







SpeechVerse: A Large-scale Generalizable Audio Language Model
AWS AI Labs, Amazon
论文地址:https://arxiv.org/abs/2405.08295
Abstract
大规模语言模型(LLMs)在需要自然语言指令语义理解的任务中表现出了惊人的能力。最近,许多研究进一步扩展了这些模型感知多模态音频和文本输入的能力,但它们的功能通常限于特定微调任务,如自动语音识别(ASR)和翻译。因此,我们开发了SpeechVerse,一个稳健的多任务训练和课程学习框架,它通过一小组可学习参数结合预训练的语音和文本基础模型,并在训练过程中保持预训练模型冻结。模型使用从语音基础模型提取的连续潜在表示进行指令微调,以通过自然语言指令在各种语音处理任务上实现最佳零样本性能。我们进行了广泛的基准测试,包括在多个数据集和任务中将我们的模型性能与传统基线进行比较。此外,我们通过测试域外数据集、新颖的提示和未见任务来评估模型的指令泛化能力。我们的实验证明,我们的多任务SpeechVerse模型在11个任务中的9个上表现优于传统任务特定基线。
1 Introduction
大型语言模型(LLMs) [1-3] 通过在大规模文本语料库上的自监督预训练,在各种自然语言任务中取得了显著的性能。通过进一步的指令微调,它们还展示了令人惊讶的能力,可以遵循用户给出的开放式指令,从而实现强大的泛化能力。然而,尽管取得了成功,这些语言模型无法感知非文本模式,例如图像和音频,这仍然是一个重大局限性。
尤其是语音,它代表了人类交流的最自然方式。赋予LLMs深入理解语音的能力,可以显著增强人机交互 [8] 和多模态对话代理 [9, 10] 。因此,赋予LLMs理解语音的能力最近受到了广泛关注。一些方法首先通过自动语音识别(ASR)系统转录语音,然后使用LLM处理文本以改进转录 [11-13] 。然而,这样的管道无法捕捉到非文本的副语言和韵律特征,如说话者的音调、语调、情感、价值等。
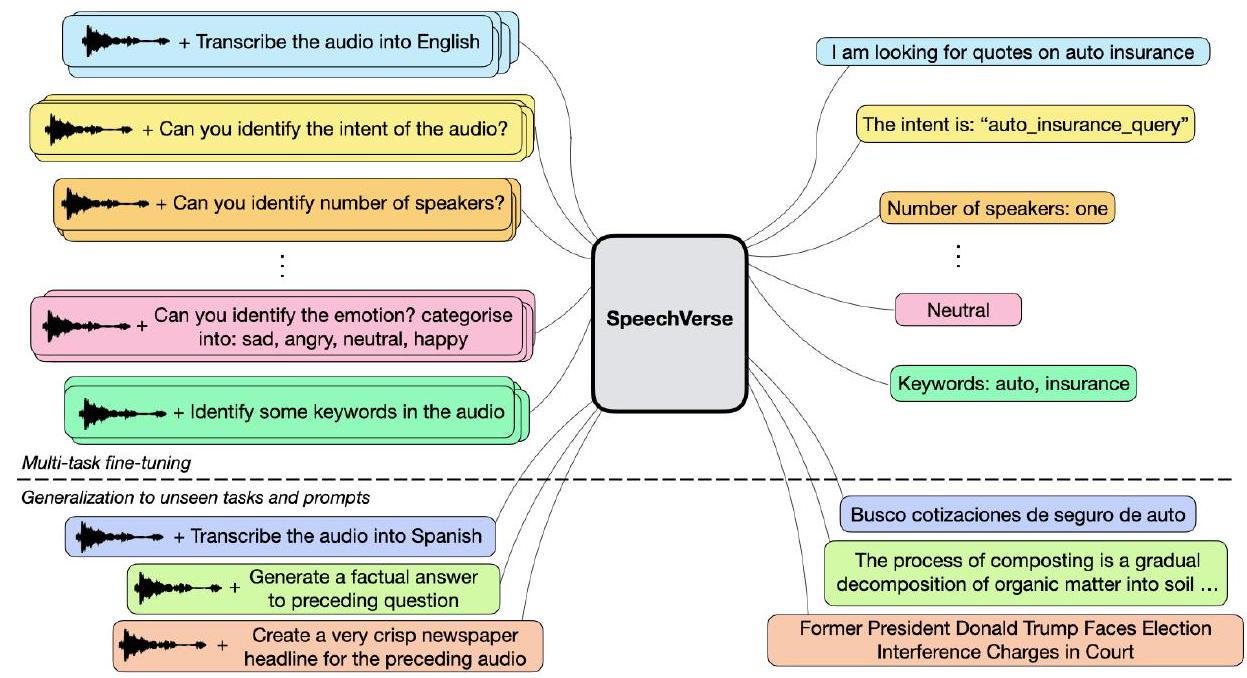
Figure 1: Schematic diagram of the SpeechVerse framework.
