




10 年的数据科学可视化

我在数据科学领域的职业生涯始于十年前,当时我在加州大学圣克鲁斯分校(UC Santa Cruz)上了第一门机器学习课程。从那以后,我在各种团队中工作过,使用过许多不同的可视化工具。虽然我在行业中的许多经验都集中在业务和产品指标上,但我想分享一些我在过去 10 年中收集的可视化数据。我从过去十年的每一年中挑选了一个可视化的例子,目的是展示我对不同工具的偏好是如何随着时间的推移而变化的。这些不一定是每年最有影响力的可视化,因为该列表过于 excel 化,可能会暴露敏感信息。以下是过去 10 年我对可视化工具偏好的时间表:

2007
早在深度学习主导图像分类任务之前, AdaBoost 是机器学习任务的一种流行方法,如人脸检测。在加州大学圣克鲁斯分校研究生院的第一年,我选修了曼弗雷德·沃穆思的机器学习课程。他的课程向我介绍了各种工具,包括 MATLAB 和 Mathematica。在我的学期项目中,我在 MATLAB 中实现了 Viola 和 Jones 的图像检测算法,并将其应用于图像中检测飞机的任务,结果如下图所示。分类器表现不佳,主要是因为缺乏高质量的训练数据和有限的特征集(Haar 基函数)。

Aircraft Image Detection — MATLAB- UC Santa Cruz (CMPS 242)
这篇博文的横幅图像是作为该项目的一部分生成的。该图像示出了一些验证数据集图像的检测到的面部。
2008
对于我的论文项目,我想建立一个从演示中学习的系统,并受到职业星际争霸玩家的启发。在育雏战争 API 发布之前,可以为星际争霸编写机器人,可以使用 LM 重播浏览器等工具分析重播数据。下面的图片展示了我对专业回放分析的一些初步工作。我写了一个 Java 应用程序,在一个星际争霸游戏中画出对应于军队移动的点和线。

StarCraft: Brood War Gameplay Traces —Java — UC Santa Cruz
2009
在收集和挖掘了成千上万的回放后,我训练了各种分类算法来检测星际争霸 1 中不同的建造顺序。此分析的结果显示在下面的 excel 图表中。这项分析的一个有趣的结果是,一些算法优于用于标记图像的规则集分类器。我在 2009 年 IEEE CIG 会议上发表了这个结果和其他发现。

StarCraft 1 Build Order Prediction — Excel — UC Santa Cruz (EISBot)
几个月前,我在写了一篇博文,讲述了在我目前偏爱脚本和可视化工具的情况下,我会如何进行这项分析。
2010
在 2010 年秋季我在电子艺界实习期间,我有机会对从 Madden NFL 11 收集的万亿字节的数据进行数据挖掘。我进行的一项分析是基于偏好的游戏模式,观察《马登》中不同的玩家原型。我用 Weka 来执行这个任务,结果显示在下面的 PCA 可视化中。在艺电实习期间,我还参与了玩家保持模型的工作,并收集了一些有趣的商业指标的数据。

Player Archetypes in Madden NFL 11 — Weka — Electronic Arts
2011
我在制作星际机器人时面临的挑战之一是处理战争迷雾,这限制了玩家对地图的可视性。我创建了一个粒子模型来追踪以前不再被机器人观察到的敌人单位。我用 Java 写了一个脚本来创建下面的视频,它可视化了机器人的观察。结果发表在 2011 年 AIIDE 上。
State Estimation in StarCraft — Java — UC Santa Cruz (EISBot)
2012
我将在我的论文项目中展示的最后一个可视化图是一个显示代理行为树中的行为的图表,它用于决策。该机器人是用 ABL 反应式规划语言编写的,我用 Java 编写了一个脚本来解析代码并输出图形格式。然后,我使用 protoviz 库来创建图表的渲染。

EISBot’s Behavior Tree — Protoviz— UC Santa Cruz (EISBot)
2013
当我在微软的工作室用户研究团队工作时,我帮助这个团队为 Ryse: Son of Rome 和 Sunset Overdrive 的游戏测试建立可视化。黛博拉·亨德森在 GDC 2017 上展示了这项工作的一些成果。下图显示了使用 Tableau 可视化的游戏测试中敌人的死亡地点。我们发现,除了参与者的反馈之外,还包括可视化效果会让游戏工作室更加关注这些报告。

Ryse: Son of Rome Playtesting — Tableau — Microsoft Studios User Research
2014
在索尼在线娱乐公司,我继续使用 Tableau 来报告业务指标,并在我们的 MMO 中整合玩家活动的可视化效果。我收集的一些最有影响力的视觉效果是玩家漏斗,它显示了玩家在游戏过程中下落的位置。我还做了一堆热图,没有那么多可操作的结果,但确实得到了游戏团队更多的关注。

Activity heatmap in DC Universe Online — Tableau — Sony Online Entertainment
2015
在电子艺界,我将大部分分析切换到 R,并开始探索 R 生态系统中的各种可视化工具,包括 Shiny 和 htmlwidgets 。我在 EA 工作的一个项目是运行分析团队 R 脚本的服务器。我写了一个闪亮的脚本来创建一个可视化服务器负载的 web 应用程序,如下图所示。我在 useR 上展示了 RServer 项目!2016.然而,我目前的建议是让团队使用更成熟的项目,比如 Airflow 。

RServer Load — R(Shiny) + dygraphs package — Electronic Arts (Global Analytics & Insights)
2016
Twitch 的科学团队做了大量的 A/B 实验,以确定向用户群推出哪些功能。我们还遇到了 A/B 测试不实际的情况,而是使用分阶段的展示来分析重大应用程序重写的影响。我在 R 中使用了 CausalImpact 包来评估分阶段部署对应用会话数量的影响,结果如下所示。我之前在这里更详细地讨论了这种方法。

Staged rollout impact on mobile sessions — R + CausalImpact package — Twitch
2017
我继续使用 R 进行可视化,尽管我最近从游戏行业转向了金融技术。我做的一个改变是在 Jupyter 笔记本上而不是 RStudio 上做更多的分析。在接下来的几个月里,我会写更多关于我在意外收获数据所做的分析类型的博文。目前,这是从人口普查数据生成的美国人口热图。

US Population Map — R + ggplot2 package — Windfall Data
在过去的十年里,我使用了各种不同的工具,并且发现每种工具都有利弊。这些年来,我的关注点已经转移到了开源工具上,这些工具支持可重复的研究。
从 Alexa 奖中我们又学到了 11 课

我们又参加了 Alexa 奖。我们开发了 Alquist 2.0 ,在此期间我们学到了很多关于对话式人工智能的知识。我愿意与你分享我们新获得的知识。这篇文章是我们从亚马逊 Alexa 奖中学到的 13 课的延续。前一篇文章中包含的信息仍然有效,我强烈推荐它。这是我们今年发现很有帮助的新的 11 点。
1.将对话分成小部分

我们决定从大量专注于单一事物的小型对话中构建系统。这意味着我们有单独的对话,关于用户在哪里看电影,关于他如何选择一部电影来看,或者询问用户最喜欢的电影。每个对话最多有四个回合。它们的小尺寸带来了几个好处。这种对话创建起来简单快捷,易于调试,单个对话中的任何问题(例如错误识别)只适用于对话式人工智能的整个内容的一小部分。
2.创建主题的互联图

大量的小对话带来了新的挑战。你必须以某种方式将它们结合起来,形成一个有趣的对话,而不是在主题之间随意跳跃。我们用 T opic 图解决了这个问题。这是一个连接话题和对话的图表。图的一个基本积木就是一个主题(电影、电影、音乐、人物、演员)。每个主题都包含对话。主题音乐包含关于一般音乐的对话,如关于用户最喜欢的流派的对话或询问用户是否是一个好歌手的对话。这些主题由图的边连接起来。从具体话题到一般话题都有边缘。从电影(它包含关于特定电影的对话)到电影(关于一般电影的对话)或者从演员到人物有一个边缘。
如果我们检测到用户想要谈论矩阵,我们选择主题电影。我们从电影主题中随机选取一些对话。当前一个对话结束时,我们随机选择下一个对话,直到我们没有使用完电影主题中的所有对话。当我们使用 all 时,我们可以从通过一条边连接到电影主题的主题中随机选择任何对话。在我们的例子中,它可以是来自电影主题的任何对话。通过这种方法,我们可以创建连贯的对话,在相关话题之间平滑过渡。此外,每个对话略有不同,因为我们随机选择下一个对话。
要解决的有趣问题可以是确定将最大化用户满意度的下一个对话。这意味着使用一些更智能的功能,而不是随机选择。我猜强化学习可能会有帮助。
3.开发工具来加速内容创建

去年我们在 12 个月内开发了 17 个主题。主题由状态自动机表示的对话组成,我们从 60%的预制状态和 40%的特殊硬编码状态中创建了状态自动机。这是一项痛苦而缓慢的任务。
今年我们只有 8 个月。我们决定投资一个月来开发一个图形工具,以加速对话的发展。这提高了我们的生产力,我们能够创建 27 个主题。
我们使用编辑器来创建对话树,随后我们基于混合代码网络为我们新开发的对话管理器生成训练数据。
4.使用机器学习作为制定规则的快速方法

如果你有很多数据,机器学习是很棒的。但在大多数情况下,你没有足够的数据,而且获取更多数据的成本很高。这就是为什么对我们来说使用不像已经提到的混合代码网络那样数据饥渴的模型很重要的原因。我们用它来进行对话管理。它将学到的部分与硬编码的规则结合起来。这使得我们可以用少量的例子来做决定。
但少量例子的问题是,机器学习算法将与看不见的例子斗争。然而,如果你仔细想想,这并不是一个大问题。为什么?因为你还有其他选择吗?你可以完全抛弃机器学习,硬编码一些规则。但是你确定你能写出涵盖所有例子的规则吗?还有,需要多长时间?
这就是我们使用机器学习的原因。我们并不期望我们的机器学习能够概括和处理所有的例子。我们认为机器学习是一种产生与硬编码规则相当的结果的方法,但它是自动创建的,速度更快。总而言之,我们知道我们的模型不是完美的,但是它们节省了我们的开发时间。
5.并非用户所说的一切都很重要

去年我们遇到了长用户消息的问题。一些用户简单地用长句回答,并不是句子中的所有内容都很重要。这种信息的一个例子可以是:“你知道,我是一个非常糟糕的厨师。但我想问你,你最喜欢的食物是什么?”句子中最重要的部分是*“你最喜欢的食物是什么,”*只处理这一部分并扔掉其余部分要容易得多。我们使用的解决方案是用标点符号将句子分开,只处理最后一部分。
但是这里有一个问题。Alexa 的 ASR 不识别标点符号。它只返回令牌。这是一个我们必须通过给句子添加标点符号的神经网络来解决的问题。好消息是这项任务有大量的数据。你只需要任何包含标点符号的文本语料库。
6.很难确定用户没有回答你的问题

我们的人工智能问了很多问题。有些很普通,有些有点奇怪。我们最大的问题之一是发现用户没有回答我们提出的问题,或者她回答了问题,但以某种我们没有预料到的方式回答了问题。如果出现这种情况,我们准备的答案没有任何意义。我们决定解决这个问题。我们最初的想法是这是一个容易解决的问题。我们将创建一个有两个输入的神经网络,即问题,并回答它。并且神经网络的任务将是分类该答复是否可以被认为是对问题的回答。我们使用对话数据集中的所有问题和答案作为正面例子,使用带有一些随机句子的问题作为负面例子。我们坚持训练,瞧,表演糟透了。遗憾的是,我们没有时间找出这次失败的原因。可能是数据量小,也可能是类不平衡造成的。需要更多的努力来解决这个重要的问题。
7.添加通用对话

我们今年设定的大目标是能够就任何实体或主题进行对话。这意味着我们希望能够谈论捕鱼、炼铁、战争或维多利亚女王。你不能准备所有话题的对话,而且在很多情况下,你甚至不能找到用户想要谈论的实体类型。我们称这样的实体为“通用实体”你唯一知道的是它的名字。幸运的是,你可以用这个名字找到新闻文章、趣闻,以及关于它的淋浴想法。你可以将这些组合成对话,适用于任何主题或实体。问题是这些对话不够有趣,所以它们只在几个回合中起作用,然后你应该尝试将对话的主题改为对话式人工智能中更有趣的部分。
8.创造观点

我们注意到用户会问类似*“你觉得 X 怎么样?”、“你最喜欢的 Y 是什么?”,或者“你知道 Z 吗?”*经常。所以我们不能对这些问题置之不理。
我们通过获取包含 X 的最近推文,并测量他们的平均情绪,解决了*“你对 X 有什么看法”。我们获得了一个介于 0.0 和 1.0 之间的数字,并设置了两个阈值。如果平均值低于 0.4,我们回答说我们不喜欢 X 。如果分数在 0.4 到 0.6 之间,我们回答说 X 有积极和消极的方面,如果分数高于 0.6,我们回答说我们喜欢 X 。我们必须缓存分数,因为它对于实时使用来说太慢了。但是,我建议您小心使用这种方法,因为计算出的【恐怖主义】的分数介于 0.4 和 0.6 之间。这导致了答案*“有积极的一面,也有消极的一面。”这是你绝对不想回答的问题。我们不得不筛选像这样敏感话题的答案。**
我们用微软概念图对“你最喜欢的 Y 是什么”的处理,如果 Y 是书*,我们在里面找到概念书,回答人气最大的实体。在我们的例子中,答案是*“我最喜欢的书是百科全书】。
最后一个问题“你知道 Z 吗”如你所料简单。我们刚刚在维基百科上找到了 Z ,并由回答“是的,我知道 Z。它是……”**
你可能觉得这些答案没那么有趣。是的,你是对的,但这不是目标。我们的目标是建立一个系统,能够回答任何实体或主题的这些问题。他们确实这么做了。产生引人入胜的答案是我们随后进行的对话的目标。
9.为回访用户创建内容

你也应该花一些时间为已经和你交谈过的用户提供内容。我们去年在有限的范围内对回归用户做出了反应。这意味着我们记住了她的名字和我们谈论的话题。我们决定今年更进一步。我们的方法是使用她告诉我们的信息,并在她下次与我们交谈时尝试使用这些信息进行对话。
如果她告诉我们她有一只宠物,我们会在接下来的对话中问这个宠物怎么样。如果她告诉我们她有一个兄弟姐妹,我们会在接下来的对话中询问他的名字。这就产生了这样一种感觉:我们记住了用户告诉我们的内容。但是如果你没有好的内容给第一次使用的用户,这种技术是没有用的。原因是不满意的首次用户将永远不会回来。所以首先关注首次用户,然后为回头客添加内容。但是我认为这个建议很明显。
10.迷路了就聊聊平常的事

有时候会这样。你收到一些奇怪的输入,尽管你很努力,但所有的分类器都没有捕捉到任何主题或合适的答案。在这种情况下该怎么办?我们的方法是说“对不起”,然后从一些非常基本的对话开始,比如“你喝自来水吗?”、“你有宠物吗?”或“你早上会按贪睡键吗?”多亏了这一策略,我们才得以化险为夷,继续对话。
11.转述是很酷的技巧

转述是一种有用的交流技巧。它是用不同的词重述课文的意思。它的主要目的是向交流伙伴发出信号,表明我们理解他。我们实现了它,并惊讶地发现用它对话听起来更自然。
我们的系统将用户的信息“我喜欢煎饼,我的父母喜欢蛋糕”由转述,“所以你试图告诉我,你喜欢煎饼,你的妈妈和爸爸喜欢蛋糕。”释义系统的主要部分是一个数据库,包含我们交换的成对短语。有成对的、、、【我是】、【你是】、、、【我的父母】、【你的爸爸妈妈】、等等。我们也有一个转述句子开头的数据库,包含“所以你试图对我说“、”,所以你说的是“或”,例如“如果我理解正确的话”。如果用户的信息是一个问题(我们通过 wh-word 的存在来确定),我们准备了不同的短语,如“你在问”、“你想知道”或“你问了我一个非常有趣的问题。”我们以小概率随机执行了转述系统。
结论

这些是我的 11 条建议,我们是通过 Alexa Prize 和我们的对话 AI Alquist 了解到的。我相信,我们在减少创建对话式人工智能内容所需的时间方面取得了很大的进展,我们创造了允许我们谈论任何话题或实体并发表意见的技术,还实际测试了几个对话技巧,如返回用户的内容或释义。我希望这篇文章能激励你参与对话式人工智能的开发。
另外,你可能感兴趣的最后一件事是,对话式人工智能现在还有多远?现在我们只是在制造一个人工智能可以对话的假象。我们用了很多技巧让它看起来更聪明,但实际上,并不是这样。你可能觉得我的回答很怀疑,但实际上并不是。这意味着有很大的改进空间,我们需要很多聪明的人来实现我们的目标,即真正智能的对话式人工智能。这将是具有挑战性的。但是要记住!我们选择这个目标不是因为它容易,而是因为它难!
原载于petr-marek.com*。*
喜欢这篇文章吗?点击👏下面把它推荐给其他感兴趣的读者!
我在数据中的 117 天 Tinder 个人资料

Image by Solen Feyissa on Pixabay
大约 4 个月前——在我结束了 3 年的恋情之后——我决定创建一个 Tinder 个人资料。以下是那个侧面的故事(有数据)。如果你很懒,不在乎细节,跳到最下面有一个 Sankey 图,总结了很多。
让我们先了解一些基础知识,因为这些话题不可避免地会出现。
男的还是女的?
男,22。直男。
我住在哪里?
拥有大约一百万人口的加拿大城市。
我好看吗?
我可能是一个长相相当普通的人,可能略高于平均水平,但肯定不是模特。目前在我的 Tinder 个人资料上的照片有着从 7.7 到 9.3 不等的吸引力评分。然而,请记住,我确实为我的个人资料拍了一些好照片。
我有金子吗?
是的。
我的偏好设置是什么?
我的偏好最初设定得很宽,但随着时间的推移已经缩小了。目前,它被设定为 100 公里内 18-25 岁的女性。
现在是有趣的事情。
活动
我的 Tinder 活跃度(以应用每天打开次数衡量)从 0 到 153 不等——平均值为 29 次,中位数为 20 次。

我在 Tinder 上的第一周是我最活跃的一周。然而,除此之外,我的活动没有显示出明确的趋势,但高活动期似乎确实会突然出现,中间会有间歇。
偷窃
在近 4 个月的时间里,我记录了 16561 次刷卡。这意味着平均每天刷卡 141.5 次,中位数为 96 次。

在 16,561 次刷卡中,7,886 次是赞,8,675 次是通过,总体赞率为 47.3% 。

数据还显示,随着时间的推移,我的刷卡变得更加有选择性——尽管这可能是因为我的偏好发生了变化,或者 Tinder 的算法向我显示了更好的配置文件。有趣的是,我确实相信随着时间的推移,我变得更有选择性了。
比赛
我总共收到了 290 条匹配——平均每天 2.5 条。这意味着大约 1.75%的我的刷卡会导致匹配,大约 3.7%的我的喜欢。

在任何一天,我都会收到 0 到 10 个匹配。每天比赛的分布严重向右倾斜,模式为 2。

信息发送
我在 Tinder 上总共交换了 504 条信息——发送了 274 条,收到了 230 条。这个数字相对较低,因为我通常试图在几条消息中得到一个电话号码。

