






一、感知器
最简单的神经网络单元是感知器。感知器在历史上是非常松散地模仿生物神经元的。它是一种最简单的人工神经网络模型
1、基本组成
(1)输入权重(Input Weights):每个输入信号都与一个权重相关联。这些权重表示了输入信号对感知器输出的重要性。较高的权重值意味着该信号对感知器的影响更大。
(2)总和函数(Summation Function):感知器将每个输入信号乘以相应的权重,并将它们求和,得到一个加权总和。这个加权总和被称为感知器的激活值。
(3)激活函数(Activation Function):激活函数会对感知器的激活值进行处理,产生一个输出值。常用的激活函数有阶跃函数、sigmoid函数和ReLU函数等。激活函数决定了感知器是否激活并输出一个信号。
(4)阈值(Threshold):感知器的输出值需要与一个阈值进行比较。如果输出值超过了阈值,则感知器被激活,否则不激活。
2、工作原理
(1)输入信号被乘以相应的权重,并求和得到加权总和。
(2)加权总和经过激活函数处理,产生输出值。
(3)输出值与阈值进行比较,确定感知器是否激活。
(4)激活的感知器可以将输出信号传递给其他神经元或执行特定的任务。
3、示例代码
实现一个感知器
import torch
import torch.nn as nn
class Perceptron(nn.Module):
""" 感知机是一个线性层 """
def __init__(self, input_dim):
"""
参数:
input_dim (int): 输入特征的大小
"""
super(Perceptron, self).__init__()
self.fc1 = nn.Linear(input_dim, 1)
def forward(self, x_in):
""" 感知机的前向传播
参数:
x_in (torch.Tensor): 输入数据张量。
x_in.shape 应为 (batch, num_features)
返回:
结果张量。tensor.shape 应为 (batch,)
"""
return torch.sigmoid(self.fc1(x_in)).squeeze()
感知器虽然简单,但它具有一定的局限性,例如只能处理线性可分问题。然而,通过堆叠多个感知器,可以构建更复杂的神经网络,进而解决更加复杂的任务。
二、激活函数
激活函数是神经网络中的一种数学函数,用于对神经元的输入进行非线性变换,并产生相应的输出。激活函数的作用是引入非线性特性,使得神经网络可以更好地拟合和表示非线性数据。在神经网络中,每个神经元接收来自前一层神经元的输入,并将这些输入加权求和后应用激活函数进行处理。激活函数的输出作为该神经元的输出,同时传递给下一层神经元。
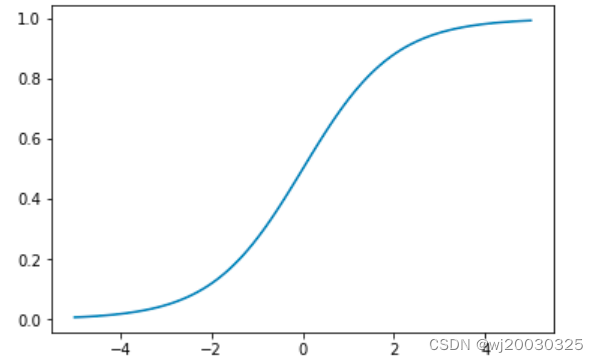
1、sigmoid函数
Sigmoid函数是一种常用的激活函数,它将输入映射到一个取值范围在0到1之间的输出。其数学表达式为:
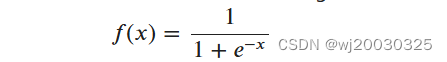
函数实现:
import torch
import matplotlib.pyplot as plt
# 生成输入数据
x = torch.arange(-5., 5., 0.1)
y = torch.sigmoid(x)
# 绘制sigmoid函数图像
plt.plot(x.numpy(), y.numpy())
plt.show()
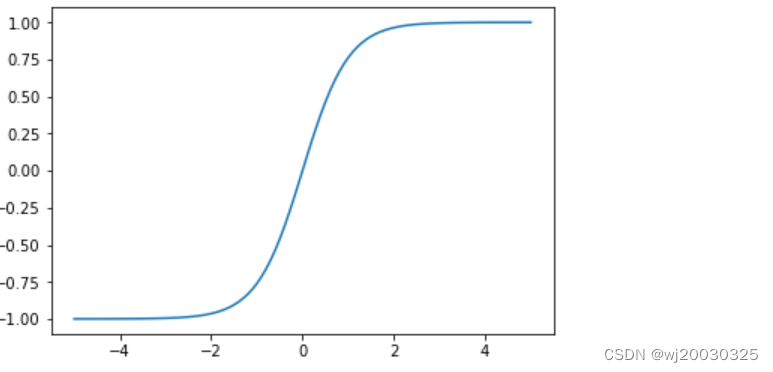
2、Tanh函数
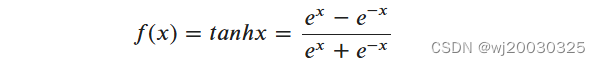
性质与特点
- 取值范围: 输出值在-1到1之间。
- 对称性: Tanh函数是关于原点对称的,这种对称性使得它在训练过程中比Sigmoid函数更有效,因为输出的均值更接近0,有助于减少偏移。
- 平滑性: Tanh函数是平滑且连续的,其导数也是连续的,有利于梯度下降算法的应用。
- 梯度问题: 虽然Tanh函数在某些方面优于Sigmoid函数,但它仍然存在梯度消失问题。当输入值非常大或非常小时,导数趋近于零,导致梯度更新变得非常缓慢。
函数实现
import torch
