




每个数据科学家在面试时都应该问的问题

Photo by Nik MacMillan on Unsplash
你说呢?请告诉我更多
你可能刚从大学毕业,从计算机科学、工程或其他相关领域毕业,或者你可能一直在努力改变你的职业道路。无论你是如何来到这里的,重要的是你现在正在寻找一份数据科学方面的工作。
数据科学家的工作是最受关注的工作之一。它得益于诸如“21 世纪最性感的工作”等迷人的标题,而且自从有了这个概念以来,这个数字一直在增长。这些职位变化很大,有些主要是基于创建模型来做预测,有些则是关于编写管道来将原始数据转换为结构化数据,或者与提高效率有关;总的来说,它将是所有这些东西的混合。
无论如何,只要你能胜任这份工作,他们就会找你,而不是相反,但他们不会这么做。每个优秀的谈判者都知道,达成好交易的最佳方式是扭转局面:他们需要你,但他们会让你觉得你也需要他们。招聘人员在创造这种感觉方面训练有素,正如每个优秀的科学家都知道的那样,最好的战斗方式是进行基于证据的分析,而不是让你的感觉来决定。
你现在怎么拿到这个证据?这里有几个你应该问的问题和你应该寻找的东西。
你说呢?询问示例
通常,这些公司会试图通过告诉你他们如何使用最先进的技术来吸引你,特别是,他们可能会使用脏话:“我们使用人工智能”
你说呢?请告诉我更多
这些话应该敲响警钟。一听到他们,就问例子。90%声称使用人工智能的公司实际上并没有使用人工智能。不要满足于一些泛泛的回答,至少询问一些细节,无论你最感兴趣的是什么。他们可能只有非常基本的模型(我在这里说的是线性回归),他们向客户过度推销这些模型,并试图对你做同样的事情。
如果他们不准备给你任何细节,用“知识产权”这样的借口,带着你的东西尽快离开。他们要么在撒谎,要么遮遮掩掩,这只会造成一个有害的工作环境。例如,像“我们修改了深度学习计算机视觉,如更快的 R-CNN 来检测,数据科学家负责质量测试”这样的答案不会以任何方式侵犯知识产权,但会提供所有必要的信息来了解工作。
如果事实证明它们确实能与人工智能一起工作(无论这对你意味着什么),你会很高兴知道这一点。如果他们没有,但他们解释了他们做的分析类型,而且仍然很有趣,你会很高兴知道的。此外,这种问题也有助于你的面试过程,因为它可能会引发讨论,在讨论中你将能够显示你是知识渊博的:双赢!
询问他们的日常工作
这与前一点密切相关。公司试图吸引人才,这不是秘密。人才通常工作得更好、更快,不需要那么多管理。为了得到他们,他们会毫不犹豫地让事情看起来比他们更好,甜言蜜语,只展示事情有趣的一面。
在这个过程中,当你遇到你未来的同事时,你的工作就是尽可能多地探究他们。询问他们前一天做了什么,这项工作的工作量是多少,每项工作需要多少时间。你可能会发现他们的大部分工作都是基于 excel 表格,或者管理工作量超出了你的预期和愿望。
所以你有股票期权?
一些公司可能会提供股票期权。如果是这种情况,而且是你感兴趣的事情,一定要获取更多的相关信息。例如,你需要多长时间才能解锁,代价是什么?转售条件是什么?如果有试用期或其他类似情况,一定要问清楚试用期是否已经计入解锁时间。
询问远程工作
除了远程工作提供的实际好处之外,我个人认为它能告诉我们公司的很多情况。如果他们对此感到尴尬,那应该会引起警惕。我个人认为这是公司更深层次问题的征兆,比如微观管理,缺乏信任等等。在任何情况下,无论问题的结果如何,都不要犹豫去询问更多的信息。
协商你的薪水
这是一个令人伤脑筋的问题,即使你越来越有经验,有些人还是不放心谈论钱。不幸的是,这是一个常见的错误。没有必要对它指手画脚,只是询问,简单地问。最坏的结果,他们拒绝,但不会影响进程,只要你不要逼得太紧。
查看他们的网站和社交媒体
这是额外的一点,但个人认为也相当重要。因为我也喜欢写文章,所以我喜欢看到那些给员工时间和空间来写博客的公司。这已经变得很普遍了,我相信这证明公司有一个良好的工作环境。
最后一点
不幸的是,许多公司会试图以各种方式利用你。无论是误导你,没有给你完整的信息,增加额外的条款,没有提到的过程中。所有这些对新手来说都是真实的,因为他们缺乏经验。确保不要太天真或太好,仔细阅读你的合同,如果你注意到一些灰色地带,请询问一下。
此外,我提出的很多观点都是关于提问的。这通常很容易看到,除非它开始感觉像警察试镜。在整个面试过程中,尽可能让问题自然,如果你觉得你问了太多问题,这里有一个窍门:把问题转化成陈述。有趣的是,这个过程很像调情。你不想当警察,但同时又想知道更多。使用开放式陈述,利用过去的经验开始讨论,等等。
最重要的是,要友善!虽然这篇文章给出了一个黯淡的公司形象,但它只是作为一种保护和未来证明自己的手段。大多数人都很好,不会试图利用你。
祝你好运!
干得好,你通过了测试!这个统计数字实际上完全是捏造的,尽管个人经验表明它与事实相差不远。
悄无声息的半监督革命
是时候掸去未标记数据的灰尘了?

对于机器学习工程师来说,最熟悉的设置之一是访问大量数据,但只有少量资源来注释这些数据。处于这种困境中的每个人最终都会经历这样一个逻辑步骤:当他们只有有限的监督数据,但有大量未标记的数据时,他们会问自己该怎么办,而文献似乎已经有了现成的答案:半监督学习。
这通常是事情出错的时候。
从历史上看,半监督学习是每个工程师都经历的一个兔子洞,只是为了发现对普通旧数据标记的新发现。每个问题的细节都是独一无二的,但大致来说,它们通常可以描述如下:

在低数据状态下,半监督训练确实有助于提高表现。但在实际环境中,你经常会从“糟糕到无法使用”的表现水平,变成“不太糟糕但仍然完全无法使用”本质上,当你处于半监督学习实际上有所帮助的数据体制中时,这意味着你也处于你的分类器只是简单糟糕并且没有实际用途的体制中。
此外,半监督通常不是免费的,使用半监督学习的方法通常不会为您提供监督学习在高数据领域中提供的渐近属性,例如,未标记的数据可能会引入偏差。参见第 4 节。深度学习早期非常流行的半监督学习方法是首先在未标记数据上学习自动编码器,然后在标记数据上进行微调。几乎没有人再这样做了,因为通过自动编码学习到的表示往往会在经验上限制微调的渐近性能。有趣的是,即使大大改进的现代生成方法也没有改善这种情况,可能是因为好的生成模型不一定就是好的分类器。因此,当你看到工程师今天微调模型时,通常是从监督数据上学习的表示开始的——是的,我认为文本是用于语言建模的自我监督数据。只要可行,从其他预先训练好的模型中进行迁移学习是一个更强的起点,这是半监督方法难以超越的。
所以一个典型的机器学习工程师在半监督学习的沼泽中的旅程是这样的:

1:一切都很可怕,我们试试半监督学习吧!(毕竟那是工程工作,比标注数据有趣多了……)
2:看,数字上去了!不过,还是很糟糕。看来我们终究还是要给数据贴标签了…
3:数据越多越好,耶,但是你试过如果你丢弃半监督机器会发生什么吗?
4:哎,你懂什么,其实更简单更好。我们可以通过完全跳过 2 和 3 来节省时间和大量的技术债务。
如果您非常幸运,您的问题也可能无可否认地具有这样的性能特征:

在这种情况下,有一个狭窄的数据体制,其中半监督是不可怕的,也提高了数据效率。以我的经验来看,很少能达到最佳状态。考虑到额外复杂性的成本,标记数据量的差距通常不是更好的数量级,以及收益递减,很少值得麻烦,除非你在学术基准上竞争。
但是等等,这篇文章的题目不是叫《安静的半监督革命》吗?
一个有趣的趋势是,半监督学习的前景可能会变得更像这样:

这将改变一切。首先,这些曲线符合人们对半监督方法应该做什么的心理模型:数据越多越好。半监督和监督之间的差距应该严格为正,即使对于监督学习做得很好的数据制度。越来越多的情况下,这种情况的发生不需要任何成本,而且非常简单。“神奇地带”起点较低,同样重要的是,它不受高数据范围的限制。
有什么新鲜事?很多事情:许多聪明的方法来自我标记数据,并以一种与自我标记的噪音和潜在偏见兼容的方式表达损失。最近的两部作品举例说明了最近的进展,并指向相关文献: MixMatch:半监督学习的整体方法和无监督数据增强。
半监督学习领域的另一个根本转变是认识到它可能在机器学习隐私方面发挥非常重要的作用。例如,PATE 方法(用于从私人训练数据进行深度学习的半监督知识转移,利用 PATE 的可扩展私人学习),其中监督数据被假定为私人的,并且仅使用未标记的(假定为公共的)数据来训练具有强隐私保证的学生模型。提取知识的隐私敏感方法正在成为联合学习的关键促成因素之一,它提供了高效分布式学习的承诺,不依赖于访问用户数据的模型,具有强大的数学隐私保证。
这是一个令人兴奋的时刻,在实践中重新审视半监督学习的价值。看到一个人长期持有的假设受到挑战,是该领域发生惊人进展的一个很好的指标。这种趋势是最近才出现的,我们必须看看这些方法是否经得起时间的考验,但这些进步可能导致机器学习工具架构的根本转变,这种可能性非常有趣。
数据可视化竞赛:Tableau 的魔力是什么?

比赛刚刚升温。6 月 6 日,谷歌宣布他们将收购数据查询和探索工具 Looker。考虑到 Looker 与谷歌的数据工作室有些重叠,这是一笔有趣的收购。(然而,当我回想起谷歌下一次发布会时,我不记得有一次提到 Data Studio。)收购 Looker 的目的当然是为了缩小谷歌云在大数据和商业分析解决方案市场上落后于亚马逊网络服务和微软的差距。根据 IDC 的数据,这个市场到 2022 年可能达到 2600 亿美元。
尽管这对谷歌来说是一个重大举措,但更大的消息来自 Salesforce,他们宣布计划以 157 亿美元收购 Tableau!这对 Salesforce 意味着什么?我有两个想法。
首先,Tableau 将极大地扩大 Salesforce 的客户群。Tableau 与 Salesforce 平台和 Einstein 等技术非常契合,提供了更易于使用的企业标准可视化工具。这就是为什么以前不是 Salesforce 客户的许多人和公司现在会成为 Salesforce 客户的一个原因,首先是现有的 Tableau 用户,他们可能会将 sales force 带入他们的技术武器库。小公司、独立承包商或只是数据可视化爱好者将很快成为 Salesforce 每月经常性收入的一部分。(虽然,并不是所有的 Tableau 客户都满意。虽然 Salesforce 承诺保持 Tableau 的多平台方法和对多个数据集的连接,但许多现有的 Tableau 用户需要被说服。毕竟,他们是与 Salesforce 目前的用户群完全不同的用户群。)

其次,这使 Salesforce 更接近与谷歌和微软竞争。这两家科技巨头已经分别提供了数据探索工具 Data Studio(和 Looker)和 Power BI。虽然这些软件解决方案很好,但我不认为有人会说它们与 Tableau 处于同一水平。事实上,画面似乎有某种魔力。人们不仅喜欢使用它,当他们谈论它时,他们真的很兴奋。没有多少应用程序可以这么说。那么为什么 Tableau 会出现这种情况呢?
完美的平衡
现在是完全不同的东西,Python。Python 在过去十年中经历了飞速发展。它已经从一些人认为的玩具语言变成了不仅仅是计算机科学家的通用语言,而是所有科学家的通用语言。无论你是天文学家还是化学家,如果你编程,很可能是用 Python。许多人将这一成功归功于 Python 简单而强大的平衡。Python 中的 Hello world 是一个简单的 liner,print(“Hello World”)。这在 Java 中需要三行,在 C 中需要六行(取决于您如何格式化代码)。伴随着编码的简易性而来的还有不错的处理速度。没错,Python 没有 Fortran 快,但是对于一个从 Excel 走过来的人来说,就是闪电了。
Tableau 似乎也发现了这个“恰到好处”的金发女孩地带。它为探索数据提供了高度的可修复性,学习曲线非常平缓。数据可视化的守护神爱德华·塔夫特对此做了很好的总结。“卓越的图形是在最短的时间内给浏览者提供最多的想法…”。
这似乎是 Tableau 的核心设计理念。使用户能够在尽可能少的培训下快速浏览数据。当然,随之而来的是权衡。Tableau 能像 R 的 ggplot2 包一样可定制吗,不能。它能像 D3.js 一样无缝集成到网页中吗,不能。但是与其他两个相比,Tableau 的学习曲线要容易得多。你可以和一个从未使用过 Tableau 的人坐下来,几分钟后他们就会自己去试验和探索数据。Tableau 融合了这些选项的一些最佳特性。它利用了 ggplot 使用的图形语法,并结合了 D3 的交互特性。是的,您失去了一些灵活性,但是在大多数情况下,您获得的速度是值得的。
美丽很难获得
任何试图从零开始设计图表或图形的人都很清楚需要选择的因素的数量。有颜色、背景色、刻度线、线条不透明度、比例、字体大小等。这是一项艰巨的任务。最终你会在编辑过程中的某一点,你甚至不确定这是否是一个积极的改变。如果你想知道选择颜色有多难,看看这个 YouTube 关于 matplotlib 重新设计默认颜色图的过程。
幸运的是,Tableau 为你做了设计选择的重担,10 次有 9 次,它看起来很棒。我问一个同事为什么喜欢 Tableau,他说“它让你的数据看起来很漂亮,你甚至不用去尝试”。蛮的价值不可小觑。
在星盘中,美丽通常是没有干扰。如果颜色不对,或者有太多的刻度线,这会分散观众对数据信息的注意力。弗洛伦斯·南丁格尔有一个很好的例子。她使用了一个简单的极区图,使观众的注意力集中在数据讲述的故事上(这里有一个 Tableau 工作簿的链接,一些人复制了南丁格尔的著名图表)。

可悲的是,其他可视化工具在这一领域仍然落后。
Tableau 的这种开箱即用的美感,结合其平衡的用户易用性,使其成为数据探索和可视化的事实上的工具。Tableau 的用户遍布各行各业,涉及各种工作职能。事实上,可能唯一比 Tableau 更普遍的数据工具就是 Excel 了。
舞台颂歌
我一直很喜欢 Tableau。这是一个很棒的产品,提供了很好的服务。当我听到他们被收购的消息时,我的第一想法是我为他们感到高兴。就好像我听说一个老朋友找到了一份好工作。我仍然记得我的第一本 Tableau 练习册。我在硕士项目的训练营做的。它着眼于 IMDb 的电影评论与烂番茄的电影评论有何不同(这个话题我会再次提及)。从那以后,我可能已经做了一百多个 Tableau 练习册。我用得太多了,已经开始影响到我女儿了。有一次我在家工作,她来到我的办公室,给我看了一张她用彩色笔手绘的图表。这是一个条形图,显示了她有多爱不同的动物,第一是猫。我把它拿过来,用 Tableau 重新制作,让她看看她的作品有多好。

Tableau 对我建立投资组合也很重要。甚至我以静态图像结束的数据可视化也是从我通过 Tableau 工作簿探索数据开始的。无论是展示我在研究生院写了多少行代码,还是展示我在塔可钟吃过多少次,Tableau 都是帮助我讲述故事的工具。
我的个人资料上写着“我是一名数据科学家、数据插画师和作家”。我可能从像尼古拉斯·费尔顿和蒂芙尼·法兰特·冈萨雷斯这样的艺术家那里找到了灵感,但是是画面帮助我实现了这个中间角色。它给了我一个艺术的出口,也给了我一种将美运用到日常工作中的方式。
祝贺 Salesforce 收购了一家伟大的公司。我希望 Tableau 的下一个阶段只会给使用它的公司和人们带来最好的东西,也给那些第一次发现它的人带来最好的东西。
处理缺失数据的真正正确方法

作为一家咨询公司的首席数据科学家,我工作的一个重要部分是面试和聘用数据科学人才,以满足我们不断增长的客户群的需求。我们的数据科学团队的结构对医疗行业的人来说肯定是熟悉的。当你生病或受伤时,你通常会去医院。医院在任何时候都有很多病人,所以给你看病的医生几乎肯定不会是主治医生或内科主任。相反,你更有可能首先被住院医生或实习医生,或者现在的医生助理或执业护士看到。
这些专业人员是第一道防线,必须接受培训,以处理大多数基本和世俗的案件。主治医生监督病人的护理,只有当实习医生或住院医生不确定该如何处理时,他才会被叫去看望某个病人。同样,我们的咨询业务在任何时候都有很多客户,我监督我们所有的项目。然而,因为我不能同时出现在所有地方,所以我通常不是部署到客户站点的顾问。我会派我们的顾问去,因为我知道他或她至少有能力处理客户需要解决的大部分任务。我希望顾问们能够独立处理项目,只需要在最具挑战性的问题上找我。
因为这是我们的商业模式,我需要确保我们只引进最优秀的人才。我在筛选过程中非常仔细。如果顾问没有技能和知识,他们最终会向我寻求帮助。然后那些顾问的项目占用了我所有的时间。我最终加班加点,只是为了跟上项目进度,并确保我们的交付物是高质量和准时的。
在我的筛选工作中,我开始注意到我面试的候选人中的一个趋势。这种趋势体现在我对一个具体问题的回答中:“你如何处理丢失的数据?”最近每次我问这个问题,总是得到这样的回答:“你要么删除带有缺失信息的观察值,要么用某种集中趋势的度量来填充缺失值,比如数值变量的均值或分类变量的模式。”这个答案如此一致,以至于我觉得有必要解决它。
你可能会问自己,“这个答案有什么问题?我以前也这样做过。”我也是。然而,这通常不是我做过的项目,当我做过的时候,这是最后的手段。这个答案我称之为象牙塔答案,因为它来自纯理论。这表明,作为一名行业数据科学家或在项目中与客户打交道,绝对没有实际知识。
那么,真正的答案是什么?简单。你和你的客户谈过了。现在,这个答案是如此的简短,如此的简单,以至于对你们中的一些人来说,这个答案可能会彻底的令人失望。那么请允许我通过分享一个我曾经的经历来阐述。
几年前,我是一个团队的成员,该团队为一个客户建立了一个模型,该客户的业务主要是围绕大订单报价而建立的。该模型向报价专家提供建议,说明如何根据订单中的内容、订购的数量以及客户之前的购买行为等对报价中的项目进行折扣。我们的想法是建立一个可以达到理想平衡的模型,在这个模型中,商品的折扣只是足以让客户购买订单,但不会超过必要的折扣,这样利润仍然可以最大化。
除了你可能会想到的所有贝叶斯统计和机器学习算法都进入了这个模型的设计之外,对客户来说,我们纳入某些业务规则也很重要。例如,他们希望对任何售出的商品保持 25%的最低利润率。客户也希望尊重公布的标价。也就是说,即使数据表明客户可能会支付更高的价格,客户也不会想要出价高于标价。模型的这些限制要求我们知道客户目录中每件商品的成本和标价。
客户拥有这些数据似乎是理所当然的。然而,一旦管理人员将他们目录中所有商品的数据集发给我们,我们发现我们要么遗漏了成本,要么遗漏了相当大一部分商品的标价。举个例子,这个客户卖的东西少则 10 美分,多则 4000 美元。将所有缺失的成本或标价设定为平均值不太可能给出合理的值。那么,我们做了什么?
我们和客户公司的销售主管通了五分钟的电话。我们解释了情况,他告诉我们,他们几乎总是调整价格,使成本在标价的 40%左右。因此,只要我们有标价,但没有成本,我们就可以估算标价 40%的成本。对于任何有成本但没有标价的项目,我们可以估算标价,这样成本就是估算标价的 40%。就这么简单!
在这种情况下,没有集中趋势或数学定理可以给我们正确的答案。我们只知道通过与我们的客户交谈来做什么,所以我们可以理解围绕所讨论的变量的业务逻辑。一些读者可能会想,也许我们可以构建一个简单的模型来推断成本和标价之间的关系。虽然这可能是真的,但这仍然是一个非常象牙塔的答案。使用模型来推断这种关系仍然比不上直接洞察客户的业务逻辑,更重要的是,在商定的前进道路上获得客户的祝福。
这就把我们带到了“利益相关者买入”的话题上要有一个成功的数据科学项目,您需要利益相关者认可您正在做的事情、您是如何做的以及使用哪些数据。我已经看到一个项目中的分析和建模的整个途径被减慢或完全停止,因为,虽然分析背后的数学和理论是合理的,但是涉众就是不能或不愿意参与进来。有时,这可以通过简单地找到一种更清晰和简洁的方式向涉众解释分析来解决。然而,有时这是不可能的,因为利益相关者反对的原因与他们的商业逻辑、价值观或目标有关。
这一点的重要性怎么强调都不为过。我们应该始终考虑客户的商业逻辑、价值观和目标,确保客户的目标就是我们的目标。强力方法,如放弃观察或假设所有缺失值都可以用平均值代替,只应在客户没有明确指导的情况下作为最后手段使用。即使在这些情况下,你也只有在得到客户同意的情况下才能这么做。你肯定不希望在你已经采用这种方法后,发现公司领导觉得这种方法有点过于粗糙或随意。相反,最好是确保每个人都对项目在每个阶段的进展感到满意。
这看起来似乎是低效和缓慢的,截止日期是任何咨询工作中非常真实的一部分。花更多的时间做额外的分析来看看你得到了什么样的结果,用集中趋势的度量来代替缺失的值,以确定要使用的最佳度量,并向你的客户清楚地解释任何特定选择的利弊,这可能很难让人感觉良好。然而,您的项目时间范围正是您需要以这种方式处理这个问题的原因。它最终会节省时间,确保你不会浪费时间去追求那些你的利益相关者会怀疑,并且可能永远不会同意的事情。
如果您的客户无法提供任何关于如何处理丢失数据的有用指导,那么如何继续的最后一个想法是:看看您是否可以为他们尽可能小而简单地解决问题。假设我们与销售主管的谈话并不顺利。说他们在成本和标价之间的关系上没有一个清晰一致的战略。然后呢?作为头脑风暴解决方案过程的一部分,我会把重点放在减少我们为了解决问题所需的要求的方法上。
在这个特殊的例子中,我们很幸运。这些项目被组织成部门,并在每个部门内被划分成项目类别。我不会简单地计算整个数据集的平均成本或标价,而是会尝试在计算集中趋势之前,将项目类别和子类别中的项目聚集起来。这样,我可以知道,并告诉我的客户,所使用的措施只涉及类似的项目。这样,我就不会要求涉众接受如此粗糙的东西。此外,如果在某些情况下,他们对取得的结果不满意,那么我需要成本或标价的数据点就会少得多。使用这种方法,我对客户的要求可能比试图找出所有项目的平均值要小得多,也简单得多。
我确信会有读者想出各种各样的“如果”,关于一个人可能会发现自己在不同的特定场景中会怎样。我不可能在这篇文章中涵盖所有可能的场景。这些例子只是为了说明处理这个问题时的一般方法和思维方式。我将尝试用几条简单的规则来总结这些想法。
1.总是和你的客户谈论数据中缺失的值。
2.如果他们有明确的指导,就接受吧。如果没有,看看你能否理解数据所描述的过程,以及细节如何转化为你在数据中看到的具体表现。尝试了解他们的业务逻辑、价值和围绕数据中表示的流程的目标。即使他们对你有明确的指导,你也应该试着理解所有这些。如果他们不这样做,这应该用来尝试得出你可以遵循的明确的指导方针。
3.如果所有其他方法都失败了,继续使用简单的模型来推断关系,或者测量集中趋势。
4.在进行之前,一定要获得客户的同意,用你认为最好的方法进行。
遵循这些指导方针总会让你的项目进行得更顺利,让你的客户比你先求助于上面提到的象牙塔答案更开心。
数据民主化的真正含义和过程。
如何做以及为什么现在就做…
场景:印度农村的一个小村庄。当公共记录被宣读时,全村的人都聚在一起听。一名村民在公共记录中被列为将他的犁出租给政府赞助的灌溉项目。“不,”他说,“我没有那样做。那时我在德里参加我表兄的婚礼。”有笑声,也有愤怒,因为人们立即发现他们是如何被欺骗的,公共资金是如何从他们和他们的村庄被抽走的。更多的虚假信息被揭露出来:例如,6 公里运输材料的账单项目,而实际上,实际距离只有 1 公里。一名工人,根据政府记录受雇于一条新运河的建设,站起来问:“什么运河?”参与建房的工人证实,供应和使用了 50 袋水泥,而不是 100 袋。在公众听证会结束时,圣歌响起:“我们想要什么?信息。我们想要什么?信息:理查德·卡兰博士讲的故事
在过去的五十年里,许多国家及其政府已经正式承认了针对这些主张的知情权。越来越多的国家,例如南非,在其宪法中确立了知情权。如果机构努力维护公众的合法性,那么对访问权的正式承认是显而易见的。走向更多民主的道路是数据民主化的道路。获取信息与民主的存在之间存在着非常严格的关联。简而言之:为了做出正确的决定并在选票上正确打勾,公民必须被告知。获取信息对于人们实现参与国家治理的基本权利以及在基于公民知情同意的制度下生活至关重要。在任何国家,特别是在民间社会的政策分析能力不发达的国家,如果不能获得政府信息,就无法有效行使政治参与权。听起来很明显?很好:让我们继续,因为除了谈论我的“雄心壮志”,我还想概括地介绍一点关于数据民主化的理论,回答两个主要问题:为什么是现在?又是怎么做到的?以相反的顺序。
数据如何民主化?
我找到的解决方案是建立一个搜索引擎。这显然不是唯一的方法——远非如此。但由于数据科学的出现,这是一个既灵活又强大的领域。
在我选择的这个过程中,我看到了三个主要步骤,我将逐一介绍:
1.使数据易于查找
大多数可以被大众化的数据都可以在某个地方找到。但问题是,就数据有用性而言,“某处”或多或少与“无处”是一样的。如果只有政治竞选经理看到这些数据,你就不能称之为民主化。问题在于发布数据的人的错误 KPI(关键绩效指标)。他们中的大多数人关注的是如何将尽可能多的数据推送到互联网上,而不是关注有多少人会看到这些数据。
如果我们最终同意改变这个焦点,我们将如何实现绩效?这就需要一个好的搜索引擎,有好的搜索引擎优化。一个好的搜索引擎是智能的。与只寻找关键字匹配的简单搜索引擎相反,智能搜索引擎通过识别或推断用户想要的结果的性质来解释查询,识别查询中提到的时间和位置等重要参数,并最终考虑搜索的上下文。一旦它可用,它也需要被使用。可以通过多种方式接触用户。统计显示,数据大多是通过谷歌这样的搜索引擎搜索出来的。因此,良好的 SEO 是实现数据搜索便利化目标的关键一步。
2.简单、易懂且高质量的数据表示
一旦搜索引擎开始工作并可访问,下一步就是显示结果。这一部分看似简单,实质上也很简单。但是试着设计和构建一些看起来和感觉上用户友好的东西,但是要足够复杂以理解整个画面,你会发现这个任务并不是说起来容易做起来难。事实上,大多数想要实现数据民主化的解决方案都远远不符合这些标准。以下是解决方案在以最佳方式显示数据时面临的主要问题:
- 缺乏直接性是由解决方案处理数据的方式造成的:许多解决方案将数据分组放在表中,因此无法显示单个值,失去了直接性;
- 事实上的不精确扼杀了整个交易。可能很难保证完全精确,但落入这个陷阱是肯定的;
- 不回答问题也是用户可能得到的非常令人沮丧的体验之一;
- 来源是必要的;
- 数据上下文是必须的;
- 代表性的视觉效果(如信息图)对理解有很大的帮助

An example of poor quality data representation
一篇关于数据表示体验的更深入的文章即将发表……
3.在增加数据量的同时重复前两个步骤
第三步是在两个方面一直被忽视的一步。
要么是一个解决方案冲进来,添加了所有可能的数据,却无法处理这些数据,要么是相反的情况——添加的数据太少,用户无法从产品中获得足够的价值来使用这些数据。

Illustration by Katerina Limpitsouni
第一种选择是最常见的。我们看到 Statista.com 有很多很多的数据,管理不善,因此搜索功能和 UX 很差。他们的数据从人均 GDP 到电子竞技专业人士统计的堡垒之夜碎片数量不等。几乎所有事情都是如此(除了少数例外):选择数量会损害质量。
相反的问题就不言自明了。
数据民主化需要找到它的速度平衡:搜索和数据曲线的质量与拥有用户所必需的数量之间的交叉点。
为什么现在要民主化数据?
这听起来像是一个荒谬的问题,因为我在引言中提倡数据民主化。我向你保证,我没有改变主意。我只是相信,现在是加快信息传播速度、让更多人看到信息的最佳时机。
**首先,**我们每天都有大量的数据产生,并且越来越容易被使用。政府正在收集比以往更多的数据,并向公众开放,这些数据的质量正在提高,尽管这一积极趋势的速度和程度在很大程度上取决于国家和地区。守旧、腐败的市长和政府官员可能会造成短期封锁,但从长期和大范围来看,这不会造成问题。
由于数据科学的进步,数据解释也在增加。我将发表一篇文章(与几位伟大的数据科学和开放数据专家合作),介绍如何利用人工智能从数据中获得有趣的见解。

