







第八章:查询性能优化
在前几章中,我们解释了模式优化和索引,这对于高性能是必要的。但这还不够——您还需要设计良好的查询。如果您的查询不好,即使是设计最佳的模式和索引也不会表现良好。
查询优化、索引优化和模式优化是相辅相成的。随着在 MySQL 中编写查询的经验增加,您将学会如何设计表和索引以支持高效的查询。同样,您所学到的关于最佳模式设计将影响您编写的查询类型。这个过程需要时间,因此我们鼓励您在学习过程中参考这三章。
本章从一般查询设计考虑开始:当查询性能不佳时,您应该首先考虑的事项。然后我们深入研究查询优化和服务器内部。我们将向您展示如何找出 MySQL 如何执行特定查询,并学习如何更改查询执行计划。最后,我们将看看 MySQL 无法很好地优化查询的一些地方,并探索有助于 MySQL 更有效地执行查询的查询优化模式。
我们的目标是帮助您深入了解 MySQL 如何真正执行查询,以便您可以思考什么是高效或低效的,利用 MySQL 的优势,避免其弱点。
查询为什么慢?
在尝试编写快速查询之前,请记住这一切都关乎响应时间。查询是任务,但它们由子任务组成,这些子任务消耗时间。要优化查询,必须通过消除它们、减少发生次数或加快发生速度来优化其子任务。
一般来说,您可以通过在脑海中跟随查询的序列图,从客户端到服务器,解析、规划和执行,然后再返回客户端,来思考查询的生命周期。执行是查询生命周期中最重要的阶段之一。它涉及大量调用存储引擎以检索行,以及后检索操作,如分组和排序。
在完成所有这些任务的同时,查询在网络、CPU 和诸如统计、规划、锁定(互斥等待)以及尤其是调用存储引擎检索行等操作上花费时间。这些调用在内存操作、CPU 操作以及特别是 I/O 操作中消耗时间,如果数据不在内存中的话。根据存储引擎的不同,可能还涉及大量的上下文切换和/或系统调用。
在每种情况下,由于操作是不必要地执行、执行次数过多或速度太慢,可能会消耗过多时间。优化的目标是通过消除或减少操作或使其更快来避免这种情况。
再次强调,这并不是查询生命周期的完整或准确图景。我们在这里的目标是展示理解查询生命周期的重要性,并从时间消耗的角度思考。有了这个理念,让我们看看如何优化查询。
慢查询基础知识:优化数据访问
查询性能不佳的最基本原因是因为它处理了太多数据。有些查询必须筛选大量数据,这是无法避免的。不过,这种情况并不常见;大多数糟糕的查询可以更改以访问更少的数据。我们发现分析性能不佳的查询有两个步骤是有用的:
-
查找应用程序是否检索了比所需更多的数据。通常这意味着它访问了太多行,但也可能访问了太多列。
-
查找MySQL 服务器是否分析了比所需更多的行。
您是否请求了不需要的数据?
有些查询请求了比所需更多的数据,然后丢弃了其中一些。这会给 MySQL 服务器增加额外的工作量,增加网络开销,并在应用程序服务器上消耗内存和 CPU 资源。
以下是一些典型的错误:
检索比所需更多的行
一个常见的错误是假设 MySQL 按需提供结果,而不是计算并返回完整的结果集。我们经常在由熟悉其他数据库系统的人设计的应用程序中看到这种情况。这些开发人员习惯于发出返回许多行的SELECT语句,然后获取前*N*行并关闭结果集(例如,在新闻网站上获取最近的 100 篇文章,而他们只需要在首页显示其中的 10 篇)。他们认为 MySQL 会提供这 10 行并停止执行查询,但 MySQL 实际上会生成完整的结果集。客户端库然后获取所有数据并丢弃大部分数据。最佳解决方案是在查询中添加LIMIT子句。
从多表连接中检索所有列
如果你想检索出出现在电影Academy Dinosaur中的所有演员,不要这样写查询:
SELECT * FROM sakila.actor
INNER JOIN sakila.film_actor USING(actor_id)
INNER JOIN sakila.film USING(film_id)
WHERE sakila.film.title = 'Academy Dinosaur';
这会返回三个表中的所有列。相反,将查询写成如下形式:
SELECT sakila.actor.* FROM sakila.actor...;
检索所有列
当你看到SELECT *时,你应该持怀疑态度。你真的需要所有的列吗?可能不需要。检索所有列可能会阻止优化,如覆盖索引,并为服务器增加 I/O、内存和 CPU 开销。一些数据库管理员普遍不赞成SELECT *,因为这个事实以及为了减少当有人修改表的列列表时出现问题的风险。
当然,并不总是坏事要求比实际需要的数据更多。在我们调查的许多情况下,人们告诉我们这种浪费的方法简化了开发,因为它允许开发人员在多个地方使用相同的代码片段。只要你知道这在性能方面的代价,��是一个合理的考虑。如果你的应用程序中使用某种类型的缓存,或者你有其他目的,检索比实际需要的数据更多可能也是有用的。检索和缓存完整对象可能比运行许多单独的查询检索对象的部分更可取。
重复检索相同的数据
如果不小心,很容易编写应用程序代码,从数据库服务器中重复检索相同的数据,执行相同的查询以获取它。例如,如果你想找出用户的个人资料图片 URL 以显示在评论列表旁边,你可能会为每条评论重复请求这个信息。或者你可以在第一次获取后缓存它并在以后重复使用。后一种方法更有效。
MySQL 是否检查了太多数据?
一旦确定你的查询只检索你需要的数据,你可以寻找生成结果时检查了太多数据的查询。在 MySQL 中,最简单的查询成本指标是:
-
响应时间
-
检查的行数
-
返回的行数
这些指标都不是衡量查询成本的完美方式,但它们大致反映了 MySQL 执行查询时必须内部访问多少数据,并大致转化为查询运行的速度。这三个指标都记录在慢查询日志中,因此查看慢查询日志是发现检查了太多数据的查询的最佳方法之一。
响应时间
警惕只看查询响应时间。嘿,这不是我们一直告诉你的相反吗?其实不然。响应时间仍然很重要,但有点复杂。
响应时间是服务时间和队列时间的总和。服务时间是服务器实际处理查询所需的时间。队列时间是响应时间中服务器实际上并未执行查询的部分——它在等待某些事情,比如等待 I/O 操作完成、等待行锁等。问题在于,除非你可以单独测量这些组件,否则你无法将响应时间分解为这些组件。通常,你会遇到的最常见和重要的等待是 I/O 和锁等待,但你不应该只依赖这两种,因为情况变化很大。I/O 和锁等待之所以重要,是因为它们对性能的影响最大。
因此,在不同负载条件下,响应时间并不一致。其他因素——如存储引擎锁(如行锁)、高并发和硬件——也会对响应时间产生相当大的影响。响应时间也可能是问题的症状和原因,而且并不总是明显哪种情况。
当你查看查询的响应时间时,你应该问自己查询的响应时间是否合理。我们在本书中没有详细解释的空间,但你实际上可以使用 Tapio Lahdenmaki 和 Mike Leach 的书关系数据库索引设计和优化器(Wiley)中解释的技术计算查询响应时间的快速上限估计(QUBE)。简而言之:检查查询执行计划和涉及的索引,确定可能需要多少个顺序和随机 I/O 操作,并将这些乘以硬件执行它们所需的时间。把它们加起来,你就有一个判断查询是否比可能或应当更慢的标准。
检查的行数和返回的行数
在分析查询时,考虑检查的行数是有用的,因为你可以看到查询是否高效地找到你需要的数据。然而,这并不是一个找到“坏”查询的完美指标。并非所有行访问都是相等的。较短的行访问速度更快,从内存中获取行比从磁盘中读取行要快得多。
理想情况下,检查的行数应该与返回的行数相同,但实际上这很少可能。例如,在构建连接行时,服务器必须访问多个行以生成结果集中的每一行。检查的行数与返回的行数的比率通常很小——比如,1:1 到 10:1 之间,但有时可能相差几个数量级。
扫描的行数和访问类型
当你考虑查询的成本时,考虑在表中找到单个行的成本。MySQL 可以使用多种访问方法来查找和返回行。有些需要检查许多行,但其他可能能够在不检查任何行的情况下生成结果。
访问方法出现在EXPLAIN输出的type列中。访问类型从完整表扫描到索引扫描、范围扫描、唯一索引查找和常量。每种访问类型都比前一种更快,因为它需要读取的数据更少。你不需要记住访问类型,但你应该理解扫描表、扫描索引、范围访问和单值访问的一般概念。
如果你没有得到一个好的访问类型,通常解决问题的最佳方法是添加一个适当的索引。我们在前一章讨论了索引;现在你可以看到为什么索引对查询优化如此重要。索引让 MySQL 能够以更有效的访问类型找到行,从而减少数据的检查。
例如,让我们看一个在 Sakila 示例数据库上的简单查询:
SELECT * FROM sakila.film_actor WHERE film_id = 1;
这个查询将返回 10 行,EXPLAIN显示 MySQL 使用idx_fk_film_id索引上的ref访问类型来执行查询:
mysql> EXPLAIN SELECT * FROM sakila.film_actor WHERE film_id = 1\G
*************************** 1\. row ***************************
id: 1
select_type: SIMPLE
table: film_actor
partitions: NULL
type: ref
possible_keys: idx_fk_film_id
key: idx_fk_film_id
key_len: 2
ref: const
rows: 10
filtered: 100.00
Extra: NULL
EXPLAIN 显示 MySQL 估计只需要访问 10 行。换句话说,查询优化器知道所选的访问类型可以有效地满足查询。如果查询没有合适的索引会发生什么?如果我们删除索引并再次运行查询,MySQL 将不得不使用一个不太优化的访问类型,正如我们可以看到的:
mysql> ALTER TABLE sakila.film_actor DROP FOREIGN KEY fk_film_actor_film;
mysql> ALTER TABLE sakila.film_actor DROP KEY idx_fk_film_id;
mysql> EXPLAIN SELECT * FROM sakila.film_actor WHERE film_id = 1\G
*************************** 1\. row ***************************
id: 1
select_type: SIMPLE
table: film_actor
partitions: NULL
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 5462
filtered: 10.00
Extra: Using where
1 row in set, 1 warning (0.00 sec)
可预测的是,访问类型已经变为全表扫描(ALL),MySQL 现在估计它将需要检查 5,462 行来满足查询。Extra列中的“Using where”显示 MySQL 服务器正在使用WHERE子句在存储引擎读取行后丢弃行。
一般来说,MySQL 可以以三种方式应用WHERE子句,从最好到最差:
-
将条件应用于索引查找操作,以消除不匹配的行。这发生在存储引擎层。
-
使用覆盖索引(
Extra列中的“Using index”)避免行访问,并在从索引检索每个结果后过滤掉不匹配的行。这发生在服务器层,但不需要从表中读取行。 -
从表中检索行,然后过滤不匹配的行(“在
Extra列中使用 where”)。这发生在服务器层,需要服务器在过滤行之前从表中读取行。
这个例子说明了拥有良好索引是多么重要。良好的索引帮助你的查询获得良好的访问类型,并仅检查它们需要的行。然而,添加索引并不总是意味着 MySQL 将访问和返回相同数量的行。例如,这里有一个使用COUNT()²聚合函数的查询:
mysql> SELECT actor_id, COUNT(*)
-> FROM sakila.film_actor GROUP BY actor_id;
+----------+----------+
| actor_id | COUNT(*) |
+----------+----------+
| 1 | 19 |
| 2 | 25 |
| 3 | 22 |
.. omitted..
| 200 | 20 |
+----------+----------+
200 rows in set (0.01 sec)
此查询仅返回 200 行,但它需要读取多少行?我们可以通过EXPLAIN来检查,就像我们在上一章中讨论的那样:
mysql> EXPLAIN SELECT actor_id, COUNT(*)
-> FROM sakila.film_actor GROUP BY actor_id\G
*************************** 1\. row ***************************
id: 1
select_type: SIMPLE
table: film_actor
partitions: NULL
type: index
possible_keys: PRIMARY
key: PRIMARY
key_len: 4
ref: NULL
rows: 5462
filtered: 100.00
Extra: Using index
糟糕!读取数千行只需要 200 行意味着我们做了比必要更多的工作。对于这样的查询,索引无法减少检查的行数,因为没有WHERE子句来消除行。
不幸的是,MySQL 不会告诉你它访问的行中有多少被用来构建结果集;它只告诉你它访问的总行数。这些行中的许多行可能会被WHERE子句消除,并最终不会对结果集做出贡献。在前面的例子中,删除sakila.film_actor上的索引后,查询访问了表中的每一行,而WHERE子句丢弃了除了其中的 10 行之外的所有行。只有剩下的 10 行被用来构建结果集。理解服务器访问了多少行以及它实际使用了多少行需要对查询进行推理。
如果发现为了生成相对较少的结果而检查了大量行,你可以尝试一些更复杂的修复方法:
-
使用覆盖索引,它存储数据,使得存储引擎不必检索完整的行。(我们在第七章中讨论过这些。)
-
更改模式。一个例子是使用摘要表(在第六章中讨论)。
-
重写一个复杂的查询,以便 MySQL 优化器能够最佳地执行它。(我们将在本章后面讨论这个问题。)
重构查询的方法
在优化有问题的查询时,你的目标应该是找到获取你想要的结果的替代方法,但这并不一定意味着从 MySQL 中获得相同的结果集。有时候,你可以将查询转换为返回相同结果且性能更好的等价形式。然而,你也应该考虑重写查询以检索不同的结果,如果这样做能提高效率的话。最终,通过改变应用程序代码以及查询,你可能能够完成相同的工作。在本节中,我们将解释一些技术,帮助你重构各种查询,并告诉你何时使用每种技术。
复杂查询与多个查询
一个重要的查询设计问题是是否更倾向于将复杂查询分解为几个简单查询。传统的数据库设计方法强调尽可能用尽可能少的查询来完成尽可能多的工作。这种方法在历史上更好,因为网络通信的成本和查询解析和优化阶段的开销。
然而,这个建议在 MySQL 上不太适用,因为它被设计为非常高效地处理连接和断开连接,并且对小型、简单的查询作出快速响应。现代网络也比以前快得多,减少了网络延迟。根据服务器版本,MySQL 可以在商品服务器硬件上每秒运行超过十万个简单查询,并且在千兆网络上从单个对应方每秒运行超过两千个 QPS,因此运行多个查询并不一定是一件坏事。
与 MySQL 每秒内部遍历的行数相比,连接响应仍然很慢,尽管对于内存数据,每秒可以计数为百万级。其他条件相同的情况下,尽可能使用较少的查询仍然是个好主意,但有时你可以通过分解查询并执行几个简单的查询而不是一个复杂的查询来使查询更有效。不要害怕这样做;权衡成本,选择导致工作量较少的策略。我们稍后在本章中展示了一些这种技术的例子。
使用过多查询是应用设计中的常见错误。例如,一些应用程序执行 10 个单行查询以从表中检索数据,而实际上它们可以使用一个包含 10 行的查询。我们甚至看到一些应用程序会逐个检索每一列,多次查询每一行!
分解查询
另一种分解查询的方法是分而治之,保持基本相同但在影响更少行的情况下以较小的“块”运行它。
清理旧数据是一个很好的例子。定期清理作业可能需要删除大量数据,如果在一个巨大的查询中执行此操作可能会锁定很多行很长时间,填满事务日志,占用资源,并阻塞不应被中断的小查询。分解DELETE语句并使用中等大小的查询可以显著提高性能,并在查询被复制时减少复制延迟。例如,与其运行这个庞大的查询:
DELETE FROM messages
WHERE created < DATE_SUB(NOW(),INTERVAL 3 MONTH);
您可以做类似以下伪代码:
rows_affected = 0
do {
rows_affected = do_query(
"DELETE FROM messages WHERE created < DATE_SUB(NOW(),INTERVAL 3 MONTH)
LIMIT 10000")
} while rows_affected > 0
每次删除 10,000 行通常是一个足够大的任务,使每个查询都有效,并且足够短的任务以最小化对服务器的影响³(事务存储引擎可能受益于更小的事务)。在DELETE语句之间添加一些休眠时间以分散负载并减少锁定时间也可能是个好主意。
连接分解
许多高性能应用程序使用连接分解。您可以通过运行多个单表查询而不是多表连接来分解连接,然后在应用程序中执行连接。例如,与其这样的单个查询:
SELECT * FROM tag
JOIN tag_post ON tag_post.tag_id=tag.id
JOIN post ON tag_post.post_id=post.id
WHERE tag.tag='mysql';
您可能会运行这些查询:
SELECT * FROM tag WHERE tag='mysql';
SELECT * FROM tag_post WHERE tag_id=1234;
SELECT * FROM post WHERE post.id in (123,456,567,9098,8904);
为什么要这样做?乍一看,这看起来是浪费的,因为您增加了查询的数量,却没有得到任何回报。然而,这种重组实际上可以带来显著的性能优势:
-
缓存可能更有效。许多应用程序会缓存直接映射到表的“对象”。在这个例子中,如果带有标签
mysql的对象已经被缓存,应用程序可以跳过第一个查询。如果在缓存中找到 ID 为 123、567 或 9098 的帖子,可以将它们从IN()列表中移除。 -
有时逐个执行查询可以减少锁争用。
-
在应用程序中进行连接使得通过将表放置在不同的服务器上更容易扩展数据库。
-
查询本身可能更有效率。在这个例子中,使用
IN()列表而不是连接让 MySQL 对行 ID 进行排序,并更优化地检索行,这可能比使用连接更有效。 -
您可以减少冗余的行访问。在应用程序中进行连接意味着您只检索每行一次,而在查询中进行连接本质上是一种反规范化,可能会重复访问相同的数据。出于同样的原因,这种重组也可能减少总网络流量和内存使用。
因此,在应用程序中进行连接时,如果您从先前的查询中缓存和重复使用大量数据,将数据分布在多个服务器上,将连接替换为IN()列表在大表上,或者连接多次引用同一表时,可能会更有效率。
查询执行基础知识
如果您需要从 MySQL 服务器获得高性能,最好的投资之一是学习 MySQL 如何优化和执行查询。一旦您理解了这一点,大部分查询优化都是根据原则推理,查询优化变得非常逻辑。
让我们重新审视我们之前讨论的内容:MySQL 执行查询的过程。图 8-1 展示了当您向 MySQL 发送查询时会发生什么:
-
客户端将 SQL 语句发送到服务器。
-
服务器将其解析、预处理并优化为查询执行计划。
-
查询执行引擎通过调用存储引擎 API 执行计划。
-
服务器将结果发送给客户端。
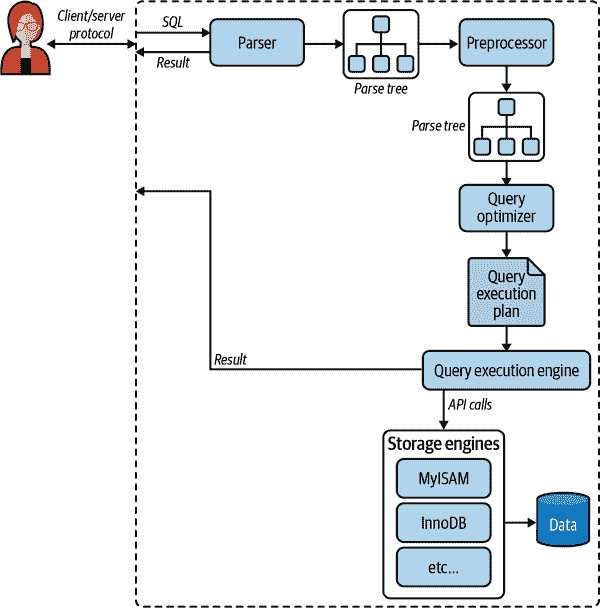
图 8-1. 查询的执行路径
每个步骤都有一些额外的复杂性,我们将在接下来的章节��讨论。我们还会解释在每个步骤中查询将处于哪些状态。查询优化过程特别复杂且重要。还有一些例外或特殊情况,比如在使用准备语句时执行路径的差异;我们将在下一章中讨论。
MySQL 客户端/服务器协议
尽管您不需要了解 MySQL 客户端/服务器协议的内部细节,但您需要在高层次上了解它是如何工作的。该协议是半双工的,这意味着在任何给定时间 MySQL 服务器可以发送或接收消息但不能同时进行两者。这也意味着没有办法截断消息。
这种协议使得 MySQL 通信简单快速,但也在某些方面限制了它。首先,这意味着没有流量控制;一旦一方发送消息,另一方必须在回复之前获取整个消息。这就像一个来回传球的游戏:任何时候只有一方拿着球,除非你拿到球,否则你无法传球(发送消息)。
客户端将查询作为单个数据包发送到服务器。这就是为什么如果您有大型查询,max_allowed_packet 配置变量很重要。⁴ 一旦客户端发送查询,它就不再控制局面;它只能等待结果。
相比之下,服务器的响应通常由许多数据包组成。当服务器响应时,客户端必须接收整个结果集。它不能简单地获取一些行然后要求服务器不再发送其余的行。如果客户端只需要返回的前几行,它要么等待所有服务器的数据包到达然后丢弃它不需要的部分,要么不正常地断开连接。这两种方式都不是好主意,这就是为什么适当使用LIMIT子句如此重要。
这里有另一种思考方式:当客户端从服务器获取行时,它认为自己是在拉它们。但事实是,MySQL 服务器在生成行时是在推行。客户端只接收被推送的行;它无法告诉服务器停止发送行。客户端就像在“从消防水龙头中喝水”,可以这么说。(是的,这是一个技术术语。)
大多数连接到 MySQL 的库都可以让您获取整个结果集并将其缓冲在内存中,或者在需要时获取每一行。默认行为通常是获取整个结果并将其缓冲在内存中。这很重要,因为在获取所有行之前,MySQL 服务器不会释放查询所需的锁和其他资源。查询将处于“发送数据”状态。当客户端库一次性获取所有结果时,它减少了服务器需要做的工作量:服务器可以尽快完成并清理查询。