下面是我的信息是如何随着时间的推移而积累起来的:

在我的 290 次匹配中,有 99 次(34%)至少交换了一条信息。在这 99 人中,有 12 人给我发了信息,但我没有回复,这意味着我给 30%的匹配者发了信息。
在我发送的 87 条匹配信息中,有 56 条至少回复了一次,回复成功率约为 64%。这个比例可能比它应该的要低,因为我经常等几天或几周才收到我不太感兴趣的比赛的消息。我自己对三天内发送的比赛信息的追踪显示回复率为 78%,而我最好的开场白的回复率为 84%。
超级旅行
我也开始追踪我自己的超级跑步成功率。在 183 次超级相似中,有 14 次匹配,成功率为 8%。这是按年龄划分的成功案例:

以及按年龄划分的成功率:

我有一个个人理论,年轻女孩的成功率会更高,但迄今为止,没有明显的趋势出现。
总结果
我打火的最终结果可以用这张图表来概括:

Built in SankeyMatic
总的来说,我和约会的次数超过了我的对手的 1%。我认为这个数字相当保守;我很有信心,如果我想的话,我可以得到更多的约会。
我选择发送多少条信息主要取决于我那周有多忙,我是否有其他约会计划(来自 Bumble 或我在现实生活中遇到的女孩),或者我当时有多想去约会。
数据来源
这里所有的数据都来自我自己的 Tinder 个人资料。其中大部分来自对 Tinder 的数据请求,还有一部分是自我跟踪的。
数据科学家将完全涉及的 12 种情况

数据科学家是比任何软件工程师更擅长统计,比任何统计学家更擅长软件工程的人。
——约什·威尔斯,克劳德拉
数据科学无疑是当今市场上最受欢迎的技能之一。根据美国消费者新闻与商业频道的一篇文章,“数据科学家”在 2017 年十大职业中名列前茅,这些职业包括就业增长、工资中位数、所需体力、压力水平等等。工资中位数为 111,267 美元,预计就业增长率为 16%,数据科学领域的职业确实非常有利可图。
话虽如此,成为一名数据科学家需要付出很多。这份工作需要丰富的想象力和扎实的技能,尤其是数字方面的技能。一个人必须有能力收集正确的数据,形成用于分析的数据,设计创造性的方法来可视化数据,并根据数据的洞察力回答特定的相关问题。
正是因为这个原因,一个顶尖的数据科学家经常在技术公司受到摇滚明星般的待遇。然而,数据极客的生活并不轻松。随着新工具和不同问题解决技术的不断涌现,数据科学家需要不断学习,以保持知识和技能的更新,并保持其组织的宝贵资产。
也就是说,以下 12 种情况完美地描述了数据科学家的处境。
当有人问你,“什么是大巴塔?”
真的吗?
我们生活在一个高度数字化的世界,大数据无处不在。我们不断产生数量惊人的数据——想想社交媒体、网上银行、移动购物、GPS 等等。事实上,据报道,我们一天产生大约 2.5 万亿字节的数据!
大数据改变了我们与人沟通和管理生活的方式。来自大数据的见解有助于零售网站向您发送完全符合您偏好的产品推荐,政府当局了解和预测犯罪,交通机构管理和控制交通,或者医疗从业者识别处于风险中的人。
大数据的应用确实是无止境的,并且在很大程度上提高了我们的生活质量。因此,每个人都应该熟悉术语“大数据”。
当你的 R 代码第一次工作时
初露头角的数据科学家会和这张 GIF 联系起来。r 编程是数据科学领域最需要的技能之一。根据 KDnuggets 的一篇文章,R 是 2016 年最受欢迎的分析和数据科学软件,其次是 Python。
考虑到软件在市场上的需求,当你的 R 代码按照预期的方式工作时,你会情不自禁地想象自己是最大的数据呆子。
当您必须处理非结构化流数据时
非结构化数据分析领域通常被称为“黑暗分析”。这听起来确实令人生畏,也确实如此。
即使是最熟练的数据科学家,处理非结构化流数据也是一件难事。无论是来自社交媒体、视频、客户日志文件还是地理空间服务的数据,分析都需要随着多条记录的创建而循序渐进。此外,在处理这些数据时,时间是至关重要的。
因此,当你陷入黑暗分析时,你肯定会感觉类似于试图揭开宇宙奥秘的太空科学家。
当您的模型预测准确率超过 90%时
这是一件大事。数据科学家必须花费大量时间来研究、理解、准备和操作数据以进行分析。这个过程需要极大的耐心和努力。然而,当你建立的模型提供超过 90%的准确率时,回报是巨大的。
当你的客户、经理和同事对你赞不绝口时,你心中只有一件事,因为你骄傲自大——一个无拘无束的狂欢周末!
当你试图在你的模型中发现一个问题时
试图在数百或数千行代码中寻找错误与在宿醉中大海捞针没有太大区别。
但是让我们面对现实吧。这都是游戏的一部分。
当您的经理询问您关于漏洞修复的情况时
通常,数据科学组织中的经理不理解技术任务的本质,无论是调试还是调整机器学习模型。经理通常更关心项目管理方面(理解为:截止日期)。
在这种情况下,作为一名数据科学家,你所能做的就是再拖延一些时间,或者在极少数情况下神秘消失。
当你对模型一无所知的朋友解决了问题
你已经徒劳地盯着你的代码看了几个小时,你已经快要放弃了。而一个朋友随便看看你有什么,秒指出错误。
虽然这可能是发生的最令人讨厌的事情之一,但那些最初的尴尬和烦躁很快就会变成解脱,因为你现在少了一件需要担心的事情。
没事的。有时候,你需要一双新鲜的眼睛来完成工作。
当您的 SQL 查询永远无法执行时
缓慢的服务器,糟糕的互联网,或者无论什么原因,等待 SQL 查询的执行就像看着油漆变干,除非你太偏执而不能离开你的系统。
这很无聊,也是对耐心的极大考验。尽管我们都经历过。
当您完成建模并且您的客户端更改了数据时
在做了令人麻木的努力来分析数据和识别无数的趋势或模式后,你最不想听到的就是你使用的数据不是“正确的”数据。
当你得到一个完全不同的数据集时,这意味着你必须对模型本身做出重大改变。所以,就这样,你又一次从头开始工作。痛苦啊!
当你在 20 分钟后有一个客户演示,而你还没有完成你的演示
你刚刚为客户准备完一份演示文稿。你已经准备好摇滚了,对吧?大多数情况下,不是。
数据科学家必须由他或她的同事和经理进行演示。这通常意味着一件事——大量的最后一刻的改变。做出这样的改变可能会非常有压力,因为除了你的个人声誉,还有很多东西处于危险之中:潜在的销售、公司的形象,甚至你的职业发展。
但是最终,当你从客户那里得到肯定的答复时,你会意识到其中的一些改变是至关重要的,事实上,这让你的理由更加充分。
正如传奇人物史蒂夫·乔布斯曾经说过的:
“生意场上的大事,从来不是一个人做出来的;它们是由一队人完成的。”
当客户最终同意您的模型输出时
这是数据科学家幻想的“老板”时刻——当你知道自己对组织的业务做出了巨大贡献时。
客户可能非常苛刻和挑剔,所以你不知疲倦地工作,使你的模型尽可能准确和有效。你必须根据客户的奇思妙想行事,这并不总是有趣的。但是,最后,当客户给你一个明确的竖起大拇指,就是最终的胜利。
柯克·伯恩博士说得对:
“客户可能不总是对的,但客户永远是客户。”
当新的大数据技术进入市场时
分析行业发展迅速,新的工具和技术也是如此。数据科学家正在看到各种大数据、分析和深度学习工具的出现。
作为天生的不断学习者,数据极客对这些新发展持开放态度,因为他们有机会拓宽自己的知识和技能。
(GIF 图片来源:giphy.com)
(这篇特写首次出现在 BRIDGEi2i 博客 )
非常感谢你的阅读!如果这篇文章让你发笑,请点击下面的心形按钮,让更多的人看到它。
关于机器学习要知道的 12 件有用的事情

机器学习算法可以通过从示例中进行归纳来找出如何执行重要任务。在手动编程不可行的情况下,这通常是可行的且成本有效的。随着越来越多的数据可用,更多雄心勃勃的问题可以得到解决。因此,机器学习被广泛应用于计算机等领域。然而,开发成功的机器学习应用程序需要大量在教科书中很难找到的“黑色艺术”。
我最近读了一篇令人惊叹的技术论文,作者是华盛顿大学的 Pedro Domingos 教授,题目是“ 关于机器学习需要知道的一些有用的事情”。 ”它总结了机器学习研究人员和实践者学到的 12 条关键经验,包括要避免的陷阱、要关注的重要问题和常见问题的答案。我想在本文中分享这些经验,因为它们在考虑解决下一个机器学习问题时非常有用。
1 —学习=表示+评估+优化
所有机器学习算法通常只由 3 个部分组成:
- 分类器必须用计算机能够处理的某种形式语言来表示。相反,为学习者选择一个表示就相当于选择它可能学习的一组分类器。这个集合被称为学习者的假设空间。如果分类器不在假设空间中,它就不能被学习。一个相关的问题是如何表示输入,即使用什么特征。
- **评估:**需要一个评估函数来区分好的分类器和坏的分类器。算法内部使用的评估函数可能不同于我们希望分类器优化的外部函数,这是为了便于优化,也是由于下一节中讨论的问题。
- **优化:**最后,我们需要一种方法在语言的分类器中搜索得分最高的分类器。优化技术的选择对于学习者的效率是关键的,并且如果评估函数具有一个以上的最优值,也有助于确定产生的分类器。对于初学者来说,开始使用现成的优化器是很常见的,这些优化器后来被定制设计的优化器所取代。

2 —概括才是最重要的
机器学习的基本目标是将推广到训练集中的示例之外。这是因为,无论我们有多少数据,我们都不太可能在测试时再次看到那些精确的例子。在训练中做得好很容易。机器学习初学者最常见的错误就是在训练数据上进行测试,产生成功的错觉。如果选择的分类器然后在新的数据上被测试,它通常不比随机猜测好。所以,如果你雇人来构建一个分类器,一定要把一些数据留给自己,并在上面测试他们给你的分类器。相反,如果你被雇来建立一个分类器,从一开始就把一些数据放在一边,只在最后用它来测试你选择的分类器,然后在整个数据上学习你的最终分类器。

3 —仅有数据是不够的
将一般化作为目标还有另一个主要后果:不管你有多少数据,光有数据是不够的。
这似乎是相当令人沮丧的消息。那么我们怎么能希望学到东西呢?幸运的是,我们想要在现实世界中学习的函数并不是从所有数学上可能的函数集中统一得出的!事实上,非常一般的假设——比如平滑度、类似的例子具有类似的类、有限的依赖性或有限的复杂性——通常足以做得非常好,这也是机器学习如此成功的很大一部分原因。和演绎一样,归纳(学习者所做的事情)是一个知识杠杆:它把少量的输入知识变成大量的输出知识。归纳法是一个比演绎法强大得多的杠杆,它需要少得多的输入知识来产生有用的结果,但它仍然需要比零输入知识更多的知识来工作。而且,就像任何杠杆一样,我们放进去的越多,出来的就越多。

回想起来,学习对知识的需求应该不足为奇。机器学习不是魔术;它不可能无中生有。它所做的是用更少的资源获得更多。像所有工程一样,编程是一项繁重的工作:我们必须从头开始构建一切。学习更像耕作,让大自然做大部分的工作。农民将种子和养分结合起来种植作物。学习者将知识与数据相结合来开发程序。
4-过度拟合有许多面
如果我们拥有的知识和数据不足以完全确定正确的分类器怎么办?那么我们就有可能产生一个分类器(或它的一部分)的幻觉,这个分类器不是基于现实的,只是在数据中编码随机的怪癖。这个问题被称为过拟合,,是机器学习的 bugbear。当您的学习者输出一个对训练数据 100%准确,但对测试数据只有 50%准确的分类器时,实际上它可以输出一个对两者都有 75%准确的分类器,它已经过拟合了。
机器学习中的每个人都知道过度拟合,但它以许多形式出现,不会立即显而易见。理解过度拟合的一种方法是将泛化误差分解为偏差和*方差。*偏见是学习者总是学习同样错误的东西的倾向。方差是学习随机事物而不考虑真实信号的趋势。线性学习者有很高的偏见,因为当两个类之间的边界不是超平面时,学习者无法诱导它。决策树没有这个问题,因为它们可以表示任何布尔函数,但另一方面,它们可能会受到高方差的影响:在同一现象生成的不同训练集上学习到的决策树往往非常不同,而实际上它们应该是相同的。

交叉验证有助于对抗过度拟合,例如通过使用它来选择学习决策树的最佳大小。但是它不是万灵药,因为如果我们用它来做太多的参数选择,它本身就会开始过度适应。
除了交叉验证之外,还有许多方法来对抗过度拟合。最流行的方法是在评估函数中增加一个正则项。例如,这可能不利于具有更多结构的分类器,从而有利于较小的分类器,较小的分类器具有较小的过度适应空间。另一种选择是在添加新结构之前执行统计显著性测试,如卡方检验,以确定使用和不使用该结构时类的分布是否真的不同。当数据非常缺乏时,这些技术特别有用。然而,你应该对声称一种特殊的技术“解决”过度拟合问题持怀疑态度。通过陷入与欠拟合(偏差)相反的错误,很容易避免过拟合(方差)。同时避免这两者需要学习一个完美的分类器,如果事先不知道,就没有一种技术总是做得最好(没有免费的午餐)。
5——直觉在高维空间失效
过拟合之后,机器学习最大的问题就是*维数灾难。*这个表达是 Bellman 在 1961 年创造的,指的是当输入是高维时,许多在低维工作良好的算法变得难以处理。但在机器学习中,它指的远不止这些。随着示例维数(要素数量)的增加,正确概化变得更加困难,因为固定大小的训练集覆盖了输入空间中不断缩小的部分。

高维度的普遍问题是,我们来自三维世界的直觉通常不适用于高维度。在高维中,一个多元高斯分布的大部分质量并不在均值附近,而是在它周围越来越远的“壳”中;而且一个高维橙子的大部分体积都在果皮里,而不是果肉里。如果恒定数量的样本均匀分布在高维超立方体中,在某些维度之外,大多数样本比它们的最近邻居更靠近超立方体的面。如果我们通过在超立方体中雕刻来近似一个超球面,在高维空间中,几乎所有超立方体的体积都在超球面之外。这对机器学习来说是个坏消息,在机器学习中,一种类型的形状通常由另一种类型的形状来近似。
构建二维或三维分类器很容易;我们可以通过目测在不同类别的例子之间找到合理的边界。但是在高维度中,很难理解发生了什么。这反过来使得设计一个好的分类器变得困难。有人可能天真地认为,收集更多的特性不会有什么坏处,因为在最坏的情况下,它们不会提供关于该类的新信息。但事实上,它们的好处可能会被维数灾难盖过。
6 —理论上的保证并不像它们看起来那样
机器学习论文充满了理论保障。最常见的类型是对确保良好概括所需的示例数量的限制。你应该如何看待这些保证?首先,值得注意的是,它们甚至是可能的。归纳传统上与演绎相反:在演绎中,你可以保证结论是正确的;在诱导阶段,所有的赌注都是无效的。或者说这是许多世纪以来的传统观点。最近几十年的主要发展之一是认识到事实上我们可以对归纳的结果有保证,特别是如果我们愿意满足于概率保证的话。
我们必须小心像这样的界限意味着什么。例如,它并没有说,如果你的学习者返回了一个与特定训练集一致的假设,那么这个假设很可能是通用的。也就是说,给定一个足够大的训练集,你的学习者很有可能要么返回一个概括得很好的假设,要么无法找到一个一致的假设。这个界限也没有说明如何选择一个好的假设空间。它只告诉我们,如果假设空间包含真正的分类器,那么学习者输出坏分类器的概率随着训练集大小而降低。如果我们缩小假设空间,界限会改善,但是它包含真实分类器的机会也会缩小。

另一种常见的理论保证是渐近的:给定无限的数据,保证学习者输出正确的分类器。这是令人放心的,但由于其渐近保证,选择一个学习者而不是另一个学习者是轻率的。实际上,我们很少处于渐近状态(也称为“渐近状态”)。并且,由于上面讨论的偏差-方差权衡,如果给定无限数据,学习者 A 比学习者 B 好,则 B 通常比给定有限数据好。
理论保障在机器学习中的主要作用不是作为实际决策的标准,而是作为算法设计的理解来源和驱动力。在这种情况下,他们是非常有用的;事实上,理论和实践的密切相互作用是机器学习多年来取得如此大进展的主要原因之一。但是*买者自负:*学习是一种复杂的现象,仅仅因为一个学习者有理论上的正当理由并在实践中工作并不意味着前者是后者的原因。
7 —特征工程是关键
最终,一些机器学习项目成功了,一些失败了。有什么区别?很容易,最重要的因素是所使用的特性。如果你有许多独立的特性,并且每一个都和这个类有很好的关联,那么学习就很容易。另一方面,如果类是一个非常复杂的功能特性,你可能无法学习它。通常,原始数据不是一种易于学习的形式,但是您可以从中构建出易于学习的特征。这通常是机器学习项目中大部分努力的方向。这通常也是最有趣的部分之一,直觉、创造力和“黑色艺术”与技术一样重要。
第一次接触机器学习的人通常会惊讶于在一个机器学习项目中实际花在机器学习上的时间是如此之少。但是,如果你考虑到收集数据、整合数据、清理数据和预处理数据是多么耗时,以及在功能设计中可以进行多少尝试和错误,这是有道理的。此外,机器学习不是建立数据集和运行学习器的一次性过程,而是运行学习器、分析结果、修改数据和/或学习器并重复的迭代过程。学习通常是最快的部分,但那是因为我们已经掌握得很好了!特征工程更难,因为它是特定领域的,而学习者可以是通用的。然而,这两者之间并没有明显的界限,这也是为什么最有用的学习者是那些促进知识融合的人。

8-更多的数据胜过更聪明的算法
在大多数计算机科学中,两个主要的有限资源是时间和内存。在机器学习中,还有第三个:训练数据。哪一个是瓶颈,十年换十年。在 20 世纪 80 年代,它倾向于数据。今天通常是时间。海量的数据可用,但没有足够的时间来处理这些数据,因此这些数据被闲置。这导致了一个悖论:尽管原则上更多的数据意味着可以学习更复杂的分类器,但在实践中,更简单的分类器最终被使用,因为复杂的分类器需要太长的时间来学习。部分答案是想出快速学习复杂分类器的方法,事实上在这个方向上已经有了显著的进展。
使用更聪明的算法的回报比你预期的要小,部分原因是,在第一个近似值上,它们都做同样的事情。当你考虑到不同的表现形式,比如说,不同的规则集和神经网络时,这是令人惊讶的。但事实上,命题规则很容易被编码为神经网络,其他表示之间也存在类似的关系。所有的学习者本质上都是通过把附近的例子分组到同一个班级来工作的;关键的区别在于“附近”的含义使用非均匀分布的数据,学习者可以产生非常不同的边界,同时仍然在重要的区域(具有大量训练示例的区域,因此也是大多数文本示例可能出现的区域)中做出相同的预测。这也有助于解释为什么强大的学习可能不稳定,但仍然准确。

