







Google新出基础世界模型,图片生成交互环境
论文链接: https://arxiv.org/pdf/2402.15391.pdf
案例链接: https://sites.google.com/view/genie-2024/home
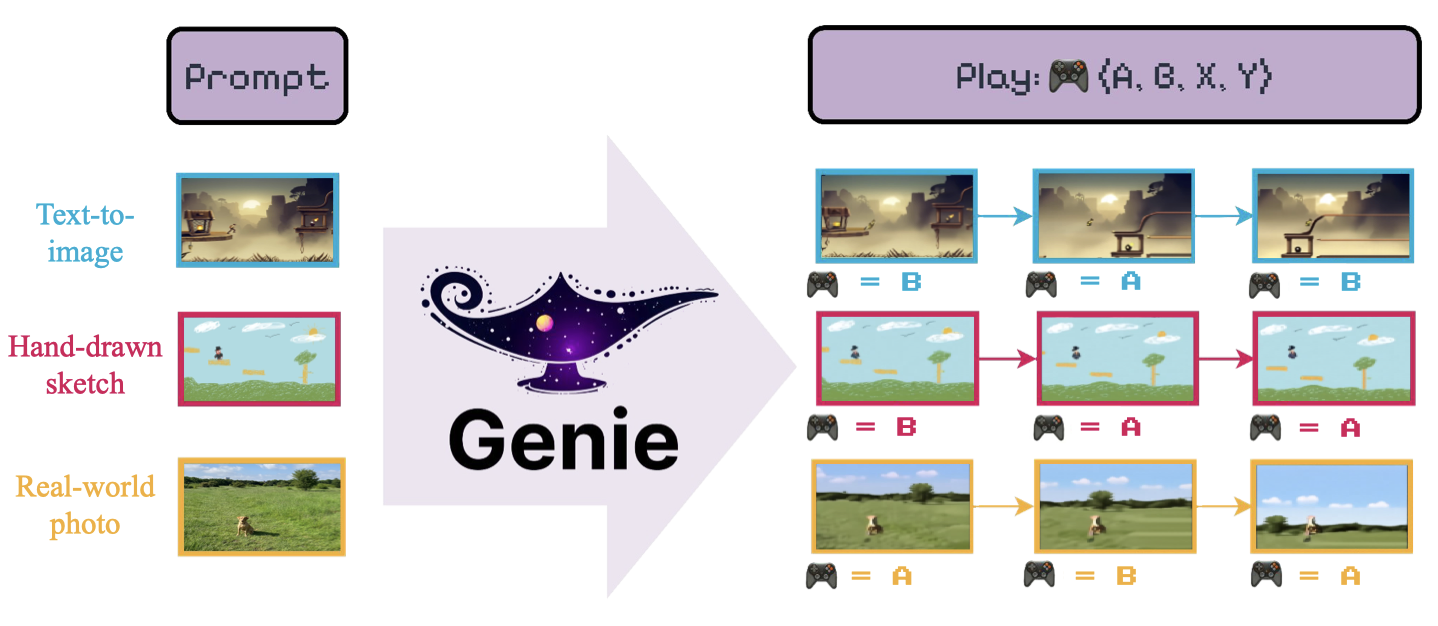
图1 | 一个全新的世界:Genie能够将各种不同的提示转化为交互式的、可玩的环境,用户可以轻松地创建、进入和探索这些环境。这是通过从互联网视频中无监督学习的潜在动作接口实现的。右侧是生成的两个潜在动作的几个步骤。在我们的网站上可以看到更多示例。
我们介绍了Genie,这是第一个从未标记的互联网视频中无监督训练的生成交互环境。该模型可以根据文本、合成图像、照片甚至草图生成各种可控制的虚拟世界。Genie具有110亿个参数,可以被视为一个基础世界模型。它由一个时空视频分词器、一个自回归动力学模型和一个简单且可扩展的潜在动作模型组成。尽管在训练过程中没有使用任何真实的动作标签或其他通常在世界模型文献中找到的领域特定要求,但Genie使用户能够在生成的环境中逐帧进行操作。此外,所得到的学习潜在动作空间有助于训练代理从未见过的视频中模仿行为,为训练未来的通用代理打开了道路。
关键词:生成人工智能,基础模型,世界模型,视频模型,开放性
引言
过去几年出现了一种生成人工智能的兴起,模型能够生成新颖且有创造力的内容。在transformer架构(Vaswani等人,2017)的突破、硬件的进步以及对模型和数据集规模的关注推动下,我们现在可以生成连贯的对话语言(Brown等人,2020;Radford等人,2018;2019),以及从文本提示中生成清晰而美观的图像(Ramesh等人,2021;2022;Rombach等人,2022;Saharia等人,2022)。早期的迹象表明,视频生成也将成为另一个前沿,最近的研究结果表明,这样的模型也可能受益于规模(Blattmann等人,2023;Esser等人,2023;Ho等人,2022;Hong等人,2023)。然而,视频生成模型在交互和参与度方面与ChatGPT等语言工具之间仍存在差距,更不用说更沉浸式的体验了。
如果我们能够在大量的互联网视频语料库的基础上,不仅训练模型生成新颖的图像或视频,还能生成整个交互式体验,会怎么样呢?我们提出了一种新的生成人工智能范式,即生成交互环境,通过单个文本或图像提示可以生成交互式环境。我们的方法Genie是通过训练一个包含超过20万小时公开可用的互联网游戏视频的大型数据集而得到的,尽管训练过程中没有使用任何动作或文本注释,但它可以在逐帧的基础上通过学习到的潜在动作空间进行控制(见表1与其他方法的比较)。Genie具有110亿个参数,表现出了通常在基础模型中看到的特性,它可以将未见过的图像作为提示,从而可以创建和玩完全想象的虚拟世界(例如图2)。
Genie基于最先进的视频生成模型(Gupta等人,2023;Villegas等人,2023),其中核心设计选择是时空(ST)transformer(Xu等人,2020),它被用于我们的所有模型组件。Genie利用了一种新颖的视频分词器,并通过因果动作模型提取潜在动作。视频分词器和潜在动作都被传递给动力学模型,该模型使用MaskGIT(Chang等人,2022)自回归地预测下一帧。我们对我们的架构进行了严格的扩展性分析,涉及批处理和模型大小,我们将参数从40M变化到2.7B。结果表明,我们的架构随着额外的计算资源的增加而平稳扩展,最终得到一个具有110亿个参数的模型。我们使用来自数百个2D平台游戏的30,000小时的互联网游戏视频的筛选集对Genie进行训练,为这个设置产生了一个基础世界模型。
