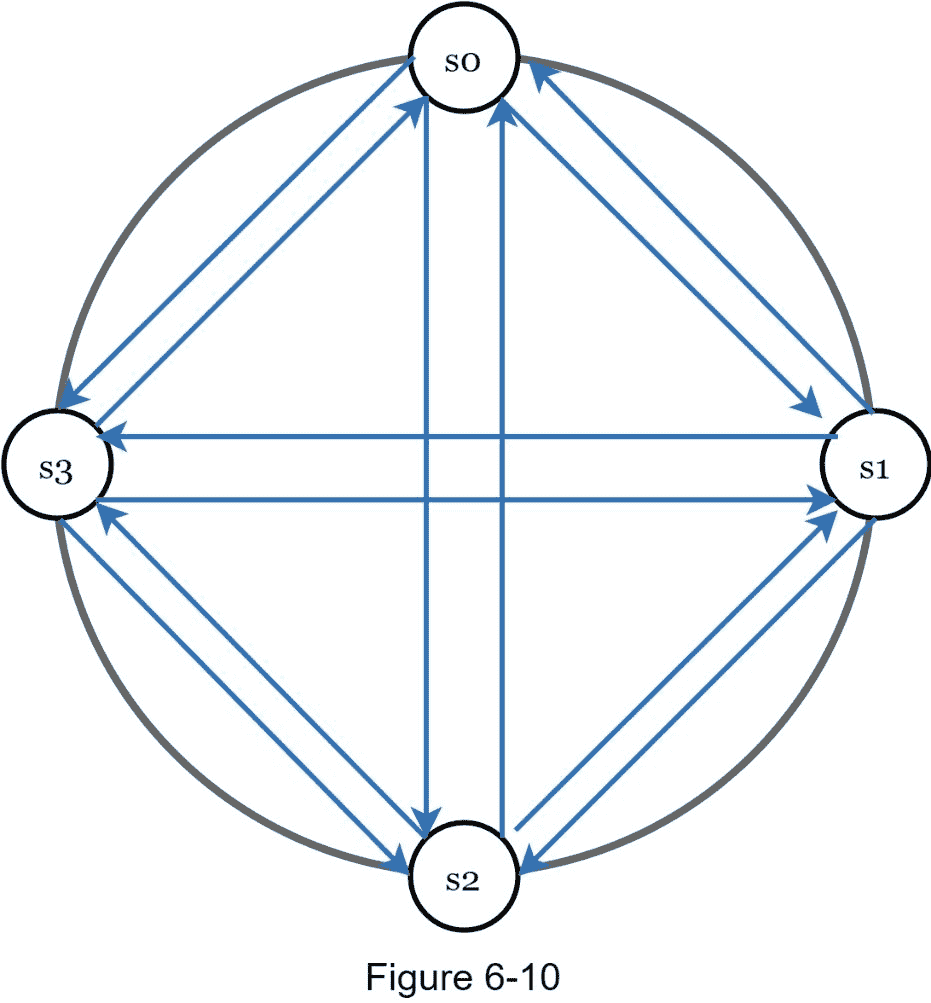
在一个分布式系统中,仅仅因为一个服务器说另一个服务器关闭了,就认为这个服务器关闭了是不够的。通常,至少需要两个独立的信息源来标记服务器停机。
如图 6-10 所示,所有对所有的多播是一个简单的解决方案。然而,当系统中有许多服务器时,这是低效的。
更好的解决方案是使用分散式故障检测方法,如 gossip 协议。八卦协议的工作原理如下:
每个节点维护一个节点成员列表,其中包含成员 id 和心跳计数器。
每个节点周期性地递增其心跳计数器。
每个节点周期性地向一组随机节点发送心跳,心跳又传播到另一组节点。
一旦节点接收到心跳,成员列表将更新为最新信息。
如果心跳没有增加超过预定义的时间段,则该成员被视为离线。
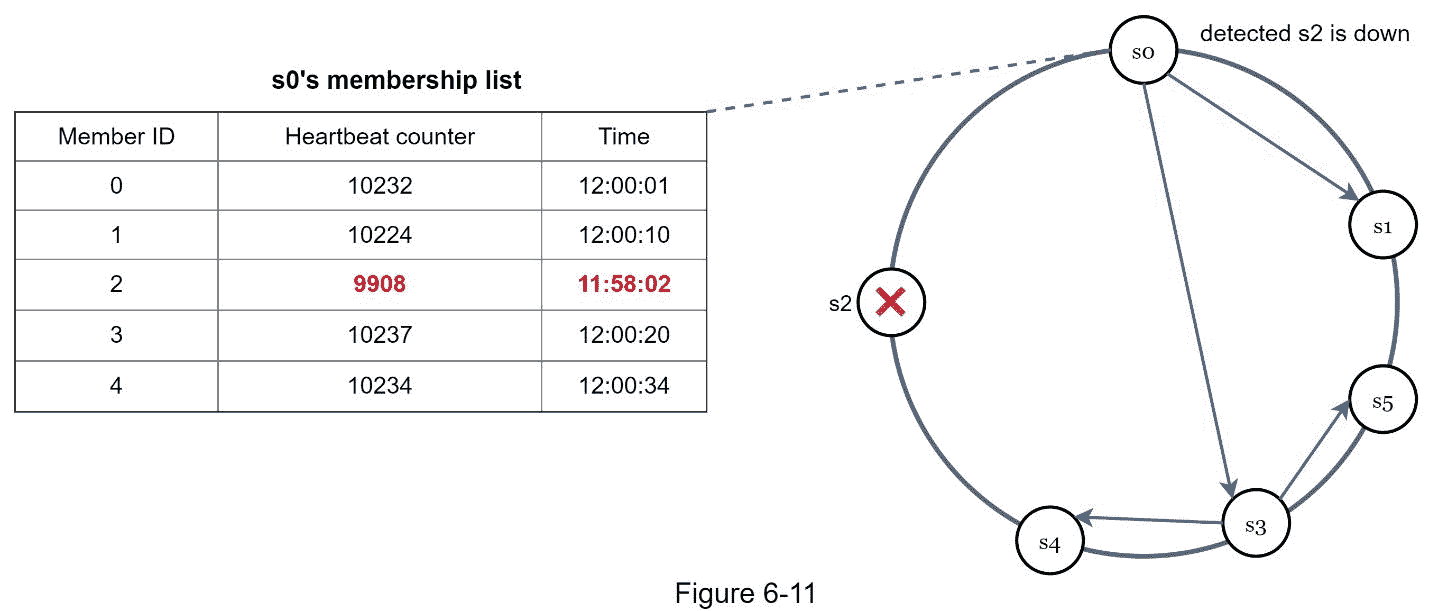
如图 6-11 所示:
节点s0维护左侧显示的节点成员列表。
节点s0注意到节点 s2(成员ID = 2)的心跳计数器长时间没有增加。
节点s0向一组随机节点发送包含s0信息的心跳。一旦其他节点确认【s0】的心跳计数器长时间没有更新,节点s0被标记为下线,这个信息被传播到其他节点。
处理临时故障
通过 gossip 协议检测到故障后,系统需要部署某些机制来确保可用性。在严格仲裁方法中,读写操作可能会被阻止,如仲裁共识部分所示。
一种被称为“草率法定人数”的技术[4]被用来提高可用性。系统选择第一个 W 健康服务器进行写操作,第一个 R 健康服务器进行哈希环上的读操作,而不是强制执行定额要求。脱机服务器被忽略。
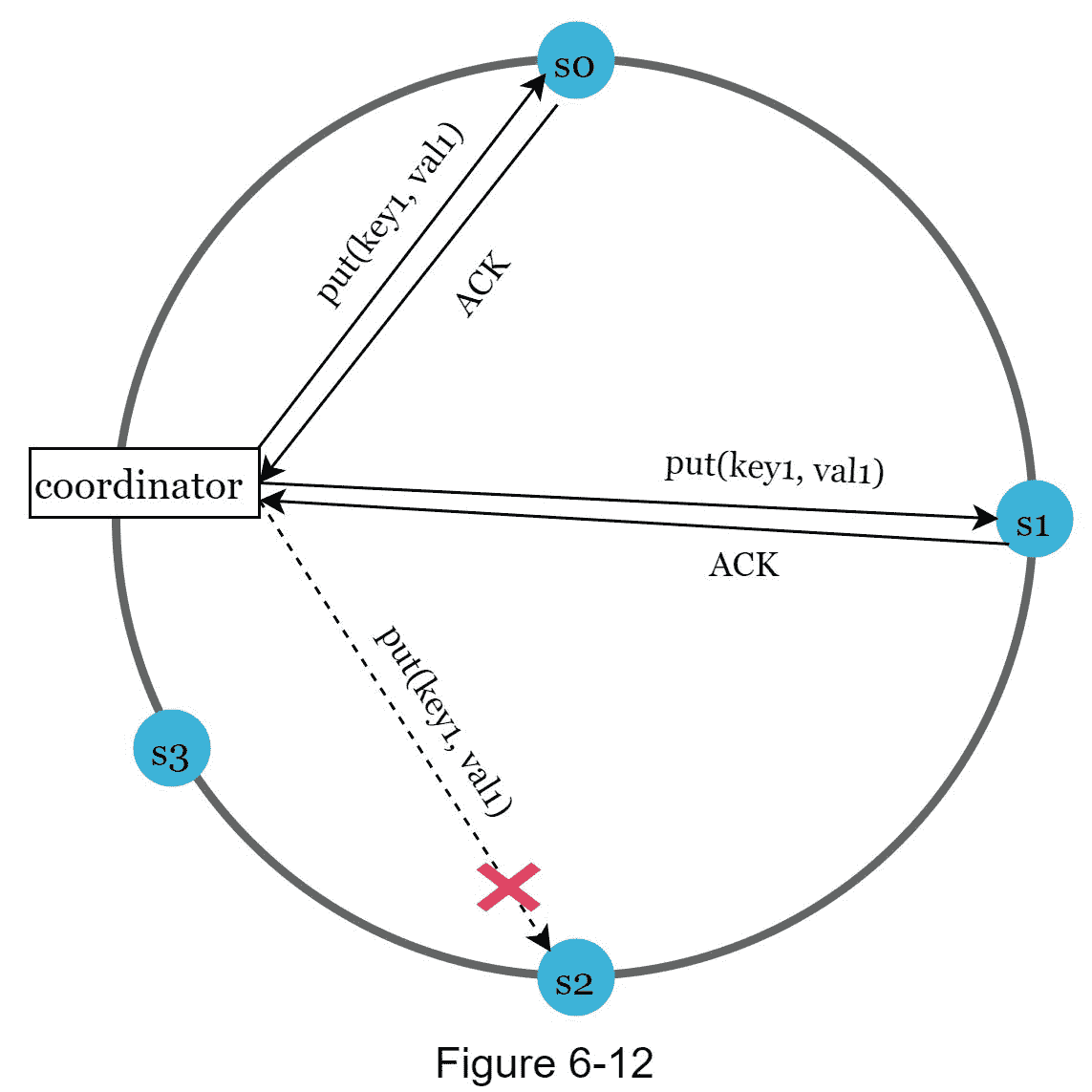
如果一个服务器由于网络或服务器故障而不可用,另一个服务器将临时处理请求。当关闭的服务器启动时,更改将被推回以实现数据一致性。这个过程被称为提示切换。由于s2在图 6-12 中不可用,读写将暂时由s2处理。当s2重新上线时,s2会将数据交还给s2。
处理永久性故障
提示切换用于处理临时故障。如果副本永久不可用怎么办?为了处理这种情况,我们实现了一个反熵协议来保持副本同步。反熵包括比较副本上的每一条数据,并将每个副本更新到最新版本。Merkle 树用于不一致性检测和最小化传输的数据量。
引自维基百科[7]:“哈希树或 Merkle 树是 中的树,其中每个非叶节点都用其子节点的标签或值(在叶的情况下)的哈希来标记。哈希树允许高效和安全地验证大型数据结构的内容”。
假设密钥空间从 1 到 12,下面的步骤展示了如何构建 Merkle 树。突出显示的方框表示不一致。
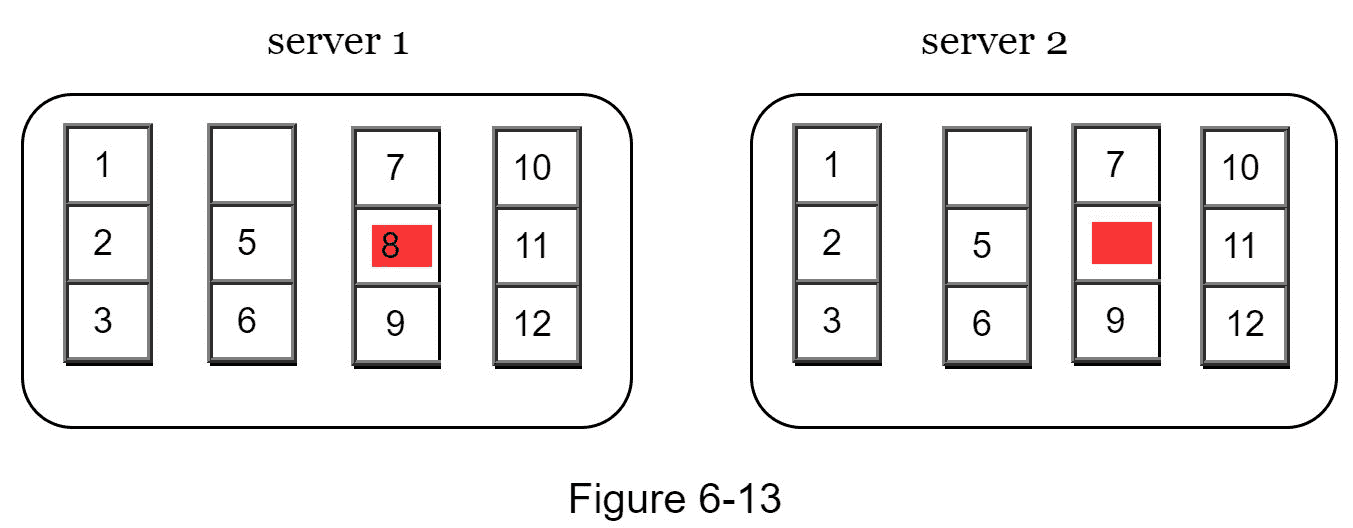
步骤 1:将键空间划分成桶(在我们的例子中是 4 个),如图 6-13 所示。一个存储桶被用作根级节点,以保持树的有限深度。
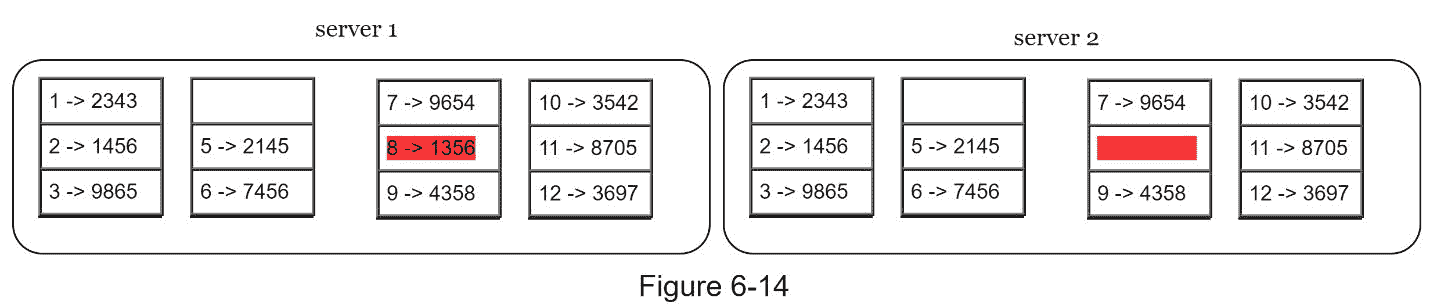
步骤 2:一旦创建了存储桶,使用统一的哈希方法对存储桶中的每个关键字进行哈希(图 6-14)。
第三步:为每个桶创建一个哈希节点(图 6-15)。

第四步:通过计算子节点的哈希值,向上构建树直到根节点(图 6-16)。

要比较两个 Merkle 树,先从比较根哈希开始。如果根哈希匹配,两台服务器具有相同的数据。如果根哈希不一致,则先比较左边的子哈希,然后比较右边的子哈希。您可以遍历树来查找哪些存储桶没有同步,并只同步那些存储桶。