通常,首先尝试最简单的学习者是值得的(例如,在逻辑回归之前的朴素贝叶斯,在支持向量机之前的 k-最近邻)。更复杂的学习者是诱人的,但他们通常更难使用,因为他们有更多的旋钮需要你去转动以获得好的结果,也因为他们的内部更不透明)。
学习器可以分为两种主要类型:一种是表示具有固定大小的,如线性分类器,另一种是表示可以随着数据增长的,如决策树。固定规模的学习者只能利用这么多的数据。给定足够的数据,可变大小学习器原则上可以学习任何函数,但实际上,由于算法或计算成本的限制,它们可能无法学习。此外,由于维数灾难,现有的数据量可能是不够的。出于这些原因,聪明的算法——那些充分利用数据和计算资源的算法——最终往往会有回报,只要你愿意付出努力。设计学习者和学习分类器之间没有明显的界限;更确切地说,任何给定的知识都可以被编码在学习者的大脑中,或者从数据中学习。因此,机器学习项目往往以学习者设计的重要组成部分告终,从业者需要在这方面有一些专业知识。
9-学习多种模式,而不仅仅是一种
在机器学习的早期,每个人都有自己最喜欢的学习者,以及一些相信其优越性的先验理由。大部分的努力都花在了尝试它的许多变化和选择最好的一个上。然后,系统的经验比较表明,最佳学习者因应用程序而异,包含许多不同学习者的系统开始出现。现在努力尝试许多学习者的许多变化,并且仍然选择最好的一个。但是后来研究人员注意到,如果我们不选择找到的最佳变体,而是组合许多变体,结果会更好——通常好得多——并且对用户来说没有额外的努力。

创建这样的模型集合现在是标准。在最简单的技术中,称为 *bagging,*我们简单地通过重采样生成训练集的随机变化,在每个变化上学习一个分类器,并通过投票组合结果。这是可行的,因为它极大地减少了方差,而只是略微增加了偏差。在 *boosting 中,训练样本具有权重,这些权重是可变的,以便每个新的分类器专注于先前的分类器容易出错的样本。在堆叠中,*单个分类器的输出成为“高级”学习器的输入,该学习器找出如何最好地组合它们。
存在许多其他技术,并且趋势是越来越大的集合。在网飞奖中,来自世界各地的团队竞相打造最佳视频推荐系统。随着比赛的进行,团队发现他们通过将他们的学习者与其他团队结合起来获得了最好的结果,并合并成越来越大的团队。冠军和亚军都是超过 100 名学习者的组合,将这两个组合结合起来进一步改善了结果。毫无疑问,我们将来会看到更大的规模。
10-简单并不意味着准确
奥卡姆剃刀的著名论断是,实体的繁殖不应超过需要。在机器学习中,这通常意味着,给定两个具有相同训练误差的分类器,两个分类器中较简单的一个可能具有最低的测试误差。这种说法的所谓证据经常出现在文献中,但事实上有许多反例,而“没有免费的午餐”定理暗示这不可能是真的。

我们在上一节看到了一个反例:模型集合。即使在训练误差已经达到零之后,通过增加分类器,增强集成的泛化误差继续改善。因此,与直觉相反,模型的参数数量与其过度拟合的趋势之间没有必然的联系。
相反,更复杂的观点将复杂性等同于假设空间的大小,其基础是更小的空间允许假设由更短的代码来表示。像上面理论保证一节中那样的界限可能会被认为是暗示更短的假设概括得更好。这可以通过给空间中的假设分配更短的代码来进一步细化,我们对该空间有一些先验的偏好。但将此视为准确性和简单性之间权衡的“证据”是循环推理:我们通过设计使我们偏好的假设更简单,如果它们是准确的,那是因为我们的偏好是准确的,而不是因为假设在我们选择的表示中是“简单的”。
11-可表示并不意味着可学习
基本上,可变大小学习器中使用的所有表示都有相关的定理,其形式为“使用这种表示,每个函数都可以被表示,或者被任意近似。”对此感到放心后,该代表的粉丝通常会忽略所有其他人。但是,一个函数可以被表示出来,并不代表它可以被学习。例如,标准决策树学习者不能学习比训练样本更多的叶子的树。在连续空间中,使用一组固定的基元来表示即使是简单的函数,通常也需要无限数量的组件。

此外,如果假设空间具有许多评估函数的局部最优值,这是经常发生的情况,学习者可能找不到真正的函数,即使它是可表示的。给定有限的数据、时间和记忆,标准学习者只能学习所有可能函数的极小子集,这些子集对于具有不同表征的学习者是不同的。因此,关键问题不是“它能被表现出来吗?”对此,答案往往是琐碎的,但“它能被学习吗?”尝试不同的学习者(并可能结合他们)是值得的。
相关性并不意味着因果关系
相关性并不意味着因果关系的观点经常被提出,因此也许不值得赘述。但是,即使我们一直在讨论的这种学习者只能学习相关性,他们的结果也经常被视为代表因果关系。这难道不是错的吗?如果是,那么人们为什么要这么做?

通常情况下,学习预测模型的目的是将它们用作行动指南。如果我们发现啤酒和尿布经常在超市一起购买,那么也许把啤酒放在尿布区旁边会增加销售额。但是除非真的做实验,否则很难说。机器学习通常应用于观察数据,其中预测变量不受学习者控制,与实验数据相反,预测变量受学习者控制。一些学习算法可以潜在地从观察数据中提取因果信息,但是它们的适用性相当有限。另一方面,相关性是潜在因果联系的标志,我们可以用它作为进一步调查的指南。
结论
像任何学科一样,机器学习有许多“民间智慧”,它们可能很难获得,但对成功至关重要。多明戈斯教授的论文总结了一些你需要知道的最重要的项目。
— —
如果你喜欢这首曲子,我希望你能按下拍手按钮👏所以其他人可能会偶然发现它。你可以在GitHub上找到我自己的代码,在https://jameskle.com/上找到更多我的写作和项目。也可以在 上关注我【推特】*直接发邮件给我 或者 在 LinkedIn 上找我 。 注册我的简讯 就在你的收件箱里接收我关于数据科学、机器学习和人工智能的最新想法吧!*
2018 年你需要知道的 15 个人工智能(AI)统计数据

人工智能(AI)每天都在以惊人的速度增长,随之而来的是,围绕该行业及其正在变革的各种行业的统计数据也在发生变化。该技术已经在简化医疗保健行业的工作流程、减少教育部门管理任务的工时以及降低制造业的间接成本方面取得了巨大成功。似乎每天都有新的人工智能初创公司冒出来,目的是改变我们日常的思维、互动和工作方式。
为了向这项技术致敬,我们收集了大量与人工智能相关的数据,以便让你了解这项技术如今有多流行。这些统计数据涵盖了截至 2018 年的技术状况,其中包括像 WorkFusion 这样的公司成为该行业的领导者。这家软件公司为寻求提高投资回报率的企业提供各种智能自动化解决方案。

以下是 2018 年你需要知道的 15 个 AI 统计:
- 根据 Adobe 的数据,截至目前,只有 15%的企业在使用人工智能,但预计 31%的企业将在未来 12 个月内添加人工智能。
- 据斯坦福大学统计,自 2000 年以来,活跃的创业公司数量增加了 1400%。
- 据 Adobe 称,自 2000 年以来,风险资本家对人工智能初创公司的投资飙升了 6 倍。
- 根据 Adobe 的数据,自 2013 年以来,需要人工智能的工作份额增加了 450%。
- 斯坦福大学的数据显示,对于使用人工智能的企业,表现最佳的公司表示,他们使用该技术进行营销的可能性是行业同行的两倍多,分别为 28%和 12%。
- 根据 BridghtEdge 的说法,下一个大的营销趋势被视为消费者个性化(29%),其次是人工智能(26%)。
- Monster.com 最受欢迎的三项技能是机器学习、深度学习和自然语言处理。
- 国际数据公司(IDC)预测,到 2021 年,全球人工智能发送的复合年增长率将为 50.1%,达到 576 亿美元。这要归功于对零售、银行、医疗保健和制造业的投资,这些领域将占全球人工智能支出的一半以上。
- Adobe 还发现,47%的数字化成熟组织,即那些拥有先进数字化实践的组织,都有明确的人工智能战略。
- Juniper Research 在一项研究中发现,到 2022 年,全球人工智能支出将从 2018 年的 20 亿美元增长到每年 73 亿美元。这是因为公司将大力投资于人工智能工具,这些工具将帮助他们区分和改善他们为客户提供的服务。
- 根据叙事科学的数据,大约 61%拥有创新战略的公司正在使用人工智能来识别数据中的机会,否则他们会错过这些机会。对于没有这一战略的公司,这一数字仅为 22%。
- 佩奇表示,约 38%的消费者认为人工智能将改善客户服务。
- PointSource 的一项研究发现,当人工智能被战术性地部署时,34%的购物者将在网上花更多的钱。约 49%的人表示,当人工智能出现时,他们愿意更频繁地在线购物。
- 根据埃森哲的数据,人工智能医疗保健市场预计到 2021 年将达到 66 亿美元。该研究补充说,到 2026 年,临床健康人工智能应用可以为美国医疗保健经济每年节省 1500 亿美元。
- 根据 IDC 的数据,在全球范围内,机器人进口已经从 2000 年的大约 10 万台增加到 2015 年的大约 25 万台。
加入 15 个数据科学 Slack 社区
放松时伸出援手,提升你的职业生涯

image created by Formulated.by :]
【2020 年 11 月:此榜单已更新 此处 。
他们说这需要一个村庄,但在这个数字时代,它实际上只需要一个聊天室,就可以立即将你与世界各地的资源联系起来,从而推动你的职业生涯。我们梳理了我们的联系人和数据,为您带来了一些最佳数据科学和机器学习 slack 社区的列表。来吧,登录并花些时间与您的同事讨论在您的工作流程中阻碍您的问题、要避免的陷阱或让生活更轻松的提示。快乐懈怠!
- Data Quest(7829):Slack chat,来自世界各地的数据科学家在这里交流
- 数据科学沙龙(1500)DSS和 DSSelevate 社区官方 slack 频道。电子邮件 info@formulated.by 请求加入
- Watson 开发者社区(wвC)(6671):IBM Watson 开发者
- Verta 社区(140):MLOps 社区的 Slack 聊天
- 数据话语 (2962):谈论大数据
- R-数据分析团队 (420):学习和探索 R 数据分析工具的全球聊天
- 数据科学家/spark ml 小组(不适用):Apache Spark、Python Scikit-Learn、Scala Breeze、R 关于数据科学和机器学习的讨论,或关于大数据领域的任何其他主题
- 数据科学家(不适用):数据科学家、数据仓库和 BI 相关的东西
- 开放数据社区 (5510):基于 Slack 的数据科学家社区
- Spark NLP (1000):专注自然语言处理的 Slack 社区,涵盖所有 NLP 相关主题。
- Grakn 社区 (665):分布式知识库
- uda city 上的深度学习(13646):uda city 上的深度学习社区
- 人工智能研究人员 (2242):人工智能松弛聊天
- AI Meetup 系列 (805):各种线下 AI 赛事
- 机器学习组 (2069): ML 专家
- ML-AI (578):一般行业聊天
- 数据科学社区(不适用):为数据从业者提供的聊天平台,以及与来自世界各地的数据科学家交流的场所
- 泰姆莱松弛社区(不适用)通过https://twimlai.com/meetup.的注册表格加入
- AI-ML-数据科学爱好者 (300):数据科学家和 ML 专家分享技巧和寻找项目的地方。
我们错过什么了吗?请随意将您最喜欢的 ML Slack 社区添加到此列表中。
15 个惊人的数据可视化(以及你能从中学到什么)

我们淹没在数据中。每天都有 2.5 万亿字节的数据产生。这相当于全球 90%的信息——仅在过去两年中就产生了这些信息。这就是我们所说的“大数据”
但是它从哪里来呢?无处不在,从传感器和社交媒体网站到数字图像和视频。我们拥有的数据比我们知道的要多得多,所以现在是时候组织和理解这些数据了。
这就是数据可视化发挥作用的地方。在等待我们的地震式转变中,有些人称之为数据的工业革命,我们必须更好、更有效地创建创新的数据可视化,使复杂的数据易于理解。
为了启发你自己的工作,我们汇编了 15 个数据可视化,它们不仅会让你大吃一惊,还会让你更清楚地了解什么是好的可视化,什么是坏的可视化。
1.它是互动的

互动作品著名创意人士的日常事务是数据可视化的一个完美例子,它结合了一个有效和引人入胜的作品的所有必要成分:它将大量数据结合到一个页面中;它用颜色来轻松区分趋势;它可以让浏览者对数据有一个整体的了解;它通过允许用户与作品互动来吸引用户;令人惊讶的是,它简单易懂,一目了然。
2.它揭示了趋势

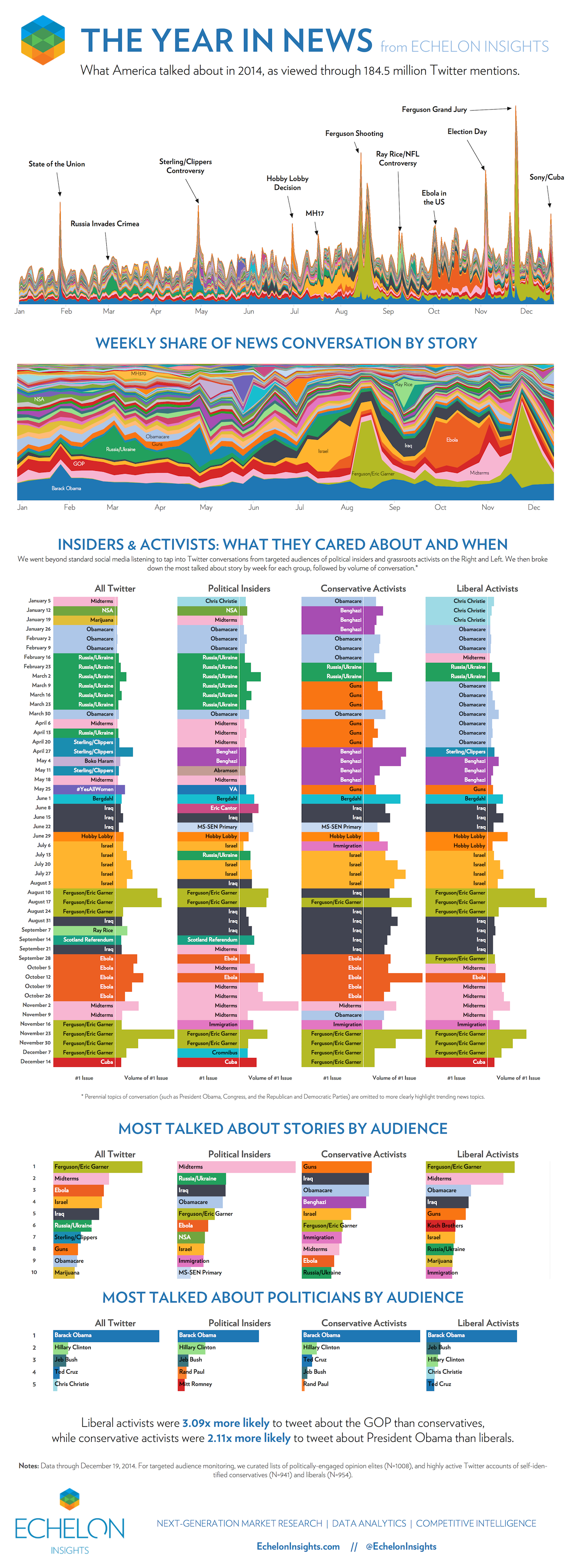
一年新闻是一个很好的例子,说明一个熟练执行的数据可视化可以揭示隐藏在数据山表面下的模式和趋势。通过分析 1.845 亿次 Twitter 提及,Echelon Insights 能够提供美国在 2014 年谈论什么的鸟瞰图。
3.它使用动画

皮尤研究中心创建的美国年龄金字塔是一个值得注意的例子,说明了如何通过使用执行良好的动画来有效地传达随着时间的推移而发生的变化和趋势。这种类型的数据可视化不仅将大量信息打包到一个单一的视觉效果中——23 个条形图被合并到一个单一的 GIF 合成中——它还可以在社交媒体上轻松共享并嵌入到任何地方。
4.它使用真实的图像

如今有如此多的数据可视化,很难找到一个尚未被探索的独特角度。然而,设计师 Marion Luttenberger 创作的这组极富想象力的信息图却并非如此。
Luttenberger 使用现实生活中的图像作为他的信息图表的基础,能够为一个向奥地利吸毒者提供援助的组织起草一份完整的年度报告,并且仍然清晰有效地传达该组织的使命。
5.它使用隐喻

交流复杂思想的有效方法是使用符号和隐喻。举个例子,这个雄心勃勃的互联网数据可视化是由 Ruslan Enikeev 创建的。通过使用太阳系中行星的比喻,Enikeev 能够创建一个“互联网地图”,帮助用户可视化每个网站的相对范围和影响力。例如,网站流量由地图上圆圈的大小来表示。
6.它将数据放入上下文中

数据可视化的最大优势之一是,它们能够将孤立的信息片段放到更大的环境中,这是无与伦比的。尼康的这个富有洞察力的互动作品的目标是通过使用比较,给用户一种物体大小的感觉,无论是大的还是小的。例如,在银河系旁边,一个普通的物体,比如一个球或一辆车,似乎比我们想象的要小。
7.它节省你的时间

有效数据可视化的另一个标志是它能够总结大量信息,并在这个过程中节省您的时间和精力。举例来说,这种数据可视化在一页上代表了 100 年来岩石的演变。它不仅为您简化了信息——将一个世纪的信息浓缩到一段不到一分钟就可以观看的内容中——它还提供了从电子蓝调到黑暗金属等各种流派的实际音频样本。
8.它给你视角

作为人类,我们不能不从自己的自我中心和完全独特的角度来看待宇宙和生命。然而,这种数据可视化通过将我们自己的生活——以及当天的事件——置于更大的时间背景中,从当年到当前的千年,为我们提供了一些视角。
9.它解释了一个过程

本着使复杂的事物易于理解的目标,这张信息图提供了一个咖啡豆从咖啡豆到杯子的旅程的视觉呈现。通过将这个过程分解成几个部分,这种数据可视化为读者提供了一点点易于消化的信息。
10.它激发了用户的想象力

一个好的信息图不仅能消化复杂的数据,还能激发读者的想象力,让他们想象出不同的假设情况和可能性,就像这个例子一样。通过呈现一种互动的、类似游戏的体验,这张信息图迅速吸引了用户,让他们从头到尾都保持兴趣。
11.它漂亮地展示了数据

这张信息图采用密集的材料,如指标和数字,并以一种美丽、干净和吸引人的格式呈现出来。这种设计不仅看似简单实用,还为用户提供了许多与图形交互的选项,例如添加国家、指标和关系类型。
12.它讲述了一个故事

有效的数据可视化不仅能以令人信服的方式传达信息,还能讲述一个值得讲述的故事。例如,这篇文章讲述了巴基斯坦每一次已知的无人机袭击和受害者的故事。通过将信息提炼为易于理解的视觉格式,这张信息图戏剧性地揭示了不应被忽视的令人不安的事实。
13.它提供对原始数据的访问