Photo by Elena Koycheva on Unsplash
**第二,**我们有资源让人们的目光追随这些数据。用户体验的进步(在其广泛的定义中)使我相信“无聊”是可能的,但对决策数据到达大量受众是重要的。在过去的 10 年里,设计师和工程师的合作已经产生了新类型和新设计的界面,它们更方便,更美观,总的来说,它们提供了更好的用户体验。尽管注意力持续时间缩短了,但我们学会了如何更频繁地获得这种注意力。几乎没有人会在 Instagram 上连续花两个小时,但如果你总结一下每天花在上面的时间,你可能会发现一个不同的故事。告诉我我是否天真,但我认为 Instagram 并没有因为其出色的用户体验而享有特权,其他产品,如代表统计信息的产品,可以提供同等的竞争对手来吸引注意力。
最后,但可能是最重要的,现在是时候做这件事了。不是明天。我们有即将到来的选举,我们有许多危机和大量的决定要做。如果我们跟着直觉走,而不是跟着数据走,我们在大多数情况下都会失败。
这里有个问题问你。如果两个候选人竞选连任。更合理的决定是基于新的竞选承诺,还是基于他们在上一个任期内参加会议的记录以及他们的投票历史?
我会选择第二个选项。我相信,如果更多的人选择第二种选择,这个社会将得到更好的代表。
我认为这是一项值得关注的事业。我甚至认为这是一个值得采取行动的原因。
在我最近开始写的一篇公开日记中,我宣布了一个全新项目的开始,我需要一个团队。在我写这篇文章的时候,我已经组建了一个相当大的团队,我正在清除我的想法在我自己和其他人心中的灰尘。如果你觉得你可以做出贡献,请随时给我写信。

This is the HIVERY trademark tagline
全球核武器的现实和俄罗斯核武器如何打开你的灯

India’s Polar Satellite Launch Vehicle (not a nuclear weapon!) launches in 2018 (Source)
探索全球核储备下降的数据和你从未听说过的最有趣的政府项目:现实项目第 3 集
2018 年一个温暖的夏天,我正坐在哈奇纪念馆的草坪上,准备欣赏我最喜欢的交响乐——T2·霍尔斯特的《行星》——这时我看到了由忧思科学家联盟搭建的帐篷。作为一个普遍关心科学现状的人,我走了过去,当我走近时,被一群人吸引住了,他们正围着一个男人讨论核武器的威胁。刚刚读完史蒂芬·平克的enlightning Now,我希望听到更多关于过去 30 年来核武器库存大幅削减的积极消息。
相反,这个人的演讲——正如平克告诉我们对学者的期待——完全是负面的。要点是,人类的愚蠢导致我们制造出能把我们这个物种从地球上抹去的武器,我们处于严重的危险之中。不知所措的是,当那个人停下来喘口气时,我举起手问他是否知道世界上有多少核武器,以及这与过去的数字相比如何。他自信地回答道:“现在比以往任何时候都多,尽管我不知道确切的数字。”
此时,在拥有别人没有的数据所带来的自信(和傲慢)的鼓舞下,我强调了我的事实优势的所有价值:“1985 年,世界上大约有 70,000 件核武器,而今天,在 2018 年,只有不到 15,000 件。这意味着减少了近 80%,此外,今天拥有核武器的国家减少了 4 个。”惊讶之余,这个人要求核实事实,在咨询了一个可接受的来源后,他承认乐观的数字是正确的。虽然我的本意并不是要方得这个人,但这是意料之外的效果,人群开始慢慢散去,人们对他的宣言的热情也消失了。
虽然我无意中失去了他的所有听众,但他同意与我进行讨论(在我为智力伏击道歉后),我们进行了富有成效的辩论,双方都做出了让步:我同意零核武器是最佳选择(尽管目前不现实),他说他将重新构建他的信息,以强调我们在削减核武器方面取得的进展。后来,当我坐在那里听霍尔斯特宏伟作品的音时,我想到了这次经历教给我的东西:
- 即使是专家对世界的看法也是严重错误的。
- 在缺乏数据的情况下,人们会假设人性最坏的一面。
- 当你纠正某人时,不要表现得高人一等。记住,在你阅读统计数据之前,你也是无知的。
在这篇文章中,我们将检查世界各地有关核武器的数据。上述基本数据是正确的——在过去 30 年里,核武器数量和拥有核武器的国家数量都大幅下降。然而,也有一些我们应该担心的问题,包括美国和俄罗斯之间的紧张关系,这威胁到军备控制条约和不稳定国家拥有核武器。除了这些数字,我们还将了解兆吨变兆瓦,你可能从未听说过的最有趣的政府项目,在这个项目中,俄罗斯的炸弹真的打开了你的灯。
本文是现实项目的第三集,旨在减少对数据世界的误解。你可以在这里找到以前的文章和所有的文章,通过搜索现实项目标签。
事实
本文中我们的数据将来自于我们数据中的世界:核武器、美国科学家联合会:世界核力量现状以及史蒂芬·平克的《我们本性中更好的天使(引用了斯科特·萨根)。我们还将利用来自军备控制协会和国务院的信息谈论核武器条约。关于兆吨到兆瓦项目的信息来自军备控制协会。
核武库规模的确切数据是严格保密的,尽管如此,由于国际协议和监控项目,我们可以得到相当可靠的估计。从客观数据来看,我们清楚地看到全球核武器数量呈下降趋势。以下是一段时间以来全球核武器总数(来自《我们的世界》的数据):

Total number of nuclear weapons (deployed, stockpiled, and retired) over time.
全球核储备在 1985 年达到顶峰,此后一直在快速下降。同样,确切的估计数字有所不同,但美国科学家联合会表示,截至 2018 年,数字从 70,300 增加到 14,485。这代表了核武器总量下降了近 80%!
今天,有 9 个国家确认拥有核武器(由于技术/材料需求和国际监督,不太可能有更多的国家拥有核武器):

Countries with nuclear weapons and total numbers in 2018
俄罗斯目前拥有更多整体核武器,而美国拥有更多部署武器*。核武器的状态和类型与数量同样重要:*
- 部署在洲际弹道导弹或重型轰炸机上,可以瞬间发射
- 库存:存放在军队中,并“指定由委托交付的车辆使用”(可能会部署)
- 退役:退役,等待拆除。
- 战略武器:更大的武器——比如洲际弹道导弹——可以从千里之外的国家发射或者搭载在轰炸机上
- 非战略(战术)武器:较小当量,设计用于战场,可能在友军附近使用
军事用途(部署+储存)总数不到 10,000 件,约 1,800 件武器处于高度戒备状态。就所有类型的核武器而言,全球总量已大幅下降。例如,1986 年,俄罗斯拥有 4 万枚核武器,现在不到 7000 枚。美国从 1966 年的 31000 人下降到 2018 年的 7000 人以下。
另一个令人惊讶的消息是,现在拥有核武器的国家越来越少。4 个国家曾经拥有核武器,但现在不再拥有了:南非、白俄罗斯、哈萨克斯坦(拥有 1400 枚核武器)和乌克兰,后者自愿放弃了 5000 枚核武器,这是世界上第三大核武库。此外,许多曾经追求核武器的国家已经放弃了他们的核武器发展。
在下面的图表中,我们看到了各国开始和放弃发展核武器的时间。

Countries that started and then stopped nuclear weapon development (from Pinker with data from Sagan).
不仅拥有核武器的国家正在努力减少核武器数量,而且许多其他国家也认为发展核武器不是他们想做的事情。1990 年,世界上有 13 个国家拥有核武器,现在已经减少到 9 个。这当然是积极的,但三个拥有核武器的国家对此表示担忧。印度和巴基斯坦已经打了 3 场战争,而朝鲜完全是个未知数。
核试验的减少甚至比核武器的减少更令人印象深刻。自 1996 年《全面禁止核试验条约》生效以来(该条约尚未生效,但被世界主要大国遵守),美国和俄罗斯没有进行过一次核试验。此外,自 1999 年以来,只有一个国家,朝鲜,进行过核试验。

Nuclear Weapons Testing (from Wikipedia which cites this SIPRI document)
全世界核试验的累计总数超过 2000 次,但只有 6 次(0.3%)发生在 2000 年之后。我们可以在这张地图上看到这些测试发生在哪里:

Map of Global Nuclear Tests and Explosions (from Radical Cartography)
总之,今天世界上大约有 15,000 件核武器(其中 9,300 件用于军事用途)由 9 个国家持有。四个国家已经放弃了他们的武器,而至少十几个其他国家已经停止发展。自 1999 年以来,只有朝鲜进行过核试验,核试验数量已降至接近 0。最后,对 2020 年的预测表明,世界上总共将有大约 8000 枚核武器。
我们是怎么到这里的?武器削减条约
全球核武库规模的下降无疑是积极的,正如任何统计数据一样,理解为什么会出现这种情况是有帮助的,这样我们就可以弄清楚这种情况是否会持续,以及我们可以做些什么来保持这一趋势。
简而言之,核武器的减少是因为旨在减少武库的国际条约。我们没有足够的空间来讨论所有这些问题(查看这里的完整列表),但是我们将讨论美俄之间的一些问题。这两个国家总共控制了超过 90%的核武器,因此这些协议具有重大影响。
这里是美国和俄罗斯之间削减核武器条约的概述:

Overview of nuclear agreements between US and USSR/Russia (Source)
从表中我们可以看出,并不是每次谈判都是成功的。然而,已经达成一致的条约是有效的。例如,罗纳德·里根在 20 世纪 80 年代提出的《第一阶段削减战略武器条约》(START I)实现了所有目标,俄罗斯和美国到 2001 年将各自的武器削减至 6000 件。
《第一阶段削减战略武器条约》于 2009 年到期,但在那时,《削减进攻性战略武器条约》已经生效,进一步限制了美国和俄罗斯的库存。令人乐观的是,该条约在参议院以 95 比 0 的投票结果获得通过,这表明双方至少可以同意,我们不需要毁灭的威胁像一把毁灭之剑一样悬在我们头上。目前限制核武器的条约,新的削减战略武器条约,于 2010 年获得批准,并于 2018 年完成削减。我们可以通过比较完成前(左)和完成后(右)的核弹头数量来检验该条约的效果:


Number of nuclear weapons in Russia and US before New START (left) and after (right).
根据最终数字(最右边一栏),但是美国和俄罗斯部署的核弹头数量比条约要求的要少(1550 枚)!新的《削减战略武器条约》将于 2021 年正式到期,并可选择延长 5 年。美国现任总统对《新削减战略武器条约》表示不屑,但是没有迹象表明该条约会提前结束。(关于当前发展的讨论,参见军备控制协会的本页。在目前的政治气候下,还不清楚未来会出台什么样的军备控制削减措施。鉴于此前努力的成功,进一步削减武器条约必须成为美国和俄罗斯的优先事项。
这些条约的核查包括现场视察、信息交流、远程监测和包括卫星在内的监视。为了证明美国遵守了第一阶段削减战略武器条约,365 架 B-52 轰炸机被空运到亚利桑那州,被卸下有用的部件,然后被切成碎片。他们被排除在外 3 个月,让俄罗斯卫星确认销毁。

Destroyed B-52s as part of START I (source)
其他减少核战争威胁的措施都是在没有双边协议的情况下实现的,包括 1991 年老布什宣布,随着苏联解体,美国将从部署中移除几乎所有的非战略核武器(这些是 T2,也称为战术核武器,旨在用于战场)。按照计划,苏联以牙还牙,米哈伊尔·戈尔巴乔夫承诺从海军部署中撤出所有苏联战术核武器。仅这一项被正式称为总统核倡议(PNI) 的法案就将全球核武器总数减少了约 18000 枚。尽管俄罗斯和美国仍然拥有战略和非战略核武器,但总数处于历史最低点(关于这种情况是否会持续的讨论,见这里)。
兆吨变兆瓦:你从未听说过的最酷的政府项目
有时候,特别是当世界的命运悬而未决的时候,政府可以做一些惊人的事情。一个不太为人所知的案例是 【兆吨转兆瓦】计划 ,其中来自俄罗斯核武器的 500 吨高浓缩铀(HEU)被 转化为低浓缩铀(LEU)出售给美国公司,用作核电站的燃料。
这个惊人计划的总体影响是,500 公吨 HEU——足以制造 20,000 枚核弹头——被转化为 14,000 吨低浓缩铀,用于为美国各地的核反应堆提供动力。(这项为期 20 年的计划对纳税人的成本是 0 美元,因为 120 亿美元的铀被美国浓缩公司买走了。)
在该计划的 18 年中(1995 年至 2013 年),低浓缩铀燃料提供了美国核反应堆消耗的全部铀的大约 50%,这意味着美国几乎 10%的电力来自旧的俄罗斯核武器!如果你从核电站获得任何电力,那么你的灯实际上是由俄罗斯的核武器点亮的:

Nuclear power plants in the United States (Source)
兆吨到兆瓦的总收益对两国来说都是巨大的。美国的核反应堆需要燃料,苏联解体后,俄罗斯需要现金。随着该计划在 2013 年成功结束,双方都得到了他们所需要的东西。从那时起,美国已经自愿将其部分 HEU 转化为低浓缩铀,这样它就不能被用于制造武器;2008 年签署了一项协议,允许俄罗斯核工业在 2020 年前供应美国铀产品需求的 20%。
除了物质利益之外,兆吨转兆瓦项目的重要性在于,它表明各国能够克服分歧,特别是当这样做符合双方的经济利益时。这也证明了以前的敌人可以携手合作,和平解决争端。当我们思考如何在个人生活中和国际范围内解决问题时,我们应该明智地记住这个计划:妥协意味着双方都没有得到他们想要的一切,但每个人最终都会受益。
结论
在可预见的未来,核武器不会消失。虽然在一个完美的世界里没有核武器,但我们生活在现实中,而不是乌托邦。因此,作为一个短期现实主义者和长期乐观主义者,我赞赏我们取得的重大进展——大规模削减核武器数量——同时承认需要继续削减。
此外,虽然我很高兴有一些忧心忡忡的科学家,但我更希望他们在站在显要位置上发表意见之前,先把事实搞清楚。告诉人们这个世界比实际情况更糟糕不会导致行动,而是会导致幻想破灭和事情永远不会变好的信念。值得记住的是,进步从来都不是直接线性的,而是在人类历史的大部分时间里一直呈积极趋势,而且在过去几十年里已经加速。正如核武器所证明的那样,事情既可能变得更糟,也可能变得更好,而国际努力确实在全球范围内发挥了作用。
一如既往,我欢迎反馈和建设性的批评。可以在 Twitter @koehrsen_will 上找到我。
生物智能和人工智能的关系
内部 AI
智力可以被定义为一种主要的人类能力,它能完成通常对计算机和动物来说很难的任务。人工智能[AI]是一个试图用计算机完成这些任务的领域。人工智能正变得越来越普遍,关于它与生物智能关系的说法也是如此。通常,这些说法意味着某项技术成功的几率更高,基于这样的假设:模仿生物智能机制的人工智能系统应该更成功。
在这篇文章中,我将讨论人工智能和我们对生物学中智能机制的了解程度之间的异同,特别是在人类内部。我还将探索人工智能系统中的仿生有助于其进步这一假设的有效性,我将认为人工神经网络处理任务的方式与生物系统的现有相似性是由于设计决策,而不是潜在机制的内在相似性。这篇文章的目标读者是那些理解人工智能(尤其是人工神经网络)基础知识的人,他们希望能够更好地评估关于人工智能中仿生价值的经常是疯狂的主张。
从符号人工智能到机器学习
直到 90 年代初,符号人工智能一直是人工智能的主流方法。它依赖人类程序员编写复杂的规则,使机器能够完成复杂的任务。这种方法在解决许多对智能至关重要的任务方面的持续失败,与机器学习形成了很好的对比——机器学习是人工智能的替代方法,对当前人工智能机器的出现至关重要。
1994 年,国际象棋冠军加里·卡斯帕罗夫被“深蓝”击败。这对当时的 IBM 来说是一个巨大的成功,对人工智能来说也是如此。然而,深蓝虽然能够下世界级的象棋,却不能移动棋子——这项任务需要一个人类助手。我们将通过研究决定棋步和物理移动棋子任务之间的区别,开始探索人工智能和生物智能之间的关系。
虽然国际象棋通常被认为是一种困难的游戏,但它的规则实际上非常简单,可以很容易地放在一张 A4 纸上。“深蓝”被编程为根据这些规则计算许多可能的前进方向。在这些步骤中,深蓝选择了最有利的一步。直到 1994 年计算机才击败人类国际象棋冠军的原因是计算能力的限制。虽然国际象棋的规则很简单,但有很多可能的走法——探索其中的一小部分都需要大量的计算。(深蓝的成功实际上在很大程度上也是由于决定避免探索游戏的哪些方面。不过,这个事实与目前的争论没有任何关系。)在深蓝出现之前,计算机无法在现实时间框架内进行如此多的计算,但如今深蓝的计算能力大致相当于一部普通智能手机。因为规则非常简单,任何具有基本编程技能的人都可以编写一个国际象棋程序,只要有足够的计算能力,通过应用这些规则就可以打败世界象棋冠军。这种方法被称为符号人工智能,因为计算机通过遵循预定义的规则(通常称为符号计算)来达成解决方案。
不幸的是,并不是所有的问题都适合用这种方式解决。移动棋子就是一个很好的例子——我鼓励你停下来看一会儿,想想你需要应用什么规则来选择和移动棋子。你必须从头开始,并识别该作品当前的位置——这是图像识别系统的标准任务,目前图像识别系统正获得如此多的关注。棋子是什么样子的?你能定义规则,让计算机在任何光线条件下从任何角度识别棋子吗?形状新颖、人类可以立即识别的作品怎么样?考虑图 1 中的各种棋子。做出这些定义的困难是符号人工智能最终未能转化为图像识别等“简单”任务的原因,尽管它在国际象棋等“困难”任务中取得了巨大成功。同时,符号人工智能的硬编码规则与生物智能的模糊本质没有任何相似之处。基于机器学习的方法比基于符号人工智能的方法更类似于人类智能,但这真的是其巨大成功背后的驱动力吗?

顾名思义,机器学习是人工智能的一个分支,在这个分支中,机器学习自己解决问题,而不是给定一套如何解决任务的明确规则。这通常是通过在任务中反复尝试来学习新的规则,以及每次成功程度的反馈来实现的。这是人工智能和生物智能当前进展之间的第一个基本相似之处。我们生来就没有识别周围物体的能力,也没有(在很大程度上)被告知允许我们识别这些物体的规则。相反,我们看到了大量有时被贴上标签的物体(想想父母给孩子指出的物体),并从经验中学习。
从表面上看,机器学习的工作方式非常相似。电脑会看到数百万张各种物体的图片,直到它们逐渐学会什么是狗、帽子、猫等等。看起来像。尽管这种相似性可能看起来微不足道和肤浅,但它是目前推动人工智能成功的最重要的原则。虽然人工智能和生物智能之间的相似性要深得多,但重要的差异仍然存在。允许计算机学习这些强大规则的机器——人工神经网络(ann)——直接受到生物大脑中神经网络的启发。在本文的其余部分,我们将研究这种相似性与这种技术的能力有多相关,以及这些相似性到底有多深。
神经元
人工神经网络完成的任务在某种程度上类似于生物智能完成的任务,这两类智能系统的构件也是如此。(出于参考目的,图 2 中提供了生物神经元的基本描述。)人工神经元和生物神经元之间的相似性和差异已经被用来论证人工复制生物智能的方法的有效性。然而,这种观点被大大简化了。在这一节中,我将批判性地逐一评估其中一些主张;然而,我将论证的基本结论是,人工神经元和生物神经元之间的相似性不是人工智能有效性的有效推理路线。

简而言之,这两种类型的神经元整合来自多个其他神经元的信号,用非线性函数对其进行转换,并将其输出到其他神经元。
许多人正确地指出,生物神经元使用离散信号进行操作,而人工神经元传递连续的数值。事实上,动作电位是二进制的——在开和关之间没有任何分级。然而,单个动作电位尖峰通常不会显著影响生物神经元。相反,峰值速率(频率)似乎很重要。频率本身是一个连续的值,与人工神经元传递的信息没有本质区别。因此,这种差异的有效性受到质疑。
两种类型的神经元所应用的非线性类型的相似性也有待商榷。的确,生物神经元的二元激活函数(阶跃函数)很难被传统上用于 ann 的 s 形非线性所复制。然而,如果我们认为人工神经元输出的值类似于生物神经元的放电频率,那么我们必须比较一段时间放电产生的功能。模糊阶跃函数的多次迭代的叠加很好地用 s 形非线性来表示,这表明在激活函数中实际上可能存在某种程度的相似性。
不久前,通过引入一种新的激活函数,人工神经网络的性能有了很大的提高。整流线性函数,也称为 ReLU [7],由于其优雅的数学属性,有助于神经元在以前不可能的情况下学习。这一发现的作者还称赞了 ReLU 的生物学合理性。那场争论背后的逻辑我一直不清楚。虽然我确实同意,从表面上看,s 形激活函数并不遵循生物神经元的激活函数,但 ReLU 甚至没有停留在生物学上似乎合理的范围内。相反,它永远不会饱和——这意味着更多的输入总是意味着更多的输出,没有任何限制。生物神经元对它们可以发射多少有一个天然的上限——当发射过多时,它们会疲劳甚至死亡。
长期以来,人们认为神经元执行单一的信号处理操作;然而,最近神经科学家揭示,信号的整合和简单逻辑处理实际上在单个神经元内发生多次。发现该处理已经发生在树突上——在来自许多树突的信号合并之前——而不是仅限于细胞体(参见图 2) [17]。这一发现使得神经元进行的计算比几年前认为的要复杂几个数量级。然而,计算并没有不同,只是在一个神经元内执行多次。因此,在以前使用单个人工神经元的地方使用多个人工神经元应该可以解决这个问题。
人们还发现,神经元对刺激的时间模式很敏感,这与莫尔斯电码有点类似,莫尔斯电码将信息编码为时间上的二进制信号。虽然人工神经元不具有任何这种能力,但是任何 n 位时间模式都可以由跨越 n 个神经元的静态模式来等同地表示。因此,复制这一发现只会增加所需人工神经元的数量,而不会增加它们各自的复杂性。
虽然大量强调人工神经元和生物神经元之间差异的论点经不起推敲,但生物神经元的许多方面肯定不会被人工神经元复制到任何程度。当放电时间过长时,生物神经元会疲劳甚至死亡,它们的功能受激素调节,它们循环神经递质,并且它们受盐和钾浓度等的影响。其复杂性令人震惊,我们还远未理解生物神经元是如何工作的。
事实上,只有一小部分计算是由神经元完成的。几十年来,大约占大脑四分之三的神经胶质细胞被认为只是为大脑中的神经元提供支持功能。然而,人们发现它们以一种以前只有神经元才知道的方式接收、处理和分发信号[10]。到目前为止,由神经胶质细胞执行的计算的含义还远未被理解。
此外,丹尼斯·布雷(Dennis Bray)等生物学家长期以来一直认为,计算不是大脑独有的,而是在生物体内无处不在,蛋白质合成和其他细胞过程不能否认计算的地位。然而,这些过程仅限于细胞内,并不能真正直接影响有机体的行为(尽管对其功能至关重要),因此这对我们理解智力应该没有什么影响。然而,这一观点正受到当前研究的挑战。
去年,一系列发现在科学界引起了轰动,当时发现果蝇细胞可以合成类似病毒的蛋白质,并用它们与其他细胞交流[15]。虽然还不清楚人类是否存在类似的现象,而且这种通信的速度可能非常低,但这是细胞内计算的一个例子,而不是神经元在有机体之间进行通信。这是我们过去认为神经元,或者后来认为大脑的特殊之处。鉴于生物体内计算和交流的巨大复杂性,指望神经元能为我们带来技术进步,以任何程度的准确性对其建模似乎都是徒劳的。
在可预见的未来,人工神经元仍将是一种非常不准确的生物神经元模型,而生物神经元只是用于执行生物智能所需的计算和通信的机器的一部分。这是否意味着人工神经网络实现的人工智能原则上不能实现类似于生物智能的能力?
在结构上,人工神经元是生物神经元的一个极其有限的模型。然而,更详细的神经元模型(如 Numenta)或通过离散尖峰信号进行通信的神经网络(如 SpiNNaker)却未能给 AI 带来任何优势。因此,对人工智能来说,神经元之间的结构相似性可能没有神经元的功能那么重要。事实上,作为执行基本逻辑处理的基本单位,这两种类型的神经元可以被视为非常相似。
我一直把神经网络理解为通用函数逼近器,不管它们是生物的还是人工的(除了逼近器它们还能是什么!).函数逼近器的精确结构不会影响其计算能力,只要它足够通用以逼近期望的函数,并且可以在有限时间内训练。给定足够数量的神经元,人工神经网络可以逼近任何函数[11]。因此,没有理由说它们不能近似生物神经元所执行的功能。这同样适用于任何其他通用函数逼近器,例如不希望与生物神经元有任何相似性的多项式。人工神经网络在人工智能领域比多项式获得更多关注的原因是它们相对容易训练,然而这种情况可能不会持续很久,因为新的研究表明多项式可以在许多 ML 基准问题上击败人工神经网络[19]。带来多项式进步的变化不是它们的结构或计算能力的变化,而是训练它们执行所需功能的新方法。总之,从理论上讲,人工神经网络有可能在基本构件没有相似性的情况下逼近生物功能。剩下的问题是我们能否训练人工神经网络来执行我们感兴趣的功能。
网络和学习
到目前为止,我们只讨论了单个神经元的基本特性。然而,神经元组成网络和训练的方式在历史上对其性能的影响比单个单元的结构更大。
第一个实用的人工神经网络是由弗兰克·罗森布拉特在 20 世纪 50 年代提出的,叫做感知器。它不包括任何隐藏层,因此是非常有限的。然而,其并行特性使其能够轻松学习简单的逻辑——对并行输入执行逻辑比串行输入容易得多,因为不需要存储器来存储中间值。深层还没有出现,主要是因为没有人知道如何训练它们。Minsky 和 Pappert 在 1969 年证明了这种基本的人工神经网络体系结构永远不能解决线性不可分的问题(例如,执行像异或这样的逻辑运算),并得出结论,它们永远不能解决任何实际上感兴趣的问题。在他们的书中,他们错误地认为这个问题是所有人工神经网络的通病,这导致了对人工神经网络的兴趣/资助的大幅下降,基本上停止了该领域近二十年的研究。
直到 20 世纪 80 年代才抢救出安的遗物。一个国际研究小组(David Rumelhart、Jeff Hinton 等人)提出了一种训练深度神经网络的方法,称为反向传播。这立即否定了明斯基和帕佩特的猜想,并开始了对人工神经网络的大规模研究。值得注意的是,反向传播可能是人工神经网络中最被广泛批评为生物学上不可信的方面。
反向传播依靠通过深层人工神经网络反向传播误差来校正/训练深层。反向传播算法起源于自动微分,这是牛顿在本质上没有理解智能背后的生物学的时候开发的一种方法。因此,声称生物灵感是它的起源是愚蠢的。
对反向传播的生物学合理性的主要批评集中在向后反馈信号的要求上,已知生物神经元无法做到这一点(这并不完全正确,因为已经报道了一些向后信号的边缘情况)。然而,神经科学家很早就知道,神经元并不是均匀的同质物质,而是在具有反馈连接的结构化集合中重复出现[2]。因此,完全有可能的是,至少在某些大脑区域,神经元成对存在,其中一个向前反馈,而另一个向后反馈,使得反向传播在神经组件中完全可能。这就是说,到目前为止,还没有令人信服的证据证明错误在大脑中的反向传播——如果这是生物神经网络的一个突出特征,我们应该希望这相对容易观察到。
反向传播是深度神经网络的必要进步,因为深度是给 ann 带来的最强大的概念之一。深度允许问题的层次化表示,即先解决较小的问题(例如检测边缘),然后再处理较大的问题(例如从边缘集合中识别对象)。等级自然也是大脑信息处理的一个显著特征[16],在生物和人工智能之间提供了一个优雅的排列。
人工神经网络功能的另一大改进是引入卷积作为主要成分之一[13]。卷积本质上意味着在数据中移动过滤器以识别特征。这给人工神经网络的训练带来了很大的优势,因为它大大减少了需要调整的自由参数的数量。有趣的是,有充分的证据表明,类似的原理正在大脑中应用[6],这也许是让大脑非常有效地处理视觉刺激的关键现象之一。
到目前为止,我们已经看到,对反向传播的生物学不可行性的批评是站不住脚的(尽管到目前为止还没有发现生物神经网络中反向传播的证据),卷积似乎在生物学上有充分的依据。然而,当代人工神经网络的最后一个方面并不遵循这一推理路线。通过单位矩阵[12]初始化权重是一种有助于训练更深层次网络的技术。它之所以有效,是因为最初深层只是原封不动地传递它们的输入——这是一个比从随机的复杂变换中学习更好的起点。正如你可能预料的那样,这并不适合与大脑进行任何有意义的比较,说明生物学虽然是人工智能架构的有用灵感,但迄今为止并不是人工智能进步的唯一手段。
总之,推动人工神经网络目前成功的主要进步集中在如何训练人工神经网络,而不是它们到底是什么。这些进步主要是务实的工程选择和一些可疑的生物灵感的混合,这也是一个很好的工程选择。
智力
到目前为止,人工神经网络与生物神经网络的机制的比较还没有简单的结论。在这里,我将尝试比较人工和生物神经网络产生的智能(高级功能)。为了获得人工神经网络和生物智能之间更深层次关系的真正结论性证据,从一个我们没有明确设计的系统中看到类似生物的行为将是有用的。使用简单神经网络的涌现特性来解释鲜为人知的大脑特性,如大脑区域之间的特殊功能划分,是我自己第一次进入学术研究的议程。
研究人工神经网络的早期动机是它们在某些方面的表现与人类行为的相似性,尽管它们还没有强大到足以解决实际任务。大卫·鲁梅尔哈特和杰伊·麦克莱兰利用这些相似之处,在心理学领域启动了一个完整的研究项目。他们证明,当阅读部分模糊的单词时,人工神经网络和人类以惊人相似的方式推断模糊的部分[14]。后来,Matt Lambon-Ralph 证明了当接触到一种新的语言时,ann 能够以类似于人类儿童的方式学习单词。还有许多其他例子证明了非常简单的人工神经网络和人类行为之间的相似性。
简单人工神经网络和人类的表现之间的相似性并不令人印象深刻,因为这些特定的网络无法解决玩具任务之外的任何问题,因此与人类智能的建模相去甚远。然而,最近,人工神经网络获得了执行一些基本现实任务的能力。对这些的研究表明,当处理相同的视觉刺激时,深度卷积神经网络和人脑的内部状态有相似之处[9]。具体来说,已经证明了两个系统中的表示都是基于分层模式识别的。
然而,这些结果不应该让任何人感到惊讶。神经科学家早就知道,大脑中的视觉处理类似于分层模式识别。Guclu 和 Gerven 的 ann 只是分级模式识别系统的数学规范。因此,这种相似性反映了一种设计决策,而不是一种突现的特性,并且很难用来论证人工神经网络和生物智能之间更深层次的相似性。事实上,大部分涌现的特性为人工神经网络和生物智能之间的功能相似性提供了令人信服的论据。
长期以来,人们一直认为,训练当代人工神经网络所需的数据量与动物能够从很少的观察中学习明显不同。2017 年,谷歌 Deep Mind 在《自然》杂志上发表了一篇论文,吹嘘他们成功地在短短 36 小时内训练了一个名为 AlphaGoZero 的网络,不仅击败了任何人类围棋选手,还击败了 alpha Go——之前最强的围棋选手[18]。然而,对前述《自然》杂志论文的深入研究显示,在这 36 个小时里,AlphaGoZero 玩了 490 万个游戏。这大致相当于以人类的速度不停地走了 559 年,进一步强调了人工神经网络的数据需求与人类学习相同任务的距离有多远。
Dubey 和他的同事在 2018 年很好地证明了类似的问题[3]。与人类相比,人工神经网络需要更长时间的训练来学习玩《蒙特祖马的复仇》(一款老式电子游戏)的基础知识。在混合了游戏中的纹理(例如,天空有地面纹理)后,这个游戏对人类来说不再有意义,而人工神经网络在大约与原始游戏相同的时间内学会了改变的游戏。这个发现暗示了人工神经网络和人类处理新情况的方式之间的显著差异。人类将他们过去的知识应用到新的情况中——例如,他们可能试图爬上游戏中呈现的梯子,尽管与现实世界的梯子存在巨大的视觉差异。然而,这使得人类很难理解看起来像地面的天空。首先,人工神经网络需要更长的时间来学习游戏,因为它们无法应用在不同背景下获得的知识(例如,现实生活),并且当学习新东西时,它们也不受先前假设的约束。如何让人工神经网络应用在不同背景下收集的知识,还远未明朗。在旨在使人工神经网络能够执行这些任务的迁移学习领域已经取得了一些进展,然而,即使是最先进的系统也深深地局限于特定的任务/环境。
这个问题——缺乏进行传递性推理的能力——在我看来是人工智能进步的最大障碍。Hector Levesque 在他的名为《常识、图灵测试和对真正人工智能的探索》的书中简明扼要地总结了这个问题,他提出了一个问题:鳄鱼在障碍赛中表现如何?虽然找到一个答案对你来说似乎微不足道,但它需要迄今为止在任何人工神经网络中从未见过的传递性推理的数量,除了那些专门为此目的制作的人工神经网络——它们无法以合理的标准执行其他功能。
即使人工神经网络能够进行传递性推理,它们的先验知识仍然会与我们的有根本的不同,很可能导致完全不同的行为。这是基于这样一个事实,即人工神经网络使用的训练集与动物可用的训练集如此不同。Linda B. Smith 一直在带头收集幼儿的头部摄像机镜头[1],这与 ML 对象识别数据集相去甚远。最普遍的物体是脸,和一些抽象的图像,比如在天空下画的墙角或树枝;这与用于训练人工神经网络的互联网图像的一般横截面有着明显的不同。我看到了在这个镜头上训练的人工神经网络的巨大潜力,它的表现方式比以前的任何模型都更接近人类。
传递性推理可能只是一个我们还没有实现的功能。然而,有充分的理由相信,即使是目前人工神经网络在特定任务中的成功,也是以与人类非常不同的方式实现的。考虑我通过 Clarifai 公司提供的人口统计估计产品,从一幅图像中估计我自己的人口统计数据的两次尝试(如图 3 所示)。第一次尝试相当准确,结论是照片 99%可能是男性,51%可能是 27 岁,98%可能是白人“多元文化外表”。第二次尝试的结果是 84%可能是女性,61%可能是 23 岁(感谢 Clarifai!)和 40%可能是西班牙裔“多元文化外表”。我还被认为有 18%的可能是黑人或非裔美国人。

