







用 Gemini Pro Vision 打造医疗助手,守护你的健康
文章目录
引言
如今,AI 在几乎所有领域都得到了应用。从银行到医疗应用,AI 无处不在。在了解到 ChatGPT 的可能性之后,其他几家公司也开始努力构建一个更好的 transformer,以提高准确性。在本文中,我们将看到如何使用谷歌的 Gemini Pro 模型来分析图像并给出医疗诊断。这将非常令人兴奋,让我们开始吧。

学习目标
- 我们将对上传的图像进行医学分析
- 我们将通过使用 Gemini Pro 来获得实践经验
- 我们将构建一个基于 Streamlit 的应用程序,在交互环境中查看结果。
目录
什么是 Gemini?
Gemini 是谷歌推出的一系列新的基础模型。与 PaLM 相比,这是迄今为止谷歌最大的一组模型,并且从一开始就专注于多模态。这使得 Gemini 模型能够处理不同类型的信息组合,包括文本、图像、音频和视频。目前,API 支持图像和文本。Gemini 在基准测试中证明了其达到了最先进的性能,并在许多测试中击败了 ChatGPT 和 GPT4-Vision 模型。
配置 Gemini Pro Api Key
我们将按照以下步骤创建 Gemini Pro Api Key:
步骤 1:访问 Google AI Studio 并使用您的 Google 帐号登录。
步骤 2:登录后,您将看到类似于下面的界面。点击“创建 API 密钥”。
步骤 3:然后您将看到类似于下面的界面。如果您是第一次创建 Google 项目,请点击“在新项目中创建 API 密钥”。
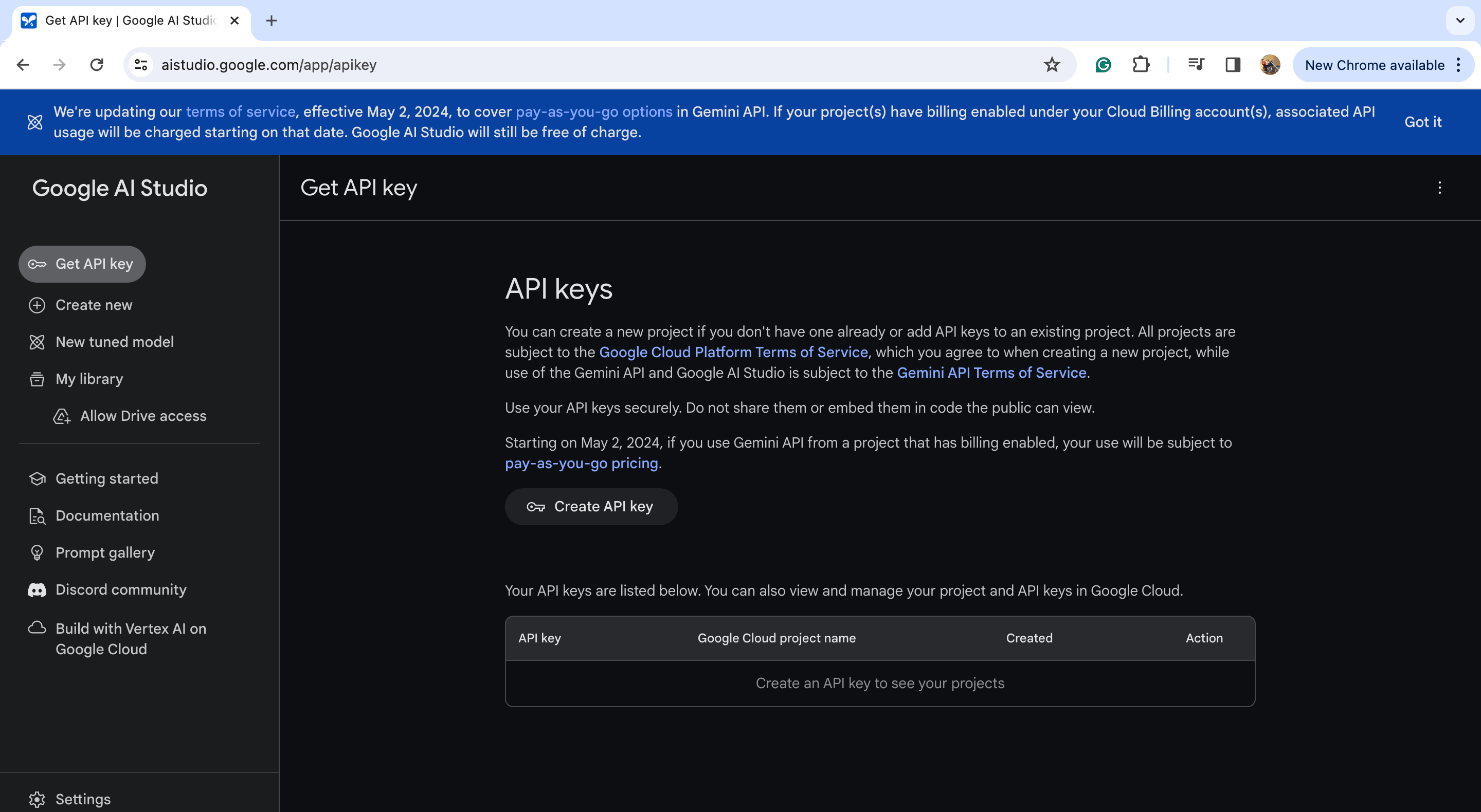