大多数客户端库让您将结果集视为从服务器获取,尽管实际上您只是从库内存中的缓冲区获取。这在大多数情况下运行良好,但对于可能需要很长时间才能获取并使用大量内存的大型结果集,这不是一个好主意。如果指示库不缓冲结果,您可以使用更少的内存并更早开始处理结果。缺点是,当您的应用程序与库交互时,服务器上的锁和其他资源将保持打开状态。⁵
让我们看一个使用 PHP 的示例。这是您通常从 PHP 查询 MySQL 的方式:
<?php
$link = mysql_connect('localhost', 'user', 'p4ssword');
$result = mysql_query('SELECT * FROM HUGE_TABLE', $link);
while ( $row = mysql_fetch_array($result) ) {
// Do something with result
}
?>
代码似乎表明您只在需要时在while循环中获取行。然而,代码实际上通过mysql_query()函数调用将整个结果获取到缓冲区中。while循环只是遍历缓冲区。相比之下,以下代码不会缓冲结果,因为它使用mysql_unbuffered_query()而不是mysql_query():
<?php
$link = mysql_connect('localhost', 'user', 'p4ssword');
$result = mysql_unbuffered_query('SELECT * FROM HUGE_TABLE', $link);
while ( $row = mysql_fetch_array($result) ) {
// Do something with result
}
?>
编程语言有不同的方法来覆盖缓冲。例如,Perl 的DBD::mysql驱动程序要求您指定 C 客户端库的mysql_use_result属性(默认为mysql_buffer_result)。这是一个示例:
#!/usr/bin/perl
use DBI;
my $dbh = DBI->connect('DBI:mysql:;host=localhost', 'user', 'p4ssword');
my $sth = $dbh->prepare('SELECT * FROM HUGE_TABLE', { mysql_use_result => 1 });
$sth->execute();
while ( my $row = $sth->fetchrow_array() ) {
# Do something with result
}
注意,调用prepare()指定“使用”结果而不是“缓冲”结果。您也可以在连接时指定这一点,这将使每个语句都是非缓冲的:
my $dbh = DBI->connect('DBI:mysql:;mysql_use_result=1', 'user', 'p4ssword');
查询状态
每个 MySQL 连接,或线程,都有一个状态,显示其在任何给定时间正在做什么。有几种查看这些状态的方法,但最简单的方法是使用SHOW FULL PROCESSLIST命令(状态显示在Command列中)。随着查询在其生命周期中的进展,其状态会多次更改,有数十种状态。MySQL 手册是所有状态信息的权威来源,但我们在这里列出了一些并解释了它们的含义:
休眠
线程正在等待来自客户端的新查询。
查询
线程正在执行查询或将结果发送回客户端。
锁定
线程正在等待服务器级别授予表锁。由存储引擎实现的锁,例如 InnoDB 的行锁,不会导致线程进入Locked状态。
分析和统计
线程正在检查存储引擎统计信息并优化查询。
复制到临时表[在磁盘上]
线程正在处理查询并将结果复制到临时表,可能是为了GROUP BY,进行文件排序,或满足UNION。如果状态以“on disk”结尾,MySQL 正在将内存表转换为磁盘表。
排序结果
线程正在对结果集进行排序。
至少了解基本状态是有帮助的,这样您就可以了解查询的“谁在掌握主动权”。在非��繁忙的服务器上,您可能会看到通常很短暂的状态,例如statistics,开始占用大量时间。这通常表示出现了问题。
查询优化过程
查询生命周期中的下一步将 SQL 查询转换为查询执行引擎的执行计划。这包括几个子步骤:解析、预处理和优化。错误(例如,语法错误)可能在过程的任何时候引发。我们并不打算在这里记录 MySQL 的内部情况,因此我们将采取一些自由,例如即使它们通常为了效率而完全或部分地合并,我们也会单独描述步骤。我们的目标只是帮助您了解 MySQL 如何执行查询,以便您可以编写更好的查询。
解析器和预处理器
首先,MySQL 的解析器将查询分解为标记,并从中构建“解析树”。解析器使用 MySQL 的 SQL 语法来解释和验证查询。例如,它确保查询中的标记有效且顺序正确,并检查是否存在未终止的引号字符串等错误。
预处理器然后检查解析树的结果,以解决解析器无法解决的附加语义。例如,它检查表和列是否存在,并解析名称和别名以确保列引用不会产生歧义。
接下来,预处理器检查权限。除非您的服务器具有大量权限,否则这通常非常快。
查询优化器
解析树现在有效并准备好供优化器将其转换为查询执行计划。一个查询通常可以以许多不同的方式执行并产生相同的结果。优化器的工作是找到最佳选项。
MySQL 使用基于成本的优化器,这意味着它试图预测各种执行计划的成本并选择最便宜的。成本单位最初是一个单个随机的 4 KB 数据页读取,但现在已变得更加复杂,现在包括诸如执行WHERE子句比较的估计成本等因素。您可以通过运行查询,然后检查Last_query_cost会话变量来查看优化器估计查询的成本有多昂贵:
mysql> SELECT SQL_NO_CACHE COUNT(*) FROM sakila.film_actor;
+----------+
| count(*) |
+----------+
| 5462 |
+----------+
mysql> SHOW STATUS LIKE 'Last_query_cost';
+-----------------+-------------+
| Variable_name | Value |
+-----------------+-------------+
| Last_query_cost | 1040.599000 |
+-----------------+-------------+
这个结果意味着优化器估计执行查询需要大约 1040 个随机数据页读取。它基于统计数据:每个表或索引的页数,索引的基数(不同值的数量),行和键的长度,以及键的分布。优化器在其估计中不包括任何类型缓存的影响;它假设每次读取都会导致磁盘 I/O 操作。
优化器可能并不总是选择最佳计划,原因有很多:
-
统计数据可能不准确。服务器依赖存储引擎提供统计信息,它们的准确性可能从完全正确到极不准确。例如,InnoDB 存储引擎由于其 MVCC 架构不维护关于表中行数的准确统计信息。
-
成本度量标准并不完全等同于运行查询的真实成本,因此即使统计数据准确,查询的成本可能比 MySQL 的近似值更昂贵或更便宜。在某些情况下,读取更多页的计划实际上可能更便宜,例如当读取是顺序的时,磁盘 I/O 更快,或者当页已缓存在内存中时。MySQL 也不了解哪些页在内存中,哪些页在磁盘上,因此它实际上不知道查询会导致多少 I/O。
-
MySQL 的“最佳”概念可能与您的不同。您可能希望获得最快的执行时间,但 MySQL 实际上并不试图使查询快速;它试图最小化它们的成本,正如我们所见,确定成本并不是一门确切的科学。
-
MySQL 不考虑同时运行的其他查询,这可能会影响查询运行的速度。
-
MySQL 并不总是进行基于成本的优化。有时它只是遵循规则,例如“如果有一个全文
MATCH()子句,如果存在FULLTEXT索引,则使用它”。即使使用不同的索引和带有WHERE子句的非FULLTEXT查询更快,它也会这样做。 -
优化器不考虑不受其控制的操作的成本,例如执行存储函数或用户定义的函数。
-
正如我们将在后面看到的,优化器并不总是能够估计每种可能的执行计划,因此可能会错过最佳计划。
MySQL 的查询优化器是一个非常复杂的软件部分,它使用许多优化来将查询转换为执行计划。有两种基本类型的优化,我们称之为静态和动态。静态优化 可以通过检查解析树简单地执行。例如,优化器可以通过应用代数规则将 WHERE 子句转换为等效形式。静态优化与值无关,例如 WHERE 子句中常量的值。它们可以执行一次,并且在使用不同值重新执行查询时始终有效。您可以将其视为“编译时优化”。
相比之下,动态优化 基于上下文,并且可能取决于许多因素,例如 WHERE 子句中的值或索引中的行数。它们必须在每次执行查询时重新评估。您可以将其视为“运行时优化”。
在执行预处理语句或存储过程时,区别很重要。MySQL 可以进行静态优化一次,但必须每次执行查询时重新评估动态优化。有时,MySQL 甚至在执行过程中重新优化查询。⁶
以下是 MySQL 知道如何执行的一些优化类型:
重新排序连接
表不一定要按照查询中指定的顺序连接。确定最佳连接顺序是一项重要的优化;我们稍后在本章中深入解释。
将 OUTER JOIN 转换为 INNER JOIN
OUTER JOIN 不一定要作为 OUTER JOIN 执行。某些因素,例如 WHERE 子句和表模式,实际上可能导致 OUTER JOIN 等效于 INNER JOIN。MySQL 可以识别这一点并重写连接,从而使其有资格进行重新排序。
应用代数等价规则
MySQL 应用代数变换来简化和规范化表达式。它还可以折叠和减少常量,消除不可能的约束和常量条件。例如,术语 (5=5 AND a>5) 将简化为 a>5。类似地,(a<b AND b=c) AND a=5 变为 b>5 AND b=c AND a=5。这些规则对于编写条件查询非常有用,我们稍后在本章中讨论。
COUNT()、MIN() 和 MAX() 优化
索引和列的可空性通常可以帮助 MySQL 优化这些表达式。例如,要找到 B 树索引中最左边的列的最小值,MySQL 可以只请求索引中的第一行。它甚至可以在查询优化阶段执行此操作,并将该值视为常量用于查询的其余部分。类似地,要找到 B 树索引中的最大值,服务器会读取最后一行。如果服务器使用此优化,您将在 EXPLAIN 计划中看到“选择表已优化” 。这实际上意味着优化器已将表从查询计划中移除,并用常量替换。
评估和简化常量表达式
当 MySQL 检测到表达式可以简化为常量时,它会在优化过程中这样做。例如,如果用户定义的变量在查询中没有更改,它可以转换为常量。算术表达式是另一个例子。
也许令人惊讶的是,即使你可能认为是一个查询的东西也可以在优化阶段被减少为一个常量。一个例子是对索引的MIN()。这甚至可以扩展到对主键或唯一索引的常量查找。如果WHERE子句对这样的索引应用一个常量条件,优化器知道 MySQL 可以在查询开始时查找值。然后它将在查询的其余部分将该值视为常量。这里有一个例子:
mysql> EXPLAIN SELECT film.film_id, film_actor.actor_id
-> FROM sakila.film
-> INNER JOIN sakila.film_actor USING(film_id)
-> WHERE film.film_id = 1\G
*************************** 1\. row ***************************
id: 1
select_type: SIMPLE
table: film
partitions: NULL
type: const
possible_keys: PRIMARY
key: PRIMARY
key_len: 2
ref: const
rows: 1
filtered: 100.00
Extra: Using index
*************************** 2\. row ***************************
id: 1
select_type: SIMPLE
table: film_actor
partitions: NULL
type: index
possible_keys: NULL
key: PRIMARY
key_len: 4
ref: NULL
rows: 5462
filtered: 10.00
Extra: Using where; Using index
MySQL 以两个步骤执行此查询,对应于输出中的两行。第一步是在film表中找到所需的行。MySQL 的优化器知道只有一行,因为film_id列上有一个主键,并且在查询优化阶段已经查询了索引以查看将找到多少行。因为查询优化器有一个已知数量(WHERE子句中的值)用于查找,所以这个表的ref类型是const。
在第二步中,MySQL 将第一步找到的film_id列视为已知数量。它可以这样做,因为优化器知道当查询到达第二步时,它将知道第一步的所有值。请注意,film_actor表的ref类型是const,就像film表的一样。
另一种你会看到常量条件应用的方式是通过从一个地方传播值的常量性到另一个地方,如果有一个WHERE、USING或ON子句将值限制为相等。在这个例子中,优化器知道USING子句强制film_id在查询中的任何地方具有相同的值;它必须等于WHERE子句中给定的常量值。
覆盖索引
当索引包含查询所需的所有列时,MySQL 有时可以使用索引来避免读取行数据。我们在上一章节中详细讨论了覆盖索引。
子查询优化
MySQL 可以将某些类型的子查询转换为更高效的替代形式,将它们减少为索引查找而不是单独的查询。
早期终止
MySQL 可以在满足查询或步骤时立即停止处理查询(或查询中的步骤)。明显的情况是LIMIT子句,但还有几种其他类型的早期终止。例如,如果 MySQL 检测到一个不可能的条件,它可以中止整个查询。你可以在以下示例中看到这一点:
mysql> EXPLAIN SELECT film.film_id FROM sakila.film WHERE film_id = −1;
*************************** 1\. row ***************************
id: 1
select_type: SIMPLE
table: NULL
partitions: NULL
type: NULL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: NULL
filtered: NULL
Extra: Impossible WHERE
这个查询在优化步骤中停止了,但 MySQL 也可以在其他一些情况下提前终止执行。当查询执行引擎识别到需要检索不同值或在值不存在时停止时,服务器可以使用这种优化。例如,以下查询找到所有没有任何演员的电影:⁷
SELECT film.film_id
FROM sakila.film
LEFT OUTER JOIN sakila.film_actor USING(film_id)
WHERE film_actor.film_id IS NULL;
这个查询通过消除任何有演员的电影来工作。每部电影可能有很多演员,但一旦找到一个演员,它就会停止处理当前电影并移动到下一个,因为它知道WHERE子句禁止输出该电影。类似的“Distinct/not-exists”优化可以应用于某些类型的DISTINCT、NOT EXISTS()和LEFT JOIN查询。
等式传播
MySQL 识别查询将两列视为相等时,例如在JOIN条件中,并在等效列之间传播WHERE子句。例如,在以下查询中:
SELECT film.film_id
FROM sakila.film
INNER JOIN sakila.film_actor USING(film_id)
WHERE film.film_id > 500;
MySQL 知道WHERE子句不仅适用于film表,也适用于film_actor表,因为USING子句强制两列匹配。
如果你习惯于另一个不能做到这一点的数据库服务器,你可能会被建议通过手动指定两个表的WHERE子句来“帮助优化器”,就像这样:
... WHERE film.film_id > 500 AND film_actor.film_id > 500
这在 MySQL 中是不必要的。它只会使你的查询更难维护。
IN()列表比较
在许多数据库服务器中,IN()只是多个OR子句的同义词,因为两者在逻辑上是等价的。但在 MySQL 中不是这样,它对IN()列表中的值进行排序,并使用快速二进制搜索来查看值是否在列表中。这在列表大小为 O(log n)时,而等效的OR子句系列在列表大小为 O(n)时(即对于大型列表来说要慢得多)。
前面的列表非常不完整,因为 MySQL 执行的优化比我们在整个章节中能够涵盖的要多,但它应该让您了解优化器的复杂性和智能。如果有一件事情您应该从这个讨论中记住,那就是不要试图预先聪明地超越优化器。您可能最终只是击败它或使查询变得更加复杂且难以维护,而没有任何好处。一般来说,您应该让优化器自行处理。
��然,优化器再聪明,有时候也不会给出最佳结果。有时候您可能了解一些优化器不知道的数据,比如由于应用逻辑保证为真的事实。此外,有时候优化器没有必要的功能,比如哈希索引;在其他时候,正如前面提到的,其成本估算可能更喜欢一个比另一个更昂贵的查询计划。
如果您知道优化器没有给出好的结果并且知道原因,您可以帮助它。一些选项包括向查询添加提示,重写查询,重新设计模式或添加索引。
表和索引统计信息
回想一下 MySQL 服务器架构中的各个层次,我们在图 1-1 中进行了说明。服务器层包含查询优化器,不存储数据和索引的统计信息。这是存储引擎的工作,因为每个存储引擎可能保留不同类型的统计信息(或以不同方式保留)。
因为服务器不存储统计信息,MySQL 查询优化器必须向引擎请求查询中表的统计信息。引擎提供优化器统计信息,例如每个表或索引的页数,表和索引的基数,行和键的长度,以及键分布信息。优化器可以使用这些信息来帮助它决定最佳执行计划。我们将在后面的章节中看到这些统计信息如何影响优化器的选择。
MySQL 的连接执行策略
MySQL 比您可能习惯的更广泛地使用连接这个术语。总之,它认为每个查询都是一个连接——不仅仅是从两个表中匹配行的每个查询,而是每个查询,无论是子查询还是甚至针对单个表的SELECT。因此,了解 MySQL 如何执行连接非常重要。
考虑一个UNION查询的示例。MySQL 将UNION执行为一系列单个查询,其结果被拼接到临时表中,然后再次读取出来。每个单独的查询在 MySQL 术语中都是一个连接,从结果临时表中读取也是如此。
MySQL 的连接执行策略曾经很简单:它将每个连接都视为嵌套循环连接。这意味着 MySQL 运行一个循环来查找表中的一行,然后运行一个嵌套循环来查找下一个表中的匹配行。直到在连接中的每个表中找到匹配行为止。然后根据SELECT列表中的列构建并返回一行。它尝试通过在最后一个表中查找更多匹配行来构建下一行。如果找不到任何匹配行,则回溯一个表并在那里查找更多行。它一直回溯,直到在某个表中找到另一行,然后在下一个表中查找匹配行,依此类推。
从版本 8.0.20 开始,不再使用块嵌套循环连接;取而代之的是 哈希连接。这使得连接过程的执行速度与以前一样快,甚至更快,尤其是如果其中一个数据集可以存储在内存中。
执行计划
MySQL 不会生成字节码来执行查询,就像许多其他数据库产品那样。相反,查询执行计划实际上是一个指令树¹⁰,查询执行引擎遵循该树以生成查询结果。最终计划包含足够的信息来重建原始查询。如果在查询上执行 EXPLAIN EXTENDED,然后是 SHOW WARNINGS,你将看到重建的查询。¹¹
任何多表查询在概念上都可以表示为一棵树。例如,可能可以像 图 8-2 所示的那样执行一个四表连接。
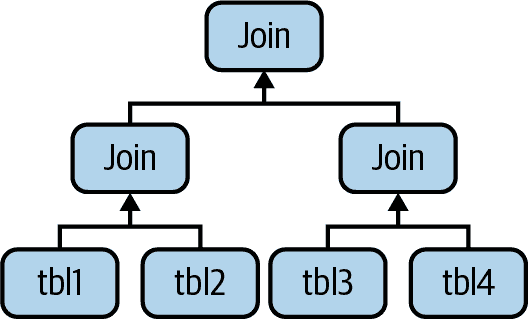
图 8-2. 多表连接的一种方式
这就是计算机科学家所说的平衡树。然而,这不是 MySQL 执行查询的方式。正如我们在前一节中描述的那样,MySQL 总是从一个表开始,并在下一个表中查找匹配的行。因此,MySQL 的查询执行计划总是采用左深树的形式,如 图 8-3 所示。
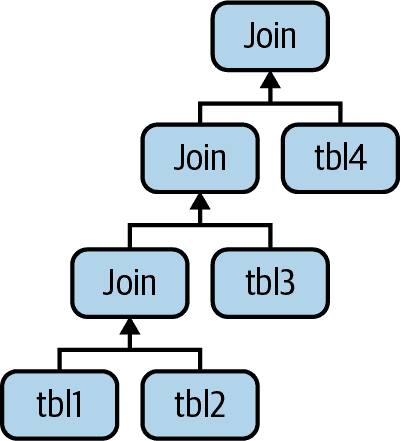
图 8-3. MySQL 如何连接多个表
连接优化器
MySQL 查询优化器中最重要的部分是连接优化器,它决定了多表查询的最佳执行顺序。通常可以以几种不同的顺序连接表并获得相同的结果。连接优化器估计各种计划的成本,并尝试选择成本最低的计划,以获得相同的结果。
这是一个查询,其表可以以不同的顺序连接而不改变结果:
SELECT film.film_id, film.title, film.release_year, actor.actor_id,
actor.first_name, actor.last_name
FROM sakila.film
INNER JOIN sakila.film_actor USING(film_id)
INNER JOIN sakila.actor USING(actor_id);
你可能会想到几种不同的查询计划。例如,MySQL 可以从 film 表开始,使用 film_actor 表中的 film_id 索引找到 actor_id 值,然后查找 actor 表的主键行。Oracle 用户可能会将其表述为“film 表是 film_actor 表的驱动表,film_actor 表是 actor 表的驱动表。” 这应该是有效的,对吧?现在让我们使用 EXPLAIN 看看 MySQL 想要如何执行查询:
*************************** 1\. row ***************************
id: 1
select_type: SIMPLE
table: actor
partitions: NULL
type: ALL
possible_keys: PRIMARY
key: NULL
key_len: NULL
ref: NULL
rows: 200
filtered: 100.00
Extra: NULL
*************************** 2\. row ***************************
id: 1