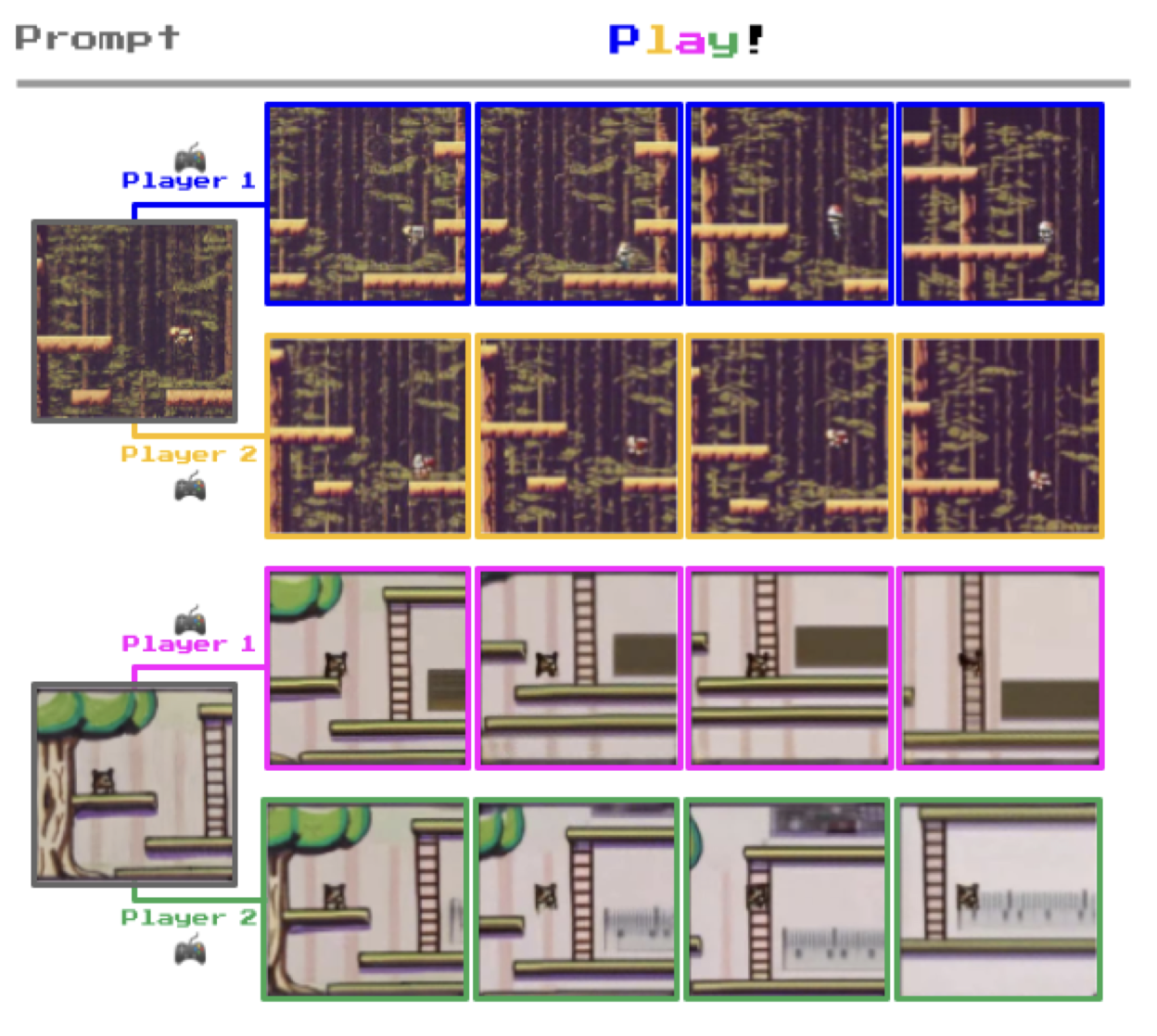
图2 | 多样的轨迹:Genie是一个生成模型,可以用作交互环境。该模型可以通过多种方式进行提示,例如生成的图像(顶部)或手绘草图(底部)。在每个时间步,模型接受用户提供的潜在动作来生成下一帧,产生具有有趣和多样的角色动作的轨迹。
为了展示我们方法的普适性,我们还在RT1数据集(Brohan等人,2023)中的无动作机器人视频上训练了一个单独的模型,学习了一个具有一致潜在动作的生成环境。最后,我们展示了从互联网视频中学习到的潜在动作可以用于推断未见过的无动作视频的模拟强化学习(RL)环境的策略,这表明Genie可能是解锁无限数据来训练下一代通用代理的关键(Bauer等人,2023;Clune,2019;Open Ended Learning Team等人,2021;Reed等人,2022)。
表1 | 一种新的生成模型类别:Genie是一种新颖的视频和世界模型,可以逐帧进行控制,只需要训练时的视频数据。

方法
Genie是一个从仅视频数据中训练的生成交互环境。在本节中,我们将从初步工作开始,然后解释我们模型的主要组成部分。
Genie架构中的几个组件基于Vision Transformer(ViT)(Dosovitskiy等人,2021;Vaswani等人,2017)。值得注意的是,transformer的二次存储成本对于视频来说是一个挑战,因为视频可以包含多达𝑂(10⁴)个标记。因此,我们采用了一种内存高效的ST-transformer架构(受到Xu等人,2020的启发,见图4),在所有模型组件中都使用它,平衡了模型容量和计算约束。
与传统的transformer不同,其中每个标记都与其他标记相互关联,ST-transformer包含𝐿个时空块,其中交替使用空间和时间注意力层,后跟标准的前馈层(FFW)注意力块。空间层的自注意力关注每个时间步内的1×𝐻×𝑊个标记,而时间层的自注意力关注𝑇×1×1个标记,跨越𝑇个时间步。与序列transformer类似,时间层假设具有因果结构和因果掩码。关键是,我们架构中计算复杂性的主导因素(即空间注意力层)与帧数呈线性关系,而不是平方关系,使其在具有一致动力学的长时间交互中更加高效。此外,请注意,在ST块中,我们在空间和时间组件之后只包含一个FFW,省略了空间后FFW,以便扩展模型的其他组件,我们观察到这显著改善了结果。
模型组件
如图3所示,我们的模型包含三个关键组件:1)潜在动作模型,用于推断每对帧之间的潜在动作𝒂;2)视频分词器,将原始视频帧转换为离散标记𝒛;3)动力学模型,在给定潜在动作和过去帧标记的情况下,预测视频的下一帧。该模型按照标准的自回归视频生成流程进行两个阶段的训练:首先训练视频分词器,然后共同训练潜在动作模型(直接从像素开始)和动力学模型(在视频标记上)。
潜在动作模型(LAM) 为了实现可控的视频生成,我们将每个未来帧的预测都条件于前一帧的动作。然而,在互联网视频中很少有这样的动作标签,并且获取动作注释可能是昂贵的。因此,我们以完全无监督的方式学习潜在动作(见图5)。
首先,编码器将所有先前的帧𝒙1:𝑡 = (𝑥1*,* · · · 𝑥_(𝑡))以及下一帧𝑥_(𝑡)+1作为输入,并输出相应的连续潜在动作𝒂˜_(1:𝑡) = (𝑎˜₁*,* · · · 𝑎˜*(𝑡))。然后,解码器将所有先前的帧和潜在动作作为输入,并预测下一帧𝑥*ˆ(𝑡+1)。