使用 Merkle 树,需要同步的数据量与两个副本 、 之间的差异成正比,而与它们包含的数据量无关。在现实世界的系统中,桶的大小相当大。例如,一种可能的配置是每十亿个键有一百万个存储桶,所以每个存储桶只包含 1000 个键。
处理数据中心故障
停电、网络中断、自然灾害等都可能导致数据中心中断。要构建能够处理数据中心停机的系统,跨多个数据中心复制数据非常重要。即使一个数据中心完全离线,用户仍然可以通过其他数据中心访问数据。
系统架构图
既然我们已经讨论了设计键值存储时不同的技术考虑,我们可以把注意力转移到架构图上,如图 6-17 所示。
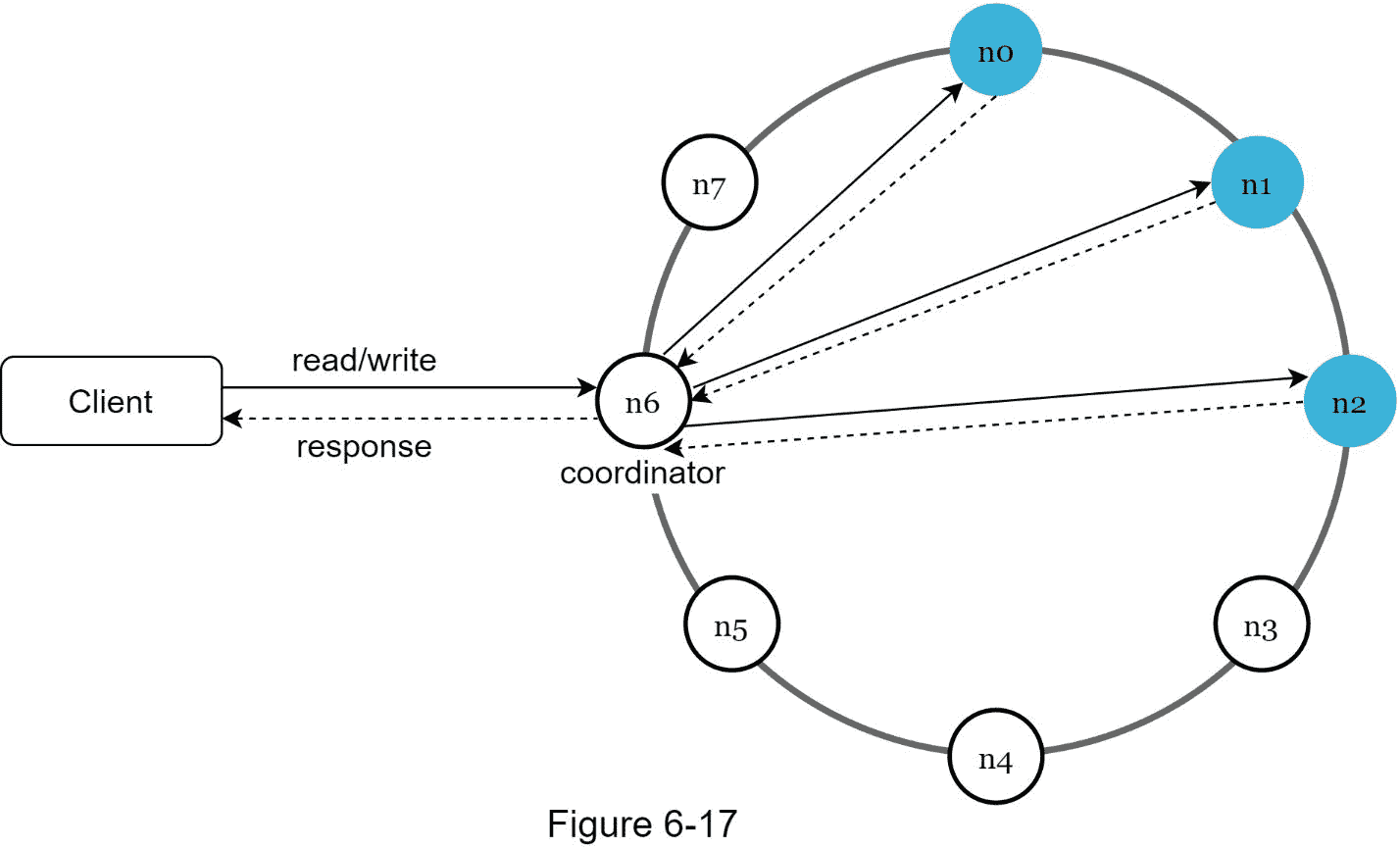
该架构的主要特点如下:
客户端通过简单的 API 与键值存储进行通信: get(key) 和 put(key,value) 。
协调器是充当客户端和键值存储之间的代理的节点。
使用一致哈希法将节点分布在环上。
系统是完全分散的,因此添加和移动节点可以是自动的。
数据在多个节点复制。
没有单点故障,因为每个节点都有相同的职责。
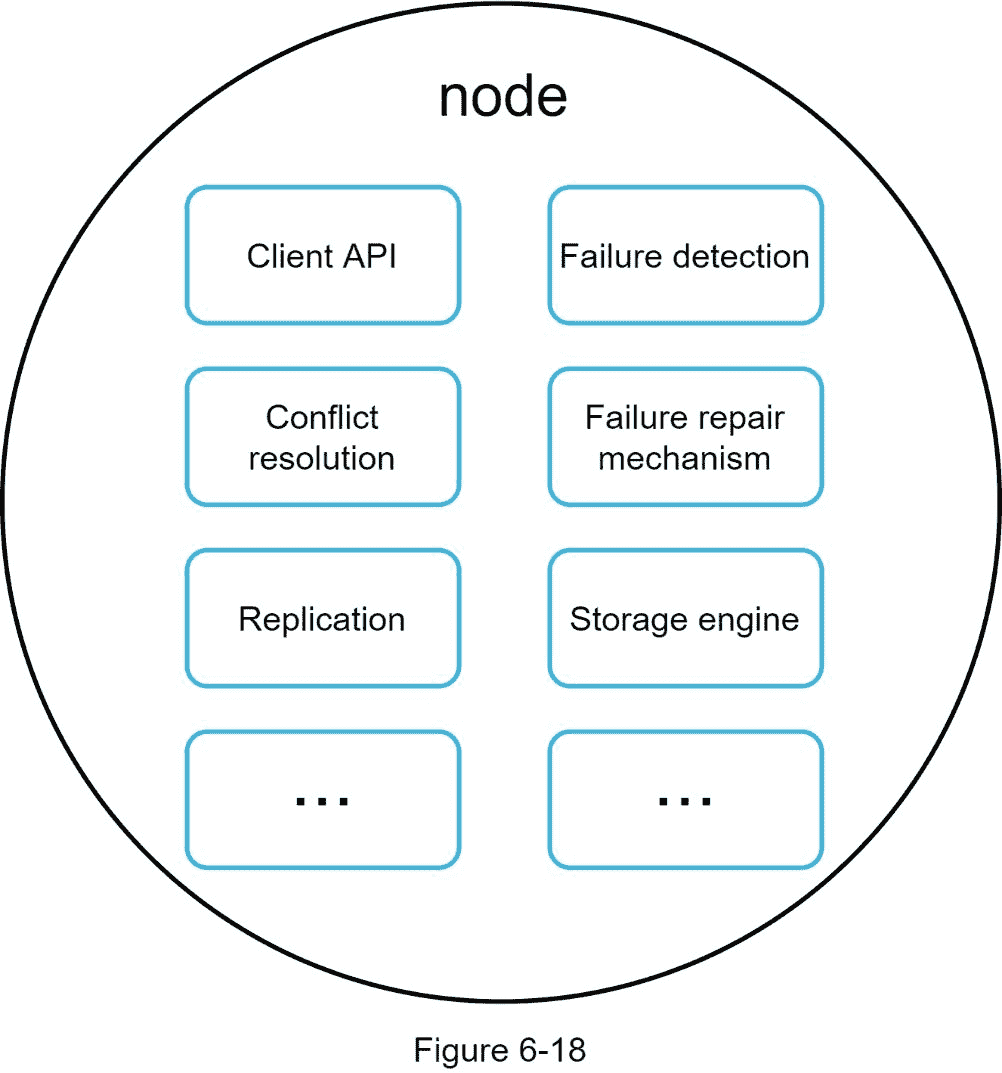
由于设计是分散的,每个节点执行许多任务,如图 6-18 所示。
写路径
图 6-19 解释了写请求指向特定节点后会发生什么。请注意,建议的写/读路径设计主要基于 Cassandra [8]的架构。
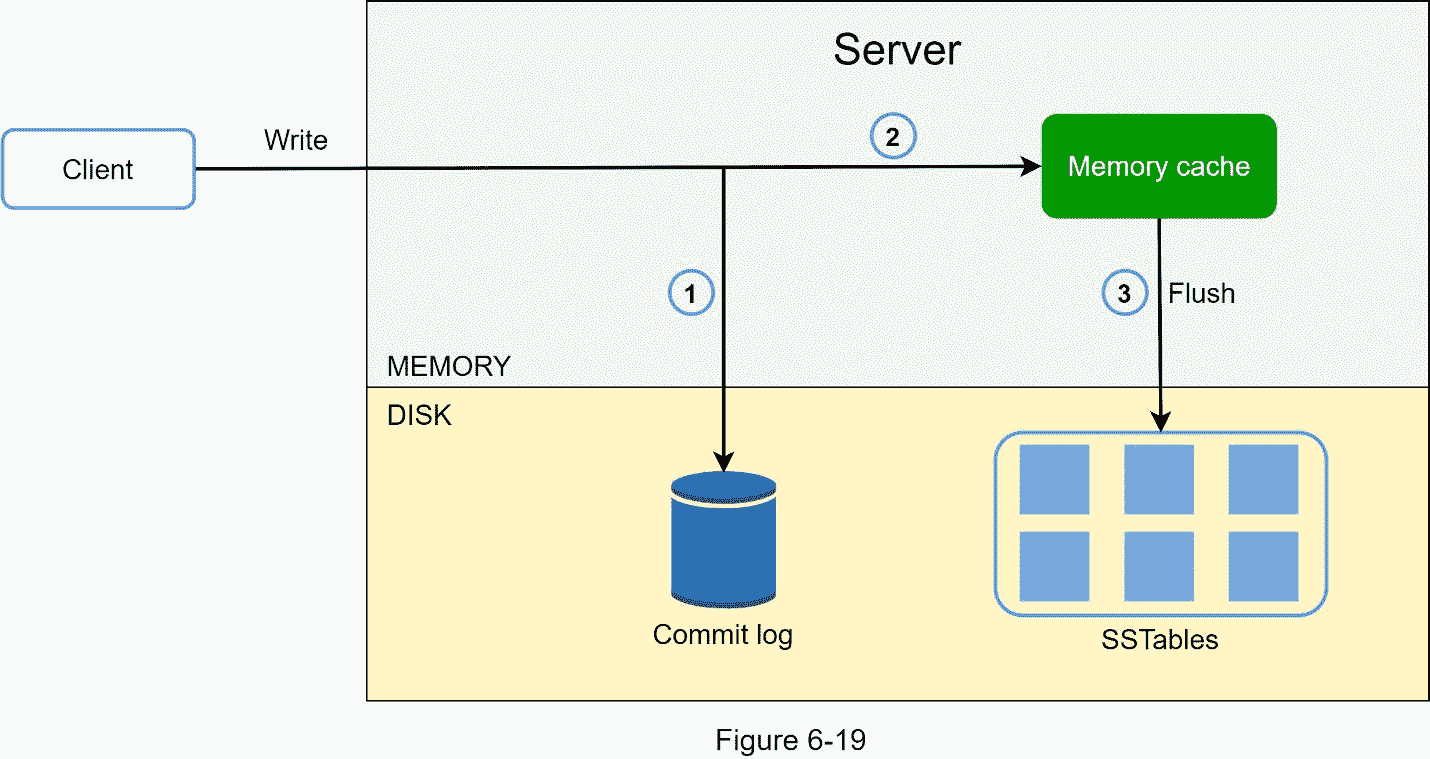
1。写请求保存在提交日志文件中。
2。数据保存在内存缓存中。
3。当内存缓存已满或达到预定义的阈值时,数据将被刷新到磁盘上的 SSTable [9]中。注意:排序字符串表(SSTable)是一个由键值对组成的排序列表。对于有兴趣了解 SStable 更多信息的读者,请参考参考资料[9]。
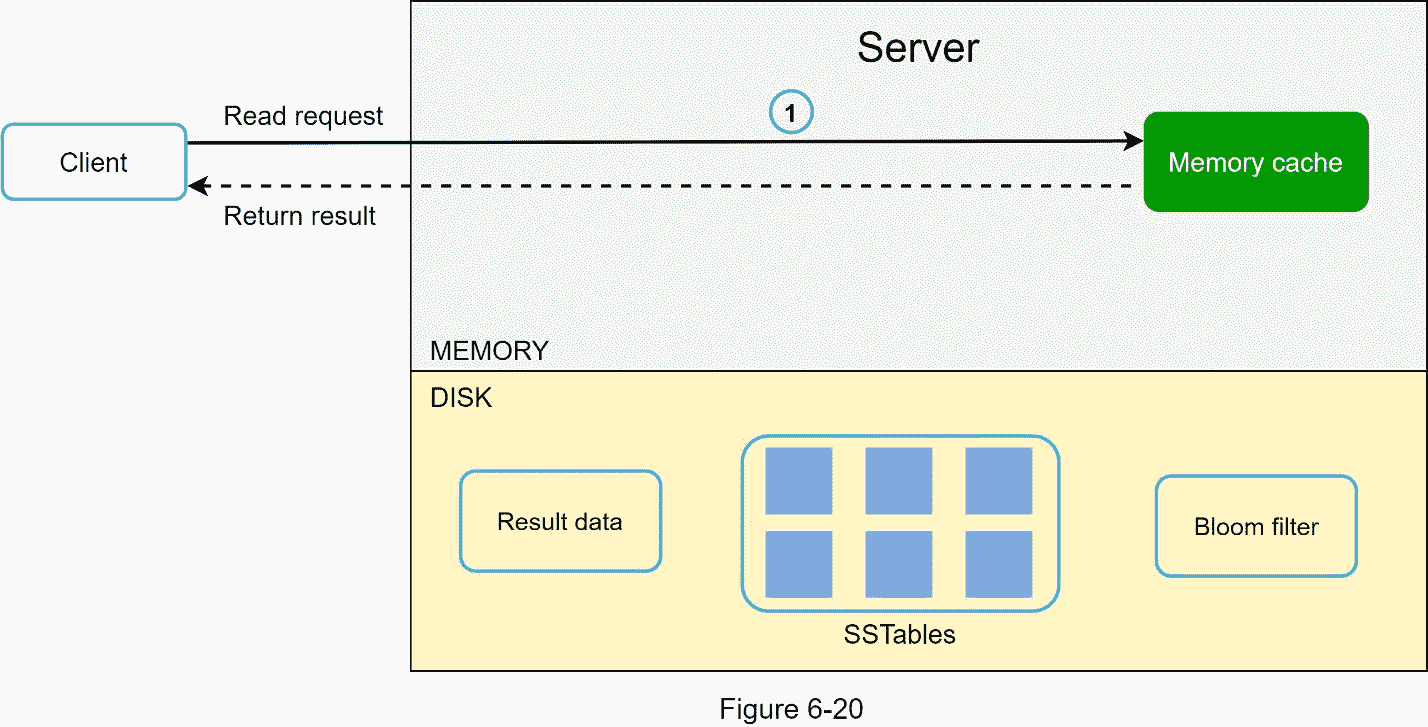
阅读路径
将读取请求定向到特定节点后,它首先检查数据是否在内存缓存中。如果是,数据将返回给客户端,如图 6-20 所示。
如果数据不在内存中,将从磁盘中检索。我们需要一种有效的方法来找出哪个表包含密钥。布鲁姆过滤器[10]通常用于解决这个问题。
当数据不在内存中时,读取路径如图 6-21 所示。
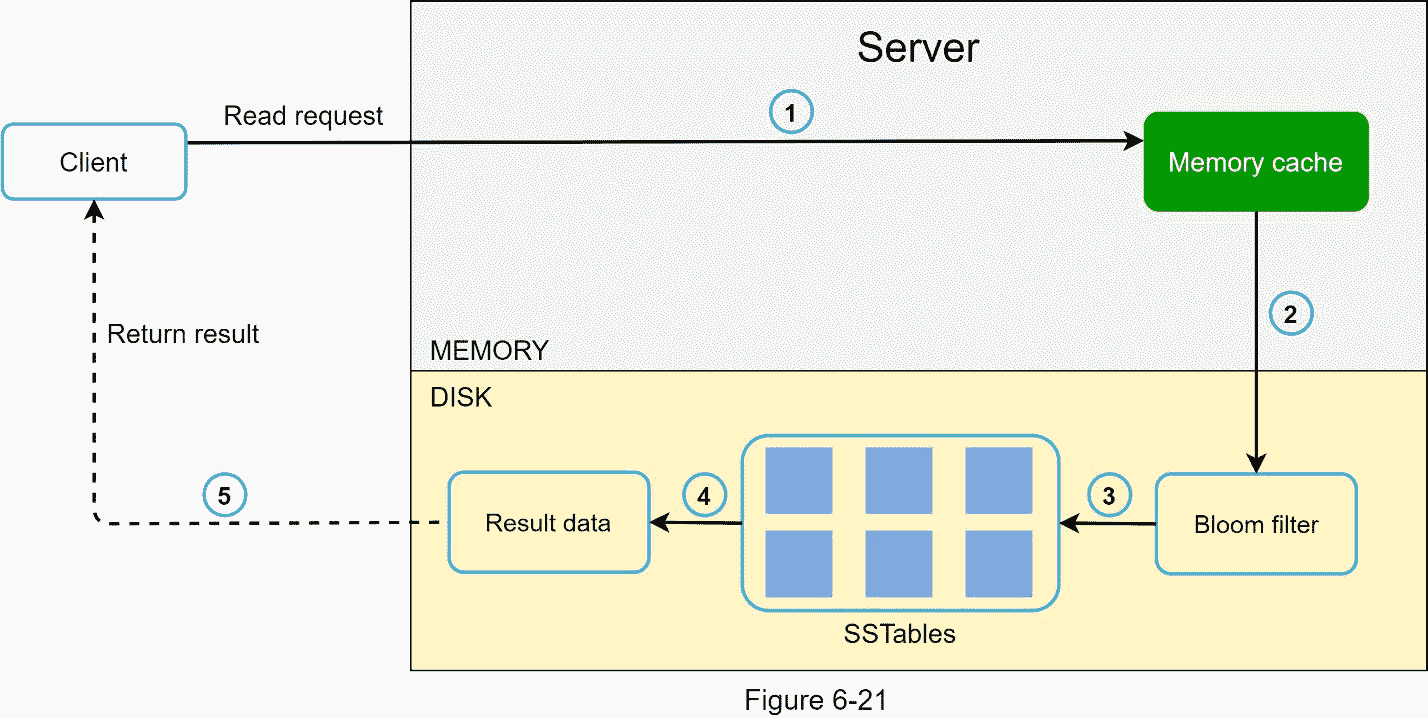
1。系统首先检查数据是否在内存中。如果没有,请转到步骤 2。
2。如果数据不在内存中,系统会检查布隆过滤器。
3。布隆过滤器用于确定哪些表可能包含该密钥。
4。SSTables 返回数据集的结果。
5。数据集的结果被返回给客户端。
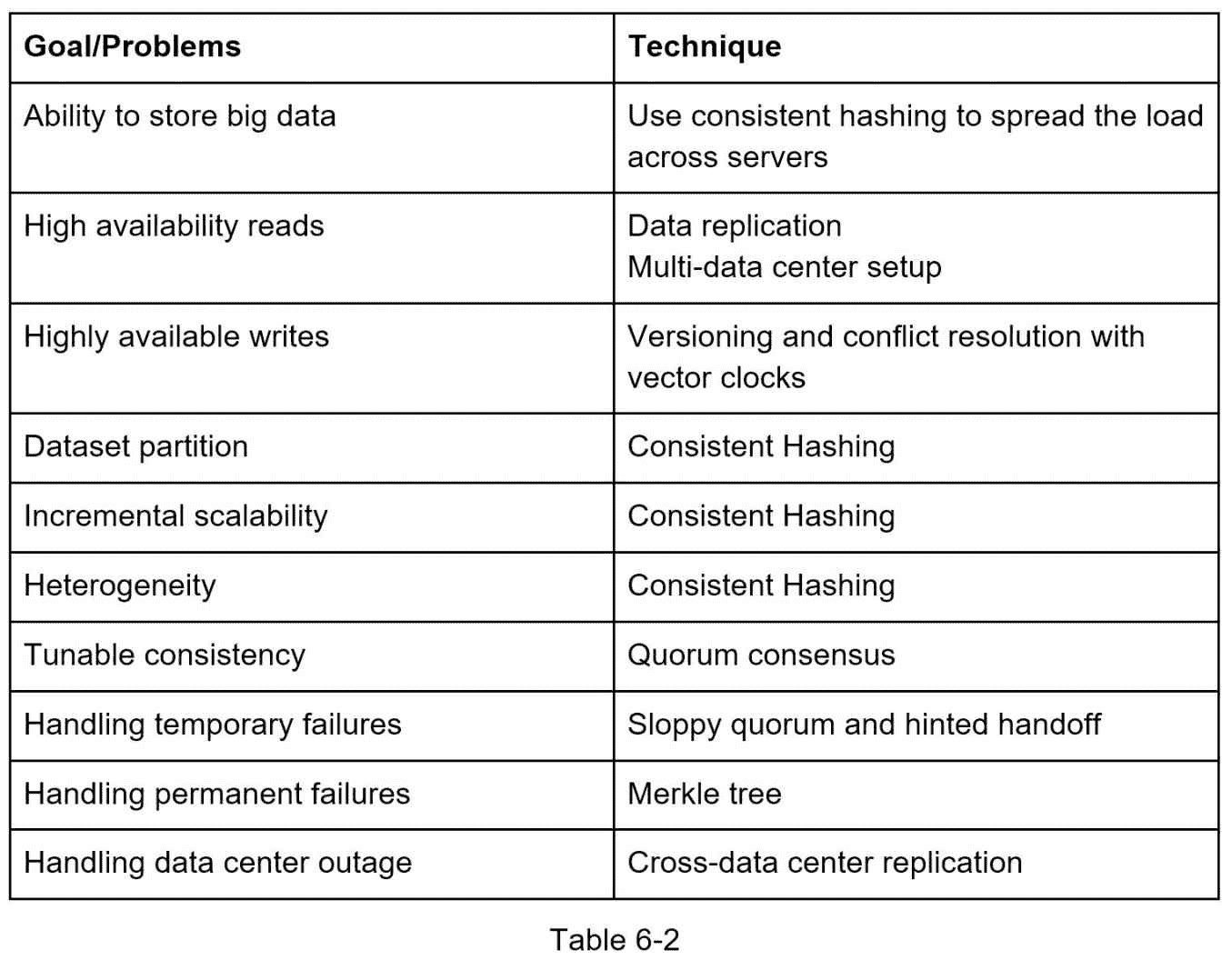
总结
本章涵盖了许多概念和技术。为了提醒您,下表总结了分布式键值存储所使用的功能和相应的技术。
参考资料
[1] Amazon DynamoDB: https://aws.amazon.com/dynamodb/
[2] memcached: https://memcached.org/
[3] Redis: https://redis.io/
[4] Dynamo: Amazon’s Highly Available Key-value Store: https://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf
[5] Cassandra: https://cassandra.apache.org/
[6] Bigtable: A Distributed Storage System for Structured Data: https://static.googleusercontent.com/media/research.google.com/en//archive/bigtable-osdi06.pdf
[7] Merkle tree: https://en.wikipedia.org/wiki/Merkle_tree
[8] Cassandra architecture: https://cassandra.apache.org/doc/latest/architecture/
[9] SStable: https://www.igvita.com/2012/02/06/sstable-and-log-structured-storage-leveldb/
[10] Bloom filter https://en.wikipedia.org/wiki/B
七、设计分布式系统中的唯一 ID 生成器
在这一章中,你被要求在分布式系统中设计一个唯一的 ID 生成器。您首先想到的可能是在传统数据库中使用带有 auto_increment 属性的主键。然而, auto_increment 在分布式环境中不起作用,因为单个数据库服务器不够大,并且在最小延迟的情况下跨多个数据库生成唯一的 id 具有挑战性。
这里有几个唯一 id 的例子:

步骤 1 -了解问题并确定设计范围
提出澄清性问题是解决任何系统设计面试问题的第一步。下面是一个应聘者与面试官互动的例子:
候选人 :唯一 id 有什么特点?
采访者 :身份证必须是唯一的,可排序的。
候选人 :每增加一条新记录,ID 增加 1 吗?
面试官:ID 随时间递增,但不一定只递增 1。同一天晚上创建的 id 比早上创建的 id 大。
候选人:id 只包含数值吗?
面试官 :是的,没错。
考生 :身份证长度有什么要求?
采访者 :身份证应该是 64 位的。
候选人 :系统的规模是多少?
面试官 :系统每秒应该能生成 10000 个 id。
以上是你可以问面试官的一些问题。理解需求和澄清歧义是很重要的。对于这个面试问题,要求如下:
id 必须唯一。
id 仅为数值。
IDs 适合 64 位。
id 按日期排序。
每秒生成超过 10,000 个唯一 id 的能力。
第二步——提出高水平的设计并获得认同
在分布式系统中,可以使用多个选项来生成唯一的 id。我们考虑的选项有:
多主复制
UUID
票务服务器
推特雪花逼近
让我们来看看每一种方法,它们是如何工作的,以及每种方法的优缺点。
多主机复制
如图 7-2 所示,第一种方法是多主机复制。
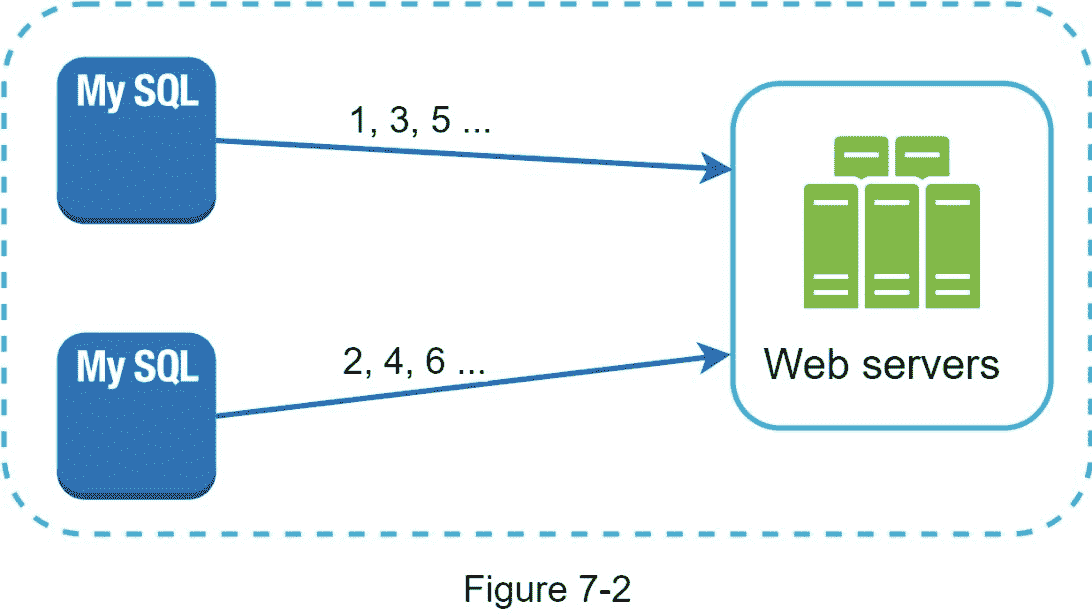
这种方式使用了数据库的 auto_increment 特性。我们没有将下一个 ID 增加 1,而是增加了k, ,其中 k 是正在使用的数据库服务器的数量。如图 7-2 所示,要生成的下一个 ID 等于同一服务器中的前一个 ID 加 2。这解决了一些可伸缩性问题,因为 IDs 可以随着数据库服务器的数量而伸缩。然而,这种策略有一些主要的缺点:
难以扩展多个数据中心
跨多台服务器的 IDs 不随时间上升。
添加或删除服务器时,它无法很好地扩展。
UUID
UUID 是获得唯一 ID 的另一种简单方法。UUID 是一个 128 位的数字,用于识别计算机系统中的信息。UUID 获得共谋的概率非常低。引用维基百科,“在大约 100 年内每秒生成 10 亿个 UUIDs 后,创建一个单一副本的概率会达到 50%”[1]。
下面举个 UUID 的例子:09 c93e 62-50 B4-468d-bf8a-c 07e 1040 bfb 2。可以独立生成,不需要服务器之间的协调。图 7-3 展示了 UUIDs 的设计。
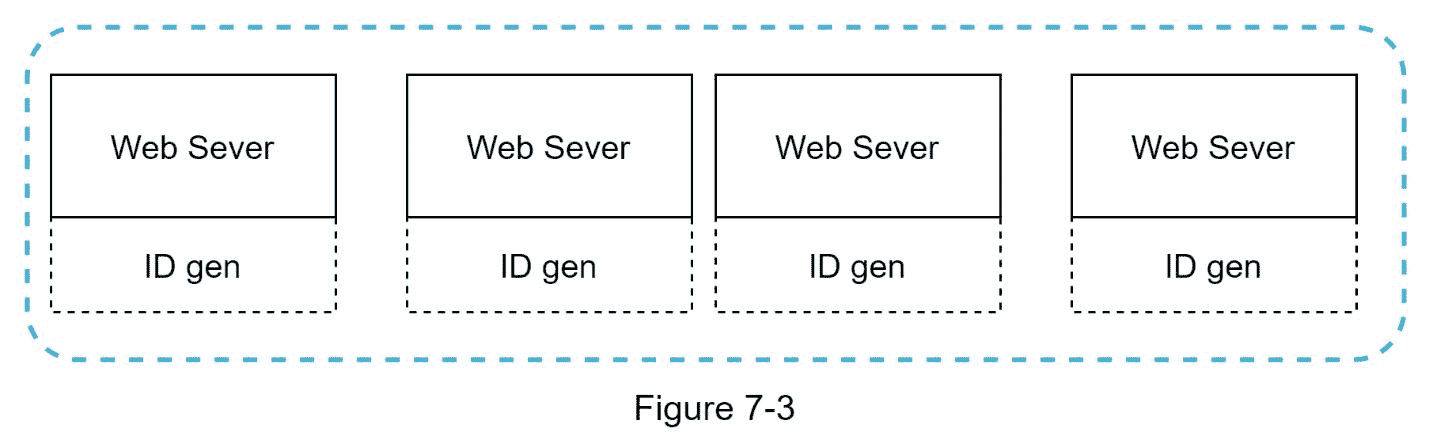
在这个设计中,每个 web 服务器都包含一个 ID 生成器,一个 web 服务器独立负责生成 ID。
优点:
生成 UUID 很简单。服务器之间不需要协调,所以不会有任何同步问题。
这个系统很容易扩展,因为每个 web 服务器负责生成它们所使用的 id。ID 生成器可以很容易地与 web 服务器一起伸缩。
缺点:
id 是 128 位长,但我们的要求是 64 位。
id 不随时间而涨。
id 可以是非数字的。
票务服务器
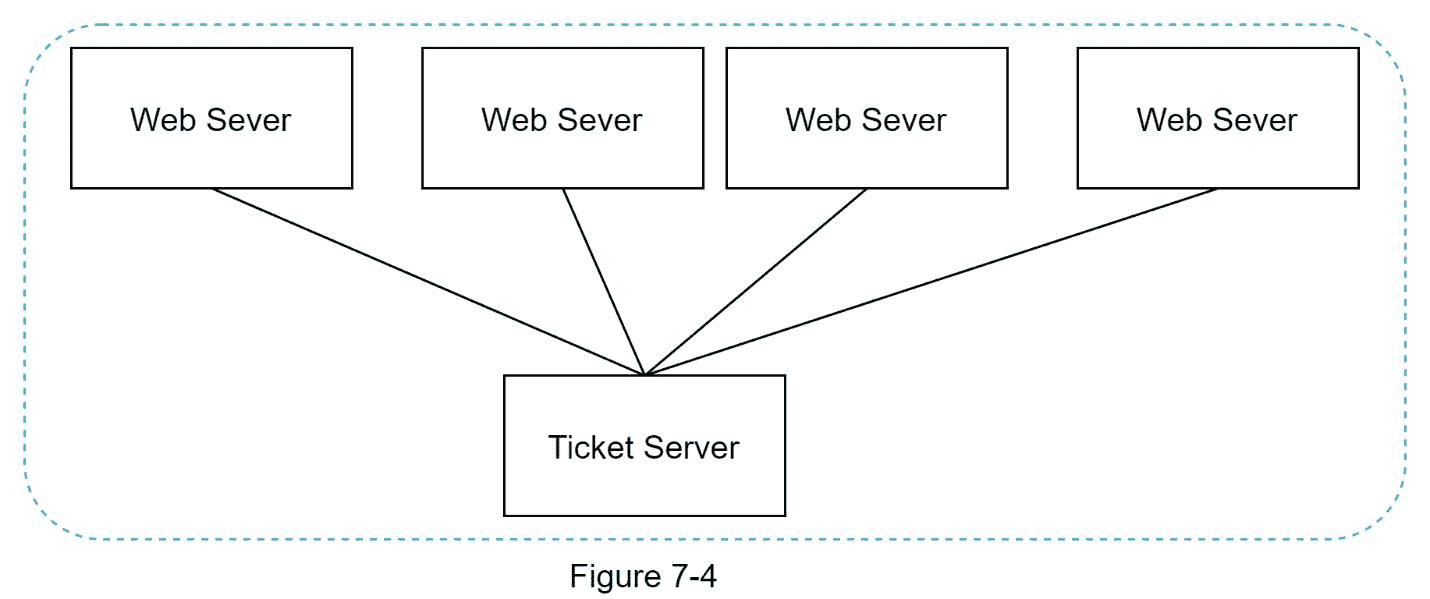
票证服务器是另一种生成唯一 id 的有趣方式。Flicker 开发了票证服务器来生成分布式主键[2]。值得一提的是这个系统是如何工作的。
这个想法是在单个数据库服务器(票证服务器)中使用集中式的 自动增量 功能。要了解这方面的更多信息,请参考 flicker 的工程博客文章[2]。
优点:
数字标识。
易于实现,适用于中小型应用。
缺点:
单点故障。单一票证服务器意味着如果票证服务器宕机,所有依赖它的系统都将面临问题。为了避免单点故障,我们可以设置多个票证服务器。然而,这将引入新的挑战,例如数据同步。
推特雪花接近
上面提到的方法给了我们一些关于不同 ID 生成系统如何工作的想法。然而,它们都不符合我们的具体要求;因此,我们需要另一种方法。Twitter 独特的 ID 生成系统叫做“雪花”[3]很有启发性,可以满足我们的要求。
分而治之是我们的朋友。我们不是直接生成 ID,而是将 ID 分成不同的部分。图 7-5 显示了一个 64 位 ID 的布局。

每一部分解释如下。
标志位:1 位。它将永远是 0。这是为将来使用而保留的。它可以潜在地用于区分有符号和无符号数。
时间戳:41 位。自纪元或自定义纪元以来的毫秒数。我们使用 Twitter 雪花默认纪元 1288834974657,相当于 2010 年 11 月 4 日 01:42:54 UTC。
数据中心 ID: 5 位,这给了我们 2 ^ 5 = 32 数据中心。
机器 ID: 5 位,即每个数据中心有 2 ^ 5 = 32台 机器。
序号:12 位 。对于在该机器/进程上生成的每个 ID,序列号增加 1。该数字每毫秒重置为 0。
步骤 3 -设计深度潜水
在概要设计中,我们讨论了在分布式系统中设计唯一 ID 生成器的各种方案。我们决定采用一种基于 Twitter 雪花 ID 生成器的方法。让我们深入研究一下这个设计。为了提醒我们,下面重新列出了设计图。

