




从你的活动跟踪器的日志中创建一个热图
如何使用 Python 从应用程序和设备导入数据并从 GPX 文件创建热图。

热图(图片由作者提供)
我的电脑里有 7 年的步行记录。这些年来,从独立的 GPS 接收器,到 SportsTracker,再到 Garmin,这些都是通过几种设备和应用程序收集的。幸运的是,他们都有一个共同点,那就是记录的路线是 GPX 格式的。获取这些文件可能没有那么简单困难。
什么是 GPX?
GPS 交换格式(GPX)是 XML 格式的 GPS 数据格式。它是一种开放的、免许可的格式,描述了路点、轨迹和路线。它被广泛采用,因此是交换位置数据的绝对标准。位置以经度-纬度(十进制度数)对的形式存储,并可选择使用海拔(米)、时间(UTC)和供应商特定信息进行扩展。

GPX 格式的音轨(图片由作者提供)
上面的例子是 Garmin 存储的轨迹,例如 SportsTracker 和 Fitbit 存储的轨迹具有相同的结构,但细节不同。
根元素是 gpx 。它包含一个 元数据 元素和一个 trk 元素。 元数据 指定文件的来源和创建时间。 trk 元素包含存储的音轨。一个轨迹由一个或多个片段组成,每个片段存储在一个 trkseg 元素中。在曲目级别,有些字段包含曲目的名称和类型。该规范允许更多的字段,但这些字段并未被 Garmin 等公司使用。
trkseg 段元素包含一个轨迹点列表( trkpt )。线段是一组连续的点。如果跟踪被中断,例如失去连接或电源故障,应该创建一个新的段。
一个 trkpt 有强制属性 lat 和 lon 来指定位置。有时间( 时间 )和标高( ele )等可选字段。元素 扩展 允许每个设备/应用添加额外的信息,如心率(上面 Garmin 示例中的 hr )、速度或路线(Garmin 不使用)。
使用 SportsTracker 创建的轨迹包括经度/纬度属性以及时间和海拔元素。他们没有像 Garmin 那样的扩展。假设以下数据结构用于解析 GPX 文件:
<gpx>
<metadata>
<name>02-01-20 13:29</name>
</metadata>
<trk>
<trkseg>
<trkpt lat="52.12345" lon="6.31235">
<ele>71.1</ele>
<time>2021-08-02T12:29:18Z</time>
</trkpt>
</trkseg>
</trk>
</gpx>
导入 GPX 文件
为了读取 GPX 文件,有几个 Python 库可用,比如 gpxpy 。但是出于教育目的,提供了一个实现。这个实现利用了 Python 中默认 XML 实现的ElementTree。要从目录中读取所有 gpx 文件:
这段代码从目录data中检索所有文件,并解析扩展名为.gpx的所有文件(来自第 18 行)。从文档中检索根元素(第 19 行),在本例中是<gpx>元素。所有元素都位于第 6 行定义的名称空间中。
跟踪日志的开始时间存储在元素<metadata>的子元素<time>中。然后(第 21 行)选择音轨,在这种情况下使用.find()方法。这将查找具有指定名称的元素的第一个匹配项。这就足够了,因为我的 GPX 文件中没有一个包含多个音轨,甚至是多个片段。在多轨道的情况下,可以通过迭代.findAll()的结果来替换.find()。track 元素包含元素name和type,这两个元素包含活动的名称和活动的类型(例如步行)(第 22–23 行)。
从轨道中选择第一个(也是唯一的)片段(第 24 行)。该段包含所有记录的位置,因此通过迭代该段,所有记录的位置都被解析(第 25 行)。点(元素trkpnt)包含纬度和经度(26–27)两个属性,以及日志条目的时间戳和海拔(第 28–31 行)两个子元素。高程可能不存在,因此我们需要在转换之前检查它的存在(第 31 行)。
所有信息都被添加到一个数组中,该数组在第 33 行被转换成一个数据帧。最后,两个时间字段都被转换为时间戳对象,因此我们最终得到以下数据帧(在本例中有将近一百万个位置):

GPX 所有记录位置的数据框(图片由作者提供)
大部分的活动日志是在我居住的地方,在假期有少量的。过滤我家周围的位置可以得到热图的第一个概念。
df[(df.lat > LAT_MIN) & (df.lat < LAT_MAX) &
(df.lon > LON_MIN) & (df.lon < LON_MAX)]. \
plot.scatter('lon', 'lat', figsize=(10,10), s=0.1)
在(x,y)坐标系中,经度为x,纬度为y。

跟踪的活动(作者图片)
创建热图
最初的图给出了所有活动的一个很好的概述,但是没有提供大多数访问区域的洞察力。为此,我们将创建一个热图。我们会从头开始做这个。
热图将在大小为<size_x, size_y>的 numpy 数组中创建。所以首先我们要把经纬度转换成这个维度;最小经度到0,最大经度到size_x,纬度也一样。
首先,删除经度/纬度范围之外的所有位置。然后为x和y创建新的列,并使用线性转换为其分配适当的值。这些值被转换成整数,因为我们将使用它们来寻址 numpy 矩阵中的点。
对于那些感兴趣的人来说,线性回归背后的数学:

线性回归解释(图片由作者提供)
下一步是创建一个用所需大小的零填充的矩阵。每个被跟踪的点将被添加到这个矩阵中。不仅添加了确切的位置,还添加了围绕它的正方形(基于width)。这对于高分辨率图像特别有用,在这种图像中,宽度为一个像素的线条几乎看不见。
我们可以迭代df2并逐个添加每个点。但是我们通过首先对(x,y)进行分组并计算出现的次数来优化它。当相同的位置出现例如 7 次时,它仅被添加一次而不是 7 次。由于宽度的使用,仍然需要加法(第 8 行)而不是赋值。由于宽度的使用,相邻的位置会累加起来。
由于宽度增加的附加效应,使用频率高的路线会变亮。为了防止他们丢弃较少使用的路线,计数被最大化(第 11 行)为数据集中路线的数量。可以添加一个因子来优化最终结果(第 10 行)。
现在我们已经用每个<x,y> 的出现次数填充了数组,我们可以把它转换成一个色标。将这些值标准化后,将应用 matplotlib 色彩映射表。在这种情况下,使用’hot’色图,因为它在黑色背景下工作良好(从等于黑色的数组中的零开始)。
最后一步是使用 matplotlib 绘制图像:
origin=”lower”是必需的,因为图像的零点在左下角,但默认是左上角。我们努力的结果:

生成的热图(图片由作者提供)
这是我们自己的热图。可以通过添加高斯模糊来使图片看起来更友好。但是现在,我对结果很满意。
最终世界
我们已经看到从任何来源导入 GPX 文件是多么简单。根据这些数据,我们创建了一个热图来直观显示游览地点。通过给图像添加模糊或者甚至添加一张地图作为背景,改进是可能的(很多工作,但是值得)。
在下一篇文章中,我将向你展示如何计算指标,如行驶距离、速度和方位。
我希望你喜欢这篇文章。要获得更多灵感,请查看我的其他文章:
免责声明:本文包含的观点和看法仅归作者所有。
用 FastAPI 和 Heroku 创建一个隐私过滤器 Web 服务
如何使您的 PII 删除服务易于使用,增加使用率,从而提高隐私保护。

西蒙·马格 ( Unsplash )摄影
在我的上一篇文章中,我展示了如何构建一个 Python 类来过滤掉自由文本中的个人身份信息。在本文中,我们将使用 FastAPI 构建一个基于该类的 web 服务,并使其可用于 Heroku。
创建 API
用 FastAPI 创建一个 API 很简单,它使你能够为你的代码创建一个 REST API。首先,您需要安装 FastAPI,如果您想在本地运行它,还需要安装uvicon。Uvicorn 是一个轻量级、超快的异步 web 服务器实现。它将用于运行 FastAPI 服务器的本地副本。
现在,我们准备好了!
要运行 FastAPI 服务器,需要一个FastAPI-对象。可以使用方法标记添加该对象的终结点。一个简单的例子:
第 3 行创建了 FastAPI 对象,第 5 行添加了一个端点。端点的名称为“/过滤器”。当被调用时,它返回值“< PRIVATE >”。
要测试端点,需要一个 web 服务器。FastAPI 应用程序可以从命令行或 main 方法启动。使用最后一种方法,其工作方式如下:
PrivacyFilterAPI 是 python 源文件的名称,privacyFilterApp 是指在上一步中创建的 FastAPI 对象。运行 Python 脚本启动一个具有可用端点的 Uvicorn 服务器。Uvicorn 的 reload=True 参数允许在检测到源代码更改时重新加载应用程序。从编辑器中保存源代码足以在 Uvicorn 中重新加载应用程序,无需在代码更改后重启服务器。
在浏览器中打开http://127 . 0 . 0 . 1:8000/filter应该会得到 JSON 响应:
下一步是用文本 tot 过滤器向 API 添加一个参数。输入文本将作为 POST 请求的请求正文发送。使用 POST 是用参数调用 REST 服务的首选方式。参数作为请求体发送。定义请求体一个 Pydantic 模型。
通过从 Pydantic 扩展 BaseModel 来创建参数类。这个类保存一个变量,文本和方法的输入文本。方法签名被更改为 post(第 12 行),并有一个类型为参数的输入参数项。条目是一个 Python 字典,可以进行相应的访问。
最后,通过添加 PrivacyFilter 类,webservice 就完成了:
当 web 服务启动时, PrivacyFilter 类的一个实例被实例化和初始化。这个实例将用于每次调用过滤器方法。 /filter 端点返回包含原始文本和过滤文本的字典。
启动 web 服务后,文档可从 http://127.0.0.1:8000/docs 获得。这些 swagger 页面由 FastAPI 自动生成:

FastAPI 生成的 API 文档(图片由作者提供)
通过点击绿色的*/过滤器*部分,然后点击“试用”按钮,可以向 API 发送请求。这些参数在请求正文部分指定:

尝试 API(图片由作者提供)
按“执行”发送 post 请求并显示结果:

请求结果(图片由作者提供)
在响应中,原始文本和过滤后的文本都被返回。在这种情况下,我的名字被标记代替,标记表示一个名字(Naam 是荷兰语的名字)。这表明我们有一个隐私过滤器 API 的操作实现。
确保服务安全
通过 HTTP 发送隐私信息不是个好主意,所以我们需要将 REST API 升级到 HTTPS。为此,我们需要一个密钥文件和一个认证文件。我们可以用 openSSL 创建这些文件:
这会产生两个文件,一个包含密钥,另一个包含证书。确保通用名称与 API 将在生产中运行的 URL 相匹配。我们可以通过指定密钥和证书文件在 HTTPS 模式下启动 Uvicorn 服务器:
该服务现在在地址https://127 . 0 . 0 . 1:8000/filter上可用,并且请求由 SSL 保护。
在 Heroku 上运行服务
Heroku 是一个支持 Python(以及其他)的云平台。在虚拟化的 Linux 容器中部署您的应用程序是可能的。你可以一个月免费运行 500 个小时集装箱。30 分钟不活动后,容器进入睡眠状态。如果你的账户里有一个容器,它可以免费运行 67%的时间。
要在 Heroku 上运行 FastAPI 服务,需要两个文件。首先, requirements.txt 文件需要是最新的。该文件指定了所有必需的 python 库。Heroku 使用这个文件创建一个能够运行应用程序的 Python 环境。如果不存在,您可以按如下方式创建该文件:
该命令将捕获所有已安装的模块及其版本,并将这些信息写入 requirements.txt 文件。
Heroku 需要的第二个文件是部署配置文件,名为 Procfile (没有扩展名)。Heroku 使用该文件来确定启动应用程序时要执行的操作。
这个 Procfile 告诉 Heroku 启动一个 web 应用程序并启动 Uvicorn。Uvicorn 启动指定的 API 应用程序。应用程序被指定为类似于本地运行。注意,Heroku 需要主机指定一个端口来连接到 Uvicorn 服务器。
导航到heroku.com并创建一个免费账户。在此帐户中,创建一个应用程序:

Heroku 应用创建(作者截图)
为应用程序取一个易于识别的名称,然后单击“创建应用程序”按钮。不需要将其添加到管道中。
Heroku 将从 Github 获取应用程序,因此下一步是连接 Gihub。单击 connect 按钮,按照在线流程连接到 GitHub OAuth 接口。

将 Heroku 连接到 GitHub(作者截图)
当 Heroku 成功连接到 GitHub 时,可以将 GitHub 存储库连接到 Heroku 应用程序。在搜索字段中键入存储库名称的一部分,然后按“搜索”。从搜索结果中选择适当的存储库。

连接 GitHub 库(作者截图)
当存储库连接成功时,可以在 Heroku 上部署一个分支。向下滚动到“手动部署”,选择正确的分支并点击“部署分支”按钮。

在 Heroku 上部署分支(作者截图)
这将启动构建过程,根据需求文件创建 Python 环境。第一次这将花费一些时间,但是连续的构建将使用缓存的环境(直到需求改变)。
检查应用程序日志(右上角的“更多”按钮)并等待构建成功的消息。该应用程序现已在 https://privacyfilter.herokuapp.com/发布。我们现在可以使用/docs 入口点在本地实例上运行相同的 API 测试。
恭喜你,你有一个隐私过滤器启动并运行!
请注意,Heroku 的免费版本仅限于 500MB 的容器。运行完整的隐私过滤器需要更多的空间,因此需要从 Heroku 订阅爱好。为了能够在免费版本中运行,我从过滤器中删除了街道名称,因为它们占用了大部分空间。
这个项目的所有源代码都可以在 GitHub 上找到: PrivacyFilter 。
我希望你喜欢这篇文章。要获得灵感,请查看我的其他文章:
- 用 Python 删除文本中的个人信息
- 用 Python 实现并行 web 请求
- 所有公共交通工具都通向乌得勒支,而不是罗马
- 使用开放数据和开普勒可视化荷兰火车的拥挤程度
- 使用 OTP 和 QGIS 可视化行程时间
免责声明:本文包含的观点和看法仅归作者所有。
创建量子贝叶斯网络
实用指南
本帖是本书的一部分: 用 Python 动手做量子机器学习 。
贝叶斯网络是对不确定领域的知识进行建模的概率模型。例如泰坦尼克号上一名乘客的生还。
贝叶斯网络建立在与朴素贝叶斯分类器相同的直觉上。但是与朴素贝叶斯相比,贝叶斯网络并不局限于只表示独立的特征。它们允许我们包含尽可能多的在当前环境下看起来合理的相互依赖。
贝叶斯网络被表示为具有节点和边的有向无环图。

作者弗兰克·齐克特的图片
这些节点代表随机变量,如乘客的性别或他/她是否是个孩子。
边缘对应于一个变量对另一个变量的直接影响。换句话说,边定义了两个变量之间的关系。箭头的方向也很重要。连接到箭头尾部的节点是父节点。连接到头部的节点是子节点。子节点依赖于父节点。
我们使用离散变量的条件概率表(CPT)和连续变量的条件概率分布(CPD)来量化这种依赖性。
下表描述了给定乘客性别(Sex)的后验生存概率。

女性乘客比男性乘客有更好的生存机会。
虽然只有两种性别(在我们的数据集中),但有许多不同年龄的乘客。从技术上讲,作为一个离散变量,将年龄建模为一个连续变量似乎更合适。下图描述了给定乘客的Age后验生存概率的 CPD。

