







文章目录
在这篇博客中,我们提供了一份详尽的分析和实用指南,用于进行微调。我们在三个真实世界的使用案例下研究了Llama-2模型,并展示了微调在各个方面都能显著提高准确性(在某些特定情况下,甚至比GPT-4更好)。实验是使用这个 脚本进行的。
近几个月来,大型开放语言模型取得了重大进展,为适用于企业应用的商业化解决方案铺平了道路。其中Llama-2和Falcon模型是值得注意的。虽然像GPT-4和Claude-2这样功能强大的通用语言模型为项目提供了快速访问和快速反馈,但它们往往对许多应用的需求来说过于庞大。
例如,如果目标是总结支持票并将问题分类到预定的桶中,那么就没有必要使用能够以莎士比亚风格生成散文的模型。将安全问题放在一边,对于这样的任务使用GPT-4就像是用太空船进行市内通勤。为了支持这一观点,我们研究了在三个任务上对不同规模的Llama-2模型进行微调:
-
从非结构化文本中提取的功能表示(ViGGO)
-
SQL生成(SQL-create-context)
-
小学数学问题回答(GSM8k)
我们具体展示了在某些任务上(例如SQL生成或功能表示),我们可以通过微调小型Llama-2模型使其变得比GPT-4更好。与此同时,即使经过微调,开源模型在数学推理和理解等任务上仍然稍逊一筹。
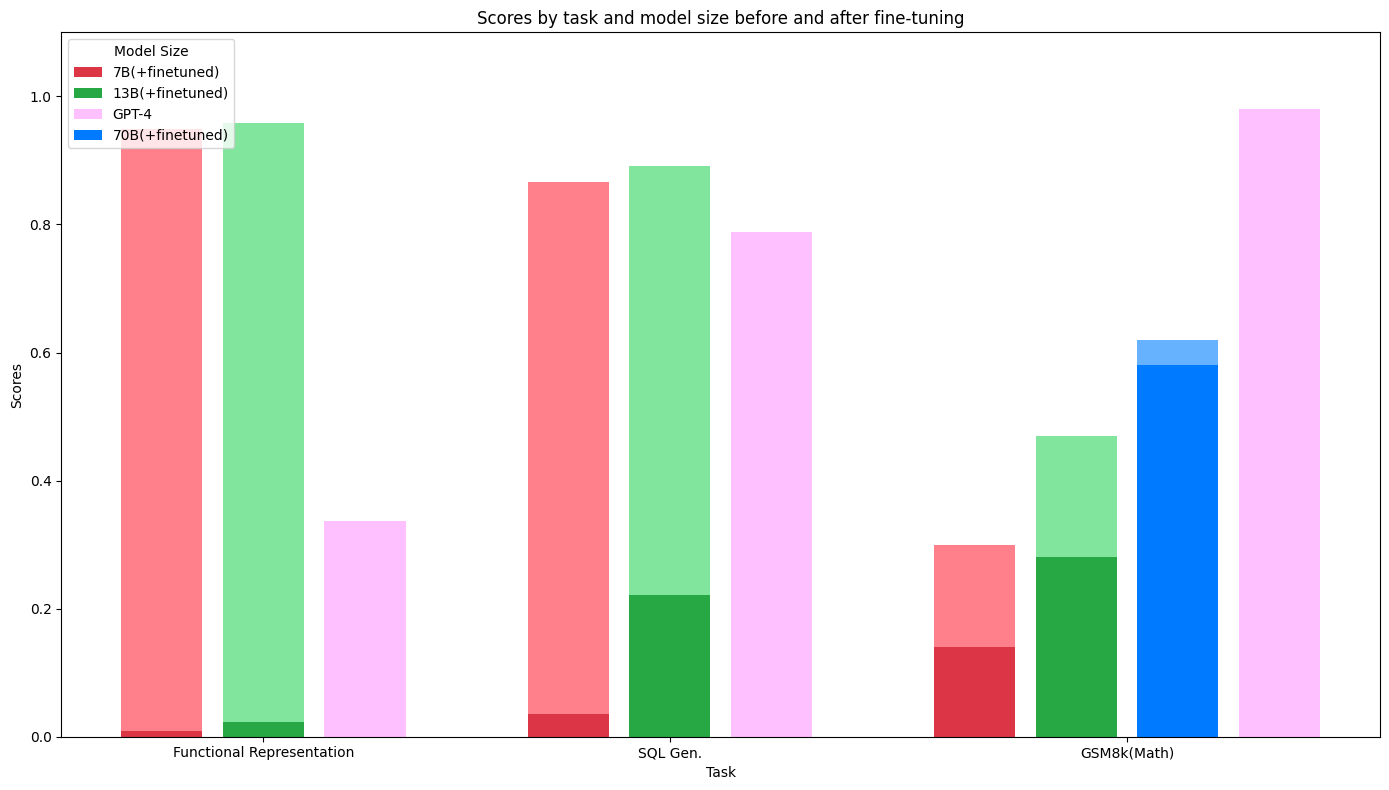
Llama-2模型通过在每个任务上进行微调获得的性能提升。每种颜色的较深色阴影表示带有基准提示的Llama-2-chat模型的性能。紫色显示具有相同提示的GPT-4的性能。堆叠的条形图显示了通过微调Llama-2基础模型获得的性能提升。在功能表示和SQL生成任务中,通过微调,我们可以实现比GPT-4更好的性能,而在某些其他任务(如数学推理),微调模型虽然在基础模型上有所改进,但仍无法达到GPT-4的性能水平。
特别是,我们展示了使用Llama-13b变体在功能表示中从58%提高到98%,在SQL生成中从42%提高到89%,在GSM上从28%提高到47%的准确性。所有这些实验都是使用Anyscale Endpoints提供的Anyscale微调和服务平台完成的。
除了提供更多的定量结果外,本博客文章还将深入探讨如何利用Llama-2模型进行专门任务。我们将讨论正确的问题形式化,评估管道的设置等等。我们将比较提示工程和少量提示与微调等方法,沿途提供具体的优缺点。
微调这些模型并不是一项简单的任务。然而,Ray和Anyscale提供了独特的功能,使这个过程更快、更便宜、更易于管理。我们的使命是尽可能迅速地使企业能够利用最新的AI进展。
我们希望本文所涵盖的细节可以帮助其他人通过强调数据质量和评估程序从他们的LLM中提取更多的价值。
微调基础知识
对于所有三个任务,我们使用标准的全参数微调技术。模型进行下一个令牌预测的微调,模型中的所有参数都受到梯度更新的影响。虽然训练LLM的确有其他技术,例如冻结选择的变压器块和LoRA,但为了保持狭窄的范围,我们将训练技术本身从任务到任务保持不变。
在这种规模的模型上进行全参数微调并不是一项容易的任务。然而,如果我们使用正确的库组合,我们的生活可以变得更加轻松。我们用于在本博客文章中产生结果的脚本可以在此处找到。该脚本建立在Ray Train、Ray Data、Deepspeed和Accelerate之上,允许您轻松运行Llama-2 7B、13B或70B模型。我们将在以下子部分中概述一些高级细节,但我们建议您查看脚本本身以获取有关如何运行它的详细信息。
一般的训练流程
在没有跨多个节点扩展工作负载的情况下,训练这些大规模模型非常困难。我们的脚本围绕一个单一的训练函数展开,其中模型的梯度更新实际发生:
# 定义一个训练函数,参数为一个字典类型的kwargs
def training_function(kwargs: dict):
# 打印训练函数被调用的信息
print("training_function called")
…