这种数据可视化不仅具有前面提到的所有特性,还允许用户直接访问所有原始数据(右下角的查看链接)。此外,通过使用根据数据泄露的大小而形成的气泡,查看者可以获得数据泄露“情况”的真实概览如果观众想深入了解信息的细节,他们也可以通过浏览不同的过滤器和原始数据来深入或浅显地了解信息。
14.它赋予用户权力

与信息访问民主化和赋予用户权力的全球趋势相一致,这种数据可视化出色地揭示了平衡国家预算的过程。通过将预算平衡交给日常用户,该项目利用集体思维的力量来解决大问题。
15.它是有教育意义的

这一块超越了一个普通的数据可视化,成为一个教育和互动的微型网站。通过将足够的数据和信息组合到一个交互式应用程序中,这种数据可视化成为学生学习风、海洋和天气情况的有用课堂工具。
轮到你了
交互式数据可视化是独一无二的,因为它们吸引了五种感官中的几种:通过音频吸引了听觉,通过惊人的视觉吸引了视觉,通过点击、悬停和滚动内容的交互式体验吸引了触觉。
虽然您可能认为自己制作数据可视化过于昂贵和耗时,但是您可以探索一些免费的工具,这些工具允许非设计人员和非程序员创建他们自己的交互式内容。
例如,Visme 是一个在线工具,允许你创建交互式图表、图形和地图。这里可以免费试用。
如果你想获得更多成为更好的视觉传达者的提示和指导,别忘了订阅我们下面的每周时事通讯。
本帖 原版 最早出现在 Visme 的视觉学习中心 。
给有抱负的数据科学家的 16 条有用建议

数据科学为什么性感?它与如此多的新应用有关,大量数据的明智使用催生了全新的行业。例子包括语音识别、计算机视觉中的物体识别、机器人和自动驾驶汽车、生物信息学、神经科学、系外行星的发现和对宇宙起源的理解,以及组建廉价但获胜的棒球队。在每一种情况下,数据科学家都是整个企业的核心。他/她必须将应用领域的知识与统计专业知识相结合,并使用最新的计算机科学思想来实施。
最后,性感归结为有效。我最近读了 塞巴斯蒂安·古提耶雷兹的《工作中的数据科学家》 ,其中他采访了 16 位来自 16 个不同行业的数据科学家,以了解他们如何从理论上思考 it,也非常实际地了解他们正在解决什么问题,数据如何提供帮助,以及如何取得成功。所有 16 名受访者都站在理解和提取各种公共和私人组织类型的数据价值的前沿,从初创公司和成熟公司到主要研究团体和人道主义非营利组织,以及各种行业,如广告、电子商务、电子邮件营销、企业云计算、时尚、工业互联网、互联网电视和娱乐、音乐、非营利组织、神经生物学、报纸和媒体、专业和社交网络、零售、销售智能和风险投资。
特别是,Sebastian 提出了开放式的问题,以便每个受访者的个性和自发的思维过程能够清晰准确地展现出来。本书中的从业者分享了他们关于数据科学对他们意味着什么以及他们如何看待它的想法,他们关于如何加入该领域的建议,以及他们通过经验获得的关于数据科学家必须深刻理解才能在该领域取得成功的智慧。
在这篇文章中,我想分享这些数据科学家对这个问题给出的最佳答案:
“你会给刚开始从事数据科学的人什么建议?”
1 — 克里斯·维金斯 , 纽约时报首席数据科学家 哥伦比亚大学应用数学副教授
“创造力和爱心。你必须真正喜欢某样东西,才会愿意花很长时间去认真思考它。此外,某种程度的怀疑。所以这是我喜欢博士生的一点——五年的时间足够让你有所发现,然后让你意识到你一路上做错的所有事情。从思考“冷聚变”到意识到“哦,我实际上完全搞砸了”,并因此犯下一系列错误并修复它们,这对你的智力来说是很棒的。我确实认为读博士的过程有助于让你对看似确定的事情持怀疑态度,尤其是在研究领域。我认为这是有用的,因为,否则,你很容易太快地走上一条错误的道路——仅仅因为你第一次遇到这条道路看起来很有希望。
虽然这是一个无聊的答案,但事实是你实际上需要有技术深度。数据科学还不是一个领域,所以还没有证书。比如说,机器学习很容易获得维基百科级别的理解。但是,对于实际操作来说,您真的需要知道对于正确的工作什么是正确的工具,并且您需要很好地理解每个工具的所有限制。这种经历没有捷径可走。你必须犯很多错误。你必须发现自己把一个分类问题硬塞给一个聚类问题,或者把一个聚类问题硬塞给一个假设检验问题。
一旦你发现自己在尝试某件事,确信这是正确的,然后最终意识到你完全错了,并经历了很多次——这种经历真的没有捷径可走。你只需要去做,然后不断犯错,这是我喜欢在这个领域工作了几年的人的另一点。成为某方面的专家需要很长时间。它需要多年的错误。几个世纪以来都是如此。著名物理学家尼尔斯·玻尔曾说过一句话,他认为成为某个领域的专家的方法就是在该领域犯下所有可能的错误。"
2——T3【凯特琳】斯莫尔伍德 T5**、**科学与算法副总裁 网飞
“我想说的是,在你做任何事情之前,要始终咬紧牙关,首先理解数据的基础,即使这并不性感,也不有趣。换句话说,努力理解数据是如何捕获的,准确理解每个数据字段是如何定义的,并理解数据何时丢失。如果数据丢失,这本身是否意味着什么?是不是只有在特定的情况下才会缺失?这些微小的细微差别的数据将真正得到你。他们真的会。
你可以使用世界上最复杂的算法,但还是老一套的垃圾进垃圾出。你不能对原始数据视而不见,不管你对建模的有趣部分有多兴奋。在开始开发模型之前,做好准备,尽可能地检查底层数据。
随着时间的推移,我学到的另一件事是,在系统环境中,混合算法几乎总是比单一算法更好,因为不同的技术利用数据中模式的不同方面,特别是在复杂的大型数据集中。因此,虽然你可以选择一个特定的算法,并不断迭代使它变得更好,但我几乎总是看到算法的组合往往比一个算法做得更好。"
3——T3【Yann le Cun, 脸书人工智能研究主任兼 NYU 数据科学/计算机科学/神经科学教授
“我总是给出同样的建议,因为我经常被问到这个问题。我的看法是,如果你是本科生,学习一个专业,在那里你可以尽可能多地学习数学和物理课程。不幸的是,它必须是正确的课程。我要说的听起来很矛盾,但工程或物理专业可能比数学、计算机科学或经济学更合适。当然,你需要学习编程,所以你需要上大量的计算机科学课,学习如何编程的机制。然后,再后来,做数据科学的研究生。参加本科机器学习、人工智能或计算机视觉课程,因为你需要接触这些技术。然后,在那之后,上所有你能上的数学和物理课。尤其是像最优化这样的连续应用数学课程,因为它们让你为真正的挑战做好准备。
这取决于你想去哪里,因为在数据科学或人工智能的背景下有很多不同的工作。人们应该真正思考他们想做什么,然后学习这些科目。现在的热门话题是深度学习,这意味着学习和理解神经网络的经典工作,学习最优化,学习线性代数,以及类似的主题。这有助于你学习我们每天面对的基本数学技巧和一般概念。"
4 — 艾琳·谢尔曼 **,**Zymergen 的数据科学经理,诺德斯特龙数据实验室和 AWS S3 的前数据科学家
“对于仍在决定学什么的人,我想说 STEM 领域是不用动脑筋的,尤其是 TEM 领域。学习 STEM 课程会给你测试和理解世界的工具。这就是我对数学、统计学和机器学习的看法。我对数学本身并不感兴趣,我感兴趣的是用数学来描述事物。这些毕竟是工具集,所以即使你对数学或统计学不感兴趣,投资它们并考虑如何将它们应用到你真正感兴趣的事情上仍然是非常值得的。
对于像我一样试图转型的人,我会说,首先,这很难。要知道改变行业是很难的,你必须为此努力。这不是数据科学独有的,这就是生活。在这个领域没有任何关系是困难的,但你可以通过与慷慨的人会面和咖啡约会来解决这个问题。我生活中的首要原则是“跟进”如果你和某个有你想要的东西的人交谈,继续跟进。
数据科学家的帖子可能相当吓人,因为大多数帖子读起来像数据科学术语表。事实是,技术变化如此之快,以至于没有人拥有可以写在帖子上的所有内容的经验。当你看到这个的时候,它可能会让人不知所措,你可能会觉得,“这不适合我。这些技能我都没有,也没什么可贡献的。”我会鼓励反对这种心态,只要你能接受改变,并一直学习新事物。
最终,公司想要的是一个能够严格定义问题并设计解决方案的人。他们也想要善于学习的人。我认为这些是核心技能。"

5 — 丹尼尔·唐克朗 **,***Twiggle 首席搜索传道者,*LinkedIn
“对于来自数学或物理科学的人,我建议投资学习软件技能——特别是 Hadoop 和 R,这是最广泛使用的工具。来自软件工程的人应该参加机器学习的课程,用真实的数据做一个项目,其中很多数据是免费的。正如很多人所说,成为数据科学家最好的方法就是做数据科学。数据就在那里,科学并不那么难学,尤其是对那些受过数学、科学或工程训练的人来说。
阅读“数据的不合理有效性”——谷歌研究人员阿龙·哈勒维、彼得·诺维格和费尔南多·佩雷拉的经典文章。这篇文章通常被总结为“更多的数据胜过更好的算法。”整篇文章值得一读,因为它概述了最近在使用网络规模的数据来提高语音识别和机器翻译方面的成功。然后,为了更好地衡量,听听 Monica Rogati 对更好的数据如何击败更多的数据有什么看法。理解并内化这两种见解,你就能顺利地成为一名数据科学家。"
6 — 约翰·福尔曼 , 产品管理副总裁、前 MailChimp 首席数据科学家
“我发现很难找到并雇佣合适的人。这实际上是一件很难做到的事情,因为当我们想到大学系统时,无论是本科生还是研究生,你只关注一件事。你专攻。但数据科学家有点像新文艺复兴时期的人,因为数据科学本质上是多学科的。
这就引出了一个大笑话:数据科学家比计算机程序员知道更多的统计数据,比统计学家更会编程。这个笑话在说什么?据说数据科学家是对两件事略知一二的人。但是我想说他们知道的不仅仅是两件事。他们也必须知道如何交流。他们还需要知道不仅仅是基本的统计数据;他们必须知道概率、组合学、微积分等。一些可视化印章不会伤害。他们还需要知道如何处理数据,如何使用数据库,甚至可能会一点点。有很多事情他们需要知道。所以找到这些人真的很难,因为他们必须接触过很多学科,他们必须能够聪明地讲述他们的经历。这对任何申请人来说都是一项艰巨的任务。
雇佣一个人需要很长时间,这就是为什么我认为人们一直在谈论现在没有足够的数据科学人才。我认为那在某种程度上是真实的。我认为一些正在启动的学位项目会有所帮助。但即使如此,对于 MailChimp 来说,从这些学位课程中,我们会看你如何向我们表达和交流你如何使用这个特定课程教给你的跨许多学科的数据科学知识。这将会淘汰很多人。我希望有更多的项目关注在工作场所成为数据科学家的沟通和协作方面。"
**7 — 罗杰·埃伦贝尔 **、IA Ventures 管理合伙人
我认为机遇最大的领域也是挑战最多的领域。医疗保健数据显然有一些最大的 PII 和隐私问题。除此之外,您还会遇到僵化的官僚机构、僵化的基础架构和数据孤岛,这使得解决需要跨多个数据集集成的难题变得非常困难。这将会发生,我认为我们在这里谈论的许多技术都与使医疗保健更好、更便宜、更分散直接相关。我认为这代表了一代人的机会。
另一个早期的巨大领域是风险管理——无论是在金融、贸易还是保险领域。当你谈论将新数据集纳入风险评估时,这是一个非常困难的问题,特别是当将这些技术应用于保险等行业时,保险和医疗保健一样,有许多隐私问题和数据被困在大型官僚机构中。与此同时,这些陈旧僵化的公司现在刚刚开始开放,并找出如何最好地与创业社区互动,以利用新技术。这是另一个让我感到无比兴奋的领域。
我热衷的第三个领域是重塑制造业,让它更有效率。制造业有迁回国内的趋势。一个更强大的制造业可能是重建美国充满活力的中产阶级的桥梁。我认为技术可以帮助加速这种有益的趋势。
**8 — 克劳迪娅·珀里奇 **,d stilley 首席科学家
“我认为,最终,学习如何做数据科学就像学习滑雪一样。你必须这么做。只能听这么多视频,看着它发生。在一天结束的时候,你必须穿上你那该死的滑雪板下山。你会在路上撞车几次,这没关系。那才是你需要的学习体验。事实上,我更喜欢问受访者那些不顺利的事情,而不是那些成功的事情,因为这能告诉我他们在这个过程中学到了什么。
每当有人来问我:“我该怎么办?”我说,“是的,当然,参加机器学习技术的在线课程。毫无疑问,这是有用的。很明显,你必须会编程,至少在某种程度上。你不必成为一名 Java 程序员,但是你必须以某种方式完成一些事情。我不在乎如何。”
最终,无论是在 DataKind 做志愿者,花时间在非政府组织帮助他们,还是去 Kaggle 网站并参加他们的一些数据挖掘比赛——只要做好准备就行了。特别是在 Kaggle 上,阅读其他人告诉你的关于这个问题的讨论论坛,因为在那里你可以了解人们做了什么,什么对他们有效,什么对他们无效。所以,任何能让你真正参与到用数据做事情的事情,即使你并没有因此而获得报酬,都是一件很棒的事情。
记住,你必须从山上滑下来。这是没有办法的。你不能学习任何其他方式。所以,自愿贡献你的时间,用你能想到的任何方式来弄脏你的手,如果你有机会做实习——完美。不然有很多机会你可以刚入门。所以就去做吧。"

**9 — 乔纳森·莱纳汉 **、place IQ 首席科学家兼产品开发高级副总裁
“首先,自我批评非常重要:总是质疑自己的假设,对自己的产出保持偏执。这是容易的部分。就人们如果真的想在数据科学领域取得成功应该具备的技能而言,拥有良好的软件工程技能是必不可少的。因此,即使我们可能会雇佣那些几乎没有编程经验的人,我们也会非常努力地向他们灌输工程、工程实践和许多优秀的敏捷编程实践的重要性。这对他们和我们都有帮助,因为现在这些几乎都可以一对一地应用于数据科学。
如果你现在看一下开发运营,他们有诸如持续集成、持续构建、自动化测试和测试工具之类的东西,所有这些都非常容易地从开发运营世界映射到数据运营(我从 Red Monk 那里偷来的一个短语)世界。我认为这是一个非常强大的概念。为你的所有数据建立测试框架是很重要的,这样如果你修改了代码,你就可以回过头来测试你的所有数据。拥有工程思维对于在数据科学世界中高速前进至关重要。阅读 代码完成 和 务实的程序员 会比阅读机器学习书籍让你走得更远——尽管你当然也必须阅读机器学习书籍。"
**10 — 安娜·史密斯 **,Spotify 高级数据工程师,《出租跑道》前分析工程师
“如果有人刚刚开始从事数据科学,最重要的是要明白,可以向人们提问。我也觉得谦虚很重要。你必须确保你不会被你正在做的事情束缚住。你可以随时做出改变,重新开始。我认为,当你刚开始的时候,能够废弃代码真的很难,但最重要的是做点什么。
即使你没有数据科学方面的工作,你仍然可以在你的休息时间探索数据集,并且可以提出问题来询问数据。在我的私人时间里,我摆弄过 Reddit 数据。我问自己,“用我有的或没有的工具,我可以探索 Reddit 的哪些方面?”这很好,因为一旦你开始了,你可以看到其他人是如何处理同样的问题的。运用你的直觉,开始阅读别人的文章,然后像这样,“我可以在我的方法中使用这种技术。”慢慢开始,慢慢移动。当我开始的时候,我试着阅读了很多,但是我认为这并没有多大帮助,除非你真正地用代码和数据来理解它实际上是如何工作的,它是如何运动的。当人们把它呈现在书中时,它都是美好的。现实生活中,真的不是。
我认为尝试很多不同的事情也很重要。我想我从没想过我会在这里。我也不知道五年后我会在哪里。但也许这就是我学习的方式,通过在许多不同的学科中做一些事情,试图了解什么最适合我。"
**11—Andre Karpistsenko**、taxi fy 数据科学负责人,PlanetOS 联合创始人兼研究负责人
”尽管这是一个有些笼统的建议,但我认为你应该相信自己,追随自己的激情。我认为很容易被媒体上的新闻和媒体呈现的期望分散注意力,选择一个你本来不想走的方向。因此,当谈到数据科学时,你应该将其视为职业生涯的起点。拥有这样的背景对你做任何事情都有好处。拥有创建软件的能力和处理统计数据的能力将使你在你选择的任何领域做出更明智的决定。例如,我们可以通过数据了解运动员的成绩是如何提高的,就像有人成为跳远金牌得主,因为他们优化并练习了他们应该跳跃的角度。这一切都是由数据驱动的体育方法引领的。
如果我要进入更具体的技术建议,那么它取决于接受建议的人的雄心。如果这个人想创造新的方法和工具,那么这个建议会非常不同。你需要坚持,沿着你的方向一直走下去,你会成功的。但是如果你的目的是在许多情况下变得多样化和灵活,那么你需要一个不同方法的大工具箱。
我认为给我的最好的建议来自斯坦福大学的一位教授,我前阵子听过他的课。他建议有一个 T 形的能力轮廓,但在核心能力旁边有一个小的第二能力,这样如果你需要它或想要它,你在生活中就有了一条替代路线。除了单一领域专业知识的垂直主干,他还建议你有足够宽的背景水平,这样你就可以在许多不同的情况下与许多不同的人共事。因此,当你在大学的时候,建立一个 T 型,并在其中加入一些小的能力,可能是最好的选择。
也许最重要的是让你周围的人都比你强大,并向他们学习。这是最好的建议。如果你在大学里,那是观察人们能力差异的最佳环境。如果你能和最优秀的人一起工作,那么你会在任何事情上取得成功。"
**12—Amy Heineike**,PrimerAI 技术副总裁,Quid 前数学总监
“我认为,或许他们需要从审视自己开始,弄清楚自己真正关心的是什么。他们想做什么?现在,数据科学是一个有点热门的话题,所以我认为有很多人认为,如果他们能够拥有“数据科学”的标签,那么魔法,幸福和金钱就会降临到他们身上。所以我真的建议弄清楚你真正关心的是数据科学的哪些方面。这是你应该问自己的第一个问题。然后你想知道如何做得更好。你也要开始思考什么样的工作是你真正感兴趣的。
一个策略是深入你需要知道的一部分。我们的团队中有人是自然语言处理方面的博士,或者是物理学方面的博士,他们使用了很多不同的分析方法。所以你可以深入到一个领域,然后找到那些认为这种问题很重要的人,或者你可以用同样的思维来解决的类似问题。这是一种方法。
另一种方法是尝试新事物。那里有很多数据集。如果你在做一份工作,并试图换一份工作,试着想一想,在你目前的工作中,是否有你可以用得上的数据,你可以去获取这些数据,并以有趣的方式处理它们。找个借口去尝试一些事情,看看这是不是你真正想做的。或者只是在家里,你可以找到公开的数据。只是四处看看你能找到什么,然后开始玩那个。我认为这是一个很好的开始。现在有许多不同的角色被冠以“数据科学”的名称,也有许多角色可能是你认为的数据科学,但还没有标签,因为人们不一定会使用它。想想你真正想要的是什么。"