作者弗兰克·齐克特的图片
乍一看,似乎乘客的年龄对生还的机会没有明显的影响。更糟糕的是,在随后的几个年龄段中,存活的几率相差很大。例如,一名 47 岁的乘客有 0.1 的生存机会,而一名 48 岁的乘客有 0.6 的生存机会。

这种变化似乎不合理。
相反,如果我们考虑作为一个孩子的特点(isChild)而不是一个乘客的Age。8 岁或以下的儿童比成人有更大的生存机会。

让我们考虑具有三个节点的贝叶斯网络。变量Sex和 a Child表示父节点。这些节点本身没有父节点。它们是根节点。他们的 CPT 以一组空的变量为条件。因此,它们等于边际(或先验)概率。注意,这些不是存活的概率,而是各自特征出现的概率。
Survival泰坦尼克号沉船的子节点。此 CPT 取决于父节点的值,如下图所示。

作者弗兰克·齐克特的图片
给定这样一组 CPT,我们可以计算生存的边际概率。
由于节点Sex和isChild之间的独立性(它们的值是独立的,因为我们没有建模任何依赖性,但是它们对Survival的影响不是独立的),乘客具有某个Sex和isChild的联合概率可以计算为 p(sex,ischild)=p(sex)⋅p(ischild).
因此,给定某个Sex和isChild的生存条件概率是 p(survival)=p(survival|sex,ischild)⋅p(sex)⋅p(ischild).
首先,贝叶斯网络是一种数据结构。首先,它代表了条件独立性假设的集合。没有通过边连接的任何两个节点都被认为是相互独立的。第二,贝叶斯网络以紧凑和分解的方式包含概率表和分布。
这种数据结构使我们能够推断人口的特性。贝叶斯网络支持正向和反向推理。例如,我们可以通过对子节点的分布进行积分来计算总的生存机会(正向推理)。并且,给定关于乘客生存的知识,我们可以推断出某些特征在多大程度上促成了他或她的生存。例如,如果我们查看子节点的图表,我们可以看到乘客的性别非常重要,除非乘客是孩子。按照妇孺优先的标准,他们并没有重男轻女。Sex和isChild之间的这种相互依赖性不能包含在朴素贝叶斯分类器中。
这种数据结构,贝叶斯网络图,可以用两种不同的方法创建。给定依赖关系的足够知识,它可以由开发者预先设计。或者,也可以由机器自己学习。
在我们通往量子机器学习的道路上,我们将双管齐下。我们从一个我们自己建模的小型量子贝叶斯网络(QBN)开始。然后,我们让机器从数据中学习。
电路实现
我们从目前为止我们的例子的实现开始,一个乘客的Sex和作为一个孩子的isChild对泰坦尼克号沉船的Survival的影响。
贝叶斯网络中的每个节点都由一个量子位表示。因为我们所有的节点都是二进制的(Sex、isChild、Survival),每个节点一个量子位就足够了。如果我们有更多的离散态或连续分布,我们将需要更多的量子位。量子位状态代表相应变量的边际(对于根节点)和条件(对于Survival节点)概率幅度。
|0⟩代表男性乘客或成年人。|1⟩是女性还是儿童。量子位的叠加表示任一状态的概率

我们通过绕 Y 轴旋转来初始化这两个量子位。
我们计算成为孩子(第 21 行)和女性(第 25 行)的概率。我们使用 RY 门让量子位 q0(第 31 行)和 q1(第 34 行)代表这些边际概率。
接下来,我们将Survial的 CPT 添加到电路中。这是一个多一点的工作。
父节点值有四种不同的组合,Sex和isChild。他们是,一个成年男性(|00⟩),一个男孩(|01⟩),一个成年女性(|10⟩)和一个女孩(|11⟩).)因此,我们有四个旋转角度,每个父节点组合一个。
对于这些组合中的每一个,我们使用一个受控的 RYRY-gate (CCRY)来指定Survival的概率。如果有 n 个父节点,那么我们将实现一个 CnRY-gate。
如下图所示,我们将每个旋转封装到 X-gate 中。对于一个 CCRY-gate 来说,如果两个控制量子位都处于|1⟩状态,则只对控制量子位应用旋转,领先的 x-gate 选择相应的组合,而尾随的 x-gate 反转该选择。
例如,要应用一个成年男性(|00⟩)的条件概率,我们需要翻转两个量子位。这就是我们的工作。在应用具有相应角度的 CCRY-gate 后,我们将量子位翻转回初始状态。

作者弗兰克·齐克特的图片
在 Qiskit,没有 CCRY-gate。但是我们在这篇文章中学习了如何创建一个。函数ccry(第 1-6 行)为我们的电路增加了这样一个门。
在下面的代码中,我们计算了四种情况下的条件概率。我们分离人群,例如,女性儿童(第 3 行),分离其中的幸存者(第 4 行),用幸存者人数除以乘客中女性儿童总数(第 5 行)计算他们的生存概率。
我们对女性成人(第 8-10 行)、男性儿童(第 13-16 行)和男性成人(第 19-21 行)也是如此。
接下来,我们选择代表这些乘客组的状态,并以相应的概率应用 CCRY-gate。
我们现在准备运行电路。让我们看一看。

作者弗兰克·齐克特的图片
我们可以看到八种不同的状态。这些属于四个组的受害者(量子位 q2=0)和幸存者(q2=1)。因此,幸存的总边际概率是量子位 q2=1 的所有状态的总和。
为了避免手动添加,让我们在电路中加入一个测量值。我们在电路中加入了一个ClassicalRegister。
然后,我们需要应用所有的门(为简洁起见,跳过)。我们添加一个度量(第 3 行)。这里,我们对量子位 q2q2 感兴趣。
最后,我们选择合适的后端(qasm_simulator)并运行电路几次(这里是 1000 次)(第 9 行)。
结果显示我们接近 0.38 的实际生存概率。实际结果略有不同,因为我们没有计算,而是根据经验模拟这一结果。

作者弗兰克·齐克特的图片
结论
对于一组二进制状态变量,量子贝叶斯网络的实现是直接的,因为我们可以用单个量子位来表示每个变量。即使我们有两个以上状态的变量,结构也不会改变。我们仍然会通过 X 门激活每个状态,并应用相应的受控旋转。但是,我们将不得不应付更多的州。
本帖是本书的一部分: 动手用 Python 学习量子机器 。

免费获取前三章这里。
创建重复测量的雨云
用 R 可视化组间差异的有效方法

雨云图
Raincloud 图将抖动的数据点与半小提琴和箱形图结合起来,给出了给定数据集的综合图。在的上一篇文章中,我介绍了使用 python 绘制雨云图。多亏了 Jordy van Langen 和他的同事们的工作,雨云图在 r。
R 中的 jorvlan raincloudplots 包展示了一种创建分组和重复测量数据的简单可视化的方法。此外,它提供了独立链接的重复测量可视化,这为许多主题间/主题内设计添加了细节和丰富性。下面,我们探索创建一个类似蝴蝶外观的 2 x 2 (2 个条件,2 组)重复测量图。
在此阅读有关 jorvlan/raincloudplots 知识库的更多信息:
https://github.com/jorvlan/raincloudplots
关于雨云地块的进一步阅读,请查看原始出版物:
https://wellcomeopenresearch.org/articles/4-63
装置
从 jorvlan 的存储库中安装 raincloudplots 包。
if (!require(remotes)) {
install.packages("remotes")
}
remotes::install_github('jorvlan/raincloudplots')
library(raincloudplots)
输入数据
本教程使用代表两种不同运动类型(内旋、外旋)的两种不同临床测试(进行、断开)的数据集,使我们的数据集成为 2x2 设计。通断测试通常由康复从业者进行,例如物理治疗师或运动训练师。在进行测试期间,患者施加力量对抗医师的手的阻力。在断裂测试期间,医师对患者的前臂施力。两项测试都评估了肩关节的内旋和外旋。力(磅 lbs)由专业人员用手持设备测量。
以下数据集展示了作者创建的示例数据,并不代表真实的患者数据。
df_2x2 <- read.csv(file = 'make_break.csv')

示例数据—由作者创建
- 每个患者的力(磅)列在 y 轴栏中
- 组分配列在 x 轴上
- 参与者分配列在 id 列中
- 一致性列在“组”列中
- jit 列中列出了抖动值
创造情节
绘制重复测量雨云。
raincloud_2x2 <- raincloud_2x2_repmes(
data = df_2x2,
colors = (c('dodgerblue', 'azure4', 'dodgerblue', 'azure4')),
fills = (c('dodgerblue', 'azure4', 'dodgerblue', 'azure4')),
size = 1,
alpha = .6,
spread_x_ticks = FALSE) +scale_x_continuous(breaks=c(1,2), labels=c("Make", "Break"), limits=c(0, 3)) +
ylab("Pounds of Force (lbs)") +
theme_classic()raincloud_2x2

蝴蝶般的雨云情节——作者创作
data_2x2创建 2 x 2 重复测量雨云所需的长格式数据帧colordodgerblue 和 azure4 区分群——内旋(IR)和外旋(ER)labels连接两个组标签的字符串——接通和断开spread_x_ticks2 个 x 轴刻度为假-同时显示两组
结论
本文概述了如何使用 jorvlan/raincloudplots 存储库来创建链接的重复测量可视化。如果你有兴趣了解更多用 R 创建 raincloud plots 的方法,请查看 JOR VLAN/rain cloud plotsgithub页面(也在上面列出)。
感谢您的阅读!
作者的相关文章—
使用 Neo4j 从节点属性创建相似性图
本文的原始版本和附带的视频使用的 Neo4j 沙盒版本已经过时。我已经更新了代码,以使用 GDS 2.0.1 和 Neo4j 沙盒的版本,该版本是 2022 年 7 月的版本。
聚类分析帮助我们发现隐藏在数据中的结构。我们可以使用无监督的机器学习算法将数据项分组到聚类中,以便项与其聚类内的其他项比与其聚类外的项有更多的共同点。
当我们将数据集组织成相似项目的子集时,诸如客户细分、推荐和异常检测等任务变得更加容易。
相似度 的概念是聚类分析的核心。Neo4j Graph 数据科学库为我们提供了工具,用于根据节点的属性 发现数据集中节点之间的相似性,即使我们的数据 中不存在预先存在的关系。
然后布鲁姆图可视化应用允许用户以一种可访问的、可解释的方式交互地探索相似性。这可以帮助无监督的机器学习远离黑盒魔法的领域,成为商业用户使用的直观工具。图形数据科学库随后允许我们基于相似性关系找到密切相关的节点集群。
对于这个例子,我使用了美国人口普查局提供的 2019 年美国社区调查五年估计值中关于大都市统计区域 (MSAs)的 数据。
我选择了四个人口统计特征来描述每个 MSA:
- 人口,
- 中等家庭收入,
- 房价中位数,以及
- 25 岁以上拥有学士学位的人口比例。
在本教程中,我们将使用相似性算法根据四个人口统计特征来识别相似的 MSA 对。然后,我们将使用相似性关系来识别 MSA 的聚类。

麦肯齐·韦伯在 Unsplash 上的照片
你可以和我一起创建一个免费的 Neo4j 沙箱。选择创建“空白沙盒—图形数据科学”,因为我们会加载自己的数据。然后点击“打开”按钮,启动 Neo4j 浏览器开始使用。
在加载数据之前,我们将为 MSA 的名称创建一个唯一的约束。
CREATE CONSTRAINT msa_name ON (m:MSA) ASSERT m.name IS UNIQUE
使用此命令从 GitHub 上的 CSV 文件加载 MSA 数据。
LOAD CSV WITH HEADERS FROM "[https://raw.githubusercontent.com/smithna/datasets/main/CensusDemographicsByMetroArea.csv](https://raw.githubusercontent.com/smithna/datasets/main/CensusDemographicsByMetroArea.csv)" AS rowWITH row WHERE row.name CONTAINS 'Metro'MERGE (m:MSA {name:row.name})
SET m.population = toInteger(row.population),
m.medianHouseholdIncome = toInteger(row.medianHouseholdIncome),
m.medianHomePrice = toInteger(row.medianHomePrice),
m.percentOver25WithBachelors = toFloat(row.percentOver25WithBachelors)
RETURN m
注意,LOAD CSV实用程序将每个字段视为一个字符串,所以我们使用toInteger()和toFloat()函数将数值转换为适当的数据类型。运行该命令后,您应该看到已经创建了 MSA 节点。

代表大都市地区的节点。图片作者。
与大多数 Neo4j 项目不同,我们在开始时没有任何关系要加载。相反,我们将使用图形数据科学库来发现相似的节点,并在它们之间创建关系。
我们将根据 欧氏距离 来定义相似度。欧几里德距离公式是勾股定理的延伸,勾股定理说的是直角三角形斜边长度的平方等于其他两条边的平方之和。

勾股定理。图片作者。
在我们的例子中,我们是沿着四个维度而不是两个维度比较 MSA,但是概念是相似的。两个 MSA 之间的欧几里德距离是每个人口统计指标的平方差总和的平方根。

欧几里德距离公式
在计算距离之前,我们希望四个属性从最小值到最大值的范围大致相同。如果范围差异大,则范围大的属性将主导距离计算;范围较小的属性几乎不会影响距离计算。所以我们需要把它们都归一化到相同的范围。
运行这个查询来查看我们加载的四个属性的值的范围。
MATCH (n)
WITH n,
["population", "medianHouseholdIncome", "medianHomePrice", "percentOver25WithBachelors" ] AS metrics
UNWIND metrics as metric
WITH metric, n[metric] AS value
RETURN metric, min(value) AS minValue,
percentileCont(value, 0.25) AS percentile25,
percentileCont(value, 0.50) AS percentile50,
percentileCont(value, 0.75) AS percentile75,
max(value) AS maxValue

显示每个属性的值范围的表。图片作者。
人口范围从 54,773 人到 19,294,236 人。这与 25 岁以上拥有大学学位的人的百分比范围(从 12.9%到 67.4%)有着巨大的差异。
我们还可以看到,第 50 和第 75 百分位人口(336,612 名公民)之间的差异要比第 25 和第 50 百分位人口(94,771.25 名公民)之间的差异大得多。我下载了数据,并用标准刻度和对数刻度绘制了直方图,以检查分布情况。

单位和对数标度的度量直方图。图片作者。
如果我们应用对数变换,我们所有的指标看起来更接近正态分布。当我考虑到在一个拥有 60,000 人口的 MSA 中增加 10,000 名居民会对都会区的特征产生很大的改变,但是在一个拥有 1,900 万人口的 MSA 中增加 10,000 名居民产生的影响要小得多时,这在直觉层面上对我来说是有意义的。另一方面,在任何规模的 MSA 中,10%的人口变化都是显而易见的。
运行以下命令,将对数变换应用于人口、中值房价和 25 岁以上拥有学士学位的人口百分比。
MATCH (m:MSA)
SET
m.logPopulation = log(m.population),
m.logMedianHouseholdIncome = log(m.medianHouseholdIncome),
m.logMedianHomePrice = log(m.medianHomePrice),
m.logPercentOver25WithBachelors = log(m.percentOver25WithBachelors)
t he 图形数据科学库中的MinMax缩放器将应用下面的公式来 重新缩放每个属性值 。最小值设置为 0,最大值设置为 1,所有其他值根据它们在原始数据集中的位置成比例地落在 0 和 1 之间。