# 循环训练num_epochs次
for epoch in range(num_epochs):
…
# 将模型设置为训练模式
model.train()
…
关键在于这个训练函数在每个独立的工作进程上运行,可能分布在多台机器上。在Ray Train中,我们使用TorchTrainer类作为进程调度器,并在我们的集群上扩展这个训练循环。我们可以让TorchTrainer知道我们想要使用多少个工作进程以及每个进程需要多少资源:
scaling_config=air.ScalingConfig(
...
num_workers=args.num_devices, # 设置工作节点的数量为args.num_devices
use_gpu=True, # 使用GPU加速
resources_per_worker={"GPU": 1}, # 每个工作节点分配1个GPU资源
),
从这里开始,主要的挑战是如何在我们的个别训练函数之间分割工作。直观上,在训练模型时有两种方法可以"分割"工作:一种是将模型、梯度和优化器状态分片分配给工作节点,同时也将数据分片分配给它们。在数据方面,Ray Train帮助我们管理数据摄取和数据集在训练循环中的分片。在训练循环的顶部,工作节点可以通过以下方式访问分配给它的数据集分片:
# 获取训练数据集
train_ds = session.get_dataset_shard("train")
# 获取验证数据集
valid_ds = session.get_dataset_shard("valid")
模型分片是通过DeepSpeed完成的。DeepSpeed定义了一种策略,用于如何在节点之间拆分模型以及何时将计算和内存从GPU卸载到CPU(我们使用带有优化器状态卸载的ZeRO阶段3)。请注意,由于模型的不同块被委派给不同的工作人员,如果我们想在任何一个节点上完整地访问模型(例如,如果我们想对其进行检查点),我们需要“展开”模型:
unwrapped_model = accelerator.unwrap_model(model) # 使用加速器解封装模型
unwrapped_model.save_pretrained(
ckpt_path_epoch, # 指定保存路径
is_main_process=accelerator.is_main_process, # 判断当前进程是否为主进程
save_function=accelerator.save, # 保存函数
safe_serialization=True, # 安全序列化
state_dict=accelerator.get_state_dict(model), # 获取模型的状态字典
)
特殊标记
为了有效地进行微调,数据需要适当地结构化。我们可以通过使用“特殊标记”将任务的提示编码为纯文本,而不是将其描述为LLM的指令:
之前:
{"text": "You are to solve the following math question. Please write
out your reasoning ... etc ... {question}\n{answer}"}
之后:
# 定义一个字符串变量,表示语料的格式
corpus = '{"text": "<START_Q>{question}<END_Q><START_A>{answer}<END_A>}'
特殊标记允许我们轻松地编码任务的结构,并提供一个信号,告诉模型何时停止生成输出。在上面的示例中,我们可以定义“<END_A>”作为停止标记。这将确保模型在完成任务后停止生成输出,而不是等待它输出一个句子结束标记。
Llama模型的分词器默认输出32000个唯一的标记ID。在将上述四个特殊标记添加到分词器后,它将输出32004个唯一的ID - “<START_Q>”的ID为32000,“<END_Q>”的ID为32001,依此类推。在我们的脚本中,这些特殊标记被添加如下:
tokenizer = AutoTokenizer.from_pretrained(pretrained_path, ...)