**13—Victor Hu**、QBE 保险数据科学主管,Next Big Sound 前首席数据科学家
“首先,你必须讲一个故事。在一天结束时,你所做的是真正挖掘一个系统、一个组织或一个行业如何运作的基础。但是为了让它对人们有用并且可以理解,你必须讲一个故事。
能够写下你所做的事情,能够谈论你的工作是非常重要的。同样值得理解的是,你也许应该少担心你所使用的算法。更多的数据或更好的数据胜过更好的算法,所以如果你能建立一种方法让你分析并获得大量好的、干净的、有用的数据——太好了!"
14 — 基拉·雷丁斯基 , 易贝首席科学家兼数据科学总监,SalesPredict 前首席技术官兼联合创始人
“找到一个让你兴奋的问题。对我来说,每次我开始新的东西,只是学习而没有一个我试图解决的问题真的很无聊。开始阅读材料,尽可能快地开始处理它和你的问题。随着你的发展,你会开始发现问题。这会引导你找到其他的学习资源,无论是书籍、论文还是人。所以花时间和问题和人在一起,你就没事了。
深刻理解基础知识。了解一些基本的数据结构和计算机科学。理解你使用的工具的基础,理解它们背后的数学原理,而不仅仅是如何使用它们。理解输入和输出,以及内部实际发生了什么,因为否则你不知道什么时候应用它。此外,这取决于你正在解决的问题。有许多不同的工具可以解决许多不同的问题。你必须知道每种工具能做什么,你必须知道你做得很好的问题,知道应用哪种工具和技术。"
15—Eric Jonas, 加州大学伯克利分校 EECS 分校博士后,Salesforce 前首席预测科学家
“他们应该彻底理解概率论。我现在在这一点上,我学到的其他一切,然后映射回概率论。它很棒,因为它提供了这个惊人的、深刻的、丰富的基础集,我可以沿着这个基础集投射其他的一切。E. T. Jaynes 写了一本书叫做概率论:科学的逻辑,这是我们的圣经。某种意义上我们真的买了。我喜欢概率生成方法的原因是你有这两个正交轴——建模轴和推理轴。这基本上就是我如何表达我的问题,以及如何计算给定数据下我的假设的概率?从贝叶斯的角度来看,我喜欢的一点是,你可以沿着这些轴中的每一个独立地进行设计。当然,他们不是完全独立的,但是他们足够接近独立,你可以这样对待他们。
当我看到像深度学习或任何一种基于套索的线性回归系统这样的东西时,这些东西在很大程度上可以算作机器学习,它们沿着一个轴或另一个轴进行工程设计。他们已经把它推倒了。作为一名工程师,使用这些基于套索的技术,我很难思考:“如果我稍微改变这个参数,那到底意味着什么?”线性回归作为一个模型,有一个非常明确的线性加性高斯模型。如果我想让事情看起来不一样呢?突然间,所有这些正则化的最小二乘法都土崩瓦解了。推理技术甚至不接受这是你想要做的事情。"
**16 — 杰克·波瓦尔 **、data kind 创始人兼执行董事
“我认为强大的统计背景是一个先决条件,因为你需要知道你在做什么,并了解你建立的模型的内容。此外,我的统计项目也教授了很多关于伦理的知识,这是我们 DataKind 经常思考的问题。你总是要考虑你的工作将如何被应用。你可以给任何人一个算法。你可以给某人一个使用拦截搜身数据的模型,警察会在哪里进行逮捕,但是为什么和为了什么?这真的就像建立任何新技术一样。你必须考虑风险和收益,并真正权衡利弊,因为你要为自己创造的东西负责。
不管你来自哪里,只要你理解你用来得出结论的工具,那就是你能做的最好的事情。我们现在都是科学家,我说的不仅仅是设计产品。我们都在对我们生活的世界下结论。这就是统计学——收集数据来证明一个假设或创建一个世界运行方式的模型。如果你只是盲目地相信那个模型的结果,那是危险的,因为那是你对世界的解释,尽管它有缺陷,但你的理解是结果会有多缺陷。
总之,学统计学,要有思想。"
我强烈推荐你阅读 工作中的数据科学家 。这本书展示了一些世界顶级数据科学家如何在令人眼花缭乱的各种行业和应用中工作——每个人都利用自己的领域专业知识、统计学和计算机科学的混合来创造巨大的价值和影响。
数据呈指数级增长,现在比以往任何时候都更需要那些能够理解这些数据并从中提取价值的人。如果你渴望加入下一代数据科学家,来自这些有思想的从业者的关于数据和模型的来之不易的教训和快乐将是非常有用的。
— —
如果你喜欢这首曲子,我希望你能按下鼓掌按钮👏这样别人可能会偶然发现它。你可以在 GitHub 上找到我自己的代码,在【https://jameskle.com/】上找到更多我的写作和项目。也可以在 推特 , 上关注我直接发邮件给我 或者 在 LinkedIn 上找我。 注册我的简讯 就在你的收件箱里接收我关于数据科学、机器学习和人工智能的最新想法吧!**
17 个完全免费的维恩图模板

在你的演讲中加入数据是支持你观点的好方法。显示数据可以进一步增强你的文字,但有时普通的图表并不是可视化概念之间关系的最佳选择。如果是这样,也许尝试一个文氏图是正确的方法。
什么是维恩图?
维恩图可用于任何研究领域,直观地表示概念之间的关系。每组元素表示为圆形或其他形状,重叠区域用于描述两个或多个概念的共同点。根据需要,它们可以非常复杂,也可以非常简单。
我们在这里收集了 17 个有用的维恩图模板来帮助你开始。
找到正确的维恩图模板
1.双圆文氏图

用您自己的信息自定义此模板。免费下载
可能是最常见的维恩图,也是最简单的,这个模板最适合用来比较两个对象。你可能在无数的演讲和课堂上见过它。然而,如果使用得当,这是一个有效的工具。
这个文氏图相对来说比较容易使用——选择你的两个焦点,把它们放在两边各自的圆圈里,列出它们的特质,然后把它们的共同特质放在中间。
为了让你的视觉不感到懒惰,确保你考虑了排版,以及什么能最好地支持你的文字。尝试添加背景或尝试不同的视觉风格。
一个很好的例子是本页顶部的文氏图。很简单,但是看起来很专业。颜色和文字配合得很好,白线有助于定义中间部分。有时候,简单更好。
2.雨滴模板

如果想要一个更有创意、更环保的两圈维恩图,可以尝试使用“雨滴”模板。本质上,你不用两个圆,而是用两个雨滴状的形状在它们较大的一端连接起来。
因为这在很大程度上是一种风格上的改变,所以您可以使用您也用于双圆图的任何信息。然而,由于环境主题,这种类型可能更好地用于表示可持续性和能源消耗之间的关系,或其他类似的主题。尝试与你的主题相关的不同形状,看看哪种效果最好。
3.三圈文氏图

比两个圆稍微高级一点,但同样普通,这个文氏图可以让你想象三个对象之间的关系,而不是两个。
这个文氏图是一个比较好的例子。它用重叠的圆圈提醒读者,有意义的工作不仅报酬丰厚,而且让你充满激情,自然而然地来到你身边。
在编辑这个模板时,一定要记住不仅要想象三个不同的主题是如何分别与它们的对应主题进行交互的,还要想象它们是如何组合在一起的——这是所有更高级的模板都要记住的。
4.三角形文氏图

如果你想要一个有趣的三主题维恩图,那么三角形模板提供了一个很好的例子。就像三个圆一样,这个模板包括三个互锁的形状——只是这一次,它们创建了一个三角形,而不是一个无定形的形状。
三角形的三个“边”包含各个主题,每个角代表这些主题如何交互。三角形的中心可以显示它们是如何相互作用的,也可以是空的。侧面可以是椭圆形、矩形或任何你喜欢的形状。
5.三集维恩图

用您自己的信息自定义此模板。免费下载
这张政党流程图是三集维恩图的一个很好的例子,圆圈内的文字有助于进一步解释每个主题,中心是一切交汇的“甜蜜点”。透明的三个圆圈强调了每个主题之间的联系,并有助于使圆圈重叠的区域更加清晰。
6.四圆文氏图

稍微复杂一点,这个例子可以使用四个圆或椭圆来比较它的四个不同部分。
以营销领域为例。每个圆圈代表营销的一个不同方面,相互连接的部分代表每个方面使用的格式。
7.菱形/矩形模板

四主题模板的一个变体,这个特殊的例子可以用来给你的视觉效果增加一些亮点。
菱形/矩形模板包括重叠(你猜对了)菱形或矩形,而不是圆形,允许不同的外观和眼睛容易跟随的轨迹。
这些模板也可能相对复杂。举个例子,这张关于狗品种的钻石文氏图。图表为每个矩形列出了不同的特征,然后在里面列出了具有这些特征的犬种,或者它们的组合。通过这些钻石的多重连接,可以展示各种不同的例子,混合的颜色和直线有助于移动眼睛。
8.星形维恩图模板

想要一些真正复杂但又有趣的东西吗?试着创造一个明星。
这个“星星”是由五个不同的椭圆组成的,所有的椭圆都以不同的方式重叠在一起。这可以让你看到五个主题如何相互作用,创造出各种独特的选择。
因为这个模板相当复杂,所以尽量让它简单易懂。例如,对每个椭圆进行颜色编码,用混合的颜色代表两个独立对象之间的公共区域,或者创建一个标签系统,使交互更容易跟踪。
9.奥林匹克模板

这个五个主题的文氏图对任何体育迷来说都是很棒的,它用圆环创造了一个像奥运会标志一样的图像。
当然,每个环代表一个不同的主题,它们相互交叉的地方显示了主题是如何互动的。虽然比“明星”的例子更容易理解,但它也允许更少的互动,所以确保每个主题都是最有效的。
这可以很好地用来展示某些概念如何与其他概念相互作用。例如,您可以显示故事情节中的两个元素如何相互关联,以及另一个单独的元素如何仅与一个元素相关,等等。
10.多层文氏图

用您自己的信息自定义此模板。免费下载
如果你想对维恩图有一点不同的方法,多层模板可能是正确的选择。在这个模板中,您从一个大的外部圆开始,然后在内部嵌套较小的圆。外面的圆圈通常包含一个主题,嵌套的圆圈,而不是包含主题本身,显示每个新添加的内容如何改变原来的内容。
看看这个圆筒文氏图。它着眼于英国各岛屿之间的关系。每个圆圈代表一个不同的区域;一些包含在另一些中,而另一些作为单独的实体出现。
11.3D/嵌套模板

如果你想要一些突出的东西,这种类型的文氏图可以很好地工作。它在执行中使用了类似于多层模板的方法,只是它采用了 3D 嵌套图像的形式。
这个模板让你变得更有创造力。例如,您可以使用实际的嵌套玩偶来玩“主题中的主题”方面,或者使用地球各层的图表来显示每个层如何相互作用。
12.电弧维恩图模板

这个模板的主要兴趣在于各种主题如何与单个主题互动,但它以一种非常有趣的方式进行互动:与主题相关的圆圈沿着最大的圆圈的边缘上升,随着它们的上升而变大。
这是一个很好的方式来展示每个主题与主要主题的交互的重要性,最小的主题最不重要,最大的主题最重要。它还可以用来显示与焦点交互的不同主题的复杂性或数量。
13.备选尺寸图

类似于“弧形”模板,这个模板使用不同大小的圆来获得一个点;与前者不同,这个模板展示了它们和是如何互动的。
很像弧形文氏图,这可以显示不同主题的重要性或相对大小。
这是一个特别好的例子,集中在社交媒体平台。中心圈(社交品牌)与它之外的其他几个互动,所有这些都列出了最适合给定组合的社交媒体网站。
14.基于图片的维恩图

一张图片可以表达千言万语,那么还有什么比使用图片更好的方式来展示主题之间的互动呢?
这个模板通常使用很少的文字,而是让图像来说话。例如,这幅画幽默地展示了河马和板条箱的组合。
你可以用其他有创意的例子来解释主题,比如把两个不同主题的图片放在外面的圆圈里,然后让连接点成为一个完全不同的图片,代表两者结合后产生的东西。
15.混合文氏图

用您自己的信息自定义此模板。免费下载
只有一种风格不适合你?尝试混合几种不同的风格,以获得您想要的效果。例如,你可以将两个圆形和一个多层组合起来,展示一个组合的多重效果如何渗透到另一个主题中。
一个很好的例子是由伊丽莎白托比创作的,她将嵌套和交替的尺寸结合成一个复杂的、多面的视觉效果。
这些往往非常复杂,所以要确保你的观众能跟上信息的呈现。
16.三组欧拉图

欧拉图类似于维恩图,因为它们说明了两个或多个主题,但在一个关键特征上有所不同:至少有一个主题与另一个主题不重叠。这些对于展示两个主题的不同非常有用。
17.两组欧拉图

用您自己的信息自定义此模板。免费下载
欧拉图可以单独使用(例如让两个圆靠在一起,但不重叠),也可以与维恩图结合使用(例如让两个圆重叠,一个圆放在更远的地方,如前面的例子所示)。对它们进行测试,看看使用这样的图表是否适合您的项目。
轮到你了
这些只是你可以修改维恩图模板来显示概念之间关系的几种方法。有哪些你喜欢的模板,或者在上面你有什么变化?在下面的评论区和我们分享吧!
你需要知道的 18 种大数据工具
在当今的数字化转型中,大数据为组织提供了分析客户行为的优势&高度个性化每一次互动,从而带来交叉销售、改善的客户体验和明显更多的收入。随着越来越多的企业实施数据驱动战略,大数据市场稳步增长。虽然 Apache Hadoop 是最成熟的大数据分析工具,但还有成千上万种大数据工具。它们都承诺为您节省时间和金钱,并帮助您发现前所未见的商业洞察力。我挑选了一些来帮助你。
Avro:由 Doug Cutting &开发,用于对 Hadoop 文件的模式进行编码的数据序列化。
Cassandra: 是一个分布式开源数据库。旨在处理跨商用服务器的大量分布式数据,同时提供高度可用的服务。这是一个最初由脸书开发的 NoSQL 解决方案。它被许多组织使用,如网飞,思科,Twitter。
Drill: 对大规模数据集进行交互分析的开源分布式系统。它类似于 Google 的 Dremel,由 Apache 管理。
**elastic search:**基于 Apache Lucene 构建的开源搜索引擎。它是在 Java 上开发的,可以支持支持数据发现应用程序的极快的搜索。
Flume: 是一个用来自 web 服务器、应用服务器和移动设备的数据填充 Hadoop 的框架。它是源代码和 Hadoop 之间的管道。
HCatalog: 是 Apache Hadoop 的集中式元数据管理和共享服务。它允许 Hadoop 集群中所有数据的统一视图,并允许各种工具(包括 Pig 和 Hive)处理任何数据元素,而无需知道数据存储在集群中的物理位置。
Impala: 使用与 Apache Hive 相同的元数据、SQL 语法(Hive SQL)、ODBC 驱动程序和用户界面(Hue 蜂蜡),直接对存储在 HDFS 或 HBase 中的 Apache Hadoop 数据提供快速的交互式 SQL 查询。这为面向批处理或实时查询提供了一个熟悉而统一的平台。
JSON: 当今的许多 NoSQL 数据库都以 JSON (JavaScript Object Notation)格式存储数据,这种格式在 Web 开发人员中很流行
Kafka: 是一个分布式的发布-订阅消息传递系统,它提供了一个能够处理所有数据流活动并在消费者网站上处理这些数据的解决方案。这种类型的数据(页面浏览、搜索和其他用户行为)是当前社交网络中的一个关键要素。
MongoDB: 是一个面向文档的 NoSQL 数据库,在开源理念下开发。这带来了完全的索引支持,以及在不影响功能的情况下索引任何属性和水平伸缩的灵活性。
Neo4j: 是一个图形数据库&与关系数据库相比,性能提高了 1000 倍甚至更多。
Oozie:是一个工作流处理系统,让用户定义一系列用多种语言编写的作业——比如 Map Reduce、Pig 和 Hive。它进一步智能地将它们彼此联系起来。Oozie 允许用户指定依赖关系。
Pig: 是雅虎开发的基于 Hadoop 的语言。它相对容易学习,擅长非常深、非常长的数据管道。
**暴风:**是一个实时分布式计算的系统,开源且免费。Storm 可以轻松可靠地处理实时处理领域的非结构化数据流。Storm 是容错的,几乎可以与所有编程语言一起工作,尽管通常使用 Java。Storm 是阿帕奇家族的后裔,现在归 Twitter 所有。
Tableau: 是一个数据可视化工具,主要关注商业智能。你可以创建地图,条形图,散点图等,而不需要编程。他们最近发布了一个 web 连接器,允许您连接到数据库或 API,从而让您能够在可视化中获得实时数据。
ZooKeeper: 是为大型分布式系统提供集中配置和开放代码名称注册的服务。
每天都有越来越多的工具被添加到大数据技术堆栈中,应对每一种工具都极其困难。选择少数你能掌握的,继续提升你的知识。
数据科学竞赛一等奖-企鹅的随机漫步
在由 DrivenData 主办的数据科学竞赛企鹅随机漫步中荣获一等奖。在此分享制胜之道。

Penguins — Photo by Loïc Mermilliod on Unsplash
介绍
企鹅是世界上最有魅力的动物之一,已经抓住了新闻人物、科学家、电影制片人和普通大众的想象力。除了一般的内在价值,它们被认为是重要的生态系统指标。换句话说,监测这些美丽的物种可以告诉我们许多关于南极总体健康状况的信息,因为企鹅是重要的磷虾和鱼类捕食者,影响猎物数量和环境条件的变化(自然或人为)最终将通过分布或种群数量的变化来检测。
关于企鹅数量的数据是有限的,因为大多数被监测的群体都在永久性的研究站附近,而其他地点只是偶尔被调查。由于数据非常零散,时间序列相对较短,很难建立统计模型来解释过去的动态或提供可靠的未来预测。目标是创建更好的模型来估计南极难以到达的地点的数量,从而大大提高我们使用企鹅来监测南大洋健康状况的能力!
这个项目是由 Oceanites 公司、Black Bawks 数据科学有限公司和石溪大学希瑟·林奇博士的实验室合作完成的。由 NASA 慷慨提供的奖品(奖项 NNX14AC32G) 。
所提供数据的详细信息
从 1875 年到 2013 年在南极洲的 548 不同地点提供了三种企鹅的数据,即阿德利企鹅、帽带企鹅和巴布亚企鹅。总共有 648 种企鹅类型和地点的组合。数据中有许多缺失值。挑战在于从 2014 年到 2017 年增加企鹅数量。
模型概述
该解决方案分为两个主要部分
- 数据的插补
- 模型结构
数据的插补
在运行模型之前,对每个站点和企鹅类型组合进行了数据插补。插补按以下顺序进行
- 对于 R 模型是 Stine,对于 Python 模型是 Linear
- 最后一次观察仅在 R 车型中进行
- 在 R 和 Python 模型的情况下,下一个观察向后进行
- 在 R 模型和 Python 模型中替换为零
模型结构