一种新的有前途的范式是直接将文本LLMs与语音编码器融合在一个端到端训练框架中 [14, 15] 。联合建模语音和文本相对于仅文本方法来说,有望提供更丰富的语音和音频理解能力。特别是,能够遵循指令的多模态音频-语言模型 [ 16 − − 18 ] [16--18] [16−−18] 因其泛化能力而越来越受到关注。尽管取得了一些成功,现有的多任务音频-语言模型如SpeechT5 [19],Whisper [20],VIOLA [15],SpeechGPT [18] 和 SLM [17] 只能处理少量的语音任务。
因此,我们提出了SpeechVerse,一个利用监督指令微调以整合各种语音任务的稳健多任务框架(见图1)。与SpeechGPT [18] 相比,我们提出使用从自监督预训练语音基础模型中提取的连续表示,专注于生成仅文本输出的任务。最近, [16] 提出了Qwen-Audio,一个能够感知人类语音和声音信号的多任务音频-语言模型,并在包括音乐和歌曲在内的30种音频任务上进行训练。然而,这需要精心设计的层次标签和大规模监督音频编码器进行融合,使其在未见的语音任务上表现不佳。相比之下,我们的训练范式结合了多任务学习和监督指令微调于一体,不需要任务特定的标签,允许通过自然语言指令泛化到未见任务。
我们总结了我们的贡献如下:
- 可扩展的多模态指令微调用于多样化的语音任务。SpeechVerse是一个新颖的基于LLM的音频-语言框架,可以在多达11个不同的任务中展示强大的性能。我们在涵盖ASR、口语理解和副语言语音任务的公开数据集上进行了广泛的基准测试。
- 新型开放式任务的多功能指令跟随能力。我们展示了 SpeechVerse 模型利用其强大的 LLM(大型语言模型)理解能力,以适应在多模态微调过程中未见过的开放式任务的能力。
- 提高对未见任务的泛化策略。我们进一步研究了包括约束解码和联合解码在内的提示和解码策略,这些策略可以增强模型对完全未见任务的泛化能力,将绝对指标提高了最多 21 % 21 \% 21%。
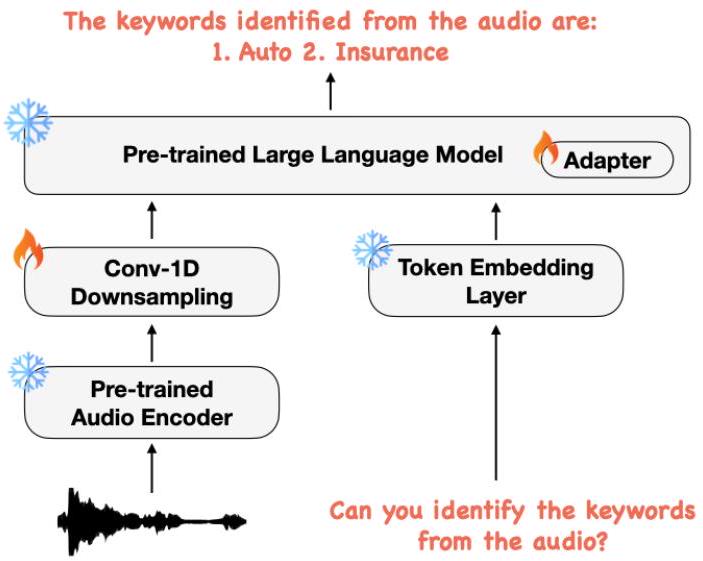
图 2:SpeechVerse 架构的模块图。
2 方法
2.1 架构
如图 2 所示,我们的多模态模型架构包含三个主要组件:(1) 一个预训练音频编码器,用于将音频信号编码成特征序列,(2) 一个作用于音频特征序列的 1-D 卷积模块,用于缩短序列长度,以及 (3) 一个预训练的 LLM,用于使用这些音频特征和文本指令完成所需任务。以下是各子系统的详细描述。