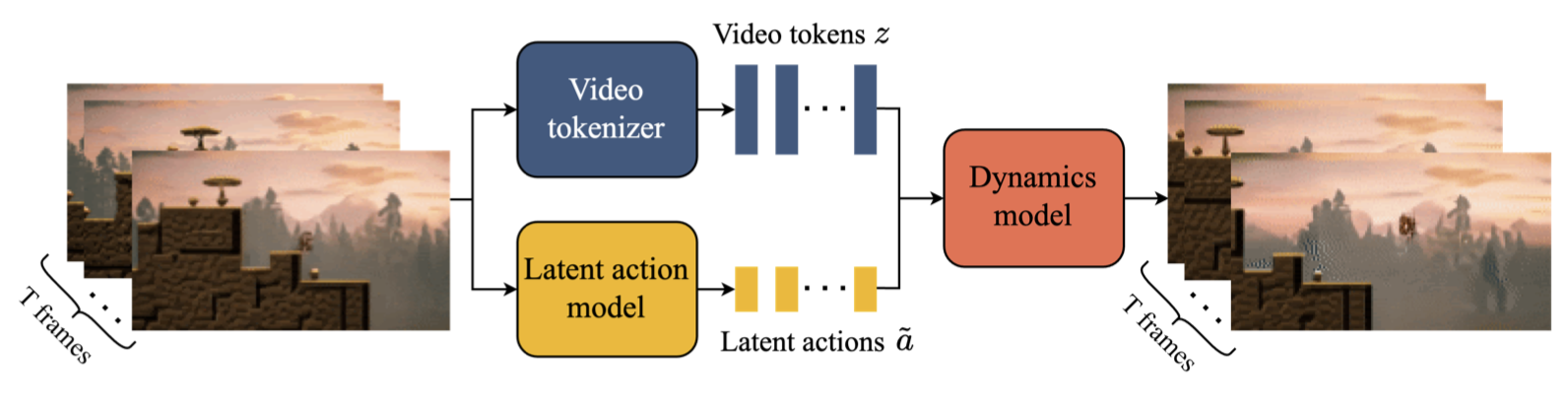
图3 | Genie模型训练:Genie将𝑇帧视频作为输入,通过视频分词器将其标记为离散的标记𝒛,并使用潜在动作模型推断出每帧之间的潜在动作𝒂˜。然后将它们传递给动力学模型,以迭代方式生成下一帧的预测。
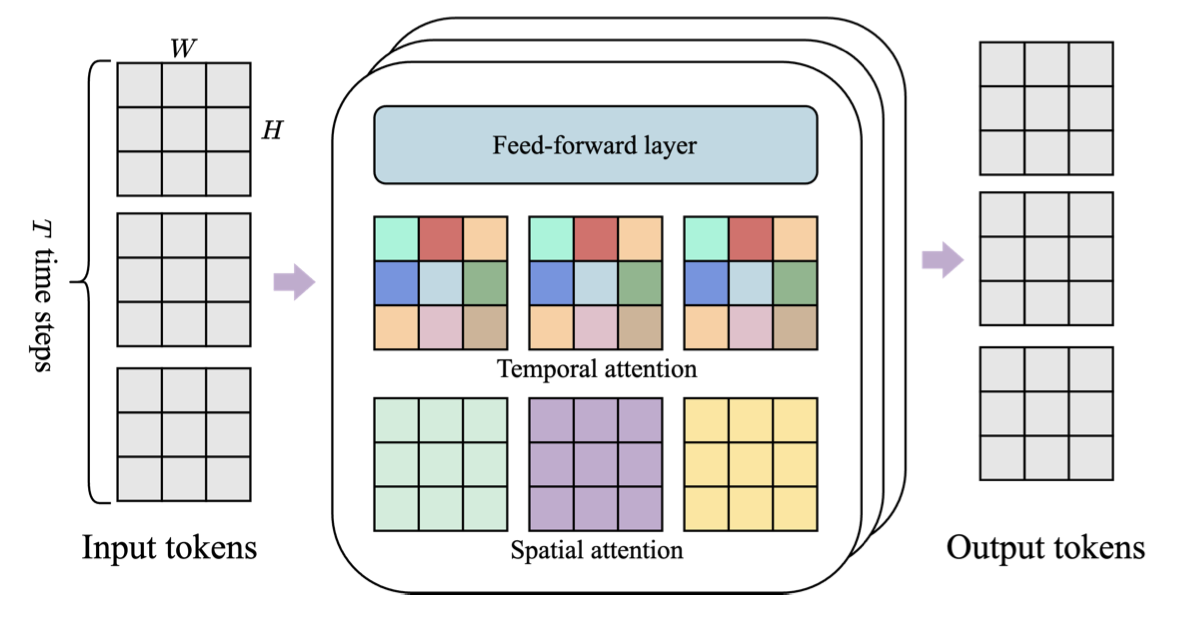
图4 | ST-transformer架构。该架构由L个时空块组成,每个块包含一个空间层、一个时间层和一个前馈层。每种颜色代表一个自注意力图,其中空间层关注单个时间步内的𝐻×𝑊个标记,而时间层关注跨越𝑇个时间步的同一标记。
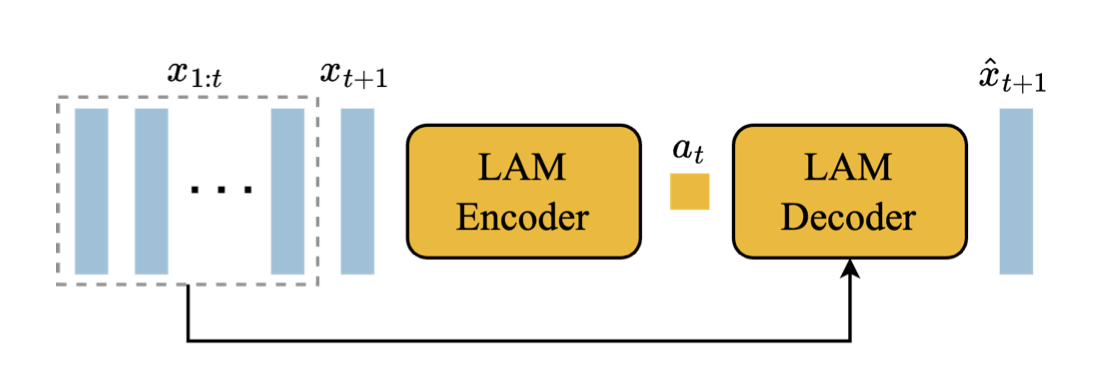
图5 | 潜在动作模型:从未标记的视频帧中无监督地学习动作𝑎_(𝑡)。
我们利用ST-transformer架构来实现潜在动作模型。时间层中的因果掩码使我们能够将整个视频𝒙1:𝑇作为输入,并生成所有帧之间的潜在动作𝒂˜_(1:𝑇) ⁻¹。
视频分词器 在之前的工作(Gupta等,2023年;Villegas等,2023年;Yan等,2023年)的基础上,我们将视频压缩为离散的标记,以减少维度并实现更高质量的视频生成(见图6)。我们再次使用VQ-VAE,它将𝑇帧视频𝒙1:𝑇 = (𝑥1*, 𝑥2,* · · · , 𝑥_(𝑇) ) ∈ ℝ*^(𝑇)* ^(×𝐻×𝑊×𝐶)作为输入,为每帧生成离散的表示𝒛1:𝑇 = (𝑧1*, 𝑧2,* · · · , 𝑧_(𝑇) ) ∈ ^(𝑇) ^(×𝐷),其中𝐷是离散潜在空间的大小。使用标准的VQ-VAE目标训练分词器,覆盖整个视频序列。
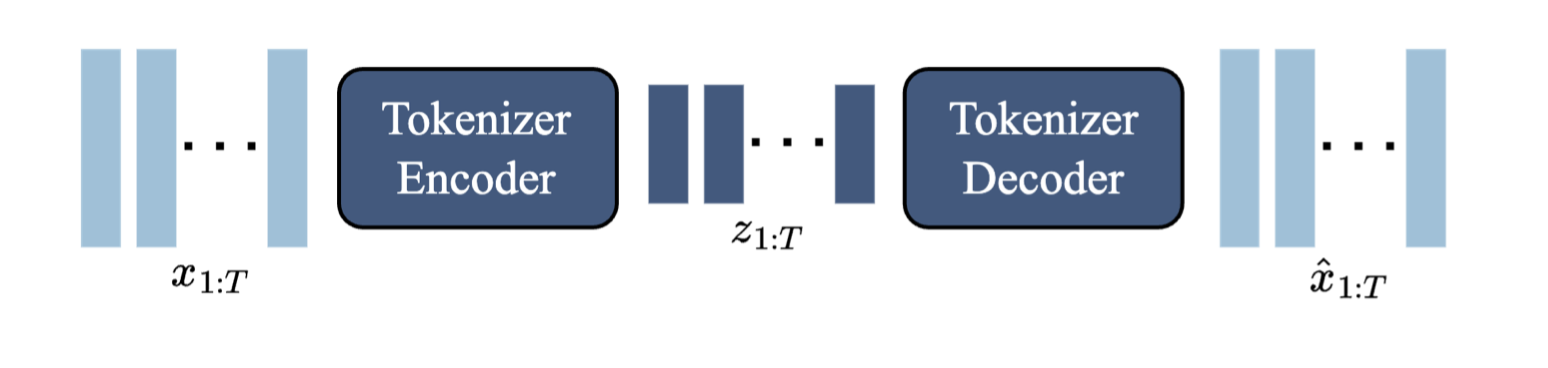
图6 | 视频分词器:带有ST-transformer的VQ-VAE。
与之前在分词阶段仅关注空间压缩的工作(Gupta等,2023年;Hong等,2022年;Wu等,2022年)不同,我们在编码器和解码器中都使用ST-transformer来融入时间动态,从而提高视频生成质量。由于ST-transformer的因果性质,每个离散编码*𝑧_(𝑡)*包含了视频𝒙1:𝑡中所有先前看到的帧的信息。Phenaki(Villegas等,2023年)也使用了一个具有时间感知的分词器C-ViViT,但这种架构的计算成本很高,因为成本随着帧数的增加呈二次增长,相比之下,我们基于ST-transformer的分词器(ST-ViViT)在计算效率上更高,其成本的主导因素与帧数呈线性增长。
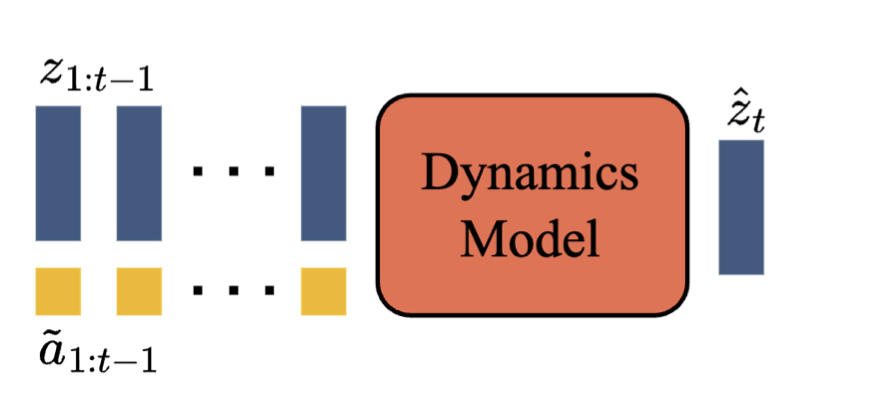
图7 | 动力学模型:接收视频标记和动作嵌入,并预测未来的遮罩视频标记。
动力学模型 是一个仅有解码器的MaskGIT(Chang等,2022年)变换器(图7)。在每个时间步𝑡 ∈ [1*, 𝑇* ],它接收标记化的视频𝒛1:𝑡−1和stopgrad潜在动作𝒂˜_(1:𝑡−1),并预测下一帧的标记ˆ𝑧_(𝑡)。我们再次使用ST-transformer,其因果结构使我们能够使用所有(𝑇−1)帧𝒛1:𝑇−1和潜在动作𝒂˜_(1:𝑇) ⁻¹作为输入,并为所有下一帧ˆ𝒛2:𝑇生成预测。模型使用预测的标记ˆ𝒛2:𝑇和真实标记𝒛2:𝑇之间的交叉熵损失进行训练。在训练时,我们随机屏蔽输入标记𝒛2:𝑇−1,屏蔽率根据均匀采样的伯努利分布在0.5到1之间。需要注意的是,训练世界模型的常见做法,包括基于变换器的模型,是将动作在时间𝑡上与相应的帧进行连接(Micheli等,2023年;Robine等,2023年)。然而,我们发现将潜在动作视为潜在动作和动力学模型的“加性嵌入”有助于提高生成的可控性。