Model Builder
为每个站点和企鹅类型组合建立 5 个模型。因此,对于站点和企鹅类型的 648 个组合中的每一个,构建了以下模型
- Python 中的 XGBoost
- Python 中的 RandomForest
- R 中的 ARIMA
- R 中的 ETS
- 先知在 R
每 648 个组合就产生一个所有这些模型的平均值。
感谢阅读。如果你仍然喜欢它,请访问驱动数据博客中一篇有趣的博文
2 种潜在的降维和主题建模方法

Photo: https://pixabay.com/en/golden-gate-bridge-women-back-1030999/
在最先进的单词嵌入技术之前,潜在语义分析(LSA)和潜在狄利克雷分配(LDA)区域是处理自然语言处理问题的好方法。LSA 和 LDA 都有相同的输入,即矩阵格式的单词包。LSA 专注于降低矩阵维数,而 LDA 解决主题建模问题。
我将不会讨论数学细节,因为这方面有很多很好的材料。你可以参考一下。为了便于理解,我没有做停用词去除等预处理。当你使用 LSA、LSI 和 LDA 时,这是很关键的部分。看完这篇文章,你会知道:
- 潜在语义分析(LSA)
- 潜在狄利克雷分配
- 拿走
潜在语义分析(LSA)
用于自然语言处理任务的 LSA 是由 Jerome Bellegarda 在 2005 年提出的。LSA 的目标是降低分类维数。这个想法是,如果单词有相似的意思,它们会出现在相似的文本中。在自然语言处理领域,我们通常使用潜在语义索引(LSI)作为替代名称。
首先,我们有 m 个文档和 n 个单词作为输入。当列和行分别是文档和单词时,可以构造 m * n 矩阵。您可以使用计数出现或 TF-IDF 分数。然而,在大多数情况下,TF-IDF 优于计数出现,因为高频率并不能说明更好的分类。

Photo: http://mropengate.blogspot.com/2016/04/tf-idf-in-r-language.html
TF-IDF 的思想是高频可能不能提供太多的信息增益。换句话说,生僻字为模型贡献了更多的权重。如果在同一文档(即培训记录)中出现的次数增加,单词的重要性将增加。另一方面,如果它出现在语料库(即其他训练记录)中,则会减少。详情你可以查看这个博客。
挑战在于矩阵非常稀疏(或高维)且有噪声(或包含大量低频词)。因此采用截断奇异值分解来降低维数。

奇异值分解的思想是寻找最有价值的信息,用低维 t 来表示同一事物。
tfidf_vec = TfidfVectorizer(use_idf=True, norm='l2')
svd = TruncatedSVD(n_components=dim)transformed_x_train = tfidf_vec.fit_transform(x_train)
transformed_x_test = tfidf_vec.transform(x_test)print('TF-IDF output shape:', transformed_x_train.shape)x_train_svd = svd.fit_transform(transformed_x_train)
x_test_svd = svd.transform(transformed_x_test)print('LSA output shape:', x_train_svd.shape)explained_variance = svd.explained_variance_ratio_.sum()
print("Sum of explained variance ratio: %d%%" % (int(explained_variance * 100)))
输出
TF-IDF output shape: (11314, 130107)
LSA output shape: (11314, 50)
Sum of explained variance ratio: 8%
我们可以看到维数从 130k 减少到 50。
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import cross_val_score, KFoldlr_model = LogisticRegression(solver='newton-cg',n_jobs=-1)
lr_model.fit(x_train_svd, y_train)cv = KFold(n_splits=5, shuffle=True)
scores = cross_val_score(lr_model, x_test_svd, y_test, cv=cv, scoring='accuracy')
print("Accuracy: %0.4f (+/- %0.4f)" % (scores.mean(), scores.std() * 2))
输出
Accuracy: 0.6511 (+/- 0.0201)
潜在狄利克雷分配
2003 年,大卫·布莱、吴恩达和迈克尔·乔丹推出了《LDA》。它是无监督学习,主题模型是典型的例子。假设每个文档混合了各种主题,每个主题混合了各种单词。

Various words under various topics
直观地说,您可以想象我们有两层聚合。第一层是类别分布。例如,我们有财经新闻、天气新闻和政治新闻。第二层是词在类别中的分布。例如,我们可以在天气新闻中找到“晴天”和“云”,而在财经新闻中则有“钱”和“股票”。
然而,“a”、“with”和“can”对主题建模问题没有贡献。这些单词存在于文档中,并且在类别之间具有大致相同的概率。因此,停用词的去除是获得更好结果的关键步骤。

对于特定的文档 d,我们得到主题分布θ。从这个分布(θ)中,题目 t 将被选择,并从ϕ.中选择相应单词
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import LatentDirichletAllocationdef build_lda(x_train, num_of_topic=10):
vec = CountVectorizer()
transformed_x_train = vec.fit_transform(x_train)
feature_names = vec.get_feature_names()lda = LatentDirichletAllocation(
n_components=num_of_topic, max_iter=5,
learning_method='online', random_state=0)
lda.fit(transformed_x_train)return lda, vec, feature_namesdef display_word_distribution(model, feature_names, n_word):
for topic_idx, topic in enumerate(model.components_):
print("Topic %d:" % (topic_idx))
words = []
for i in topic.argsort()[:-n_word - 1:-1]:
words.append(feature_names[i])
print(words)lda_model, vec, feature_names = build_lda(x_train)
display_word_distribution(
model=lda_model, feature_names=feature_names,
n_word=5)
输出
Topic 0:
['the', 'for', 'and', 'to', 'edu']
Topic 1:
['c_', 'w7', 'hz', 'mv', 'ck']
Topic 2:
['space', 'nasa', 'cmu', 'science', 'edu']
Topic 3:
['the', 'to', 'of', 'for', 'and']
Topic 4:
['the', 'to', 'of', 'and', 'in']
Topic 5:
['the', 'of', 'and', 'in', 'were']
Topic 6:
['edu', 'team', 'he', 'game', '10']
Topic 7:
['ax', 'max', 'g9v', 'b8f', 'a86']
Topic 8:
['db', 'bike', 'ac', 'image', 'dod']
Topic 9:
['nec', 'mil', 'navy', 'sg', 'behanna']
拿走
要访问所有代码,你可以访问我的 github repo。
- 两者都使用词袋作为输入矩阵
- 奇异值分解的挑战在于我们很难确定最优维数。一般来说,低维消耗较少的资源,但我们可能无法区分相反意义的词,而高维克服它,但消耗更多的资源。
关于我
我是湾区的数据科学家。专注于数据科学和人工智能领域的最新发展,尤其是 NLP 和平台相关领域。你可以通过 Medium 、 LinkedIn 或者 Github 联系到我。
参考
[2]http://www1.se.cuhk.edu.hk/~seem5680/lecture/LSI-Eg.pdf CUHK LSI 教程:
[3]斯坦福 LSI 教程:https://nlp.stanford.edu/IR-book/pdf/18lsi.pdf
[4]https://cs.stanford.edu/~ppasupat/a9online/1140.html 和 LSA 解释:
开始数据分析前要问的 20 个问题

在开始数据分析之前,询问正确的问题和/或理解问题是至关重要的。以下是在深入分析之前你需要问的 20 个问题:
- 谁是将使用分析结果的受众?(董事会成员、销售人员、客户、员工等)
- 结果将如何使用?(做出业务决策、投资产品类别、与供应商合作、识别风险等)
- 观众对我们的分析会有什么疑问?(能够筛选关键细分市场、查看不同时间的数据以确定趋势、深入了解细节等)
- 应该如何对问题进行优先排序以获得最大价值?
- 确定关键利益相关者,并就感兴趣的问题征求他们的意见
- 谁应该能够访问这些信息?考虑保密性/安全性问题
- 谁将开发和维护该报告?
- 每份报告将包含哪些信息?
- 目前有哪些其他格式的报告?现有报告可能会有哪些变化?
- 如果有的话,需要开发哪些 ETL 或存储过程?
- 为满足报告要求,需要对数据库进行哪些增强?
- 每份报告什么时候交付?
- 数据需要多长时间更新一次?确保流通
- 可以使用哪些数据源?
- 我是否拥有访问分析所需数据所需的权限或凭证?
- 每个数据集的大小是多少,我需要从每个数据集获取多少数据?
- 我对每个数据库中的底层表和模式有多熟悉?我需要和其他人一起理解数据结构吗
- 我需要所有的数据来进行更精细的分析,还是需要一个子集来确保更快的性能?
- 数据会因为悬殊而需要标准化吗?
- 我是否需要分析来自外部来源的数据,这些数据位于我的组织数据之外?
来源:
https://www . si sense . com/blog/requirements-elicitation-enterprise-business-analytics/
2018 年美国 20 所攻读数据科学硕士学位的大学(校内)

Image source: FT US Healthcare & Life Sciences Summit
在过去的一年中,我一直在研究美国提供数据科学硕士(MS)或计算机科学硕士(MS)的数据科学专业的大学。
考虑到各种因素,如提供的课程,课程的持续时间,大学的位置,进行的研究和就业前景,我想出了最好的 20 所大学,以帮助您快速选择。这篇文章最适合没有或很少研究经验的人,他们希望在完成硕士学位后从事该行业。
如果你只是在寻找大学的名字,请随意跳到最后。
注 : 下面提到的大学排名不分先后。
1.卡内基梅隆大学
姓名:计算数据科学硕士
课程时长 : 2 年
地点:宾夕法尼亚州匹兹堡
**核心课程:**机器学习、云计算、交互式数据科学、数据科学研讨会
可用课程::系统、分析学、以人为中心的数据科学
单元完成 : 144
虽然卡耐基梅隆大学的机器学习专业的 MS 很有竞争力,但是 MIIS 的项目也值得考虑。
2.斯坦福大学
姓名:统计学硕士:数据科学
课程时长 : 2 年
地点:加州斯坦福
核心课程:数值线性代数、离散数学与算法、最优化、工程中的随机方法或随机算法与概率分析、统计推断导论、回归模型与方差分析或统计建模导论、现代应用统计学:学习、现代应用统计学:数据挖掘
3.佐治亚理工学院
姓名:分析学理学硕士
课程期限 : 1 年
地点:佐治亚州亚特兰大
核心课程:商业中的大数据分析,以及数据和可视化分析、
可用课程:分析工具、商业分析和计算数据分析
学分 : 36
专攻机器学习的计算机科学硕士也是最好的项目之一。
4.华盛顿大学
姓名:数据科学理学硕士
课程时长 : 2 年
地点:华盛顿州西雅图
核心课程:统计学导论&概率、信息可视化、应用统计学&实验设计、数据科学的数据管理、数据科学家的统计机器学习、数据科学的软件设计、可扩展数据系统&算法、以人为中心的数据科学。
学分 : 45
统计系提供收费的理学硕士(MS)方向“统计学——高级方法和数据分析”也很神奇,值得一看。
5.哥伦比亚大学
姓名:数据科学硕士
课程时长 : 1.5 年
地点:纽约市纽约
核心课程:概率论、数据科学算法、统计推断与建模、数据科学计算机系统、数据科学机器学习、探索性数据分析与可视化
学分 : 30
哥伦比亚大学的计算机科学 MS 与机器学习赛道对于学习和加深你对机器学习的理解也是很神奇的。
6.纽约大学
姓名:数据科学硕士
课程时长 : 2 年
地点:纽约市纽约
核心课程:数据科学导论、数据科学的概率与统计、机器学习、大数据
**可用课程:**数据科学、数据科学大数据、数据科学数学与数据、数据科学自然语言处理、数据科学物理、数据科学生物学 学分
7.明尼苏达大学双城分校
姓名:数据科学硕士
课程时长 : 2 年
地点:明尼苏达州明尼阿波利斯
核心课程:数据挖掘导论、数据库系统原理、应用回归分析、并行计算导论:架构、算法和编程、非线性优化导论、应用多元方法
**必修课程:**统计学、算法和基础设施
8.西北大学
姓名:分析学理学硕士
课程期限 : 15 个月
地点:伊利诺伊州埃文斯顿
核心课程:统计学、机器学习、优化、数据库和数据管理方面的课程构成了 MSiA 固定课程的核心。
这个项目竞争非常激烈,因为招收的学生只有大约 35 名,来自不同的背景。
9.北卡罗来纳州立大学
姓名:分析学理学硕士
课程时长 : 10 个月
地点:北卡罗来纳州罗利
课程:固定课程,重点是分析工具和技术、分析基础、分析方法和应用 I 以及分析方法和应用 II
10.康奈尔大学
姓名:应用统计学专业研究硕士(MPS)
课程时长 : 1 年
地点:纽约州伊萨卡
核心课程:带矩阵的线性模型、概率模型与推理、MPS 专业发展、应用统计学 MPS 数据分析项目
可选项:统计分析与数据科学
学分 : 30
11.德克萨斯大学奥斯汀分校
姓名:计算机科学硕士(申请方向)
课程期限 : 2 年
地点:得克萨斯州奥斯汀
核心课程:由学生选择
**可提供的方向:**理论、系统、申请
学分 : 30
12.马萨诸塞大学阿姆赫斯特分校
名称:计算机科学硕士(数据科学专修)
课程期限 : 2 年
地点:马萨诸塞州阿姆赫斯特
核心课程:从数据科学理论、数据系统和数据科学 AI 核心 学分 : 30
13.加州大学圣地亚哥分校
姓名:计算机科学硕士(AI 深度)
课程时长 : 2 年
地点:加州圣地亚哥
**深度地区:**人工智能。你可以选择像人工智能这样的课程:概率推理和学习,机器学习,神经网络,统计学习理论等等。
学分:根据硕士计划在论文和综合考试中选择而变化。
14.宾夕法尼亚大学
姓名:数据科学工程硕士
课程时长 : 1.5 年
地点:宾夕法尼亚州费城
核心课程:概率介绍&统计学、编程语言&技术、数理统计、大数据分析与机器学习
**可提供的课程:**论文、以数据为中心的编程、统计学-数学基础、数据收集-表示-管理-检索、数据分析-人工智能
15.南加州大学
姓名:计算机科学硕士(数据科学方向)
课程时长 : 2 年
地点:美国加州洛杉矶
核心课程:人工智能的算法分析、数据库系统与基础
**可修课程:**数据系统与数据分析 学分 : 32
16.芝加哥大学
姓名:分析学理学硕士
课程期限 : 1.5 年
地点:伊利诺伊州芝加哥
核心课程:统计分析、商业应用的线性和非线性模型、机器学习和预测分析、时间序列分析和预测、数据挖掘原理、大数据平台、用于分析的数据工程平台、领导技能:团队、战略和沟通 要完成的课程 : 14
17.科罗拉多大学博尔德分校
姓名:计算机科学专业理学硕士
课程时长 : 2 年
地点:科罗拉多州博尔德
课程:机器学习、神经网络与深度学习、自然语言处理、大数据、HCC 大数据计算以及更多
**可用曲目:**数据科学与工程 学分
18.达拉斯德克萨斯大学
姓名:计算机科学硕士(数据科学方向)
课程时长 : 2 年
地点:得克萨斯州达拉斯
课程:机器学习、计算机算法设计与分析、大数据管理与分析、数据科学统计方法 学分 : 27
19.罗格斯大学
姓名:数据科学硕士
课程时长 : 2 年
地点:新泽西州新不伦瑞克
核心课程:概率统计、数据结构与算法、海量数据存储与检索工具、海量数据挖掘、数据交互与可视化分析 学分 : 36
这是一个新项目,还没有毕业生。
20.马里兰大学,学院公园
姓名:计算机科学理学硕士
课程时长 :
地点:马里兰州大学城
**数据科学选修课程:**计算机算法设计与分析 学分 : 30
数据科学研究生证书如果你负担不起整整两年的硕士学习,也可以考虑。
总结一下,我把大学的名字列在下面-
- MCDS 卡耐基梅隆大学
- 斯坦福大学—统计学(数据科学)硕士
- 佐治亚理工学院-分析学硕士
- 华盛顿大学—数据科学硕士
- 哥伦比亚大学—数据科学硕士
- 纽约大学—数据科学硕士
- 明尼苏达大学双城分校——数据科学硕士
- 西北大学-分析学硕士
- 北卡罗来纳州立大学-分析学硕士
- 康奈尔大学-应用统计学硕士
- 德克萨斯大学奥斯汀分校—计算机科学硕士(应用方向)
- 马萨诸塞大学阿姆赫斯特分校—计算机科学硕士(数据科学专业)
- 加州大学圣地亚哥分校—计算机科学硕士(人工智能深度)
- 宾夕法尼亚大学-数据科学硕士
- 南加州大学—计算机科学硕士(数据科学方向)
- 芝加哥大学-分析学硕士
- 科罗拉多大学博尔德分校——计算机科学专业硕士
- 德克萨斯大学达拉斯分校—计算机科学硕士(数据科学方向)
- 罗格斯大学—数据科学硕士
- 马里兰大学帕克学院-计算机科学硕士
请在评论中随意提及你认为应该进入追求数据科学前 20 名的大学。
附:我不再关注这篇文章,因为我已经有一段时间没有研究大学了。感谢您抽出时间阅读。万事如意!
20 年的数据,10 个结论
我在 1999 年得到了我的第一份“真正的”工作,为哥本哈根的一家电力公司工作(大声喊给 Lars ),用 Excel 创建电价报告。从那以后,我在许多行业的小公司、初创公司和大公司工作过。我和充满激情的创始人以及雇佣的人一起工作过,我坐在桌子的两边(内部和咨询)。
我庆祝了我 20 年的“职业纪念日”,反思并写下我脑海中出现的前十件事。

→没有疯狂的数据科学泡沫在继续。最疯狂的是:15 年前,大公司通常只有少数数据科学家(或我们过去常说的“数据矿工”),但却有数百名营销人员(不是针对营销人员!).如今,拥有 100 名数据科学家并不被视为异类。
→真实 **奔忙激励和鼓舞。**虚假的骗局恰恰相反。
忙碌不是目标或成就。把正确的事情做好才是。不让自己不知所措才是。找到平衡才是。
→工作场所是一个缩影,在这里,小问题被放大和夸大。作为一名领导者,你的工作是客观看待事情,而不是火上浇油。
→虽然能感觉到官僚,但是流程真的很重要。短跑和 okr 能产生注意力和透明度。但是不要忘记,一个过程的目标并不是过程本身。
→初创企业更好玩。从零开始构建,而不是没完没了地管理成员,这是我最有收获的职业经历之一。
→ 对于消费类公司,漏斗转化率将随时间下降,客户获取成本将上升。是重力*。这是预料之中的。关键是尽早制定一个应对策略,这样你就可以在(不可避免的)发生时避免被打败。*
→ 如果你正在组建一个团队,招聘必须是第一要务——一直如此。没有任何会议、代码、分析或幻灯片比让关键人才加入你的团队更重要。玩长线游戏。
→ 不管你的角色是什么——技术或非技术——学会如何沟通。如果你不能有效地交流你的想法,你就不会充分发挥你的潜力。就这么简单。
→ 商业世界已经从对数据科学的怀疑(见我的第一点)到在完全接受它。但我们不要完全丢掉怀疑态度。最近人工智能蛇油的激增就是一个很好的例子——在传单上贴上人工智能标签不会自动使产品变得有用或可信。
2018 年人工智能预测

