







目录
未经允许,禁止将其复制下来上传到百度文库等平台。如有转载请注明本文博客的地址(链接)
分析所要爬取的数据
在爬虫之前需要分析自己需要爬的数据。本文爬取的是所有http://esf.hf.fang.com/链接对应的房源的id,title,url。如下图所示:
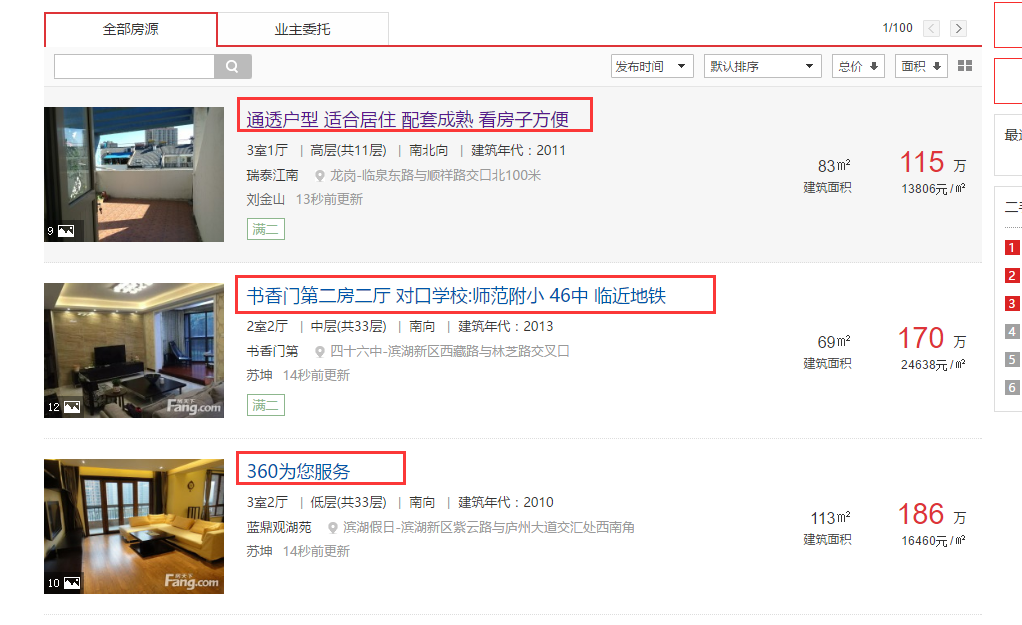
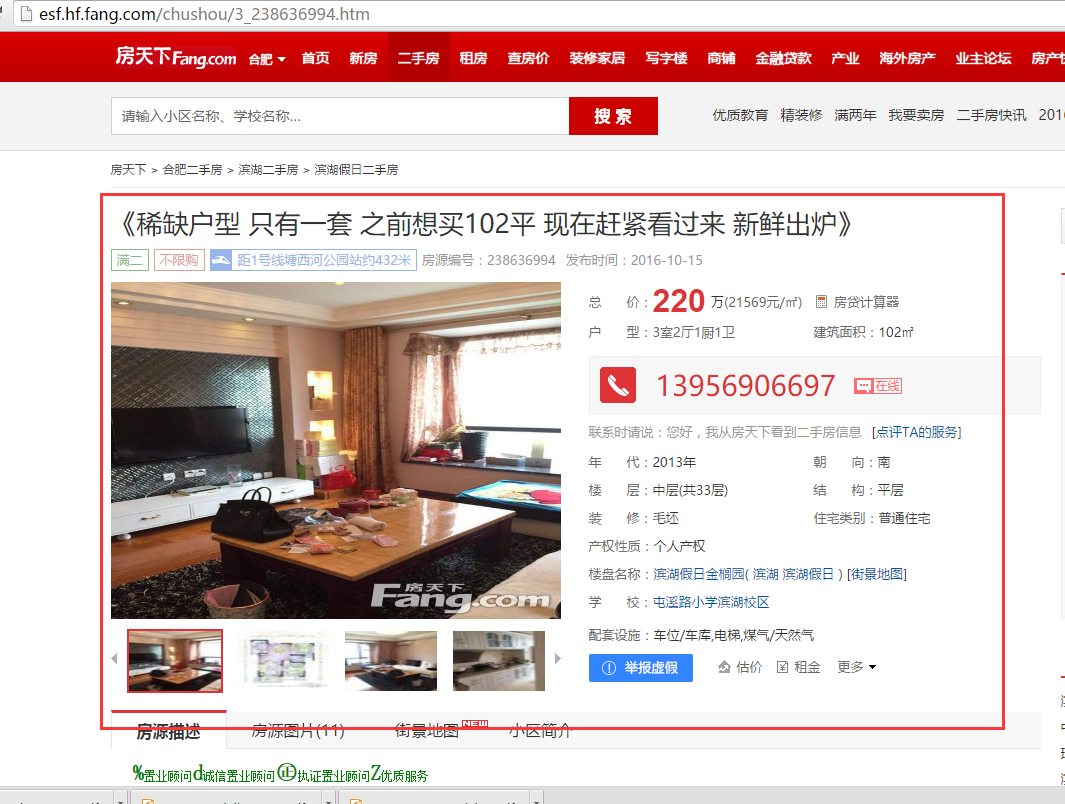
这属于第一层所要获取的数据。第二层是获取每个房源对应的详细信息。其爬取的种子url,来自于第一层所获得的所有url。如下图所示:为第二层次所要获取的信息内容。
爬虫框架
本文的爬虫框架如下图所示:
有不明白框架里的内容含义的话,请看我写的其他相关博客。
基于java的网络爬虫框架(实现京东数据的爬取,并将插入数据库):
http://blog.csdn.net/qy20115549/article/details/52203722
Java多线程网络爬虫(时光网为例):http://blog.csdn.net/qy20115549/article/details/52648631
首先,我的工程都是使用maven建的,不会使用maven的,请看之前写的网络爬虫基础。使用spring MVC框架编写过网站的同学,可以看出框架的重要性与逻辑性。在我的网络爬虫框架中,包含的package有db、main、model、parse、util五个文件。
db:主要放的是数据库操作文件,包含MyDataSource【数据库驱动注册、连接数据库的用户名、密码】,MYSQLControl【连接数据库,插入操作、更新操作、建表操作等】。
model:用来封装对象,比如我要获取京东书籍的ID、书名、价格,则需要在model写入对应的属性。说的直白一些,封装的就是我要操作数据对应的属性名。有不明白的看之前写的一个简单的网络爬虫。
util:主要放的是httpclient的内容,主要作用时将main方法,传过来的url,通过httpclient相关方法,获取需要解析的html文件或者json文件等。
parse:这里面存放的是针对util获取的文件,进行解析,一般采用Jsoup解析;若是针对json数据,可采用正则表达式或者fastjson工具进行解析,建议使用fastjson,因其操作简单,快捷。
main:程序起点,也是重点,获取数据,执行数据库语句,存放数据。
model
用来封装对象,即我要爬取的相关信息。如针对搜房网而言,我需要爬取的数据为:发布房源的标题(title),这条房源信息的id等。
package model;
/*
* author:合肥工业大学 管院学院 钱洋
*1563178220@qq.com
*博客地址:http://blog.csdn.net/qy20115549/
*/
public class Address {
private String addr_id;
private String addr_url;
private String title;
private String craw_time;
public String getAddr_id() {
return addr_id;
}
public void setAddr_id(String addr_id) {
this.addr_id = addr_id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getAddr_url() {
return addr_url;
}
public void setAddr_url(String addr_url) {
this.addr_url = addr_url;
}
public String getCraw_time() {
return craw_time;
}
public void setCraw_time(String craw_time) {
this.craw_time = craw_time;
}
}
以下Contents 表示的下面图片中的信息。
package model;
/*
* author:合肥工业大学 管院学院 钱洋
*1563178220@qq.com
*博客地址:http://blog.csdn.net/qy20115549/
*/
public class Contents {
private String id;
private String title;
private String publishtime;
private String price;
private String housetype;
private String acreage;
private String useacreage;
private String years;
private String orientation;
private String floor;
private String structure;
private String decoration;
private String type;
private String buildingtype;
private String propertyright;
private String estate;
private String school;
private String facilities;
public String getUseacreage() {
return useacreage;
}
public void setUseacreage(String useacreage) {