数据中心 id 和机器 id 在启动时选择,通常在系统启动运行后固定。数据中心 ID 和机器 ID 的任何更改都需要仔细检查,因为这些值的意外更改会导致 ID 冲突。ID 生成器运行时会生成时间戳和序列号。
时间戳
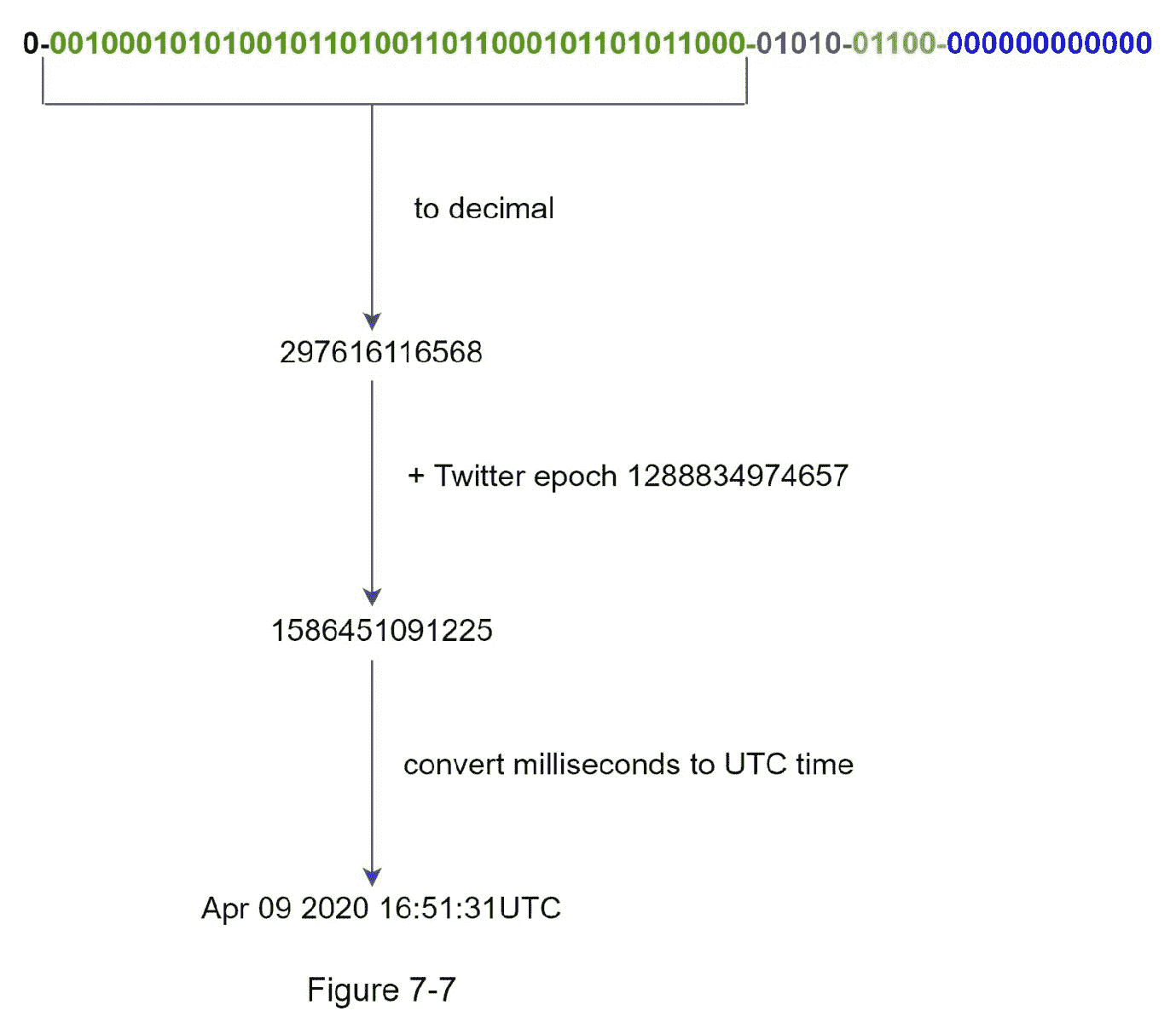
最重要的 41 位组成时间戳部分。随着时间戳随着时间的增长,id 可以按时间排序。图 7-7 显示了一个二进制表示如何转换成 UTC 的例子。您也可以使用类似的方法将 UTC 转换回二进制表示。
可以用 41 位表示的最大时间戳是
2 ^ 41 - 1 = 2199023255551 毫秒(ms),由此我们得到:~ 69 年 = 2199023255551 毫秒 / 1000 秒 / 365 天 / 24 小时 / 3600 秒。这意味着 ID 生成器将工作 69 年,拥有一个接近今天日期的自定义纪元时间会延迟溢出时间。69 年后,我们将需要一个新的纪元时间或采用其他技术来迁移 IDs。
序号
序列号是 12 位,这给我们 2 ^ 12 = 4096 个组合。除非在同一台服务器上一毫秒内生成了多个 ID,否则该字段为 0。理论上,一台机器每毫秒最多可以支持 4096 个新 id。
步骤 4 -总结
在本章中,我们讨论了设计唯一 ID 生成器的不同方法:多主机复制、UUID、票据服务器和 Twitter 雪花型唯一 ID 生成器。我们选择了雪花,因为它支持我们所有的用例,并且可以在分布式环境中扩展。
如果在采访结束时有额外的时间,这里有一些额外的谈话要点:
时钟同步。在我们的设计中,我们假设 ID 生成服务器具有相同的时钟。当服务器在多个内核上运行时,这种假设可能不成立。在多机场景中也存在同样的挑战。时钟同步的解决方案超出了本书的范围;然而,了解问题的存在是很重要的。网络时间协议是解决这个问题的最流行的方法。感兴趣的读者可以参考参考资料[4]。
分段长度调谐。例如,更少的序列号但更多的时间戳位对于低并发性和长期应用程序是有效的。
高可用性。因为 ID 生成器是一个任务关键型系统,所以它必须高度可用。
祝贺你走到这一步!现在给自己一个鼓励。干得好!
参考资料
[1] Universally unique identifier: https://en.wikipedia.org/wiki/Universally_unique_identifier
[2] Ticket Servers: Distributed Unique Primary Keys on the Cheap:
https://code.flickr.net/2010/02/08/ticket-servers-distributed-unique-primary-keys-on-the-cheap/
[3] Announcing Snowflake: https://blog.twitter.com/engineering/en_us/a/2010/announcing-snowflake.html
[4] Network time protocol: https://en.wikipedia.org/wiki/Ne
八、设计 URL 缩短器
在这一章中,我们将解决一个有趣而经典的系统设计面试问题:设计一个像 tinyurl 这样的 URL 缩短服务。
第一步——了解问题并确定设计范围
系统设计面试问题有意留有开放性。要设计一个精心制作的系统,提出澄清性问题至关重要。
候选人 :你能举例说明网址缩写是如何工作的吗?