推理:可控动作视频生成
现在我们来描述如何在推理时使用Genie进行可控动作视频生成(见图8)。玩家首先用一张图像𝑥₁作为初始帧¹提示模型。图像使用视频编码器进行分词,得到𝑧₁。然后玩家通过选择[0*,* | 𝐴|)范围内的任意整数值来指定一个离散的潜在动作𝑎₁。动力学模型接收帧标记𝑧₁和对应的潜在动作𝑎˜₁(通过使用离散输入𝑎₁从VQ码本中索引得到),预测下一帧标记𝑧₂。这个过程以自回归的方式重复进行,当动作继续传递给模型时,标记被解码为视频帧𝒙ˆ_(2:𝑇)。请注意,我们可以通过向模型传递起始帧和从视频中推断出的动作来重新生成数据集中的真实视频,或者通过改变动作来生成全新的视频(或轨迹)。
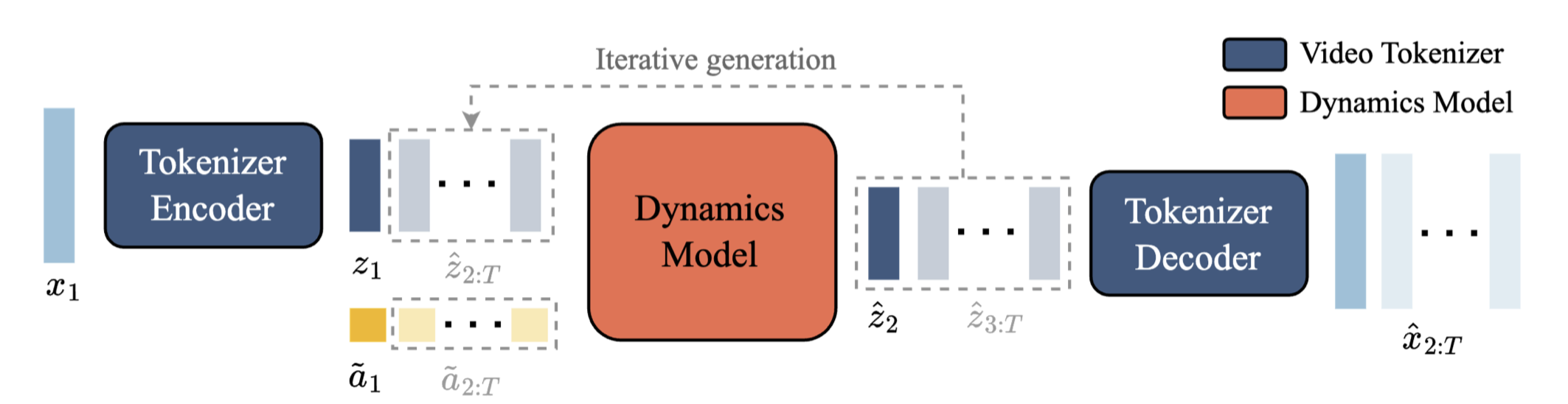
图8 | Genie推理:将提示帧进行分词,与用户采取的潜在动作结合,并传递给动力学模型进行迭代生成。然后通过分词器的解码器将预测的帧标记解码回图像空间。
实验结果
数据集 我们使用从公开可用的2D平台游戏互联网视频中收集的大规模数据集对Genie进行训练(以下简称“Platformers”)。我们通过筛选公开可用的视频,使用与平台游戏相关的关键词,得到了55M个10FPS的16秒视频剪辑,分辨率为160x90。最终数据集包含了6.8M个16秒的视频剪辑(30k小时),与其他流行的互联网视频数据集(Bain等,2021年;Wang等,2023年)相差不大。有关更多详细信息,请参见附录B.1。除非另有说明,否则结果是基于在该数据集上训练的一个具有11B参数的模型。

图9 | 扩展结果。左:不同模型大小的训练曲线,中:每个模型大小的最终训练损失,平均计算最后300次更新,右:2.3B模型在不同批次大小下的最终训练损失。
为了验证我们方法的普适性,我们还考虑了用于训练RT1的机器人数据集(Brohan等,2023年),将其与一个单独的模拟数据集和先前工作中的209k个真实机器人数据集(Kalashnikov等,2018年)结合起来。请注意,我们不使用这些数据集中的任何动作,只将它们视为视频。为简单起见,我们将这个数据集称为“Robotics”。
指标 我们通过两个因素来检验Genie的视频生成性能,即视频保真度(video fidelity),即视频生成的质量,和可控性(controllability),即潜在动作对视频生成的影响程度。对于视频保真度,我们使用Frechet Video Distance(FVD),这是一个视频级别的指标,已经被证明与人类对视频质量的评估高度一致(Unterthiner等,2019年)。对于可控性,我们设计了一个基于峰值信噪比(PSNR)的指标,称为
Δ
t
\Delta_{t}
Δt PSNR,用于衡量在基于从真实帧推断出的潜在动作
(
x
^
t
)
\left(\hat{x}_{t}\right)
(x^t)和从随机分布中采样的潜在动作
(
x
^
t
′
)
\left(\hat{x}_{t}^{\prime}\right)
(x^t′)条件下,视频生成之间的差异程度:
Δ
t
PSNR
=
PSNR
(
x
t
,
x
^
t
)
−
PSNR
(
x
t
,
x
^
t
′
)
,
\Delta_{t} \operatorname{PSNR}=\operatorname{PSNR}\left(x_{t}, \hat{x}_{t}\right)-\operatorname{PSNR}\left(x_{t}, \hat{x}_{t}^{\prime}\right),