我想在这里提出的论点并不是 Clarifai 的人口统计估计产品不好(我让读者来判断),而是它估计人口统计的原则必须与人类完成任务的方式有根本的不同。当然,人们估计人口统计的能力各不相同;然而,如果有人像 Clarifai 一样估计第一张照片中的人口统计数据,那么他们在第二张照片中似乎不太可能如此悲惨地失败。
人工神经网络和人类之间用于视觉对象识别的特征的明显差异可能最好由对立的例子来说明[8]。这些例子是对原始图像的微小扰动,诱使人工神经网络将一个物体识别为与扰动前完全不同的东西。对立的例子骗不了人类,因为我们甚至无法察觉这种干扰。事实证明反过来也是一样的。人工神经网络不会被人类的视错觉欺骗[20]。
人工神经网络显示的智能可以非常类似于人类的智能,只要人工神经网络为此目的被成功训练。例如,经过训练来识别图像的人工神经网络将擅长这项任务,就像生物智能一样,但它几乎不会复制我们完成这项任务的方式,因为这不是训练的目标。因此,人工神经网络在接受训练的任务中的表现,绝不会暗示智力基础上的相似性,而是暗示在工程任务中的成功。此外,人工神经网络需要比人类多几个数量级的数据来学习,目前还没有已知的方法来让它们成功地进行传递性推理——这是一项我们几乎一直在进行的任务,对我们有很大的好处。
结论
这篇文章从多个角度比较了人工智能和生物智能。我提出了一个观点,即没有理由期望两个不同的通用函数近似器具有不同的计算特性——人工神经元和生物神经元无疑都是如此。因此,我们有充分的理由不用担心生物和人工神经元之间的巨大结构差异对从这种机制中产生的智能行为的影响。似乎更重要的是如何学习所需的功能。在这方面,人工智能和生物智能之间鲜有相似之处,除了两者都能够成功地学习我们感兴趣的许多任务。这两种类型的智能之间缺乏相似之处,这突出表现在人工神经网络被明确训练来模仿生物智能的任何任务的表现上的巨大差异。
关于人工神经网络机制缺乏生物学合理性的广泛传播的批评中,很大一部分似乎源于缺乏最新的神经生物学知识。然而,即使排除了不成立的论点,这两种类型神经元之间的差异仍然非常显著,特别是当我们考虑当代神经生物学揭示的令人困惑的复杂性时。与常识中的描述相反,神经元并不是唯一能够进行计算和交流的细胞,这一事实加剧了这种差异。这种能力可能会扩散到神经系统或大脑之外,而且大部分是未知的。此外,目前科学界甚至对神经元的特性也知之甚少。因此,专注于生物神经元表征的真实性似乎相当幼稚。
当我们观察单个神经元之外的人工神经网络结构时,这个故事变得稍微复杂了一些。推动当前 ML 革命的一些技术进步显然在生物学上是不可信的(单位矩阵权重初始化等。),同时也是人工神经网络取得当前绩效的关键。另一方面,一些生物学上有充分基础的思想的实现,如层次模式识别,已经对人工神经网络的性能做出了重要和积极的贡献。
在上一节中,我讨论了人工神经网络和动物智能之间的功能差异。有一项长期的研究工作证明了平凡的人工神经网络和人类之间类似的表现模式。然而,目前还不清楚玩具模型在玩具任务上的表现能告诉我们什么是真正的智力。
最近,人们一直在努力找出能够实际解决现实世界任务的人工神经网络和人脑之间的共同模式。在我看来,这些发现到目前为止还没有发现任何相似的模式,这些模式不是在人工神经网络构建过程中做出的简单设计决策。相反,有大量证据表明,这两种类型的智力是根本不同的。学习所需的数据量相差几个数量级,并且没有能力使用先前的知识或执行传递性推理。最后,用来完成任务的特性是完全不同的。
我想用一种不那么糟糕的语气来结束这篇文章。尽管人工神经网络和生物智能在结构和功能上有很大的不同,但有必要记住一些基本原则(平行、层次、非线性等)。)在人工神经网络中的应用导致了他们惊人的成功,而且可能会有更多的成功。
承认
我感谢凯特·威尔金森对这篇文章的大量编辑和校对。没有她的帮助,阅读这篇文章将是一种折磨。克里斯詹·卡尔姆博士对这篇文章的评论对文章的科学完整性至关重要;然而,并非本文表达的所有观点都反映了 Kristjan 自己的观点。最后,我要感谢 illumr Ltd,特别是其创始人兼首席执行官杰森·李,赞助这项工作。
参考
[1]斯文·班巴赫、大卫·克兰德尔、琳达·史密斯和陈郁。幼儿启发的视觉对象学习。《神经信息处理系统进展》,第 1209-1218 页,2018 年。安德烈·M·巴斯托斯、W·马丁·乌斯利、里克·A·亚当斯、乔治·R·曼贡、帕斯卡尔·弗里斯和卡尔·J·弗里斯顿。预测编码的标准微电路。神经元,76(4):695–711,2012。
[3]拉奇特·杜贝、普尔基特·阿格拉瓦尔、迪帕克·帕沙克、托马斯·格里菲斯和阿列克谢·埃夫罗斯。调查人类玩电子游戏的前科。arXiv 预印本 arXiv:1802.10217,2018。
[4]安德鲁·W·埃利斯,兰邦·拉尔夫,还有一个马修。成人词汇加工中的年龄习得效应反映了成熟系统中可塑性的丧失:来自联结主义网络的见解。实验心理学杂志:学习、记忆和认知,26(5):1103,2000。
[5]埃伯哈德 E 费茨。神经群体中的时间编码?科学,278(5345):1901–1902,1997。
[6] VD Glezer,VA Ivanoff,和 TA Tscherbach。猫视皮层复杂和超复杂感受野作为空间频率滤波器的研究。视觉研究,13(10):1875-1973 年 6 月。
【7】泽维尔·格洛特,安托万·博德斯,约舒阿·本吉奥。深度稀疏整流器神经网络。《第十四届人工智能与统计国际会议论文集》,315–323 页,2011 年。
[8]伊恩·古德费勒、让·普盖-阿巴迪、迈赫迪·米尔扎、徐炳、戴维·沃德-法利、谢尔吉尔·奥泽尔、亚伦·库维尔和约舒阿·本吉奥。生成对抗网络。《神经信息处理系统进展》,第 2672-2680 页,2014 年。
[9]Umut Gülü和 Marcel AJ van Gerven。深度神经网络揭示了跨腹侧流的神经表示的复杂性的梯度。神经科学杂志,35(27):10005–10014,2015。
【10】菲利普·克海顿。胶质细胞:听和对突触说话。自然评论神经科学,2(3):185,2001。
[11]库尔特·霍尼克、麦克斯韦·斯廷奇科姆和哈尔伯特·怀特。多层前馈网络是通用逼近器。神经网络,2(5):359–366,1989。
[12]阔克·V·勒、纳夫迪普·贾伊特利和杰弗里·E·辛顿。一种初始化整流线性单元递归网络的简单方法。arXiv 预印本 arXiv:1504.00941,2015。
【13】Yann le Cun,Yoshua Bengio 等,《图像、语音和时间序列的卷积网络》。大脑理论和神经网络手册,3361(10):1995,1995。
[14]詹姆斯·麦克莱兰和戴维·鲁梅尔哈特。字母知觉中语境效应的互动激活模型:I .对基本发现的说明。心理评论,88(5):375,1981。
【15】Elissa D Pastuzyn,Cameron E Day,Rachel B Kearns,Madeleine Kyrke-Smith,Andrew V .塔伊比,约翰·麦考密克,Nathan Yoder,David M Belnap,Simon Erlendsson,Dustin R Morado 等。神经元基因 arc 编码一种调节细胞间 rna 转移的再利用反转座子 gag 蛋白。单元格,172(1):275–288,2018。
[16]马克西米利安·里森胡贝尔和托马索·波吉奥。皮层中物体识别的层次模型。自然神经科学,2(11):1019,1999。
[17]希拉·萨尔迪、罗尼·瓦尔迪、安东·谢宁、阿米尔·金牙尔和伊多·坎特。新类型的实验揭示了一个神经元作为多个独立的阈值单元起作用。科学报告,7(1):18036,2017。
【18】David Silver、Julian Schrittwieser、、Ioannis Antonoglou、Aja Huang、Arthur Guez、Thomas Hubert、Lucas Baker、Matthew Lai、Adrian Bolton 等人《在没有人类知识的情况下掌握围棋游戏》。自然,550(7676):354,2017。
[19]唐纳德·F·施派特。通用回归神经网络。IEEE 神经网络汇刊,2(6):568–576,1991。
【20】罗伯特马克斯威廉姆斯和罗曼 V 扬波尔斯基。视错觉图像数据集。arXiv 预印本 arXiv:1810.00415,2018。
财富和教育之间的关系
看看财政资源可能在多大程度上影响加州的标准化考试成绩。

Photo by Robert Bye on Unsplash
在读了一篇由Jorge Castaón撰写的关于解读大学录取的文章后,我决定看看财政资源尤其是如何影响加州的标准化考试成绩。我最初的假设是,来自更富裕社区的学生可能在标准化测试中表现更好,然而,我真的很好奇,想知道是否有任何公开的数据支持这一假设,或者它是否会揭示完全不同的东西。如果说数据科学教会了我什么的话,那就是我最初对事物如何工作的看似可能的假设实际上有时是错误的,所以我开始寻找一些答案。
数据
由于我无法获得每个人的资产净值,我认为另一个衡量财务资源的好方法是住房。住在百万美元房子里的人通常比住在十万美元房子里的人富裕得多。我从 Zillow Research 获得了房屋价值数据,这些数据在这里可供公众使用。
虽然肯定不是衡量智力的最佳标准,但像 SAT 这样的标准化考试确实提供了一个很好的衡量教育的综合标准。我从 Data World 获得了加州 SAT 数据,这里也有公开消费。
有了这两个数据集,我觉得我有足够的信心来揭示加州财政资源和教育之间的关系。
方法
我要做的第一件事是清理和转换数据,使其更有用。这是数据科学项目中非常常见的一步,因为对于您的特定用例来说,数据几乎永远不会处于最理想的状态。这通常也使得在某一列上合并两个数据集变得更加容易,然后我按县进行了合并。组合数据集包含各县、12 年级注册学生人数(注册 12)、实际参加测试的学生百分比(PercentTesting)、zillow 家庭价值指数(ZHVI)和平均总分(ATS ),所有数据均按县汇总。随着这个新数据集的创建,我准备开始生成一些答案!
我首先创建了一个 pearson 相关矩阵,以查看每一列与其他列之间的关系。这产生了一些有趣的结果。正如所怀疑的那样,ZHVI 和安非他明类兴奋剂之间的联系强度很大。这也揭示了 ZHVI 和百分比测试之间的关系,这种关系比 ZHVI 和苯丙胺类兴奋剂之间的关系更强。我会让你思考为什么会这样。😉

Pearson Correlation Matrix
然后,我使用这些数据来训练一个随机森林回归器,它接受注册 12、百分比测试和 ZHVI,并输出预测的 ATS。我得到的是一个样本数据的均方误差为 767.69、r2 值为 0.91 的模型。为了了解哪些特征对预测影响最大,我查看了它们的排列重要性,结果显示 ZHVI 是迄今为止影响最大的人。然后,我为每个特征创建了部分依赖图,以进一步探索每个特征如何影响预测,我将在下面与您分享。
对于那些不熟悉部分依赖图的人来说,它们是一种快速简单的方法,可以直观显示每个特性对预测的影响程度。这非常有用,因为某些特征可能会对预测产生巨大影响,但只是在某一点上,超过该阈值后可能不会有太大影响。
y 轴上是每个特征增加或减少预测 ATS 的量,x 轴上是特征。



我发现三幅图中最有趣的是最后一幅的形状。随着参加考试的学生比例增加,预测的 ATS 减少,然后增加,然后再次减少。
最后,为了测试模型在样本外数据上的表现,我用它来预测前几年 SAT 数据的 ATS,得到的均方误差为 1812.11,r2 值为 0.78。
总结
似乎来自加州更富裕社区的学生确实在 SAT 考试中表现更好,然而,我认为经济来源只是更大的一组特征中的一个特征(不幸的是,我们没有这些特征),可以用来更准确地衡量学生在像 SAT 这样的标准化考试中可能获得的分数。
特别感谢Jorge Castaón启发我写这篇文章。
作者克里斯蒂安·约翰逊
过分热心的数据科学家
两大政党的宗教构成
我做了很多数据可视化。大多数时候,在我写代码之前,我对计算的结果有一个很好的想法。事实上,有些结果是如此明显,以至于我甚至不把它们放在任何地方,它们就在我的硬盘上,直到它失效。有时我会做一些图表,盯着看很久,仍然会发现第一次检查时没有发现的新东西。这就是周末发生的事情。举个例子,我在想,在 20 世纪 80 年代和 90 年代,我对两大政党的宗教构成了解有多少。众所周知,宗教右翼已经改变了美国政治,但这又是如何改变共和党的构成的呢?而且,现在非宗教人士占人口的四分之一,他们的存在一定会被民主党和共和党感觉到。
所以我只是做了一些简单的分析。
从 1978 年开始,每十年一次,我拿起一般社会调查,然后对共和党和民主党的宗教构成做了一个快照。我确实对传统的 RELTRAD 类别做了一个修改,将犹太人、少数宗教(佛教、印度教徒、摩门教等)和 RELTRAD 中未分类的人合并成一个类别,我称之为“其他信仰”这使得解释图表更加容易。让我们开门见山:这是过去四十年来民主党的宗教构成。

我首先想到的是,1978 年民主党中最大的群体是天主教徒,其次是福音派,占 22.4%。请记住:1978 年,近四分之一的民主党人是福音派新教徒。主流新教徒紧随其后,占 19.4%。黑人新教徒占民主党的 12.4%(基本上没有随着时间的推移而改变)。反对票约占所有民主党人的 9%。
后来事情发生了很大的变化。主流新教徒占民主党人的比例已经减少了一半,从大约 20%下降到现在的 10%。这不是因为主流人群转向共和党,而是因为主流人群完全消失了。信奉天主教的民主党人的比例也减少了基本相同的数量,10 个百分点。此外,民主党在福音派中失去了份额,福音派现在占民主党的 14.1%,高于我现在的猜测,仍然是民主党中的第三大群体。
那是很大的损失。总的来说,这是主流派、福音派和天主教徒之间 27%的损失。收益从何而来?嗯,大部分是非主流。事实上,自 1978 年以来,认为自己一无是处的民主党人的比例上升了近 20 个百分点。与此同时,“其他信仰”的比例也大幅上升,上升了近 7 个百分点。这真的是民主党转变的全部:福音派和主流新教徒和天主教徒的损失,无党派人士和其他人的巨大收益。

共和党怎么样?1978 年,三分之二的共和党人被认为是福音派或主流新教徒。这仍然让我震惊。正如我们之前所写的,我们需要抛弃主流新教徒是“自由”型新教的观点,在他们的全盛时期,主流新教徒成为共和党人的可能性是民主党人的两倍。在图表的右边,我们看到天主教徒占共和党的 18.6%,而非天主教徒约占 5%。
共和党联盟内部的一些变化令人震惊。例如,40%的共和党人是主流新教徒,现在已经减少到 15%。一组输了 25 分。再说一遍,这基本上是因为主流新教徒现在的规模是 1972 年的三分之一。这确实是共和党中支持率下降的群体。增益怎么样?福音派人数有所上升,但没有人们想象的那么多:只有 7.6%。今天,准确地说,三分之一的共和党人是福音派——这意味着这是两个政党中最大的信仰团体。天主教徒的支持率也有显著上升,仅超过 6 个百分点。这与福音派的收获没有太大的不同,但这似乎是一个被媒体揭露的故事。同样值得注意的是,非共和党人现在占共和党联盟的 13.6%。事实上,非主流的共和党人和主流新教徒的比例差不多。回想一下早些时候,民主党从无党派人士那里获得了大约 20 个百分点,但共和党自己也获得了近 9 个百分点。所以,说非主流完全被民主党俘获是不准确的;相反,如果你只看无党派人士,似乎三分之二是民主党人,其余的是共和党人。
令人欣慰的是,美国的两大政党都不是由一个特定的宗教团体主导的。我知道有大量的文章把福音派和共和党联系在一起,但是数据显示今天超过三分之二的共和党人不是福音派。民主党人也是如此。对他们来说最大的群体(无党派人士)如今只占十分之三的民主党人。任何宗教团体的成员都可以在两个帐篷中找到自己的位置。
Ryan P. Burge 在伊利诺伊州查尔斯顿的东伊利诺伊大学任教。可以通过 推特 或者他的 个人网站 联系他。帖子的语法可以在 这里 找到。
原载于 2019 年 4 月 25 日http://religion inpublic . blog。
推荐系统的非凡世界
推荐系统概述以及它们如何提供一种有效的定向营销形式。

Image by PatternPictures from Pixabay
很多时候,人们不知道他们想要什么,直到你展示给他们看:史蒂夫·乔布斯
以下节选自克里斯·安德森:的《长尾 T3》一书:1988 年,一位名叫乔·辛普森的英国登山者写了一本名为“ 触摸虚空” 的书,讲述了秘鲁安第斯山脉濒临死亡的悲惨遭遇。它得到了很好的评价,但是,仅仅是一个小小的成功,它很快就被遗忘了。然后,十年后,一件奇怪的事情发生了。乔恩·科莱考尔写了’ ‘消失在空气中’ ,这是另一本关于登山悲剧的书,在出版界引起了轰动。突然 碰到虚空 又开始卖。
对’**触摸虚空’**的需求如此之高,以至于一段时间后,它甚至比’卖得还要少。但是这里到底发生了什么?嗯,事实证明,由于这两本书基于相同的主题,亚马逊建议喜欢《走进稀薄的空气》的读者也会喜欢《触摸虚空》的读者。当人们接受这些建议时,他们实际上喜欢这本书,因此写了积极的评论,这导致了更多的销售,最终导致更多的推荐,从而形成了积极的反馈循环。这就是推荐系统的力量。
推荐系统
推荐引擎试图向人们推荐产品或服务。在某种程度上,推荐者试图通过向人们提供他们最有可能购买或使用的建议来缩小选择范围。从亚马逊到网飞,推荐系统几乎无处不在;从脸书到 Linkedin。事实上,亚马逊收入的很大一部分来自推荐。像 Youtube 和网飞这样的公司依靠他们的推荐引擎来帮助用户发现新内容。我们日常生活中的一些建议示例如下:
- 亚马逊
亚马逊使用来自数百万顾客的数据来确定哪些商品通常是一起购买的,并在此基础上提出建议。Amazon.com 的推荐是基于明确提供的评级、购买行为和浏览历史提供的。

I intended to buy ‘Show Dog’ but ended up buying ‘The Compound effect’ too!
Linkedin 利用你过去的经历、现在的职位和认可的数据向你推荐可能的工作。

- 网飞
当我们在网飞上对一部电影进行评级或设置我们的偏好时,它会使用这些数据以及来自数百名其他订户的类似数据来推荐电影和节目。这些评级和行动随后被网飞用来提出建议。

- 脸书
推荐系统,如脸书,不直接推荐产品,但他们推荐联系。

除此之外, **Spotify、Youtube、IMDB、Trip Advisor、Google News、**以及许多其他平台不断给出适合我们需求的推荐和建议。
为什么推荐人
今天,网上商店蓬勃发展,我们几乎可以通过点击鼠标获得任何商品。然而,在实体时代,存放商品的物理空间有限,因此店主只展示最受欢迎的商品。这意味着许多产品甚至没有展示出来,尽管它们像书籍或 CD 一样质量很好。简而言之,店主必须预先过滤内容。
然而,网购行业改变了这种情况。因为有无限的空间,预过滤的需要消失了。相反,这导致了后来被称为长尾效应的现象。

效果就是受欢迎的产品很少,线上和线下都可以找到。另一方面,不太受欢迎的产品很多,只能在网上商店找到,最终构成了长尾。然而,即使是不受欢迎的产品也可能是好的,在网站上找到这样的产品是一项艰巨的任务,需要某种形式的过滤器。这样的过滤器实际上构成了一个推荐系统。
推荐问题的表述
创建推荐系统主要是为了回答以下两个问题中的任何一个:
- 预测版本
这个版本处理预测用户-项目组合的评级值。在这种情况下,我们有由用户给出的评级组成的训练数据。目的是利用这些数据,预测用户没有与之互动的项目的评分。
- 排名版
老实说,没有必要为了推荐而预测用户对特定项目的评价。在线零售商或电子商务公司并不太关心他们用户的预测。相反,他们更感兴趣的是制作一个有限的清单,列出最好的东西,展示给某个人。此外,客户不想看到系统预测他们对某个项目的评分的能力,他们只想看到他们可能喜欢的东西。
推荐引擎的成功取决于它为人们找到最佳推荐的能力,因此专注于寻找人们喜欢的东西而不是预测人们讨厌的东西是有意义的。
推荐系统的目标

Recommendations will only be valuable if they are relevant
推荐系统的最终目标是增加公司的销售额。要做到这一点,推荐系统应该只向用户显示或提供有意义的项目。 Charu C Aggarwal 在他的著作推荐系统 中将推荐引擎的预期目标总结为以下四点:
- 相关性
推荐的项目只有在与用户相关时才有意义。用户更有可能购买或消费他们感兴趣的商品。
- 新颖性
除了相关性,新鲜感是另一个重要因素。如果商品是用户以前没有见过或消费过的东西,推荐商品会更有意义。
- 意外之喜
有时推荐一些有点出乎意料的商品也能促进销售。然而,意外之喜不同于新奇。用作者的话说:
“如果一家新的印度餐馆在附近开业,那么向通常吃印度食物的用户推荐该餐馆是新颖的,但不一定是偶然发现的。另一方面,当向同一用户推荐埃塞俄比亚食物时,该用户不知道这种食物可能会吸引她,则该推荐是偶然发现的”。
- 多样性
增加建议的多样性也同样重要。简单地推荐彼此相似的项目没有多大用处。
推荐系统的工作原理
那么推荐系统是如何工作的呢?比方说,亚马逊想向您展示图书类别中的 10 大推荐。在这里,亚马逊的推荐系统将从你的某种数据开始,以便找出你的个人品味和兴趣。然后,它会将你的这些数据与像你一样的其他人的集体行为相结合,向你推荐你可能喜欢的东西。但是这些关于你喜欢和不喜欢的数据从何而来?