音频编码器:为了从给定的音频中提取语义特征,我们使用一个大型预训练的自监督语音基础模型作为音频编码器。我们可以将音频编码器表示为 L 层的级联集合,其中每个中间层 l 返回一个特征序列 h ( l ) = f A E ( h ( l − 1 ) ; θ A E ( l ) ) \mathbf{h}^{(l)}=f_{A E}\left(\mathbf{h}^{(l-1)} ; \theta_{A E}^{(l)}\right) h(l)=fAE(h(l−1);θAE(l)),其中 h ( 0 ) = x \mathbf{h}^{(0)}=\mathbf{x} h(0)=x 是输入音频。这里, θ A E ( l ) \theta_{A E}^{(l)} θAE(l) 表示预训练语音模型第 l 层的学习权重。为了捕捉多种形式的特征语义,我们计算音频编码器的输出为:
$$
\begin{equation*}
A E(\mathbf{x})=\frac{1}{L} \sum_{l=1}^{L} w^{(l)} \mathbf{h}^{(l)} \tag{1}
\end{equation*}
$$
其中,标量 { w ( 1 ) , … w ( L ) } \left\{w^{(1)}, \ldots w^{(L)}\right\} {w(1),…w(L)} 是一组可学习参数。由于这种方法同时编码了语音基础模型的多个中间层的特征,它能够同时捕捉不同形式的语义(高级特征和低级特征),从而更好地泛化到各种任务。我们还进行了只取音频编码器最后一层输出的实验,即 A E ( x ) = h ( L ) A E(\mathbf{x})=\mathbf{h}^{(L)} AE(x)=h(L)。
卷积下采样模块:训练在仅有文本输入的 LLM,会编码的 token 序列通常比语音基础模型编码的特征序列短得多。为了减轻音频特征和文本 token 之间长度分布的巨大差异,我们通过一个可学习的卷积模块对编码的音频特征进行下采样。该模块包括连续的块,每个块有一个 1-D 卷积层,后接层归一化。对于 1-D 卷积,我们使用核大小为 3,确保每个输出帧的输入帧左右都有上下文。在我们的实验中,我们使用尽可能多的这些下采样块,以使音频的采样率为 12.5 H z 12.5 \mathrm{~Hz} 12.5 Hz,即每个输出帧对应 80 m s 80 \mathrm{~ms} 80 ms 的音频。通过微调卷积下采样模块,可以将音频编码器的输出从一个仅有音频的特征空间转换为一个联合的音频-文本语义空间。因此,我们将 1-D 卷积的输出通道数设置为下游 LLM 的 token 嵌入的特征维度。我们可以将卷积下采样模块的输出表示为 C N N ( x ) = f C N N ( A E ( x ) ; θ C N N ) C N N(\mathbf{x})=f_{C N N}\left(A E(\mathbf{x}) ; \theta_{C N N}\right) CNN(x)=fCNN(AE(x);θCNN),其中 θ C N N \theta_{C N N} θCNN 表示 1-D 卷积块的可学习参数。