select_type: SIMPLE
table: film_actor
partitions: NULL
type: ref
possible_keys: PRIMARY,idx_fk_film_id
key: PRIMARY
key_len: 2
ref: sakila.actor.actor_id
rows: 27
filtered: 100.00
Extra: Using index
*************************** 3\. row ***************************
id: 1
select_type: SIMPLE
table: film
partitions: NULL
type: eq_ref
possible_keys: PRIMARY
key: PRIMARY
key_len: 2
ref: sakila.film_actor.film_id
rows: 1
filtered: 100.00
Extra: NULL
这与前一段中建议的计划完全不同。MySQL 希望从 actor 表开始(我们知道这是因为它在 EXPLAIN 输出中首先列出),并按相反的顺序进行。这真的更有效吗?让我们看看。STRAIGHT_JOIN 关键字强制连接按查询中指定的顺序进行。这是修改后查询的 EXPLAIN 输出:
mysql> EXPLAIN SELECT STRAIGHT_JOIN film.film_id...\G
*************************** 1\. row ***************************
id: 1
select_type: SIMPLE
table: film
partitions: NULL
type: ALL
possible_keys: PRIMARY
key: NULL
key_len: NULL
ref: NULL
rows: 1000
filtered: 100.00
Extra: NULL
*************************** 2\. row ***************************
id: 1
select_type: SIMPLE
table: film_actor
partitions: NULL
type: ref
possible_keys: PRIMARY,idx_fk_film_id
key: idx_fk_film_id
key_len: 2
ref: sakila.film.film_id
rows: 5
filtered: 100.00
Extra: Using index
*************************** 3\. row ***************************
id: 1
select_type: SIMPLE
table: actor
partitions: NULL
type: eq_ref
possible_keys: PRIMARY
key: PRIMARY
key_len: 2
ref: sakila.film_actor.actor_id
rows: 1
filtered: 100.00
Extra: NULL
这说明了为什么 MySQL 希望反转连接顺序:这样做将使其能够检查第一个表中的行数更少。¹² 在这两种情况下,它将能够在第二个和第三个表中执行快速的索引查找。不同之处在于它将不得不执行多少这样的索引查找。将 film 放在第一位将需要大约一千次探测(参见 rows 字段)到 film_actor 和 actor,即第一个表中的每一行都需要一次。如果服务器首先扫描 actor 表,它只需要对后续表进行两百次索引查找。换句话说,反转的连接顺序将需要更少的回溯和重读。
这是 MySQL 的连接优化器可以重新排列查询以使其执行成本更低的简单示例。重新排序连接通常是一种非常有效的优化。然而,有时不会得到最佳计划,对于这些情况,你可以使用 STRAIGHT_JOIN 并按照你认为最佳的顺序编写查询,但这样的情况很少见。在大多数情况下,连接优化器将胜过人类。
连接优化器试图生成具有最低成本的查询执行计划树。在可能的情况下,它检查所有子树的潜在组合,从所有单表计划开始。
不幸的是,对n个表进行连接将有n阶乘的连接顺序组合要检查。这被称为所有可能查询计划的搜索空间,并且增长非常快:一个包含 10 个表的连接可以以 3,628,800 种不同的方式执行!当搜索空间增长过大时,优化查询可能需要花费太长时间,因此服务器停止进行完整分析。相反,它会采用“贪婪”搜索等快捷方式,当表的数量超过optimizer_search_depth变量指定的限制时(如果需要,您可以更改该变量)。
MySQL 拥有许多启发式方法,通过多年的研究和实验积累而来,用于加速优化阶段。这可能是有益的,但也可能意味着 MySQL 可能(在极少数情况下)错过一个最佳计划并选择一个不太优化的计划,因为它试图避免检查每个可能的查询计划。
有时查询无法重新排序,连接优化器可以利用这一事实通过消除选择来减少搜索空间。LEFT JOIN是一个很好的例子,相关子查询也是(稍后会详细介绍子查询)。这是因为一个表的结果取决于从另一个表检索的数据。这些依赖关系帮助连接优化器通过消除选择来减少搜索空间。
排序优化
对结果进行排序可能是一个昂贵的操作,因此您通常可以通过避免排序或在较少行上执行排序来提高性能。
当 MySQL 无法使用索引生成排序结果时,它必须自行对行进行排序。它可以在内存中或磁盘上执行此操作,但无论如何,它总是将此过程称为文件排序,即使实际上并未使用文件。
如果要排序的值将适合排序缓冲区,MySQL 可以完全在内存中执行排序,使用快速排序。如果 MySQL 无法在内存中执行排序,则通过对值进行分块排序在磁盘上执行排序。它使用快速排序对每个块进行排序,然后将排序的块合并到结果中。
有两种文件排序算法:
两次遍历(旧)
读取行指针和ORDER BY列,对它们进行排序,然后扫描排序列表并重新读取行以输出。
两次遍历算法可能非常昂贵,因为它从表中读取两次行,第二次读取会导致大量随机 I/O。
单次遍历(新)
读取查询所需的所有列,按ORDER BY列对它们进行排序,然后扫描排序列表并输出指定的列。
它可能更有效率,特别是对于大型 I/O 受限数据集,因为它避免了从表中两次读取行,并将随机 I/O 交换为更多的顺序 I/O。然而,它有可能使用更多的空间,因为它保存每行的所有所需列,而不仅仅是用于排序行的列。这意味着更少的元组将适合排序缓冲区,文件排序将不得不执行更多的排序合并传递。
MySQL 可能为文件排序使用比您预期的更多的临时存储空间,因为它为将要排序的每个元组分配了固定大小的记录。这些记录足够大,可以容纳最大可能的元组,包括每个VARCHAR列的完整长度。此外,如果您使用 utf8mb4,MySQL 为每个字符分配 4 个字节。因此,我们曾看到过,优化不良的模式导致用于排序的临时空间比磁盘上整个表的大小大几倍。
当对连接进行排序时,MySQL 可能在查询执行过程中的两个阶段执行文件排序。如果ORDER BY子句仅涉及连接顺序中第一个表的列,MySQL 可以对该表进行文件排序,然后继续连接。如果发生这种情况,EXPLAIN在Extra列中显示“Using filesort”。在所有其他情况下,例如对连接顺序中不是第一个表的表进行排序,或者ORDER BY子句包含多个表的列时,MySQL 必须将查询结果存储到临时表中,然后在连接完成后对临时表进行文件排序。在这种情况下,EXPLAIN在Extra列中显示“Using temporary; Using filesort”。如果有LIMIT,它将在文件排序之后应用,因此临时表和文件排序可能非常大。
查询执行引擎
解析和优化阶段输出查询执行计划,MySQL 的查询执行引擎使用该计划来处理查询。该计划是一个数据结构;它不是可执行的字节码,这是许多其他数据库执行查询的方式。
与优化阶段相比,执行阶段通常并不那么复杂:MySQL 只需按照查询执行计划中给出的指令进行操作。计划中的许多操作调用存储引擎接口实现的方法,也称为处理程序 API。查询中的每个表都由处理程序的实例表示。例如,如果查询中的表出现三次,服务器将创建三个处理程序实例。尽管我们之前略过了这一点,但 MySQL 实际上在优化阶段早期创建处理程序实例。优化器使用它们获取有关表的信息,例如它们的列名和索引统计信息。
存储引擎接口具有许多功能,但只需要十几个“构建块”操作来执行大多数查询。例如,有一个操作用于读取索引中的第一行,另一个操作用于读取索引中的下一行。这对于执行��引扫描的查询已经足够了。这种简单的执行方法使得 MySQL 的存储引擎架构成为可能,但也带来了我们讨论过的优化器限制之一。
注意
并非所有操作都是处理程序操作。例如,服务器管理表锁。处理程序可能实现自己的较低级别锁定,就像 InnoDB 使用行级锁一样,但这并不取代服务器自己的锁定实现。如第一章中所述,所有存储引擎共享的内容都在服务器中实现,例如日期和时间函数、视图和触发器。
为执行查询,服务器只需重复指令,直到没有更多行可检查为止。
向客户端返回结果
执行查询的最后一步是向客户端发送响应。即使查询不返回结果集,也会向客户端连接发送有关查询的信息,例如它影响了多少行。
服务器逐步生成并发送结果。一旦 MySQL 处理完最后一个表并成功生成一行,它就可以并且应该将该行发送给客户端。这有两个好处:它让服务器避免在内存中保存行,而且意味着客户端尽快开始获取结果。¹³结果集中的每一行在 MySQL 客户端/服务器协议中以单独的数据包发送,尽管协议数据包可以在 TCP 协议层缓冲并一起发送。
MySQL 查询优化器的限制
MySQL 对查询执行的方法并非对于优化每种类型的查询都是理想的。幸运的是,MySQL 查询优化器做得不好的情况有限,通常可以更有效地重写这些查询。
UNION 的限制
MySQL 有时无法将UNION外部的条件“推入”到内部,这些条件可以用于限制结果或启用其他优化。
如果你认为UNION中的任何一个单独查询会受益于LIMIT,或者如果你知道它们将与其他查询组合后受到ORDER BY子句的影响,那么你需要将这些子句放在每个UNION部分中。例如,如果你将两个表UNION在一起,并将结果限制为前 20 行,MySQL 将把两个表存储到临时表中,然后从中检索出 20 行:
(SELECT first_name, last_name
FROM sakila.actor
ORDER BY last_name)
UNION ALL
(SELECT first_name, last_name
FROM sakila.customer
ORDER BY last_name)
LIMIT 20;
此查询将从actor表中存储 200 行,从customer表中存储 599 行到临时表中,然后从该临时表中获取前 20 行。您可以通过在UNION中的每个查询中多余地添加LIMIT 20来避免这种情况:
(SELECT first_name, last_name
FROM sakila.actor
ORDER BY last_name
LIMIT 20)
UNION ALL
(SELECT first_name, last_name
FROM sakila.customer
ORDER BY last_name
LIMIT 20)
LIMIT 20;
现在临时表将只包含 40 行。除了性能提升外,您可能需要更正查询:从临时表中检索行的顺序是未定义的,因此在最终LIMIT之前应该有一个整体ORDER BY。
等式传播
等式传播有时可能会产生意想不到的成本。例如,考虑一个巨大的IN()列表,优化器知道它将等于其他表的某些列,这是由于WHERE,ON或USING子句将列设置为相等。
优化器将通过将列表复制到所有相关表中的相应列来“共享”列表。这通常是有帮助的,因为它为查询优化器和执行引擎提供了更多实际执行IN()检查的选项。但是当列表非常大时,它可能导致优化和执行变慢。在撰写本文时,还没有这个问题的内置解决方法 - 如果这对您是个问题,您将不得不更改源代码。 (对大多数人来说这不是问题。)
并行执行
MySQL 无法在多个 CPU 上并行执行单个查询。这是一些其他数据库服务器提供的功能,但 MySQL 不支持。我们提到这一点是为了让您不要花费大量时间来尝试如何在 MySQL 上实现并行查询执行!
在同一表上进行 SELECT 和 UPDATE
MySQL 不允许您在从表中SELECT的同时对其运行UPDATE。这实际上不是一个优化器的限制,但了解 MySQL 如何执行查询可以帮助您解决问题。这是一个被禁止的查询示例,即使它是标准 SQL。该查询将每一行更新为表中相似行的数量:
mysql> UPDATE tbl AS outer_tbl
-> SET c = (
-> SELECT count(*) FROM tbl AS inner_tbl
-> WHERE inner_tbl.type = outer_tbl.type
-> );
ERROR 1093 (HY000): You can't specify target table 'outer_tbl'
for update in FROM clause
要解决这个问题,您可以使用派生表,因为 MySQL 将其实例化为临时表。这实际上执行了两个查询:一个在子查询中执行SELECT,一个在表和子查询的连接结果上执行多表UPDATE。子查询在外部UPDATE打开表之前打开并关闭表,因此查询现在将成功:
mysql> UPDATE tbl
-> INNER JOIN(
-> SELECT type, count(*) AS c
-> FROM tbl
-> GROUP BY type
-> ) AS der USING(type)
-> SET tbl.c = der.c;
优化特定类型的查询
在本节中,我们提供了如何优化某些类型查询的建议。我们在书中的其他地方已经详细介绍了大部分这些主题,但我们想列出一些常见的优化问题,以便您可以轻松参考。
本节中的大部分建议是与版本相关的,可能在未来的 MySQL 版本中不适用。服务器未来可能会自动执行这些优化的原因是没有理由的。
优化COUNT()查询
COUNT()聚合函数以及如何优化使用它的查询,可能是 MySQL 中前 10 个最被误解的主题之一。您可以进行网络搜索,找到更多关于这个主题的错误信息,我们不想去想。
在我们深入优化之前,重要的是您了解COUNT()的真正作用。
COUNT()的作用
COUNT()是一个特殊的函数,以两种非常不同的方式工作:它计算值和行。一个值是一个非NULL表达式(NULL是值的缺失)。如果你在括号内指定列名或其他表达式,COUNT()会计算该表达式具有值的次数。这对许多人来说很令人困惑,部分原因是值和NULL很令人困惑。如果你需要了解 SQL 中的工作原理,我们建议阅读一本关于 SQL 基础的好书。(互联网在这个主题上并不一定是准确信息的好来源。)
COUNT()的另一种形式简单地计算结果中的行数。这是 MySQL 在知道括号内表达式永远不会是NULL时所做的。最明显的例子是COUNT(*),这是COUNT()的一种特殊形式,不会将*通配符扩展为表中的所有列的完整列表,正如你可能期望的那样;相反,它完全忽略列并计算行数。
我们经常看到的一个最常见的错误是在想要计算行数时在括号内指定列名。当你想知道结果中的行数时,应该始终使用COUNT(*)。这清楚地传达了你的意图,并避免了性能不佳。
简单的优化
一个常见的问题是如何在同一列中检索多个不同值的计数,只需一个查询,以减少所需的查询数量。例如,假设你想创建一个单一查询,计算每种颜色的物品数量。你不能使用OR(例如,SELECT COUNT(color = 'blue' OR color = 'red') FROM items;),因为这不会将不同颜色的计数分开。你也不能将颜色放在WHERE子句中(例如,SELECT COUNT(*) FROM items WHERE color = 'blue' AND color = 'red';),因为颜色是互斥的。以下是解决这个问题的查询:¹⁴
SELECT SUM(IF(color = 'blue', 1, 0)) AS blue,SUM(IF(color = 'red', 1, 0))
AS red FROM items;
这里有另一个等效的例子,但是不使用SUM(),而是使用COUNT(),并确保表达式在条件为假时没有值:
SELECT COUNT(color = 'blue' OR NULL) AS blue, COUNT(color = 'red' OR NULL)
AS red FROM items;
使用近似值
有时候你不需要准确的计数,所以可以使用近似值。优化器在EXPLAIN中的估计行数通常很好用。只需执行一个EXPLAIN查询,而不是真实查询。
有时,准确的计数比近似值要低效得多。一位客户要求帮助计算网站上活跃用户的数量。用户计数被缓存并显示 30 分钟,之后重新生成并再次缓存。这本质上是不准确的,所以近似值是可以接受的。查询包括几个WHERE条件,以确保不计算非活跃用户或“默认”用户,这是应用程序中的特殊用户 ID。删除这些条件只会稍微改变计数,但使查询更有效。进一步的优化是消除一个不必要的DISTINCT以消除一个文件排序。重写后的查询速度更快,几乎返回完全相同的结果。
更复杂的优化
一般来说,COUNT()查询很难优化,因为它们通常需要计算大量行(即访问大量数据)。在 MySQL 本身内部进行优化的另一种选择是使用覆盖索引。如果这不够帮助,你需要对应用程序架构进行更改。考虑使用外部缓存系统,如memcached。你可能会发现自己面临熟悉的困境,“快速、准确和简单:选择其中两个。”
优化连接查询
实际上,这个主题在大部分书中都有涉及,但我们将提到一些重点:
-
确保在
ON或USING子句中的列上有索引。在添加索引时考虑连接顺序。如果您在列c上将表A和B连接,并且查询优化器决定以B,A的顺序连接表,则不需要在表B上索引该列。未使用的索引是额外的开销。通常情况下,只需要在连接顺序中的第二个表上添加索引,除非出于其他原因需要。 -
尽量确保任何
GROUP BY或ORDER BY表达式仅引用来自单个表的列,这样 MySQL 可以尝试为该操作使用索引。 -
在升级 MySQL 时要小心,因为连接语法、运算符优先级和其他行为在不同时间发生了变化。曾经是正常连接的东西有时会变成交叉乘积,这是一种返回不同结果甚至无效语法的不同连接类型。
使用 ROLLUP 优化 GROUP BY
分组查询的变体之一是要求 MySQL 在结果中进行超级聚合。您可以使用WITH ROLLUP子句实现这一点,但可能不如您需要的那样优化。使用EXPLAIN检查执行方法,注意分组是通过文件排序还是临时表完成的;尝试移除WITH ROLLUP,看看是否得到相同的分组方法。您可能可以通过我们在本节前面提到的提示来强制分组方法。
有时在应用程序中进行超级聚合更有效,即使这意味着从服务器获取更多行。您还可以在FROM子句中嵌套子查询或使用临时表保存中间结果,然后使用UNION查询临时表。
最好的方法可能是将WITH ROLLUP功能移至应用程序代码中。
优化 LIMIT 和 OFFSET
具有LIMIT和OFFSET的查询在进行分页的系统中很常见,几乎总是与ORDER BY子句一起使用。拥有支持排序的索引是很有帮助的;否则,服务器就必须进行大量的文件排序。
一个常见的问题是偏移量值很高。如果您的查询看起来像LIMIT 10000, 20,那么它将生成 10,020 行并丢弃其中的前 10,000 行,这是非常昂贵的。假设所有页面被均匀访问,这样的查询平均扫描一半的表。为了优化它们,您可以限制分页视图中允许的页面数量,或者尝试使高偏移量更有效。
提高效率的一个简单技巧是在覆盖索引上执行偏移,而不是完整行。然后,您可以将结果与完整行连接并检索所需的其他列。这可能更有效。考虑以下查询:
SELECT film_id, description FROM sakila.film ORDER BY title LIMIT 50, 5;
如果表非常大,则最好按以下方式编写此查询:
SELECT film.film_id, film.description
FROM sakila.film
INNER JOIN (
SELECT film_id FROM sakila.film
ORDER BY title LIMIT 50, 5
) AS lim USING(film_id);
这种“延迟连接”之所以有效,是因为它让服务器在索引中检查尽可能少的数据而不访问行,然后一旦找到所需的行,就将它们与完整表进行连接以检索行中的其他列。类似的技术也适用于带有LIMIT子句的连接。
有时您还可以将限制转换为位置查询,服务器可以将其执行为索引范围扫描。例如,如果您预先计算并索引一个位置列,可以将查询重写为以下形式:
SELECT film_id, description FROM sakila.film
WHERE position BETWEEN 50 AND 54 ORDER BY position;
排名数据提出了类似的问题,但通常将GROUP BY混入其中。您几乎肯定需要预先计算和存储排名。
LIMIT和OFFSET的问题实际上是OFFSET,它表示服务器正在生成和丢弃的行。如果使用一种类似游标的方式记住您获取的最后一行的位置,您可以通过从该位置开始而不是使用OFFSET来生成下一组行。例如,如果您想从最新的租赁记录开始向后工作进行分页,您可以依赖于它们的主键始终递增。您可以像这样获取第一组结果:
SELECT * FROM sakila.rental
ORDER BY rental_id DESC LIMIT 20;
此查询返回租赁记录 16049 到 16030。下一个查询可以从那个点继续:
SELECT * FROM sakila.rental
WHERE rental_id < 16030
ORDER BY rental_id DESC LIMIT 20;
这种技术的好处是,无论您分页到表的多远,它都非常高效。
其他替代方法包括使用预先计算的摘要或与仅包含主键和您需要的ORDER BY列的冗余表连接。
优化 SQL_CALC_FOUND_ROWS