最小最大标量公式
我们将创建一个名为“metro-graph”的 内存图 来一次有效地在所有节点上执行缩放计算。我们将把标签为MSA的所有节点加载到内存图中。由于我们的图中还没有任何关系,我们将使用一个*通配符作为占位符。
CALL gds.graph.project('msa-graph',
'MSA',
'*',
{nodeProperties:["logPopulation", "logMedianHouseholdIncome", "logMedianHomePrice", "logPercentOver25WithBachelors"]})
运行下面的命令,在内存图中创建一个名为scaledProperties的新属性。新的属性将是一个由四个值组成的 vector (有序列表):population、medianHouseholdIncome、medianHomePrice、percentOver25WithBachelors。在将属性添加到 vector 之前,将对每个属性应用MinMax缩放器,以便所有值都在范围[0,1]内。
CALL gds.alpha.scaleProperties.mutate('msa-graph',
{nodeProperties: ["logPopulation", "logMedianHouseholdIncome", "logMedianHomePrice", "logPercentOver25WithBachelors"],
scaler:"MinMax",
mutateProperty: "scaledProperties"})
YIELD nodePropertiesWritten
我们可以使用刚刚创建的scaledProperties来计算节点之间的距离。欧几里德距离公式告诉我们在四维空间中MSA 相距多远。距离值越高,两个 MSA 越不相似。我们对 MSA 之间的相似性感兴趣,所以我们将使用一种将距离转换为相似性的算法。

欧几里德相似公式
属性similarity的值越高,两个 MSA 越相似。
K-Nearest Neighbors 算法将根据欧几里德相似性公式在我们的图中创建从每个节点到其最近邻居的关系。topK参数告诉算法创建从每个节点到其最近的 15 个邻居的关系IS_SIMILAR。在 write 模式下运行算法之前,让我们在 stats 模式下运行它,并检查相似性得分的分布。
*CALL gds.knn.stats("msa-graph",
{
nodeProperties:{scaledProperties:"EUCLIDEAN"},
topK:15,
sampleRate:1,
randomSeed:42,
concurrency:1
}
) YIELD similarityDistribution
RETURN similarityDistribution-----------------------------------{
"p1": 0.8350143432617188,
"max": 0.9999847412109375,
"p5": 0.9390525817871094,
"p90": 0.996307373046875,
"p50": 0.9895782470703125,
"p95": 0.9975738525390625,
"p10": 0.9621849060058594,
"p75": 0.9938201904296875,
"p99": 0.998992919921875,
"p25": 0.9813117980957031,
"p100": 0.9999847412109375,
"min": 0.77587890625,
"mean": 0.9814872709261316,
"stdDev": 0.027092271447973864
}*
我们可以看到,99%的关系相似度得分在 0.835 以上,最小相似度在 0.776 左右。当我们用相似性关系更新内存中的图时,我们将使用similarityThreshold 参数来排除相似性分数在倒数 1%的关系。
*CALL gds.knn.mutate("msa-graph",
{nodeProperties: {scaledProperties: "EUCLIDEAN"},
topK: 15,
mutateRelationshipType: "IS_SIMILAR",
mutateProperty: "similarity",
similarityCutoff: 0.8350143432617188,
sampleRate:1,
randomSeed:42,
concurrency:1}
)*
在 mutate 模式下运行 KNN 在内存图形投影中创建了IS_SIMILAR关系。现在将它们写到 Neo4j 图中,这样就可以用 Cypher 查询它们,并在 Bloom 中可视化。
*CALL gds.graph.writeRelationship(
"msa-graph",
"IS_SIMILAR",
"similarity"
)*
让我们给IS_SIMILAR关系添加一个rank属性,这样我们就可以过滤每个节点排名靠前的关系。
*MATCH (m:MSA)-[s:IS_SIMILAR]->()
WITH m, s ORDER BY s.similarity DESC
WITH m, collect(s) as similarities, range(0, 11) AS ranks
UNWIND ranks AS rank
WITH rank, similarities[rank] AS rel
SET rel.rank = rank + 1*
现在让我们看看 Bloom graph 可视化应用程序中的图表。返回 Neo4j 沙盒主页,选择“打开 Bloom”

启动 Bloom。图片作者。
使用您的沙盒凭据登录。因为这是我们第一次使用 Bloom 处理这个数据集,所以点击“创建透视图”然后,单击“生成透视图”让 Bloom 为您设置一个透视图。最后,点击你新生成的视角进入绽放场景。

单击“使用视角”以使用您的新 Bloom 视角。图片作者。
让我们配置“IS_SIMILAR”关系的显示,以便线宽对应于节点的相似性。单击屏幕右侧面板上的“关系”,然后单击“IS_SIMILAR”关系旁边的线条。

单击 IS_SIMILAR 旁边的行。图片作者。
在出现的弹出菜单中,选取“基于规则”然后,单击加号添加新的基于规则的样式。
从属性键下拉列表中选择“相似性”。选择“范围”的单选按钮单击“大小”按钮创建一条控制线宽的规则。切换按钮以应用大小规则。
在最小点框中,输入 0.83 并将最小大小设置为 0.25 倍。在最大点框中,输入 1 并将最大大小设置为 4 倍。您的配置应该如下图所示。

基于规则的样式配置。作者图片
现在,让我们使用 Bloom 来搜索 MSA 及其最接近的对等体。如果你开始在 Bloom 搜索框中键入“纽约”,Bloom 的自动完成应该会建议“纽约-纽瓦克-泽西城,NY-NJ-PA 都会区。”按 tab 键接受建议。一旦你有了纽约 MSA 的一个节点,Bloom 会自动建议涉及该节点的模式。选择从具有 IS_SIMILAR 关系的纽约节点扩展的模式,然后按 enter 键。

Bloom 搜索框。图片作者。
Bloom 将返回一个可视化结果,显示纽约 MSA 及其 15 个最相似的 MSA,基于我们使用的四个人口统计指标。

与纽约最相似的管理服务协议。图片作者。
基于出站箭头的粗细,我们可以看到洛杉矶是与纽约最相似的 MSA。
我们可能会惊讶地发现,有往来于纽约和洛杉矶、圣地亚哥、波士顿、华盛顿和西雅图的关系,但没有可视化中的其他城市。我们告诉欧几里德距离算法为每个节点的前 15 个最近的 MSA创建关系。如果我列出离纽约最近的 15 个 MSA,亚特兰大包括在内。然而,如果我列出离亚特兰大最近的 12 个 MSA,纽约没有入选。这就是为什么有从纽约到亚特兰大的关系,但没有从亚特兰大到纽约的关系。**
让我们过滤显示内容,查看与纽约最相似的前 5 个城市。单击 Bloom 屏幕左侧的漏斗图标以展开过滤器面板。在下拉列表中选择 IS_SIMILAR。选择“等级”属性。选择“小于或等于”条件,并将值设置为 5。切换“应用过滤器”以突出显示纽约的前 5 个最强相似性关系。

过滤关系。作者图片
我们研究了单个 MSA 的邻居。现在让我们来看一下全局。右键单击 Bloom 画布并从上下文菜单中选择“清除场景”。在搜索框中,输入“MSA”并按 tab 键。选择(MSA)-IS_SIMILAR-()模式,然后按 enter 键。我们会看到完整的 MSA 图。

完整的 MSA 相似图。图片作者。
再次打开过滤器面板。为大于或等于 0.96 的“相似性”在 IS_SIMILAR 关系上创建新过滤器。切换“应用过滤器”,然后单击面板底部的“消除过滤的元素”按钮。我们开始看到一些岛屿和半岛从主节点群中分化出来。有三个离群节点,其中它们的 15 个最相似的邻居没有一个具有大于 0.96 的相似性。我们将使用社区检测算法进一步探索图的结构。

过滤 MSA 相似图。作者图片
返回 Neo4j 浏览器,运行以下命令进行社区检测。我们将针对内存中的图形执行 Louvain 社区检测算法,并将社区 id 写回到主 Neo4j 图形中。我们告诉算法使用similarity属性来加权节点之间的关系。通过将consecutiveIds参数设置为 true,我们告诉算法我们希望生成的communityId属性的值是连续的整数。
*CALL gds.louvain.write('msa-graph',{relationshipTypes: ["IS_SIMILAR"],
relationshipWeightProperty:"similarity",
writeProperty:"communityId"})YIELD communityCount, modularities
RETURN communityCount, modularities*

社区检测结果。图片作者。
输出显示我们检测到了 6 个社区。算法的连续迭代将社区分区的模块性从 0.625 增加到 0.667。
运行下面的查询来收集关于我们定义的社区的汇总统计信息。除了统计数据之外,我们还通过列出每个社区中与同一社区中的其他 MSA 具有最高相似性的三个 MSA 来添加上下文。这些管理服务协议应该是其社区的典型范例,而其他管理服务协议的社区内关系可能更少或更弱。
*MATCH (m:MSA)
WITH m
ORDER BY apoc.coll.sum([(m)-[s:IS_SIMILAR]->(m2)
WHERE m.communityId = m2.communityId | s.similarity]) desc
RETURN m.communityId as communityId,
count(m) as msaCount,
avg(m.population) as avgPopulation,
avg(m.medianHomePrice) as avgHomePrice,
avg(m.medianHouseholdIncome) as avgIncome,
avg(m.percentOver25WithBachelors) as avgPctBachelors,
collect(m.name)[..3] as exampleMSAs
ORDER BY avgPopulation DESC*

汇总社区功能的表格。图片作者。
knn 和 Louvain 算法是 id 81 社区中 MSAs 人口最多的社区,平均人口接近 200 万。社区 54 也有很高的 MSA 人口,但是收入和房价低于社区 81。社区 234 和 330 非常相似,但 234 人口更多,330 房价更高。与人口规模相似的社区相比,社区 75 拥有受过高等教育的公民。社区 264 有少量的 MSA。385 社区有低收入管理事务协议。
让我们给社区起一个比自动生成的 id 更人性化的名字。
*MATCH (m:MSA)
SET m.communityName = CASE m.communityId
WHEN 54 THEN "Large mid-cost metros"
WHEN 75 THEN "College towns"
WHEN 81 THEN "Large high-cost metros"
WHEN 234 THEN "Mid-size metros"
WHEN 264 THEN "Small metros"
WHEN 330 THEN "Mid-price metros"
WHEN 385 THEN "Low-income metros"
END
return m.communityName, m.communityId, count(*)*
要使 communityName 属性在 Bloom 中可搜索,请在该属性上创建一个索引。
*CREATE INDEX msa_community_name IF NOT EXISTS
FOR (m:MSA)
ON (m.communityName)*
让我们来看看 Bloom 中的结果。我们将配置透视图以反映我们添加的新社区。单击屏幕左上角的图标打开透视图面板。然后,单击数据库图标来刷新透视图,以包含我们添加到数据库中的新的communityName属性。

刷新 Bloom 透视图以在数据库中包含新属性。图片作者。
在屏幕右侧的面板中,单击 MSA 旁边的圆圈来设置 MSA 节点的样式。在出现的弹出菜单中,选取“基于规则”然后,单击加号添加新的基于规则的样式。从属性键下拉列表中选择“communityName”。选择“唯一值”的单选按钮切换按钮以应用颜色规则。

communityName 的基于规则的样式配置。图片作者。
让我们添加第二个条件样式来根据人口设置节点的大小。单击加号添加新的基于规则的样式规则。
从属性键下拉列表中选择“人口”。选择“范围”的单选按钮单击“大小”按钮创建控制节点大小的规则。切换按钮以应用大小规则。
在“最小点”框中,输入 55000 并将最小大小设置为 1x。在 Maxpoint 框中,输入 19000000,并将最大大小设置为 4x。您的配置应该如下图所示。

基于规则的群体样式。图片作者。
现在右键单击并从上下文菜单中选择“清除场景”。在搜索框中,键入“大学城”,然后按 enter 键。返回的结果包括州立大学、PA Metro、Ithaca、NY Metro、Champaign-Urbana、IL Metro 和 Charlottesville、VA Metro。这些大都市区是宾夕法尼亚州立大学、康奈尔大学、伊利诺伊大学和弗吉尼亚大学的所在地。根据我们对这些大都市地区的了解,该算法似乎已经发现了一些明显的共性。

一些 MSA 通过搜索“大学城”返回。图片作者。
我们来看看还有哪些大都市和大学城最相似。点按 Command-A 以选择所有节点。然后右键单击其中一个节点,并从上下文菜单中选择 Expand:

最像大学城的城市。图片作者。
当我缩小时,我可以看到我们添加了几个大型地铁区域(紫色)、中型地铁区域(橙色)、小型中等收入区域(青色)和一个中型高成本地铁区域(红色)。双击节点或放大以查看节点详细信息。我们增加的几个 MSA,如麦迪逊、威斯康星大都会区和北卡罗莱纳州的达勒姆-查佩尔山恰好是主要大学的所在地。
使用该数据集进行实验,以进一步探索相似性图表。运行gds.alpha.similarity.euclidean时,通过减少topK参数或设置similarityThreshold参数来减少相似性关系的数量,将会在运行gds.louvain时产生更多的社区。运行gds.alpha.scaleProperties时,尝试除MinMax之外的缩放器。
图形数据科学库支持其他几种相似度算法。K-最近邻算法提供了一种基于余弦相似度生成链接的有效方法。
Louvain 社区检测是几个社区检测算法中的一个选项。通过运行标签传播算法,查看您的结果有何不同。
GitHub 上的数据 CSV 除了大都市统计区域外,还包括小城市统计区域。从LOAD CSV脚本中移除WHERE row.name INCLUDES 'Metro'来加载这些节点并探索它们的属性。
您会发现图实际上无处不在*,即使一开始关系在数据模型中并不明显。*
意甲(足球)——带有 Plotly 和 Dash 的简单仪表盘
自从上次我使用意甲数据并用 Plotly 创建了一些图表(通过下面的链接查看文章),我想我应该更进一步,尝试创建一个仪表板,这样我就可以在一个页面上显示所有有趣的图表——这就是今天更新的开始。

先决条件:
类似前面文章提到的步骤,玩数据前的第一件和两件事是:获取数据和清理数据。
当前项目使用的数据来自 Kaggle,提供 Massimo Belloni 。https://www.kaggle.com/massibelloni/serie-a-19932017
运行几行代码来组合来自不同 csv 文件的所有数据:
# Import the packages for data cleaning:
import pandas as pd
import glob
import numpy as np# Setup the file path & get all files
path = r'....\SerieA'
all_files = glob.glob(path + "/*.csv")table = []for filename in all_files:
data = pd.read_csv(filename, index_col=None, header=0)
table.append(data)frame = pd.concat(table, axis=0, ignore_index=True)#Only use the first eight columns
df = frame.iloc[:,0:7]
我还为接下来的可视化添加了几列:
# Identify the winner:
df['Winner'] = np.where(df['FTR'] == 'H',df['HomeTeam'],
np.where(df['FTR'] == 'A', df['AwayTeam'], "Draw"))# Identify if the winner is home team or away team:
df['Result'] = np.where(df['FTR'] == 'H','HomeTeamWin',
np.where(df['FTR'] == 'A', 'AwayTeamWin', "Draw"))# The year of the match:
df['Year']=pd.DatetimeIndex(df['Date']).year
我将清理后的数据保存到文件夹中,这样我下次就可以轻松地使用它,而不用再次运行上面的代码:
df.to_csv('seriearaw.csv')
准备好图表:
对于这个控制面板,我希望有四个图表—两个饼图、一个树状图和一个折线图。
# get the right package:
import plotly.express as pxchart1 = px.pie(df, values =df.groupby('Result')['Result'].count(),
title='Serie A - results from 1993 - 2017',
height = 500)
chart1.update(layout=dict(title=dict(x=0.5)))