这很难相信,但 2017 年即将结束,2018 年即将到来。像大多数公司一样, Aiden.ai 正在为新的一年进行规划和优先排序。我们有一些令人兴奋的大项目正在进行中!
但我们也想分享我们对 2018 年的预测。随着人工智能继续在很大程度上扰乱多个行业,我们认为明年将是真正的变革。以下是我们的五大预测:
1。不是一个人工智能可以统治所有人——而是很多。
福布斯报道称 80%的企业都在投资人工智能。一个全能、多功能的人工智能来帮助我们生活的各个方面还需要很多年。相反,我们将看到许多不同的人工智能和机器人,每一个都有一个特定的利基,它们将在其中越来越好地发挥作用。人工智能技术仍处于早期阶段,我们还需要许多年才能看到重大的行业整合,这需要一个人工智能来统治所有人。这是好事!行业从未像最初诞生和不断试验、学习和变化时那样富有创新性。
2。和机器对话会变得很正常。
据估计,Alexa 设备已经售出超过 1000 万台,在网络星期一购买的还有“数百万”台,然而 Siri 和 Alexa 等技术对普通人来说仍然感觉别扭。除了偶尔问一些关于天气或早晨交通的问题,我们大多数人还不太习惯于像一个人、同事或客户服务人员一样与机器交谈。
我们将如何克服这一点?两种方式。
首先,它让人感到尴尬,因为新闻快讯— 它是尴尬。上一次你问 Siri 问题的时候,你不得不重复或重新措辞一个问题多少次?她有很多东西要学。这些对话技术将在 2018 年得到改善,并在捕捉人类意图甚至可能是情感方面变得更好。随着自然语言处理的改进,像聊天机器人和信使机器人这样的东西将帮助我们这个社会克服这一点。
第二,我们将有更多的机会习惯与机器互动。许多品牌如 7-Eleven 和乐高已经发布了聊天机器人和信使机器人,通过他们日常使用的渠道接触消费者。人工智能、聊天机器人和对话技术几乎将颠覆世界上的每一个行业,所以请做好准备,在你的家庭生活、工作生活甚至更远的地方看到它们!我们保证,你会习惯的。
3。人类将要求机器帮助进行数据管理。
对于企业来说,可用的数据源比以往任何时候都多。不幸的是,大多数公司都没有充分利用这些信息。对于企业来说,这是一个前所未有的好机会,让它们变得更智能、更实时、更受数据驱动。坏消息呢?这些数据孤岛对人类来说太多了,他们自己无法承担。更大的 excel 电子表格不是答案!什么是?人工智能。
人类将会习惯于作为同事与机器一起工作的想法,一旦他们这样做了,他们的工作将会提高,因为他们变得更加准确和高效。我们将在 2018 年看到这方面的重大举措。
4。人工智能将创造比以往更多的就业机会。
对于任何新的颠覆性创新,人们经常持怀疑态度,业界也听到了很多关于人工智能导致失业的说法。然而,Gartner 估计,到 2020 年,人工智能将创造 230 万个工作岗位。希望 2018 年将是证明这一错误的一年,并表明人工智能将创造无数的工作和机会,而不是威胁它们。所有这些技术都需要人们去制造、销售,或许最重要的是——使用它们。可以肯定地说,人工智能将改善职业人士的生活,而不是让他们失业。
5。流行语消失了。
众所周知,像“人工智能”和“机器学习”这样的词现在很流行。许多公司都在赶时髦,声称拥有人工智能产品。2018 年,我们预测装腔作势的人将与真正的技术分离。
在 Aiden.ai,我们正在为营销人员打造第一个人工智能驱动的同事,2018 年,我们将招聘员工!在这里找到我们的职位空缺并加入冒险!
你对 2018 年有什么想法和预测?加入对话,让我们知道!
通过迭代器和 Zip 函数实现 2018 世界杯进球
所有进球的 Python EDA 技术要点
唷,这是多么精彩的一个足球月啊。随着法国成为充满冷门、假摔和进球的锦标赛当之无愧的赢家,让我们回顾一下整届锦标赛的 169 个进球。

The agony of having to wait 4 years for the next one.
使用的数据集来自于 football.db ,其中包含了其他真正有趣的数据集,供其他球迷参考。我还从的国际足联 API 中提取了一些国家排名和国际足联积分的数据。
和往常一样,数据集并不能立即用于分析。世界杯的主要数据集是按比赛组织的,每场比赛的进球由一个字典列表表示,如下所示:

这意味着我们必须循环所有的比赛,循环所有的进球,并填写其他比赛的具体信息。通过一些功能工程和团队特定信息的合并,我们将每个目标表示为一个字典,如下所示:

有了这个新形成的目标数据框架,是时候开始一些可视化了。从这个特定的 EDA 中,我有两个主要的技术收获,都围绕着 zip 函数。
1.通过元组对字典进行排序
在计算每场比赛的平均进球数并根据结果创建一个字典后,它看起来像这样:

理想情况下,我们希望以降序来绘制这些值,因此需要在这个字典中进行排序。
要对字典进行排序,必须运行排序函数,并使用 lambda 函数来确保键和值对被排序在一起。元组的结果列表如下所示:

出于绘制国家平均值图表的目的,将元组中的数据分为 x 值列表和 y 值列表会有所帮助。
基本的 zip 函数有助于跨可重复项聚合元素。
什么是可迭代的?基本上任何可以循环的东西。
下面是一个简单的例子,其中一个迭代器的第一个元素与第二个迭代器的第一个元素匹配。这在迭代器的长度上是连续的。将返回一个包含元组的迭代器,可以转换成列表。

zip 函数也可以解包“压缩”的结果。通过使用*操作符,我们可以将元素赋回给它们各自的迭代器。

正是使用这种技术,我们对 sorted_average 列表进行解包,以获得按所需顺序排列的国家列表和平均值列表。

2.通过 ax.annotate 创建自定义数据标签
我原以为添加数据标签可能是另一种类似于 matplotlib.pyplot.xlabel 或 matplotlib.pyplot.ylabel 的方法。
让我们以标记每个体育场的进球为例。

要显示数据标签,需要两个迭代器:一个迭代器包含对图上补丁的引用,另一个迭代器包含所需的标签。补丁是指图表上的颜色补丁,在条形图的情况下是每个单独的条。因为我们希望标签是每个体育场的进球数,所以我使用 goals_df[‘stadium’]的值。value_counts()。
请注意,如果我们想要显示每个体育场的名称,我们应该使用 goals_df[‘stadium’]。value_counts()。返回带有索引值的迭代器。

现在,我们遍历图中的每个元素,并调用 ax.annotate()来添加标签。我们使用 ax.patches(返回所有补丁的迭代器)和体育场列表作为参数,循环遍历 zip 函数生成的聚合迭代器。
这意味着每次我们调用 ax.annotate()时,都会调用正确的补丁和标签对。使用 p.get_x()和 p.get_height()值将标签居中,这样就完成了!

现在我们已经讨论了一些技术问题,目标告诉了我们什么?
1.欧洲是得分最高的大陆

欧洲约占本届锦标赛总进球数的 60%。考虑到有 14 支欧洲球队参加了世界杯,这是意料之中的。他们也比其他大洲打了更多的比赛,因为他们进入了锦标赛的后几轮。
2.单个欧洲球队在总进球数和平均进球数排行榜上名列前茅

自然地,欧洲各队在进球数排行榜上名列前茅,锦标赛中的前 5 名射手都来自欧洲。巴西是继比利时、法国、克罗地亚、英格兰和俄罗斯之后第一个溜进排行榜的非欧洲球队。

欧洲球队的进球能力不应该仅仅归功于他们踢了最多的比赛。他们最终也超过了平均每场比赛的进球数。
突尼斯出人意料地排在第七位,领先于另一个非欧洲竞争者巴西。
3.高分淘汰赛


小组赛阶段的总进球数远远超过淘汰赛阶段并不奇怪,因为前者有 48 场比赛,后者有 16 场。
每场比赛的平均进球数显示,淘汰赛的得分更高,平均为 2.94 球,而小组赛为 2.54 球。
4.大多数进球都是在比赛进行到一半时打进的


比赛日 10、11 和 12 是得分最高的比赛日。把这归因于比利时和突尼西亚的先发制人心态,或者巴拿马的防守在哈里·基恩面前的无能为力。
5.乌龙球和点球的出现

虽然对“乌龙球”成为本届世界杯最佳射手没有一个合理的解释,但点球得分的显著上升很可能要归因于 VAR 的使用。
6.索契得到了款待

索契的观众在小组赛阶段观看了两场最精彩的比赛:葡萄牙对西班牙,比利时对突尼斯。两场比赛一共进了 13 个球。
7.国际足联的排名并不能很好地预测得分

通过将每个国家的平均进球数与他们的国际足联分数进行对比,我们看到排名靠前的球队并没有都达到标准。
我们用每场比赛的平均进球数和国际足联积分的中值来过滤掉令人失望的表现者和超额完成者。

在这些球队中,俄罗斯是一个巨大的惊喜,东道主在第一场比赛中摧毁了沙特阿拉伯,然后在 16 强赛中震惊了西班牙。突尼斯队积极的进攻赢得了球迷的支持,而日本队在令人心碎的最后一分钟输给比利时之前,在整个比赛中都保持了自己的风格。

毫无疑问,德国队在本届世界杯上令人失望,受到了冠军的诅咒,未能从小组中出局。进球对他们来说已经枯竭,他们拥有球队中最低的得分记录之一。莱万多夫斯基未能激发波兰队的努力,而墨西哥队击败德国队的比赛也没有延续他们在随后比赛中的得分记录。
随着本届世界杯的结束,我所代表的克罗地亚队在最后一关倒下了,我现在只希望路卡·莫德里奇赢得一个当之无愧的金球奖。

感谢阅读!
数据科学家的 23 只大熊猫代码

想获得灵感?快来加入我的 超级行情快讯 。😎
这里有 23 个熊猫代码,供数据科学家帮助更好地理解你的数据!
基本数据集信息
(1)读入 CSV 数据集
pd.DataFrame.from_csv(“csv_file”)
运筹学
pd.read_csv(“csv_file”)
(2)读入 Excel 数据集
pd.read_excel("excel_file")
(3)将您的数据框直接写入 csv
逗号分隔,不带索引
df.to_csv("data.csv", sep=",", index=False)
(4)基本数据集特征信息
df.info()
(5)基本数据集统计
print(df.describe())
(6)打印表格中的数据框
print(tabulate(print_table, headers=headers))
其中“print_table”是列表的列表,“headers”是字符串头的列表
(7)列出列名
df.columns
基本数据处理
(8)丢弃丢失的数据
df.dropna(axis=0, how='any')
返回给定轴上的标签被忽略的对象,其中部分或全部数据交替丢失
(9)替换丢失的数据
df.replace(to_replace=None, value=None)
用“值”替换“to_replace”中给定的值。
(10)检查 nan
pd.isnull(object)
检测缺失值(数值数组中的 NaN,对象数组中的 None/NaN)
(11)删除一个特征
df.drop('feature_variable_name', axis=1)
对于行,轴为 0;对于列,轴为 1
(12)将对象类型转换为浮点型
pd.to_numeric(df["feature_name"], errors='coerce')
将对象类型转换为数字,以便能够执行计算(如果它们是字符串)
(13)将数据帧转换为 numpy 数组
df.as_matrix()
(14)获得数据帧的前“n”行
df.head(n)
(15)按特征名称获取数据
df.loc[feature_name]
对数据帧进行操作
(16)将函数应用于数据帧
这将使数据框的“高度”列中的所有值乘以 2
df["height"].apply(**lambda** height: 2 * height)
运筹学
def multiply(x):
return x * 2df["height"].apply(multiply)
(17)重命名列
这里,我们将数据框的第 3 列重命名为“大小”
df.rename(columns = {df.columns[2]:'size'}, inplace=True)
(18)获取列的唯一条目
在这里,我们将获得列“name”的唯一条目
df["name"].unique()
(19)访问子数据帧
在这里,我们将从数据框中选择“名称”和“大小”列
new_df = df[["name", "size"]]
(20)关于您的数据的摘要信息
**# Sum of values in a data frame** df.sum()**# Lowest value of a data frame** df.min()**# Highest value** df.max()**# Index of the lowest value** df.idxmin()**# Index of the highest value** df.idxmax()**# Statistical summary of the data frame, with quartiles, median, etc.** df.describe()**# Average values** df.mean()**# Median values** df.median()**# Correlation between columns** df.corr()**# To get these values for only one column, just select it like this#** df["size"].median()
(21)整理你的数据
df.sort_values(ascending = False)
(22)布尔索引
这里我们将过滤名为“size”的数据列,只显示等于 5 的值
df[df["size"] == 5]
(23)选择值
让我们选择“大小”列的第一行
df.loc([0], ['size'])
喜欢学习?
在推特上关注我,我会在那里发布所有最新最棒的人工智能、技术和科学!也在 LinkedIn 上与我联系!
25 盏灯
第一部分:问题介绍和简单解决方案
第二部分:使用真实世界的数据
现在是进入机器学习的绝佳时机。有一些工具和资源可以帮助任何拥有一些编码技能和需要解决的问题的人去做有趣的工作。我一直在关注针对程序员的 实用深度学习 和大卫·西尔维的强化学习课程没有博士学位的机器学习 是对深度学习技术的极好介绍。这些,连同所有链接自《黑客新闻》的论文和 两分钟论文 都激励我尝试一些想法。
我过去曾做过物联网设备的设置过程,通过 BTLE 从 iPhone 连接到它。依赖单一通道进行设置的漏洞之一是中间人攻击。击败 MitM 的一种方法是对交换的公钥使用带外认证。这可以通过在设备的发光二极管上编码一个随机的位模式,并从手机的摄像头中读取它们来实现。这将是 Apple Watch 设置协议的一个不太复杂的版本,但仍然非常有效。
我正在考虑的设备在前面有一个 5x5 的灯阵列。2 ⁵可以编码 33,554,432 种可能性,非常适合密钥交换验证。现在的挑战是找到一种从图像中自动提取位模式的方法。
首先,我尝试改编了 Fast.ai MOOC 早期使用的 VGG16 net。我尝试了几轮培训,并应用标准建议来微调网络。这未能产生有意义的结果。VGG16 和像它一样的深网在识别单一类别方面很棒,但我不确定它是否能跟踪 25 盏灯。在第二部分中,我展示了类似 VGG16 的网络是如何工作的。休息之后,思考和阅读其他项目和技术,我遇到了自动编码器。自动编码器是一种神经网络,它将输入编码成较小的向量,然后将该向量解码回原始大小。损失函数用于比较输入和输出之间的差异。然后,可以训练自动编码器来最小化损失。

Autoencoder diagram from the Keras blog
自动编码器不是最复杂的技术,但最好从简单的解决方案开始。 在 Keras 中构建 auto encoders是一个很好的介绍,我在这里的探索紧随那个帖子。
图象生成
为了训练自动编码器,我们需要一些图像。下面是绘制我们想要识别的图像的 Python 代码。幸运的是,我们可以很容易地生成训练所需的图像。真实世界的图像将很难获得这里所需要的数量。
简单自动编码器
现在我们有了图像生成器,我们可以制作一个非常简单的自动编码器。这几乎与 Keras 博客中的第一个自动编码器相同。
在批量大小为 128 的 500 次迭代之后,我们得到 0.1012 的损失。这大约是 autoencoder 博客中第一次尝试的损失水平。这是我们看到的。输入图像在顶部,解码在底部。

这看起来没有我希望的那么好,但是请注意点颜色的细微变化。再给它几千次迭代吧。
5000 次迭代得到 0.0031 的损失。

这还差不多。现在又多了 5000,应该不错。
迭代 10000 次后,损耗为 0.000288。

它看起来不错,但这种简单的网络经不起真实世界的输入。看看我的下一篇文章,我将展示如何识别照片中的点图案。然后如何用 CoreML 在 iPhone 上运行网络。
第二部分:使用真实世界的数据
25 盏灯
第二部分:使用真实世界的数据
在第部分 I 中,我展示了一个简单的全连接自动编码器,可以用随机位模式再现图像。autoencoder 是一个很好的选择,可以用来说明网络训练时发生了什么,并表明它在理论上是可行的。然而,一个简单的全连接网络在现实生活中是行不通的。这是因为将图像展平成一维会丢失很多空间信息。此外,一个单独的隐藏层并不能处理真实照片在大小、位置、旋转、模糊等方面的所有变化。
处理照片
我的目标是构建一个演示 iPhone 应用程序,它可以拍摄模式的照片,并显示检测到的位模式。这意味着训练集将不得不使用照片,而不是纯粹的计算机生成的图像。处理真实世界的照片需要比第一篇文章更复杂的方法。幸运的是,在图像识别方面有大量的研究可以借鉴。 ImageNet 竞赛的获胜者发布他们的结果,复制获胜的网络是一个很好的开始。一个用于迁移学习的流行网络是 VGG-16。在我们设计中,我们可以大量借鉴网络。VGG-16 是一个深度卷积网络(DCNN)。如果你对 CNN 不熟悉,我发现这个视频是一个极好的教程。简短的解释是,CNN 使用一堆卷积滤波器,这些滤波器擅长提取空间信息和空间关系。
下面是我用过的网络。它不同于 VGG,因为它使用平均池代替最大池,具有更少的层和不同的损失函数。
对于笔记本的其余部分,请查看完整的 jupyter 笔记本和支持工具。我已经包括了 macOS 图像服务器、iOS 图像记录器和最终的 iOS 识别应用程序。
创建培训和验证集
现在我们已经建立了我们的网络,我们需要更好的数据来训练。在我们的第一个例子中,我们使用了按需绘制的简单图像。这些照片太干净了,没有一张真正的照片会有的任何不规则性。由于所需的数量,使用真实照片是一个挑战。我最初尝试使用纯合成图像,但未能通过真实照片验证。然后,我创建了一个大约 15k 照片的训练集。这些照片是由一部指向电脑屏幕的 iPhone 拍摄的。手机通过本地网络连接检索位模式,然后将图片保存到磁盘。直到大约 90k 的图像被包含在训练集中,我才能够得到好的结果。为了提高训练的质量,对图像应用了随机仿射变换。应用此变换可以移动、缩放和倾斜图像。

iOS app capturing images from the screen
收集完图像后,我保留了其中的 10%作为验证集。一个好的验证集将使你知道训练进展如何,以及要达到你的目标还需要哪些额外的步骤。fast.ai 的 Rachel Thomas 有一篇关于这个话题的优秀文章。
过度拟合

This is what overfitting looks like
我第一次尝试使用一个类似 VGG 的网络,并没有包括任何正规化。这显然是个错误。上图是过度拟合的经典案例。左边的损失图显示了网络在训练数据上的表现。右边的 val_loss 显示了网络如何处理验证集。我喜欢认为神经网络是懒惰的骗子,它们会利用任何优势来获得正确的答案。一个大的网络和一个小的训练集必然会导致过度拟合。最初的训练集是 10k 张图像。在这种尺寸下,网络更容易“记住”每张图像的值,而不是学会以概括的方式看到这些点。
如何避免过度拟合