tokenizer.add_tokens(special_tokens, special_tokens=True)
# 这将为专用的特殊标记创建新的可学习参数
model.resize_token_embeddings(len(tokenizer))
计算细节
对于7B和13B模型,我们使用了16个A10G,对于70B模型,我们使用了32个A10G(跨4个g5.48xlarge实例)。使用Ray时,无需安全地对A100进行全参数微调这些模型!该过程仅针对每个任务重复进行。下面的图表显示了基于512个上下文长度,在GSM8k数据集上每个时期总共有3.7M有效令牌的示例运行。
我们最多运行10个时期的训练,并根据验证集上最小困惑度得分选择最佳检查点。
对非结构化文本的功能表示(ViGGO)
我们首先要研究的任务是基于ViGGO数据集。这是一个以英语为基础的数据到文本生成数据集,其中的数据围绕着对视频游戏的意见。原始任务涉及将“功能表示”(一组属性-值对)转化为连贯的文本,其中包含了这些属性。然而,我们将颠倒这个任务:将非结构化文本转化为结构化且可解析的“功能表示”。这种表示压缩了文本中存在的信息,并可用于索引和其他下游应用。虽然领域只是视频游戏,但这个一般性问题是许多企业渴望解决的问题。
示例数据点
让我们来看一个来自这个任务的示例,以了解它对LLM可能带来的困难程度。

给定一个目标句子,模型必须将输入句子的基本含义构建为具有属性和属性值的单个函数。该函数应准确描述目标字符串,并且必须是以下之一:
['inform', 'request', 'give_opinion', 'confirm', 'verify_attribute',
'suggest', 'request_explanation', 'recommend', 'request_attribute']
属性必须是以下之一:
['name', 'release_year', 'esrb', 'genres', 'platforms', 'available_on_steam',
'has_linux_release', 'has_mac_release', 'specifier', 'rating', 'player_perspective',
'has_multiplayer', 'developer', 'exp_release_date']
让我们提示一些模型,看看它们是否能够接近我们的意图。以下是我们使用的提示:
Given a target sentence construct the underlying meaning representation
of the input sentence as a single function with attributes and attribute
values. This function should describe the target string accurately and the
function must be one of the following ['inform', 'request', 'give_opinion',
'confirm', 'verify_attribute', 'suggest', 'request_explanation',
'recommend', 'request_attribute'] .
The attributes must be one of the following:
['name', 'exp_release_date', 'release_year', 'developer', 'esrb', 'rating',
'genres', 'player_perspective', 'has_multiplayer', 'platforms',
'available_on_steam', 'has_linux_release', 'has_mac_release', 'specifier']
The order your list the attributes within the function must follow the
order listed above. For example the 'name' attribute must always come
before the 'exp_release_date' attribute, and so forth.
For each attribute, fill in the corresponding value of the attribute
within brackets. A couple of examples are below. Note: you are to output
the string after "Output: ". Do not include "Output: " in your answer.
Example 1)
Sentence: Dirt: Showdown from 2012 is a sport racing game for the
PlayStation, Xbox, PC rated E 10+ (for Everyone 10 and Older).
It's not available on Steam, Linux, or Mac.
Output: inform(name[Dirt: Showdown], release_year[2012],
esrb[E 10+ (for Everyone 10 and Older)], genres[driving/racing, sport],
platforms[PlayStation, Xbox, PC], available_on_steam[no],
has_linux_release[no], has_mac_release[no])
Example 2)
Sentence: Were there even any terrible games in 2014?
Output: request(release_year[2014], specifier[terrible])
Example 3)
Sentence: Adventure games that combine platforming and puzzles
can be frustrating to play, but the side view perspective is
perfect for them. That's why I enjoyed playing Little Nightmares.
Output: give_opinion(name[Little Nightmares], rating[good],
genres[adventure, platformer, puzzle], player_perspective[side view])
Example 4)
Sentence: Since we're on the subject of games developed by Telltale
Games, I'm wondering, have you played The Wolf Among Us?
Output: recommend(name[The Wolf Among Us], developer[Telltale Games])
Example 5)
Sentence: Layers of Fear, the indie first person point-and-click adventure game?
Output: confirm(name[Layers of Fear], genres[adventure, indie,
point-and-click], player_perspective[first person])
Example 6)
Sentence: I bet you like it when you can play games on Steam, like
Worms: Reloaded, right?
Output: suggest(name[Worms: Reloaded], available_on_steam[yes])
Example 7)
Sentence: I recall you saying that you really enjoyed The Legend
of Zelda: Ocarina of Time. Are you typically a big fan of games
on Nintendo rated E (for Everyone)?
Output: verify_attribute(name[The Legend of Zelda: Ocarina of Time],
esrb[E (for Everyone)], rating[excellent], platforms[Nintendo])
Example 8)
Sentence: So what is it about the games that were released in 2005
that you find so excellent?
Output: request_explanation(release_year[2005], rating[excellent])
Example 9)
Sentence: Do you think Mac is a better gaming platform than others?
Output: request_attribute(has_mac_release[])
Give the output for the following sentence:
{input}
输入查询: 你喜欢玩哪个有多人游戏模式的快节奏游戏?
期望输出: 请求(有多人游戏模式[是],特定要求[快节奏])

观察到,这些模型与我们预期的输出不太匹配。这个特定的任务不是仅通过提示工程就能轻松完成的。同时注意到这些模型传递的输入上下文长度很长,这使得产生输出的推理时间比输入文本本身要长得多。考虑到这一切,我们有兴趣探索在这个任务上我们可以推动微调的极限。
为什么微调有前途?
在我们之前的一篇博客文章中,我们讨论了“微调是为了形式,而不是事实”的想法。那么,在这个特定的任务上,期望微调模型能够胜过其他方法,如提示工程或少量提示吗?