this.useacreage = useacreage;
}
public String getId() {
return id;
}
public String getPublishtime() {
return publishtime;
}
public void setPublishtime(String publishtime) {
this.publishtime = publishtime;
}
public void setId(String id) {
this.id = id;
}
public String getPrice() {
return price;
}
public void setPrice(String price) {
this.price = price;
}
public String getHousetype() {
return housetype;
}
public void setHousetype(String housetype) {
this.housetype = housetype;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getAcreage() {
return acreage;
}
public void setAcreage(String acreage) {
this.acreage = acreage;
}
public String getYears() {
return years;
}
public void setYears(String years) {
this.years = years;
}
public String getOrientation() {
return orientation;
}
public void setOrientation(String orientation) {
this.orientation = orientation;
}
public String getFloor() {
return floor;
}
public void setFloor(String floor) {
this.floor = floor;
}
public String getStructure() {
return structure;
}
public void setStructure(String structure) {
this.structure = structure;
}
public String getDecoration() {
return decoration;
}
public void setDecoration(String decoration) {
this.decoration = decoration;
}
public String getType() {
return type;
}
public void setType(String type) {
this.type = type;
}
public String getBuildingtype() {
return buildingtype;
}
public void setBuildingtype(String buildingtype) {
this.buildingtype = buildingtype;
}
public String getPropertyright() {
return propertyright;
}
public void setPropertyright(String propertyright) {
this.propertyright = propertyright;
}
public String getEstate() {
return estate;
}
public void setEstate(String estate) {
this.estate = estate;
}
public String getSchool() {
return school;
}
public void setSchool(String school) {
this.school = school;
}
public String getFacilities() {
return facilities;
}
public void setFacilities(String facilities) {
this.facilities = facilities;
}
}
main
主方法,尽量要求简单,这里由于注释清晰,我就不多写了。
package main;
import java.io.IOException;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.List;
import model.Address;
import org.apache.http.ParseException;
import org.apache.http.client.HttpClient;
import org.apache.http.impl.client.DefaultHttpClient;
import db.MYSQLControl;
import util.SouFangAddressFecter;
/*
* author:合肥工业大学 管院学院 钱洋
*1563178220@qq.com
*博客地址:http://blog.csdn.net/qy20115549/
*/
public class SouFangAddress {