The same data as above, but with batch normalization and dropout
避免过度拟合的一些技巧是:
- 更大的训练集(更大的训练集、数据论证、更多样的输入源)
- 正规化(批量正规化,退出)
- 改变网络拓扑(使网络变小)
增加漏失和批量归一化非常有效地防止了第一张图中看到的失控过拟合。然而,数据集仍然太小,无法在验证集上获得好的结果。早期训练仅导致 0.4 的验证损失和 0.1 以下的训练损失。这个差异被称为差异。要获得好的结果,需要低于 0.02 的验证损失。当使用更大、更多样的训练集时,可以获得更好的结果。

Final training run
调试网络
一旦训练达到一个合理的表现水平,检查网络出错的情况是一个好主意。对这些情况进行简单的目视检查通常就足够了。
第一件事是计算有多少图像有一个或多个不正确的位。大约 92%的图像是完全正确的。那么剩下的 8%是怎么回事呢?以下是一些错过的图片:

有一堆重影和模糊的照片,合理的东西要错过。我回去删除了所有有重影或其他主要问题的照片,然后从头开始重新运行培训。结果如下:

Final loss of 0.04 and validation loss of 0.02
最终错误率为 97%。如果有必要接近 100%,就需要更多种类的图像,集中在当前网络做得不好的情况下。
iPhone 实现和 CoreML
我打算写第三篇关于用训练好的模型制作一个 iOS 应用的文章。然而,它真的很简单,不值得一提。
一旦你训练好你的模型,安装 CoreML 工具。你需要有一个 Python 2.7 环境,因为 CoreML 不支持 Python 3。然后在您的笔记本中创建一个新的单元格,并运行以下命令。
import coremltoolscoreml_model = coremltools.converters.keras.convert(model)
coreml_model.save(“Lights.mlmodel”)
一旦您导出了您的模型,创建一个新的项目并导入它。唯一棘手的部分是将图像转换成 CoreML 模型的输入。
要将图像转换为 CoreML:
- 按照我们的模型输入的形状制作一个多层阵列。在这种情况下是 1×128×128,32 位浮点。
- 将图像渲染到 8 位灰度绘图环境中。
- 提取字节并将其转换为浮点数,然后将其写入数组。
- 为模型创建一个输入对象,并从 MLModels predictionFromFeatures 方法获取预测。
更多细节请看一下 iOS CoreML 代码。
关于如何使用 CoreML 模型的完整教程,请查看 CoreML 和视觉机器学习。
结论
用错误的方法解决这个问题太麻烦了!有很多图像识别系统的例子可以在不使用深度卷积网络的情况下完成这种任务。传统的 CV 技术可以用更小的二进制数更快地解决这个问题。然而,这是一个非常有趣的学习练习,帮助我找到了如何解决新的 ML 任务带来的问题。
当我把这个问题作为一个 ML 训练练习来考虑时,我不确定它是否可行。我遇到的所有例子都是分类任务,比如 ImageNet。这些分类任务有一个最终的热门矢量输出,并使用了损失函数,如分类交叉熵。在对其他网络做了更多的阅读并对损失函数有了更好的理解后,我意识到像二进制交叉熵这样的东西应该是可行的。事后看来,我应该更早开始详细阅读损失函数。
所需的训练数据的大小和呼吸也有点令人兴奋。与其他训练集相比,超过 85,000 个示例并不算大,但仍然非常大。用胶囊网络再试一次会很有趣。胶囊网络应该具有更好的相对位置感,并且需要更少的例子。
把我学会使用的所有技术放在一起,看着它们工作是非常令人满意的。吴恩达的和杰瑞米·霍华德的视频课程是很好的向导。在大多数 ML 课程材料中,有大量的时间花在正则化和管理你的训练数据和验证集上。我希望我已经证明了这是有充分理由的。感谢您阅读我的项目。我很想在下面的评论中听到关于这篇文章的任何评论或建议。
第二场总统辩论——热门推文时刻分析

情绪 =-0.72:
毫不奇怪,观众对第二次总统辩论持中立或消极态度,并且/或者对未来的美国总统感到焦虑。这一点可以从情绪量表上直观的观察到,略负的分数。
地理反应:
地理位置分析表明,美国并不是唯一对这场引起争论感兴趣的国家。显然,德国和法国等一些欧洲国家对下一任美国总统表现出强烈的担忧和担心。相反,最近投票脱离欧盟的英国表现出相当乐观的态度。
有人怀疑俄罗斯试图影响美国大选(来源:https://www . the guardian . com/us-news/2016/sep/05/Russia-influence-us-president-election-investigation)一些未知地点的推文会不会来自俄罗斯?


“真正的赢家”:

Ken Bone
在唐纳德·特朗普和希拉里·克林顿的第二次总统辩论中,肯·伯恩的红色开衫、白色领带和黑框眼镜无疑吸引了更多的眼球。大多数观众欣赏他在全国舞台上的首次亮相。他成了网络红人,给辩论的基调带来了感染力。伯恩先生为让美国再次伟大做出了自己的主张!

Ken Bone’s Cardigan
Ken Bone 的羊毛衫可能是今年最受欢迎的万圣节服装或圣诞礼物之一。 GQ 在这里展示了你可以在哪里买到它。
在 Stratifyd Signals 平台中,分析来自社交媒体渠道的情绪很容易。Twitter、脸书、YouTube 和 Yelp 的内置数据连接器可以快速导入数据。Signals 通过机器学习处理数据,提取出最重要的主题和趋势,并在易于使用的可视化界面中呈现出来。
尝试我们的一个自助服务用户帐户,了解可视化分析有多简单。这里是应用商店中 Priceline 应用的视觉分析的链接。App Store 和 Google Play 只是 Signals 中许多预建数据连接器中的两个。也可以上传自己的数据。
获得您的试用帐户,看看用户说什么。与我们聊天,或发送电子邮件到 clientsupport@stratifyd.com。
www。stratifyd.com
比单词嵌入更好的单词袋中的 3 种基本方法

Photo: https://pixabay.com/en/hong-kong-china-city-chinese-asian-383963/
如今,每个人都在谈论单词(或字符、句子、文档)嵌入。单词袋还值得用吗?我们应该在任何场景中应用嵌入吗?
看完这篇文章,你会知道:
- 为什么人们说单词嵌入是灵丹妙药?
- 什么时候单词袋会战胜单词嵌入?
- 词汇袋中的 3 种基本方法
- 我们如何用几行文字构建单词包?
为什么有人说嵌入这个词是灵丹妙药?

Photo: https://pixabay.com/en/books-stack-book-store-1163695/
在自然语言处理领域,嵌入是解决文本相关问题的成功方法,其性能优于单词袋(BoW)。事实上,BoW 引入了诸如大特征维数、稀疏表示等限制。关于文字嵌入,你可以看看我之前的帖子。
我们还应该用弓吗?在某些情况下,我们可以更好地使用 BoW
什么时候单词袋会战胜单词嵌入?

在以下情况下,您仍然可以考虑使用 BoW 而不是 Word 嵌入:
- 构建基线模型。通过使用 scikit-learn,只需要几行代码就可以构建模型。以后,可以用深度学习来咬它。
- 如果您的数据集很小,并且上下文是特定于领域的,BoW 可能比单词嵌入更好。上下文是非常领域特定的,这意味着你不能从预先训练的单词嵌入模型(GloVe,fastText 等)中找到相应的向量。
我们如何用几行文字构建单词包?
使用传统的强大的 ML 库,有 3 种简单的方法来构建 BoW 模型。
统计出现次数

Photo: https://pixabay.com/en/home-money-euro-calculator-finance-366927/
统计单词出现次数。使用这种方法的原因是关键字或重要信号会反复出现。所以如果出现的次数代表单词的重要性。更多的频率意味着更多的重要性。
doc = "In the-state-of-art of the NLP field, Embedding is the \
success way to resolve text related problem and outperform \
Bag of Words ( BoW ). Indeed, BoW introduced limitations \
large feature dimension, sparse representation etc."count_vec = CountVectorizer()
count_occurs = count_vec.fit_transform([doc])
count_occur_df = pd.DataFrame(
(count, word) for word, count in
zip(count_occurs.toarray().tolist()[0],
count_vec.get_feature_names()))
count_occur_df.columns = ['Word', 'Count']
count_occur_df.sort_values('Count', ascending=False, inplace=True)
count_occur_df.head()
输出
Word: "of", Occurrence: 3
Word: "bow", Occurrence: 2
Word: "way", Occurrence: 1
归一化计数出现次数
如果你认为极高的频率可能会主导结果并造成模型偏差。标准化可以容易地应用于流水线。
doc = "In the-state-of-art of the NLP field, Embedding is the \
success way to resolve text related problem and outperform \
Bag of Words ( BoW ). Indeed, BoW introduced limitations \
large feature dimension, sparse representation etc."norm_count_vec = TfidfVectorizer(use_idf=False, norm='l2')
norm_count_occurs = norm_count_vec.fit_transform([doc])
norm_count_occur_df = pd.DataFrame(
(count, word) for word, count in zip(
norm_count_occurs.toarray().tolist()[0],
norm_count_vec.get_feature_names()))
norm_count_occur_df.columns = ['Word', 'Count']
norm_count_occur_df.sort_values(
'Count', ascending=False, inplace=True)
norm_count_occur_df.head()
输出
Word: "of", Occurrence: 0.4286
Word: "bow", Occurrence: 0.4286
Word: "way", Occurrence: 0.1429
术语频率-逆文档频率(TF-IDF)

Photo: http://mropengate.blogspot.com/2016/04/tf-idf-in-r-language.html
TF-IDF 采用了另一种方法,这种方法认为高频可能不能提供太多信息增益。换句话说,生僻字为模型贡献了更多的权重。
如果在同一文档(即培训记录)中出现的次数增加,单词的重要性将增加。另一方面,如果它出现在语料库(即其他训练记录)中,则会减少。
doc = "In the-state-of-art of the NLP field, Embedding is the \
success way to resolve text related problem and outperform \
Bag of Words ( BoW ). Indeed, BoW introduced limitations \
large feature dimension, sparse representation etc."tfidf_vec = TfidfVectorizer()
tfidf_count_occurs = tfidf_vec.fit_transform([doc])
tfidf_count_occur_df = pd.DataFrame(
(count, word) for word, count in zip(
tfidf_count_occurs.toarray().tolist()[0],
tfidf_vec.get_feature_names()))
tfidf_count_occur_df.columns = ['Word', 'Count']
tfidf_count_occur_df.sort_values('Count', ascending=False, inplace=True)
tfidf_count_occur_df.head()
输出(该值与标准化计数发生次数完全相同,因为演示代码只包含一个文档)
Word: "of", Occurrence: 0.4286
Word: "bow", Occurrence: 0.4286
Word: "way", Occurrence: 0.1429
密码
此示例代码将在计数发生、标准化计数发生和 TF-IDF 之间进行比较。
使用不同的矢量化方法获取模型的样本函数
def build_model(mode):
# Intent to use default paramaters for show case
vect = None
if mode == 'count':
vect = CountVectorizer()
elif mode == 'tf':
vect = TfidfVectorizer(use_idf=False, norm='l2')
elif mode == 'tfidf':
vect = TfidfVectorizer()
else:
raise ValueError('Mode should be either count or tfidf')
return Pipeline([
('vect', vect),
('clf' , LogisticRegression(solver='newton-cg',n_jobs=-1))
])
使用另一个示例函数来构建两端管道
def pipeline(df, mode):
x = preprocess_x(df)
y = preprocess_y(df)
model_pipeline = build_model(mode)
cv = KFold(n_splits=10, shuffle=True)
scores = cross_val_score(
model_pipeline, x, y, cv=cv, scoring='accuracy')
print("Accuracy: %0.4f (+/- %0.4f)" % (
scores.mean(), scores.std() * 2))
return model_pipeline
让我们检查一下需要处理的词汇数量
x = preprocess_x(x_train)
y = y_train
model_pipeline = build_model(mode='count')
model_pipeline.fit(x, y)print('Number of Vocabulary: %d'% (len(model_pipeline.named_steps['vect'].get_feature_names())))
输出
Number of Vocabulary: 130107
通过传递“计数”(计数发生)、“tf”(正常计数发生)和“tfi df”(TF-IDF)来调用管道
print('Using Count Vectorizer------')
model_pipeline = pipeline(x_test, y_test, mode='count')print('Using TF Vectorizer------')
model_pipeline = pipeline(x_test, y_test, mode='tf')print('Using TF-IDF Vectorizer------')
model_pipeline = pipeline(x_test, y_test, mode='tfidf')
结果是
Using Count Vectorizer------
Accuracy: 0.8892 (+/- 0.0198)
Using TF Vectorizer------
Accuracy: 0.8071 (+/- 0.0110)
Using TF-IDF Vectorizer------
Accuracy: 0.8917 (+/- 0.0072)
结论
你可以从 github 中找到所有代码。
根据以前的经验,我试图通过给出一个简短的描述来解决产品分类的问题。例如,给定“新鲜苹果”,预期类别是“水果”。仅仅通过使用计数发生方法已经能够有 80+的精确度**。**
在这种情况下,由于每个训练记录的字数只有几个字(从 2 个字到 10 个字)。使用单词嵌入可能不是一个好主意,因为没有的邻居(单词)来训练向量。
另一方面,scikit-learn 提供了其他参数来进一步调整模型输入。您可能需要了解以下特性
- ngram_range:除了使用单个单词,还可以定义 ngram
- 二进制:除了计算出现次数,还可以选择二进制表示。
- max_features:可以选择最大字数来减少模型的复杂性和大小,而不是使用所有的单词。
此外,一些预处理步骤可以在上述库中执行,而不是自己处理。例如,停用字词删除、小写字母等。为了有更好的灵活性,我将使用我自己的代码来完成预处理步骤。
关于我
我是湾区的数据科学家。专注于数据科学、人工智能,尤其是 NLP 和平台相关领域的最新发展。你可以通过媒体博客、 LinkedIn 或 Github 联系我。
3 文本挖掘中的基本距离度量

Photo Credit: https://pixabay.com/en/hong-kong-night-light-rail-city-2288999/
在自然语言处理中,我们还想发现句子或文档之间的相似性。文本不像数字和坐标那样,我们不能比较“苹果”和“桔子”之间的不同,但是可以计算相似性得分。
为什么?
因为我们不能简单地在“苹果是水果”和“橘子是水果”之间做减法,所以我们必须找到一种方法将文本转换成数字来计算它。有了分数,我们就能明白两个物体之间有多么相似。
什么时候?
在我的数据科学工作中,我尝试:
- 比较两篇文章是否描述相同新闻
- 识别相似文档
- 通过给出产品描述来分类
怎么会?
在本文中,我们将介绍 4 种基本的距离测量方法:
- 欧几里得距离
- 余弦距离
- 雅克卡相似性
在进行任何距离测量之前,必须对文本进行标记。如果你不熟悉分词,你可以访问这篇文章。
欧氏距离

Photo Credit: http://dataaspirant.com/2015/04/11/five-most-popular-similarity-measures-implementation-in-python/
比较两个物体之间的最短距离。它使用从中学学到的勾股定理。
分数是指两个物体之间的距离。如果为 0,则表示两个对象是相同的。以下示例显示了比较第一个句子时的得分。
print('Master Sentence: %s' % news_headlines[0])
for i, news_headline in enumerate(news_headlines):
score = sklearn.metrics.pairwise.euclidean_distances([transformed_results[i]], [transformed_results[0]])[0][0]
print('-----')
print('Score: %.2f, Comparing Sentence: %s' % (score, news_headline))
输出
Master Sentence: Elon Musk's Boring Co to build high-speed airport link in Chicago
-----
Score: 0.00, Comparing Sentence: Elon Musk's Boring Co to build high-speed airport link in Chicago
-----
Score: 1.73, Comparing Sentence: Elon Musk's Boring Company to build high-speed Chicago airport link
-----
Score: 4.36, Comparing Sentence: Elon Musk’s Boring Company approved to build high-speed transit between downtown Chicago and O’Hare Airport
-----
Score: 4.24, Comparing Sentence: Both apple and orange are fruit
余弦相似度

Photo Credit: http://dataaspirant.com/2015/04/11/five-most-popular-similarity-measures-implementation-in-python/
确定两个物体之间的角度是寻找相似性的计算方法。分数的范围是 0 到 1。如果得分为 1,则表示它们的方向相同(而不是大小相同)。以下示例显示了比较第一个句子时的得分。
print('Master Sentence: %s' % news_headlines[0])
for i, news_headline in enumerate(news_headlines):
score = sklearn.metrics.pairwise.cosine_similarity([transformed_results[i]], [transformed_results[0]])[0][0]
print('-----')
print('Score: %.2f, Comparing Sentence: %s' % (score, news_headline))
输出
Master Sentence: Elon Musk's Boring Co to build high-speed airport link in Chicago
-----
Score: 1.00, Comparing Sentence: Elon Musk's Boring Co to build high-speed airport link in Chicago
-----
Score: 0.87, Comparing Sentence: Elon Musk's Boring Company to build high-speed Chicago airport link
-----
Score: 0.44, Comparing Sentence: Elon Musk’s Boring Company approved to build high-speed transit between downtown Chicago and O’Hare Airport
-----
Score: 0.00, Comparing Sentence: Both apple and orange are fruit
Jaccard 相似度

Photo Credit: http://dataaspirant.com/2015/04/11/five-most-popular-similarity-measures-implementation-in-python/
该度量是指所有单词中常见单词的数量。更多的共同点意味着两个对象应该是相似的。
Jaccard 相似度=(A 和 B 的交集)/(A 和 B 的并集)
范围是 0 到 1。如果分数为 1,则表示它们是相同的。第一句和最后一句之间没有任何常用词,所以得分为 0 分。以下示例显示了比较第一个句子时的得分。
print('Master Sentence: %s' % news_headlines[0])
for i, news_headline in enumerate(news_headlines):
y_compare = calculate_position(transformed_results[i])
x1, x2 = padding(y_actual, y_compare)
score = sklearn.metrics.jaccard_similarity_score(x1, x2)
print('-----')
print('Score: %.2f, Comparing Sentence: %s' % (score, news_headline))
输出
Master Sentence: Elon Musk's Boring Co to build high-speed airport link in Chicago
-----
Score: 1.00, Comparing Sentence: Elon Musk's Boring Co to build high-speed airport link in Chicago
-----
Score: 0.67, Comparing Sentence: Elon Musk's Boring Company to build high-speed Chicago airport link
-----
Score: 0.17, Comparing Sentence: Elon Musk’s Boring Company approved to build high-speed transit between downtown Chicago and O’Hare Airport
-----
Score: 0.00, Comparing Sentence: Both apple and orange are fruit
结论
你可以从 github 中找到所有代码。
三种方法也有相同的假设,即文档(或句子)相似,如果有共同的单词。这个想法非常简单明了。它适合一些基本情况,如比较前两句话。然而,通过比较第一句和第三句,得分相对较低,尽管两句都描述了相同的新闻。
另一个限制是上述方法不处理同义词场景。例如购买和购买,它应该有相同的意思(在某些情况下),但上述方法将对待这两个词是不同的。
那么暗示是什么呢?你可以考虑使用 Tomas Mikolov 在 2013 年提出的单词嵌入。
关于我
我是湾区的数据科学家。专注于数据科学、人工智能,尤其是 NLP 和平台相关领域的最新发展。
中:【http://medium.com/@makcedward/】T2
领英:【https://www.linkedin.com/in/edwardma1026
github:https://github.com/makcedward
https://www.kaggle.com/makcedward


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}