这个问题的答案并不简单,需要进行实验。然而,有几个关键的有见地的问题可以指导你制定一个假设,判断微调是否能够为你的特定用例增加实质性的价值:
-
新概念: 我们能否假设基础模型在其预训练数据中遇到了这个任务中的概念(与视频游戏相关的概念等),还是这是一个全新的概念?如果这是一个全新的概念(或事实),那么通过小规模微调学习它的机会相当低。
-
有前途的少量提示: 当你使用少量提示时,你是否观察到了改进?这种技术涉及向模型展示一些输入和输出的示例,然后要求它按照相同的模式完成答案。如果你注意到了显著的改进,微调可能会提供更好的结果。这是因为微调允许你将更多的示例纳入模型的内部神经网络权重中,而不是受到上下文长度的限制并消耗提示前缀的令牌。
-
令牌预算: 即使提示工程对你起作用,你必须为每个请求提供通常很长的提示作为输入。这种方法可能很快消耗你的令牌预算。从长远来看,为特定任务微调一个利基模型可能更具成本效益,从而节省资金。
这个特定的任务围绕着模式识别,需要对语言和基本概念有基本的理解,但不需要复杂的逻辑推理。更重要的是,这个任务是基于实际的,意味着其输出所需的所有“事实”已经嵌入到输入中。很明显,一个更长的输入提示包含示例有助于模型理解我们的意图,这是一个很好的指标,即使微调较小的Llama-2模型也可以显著提高解决这个任务的性能。
评估
评估这个任务可以从几个角度来进行。虽然这个任务足够确定,可以检查是否存在精确的字符匹配,但这对于非微调模型来说并不公平。相反,我们首先检查输出函数是否被正确预测。从那里开始,我们还检查属性类型是否正确。函数中的属性类型遵循严格的优先顺序,因此我们检查模型输出是否遵循这个顺序。这在指令跟随模型的提示中提到(即GPT、llama-2-chat),因此这些模型预计会按照这个规则输出属性。这是从仅有几个示例中学习的一个严格的指导方针,模型必须注意特定的规则并理解其背后的含义。
为了加速评估,我们利用了Ray的批量推理API来扩展推理,结合Anyscale的Aviary为我们提供定制的LLM服务。利用这两个组件,我们可以将LLM生成与后处理链接起来,并在许多机器上分发它。投资于一个强大的评估框架非常重要,因为它构成了任何模型开发过程的基础。
结果
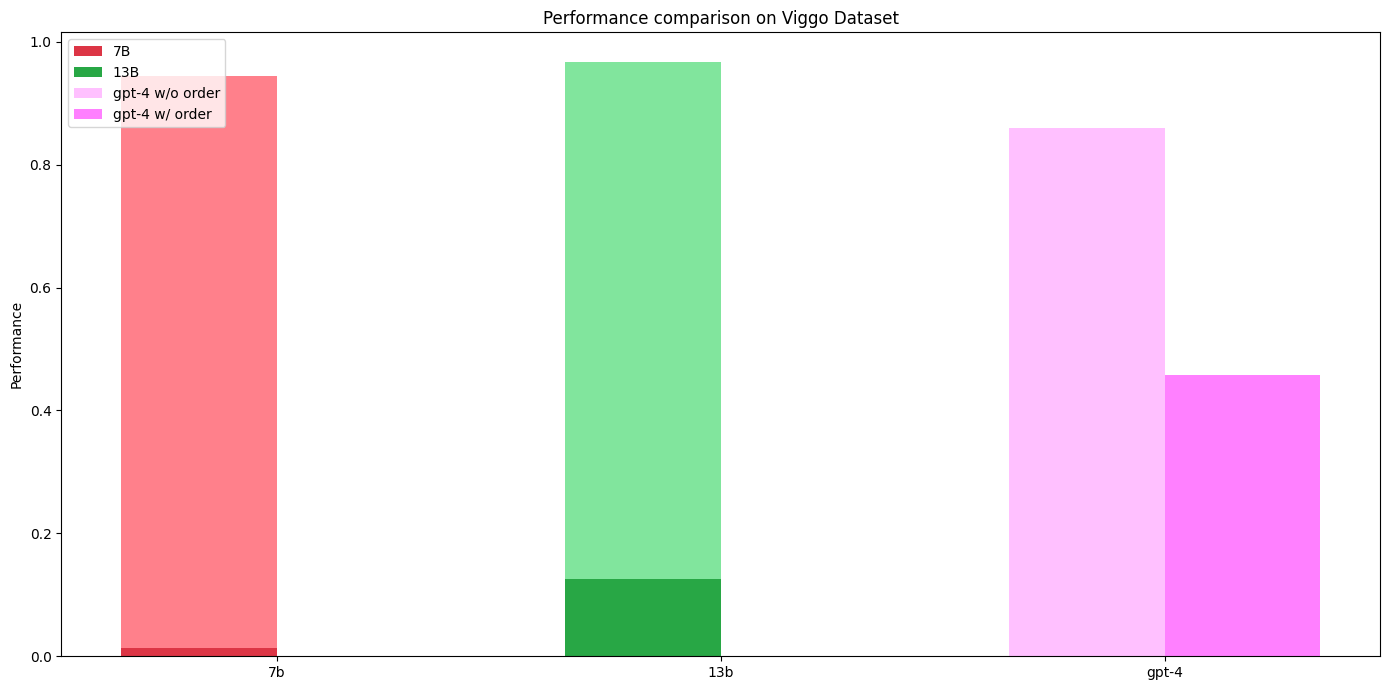
深色表示使用所提及的提示的聊天模型性能。对于GPT-4,我们报告了两种评估指标:考虑属性顺序重要性和不考虑属性顺序重要性。经过微调的模型在这两种评估方法中始终能够保持>90%的成功率,从未违反优先规则。
7b和13b模型在经过微调后的准确性显著提高。尽管考虑属性顺序时,GPT-4的准确性显著下降,但经过微调的模型的输出始终遵循优先规则,并且在这种额外的评估约束下准确性保持不变。
总结
ViGGO数据集突出了微调的最强优势,并且结果明确支持这一观点。当需要结构化形式时,微调可以提供可靠且高效的方法来完成任务。这个任务还表明,需要“结构化形式”并不仅仅意味着匹配简单的正则表达式或JSON格式,这些任务可能可以使用像guidance这样的库来完成。对于ViGGO,LLM需要确定是否应该包含一个参数,并确保所包含参数的顺序遵循优先规则。
还有一个效率的问题。除了通用模型需要更多的输入标记之外,微调的结果仅使用了7b和13b模型。使用Llama 7b模型比支付GPT-4端点调用的费用要便宜得多,尤其是在您的服务规模扩大时。