面试官 :假设 URL https://www.systeminterview.com/q=chatsystem&c=loggedin&v=v3&l=long 是原 URL。您的服务创建了一个较短的别名:https://tinyurl.com/y7keocwj。如果您单击别名,它会将您重定向到原始 URL。
候选人 :车流量是多少?
面试官 :每天产生 1 亿个网址。
候选人 :网址缩短后有多长?
面试官 :尽量简短。
候选人 :网址缩写中允许使用哪些字符?
面试官 :网址缩写可以是数字(0-9)和字符(a-z,A-Z)的组合。
候选人 :可以删除或更新缩短的网址吗?
采访者 :为了简单起见,我们假设被缩短的网址不能被删除或更新。
以下是基本用例:
1。URL 缩短:给定一个长 URL => 返回一个短得多的 URL
2。URL 重定向:给定一个较短的 URL => 重定向到原来的 URL
3。高可用性、可扩展性和容错考虑
信封估算的背面
写操作:每天产生 1 亿个 URL。
每秒写操作数:1 亿 / 24 / 3600 = 1160
读操作:假设读操作与写操作之比为 10:1,每秒读操作数:1160 * 10 = 11600
假设网址缩写服务将运行 10 年,这意味着我们必须支持1 亿 * 365 = 365 亿条记录。
假设平均 URL 长度为 100。
超过 10 年的存储需求:3650 亿* 100 字节* 10 年= 365 TB
对你来说,和你的面试官一起回顾假设和计算是很重要的,这样你们两个就能达成共识。
第二步——提出高层次设计并获得认同
在本节中,我们将讨论 API 端点、URL 重定向和 URL 缩短流程。
API 终点
API 端点促进了客户端和服务器之间的通信。我们将设计 REST 风格的 API。如果对 restful API 不熟悉,可以参考外部资料,比如参考资料[1]中的那个。一个 URL shortener primary 需要两个 API 端点。
1。URL 缩短。为了创建一个新的短 URL,客户端发送一个 POST 请求,其中包含一个参数:原始的长 URL。API 看起来是这样的:
POST api/v1/data/shorten
请求参数:{longURL: longURLString}
返回快捷链接
2。URL 重定向。为了将短 URL 重定向到相应的长 URL,客户端发送 GET 请求。API 看起来是这样的:
GET api/v1/shortURL
返回 HTTP 重定向的 longURL
网址重定向
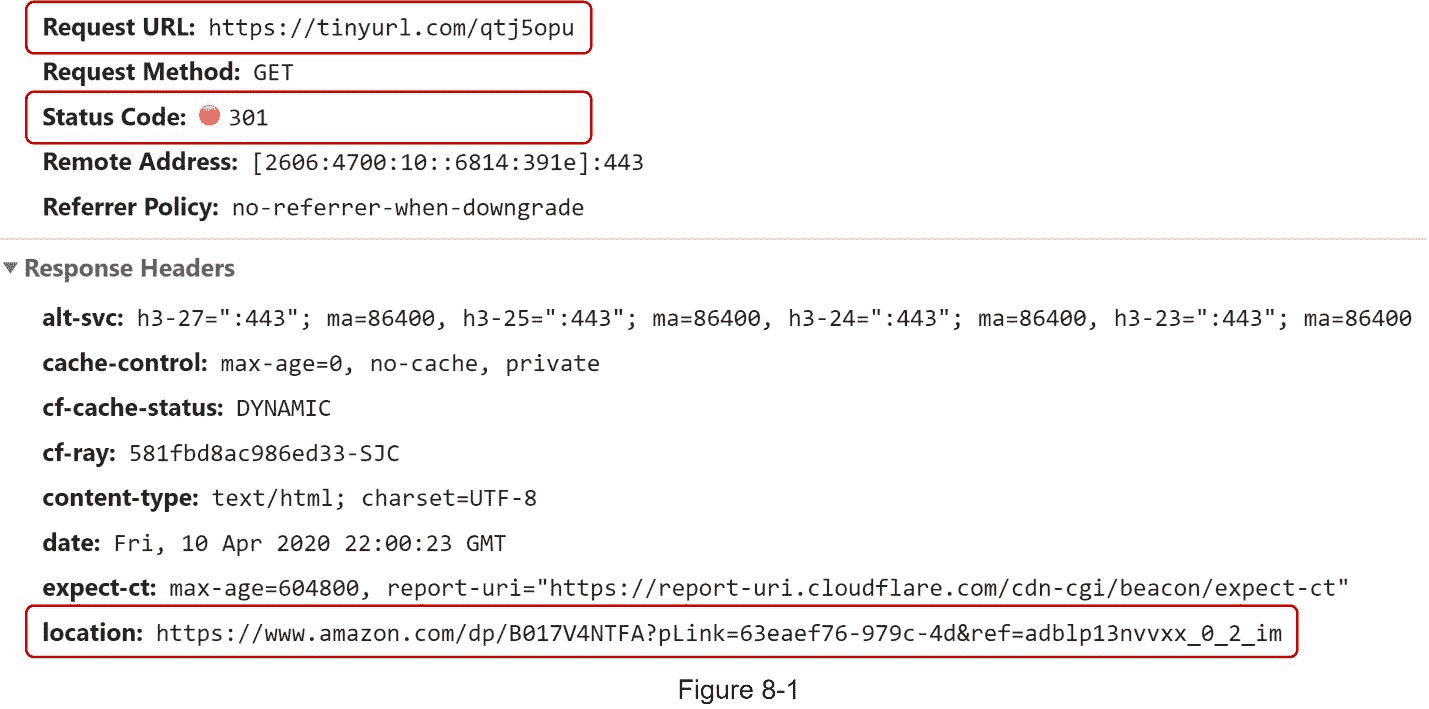
图 8-1 显示了当你在浏览器上输入一个短 url 时会发生什么。一旦服务器接收到短 url 请求,它会使用 301 重定向将短 url 更改为长 URL。
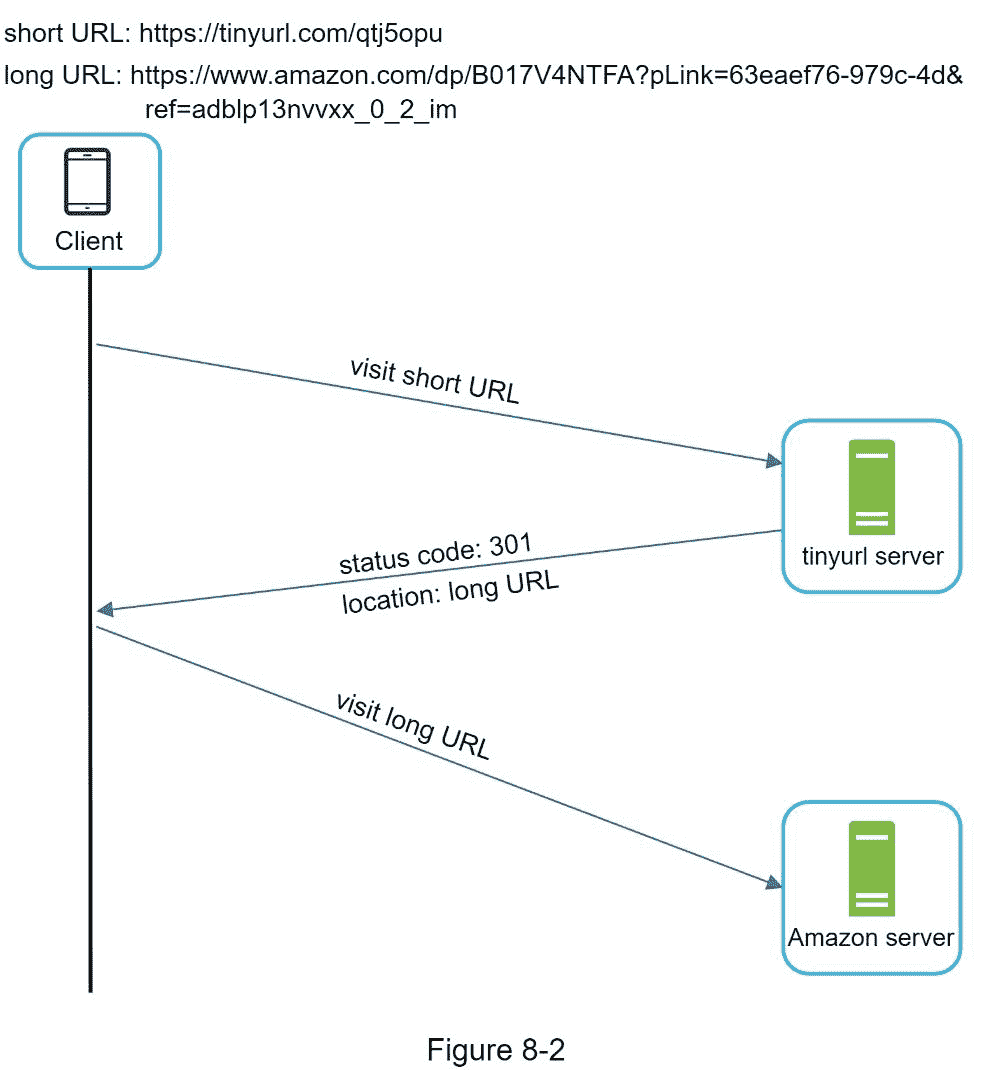
客户端和服务器之间的详细通信如图 8-2 所示。
这里值得讨论的一点是 301 重定向 vs 302 重定向。
301 重定向 。301 重定向显示所请求的 URL 被“永久”移动到长 URL。因为它是永久重定向的,所以浏览器缓存响应,并且对同一 URL 的后续请求将不会被发送到 URL 缩短服务。相反,请求被直接重定向到长 URL 服务器。
302 重定向 。302 重定向意味着 URL 被“临时”移动到长 URL,这意味着对同一 URL 的后续请求将首先被发送到 URL 缩短服务。然后,它们被重定向到长 URL 服务器。
每种重定向方法都有其优点和缺点。如果优先考虑的是减少服务器负载,使用 301 重定向是有意义的,因为只有相同 URL 的第一个请求被发送到 URL 缩短服务器。然而,如果分析很重要,302 重定向是一个更好的选择,因为它可以更容易地跟踪点击率和点击来源。
实现 URL 重定向最直观的方法是使用哈希表。假设哈希表存储了短 URL 长 URL 对,URL 重定向可以通过以下方式实现:
获取 长 URL:longURL = hashtable.get(shortURL)