public static void main(String[] args) throws ParseException, IOException, SQLException, InterruptedException {
HttpClient client = new DefaultHttpClient(); //初始化HTTPclient
//初始地址
String _url ="http://esf.hf.fang.com/";
List<Address> addresses=new ArrayList<Address>();
/调用函数,爬取数据
addresses= SouFangAddressFecter.htmlGet(client, _url);
//操作数据库,将获取的数据插入数据库
MYSQLControl.executeAddressUpdate(addresses);
}
}
util
SouFangAddressFecter类与HTTPUtils的作用时将main方法传来的url,使用httpclient的方法,向后台请求数据,并返回html。
package util;
import java.io.IOException;
import org.apache.http.HttpResponse;
import org.apache.http.HttpStatus;
import org.apache.http.HttpVersion;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.message.BasicHttpResponse;
/*
* author:合肥工业大学 管院学院 钱洋
*1563178220@qq.com
*博客地址:http://blog.csdn.net/qy20115549/
*/
public abstract class HTTPUtils {
public static HttpResponse getRawHtml(HttpClient client, String personalUrl) {
//创建请求方法,这里可采用get方式
HttpGet getMethod = new HttpGet(personalUrl);
HttpResponse response = new BasicHttpResponse(HttpVersion.HTTP_1_1,
HttpStatus.SC_OK, "OK");
try {
//执行get方法,请求数据
response = client.execute(getMethod);
} catch (IOException e) {
e.printStackTrace();
} finally {
// getMethod.abort();
}
return response;
}
}
SouFangAddressFecter 类中,一般获取entity (html)的内容一般一行代码就行了。
String entity = EntityUtils.toString (response.getEntity(),"UTF-8");但通过我的分析,直接这样请求数据会出现乱码。原因是 Content-Encoding :gzip。数据是经过压缩的。所以,要先解压流数据。
GzipDecompressingEntity zipRes = new GzipDecompressingEntity(response.getEntity());
String s = EntityUtils.toString(zipRes, "gb2312");完整的SouFangAddressFecter 的代码如下。
package util;
import java.io.IOException;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.List;
import model.Address;
import org.apache.http.HttpResponse;
import org.apache.http.ParseException;
import org.apache.http.client.HttpClient;
import org.apache.http.client.entity.GzipDecompressingEntity;
import org.apache.http.util.EntityUtils;
import parse.SouFangAddressParser;
/*
* author:合肥工业大学 管院学院 钱洋
*1563178220@qq.com
*博客地址:http://blog.csdn.net/qy20115549/
*/
public class SouFangAddressFecter {
public static List<Address> htmlGet (HttpClient client, String url) throws ParseException, IOException, SQLException, InterruptedException {
List<Address> AddressInfo = new ArrayList<Address>();
HttpResponse response = HTTPUtils.getRawHtml(client, url);
int StatusCode = response.getStatusLine().getStatusCode();
if(StatusCode == 200){
//由于此方法总是出现乱码