使用经过微调的Llama-2模型进行SQL生成
接下来我们要研究的任务是SQL生成。目标是将自然语言查询转换为可以在数据库上执行的功能性SQL查询。对于这个任务,我们使用了Hugging Face的b-mc2/sql-create-context数据集,该数据集是WikiSQL和Spider数据集的组合。
每个数据点都包含一个自然语言查询、相应的SQL CREATE TABLE语句,以及对应于自然语言问题的SQL查询。LLM的目标是将自然语言查询和SQL CREATE TABLE语句作为上下文输入,并生成一个可以查询给定SQL表并产生回答自然语言查询的SQL输出。
示例数据点
这个数据集特有的一个问题是需要过滤掉不正确的标准答案SQL输出。在许多数据点中,被标记为整数的属性在CREATE TABLE语句中被标记为VARCHAR类型。
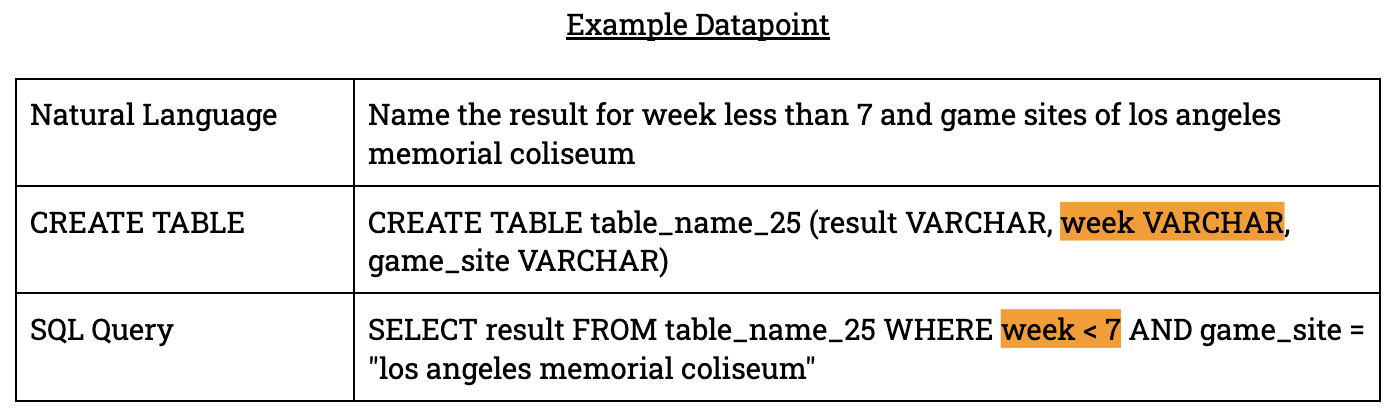
请注意,在CREATE TABLE语句中,属性“week”被定义为字符串,但在SQL查询中被视为整数。为了避免在测试时出现问题,我们过滤掉了所有假设属性为整数的SQL查询,将数据集从70k个数据点减少到45k个数据点。尽管这对数据集是一个很强的限制,但我们使用的Python SQL引擎没有一种简单的方法在CREATE TABLE和SQL查询语句之间进行类型检查 - 除非我们想要编写一个算法来解析AST并进行类型检查。尽管如此,最终的数据集仍然具有很多棘手的数据点,如下所示:

为什么微调可能是有前途的?
这个任务与ViGGO有一些相似之处 - LLM试图输出自然语言的结构化表示,这种情况下是SQL。与ViGGO不同,这个任务稍微有些模糊,因为在数据表上执行时可能有几个SQL查询可以输出正确的答案。尽管如此,这个任务非常适合微调,因为成功取决于LLM学习SQL的“结构”并将自然语言转换为这种结构的能力。
评估
这样的SQL任务面临的一个主要挑战是评估。一旦模型输出了一个SQL查询,我们如何检查它是否正确?一种简单的方法是逐个字符地比较生成的SQL代码和数据集提供的真实查询之间的等价性。这种方法对于可能导致假阴性数量增加的许多因素都很敏感。另一种方法是检查两个查询的抽象语法树(AST)的等价性。然而,这也容易受到变量名称顺序等因素的影响。最可靠的最后一种方法是在一个虚假数据集上运行代码并检查输出的等价性。
我们决定为这个任务使用OpenAI的GPT-3.5端点为几百个这样的示例生成单元测试。GPT-3.5被提示查看问题、表模式和答案,并生成一个带有十个数据点的虚假表。这个小的数据表可以用来比较和测试SQL查询的有效性。
# 导入execute函数
from sqlglot.executor import execute
# 定义一个包含表格数据的字典
gpt_data_table = {
"table_name_64": [
{
"position": "mayor",
"first_election": "1988 as vice mayor 2009"
},
...
{
"position": "mayor",
"first_election": "2007 as councilor 2014"
}
]
}
# 获取LLAMA模型的SQL响应
model_sql = get_llama_response(sql_prompt.format(create_table=..., query=...))