ΔtPSNR=PSNR(xt,x^t)−PSNR(xt,x^t′),
其中
x
t
x_{t}
xt表示时间
t
t
t的真实帧,
x
^
t
\hat{x}_{t}
x^t表示从真实帧推断出的潜在动作
a
~
1
:
t
\tilde{\boldsymbol{a}}_{1: t}
a~1:t生成的帧,
x
^
t
′
\hat{x}_{t}^{\prime}
x^t′表示从随机采样的潜在动作序列生成的相同帧。因此,
Δ
t
\Delta_{t}
Δt PSNR越大,从随机潜在动作生成的视频与真实帧之间的差异越大,这表明潜在动作的可控性更高。在所有实验中,我们报告
Δ
t
\Delta_{t}
ΔtPSNR,其中
t
=
4
t=4
t=4。
缩放结果
在本节中,我们研究了我们模型的缩放行为。为此,我们进行了一系列研究,探索了模型大小和批量大小的影响。有关架构和计算使用情况的更多详细信息,请参见附录D。
缩放模型大小 在固定的视频分词器和动作模型架构的情况下,我们训练了一系列的动力学模型,从40M到规模优雅地缩放模型参数,每增加一次大小,最终训练损失都会相应地减少。这明确表明我们的方法受益于缩放,我们在主要的Genie模型中利用了这一点。

图10 | 从图像提示中播放:我们可以用文本到图像模型生成的图像、手绘草图或真实世界照片提示Genie。在每种情况下,我们展示了提示帧和连续四次采取潜在动作后的第二帧。在每种情况下,我们都可以看到明显的角色移动,尽管其中一些图像在视觉上与数据集不同。
缩放批量大小 我们还研究了缩放批量大小的效果,考虑到一个具有2.3B模型的批量大小为128、256和448,相当于1.9M、3.8M和6.6M个标记。如图9所示,增加批量大小会导致模型性能的类似有利增益。
Genie模型 很明显,增加模型大小和批量大小有助于提高模型性能。因此,对于我们的最终模型,我们训练了一个具有10.1B动力学模型和512批量大小的模型,总共进行了125k步训练,使用了256个TPUv5p。当与分词器和动作模型结合使用时,总共有10.7B个参数,训练了942B个标记,我们将其称为Genie模型。对于我们的网站,我们训练了一个将标记映射到360p视频的更大的解码器,增加了额外的参数。
定性结果
现在,我们展示了来自Genie模型的定性结果。我们展示了在Platformers数据集上训练的一个具有11B参数的模型和在Robotics数据集上训练的一个较小模型。我们的模型在不同领域生成了高质量、可控的视频。值得注意的是,我们使用仅限于分布外(OOD)图像提示对我们在Platformers数据集上训练的模型进行了定性评估,包括从文本到图像模型生成的图像、手绘草图甚至真实照片。能够推广到如此显著的OOD输入强调了我们方法的鲁棒性以及在大规模数据上进行训练的价值,这是使用真实动作作为输入不可行的。
Platformers训练模型 图10展示了我们的模型从OOD图像生成的示例,包括(顶行)从Imagen2生成的图像(Ho et al., 2022a; van den Oord et al.),(第二行)手绘草图和(底行)真实世界照片。Genie能够将这些想象的世界变得栩栩如生,我们在与每个示例交互时看到了类似游戏的行为。我们在附录A中展示了模型的更多生成示例,此外还突出了潜在动作的一致性。

图11 | 学习模拟可变形物体:我们展示了模型中十个步骤轨迹的帧,采取相同的动作。Genie能够学习到像袋装薯片这样的物体的物理特性。