大型语言模型:一个 LLM 通常接收一个输入文本 token 序列 z \mathbf{z} z 并对观察到的输出文本序列 y y y 作为输入文本的可能下一个 token 的概率进行建模。文本 token 通过一个在训练期间学习的查找矩阵转换为向量化的嵌入 EMB ( z ) \operatorname{EMB}(\mathbf{z}) EMB(z)。LLM 的输出可以表示为 LLM ( z ) = f L L M ( E M B ( z ) ; θ L L M ) \operatorname{LLM}(\mathbf{z})=f_{L L M}\left(E M B(\mathbf{z}) ; \theta_{L L M}\right) LLM(z)=fLLM(EMB(z);θLLM),其中 θ L L M \theta_{L L M} θLLM 是 LLM 的权重。在本工作中,我们利用一个预训练的 LLM 进行多模态任务。对于包含音频 x \mathbf{x} x 和文本序列 z \mathbf{z} z 的多模态输入,我们简单地将下采样后的音频特征 ( C N N ( x ) ) (C N N(\mathbf{x})) (CNN(x)) 与 token 嵌入 ( ( E M B ( z ) ) ((E M B(\mathbf{z})) ((EMB(z)) 在序列维度上连接起来,如图 2 所示。因此,我们可以表示多模态口语语言模型(SLM)输出的概率分布为:
$$
\begin{equation*}
S L M(\mathbf{x}, \mathbf{z})=f_{L L M}\left([C N N(\mathbf{x}), \operatorname{EMB}(\mathbf{z})] ; \theta_{L L M}\right) \tag{2}
\end{equation*}
$$
### 2.2 Multimodal Instruction Finetuning
让 $\mathcal{D}^{\tau}=\left\{\mathbf{x}^{\tau}, \mathbf{y}^{\tau}\right\}_{1}^{n^{\tau}}$ 代表任务 $\tau$ 的一个标注数据集,该数据集包含 $n^{\tau}$ 样本,每个样本由音频序列 $\mathbf{x}^{\tau}$ 和对应的文字标签序列 $\mathbf{y}^{\tau}$ 组成。令 $\mathcal{P}^{\tau}=\left\{\mathbf{p}^{\tau}\right\}_{1}^{m^{\tau}}$ 为任务描述的 $m^{\tau}$ 文本提示/指令序列集合 $\mathbf{p}^{\tau}$。在我们的实验中,我们对每一个训练任务的各个数据集 $\left\{w^{\tau}, \mathcal{D}^{\tau}\right\}_{1}^{M}$ 进行加权组合,其中 $w^{\tau}$ 是分配给任务 $\tau$ 每个样本的权重。