# 从响应中提取SQL语句并转换为小写
model_sql = model_sql[model_sql.find("<SQL>")+len("<SQL>"):model_sql.find("</SQL>")]
model_sql = model_sql.lower()
try:
# 执行给定的SQL查询并返回结果
queryresult = execute(sql_query, tables=table)
# 执行LLAMA模型生成的SQL查询并返回结果
modelresult = execute(model_sql, tables=table)
# 如果两个结果相同,则输出正确
if str(queryresult) == str(modelresult):
# output is correct
except Exception as e:
# 如果出现异常,则打印异常信息
print(e)
为了确保GPT-3.5生成的数据表的质量,我们首先对其执行了真实的SQL查询。如果结果表为空,或者与初始表的长度相同,则丢弃该示例。这样过滤掉了大约50%的GPT生成的数据表。
结果
Llama-7b和13b经过微调的模型都优于70b-chat和GPT-4模型。Llama聊天模型的一个常见错误是它不会始终将其输出的SQL放在标签中,而是按照提示进行指示 - 这在7b和13b聊天模型中比在70b模型中更常见。
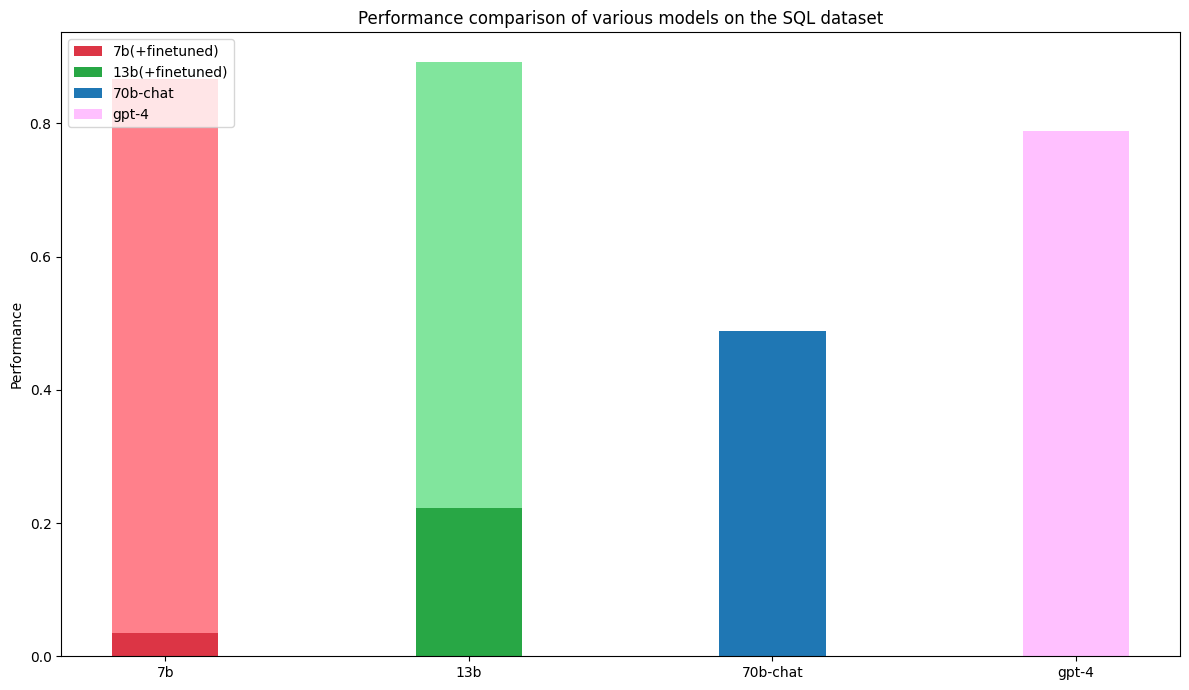
深色表示聊天模型的性能。经过微调的模型达到了约90%的成功率。
需要注意的是,SQL数据集中的一些自然语言查询并不是完美的英语。这些数据集中的噪声可能会对GPT-4的结果产生轻微影响。然而,这也凸显了一个关于微调的重要观点——这些模型将迅速适应数据集的特点,无论这些特点是什么。
主要观点
在这个例子中,无论是7b还是13b的微调模型都优于GPT-4和70b的聊天模型。还要记住,对于每次调用GPT和Llama基础聊天模型,都需要输入一个冗长的提示。此外,虽然对于GPT来说这不是一个问题,但Llama聊天模型通常会输出数百个与任务无关的标记,这进一步减慢了它们的推理时间(例如“当然!很乐意帮助…”)。
小学数学推理(GSM8k)
我们考虑的最后一个任务是GSM8k。这个任务是一个用于评估LLM在数学推理和理解方面的标准学术基准。与前两个任务不同,微调这个数据集的挑战在于,我们想看到LLM在解决数学问题的能力上能有多大提升。
示例数据点
Question
Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?
Answer
Natalia sold 48/2 = 24 clips in May. \n Natalia sold 48+24 = 72 clips altogether in April and May. \n#### 72
虽然一个LLM能够立即给出答案72是令人印象深刻的,但目前的LLM无法内化其导致最终答案的"思考"过程。相反,它们必须作为输出的一部分生成它们的"思考"过程,确保每个后续单词的生成都基于一个可靠的推理过程。这个数据集中的目标答案的格式被设计为概述思考过程,并以#### {答案}的格式结束,以便于解析。
这个任务要求语言模型不仅要理解简单的计算,还要知道如何从给定的假设推进到中间结论,最终得出最终答案。因此,LLM需要对语言有牢固的掌握(包括对概念及其相互关系的理解),以及能够清晰地陈述思维的逻辑链条。有趣的问题是,聊天微调模型在这个任务上表现如何,微调能带来多大的收益?
评估
要有效评估LLM在这个任务上的表现,您需要一种可靠的方法来提取语言模型生成的最终答案,并将其与真实答案进行比较。虽然对于微调模型来说这不是一个问题,但通用语言模型的一个常见挑战是它们无法始终遵循所需的输出格式,这使得评估变得棘手。有关受限生成的各种提议解决方案,例如在提示中提供指导,提示约束,或提供少量示例。然而,为了简单起见,并确保自动化评估过程的特定输出格式,我们使用了OpenAI的函数调用API。
这个想法是使用gpt-4或gpt-3.5-turbo模型来处理LLM生成的响应,以提取没有预定输出结构的LLM的最终答案。给定问题,这些模型可以提取最终答案,而无需对其进行更正(如果有任何错误)。以下代码演示了提取过程:
def extract_number_from_text(question: str, text: str) -> int:
## 使用GPT-3.5-turbo的功能API从文本中提取数字
functions = [
{
"name": "report_answer",
"description": "从文本中报告最终答案。",
"parameters": {
"type": "object",
"properties": {
"number": {
"type": "integer",
"description": ...