另一种常见的分页显示技术是在带有LIMIT的查询中添加SQL_CALC_FOUND_ROWS提示,这样您就会知道没有LIMIT时会返回多少行。这里似乎有一种“魔法”发生,服务器预测它会找到多少行。但不幸的是,服务器并没有真正做到这一点;它无法计算实际未找到的行数。这个选项只是告诉服务器生成并丢弃其余的结果集,而不是在达到所需行数时停止。这是非常昂贵的。
更好的设计是将分页器转换为“下一页”链接。假设每页有 20 个结果,那么查询应该使用 21 行的LIMIT,并且只显示 20 个。如果结果中存在第 21 行,则有下一页,您可以呈现“下一页”链接。
另一种可能性是获取并缓存比您需要的更多行,比如 1,000 行,然后为连续的页面从缓存中检索它们。这种策略让您的应用程序知道完整结果集有多大。如果少于 1,000 行,应用程序就知道要呈现多少页链接;如果超过 1,000 行,应用程序只需显示“找到超过 1,000 个结果”。这两种策略比重复生成整个结果并丢弃大部分结果要高效得多。
有时您也可以通过运行EXPLAIN查询并查看结果中的rows列来估计结果集的完整大小(嘿,即使 Google 也不显示确切的结果计数!)。如果无法使用这些策略,使用单独的COUNT(*)查询来查找行数可能比SQL_CALC_FOUND_ROWS快得多,如果它可以使用覆盖索引。
优化 UNION
MySQL 总是通过创建临时表并填充UNION结果来执行UNION查询。MySQL 无法对UNION查询应用您可能习惯的许多优化。您可能需要通过手动“推送”WHERE、LIMIT、ORDER BY和其他条件(即从外部查询复制到UNION中的每个SELECT中)来帮助优化器。
始终使用UNION ALL很重要,除非您需要服务器消除重复行。如果省略ALL关键字,MySQL 会向临时表添加 distinct 选项,该选项使用完整行来确定唯一性。这是非常昂贵的。请注意,ALL关键字并不消除临时表。即使不是真正必要的情况下(例如,结果可以直接返回给客户端时),MySQL 也总是将结果放入临时表,然后再次读取它们。
摘要
查询优化是模式、索引和查询设计相互交织的拼图中的最后一块,以创建高性能应用程序。要编写良好的查询,您需要了解模式和索引,反之亦然。
最终,这仍然是关于响应时间和理解查询执行的方式,以便你可以推断时间消耗的位置。通过添加一些东西,比如解析和优化过程,这只是理解 MySQL 如何访问表和索引的下一步,我们在上一章中讨论过。当你开始研究查询和索引之间的相互作用时,出现的额外维度是 MySQL 如何基于在另一个表中找到的数据访问一个表或索引。
优化始终需要三管齐下的方法:停止做某些事情,减少做的次数,以及更快地完成。
¹ 如果应用程序与服务器不在同一主机上,网络开销最严重,但即使它们在同一台服务器上,MySQL 和应用程序之间的数据传输也不是免费的。
² 请参阅本章后面的“优化 COUNT()查询”了解更多相关内容。
³ Percona Toolkit 的pt-archiver工具使这类工作变得简单且安全。
⁴ 如果查询太大,服务器将拒绝接收更多数据并抛出错误。
⁵ 你可以通过SQL_BUFFER_RESULT来解决这个问题,稍后我们会看到。
⁶ 例如,范围检查查询计划会为JOIN中的每一行重新评估索引。你可以通过在EXPLAIN中的Extra列中查找“range checked for each record”来查看这个查询计划。这个查询计划还会增加Select_full_range_join服务器变量。
⁷ 我们同意,一部没有演员的电影很奇怪,但 Sakila 示例数据库中没有列出Slacker Liaisons的演员,它描述为“一部关于鲨鱼和一名学生在古代中国必须与鳄鱼见面的快节奏故事。”
⁸ 请参阅 MySQL 手册中关于版本特定提示的“索引提示”和“优化器提示”以了解可用的提示以及如何使用它们。
⁹ 正如我们后面所展示的,MySQL 的查询执行并不是那么简单;有许多优化措施使其变得复杂。
¹⁰ 你可以在语句之前使用EXPLAIN FORMAT=TREE …来查看这一点。
¹¹ 服务器从执行计划生成输出。因此,它具有与原始查询相同的语义,但不一定具有相同的文本。
¹² 严格来说,MySQL 并不试图减少它读取的行数。相反,它试图优化更少的页面读取。但是行数通常可以让你大致了解查询的成本。
¹³ 如果需要,你可以通过SQL_BUFFER_RESULT提示来��响这种行为。请参阅官方 MySQL 手册中的“优化器提示”了解更多信息。
¹⁴ 你也可以将SUM()表达式写成SUM(color = 'blue'), SUM(color ='red')。
第九章:复制
MySQL 内置的复制是在 MySQL 之上构建大型、高性能应用程序的基础,使用所谓的“横向扩展”架构。复制允许您将一个或多个服务器配置为另一个服务器的副本,使它们的数据与源副本同步。这不仅对高性能应用程序有用——它也是许多高可用性、可扩展性、灾难恢复、备份、分析、数据仓库等任务策略的基石。
在本章中,我们的重点不在于每个功能是什么,而在于何时使用它。官方 MySQL 文档在解释诸如半同步复制、多源复制等功能方面非常详细,您在设置这些功能时应参考此文档。
复制概述
复制解决的基本问题是在同一拓扑结构内保持数据库实例之间的数据同步。它通过将修改数据或数据结构的事件写入源服务器上的日志来实现这一点。副本服务器可以从源上的日志中读取事件并重放它们。这创建了一个异步过程,其中副本的数据副本在任何给定时刻都不能保证是最新的。副本延迟——实时和副本所代表的内容之间的延迟——没有上限。大型查询可能导致副本落后源几秒、几分钟,甚至几小时。
MySQL 的复制大多是向后兼容的——也就是说,新版本的服务器通常可以成为旧版本服务器的副本而无需麻烦。但是,旧版本的服务器通常无法作为新版本的副本:它们可能不理解新版本服务器使用的新功能或 SQL 语法,复制使用的文件格式可能存在差异。例如,您无法从 MySQL 5.6 源复制到 MySQL 5.5 副本。在从一个主要或次要版本升级到另一个主要或次要版本(例如从 5.6 到 5.7 或从 5.7 到 8.0)之前,最好测试您的复制设置。在次要版本内的升级,例如从 5.7.34 到 5.7.35,预计是兼容的;阅读发布��明以了解从一个版本到另一个版本的确切变化。
复制相对于扩展读取而言效果较好,您可以将读取定向到副本,但除非设计正确,否则它不是扩展写入的好方法。将许多副本连接到源只会导致写入在每个副本上执行多次。整个系统受限于最弱部分可以执行的写入数量。
以下是复制的一些常见用途:
数据分发
MySQL 的复制通常不会占用太多带宽,尽管后面会看到,基于行的复制可能比传统的基于语句的复制使用更多带宽。您还可以随时停止和启动复制。因此,它对于在地理上较远的位置(如不同的数据中心或云区域)维护数据副本非常有用。远程副本甚至可以与间歇性(有意或无意地)的连接一起工作。但是,如果您希望副本具有非常低的复制延迟,您将需要一个稳定的、低延迟的链接。
扩展读取流量
MySQL 复制可以帮助您在多个服务器之间分发读取查询,这对于读取密集型应用程序非常有效。您可以通过简单的代码更改进行基本的负载平衡。在小规模上,您可以使用简单的方法,如硬编码主机名或轮询 DNS(将单个主机名指向多个 IP 地址)。您还可以采取更复杂的方法。标准的负载平衡解决方案,如网络负载平衡产品,可以很好地在 MySQL 服务器之间分发读取。
备份
复制是一种有助于备份的有价值的技术。然而,副本既不是备份,也不是备份的替代品。
分析和报告
为报告/分析(在线分析处理,或 OLAP)查询使用专用副本是一个很好的策略,可以将该负载与您的业务需要为外部客户请求提供的服务隔离开来。复制是实现这种隔离的一种方式。
高可用性和故障转移
复制可以帮助避免使 MySQL 成为应用程序的单点故障。涉及复制的良好故障转移系统可以显著减少停机时间。
测试 MySQL 升级
常见做法是使用升级后的 MySQL 版本设置一个副本,并在升级每个实例之前使用它来确保您的查询按预期工作。
复制的工作原理
在深入了解设置复制的细节之前,让我们快速看一下 MySQL 实际如何复制数据。在这个解释中,我们涵盖了最简单的复制拓扑结构,一个源和一个副本。
从高层次上看,复制是一个简单的三部分过程:
-
源在其二进制日志中记录其数据的更改为“二进制日志事件”。
-
副本将源的二进制日志事件复制到自己的本地中继日志。
-
副本通过在中继日志中重放事件,将更改应用于自己的数据。
图 9-1 更详细地说明了复制的最基本形式。
这种复制架构将在副本上获取和重放事件的过程解耦,这使它们可以是异步的,即 I/O 线程可以独立于 SQL 线程工作。
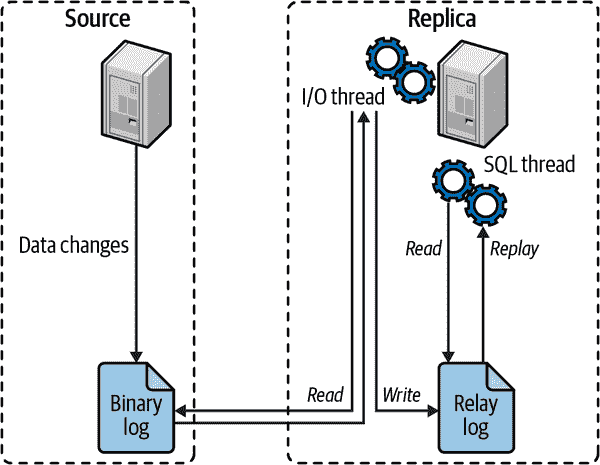
图 9-1. MySQL 复制的工作原理
复制内部机制
现在我们已经为您复习了复制的基础知识,让我们深入了解它。让我们看看复制实际如何工作,看看它的优点和缺点,以及检查一些更高级的复制配置选项。
选择复制格式
MySQL 为复制提供了三种不同的二进制日志格式:基于语句的、基于行的和混合的。这些是通过binlog_format配置参数控制的,该参数控制数据如何写入二进制日志。
基于语句的复制通过记录更改源数据的查询来工作。当副本从中继日志中读取事件并执行它时,它重新执行源执行的实际 SQL 查询。这种格式的主要优点是简单和紧凑。更新大量数据的查询可以在二进制日志中只有几十个字节。基于语句的最大缺点通常是它在非确定性查询方面存在问题。考虑一个删除一千行表中的一百行的语句,没有ORDER BY子句。如果行在源和副本之间以不同的方式排序,您可能在每个副本上删除不同的一百行,导致不一致性。
基于行的复制将事件写入二进制日志,指示行如何更改。这听起来非常简单,但与基于语句的复制相比,这是一个很大的改变,因为它是确定性的。使用基于行的复制,您可以查看二进制日志,看到确切哪些行发生了变化以及值变成了什么。使用基于语句的复制,SQL 在执行时被解释,服务器在执行时找到的任何行都会发生变化。基于行的缺点是为每个受影响的行写入事件可能会显��增加二进制日志的大小。
混合方法试图结合两种方法的优点,使用基于语句的格式作为默认,并在需要时切换到基于行的格式。我们说“试图”是因为虽然它非常努力,但它有很多条件¹ 需要满足何时写入每种格式,这会导致二进制日志中发生不可预测的事件。我们认为二进制日志数据应该是其中一种,而不是混合使用两种格式。
我们建议除非您有使用基于语句的临时需求,否则坚持使用基于行的复制。基于行提供了最安全的数据复制方法。
全局事务标识符
直到 MySQL 5.6,副本必须跟踪连接到源时正在读取的二进制日志文件和日志位置。例如,一个副本连接到上游源并从 binlog.000002 的位置 2749 读取数据。当副本从该二进制日志中读取事件时,每次都会推进位置。然后,灾难发生了!源崩溃了,您不得不从备份中重建数据。问题是:如果二进制日志重新开始,您如何重新连接您的副本?这是一个相当复杂的过程,需要读取事件并确定何时连接。如果您��了错误并连接得太早,您可能会重复事件,如果太晚,您会跳过事件。无论哪种方式,都很容易错误地连接副本。
为了解决这个问题,MySQL 添加了一种替代方法来跟踪复制位置:全局事务标识符(GTID)。使用 GTID,源服务器提交的每个事务都被分配一个唯一标识符。这个标识符是 server_uuid² 和递增的事务编号的组合。当事务写入二进制日志时,GTID 也会随之写入。在本章前面的复习中,您会记得副本将二进制日志事件复制到本地中继日志,并使用 SQL 线程将更改应用到本地副本。当 SQL 线程提交一个事务时,它也记录了 GTID 已经完成。
为了更好地说明这一点,让我们举个例子。假设我们的源服务器刚刚设置好,里面没有任何数据,甚至没有创建数据库。在这个源服务器上,我们的 server_uuid 也生成为 b9acac5a-7bbe-11eb-a043-42010af8001a。我们已经在我们的副本上做了同样的事情,并使用适当的命令指示我们的副本使用源服务器进行复制。
在我们的源服务器上,我们需要创建一个新的数据库:
CREATE DATABASE misc;
此事件将被写入二进制日志,以便我们的副本也可以创建数据库。在二进制日志中,我们会看到一个由 GTID 标识的单个事件:
b9acac5a-7bbe-11eb-a043-42010af8001a:1
当副本服务器应用此事件时,它会记住已经完成了事务 b9acac5a-7bbe-11eb-a043-42010af8001a:1。
在我们编造的例子中,假设我们在副本上停止了 MySQL。它已经提交了一个事务。如果我们的源继续接收写入,我们的事务列表将继续增长:2、3、4、5 等等。当我们重新启动我们的副本时,³ 它知道它已经看到了事务 1,并且可以开始处理事务 2。
GTID 解决了运行 MySQL 复制时的一个更痛苦的部分:处理日志文件和位置。我们强烈建议您始终按照官方 MySQL 文档中的指南启用 GTID 用于您的数据库。
使复制具有崩溃安全性
尽管 GTID 解决了日志文件和位置问题,但还有许多其他问题困扰着 MySQL 的管理员。在本章后面,我们将讨论常见的故障模式;然而,在此之前,有一些配置设置可以极大地改善您使用复制的体验。
为了最大程度地减少复制中断的机会,我们建议设置以下内容:
innodb_flush_log_at_trx_commit = 1
虽然不严格属于复制设置,但这确保了每个事务的日志都被写入并同步到磁盘。这是完全符合 ACID 的设置,将最大程度地保护您的数据,即使有复制。这是因为二进制日志事件首先被提交,然后事务将被提交并刷新到磁盘。将此设置为1将增加磁盘写入操作,同时确保您的数据是持久的。
sync_binlog = 1
此变量控制 MySQL 将二进制日志数据同步到磁盘的频率。将此值设置为1意味着在每个事务之前。这可以防止在服务器崩溃时丢失事务。与前面的设置一样,这将增加磁盘写入。
relay_log_info_repository = TABLE
MySQL 复制过去依赖于磁盘上的文件来跟踪复制位置。这意味着由复制完成的事务必须作为第二步同步到磁盘。如果在事务提交和同步之间发生崩溃,磁盘上的文件将具有不正确的文件和位置。该信息已经移动到 MySQL 内部的 InnoDB 表中,允许复制在同一事务中更新事务和中继日志信息。这创建了一个原子操作,并有助于崩溃恢复。
relay_log_recovery = ON
简单来说,relay_log_recovery在检测到崩溃时丢弃所有本地中继日志,并从源获取丢失的数据。这确保了在崩溃中可能发生的任何损坏或不完整的中继日志在磁盘上是可恢复的。此设置还消除了使用sync_relay_log的需要,因为在崩溃事件中,中继日志将被删除。没有必要进行额外的操作将它们同步到磁盘。
延迟复制
在某些情况下,在您的拓扑中拥有一个延迟副本可能是有利的。这种策略可以用来保持数据在线和运行,但保持其在实时之后许多小时或几天。这是通过CHANGE REPLICATION SOURCE TO语句和SOURCE_DELAY选项进行配置的。
想象一下,您正在处理大量数据,发生了意外更改:一个表被删除了。您可能需要几个小时才能从备份中恢复。通过延迟副本,您可以找到DROP TABLE语句的 GTID,并将复制追赶到该表被删除之前的点。这通常可以导致更快的补救时间。
然而,没有什么是没有取舍的。虽然延迟复制在减轻某些数据丢失场景方面非常有用,但它也给许多其他运营方面带来了复杂性。如果您决定需要使用延迟复制,您还应考虑如何正确排除这个延迟副本不成为源节点候选人(如果您的写故障转移是自动化的,这更加重要),如何监视复制以及如何处理这个特殊副本。这些只是引入延迟副本时您应该解决的一些额外复杂性。
多线程复制
复制的一个历史性挑战是,虽然您可以在源上进行并行写入,但您的副本是单线程的。现代 MySQL 版本提供了多线程复制(参见图 9-2),您可以运行多个 SQL 应用程序线程来在本地应用中继日志的更改。
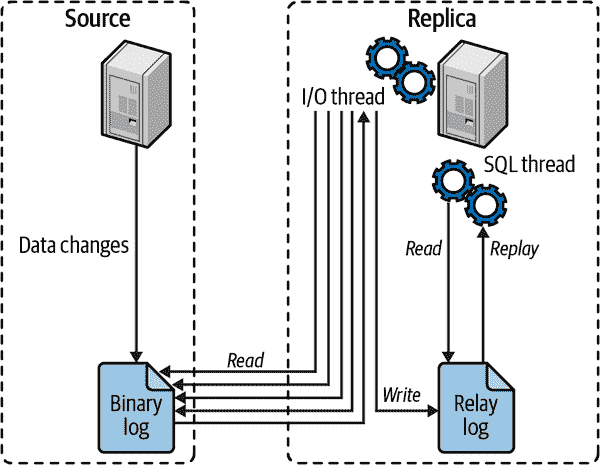
图 9-2。多线程复制设置
多线程复制有两种模式:DATABASE和LOGICAL_CLOCK。DATABASE选项使用多个线程更新不同的数据库;没有两个线程会同时更新同一个数据库。如果您在 MySQL 中将数据分布在多个数据库中并且一致并发地更新它们,这种方法效果很好。另一个选项LOGICAL_CLOCK允许对同一个数据库进行并行更新,只要它们是同一个二进制日志组提交的一部分。
在大多数情况下,您可以简单地打开这个功能,并通过将replica_parallel_workers设置为非零值立即看到好处。如果您只操作一个数据库,还需要将replica_parallel_type更改为LOGICAL_CLOCK。由于多线程复制使用一个协调线程,该线程会有一些开销来管理所有其他线程的状态。此外,请确保您的副本以replica_preserve_commit_order运行,以防止乱序提交导致问题。查看官方文档中的“Gaps”部分以获取为什么这一点很重要的详细解释。
有两种方法可以确定最佳的replica_parallel_workers值。不精确的方法是停止复制,然后测量使用不同数量的线程追赶的时间��直到找到最佳设置。这种方法存在缺陷,因为它假设一致数量的数据操作语言(DML)语句被发送到复制,并且它们的执行几乎相同。实际上,这几乎不可能。
更精确的方法是查看每个应用线程在您的工作负载中有多忙,以确定您获得了多少并行性。为此,我们需要启用性能模式的消费者和工具,允许其收集一些信息,然后查看结果。
首先,我们需要启用以下内容:⁴
UPDATE performance_schema.setup_consumers SET ENABLED = 'YES'
WHERE NAME LIKE 'events_transactions%';
UPDATE performance_schema.setup_instruments SET ENABLED = 'YES', TIMED = 'YES'
WHERE NAME = 'transaction';
允许复制处理一段时间内的事件。理想情况下,您应该在最繁忙的写入工作负载期间或任何看到复制延迟增加的时候查看这一点:
mysql> USE performance_schema;
events_transactions_summary_by_thread_by_event_name.thread_id AS THREAD_ID,
events_transactions_summary_by_thread_by_event_name.count_star AS COUNT_STAR
FROM events_transactions_summary_by_thread_by_event_name
WHERE
events_transactions_summary_by_thread_by_event_name.thread_id IN (SELECT
replication_applier_status_by_worker.thread_id
FROM replication_applier_status_by_worker);
+-----------+------------+
| THREAD_ID | COUNT_STAR |
+-----------+------------+
| 1692957 | 23413 |
| 1692958 | 7150 |
| 1692959 | 1568 |
| 1692960 | 291 |
| 1692961 | 46 |
| 1692962 | 9 |
+-----------+------------+
6 rows in set (0.00 sec)
这个查询将帮助您确定每个线程处理了多少个事务。从这个样本工作负载的结果中可以看出,我们的最佳使用情况在三到四个线程之间,超过这个数量的线程几乎没有被使用。
半同步复制
当您启用半同步复制时,源数据库提交的每个事务必须得到至少一个副本的确认已接收。⁵ 这个确认表示副本已接收并成功写入到自己的中继日志(但不一定应用到本地数据)。
由于每个事务必须等待其他节点的响应,这个特性会给服务器的每个事务增加额外的延迟。这意味着您需要考虑所涉及的权衡。
这里非常重要的一点是,如果在时间范围内没有副本确认事务,MySQL 将恢复到其标准的异步复制。它不会使事务失败。这真的有助于说明半同步复制不是用来防止数据丢失的工具,而是一个更大工具集的基础,使您能够拥有更具弹性的故障转移。
鉴于回退到异步复制,我们很难找到一个好的使用案例来解释为什么要启用这个功能。逻辑上的使用案例是确认,在网络分区的情况下,孤立的源数据库是否仍在写入数据而与其副本分隔。不幸的是,该源数据库将会回退到异步并继续接受写入。因此,我们建议不依赖于这一点来保证任何数据完整性。
复制过滤器
复制过滤选项让你只复制服务器数据的一部分,这并不像你想象的那么好。有两种复制过滤器:一种是从源二进制日志中过滤事件,另一种是从副本中继日志中过滤事件。图 9-3 展示了这两种类型。
控制二进制日志过滤的选项是 binlog_do_db 和 binlog_ignore_db。除非你认为你会喜欢向老板解释为什么数据永久丢失且无法恢复,否则不应启用这些选项。
在副本上,replicate_* 选项在复制 SQL 线程从中继日志读取事件时过滤事件。你可以复制或忽略一个或多个数据库,将一个数据库重写为另一个数据库,并根据 LIKE 模式匹配语法复制或忽略表。
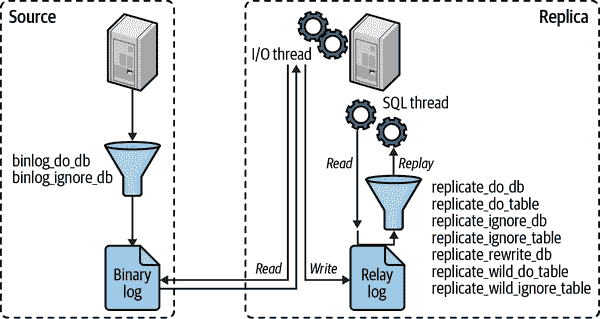
图 9-3. 复制过滤选项
关于这些选项最重要的理解是,*_do_db 和 *_ignore_db 选项,在源和副本上,不像你期望的那样工作。你可能认为它们是根据对象的数据库名称进行过滤,但实际上它们是根据当前默认数据库进行过滤——也就是说,如果你在源上执行以下语句:
USE test;
DELETE FROM sakila.film;
*_do_db 和 *_ignore_db 参数将在 test 上过滤 DELETE 语句,而不是在 sakila 上。这通常不是你想要的,它可能导致错误的语句被复制或忽略。*_do_db 和 *_ignore_db 参数有用处,但它们是有限的和罕见的,你应该非常小心使用它们��如果你使用这些参数,复制很容易出现不同步或失败。