这是为了保证不同复杂程度和训练数据大小的任务之间的平衡。因此,每个样本可以表示为一个元组 $\left(\mathbf{x}^{\tau}, \mathbf{p}^{\tau}, \mathbf{y}^{\tau}\right)$,其中 $\mathbf{x}^{\tau}$ 是音频样本,$\mathbf{p}^{\tau}$ 是从 $\mathcal{P}^{\tau}$ 中均匀采样的提示/指令,$\mathbf{y}^{\tau}$ 是标签。然后,预测标签 $\mathbf{y}^{\tau}$ 的概率可以定义为:
$$
\begin{equation*}
p\left(\mathbf{y}^{\tau} \mid \mathbf{x}^{\tau}, \mathbf{p}^{\tau} ; \Theta\right)=\operatorname{SLM}\left(\mathbf{x}^{\tau}, \mathbf{p}^{\tau}\right) \tag{3}
\end{equation*}
$$
其中,$\Theta=\left\{\theta_{A E}, \theta_{C N N}, \theta_{L L M}\right\}$ 是我们的音频语言模型的所有参数。LLM 中的自注意力层同时关注音频和文本指令,以生成任何与音频相关任务所需的输出。我们使用标准的梯度下降方法来最大化训练数据集中每个样本的目标标签 $\mathbf{y}^{\tau}$ 的生成可能性,如下定义:
$$
\begin{equation*}
\mathcal{L}(\Theta)=-\log p_{\left(\mathbf{x}^{\tau}, \mathbf{p}^{\tau}, \mathbf{y}^{\tau}\right) \sim\left\{\mathcal{D}^{\tau}\right\}_{1}^{M}}\left(\mathbf{y}^{\tau} \mid \mathbf{x}^{\tau}, \mathbf{p}^{\tau} ; \Theta\right) \tag{4}
\end{equation*}
$$
### 2.3 课程学习与参数高效微调
为了确保更快的收敛速度,并避免预训练 LLM 产生灾难性遗忘和过拟合现象,我们采用基于低秩适应 [21](或者 LoRA)的方法进行参数高效的多模态模型训练。在本工作中,我们冻结预训练的音频编码器和 LLM,仅训练卷积降采样模块和 LoRA 适配器。由于大部分参数 $\left(\theta_{A E}\right.$ 和 $\left.\theta_{L L M}\right)$ 在整个训练过程中不会被更新,它使得我们的框架在计算效率上具有优势,并且允许我们在有限的计算资源下扩展到大量不同的数据集和任务。此外,这还使我们能够利用已有的预训练音频和语言模型的能力,而不发生灾难性遗忘。然而,当从头开始在一个多样化的语音任务集合上同时训练降采样模块和 LoRA 适配器时,我们经常观察到梯度爆炸现象,导致次优收敛。因此,我们精心设计了分为两个阶段的课程学习方法来进行训练。