},
},
"required": ["number"],
},
}
]
resp = openai.ChatCompletion.create(
model="gpt-3.5-turbo-0613",
messages=[...],
functions=functions,
function_call={"name": "report_answer"},
)
resp_msg = resp["choices"][0]["message"]
function_args = json.loads(resp_msg["function_call"]["arguments"])
return function_args["number"]
我们指示gpt-3.5模型阅读问题并利用一个名为report_answer的函数,该函数接受一个整数作为输入。这种方法确保模型始终输出另一个模型生成的内容中找到的最终整数。例如,如果模型回答“答案是四”,我们仍然可以解析答案为answer = 4。我们已经在数据集中提供的答案上进行了测试,以确认其有效性并确保它不会出现任何边缘情况。这种方法的缺点是我们需要支付OpenAI令牌进行评估。
值得注意的是,经过微调的模型很快学会遵循目标答案中展示的模式,并且很少偏离这个模式-即使答案本身是错误的,输出结构也是非常可预测的。因此,在评估经过微调的模型时,我们只需将这些模型生成的输出应用正则表达式模式#### {answer},而无需使用OpenAI端点进行后处理,从而在评估过程中节省金钱。
为什么微调有希望?
对于这个任务,我们相信模型在预训练阶段已经接触到了足够的数学概念。因此,它应该能够从中进行泛化,并且微调应该有助于激活其内部知识的适当模式。此外,如果我们检查Llama-2上发布的基准测试,在GSM8k数据集上表现出色,有8个少样本示例,超过其他模型。这凸显了广泛的预训练数据的重要性。那么问题就变成了:我们能否通过微调进一步提高这些数字呢?

基准线
建立正确的基准线对于系统地衡量进展和不同方法的有效性至关重要。对于这个测试,我们考虑了以下基准线:
-
使用基础预训练模型的报告的8-shot提示方法(请注意,我们没有重新运行这些实验;我们只是引用了已发布的结果)。
-
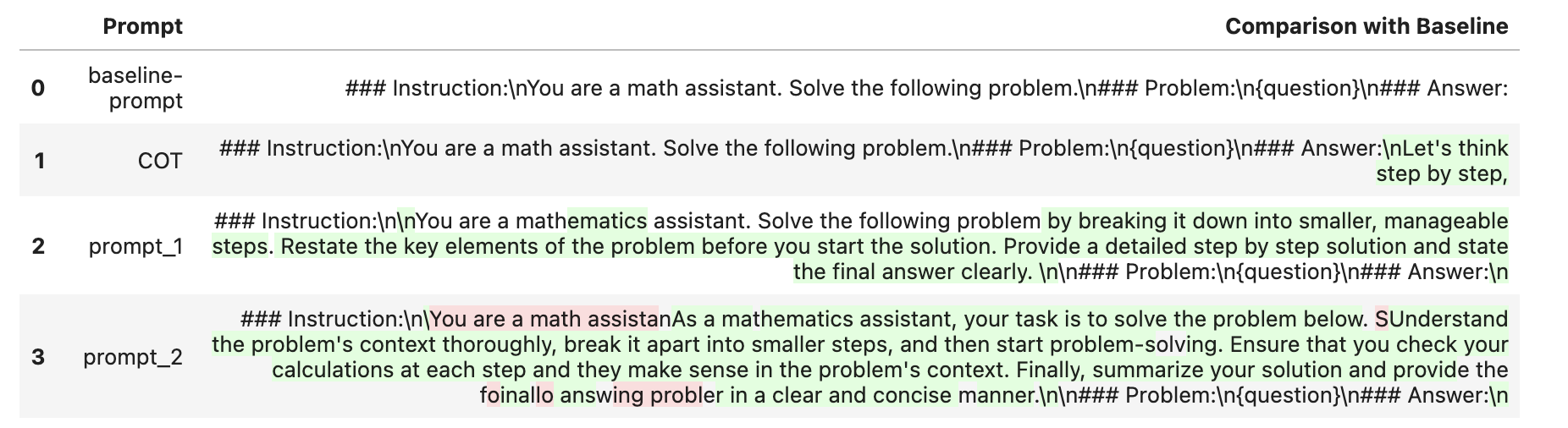
几个针对聊天调整的Llama变体的提示工程模板。这些“聊天调整”模型是由Meta使用RLHF进行训练的,以作为通用助手模型。如果RLHF训练像OpenAI的方法一样严谨,我们也应该从这些模型中获得高质量的结果。下表展示了我们使用的提示模板的视图,并说明了它们之间的区别。
结果
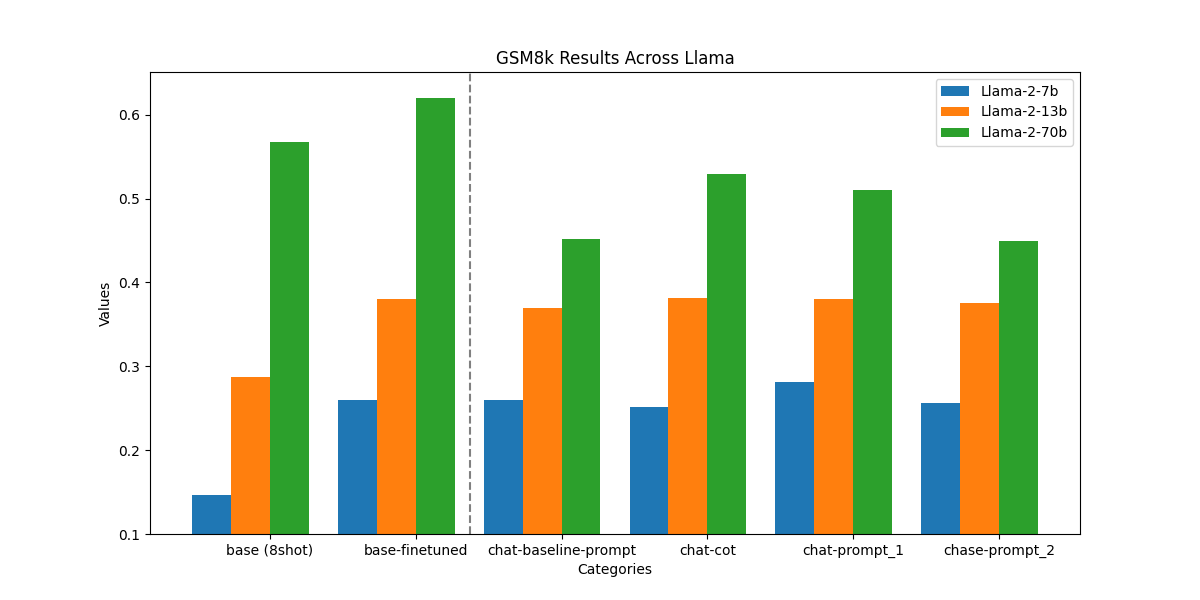
经过微调的7b和13b模型与它们的基础模型相比,准确率提高了10%。与聊天微调的基准模型相比,差距较小,因为这些模型很可能在聊天微调过程中使用了数学示例进行训练。
从这些结果中可以得出以下几点:
-
**对基础模型进行微调可以始终提高其在特定任务上的性能。**然而,它可能并不一定比聊天微调的模型的结果显著更好。请记住,聊天模型经过微调以具有多功能性,因此确定它们是否足够适用于您的任务需要尝试不同的提示。
-
**对经过微调的模型进行提示并不总是比基础模型表现更好。**例如,Llama-2-70B-chat在使用8个示例提示时实际上可能表现不如基础模型,而经过微调的模型始终比使用8个示例提示的基础模型表现更好。
-
对于这个任务,经过微调的模型在所有模型大小上都表现出优越的性能,同时在服务过程中可能比其他基准模型的成本要低得多。对于这个任务,您将为每个请求中提示的所有标记付费,但对于经过微调的模型,您实际上只需要支付问题中的标记数量。根据您所针对的服务流量,使用性能更好、定制化的模型可能会降低您的总体成本。
-
**聊天微调的模型表现优于未经微调的基础模型。**重要的是要区分聊天微调模型和基础预训练模型。聊天微调模型很可能在聊天微调过程中使用了数学示例进行训练,从而比基础模型具有更高的准确性。
进一步改进微调结果