图12 | 模拟视差,这是平台游戏中的常见特征。从这个初始的文本生成的图像开始,前景移动的幅度大于近处和远处的中间地带,而背景只略微移动。
我们模型的另一个新能力是理解3D场景并模拟视差,这在平台游戏中很常见。在图12中,我们展示了由Imagen2生成的图像,其中采取潜在动作时,前景与背景以不同的速率移动(如不同颜色箭头的长度所示)。
Robotics训练模型 我们使用相同的超参数在Robotics数据集上训练了一个具有2.5B参数的模型,该模型在测试集上的FVD为82.7。如图13所示,该模型成功地从视频数据中学习到了不同且一致的动作,无需文本或动作标签(例如Yang et al. (2023))。值得注意的是,我们的模型不仅学习了机械臂的控制,还学习了各种物体的相互作用和变形(图11)。我们认为这表明我们的方法为使用来自互联网的更大规模视频数据创建用于机器人技术的基础世界模型提供了一条途径,具有低级可控的模拟,可用于各种应用。

图13 | 机器人中的可控、一致的潜在动作:从我们的Robotics数据集中的三个不同起始帧开始的轨迹。每列显示了采取相同潜在动作五次后的结果帧。尽管没有使用动作标签进行训练,但相同的动作在不同的提示帧上是一致的,并且具有语义含义:下、上和左。
训练智能体
我们相信Genie有朝一日可以用作训练通用智能体的基础世界模型。在图14中,我们展示了该模型已经可以用于在未见过的强化学习环境中生成多样的轨迹,给定起始帧。我们进一步研究了从互联网视频中学习的潜在动作是否可以用于模仿未见视频中的行为。我们使用一个冻结的LAM对目标环境的一系列专家视频进行标记,标记为离散的潜在动作,然后训练一个策略来预测在给定观察下专家采取潜在动作的可能性。然后,我们使用一个包含专家真实动作的小型数据集来将潜在动作映射到真实动作(有关更多详细信息,请参见附录E)。
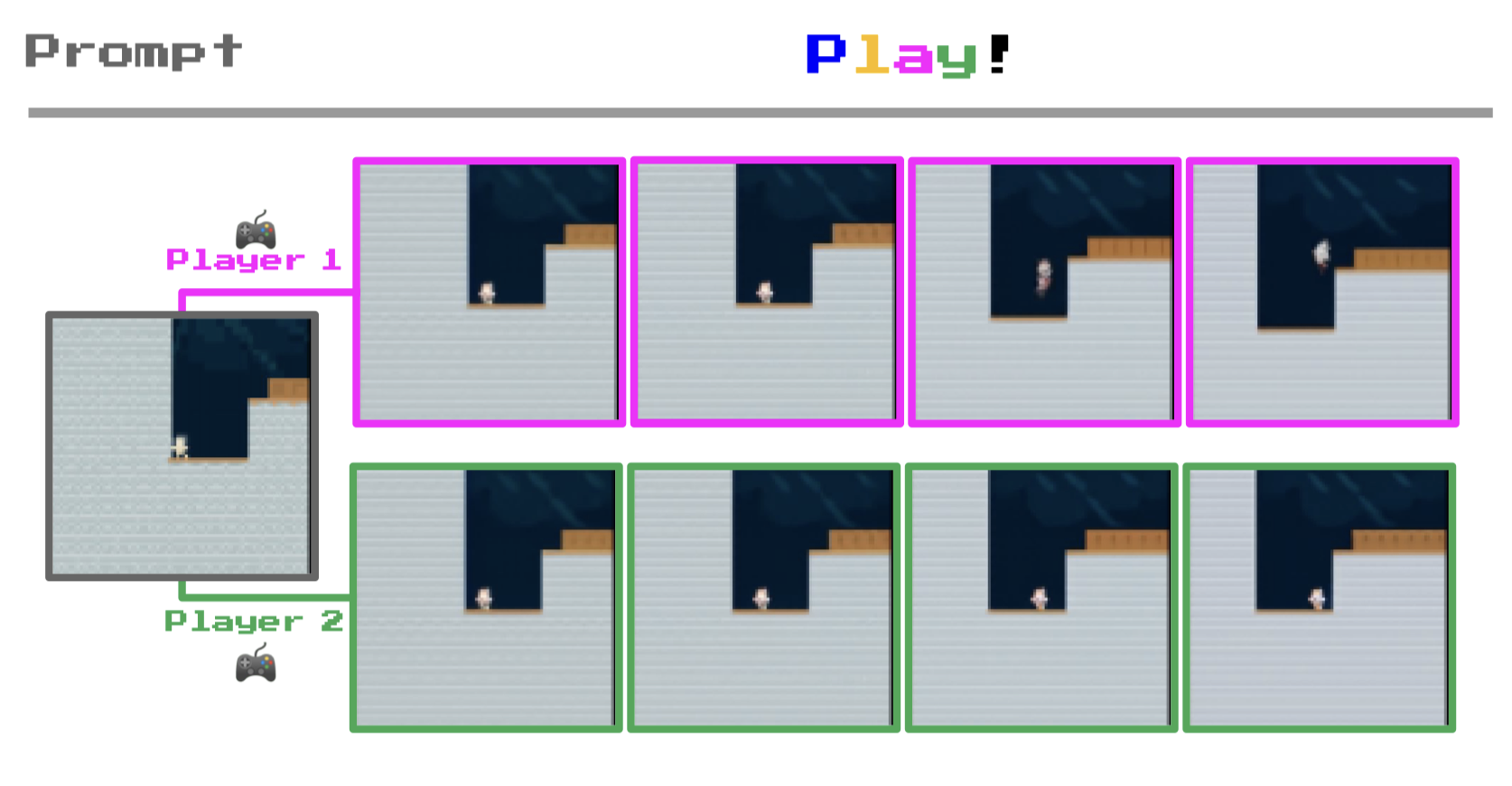
图14 | 从强化学习环境中播放:Genie可以在给定未见强化学习环境图像的情况下生成多样的轨迹。
我们在一个由程序生成的2D平台游戏环境CoinRun(Cobbe et al., 2020)的困难和简单设置中进行评估,并与一个具有专家动作作为上限的oracle行为克隆(BC)模型和一个随机智能体进行比较(图15)。基于LAM的策略在只有200个专家样本用于适应的情况下就达到了与oracle相同的分数,尽管几乎肯定从未见过CoinRun。这表明学到的潜在动作在转移方面是一致且有意义的,因为从潜在到真实的映射不包含关于当前观察的任何信息。
消融研究
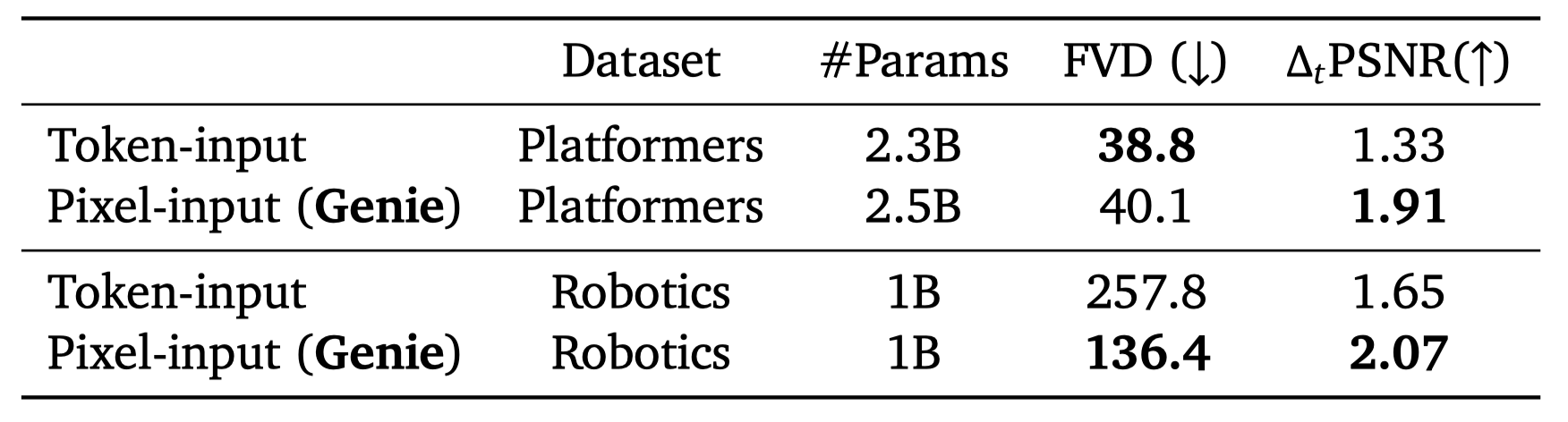
潜在动作模型的设计选择 在设计潜在动作模型时,我们仔细考虑了要使用的输入类型。虽然我们最终选择使用原始图像(像素),但我们对比了这种选择与使用标记化图像(在图5中将x替换为z)的替代方法。我们将这种替代方法称为“标记输入”模型(见表2)。
虽然该模型在Platformers数据集上的FVD得分略低,但在Robotics数据集上并没有保持这种优势。更重要的是,在这两个环境中,标记输入模型的可控性更差(通过Δ*_(𝑡)*PSNR测量)。这表明在标记化过程中可能丢失了一些关于视频动态和运动的信息,因此让潜在动作模型接收原始视频作为输入是有益的。
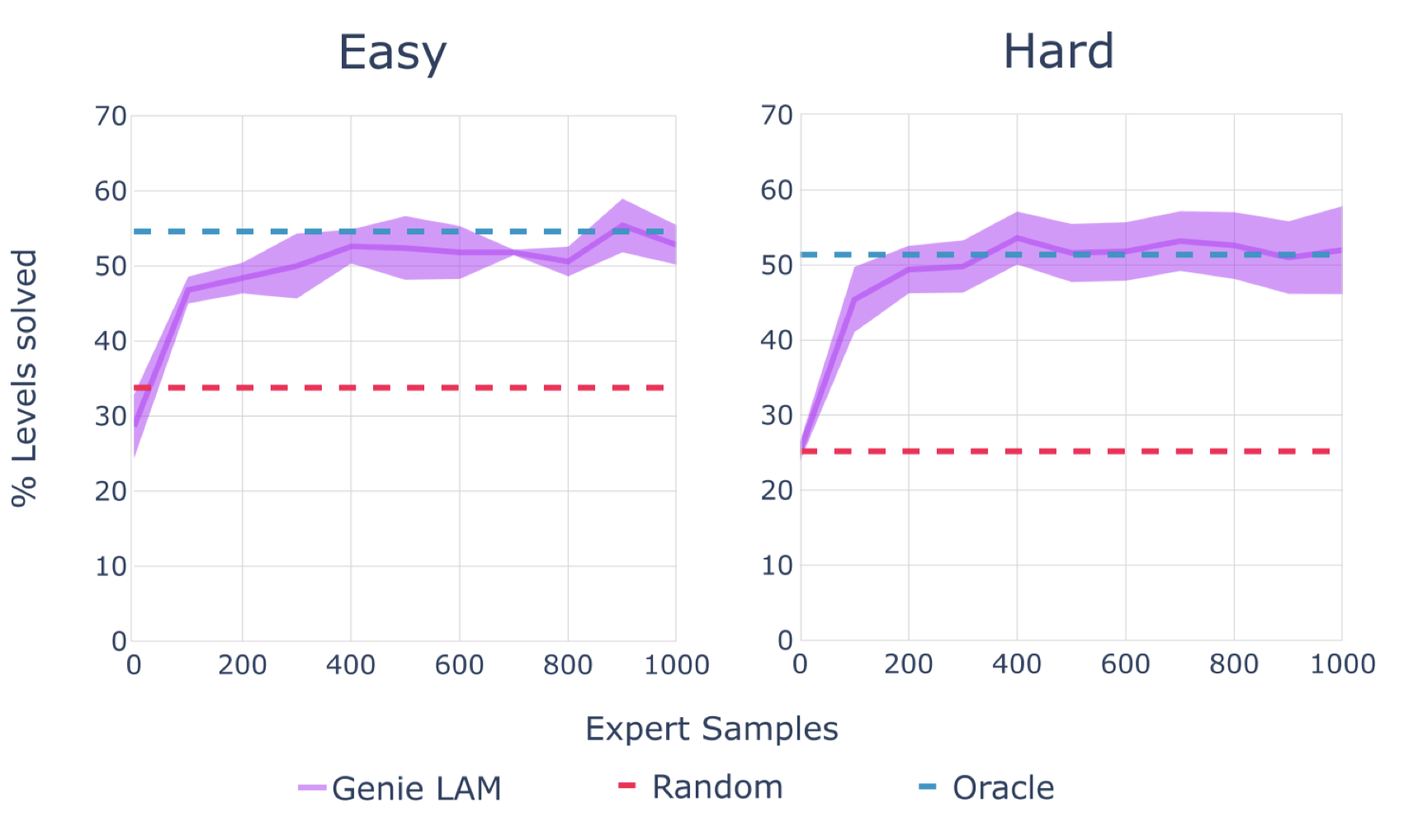
图15 | BC结果。在100个样本中解决的关卡的平均百分比,平均值基于5个种子,带有95%的置信区间。
表2 | 潜在动作模型输入消融。我们可以看到Genie实现了更高的可控性。