在第一阶段,我们仅训练卷积降采样模块和中间层权重,无需引入 LoRA 适配器。此外,在此阶段只使用自动语音识别(ASR)任务的样本。由于编码后的语音特征向量可能与文本输入的令牌嵌入非常不同,此阶段可以帮助它们更容易地在公共嵌入空间中对齐,只在 ASR 任务的限定任务空间内学习卷积降采样模块的参数。这使得预训练的基于文本的 LLM 能够关注音频序列的内容并生成语音转录。
在第二阶段,我们现在引入 LoRA 适配器进行模型训练。此阶段解冻中间层权重、降采样模块以及 LoRA 适配器。由于 LoRA 适配器从头开始训练,我们首先通过仅在 ASR 任务上训练来让适配器权重预热,以便与第一阶段中卷积降采样模块学习的公共嵌入空间对齐。最后,我们在 ASR 任务基础上引入其他任务并继续训练,同时冻结预训练的音频编码器和 LLM 权重。由于仅使用 ASR 任务进行的预热使得模型能够理解音频的内容,我们的课程学习方法可以在依赖于音频中语音内容的各种语音任务上更快地收敛。
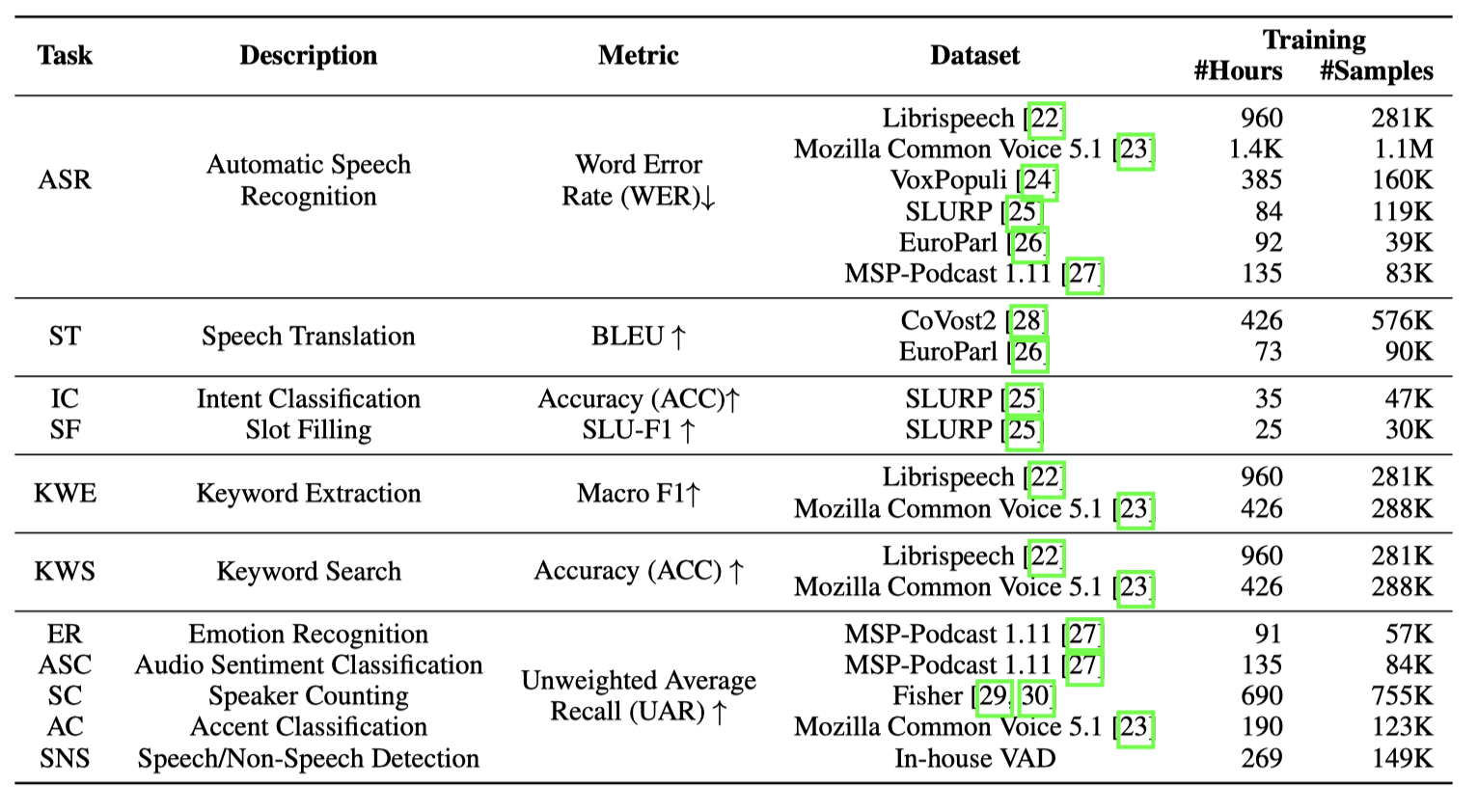
表 1: 我们的任务、训练数据集和评估指标的详细信息。ST, IC, SF, KWE 和 KWS 任务被称为口语理解(SLU)任务,而 ER, ASC, SC, AC 和 SNS 代表副语言处理(PSP)任务
## 3 实验
### 3.1 任务
在这项工作中,我们使用了从各种任务中收集的大量公开数据集。表 1 提供了这些任务的数据集和评估指标的总结,而表 10 列出了示例和提示信息。我们的训练任务包括自动语音识别(ASR)、五个口语理解(SLU)任务和五个副语言处理(PSP)任务。SLU 任务包括可以通过级联 ASR 模型和 LLM 来解决的任务,而 PSP 任务则是基于音频的分类任务,通常用于音频分析。对于 IC/SL 任务,我们将 SLURP 数据集拆分成已见和未见的意图/槽标签类别,并分别研究它们,以了解模型的泛化能力。KWE 任务是从音频中找到重要的关键词,而在 KWS 任务中,我们学习如何判断某个特定关键词是否存在于音频中。这两个任务的目标标签都是使用 LLM 人工合成的。所有其他任务都是标准任务,感兴趣的读者可以参见附录 A.3 获取更多详情。我们为每个任务创建了至少 15 个描述任务目标的提示语。为了进一步丰富任务的多样性,我们使用了 Alpaca 数据集的文本转语音(TTS)版本 [31]。该数据集包含多种提示、输入、输出三元组,其中提示描述任务,输入是任务的输入,输出包含目标标签。然而,该数据集中没有相应的音频。按照现有的工作 [17],我们使用 TTS 系统(在我们的案例中是 AWS Polly)生成输入文本的合成音频,使用的是 10 位不同说话人的音库。