// String entity = EntityUtils.toString (response.getEntity(),"UTF-8");
//输出实体内容,不会乱码,乱码解决。由于数据是通过zip压缩的
GzipDecompressingEntity zipRes = new GzipDecompressingEntity(response.getEntity());
String s = EntityUtils.toString(zipRes, "gb2312");
//解析实体内容
AddressInfo = SouFangAddressParser.getdata(s);
EntityUtils.consume(response.getEntity());
}else {
//关闭HttpEntity的流实体
EntityUtils.consume(response.getEntity());
}
return AddressInfo;
}
}
parse
此部分内容复制解析SouFangAddressFecter传过来的内容,即html。这里面包含了如何翻页。
package parse;
import java.io.IOException;
import java.sql.SQLException;
import java.text.DateFormat;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Date;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import model.Address;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
/*
* author:合肥工业大学 管院学院 钱洋
*1563178220@qq.com
*博客地址:http://blog.csdn.net/qy20115549/
*/
public class SouFangAddressParser {
public static List<Address> getdata(String entity) throws SQLException, InterruptedException, IOException {
List<Address> addresses = new ArrayList<Address>();
//获取html文件
Document doc = Jsoup.parse(entity);
//获取总页数
int sumpages=Integer.parseInt(doc.select("div[class=fanye gray6]").select("span[class=txt]").text().replaceAll("\\D", ""));
//由于此网站,第一页和第二页等有重复的房源,有重读的id。防止有重复id出现,这里使用map
Map<String, Integer> keymap=new HashMap<String, Integer>();
for (int i = 1; i < sumpages; i++) {
String everypageurl="http://esf.hf.fang.com/house/i3"+i;
//这里我就直接用Jsoup请求了
Document document = Jsoup.connect(everypageurl).timeout(50000).userAgent("bbbb").get();
Elements elements=document.select("dl[id~=D03_?]");
//获取每一个子内容
for (Element ele:elements) {
String id=ele.select("dd[class=info rel floatr]").select("p").select("a").attr("href").replaceAll("/chushou/", "").replaceAll(".htm", "");
if (!keymap.containsKey(id)){
keymap.put(id, 1);
String url="http://esf.hf.fang.com/"+ele.select("dd[class=info rel floatr]").select("p").select("a").attr("href");
String title=ele.select("dd[class=info rel floatr]").select("p[class=title]").select("a").text();
Date date=new Date();
DateFormat format=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String craw_time=format.format(date);
Address address = new Address();
address.setAddr_id(id);
address.setAddr_url(url);
address.setCraw_time(craw_time);
address.setTitle(title);
addresses.add(address);
}
}
}
//获取拼接地址
return addresses;
}
}
db数据库操作
db中包含两个java文件,MyDataSource,MYSQLControl。这两个文件的作用已在前面说明了。
package db;
import javax.sql.DataSource;