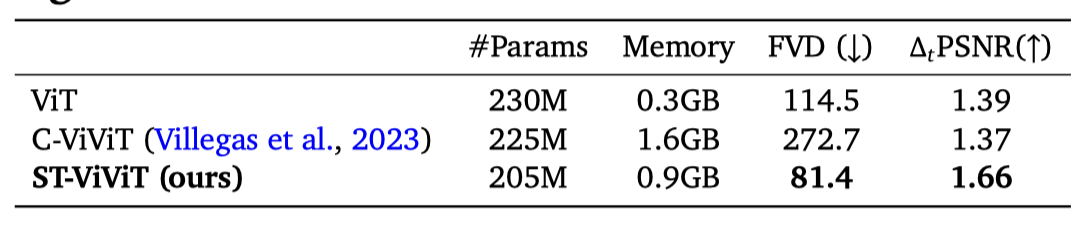
分词器架构消融 我们比较了三种分词器的性能,包括1)(仅空间)ViT,2)(时空)ST-ViViT和3)(时空)C-ViViT(表3)。为了进行比较,我们对所有分词器使用类似数量的参数,批量大小为128,序列长度为16。然后,我们在这三种不同的分词器上训练相同的动力学和潜在动作模型,并报告它们的FVD以及Δ*_(𝑡)*PSNR。
表3 | 分词器架构消融:我们的ST-ViViT架构表现最好。
相关工作
世界模型 生成交互式环境可以被视为一类世界模型(Ha and Schmidhuber, 2018; Oh et al., 2015),它们可以在动作输入的条件下进行下一帧预测(Bamford and Lucas, 2020; Chiappa et al., 2017; Eslami et al., 2018; Hafner et al., 2020, 2021; Kim et al., 2020, 2021; Micheli et al., 2023; Nunes et al., 2020; Pan et al., 2022; Robine et al., 2023)。这样的模型对于训练智能体非常有用,因为它们可以在智能体训练时学习策略,而无需直接从环境中获取经验。然而,学习模型本身通常需要直接从环境中获得的动作条件数据。相比之下,我们的方法旨在仅通过视频无监督地学习世界模型。最近,对于扩展世界模型的重视有所增加。GAIA-1(Hu et al., 2023)和UniSim(Yang et al., 2023)分别学习用于自主驾驶和机器人操作的世界模型。这些方法都需要文本和动作标签,而我们专注于仅使用公开可用的互联网视频的仅视频数据进行训练。
视频模型 我们的工作与视频模型相关,这些模型通常以初始帧(或文本)为条件,预测视频中的其余帧(Blattmann et al., 2023b; Brooks et al., 2024; Clark et al., 2019; Finn et al., 2016; Ho et al., 2022a,b; Höppe et al., 2022; Kalchbrenner et al., 2017; Le Moing et al., 2021; Lotter et al., 2017; Luc et al., 2020; Singer et al., 2023; Walker et al., 2021; Yan et al., 2021; Yu et al., 2023)。我们的方法与最近基于Transformer的模型(如Phenaki(Villegas et al., 2023),TECO(Yan et al., 2023)和MaskViT(Gupta et al., 2023))最相似,因为我们使用了MaskGIT(Chang et al., 2022)和ST-Transformer(Xu et al., 2020)对标记化的图像进行建模。虽然视频模型越来越可控(例如(Huang et al., 2022)),但我们追求更具主动性的目标,并明确从数据中学习潜在动作空间,允许用户或智能体使用潜在动作条件的预测来“玩”模型。
可玩视频生成 Genie不仅限于可玩视频生成(PVG)(Mena- pace et al., 2021),PVG使用潜在动作来控制直接从视频中学习的世界模型(Menapace et al., 2021, 2022)。与Genie不同,PVG考虑了特定领域的静态示例,而不是通过提示生成全新的环境。因此,要在这种设置之外进行扩展,需要进行非平凡的架构更改,放弃归纳偏见以换取一种通用方法。