图 1
chart2 = px.pie(df, values = df.groupby('Winner')['Winner'].count(),title = "Serie A Result from 1993 - 2017 - Most Win Team", height = 500)chart2.update(layout=dict(title=dict(x=0.5)))
chart2.update_traces(textposition='inside', textinfo='percent')

图 2
chart3 = px.treemap(df, path=['Winner'], values = 'TotalGoal',height = 500, title = "Serie A Result from 1993 - 2017 - Most Win Team")chart3.update(layout=dict(title=dict(x=0.5)))
chart3.update_traces(textinfo = 'label + value')

图 3
# Create a different dataframe for chart4:
total_goal =df.groupby('Year')['TotalGoal'].agg('sum').reset_index(name ='Sum')
total_goal = total_goal[(total_goal.Year != 2017) & (total_goal.Year != 1993)]chart4 = px.line(data_frame = total_goal, x ='Year', y = 'Sum', title = 'Total Goals by Year',
line_shape = 'spline',height=500)
chart4.update(layout=dict(title=dict(x=0.5)))
chart4

图 4
设置仪表板:
包:构建仪表板需要三个包:
import dash# html is used to set up the layout, and dcc is used to embed the graphs to the dashboard:
import dash_core_components as dcc
import dash_html_components as html
样式:当前仪表板采用了外部表的样式。我的理解是,你非常欢迎创造自己的风格,但为了使起点更容易,有一些模板可用。
# Setup the style from the link:
external_stylesheets = ['https://codepen.io/chriddyp/pen/bWLwgP.css']# Embed the style to the dashabord:
app = dash.Dash(__name__, external_stylesheets=external_stylesheets)
嵌入图表:为了将我们刚刚创建的四个图表嵌入 dash,我们使用 dash_core_components 包。我们还在这里设置了这些图表的布局。
请不要在这里使用“ className ”,它用于定义图表看起来有多大。想象一下,一个仪表板页面可以平均分为 12 列,如果一个图形等于“四列”,这意味着该图形将是仪表板的三分之一(4/12)宽。在下面的代码中,我们用 graph 1–3 表示 4 列,用 graph4 表示 12 列。猜猜仪表盘长什么样?
graph1 = dcc.Graph(
id='graph1',
figure=chart1,
className="four columns"
)graph2 = dcc.Graph(
id='graph2',
figure=chart2,
className="four columns"
)graph3 = dcc.Graph(
id='graph3',
figure=chart3,
className="four columns"
)graph4 = dcc.Graph(
id='graph4',
figure=chart4,
className="twelve columns"
)
定义每个图表的样式后,我们定义这些图表在仪表板中的位置。从上面的代码中,您可能会发现,我们将把 graph1、2 和 3 放在一行,而把 graph4 放在另一行:
# setup the header
header = html.H2(children="SerieA Dataset Analysis")# setup to rows, graph 1-3 in the first row, and graph4 in the second:
row1 = html.Div(children=[graph1, graph2, graph3],)
row2 = html.Div(children=[graph4])# setup & apply the layout
layout = html.Div(children=[header, row1, row2], style={"text-align": "center"})
app.layout = layout
酷,我们已经创建了图表并设置了仪表板布局,最后一步是运行应用程序,看看您的仪表板看起来如何:
if __name__ == "__main__":
app.run_server()
请注意,我在这个项目中使用的是 jupyter notebook,这些代码可以很好地使用它。当我在看其他一些文章时,他们用“app.run_serviver(debug = True)”来运行仪表板,但这对我不起作用。
这就是这个简单仪表板的最终外观!玩得开心!

为你自己和你的伴侣或朋友创建一个 Spotify 播放列表
实践教程
使用 spotify 库创建一个版本的 Spotify Duo Mix

Spotify 提供阿朵订阅,附带一个名为 Duo Mix 的独特播放列表。这个播放列表是为两个用户准备的,结合了他们的音乐品味。
我女朋友和我都很想看看这个播放列表是关于什么的。我们开始听,但不知何故感觉有点不对劲。艺术家是“正确的”,但歌曲不是,播放列表几乎没有我们两人实际听过的歌曲。它也很难在不同风格之间转换,从一首冰冷的爵士歌曲变成了电子乐、说唱或金属核心(好吧,这可能对我来说也有点……)。我们不满意,也不再听播放列表中的每周更新。然而,我喜欢这个想法,并认为一定有一种方法来创建我们都希望的播放列表。
所以我决定自己创建一个播放列表,但不是手动的,因为我想每周更新。我首先想到使用机器学习和其他更复杂的方法,但后来我提醒自己,我有一个需要工作解决方案的问题。如果问题不需要,我们的目标不是尝试新的机器学习算法。
我的目标是:
- 包括一些我们最喜欢的歌曲以及我们最近都喜欢的歌曲
- 包括基于这些收藏夹的新歌
- 限制一位艺术家的歌曲数量
- 基于共同喜欢的音乐创造整体的聆听体验,而不仅仅是提供个人品味的混合
我最终得到了一个可行的解决方案,但没有使用机器学习和,它实际上只是一点数据争论,通过相似性度量对 Spotify 的推荐进行一些提炼,还有一点随机性。但它很有效,我们对目前的播放列表很满意,并将继续改进它,可能通过机器学习。如果有我们喜欢和不喜欢的歌曲的数据,一个训练有素的模型可以改善一切。
准备创建播放列表
获取数据
我开始使用我已经创建的 Spotify 应用程序,并通过该应用程序验证我们的帐户。如果你不确定如何做这些事情,看看我之前的文章带你完成这个过程。
我首先为我们两个查询以下数据:
- 长期、中期和短期顶级艺术家
- 长期、中期和短期的顶部跟踪
- 和一些保存的用户曲目(最近 50 首)
我使用了下面的函数,它实际上只是组合了一堆查询并产生了三个数据帧。
请注意,我在这里调用我编写的函数,是为了将 Spotify API 查询结果转换成可用的数据框架。我不会在这里一一细说。一些在我关于 Spotify 的另一篇文章中(见上文)。你可以在 Github 上找到完整的代码(查看所有功能,请参阅 spotifuncs.py)。
第一个重要的数据是用户的所有热门曲目,我把它们合并成一个完整的热门曲目列表,涵盖了从短期到长期的所有热门曲目。请注意,我只从长期顶级曲目中抽取了 15 首歌曲,这样做而没有为设置随机种子,而不是在每次运行代码时得到相同的结果。在这个过程中,总是使用长期收藏的完整列表会导致在几周的时间里重复太多,从而导致播放列表的重复。
第二个重要的部分是顶级艺术家的数据,就像所有时间帧的曲目一样。艺术家对以后的过滤过程很重要。
最后,我还检索了用户保存的最新 50 首曲目。这里 50 是上限,这很不幸,因为这实际上限制了数据的使用。
上周播放列表
为了避免连续两周遇到相同的歌曲(这很可能是因为短期和中期的热门歌曲不会有太大变化),上周的播放列表是从“Playlist.csv”中读取的。这个文件只是一个空的。我第一次运行代码的时候。但是在播放列表创建过程结束时,新创建的播放列表会保存在其中。csv 文件,所以它包含上周的播放列表。我用了其中的数据。csv 文件,用于在该过程的各个阶段为新的播放列表过滤歌曲。
建立播放列表
创建播放列表需要几个步骤来“组装”组成它的所有构件。这些是:
- 上周播放列表中没有的常见热门曲目
- 每个用户与其他用户的顶级曲目最相似的顶级曲目的示例
- 每个用户都喜欢的艺术家(他们的顶级艺术家之一)的顶级曲目样本
- 用户保存的歌曲示例
- 步骤 1 中添加到播放列表的每首曲目的推荐曲目(通过 Spotify API 和附加过滤)。-4.
公共顶部轨道
播放列表是由常见的热门曲目启动的,上周的播放列表中还没有出现这些曲目。因为这些歌曲都是用户的最爱,理论上他们应该喜欢。
我创建了一个数据框架,通过查找出现在两个用户的顶级曲目数据框架中的曲目来查找常见的顶级曲目。这可以通过多种方式来实现,我使用了以下函数进行所有数据帧的比较:
只有在上周的播放列表中没有出现的常用热门曲目才会被添加到播放列表中。
用户最喜欢彼此相似的曲目
下一个构建块由来自两个用户的顶级曲目的歌曲组成,这些歌曲在音频特征的水平上彼此最相似。
对于这个任务,提取每个用户唯一的顶部轨迹,并计算相似性矩阵。相似度基于音频特征(不包括“调”和“模式”),并通过余弦相似度进行计算(请参见 spotifuncs.py 中的 create_similarity_score())。从该矩阵中,提取 30 个最高相似性得分和相应的指数。对应于这些索引的歌曲被放入数据帧中,任何重复的被丢弃,并且为新的播放列表抽取 10 首歌曲的样本。
普通顶级艺术家
下一步根据普通艺术家过滤热门曲目。我试图找到共同的艺术家(在 2 个用户中),然后通过这些艺术家过滤他们的热门歌曲。这背后的逻辑如下:
一首曲目可能仅在一个用户的“热门曲目”中,然而,它可能是由两个用户都喜欢的艺术家创作的。在这种情况下,该曲目是双人播放列表的良好候选,因为两个用户都可能会喜欢它,但它可能是其中一个用户的新发现。如果双方都已经知道并喜欢它:仍然是一个很好的播放列表适合!
潜在问题
对我来说,这种过滤方法经常导致歌曲列表只包含很少的艺术家,而是该艺术家的几首歌曲(这也是因为 Spotify 真的注意到了你何时无法停止听一张专辑…).为了在新的播放列表中没有太多同一艺术家的歌曲,我从数据帧中取样。为此,我根据艺术家出现的频率为行分配权重,然后从两个数据帧中取样。
这种方法工作得相当好,但是仍然有一些缺陷(这可能部分是由我的倾听行为造成的)。
从存储的轨道采样
在创建播放列表时,我的目标是大约 25 首已知曲目(以及 25 首推荐的新歌)。为了实现这一点,并以某种方式考虑到前面步骤的随机性质,我在最后一步用采样保存的曲目填充播放列表。对于这一步,我还要确保没有一首抽样歌曲已经出现在上周的播放列表中。
从 Spotify 推荐中添加新曲目
在这最后一步,我添加了新的曲目来填充播放列表的另一半。
我不想简单地添加 Spotify 根据歌曲推荐的歌曲,这些歌曲已经在播放列表中了。因此,获得 Spotify 推荐只是第一步。我正在检索每首歌曲的多首歌曲推荐,然后根据相似性评分再次过滤。
不幸的是,Spotify API 不接受 25 首种子曲目用于推荐查询,因此,我最终将该过程分成 5 首种子曲目的“包”,每个“包”检索 25 首曲目。这 125 个推荐通过它们与播放列表中已知曲目的相似性被进一步过滤。
播放列表完成了!
现在剩下唯一要做的就是将曲目添加到播放列表中(在播放列表描述中添加一张漂亮的图片并感谢你的伴侣的耐心不是可选的)。
我希望你能以此为灵感,为自己和他人建立一个播放列表。我也希望你发挥创造力,找到解决这个问题的其他方法。让我知道你造了什么!
附注:我故意跳过了一些代码,以保持文章的合理长度,如果你想看,都在 Github 上。
-梅林
https://ms101196.medium.com/membership
创建一个网上冲浪应用程序
python 如何帮助你找到完美的冲浪板

企业支付天文数字的数据,以确保他们领先竞争对手一步。有了免费的数据集,特别是关于最理想的冲浪板,冲浪就意味着商业,对吗?
什么是 Python Web App?
Python web 应用程序是一个网页,其中的指令/动作是使用 Python 编程创建的。例如,以下代码片段创建了一个下拉选项,用户可以在其中选择多个波高作为过滤器:
wave_height = st.sidebar.multiselect(**"Wave height"**, df[**'wave_height'**].unique())
st.write(**"Wave height selected"**, wave_height)
这是一种创造性的方式来展示您的 python 脚本可以做什么,而不需要其他人在他们的计算机上安装 python-他们所需要的只是互联网连接。
虽然 python 有助于定义您在 web 应用程序上的操作,但 web 框架会处理细节。这就是 细流 的用武之地。 Streamlit 为您设计仪表板。
“Streamlit 可在几分钟内将数据脚本转化为可共享的 web 应用。
全部用 Python。全部免费。不需要前端经验。”— 细流公司,2021 年
本教程将使用 Streamlit 作为 web 框架的选择,但是,理解其他选择也是有好处的
Web 框架
用于使用基于 Python 的编程来构建 web 应用的流行 web 框架包括: Dash ,Streamlit,Voila,Flask和Django。
Flask 是一个没有数据分析能力的 web 框架。它更像是一个*“从零开始建造”*的工程工具,允许更多的定制。它更擅长构建较小的定制应用和网站,如 Reddit 和 Airbnb。而 Django 则致力于帮助创建流量更大的复杂网站,如 Spotify 和 Instagram。
在 Flask 是一个 web 框架的情况下, Streamlit 和 Dash 将例如在 Flask 上运行,因为它们被认为是*“仪表板工具”。* Streamlit 是向利益相关者展示“价值证明”的绝佳方式,而 Dash 则是在您需要将仪表板投入生产并供公司使用的情况下。
如果你在 Jupyter Notebook 中编写代码,并希望在网页上显示你的发现,那么你可以使用像 Viola 这样的插件。Streamlit 还不能在 Jupyter 笔记本上使用,但是可以运行你的*。例如 PyCharm 中的 py* 文件。
在选择了最适合的 web 框架之后,你还需要选择一个 web 服务器来托管你的网站,这里有各种免费和付费的选项。
一个流行的例子是谷歌应用引擎,它是在你的谷歌云项目下创建的。其他受欢迎的云提供商包括亚马逊网络服务(AWS) 和微软 Azure 。
这里的是比较这三种云服务的备忘单:

(崔佛·琼斯,2020,来源)
工作示例
数据
你可以从 kaggle (作者:【洛雷罗】 ) 下载我在这个工作示例中使用的公开可用的数据集。 df_surf.csv 数据集是由冲浪者回答的在线调查。每一行代表一个单独的冲浪者,每一列代表回答的问题。这些问题涉及冲浪板、波浪、冲浪者、操作和冲浪者的表现。
创建您的项目
通过在 PyCharm 中创建新项目,它将为您创建一个‘main . py’文件。将 df_surf.csv 保存在与此 main.py 文件相同的位置。您可以重命名。py 文件,但是要确保修改我的代码来导入您重命名的文件。
在 PyCharm 终端中,安装以下软件包:
pip install streamlit
pip install pandas
pip install numpy
在 main.py 脚本中,插入以下代码,并查看我的注释。如果你是 Streamlit 的新手,[这里的](https://share.streamlit.io/daniellewisdl/streamlit-cheat-sheet/app.py #streamlit #python)是一张可以在 streamlit 网站上找到的备忘单,由 Daniel Lewis 于 2021 年创建。
#import the packagesimport pandas as pd
import numpy as np
import streamlit as st*#import the dataset and create a checkbox to shows the data on your website*
df1 = pd.read_csv(**"df_surf.csv"**)
if st.checkbox(**'Show Dataframe'**):
st.write(df1)#Insert some sentences in markdown format**'''
# Surfing App
'''**#Read in data again, but by using streamlit's caching aspect. Our whole app re-runs every time we make small changes, which is infeasible the more complicated our code becomes. So this is the recommended way to import the data.df = st.cache(pd.read_csv)(**"df_surf.csv"**)#create side bars that allow for multiple selections:age = st.sidebar.multiselect(**"Select age"**, df[**'surfer_age'**].unique())
st.write(**"Age selected"**, age)weekly_surfs = st.sidebar.multiselect(**"Surfer Exercise frequency"**, df[**'surfer_exercise_frequency'**].unique())
st.write(**"Frequency selected"**, weekly_surfs)surfer_experience = st.sidebar.multiselect(**"Surfer Experience"**, df[**'surfer_experience'**].unique())
st.write(**"Experience selected"**, surfer_experience)surfer_gender = st.sidebar.multiselect(**"Surfer Gender"**, df[**'surfer_gender'**].unique())
st.write(**"Gender selected"**, surfer_gender)wave_height = st.sidebar.multiselect(**"Wave height"**, df[**'wave_height'**].unique())
st.write(**"Wave height selected"**, wave_height)board_type = st.sidebar.multiselect(**"Board Type"**, df[**'board_type'**].unique())
st.write(**"Board type selected"**, board_type)#create a sidebar to select the variable output you want to see after making your multiple selectionsvariables = st.sidebar.multiselect(**"Select what you want to see for your selection"**, df.columns)
st.write(**"You selected these variables"**, variables)# return the sub-set data of variables you want to seeselected_data = df[(df[**'surfer_age'**].isin(age))]
subset_data = selected_data[variables]
data_is_check = st.checkbox(**"Display the data of selected variables"**)
if data_is_check:
st.write(subset_data)
在您的终端中,您将运行以下命令:
streamlit run main.py
终端中将出现以下内容:

作者图片
单击本地主机链接,您的 web 应用程序将在浏览器中打开:

作者图片
这就是了。您自己的网络应用程序,探索棋盘类型和策略。
结论
通过观察向这些冲浪者提出的一系列问题,你可以对实现特定动作所使用的冲浪板类型以及冲浪者的类型有所了解。一个从未在 5 英尺浪上做过削减的专业人士,还是一个用他/她的长板偷走所有乐趣的初学者?
本教程只是一个入门,但你可以添加更多的数据,可视化,甚至视频剪辑来丰富你的故事。但在那之前,现在是时候去得到那个完美的波浪了。

使用 Streamlit、MongoDB 和 Heroku 在 30 分钟内创建一个 Web 应用程序
快速开发和部署可伸缩 web 应用程序的有志全栈开发人员指南

克里斯里德在 Unsplash 上的照片
曾几何时,创建 web 应用程序还是像马克·扎克伯格和埃隆·马斯克这样的神童的工作。或者,你可以进入一所名牌大学,用你生命中最好的四年时间(和你父母的退休储蓄)学习编程,然后最终开发出低于 90 年代风格的网络应用程序。从那以后我们已经走了很长一段路。随着开源工具和云基础设施的泛滥,开发和部署非凡的应用程序在很大程度上已经大众化了。老实说,做一名开发人员可能从来没有这么简单过,你所需要的只是一堆正确的工具,而且你可以胜任大多数工作。
我将向您介绍三个主要工具,我自己曾大量使用它们来开发前端用户界面、提供服务器端基础设施,以及最终将所有优点部署到 web 服务器上。在本教程中,我们将创建一个简单的工作推荐应用程序。用户将选择他们希望工作的国家,然后上传他们的简历。随后,该应用程序将分析上传的文件中的关键词,并将搜索公司数据库以找到最相似的匹配。在我们继续之前,我假设你已经精通 Python 和它的一些包,比如 Pandas 和 NLTK,并且你有一个 GitHub 帐户。
1.细流
Streamlit 是一个全新的 web 框架,它几乎填补了 Python 开发者的 web 开发空白。以前,人们必须使用 Flask 或 Django 将应用程序部署到 web 上,这需要对 HTML 和 CSS 有很好的理解。幸运的是,Streamlit 是一个纯粹的 Python 包,学习曲线非常浅,将开发时间从数周减少到了数小时,真的。虽然它被标榜为机器学习和数据科学应用程序的框架,但我发现这相当不光彩;事实上,许多人(包括我自己)已经使用 Streamlit 来炫耀令人眼花缭乱的通用应用程序。
在本节中,我将向您展示如何实时安装、构建和运行 Streamlit 应用程序。首先,在您的环境中安装 Anaconda 和 Streamlit。或者,您可以在 Anaconda 提示符下运行以下命令。
pip install streamlit
一旦解决了这个问题,继续打开您选择的 Python IDE,并在您刚刚下载 Streamlit 的环境中打开它。现在让我们创建一个简单的界面,用户可以选择他们想要工作的国家,也可以上传他们的简历。最初,我们需要导入所有包,如下所示:
除了 Streamlit 和 Pandas,我们还需要 pdfplumber 和 PyPDF2 来处理我们上传的简历。rake_nltk、nltk 和它们的相关单词库需要从简历文本中解析关键短语,io 需要将二进制简历文件转换成 Python 可读的解码形式。
随后,我们创建用户界面,为国家/地区添加文本输入,为简历添加文件上传程序,并通过多选单词框选择获得的关键短语,如下所示:
上面调用的函数“keyphrases”通过使用 nltk 库来分析简历文本以发现相关的关键字。该功能如下所示:
最后,我们将 Python 脚本保存在我们环境的目录中,并在 Anaconda 提示符下执行以下命令,以在本地运行我们的 Streamlit 应用程序:
streamlit run *file_name.py*
您会注意到 web 应用程序将被转发到您的本地主机端口:
[http://localhost:8501](http://localhost:8501)
现在,您应该看到以下内容:

简化页面。图片作者。
继续上传您的简历,生成如下所示的关键短语:

关键短语生成。图片作者。
Streamlit 的美妙之处在于,您可以实时更新您的代码,并即时观察您的更改。因此,您可以随时进行尽可能多的修改。
2.MongoDB
没有服务器端组件的 web 应用程序是不完整的,还有什么比 MongoDB 更好的学习与数据库交互的方法呢?虽然在这种情况下,我们的数据集是结构化的,并且使用像 MongoDB 这样的非关系数据库架构是多余的,但与所有可扩展的应用程序一样,在某种程度上,您可能会最终处理大量的非结构化数据,所以最好在一开始就进入正确的生态系统。更不用说 MongoDB 必须提供的一系列特性,比如全文索引和模糊匹配。
对于这个应用程序,我从 kaggle.com 下载了一个全球公司的公共数据集。我已经删除了它的一些属性,将数据集的总大小减少到 100 兆字节;请记住,MongoDB 提供了一个高达 512 兆存储的免费层集群。接下来,继续开设 MongoDB Atlas 帐户,然后注册一个组织和一个项目。随后在 AWS 的 US-East-1 区域建立一个名为“M0 沙盒”的免费层集群。这将确保我们有最小的延迟,因为我们的 Heroku web 服务器也将托管在同一地区。

构建 MongoDB 集群。图片作者。

选择 MongoDB 自由层集群。图片作者。

选择 MongoDB 集群区域。图片作者。
创建集群后,MongoDB 需要几分钟的时间来配置服务器。配置完成后,您需要将用于连接到集群的 IP 地址列入白名单。虽然出于明显的安全原因,我不推荐这样做,但是为了简单起见,您可以将所有 IP 地址列入白名单。从“安全”菜单中选择“网络访问”,如下所示:

配置 MongoDB 集群的网络访问。图片作者。
随后,选择“允许从任何地方访问”,并选择所需的时间范围,如下所示:

将 MongoDB 集群的 IP 地址列入白名单。图片作者。
接下来,您需要设置一个连接字符串来远程连接到您的集群。从“数据存储”菜单中选择“集群”,然后单击集群窗口上的“连接”,如下所示:

正在设置 MongoDB 连接。图片作者。
输入将用于连接到该群集的用户名和密码,如下所示:

为 MongoDB 集群访问选择用户名和密码。图片作者。
创建用户后,单击“选择连接方法”继续下一步,您应该选择“连接您的应用程序”,如下所示:

正在为 MongoDB 集群创建连接字符串。图片作者。
出现提示时,选择“Python”作为驱动程序,选择“3.6 或更高版本”作为版本。将为您创建一个连接字符串,如下所示:

MongoDB 连接字符串。图片作者。
您的连接字符串和完整的驱动程序代码应该是:
client = pymongo.MongoClient("mongodb+srv://test:<password>[@cluster0](http://twitter.com/cluster0).nq0me.mongodb.net/<dbname>?retryWrites=true&w=majority")
db = client.test
复制该字符串并用您在前面步骤中创建的实际密码替换’'部分。
现在我们已经了解了 MongoDB 的所有逻辑,让我们加载数据集吧!选择集群中的“收藏”,然后点击“添加我自己的数据”。

将数据加载到 MongoDB 集群中。图片作者。
出现提示时,输入数据库和集合的名称以继续加载数据。请注意,MongoDB 中的“集合”与任何其他数据库中的表同义;同样,“文档”与其他数据库中的行相同。有多种方法可以将数据集加载到新创建的数据库中;最简单的方法是使用 MongoDB Compass 桌面应用程序,你可以在这里下载。下载并安装后,使用之前生成的连接字符串继续连接到集群,如下所示:

MongoDB 指南针桌面应用程序。图片作者。

MongoDB 指南针数据库。图片作者。
连接后,您应该能够找到您在前面的步骤中创建的数据库和集合。继续并点击“导入数据”将您的数据集上传到您的收藏中。一旦加载了数据,就需要创建一个全文索引,以便以后查询数据。全文索引实际上是对数据库中的每个单词进行索引;这是一种非常强大的索引形式,非常类似于搜索引擎所使用的。为此,您需要在互联网上导航回您的 MongoDB 集群,并在您的集合中选择“搜索索引”选项卡,如下所示:

在 MongoDB 中创建全文索引。图片作者。
单击“创建搜索索引”。这将通过以下窗口提示您,您可以在其中修改索引,但是,您可以通过单击“创建索引”继续使用默认条目。

在 MongoDB 中创建全文索引。图片作者。
既然已经配置了数据库、加载了数据集并创建了索引,您就可以在 Python 中创建查询函数,使用用户输入从数据库中提取记录,如下面的函数所示:
上面代码片段中的第一行建立了到数据库中集合的连接;请确保输入您的密码。或者,您可以将您的密码存储在一个配置文件中,并在您的代码中作为一个参数调用它,如果您希望更安全地处理密码的话。
为了查询您的 MongoDB 集合,您需要使用“聚合”特性,它只是 MongoDB 中的一个过滤管道。管道的第一阶段( s e a r c h ) 是利用我们的全文索引的部分;这里,我们使用模糊匹配来匹配我们先前生成的简历关键短语和数据集中的“行业”属性。下一阶段 ( search)是利用我们的全文索引的部分;这里,我们使用模糊匹配来匹配我们先前生成的简历关键短语和数据集中的“行业”属性。下一阶段( search)是利用我们的全文索引的部分;这里,我们使用模糊匹配来匹配我们先前生成的简历关键短语和数据集中的“行业”属性。下一阶段(project)使用文档排名来按照分数降序排列匹配的查询。第三阶段( m a t c h ) 过滤掉不包含用户指定的国家的文档。最后一个阶段 ( match)过滤掉不包含用户指定的国家的文档。最后一个阶段( match)过滤掉不包含用户指定的国家的文档。最后一个阶段(limit)只是将返回结果的数量限制为 10 个。
既然我们已经整理了查询函数,我们需要在我们的 Streamlit 页面代码中再添加几行代码,以添加一个执行查询并显示搜索结果的搜索按钮,如下所示:

求职推荐网站。图片作者。
3.赫罗库
如果你已经做到了这一步,那么你会很高兴地知道你离完成只有几下鼠标的距离。多亏了 Heroku,将一个网络应用程序部署到云端只需点击几下鼠标。值得一提的是,Streamlit 开发了自己的【一键部署】选项,您可以将 GitHub 存储库与 Streamlit 集成,并免费部署您的应用。然而,问题是您的存储库需要是公共的,直到 Streamlit 发布其企业部署版本来迎合私有存储库,然后对许多人来说这将是一个交易破坏者。
在我们继续之前,您需要创建四个将与您的源代码一起部署的文件。
1.requirements.txt
您需要一个 requirements.txt 文件,其中包含 Heroku 需要为您的应用程序安装的所有软件包。这可以使用“pipreqs”包生成。在 Anaconda 提示符下键入以下命令来安装 pipreqs:
pip install pipreqs
然后把你的目录换成一个文件夹,只有和包含你的源代码,其他什么都没有。
cd C:/Users/..../folder/
然后键入以下内容:
pipreqs
将使用以下软件包生成 requirments.txt 文件:
pymongo[tls,srv]==3.6.1
lxml==4.5.2
nltk
pdfplumber==0.5.24
pymongo==3.11.0
pandas==1.0.5
rake_nltk==1.0.4
streamlit==0.69.2
PyPDF2==1.26.0
2.setup.sh
setup.sh 文件告诉 Heroku 如何配置 Streamlit 应用程序,可以使用文本编辑器如 Atom 创建,并且必须以. sh 扩展名保存。
3.Procfile
类似地,Procfile 是一个配置文件,它告诉 Heroku 在启动时运行我们的源代码。它也可以用 Atom 文本编辑器创建,请注意它没有扩展名。
4.nltk.txt
nltk.txt 文件告诉 Heroku 使用哪个单词库。只需将以下内容添加到文件中,并确保使用文本文件的“LF”UNIX 格式保存它。
wordnet
pros_cons
reuters
准备好源代码和这四个文件后,将它们上传到一个私有的 GitHub 存储库中(以免公开任何密码)。然后去 Heroku 开个账户,如果你还没有的话。我们将使用免费的 Dyno 层,这足以部署一个实验性的应用程序。选择下面的“新建”按钮,继续创建新应用程序:

创建 Heroku 应用程序。图片作者。
出现提示时,输入您的名称,并选择“美国”地区。

创建 Heroku 应用程序。图片作者。
随后,选择“GitHub”部署方法和您的存储库,如下所示:

GitHub 与 Heroku 的集成。图片作者。
向下滚动到底部,选择存储库的正确分支,然后选择“部署分支”按钮来部署您的应用程序。Heroku 轻松构建您的应用程序时,请高枕无忧。完成后,假设没有错误,您将获得 web 应用程序的链接。鉴于你使用的是免费层,你第一次运行该应用程序将需要一段时间来曲柄启动。
由于您的 Heroku 帐户与 GitHub 集成在一起,您可以随时更新/修改您的代码,并像以前一样重新部署应用程序。有了 Heroku,你甚至可以设置自动操作,这样每当你的存储库更新时,应用程序就会自动重新部署。您还可以随时向 MongoDB 数据库添加数据,这些数据会立即反映在 web 应用程序中。因此得名“可扩展的 web 应用程序”。祝贺您使用 Streamlit、MongoDB 和 Heroku 部署您的 web 应用程序!
有用的链接
如果您想了解更多关于数据可视化、Python 以及将 Streamlit web 应用程序部署到云中的信息,请查看以下(附属链接)课程:
使用 Streamlit 开发 Web 应用程序:
使用 Python 实现数据可视化:
面向所有人的 Python 专业化:
使用 Streamlit 和 Python 构建数据科学 Web 应用程序:
GitHub 资源库:
https://github.com/mkhorasani/JobMatch
新到中?您可以在此订阅和解锁无限文章。
使用 Merchant Center BigQuery exports 创建高级 Google 购物洞察
利用产品级别价格竞争力、需求和受欢迎程度数据,基于所有谷歌购物商家

商品级别价格竞争力和基准数据,已经在商家中心界面提供,可以导出到 Google BigQuery。利用这些导出,您可以创建对产品目录的高级见解,这些见解也可以用于自动化。
在本教程中,您将学习如何:
- 基于从 Google Shopping 上的所有商家到 Google BigQuery 的数据**,导出产品和品牌层面的市场洞察数据**
- 使用商家中心的数据丰富您的产品信息,如价格竞争力、相对需求或产品排名来创建有价值的高级见解。
- 使用示例查询将数据合并并加入到您的产品提要中。
- 将出口用于其他实际用例。
注: 你喜欢这篇文章吗?阅读 原文 (以及其他许多动手营销技术相关文章)上【stacktonic.com】🚀
将商业中心连接到 Google BigQuery
第一步,你需要一个有效的计费帐户谷歌云项目。如果不存在,您可以查看这些说明。
官方的谷歌文档提供了在商业中心和谷歌大查询之间建立数据传输服务的所有信息。建立连接后,Merchant Center 将每天导出几份报告。

来源:谷歌
商户中心出口解释
传输服务可以导出几种报告类型。您不必导出所有报告(可以在设置导出时进行配置)。
要知道,以 GBs 来说,商业中心的出口并没有那么小。例如,对于每个可用的谷歌产品类别和国家,它将导出 10.000 个顶级产品。所以这可能会在你的谷歌云项目中产生一些成本。参见本文最后一章的提示。
最重要的出口;

另见 本概述 在谷歌官方文档中。
一些最有趣的性质和定义;
- price_benchmark_value :特定产品的平均(点击加权)价格,基于所有在购物广告上宣传相同产品的商家。商家之间匹配产品是以 GTIN 为基础的。
- 排名:该产品在购物广告、谷歌产品类别和国家级别上的受欢迎程度。受欢迎程度是基于销售产品的估计数量。排名每天更新,但导出的数据最多会延迟 2 天。
- previous_rank :过去 7 天的排名变化。
- 相对 _ 需求.最小/。max /。bucket :一个产品相对于在同一个类别和国家中具有最高流行等级的产品的当前估计需求。还包括桶(例如非常高)
- 上一个 _ 相对 _ 需求.最小/。max /。桶:同上,只计算最近 7 天。
- price _ range . min
/price _ range . max:不含小数的价格范围下限和上限。不包括运费。
实际使用案例
结合不同的报告,您可以想到以下用例;
- 产品反馈状态:获取与您的产品反馈相关的商家中心和购物错误及通知。
- 产品库存优化:使用畅销书报告,你可以根据谷歌产品类别和国家的顶级产品完整列表,检查哪些热门产品已经在你的库存中,哪些潜在产品可以添加。
- ***价格和投标优化:*使用价格竞争力基准信息,您可以检查自己在价格方面相对于竞争对手的表现。
- 趋势产品和品牌:根据过去 X 天/周/月畅销书排行榜的变化,确定趋势产品/品牌。每个国家有所不同
- 产品提要丰富化:用谷歌市场洞察数据丰富你的产品提要
- 基于规则的自动化:根据产品反馈的丰富程度,暂停和启用渠道中的活动/产品(如谷歌购物)或调整出价。例如基于价格竞争力。

利用商家中心的市场洞察丰富产品数据
示例查询
为了向您展示如何组合数据,我构建了一个查询,该查询将在产品级别上连接和组合不同的 Merchant Center 表中的数据。
一些评论:
- 谷歌并没有为你 feed 中的每一个产品提供数据。要么是某个产品不在畅销书排行榜上,要么就是谷歌不提供或者不计算(数据不够,可能还有其他一些原因)。或者你有其他商家不提供的独特产品。
- 使用畅销书 _ 顶级产品 _ 库存作为映射表,通过连接 rank_id (在两个表中都可用),将畅销书 _ 顶级产品数据与您的产品数据连接起来
- 您系统中已知的“原始”产品 ID 在不同的出口中并不直接可用。它在 product_id 字段中可用,但是您必须拆分该值并选择最后一部分,因为 Google 向其添加了附加信息,例如:online:NL:NL:
- 这些报告包含大量数据。例如,畅销书报告包含每个谷歌产品类别和国家的 10.000 本畅销书。出于效率原因,尽量只选择需要的国家。同样重要的是,在谷歌提供的表格中,同一产品可以在不同的国家重复出现。
- 报告包含嵌套和重复的数据,请确保您理解表格结构。例如,产品错误和通知是嵌套的。
示例:用基准和价格竞争力数据丰富产品提要
下面的查询将产生这个表,您可以在您的原始产品提要上匹配它,并且可以作为自动化规则的输入(在产品级别上)

确保根据您的情况用正确的值替换数据集/表名
结束语
使用 BigQuery Merchant Center 导出,您可以大规模生成洞察,并将其用于自动化。但是请记住,导出保存了大量数据,因此可能会在您的 Google Cloud 项目中产生一些成本(您可能不需要所有的数据)。这些表是按日期分区的,因此您可以编写一个 Python 脚本或使用 Airflow 删除超过 X 天的分区,以保持 BigQuery 中的数据量(可能在您创建了一些聚合报告之后)。
使用 cli 权限创建气流角色
直接从 cli 而不是 UI 创建具有 dag 级别气流权限的角色

作者图片
成为管理员
Airflow 提供了一种通过 RBAC 角色管理多个用户权限的方法。这些权限可以直接从 Airflow 的 UI 编辑(RBAC 默认使用 Airflow ≥ 2.0 激活。

图片作者。气流中默认 RBAC 角色的 UI 视图
只有当连接的用户拥有管理员角色时,才能访问这些角色。
默认情况下,当您第一次连接到 Airflow 时,角色是 Op,这是仅次于 Admin 的第二高角色。此角色没有足够的权限来管理角色。要成为管理员,请使用以下命令:
airflow users add-role -e *your_email* -r Admin
现在您是管理员,刷新气流页面,您应该可以访问具有角色和权限的安全菜单。
您将看到可以直接从 UI 编辑角色和权限。还可以创建 dag 级别的权限,即仅适用于给定 dag 的权限。现在假设您希望一些用户只访问一些特定的 Dag。直接从用户界面对多个 dag 使用 Dag 级别的权限非常容易出错且非常耗时,因为您必须从用户界面手动选择权限,甚至无法进行复制粘贴。
这就是为什么我创建了一个脚本,用于直接从 cli 创建具有预定义权限的角色。
剧本
以下是用于创建具有足够权限来管理特定 Dag 的角色的脚本。
最新版本托管在本回购。
默认情况下,该脚本使用预定义的权限,允许用户仅访问参数中给定的 Dag,以便可以在同一个气流中托管由多个 Dag 组成的多个项目。
请注意,可以根据您的特定用例在代码中直接编辑权限。气流 RBAC 许可语法的详细列表可以在气流代码中找到。
例子
假设我的气流中有两把匕首。每个项目一个。我想为这两个项目创建一个角色,以便只授权从事特定项目的用户查看相应的 dag。

图片作者。气流中的两个 Dag
创建角色
然后,我使用该脚本为 Dag“tutorial”创建一个访问受限的新角色。
python3 rbac_roles_cli.py \
-u http://localhost:4444 \
-r TutorialRole \
-d tutorial
- -u:(url)air flow UI 根页面的 URL。
- -r: (role)新角色的名称。
- -d:(Dag)允许访问的 Dag 列表,用空格分隔。
如果返回错误,请检查您是否是 Airflow 的管理员,以及使用-d 选项指定的 Dag 是否存在。
向用户添加角色
现在,我们必须使用 Airflow 的 cli 向现有用户添加新角色。如果用户尚未在 Airflow 中创建,请遵循这些步骤。
airflow users add-role -e tutorial_user@gmail.com -r TutorialRole
从管理员用户的角度来看,我们可以在“Security menu”>“List Roles”中看到已经正确创建了角色。通过分析权限,您可以看到 dag 级别的权限也被添加到角色中。

图片作者。在气流 UI 视图中创建的角色
现在,为了确保用户只拥有已创建的角色,您可以使用以下命令删除其他角色,如 Op 或 Admin:
airflow users remove-role -e tutorial_user@gmail.com -r Op
airflow users remove-role -e tutorial_user@gmail.com -r Admin
如果一个给定的用户有多个角色,这个用户的权限将是每个角色权限的总和,所以你必须小心,这个用户只有这一个角色。
测试权限
现在,使用创建的角色登录帐户。

图片作者。用户对创建的角色中定义的 Dag 具有有限的访问权限。
用户现在只能访问创建角色时给出的 dag:在本例中,只能访问 Dag“tutorial”。用户甚至可以编辑 dag,查看日志和代码。如果您想个性化该用户的权限,您可以在代码中自由添加/删除一些权限。
与 Cloud Composer 兼容
有人用 Cloud Composer 直接在 Google 云平台管理自己的气流。因为 Composer 在访问 GCP 的资源之前需要对 Google 进行认证,所以我们必须生成一个 Google 访问令牌,以便在使用脚本之前对 GCP 进行认证。
创建 OAuth 凭据
为了与 Google APIs 通信,我们必须使用在 GCP 创建的个人令牌。这个令牌是 OAuth 令牌。要创建该令牌,请执行以下操作:
在 GCP:API&服务**>凭证 > 创建凭证 > OAuth 客户端 ID > 电视和受限设备**
创建了 OAuth 令牌,现在您拥有了一个客户端 ID 和一个客户端秘密。
获取授权码
在以下 URL 中替换您的用户 ID,并在浏览器中直接调用它。
该页面要求您使用您的 Google 帐户登录,然后复制显示的代码:这是授权代码。这个代码是临时的,所以我们将创建一个比这个更长的令牌。

图片作者。谷歌授权码
获取访问令牌
现在启动一个新的终端,粘贴这个 curl 并用您在上一步中复制的代码替换authorization _ code,用在 GCP 用 OAuth 令牌创建的客户端 id 和 secret 替换 client_id 和 client_secret 。
curl -s \
— request POST \
— data \
“code=***authorization_code***&client_id=***client_id***&client_secret=***client_secret***&redirect_uri=urn:ietf:wg:oauth:2.0:oob&grant_type=authorization_code” \
[https://accounts.google.com/o/oauth2/token](https://accounts.google.com/o/oauth2/token)
此 post 请求的响应应遵循以下模式:
{
“***access_token***”: “ya29.a0ARrdaM-az...”,
“expires_in”: 3599,
“refresh_token”: “1//03uXjr...”,
“scope”: “https://www.googleapis.com/auth/userinfo.profile",
“token_type”: “Bearer”,
“id_token”: “eyJaaza...“
}
复制响应中给出的 access_token。
使用脚本
最后,我们将使用之前用于标准气流的相同命令,只是我们必须为访问令牌指定一个选项,以便与受 Google 保护的 Composer Airflow 页面进行交互。
python3 rbac_roles_cli.py \
-u ***https://...composer.googleusercontent.com*** \
-r TutorialRole \
-d tutorial \
***-t access_token***
将用户添加到角色
可以使用 gcloud beta cli API 添加用户。
gcloud beta composer environments run example-environment — location europe-west1 users add-role — -e name[@organization.com](mailto:tristan_bilot@carrefour.com) -r TutorialRole
结论
Airflow 没有提供一种直接在 cli 中创建具有特定权限的角色的本机方法,除非使用一个复杂的、糟糕的、带有长卷的 API。提议的脚本使用 Python 轻松地操作这个 API,以便创建具有权限的角色。如果发生任何问题,请随时提出问题。尽情享受吧!
使用 PyWebIO 创建一个处理无聊的应用程序
实践教程
建议用户在无聊时使用 Python 进行哪些活动
动机
你有没有无聊到在谷歌上搜索:“无聊的时候做什么?”如果您可以创建一个应用程序,使用 Python 向用户推荐当天的随机活动以及与该活动相关的书籍,这不是很好吗?

作者 GIF
可以在这里用上面所示的 app 玩。在本文中,我将向您展示如何使用 PyWebIO、Bored API 和 Open Library 用几行代码创建这个应用程序。
在进入代码之前,让我们收集创建应用程序所需的工具。
工具
PyWebIO —用 Python 创建一个 Web 应用程序
PyWebIO 是一个 Python 库,允许你在没有 HTML 和 Javascript 知识的情况下构建简单的 web 应用。它比 Django 和 Flask 更容易学习,但比 Streamlit 更容易定制。
要安装 PyWebIO,请键入:
pip install pywebio
无聊的 API——无聊的时候找些事情做
无聊 API 帮你无聊的时候找事情做。你只要去 https://www.boredapi.com/api/activity就能得到一项活动的建议。
刷新页面会得到不同的结果:
如果您喜欢参与某一类型的活动,请将?type=activity-name添加到 API:
[https://www.boredapi.com/api/activity?type=education](https://www.boredapi.com/api/activity?type=education)
输出:
开放图书馆
开放图书馆是一个开放的、可编辑的图书馆目录,收录了所有出版过的书籍。Open Library 提供了一套 API 来帮助开发人员使用他们的数据。
您可以通过访问以下网址获得 Open Library 搜索结果的 JSON 文件:
[https://openlibrary.org/search.json?title=friends+influence+people](https://openlibrary.org/search.json?title=friends+influence+people)
产出摘要:
现在我们已经收集了创建应用程序所需的工具,让我们利用这些工具来创建一个应用程序。
创建应用程序
创建下拉列表
首先,创建一个下拉列表来显示所有活动类型:
上述代码的详细信息:
put_markdown:写减价select:创建下拉菜单start_server:启动一个 web 服务器,在上面服务 PyWebIO 应用。debug=True告诉服务器当代码改变时自动重新加载。

作者 GIF
根据所选选项显示活动
正常情况下,PyWebIO 的输入表单在成功提交后会被销毁。

作者 GIF
然而,用户可能希望使用不同的输入,所以我们需要找到一种方法来防止输入表单在成功提交后消失。这可以用pywebio.pin轻松完成。
对上述代码的解释:
while True:允许用户无限期插入新输入put_select:类似于select小部件,但是被pin小部件函数用来检测输入的变化pin_wait_change:监听一列 pin 小工具。当任何小部件的值改变时,该函数返回改变的小部件的名称和值。with use_scope('activity', clear=True):当范围内有新的输出时,清除最后一个输出
输出:

作者 GIF
使用 Bored API 获得一个随机活动
接下来,我们将使用 Bored API 获得一个基于活动类型的随机活动。为此,我们将:
- 创建一个名为
get_activity_content的函数,它使用requests.get向[https://www.boredapi.com/api/activity](https://www.boredapi.com/api/activity)发出请求。 - 将我们从下拉栏获得的输入传递给函数
get_activity_content。如果输入的值是education,API 将是[https://www.boredapi.com/api/activity?type=education](https://www.boredapi.com/api/activity?type=education)。

作者 GIF
不错!
使用 Open Library 获取图书建议
建议要做的活动是好的,但不是很足智多谋。如果用户想了解他们将要做的活动的更多信息,该怎么办?这就是为什么我们也会建议他们使用开放图书馆阅读一些有用的资源。
从开放图书馆获取相关书籍的步骤:
- **获取活动名称:**下图中,活动名称为“给你生命中有影响力的人写一封感谢信”

作者图片
- **从活动名称中提取名词短语:**名词短语是以一个名词如“一个漂亮的女孩”为首的一组两个或两个以上的词。我们将使用 spaCy 从文本中提取名词短语:
$ pip install spacy
$ python -m spacy download en_core_web_sm
['a thank', 'you', 'an influential person', 'your life']
- **使用提取的名词短语搜索书名。**例如,为了搜索标题与
your life相关的书籍,我们将把?title=your+life添加到 API 中:
[https://openlibrary.org/search.json?title=your+life](https://openlibrary.org/search.json?title=your+life)
在下面的代码中,我们使用从名词短语中提取的查询从 Open Library 获取相关书籍:
第一本书的输出示例:
- **显示书名和作者的表格:**JSON 输出很无聊。让我们使用
pywebio.output.put_table将 JSON 结果转换成表格:
输出:

作者图片
太棒了。由于请求图书可能需要很长时间,我们还将在代码中添加put_loading,以便用户知道网站仍在加载:
结果:

作者 GIF
不错!
结论
恭喜你!你刚刚学习了如何使用 PyWebIO、Bored API 和 Open Library 创建一个 app 。我希望这篇文章能给你用 Python 创建一个有趣的应用程序的动力。
既然使用 PyWebIO 创建一个应用只需要几行代码,为什么不试一试呢?
请在这里随意使用本文的源代码:
https://build.pyweb.io/get/khuyentran1401/bored_app
我喜欢写一些基本的数据科学概念,并尝试不同的算法和数据科学工具。你可以在 LinkedIn 和 Twitter 上与我联系。
如果你想查看我写的所有文章的代码,请点击这里。在 Medium 上关注我,了解我的最新数据科学文章,例如:
[## 使用 SimPy 在 Python 中模拟真实事件
towardsdatascience.com](/simulate-real-life-events-in-python-using-simpy-e6d9152a102f)
创建一个出色的 Streamlit 应用程序,并使用 Docker 进行部署
本文全面概述了使用 streamlit 和 Docker 部署简单情感分析应用程序的分步指南

由 Timelab Pro 在 Unsplash 上拍摄的照片
介绍
作为机器学习或软件工程师,我们希望与他人分享我们的应用程序/模型及其依赖性。如果处理不当,这个过程不仅会耗费我们的时间,还会耗费我们的金钱。如今,与其他开发人员合作的最受欢迎的方式之一是使用源代码管理系统(例如 Git)。这可能还不够,因为您在自己的计算机上开发的令人惊叹的模型可能因为不同的原因而无法在其他人的计算机上运行。所以解决这个问题的一个更好的方法可能是使用 Docker 容器,以便能够“复制”你的计算机,并让其他人可以访问它。在本文中,我们将按照以下顺序学习这一概念:
- 训练一个简单的情感分类器
- 使用良好的软件项目结构创建相应的 Streamlit 应用程序
- 为 streamlit 应用程序创建 Docker 映像
- 运行容器中的图像
机器学习模型
因为主要目标是引导您完成使用 Streamlit 和 Docker 部署模型的步骤,所以我们不会在模型培训上花费太多时间。
笔记本中的模型训练
有用的库 以下是有用的库

(图片由作者提供)
读取垃圾数据 读取数据集并显示 3 个随机样本

(图片由作者提供)
spam_data.v1.unique() == >数组([‘ham ‘,’ spam’],dtype=object)
**观察:**我们有两个标签,对应一个 2 类分类问题。然后,我们需要将这两个标签编码成数字格式,用于模型训练。

(图片由作者提供)
特征和目标

(图片由作者提供)
特征提取&模型训练 我们使用朴素贝叶斯分类器

(图片由作者提供)
什么是 Streamlit 以及它如何有用
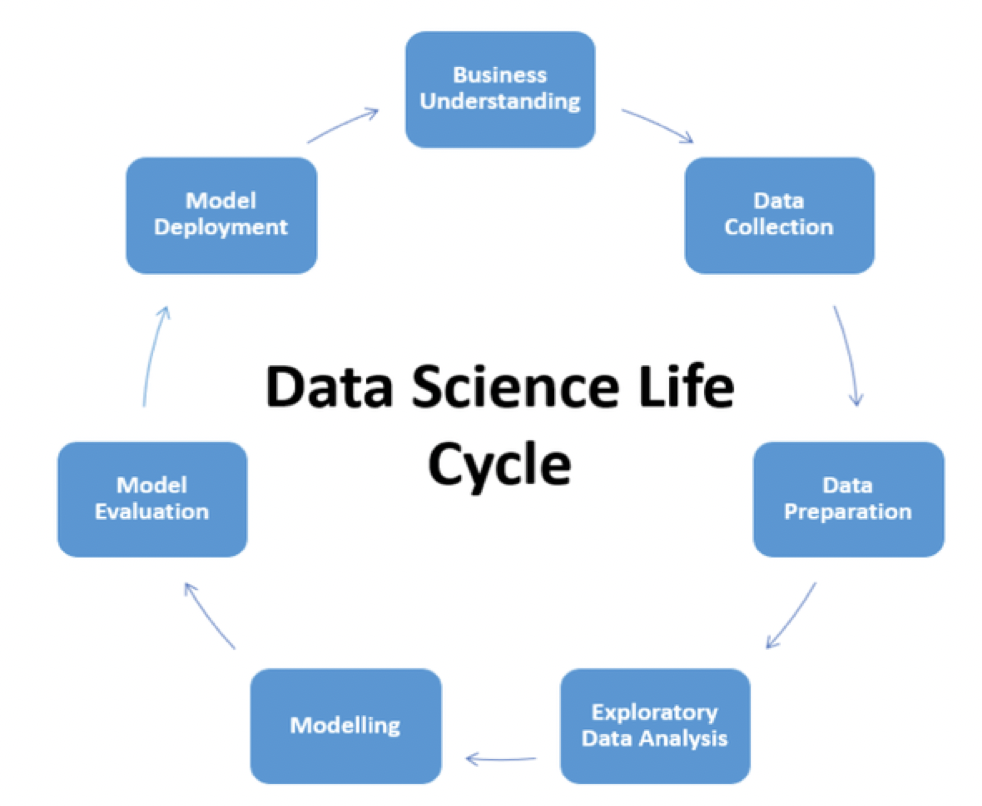
Streamlit 是一个开源框架,数据科学和机器学习团队可以使用它来为业务执行更好的数据可视化,还可以将模型部署到生产环境中(而不是使用 Flask、Django、FastAPI,它们可能需要相当长的模型部署时间),如下面的数据科学生命周期所示。

图片由作者根据 Analytics Vidhya 定制
创建我们的 Streamlit 应用
先决条件
- 创建并激活虚拟环境

(图片由作者提供)
2.安装项目依赖项

(图片由作者提供)
3。构建项目
以如下所示的方式构建项目具有以下优势:
- 简化协作
- 维护干净健壮的代码
- 使部署更加容易
- 等等。

(图片由作者提供)
实现
项目包
_ _ init _ _。py 是一个空文件。下面是其余两个文件(data_processor.py 和 model_trainer.py)的内容

data _ processor . py 的内容

model_trainer.py 的内容

train_model.py 内容

app.py 的内容
运行 app
运行模型主要有两个步骤。必须从项目的根本着手:

(图片由作者提供)
运行第二个命令后,我们终于可以与应用程序进行交互了。下面是两个场景:
- 所提供的消息被分类为垃圾邮件的情况

(图片由作者提供)
2.提供的消息被分类为垃圾消息(非垃圾邮件)的情况

(图片由作者提供)
申请归档的时间到了
创建 docker 层 为了能够对应用程序进行 docker 化,我们需要在 docker 文件夹中创建一个 Docker 文件。该文件包含如下所示的七条主要指令。
- (来自):从 docker hub 获取一个官方的 python 映像,然后我们的文件将从该映像构建。
- (WORKDIR):创建/app 作为应用程序的工作目录
- (复制源目标):将文件从源文件夹复制到目标文件夹。
- (运行):运行 requirements.txt 文件以安装项目依赖项。
- (EXPOSE):用于公开模型要使用的端口。
- (ENTRYPOINT) & (CMD):创建一个入口点,以便最终使映像可执行。

(图片由作者提供)
构建 Docker 映像 以下命令构建名为streamlitspamapp的映像,标记为 最新 版本。这个图像是从以前的 docker 文件构建的。

(图片由作者提供)

(图片由作者提供)
从 docker build 命令的上一个结果中,我们可以看到我们的映像已经按照前面的解释创建好了。
运行容器 镜像构建完成后,我们需要用下面的命令将它运行到一个容器中。
🚫确保在运行这个命令之前停止之前的 streamlit 应用程序,否则,您可能会遇到一个漂亮的消息错误,告诉您端口已经被使用

(图片由作者提供)
前面的命令会自动生成两个 URL。你的可能和我的不一样。

(图片由作者提供)
您使用 docker 部署了您的 streamlit 应用程序🎉🎉🎉!
文章结尾
在本文中,您已经学习了如何构建一个简单的机器学习模型,实现相应的 streamlit 应用程序,并最终使用 Docker 进行部署。您现在可以使用一些云提供商平台,如 Azure、AWS、GCP,在几分钟内部署容器!
如需进一步阅读,请随时关注我在 YouTube 上的文章,并参考以下链接:
额外资源
再见🏃🏾
你能创建一个空的熊猫数据框,然后填充它吗?
讨论为什么应该避免创建空的数据帧,然后一次追加一行

照片由 Glen Carrie 在 Unsplash 上拍摄
介绍
在 pandas 的上下文中,一个非常常见的问题是,您是否真的可以创建一个空的数据帧,然后通过一次追加一行来迭代地填充它。然而,这种方法往往效率很低,应该不惜一切代价避免。
在今天的文章中,我们将讨论一种替代方法,它将提供相同的结果,但比创建一个空的数据帧,然后使用循环在其中追加行要有效得多。
要避免什么
当然,实际上可以创建一个空的 pandas 数据帧,然后以迭代的方式追加行。这种方法看起来特别像下面这样:
import numpy as np
import pandas as pd
from numpy.random import randint# Make sure results are reproducible
np.random.seed(10)# Instantiate an empty pandas DF
df = pd.DataFrame(columns=['colA', 'colB', 'colC'])# Fill in the dataframe using random integers
**for i in range(7):
df.loc[i] = [i] + list(randint(100, size=2))**print(df)
*colA colB colC
0 0 9 15
1 1 64 28
2 2 89 93
3 3 29 8
4 4 73 0
5 5 40 36
6 6 16 11*
尽管上面的方法可以达到目的,但必须避免,因为它效率很低,而且肯定有更有效的方法,而不是创建一个空的数据帧,然后使用迭代循环来构建它。
一个更糟糕的方法,是在循环中使用append()或concat()方法。
值得注意的是,
[**concat()**](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.concat.html#pandas.concat)(因此也是**append()**)制作了数据的完整副本,不断地重用这个函数会对性能产生重大影响。如果需要在几个数据集上使用该操作,请使用列表理解。— 熊猫文档
改为使用列表
不用使用loc[]属性或append/concat方法以迭代的方式追加行,您实际上可以将数据追加到一个列表中,最后直接从预先创建的列表中实例化一个新的 pandas DataFrame。这甚至在官方的熊猫文档中也有提及。
迭代地将行追加到数据帧可能比单个连接计算量更大。更好的解决方案是将这些行追加到一个列表中,然后将该列表与原始数据帧连接在一起。
— 熊猫文件
import numpy as np
import pandas as pd
from numpy.random import randint# Make sure results are reproducible
np.random.seed(10)data = []
for i in range(7):
data.append([i] + list(randint(100, size=2))df = pd.DataFrame(data, columns=['colA', 'colB', 'colC'])print(df)
*colA colB colC
0 0 9 15
1 1 64 28
2 2 89 93
3 3 29 8
4 4 73 0
5 5 40 36
6 6 16 11*
使用列表(追加或删除元素)要高效得多,而且在迭代地将行追加到 pandas 数据帧时,您必须始终首选这种方法。
最后的想法
在今天的文章中,我们讨论了为什么避免创建空的 pandas 数据帧并迭代填充它们是重要的,因为这将显著影响性能。
相反,我们探索了如何使用列表迭代地构建这样的结构,并最终从创建的列表中创建新的 pandas 数据帧。
成为会员 阅读介质上的每一个故事。你的会员费直接支持我和你看的其他作家。你也可以在媒体上看到所有的故事。
你可能也会喜欢
从美国劳工统计局平面文件网站创建可供分析的数据集
循序渐进的指南
美国劳工统计局(BLS)网站是美国经济数据的丰富来源之一,研究经济学家、数据科学家、金融专业人士、记者和数据爱好者经常访问该网站来搜索有关经济的信息。网站定期发布关于就业、失业、通货膨胀和价格、生产率、消费者支出和时间使用等经济指标的数据。虽然大多数指标是以汇总(或国家)数据的形式提供的,但有些指标是细分到国家以下各级的。本文特别面向那些不熟悉使用值和元数据分开存储的数据的分析师,旨在帮助这些分析师快速准备好数据以供分析。
BLS 网站不遗余力地简化对数据的访问,包括以表格、摘要和可视化形式排列已发布的系列。一些经常被访问的主题被超链接到一个交互式数据查看器(,就像这个)上,从这里可以下载数据。BLS 网站还有一个数据检索工具(这里是),用户可以通过这个工具从网上获取数据。数据也可以通过公共数据应用编程接口 (API)来检索,以实现对经济数据的编程访问,出版商希望开发者能够利用这些数据来创建应用。该 API 有两种格式,具有不同的需求和功能。访问 BLS 数据的说明总结在这样一个页面上 one ,包括如何访问平面文件 FTP 站点(参见示例)。在需要大量数据的情况下,需要平面文件,而获取数据超出了可用数据检索工具的能力。
虽然这些说明告诉您不同的文件是如何关联的,但它没有告诉新手如何将不同的文本文件组合成对分析有用的数据集。本文的目的是提供一个详细步骤的示例,分析师(尤其是使用这种文件的新手)可以使用这些步骤将不同平面文件中的信息组合成可用的格式。这些步骤是用 python 完成的( R 也可以用),因为以编程方式工作时操作更容易。此外,由于我试图从本地失业统计(LAUS)网站获取美国大都市统计区(MSA)的月度失业数据,因此我在此描述的示例将集中于此,但同样的步骤也可以(很可能)用于获取其他指标。
在下载和使用数据集的过程中,一些数据集被组织成用于数据值的文件以最小化文件大小,而包含关于数据的元数据的数据字典在单独的文件中可用。FTP 平面文件就是这种情况。数据字典解释了数据文件的组织(参见此处的、此处的和此处的用于 LAUS 平面文件数据)以及关于数据的其他信息。还建议用户阅读上面示例链接末尾的信息,以便更好地理解数据。本指南还可以作为清理数据集并为分析做好准备的教程。该任务的最终产品是 1990 年至 2021 年 9 月美国大都市统计区域(MSA)月度失业率的纵向(或面板)数据集。
实施流程:GitHub 回购可在:https://github.com/tyngbayi/Using_LAUS_flatfiles找到
步骤 1 :导入相关 python 库,检索 metro 和 area 数据集,并另存为。csv 文件。
import pandas as pd
import numpy as npimport urllib
from urllib.request import urlretrieve# urls for time series and area code data
url1='[https://download.bls.gov/pub/time.series/la/la.data.60.Metro](https://download.bls.gov/pub/time.series/la/la.data.60.Metro)'
url2='[https://download.bls.gov/pub/time.series/la/la.area](https://download.bls.gov/pub/time.series/la/la.area)'
第二步:读入数据,检查一些信息
df1 = pd.read_csv(‘filepath/timeseries.csv’, delimiter=”\t”) df.head()