一旦获得长 URL,就执行 URL 重定向。
网址缩短
让我们假设短 URL 是这样的:www.tinyurl.com/{hashvalue}。为了支持 URL 缩短用例,我们必须找到一个哈希函数 nfx 将一个长 URL 映射到哈希值,如图 8-3 所示。
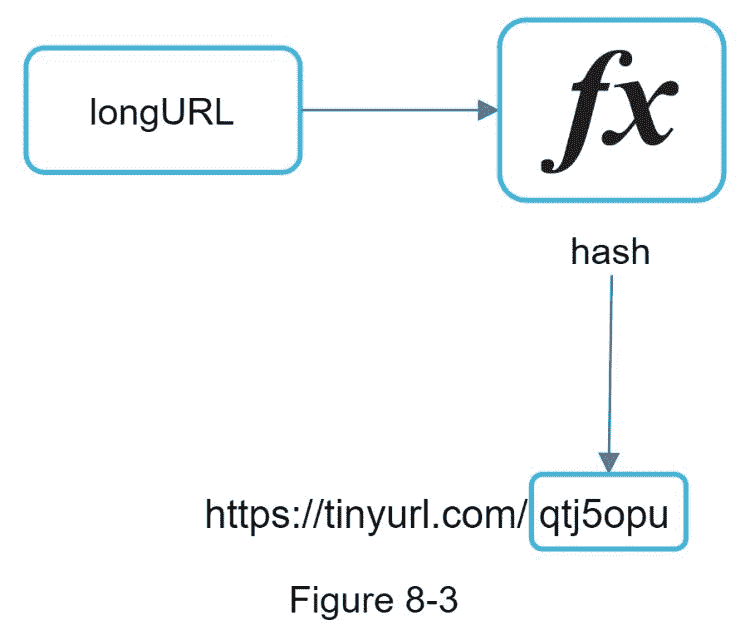
哈希函数必须满足以下要求:
每个 长 URL 都必须哈希为一个 哈希值 。
每个 的哈希值 都可以映射回 长 URL 。
深入讨论哈希函数的详细设计。
步骤 3 -设计深度潜水
到目前为止,我们已经讨论了 URL 缩短和 URL 重定向的高级设计 - 。在本节中,我们将深入探讨以下内容:数据模型、哈希函数、URL 缩短和 URL 重定向。
数据模型
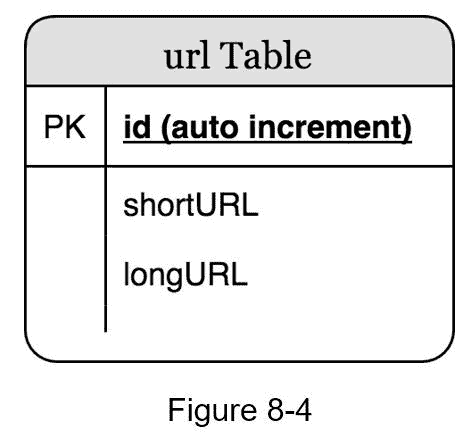
在高层设计中,一切都存储在哈希表中。这是一个很好的起点;然而,这种方法对于真实世界的系统是不可行的,因为存储器资源是有限的并且昂贵的。更好的选择是在关系数据库中存储 < 短 URL,长 URL > 映射。图 8-4 显示了一个简单的数据库表设计。表格的简化版包含 3 列: id , 短 URL,长 URL 。
哈希函数
哈希函数用于将一个长 URL 哈希成一个短 URL,也称为哈希值。
哈希值长度
的哈希值 由[0-9, a-z, A-Z]的字符组成,包含 10 + 26 + 26 = 62 个可能的字符。求 的长度有一个值 ,求最小的 n 使得62^n ≥ 3650亿 。该系统必须支持高达 3650 亿网址的基础上回来的信封估计。表 8-1 显示了哈希值的长度及其对应的可以支持的最大 URL 数。
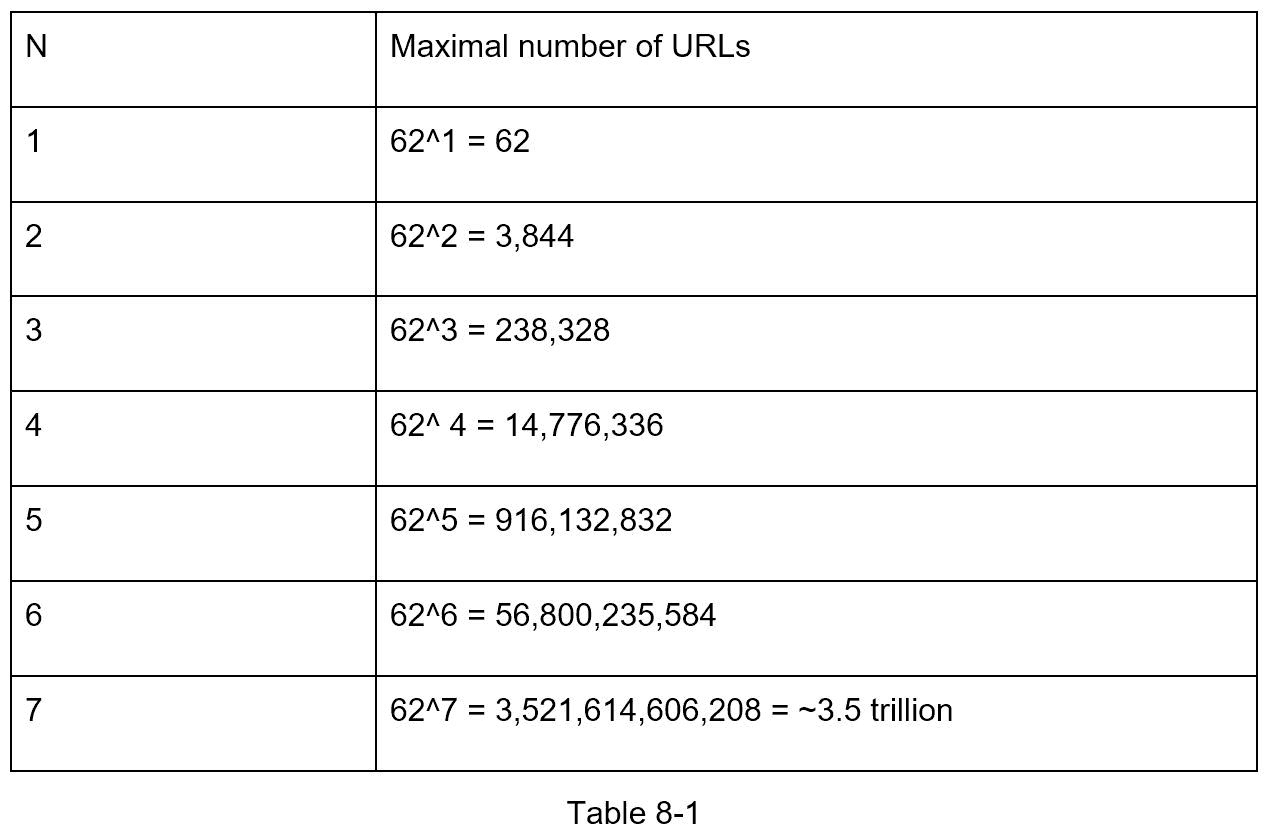
当 n = 7,62 ^ n = ~3.5 万亿 时,3.5 万亿容纳 3650 亿个 URL 绰绰有余,所以哈希值的长度为 7。
我们将探讨两种类型的 URL 缩写哈希函数。第一个是“哈希+冲突解决”,第二个是“base 62 转换”。让我们一个一个来看。
哈希+冲突解决
为了缩短一个长 URL,我们应该实现一个哈希函数,将一个长 URL 哈希成一个 7 个字符的字符串。一个简单的解决方案是使用众所周知的哈希函数,如 CRC32、MD5 或 SHA-1。下表比较了对该 URL 应用不同哈希函数后的哈希结果:https://en.wikipedia.org/wiki/Systems_design.
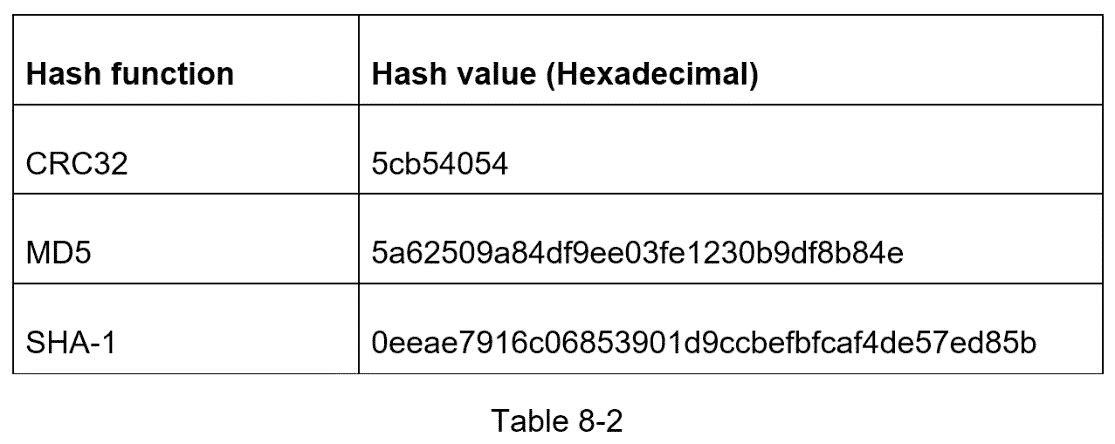
如表 8-2 所示,即使是最短的哈希值(来自 CRC32)也太长(超过 7 个字符)。怎么才能让它变短?
第一种方法是收集哈希值的前 7 个字符;但是,这种方法会导致哈希冲突。为了解决哈希冲突,我们可以递归地添加一个新的预定义字符串,直到不再发现冲突。这个过程如图 8-5 所示。
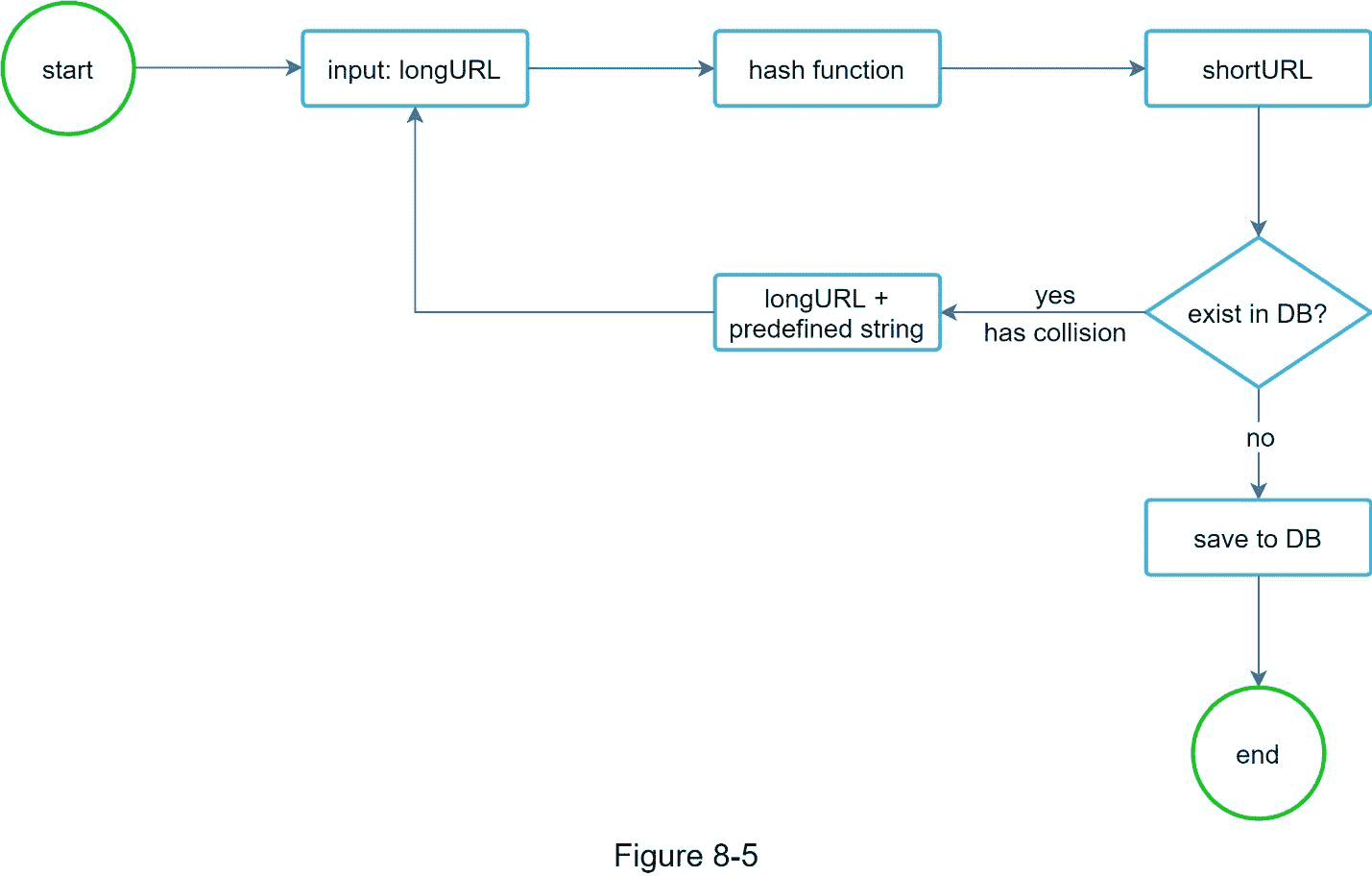
这种方法可以消除碰撞;然而,查询数据库来检查是否每个请求都有一个 短 URL 是很昂贵的。一种叫做 bloom filters [2]的技术可以提高性能。布隆过滤器是一种节省空间的概率技术,用于测试元素是否是集合的成员。更多详情请参考参考资料[2]。
基数 62 转换
基本转换是 URL 缩写常用的另一种方法。基本转换有助于在不同的数字表示系统之间转换相同的数字。由于 的哈希值 有 62 个可能的字符,所以使用 62 进制转换。让我们用一个例子来说明转换是如何进行的:将 1115710 转换为基数为 62 的表示(1115710 在基数为 10 的系统中表示 11157)。
顾名思义,base 62 是使用 62 个字符进行编码的一种方式。映射的是: 0-0、…、9-9、10-a、11-b、…,35-z,36-A,…,61-Z,其中a代表 10,Z代表 61,以此类推。