import org.apache.commons.dbcp2.BasicDataSource;
/*
* author:合肥工业大学 管院学院 钱洋
*1563178220@qq.com
*博客地址:http://blog.csdn.net/qy20115549/
*/
public class MyDataSource {
public static DataSource getDataSource(String connectURI){
BasicDataSource ds = new BasicDataSource();
//MySQL的jdbc驱动
ds.setDriverClassName("com.mysql.jdbc.Driver");
ds.setUsername("root"); //所要连接的数据库名
ds.setPassword("112233"); //MySQL的登陆密码
ds.setUrl(connectURI);
return ds;
}
}
package db;
import java.sql.SQLException;
import java.util.List;
import javax.sql.DataSource;
import org.apache.commons.dbutils.QueryRunner;
import org.apache.commons.dbutils.handlers.BeanListHandler;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import model.Address;
import model.Contents;
/*
* author:合肥工业大学 管院学院 钱洋
*1563178220@qq.com
*博客地址:http://blog.csdn.net/qy20115549/
*/
public class MYSQLControl {
static final Log logger = LogFactory.getLog(MYSQLControl.class);
static DataSource ds = MyDataSource.getDataSource("jdbc:mysql://127.0.0.1:3306/soufang");
static QueryRunner qr = new QueryRunner(ds);
//查询数据的类
public static <T> List<T> getListInfoBySQL (String sql, Class<T> type ){
List<T> list = null;
try {
list = qr.query(sql,new BeanListHandler<T>(type));
} catch (SQLException e) {
e.printStackTrace();
}
return list;
}
//插入数据soufang_address
public static void executeAddressUpdate(List<Address> addresses) throws SQLException {
//定义一个Object数组,行列
Object[][] params = new Object[addresses.size()][4];
for ( int i=0; i<params.length; i++ ){
params[i][0] = addresses.get(i).getAddr_id();
params[i][1] = addresses.get(i).getTitle();
params[i][2] = addresses.get(i).getAddr_url();
params[i][3] = addresses.get(i).getCraw_time();
}
try{
qr.batch("insert into soufang_address (id, title,url,craw_time)"
+ "values (?,?,?,?)", params);
}catch( Exception e){
logger.error(e);
}
}
//操作数据库,插入房源的详细信息
public static void executeContentInsert(List<Contents> contentinfo) throws SQLException {
Object[][] params = new Object[contentinfo.size()][18];
for ( int i=0; i<params.length; i++ ){
params[i][0] = contentinfo.get(i).getId();
params[i][1] = contentinfo.get(i).getTitle();
params[i][2] = contentinfo.get(i).getPublishtime() ;
params[i][3] = contentinfo.get(i).getPrice();
params[i][4] = contentinfo.get(i).getHousetype();
params[i][5] = contentinfo.get(i).getAcreage() ;
params[i][6] = contentinfo.get(i).getUseacreage();
params[i][7] = contentinfo.get(i).getYears();
params[i][8] = contentinfo.get(i).getOrientation() ;