The flow of data into a recommendation engine
用户偏好数据以两种方式收集:
- 显式数据
让用户对一个项目进行一到五颗星的评级,或者对他们看到的内容进行赞或否定的评级,就是一个显式数据收集的例子。在这种情况下,用户会被明确地询问他们是否喜欢某个特定的商品,然后这些数据会被用来建立用户的兴趣档案。
然而,有一个缺点,因为不是每个用户都留下反馈或评级,即使他们留下评级,对不同的人来说也可能意味着不同。例如,3 ⭐️评级可能对一个人来说很好,但对另一个人来说很一般。
- 隐含数据
隐含数据来自用户与网站的交互,并将它们解释为感兴趣或不感兴趣的指示。例如,从亚马逊购买产品或观看完整的 youtube 剪辑被认为是积极兴趣的标志。隐式交互可以给你更多的数据来处理,在购买数据的情况下,它甚至可能是更好的开始数据。
推荐系统的基本模型
如今,在这个行业中有很多种推荐人。然而,重要的决定是决定哪种类型适合我们的需要,哪种类型的数据可供我们使用。选择主要取决于:
- 我们想要识别的,
- 我们的数据中指定了什么类型的关系?
一些常用的建议方法包括:

Approaches used for Recommendation systems
让我们对其中的每一项进行简要概述:
基于内容的过滤
基于内容的过滤包括根据项目本身的属性推荐项目。基于内容的过滤器所做的推荐使用个人的历史信息来通知所显示的选择。这种推荐器寻找一个人过去已经购买或喜欢的项目或产品之间的相似性,以推荐将来的选项。

例如,如果用户喜欢“文学”类别的书,向用户推荐相同类别的书是有意义的。此外,推荐同一年由同一作者出版的书籍也是一个好主意。这就是基于内容的过滤的工作原理。
基于内容的方法的优势在于,我们并不真的需要大量的交易来构建我们的模型,因为我们只需要关于产品的信息。然而,缺点是该模型不从事务中学习,所以随着时间的推移,基于内容的系统的性能没有太大的改善。
协同过滤
协同过滤使用由许多用户/顾客提供的评级的组合力量来呈现推荐。这意味着根据其他人的合作行为来推荐东西。

协作过滤有两种方法:
- 基于记忆的方法,也称为基于邻域的协同过滤算法,其中用户-项目组合的评级是基于它们的邻域来预测的。这些邻域可以进一步以两种方式之一来定义:
- T3【基于用户的协同过滤:
找到像你一样的人,并推荐他们喜欢的物品。
- 基于项目的协同过滤:
推荐那些也买了你喜欢的东西的人买的东西。
2。基于模型的方法通过将问题视为正常的机器学习问题,使用机器学习方法提取评级数据的预测。可以使用 PCA、SVD、矩阵分解、聚类、
神经网络等技术。
基于混合和集成

Hybrid filtering
基于内容的方法和协作方法都有各自的优点和缺点,通过将许多算法结合在一起,我们称之为混合方法,可以得到一个更好的系统。混合系统利用项目数据和交易数据来给出建议。
使用混合方法的一个很好的例子是网飞。在网飞,推荐不仅基于人们的观看和搜索习惯(协作系统),还会推荐具有相似特征的电影(基于内容)。

How Hybrid Systems work
评估推荐系统:围绕准确性的炒作
用户并不真正关心准确性
没有一种简单的方法来衡量推荐系统有多好。这一领域的许多研究倾向于集中在预测用户对他们尚未评价的事物的评价问题上,无论是好的还是坏的。但这与推荐系统在现实世界中需要做的事情非常不同。衡量准确性并不是我们真正想要推荐系统做的事情。那么,在推荐系统领域,为什么 RMSE 和准确性如此重要呢?
这很大程度上要追溯到 2006 年,当时网飞宣布了著名的 100 万美元奖金挑战。这场比赛是为了打破他们 0.9525 的 RMSE,终点线将其减少到 0.8572 或更少。由于该奖项的焦点是 RMSE,人们只关注它,这种影响一直持续到今天。

有趣的是,三年竞赛中产生的大多数算法从未被集成到网飞中。正如在网飞博客上讨论的:
你可能想知道两年后赢得 100 万美元的最终大奖合奏发生了什么……我们离线评估了一些新方法,但我们测量的额外精度增益似乎并不证明将它们引入生产环境所需的工程努力是合理的。
我们的业务目标是最大限度地提高会员满意度和月度订阅保留率……现在很明显,Netflix 奖的目标——对电影评级的准确预测——只是优化会员娱乐的有效推荐系统的众多组成部分之一。
结论
在本文中,我们概述了推荐系统,以及它们如何通过为每个客户创造个性化的购物体验来提供有效的定向营销形式。但是,我们并没有深入研究各种推荐方法。这是因为每种方法都相当广泛,值得单独撰写一篇文章。在下一篇文章中,我将详细讨论推荐方法的工作原理及其优缺点。
链接下一部分: 现实世界中的推荐系统
餐馆指南:如何在 Yelp 上受欢迎
使用正则化线性模型来确定哪些餐馆应该考虑获得更多的在线牵引力
如果有什么能让你永远保持谦逊,那就是餐饮业
——安东尼·鲍代恩
动机
餐馆是一个艰难的行业——60%的餐馆在第一年内倒闭,80%在第五年倒闭。因此,出于对食物的热爱,我想发现受欢迎程度的重要预测指标,**就像 Yelp 上的评论数所显示的那样。**具体来说,我开始回答餐馆的问题:
- 我应该提供(或避免)哪种菜肴?
- 什么样的社区成功率最高?
- 食物的美感更重要还是氛围/装饰更重要?
- 我的评论中的照片重要吗?
- 价格范围重要吗?

The distribution of reviews counts per restaurant is skewed to fewer than 1000 reviews. I decided to slice the data to only include restaurants with 20 to 800 reviews to my final modeling.

数据集和要素
为了回答这些问题,我合并了 Yelp 的几个数据集,并抓取了 Yelp 的浏览页面,以获取关于业务、评论和发布的照片的信息。我只关注了一个城市,拉斯维加斯,因为我想分析一个城市中邻里之间的影响。这在我的数据集中产生了 1,165 个独特的餐馆。
数据严重失真,大多数餐厅的评论数少于 1000 条,少数餐厅的评论数高达 10000 条。为了提高可解释性,数据集被缩减到只包含 20 到 800 条评论的餐馆。这将最终模型拟合的大小减少到原始收集数据的 82%。
整个学习过程——OLS、拉索克夫、RidgeCV 或 ElasticNetCV(还有代码!)

Model of the learning process, if it was linear and not iterative/ repetitive
上图大致模拟了模型审核计数预测所采取的步骤,尽管它更多的是迭代而不是线性。简而言之,在执行特征工程时,我使用简单的线性回归来提供关于预测因子的信息。正则化技术有助于管理不重要的共线要素。思维过程和代码详述如下。
功能标准化的简单线性回归在功能工程过程中提供了见解。因为我会经常运行这个函数,所以创建一个函数是有意义的:
def split_and_validate(X, y):
"""
Split data to train, val and test set and perform linear regression
"""
columns = X.columns
X = X.values
std = StandardScaler()
# perform a train, val and test set
X_train_val, X_test, y_train_val, y_test = train_test_split(X, y, test_size=0.2,random_state=42)
X_train, X_val, y_train, y_val = train_test_split(X_train_val, y_train_val, test_size=.25, random_state=42)
# fit linear regression to training data
lr_model = LinearRegression()
lr_model.fit(std.fit_transform(X_train), y_train) # score fit model on validation data
val_score = lr_model.score(std.transform(X_val), y_val)
adjusted_r_squared = 1 - (1-val_score)*(len(y)-1)/(len(y)-X.shape[1]-1)
# report results
print('\nValidation R^2 score was:', val_score)
print('Validation R^2 adj score was:', adjusted_r_squared)
- **Lasso cv(Lasso with K-fold validation)**以特征标准化作为特征选择方法。Lasso 将没有强大预测能力的系数归零,从而将解释集中在几个关键特征上。
std = StandardScaler()# Splitting data to train and val
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Setting up alpha list and letting the model select the best alpha
alphalist = 10**(np.linspace(-2,2,200))
lasso_model = LassoCV(alphas = alphalist, cv=5) # setting K-fold
lasso_model.fit(std.fit_transform(X_train), y_train)# printing coefficients
list(zip(X_train.columns, lasso_model.coef_ / std.scale_))
- **Ridge(具有 K 倍验证的 Ridge)**通过使系数更接近于零来帮助平滑系数,而不移除它们。但更重要的是,它们对两个高度共线的特征给予了大致相等的权重。
std = StandardScaler()# Split data to train and test
X_train, X_test, y_train, y_test = train_test_split(X7, y7, test_size=0.2, random_state=42)# Fit and train model
alphalist = 10**(np.linspace(-1,2,200))
ridge_model = RidgeCV(alphas = alphalist, cv=5)
std.fit(X_train)
ridge_model.fit(std.transform(X_train), y_train)# print coefficients
list(zip(X_train.columns, ridge_model.coef_))
- **ElasticNetCV(具有 K 倍验证的脊)**线性地结合了上述套索和脊方法的 L1 和 L2 罚值。它解决了这两种方法的一些局限性。最终选择了这个模型,对岭模型的权重较高。
std = StandardScaler()l1_ratios = [.1, .5, .7, .9, .95, .99, 1]
alphas = 10**np.linspace(-2,2, 200)model = ElasticNetCV(cv=5, l1_ratio = l1_ratios, alphas = alphas, random_state=42)
std.fit(X_train)
model.fit(std.transform(X_train), y_train)
pred = model.predict(std.transform(X_test))
score = model.score(std.transform(X_test), y_test)
model.alpha_mse = mean_squared_error(np.exp(y_test), np.exp(pred))adj_r_squared = 1 - (1-score)*(len(y_test)-1)/(len(y7)-X7.shape[1]-1)print("Alpha:{0:.4f}, R2:{1:.4f},ajd_R2{2: 4f}, MSE:{2:.2f}, RMSE:{3:.2f}"
.format(model.alpha_, score,adj_r_squared, mse, np.sqrt(mse)))print(f'l1 ratio is {model.l1_ratio_}')
list(zip(X_train.columns, model.coef_ / std.scale_))
接下来的部分只深入到我们可以从模型中获得的三个推论,但是我将在摘录部分详细阐述各个系数。
我的餐厅应该供应哪些菜系?
一家餐馆可能有不止一个由 Yelp 标记的食物类别。在被分析的 1165 家餐馆中,有 146 种不同的菜系。
使用 Python 的词云,你可以看到一些类别出现了很多次(墨西哥餐馆出现了至少 135 次),而许多美食看起来很有异国情调,例如活的/生的或马来西亚食物只出现了一次(可悲!).

Word Cloud visualizing frequency of food categories in our dataset
有两种方法可以将美食作为特色:
- 一个特征:前 N 大菜系(如前 5、10 大菜系或前 20 大菜系)作为虚拟变量
- 多特性:每种食物本身就是一个虚拟变量,最多有 N 个虚拟变量。
如何确定 N:对每个 N 运行交叉验证模型。下图显示了单特征方法的每个 N,右图显示了多特征方法的每个 N。利用这种可视化,我选择了多特性方法,为每一种受欢迎的菜系创建了 21 个虚拟变量。
这仍然是一个很大的特色,但是因为我运行了一个套索模型,所以我希望删除这 21 个菜系中的一些。

Deciding how to include N cuisines as predictors in my model

最终评选出 10 大菜系(见表)。关于系数值的注意事项:由于目标变量被记录,如果你的餐馆在 Yelp 上将该菜系作为一个类别,你可以将该值读取为评论数的百分比变化。
墨西哥、美国(新)、三明治和快餐是消极的预测因素,而其余的是积极的预测因素。
不出所料,将你的餐馆定义为快餐会导致 11.9%的预测点评数下降。然而,我感到失望的是,墨西哥食物会导致 9.7%的低评论计数——在这个城市永远不会有足够的墨西哥餐馆!
邻里关系重要吗?
在《美食》中使用与上述相同的技术来确定邻里关系是否重要,我失望地发现,它根本没有显著提高模型的 R 平方。虽然零假设没有被拒绝,我认为这是一个有趣的观点。虽然向餐馆老板推荐一个社区很好,但我在这里的唯一建议是:担心其他事情,位置并不重要!
食物或环境重要吗 Instagram 测试
Yelp 的照片数据集包含带有以下标签的照片标签信息:
- 食物
- 喝
- 里面的
- 在外面
- 菜单
我发现这些标签有助于了解食物/饮料的美学或氛围(内部/外部标签)是否对餐厅的成功更重要。我为拥有超过 10 张照片的餐厅设置了这个指标,以确保相关性(拥有 20 张氛围照片和 10 张食物照片的餐厅比拥有 2 张氛围照片和 1 张食物照片的餐厅传达了更强的美学信息)。
一般来说,餐馆张贴的食物照片比环境照片多:

因此,我创建了一个名为 food_70 的虚拟变量来表示餐馆的食物/饮料比率是否至少为 70:100。
下一个特征是照片的计数。虽然照片数量和评论数量之间可能存在反馈循环关系(越受欢迎的餐厅有越多的照片),但我认为照片较少的餐厅(少于 10 张)的反馈循环关系会更弱。
因此,创建了三个虚拟变量:没有照片的餐馆、有 1-5 张照片的餐馆和有 6-10 张照片的餐馆。
在将这些特征放入模型之前,一些简单的探索性分析显示,评论越多的餐厅,平均而言,食物与氛围的比例越平衡(对于评论少于 50 条的餐厅,接近 1.5:1,而不是 3:0)。


如果你的餐馆没有照片,你获得更少评论的几率会大大增加。
毫不奇怪,没有照片对你的案例获得超过 50 个评论没有帮助。
外卖

Predicted vs Actual Reviews

The coefficient table
我使用 R Square 来选择我的最终模型,并获得了 0.50 的分数。当根据实际评论绘制预测评论时,该模型在预测评论数较高的餐馆时仍然表现不佳
贝塔系数表中的一些附加信息:
- 价格范围:价格范围上升到四个美元符号,但它们对更多评论很重要
- **照片:**没有或少于 6 张照片是受欢迎程度的主要负面预测因素
- 美食:氛围比:餐厅一般美食都比氛围照多。但是你希望你的餐厅至少有 30%的氛围(漂亮的装饰很重要!)
鉴于 R 平方得分为 0.5,线性回归可能不是预测评论数的最佳模型。然而,该模型确实给出了在一个新城市开业的餐馆应该考虑什么的有力建议。
在未来的工作中,值得将分析扩展到更多的城市,因为我们知道邻里关系并不重要。感谢阅读!
精准农业的计算机视觉
基于像素做出决策

Photo by Chris Ried on Unsplash
如果我告诉你,你看到的一切对一堆数字来说没什么不同,会怎么样?如果我说这一事实对农业综合企业、零售、运输或军事防御等行业有直接影响,你会相信吗?
很像在《黑客帝国》电影中,我们看到的是由大脑处理和解释的原始数据,这一切发生得如此之快,以至于我们甚至没有意识到。在计算术语中,任何图像都可以被认为是一组数据,其中该图像的每个像素保存一个或多个值。像素是图像的组成部分,以特定的顺序排列以表示特定类型的一些信息。就像在海战游戏中一样,图像中的每个像素都有一个特定的坐标,这给图像本身带来了意义。

在上图中,像素值是范围从 0(黑色)到 255(白色)的整数,这意味着可以对该图像(或任何其他图像)进行分析、采样、分类、预测、参数化,或对数据集执行任何其他操作。图像分析是遥感图像的关键学科之一,因为它带来了一些最有价值的见解。更具体地说,农业中的遥感图像是受现代卫星扩张影响的现代农业技术中的热门话题之一,其中一些卫星免费提供高分辨率图像。农业行业的技术和数字化正在催生新的可能性,其中一些在几年前是无法想象的。
如今,卫星和无人机(像无人机一样的无人飞行器)正在拍摄比以往任何时候都更精确的图像。时间(图像频率)和空间分辨率(衡量图像的精细程度)在过去几年中呈指数增长,航空航天业将继续以我们甚至无法预测的方式发生变化。我们的能力如此强大,以至于我们真的有能力从外太空发现一枚硬币。随着像素密度(每英寸像素,或 ppi)的增加,我们可以获得更清晰的图像和更重的数字图像文件。相反,随着像素密度的降低,我们会损失精度,但也会降低处理需求。这是当前数字图像分析中的一个基本权衡,图像的可用性增长如此之快,以至于我们似乎跟不上处理它们的能力。
通过在农业等学科中使用遥感图像,我们能够以更高效的方式执行不同的任务:
- 检测植物疾病
- 对土地覆盖(如森林)和土地利用(如农业)进行分类
- 通过识别不同的作物,如大豆、玉米、小麦等,对作物类型进行分类。
- 通过计算特定地区作物的预期产量来估计作物产量
- 识别与健康作物竞争阳光和土壤养分的杂草
- 通过检测水分胁迫监测和预测土壤湿度
- 评估除草剂、杀虫剂和杀真菌剂的有效性
- 识别作物和土壤中的污染物
- 监控播种过程的有效性
但是我们如何仅仅从一幅图像中获得所有这些信息呢?似乎有点太多了,对吧?事实上,遥感影像不仅提供了每个像素的一个值(例如颜色值),还提供了每个像素的附加值,这带来了许多额外的数据来改进任何分析或决策。为了理解这是如何工作的,我们必须先谈谈光谱图像。
看见看不见的
作为人类,我们只能看到电磁波谱中非常小的一部分(我们称之为“可见光”),而事实是,几个世纪以来,我们只是通过一把小锁来体验这个世界。
1800 年威廉·赫歇尔(发现天王星的同一个人)用棱镜分离阳光,并在每种光色下放置温度计。通过在红灯旁边放置一个额外的温度计,他发现这个额外的温度计具有所有温度计中最高的温度。这就是红外光的发现,世界第一次知道了我们用肉眼看不到的光。仅一年后,约翰·威廉·里特在可见光光谱的另一边做了同样的实验(这次在紫光边之外),发现了紫外光。电磁波谱诞生了。

现代遥感图像可以测量各种波长(远远超过我们已知的“可见光”光谱),其中许多波长是我们肉眼看不到的。这被称为多光谱图像,它是由传感器(例如卫星或无人机中的传感器)产生的,这些传感器测量电磁波谱的几个部分(或波段)内的反射能量。由于不同的物体或条件以不同的方式反射能量(例如植物反射光的方式不同于水),每个光谱带捕捉不同的属性。
在多光谱图像所代表的图像的每个像素中,可以有大约 10 或 20 个不同的波段测量值。像 Sentinel-2 这样的卫星(为全球范围内的陆地和水域监测提供免费图像)有 13 个光谱带,每个都与电磁波谱的特定波长相关联。
但是如果你认为 13 个波段还不够,那么你可以考虑高光谱。超光谱图像可以提供数百种波段测量(是的,数百种图像!)在整个电磁频谱上,这为观察中的细微变化提供了更高的灵敏度。超光谱传感器生成的图像包含的数据比多光谱传感器生成的图像多得多,并且在检测特征差异方面有很大的潜力。例如,虽然多光谱图像可用于绘制森林地区的地图,但高光谱图像可用于绘制森林中的树种。
T2 卫星公司是世界上高分辨率高光谱图像的领先供应商。除了为农业、采矿、建筑和环境测绘领域的企业提供竞争优势之外,Satellogic 还采取了大胆的举措,为开放的科学研究和人道主义事业免费提供超光谱数据。

Different Landsat bands exploded out like layers of onion skin along with corresponding spectral band wavelengths and common band names. Source: NASA
为什么数据科学是真正的游戏规则改变者?
由于图像是数据集,您可以考虑对它们进行数学运算。
通过对光谱带进行代数运算,可以将两种或多种波长结合起来突出显示特定的特征,如植被类型、燃烧区域或发现水的存在。还可以将来自不同来源(如不同卫星)的波段组合起来,以获得更深入的见解:想象一下,将不同的光反射波段与土壤湿度以及土地高程特征组合在一起,所有这些都堆叠在同一个数据集中:如果数据集中的每个波段或图像具有相同的行数和列数,则一个波段的像素与另一个波段的像素位于相同的空间位置。由于每个像素都进行了地理编码,我们可以在任何特定位置添加不同的信息层。
好消息是这并不像听起来那么难。谷歌地球引擎提供由他们自己的数据中心和 API 支持的数 Pb 的卫星图像和地理空间数据集,一切都在一个用户友好的平台上,让任何用户测试和实现自己的模型和算法。你可以执行数学和几何运算,分类像素或识别物体,同时在云中高速运行。谷歌又一次扩大和简化了几年前极其复杂和昂贵的东西。
此外,多年来遥感图像的可用性大大增加,因此有可能增加时间维度。活跃卫星的数量增加了,它们的重访时间也增加了,因此我们有可能将可靠的时间信息合并到任何模型中。通过对图像进行时间序列分析,我们摆脱了单一时间信息(只是时间上的一瞥)并进入了一个新概念,在这个概念中,属性随着周期而变化,我们可以观察到不同的周期和趋势。
在这种大数据环境中得出结论极具挑战性,因为如果我们没有能力处理这些数据,这些数据就没有任何意义。你如何管理和解释数十亿像素和巨大的数据集?
这就是数据科学正在进行真正的革命,并推动农业等行业的深刻变革。数据科学可以被认为是一门相当新的学科,专注于从数据中提取有意义的见解,用于战略决策、产品开发、趋势分析和预测。数据科学的概念和方法源自统计学、数据工程、自然语言处理、数据仓库和机器学习等学科,这些学科在处理实际的数据爆炸方面非常有效。你可以说,数据科学家在数据中游泳时,最擅长做出发现。
但在数据科学的所有子学科中,我认为机器学习值得特别关注。机器学习描述了从数据中学习而不是专门为此编程的算法,代表了解决数据丰富问题的最佳解决方案。在可预见的未来,这是数据科学最有可能提供直接和切实利益的领域。
像 Planet 这样的公司利用机器学习将图像转化为可操作的分析信息,以比免费卫星更好的空间和时间分辨率跟踪基础设施和土地使用的变化。
从庞大的机器学习算法宇宙中, 卷积神经网络(CNN)是图像处理领域的最先进技术,正被用于农业等领域,以重塑做事的方式。CNN 代表了一种有前途的技术,在精度和准确度方面具有当前的高性能结果,优于其他现有的图像处理技术。
世界上第一个农业机器人 C2-A2 使用 CNN 来保护设备和人员免受所有可能的碰撞。C2-A2 是一个人工大脑,旨在成为自主农业机械的通用控制系统,如收割机、拖拉机或喷雾器。
由于这些学科,人的能力正以惊人的速度得到加强。遥感图像等领域的技术入侵完全改变了我们与世界互动的方式,谁知道这将在哪里结束。在这种情况下,考虑处理极其复杂的输入并自己做出决策的系统并不疯狂,这样可以释放人类的时间和资源来做其他事情。
适量的建模

A tower of Data Science books not quite containing 300 algorithms (photo by author)
一些从业者看重为了给顾客留下深刻印象而做的模特的数量,但是质量当然也很重要。
最近,我遇到了一个不寻常的数据科学演示。做报告的数据科学家已经尝试了 300 多种不同的算法来寻找合适的模型。
我没见过这样的东西,所以我问他们为什么。他们的回答也引起了我的注意——稍微解释一下,这是因为(根据他们的知识)不可能预先知道哪种算法执行得最好,我们只能全部尝试。
似乎有几个原因让我们对如此大量的算法感到担忧。首先,这有可能成为 p 值挖掘的机器学习版本。也就是说,给定足够多的模型,有可能会出现一些极端的结果,这些结果并没有真正反映基础数据的预测能力,也就是说,这些结果只是由于过度拟合而出现的。事实上,顾问们推测一个模型的 AUC 值非常高,与其他模型结果相比是异常值,这与可重复的结果相反。
另一个困难是,许多所谓的不同算法似乎是彼此的近亲,例如,C4.5 和 C5.0 当然是不同的,但差异没有 C4.5 和 GUIDE 或 QUEST 之间的差异大,也没有 C4.5 和被动攻击分类器或基于感知器的分类器(无论是作为单个感知器还是在网络中)之间的差异大。
虽然我的愤世嫉俗者说,他们并不真的相信没有办法确定算法在一开始或多或少可能成功,并试图夸大他们尝试的算法数量,因为他们认为这使他们的工作听起来更令人印象深刻,但对我来说,这至少提出了几个问题。第一——在决定是否足够之前,一个人应该尝试多少种模式?第二,应该从哪里开始?第三——你如何做出有根据的猜测,哪些算法应该优先考虑,哪些应该排除?
作为第一步,数据类型以及您正在研究的是监督学习还是非监督学习是一个显而易见的起点。在这种情况下,这个问题是一个监督分类问题,所以让我们坚持下去,制定一些如何进行的原则。
首先,如果有理由相信支撑线性回归的假设没有被过分违反(在应用任何适当的变换之后),你的第一选择应该是使用你的回归或基于 GLM 的模型,因为解释和诊断将比你能想到的几乎任何其他 ML 算法都好。
这通常适用于相对较小的数据集,其中对关系有很强的先验理解。例如,我对回归的第一次体验与实验化学数据有关,在这种情况下,事先知道存在线性关系,偏差可以归因于实验或测量误差。
回归模型还有一个优点,即您可以有选择地增加模型的复杂性,例如,通过选择是否包含特定的交互作用,甚至允许一定程度的非线性。
如果需要一个可解释的模型,但在回归环境中无法实现,那么单个决策树可能是有用的,如果担心健壮性或初始准确性,可能需要尝试几个不同的树。
虽然决策树似乎可以通过自动查找交互来减少建模时间,但这有时会适得其反,因为很难在与数据紧密匹配的激进模型和概括良好的模型之间找到平衡。此外,具有许多交互的深树实际上很难解释。
如果决策树或回归模型不能提供所需的准确性,那么你可以考虑一个更不透明的模型,比如一个树的集合——随机森林、GBM 或你的个人喜好。其中最好的一个是符合你个人口味的,因为调整一个对你有意义的算法可能比当场学习一个新算法更快、更有效。
在某些时候,当数据变得足够大,并且特征变得众多而没有明显的强特征时,考虑深度学习或相关方法开始变得有用。再说一次,在哪个精确的点上移动这个舞台是值得的,这既是一个科学问题,也是一个个人品味问题。
当你运行完所有这些算法的时候,你可能已经运行了半打不同的算法,然后你才发现你没有把性能提高到足以保证花费额外的时间来制作更多的模型。
最终,时间就是金钱,因此您希望能够预测哪些模型最有可能与您的现成数据集一起工作。让算法列表尽可能短可以让花在一个问题上的时间尽可能短,并且能够在用相对少量的不同算法生成模型之后提供可信的解决方案,这应该是一个经验丰富、知识渊博的数据科学家的标志。
罗伯特·德格拉夫是《管理你的数据科学项目的作者,将于 2019 年 7 月中旬由阿普瑞斯出版社出版。
航天人艾的崛起与崛起

Image is a screenshot of the homepage of Spacemaker AI’s website June 2019
PropTech 创业公司最大化任何建筑工地的价值
当人们问我在挪威看哪家公司时,我毫不含糊地回答:它是航天制造商 AI。毫无疑问。他们所做的令人难以置信的令人兴奋,你有一个很好的理由去检查他们,和他们交谈并找出原因。作为引子,让我直接引用他们的话,说:
太空制造商 AI 开发了一项改变游戏规则的 AI 技术,该技术发现了最聪明的方法来最大化任何建筑工地的价值。
这是一个很大的承诺,对不对?事实上,他们正在建设交付能力。航天制造商 AI 仍然是一家小公司,最近雇佣了 100 名员工。它被挪威最大的商业报纸评为最热门的工作地点。几天前,据宣布,他们刚刚以 2500 万美元完成了首轮融资。正如在 TechCrunch 中提到的,他们的这轮投资由 Atomico 和 Northzone 牵头。
首轮融资是一家公司第一轮重大风险投资融资的典型名称。该名称指的是出售给投资者以换取其投资的优先股类别。
根据 Shifter 报道的 Venturescanner 的新数据,房地产技术已经从 2016 年 1137 家公司的 169.9 亿美元增长到 2019 年 1659 家公司的 550 亿美元。那是数字,但是太空制造者 AI 做什么?
Spacemaker 被描述为“世界上第一款”用于房地产开发领域的人工智能辅助设计和施工模拟软件,它声称能够帮助房地产开发专业人士,如房地产开发商、建筑师和城市规划师,快速生成和评估任何多层住宅开发的最佳环境设计。为了实现这一目标,Spacemaker 软件处理各种数据,包括物理数据、法规、环境因素和其他偏好。
-TechCrunch 2019 年 6 月 10 日
然而,让我们回溯几年来了解更多关于该公司的情况。
航天人艾的故事
根据官方公司注册显示,太空创客 AI 于 2016 年末由哈瓦德·豪克兰德和卡尔·克里斯滕森创立。Havard Haukeland 拥有建筑师的教育背景,曾在建筑和城市设计领域工作过。卡尔·克里斯滕森拥有计算机工程师的教育背景,另外还有工商管理和经济学硕士学位。
2017 年末,有一篇文章称他们的数字解决方案是一项为期 4 年的科研项目的一部分,该项目得到了阿斯佩林·拉姆、AF Eiendom、Stor-Oslo Eiendom 和 SINTEF 等公司的支持。然后,空间制造商 AI 从挪威研究委员会、创新挪威和 Simula 研究实验室获得了超过 1500 万挪威克朗(180 万美元)的资金,用于开发他们的数字解决方案。
2017 年 10 月,他们在一年内成长为一家拥有 20 名员工的小公司。他们当时正在谈论将人工智能用于城市规划和建筑工地。2017 年 9 月,一群投资者聚集在一起,向该公司投资 2200 万挪威克朗(265 万美元)。除此之外,CBRE 的挪威领导集团决定与 CBRE 一起投资,成为在纽约州注册的最大的商业地产顾问之一。这是他们的解决方案在 2017 年末的样子:

Picture by DN Norwegian Newspaper from late 2017

Sketch from the work for an early client taken by DN Norwegian Newspaper in 2017
在他们的第一个项目完成仅两周之后,他们声称已经有超过 100 家客户与他们接洽合作,而 Havard Haukeland 被提名为挪威年度最佳领导人才。
在 2017 年的时候,他们最大投资者的一位首席执行官坚持认为,如果他们敢于取得成功,那就必须是国际性的。他们的解决方案融合了建筑和人工智能领域。他们通过复杂的数学计算,对每个房地产项目的各种因素进行了预先考虑。尽管如此,他们还是承认,并非所有建筑的品质都是可以计算的。
“……我们不相信人工智能会取代建筑师。但使用人工智能的建筑师可能会取代不使用人工智能的建筑师。”
——哈瓦德·豪克兰德 2017 年 9 月接受 DN采访
2017 年的这个时候,他们还开始与哈佛大学的一名博士生研究员合作。这种合作后来蓬勃发展。Spacemaker 正在进行的另一个研究项目是与 SINTEF 合作的应用数学项目,名为 OptiSite ,已于 2017-2021 年开始滚动。
我们是 Spacemaker 创新项目 OptiSite 的研究合作伙伴。OptiSite 将使 Spacemaker 成为建筑设计和场地规划软件工具的全球领导者。在这个项目中,我们改进和发展优化和人工智能技术,以协助房地产开发。
-SINTEF,2016 年 3 月 8 日
据联合创始人Havard Haukeland称,2017 年底,太空创客 AI 被领先的非营利组织 Hello Tomorrow 评为 500 家最具创新性的创业公司之一,以加速创业和科技创业。大约在这个时候,他们收到了代理公司赛车的更名。因此,他们的研究能力和品牌都得到了发展。



研究从一开始就是公司的核心,而且似乎贯穿了整个运营过程。2018 年年中,太空创客 AI 在美国设立了办公室,并有了他们的第一位全职员工乔丹·霍夫曼。他的背景是应用数学,这似乎是对公司的一个合适的补充,因为公司在同年早些时候公布了他们的化妆。

Spacemaker AI Instagram the 15th of January
从 Magnhild Gjestvang 在官方的 Spacemaker AI 媒体页面上写的博客文章中,还提到他们正在哈佛和麻省理工学院举行会议,既招聘又学习。他们当时被邀请到麻省理工学院做客座演讲,会见那里正在探索复杂的社会技术工程系统的系统设计师。

他们还在其他技术大学,如挪威的 NTNU 大学进行了演讲。他们积极地从大学和奥斯陆的其他公司招聘一些最好的开发人员来扩大他们的团队。国际招聘似乎从第一天起就是航天制造商 AI 的一项战略,至少在目前这一点上,它显然对他们有利。

Spacemaker AI January 2019 from their Facebook page
他们被宣布为 2019 年挪威 B2B 类别的年度创业公司,正如前面提到的,他们刚刚获得了2500 万美元的首轮融资。除此之外,他们最近似乎还雇佣了一些设计人才来继续设计他们的 UX,并对他们的品牌进行更新。

Image is a screenshot of the homepage of Spacemaker AI’s website June 2019
建筑人工智能
【2019 年 2 月,哈佛大学的硕士研究生和富布莱特研究员斯塔尼斯拉斯·夏鲁在出版物中写了一篇名为建筑人工智能的文章。他描绘了建筑是如何经历发明和创新的。他把它分成四段序列。

Four-period Sequence of Inventions and Innovations in Architecture made by Stanislas Chaillou
因此,从模块化网格的简单性和可负担性开始,到计算设计的出现。从模块,这是进一步通过计算设计成为可能。
计算设计(1)允许严格控制几何形状,提高设计的可靠性、可行性和成本,(2)促进和简化设计师之间的协作,以及(3)最终实现比传统手绘更多的设计迭代。更多测试&更多选择以获得更好的设计。
——斯塔尼斯拉斯·夏鲁
之后,通过定义某些参数,可以重复设计,自动执行重复的手动过程。后来有了 BIM(建筑信息建模),建筑中的每一个元素都是参数的函数。然而,斯塔尼斯拉斯认为这种参数化设计忽略了文化和社会因素,并提出这可以通过人工智能来解决。他说:
人工智能从根本上说是一种架构的统计方法。人工智能的前提是将统计原理与计算相结合,这是一种新的方法,可以改善参数化架构的缺点。
2019 年 2 月《移位器上的一篇文章提到,太空制造商 AI 的首席技术官卡尔·克里斯滕森在麻省理工学院举办了他的讲座。它还提到,太空制造商 AI 有五名全职员工,分别来自麻省理工学院、哈佛大学或耶鲁大学。与一些最重要的研究人员和成熟的行业专业人士一起,空间制造商 AI 正在询问是否有更好的方式来设计我们的城市。

Photo taken by press and published in Shifter

Image from the publication Shifter February 2019.