1115710 = 2 X 622+55 X 621+59 X 620 = [2, 55, 59] -> [2, T, X]以 62 为基数表示。图 8-6 显示了对话过程。

这样,短网址就是 https://tinyurl.com/2TX
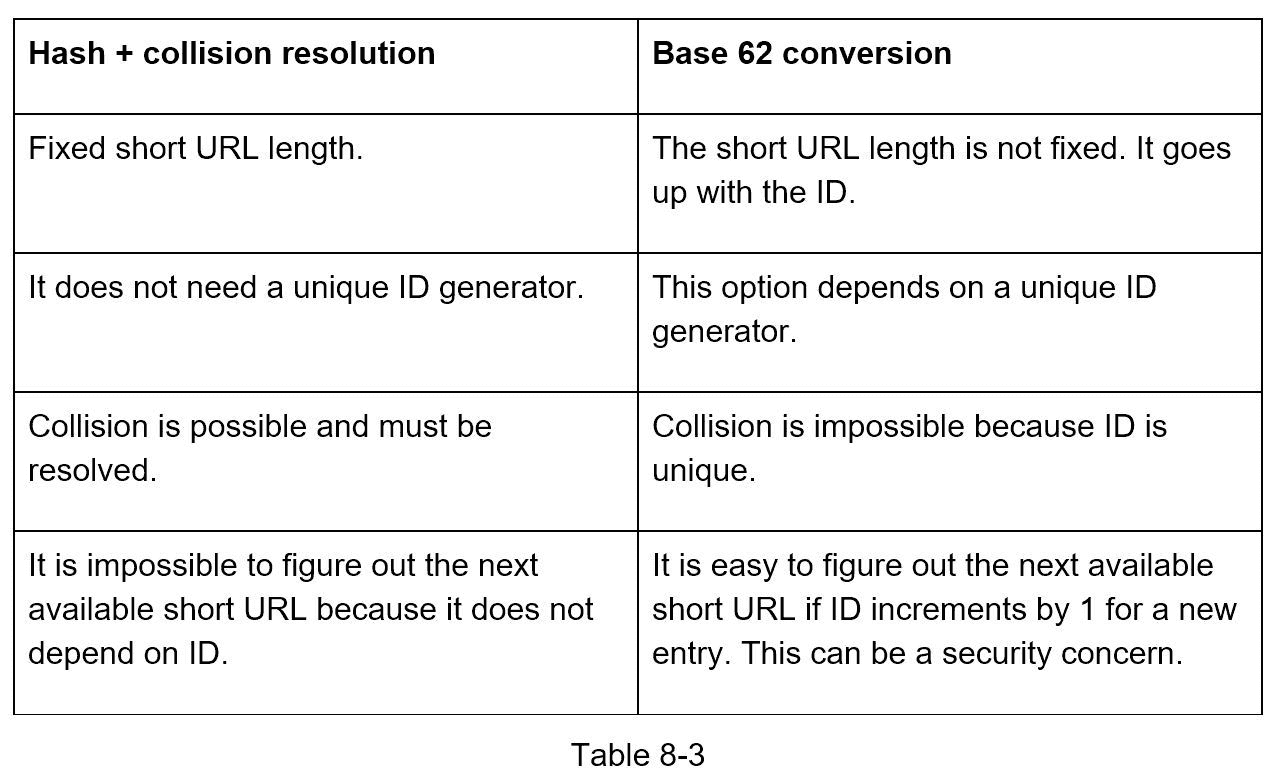
两种方法的比较
表 8-3 显示了这两种方法的区别。
网址缩短深度剖析
作为系统的核心部分之一,我们希望 URL 缩短流程在逻辑上简单且实用。我们的设计采用 62 进制转换。我们构建了下图(图 8-7)来演示这个流程。
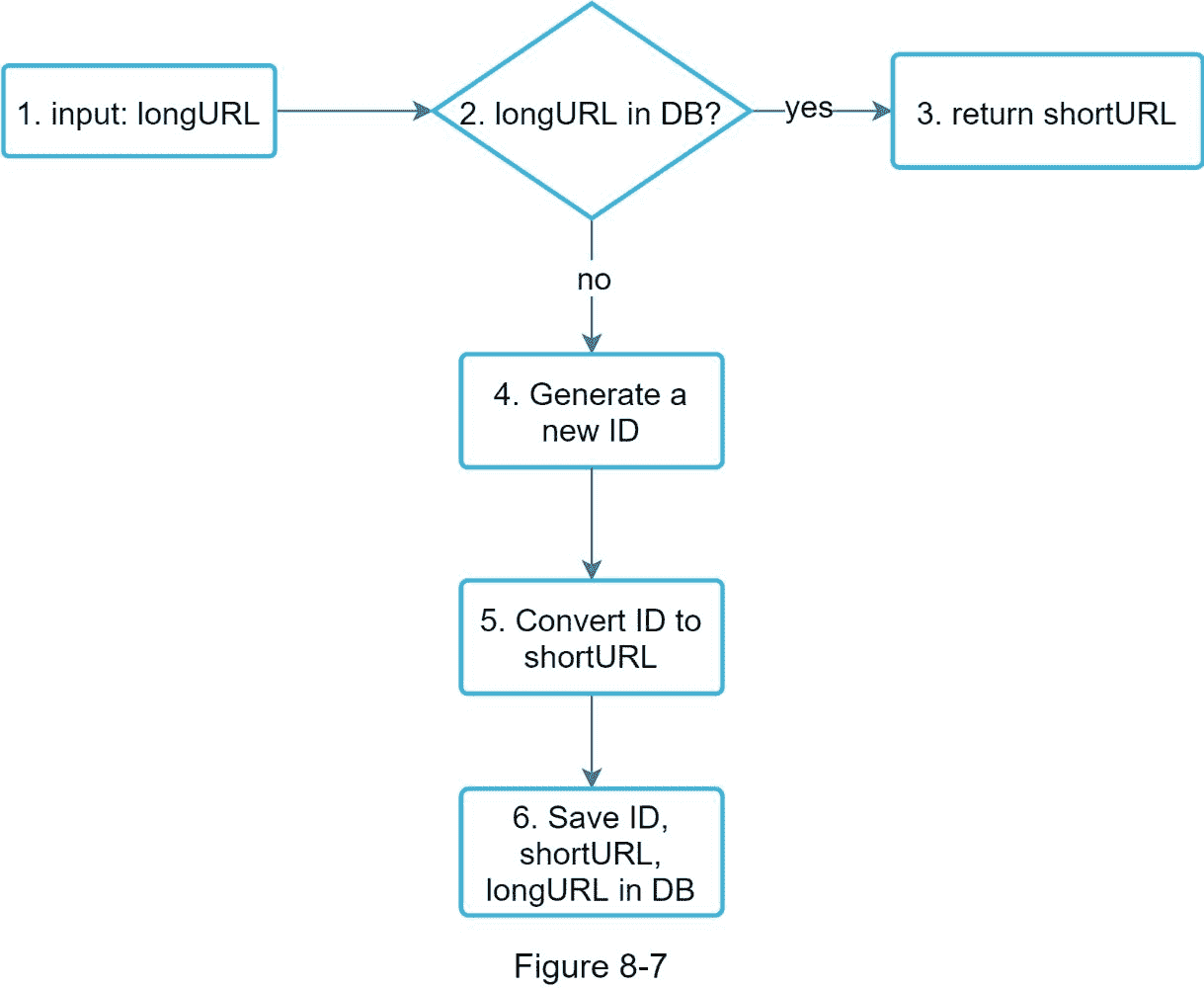
1。长 URL 是输入。
2。系统检查长 URL 是否在数据库中。
3。如果是,则意味着 长 URL 之前被转换为 短 URL。在这种情况下,从数据库获取 短 URL 并将其返回给客户端。
4。如果不是,则 长 URL 是新的。唯一 ID 生成器生成新的唯一 ID(主键)。
5。使用 base 62 转换将 ID 转换为 短 URL。
6。用 ID、短 URL 和 长 URL 创建新的数据库行。
为了让流程更容易理解,让我们看一个具体的例子。
假设输入的 长 URL 是:https://en.wikipedia.org/wiki/Systems_design
唯一 ID 生成器返回 ID: 2009215674938。
使用 62 进制转换将 ID 转换为 短 URL。ID (2009215674938)转换为zn9edcu。
将 ID、短 URL 和 长 URL 保存到数据库,如表 8-4 所示。

值得一提的是分布式唯一 ID 生成器。它的主要功能是生成全局唯一的 id,用于创建 短 URLs。在高度分布式的环境中,实现唯一的 ID 生成器是一项挑战。幸运的是,我们已经在“第七章:在分布式系统中设计唯一的 ID 生成器”中讨论了一些解决方案。你可以回头参考一下,以唤起你的记忆。
URL 重定向深潜
图 8-8 显示了 URL 重定向的详细设计。由于读取比写入多, < 短 URL,长 URL > 映射存储在缓存中以提高性能。

URL 重定向的流程总结如下:
1。用户点击一个短的网址链接:https://tinyurl.com/zn9edcu
2。负载平衡器将请求转发给 web 服务器。
3。如果 短 URL 已经在缓存中,则直接返回 长 URL。
4。如果 短 URL 不在缓存中,则从数据库中获取 长 URL。如果它不在数据库中,则可能是用户输入了无效的 短 URL。
5。将 长 URL 返回给用户。
步骤 4 -总结
在本章中,我们讨论了 API 设计、数据模型、哈希函数、URL 缩短和 URL 重定向。
如果在面试结束时有额外的时间,这里有一些额外的谈话要点。
限速器:我们可能面临的一个潜在安全问题是,恶意用户会发送大量 URL 缩短请求。速率限制器帮助过滤出基于 IP 地址或其他过滤规则的请求。如果你想回忆一下速率限制,请参考“第四章:设计一个速率限制器”。
web 服务器扩展:由于 web 层是无状态的,所以通过添加或删除 Web 服务器来扩展 Web 层是很容易的。
数据库伸缩:数据库复制和分片是常见的技术。
分析:数据对商业成功越来越重要。将分析解决方案集成到 URL shortener 中有助于回答一些重要问题,比如有多少人点击了一个链接?他们什么时候点击链接?等等。
可用性、一致性和可靠性。这些概念是任何大型系统成功的核心。我们在第一章中详细讨论了它们,请刷新您对这些主题的记忆。
祝贺你走到这一步!现在给自己一个鼓励。干得好!
参考资料
[1] A RESTful Tutorial: https://www.restapitutorial.com/index.html
[2] Bloom filter: https://en.wikipedia.org/wiki/Blo














 989
989











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}