params[i][9] = contentinfo.get(i).getFloor();
params[i][10] = contentinfo.get(i).getStructure();
params[i][11] = contentinfo.get(i).getDecoration() ;
params[i][12] = contentinfo.get(i).getType();
params[i][13] = contentinfo.get(i).getBuildingtype();
params[i][14] = contentinfo.get(i).getPropertyright() ;
params[i][15] = contentinfo.get(i).getEstate() ;
params[i][16] = contentinfo.get(i).getSchool();
params[i][17] = contentinfo.get(i).getFacilities() ;
}
try{
qr.batch("insert into soufang_content (id, title,publishtime, price,housetype,acreage,useacreage,years,orientation,floor,structure,decoration,type,buildingtype,propertyright,estate,school,facilities)"
+ "values (?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?)", params);
System.out.println("共插入:\t"+contentinfo.size()+"条数据!");
}catch( Exception e){
logger.error(e);
}
}
}
爬虫如何实现翻页(地址拼接)
如下图所示,为搜房网的页码,对应的html标签信息。
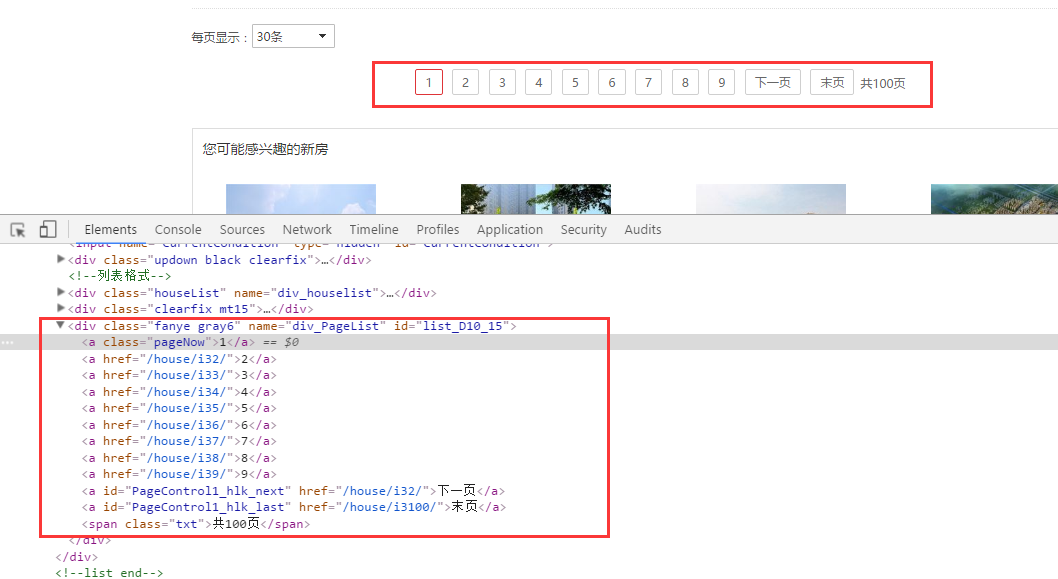
使用Jsoup将总页数获取下来,然后采用循环,爬虫每页内容。这里涉及到url的拼接。我们发现第二页和第三页的地址分别是如下两个图。


以下是代码表示:
//获取总页数
int sumpages=Integer.parseInt(doc.select("div[class=fanye gray6]").select("span[class=txt]").text().replaceAll("\\D", ""));
for (int i = 1; i < sumpages; i++){
//地址拼接
String everypageurl="http://esf.hf.fang.com/house/i3"+i;
//采用Jsoup获取每一个的响应数据,并解析
ocument document = Jsoup.connect(everypageurl).timeout(50000).userAgent("bbbb").get();
//解析数据。。。。。。。
}网络爬虫如何解决主键重复问题
在写网络爬虫时,我们经常会遇到置顶帖。这种置顶帖在每页都有。一种解决的办法,我直接利用split的方法,将前半部分过滤。另一种办法是使用map的方法。
由于搜房网,在每一页都有相同的信息,其id也是一样。为此,我使用map的方法,过滤掉重复数据,相同数据只保留一条。
//创建map用来过滤数据
Map<String, Integer> keymap=new HashMap<String, Integer>();
for (int i = 1; i < sumpages; i++) {
String everypageurl="http://esf.hf.fang.com/house/i3"+i;
//这里我就直接用Jsoup请求了
Document document = Jsoup.connect(everypageurl).timeout(50000).userAgent("bbbb").get();
Elements elements=document.select("dl[id~=D03_?]");
//获取每一个子内容
for (Element ele:elements) {
String id=ele.select("dd[class=info rel floatr]").select("p").select("a").attr("href").replaceAll("/chushou/", "").replaceAll(".htm", "");
//如果不包含id,则获取数据,否则还未为原来的数据
if (!keymap.containsKey(id)){
keymap.put(id, 1);
String url="http://esf.hf.fang.com/"+ele.select("dd[class=info rel floatr]").select("p").select("a").attr("href");
String title=ele.select("dd[class=info rel floatr]").select("p[class=title]").select("a").text();
}
}
}本文为原创博客,仅供技术学习使用。未经允许,禁止将其复制下来上传到百度文库等平台。















 536
536

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