点击该按钮后,将生成一个可用于我们项目的 API 密钥。
在文件结构中,创建一个名为 google_api_key.py 的 Python 文件,内容如下,用于存储 API 密钥。
google_api_key='YOUR_API_KEY'
配置 Gemini Pro 设置并部署为 Streamlit 应用
在开始编写代码之前,我们需要了解 prompt 的概念。prompt 是向语言模型提交的自然语言请求,用于接收响应。prompt 可以包含问题、指令、上下文信息、示例和模型完成或继续的部分输入。模型接收到 prompt 后,可以生成文本、嵌入、代码、图像、视频、音乐等,具体取决于所使用的模型。
我们可以在这里找到详细的说明。我们还可以在这里找到一些高级策略。需要记住的关键是,如果我们想构建一个更好的模型,我们需要为 Gemini Pro 模型 提供更好的提示,以便它理解。
我们将向我们的模型提供以下提示:
"""
你是一位医学图像分析领域的专家。你的任务是检查一家知名医院的医学图像。
你的专业知识将有助于识别或发现图像中可能存在的任何异常、疾病、状况或健康问题。
你的主要职责:
1. 详细分析:仔细检查每个图像,重点查找任何异常。
2. 分析报告:记录所有发现,并以结构化的格式清晰地表达。
3. 建议:根据分析,提出适用的疗法、检查或治疗建议。
4. 治疗方案:如果适用,提供详细的治疗方案,以帮助更快康复。
注意事项:
1. 响应范围:只在图像涉及人类健康问题时回应。
2. 图像清晰度:如果图像不清晰,请注意某些方面是“根据上传的图像无法正确确定的”。
3. 免责声明:在分析中附上免责声明:“在做出任何决定之前,请咨询医生。”