作者图片
df.info()

作者图片
调用 info()方法会在一些列名周围显示一些空白。这可以通过重命名列来解决。
df1.rename(columns={'series_id ':’series_id’,
' value':’unemployment’}, inplace=True)
步骤 3 :删除一些列并创建新列
df1.drop(‘footnote_codes’, axis = 1, inplace=True)df1[‘measure’] = df1[‘series_id’].apply(lambda x: x[18:].strip())df1.head()

作者图片
第四步:使用 float 函数将失业数据转换为数值数据类型。但是由于一些“坏的”值必须被删除,这就产生了错误。
cnt = 0unemployment_dict = {}for row in df1[‘unemployment’]:
if row is not None:
try:
float(row)
pass
except ValueError:
unemployment_dict[cnt] = row
cnt+=1print(unemployment_dict)

作者图片
步骤 5 :创建区号列,这是一个惟一的 MSA 标识符,将用于合并失业统计数据和区号名称
df2[“area_code”] = df2[‘series_id’].apply(lambda x: x[3:18])

作者图片
第六步:读入 MSA 名称文件,只选择 MSA 数据行(area_type_code B),准备与失业统计合并
df3 = pd.read_csv(‘filepath/area_codes.csv’, delimiter=”\t”)
df3.head(5)

作者图片
步骤 7 :合并失业统计和地铁数据集
df5 = df2.merge(df4, on=’area_code’)
第 8 步:只选择月数据的行
monthly_unemployment = df5[df5[‘period’] != ‘M13’]
monthly_unemployment.head()

作者图片
当然,可以做一些进一步的清理,例如创建城市和州名的列,或者城市名和州名的单独列;过滤季节性未调整行;或者只处理年度数据(M13 期),这取决于分析师的目标。
我希望这能帮助那些对比 BLS 网站上的其他数据检索方法所能提供的大得多的数据集感兴趣的分析师。本文特别面向那些不熟悉使用值和元数据分开存储的数据的分析师,旨在帮助这些分析师快速准备好数据以供分析。
此外,当我试图获取数据时,我正在使用 Python,并没有寻找使用 R 的选项。有一天,当我不那么忙的时候,我可以搜索一个 R 教程或图书馆,使 LAUS 的数据随时可用,如果我找不到,我可以开始工作。
用 Flask 和 Heroku 创建和部署一个简单的 Web 应用程序
通过简单的交互式 web 应用程序分享您的作品

假设您已经用 Python 编写了一个非常酷的脚本来进行一些有趣的数据分析,现在您想向其他人演示它。很有可能,发送一个.py文件并要求其他人运行它,或者演示自己在命令行上运行它,都不会像一个包装精美的 web 应用程序那样有把握。通过使用 Python 包flask,我们可以相当快地创建一个这样的交互式应用程序。在本文中,我将制作一个简单的 web 应用程序,显示主页被访问的次数,并将其部署在 Heroku 上与其他人共享。
注意——以下所有截图均由作者拍摄。
设置项目和文件夹层次
向下游部署我们的项目的最简单的方法是在 GitHub 上创建一个新的存储库,我们所有的文件都将存放在那里。因此,我开始在 github.com/n-venkatesan/sample-webapp 创建一个新的回购协议,并将其克隆到我的本地电脑上。当创建存储库时,您可以选择用一个.gitignore文件初始化——我建议从下拉菜单中选择Python,以避免不必要的文件被签入 Git。
> git clone [https://github.com/n-venkatesan/sample-webapp](https://github.com/n-venkatesan/sample-webapp)> cd sample-webapp/
现在我们需要做的就是创建一个名为templates的文件,我们的 HTML 文件将存放在这里:
> mkdir templates
文件夹结构设置完毕!
创建新的虚拟环境
我们希望我们的开发从一个全新的开始,这样我们就只安装我们的应用程序绝对需要的依赖项——这在我们以后部署我们的 web 应用程序时尤其重要。
> python3 -m venv venv> source venv/bin/activateIf you see the name of the virtual environment (venv) before the command prompt, you have successfully activated the new environment(venv) > Success!
我们现在需要安装我们的应用程序所需的依赖项,它们是flask和gunicorn,这是运行我们的应用程序所需的 Python web 服务器接口。
(venv) > pip install flask gunicorn
酷——现在我们可以开始创建我们的应用程序了!
为网页编写 HTML
在我们的templates/目录中,创建一个名为index.html的新文件。这将是当我们试图访问我们的 web 应用程序时显示的页面。要查看呈现的 HTML 是什么样子,您可以在 web 浏览器中打开该文件。本教程假设你对 HTML 和 CSS 有一个非常基本的了解,但是有很多像 W3School 这样的资源可以帮助你快速上手。
我们的页面将只包含两个元素,一个标题写着Welcome!,下面一个段落写着This site has been visited n times.,其中n是到目前为止网站被访问的实际次数。我们将把这两个元素嵌套在一个<div>块中,以便稍后做一些 CSS 样式。标签表示标题和段落之间的换行符。
<div>
<h1>Welcome!</h1><br>
<p>This site has been visited {{ count }} times.</p>
</div>
关于上面的 HTML 块,唯一可能出现的新内容是段落块中的{{ count }}文本。双花括号({{ }})意味着您正在该块中运行 Python 代码——所以我们引用变量count的值,稍后我们将把它传递给 HTML 模板。
在当前状态下,我们的页面如下所示:

非常基本——让我们添加一些格式!首先,让我们为文本选择不同的字体。我喜欢去谷歌字体,那里有各种各样的免费字体可以使用——对于这个应用程序,我选择了一种叫做 Rubik 的字体。在每个字体粗细的旁边,有一个按钮,上面写着“选择这种样式”——单击其中的至少一个,将在右边打开一个窗口,其中有代码,您可以复制/粘贴到您的 HTML 中,以访问该字体!我只是选择了Regular 400字体的粗细,并得到了下面的代码,我把它添加到了我的index.html文件的顶部:
<link rel="preconnect" href="https://fonts.gstatic.com">
<link href="https://fonts.googleapis.com/css2?family=Rubik&display=swap" rel="stylesheet">
现在我们可以使用 CSS 来设置页面的样式——我们首先在index.html中创建一个样式标签,然后将所有的 CSS 代码放在这里。我们将使页面上所有文本的字体变得像魔方一样,这可以通过改变与所有元素相对应的属性*来实现。此外,我们将把所有内容从页面顶部向下移动 50 像素,将标题设为红色,并更改标题和段落部分的字体大小。我将这段代码添加到字体链接的正下方,但在任何实际页面内容之前。
<style>
* {
font-family: "Rubik", "sans-serif";
} div {
text-align: center;
margin-top: 50px;
} h1 {
color: red;
font-size: 40pt;
} p {
font-size: 24pt;
}
</style>

看起来好多了!现在,我们可以添加运行我们的应用程序的 Python 后端了!
创建烧瓶应用程序
在我们的主项目文件夹中,我们可以创建一个名为app.py的文件,它将成为我们的 web 应用程序的后端。我们需要做的第一件事是导入所需的包。
from flask import Flask, render_template
Flask是我们将用来实例化我们的应用程序的,而render_template是我们将用来把我们上面写的 HTML 连接到我们的应用程序的。
我们现在必须创建我们的应用程序,我将把它存储在一个名为app的变量中:
app = Flask(__name__)
现在,我们需要处理路由——路由是一个 URL 模式,也就是说,你的网站的基本 URL 会有路由/,而你的网站中的另一个路由可能有路径/route_path。由于我们的应用程序只有一个页面,我们只需要为/路线编写一个函数。为了指定路径,我们在函数上方使用了一个装饰器,格式为@app.route(route_path)。该函数目前什么都不做,因为我们刚刚在主体中添加了一个pass。
@app.route("/")
def index():
pass
我们的功能需要做 4 件事:
- 加载一个名为
count.txt的文件,我们将使用它来跟踪当前访问站点的人数 - 将计数增加 1
- 用新的计数值覆盖
count.txt的内容 - 使用插入的 count 变量的值呈现我们之前编写的 HTML。
加载电流计数
让我们首先在主项目文件夹中创建一个名为count.txt的文件,其中只有0作为唯一的字符(因为我们目前没有访问者)。
(venv) > less count.txt0
count.txt (END)
现在,在我们的函数index()中,我们可以添加以下代码来读取count的当前值:
@app.route("/")
def index(): # Load current count
f = open("count.txt", "r")
count = int(f.read())
f.close()
我们以读取模式(r)打开文件count.txt,用f.read()读取文件内容,用int()将值转换为整数。最后,我们用f.close()关闭文件。
增加计数
我们可以用下面的一行代码做到这一点:
@app.route("/")
def index(): # Load current count
f = open("count.txt", "r")
count = int(f.read())
f.close() # Increment the count
count += 1
覆盖计数值
类似于我们在读取 count 时所做的,我们现在以覆盖模式(w)打开文件count.txt,并在再次关闭文件之前,将新 count 的值(用str()转换为字符串)写入文件。
@app.route("/")
def index(): # Load current count
f = open("count.txt", "r")
count = int(f.read())
f.close() # Increment the count
count += 1 # Overwrite the count
f = open("count.txt", "w")
f.write(str(count))
f.close()
渲染 HTML
既然我们每次路由到/时计数都会增加,我们需要呈现我们之前编写的 HTML,但是插入了count的值。还记得我们如何在名为templates的子文件夹中创建index.html文件吗?这是因为flask有一个名为render_template()的函数,它会自动查看这个文件夹,并可以获取与 HTML 文件中引用的变量相对应的关键字参数!在这种情况下,我们通过编写{{ count }}来引用 HTML 中名为count的变量的值。因此,通过使用render_template()传递值,我们可以在 HTML 中引用它。
@app.route("/")
def index(): # Load current count
f = open("count.txt", "r")
count = int(f.read())
f.close() # Increment the count
count += 1 # Overwrite the count
f = open("count.txt", "w")
f.write(str(count))
f.close() # Render HTML with count variable
return render_template("index.html", count=count)
运行应用程序
我们快完成了!要运行我们的应用程序,我们需要在我们的app.py代码中添加以下几行:
if __name__ == "__main__":
app.run()
当我们从命令行调用 Python 脚本时,上面的代码启动我们的应用程序 web 服务器。现在,运行我们的应用程序:
(venv) > python app.py* Serving Flask app "app" (lazy loading)
* Environment: production
WARNING: This is a development server. Do not use it in a production deployment.
Use a production WSGI server instead.
* Debug mode: off
* Running on [http://127.0.0.1:5000/](http://127.0.0.1:5000/) (Press CTRL+C to quit)
如输出所示,我们的 web 服务器运行在127.0.0.1:5000,也可以通过localhost:5000访问。导航到此 URL,您会发现:

呜哇!由于 count 的当前值也存储在count.txt文件中,所以即使您停止并重新启动 web 服务器,您也会得到准确的总计数值!
将应用程序部署到 Heroku
Heroku 是一项服务,它允许您部署这个 Python web 应用程序,这样任何拥有该链接的人都可以使用它。你应该做的第一件事是在 Heroku 上创建一个免费帐户。一旦你创建了一个帐户,从你的仪表板,点击按钮“创建新的应用程序”。在这里,为您的应用程序命名,然后单击“创建应用程序”。

在部署我们的 web 应用程序之前,我们需要添加几个文件供 Heroku 识别。第一个是名为requirements.txt的文件,本质上是一个 Python 依赖列表,Heroku server 需要安装它来运行您的应用程序。幸运的是,通过在虚拟环境中工作,您已经安装了所需的依赖项。因此,创建我们的requirements.txt文件非常简单:
(venv) > pip freeze > requirements.txt(venv) > less requirements.txtclick==7.1.2
Flask==1.1.2
gunicorn==20.0.4
itsdangerous==1.1.0
Jinja2==2.11.2
MarkupSafe==1.1.1
Werkzeug==1.0.1
requirements.txt (END)
这些都是之前运行pip install flask gunicorn时安装的依赖项。
第二个文件叫做Procfile,它是 Heroku 如何运行应用程序的指令列表。这个文件将是一行程序,它指定了两件事:
- 要使用的 web 服务器接口(
gunicorn - 应用程序的名称(
app)
web: gunicorn app:app
现在您已经创建了requirements.txt和Procfile,我们可以将所有这些签入我们的 GitHub repo:
(venv) > git add .
(venv) > git commit -m "Added web application files"
(venv) > git push origin main
现在,在我们的应用仪表板上,我们可以通过点击相关按钮来选择连接到 GitHub。然后我们将被重定向到登录 GitHub 并允许 Heroku 使用。然后,我们可以选择与我们的项目相关联的存储库。

将 Heroku 应用程序连接到 Github
最后,我们有两个选择:
- 自动部署—这将导致每次有新的推送到指定分支上的存储库时,应用程序都要重新部署。
- 手动部署—您可以通过单击按钮从指定分支手动部署应用程序

自动与手动应用程序部署
我们现在将手动部署-单击“部署”按钮后,您将看到几分钟的构建日志,之后您将看到您的应用是否已成功部署。
你可以点击“查看应用”来查看你的超棒的网络应用!你可以在这里看到这个教程的结果。请记住,如果你的应用程序没有收到很多流量,它会在几个小时后进入休眠模式,所以下次你试图访问它时,它可能需要几秒钟才能启动。此外,Heroku 机器每天重启一次,因此您将丢失对本地文件系统的更改。如果你想让count.txt文件不受影响,你应该把它放在像亚马逊 S3 这样的云文件存储系统上,并使用你的应用程序发出请求。然而,对于这个例子,我想保持简单,所以当机器重新启动时,计数会每隔一段时间重置一次。
本文中的所有代码都可以在这个库中找到。
结束语
感谢您的阅读!你可以在我的个人 GitHub 页面看到我的一些作品。我感谢任何反馈,你可以在 Twitter 上找到我,并在 LinkedIn 上与我联系,以获取更多更新和文章。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}