Picture from Demo project as shown by TechCrunch 10th of June 2019
这是我项目#500daysofAI 的第 11 天。我希望你喜欢这篇文章。
什么是#500daysofAI?
我在挑战自己,用#500daysofAI 写下并思考未来 500 天的人工智能话题。
这是受电影《夏日 500 天》的启发,主角试图找出爱情失败的原因,并在此过程中重新发现他生活中真正的激情。
如果你想了解更多,请查看我现有的一些文章:
1。 定义 AI — #500daysofAI :
2。 应用人工智能与可持续城市论文 :
3。 当前伦理人工智能资助中的一些问题 :
4。 人工智能领域的专利 :
5。 AI 为善 AI 为恶——发表于创业 :
6。 阿根廷和乌拉圭的艾治 :
7 .。 艾领域的三位作家 :
8。 斯堪的纳维亚 AI 战略 2019 :
9。 社会科学家艾 :
10。 10 对艾的思考 :
感谢您的阅读!
数据停机时间的增加
介绍“数据宕机”及其对数据驱动型组织的重要性

Photo by drmakete lab on Unsplash
你有没有遇到过这样的情况,你的首席执行官看了你展示的一份报告,说这些数字看起来很离谱?客户是否曾在您产品的仪表盘上调出不正确的数据?我肯定你没有遇到过这种情况,但是也许你有一个朋友遇到过这种问题?😃
2016 年,当我在 Gainsight 领导一个团队时,我对这些问题太熟悉了。我们负责我们的客户数据和分析,包括由我们的首席执行官每周审查和由我们的董事会每季度审查的关键报告。似乎每周一早上,我醒来都会收到一系列关于数据错误的电子邮件。感觉就像我们每次解决一个问题,都会发现另外三个问题。更糟糕的是,我们自己没有发现问题。相反,其他人,包括我们非常耐心的 CEO,都在提醒我们这些问题。最近,我与另一家公司的首席执行官交谈,他告诉我,他曾经在办公室里四处走动,在显示错误数据的显示器上贴上便签,上面写着“这是错误的”。
在 Gainsight,我有幸与数百家公司合作,这些公司在处理客户数据和获得改善业务成果的见解方面处于行业领先地位。但我亲眼看到,尽管许多公司都在努力成为数据驱动型企业,但它们都做得不够。当他们遇到与我类似的困难和挑战时,他们对自己的数据失去了信心,最终做出了次优的决策。我最近遇到的一位创始人告诉我,他的公司的数据和仪表板中持续存在的数据问题如何对他们的文化产生了负面影响,并阻碍了他们成为数据驱动型公司的雄心。

Photo by Nathan Dumlao on Unsplash
引入数据停机时间
我把这个问题称为“数据宕机”数据停机指的是数据不完整、错误、丢失或不准确的时间段。对于今天的数据驱动型组织来说,这种成本非常高,并且几乎影响到每个团队,但通常是以临时的、被动的方式来解决。
我称之为停机时间,让我们回到互联网的早期。当时,在线应用程序是一个不错的选择,如果它们宕机一段时间,也没什么大不了的。你可以承受停机时间,因为企业不会过度依赖它们。我们已经走过了 20 年,在线应用对几乎所有企业来说都是至关重要的。因此,公司会仔细测量停机时间,并投入大量资源来避免服务中断。
同样,公司越来越依赖数据来运行日常运营和做出关键任务决策。但是,我们还没有按照数据停机所要求的那样认真对待它。虽然少数公司正在实施 SLA,让数据团队对准确可靠的数据负责,但这还不是规范。在未来几年,我预计将会有更多关于数据停机时间的审查,并更加关注最大限度地减少数据停机时间。
有迹象表明数据宕机正在影响您的公司
数据停机可能由于各种原因而发生,包括例如模式中的意外更改或错误代码更改。在内部或外部客户之前发现这一点通常很有挑战性,而且了解根本原因并快速补救非常耗时。
以下是数据宕机影响您公司的一些迹象:
- 内部和外部的数据消费者打电话来抱怨您的数据,并逐渐失去信任。客户可能会想"为什么我是这家公司抽查数据错误的人?"或许 CEO 认为:“如果这个图表是错的,还有哪些图表是错的?”
- 你正在努力让数据驱动决策在你的公司得到采用,这让你在竞争中处于劣势。人们可能会说*“无论如何,数据是坏的,我们不能相信它,所以让我们跟着直觉走吧。”*
- 您的分析/BI、数据科学、数据工程和产品工程团队将时间花在救火、调试和修复数据问题上,而不是在可以为您的客户增加实质性价值的其他优先事项上取得进展。这可能包括浪费在沟通上的时间()“组织中的哪个团队负责解决这个问题?”)、问责(“谁拥有这个管道或者仪表盘?”)、故障排除(“具体哪个表或字段损坏了?”)、或者效率(“这里已经做了什么?我是在重复别人的工作吗?”).
Tomasz Tunguz 最近预测“数据工程是新的客户成功。”正如客户成功是一个新生学科,现在正成为每个企业的重要职能一样,数据工程预计也将同样增长。我完全同意,并补充说,数据停机问题跨越了数据驱动型组织中的许多团队。随着公司在使用数据方面变得越来越受数据驱动和复杂,以及业务功能越来越成为数据的重要消费者,我预计数据宕机问题将会扩大并变得越来越重要。我还期望出现更好的解决方案来帮助整个行业的团队减少数据停机时间。在未来的帖子中,我将描述我们如何试图在 Gainsight 解决这个问题,以及当公司重新获得对其数据的信任和信心时所获得的好处。
如果您经历过数据停机,我很想听听您的意见!通过电子邮件 联系 Gmail . com。
数据运营的兴起(从数据治理的灰烬中)
ML 时代打破了传统的数据治理。让我们将它重建为一个工程学科,以推动数量级的改进。

公司知道他们需要数据治理,但是在实现数据治理方面没有取得任何进展
最近,高管们对数据治理感兴趣,因为有这样的文章:
- 最近的 Gartner 研究发现,组织认为糟糕的数据质量导致每年平均 1500 万美元的损失。
- GDPR 的第一笔巨额罚款是谷歌被法国数据管理局罚款 5700 万美元
- Equifax 数据泄露已经给公司造成了 14 亿美元的损失(还在继续),尽管事实上数据从未被发现。
另一方面,绝大多数数据治理计划未能取得进展,Gartner 还将 84%的公司归类为数据治理成熟度低的公司。尽管几乎每个组织都认识到数据治理的必要性,但由于该术语在高管阶层中的强烈负面含义,许多公司甚至没有启动数据治理计划。

当前的数据治理“最佳实践”被打破
以我的经验来看,缺乏进展的原因是我们一直在以错误的方式进行数据治理,这使得它在到达时就死亡了。斯坦·克里斯汀斯在的《福布斯》文章中说得很对,尽管事实上这本质上是他的公司的一个广告(一个非常有效的广告)。我同意他的观点,过去治理失败的主要原因是因为技术还没有准备好,组织无法找到激励人们遵循填补技术空白的过程的方法。然而,我不同意现代数据目录工具提供了我们成功所需的完整技术答案(尽管它们是朝着正确方向迈出的一步)。
如果数据目录工具不是答案,那什么是呢?
数据湖工具的最新进展(特别是大规模版本化数据的能力)使我们处于一个转折点,我们可以重新设想我们治理数据的方式(即文化、结构和流程,以实现风险缓解和治理成本降低)。在转型结束时,数据治理将看起来更像 DevOps,数据管理员、科学家和工程师密切合作,在整个数据分析生命周期中编纂治理策略。尽早采纳这些变革的公司将创造巨大的竞争优势。
为了理解我是如何得出这个结论的,我们必须回顾一下软件工程的历史,在软件工程中,两项核心技术创新促成了过程和最终的文化变革,将编码从一种爱好转变为一场席卷全球的革命。然后,我们将看到类似的创新是如何成为 DevOps 运动的主要推动者的,devo PS 运动在云时代同样转变了 IT 基础架构。最后,我们将看到这些创新如何推动数据治理的类似流程和文化变革。建立这个案例需要一点时间,但我还没有找到更好的方法来表达这一点,所以请继续关注我。
背景:源代码控制和编译如何创造了软件工程

创建软件工程学科的核心创新是:
- 将一组输入编译成可执行输出的能力
- 跟踪输入的版本控制系统
在这些系统出现之前,回到 20 世纪 60 年代,软件开发是一门手艺,一个工匠必须交付一个完整的工作系统。这些创新使得新的组织结构和过程能够应用于软件的创建,编程成为一门工程学科。这并不是说编程艺术不重要,只是这不是本文的主题。

从手工到工程的第一步是通过编译器用高级语言表达程序的能力。这使得编写程序的人更容易理解程序,也更容易在团队中的多人之间共享,因为程序可以被分解成多个文件。此外,随着编译器变得更加高级,他们通过将代码传递给许多中间表示来对代码进行自动化改进。

通过在最终产生系统的代码的所有变更中添加一致的版本系统,随着时间的推移,编码艺术变得“可度量”(按照彼得·德鲁克的名言:“你不能管理你不能度量的东西”)。从那时起,各种各样的增量创新,像自动化测试、代码质量的静态分析、重构、持续集成和许多其他的被添加进来,以定义额外的度量。最重要的是,团队可以针对特定版本的代码归档并跟踪 bug,并且对他们交付的软件的特定方面做出保证。显然,已经有许多其他的创新来改进软件开发,但是很难想到在某种程度上不依赖于编译器和版本控制的创新。
一切如代码:在别处应用软件工程的核心创新
近年来,这些核心创新被应用到新的领域,导致了一场名为的运动。虽然我没有亲身经历,但我只能假设软件开发人员在 70 年代用怀疑的眼光看待 SVN 的第一个版本。同样,由“一切如代码”运动所消耗的许多新领域也受到了类似的质疑,有些人甚至声称他们的学科永远不会简化为代码。然后,在几年之内,规程中的一切都被简化为代码,这导致了对“遗留”做事方式的许多倍的改进。

Turning code into infrastructure using a “compiler” layer of virtualization and configuration management
第一个扩展领域是基础设施供应。在本例中,代码是一组配置文件和脚本,用于指定跨环境的基础架构配置,编译在云平台中进行,在云平台中,配置与脚本一起根据云服务 API 读取和执行,以创建和配置虚拟基础架构。虽然代码移动看起来像是一夜之间席卷所有基础架构团队的基础架构,但大量令人惊叹的创新(虚拟机、软件定义的网络、资源管理 API 等。)使“编译”步骤成为可能。这可能始于 VMWare 和 Chef 等公司的专有解决方案,但当公共云提供商在其平台上免费使用核心功能时,它被广泛采用。在这一转变之前,基础设施团队管理他们的环境以确保一致性和质量,因为它们很难重新创建。这导致了治理的分层,旨在在开发过程中的各个检查点应用控制。今天,DevOps 团队 eengineer他们的环境,控件可以内置到“编译器”中。这极大地提高了部署变更的能力,从几个月或几周缩短到几小时或几分钟。
这使得我们能够彻底反思改善基础设施的可能性。团队开始整理从零开始创建系统的每个阶段,使编译、单元测试、分析、基础设施设置、部署、功能和负载测试成为完全自动化的过程(连续交付)。此外,团队开始测试系统在部署前后的安全性(DevSecOps)。随着每个新组件进入版本控制,该组件的演化随着时间变得可测量,这将不可避免地导致持续的改进,因为我们现在可以对我们交付的环境的特定方面做出保证*。*
言归正传:同样的事情也会发生在数据治理上
这种现象的下一个消费领域将是数据治理/数据管理。我不确定它的名字会是什么(DataOps、Data as Code 和 DevDataOps 似乎都有点过时),但它的影响可能会比 DevOps/infrastructure as code 更有影响力。
作为编译器的数据管道
“有了机器学习,你的数据就写出了代码。”— Kris Skrinak,AWS ML 部门主管

机器学习的快速崛起提供了一种构建复杂软件的新方法(通常用于分类或预测事物,但随着时间的推移,它将做得更多)。这种将数据视为代码的心态转变将是将数据治理转化为工程学科的关键的第一步。另一个人说:
“数据管道是简单的编译器,它使用数据作为源代码.”
与软件或基础设施相比,这些“数据编译器”有三点不同,但也更复杂:
- 数据团队拥有数据处理代码和底层数据。但是如果数据现在是源代码,就好像每个数据团队都在编写自己的编译器来从数据中构建可执行的东西。
- 对于数据,我们一直通过元数据手动指定数据的结构,因为这有助于编写“数据编译器”的团队理解每一步要做什么。软件和基础设施编译器通常推断其输入的结构。

We don’t understand how data writes code
3.我们仍然没有真正理解数据是如何编写代码的。这就是为什么我们让数据* 科学家进行实验来弄清楚编译器的逻辑,然后数据工程师随后进来构建优化器。*
当前的一套数据管理技术平台(Collibra、Waterline、Tamr 等。)是为了支持这个工作流程而建立的,他们做得非常好。然而,他们支持的工作流仍然使得数据治理的定义成为在审查会议中处理的手动过程,这阻碍了我们在开发运维&基础设施作为代码出现后看到的改进类型。
缺失的环节:数据版本控制

Applying data version control. Credit to the DVC Project: https://dvc.org/
因为数据是在“真实世界”中生成的,而不是由数据团队生成的,所以数据团队一直专注于控制描述数据的元数据。这就是为什么我们在数据治理(试图管理您不能直接控制的东西)和数据工程(我们实际上是在设计数据编译器而不是数据本身)之间划了一条线。目前,数据治理团队试图在不同的点应用手动控制来控制数据的一致性和质量。对数据引入版本跟踪将允许数据治理和工程团队一起设计数据,针对数据版本归档错误,对数据编译器应用质量控制检查,等等。这将允许数据团队对数据交付的系统组件做出保证*,历史已经表明,这将不可避免地导致数据驱动系统的可靠性和效率的数量级提高。*
数据版本控制的临界点已经到来
像 Palantir Foundry 这样的平台已经像开发人员对待代码版本一样对待数据管理。在这些平台中,数据集可以被版本化、分支、由版本化代码操作以创建新的数据集。这使得数据驱动测试成为可能,数据本身的测试方式与单元测试对修改数据的代码的测试方式非常相似。当数据以这种方式流过系统时,系统会自动跟踪数据的谱系,就像在每个数据管道的每个阶段产生的数据产品一样。这些转换中的每一个都可以被视为编译步骤,在机器学习算法将最终的中间表示(数据团队通常称之为特征工程数据集)转换为可执行形式以进行预测之前,将输入数据转换为中间表示。如果你手头有 1000 万到 4000 万美元的资金,并且愿意与某个供应商合作,那么 Foundry 中所有这一切的整合是非常令人印象深刻的(声明:我没有太多 Foundry 的实践经验;这些陈述基于我在客户端看到的真实实现的演示。

The DataBricks Delta Lake open source project enables data version control for data lakes
对于我们其余的人来说,现在有开源的替代方案。数据版本控制项目是一个针对数据科学家用户的选项。对于大数据工作负载,随着他们的开源三角洲湖项目的发布,DataBricks 已经迈出了为数据湖开源真正版本控制系统的第一步。这些项目是全新的,所以分支、标记、血统跟踪、bug 归档等等。还没有添加,但是我很确定社区会在接下来的一年左右添加它们。
下一步是重建数据治理
版本控制和数据编译技术的到来促使数据团队开始重新思考他们的流程如何利用这一新功能。那些能够积极利用这种能力来做出保证的人,很可能会为他们的组织创造巨大的竞争优势。第一步是终止基于检查点的治理流程。相反,数据治理、科学和工程团队将紧密合作,在数据被数据管道编译成可执行的东西时,实现数据的持续治理。在这之后的某个地方,将会把从数据中编译的组件与纯软件和基础设施集成为一个单元;虽然我不认为有技术可以做到这一点。其余的将随着时间的推移而出现( 中的和 以及其他 帖子),实现一种治理文化,减少主要问题,同时加快机器学习计划的价值实现时间。我知道这听起来很疯狂,但这是一个令人兴奋的数据治理时代。
如果你已经读到这里,你可能对数据治理感兴趣,所以请留下评论或写下你的想法。
元学习的兴起

https://openai.com/blog/solving-rubiks-cube/
元学习描述了设计与训练深度神经网络相关的更高级组件的抽象。当提到神经网络架构的自动化设计时,术语“元学习在深度学习文献中频繁引用“ AutoML ”、“少量学习”或“神经架构搜索”。从标题滑稽的论文中脱颖而出,如“通过梯度下降学习梯度下降学习”,OpenAI 的魔方机器人手的成功证明了这一想法的成熟。元学习是推进深度学习和人工智能的最先进的最有前途的范式。
OpenAI 通过展示经过强化学习训练的机器人手的开创性能力,点燃了人工智能世界。这一成功建立在 2018 年 7 月提交的一项非常相似的研究的基础上,该研究让一只机器手按照与视觉提示匹配的配置来定向一块积木。这种从面向块到解决魔方的演变是由元学习算法推动的,该算法控制模拟中的训练数据分布,即自动域随机化(ADR)。
域名随机化—数据扩充
域随机化是一种解决 sim2 真实传输的数据扩充问题的算法。函数逼近(和深度学习)的核心功能是从它在训练中所学到的东西中归纳出从未见过的测试数据。虽然不像错误分类那样令人惊讶于几乎不可见的敌对噪声注入,但深度卷积神经网络在没有特殊修改的情况下,不会在模拟图像(显示在左下方)上训练时推广到真实的视觉数据(显示在右下方)。

“Solving Rubik’s Cube with a Robot Hand” by Ilge Akkaya, Marcin Andrychowicz, Maciek Chociej, Mateusz Litwin, Bob McGrew, Arthur Petron, Alex Paino, Matthias Plappert, Glenn Powell, Raphael Ribas, Jonas Schneider, Nikolas Tezak, Jerry Tworek, Peter Welinder, Lilian Weng, Qiming Yuan, Wojciech Zaremba, Lei Zhang
自然,有两种方法可以将模拟数据分布与真实数据分布对齐。苹果研究人员开发的一种方法叫做 SimGAN 。SimGAN 使用对抗损失来训练生成对抗网络的生成器,以使模拟图像尽可能真实地出现,由鉴别器将图像分类为属于真实或模拟数据集。该研究报告了眼睛注视估计和手姿态估计的积极结果。另一种方法是使模拟数据尽可能多样化,相反,尽可能真实。
后一种方法被称为域随机化。托宾等人 2017 年的论文中的下图很好地说明了这一想法:

“Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World” by Josh Tobin, Rachel Fong, Alex Ray, Jonas Schneider, Wojciech Zaremba, Pieter Abbeel
域随机化似乎是弥合 Sim2Real 差距的关键,允许深度神经网络在模拟训练时推广到真实数据。与大多数算法不同,域随机化带有许多需要调整的参数。下图显示了块的颜色,环境的照明,阴影的大小等等的随机化。这些随机环境特征中的每一个都有一个下限到上限的区间和某种抽样分布。例如,当对随机环境进行采样时,该环境具有非常明亮的照明的概率是多少?
在 OpenAI 的原始 Dactyl 研究中,用机械手实现块定向,域随机化数据课程在实验之前被手动编码。这种领域随机化超越了视觉世界,使物理模拟器中的组件随机化,从而产生一种策略,使机器人手能够灵巧而精确地移动。与视觉随机化的想法类似,这些物理随机化包括立方体的大小/质量和机器人手中手指的摩擦力等维度(参见附录 B 用机器人手解魔方了解更多细节)。
从 Dactyl 到 Rubik’s Cube solver 的关键是域随机化是课程定义随机化的强度是自动而不是手动设计的,在 ADR 算法的以下行中明确定义:

Image from “Solving Rubik’s Cube with a Robot Hand”. If the agent’s performance exceeds a parametric performance threshold, the intensity of the randomization is increased (given by delta with phi defining the distribution of the environment parameters)
设计自己数据的 AI
人工智能设计自己数据的最好例子之一是由优步人工智能实验室的研究人员开发的成对开放式开拓者(诗人)算法。

“Paired Open-Ended Trailblazer (POET): Endlessly Generating Increasingly Complex and Diverse Learning Environments and Their Solutions” by Rui Wang, Joel Lehman, Jeff Clune, Kenneth O. Stanley
POET 通过同时优化代理和它学习行走的环境来训练两足行走代理。POET 与 OpenAI 的魔方解算器不同,它使用进化算法,维护步行者和环境的种群。在这项研究中,主体和环境群体的结构是构建复杂性进化的关键。尽管与基于群体的学习来适应一组代理相比,使用强化学习来训练单个代理,POET 和自动领域随机化非常相似。他们都以自动化的方式开发了一系列日益具有挑战性的训练数据集。两足动物的行走环境不会随着手动编码的功能而改变,而是作为步行者在不同环境中的表现的结果,在该开始挑战地形时发出信号。
数据还是模型?
元学习的研究通常集中在数据和模型架构上,除了像元学习优化器这样的例外,它似乎仍然属于模型优化的范畴。数据空间中的元学习,如自动领域随机化,已经以数据扩充的形式进行了大量研究。
数据扩充在图像数据的环境中最容易理解,尽管我们已经看到物理数据是如何被扩充和随机化的。这些图像放大通常包括水平翻转和小幅度的旋转或平移。这种增强在任何计算机视觉管道中都是典型的,例如图像分类、对象检测或超分辨率。
课程学习是另一种数据级优化,它涉及数据呈现给学习模型的顺序。例如,让学生从简单的例子开始,比如 2 + 2 = 4,然后再引入更难的概念,比如 2 = 8。课程学习的元学习控制者根据感知难度的一些度量标准以及数据应该呈现的顺序来查看数据是如何排列的。Hacohen 和 Weinshall 最近的一项研究在 ICML 2019 年大会上展示了这一有趣的成功(如下所示)。

“On the Power of Curriculum Learning in Training Deep Networks” by Guy Hacohen and Daphan Weinshall. Vanilla SGD data selection shown on the gray bar on the far left is outperformed by curriculum learning methods
神经架构搜索或元学习模型通常比数据级优化受到更多关注。这是深度学习研究趋势的高度推动。将基础 AlexNet 架构扩展到 ResNet 架构会带来明显的性能优势,该架构率先使用在大 GPU 计算的大数据集上训练的深度卷积网络。ResNet 通过 DenseNet 等手工设计得到进一步扩展,然后被 AmoebaNet 和 EfficientNet 等元学习技术超越。图像分类基准推进的时间线可以在paperswithcode.com上找到。
元学习神经架构试图描述一个可能架构的空间,然后根据一个或多个客观指标搜索最佳架构。
高级元学习者
神经结构搜索已经采用了广泛的算法来搜索结构,随机搜索、网格搜索、贝叶斯优化、神经进化、强化学习和可区分搜索。与 OpenAI 的自动域随机化技术相比,这些搜索算法都相对复杂。自动域随机化的想法似乎可能会随着高级搜索算法的出现而得到改善,例如,像加州大学伯克利分校的研究人员或谷歌的的自动增强所证明的基于人口的搜索在数据增强中是有用的。
元学习的表达能力如何?
在神经结构搜索中经常提出的元学习的限制之一是搜索空间的约束。神经结构搜索从人工设计的可能结构的编码开始。这种人工编码自然限制了搜索可能的发现。然而,要使搜索可计算,有一个必要的折衷。
当前的架构搜索将神经架构视为有向无环图(Dag ),并试图优化节点之间的连接。诸如 Gaier 和 Ha 的“权重不可知神经网络”和谢等人的“探索用于图像识别的随机连线神经网络”的论文表明,构建 DAG 神经架构是复杂的,并且没有被很好地理解。
有趣的问题是,神经架构搜索何时能够优化节点上的操作,它们之间的连接,然后自由地发现像新颖的激活函数、优化器或标准化技术这样的东西,如批量标准化。
想想元学习控制器能有多抽象是很有趣的。例如,OpenAI 的魔方解算器本质上有 3 个“智能”组件,一个符号化的魔方解算器,一个视觉模型和一个控制机器人手的控制器网络。元学习控制器是否足够聪明,能够理解这种模块化,并设计由加里·马库斯最近发起的符号和深度学习系统之间的混合系统?
元学习数据扩充也非常受限。大多数数据扩充搜索(甚至是自动域随机化)被约束到元学习控制器可用的一组转换。这些变换可能包括图像的亮度或模拟中阴影的强度等内容。增加数据扩充自由度的一个有趣的机会是将这些控制器与能够探索非常独特的数据点的生成模型相结合。这些生成模型可以设计新的狗和猫的图像,而不是旋转现有的图像或使图像变暗/变亮。虽然非常有趣,但它似乎不像当前最先进的生成模型,如比根或 VQ-VAE-2 在 ImageNet 分类上的数据增强工作。
迁移和元学习
“元学习”经常用于描述迁移和少量学习的能力,不同于“AutoML”如何用于描述模型或数据集的优化。这种定义与通过自动域随机化解决的 Sim2Real 的域适应任务非常一致。然而,该定义也描述了学习,例如从图像网络分类转移到识别钢缺陷。

魔方求解器的一个有趣的结果是适应扰动的能力。例如,尽管将橡胶手套戴在手上,将手指绑在一起,并且覆盖立方体的遮挡,解算器仍能够继续,(视觉模型必须完全受损,因此必须由 Giiker 立方体的传感器进行感测)。这种转移元学习是用于训练机器人手控制的策略网络中的 LSTM 层的结果。我认为这种“元学习”的使用与 AutoML 优化相比更像是记忆增强网络的一个特征。我认为这表明了统一元学习和为这个术语确定一个单一定义的困难。
结论
由于机器人手协调的华丽展示,魔方解算器的成功显然引人注目。然而,这项研究更有趣的组成部分是引擎盖下的元学习数据随机化。这是一种在设计训练数据的同时进行学习的算法。Jeff Clune 的 AI-GAs 中描述的这种范式,即包含元学习架构的算法,元学习学习算法本身,并生成有效的学习环境,将成为深度学习和人工智能进步的巨大机遇。感谢您的阅读,如果您想了解更多关于 OpenAI 的论文,请查看下面的视频!
基于 SQL 的数据建模和数据操作的兴起