binlog_do_db 和 binlog_ignore_db 选项不仅有可能破坏复制;它们还会使从备份进行时点恢复变得不可能。在大多数情况下,你应该永远不要使用它们。
一般来说,复制过滤器是一个等待发生问题的问题。例如,假设你想阻止权限更改传播到副本,这是一个相当常见的目标。(希望这种愿望可能会让你意识到你正在做错事;可能有其他方法来实现你真正的目标。)系统表上的复制过滤器肯定会阻止 GRANT 语句的复制,但它们也会阻止事件和例程的复制。这种意想不到的后果是需要小心处理过滤器的原因。也许更好的主意是阻止特定语句被复制,通常使用 SET SQL_LOG_BIN=0,尽管这种做法也有其自身的危险。总的来说,你应该非常谨慎地使用复制过滤器,只有在真正需要它们的情况下才使用,因为它们很容易破坏复制并在最不方便的时候出现问题,比如在灾难恢复期间。
话虽如此,也可能存在特定情况下复制过滤器是有益的。也许你创建了多个数据库 users_1、users_2、users_3 和 users_4,现在服务器的性能受到了太大的影响。通过恢复备份并附加复制,你可以准备将 users_3 和 users_4 的查询移动到另一台服务器。这个过程完全正常,只是你在新数据库上仍然有 users_1 和 users_2。在某个时候,你将不得不删除可能影响性能的数据。考虑这种替代方案。你恢复备份然后删除 users_1 和 users_2。然后配置一个复制规则来忽略 users_1 和 users_2 并完成复制设置。现在你的新服务器上只处理 users_3 和 users_4 的事件。一旦复制追上,你就可以开始接收生产流量了。
MySQL 手册中已经对过滤选项进行了详细说明,所以我们不会在这里重复细节。
复制故障转移
在本章的开头,我们提到复制是高可用性的基石,还有其他方面。在另一个位置持续更新的数据副本,比起备份更容易从灾难中恢复。更重要的是,有时你只需进行一些需要重新启动 MySQL 的维护工作。
在这一部分,我们想谈谈正确的方式将副本晋升为源节点。很容易出错,出错可能导致数据问题和延长的停机时间。我们想澄清“晋升副本”和“故障切换”是同义词。它们都意味着将源降级为不再接受写入,并将副本晋升为源的行为。
如何处理这个问题的更详细解释在官方的 MySQL 文档中,位于“故障切换期间切换源”部分,但考虑到这个问题的重要性,我们至少想在某个层面上提及它。
计划晋升
晋升的最常见原因是某种维护事件,包括安全补丁、内核更新,甚至只是重新启动 MySQL,因为有一些配置选项需要重新启动。这种类型的晋升被称为受控或计划晋升。
要成功执行此晋升,你需要完成以下步骤:
-
确定要晋升的副本。通常情况下,这是你确信拥有所有数据的副本。这就是你的目标。
-
检查延迟,确保你的时间在几秒钟之内。
-
通过设置
super_read_only停止在源上进行写入。⁶ -
等待复制与目标同步。比较 GTIDs 以确保一致。
-
在目标上取消
read_only。 -
将应用程序流量切换到目标。
-
将所有副本重新指向新源,包括降级的副本。这在 GTIDs 和
AUTO_POSITION=1中是微不足道的。
非计划晋升
在足够长的时间轴上,每个系统都会失败,无论是软件还是硬件的结果。当这种情况发生在正在写入的源服务器上时,会对用户体验产生很大影响。大多数应用程序将简单地返回一个错误,让用户自行重试。这是需要非计划晋升的情况。
由于你没有一个实时源来检查,这是一个简化的计划晋升,你根据已经复制的数据选择要晋升的副本:
-
确定要晋升的副本。通常情况下,这是你确信拥有所有数据的副本。这就是你的目标。
-
在目标上取消
read_only。 -
将应用程序流量切换到目标。
-
将所有副本重新指向新源,包括降级的副本当它恢复服务时。这在 GTIDs 中是微不足道的。
你还应该确保当你以前的源重新上线时,默认启用super_read_only。这将有助于防止任何意外写入。
晋升的权衡
我们不得不指出,有时候你对停机的第一反应是故障切换。因为很难知道目标可能缺少多少数据,有时候不故障切换可能是一个更好的策略。
非计划晋升并不是一个经常发生的事件,也就是说,你不经常这样做。当你被要求这样做时,你可能需要查阅文档,以确保不会漏掉任何步骤。你还需要检查其他副本,以验证哪一个是可能的候选。所有这些都需要时间。在某些情况下,等待服务器或 MySQL 进程重新上线可能更快。这样做的好处是,如果你在第五章中遵循了 ACID 合规性的步骤,你不会丢失任何数据,你的副本将从中断的地方继续。
复制拓扑
您可以为几乎任何源和副本配置设置 MySQL 复制。许多复杂的拓扑结构是可能的,但即使简单的拓扑结构也可以非常灵活。单个拓扑结构可以有许多不同的用途。您可以使用复制的各种方式很容易地填满一本书。
所有这些灵活性意味着您可以轻松设计一个难以维护的拓扑结构。我们强烈建议您尽可能简化您的复制拓扑结构,同时仍满足您的需求。话虽如此,我们推荐两种几乎可以涵盖所有用例的策略。您可能有理由偏离这些策略,但请确保在变得更复杂时问问自己是否仍在解决正确的问题。
主/被动
在主/被动拓扑中,您将所有读写指向单个源服务器。此外,您保留一小部分不主动提供任何应用程序流量的被动副本。选择此模型的主要原因是您不想担心复制延迟。由于所有读取都发送到源,您可以防止应用程序可能无法容忍的写后读问题。
图 9-4 显示了具有多个副本的这种安排。
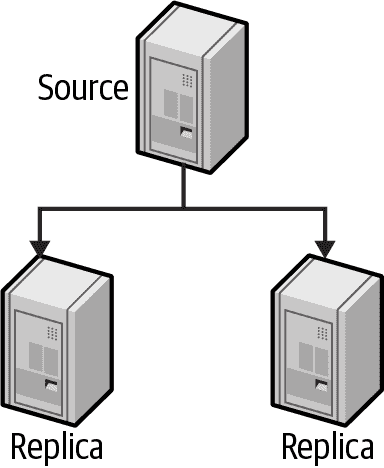
图 9-4。具有多个副本的源
配置
在这种拓扑结构中,我们期望源和副本在 CPU、内存等方面具有相同的配置。在足够长的时间内,您将需要从当前运行的源故障切换到其中一个副本,无论是为了维护、软件升级或打补丁,甚至是硬件故障。通过在副本上具有相同的硬件和软件配置,您确保可以像之前进行故障切换前一样维持流量容量和吞吐量。
冗余
在物理硬件环境中,至少需要三台总服务器的n+2 冗余。在硬件故障的情况下,您仍然有一台额外的服务器用于故障切换。如果您不放心或无法在源上进行备份,您还可以使用其中一个副本作为备用服务器。
在云环境中,如果你的数据足够小或者可以轻松复制数据,你可以通过n+1 的冗余来实现两台总服务器。否则,需要n+2。如果选择n+1 的方式,云服务提供商的动态配置特性可以使管理变得更容易。对于像打补丁这样的维护事件,更容易在需求时提供第三个副本,执行任何必要的操作(如升级内核或应用安全更新),然后替换其他副本。然后进行故障切换并在原始源上重复该过程。目标是始终保持一个准备好成为故障切换目标的副本。
在任一情况下,您可以将其中一个副本放置在地理位置较远的位置,尽管您需要注意复制延迟并确保其可用。副本应该是可恢复的,并且在您建立的指导方针内遭受任何数据丢失。我们在“定义恢复要求”中讨论了这一点,在第十章中。
注意事项
通过选择这种模型,您明确将您的读扩展绑定到单个服务器的容量。如果达到读扩展限制,您将不得不进化到活动/读池配置,或者利用分片来减少源上的读取。
主/读池
在主/读池配置中,您将所有写入指向源。读取可以发送到源服务器或读池,具体取决于应用程序需求。读池允许您为读密集型应用程序水平扩展读取。在某个时刻,由于源上的复制需求,水平扩展将会减少。
图 9-5 显示了这种安排,其中有一个单一源和一个副本池。

图 9-5. 带有读取池的源
配置
理想情况下,您希望源和至少一个副本之间的配置相同,最好是两个副本。再次强调,您最终将需要切换到这些副本之一,并且它应具有足够的容量来跟上您的流量。
如果您看到这个池随着时间增长,您可以优化成本,并为一些成员使用不同的配置。如果是这种情况,请尝试将流量加权作为一种平衡流量的方法。如果您有 32 个核心用于故障转移目标和 8 个核心用于其他副本,尝试将流量发送到 32 核心节点的流量增加四倍,以确保您获得利用率。
冗余
在这个池中,您拥有的服务器数量应满足先前给定的要求,至少有一台服务器可以充当故障转移目标。此外,您需要足够的节点来容纳您的读取流量,再加上一小部分用于节点故障的缓冲区。在读取方面,您最有可能的利用率指标将是 CPU,因此,在池中的每个节点上的利用率应在 50%–60% 之间。随着 CPU 的增加,它在工作和延迟之间的上下文切换时间增加。尝试找到满足应用程序期望的延迟和利用率之间的正确平衡点。
注意事项
当您使用读取池时,您的应用程序必须对旧的读取具有一定的容忍度。您永远无法保证您在源上完成的写入已经被复制到副本。您可能还需要一种方法来使落后于复制的节点退出池。
读取池的大小也会影响您需要做多少管理工作以及何时应该考虑自动化。一个 16 节点的池意味着您必须进行 16 次内核更新或安全补丁。自动化此任务以优雅地使节点退出池,执行补丁,重新启动,然后重新加入池,将减少您将来手动完成的工作量。
不推荐的拓扑结构
通过使用本章中提供的两个建议中的任何一个,您可以保持拓扑结构简单且易于理解。本书早期版本中还有许多其他建议,或者您可能从其他公司的拓扑结构设置中听说过。我们在这里指出一些不推荐的原因是因为它们带来的风险和复杂性超出了我们愿意看到的范围。
Active-active 模式下的双源
双源复制(也称为双向复制)涉及两台服务器,每台服务器都配置为对方的源和副本,换句话说,是一对共同源。图 9-6 展示了这种设置。

图 9-6. Active-active 模式下的双源
乍一看,这与具有两台服务器的主备模式没有任何不同,只是复制已经以相反方向配置。真正的危险在于当您明确将写入流量发送到两侧时,因此是活动/活动部分。
Active/active 模式非常难以正确实现。一些策略涉及根据奇偶哈希选择发送到哪一侧。这确保了写入后的读取对于相同行是一致的,但包含在另一侧上的规范行的查询可能不一致。更直白地说,从一侧读取 ID 1、3 和 5 的行将始终保持一致。那么对于读取 ID 1–6 的查询怎么办?您将该查询发送到哪里?如果另一侧存在更新,但由于复制延迟在这一侧没有反映出来,会怎样?
您还需要仔细平衡容量。在共源场景中,每台服务器都是另一台服务器的副本,也是最有可能的故障切换目标。您必须以确保在将流量从一侧转移到另一侧时不会耗尽 CPU 的方式规划容量。您还在进行故障切换,并引入一个完全不同的工作数据集。InnoDB 缓冲池现在会翻转,删除条目以为新的热数据集腾出空间。
请听从我们的建议,远离这种设置。也许让一个被动服务器处理流量而不是闲置会让您感觉像在“使用”它。您最终会在应用程序中引入数据不一致,并且总是担心没有足够的容量进行故障切换。一旦失去故障切换策略,您就失去了弹性。
双源主动-被动模式
在避免我们刚刚讨论的问题的双源主动-主动模式中有一种变体。主要区别在于其中一台服务器是只读的“被动”服务器,如图 9-7 所示。

图 9-7. 双源主动-被动模式
表面上这种设置并没有什么问题。它与我们对主/备份的建议唯一的不同之处在于,复制已经预先配置回到另一个服务器。这只适用于两台服务器的配置。如果运行的服务器超过两台,您需要决定哪个节点是最适合故障切换的目标。预先配置复制只会直接将您与一个节点绑定在一起,在故障情况下不会给您灵活性。
我们坚持认为设置复制是作为我们之前讨论的复制-故障切换过程的一个简单、可自动化的步骤。这是一个不必要的配置,只会引起混乱。
具有副本的双源
更进一步混合,我们可以为每个共源添加一个或多个副本,如图 9-8 所示。
图 9-8. 具有副本的双源拓扑
这保留了双源主动-主动中的大部分问题,最重要的是如何路由流量。它解决了关于容量规划和故障切换中缓冲池翻转的问题。在故障切换中,您需要额外的步骤将其中一个源指向其上新晋升的副本。
我们绝对反对这种拓扑,主要是出于数据访问方面的考虑。共源只会带来麻烦。
环形复制
环形复制有三个或更多源,其中每个服务器都是环中前一个服务器的副本,也是后一个服务器的源,如图 9-9 所示。这种拓扑结构也被称为循环复制。
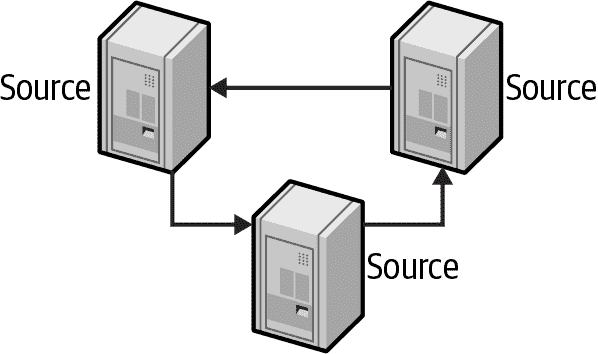
图 9-9. 复制环拓扑
如果此拓扑中的任何服务器下线,您的拓扑将中断,更新将停止在环中传播。这种情况下还有附加的副本变体,其中图 9-9 中的每个源都有一个专用的副本可用于替换。这仍然意味着环被中断,直到您将一个副本提升到原来的位置。
这种拓扑结构与简单相反,没有任何优势。
多源复制
尽管保持复制拓扑简单很重要,但可能会出现需要使用更高级功能来处理一次性功能的情况。假设您建立了一个全新的视频上传和观看网站,现在变得很受欢迎。您早期的设计决策之一是将视频数据和用户数据分开存储在两个不同的数据库集群中。随着您的发展,您发现自己希望在查询中将它们合并在一起。您可以通过多源复制实现这一点,将两个数据集合再次合并到一个副本中,如图 9-10 所示。
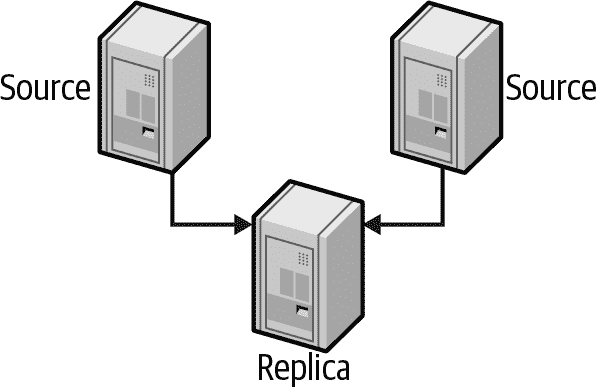
图 9-10. 多源复制
这个功能是建立在一个称为复制通道的概念之上。在前面的示例中,您需要为 MySQL 创建第三个集群。这个新的第三个集群将创建两个复制通道:一个用于视频数据,一个用于用户数据。一旦加载和复制数据,您可以进行非常短暂的停机,在这段时间内,您冻结对两个源的写入,并推送您的代码以切换读写到新的合并数据库。哇,您现在已经将两个数据库合并为一个。
在我们继续之前,有一个重要的限制需要知道:您不能配置一个副本多次使用多源复制来自同一源。
这种拓扑结构非常适用于特殊情况。我们只在您围绕这个概念构建永久拓扑结构的情况下不鼓励使用。暂时使用它来合并数据仍然是一个可以接受的用例,最终目标是回到我们的两个建议之一。
复制管理和维护
对于少量数据和一致的写入工作负载,您不太可能经常需要查看复制延迟,更糟糕的是,复制中断。大多数数据库随着时间的推移而增长,随着增长将会进行维护。
监控复制
复制增加了 MySQL 监控的复杂性。尽管复制实际上发生在源和副本上,但大部分工作是在副本上完成的,这也是最常见的问题发生的地方。所有副本都在工作吗?是否有任何副本出现错误?最慢的副本落后多少?MySQL 提供了大部分您需要回答这些问题的信息,但自动化监控过程和使复制稳健留给您自己。
在设置复制监控时,有几个我们认为最重要的观察项目:
复制需要源和副本上的磁盘空间
如前文所述,在图 9-1 中可见,复制使用源上的二进制日志和副本上的中继日志。如果源上没有空闲磁盘空间,事务将无法完成并开始超时。如果在副本上发生相同的情况,MySQL 会更加优雅地暂停复制并等待空闲磁盘空间。您需要监视可用磁盘空间,以确保持续运行。
应该监视复制的状态和错误
尽管复制是一个长期存在的功能且非常稳健,但像网络问题、数据不一致和数据损坏等外部因素可能导致其中断。因此,最好监视复制线程是否正在运行,如果没有,查看最新的错误以确定下一步应该采取什么措施。我们在“复制问题和解决方案”中更详细地介绍了如何解决特定问题。
延迟复制应该按预期延迟
既然我们之前提到了延迟复制,建议设置监控以确保延迟副本确实延迟了正确的时间。太长的延迟可能会使使用变得更加耗时。如果延迟太少,甚至更糟糕的是根本没有延迟,那��如果您需要,延迟副本可能对您毫无用处。
测量复制延迟
你需要监控的最常见事项之一是副本落后源的距离。尽管SHOW REPLICA STATUS中的Seconds_behind_source列理论上显示了副本的延迟,但实际上由于各种原因,它并不总是准确的:
-
副本通过比较服务器当前时间戳和二进制日志事件中记录的时间戳来计算
Seconds_behind_source,因此,除非处理查询,否则副本无法报告其延迟。 -
如果复制线程未运行,副本通常会报告
NULL。 -
一些错误(例如,源端和副本之间
max_allowed_packet设置不匹配或网络不稳定)可能会中断复制和/或停止复制线程,但Seconds_behind_source将报告0而不是指示错误。 -
即使复制进程正在运行,副本有时也无法计算滞后。如果发生这种情况,副本可能报告
0或NULL。 -
非常长的事务可能导致报告的滞后波动。例如,如果您有一个更新数据的事务,保持打开一个小时,然后提交,更新将在实际发生后一个小时进入二进制日志。当副本处理该语句时,它将暂时报告自己比源端滞后一个小时,然后会跳回到零秒滞后。
解决这些问题的方法是忽略Seconds_behind_source,并使用您可以直接观察和测量的内容监视副本滞后。最佳解决方案是心跳记录,这是一个时间戳,您可以在源端每秒更新一次。要计算滞后,您只需从副本上的当前时间戳减去心跳。这种方法不受我们刚提到的所有问题的影响,并且还有一个额外的好处,即创建一个方便的时间戳,显示副本数据的当前时间点。Percona Toolkit 中包含的pt-heartbeat脚本是复制心跳的最受欢迎的实现。
心跳还有其他好处。二进制日志中的复制心跳记录对许多目的都很有用,比如在其他情况下难以解决的灾难恢复场景。
我们刚提到的任何滞后指标都无法让您了解副本实际追赶源端需要多长时间。这取决于许多因素,例如副本的性能如何以及源端继续处理多少写入查询。有关更多信息,请参阅“复制问题和解决方案”部分中的“过多的复制滞后”子节。
确定副本是否与源端一致
在理想情况下,副本始终应该是源的精确副本,减去任何复制延迟。但在现实世界中,副本可能会引入不一致性。一些可能的原因包括:
-
对副本的意外写入
-
使用双源复制,两侧都进行写入
-
非确定性查询和基于语句的复制
-
MySQL 在以低耐久性模式运行时崩溃(请参阅第五章中的耐久性配置)
-
MySQL 中的错误
我们建议遵循以下规则:
始终使用启用super_read_only的副本
使用read_only可以防止没有SUPER特权的用户进行写入,但这不会阻止您的 DBA 在不知情的情况下在副本上运行DELETE或ALTER。super_read_only设置仅允许复制写入,是运行副本的最安全方式。
使用基于行的复制或确定性语句
尽管在某些情况下会使用更多的磁盘空间,基于行的复制是复制数据最一致的方式。这是因为它包含了每个条目的确切行数据更改。
在基于语句的复制中考虑以下内容:
DELETE FROM users WHERE last_login_date <= NOW() LIMIT 10;
当表中有一千个与WHERE子句匹配的用户时会发生什么?MySQL 将使用表中的自然顺序仅删除前 10 行。表的自然顺序在副本上可能不同,因此可能会影响不同的 10 行。未来运行的基于last_login_date修改或删除行的语句可能存在或不存在。这可能导致数据不一致。
编写此内容的最佳方法是使用ORDER BY使行顺序确定:
DELETE FROM users WHERE last_login_date <= NOW() ORDER BY user_id
LIMIT 10;
使用此语句,只要源端和副本之间的数据一致,将删除相同的 10 行。
不要尝试同时向复制拓扑中的多个服务器写入
这包括在两侧都有写入的共源或环形复制。最实用的��制拓扑是使用一个源,接收所有写入,并且一个或多个副本,可选地接收读取。
最后,我们强烈建议,如果你遇到任何复制错误,你使用策略在官方 MySQL 文档中重建副本。
复制问题和解决方案
MySQL 复制的简单实现使其易于设置,但也意味着有许多方法可以停止、混淆和破坏它。在本章的前面,我们讨论了崩溃安全的复制和规则,以帮助保持源和副本同步。本节讨论常见问题,它们如何表现,以及你如何解决或甚至预防它们。
源上的二进制日志损坏
如果源上的二进制日志损坏,你别无选择,只能重建你的副本。跳过损坏的条目将跳过一些事务,这些事务将不再被你的副本处理。
非唯一的服务器 ID
这是你可能在复制中遇到的更难以捉摸的问题之一。如果你意外地配置了两个具有相同服务器 ID 的副本,它们可能看起来工作正常,如果你没有仔细观察的话。但如果你观察它们的错误日志或用innotop这样的工具观察源,你会注意到一些非常奇怪的事情。
在源上,你只会看到两个副本中的一个连接。 (通常,所有副本都是连接并一直复制的。)在副本上,你会在错误日志中看到频繁的断开和重新连接错误消息,但没有提到配置错误的服务器 ID。
根据 MySQL 版本的不同,副本可能会正确但缓慢地复制,或者它们实际上可能不会正确地复制——任何给定的副本可能会错过二进制日志事件,甚至重复它们,导致重复键错误(或静默数据损坏)。你还可能因为副本之间的增加负载而在源上引起问题。如果副本之间的争斗足够激烈,错误日志可能在很短的时间内变得庞大。
这个问题的唯一解决方案是在设置副本时要小心。你可能会发现创建一个副本到服务器 ID 映射的规范列表很有帮助,这样你就不会忘记每个副本属于哪个 ID。如果你的副本完全位于一个网络子网中,你可以通过使用每台机器 IP 地址的最后一个八位来选择唯一的 ID。
未定义的服务器 ID
如果你不定义服务器 ID,MySQL 会似乎使用CHANGE REPLICATION SOURCE TO设置复制,但不会让你启动副本:
mysql> START REPLICA;
ERROR 1200 (HY000): The server is not configured as replica; fix in config file
or with CHANGE REPLICATION SOURCE TO
这个错误尤其令人困惑,如果你刚刚使用了CHANGE REPLICATION SOURCE TO并用SHOW REPLICA STATUS验证了你的设置。你可能会从SELECT @@server_id得到一个值,但那只是一个默认值。你必须显式设置该值。
临时表丢失
临时表对某些用途很方便,但不幸的是,它们与基于语句的复制不兼容。如果一个副本崩溃或者你关闭它,副本线程正在使用的任何临时表都会消失。当你重新启动副本时,任何进一步引用缺失临时表的语句将失败。
这里最好的方法是使用基于行的复制。第二好的方法是一致命名你的临时表(例如以temporary_为前缀)并使用复制规则完全跳过复制它们。
不复制所有更新
如果你错误使用SET SQL_LOG_BIN=0或不理解复制过滤规则,你的副本可能不会执行一些在源上发生的更新。有时你可能希望这样做以进行归档,但通常是意外的,后果很糟糕。
例如,假设您有一个replicate_do_db规则,只将sakila数据库复制到您的一个副本。如果您在源头上执行以下命令,则副本的数据将与源头上的数据不同:
mysql> USE test;
mysql> UPDATE sakila.actor ...