4. 您的见解对指导临床决策非常宝贵。请按照上述结构化方法进行分析。
请使用以下 4 个标题提供最终的回应:详细分析、分析报告、建议和治疗方案
"""
我们可以添加更多的指令来提高性能。然而,目前这应该是一个很好的起点。
现在,我们将专注于基于streamlit的部署代码。
代码:
import streamlit as st
from pathlib import Path
import google.generativeai as genai
from google_api_key import google_api_key
## Streamlit App
genai.configure(api_key=google_api_key)
# https://aistudio.google.com/app/u/1/prompts/recipe-creator
# 设置模型
generation_config = {
"temperature": 1,
"top_p": 0.95,
"top_k": 0,
"max_output_tokens": 8192,
}
safety_settings = [
{
"category": "HARM_CATEGORY_HARASSMENT",
"threshold": "BLOCK_MEDIUM_AND_ABOVE"
},
{
"category": "HARM_CATEGORY_HATE_SPEECH",
"threshold": "BLOCK_MEDIUM_AND_ABOVE"
},
{
"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT",
"threshold": "BLOCK_MEDIUM_AND_ABOVE"
},
{
"category": "HARM_CATEGORY_DANGEROUS_CONTENT",
"threshold": "BLOCK_MEDIUM_AND_ABOVE"
},
]
system_prompts = [
"""
你是一位医学图像分析领域的专家。你的任务是检查一家知名医院的医学图像。
你的专业知识将有助于识别或发现图像中可能存在的任何异常、疾病、状况或健康问题。
你的主要职责:
1. 详细分析:仔细检查每张图像,重点寻找任何异常。
2. 分析报告:记录所有发现,并以结构化的方式清晰地表达出来。
3. 建议:根据分析结果,提出适用的治疗、检测或治疗方法。
4. 治疗:如果适用,提供详细的治疗方案,以帮助更快康复。
注意事项:
1. 回答范围:只回答与人类健康问题相关的图像。
2. 图像清晰度:如果图像不清晰,请注意某些方面是“无法根据上传的图像正确确定的”。
3. 免责声明:在进行任何决策之前,请咨询医生。
4. 你的见解在指导临床决策方面是无价的。请按照上述结构化方法进行分析。
请使用以下四个标题提供最终的回答:详细分析、分析报告、建议和治疗。
"""
]
model = genai.GenerativeModel(model_name="gemini-1.5-pro-latest",
generation_config=generation_config,
safety_settings=safety_settings)
st.set_page_config(page_title="Visual Medical Assistant", page_icon="🩺", layout="wide")