更新:对复杂的分析前景感到困惑?查看我们的书: 《分析学设置指南》 。
原载于 2019 年 11 月 15 日我们的总工程师 Thanh 在https://www . holistics . io。
基于 SQL 的 RDBMS 的复兴
如果有一个我们都同意的分析趋势,那就是在过去十年中,我们已经看到了收集的业务数据量的巨大增长。如今,一个典型的企业使用数十个甚至数百个基于云的订阅即服务软件,用于各种目的。与几年前相比,如今普通企业加上更传统的内部企业软件会产生大量数据。
更精明的企业发现了分析数据的巨大价值,以便做出明智的决策,从而导致数据管理系统的需求和供应大幅上升。
直到几年前,传统的数据管理方式(基于 SQL 的 RDBMSs)还被认为是过去的遗留物,因为这些系统无法扩展以处理如此巨大的数据量。相反,HBase、Cassandra 和 MongoDB 等 NoSQL 系统变得流行起来,因为它们将自己标榜为可伸缩和更易于使用。
今天,基于 SQL 的数据库系统似乎有所复苏
然而今天,基于 SQL 的数据库系统似乎有所复苏。根据亚马逊首席技术官的说法,其 PostgreSQL 和 MySQL 兼容的 Aurora 数据库产品是“AWS 历史上增长最快的服务”。
基于 SQL 的 MPP(大规模并行处理)数据仓库,过去价格昂贵,只能由大企业购买,现在已经转移到云上,并日益商品化。今天,所有主要的云提供商都有自己的 MPP 数据仓库:谷歌有 BigQuery,亚马逊有 Redshift,微软有 Azure 数据仓库……更不用说雪花——一家独立的数据仓库供应商,最近估值为 39 亿美元。每个人现在都可以建立自己的数据仓库…并按分钟付费,这在十年前是闻所未闻的。
这些发展为数据分析师带来了巨大的能力和前所未有的访问权限,因为他们现在可以执行复杂的分析查询,并在几秒或几分钟内获得结果,而不是像传统的数据仓库那样需要几个小时。
用于数据分析的 SQL
对于数据分析,这种复苏的原因很容易理解:
- NoSQL 不擅长分析查询:缺少连接意味着在这些数据库上编写复杂的分析查询几乎是不可能的。
- 没有标准化的查询语言:每个供应商都创建自己的语言来查询他们的 NoSQL 数据库,这增加了分析师的摩擦和学习曲线。
另一方面,SQL 是无处不在和标准化的。几乎每个数据分析师都熟悉它。
用谷歌自己的话说,他们的大规模可扩展内部数据管理系统 Google Spanner:
Spanner 的原始 API 提供了 NoSQL 方法,用于单个表和交叉表的点查找和范围扫描。虽然 NoSQL 方法提供了启动 Spanner 的简单途径,并继续在简单的检索场景中有用,但 SQL 在表达更复杂的数据访问模式和将计算推送到数据方面提供了重要的附加值。
Spanner 的 SQL 引擎与谷歌的其他几个系统共享一种通用的 SQL 方言,称为“标准 SQL”,包括 F1 和 Dremel 等内部系统,以及 BigQuery 等外部系统……对于谷歌内部的用户来说,这降低了跨系统工作的障碍。针对 Spanner 数据库编写 SQL 的开发人员或数据分析师可以将他们对该语言的理解转移到 Dremel,而不用担心语法、空处理等方面的细微差异。
随着基于云的 MPP 数据仓库的兴起,SQL 现在已经成为一种非常有吸引力的数据分析方式。利用这一趋势,像 Mode Analytics、Periscope Data 和 Redash 这样的开源工具这样的初创公司变得越来越受欢迎。对于精通 SQL 的分析师来说,他们现在可以利用其全新的基于云的数据仓库的能力来制作漂亮的图表和仪表板,而无需学习任何专有语言或工具。此外,SQL 代码只是文本,因此可以存储在版本控制系统中,管理起来很简单。
SQL 的问题
然而,使用 SQL 进行数据分析并非一帆风顺。
任何严重依赖 SQL 的工具都是业务用户的禁区,他们不仅仅想查看静态图表和仪表板,但又不懂 SQL 语言。它迫使业务用户退回到老派的电子表格,在那里他们将原始数据导出到 Excel 并自己执行手动计算,从而导致准确性和数据一致性方面的问题。
SQL 也太低级了,当需要更复杂的分析时,查询很快变得复杂。当分析需要几个表时,大多数 SQL 查询读起来都不错。但是,当相关表的数量增加时,数据分析人员不得不跟踪多种类型的连接,并在每次编写查询时为正确的情况选择正确的连接。
这意味着 SQL 不可重用,导致逻辑略有不同的类似代码到处重复。例如,无论何时需要进行与会计相关的分析,都不能轻易地为会计目的编写一个 SQL“库”并将其分发给团队的其他成员以供重用。
传统数据建模
向非技术用户提供 BI 的传统方式是在分析师通过数据建模流程准备好数据集之后,给他们一个拖放界面。该流程允许分析师在业务逻辑和原始底层数据之间建立映射。通过软件界面向最终用户展示高级业务概念,使他们无需学习 SQL 之类的查询语言就能自己探索数据。
这个过程始于几十年前的 Cognos、SAP BI 等供应商。现代版本包括 Sisense、Tableau 和 PowerBI 等供应商。然而,无论新旧,这些工具都有相同的问题。
遗留工具并不是为了利用现代数据仓库而设计的。
首先,数据在变得有用之前被加载到每个供应商的专有数据存储中。这意味着数据现在是重复的,现代强大的 MPP 数据仓库只不过是一个简单的数据存储。原因很简单,因为这些工具不是为利用现代数据仓库而设计的。它们是在数据仓库昂贵的时代设计的,当时每个 BI 工具都很自然地构建自己的数据存储引擎。
第二,数据建模过程主要是基于 GUI 的,这意味着它不容易重用,也不能利用强大的版本控制系统(如 g it)来跟踪变化。
基于 SQL 的数据模型方法
这两种方法的优点自然为我们指出了一个新的方向:如果我们能够将 SQL 的强大功能和数据建模的易用性结合起来,会怎么样呢?答案是我们绝对可以!
最近被谷歌以 26 亿美元收购的 Looker 是使用这种方法的先驱。它提供了一种称为 LookML 的数据建模语言,作为客户数据库之上的抽象层。该软件不会将数据加载到自己的数据存储中,也不会使用专有的查询引擎。相反,当非技术用户使用 Looker 浏览数据时,该软件会将建模输入转换为 SQL 查询,然后将该查询发送到客户的数据库。这意味着用户根本不需要了解 SQL,但仍然可以利用现代 MPP 数据仓库的能力!
使用基于文本的建模语言的另一个优点是,现在整个建模层可以存储在一个强大的版本控制系统中,这使得跟踪变更和在出现问题时恢复变得很简单。
基于 SQL 的端到端数据管道
基于 SQL 的数据模型方法只是冰山一角。
以 ETL 为例。为了让我们的业务数据出现在数据仓库中并准备好进行建模,我们需要从多个来源导入数据,并将数据转换成适合分析的格式。传统上,这些任务属于一类叫做 ETL 工具的工具。该过程包括三个步骤:
- 提取-从源中提取数据。
- 转换—将数据转换为最终可用的格式。
- 加载—将转换后数据加载到数据仓库中。
随着强大的 MPP 数据仓库的出现,越来越多的数据团队开始转向 ELT 方法,而不是 ETL 方法。这个过程从数据源中提取原始数据,并将它们直接加载到数据仓库中,不涉及任何转换。一旦存储,分析师就可以使用他们最喜欢的工具——SQL——将数据转换成适合消费的最终格式。
因为数据转换现在是用 SQL 编写的,所以很自然地,我们可以对它应用相同的基于 SQL 的数据建模方法!
像 Holistics 这样的工具将 Looker 基于 SQL 的数据建模方法向前推进了一步,将建模进一步扩展到 L(加载)和 T(转换)层,覆盖了端到端的整个分析管道。

这种使用统一的基于 SQL 的建模方法来导入、转换和探索数据的方法揭示了以前没有的多种优势:
- 它使数据分析师能够从端到端拥有整个数据分析管道,显著缩短每次分析的洞察时间,同时保持相同的要求:即符合当前的行业标准 SQL。
- 数据上下文被保留。这意味着分析的最终结果可以追溯到它们的来源,使得调试数据准确性问题变得微不足道。
- 它打破了数据利益相关者如数据工程师、数据分析师、数据科学家和业务用户之间的自然孤岛,从而改善了组织的数据文化。
数据操作驱动的运动
当您开始将数据建模视为使用 SQL 的另一种逻辑编码时,数据分析和软件工程之间的相似之处变得越来越明显。软件工程的目标是通过交付软件来交付价值,而分析的目标是通过交付可探索的数据集和可视化来交付价值。这两个过程都需要编写逻辑代码(前者使用编程语言,后者使用 SQL 建模语言),然后将代码部署到“生产”环境中。
软件开发世界已经经历了几十年的过程实验。一个相对现代的运动是 DevOps 运动,它对改进软件开发起到了很大的作用。这个运动结合了自动化和连续交付,以帮助无数的组织加速软件交付,同时增加他们软件的可靠性和质量。
我的论点是,如果我们复制 DevOps 中表达的思想,我们可以显著改进数据分析过程。举几个例子:
- 将分析视为代码 —如果我们将分析逻辑视为代码,我们现在可以将它们放入我们的源代码控制系统,实现强大的跟踪、调试和(最重要的是!)自动化。
- 数据的单元测试 —通过在每个转换步骤中引入自动化测试,数据的准确性和质量可以得到极大的提高。
- 集中式数据维基 —构建集中式数据维基允许组织中的每个人在一个地方发现和探索数据。
一种新的分析范式
SQL、数据建模和 DevOps 是三个古老的概念,彼此之间几乎没有什么关系。然而,当结合起来时,我们有了一个全新的思考分析的范式,这在我们 60 年的行业中是前所未有的。
我们称之为数据操作范例。这是 Holistics 背后的指导范式,这是一个统一的分析平台,我们在过去两年中一直在努力。我们对它的未来感到无比兴奋。
数据战略家的崛起
本文原载于 丹工作室网站 。
你有没有注意到越来越多的工作职位前面都有数据这个词?早在 2012 年,“数据科学家”这个职位就被《哈佛商业评论》评为“21 世纪最性感的工作”。从那以后,正如正确预测的那样,大量带有“数据”一词的衍生产品和新的职位头衔被传播开来,成为无价的“数据科学独角兽”的雄心与正在进行的人才大战和公司和猎头的疯狂争夺相匹配,这些公司和猎头急于发现并抓住一只独角兽。

Figure 1: Data Scientist Searches on Google 2004–2018

Figure 2: Data Strategist Searches on Google 2004–2018
随着数据科学独角兽似乎非常罕见和无价,公司通过几个人寻求相同的专业知识或技能。
除了高级科学学位、SQL、R、Python、机器学习等的常见要求之外,数据科学职位描述中常见的一组技能如下:
“将业务问题转化为分析解决方案和见解的能力”
技术人员可能会对这个短语嗤之以鼻,认为它是无用商业术语的典型例子。这对于数据科学家的工作来说是如此的重要,为什么要把它放在工作描述中呢?原因很简单,那就是它是一种真正的技能,虽然它可以被训练和发展,但这种技能比人们想象的要罕见。有多少有博士学位的数据科学家有商科学位?有几个,但也不常见。
上面的定义实际上代表了数据战略家的主要技能。为了说明这在实践中意味着什么,让我们看一个电子商务的例子:
你能帮助我们更好地了解我们的客户吗?
这个问题的答案可能很棘手,需要大量的经验和信心。让我们看看接下来会发生什么:
数据科学家:你可以在 AWS 上部署一个神经网络,为不同的用户群训练一个分类器。
客户:嗯,好的。但是我们需要什么样的数据呢?
数据科学家:一个由大约几千个观察值组成的标签数据集——当然是平衡类。
委托人:???
在这些句子的所有单词中,对于希望简单了解客户的经理来说,只有几个是可以理解的。其余的也可能是一种神秘的外星语言。这个简单的例子说明了这个问题,并展示了翻译角色的必要性。这位数据科学家使用的术语是那些拥有高级科学学位的人可能理解的,但对于他们直接报告的大多数经理和商人来说是无法理解的。
让我们打电话给数据战略家,看看他们是怎么做的:
你能帮助我们更好地了解我们的客户吗?
数据战略家:好,让我们看看。那么你已经有了什么样的数据,如果有的话?
客户:我们有谷歌分析数据、我们网站上的用户行为和购买数据、数据库中的产品评论和评论数据以及社交媒体数据。[1]
基于这些数据集,我们可以尝试用几种不同的方式来回答这个问题。我们可以做的一件事是获取行为数据,并对其进行情感分析——客户对你的特定产品的感受。这很好,因为这个项目的一部分可以用来分析产品评论文本数据。我们可以在这里更进一步,看看是否有一些模式——也许是不同用户的组。通过使用这样的模型,我们可以开始了解客户反馈中是否存在共同的模式,并自动标记负面反馈,并将其转发给支持人员。这很有可能会成功,我有 80%的信心我们会有相关的结果。
客户:哦,这听起来很有趣。我们还能做什么?
数据策略师:如果我们有关于客户的良好数据集,我们可以尝试预测他们流失的概率,或者换句话说,放弃他们的提供商的概率。然后,我们可以利用这些预测来锁定那些可能会因为特价商品而流失的用户,从而让他们留在我们的平台上。这可能有点棘手,在很大程度上取决于你拥有的数据量——我认为这有 50%的可能性,可能需要更多的工作、专业知识和领域知识来建立一个客户流失模型。
你能猜到哪一个会产生更大的商业影响吗?
以下是造成差异的几点:
- 这两个对话的第一个显著区别是,后者是一个真实的对话。客户端和数据策略师之间有来有往,感觉更像是一种协作。
- 数据战略家试图先取得理解。
- 数据战略家立即将工作与业务目标联系起来。
- 第二种情况也开始考虑代码的可重用性。
- 最后,这位战略家提供了几种方法比较的一些指标——重要性、复杂性和成功的可能性。
所有这些都定义了新的数据战略家角色。这也符合数据科学领域最近不断增长的专业化和发展的成熟性。最近的文章,一些关于 HBR 和 T2 的文章,说明了这一点。
在接下来的博客文章中,我们将探讨数据战略家的新兴角色,以及我们期望这一角色如何推动商业洞察和发展。
[1]当然,并不是所有的客户都能立即获得如此全面的信息,但为了便于说明,我们假设他们都有。
[2]他们使用“数据翻译器”这个术语。
机器学习工程师的崛起
机器学习工程师是带领我们走向人工智能未来的职业。多年来,每一次技术变革都会带来新的机遇,需要一种新的职业来满足新的需求。
这些变化对公司过去的工作方式产生了重大影响,现在我们正处于另一场变革之中。
在这里,我将带你进行一次时间之旅,展示这些重大转变是如何随着时间的推移而改变公司的。
福特车型

“If I had asked people what they wanted, they would have said ‘faster horses.”
事实是福特从未说过这句话。但这让我明白了一个道理。这种模式是关于大的想法和解决实际问题。当福特发布 T 型车时,他正在解决交通堵塞(马!)、交通事故、让通勤变得实惠。
当你有很好的洞察力,人们想要你的解决方案时,这种模式很有效。但这是有风险的,因为你可以说这就像在黑暗中扔飞镖,并期望获胜。

Throwing darts in the dark
福特没有任何数据或任何人群要求更好的汽车。在他那个时代,汽车是一种昂贵/不可靠的小玩意。他的成功可以归功于他的远见和执行力。他对汽车的看法是正确的,而世界上大部分地区的看法是错误的。
这种模式的主要局限在于,你不可能在某件事情上如此正确,而世界上的其他事情却如此错误。一个现代的例子是史蒂夫·乔布斯。只要谷歌一下,看看有多少人写道,苹果发布手机是一个糟糕的主意,他们应该解雇拖累苹果的史蒂夫·乔布斯。
为了增加你成功的机会,还需要加入一些其他的东西,这就引出了下一个模型
市场调研

当福特还活着的时候,世界经历了一场变革。与商业最相关的技术变革之一是电信。电话、收音机和电报都是在 19 世纪末或 20 世纪初发明的。但像汽车一样,它们大多是昂贵的小玩意,普通人买不起。随着这种情况开始改变,通信开始变得负担得起,信息共享开始爆炸式增长。
其中一个结果是,现在你可以听到竞争对手在另一个州的表现,或者你的产品在另一个国家的接受程度。数据现在可以集中起来,一旦有了数据,人们就开始看到模式,并发展出营销中最初的一些理论。这是焦点小组和消费者理论的开端。

You can now peek the target before throwing your darts
这就产生了对新型职业的需求。在那些日子里,人们理解数据中模式的方式是让有数学和心理学背景的专业人士参与进来。别忘了,这个时候是弗洛伊德在的时候,了解并在后来操纵人的潜意识的想法是很吸引人的。这种新型的职业将成为今天市场营销部门的开端。现在,学习针对目标人群的说服技巧是市场营销课程的一个常规。
你现在可以从别人的错误中学习,但更重要的是,你现在可以在发布你的产品之前了解特定的人口统计和用户群。
如果你是一家 30 年代的公司,你会收到一份焦点小组的报告,说顾客会欢迎你不同颜色的产品。在那之后,你会推出你的产品的“限量版”来衡量人们的兴趣。但如果你想在发行后提高销量,除了投资电台广告,就没剩下多少了。这仍然是一种“一对多”的沟通类型,从客户那里获得的大部分数据都是高层次的汇总,而且是几个月前甚至几年前的数据。拥有关于客户行为的实时数据或更精细的数据是不可想象的。但这将随着下一次技术转变而改变:电脑
预测时代

这是第二次世界大战后开始的时代,我们目前正生活在它的末期。战后,计算机开始成为公司和政府中的一件东西。直接的好处是能够在几秒钟内完成一整层楼的数学家的工作。在计算机出现之前,你通常会有一群人专门花几个小时甚至几天来处理数字,只是为了给出一个是或否的答案(查看’模仿游戏’和’隐藏的数字’)。多亏了计算机,你现在可以在你的数据上运行多个场景,并且能够处理你所能收集的尽可能多的数据。
后来当互联网成为主流,实时数据变得可用。例如,你现在可以追踪有多少人在浏览你的网站时访问了他们。但是随着每一次技术的转变,需要出现一种新的职业来利用所有新的可能性。这就是数据科学家,在华尔街也被称为“定量分析师”。
这个新的职业有很强的数学背景,对产品有很强的把握。数据科学家可以利用海量数据,根据需要对其进行任意分割,以适应复杂的模型和预测。这种新型的职业使我们最终有可能了解顾客的一切,这只是一个‘我们有这方面的数据吗?’。这是从定性方法(理解消费者的心理学)到定量方法的巨大偏离(“这是数据显示的”)

darts with auto-pilot. thanks to live-ops
与之前的模型相比,最大的不同是实时运营周期(步骤 3、4、5)。因为有更多可用的数据,而且速度更快,所以您现在也可以更快地做出反应。想象一个在周一发布的网站,感谢 live-ops,你可以调整你一周的内容。全部基于用户行为/反馈。断链?没问题,这是捕获和修复在几个小时。
但是你不需要成为一家数字公司来利用这种模式。想想好莱坞,你有没有注意到一些演员在同一部电影中往往会在一起?一些演员是如何一次又一次地扮演相似的角色的?好莱坞有一个庞大的行业来预测人们想看什么。如果你经营一个电视节目,你可以跟踪每一集在发布时的表现,也可以根据社交媒体的传言对每个角色的命运做出决定。
但是这种模式还是有局限性的。现在每秒钟都有大量数据到达,我们周围的世界变化非常快。计算机可以处理所有这些数据,但人们仍然需要回家睡觉。要在竞争中领先,你需要更快。我们已经可以对未来的模式有所了解
艾的年龄

Hi! I am the new guy. I can do your job for free.
与世界其他地方相比,一些公司已经活在未来。你的网飞推荐会随着你观看的节目越来越多而更新,你的谷歌搜索结果总是与世界事件和你所处的地理环境同步,亚马逊会根据你的历史和其他用户的行为推荐新产品。你仍然可以使用以前的模式为所有这些企业提供动力。但这需要数量惊人的人来收集数据,获得洞察力,并为提到的每种产品创建一个精选列表。当你完成的时候,你需要重新开始。因为上一条推荐已经不新鲜了。
所有这些产品在幕后都有一个共同点:机器学习。这是它如何添加到之前的模型中的:

You can now sit and let robots throw the darts for you. Faster and better
不同的是,现在人工智能正在根据用户反馈运行产品,没有时间等待人们注意到数据中的新趋势。速度和规模非常重要。但是数据科学家仍然在这个模型中发挥作用,仍然需要有人带来关于人工智能正在做什么的商业见解。在网飞,人们可能会进行如下对话:
我们注意到人们比我们预期的更喜欢圣诞电影。
人物 2:是的,人工智能不断推出越来越多的电影。但是我们最终用完了它们
人物 1:我们应该尽可能多地授权那些电影。你为什么不处理一下这些数据,看看我们是否也应该投资在内部制造一些呢?这将为我们节省很多钱
请注意,推荐正确内容的所有商业收益从来都不一定来自一个精心策划的列表。人工智能设法以可能的最佳方式分发当前目录。数据科学家稍后进来,只是为了带来更深入的商业见解,这将通过提供更好的目录来帮助人工智能。
人工智能是当前的技术转变,并不是所有的公司都准备好了转型。有助于这种转变的新职业需要精通机器学习和云计算。这是一个机器学习工程师。
未来

如果你在 Linkedin 上快速搜索机器学习工程师,你会注意到大多数职位都是由 FAANG 公司发布的。这是一个有趣的关联。
机器学习工程师之所以如此重要,是因为生产中的机器学习模型需要规模化。一件事是用特定的一批数据通宵训练一个模型。另一件事是部署一个模型,该模型以流数据为食,并可以通过为数百万用户大规模读取多个数据源来转换数据。这不是一件容易的事情,这就是为什么今天的大多数模型都被卡在某个地方的 Jupyter 笔记本中,这被后端团队视为一个障碍。因为他们不知道如何利用这一点并整合到他们的服务中。机器学习工程师可以通过成为两个世界的混合体来打破这一障碍。这就是为什么机器学习工程师是将我们带到人工智能未来的职业。
“MLOps”一词的兴起
正确操作的机器学习是新的圣杯
“MLOps(机器学习和“信息技术操作”的复合物)是数据科学家和信息技术(IT)专业人员在自动化和产品化机器学习算法的同时进行协作和沟通的[一种]新学科/焦点/实践。”— 妮莎·塔拉加拉 (2018 年)
对于感兴趣的人, 我还将在 2022–23的生产课上教授机器学习!

Torrey Pines Gliderport in San Diego for intro aesthetic
对机器学习生命周期的理解是不断发展的。几年前,当我第一次看到说明这个“循环”的图形时,重点放在通常的疑点上(数据准备和清理、EDA、建模等等)。较少注意到更难以捉摸和不太有形的最终状态——通常称为“部署”、“交付”,或在某些情况下只是“预测”。
当时,我认为很多新兴的数据科学家并没有真正考虑到最后一个术语的范围(我当然没有)。“预测”不仅仅意味着.predict(),它还意味着真正的规模、生产级部署、监控和更新——一个真正的循环。由于缺乏将这一模糊概念变为现实所需的工程技能,数据科学家被困在了笔记本中。模型作为.pickle文件存在于数据科学家的本地机器上,性能用 Powerpoint 报告,ML 生命周期被打破。

A Straightforward, but Incomplete Data Science Lifecycle with the word “Modeling” spelled incorrectly
虽然端到端的 ML 生命周期一直被称为一个实际的“周期”,但迄今为止,在企业层面上实际管理这一端到端过程的成功有限,我认为原因如下:
- 数据科学家通常不是训练有素的工程师,因此并不总是遵循良好的 DevOps 实践
- 数据工程师、数据科学家和负责交付的工程师各自为政,这在团队之间造成了摩擦
- 无数的机器学习工具和框架导致整个行业缺乏标准化
- 目前还没有一个单一的托管解决方案可以满足工程师和数据科学家的需求,而不会受到某种方式的限制(订阅特定的语言、框架、提供商等)
- 总的来说,生产中的企业机器学习还不成熟
我确信还有更多的原因和大量的次级原因也有助于此——但这些高层次的问题导致了不幸的结果。企业中的机器学习速度慢,难以扩展,自动化程度低,协作困难,交付商业价值的实际可操作模型很少。

My boss made this gem
因此,我们需要良好的“mlop”——机器学习操作实践,旨在标准化和简化生产中机器学习的生命周期。然而,在我进入场景或任何更多定义之前,我想多谈一点关于为什么我们需要更好的 MLOps。
机器学习有些成熟,但部署实践和业务影响还不成熟
在学术领域,机器学习取得了突飞猛进的发展。在 NLP 这样的困难任务中,算法显示出了比以前工作的巨大进步(即使这只是谷歌扔给它更多的数据+计算),据说 arXiv 上的机器学习论文数量每 18 个月翻一倍。
这种兴奋很容易让你失去对可交付成果的关注——有形的影响。这项来自 2018 年的 Databricks 调查显示,尽管大多数公司都在采用或投资人工智能,但他们也普遍提到了他们解决方案中的困难,“人工智能”项目平均需要 6 个月才能完成。

We’ve all been there
如果你不小心的话,你可能最终会让数据科学家通过电子邮件把 Python 笔记本和模型发给工程师,进行生产部署和代码重写。对于 Docker 来说,也许这种记录不良的 Python 代码效率太低或不完整,但也将花费大量时间来翻译成 Java。没有大量的文档,工程师不知道 wtf 在那个.pickle文件中,没有模型、度量和参数的版本控制,每个人都感到困惑和愤怒,因为现在他们陷入痛苦的会议中,试图在应该花费几天而不是几个月的事情上保持一致。
不仅如此,一旦解决方案在生产中,就没有用于改进和更新的内在反馈系统。对于某些系统,随着时间的推移,模型性能可能会受到影响,并且监控并不总是标准的做法。数据科学家也没有真正接受过编写良好测试用例的训练,所以如果从 Jupyter 到生产的模型更新偶尔会破坏应用程序或提供不正确的预测,我也不会感到惊讶。

Model Drift — the importance of monitoring for change in distribution
我想说明的是,这些问题并不普遍,确实存在大量定制解决方案。然而,单一的一套实践和端到端解决方案尚未浮出水面,无法满足数据科学家、工程师和企业的需求。
输入机器学习操作(MLOps)
我将最纯粹的 MLOps 定义为自动化生产 ML 生命周期的真正实例。MLOps 的维基百科页面的第一段也说明了一切。MLOps 是对当前企业将机器学习投入生产所面临的困难的合理反应。在软件工程中,我们有 DevOps,为什么没有 MLOps 呢?好的 DevOps 确保软件开发生命周期是高效的,有良好的文档记录,并且易于排除故障。是时候我们为机器学习开发一套类似的标准了。

A slightly better infographic for the machine learning lifecycle
行业已经开始触及它的临界点,技术正在快速发展以满足需求并改变生产中 ML 的当前标准。mlflow 和 kubeflow 等开源框架竞相成为开源领域的标准,而新的创业公司则在这些解决方案上贴上 ui,试图将“专有”的 MLOps 产品推向市场。
MLOps 的状态
当然,MLOps 仍处于起步阶段(至少在实践中)。在数据科学上搜索“MLOps”只能得到少得可怜的 2 个结果(在撰写本文时)。从技术上来说,使用 mlflow 或 kubeflow 等工具的完全管理的解决方案仍然需要合理的开发和/或员工教育才能在实践中使用。

现在,你也会注意到我实际上没有给出一个精确的 MLOps 原则列表,那是因为我不确定是否存在一个普遍的集合。这种想法仍在不断变化,真正的原则将随着新框架和现实世界经验的成熟而形成。需要注意的是,与 DevOps 一样,MLOps 也有好坏之分,随着时间的推移,两者之间的界限会变得更加清晰。
目前,我发现最好遵循良好的 DevOps 实践。当然,有一些工具可以使这项工作变得更容易,但是从与框架无关的角度来看,我认为好的 MLOps 与好的 DevOps 非常相似。mlop 的目标依然清晰,优秀的 mlop 将尽可能高效地实现这些目标:
- 减少将模型投入生产的时间和难度
- 减少团队之间的摩擦,增强协作
- 改进模型跟踪、版本控制、监控和管理
- 为现代 ML 模型创建一个真正循环的生命周期
- 标准化机器学习流程,为不断增加的法规和政策做好准备
结论和警告
我敢肯定,根据你在这个行业的位置,你可能同意或不同意我对前景的猜测。这些观点是我有限经验的结果,因此容易产生误解。就像欧比万对阿纳金说的那样:“只有西斯才能处理绝对的事情”,我相信这在我对所有事物的主观分析中是正确的。

Brooklyn sunset for conclusion aesthetic
尽管如此,这篇文章的目的是介绍 MLOps 作为一个概念,并且可能是企业 ML 的下一个伟大革命之一——我希望在这方面我是有用的。请随时在 LinkedIn 上与我联系,或者在下面留下不必要的尖刻评论。✌️
人工智能外包的风险——如何成功地与人工智能初创公司合作
企业正在与科技巨头和人工智能初创公司争夺最优秀和最聪明的人工智能人才。他们越来越多地将人工智能创新外包给初创公司,以确保他们不会在人工智能竞争优势的竞争中落后。然而,外包带来了真实的和新的风险,而企业往往不具备识别和管理这些风险的能力。企业在与任何人工智能初创公司合作之前,都存在真正的文化障碍、隐含的风险和应该问的问题。
一只我似乎无处不在。阅读媒体而不了解人工智能对企业的变革性影响几乎是不可能的。 Gartner research 预测,到 2022 年,企业将从人工智能中获得高达 3.9 万亿美元的价值。从人力资源到财务到运营、销售和营销,人工智能将有助于增加收入、提高效率和建立更深层次的客户关系。聊天机器人会让你等很久才能和客户服务代表说话,这是过去的事情了。许多重复性和枯燥的公司工作,如数据输入、质量保证或候选人筛选,将实现自动化。