其他类型的语句甚至可能因为非复制依赖关系而导致复制失败。
过多的复制延迟
复制延迟是一个常见问题。无论如何,设计您的应用程序以容忍副本上的一些延迟都是一个好主意。以下是一些减少复制延迟的常见方法:
多线程复制
确保您正在使用多线程复制,并根据手册调整各种选项以获得最高效率。
使用分片
尽管这似乎是一个逃避的答案,但使用分片技术将写操作分散到多个源头是一种非常有效的策略。MySQL 的长期经验法则是:使用副本扩展读操作,使用分片扩展写操作。
暂时降低耐久性
纯粹主义者会不同意,但也许有时候当您已经尝试了所有调整和优化,而分片由于工作量或设计问题而不可行时。如果您的复制延迟主要是由于写操作限制造成的,您可以暂时将sync_binlog=0和innodb_flush_log_at_trx_commit=0设置为提高复制速度。
如果您选择这种最后的方式,您应该非常非常小心。您应该只在您的副本上这样做,如果您的副本也是您进行备份的地方,更改这些设置可能会使您无法从备份中恢复。此外,如果您的副本在此降低耐久性期间崩溃,您可能需要从源头重建。最后,如果您手动执行此操作,很容易忘记将耐久性设置回来。确保您有良好的监控或已编写某种方式来重新设置耐久性。
一个可能的策略是观察SHOW REPLICA STATUS命令中的Seconds_behind_source值,当它超过某个值时,触发以下操作:
-
确保服务器是一个不可写的副本,可能通过验证
super_read_only是否已启用来实现。 -
更改
sync_binlog和innodb_flush_log_at_trx_commit的设置以减少写操作。 -
定期检查
SHOW REPLICA STATUS以获取Seconds_behind_source的值。 -
当低于可接受的阈值时,将设置恢复为其耐久性特性。
源头传来的超大数据包
复制中另一个难以追踪的问题可能发生在源头的max_allowed_packet大小与副本的不匹配时。在这种情况下,源头可能记录一个副本认为过大的数据包,当副本检索到该二进制日志事件时,可能会遇到各种问题。这些问题包括错误和重试的无限循环,或者在中继日志中出现损坏。
没有磁盘空间
复制确实可能会用二进制日志、中继日志或临时文件填满您的磁盘,尤其是如果您在源头上执行了大量的LOAD DATA INFILE查询,并且在副本上启用了log_replica_updates。副本落后越多,它可能使用的磁盘空间就越多,用于从源头检索但尚未执行的中继日志。您可以通过监控磁盘使用情况并设置relay_log_space配置变量来防止这些错误。
复制限制
MySQL 复制可能会因其固有限制而失败或失去同步,有时即使没有错误。相当多的 SQL 函数和编程实践简单地无法可靠地复制(我们在本章中提到了许多)。要确保这些内容中没有一个进入您的生产代码,尤其是如果您的应用程序或团队规模较大。
另一个问题是服务器中的错误。我们不想听起来消极,但许多 MySQL 服务器的主要版本在历史上在复制方面存在错误,特别是在主要版本的首次发布中。新功能,比如存储过程,通常会引起更多问题。
对于大多数用户来说,这并不是避免新功能的理由。这只是一个需要仔细测试的理由,特别是当您升级应用程序或 MySQL 时。监控也很重要;您需要知道什么时候出现问题。
MySQL 复制很复杂,您的应用程序越复杂,您就需要越小心。然而,如果您学会如何使用它,它的效果相当不错。
总结
MySQL 复制是 MySQL 内置功能的瑞士军刀,它极大地增加了 MySQL 的功能和实用性范围。事实上,这可能是 MySQL 迅速变得如此受欢迎的关键原因之一。
尽管复制有许多限制和注意事项,但事实证明,其中大多数对大多数用户来说相对不重要或容易避免。许多缺点只是高级功能的特殊行为,大多数人不会使用,但对需要它们的少数用户非常有帮助。
在复制方面,你的座右铭应该是保持简单。除非你真的需要,不要做任何花哨的事情,比如使用复制环或复制过滤器。简单地使用复制来镜像整个数据副本,包括所有权限。保持副本与源相同的方式将帮助你避免许多问题。
¹ 如预期的那样,我们建议您查阅手册,以确保您了解MIXED模式如何与不同类型的 SQL 语句一起工作。
² 请注意,server_uuid与同名的server_id是不同的。server_id参数是您为服务器指定的用户定义值,而server_uuid是在 MySQL 首次启动时生成的,如果它没有检测到文件auto.cnf。
³ 这假设您在发出CHANGE REPLICATION SOURCE TO命令时使用了SOURCE_AUTO_POSITION = 1选项,这通常是您应该始终这样做的。
⁴ 性能模式的消费者和仪器使 MySQL 收集有关其内部的额外数据,这可能会使用额外的 CPU。作为提醒,您应该始终在安全环��中测试这些更改如何影响生产工作负载。
⁵ 所需的副本数量是可配置选项(rpl_semi_sync_source_wait_for_replica_count)。在更广泛的拓扑结构中,您可能考虑要求在完成原始事务之前需要两甚至三个确认。
⁶ 设置super_read_only会隐式启用read_only。相反,禁用read_only会隐式禁用super_read_only。在此过程中,没有理由同时启用或禁用这两个变量。
⁷ 这通常适用于您可能使用 LVM 快照或基于云的磁盘快照方法进行备份的情况。
第十章:备份和恢复
如果您不事先计划备份,您可能会发现自己排除了一些最佳选项。例如,您可能设置了一个服务器,然后希望使用 LVM 以便可以进行文件系统快照—但为时已晚。您可能也没有注意到配置系统进行备份会产生一些重要的性能影响。如果您不计划并练习恢复,那么当您需要执行时,情况就不会顺利。
我们不会在本章中涵盖备份和恢复解决方案的所有部分—只涵盖与 MySQL 相关的部分。以下是我们决定不在此处包括但您绝对应该在整体备份和恢复策略中包括的一些要点:
-
安全性(备份访问权限、恢复数据权限以及文件是否需要加密)
-
备份存储位置,包括与源站点的距离(在不同磁盘、不同服务器或异地)以及如何将数据从源站点移动到目的地
-
保留政策、审计、法律要求和相关主题
-
存储解决方案和媒体、压缩和增量备份
-
存储格式
-
监控和报告您的备份
-
内置到存储层或特定设备中的备份功能,例如预制文件服务器
在我们开始之前,让我们澄清一些关键术语。首先,您经常会听到所谓的热备份、温备份和冷备份。人们通常使用这些术语来表示备份的影响:“热”备份不应该需要任何服务器停机,例如。问题在于这些术语对每个人来说意义不同。有些工具甚至在其名称中使用热这个词,但绝对不执行我们认为的热备份。我们尽量避免使用这些术语,而是告诉您特定技术或工具对服务器的中断程度。
另外两个令人困惑的词是恢复和恢复。在本章中,我们以特定方式使用它们。恢复意味着从备份中检索数据,并将其加载到 MySQL 中,或将文件放在 MySQL 期望它们在的位置。恢复通常意味着在出现问题后拯救系统或系统的一部分的整个过程。这包括从备份中恢复数据以及使服务器完全功能的所有必要步骤,例如重新启动 MySQL、更改配置、启动服务器的缓存等。
对许多人来说,恢复只意味着在崩溃后修复损坏的表格。这与恢复整个服务器不同。存储引擎的崩溃恢复会协调其数据和日志文件。它确保数据文件仅包含已提交事务所做的修改,并且重新播放尚未应用于数据文件的日志文件中的事务。这可能是整体恢复过程的一部分,甚至是备份的一部分。但是,这与您可能需要在意外DROP TABLE之后进行的恢复不同,例如。根据您要从中恢复的问题,您采取的恢复措施可能大不相同。
最后,备份主要有两种类型:原始和逻辑。原始备份—有时称为物理¹ 备份—指的是来自文件系统的文件副本。逻辑备份指的是重建数据所需的 SQL 语句。
为什么备份?
以下是备份重要性的几个原因:
灾难恢复
灾难恢复是在硬件故障、恶意软件损坏数据或服务器及其数据由于其他原因变得不可用或无法使用时所做的事情。您需要准备好应对一切,从有人意外连接到错误服务器执行ALTER TABLE,到建筑物着火,到恶意攻击者或 MySQL 错误。尽管任何特定灾难发生的几率相当低,但加在一起就会增加。
人们改变主意
你会惊讶地发现,人们经常会有意删除数据,然后希望将其找回。
审计
有时候你需要知道你的数据或模式在过去的某个时间点是什么样子。例如,你可能卷入了诉讼,或者你可能发现了应用程序中的错误,需要查看代码以前是如何运行的(有时仅仅将代码放在版本控制中是不够的)。
测试
在真实数据上进行测试的最简单方法之一是定期使用最新的生产数据刷新测试服务器。如果你正在进行备份,这很容易:只需将备份恢复到测试服务器即可。
检查你的假设。例如,你是否假设你的共享托管提供商正在备份与你的帐户提供的 MySQL 服务器?你可能会感到惊讶。许多托管提供商根本不备份 MySQL 服务器,而其他人只是在服务器运行时进行文件复制,这可能会创建一个损坏的无用备份。
定义恢复要求
如果一切顺利,你永远不需要考虑恢复。但是当你需要时,即使是世界上最好的备份系统也无济于事,如果你从未测试过恢复。你需要一个出色的恢复系统。
不幸的是,使您的备份系统正常运行比构建良好的恢复流程和工具更容易。原因如下:
-
备份首先要做好。如果没有首先备份,你就无法恢复,因此在构建系统时,你的注意力自然会集中在备份上。
-
备份是通过脚本和作业自动化的。很容易花时间对备份过程进行微调,通常是不经思考的。对备份过程进行五分钟的微调可能看起来不重要,但是你是否每天都对恢复过程进行同样的关注呢?
-
备份是例行公事,但恢复通常是一种危机情况。
-
安全性成为障碍。如果你正在进行异地备份,你可能正在对备份数据进行加密或采取其他措施来保护数据。你知道如果你的数据被泄露会有多么糟糕,但是当没有人能解锁你的加密卷以恢复数据,或者当你需要从一个庞大的加密文件中提取单个文件时,情况会有多糟糕呢?
-
一个人可以规划、设计和实施备份。当灾难发生时,这个人可能不可用。你需要培训几个人并计划覆盖,这样你就不会要求一个不合格的人来恢复你的数据。
在制定备份和恢复策略时,考虑以下两个重要的要求是有帮助的。这些是恢复点目标(RPO)和恢复时间目标(RTO)。如果你注意到,这些听起来与我们在第二章中讨论的 SLOs 非常相似。它们定义了你可以接受丢失多少数据以及你可以等待多长时间才能恢复数据。在定义 RPO 和 RTO 时,尝试回答以下类型的问题:
-
你可以丢失多少数据而没有严重后果?你需要点对点恢复吗,还是可以接受自上次常规备份以来发生的任何工作丢失?是否有法律要求?
-
恢复必须有多快?可以接受多少停机时间?你的应用程序和用户可以接受什么影响(例如部分不可用),以及当这些情况发生时,你将如何构建继续运行的能力?
-
你需要恢复什么?常见的要求是恢复整个服务器、单个数据库、单个表,或者只是特定的事务或语句。
最好将这些问题的答案以及整个备份策略以及备份程序记录下来是个好主意。
设计 MySQL 备份解决方案
备份 MySQL 比看起来更困难。在最基本的层面上,备份只是数据的副本,但是你的应用程序需求、MySQL 的存储引擎架构以及系统配置可能会使得复制数据变得困难。
在我们详细介绍所有可用选项之前,我们想推荐:
-
原始备份对于大型数据库实际上是必不可少的:逻辑备份太慢且资源密集,从逻辑备份中恢复需要太长时间。基于快照的备份、Percona XtraBackup 和 MySQL Enterprise Backup 是最佳选择。对于小型数据库,逻辑备份可以很好地工作。
-
保留几代备份。
-
定期提取逻辑备份(可能来自原始备份)。
-
保留二进制日志以进行按时间点的恢复。设置
expire_logs_days足够长,以便从至少两代原始备份中恢复,这样您可以创建一个副本,并从正在运行的源开始,而无需将任何二进制日志应用于其上。独立于到期设置备份您的二进制日志,并将其保留在备份中足够长的时间,以便从至少最近的逻辑备份中恢复。 -
监控备份和备份过程,独立于备份工具本身。您需要外部验证它们是否正常。
-
通过完整的恢复过程测试您的备份和恢复过程。测量恢复所需的资源(CPU、磁盘空间、挂钟时间、网络带宽等)。
-
认真考虑安全性。如果有人入侵了您的服务器,他们是否可以访问备份服务器,反之亦然?
了解您的 RPO 和 RTO 将指导您的备份策略。您是否需要按时间点恢复能力,或者仅恢复到昨晚的备份并丢失自那时以来所做的任何工作?如果需要按时间点恢复,您可能可以定期进行备份并确保启用了二进制日志,以便通过重放二进制日志来恢复到所需点。
一般来说,您可以承受的损失越多,备份就越容易。如果您有非常严格的要求,确保您可以恢复所有内容就更加困难。还有不同类型的按时间点恢复。"软"按时间点恢复要求意味着您希望能够重新创建数据,使其与问题发生时的位置“足够接近”。"硬"要求意味着您永远不能容忍已提交事务的丢失,即使发生了可怕的事情(比如服务器着火)。这需要特殊技术,例如将二进制日志保存在单独的 SAN 卷上或使用分布式复制块设备(DRBD)磁盘复��。
在线还是离线备份?
如果可以的话,关闭 MySQL 来进行备份是获得一致数据副本的最简单、最安全和最佳方式,最小化数据损坏或不一致性的风险。如果关闭 MySQL,您可以在没有来自 InnoDB 缓冲池或其他缓存中的脏缓冲区等问题的情况下复制数据。您不需要担心在备份数据时数据被修改,因为服务器不会受到应用程序的负载影响,您可以更快地进行备份。
然而,将服务器下线的成本可能比看起来要高。因此,您几乎肯定需要设计备份,以便不需要将生产服务器下线。但根据您的一致性要求,即使在服务器在线时进行备份也可能会显著中断服务。
在计划备份时,以下是一些与性能相关的因素需要考虑:
备份时间
制作备份和将备份复制到目的地需要多长时间?
备份负载
将备份复制到目的地会对服务器的性能产生多大影响?
恢复时间
从存储位置复制备份镜像到 MySQL 服务器,重放二进制日志等需要多长时间?
最大的权衡是备份时间与备份负载。通常您可以在其中一个方面改进另一个方面;例如,您可以优先考虑备份,以牺牲服务器性能降低。
您还可以设计备份以利用负载模式。例如,如果您的服务器在夜间的八小时内只有 50% 的负载,您可以尝试设计备份以使服务器的负载低于 50%,并且仍然在八小时内完成。您可以通过许多方式实现这一点:例如,您可以使用 ionice 和 nice 来优先处理复制或压缩操作,使用不同的压缩级别,或者在备份服务器上压缩数据而不是在 MySQL 服务器上压缩。您还可以使用 lzo 或 pigz 进行更快的压缩。您可以使用 O_DIRECT 或 fadvise() 来绕过操作系统的缓存进行复制操作,以便它们不会污染服务器的缓存。像 Percona XtraBackup 和 MySQL Enterprise Backup 这样的工具还具有限速选项,您可以使用 pv 和 --rate-limit 选项来限制您自己编写的脚本的吞吐量。
逻辑备份还是原始备份?