环境生成 我们的工作还与程序内容生成(PCG)相关,例如通过机器学习生成游戏关卡(Summerville et al., 2018),最近通过直接编写游戏代码的语言模型(Sudhakaran et al., 2023; Todd et al., 2023)。语言模型本身也可以被视为交互式环境(Wong et al., 2023),尽管缺少视觉组件。相比之下,在我们的设置中,关卡可以直接从像素中学习和生成,这使我们能够利用互联网视频数据的多样性。
使用潜在动作训练智能体 先前的工作使用潜在动作进行观察的模仿(Edwards et al., 2019),规划(Ry- bkin* et al., 2019)和预训练强化学习智能体(Schmidt and Jiang, 2024; Ye et al., 2022)。这些方法与我们的潜在动作模型具有相似的目标,尽管尚未大规模应用。VPT(Baker et al., 2022)是一种最近的方法,它使用从人类提供的带有动作标签的数据学习的逆动力学模型,将互联网规模的视频标记为可以用于训练策略的动作。相比之下,我们展示了我们可以使用从互联网视频中学习的潜在动作来推断任意环境的策略,避免了昂贵且可能不具有泛化性的真实动作的需求。
结论与未来工作
我们提出了Genie,一种新型的生成式人工智能,使任何人,甚至是儿童,都能像在人类设计的模拟环境中一样构想、创建和进入生成的世界。尽管仅使用视频数据进行训练,Genie可以被提示生成多样的、可交互和可控的环境。
模型还有明显的改进空间。Genie继承了其他自回归Transformer模型的一些弱点,可能会产生不现实的未来预测。虽然我们在时空表示方面取得了进展,但我们仍然受限于16帧的记忆,这使得在长时间范围内获得一致的环境变得具有挑战性。最后,Genie目前的运行速度约为1FPS,需要未来的进展才能实现高效的交互帧率。
尽管如此,我们相信Genie为未来的研究开辟了广阔的潜力。鉴于其通用性,该模型可以从更大比例的互联网视频中进行训练,以模拟多样、逼真和想象的环境。此外,我们只是简要介绍了使用Genie训练智能体的能力,但鉴于缺乏丰富多样的环境是强化学习的主要限制之一,我们可以开辟创建更具普遍能力的智能体的新路径。
更广泛的影响
社会影响 Genie可以使大量人们生成自己的类似游戏的体验。对于那些希望以一种新的方式表达创造力的人来说,这可能是积极的,例如儿童可以设计并进入自己想象的世界。我们也认识到,随着重大进展的出现,探索使用这项技术来增强现有的人类游戏生成和创造力的可能性将至关重要,并赋予相关行业利用Genie实现其下一代可玩世界开发的能力。
训练数据和权重:我们选择不公开训练模型的检查点、模型的训练数据集或该数据的示例,以配合本文或网站。我们希望有机会进一步与研究(和视频游戏)社区进行交流,并确保任何未来的发布都是尊重、安全和负责任的。
可重现性:我们理解对于计算资源较少的研究人员来说,复现我们的主要结果可能具有挑战性。为了缓解这个问题,我们在附录F中描述了一个规模较小、完全可重现的示例,可以在单个中档TPU(或GPU)上运行。鉴于许多设计选择在这两种设置之间转化,我们相信这将使更广泛的社区能够研究未来的架构改进以及我们工作带来的其他研究方向。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












{kind=link}
{kind=link}