但人工智能行业刚刚起步,发展非常迅速,缺乏专业知识和经验。这意味着,如果想从这 3.9 万亿美元中分得一杯羹,许多企业将不得不合作并将他们的人工智能解决方案外包给成千上万的新人工智能创业公司。但与这些初创公司合作充满了潜在的地雷,包括技术、实践、法律、声誉和知识产权所有权风险。许多这些风险源于文化差异,因此在企业和创业公司合作之前,理解它们是非常必要的。
快速移动并打破东西
创业公司的文化通常是企业生活的梦魇。硅谷推广了“**快速行动,打破常规”**的理念——快速推出一些东西,它不会完美,接受它。我们还听到优步等人工智能公司如何通过故意突破现有监管的边界来推出创新的消费者服务。企业家被描述为不合理地无视可以合理完成的事情。他们不喜欢被拒绝。他们努力扩大业务规模,速度非常快。他们讨厌官僚主义。他们现在就想要解决方案,而不是几天或几周。为了达成交易,他们在营销方面很有创意。这是企业家和他们的创业公司的 DNA。
因此,缺乏企业生活经验的年轻企业家发现销售和与企业合作很困难。毫不奇怪,企业会发现与初创公司合作充满挑战。
这些文化 差异往往发生在期望有差距的时候。创业公司在享受赢得一个品牌客户,比如你的公司时,他们的眼里可能会有星星。你的品牌将有助于验证他们年轻的努力。但是,当涉及多个企业利益相关者,尤其是法律利益相关者时,创业公司是否了解决策过程需要多长时间?在同意签署一个人工智能原型或交付物之前,他们了解企业的要求有多高吗?他们知道从后端系统提取数据可能需要几个月的时间吗?他们是否明白,做一个人工智能试点项目并不能保证在整个组织中推广该解决方案?他们知道发票的支付会很慢吗?
文化差异经常会导致误解、紧张和偏见,这可能会导致项目失败,甚至更糟糕的是,初创公司在试图满足你的需求时耗尽了资金,从而走向灭亡。在建立关系之前,企业有自知之明并理解文化差异是至关重要的。
与人工智能初创公司合作充满了潜在的地雷
与人工智能初创公司合作的挑战和风险不仅是文化方面的,还包括:
- 技术和算法风险— 今天的许多人工智能技术相对不成熟,存在着在现实世界中可能不起作用的风险。我们已经看到客服聊天机器人项目被屏蔽,因为聊天机器人在与真实客户一起使用时回答的是胡言乱语。仅仅因为一个算法预测一个客户的消费贷款违约概率为 90%,这并不意味着它在根据你的数据进行训练时会有同样的准确性。
- 集成和实施风险— 众所周知,人工智能初创公司非常乐观,通常会低估集成和实施人工智能解决方案的时间和成本。概念的证明通常可以在几个月的时间内快速完成。但是在一个组织中推广这种方法可能充满挑战,例如,当与企业现有的遗留系统集成时,创建干净和有标签的数据集,以及使用现有的流程。一些调查显示,在一个组织中实施人工智能所花费的时间是初创公司预期的两倍。
- 未来 证明风险 —人工智能正在经历其淘金热时刻,最近有数千家人工智能初创公司成立。然而,如果我们快进几年,历史告诉我们,许多这些年轻的公司将半途而废。即使人工智能创业公司蓬勃发展,也不能保证他们明天就会拥有你想要的技术能力。
- 法律和声誉风险——人工智能初创公司可能会使用让你的公司面临法律和声誉风险的技术、工具和数据。数据隐私法,包括最近推出的欧洲 GDPR,已经要求处理个人数据(许多人工智能算法的燃料)的供应商遵循适当的技术和组织措施,以确保信息安全。根据 GDPR,还有一些要求,即任何具有法律效力的自动决策——如决定谁有资格获得贷款或工作的人工智能系统——都是“透明的”和“可解释的”。同样,如果一家公司对人工智能的使用被视为对某些人口统计数据有偏见,也会有品牌声誉风险。我们已经看到很多对面部识别技术的批评,面部识别技术在识别白人男性的性别方面比女性和种族群体更好。
- 知识产权 风险 —许多初创公司会辩称,他们提供的算法要聪明得多,因为它们是在来自各种各样客户的数据集上训练的。但是,如果您的数据是一项战略资产,例如一家拥有数百万客户索赔历史的保险公司,您可能不希望它被用于竞争对手的利益。需要做一个权衡。同样,你可能不希望你的人工智能解决方案的软件代码与创业公司的其他客户共享。
成功协作的关键成功因素
对于大多数企业来说,在行业发展的早期阶段,与人工智能初创公司合作可能是必要的。但在人工智能初创公司的财富中导航,以确定明天将出现的玩家并分享相同的目的地是很困难的。在评估潜在的人工智能供应商时,确保您提出以下问题:
- 文化契合度——初创公司是否有与复杂企业合作的经验?他们对这段关系有现实的期望吗?
- 技术和算法功效基准 —初创公司能否解释并证明其技术和算法的有效性和局限性?他们能解释解决方案对您的数据有多有效吗?根据你的数据训练人工智能需要多长时间?将他们的解决方案与您的系统、数据和流程集成需要多长时间?
- 产品路线图 —创业产品路线图是否符合您未来的需求?该产品与您的技术体系兼容吗?
- 财务健康——初创公司是否表现出客户和收入的增长,以及领先风险投资家的强大财务支持?
- 负责任的人工智能(Responsible AI)—初创公司是否有记录、解释和遵循的负责任的人工智能原则?他们能帮助你理解他们的人工智能解决方案的法律和声誉风险吗?他们是否遵循算法的透明性和可解释性原则?他们知道他们系统中使用的数据的来源以及数据样本偏差的风险吗?
- 知识产权所有权 —初创公司拥有知识产权还是客户拥有知识产权?
人工智能相对较新,但我们现在开始看到人工智能采购框架来帮助指导人工智能供应商的选择和管理。例如,世界经济论坛正与英国政府合作开发这样一个框架。
总而言之,最重要的是要明白,人工智能项目的大多数挑战都可以归结为人的因素。关系往往在开始的时候就结束了,所以要确保你和你的初创公司保持一致,并承诺清晰、频繁地交流你的期望和需求。但现实是,我们都需要找到一种方法,让这些关系像企业和人工智能创业公司相互需要一样发挥作用。
关于西蒙·格林曼
西蒙·格林曼(Simon Greenman)是最佳实践人工智能公司(Best Practice AI)的合伙人,这是一家人工智能管理咨询公司,帮助公司利用人工智能创造竞争优势。西蒙是世界经济论坛**全球人工智能委员会的成员;**AI 专家常驻seed camp;并担任伦敦哈佛商学院校友天使会的联合主席。他在欧洲和美国的数字化转型领域拥有 20 年的领导经验。请通过直接给他发邮件或联系,在 LinkedIn 或 Twitter 上找到他,或在媒体上关注他。
他的文章最初发表在 电子杂志:风险管理的新曙光 之后是knect 365。
通往埃勒沃恩之路
人工智能:一场无人问津的军备竞赛

现有的机器我都不害怕;我担心的是,他们正以超乎寻常的速度变得与现在大相径庭。在过去的任何时候,没有哪一类生物有如此快速的进步。在我们还能检查它的时候,难道不应该小心地观察和检查这个运动吗?(……)难道从事管理机器的人可能比从事管理人的人多吗?难道不是我们自己在创造地球上至高无上的继承者吗?每天增加他们的组织的美丽和精致,每天给他们更大的技能,提供越来越多的自我调节,自我行动的力量,这将优于任何智力?
塞缪尔·巴特勒,艾瑞沃恩。1872.
每一代人都认为他们面临的挑战是新的,但实际上很少是新的。这也是我们面临的人工智能(AI)发展的挑战。似乎他们已经预见到了 150 年前英国工业革命时期的到来。在一部写于 19 世纪的小说中读到这些反思,肯定会让你心惊肉跳。
我们关闭了科幻小说,这是我们关于这个主题的观点的第一部分,尼克·博斯特罗姆想知道在超级智能系统到来之前,我们可以做些什么来增加我们作为一个物种的生存机会。现在,一些专家说这还很遥远,而另一些人则说我们可能就在这种情景的边缘,这将在未来的 20 到 40 年内发生。考虑到多达 30%的这些专家认为,当它到来时,结果对我们来说要么是坏的,要么是非常坏的,这肯定是我们应该谈论的事情。有 30%的几率属于濒危物种绝对不酷。1%或 2%,好吧,我可以接受,但是……30%??
围绕人工智能发展的可能影响的辩论今天集中在非常严重的事情上,这些事情已经存在,当然值得辩论。我们在上一篇文章中已经提到了其中的一些:正在中国部署的社会信用系统,致命的自主武器或者警方使用的面部识别软件中的偏差效应。然而,事实上,在几年内终结者的未来可能会成为现实,但这一次没有约翰·康纳或阻力或任何希望,似乎并不困扰我们。
挺奇怪的。我们不都应该非常害怕吗?或者换一种说法:为什么几乎没人谈这个?
似乎有几个原因。首先,你会有这种“科幻小说”效应:人们倾向于认为那些敢于给出如此激进预测的人是不科学或轻率的。还有一些与人性有关的原因:我们天生就担心直接和具体的威胁,而不是未来和抽象的威胁。此外,我们的天性中也有一种“一厢情愿”的效应:如果他们告诉我们,有了人工智能,未来将会很美好,为什么要担心呢?让我们把这件事交给专家吧,他们肯定知道自己在做什么。想起来了吗?另一个可能的原因是,人们对技术进步有些厌倦:我们近年来看到了如此多的变化,以至于像 AlphaZero 这样的革命性产品几乎没有成为科技媒体的头条新闻。最后,也许其中一个关键原因是“军备竞赛”效应,在这种效应中,领导这场革命的代理人试图确保对人工智能的担忧不会设置任何额外的障碍,因为这将拖延他们,使他们的竞争对手受益。
先来看看那个“科幻”效果。直到不久前,具有人类智能的系统,更不用说人工超级智能的出现,被大多数专家认为是不真实的事件,或者至少是在很久以前值得担心的事情。然而,在过去的二十年里,这种情况发生了根本的变化。当雷·库兹韦尔在他的书精神机器时代中声称机器将在 2029 年通过图灵测试时,说得委婉点,专家们的普遍反应是不相信。许多批评家认为他不是一个严肃的科学家,其他人则认为这个预测纯属无稽之谈。大多数人确信,如果它真的发生了,这确实是非常可疑的,数百年后才会发生。所以雷在 1999 年出版了这本书。在 2013 年的一项调查,也就是说,不到 15 年后,这些专家的共识已经从“数百年后”下降到“到 2040 年代”雷说,如果他们继续保持这种节奏,他们最终会批评他是保守派,这是正确的。(事实上,2018 年在美国普通人群中进行的一项调查显示,到 2028 年,这种情况发生的可能性超过 50%)。
你必须非常小心地拒绝看起来像科幻小说的预测,因为为了让小说成为非小说,有时你必须以非常高的激励加入人才。人工智能领域的另一位主要研究人员 Stuart Russell讲述了下面的故事:发现原子蕴含大量能量的科学家欧内斯特·卢瑟福勋爵在 1933 年说,“任何期望从这些原子的转化中获得能量的人都是在胡说八道。”第二天,另一位科学家读了这篇评论,一点也不喜欢。恼怒之下,他出去散步,突然想到了核连锁反应的想法。几年后,在赢得世界大战的激励下,这个想法被付诸实践,美国制造了原子弹。斯图亚特用这个故事作为例子,让我们学会谨慎。他指出,至于激励措施,数十亿美元正被投入到人工智能的开发中;不可思议的突破事实上可能随时发生,将之前的捕风捉影或科幻小说变成科学。
然而,很明显,这种“科幻小说”的效果仍然很强。尽管这十年来取得了所有的进步,尽管像尼克·博斯特罗姆这样的人所做的工作,尽管像比尔·盖茨或斯蒂芬·霍金这样可信的公众人物已经警告我们应该认真对待最坏的情况。但是盖茨和霍金发表声明已经有几年了,事实是他们想要发起的一般性辩论并没有发生。
离开学术界,走到大街上,会有更多相同的事情发生。严肃的媒体谈论我们已经存在的问题,但对几年后会发生什么却几乎只字不提。不出所料,DeepMind 只有在有体育角度的时候才会成为一些头条新闻和大量关注:在最后的挑战中,人对抗机器, Lee Sedol vs. AlphaGo 。当我们说巨大的关注时,这在某种程度上仅限于日本、中国和韩国,在这些国家,围棋(T2 战略棋类游戏 T3)不仅仅是一项全国性的运动。也许真的要就人工智能展开一场大规模的辩论,斯蒂芬·霍金和李·塞多尔的名字应该在头条上换成金·卡戴珊和弗洛伊德·梅威瑟的名字。
让我们转到下一个为什么今天这种争论几乎不存在的原因:人性。必须明白,从进化的角度来看,我们或多或少与十万年前的生物是一样的,因此我们这个物种被设计来生活在与今天非常不同的环境中。狩猎采集者,也就是智人在地球上 90%的时间里所做的,不必应对未来和抽象的威胁,而是非常直接和具体的威胁:我宁愿不爬上那棵树去找蛋,因为它太高了,我可能会掉下来;这蘑菇看起来不太好吃,我最好不要吃它;风带来了老虎的味道,我们跑吧!至于长期战略,狩猎采集者最多评估迁移到另一个地区,以提高他们的生存机会:天气开始变冷;寻找食物变得越来越困难;这里有太多的食肉动物。
当我们不再采集水果,不再成群结队地离开自己的领地,转而在民族国家的大城市出售金融衍生品,过着定居的生活时,对威胁的战略管理变得更加复杂。我们的进化准备不再相关,也许除了那些生活在这些大城市的某些街区的人。社会制度是分层的,关于什么是对整个社会的威胁以及如何避免这种威胁的决定被委托给来自上层的少数个人。这些更高的阶层变得越来越擅长于通过制造或放大威胁来管理人口,并根据什么最符合他们的利益来排除或压制其他人。
因此,毫不奇怪,在非常严重的威胁之后做出的一些最重要的决定并不完全是对整个社会最有利的决定。尽管有大量的信息和越来越可靠的预测工具。例如,让我们强调一下导致第一次世界大战大屠杀的一连串计算错误(特别指出在战争可能爆发之前传递给民众的普遍热情)。一个更紧迫的例子是:影响气候变化挑战决策的利益冲突(对我的股东来说,将我的部分利润投资于否认气候变化的游说团体比解决问题并不得不战略性地调整我的业务更有利可图,因此也更好。)
在许多情况下,无论是个人还是集体,人性的另一个变量也会发挥作用:“一厢情愿”效应,即希望事情会变好,并据此进行规划。在人工智能的发展中,似乎有很多这样的事情。可能的有利后果是如此诱人,以至于人们真的愿意相信我们会实现它们。这很好,我们都想要那些有利的结果。然而,对任何好父亲的书来说,最明智的建议之一(也是许多商业大师效仿的建议之一)是:“抱最好的希望,做最坏的准备”。思考和工作很棒,这样人工智能将会帮助我们生活得越来越好;但与此同时,有必要做好准备和计划,这样我们就不会从新技术的袋子里拿到那个黑球,那个意味着我们毁灭的黑球。
说到新技术,上面提到的我们似乎没有太关注人工智能革命的另一个原因恰恰是技术疲劳。发生这种情况的部分原因是指数增长曲线,这对我们来说可能已经有点困难了。技术发展越来越快,范围越来越广。我们很难注意到新的东西,被提供的信息淹没了。关于像 AlphaGo 这样的人工智能的革命性新闻在几个月后随着 AlphaZero 的出现而过时。谁能跟上?
我们似乎也没有做好准备。如果你年龄够大,你可能会记得,当你习惯了互联网和电子邮件时,手机及其应用程序和社交网络大量出现。当你最终拥抱另一项技术时,它带来了前所未有的大规模控制和操纵水平(正如我们在 Bricks in your wall 中指出的)。作家尤瓦尔·诺亚·哈拉里(Yuval Noah Harari)在为《卫报》撰写的这篇专栏文章中提出了巨大的问题:“在一个政府和企业可以攻击人类的时代,自由民主如何运作?“选民最清楚”和“顾客永远是对的”这两个信念还剩下什么?当你意识到你是一种可被黑客攻击的动物,你的心脏可能是政府特工,你的杏仁核可能为普京工作,你脑海中出现的下一个想法很可能是某种算法的结果,而这种算法比你自己更了解你,你该如何生活?”想想我们已经面临的这些挑战就让人不知所措。但这并不意味着我们不应该考虑明天我们将不得不面对的挑战,在它们碾过我们之前(是的,又有那辆卡车的比喻!).
因此,我们得出了我们指出的最后一个原因:“军备竞赛”效应,这个术语似乎来自冷战。因为引领人工智能发展的是世界主要国家的政府,当然是由美国和中国领导的;以及大型科技公司,如谷歌、脸书、亚马逊、微软、IBM、百度或腾讯。演员有巨大的能力来影响一场辩论,并且有太多的利害关系来回避它。因为那些面临更多障碍(批评、监管之类的东西)的人很可能会在比赛中被拖延,从而给竞争对手带来优势。
想想吧。这场比赛的获胜者会得到什么奖励?如果一切顺利,这个系统将有能力变成超人,对于那些控制它的人来说,有能力或者负担得起。一个可能产生另一个物种的系统,一个可能像人类看待黑猩猩一样,或者更糟,像一个农民看待他的牲畜一样,将人类视为被忽略的系统。一个有可能把所有好处都给第一个人,而第二个人却一点好处都没有的体系。这是这场竞赛的关键所在。
我们之前谈到社会上层倾向于制造或放大最符合他们利益的威胁,忽视或压制阻碍他们的威胁。我们可以肯定地说,这场竞赛的参与者是那些更高阶层的精英。正如在任何比赛中发生的那样,为了第一个到达,你必须比其他人跑得更快。为此,你最好有最快的车,否则你将需要承担更多的风险来竞争。
这也许是最可怕的事情:对于这些参赛者来说,任何比他们先到终点的参赛者似乎都比冒更大的风险先到终点更具威胁,即使这意味着每个人都要拿到黑球。哦,好吧,运气不好,你打算怎么办?难怪他们都不喜欢人们大喊“灭绝!”他们会尽全力阻止这种情况发生。不是灭绝,而是人们的呼喊。
好了,这就是为什么你很可能看不到迎面驶来的卡车,直到它压在你身上的原因。现在让我们更仔细地看看那些参加比赛的人和他们在做什么。
首先,中国政府已经做出了明确而果断的承诺,要在未来几年加快步伐,并努力走在前列。这当然包括大型中国科技公司,如腾讯或百度,以及数百家获得巨额融资的新人工智能初创公司。与此一致的其他变量是庞大的人口,由于其控制的日益有效性,他们几乎没有抗议或反应的能力,以及为人工智能系统提供燃料的巨大数据收集能力。结果是越来越像乔治·奥威尔的1984反面乌托邦,一些“改进”似乎直接取自黑镜,如社会行为信用系统。至少他们不太在乎隐藏如果他们赢得比赛会发生什么。
现在美国是一个更加复杂的例子。有两个主要因素推动着人工智能的发展。第一个是五角大楼,有像现在著名的 Project Maven 这样的东西,旨在加速对军用无人机拍摄的图像进行分析,自动对物体和人的图像进行分类(花点时间想想它可能的用途)。其次,大型科技公司:首先是谷歌、脸书、亚马逊、微软和 IBM。我们说这种情况更复杂,因为在中国,所有参与者或多或少都是一致的,而在美国,五角大楼和大技术公司竞相吸引专业人才,同时还在数十亿美元的开发合同中进行合作。这导致了摩擦。例如,去年,面对自己员工的激进主义,谷歌拒绝续签其 Project Maven 合同。正如这篇文章所解释的,树各方利益冲突:一方面是专业人士,本案中的谷歌员工,他们不希望自己的工作被用来杀人;另一方面,这些公司从股东那里获得并维持数十亿美元的合同,不管承包商是谁(最终可能是中国,就像项目蜻蜓);最后但并非最不重要的是,五角大楼,它希望利用这项技术继续拥有对美国对手的军事优势,为此,他们试图建立一座桥梁,以“帮助我们,我们是这里的好人”的角度来挽救与其他两个政党的分歧。
在大型科技公司中,谷歌是该领域最活跃的公司。事实上,据估计,80%的主要人工智能研究人员和开发人员(例如 Ray Kurzweil)为谷歌或其正在收购的一些领先公司工作,如波士顿动力或 DeepMind。后者的创始人兼首席执行官德米斯·哈萨比斯这样描述它的使命:“第一步,解决智能问题。第二步,用它来解决其他一切。”整个领域都有一个坚定的共识,即 DeepMind 是实现这一目标的最佳演员之一。他们在游戏中应用深度强化学习算法的进展是第一步中非常成功的一部分,Demmis 本人预计未来几年将在科学和医学的更重要领域取得突破性进展。从这个意义上说,他们刚刚引入了 alpha fold(T7),一个预测蛋白质结构的系统。
DeepMind 创始人同意谷歌收购的原因之一是,该协议包括建立一个道德委员会,以确保他们未来创造的技术不会被滥用。关于这个委员会, Nick Bostrom 说“在我看来,一个以‘解决智能问题’为雄心的组织有一个思考成功意味着什么的过程是非常合适的,尽管这是一个长期目标(……)提前开始学习这些内容比在考试前一天晚上做准备更好。”
在人工智能及其未来的使用中,肯定不缺少关于伦理和安全的董事会、委员会、研究所、论坛和其他倡议。大型科技公司创建了一个名为人工智能伙伴关系的组织,以造福人类和社会。埃隆马斯克促成了另一个,开启 AI 。在大学领域,牛津的人类未来研究所,伯克利的机器智能研究所和人类兼容智能建筑中心,剑桥的存在风险研究中心,或者哈佛和麻省理工学院的生命未来研究所,已经负责发表了几篇重要论文和调查,这些论文和调查甚至不时会成为头条新闻。
但事实是,总体形势相当令人担忧,正如凯尔西·派珀在这篇文章中所说。他使用的类比非常清楚:“总体而言,该领域的状态有点像几乎所有的气候变化研究人员都在专注于管理我们今天已经面临的干旱、野火和饥荒,只有一个小型骨干团队致力于预测未来,大约 50 名研究人员全职工作,制定扭转局面的计划。”
简而言之:人工智能发展中的伦理和安全缺乏国际层面的公共政策协调,没有关于其最深远影响的公开和普遍的辩论,发表的关键论文几乎没有超出学术领域,致力于长期研究和预防的资源非常荒谬。与此同时,获得人工智能的竞赛获得了数十亿美元的资金,这种人工智能将给予企业或地缘战略对手明确的竞争优势。
所以,用我们开始这一切的比喻来结束,这些人在一条充满他们没有地图的曲线的道路上进行一场 8 轴拖车卡车比赛。比赛的规则很简单:赢家通吃。速度越来越快,没有人打算减速。你走在那条路上,呆呆地看着你的手机。你的孩子正在前方某处玩耍,在一个弯道后面。
祝你有愉快的一天。
Goonder 2019
数据科学中的资历之路