如前所述,有两种主要方法可以备份 MySQL 的数据:使用 逻辑备份(也称为 转储)和通过复制 原始文件。逻辑备份包含 MySQL 可以解释的数据形式,可以是 SQL 或分隔文本。² 原始文件是磁盘上存在的文件。
每种类型的备份都有优点和缺点。
逻辑备份
逻辑备份具有以下优点:
-
它们是您可以使用编辑器和命令行工具(如 grep 和 sed)操纵和检查的普通文件。这在恢复数据或仅想检查数据而不进行恢复时非常有帮助。
-
它们很容易恢复。您可以将它们导入 mysql 或使用 mysqlimport。
-
您可以通过网络进行备份和恢复——也就是说,在与 MySQL 主机不同的机器上。
-
它们可以用于基于云的 MySQL 系统,您无法访问底层文件系统。
-
它们可以非常灵活,因为大多数人喜欢使用的工具 mysqldump 可以接受许多选项,例如
WHERE子句来限制备份哪些行。 -
它们与存储引擎无关。因为您通过从 MySQL 服务器提取数据来创建它们,它们抽象了底层数据存储的差异。³
-
它们可以帮助避免数据损坏。如果您的磁盘驱动器出现故障并复制原始文件,您将收到错误消息和/或生成部分或损坏的备份,除非您检查备份,否则您不会注意到它,以后将无法使用。如果 MySQL 在内存中的数据没有损坏,有时在无法获得良好的原始文件副本时,您可以获得可信赖的逻辑备份。
逻辑备份也有其缺点:
-
服务器必须执行生成它们的工作,因此它们使用更多的 CPU 周期。
-
在某些情况下,逻辑备份可能比底层文件更大。⁴ 数据的 ASCII 表示并不总是与存储引擎存储数据的方式一样高效。例如,整数需要 4 个字节来存储,但在 ASCII 中写入时,可能需要多达 12 个字符。您通常可以有效地压缩文件并获得更小的备份,但这会使用更多的 CPU 资源,导致恢复时间更长。(如果有很多索引,逻辑备份通常比原始备份小。)
-
不总是保证将数据转储和恢复为相同的数据。浮点表示问题、错误等可能会导致问题,尽管这很少见。
-
从逻辑备份中恢复需要 MySQL 加载和解释语句,将其转换为存储格式,并重建索引,所有这些都非常慢。
最大的缺点实际上是从 MySQL 中导出数据的成本以及通过 SQL 语句加载数据的成本。如果使用逻辑备份,测试恢复数据所需的时间是至关重要的。
原始备份
原始备份具有以下优点:
-
原始文件备份只需要将所需文件复制到其他位置进行备份。这些原始文件不需要额外的工作来生成。
-
原始备份在各种平台、操作系统和 MySQL 版本之间非常易于移植。(逻辑转储也是如此。我们只是指出这一点以减轻你可能担心的任何问题。)
-
恢复原始备份可能更快,因为 MySQL 服务器不需要执行任何 SQL 或构建索引。如果你有 InnoDB 表,而这些表完全不适合服务器的内存,那么恢复原始文件可能会快得多——相差一个数量级或更多。事实上,逻辑备份最可怕的一点是其不可预测的恢复时间。
以下是原始备份的一些缺点:
-
InnoDB 的原始文件通常比相应的逻辑备份要大得多。InnoDB 表空间通常有大量未使用的空间。还有相当多的空间用于存储表数据以外的其他目的(插入缓冲区,回滚段等)。
-
原始备份并非总��在各种平台、操作系统和 MySQL 版本之间易于移植。文件名大小写敏感性和浮点格式是可能遇到问题的地方。你可能无法将文件移动到浮点格式不同的系统(然而,绝大多数处理器使用 IEEE 浮点格式)。
原始备份通常更容易且更高效。⁵ 但是,你不应该依赖原始备份来满足长期保留或法律要求,你必须至少定期进行逻辑备份。
在测试备份之前,不要认为备份(尤其是原始备份)是好的。对于 InnoDB,这意味着启动一个 MySQL 实例并让 InnoDB 恢复运行,然后运行 CHECK TABLES。你可以跳过这一步,或者只对文件运行 innochecksum,但我们不建议这样做。
我们建议两种方法的结合:制作原始副本,然后启动一个 MySQL 服务器实例并运行 mysqlcheck。然后,至少定期使用 mysqldump 将数据转储以获得逻辑备份。这样可以在转储过程中不给生产服务器带来过多负担,同时又能兼顾两种方法的优势。如果你有能力进行文件系统快照,这将特别方便:你可以拍摄快照,将快照复制到另一台服务器并释放它,然后测试原始文件并执行逻辑备份。
需要备份什么
你的恢复需求将决定你需要备份什么。最简单的策略就是只备份数据和表定义,但这是一种最基本的方法。通常情况下,你需要更多内容来恢复一个用于生产的服务器。以下是一些你可能考虑与 MySQL 备份一起包括的内容:
非明显的数据
不要忘记容易忽视的数据:例如你的二进制日志和 InnoDB 事务日志。理想情况下,你应该一起备份整个 MySQL 的数据目录。
代码
现代的 MySQL 服务器可以存储大量代码,如触发器和存储过程。如果备份 mysql 数据库,你将备份大部分代码,但随后要完全恢复单个数据库将会很困难,因为该数据库中的一些“数据”,如存储过程,实际上将存储在 mysql 数据库中。
服务器配置
如果你必须从真正的灾难中恢复——比如在地震后在新数据中心从头开始构建服务器——你会感激备份中包含了服务器的配置文件。
选择的操作系统文件
与服务器配置一样,重要的是备份任何对生产服务器至关重要的外部配置。在 Unix 服务器上,这可能包括你的cron作业、用户和组配置、管理脚本和sudo规则。
在许多情况下,这些建议很快就会转化为“备份所有内容”。然而,如果你有大量数据,这可能会变得很昂贵,你可能需要更聪明地进行备份。特别是,你可能希望将不同的数据备份到不同的备份中。例如,你可以将数据、二进制日志以及操作系统和系统配置文件分开备份。
增量备份和差异备份
处理过多数据的常见策略是定期进行增量或差异备份。差异可能有点令人困惑,所以让我们澄清一下术语:差异备份是自上次完全备份以来发生变化的所有内容的备份,而增量备份包含自上次任何类型备份以来发生变化的所有内容。
例如,假设你每周日进行完全备份。周一,你可以备份自周日以来发生变化的所有内容。周二,你有两个选择:你可以备份自周日以来发生变化的所有内容(差异备份),或者你可以仅备份自周一备份以来发生变化的数据(增量备份)。
差异备份和增量备份都是部分备份:它们通常不包含完整的数据集,因为某些数据几乎肯定没有发生变化。部分备份通常受欢迎,因为它们在服务器的开销、备份时间和备份空间上节省了开销。然而,有些部分备份实际上并没有减少服务器的开销。例如,Percona XtraBackup 和 MySQL Enterprise Backup 仍然会扫描服务器上的每个数据块,因此它们并没有节省很多开销,尽管它们确实节省了一些挂钟时间、大量用于压缩的 CPU 时间,当然还有磁盘空间。⁶
你可以使用高级备份技术变得相当复杂,但是你的解决方案越复杂,风险就越大。要注意隐藏的危险,比如多代备份彼此紧密耦合,因为如果一个代包含损坏,它也可能使所有其他代无效。
以下是一些高级备份想法:
-
使用 Percona XtraBackup 或 MySQL Enterprise Backup 的增量备份功能。
-
备份你的二进制日志。你也可以使用
FLUSH LOGS在每次备份后开始一个新的二进制日志,然后仅备份新的二进制日志。 -
如果你有包含各种语言的月份名称列表或州或地区缩写等数据的“查找”表,将它们放入单独的数据库中可能是个好主意,这样你就不必一直备份它们。一个更好的选择是将这些数据移到代码中而不是数据库中。
-
不要备份未更改的行。如果一个表只能进行
INSERT操作,比如记录网页点击的表,你可以添加一个TIMESTAMP列,仅备份自上次备份以来插入的行。这与mysqldump结合使用效果最佳。 -
不要完全备份某些数据。有时这是很有道理的,例如,如果你有一个从其他数据构建而成且在技术上是冗余的数据仓库,你可以仅备份用于构建数据仓库的数据,而不是数据仓库本身。即使通过从原始文件重新构建数据仓库来“恢复”非常慢,这也可能是一个好主意。随着时间的推移,避免备份可能会带来比通过完全备份获得的潜在更快的恢复时间更大的节省。你也可以选择不备份一些临时数据,比如保存网站会话数据的表。
-
备份所有内容,但将其发送到具有数据重复功能的目的地,例如 ZFS 文件系统。
增量备份的缺点包括增加的恢复复杂性、增加的风险和更长的恢复时间。如果可以进行完整备份,我们建议出于简单起见这样做。
无论如何,您肯定需要定期进行完整备份;我们建议至少每周一次。您不能指望从一个月的增量备份中恢复。即使一周也是很多工作和风险。
复制
从副本进行备份的最大优势是不会中断源端或给其增加额外负载。这是建立副本服务器的一个很好的理由,即使您不需要它进行负载平衡或高可用性。如果资金是一个问题,您总是可以将备份副本用于其他用途,例如报告——只要您不对其进行写入,从而更改您试图备份的数据。副本不必专门用于备份;它只需要能够及时赶上源端,以便在其其他角色使其在复制方面有时落后时进行下一次备份。
当您从副本进行备份时,使用 GTIDs 是非常明智的,如第九章中所述。这样可以避免保存有关复制过程的所有信息,例如副本相对于源端的位置。这对于克隆新副本、重新应用二进制日志以进行时间点恢复、将副本提升为源端等非常有用。还要确保在停止副本时没有打开临时表,因为它们可能会阻止您重新启动复制。
正如我们在“延迟复制”中提到的,在第九章中,有意延迟其中一个副本的复制对于从某些灾难场景中恢复非常有用。假设您将复制延迟了一个小时。如果源端运行了一个不需要的语句,您有一个小时的时间来注意到它并在副本重复其中继日志中的事件之前停止副本。然后,您可以将副本提升为源端,并重放一些相对较少的日志事件,跳过不良语句。这比我们稍后讨论的时间点恢复技术要快得多。
注意
副本可能与源端的数据不同。许多人认为副本是其源端的精确副本,但根据我们的经验,副本上的数据不匹配是常见的,MySQL 没有办法检测到这个问题。唯一检测它的方法是使用像 Percona Toolkit 的pt-table-checksum这样的工具。预防这种情况的最佳方法是使用super_read_only标志,以确保只有复制可以写入副本。
拥有数据的复制副本可能有助于保护您免受源端磁盘崩溃等问题的影响,但并不保证。复制不是备份。
管理和备份二进制日志
服务器的二进制日志是您可以备份的最重要的东西之一。它们对于时间点恢复是必要的,而且由于它们通常比您的数据小,因此更容易频繁备份。如果您在某个时间点备份了数据并备份了那时以来的所有二进制日志,您可以重放二进制日志并“向前滚动”自上次完整备份以来所做的更改。
MySQL 也使用二进制日志进行复制。这意味着您的备份和恢复策略通常会与您的复制配置互动。频繁备份二进制日志是一个好主意。如果您不能承受丢失超过 30 分钟数据的情况,至少每 30 分钟备份一次。
您需要决定一个日志过期策略,以防止 MySQL 用二进制日志填满您的磁盘。您的日志增长多大取决于您的工作负载和日志格式(基于行的日志记录导致日志条目较大)。我们建议您尽可能保留有用的日志。保留它们有助于设置副本、分析服务器的工作负载、审计以及从上次完整备份进行时点恢复。在决定要保留日志多长时间时,请考虑所有这些需求。
一个常见的设置是使用binlog_expire_logs_seconds变量告诉 MySQL 在一段时间后清除日志。不应手动删除这些文件。
binlog_expire_logs_seconds 设置在服务器启动时或 MySQL 旋转二进制日志时生效,因此如果您的二进制日志从未填满并旋转,服务器将不会清除旧条目。它通过查看文件的修改时间而不是内容来决定要清除哪些文件。
备份和恢复工具
有各种好坏不一的备份工具可用。对于原始备份,我们推荐使用 Percona XtraBackup。它是开源的、被广泛使用的,并且有很好的文档。对于逻辑备份,我们更喜欢mydumper。虽然mysqldump随 MySQL 提供,但其单线程性质可能导致初始备份和恢复时间非常长。mydumper内置了并行性,这可以使逻辑备份速度更快。
MySQL Enterprise Backup
这个工具是 Oracle 的 MySQL Enterprise 订阅的一部分。使用它不需要停止 MySQL、设��锁定或中断正常的数据库活动(尽管它会在服务器上造成一些额外的负载)。它支持压缩备份、增量备份和流式备份到另一台服务器。这是 MySQL 的“官方”备份工具。
Percona XtraBackup
Percona XtraBackup 在许多方面与 MySQL Enterprise Backup 非常相似,但它是开源且免费的。它支持流式传输、增量、压缩和多线程(并行)备份操作。它还具有各种特殊功能,以减少备份对负载较重系统的影响。
Percona XtraBackup 通过在后台线程中“尾随” InnoDB 日志文件,然后复制 InnoDB 数据文件来工作。这是一个稍微复杂的过程,具有特殊的检查以确保数据一致性。当所有数据文件都被复制时,日志复制线程也会完成。结果是所有数据的副本,但在不同的时间点。现在可以将日志应用于数据文件,使用 InnoDB 的崩溃恢复例程,将所有数据文件带入一致状态。这被称为准备过程。一旦准备就绪,备份就完全一致,并包含文件复制过程结束时的所有已提交事务。所有这些都完全在 MySQL 外部发生,因此它不需要以任何方式连接或访问 MySQL。
mydumper
几位现任和前任 MySQL 工程师根据多年经验创建了mydumper作为mysqldump的替代品。这是一个为 MySQL 设计的多线程(并行)备份和恢复工具集,具有许多出色的功能。许多人可能会发现多线程备份和恢复的速度是这个工具最吸引人的特点。
mysqldump
大多数人使用随 MySQL 一起提供的程序,因此尽管存在缺点,创建数据和模式的逻辑备份的最常见选择是mysqldump。有关如何使用此工具的详细信息,请参考官方手册。
数据备份
与大多数事物一样,实际进行备份有更好和更糟糕的方法,而明显的方法有时并不那么好。关键是最大限度地利用网络、磁盘和 CPU 容量,使备份尽可能快速。这是一个平衡的过程,您将不得不进行实验以找到“最佳点”。
逻辑 SQL 备份
大多数人熟悉逻辑 SQL 转储,因为这是 mysqldump 默认创建的。例如,使用默认选项转储小表将产生以下(摘要)输出:
$ mysqldump test t1
-- [Version and host comments]
/*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */;
-- [More version-specific comments to save options for restore]
--
-- Table structure for table `t1`
--
DROP TABLE IF EXISTS `t1`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
/*!50503 SET character_set_client = utf8mb4 */;
CREATE TABLE `t1` (
`a` int NOT NULL,
PRIMARY KEY (`a`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
/*!40101 SET character_set_client = @saved_cs_client */;
--
-- Dumping data for table `t1`
--
LOCK TABLES `t1` WRITE;
/*!40000 ALTER TABLE `t1` DISABLE KEYS */;
INSERT INTO `t1` VALUES (1);
/*!40000 ALTER TABLE `t1` ENABLE KEYS */;
UNLOCK TABLES;
/*!40103 SET TIME_ZONE=@OLD_TIME_ZONE */;
/*!40101 SET SQL_MODE=@OLD_SQL_MODE */;
-- [More option restoration]
转储文件包含表结构和数据,全部写成有效的 SQL 命令。文件以设置各种 MySQL 选项的注释开头。这些选项要么是为了使恢复工作更有效,要么是为了兼容性和正确性。接下来,你可以看到表的结构,然后是数据。最后,脚本重置了转储开始时更改的选项。
转储的输出可用于恢复操作。这很方便,但 mysqldump 的默认选项不适合进行大型备份。
mysqldump 不是唯一可以进行 SQL 逻辑备份的工具。你也可以使用 mydumper 或 phpMyAdmin 等工具来创建。我们真正想指出的不是任何特定工具的问题,而是首先进行单体 SQL 逻辑备份的缺点。以下是主要问题领域:
模式和数据存储在一起
尽管如果你想从单个文件恢复,这很方便,但如果你只需要恢复一个表或者只想恢复数据,这会让事情变得困难。你可以通过两次转储来缓解这个问题——一次用于数据,一次用于模式——但你仍然会遇到下一个问题。
巨大的 SQL 语句
服务器解析和执行所有 SQL 语句是一项繁重的工作。这是一种非常慢的加载数据的方式。
一个巨大的单一文件
大多数文本编辑器无法编辑大文件或具有非常长行的文件。虽然有时可以使用命令行流编辑器,比如 sed 或 grep,来提取所需的数据,但最好保持文件较小。
逻辑备份是昂贵的
从 MySQL 中获取数据的更有效方法比从存储引擎中提取数据并通过客户端/服务器协议发送结果集要好得多。
如你所见,逻辑备份可能很难适应你的环境。如果你需要使用逻辑备份,我们强烈建议你查看 mydumper,以避免单线程性质,并花时间测量备份对数据库的影响。
文件系统快照
文件系统快照是进行在线备份的好方法。支持快照的文件系统可以在某一时刻创建其内容的一致图像,然后你可以用它来进行备份。支持快照的文件系统和设备包括 FreeBSD 的文件系统、ZFS 文件系统、GNU/Linux 的 LVM,以及许多 SAN 系统和文件存储解决方案,比如 NetApp 存储设备。一些云提供商提供的远程附加磁盘选项也提供磁盘快照功能。
不要将快照与备份混淆。拍摄快照只是减少必须保持锁定的时间的一种方式;释放锁定后,你必须将文件复制到备份中。事实上,你甚至可以在不获取锁定的情况下选择在 InnoDB 上拍摄快照。我们将向你展示两种使用 LVM 对全 InnoDB 系统进行备份的方法,你可以选择最小或零锁定。
快照可以是一种为特定用途备份的好方法。一个例子是在升级过程中出现问题时作为备用方案。你可以拍摄一个快照,进行升级,如果出现问题,只需回滚到快照。你可以对任何不确定和风险的操作都采取同样的方式,比如修改一个庞大的表(需要未知的时间)。
LVM 快照的工作原理
LVM 使用写时复制技术创建快照——即,在某一时刻的整个卷的逻辑副本。这有点像数据库中的 MVCC,只是它只保留一个旧版本的数据。
请注意,我们没有说的是物理复制。逻辑复制似乎包含与您快��的卷相同的所有数据,但最初不包含任何数据。LVM 不会将数据复制到快照中,而是简单地记录您创建快照的时间,然后在您从快照请求数据时从原始卷中读取数据。因此,初始复制基本上是一个瞬时操作,无论您快照的卷有多大。
当原始卷中的数据发生变化时,LVM 会将受影响的块复制到快照之前保留的区域,然后再对其进行任何更改。LVM 不保留多个“旧版本”的数据,因此对于在原始卷中更改的块的额外写入不需要对快照进行进一步处理。换句话说,只有对每个块的第一次写入会导致将其复制到保留区域。
现在,当您请求快照中的这些块时,LVM 会从复制的块中读取数据,而不是从原始卷中读取。这使您可以继续在快照中看到相同的数据,而不会阻塞原始卷上的任何内容。图 10-1 描述了这种安排。
快照在*/dev*目录中创建了一个新的逻辑设备,您可以像挂载其他设备一样挂载这个设备。
使用这种技术,您可以理论上对一个巨大的卷进行快照,并占用非常少的物理空间。但是,您需要预留足够的空间来容纳您期望在保持快照打开时更新的所有块。如果没有预留足够的写时复制空间,快照将耗尽空间,设备将变为不可用。效果就像拔掉外部驱动器一样:任何正在从设备读取的备份作业都将因 I/O 错误而失败。
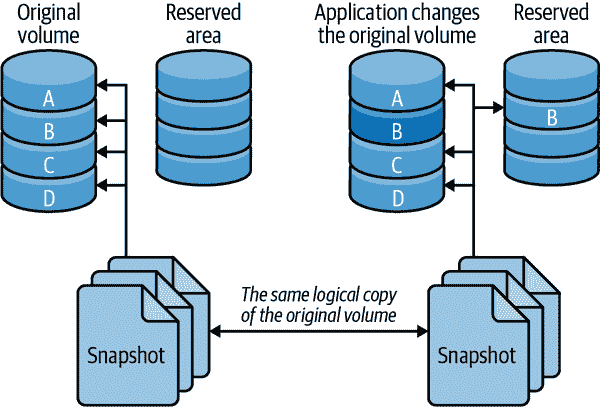
图 10-1. 写时复制技术如何减少卷快照所需的空间
先决条件和配置
创建快照几乎是微不足道的,但您需要确保系统配置得可以在单个时间点获得所有要备份的文件的一致副本。首先确保您的系统满足以下条件:
-
所有 InnoDB 文件(InnoDB 表空间文件和 InnoDB 事务日志)必须在单个逻辑卷(分区)上。您需要绝对的时间点一致性,而 LVM 无法同时对多个卷进行一致的快照(这是一个 LVM 的限制;其他一些系统没有这个问题)。
-
如果您需要备份表定义,MySQL 数据目录必须在同一个逻辑卷中。如果您使用其他方法备份表定义,比如仅将模式备份到您的版本控制系统中,您可能不需要担心这个问题。
-
您必须在卷组中有足够的空闲空间来创建快照。您需要多少取决于您的工作负载。在设置系统时,留一些未分配空间,以便以后有快照的空间。
LVM 有一个卷组的概念,其中包含一个或多个逻辑卷。您可以按以下方式查看系统上的卷组:
$ vgs
VG #PV #LV #SN Attr VSize VFree
vg 1 4 0 wz--n- 534.18G 249.18G
此输出显示一个卷组,该卷组在一个物理卷上分布了四个逻辑卷,剩余约 250 GB 空间。如果需要,vgdisplay命令可以提供更多详细信息。现在让我们看看系统上的逻辑卷:
$ lvs
LV VG Attr LSize Origin Snap% Move Log Copy%
home vg -wi-ao 40.00G
mysql vg -wi-ao 225.00G
tmp vg -wi-ao 10.00G
var vg -wi-ao 10.00G
输出显示mysql卷有 225 GB 的空间。设备名称为*/dev/vg/mysql*。这只是一个名称,尽管看起来像一个文件系统路径。为了增加混淆,文件名与真实设备节点*/dev/mapper/vg-mysql*之间有一个符号链接,您可以使用ls和mount命令查看:
$ ls -l /dev/vg/mysql
lrwxrwxrwx 1 root root 20 Sep 19 13:08 /dev/vg/mysql -> /dev/mapper/vg-mysql
# mount | grep mysql
/dev/mapper/vg-mysql on /var/lib/mysql
有了这些信息,您就可以准备创建一个文件系统快照了。
创建、挂载和删除 LVM 快照
您可以使用单个命令创建快照。您只需决定将其放在何处以及为写时复制分配多少空间。不要犹豫使用比您认为需要的空间更多的空间。LVM 不会立即使用您指定的空间;它只是为将来使用保留它,因此保留大量空间是没有害处的,除非您需要同时为其他快照留出空间。
让我们为练习创建一个快照。我们将为写时复制提供 16 GB 的空间,并将其命名为 backup_mysql:
$ lvcreate --size 16G --snapshot --name backup_mysql /dev/vg/mysql
Logical volume "backup_mysql" created
提示
我们故意将卷命名为 backup_mysql 而不是 mysql_backup,以便制表符补全不会引起歧义。这有助于避免制表符补全导致您意外删除 mysql 卷组的可能性。
现在让我们看看新创建的卷的状态:
$ lvs
LV VG Attr LSize Origin Snap% Move Log Copy%
backup_mysql vg swi-a- 16.00G mysql 0.01
home vg -wi-ao 40.00G
mysql vg owi-ao 225.00G
tmp vg -wi-ao 10.00G
var vg -wi-ao 10.00G
注意快照的属性与原始设备的属性不同,并且显示会显示一些额外信息:其来源以及当前用于写时复制的分配的 16 GB 中使用了多少。在进行备份时监视这一点是个好主意,这样您就可以看到设备是否即将满,即将失败。您可以交互式地监视设备状态,也可以使用监控系统(如 Nagios):
$ watch 'lvs | grep backup'
正如您之前从 mount 的输出中看到的那样,mysql 卷包含一个文件系统。这意味着快照卷也包含一个文件系统,您可以像使用任何其他文件系统一样挂载和使用它:
$ mkdir /tmp/backup
$ mount /dev/mapper/vg-backup_mysql /tmp/backup
$ ls -l /tmp/backup
total 188880
-rw-r-----. 1 mysql mysql 56 Jul 30 22:16 auto.cnf
-rw-r-----. 1 mysql mysql 475 Jul 30 22:31 binlog.000001
-rw-r-----. 1 mysql mysql 156 Jul 30 22:31 binlog.000002
-rw-r-----. 1 mysql mysql 32 Jul 30 22:31 binlog.index
-rw-------. 1 mysql mysql 1676 Jul 30 22:16 ca-key.pem
-rw-r--r--. 1 mysql mysql 1120 Jul 30 22:16 ca.pem
-rw-r--r--. 1 mysql mysql 1120 Jul 30 22:16 client-cert.pem
-rw-------. 1 mysql mysql 1676 Jul 30 22:16 client-key.pem
... omitted ...