st.title("Visual Medical Assistant 👨⚕️ 🩺 🏥")
st.subheader("一个用于使用图像进行医学分析的应用程序")
file_uploaded = st.file_uploader('上传要分析的图像', type=['png','jpg','jpeg'])
if file_uploaded:
st.image(file_uploaded, width=200, caption='上传的图像')
submit=st.button("生成分析结果")
if submit:
image_data = file_uploaded.getvalue()
image_parts = [
{
"mime_type" : "image/jpg",
"data" : image_data
}
]
prompt_parts = [
image_parts[0],
system_prompts[0],
]
response = model.generate_content(prompt_parts)
if response:
st.title('基于上传图像的详细分析')
st.write(response.text)
以下是逐行解释:
第1-4行 -> 我们导入必要的库和google_api_key。
第7行 -> 我们必须传递在第2步中创建的API密钥。
第11-35行 -> 在这里,我们定义了Gemini模型的基本配置和安全设置。不用担心,你可以访问Google AI Studio并点击获取代码以获取所有这些代码片段。
第37-71行 -> 在这里,我们为模型定义了提示。
第73-76行 -> 在这里,我们初始化了我们的Gemini模型。
第78-81行 -> 在这里,我们在streamlit应用程序上显示一些文本。
第83-87行 -> 注意我们将上传的图像存储在file_uploaded变量中。我们允许’png’、‘jpg’、'jpeg’图像类型。因此,如果提供其他类型的图像,上传将失败。如果图像成功上传,我们将在浏览器上显示它。
第89-113行 -> 我们创建了一个文本为“生成分析结果”的提交按钮。一旦点击该按钮,真正的魔力就会发生。我们将图像和提示传递给我们的Gemini模型。Gemini模型将返回响应给我们。然后,我们将在浏览器上显示响应。
我将此文件保存为app.py。
看它如何运行
我们需要打开Python终端并执行以下命令来调用streamlit应用程序。确保将目录更改为与app.py相同的目录。
streamlit run app.py
输出:
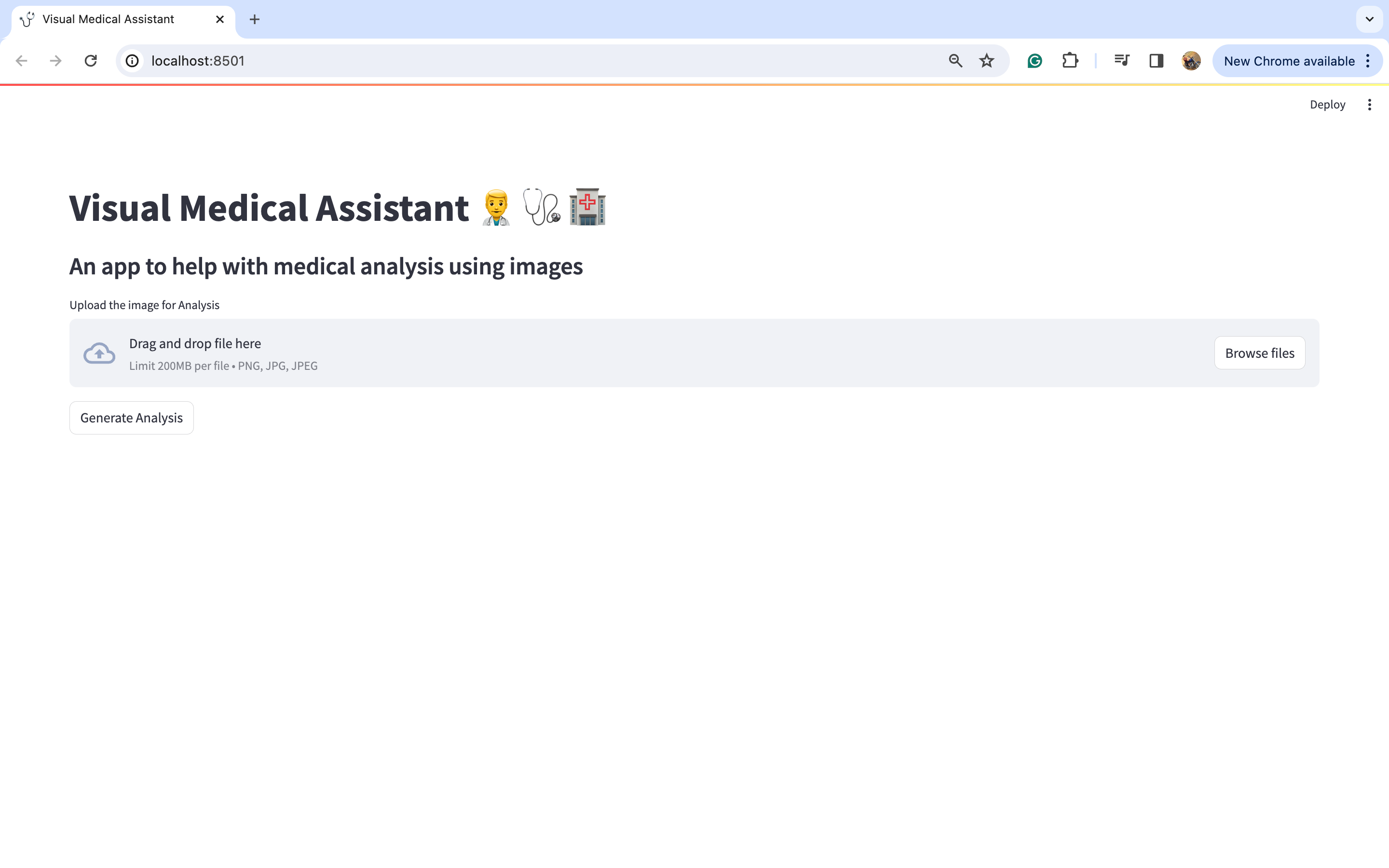
现在,我们将上传一些图片并尝试查看输出。让我们尝试查看一张歪曲图片的分析结果。我从谷歌下载了同样的图片。

让我们点击“浏览文件”按钮上传这张图片。
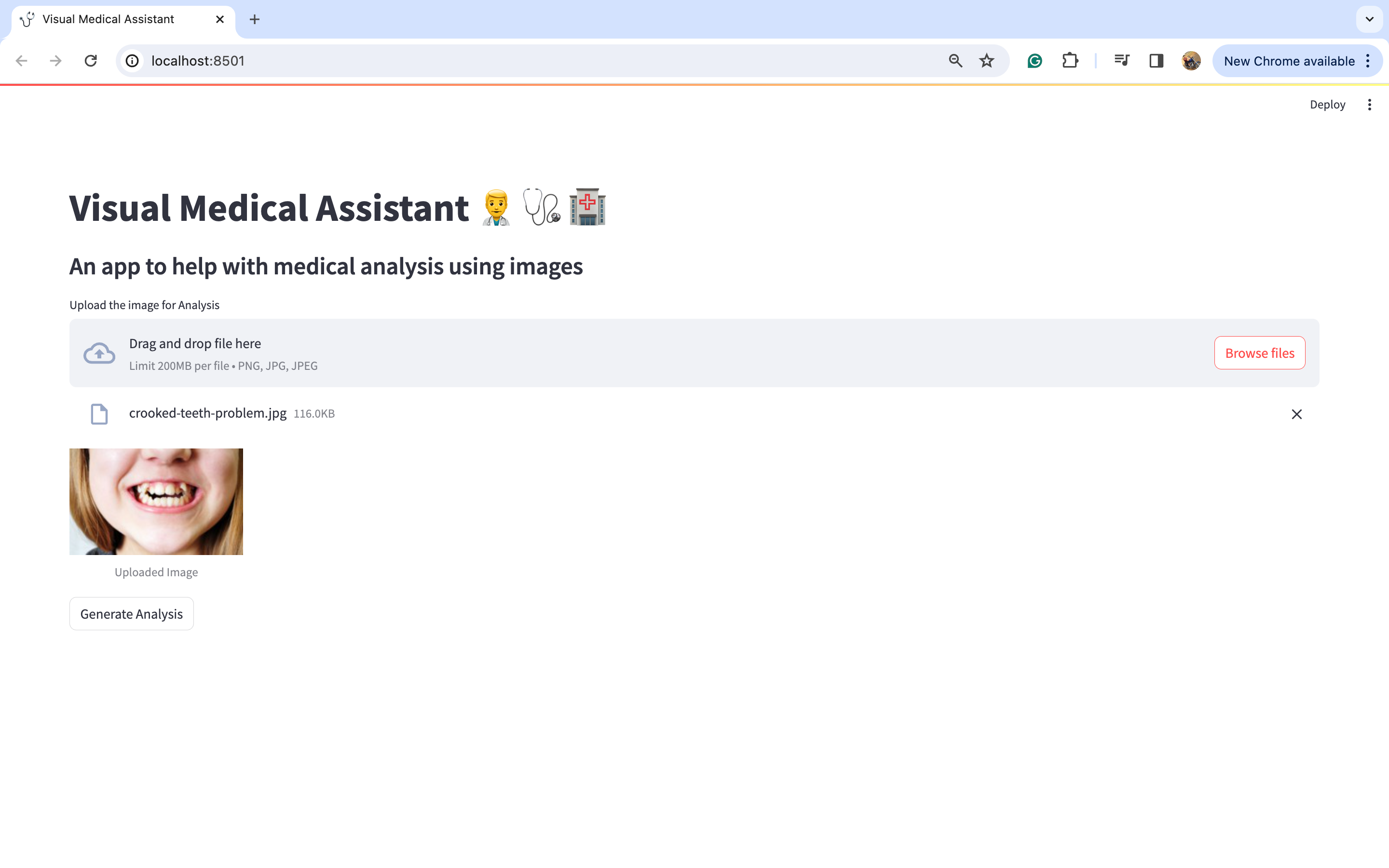
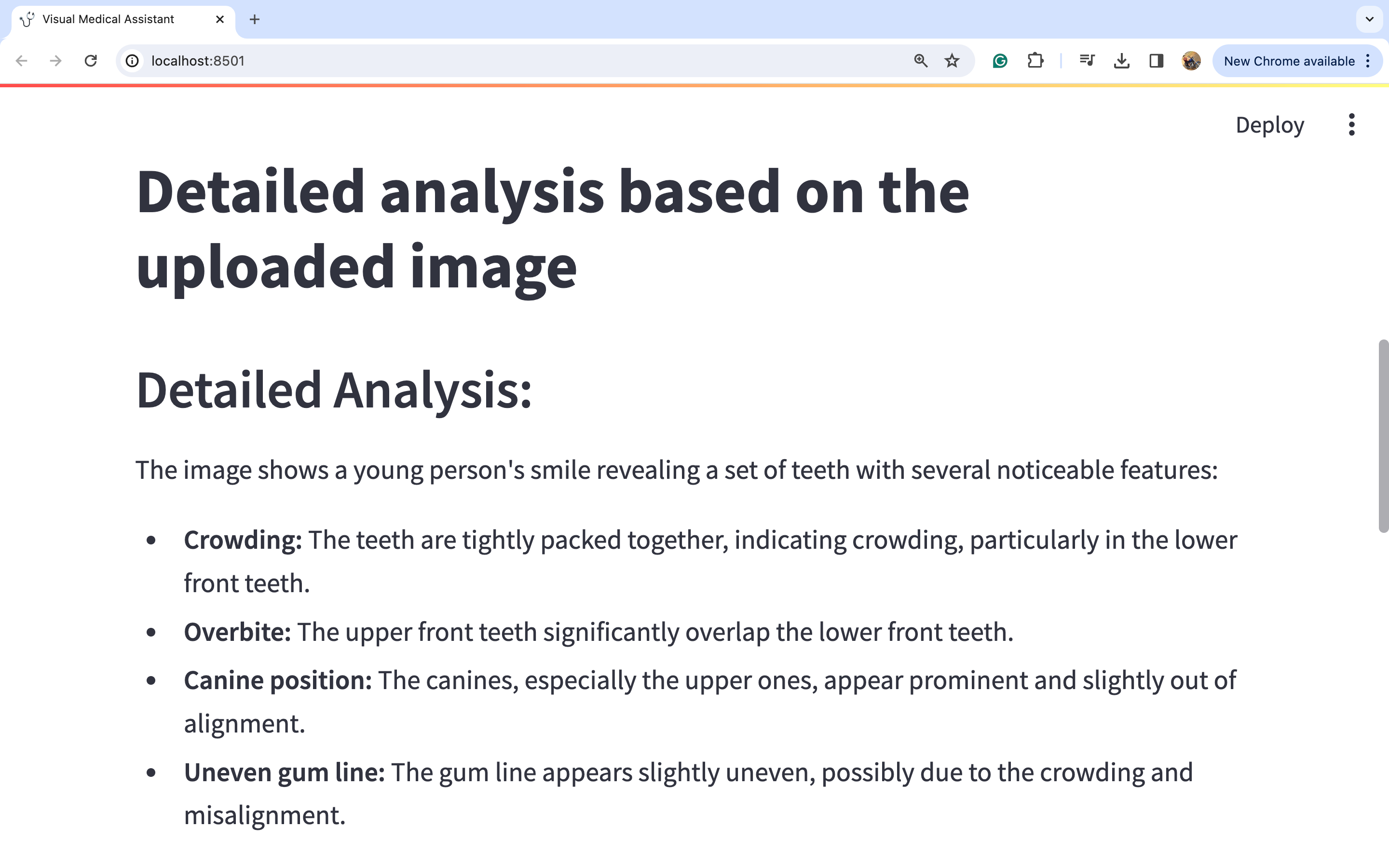
图片上传后,点击“生成分析”按钮。您将在下方看到详细的分析结果:
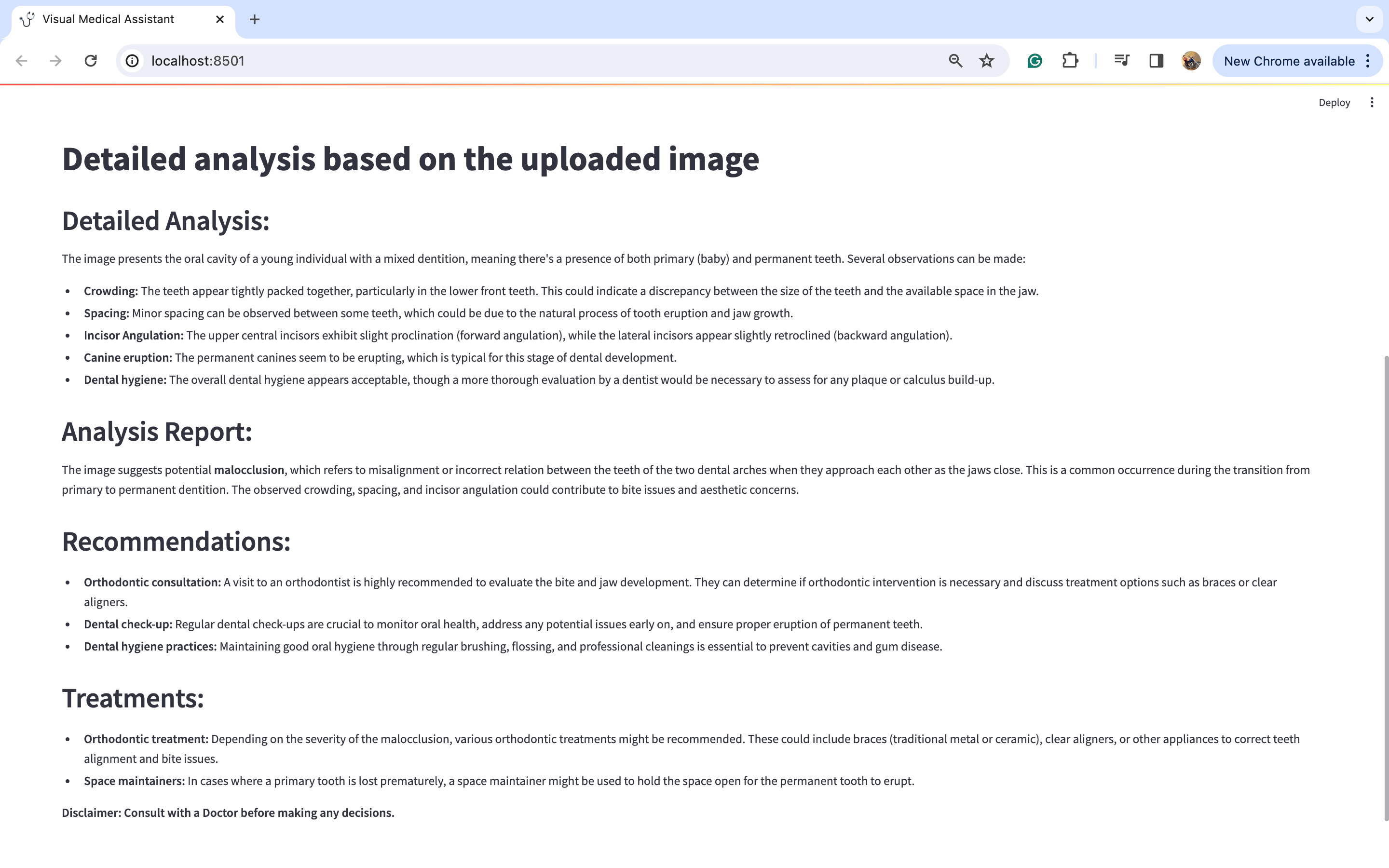