虽然我们确实看到了微调的改进,但我们想专注于Llama-13b,并查看是否可以通过标准微调技术进一步改进结果。GSM8k训练数据集相对较小,只有8k个数据点。由于学习解决数学问题比仅仅学习以特定格式输出答案更加复杂,我们认为仅有8k个数据点可能不足以发挥Llama-13b模型在该数据集上的全部潜力。
考虑到这一点,我们首先对基础的Llama-13b模型进行了MathQA数据集的微调,然后再对原始的GSM8k数据集进行了模型的微调。这一轮额外的微调使得结果进一步提高了10%,从基础模型增加了20%。
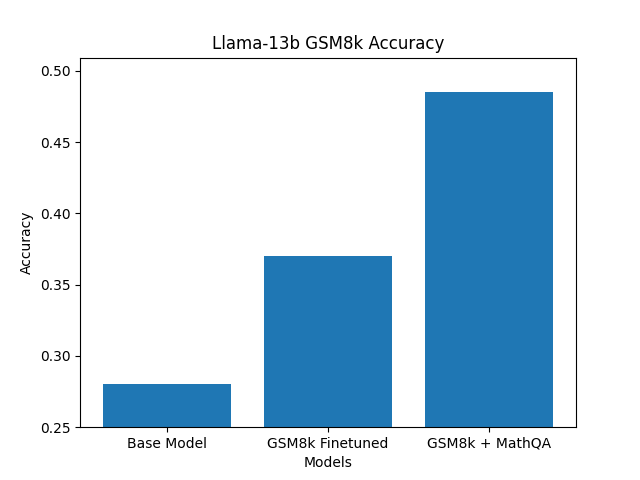
仅使用GSM8k数据进行微调可以提高10%。使用MathQA和GSM8k数据集进行两阶段微调可以累计提高10%。
尽管在机器学习中,人们可能期望这与经典的“数据越多,模型越好”的范式相一致,但考虑到MathQA数据集的性质,我们发现这些结果令人惊讶。MathQA是一个包含30,000个问题/答案对的集合,其噪声较大且结构与GSM8K数据集不同。答案的质量较差,并且与GSM8k不同,MathQA中的最终答案是多项选择。例如:
Question
the banker ’ s gain of a certain sum due 3 years hence at 10 % per annum is rs . 36 . what is the present worth ?
Answer Options
a ) rs . 400 ,
b ) rs . 300 , c ) rs . 500 , d ) rs . 350 , e ) none of these
Answer
explanation : t = 3 years r = 10 % td = ( bg × 100 ) / tr = ( 36 × 100 ) / ( 3 × 10 ) = 12 × 10 = rs . 120 td = ( pw × tr ) / 100 ⇒ 120 = ( pw × 3 × 10 ) / 100 ⇒ 1200 = pw × 3 pw = 1200 / 3 = rs . 400 answer : option a
注意奇怪的间距,并将此数据点的质量与之前的GSM8k问题/答案对进行比较:
Question
Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. How many clips did Natalia sell altogether in April and May?
Answer
Natalia sold 48/2 = 24 clips in May. \n Natalia sold 48+24 = 72 clips altogether in April and May. \n#### 72
将微调分为两轮是一种有效的方法,可以利用这个MathQA数据集,并为GSM8k数据集提供更好的最终结果。
结论
希望通过这三个例子的讨论能够让您相信,尽管像GPT-4、Claude-2等闭源模型对于原型设计和证明初始价值非常有用,但它们并不足以在生产中运行高性能的LLM应用程序。对于特定任务的微调LLM是从LLM中获取价值的有前途的解决方案之一,这不仅涉及隐私问题,还涉及延迟、成本和有时质量(例如在ViGGO和SQL示例中)。对于微调,您应该专注于收集数据并建立评估流水线,以帮助您了解与您业务相关的不同解决方案之间的权衡,而不是考虑微调的基础设施和复杂性。在Anyscale,我们基于Ray构建了最佳的微调和服务解决方案,因此您可以在自己的数据和云上重复上述过程。请查看Anyscale Endpoints以了解更多信息。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