这只是为了练习,所以我们现在使用 lvremove 命令卸载和删除快照:
$ umount /tmp/backup
$ rmdir /tmp/backup
$ lvremove --force /dev/vg/backup_mysql
Logical volume "backup_mysql" successfully removed
使用 LVM 快照进行无锁 InnoDB 备份
当你运行 MySQL 8+ 时,只使用 InnoDB 表,使用 GTIDs 和完全符合 ACID 的模式,进行备份非常容易。在 MySQL 运行时,只需拍摄一个快照,挂载快照,然后将文件复制到备份位置。不需要锁定任何文件,捕获任何输出,或者做任何特殊操作。从这些备份中恢复文件将执行 InnoDB 崩溃恢复,并且 GTID 设置将已知哪些事务已被处理。
为 LVM 备份做计划
最重要的计划是为快照分配足够的空间。我们采取以下方法:
-
请记住,LVM 需要将每个修改的块仅复制到快照一次。当 MySQL 写入原始卷中的块时,它将该块复制到快照,然后在其异常表中记录已复制的块。将来对此块的写入不会导致进一步复制到快照。
-
如果只使用 InnoDB,请考虑 InnoDB 如何写入数据。因为它将所有数据写入两次,至少一半的 InnoDB 写入 I/O 都会写入双写缓冲区、日志文件和其他相对较小的磁盘区域。这些重复使用相同的磁盘块,因此它们会对快照产生初始影响,但之后它们将停止对快照造成写入。
-
接下来,估计您的 I/O 中有多少将写入尚未复制到快照的块,而不是反复修改相同的数据。对您的估计要慷慨。
-
使用 vmstat 或 iostat 收集有关服务器每秒写入多少块的统计信息。
-
测量(或估计)将备份复制到另一个位置需要多长时间:换句话说,您需要保持 LVM 快照打开多长时间。
假设您估计一半的写入将导致写入到快照的写时复制空间,您的服务器每秒写入 10 MB。如果将快照复制到另一台服务器需要一个小时(3,600 秒),则您将需要 1/2 × 10 MB × 3,600 或 18 GB 的快照空间。谨慎起见,还要添加一些额外空间。
有时候,在保持快照打开的同时计算数据变化量是很容易的。
其他用途和替代方案
你可以使用快照不仅仅用于备份。例如,如前所述,它们可以是在潜在危险操作之前进行“检查点”的有用方式。一些系统允许你将快照提升为原始文件系统。这使得回滚到你拍摄快照的时间点变得容易。
文件系统快照并不是获取数据的瞬时副本的唯一方式。另一个选择是 RAID 分离:例如,如果你有一个三盘软件 RAID 镜像,你可以从镜像中移除一块硬盘并单独挂载它。没有写时复制的惩罚,如果需要的话,很容易将这种“快照”提升为源的副本。然而,在将硬盘重新添加到 RAID 集之后,它将需要重新同步。很遗憾,没有免费的午餐。
Percona XtraBackup
XtraBackup 是备份 MySQL 的最流行解决方案之一,原因很充分。它非常灵活,包括备份压缩、加密文件的方式。
XtraBackup 的工作原理
InnoDB 是一个崩溃安全的存储引擎。如果 MySQL 遇到崩溃,它将使用基于重做日志的崩溃恢复模式,以正确地将数据重新上线。Percona XtraBackup��是基于这个设计。当你使用 Percona XtraBackup 进行备份时,它记录日志序列号(LSN),并使用它来对备份文件执行崩溃恢复。它还在特定点进行锁定,以确保关于复制的数据与数据一致。有关更详细的解释,请参考XtraBackup 文档。
这是一个 XtraBackup 过程示例:
$ xtrabackup --backup --target-dir=/backups/
xtrabackup version 8.0.25-17 based on MySQL server 8.0.25 Linux (x86_64)
(revision id: d27028b)
Using server version 8.0.25-15
210821 17:01:40 Executing LOCK TABLES FOR BACKUP…
到目前为止,我们可以看到 XtraBackup 已经确定了 MySQL 的运行版本。这有助于确定它具有什么功能以及如何备份文件。在我们的情况下,LOCK TABLES FOR BACKUP命令可用,并且 XtraBackup 将使用它来锁定表:
210821 17:01:41 [01] Copying ./ibdata1 to /backups/ibdata1
210821 17:01:41 [01] ...done
210821 17:01:41 [01] Copying ./sys/sys_config.ibd to /backups/sys/sys_config.ibd
210821 17:01:41 [01] ...done
210821 17:01:41 [01] Copying ./test/t1.ibd to /backups/test/t1.ibd
210821 17:01:41 [01] ...done
210821 17:01:41 [01] Copying ./foo/t1.ibd to /backups/foo/t1.ibd
210821 17:01:41 [01] ...done
210821 17:01:41 [01] Copying ./sakila/actor.ibd to /backups/sakila/actor.ibd
210821 17:01:41 [01] ...done
XtraBackup 现在正在从源复制文件到目标:
210821 17:01:42 Finished backing up non-InnoDB tables and files
210821 17:01:42 Executing FLUSH NO_WRITE_TO_BINLOG BINARY LOGS
210821 17:01:42 Selecting LSN and binary log position from p_s.log_status
210821 17:01:42 [00] Copying /var/lib/mysql/binlog.40 to /backups/binlog.04
up to position 156
210821 17:01:42 [00] ...done
210821 17:01:42 [00] Writing /backups/binlog.index
210821 17:01:42 [00] ...done
210821 17:01:42 [00] Writing /backups/xtrabackup_binlog_info
210821 17:01:42 [00] ...done
复制文件完成后,它收集复制信息:
210821 17:01:42 Executing FLUSH NO_WRITE_TO_BINLOG ENGINE LOGS...
xtrabackup: The latest check point (for incremental): '35005805'
xtrabackup: Stopping log copying thread at LSN 35005815.
210821 17:01:42 >> log scanned up to (35005825)
Starting to parse redo log at lsn = 35005460
210821 17:01:43 Executing UNLOCK TABLES
210821 17:01:43 All tables unlocked
现在 XtraBackup 已经确定了 InnoDB 的最新检查点。这将帮助它应用备份期间发生的写操作。它使用UNLOCK TABLES释放之前的LOCK TABLES FOR BACKUP命令:
210821 17:01:43 [00] Copying ib_buffer_pool to /backups/ib_buffer_pool
210821 17:01:43 [00] ...done
210821 17:01:43 Backup created in directory '/backups/'
MySQL binlog position: filename 'binlog.000004', position '156'
210821 17:01:43 [00] Writing /backups/backup-my.cnf
210821 17:01:43 [00] ...done
210821 17:01:43 [00] Writing /backups/xtrabackup_info
210821 17:01:43 [00] ...done
xtrabackup: Transaction log of lsn (35005795) to (35005835) was copied.
210821 17:01:44 completed OK!
最后的步骤是记录 LSN,复制缓冲池转储,并写出最终文件。其中一个是my.cnf文件的副本,xtrabackup_info文件包含关于备份的元数据,如 MySQL UUID、服务器版本和 XtraBackup。
示例用法
我们已经突出显示了如何以常见方式使用 XtraBackup 的一些基本方法,但在此之前有一些注意事项:
-
你的 MySQL 安装应该使用密码进行保护。确保你使用
--user和--password选项指定一个具有足够权限进行备份的帐户。 -
XtraBackup 在输出中也非常详细。我们已经削减了输出以突出每种用例的最重要部分。
-
如往常一样,在运行任何命令之前,请查阅 Percona XtraBackup 的官方手册,因为语法和选项可能会发生变化。尽管我们不知道与该工具相关的任何数据丢失,但在尝试处理关键数据之前,你应该在非生产备份上进行测试。
基本备份到目录
我们想展示的第一种方法是如何使用 XtraBackup 将数据完整备份到另一个目录。这使你可以选择之后如何处理数据,可以是另一个磁盘、同一磁盘上的目录,或者更大的备份服务器上挂载的文件共享。请记住,进行这种完整备份将需要适当的空间来复制文件。
这是 XtraBackup 的最基本用法,指定模式(备份)和备份文件的位置(target-dir):
$ xtrabackup --backup --target-dir=/backups/
一旦执行,输出将类似于“XtraBackup 如何工作”下的内容。如果成功,/backups目录将包含完整的数据副本。
流式备份
将所有文件复制到新目录可能不是最理想的用例。有时在一个目录中保留多个备份更容易。这就是流式备份选项有用的地方。流式备份允许您将备份写入一个单个文件:
$ xtrabackup --backup --stream=xbstream > /backups/backup.xbstream
在这种用法中,我们仍然指定了backup模式,并删除了target-dir选项,因为输出将到STDOUT。然后我们将其重定向到文件中。
请注意,您还可以使用 Bash shell 命令和日期一起使用,将时间戳包含在输出文件名中,如下所示:
$ xtrabackup --backup --stream=xbstream > /backups/backup-$(date +%F).xbstream
这将像以前一样运行整个备份过程,使用<STDOUT>作为目标。内容将被写入/backups中的xbstream文件。
使用压缩备份
正如我们之前提到的,您需要足够的空间来制作整个数据文件的副本,或者足够的空间来存储单个xbstream文件。减轻空间需求的一个常见选项是使用 XtraBackup 的压缩功能:
$ xtrabackup --backup --compress --stream=xbstream > /backups/backup-
compressed.xbstream
您会注意到,每个表现在不再显示“Streaming”,而是报告“Compressing and streaming”。在我们的测试中,我们加载了 Sakila 示例数据库,并观察到一个 94 MB 未压缩的xbstream文件变成了一个 6.5 MB 压缩文件。
使用加密备份
我们要涵盖的最后一个示例是将加密作为备份策略的一部分。使用加密将使用更多的 CPU,并且您的备份过程将需要更长时间;然而,考虑到备份是一个轻松获取大量数据的目标,这可能是一个可以接受的权衡。我们再次使用备份模式和流式传输,但我们使用encrypt与密码和encrypt-key-file指向密钥的位置:
$ xtrabackup --backup --encrypt=AES256 --encrypt-key-
file=/safe/key/location/encrypt.key --stream=xbstream > /backups/backup-
encrypted.xbstream
我们的输出再次发生变化,对每个文件报告“加密和流式传输”。
请注意,您还可以使用--encrypt-key并在命令行上指定它。我们不建议这样做,因为密钥将在进程列表中暴露,或作为 Linux 上 /proc 文件系统的一部分。
其他重要标志
您需要注意的一个方面是备份完成所需的时间。为了帮助解决这个问题,请查看--parallel和-compress-threads选项。使用这些选项将增加 CPU 使用率,但应该减少备份所需的总时间。加密也有类似的并行化选项。
如果您有大量数据库和表,可以查看--rsync以优化文件复制过程。
从备份中恢复
如何恢复数据取决于您如何备份数据。您可能需要执行以下一些或全部步骤:
-
停止 MySQL 服务器。
-
记下服务器的配置和文件权限。
-
将数据从备份中移动到 MySQL 数据目录。
-
进行配置更改。
-
更改文件权限。
-
以有限访问权限重新启动服务器,并等待其完全启动。
-
重新加载逻辑备份文件。
-
检查并重放二进制日志。
-
验证您已恢复的内容。
-
以完全访问权限重新启动服务器。
我们将根据需要演示如何执行这些步骤。我们还将在本章后面关于这些方法或工具的部分中添加特定于某些备份方法或工具的注释。
注意
如果有可能需要文件的当前版本,请不要用备份文件替换它们。例如,如果您的备份包括二进制日志,并且您需要重放二进制日志以进行时间点恢复,请不要用备份中的旧副本覆盖当前的二进制日志。如有必要,请重命名它们或将它们移动到其他位置。
在恢复过程中,通常很重要的是使 MySQL 对除恢复过程之外的所有内容都不可访问。我们喜欢使用--skip-networking和--socket=/tmp/mysql_recover.sock选项启动 MySQL,以确保在我们检查并重新上线之前,它对现有应用程序不可用。这对于逻辑备份尤为重要,因为它们是分段加载的。
恢复逻辑备份
如果你正在恢复逻辑备份而不是原始文件,你需要使用 MySQL 服务器本身将数据加载回表中,而不是使用操作系统简单地将文件复制到指定位置。
然而,在加载那个转储文件之前,花点时间考虑一下它有多大,加载需要多长时间,以及在开始之前可能想要做的任何事情,比如通知用户或禁用应用程序的某些部分。禁用二进制日志可能是个好主意,除非你需要将恢复复制到副本:一个巨大的转储文件对服务器来说已经足够难以加载了,将其写入二进制日志会增加更多(可能是不必要的)开销。加载巨大文件也会对某些存储引擎产生影响。例如,一次性将 100 GB 的数据加载到 InnoDB 中不是个好主意,因为会产生巨大的回滚段。你应该分批加载并在每个批次后提交事务。
你可能会进行两种类型的恢复,这对应于你可以进行的两种逻辑备份。
如果你有一个 SQL 转储文件,文件将包含可执行的 SQL。你只需要运行它。假设你将 Sakila 示例数据库和模式备份到一个文件中,以下是你可能用来恢复的典型命令:
$ mysql < sakila-backup.sql
你也可以在 mysql 命令行客户端中使用 SOURCE 命令加载文件。虽然这基本上是以不同的方式做同样的事情,但它使一些事情变得更容易。例如,如果你是 MySQL 中的管理员用户,你可以关闭你的客户端连接中将执行的语句的二进制日志记录,然后加载文件而无需重新启动 MySQL 服务器:
SET SQL_LOG_BIN = 0;
SOURCE sakila-backup.sql;
SET SQL_LOG_BIN = 1;
如果你使用 SOURCE,请注意,错误不会中止一批语句,而当你将文件重定向到 mysql 时,默认会中止一批语句。
如果你压缩了备份文件,不要分别解压缩和加载它。相反,解压缩并一次性加载它。这样速度会快得多:
$ gunzip -c sakila-backup.sql.gz | mysql
如果你只想恢复单个表(例如 actor 表)怎么办?如果你的数据没有换行符,如果模式已经存在,恢复数据并不难:
$ grep 'INSERT INTO `actor`' sakila-backup.sql | mysql sakila
或者,如果文件被压缩了:
$ gunzip -c sakila-backup.sql.gz | grep 'INSERT INTO `actor`'| mysql sakila
如果你需要创建表以及恢复数据,并且整个数据库都在一个文件中,你将不得不编辑该文件。这就是为什么有些人喜欢将每个表转储到自己的文件中。大多数编辑器无法处理巨大的文件,特别是如果它们被压缩了。此外,你不想实际编辑文件本身;你只想提取相关行,因此你可能需要进行一些命令行工作。使�� grep 只提取给定表的 INSERT 语句很容易,就像我们在之前的命令中所做的那样,但要获取 CREATE TABLE 语句就比较困难。这里有一个 sed 脚本,可以提取你需要的段落:
$ sed -e '/./{H;$!d;}' -e 'x;/CREATE TABLE `actor`/!d;q' sakila-backup.sql
这相当神秘,我们承认。如果你必须做这种工作来恢复数据,那么你的备份设计很差。通过一点规划,可以避免你陷入恐慌并试图弄清楚 sed 如何工作的情况。只需将每个表备份到自己的文件中,或者更好的是,分别备份数据和模式。
从快照中恢复原始文件
恢复原始文件往往相当简单,这也就意味着选项不多。这可能是好事,也可能是坏事,取决于你的恢复需求。通常的做法就是简单地将文件复制到指定位置。
如果你正在恢复传统的 InnoDB 设置,其中所有表都存储在单个表空间中,你需要关闭 MySQL,复制或移动文件到指定位置,然后重新启动。你还需要确保 InnoDB 的事务日志文件与其表空间文件匹配。如果文件不匹配,例如,如果你替换了表空间文件但没有替换事务日志文件,InnoDB 将拒绝启动。这是备份事务日志和数据文件一起备份至关重要的原因之一。
如果你正在使用 InnoDB 的单表文件特性(innodb_file_per_table),InnoDB 将每个表的数据和索引存储在一个*.ibd文件中。你可以通过复制这些文件来备份和恢复单个表,而且你可以在服务器运行时执行此操作,但并不是很简单。这些单独的文件与整个 InnoDB 不是独立的。每个.ibd*文件都有内部信息告诉 InnoDB 文件与主(共享)表空间的关系。当你恢复这样一个文件时,你必须告诉 InnoDB“导入”文件。
在 MySQL 手册关于使用单表表空间的部分中,有许多限制,你可以阅读。最大的限制是你只能将表恢复到备份它的服务器上。在这种配置下备份和恢复表并不是不可能的,但比你想象的要棘手。
所有这些复杂性意味着恢复原始文件可能非常繁琐,很容易出错。一个好的经验法则是,恢复过程变得越困难和复杂,你就越需要通过逻辑备份来保护自己。始终保留逻辑备份是一个好主意,以防出现问题,无法说服 MySQL 使用你的原始备份。
使用 Percona XtraBackup 进行恢复
在“XtraBackup 工作原理”部分中,我们提到它使用 InnoDB 的崩溃恢复过程来进行安全备份。这意味着为了使用用 XtraBackup 备份的文件,我们需要经过额外的步骤。
如果你使用了流式备份,你需要先解压xbstream文件。对于xbstream,你可以使用xbstream命令来提取:
$ xbstream -x < backup.xbstream
这将把所有文件提取到当前位置,或者你可以使用-C选项在之前更改到特定目录。如果你使用了压缩或加密,你可以使用类似的选项来反向操作。对于压缩文件,使用--decompress,对于加密文件,使用--decrypt,同时指定--encrypt-key-file位置:
$ xbstream -x --decompress < backup-compressed.xbstream
$ xbstream -x --decrypt --encrypt-key-file=/safe/key/location/encrypt.key
< backup-encrypted.xbstream
完成后,下一步是准备文件。准备是实际执行崩溃恢复操作并确保你正在恢复所有数据的过程:
$ xtrabackup --prepare --target-dir=/restore
提示
如果你没有使用流模式,你可以在备份后执行准备阶段。这将导致备份一个准备好的备份,并减少恢复时需要做的工作量。
完成并成功后,你现在可以使用这些文件来启动 MySQL 了:
$ xtrabackup --move-back --target-dir=/restore
提示
你可以使用xtrabackup的--copy-back或--move-back标志将文件正确复制或移动到指定位置。
XtraBackup 将自动检测你的 MySQL 安装中的data-dir变量,并将文件移动到正确的位置。
在恢复原始文件后启动 MySQL
在启动你要恢复的 MySQL 服务器之前,有一些事情你需要在之前做。
第一件最重要的事情,也是最容易忘记的事情之一,就是在尝试启动 MySQL 服务器之前检查服务器的配置,并确保恢复的文件具有正确的所有者和权限。这些属性必须完全正确,否则 MySQL 可能无法启动。这些属性因系统而异,因此请查看你的笔记以了解你需要设置什么。通常你希望mysql用户和组拥有这些文件和目录,你希望这些文件和目录对该用户和组可读可写,但对其他用户不可读写。
我们还建议在服务器启动时监视 MySQL 错误日志。在类 Unix 系统上,你可以这样监视文件:
$ tail -f /var/log/mysql/mysql.err
错误日志的确切位置会有所不同。一旦你监视了文件,你可以启动 MySQL 服务器并观察错误。如果一切顺利,一旦 MySQL 启动,你将拥有一个完美恢复的服务器。
在较新的 MySQL 版本中,监视错误日志更加重要。即使服务器似乎没有问题地启动,你也应该在每个数据库中运行SHOW TABLE STATUS,然后再次检查错误日志。
总结
每个人都知道他们需要备份,但并非每个人都意识到他们需要可恢复的备份。有许多设计备份的方式与你的恢复需求相矛盾。为了避免这个问题,我们建议你定义和记录你的 RPO 和 RTO,并在选择备份系统时使用这些要求。
定期测试恢复并确保其正常运行非常重要。很容易设置mysqldump并让其每晚运行,而没有意识到随着时间的推移,你的数据可能增长到需要花费数天甚至数周才能再次导入的程度。发现你的恢复需要多长时间的最糟糕时机是在你真正需要它的时候。一个在几小时内完成的备份可能需要数周才能恢复,这取决于你的硬件、架构、索引和数据。
不要陷入认为副本就是备份的陷阱。它是获取备份的一种较少侵入性的来源,但它不是备份。同样适用于你的 RAID 卷、SAN 和文件系统快照。确保你的备份能通过DROP TABLE测试(或“我被黑了”测试),以及失去数据中心的测试。如果你从副本中获取备份,请确保你的副本是一致的,通过从源重新构建它们并从那时起强制执行super_read_only。
毫无疑问,我们首选的备份方式是使用 Percona XtraBackup 进行原始备份,使用mydumper进行逻辑备份。这两种技术都可以让你获取非侵入性的二进制(原始)数据备份,然后你可以通过启动一个mysqld实例并检查表来验证这些备份。有时你甚至可以一举两得:通过将备份恢复到你的开发或测试服务器,每天测试恢复。你还可以从该实例中导出数据以创建逻辑备份。我们还喜欢备份二进制日志,并保留足够多的备份和二进制日志的生成,以便进行恢复或设置新的副本,即使最近的备份无法使用。
¹ 原始备份也可能被误称为物理备份,意思是你正在将物理文件移动到备份目的地。我们说“令人费解”,因为文件本身根本不是物理的!
² 由mysqldump生成的逻辑备份并不总是文本文件。SQL 转储可以包含许多不同的字符集,甚至可能包含不是有效字符数据的二进制数据。对于许多编辑器来说,行可能太长了。尽管如此,许多这样的文件将包含文本编辑器可以打开和阅读的数据,特别是如果你使用--hex-blob选项运行mysqldump。
³ 请记住,尽管转储的数据是与引擎无关的,但存储引擎的特性可能不兼容。例如,你不能转储定义了外键关系的 InnoDB 数据库,并期望这些外键在不实现它们的引擎中起作用。
⁴ 根据我们的经验,逻辑备份通常比原始备份小,但并非总是如此。
⁵ 值得一提的是,原始备份更容易出现错误;很难超越mysqldump的简单性。
⁶ Percona XtraBackup 正在开发一个“真正”的增量备份功能。它将能够备份已更改的块,而无需扫描每个块。















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