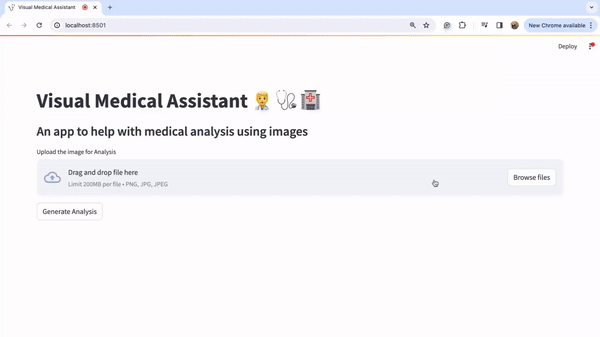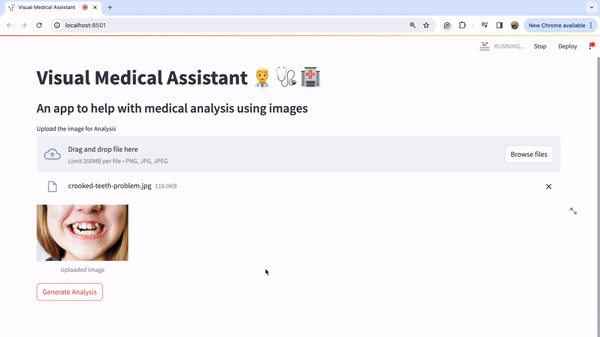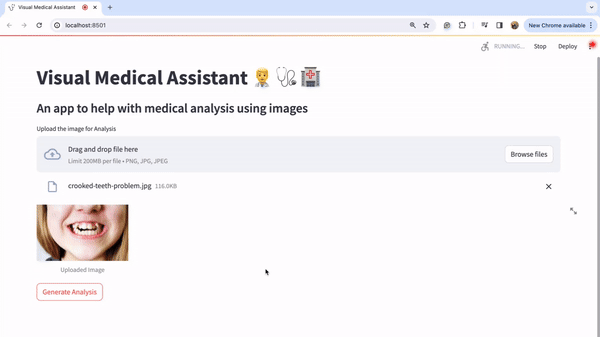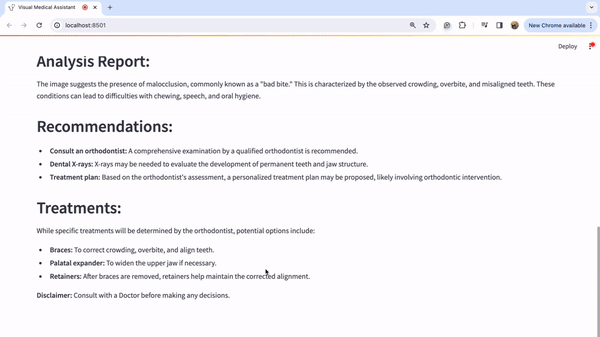
我知道图片可能有点难以阅读,所以我将分享每个标题的放大图片,以便更容易理解。
图片1:
图片2:

图片3:
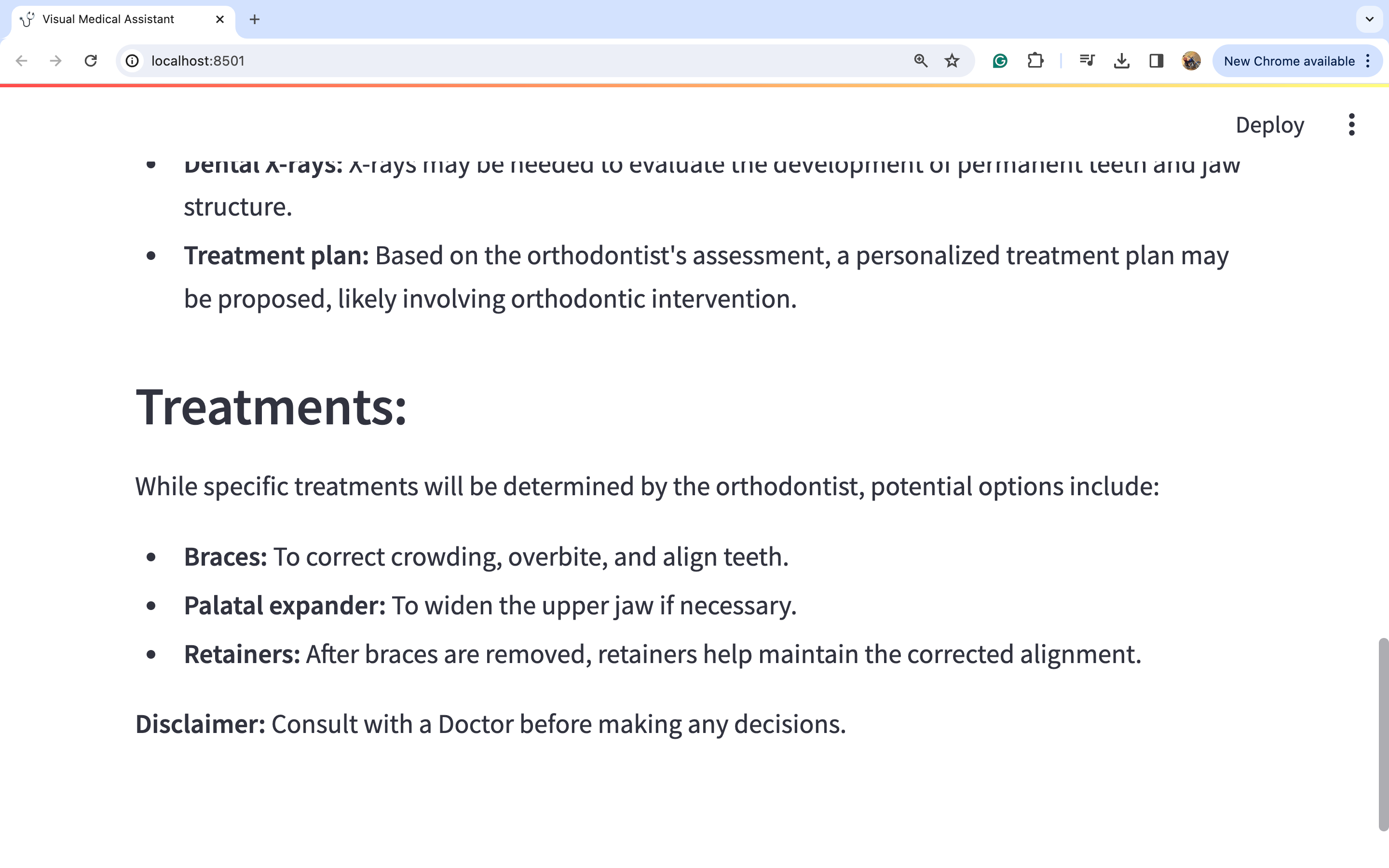
通过仔细观察图片,我们可以对潜在的医疗诊断进行深入分析。此外,考虑到这与牙齿问题有关,建议的行动方案是咨询正畸医生并进行一些牙齿X光检查。此外,在这种情况下,佩戴牙套和保持器等多种治疗选择似乎是明智的选择。
让我们看一下整个过程的样子(从头到尾)
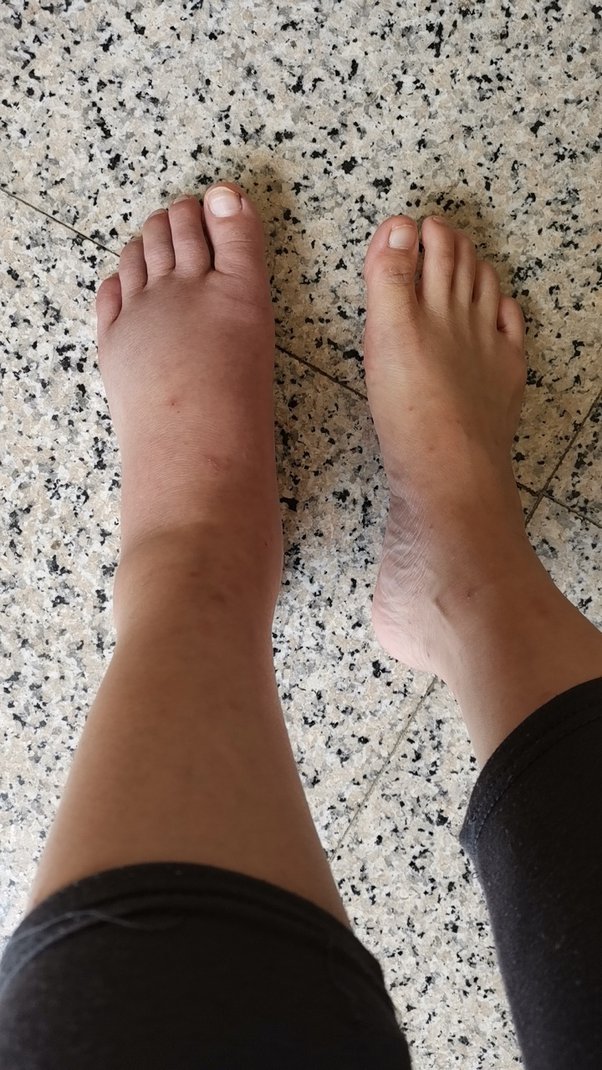
同样,让我们使用另一个例子。这里我们将上传下面的脚踝肿胀图片并检查医疗分析结果。
上传图片并点击生成的分析后,整个过程如下所示:
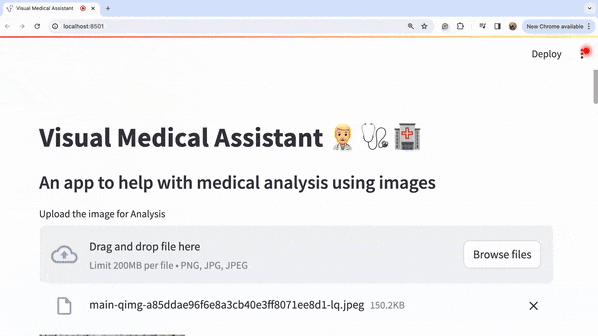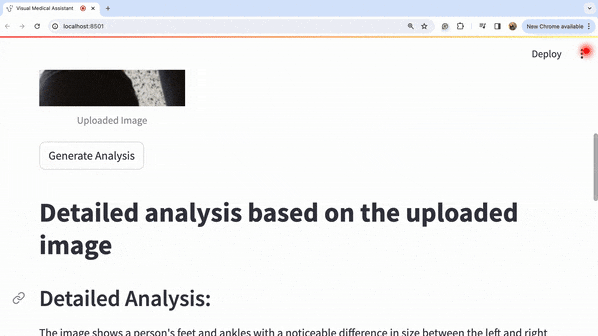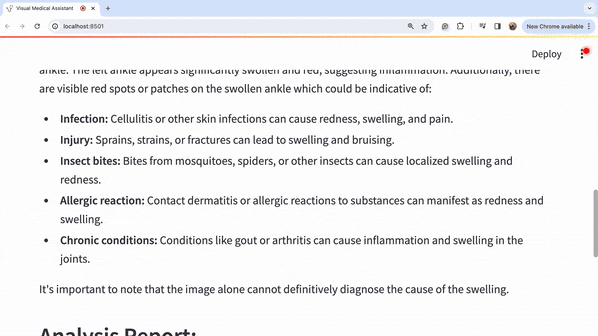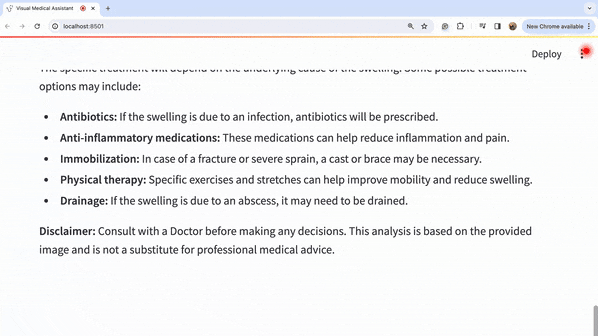
让我们看一下标题的放大图片:
图片1:
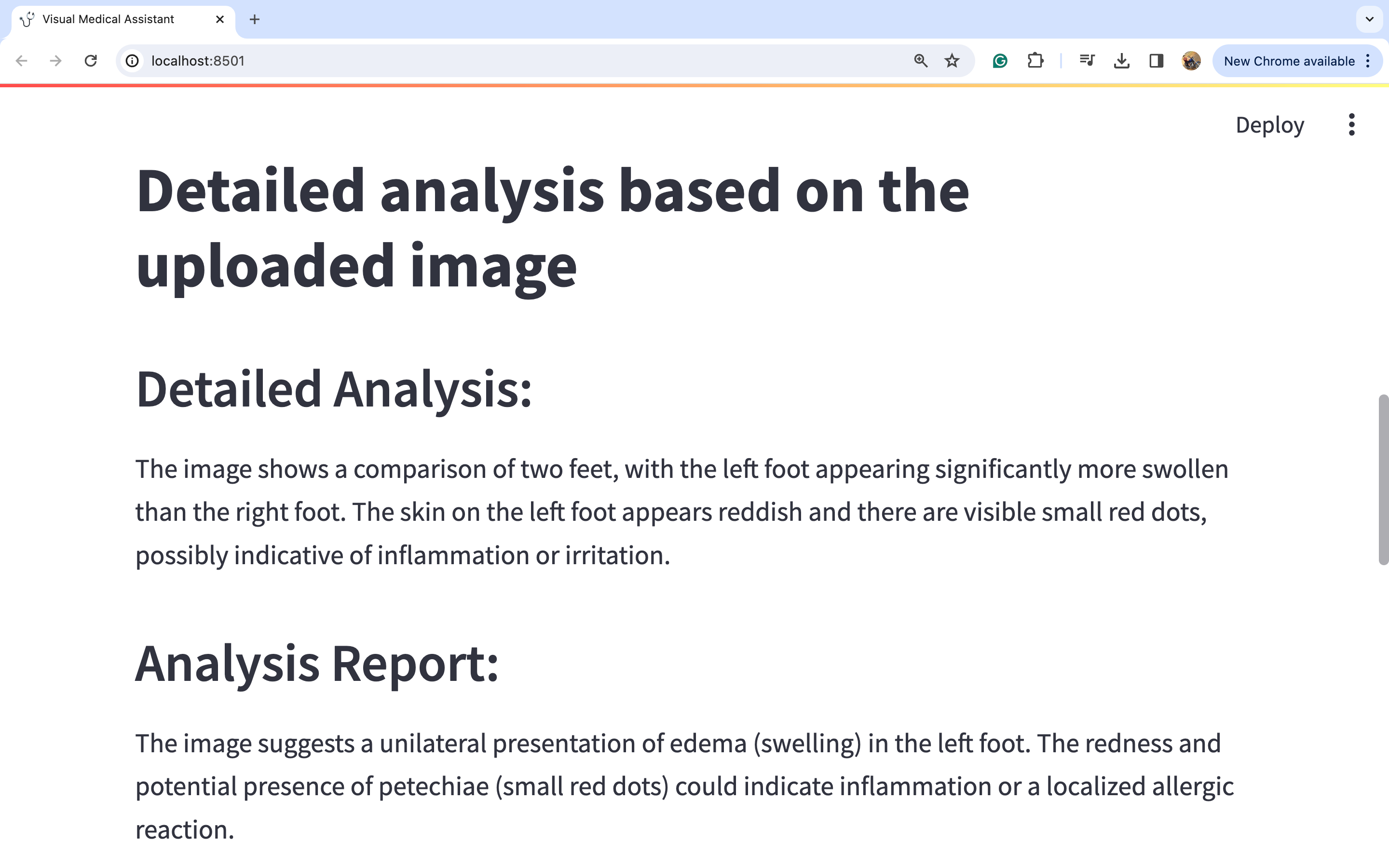
图片2:
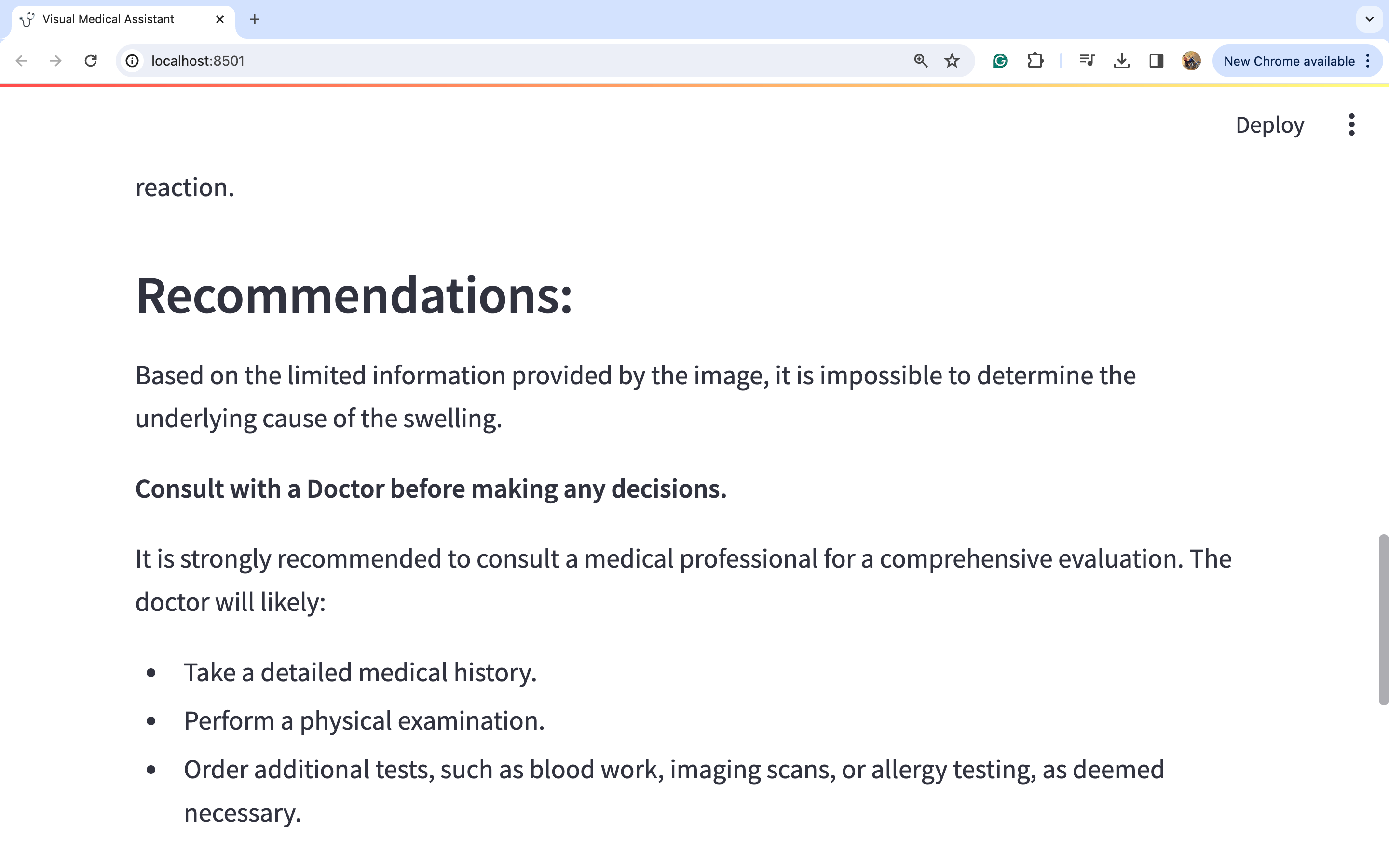
图片3:
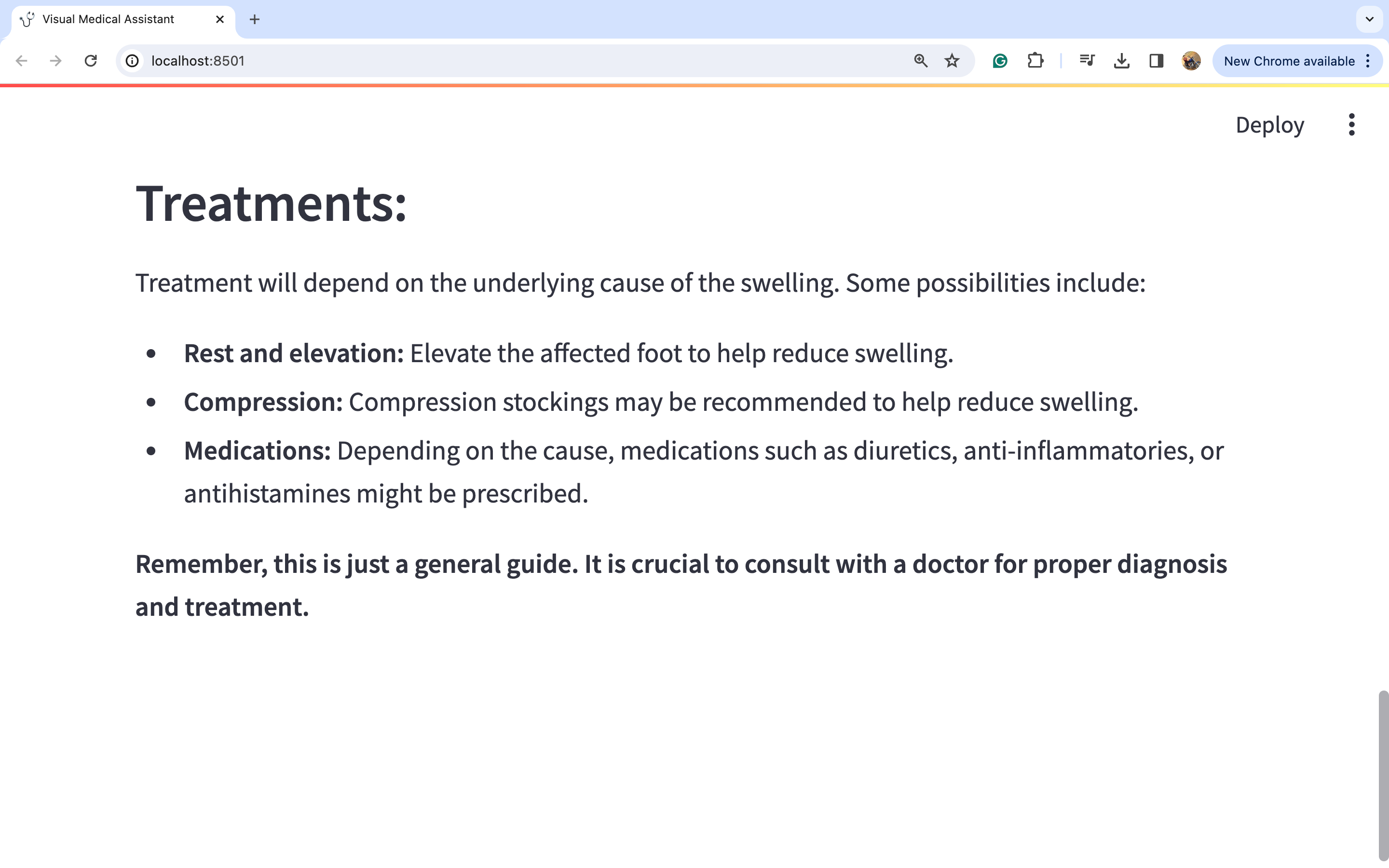