import matplotlib.pyplot as plt
# 生成输入数据
x = torch.arange(-5., 5., 0.1)
y = torch.tanh(x)
# 绘制双曲正切函数图像
plt.plot(x.numpy(), y.numpy())
plt.show()
3、ReLU函数
ReLU代表线性整流单元。这可以说是最重要的激活函数。
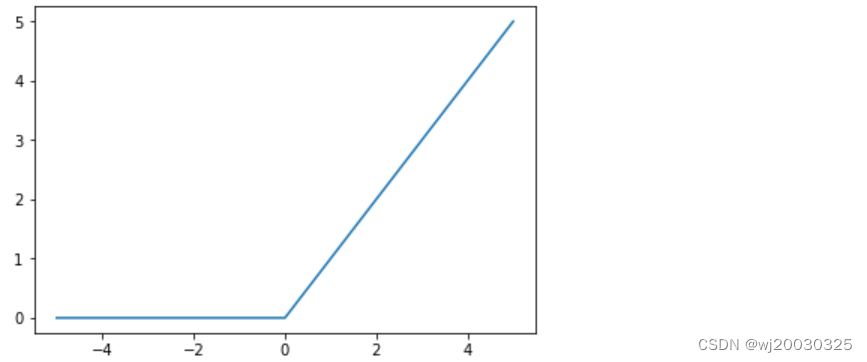
𝑓(𝑥)=𝑚𝑎𝑥(0,𝑥)
(1)图像和性质
形状: ReLU函数的图像在输入大于或等于0时是一个45度的直线,而在输入小于0时是水平的。
取值范围: 输出范围从0到正无穷。
计算简便: 由于ReLU的计算是一个简单的阈值操作,它的计算量非常小,使得训练速度更快。
代码实现:
import torch
import matplotlib.pyplot as plt
# 创建ReLU激活函数实例
relu = torch.nn.ReLU()
# 生成输入数据
x = torch.arange(-5., 5., 0.1)
y = relu(x)
# 绘制ReLU函数图像
plt.plot(x.numpy(), y.numpy())
plt.show()
4、softmax函数
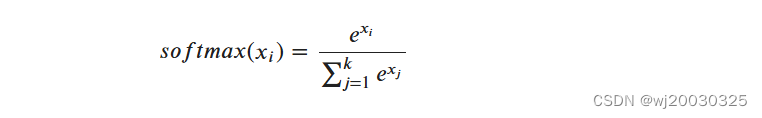
(1)性质
归一化:Softmax函数可以将输入转化为概率分布,因为它确保了所有元素的和为1。
增强大的值:Softmax函数会增强大的输入值,抑制小的输入值,使得最大的值更接近1,最小的 值更接近0。
对输入敏感:Softmax函数对输入值的大小非常敏感,所以在实践中需要小心处理数值上溢或下 溢的情况。
函数实现
import torch.nn as nn
import torch
# 创建Softmax激活函数实例,指定维度为1
softmax = nn.Softmax(dim=1)
# 生成输入数据
x_input = torch.randn(1, 3)
# 将输入数据通过Softmax函数进行转换
y_output = softmax(x_input)
# 打印输入和输出
print("输入数据:")
print(x_input)
print("Softmax转换后的输出:")
print(y_output)
print("每个样本输出的概率之和:")
print(torch.sum(y_output, dim=1))
二、损失函数
损失函数是用于度量模型预测值与实际值之间差异的函数。在机器学习和深度学习中,损失函数是用来衡量预测结果与真实值之间的误差,并作为模型优化的目标函数。
1、均方误差
是一种常用的回归任务损失函数,用于度量模型预测值与实际值之间的差异。它计算预测值与真实值之间差值的平方的均值。均方误差越小,表示模型的预测结果与真实值之间的差异越小,模型的拟合效果越好。在训练过程中,通常使用梯度下降等优化算法来最小化均方误差,以更新模型参数,提高模型的准确性和泛化能力。
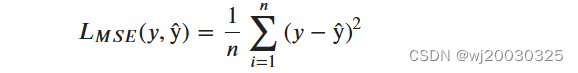
函数实现
import torch
import torch.nn as nn
# 创建均方误差损失函数实例
mse_loss = nn.MSELoss()
# 生成模型输出和目标值
outputs = torch.randn(3, 5, requires_grad=True)
targets = torch.randn(3, 5)
# 计算均方误差损失
loss = mse_loss(outputs, targets)
# 打印损失值
print("均方误差损失值:")
print(loss)
2、分类交叉熵损失
通常用于多类分类设置,其中输出被解释为类隶属度概率的预测。目标(y)是 n 个元素的向量,表示所有类的真正多项分布。如果只有一个类是正确的,那么这个向量就是 one hot 向量。网络的输出(ŷ)(ŷ)也是一个向量 n 个元素,但代表了网络的多项分布的预测。
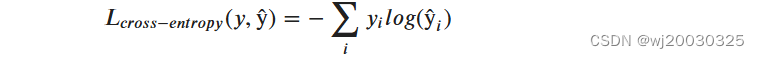
















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