Photo by Franki Chamaki on Unsplash
两年前,我努力寻找自己在市场中的位置。三年的数据科学工作经验,两年的人工智能硕士学位,把我难住了。我可以称自己是一名彻头彻尾的数据科学家,但我职业生涯的下一步是什么?一个高级数据科学家的定义是什么?
根据我从谷歌定义高级数据科学家的前 30 页收集到的信息… 并没有真正的定义。我们不能用多年的经验作为标准,因为这个领域相对较新。我们不能依赖已知技术,因为数据科学家必须是优秀的学习者而不一定是知识者。没有通常的面试编码测试题会在不到一个小时的时间里总结出编码员的 AI 知识。那么,还剩下什么?为了得到这些职位,我怎样才能提高我目前的技能?
让我们来看一些例子,看看网络在谈论什么。毕竟,我们是数据科学家。
这篇关于雇用高级数据科学家的文章列出了高级数据科学家必须具备的一系列品质:
下面是我看的四件事:对模糊问题描述的回应、建模之外的知识、高效沟通和指导/领导经验。
沟通、领导力、对大局的洞察力以及识别糟糕的必备定义的能力。有点抽象,但仍然有用。让我们把我能读到的东西汇编起来,以达到对所有这些的理解。
- 沟通容易。如何让你的团队执行你的想法,让你的老板理解你的想法,这在数据中至关重要。
合作智能:与思维方式不同的人一起思考让你洞察如何与来自你需要协调的许多领域的专业人士相处。
情商和社交智能都是很棒的书,解释了人类引擎盖下发生的事情,对自我提升和人际交流很有用。
管用的话又是一个很棒的推荐,重点是如何影响和说服人。 - 领导复杂。我更像是一个经验主义者。为了改善这一点,我宁愿投身于领导岗位的烈火中忍受。但是没有经验很难做到,所以需要用一些数据来武装自己。
管理 3.0 是敏捷经理的圣经。仅仅是这本书抛给你的大量参考资料就足以卖掉它。如何激励你的团队,如何激励生产力,如何发现有害行为……这些都在这里,以一种说教式(有时冗长)的写作方式。
- 看大图 难。需要具备与机器学习模型的开发、部署和生产相关的所有流程的经验。训练和分类只是任何简单人工智能模型漫长诞生过程中的一步。所以,我建议你在三个广泛的领域找到方向:
谷歌云平台或 AWS ,用于在云上部署模型。了解定价如何运作尤为重要,这样你才不会不小心把你团队/公司的积分都消耗掉。如果你在谷歌这边,查看一下 Pub/Sub 中不同机器上的模型之间的通信,查看一下 Stackdriver 中的集中式日志记录,以及所有不同的AI API中的 NLP、CV 和 generic AutoML 分类。
Docker ,为您精简需求流程,简化部署。熟悉 Docker Hub 和设置一次自定义 ML 图像并尽可能重复使用它的神奇之处。码头工人作曲也很棒。
Kubernetes 用于并行化您的工作、自动缩放和容器编排。Helm 也是管理部署的好工具。 - 收集信息。如今的数据科学家应该对 ML 模型有一些广泛的了解。但这并不是数据科学家必须驾驭的全部:你必须主动并培养好奇的性格从任何给定的问题中提取最大数量的信息。你不能只关注人工智能方面的事情!如何获取数据,如何正确存储数据,如何衡量数据的有效性,这些都和你的建模技能一样重要。不幸的是,对于如何改进这一点,我已经没有灵感了。这更像是软件工程和好奇心的锻炼。
这篇 dev 博客的文章描述了一位高级数据科学家,呼应了上面的一些观点,并扩展到真实的数据问题:
高级数据科学家明白软件/机器学习有一个生命周期,所以花了很多时间来思考这个问题。
在这种情况下,ML 模型的生命周期包括所有那些附属于技术项目的东西:技术债务、测试、可维护性等等。**一般的“好闻”**是一个有经验的程序员天生拥有的工具。这需要时间和练习。
作为一名 Python 程序员,我可以推荐一些这方面的好书!
- Fluent Python 是一本关于最未被充分利用(也是最棒的)Python 特性的疯狂好书。凭借清晰的用例以及对 pythonic 概念的简洁解释,这是一本非常适合放在公司茶几上的书。
- Python 的搭便车指南是另一本很棒的书,里面有很多疯狂使用 Python 库和特性的代码片段。
资深数据科学家明白**‘数据’总是有瑕疵**。这些缺陷可能是数据生成过程、数据中的偏差
有缺陷的数据是每个数据爱好者都应该警惕的事情。永远不要轻信数据。
即使你的模型和预测有很好的结果,也要记住:我为任务选择的数据是否正确地代表了我的总体?
可能是取样出错了。可能是从网上刮下来的不好。也许数据缺乏好的属性来准确区分类别。
自己动手手动检查您的数据和结果。检查正反分类的例子。把你的模型不能正确预测的东西分离出来,归类在模型误差和数据误差中。
高级数据科学家了解技术决策的“软”面。
当你在数据阶梯中向上走的时候,软技能非常重要。
在文章中,作者将重点放在了技术问题上,比如如何在 PostgreSQL 和 MongoDB,或者 GCP 和 AWS 之间做出选择,以及如何让你的团队在不损失时间、朋友和睡眠时间的情况下就你的编程堆栈决策达成一致。
这呼应了我们之前讨论的沟通点,并从技术角度加强了这一点。
高级数据科学家关注影响和价值。
关注影响和价值表示“保持简单”。首先思考:我们甚至需要 ML 来做这个吗?
数据科学家的常规教育将包括开发许多不同种类的统计模型。有些人可能倾向于只关注人工智能的智能方面。
事实是,大多数时候你不需要复杂性。当您可以比较具有相似结果的图像散列时,为什么要用 ImageNet CNN 来进行图像比较呢?当你能以更快的速度收集关键词和推断事物时,为什么要在 NER 任务中应用 BERT 呢?你真的需要那额外的 1%的准确度吗?
如果你确实需要复杂,那就慢慢来。我们知道有很多最先进的算法,但是其他的呢?
试试单词袋。然后做 TFIDF。用 PCA 减少。艾达。LSI。W2V。手套。小矢量。改变超参数。冲洗并重复。
资深数据科学家关心伦理。
道德在当今社会尤为重要,全球许多国家都在提出 GDPRs 。
在开始数据收集流程之前,考虑一下你搜集数据的合法性,以及从长远来看它会对你的公司产生怎样的影响。
还记得那些叫做使用条款的东西吗?是啊。刮之前先看。
在这篇数据科学周刊的文章中描述了一种定义数据资历的简洁方法,即衡量你的经理应该如何检查分配给科学家的任务:
高级数据科学家——你把数据交给他们,他们会处理好的。不需要登记。
中级数据科学家——你可能每周或每月检查一次,但不要参与太多。您还可以将他们与高级数据科学家配对。
初级数据科学家 —你每天检查一次,如果不是每天两次,你让他们与一名中级和高级数据科学家配对。
现在,这衡量的是完成任务的能力。责任、信任、能力、和知识。这是经验和自我提升带来的。在这篇文章中,很多关注和赞扬都给予了博士毕业生,而我从根本上不同意这一点。
虽然博士毕业生有很高的积极性,并对他们的领域有大量的知识,但学术 ML 与商业 ML 相距甚远,可能很难将其集成到大多数公司的数据科学团队中。大多数博士通常不在团队中工作,所以交流可能是一个巨大的缺点。不要用博士学位取代行业经验!
这个是初级和高级数据科学家之间的差异列表。大部分我们已经在上面提到过了,但是让我们列出并继续讨论它们。数据多了对身体不好吗?确实不是。
1.自动化任务。写代码就是写代码。
花,气流, **Kubernetes Cronjobs。**自动化对于以可伸缩的方式处理数据转换非常有用。
2.将任务外包给初级成员或顾问。
见上面的领导。知道何时委派,委派给谁。
3.管理人员,雇佣合适的人,管理向你汇报的经理。
这在这里也是领导,但它处理的是招聘的角度。管理实习生本身就是一篇文章,但我们可以用一些要点来触及它:
- 为实习生制定一个总体计划,这样他们总是有一项独立于微观管理的任务要做;
- 对日常任务和整体绩效进行质量反馈;
- 要有说教的态度,因为你是经理之前的导师。教学是一项神圣的职业。
4.培训可能不懂技术的同事。做高级经理的顾问。
同上,做导师。以身作则向上影响!
5.为一个特定的大规模项目(构建一个庞大的分类法等)确定合适的工具,并评估供应商软件和平台的优缺点。)
体验和纵观全局。
6.为特定项目确定正确的算法和统计技术。根据需要混合这些技术以获得最佳性能。
知识和工具集。要做到这一点,你必须知道多少 Python 库?不够。
7.不信任数据;识别有用的外部或内部数据源,混合各种数据源,同时清除数据冗余和其他数据问题。
我们在上面已经讨论过了!有缺陷的数据永远是个问题。
8.识别最佳特征,可能使用比率或转换,合并原始特征,使其成为更好的预测器。通常需要对你所在的行业有很好的了解。
数据表示和特征 组合是建模过程的 10%。85%是清理收集。另外 5%是实际训练。
9.理解高管谈话,并将高管的要求、问题、顾虑或想法转化为成功的数据科学实施。
我们在上面也谈到了这一点,谈到了在开始一个项目之前收集信息。这也稍微涉及到沟通以及如何交谈和理解管理行话。
10.衡量你给公司带来的投资回报率;能够让高管相信你的附加价值(或者在投资回报率为负或不被认为是正的情况下提供合理的解释,并提供纠正途径。)
冲击、数值、和测量。你的工作对公司整体有什么影响?你的模型真的在帮助它成长吗?
11.与各类经理/同事/主管/客户成功互动。主要是沟通问题。
再次沟通。看起来这很重要。
12.清楚地了解什么将为你的公司或客户创造价值,并且能够及时、一致地传递这种价值,不管内部政治和挫折如何。
影响、价值和像躲避瘟疫一样躲避管理者。当然最后一部分是个笑话。只是不要陷入办公室闹剧。
13.能够评估完成一个复杂项目需要多长时间,障碍和回报是什么,并在可交付成果和截止日期方面保持正轨。
再次冲击和值。
14.能够提出建议,创建新项目,说服利益相关者,并从头到尾管理这些项目。
来自产品创造和管理和沟通的知识来说服你的团队和经理推进你的想法。
15.能够启动自己的公司并成功管理它。
呃。
创业?我不太喜欢这个。我觉得资深数据科学家不一定是企业家。
16.提出有关数据科学实施的建议,帮助维护,并确保项目顺利开始,不会随着时间的推移而停滞不前。
ML 生命周期问题。
17.了解你不知道的,设法外包或学习新的东西(并能够识别/优先考虑你需要获取或外包的知识。)
项目 2、3 和 6 放在一起。了解你的局限,了解你同事的工具集和需要时外包。
18.了解你所在的行业,了解高管们心中的愿景,即使你的经理没有明确说明。
做你心中的产品经理。我猜这就是作者在第 15 项上想表达的意思。
数据科学家最适合提出建议和理解业务,因为他是集中和提炼所有数据的人。
19.测试,测试,测试。为什么假新闻在脸书持续存在,尽管所有的努力和花费了数百万美元来对抗这一瘟疫?缺乏测试,和/或无法找出假新闻是什么样子(缺乏商业头脑)可能是原因。骗子无时无刻不在改变他们的策略;你的算法应该识别和关注新的趋势,而不是仅仅能够检测 20 种类型的假新闻,并错过你的解决方案实施后将出现的新类型。与业务分析师和 IP 管理员合作,不断完善您的算法。使用健壮的算法和健壮的特性。正确衡量你的成功率。做有意义的交叉验证:如果你在 15 个欺诈案例(测试数据集)上训练你的算法;它是否能够识别出其他 5 个不在训练集中但出现在控制集中的欺诈案例?避免像瘟疫一样过度拟合。
这有点长,可能是 5 个项目合而为一,集中在一个特定的问题上。识别趋势对于建议新项目至关重要。
20.无法基于完美的模型交付完美的解决方案,需要三个月的工作,而一天就可以获得近似的解决方案。毕竟数据是杂乱的,所以完美的模型并不真的存在。如果你想要绝对的完美,你只是在侵蚀投资回报率。
冲击和值。
21.相信你的直觉和直觉,但只是在一定程度上。有些问题不需要编写任何代码或测试就可以回答。有时,简单的模拟可以走很长的路。事后分析也是如此(你可以称之为分析取证。)
在一个企业家的看来,这更与产品发现和管理有关。高级数据科学家熟悉这些概念是有好处的。
觉得小一点就更好了。你不一定需要把产品作为一个整体来分析,但是那些没有走过场的小特性。为什么那个饼状图被忽略了?为什么我们的推荐模块失败了?为什么团队对这个特定的任务反应如此消极?
22.花时间记录所有事情,确定优先顺序,与利益相关者讨论,并制定计划。每天至少一小时,通常更多。
即使你对当经理不感兴趣,兼顾工作和会议的组织也是基本的!数据科学家将定期被召集到产品会议上,展示他们的研究成果,并讨论公司的未来步骤。
这是对打算从事管理工作的高级数据科学家的要求。但那是给我的吗?哦,不。那不是我的事。
我想在上面已经讨论过的基础上增加一些品质。
- 对于必须在许多不同领域工作的数据科学家来说,创新思维 是很自然的事情。我们可以使用主要用于计算机视觉的算法来处理自然语言处理中的任务吗?我们能使用我们在调查中收集的数据来创建一个完全不相关的东西的分类器吗?
- 热爱教学。高级数据科学家拥有多年的机器学习经验,这些知识不能浪费!通过指导、写科技文章和更新你的老维基,在你的公司里传播这些知识。你是你们公司的一名老师。
总结:
我们可以将所有这些要点归纳为以下三大支柱:
- 你对自己了解多少 : 经验、工具包、部署、好奇心。你独立完成工作的能力,以及为了成功实现目标而积极主动的能力。
- 你对你的公司了解多少 : 产品发现、初始、管理、测量。你看到全局、最大化你的影响、最小化复杂性、提出新想法并衡量其价值的能力。
- 你对你的同事了解多少 : 沟通、领导、教学、微观管理。你向你的队友和经理推销你的想法的能力,了解每个团队成员的优点和缺点的能力,向他们传播你的个人知识的能力,以及有效领导他们的能力。
如果你想留在技术面,首先提高第一支柱。如果你想去管理方,提高第二支柱。第三是对两者都必不可少的。
差不多就是这样!
有关硬技能的更多信息,请查看 LinkedIn 上的高级数据科学家简介以及 GlassDoor、Indeed 和其他网站上该职位的招聘信息。我在这篇文章中没有关注它们,因为它们相当于一个普通的数据科学家工具包。所有其他的事情都会有所不同。
从两年前开始,我就在努力达到那个高级技能。渐渐地,我找到了窍门,但是还有很长的路要走。编写和汇编这份核心原则和价值观的清单真的很有趣,如果你有什么要补充的,请在下面的评论中提出来,或者在 LinkedIn 上联系我!
我们未来的机器人影响者:一个能演奏《我的世界》音乐的抽搐流机器人
内部 AI
我们如何将机器人技术与电子竞技相结合来吸引年轻观众
究竟是什么?
以前听说过类似的事情吗?我也没有。这个机器人是作为芬兰国家广播公司伊尔与未来项目的一部分而创造的。Yle 为电视、广播和网络制作内容。它拥有广泛的老年观众,但在吸引年轻观众方面有困难。这个项目的目标是利用新技术接触年轻观众,特别是青少年。
Yle 的内容传统上是非参与性的:表演者表演,观众观看。然而,年轻观众通常会观看更具参与性的内容,如 YouTube 视频或流媒体。我们想创造参与性的内容——表演者应该与观众互动。Yle 专门针对青少年受众的记者指出,游戏和电子竞技是受欢迎的内容。我们意识到游戏是实现这一点的完美环境:观众可以和表演者一起玩。我们想探索一个艺人,甚至是未来的影响者会是什么样子。那么为什么不创造一个流媒体机器人游戏玩家呢?

Yle’s journalists and Futurice’s roboticists coming up with the idea of a robot gamer

First drafts
这个机器人是什么样的?
我们为机器人选择了两个游戏:Flappy Bird 和《我的世界》。
《Flappy Bird》是一款风靡一时的游戏,曾在 2014 年风靡一时。我们选择 Flappy Bird 是因为这个游戏的机制很简单,并且允许用机器学习来玩这个游戏。我们想尝试一种神经进化算法,根据上一代中哪些鸟表现最好,将新的鸟进化到游戏中。这样我们可以看到当电脑在玩游戏时观众的反应。
我们选择《我的世界》是因为它的社区特色,允许玩家之间的互动。玩家可以互相合作或战斗,互相交易,互相聊天。他们会“伤害”对方——也就是惹人讨厌。玩家还可以挖掘材料,并把它们变成物品,甚至建造城市。他们可以储存珍贵的东西,耕种土地,放牧动物,和打怪物。《我的世界》还有一种叫做红石的材料,玩家可以用它来建立逻辑。实际上,玩家可以在《我的世界》内部建造一台完整的计算机。很有诗意,是吧?
为了扮演《我的世界》,我们决定由人类来控制机器人。这个游戏很复杂,与其他玩家进行真实的互动需要另一端有一个人。

Flappy Bird and the Robot
我们的团队由 Yle 的记者和未来机器人专家组成,他们定义了在这种情况下使用机器人的一些明显优势:
- 机器人不知疲倦——它可以永远玩下去,并提供全天候的内容。是理想的流光。
- 机器人可以是中性的。游戏玩家和游戏观众通常是男性,但性别中立的机器人可能会吸引更多不同的观众。
- 一个机器人可以反映玩家的行为,激起情绪。游戏文化通常是侵略性的。反过来,机器人可能会变得咄咄逼人,让游戏玩家反思自己的行为。
- 机器人可以在游戏中互动,同时聊天。人类只能有一个输出,而机器人可以有几个。

Testing our streaming equipment and having problems with interference from the robot’s face screen.
我们决定玩六个小时的游戏,轮流玩《我的世界》和 Flappy Bird。为了确定会议的用户体验,我们为机器人的设计定义了指导方针:
- 实验性用户体验——用户应该能够在与机器人的互动中探索。
- 飘带通常是强势人物。机器人是个性很强的角色。
- 机器人能引起“WTF?”玩家的反应。我们希望这次经历令人难忘,而不是平淡无味。
- 在线游戏的文化和空间是独一无二的,应该为。
基于这些指导方针,我们创造了角色 IQ_201。《智商 201》是基于激进的网络游戏玩家,他们相信自己的智力超群(参见这个关于智商超过 200 的迷因)。这个机器人会很粗鲁,会做出反应,这意味着要让与它互动的青少年做出反应。
在实施之前,该团队还想考虑一些道德因素:
- 机器人如何操作的透明度是必需的。如果这个机器人将被投入生产,用户应该能够找到关于它如何工作的信息。
- 机器人应该平等对待所有的玩家。这也是让机器人看起来中性的决定的一部分。由于有时愤怒,仇恨,甚至种族主义或性别歧视的游戏文化,我们需要仔细设计机器人的个性。它可能就在外面,甚至是粗鲁的,但绝不是可恨的。我们不想要任何激烈的游戏时刻。
- 机器人应该是粗鲁的,但不要太过分。
- 聊天需要被调节。如上所述,游戏文化可能是有毒的。我们希望密切关注《我的世界》和特维奇的聊天,以确保不会有恶作剧发生。
为了满足这些要求,我们选择了 Furhat 机器人。Furhat 机器人有一个相对易于使用的远程操作界面,允许用户输入文本以转换成机器人的语音,并在点击按钮时做出手势。
鲜花和暴力
我们有一个 6 小时的视频流,从 14 点开始,到 20 点结束。我们在游戏之间交替:14-15 是 Flappy Bird,15-17《我的世界》,17-18 Flappy Bird,然后又是 18-20《我的世界》。这个时间表允许扮演《我的世界》的机器人操作员在中间有一个急需的休息。

Our streamer
一开始,有几个人加入。渐渐的,我们收获了越来越多的人。我们在 16:20 达到峰值 Twitch 上有 49 个同时观看者。总的来说,我们有 431 个独特的观众。在《我的世界》,大约有 30 个活跃的玩家。考虑到我们的广告是如此之少(一个论坛帖子和几条推文),我们对出席人数感到惊喜。
《我的世界》会议由两个机器人操作员指导(我和另一个 Minja)。另一个 Minja 扮演《我的世界》,我操作机器人的声音和手势。第三个人在聊天中回复信息。
《我的世界》势不可挡。机器人挑衅的性格激起了青少年对它的不断杀戮。在几次逃到山里和骆驼在一起,又一次被杀死后,我们修改了机器人的行为,使其更加友好。我们想创造更多建设性的互动。

Two Minjas as robot operators
在第二部《《我的世界》之流》的结尾,青少年们正在与机器人合作。他们保护它免受剩下的几个好斗玩家的攻击,并给它送花之类的礼物。有些人甚至直接称赞机器人,让它开心。玩家开始跟随机器人,当机器人开始建造灯塔时,他们同意合作。他们还建了一座房子,并捕获了一只美洲驼,命名为:IQ_201 Junior。
在游戏中有两个明显的派别:一些在整个游戏中意图杀死机器人,一些在整个游戏中保护它。随着水流的继续,一些人变得对机器人更加适应,换边。不管怎样,机器人激起了强烈的情绪。青少年寻求与它真正的互动。没有人忽视机器人,或者感到无聊。
关于机器人如何工作的讨论贯穿始终。没有人问机器人本身,也许是出于尊重或害怕打扰它。讨论集中在机器人是否是“真实的”,即它是否是真正自动的,或者是人类在操作它。是用实际的手打字吗?或者它“侵入”了游戏并通过代码玩游戏?
“我会想你的机器人!”
之后有 16 个人回复了我们的调查。80%的球员年龄在 18 岁以下,大多数是 13 到 15 岁的孩子。80%的玩家与机器人互动。这是非常积极的,我们成功地制造了一个吸引用户的机器人。75%的玩家对机器人的评分为 3 分或以上,满分为 5 分。

Viewers over time
我们从调查中收集玩家的意见,以及《我的世界》游戏聊天。它们是从芬兰语翻译过来的,反映了我们的玩家对机器人的一些想法。
关键的第一点:
“这很有趣,也很酷。但不知何故,这感觉像是一个圈套。”【指机器人可能有人类操作员】
许多玩家想知道机器人实际上是如何工作的。这个评论把我们带回到我们之前谈到的伦理考虑:机器人如何操作的透明度。虽然我们一开始打算保持透明,但我们决定不告知用户第一个飞行员机器人的遥控操作特性。我们做出这一选择是因为我们希望让用户的“暂停怀疑”保持活跃,这意味着我们希望参与者接受他们正在与一个“真正的机器人”(一个自主机器人)对话的事实(Duffy & Zawieska,2012)。我们收到的关于机器人功能不明确的负面回应让我们清楚地知道,如果这个试点延长,更加透明是非常重要的。有可能同时保持怀疑和诚实的机器人操作(我们都知道电视节目毕竟不是现实)。
这个机器人在某些事情上有点简单,有时对人说话很刻薄,而且居高临下。这有点让人焦虑……这是故意的吗?”
一些玩家认为机器人的粗鲁行为越界了,变成了居高临下。他们希望机器人将来会更体贴。这表明即使是机器人也会伤害感情。在未来的版本中,让 IQ_201 更有同情心,更少关注机器人对人类的优越性,可能会有积极的结果。
“机器人看起来脸色有点发青,声音也有点怪。”
两个青少年不喜欢机器人的外表和声音。其中一个特别提到它的蓝色脸,问我们为什么不把它做成“正常的颜色”。这可能是由于机器人掉进了这些玩家的“恐怖谷”。恐怖谷是机器人研究人员森昌弘(Mori et al .,2012)提出的一个理论。他的理论认为,随着机器人的外形越来越接近人类,当外形非常接近时,会有一个下降。僵尸和尸体落入这个山谷。为了消除我们机器人的这种影响,在未来的解决方案中改变机器人的外观和声音可能是明智的。

The Uncanny Valley by Masahiro Mori. Wikimedia commons.
然后是积极的:
“和机器人玩游戏真的很有趣。:)希望将来我们能再次举办这类活动。😃"
大多数青少年喜欢玩机器人,看小溪。他们的反馈称赞了机器人的幽默感和游戏技巧。继续试播肯定会找到感兴趣的观众。
【对机器人】“有些人对新事物有困难。在这种情况下,这些玩家遇到了机器人的问题,因为你是新来的。”
这位玩家在游戏中安慰机器人,因为其他玩家通过不断杀死它来给它制造麻烦。这个评论很感人:玩家为机器人感到难过,并认为机器人可能也会感到难过,试图改变这一点。这是对机器人明显的移情反应。
【对机器人】“我会想你的机器人!”
当机器人离开《我的世界》时,一些玩家向它衷心道别。这些玩家发现机器人平易近人,甚至与它建立了情感纽带。这意味着我们成功地创造了一个引人注目的角色,即使只有 6 个小时。对于机器人的未来构建,玩家应该被告知机器人是如何操作的。这可以帮助他们校准与机器人之间适当的情感纽带。
机器人影响者是我们的未来吗?
玩家对机器人产生了浓厚的兴趣。他们接近它,与它互动,并形成对它的看法。这个机器人也引发了情绪反应——积极的和消极的。一些参与者真的很喜欢这个机器人,并希望未来能有更多的互动,而一些人则非常挑剔。这表明机器人影响者有能力影响我们的情绪——我不知道这种能力是否会达到人类艺人的水平。这是否可取,我也不知道。
真正让我惊讶的是,机器人的年轻用户群是媒体素养:他们批判性地审视机器人的操作模式。玩家们对今天的人工智能有一个很好的想法,什么是可能的,什么是不可能的。他们不容易上当。
这让我对我们的未来充满希望,不管它是否包含机器人艺人。当观众仍然持批评态度时,他们可以理解机器人是没有实际情感能力的机器,即使观众选择暂停怀疑。对于观众来说,与机器人的互动可以被视为一种准社会互动——观众可能会觉得他们与机器人的关系很亲密——即使这不是真正的互惠。这本身并不一定是有害的,只要我们诚实地面对这种关系到底是什么。我们应该明白,机器人正在进行一场表演,以激发我们的情感——就像人类表演者所做的那样。
[## Yle Beta | Yle Twitchbot -社交机器人设计冲刺
伊尔 Twitchbot 演示和社会机器人设计介绍。
areena.yle.fi](https://areena.yle.fi/1-50168989)
达菲,b . r .&扎维斯卡,K. (2012 年 9 月)。暂停对社交机器人的怀疑。2012 年 IEEE RO-MAN:第 21 届 IEEE 机器人与人类互动交流国际研讨会(第 484–489 页)。IEEE。
m . Mori,k . f . MacDorman,&n . kage ki(2012 年)。森昌弘的原创散文。IEEE 频谱,98–100。
ROC 曲线:揭开面纱
ROC 曲线完全指南

这篇文章的目的是解释什么是 ROC 曲线,它在评估分类算法性能中的重要性,以及如何使用它来比较不同的模型。
这个帖子可以被认为是***'***的延续:揭开了’ 【的困惑矩阵,所以如果你不熟悉困惑矩阵和其他分类度量,我推荐你去读一读。
我们开始吧。
概率阈值
当面临二元分类问题时(例如使用某个患者的健康记录来识别他是否患有某种疾病),我们使用的机器学习算法通常会返回一个概率(在这种情况下是患者患有疾病的概率),然后将其转换为预测(患者是否患有这种疾病)。

Pipeline of the previously explained scenario
为此,必须选择某个阈值,以便将该概率转换成实际预测。这是一个非常重要的步骤,因为它决定了我们的系统将输出的预测的最终标签,所以小心选择这个阈值是一项至关重要的任务。
我们如何做到这一点?好吧,第一步是考虑我们面临的任务,以及对于这样的任务是否有我们应该避免的特定错误。在上面的例子中,我们可能更倾向于预测一个特定的病人实际上并没有患病,而不是说一个病人在实际患病时是健康的。
总的来说,该阈值通过以下规则合并到先前描述的管道中:

Rule for using the probability to produce a label
开箱即用,大多数算法使用 0.5 的概率阈值:如果从模型中获得的概率大于 0.5,则预测为 1 -(在我们的情况下有疾病),否则为 0(没有疾病)。
当我们改变这个概率阈值时,对于某一组数据,相同的算法产生不同的 1 和 0 集合,也就是不同的预测集合,每个集合都有其相关的混淆矩阵、精确度、回忆等…

Figure of a confusion Matrix for a specific set of predictions
在上图中,显示了混淆矩阵的图像。让我们记住可以从中提取的指标,并加入一些新的指标:
- 模型的精度使用预测标签的真实行计算。它告诉我们,当我们的模型做出正面预测时,它有多好。在之前的医疗保健例子中,它会告诉我们,在我们的算法预测生病的所有人中,有多少患者实际上患有疾病。

Formula for the precision of the model
当我们想要避免我们的算法的真实预测中的错误时,即在我们预测为生病的患者中,这个度量是重要的。
- 我们型号的召回是使用实际或真实标签的 True 列计算的。它告诉我们,在我们的真实数据点中,算法或模型正确地捕捉了多少。在我们的案例中,它将反映出有多少实际患病的人被确定为患病。

Formula for the recall of the model
当我们想要尽可能地识别我们的数据的最真实的实例时,这个度量是重要的,例如,实际上生病的病人。这个指标有时被称为敏感度,它代表被正确分类的真实数据点的百分比。
- 我们的模型的特异性是使用实际或真实标签的假列来计算的。它告诉我们,在错误的数据点中,算法正确地捕捉了多少。在我们的案例中,是有多少真正健康的病人被认为是健康的。

Formula for the specificity of our model
当我们想要尽可能地识别数据中最错误的实例时,这个度量标准是很重要的;即没有生病的病人。这个度量也被称为 真负率 或 TNR。
ROC 曲线
在定义了评估我们的模型可能涉及的大部分指标之后,我们实际上如何选择概率阈值来为我们想要的情况提供最佳性能呢?
这就是 ROC 或接收器工作特性曲线发挥作用的地方。这是两个指标(灵敏度或召回率和特异性)在我们改变这个概率阈值时如何变化的图形表示。直观地说,这是在一个单一、简洁的信息源中,当这个阈值从 0 到 1 变化时,我们将获得的所有混淆矩阵的总结。

Figure of a standard ROC curve of a model
首先看一下这个图,我们看到纵轴上是召回率(量化我们在真实标签上做得有多好),横轴上是假阳性率(FPR),这只是特异性的补充指标:它代表我们在模型的真实阴性上做得有多好(FPR 越小,我们在数据中识别真实阴性实例就越好)。
为了绘制 ROC 曲线,我们必须首先计算各种阈值的召回率和 FPR,然后将它们彼此相对绘制。
如下图所示,从点(0,0)到(1,1)的虚线代表随机模型的 ROC 曲线。**这是什么意思?**它是一个模型的曲线,预测 0 半时间和 1 半时间,与其输入无关。

Figure of the ROC curve of a model
对于随机模型,ROC 曲线大多数时候都是与 ROC 曲线一起表示的,这样我们可以很快看到我们的实际模型做得有多好。这个想法很简单:我们离随机模型的曲线越远越好。正因为如此,我们希望从点 a 到点 b 的距离尽可能的大。换句话说,我们希望曲线尽可能靠近左上角。
下图显示了 ROC 曲线的一些特殊点:

Some important points of the ROC Curve.
- 在点 A 我们有一个概率阈值 1,这不会产生真阳性和假阳性。这意味着,根据我们的算法返回的概率,每个样本都被分类为假。你可以想象,这不是一个很好的阈值,因为基本上通过选择它,我们构建了一个只会做出错误预测的模型。从点 A 位于虚线上这一事实也可以观察到这种不良行为,虚线代表纯粹随机的分类器。
- 在点 B 上,阈值已经下降到我们开始捕获一些真阳性的点,因为具有高阳性概率的样本实际上被正确分类。此外,在这一点上没有假阳性。如果这一点有一个体面的回忆,这是完全关键的,以避免假阳性,我们可以选择它描绘的阈值作为我们的概率阈值。
- 在点 C 上,我们已经将阈值设置为 0,因此以与点 A 镜像的方式,一切都被标记为真。根据标签的实际值,我们会得到真阳性或假阳性,但从来没有对假或阴性行的预测。通过将阈值放在这里,我们的模型只创建真实的预测。
- 最后,点 D 是性能最优的点。在里面我们只有真正的积极和真正的消极。每个预测都是正确的。我们得到实际到达该点的 ROC 曲线是非常不现实的(所表示的 ROC 甚至不接近该点),但是正如我们以前说过的,我们应该尽可能接近左上角。
大多数情况下,我们最终要做的是找到曲线中 B 和 C 之间的一个点,该点满足 0 成功和 1 成功之间的折衷,并选择与该点相关的阈值。
根据我们的 ROC 曲线的形状,我们还可以看到我们的模型在分类 0 或分类 1 方面做得更好。这可以从下图中观察到:

Comparison of two different ROC curves.
左边的 ROC 曲线在分类 1 或我们数据的真实实例方面做得很好,因为它几乎总是呈现完美的回忆(这意味着它接近我们图表的上限)。然而,当它到达蓝色标记的点时,它在回忆中显著下降,同时过渡到完美的特异性。
右边的 ROC 曲线在对我们的数据的 0 或错误实例进行分类方面做得非常好,因为它几乎总是呈现出完美的特异性(这意味着它接近我们图表的左边界限)。
另一件要提到的事情是,如果 ROC 曲线太好(就像上图中说明不同场景的例子一样),这可能意味着模型过度拟合了训练数据。
很酷吧?最后,下图显示了取自不同来源的其他一些 ROC 曲线。

Group of 4 different ROC curves taken from different sources
您可能已经注意到,其中一些图表也给出了 ROC 曲线下的面积值。这是为什么?我们来看看曲线下面积。
ROC 曲线下的面积:AUC
正如我们之前提到的,我们的 ROC 曲线越靠近图表的左上角,我们的模型就越好。当我们针对特定任务尝试不同的机器模型时,我们可以使用准确性、召回率或精确度等指标来比较不同的模型,但是,仅使用其中一个指标并不能完全准确地描述我们的模型的表现,因为仅基于其中一个指标进行比较会遗漏所有其他指标提供的信息。
这就是 AUC 发挥作用的地方。该度量从 0.5(随机分类器)到 1(完美分类器)的值,并且它在单个度量中量化了我们的 ROC 曲线有多酷和好看;这反过来解释了我们的模型对真假数据点的分类有多好。较大的 AUC 通常意味着我们的模型比具有较低 AUC 的模型更好,因为我们的 ROC 曲线可能具有更酷的形状,更靠近我们图表的顶部和左侧边界,并且更接近期望的左上角。

Comparison of two ROC curves
在上图中,我们可以看到,ROC 由蓝线表示的模型比 ROC 由金线表示的模型更好,因为它下面有更多的区域(蓝线和我们图表的左、按钮和右界限之间的区域),并且在所有情况下都表现得更好。
容易吧?我们的 ROC 曲线下的面积越大,我们的模型就越好。
就是这样!我们已经了解了什么是 ROC 曲线,AUC 意味着什么以及如何使用它们。让我们总结一下我们所学到的!
结论和关键经验 :
- ROC 是为单个模型构建的,它可以是一种使用其形状或面积(AUC)来比较不同模型的方法。
- ROC 曲线的形状可以告诉你一个特定的模型在对我们的数据进行真假分类时是否做得更好。
- 使用 ROC 曲线,我们可以选择一个与我们对特定任务的兴趣相匹配的概率阈值,以避免某些错误超过其他错误。
- ROC 不仅仅是一种比较算法的方法,它还让我们根据与我们最相关的度量来选择分类问题的最佳阈值。
就这些,我希望你喜欢这个帖子。欢迎在 LinkedIn 或上与我联系,在 Twitter 上关注我,在 @jaimezorno 。还有,你可以看看我在数据科学和机器学习上的帖子这里 。好好读!
更多类似的帖子请关注我的媒体 ,敬请关注!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










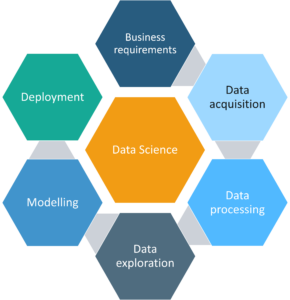{kind=link}
{kind=link}
{kind=link}