因此,我们可以通过观察图片来进行深入的详细分析,从而得出可能的医疗诊断。我们可以看到模型如何捕捉到左脚肿胀的问题。模型建议咨询医生,因为仅仅通过观察这种肿胀很难得出很多结论。然而,我们可以看到一些治疗选择,如使用压缩包和抬高左脚以减轻肿胀,在这种情况下似乎是合理的选择。
我们可以尝试分析更多类似的图片。
应用场景
这样的应用在医生不易接触的偏远地区非常有用。它们也有助于远离诊所或医院的患者。虽然我们不能完全依赖这些系统,但它们提供了相当准确的医疗指标和指导。我们可以进一步完善我们的提示,并将家庭疗法作为一个部分加入进来。如果我们能定义复杂的提示,Gemini Pro模型可以提供最先进的性能。
结论
在本文中,我们探讨了谷歌的Gemini Pro模型在医学图像分析方面的能力。我们演示了如何配置API,创建有效的提示,并部署一个用于交互式结果的Streamlit应用程序。Gemini Pro模型提供了最先进的性能,使其成为远程医学诊断和临床决策的强大工具。虽然它不能替代专业医疗建议,但它提供了有价值的见解,并可以显著提高医疗评估在服务不足地区的可访问性。随着人工智能技术的进步,像Gemini Pro这样的工具将在医疗创新中发挥越来越重要的作用。
主要观点
-
在本文中,我们演示了如何使用Gemini Pro对图像进行医学检查。
-
我们讨论了配置Gemini Pro API密钥以及如何通过定义提示来提高模型性能。
-
此外,我们使用Streamlit部署了迷你项目,使我们能够进行实验并观察结果。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