### 3.2 模型
我们使用 SpeechVerse 框架训练了三种不同的多模态模型变体,即 (1) Task-FT:这代表一组模型,每个模型单独为某一特定任务 $\tau$ 进行训练。虽然大多数任务有独立的模型,但某些相关任务如 IC/SF、KWE/KWS 和 ER/ASC 的数据集是一起训练的。(2) Multitask-WLM:这是一个多任务模型,通过将所有任务的数据集汇集在一起进行训练。两者 (1) 和 (2) 均使用预训练的 WavLM Large [32] 作为主干音频编码器,仅使用最后一层编码器输出 $A E(\mathbf{x})=\mathbf{h}^{(L)}$ 作为音频表示。(3) Multitask-BRQ:此模型与 (2) 类似,但使用 Best-RQ [33] 架构作为音频编码器。由于 Best-RQ 编码器使用随机投影量化器进行训练,如果在微调过程中冻结编码器,则中间层权重更适合下游任务。因此,我们使用统一表示,将所有层的表示通过可学习的权重结合起来,用于使用 BEST-RQ 编码器训练的多任务模型。关于这个音频编码器的预训练细节描述在附录 A.1 中。我们所有的三种模型变体均使用第 2.3 节中介绍的课程学习进行训练。所有模型均使用 Flan-T5-XL [5] 作为主干 LLM。Task-FT 模型中引入的 LoRA 适配器具有秩 $(r)=8$,而多任务模型使用 $r=16$,允许更多可学习参数以解决多任务集合。完整的超参数和训练设置列表在附录 A.2 中提供。
表 2: 自动语音识别(ASR)和口语理解(SLU)任务的结果。数据集定义如下:LTC: Librispeech test-clean; LTO: Librispeech test-other; Vox: Voxpopuli; MCV: Mozilla Common Voice; EN: English; DE: German; FR: French;
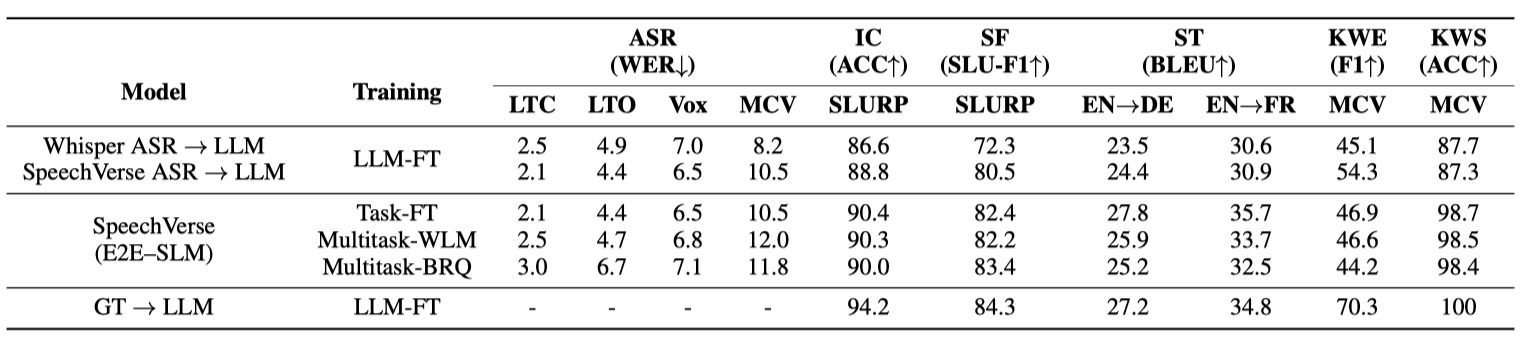
表 3: 副语言处理(PSP)任务的结果。所有报告的数据都是 UAR 指标的值。
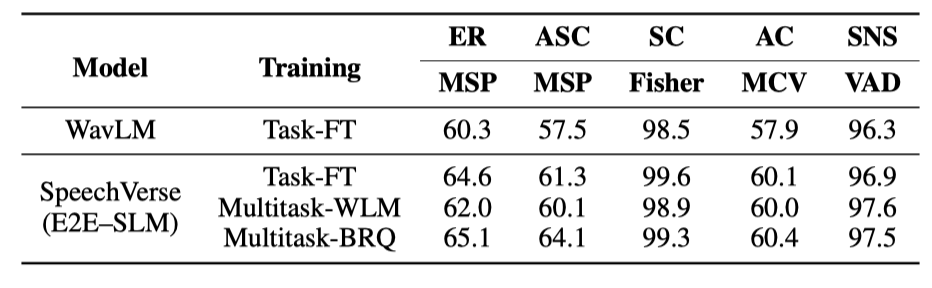
### 基线:
对于 SLU 任务,我们的模型与一个级联基线(将 LLM 应用于 ASR 假设)进行比较(ASR → LLM)。为了公平比较,我们使用了 Flan-T5-XL 的参数高效微调版作为基线中的 LLM。多任务微调的数据在我们的模型和基线之间完全相同,只是在后者中用真实文本代替了音频。我们使用来自(1)一个强大的公开可用的 Whisper-large-v2 [20] ASR 模型和(2)我们的 ASR Task-FT SpeechVerse 模型的 ASR 假设对级联方法进行基准测试,从而使多模态模型与级联方法进行真正的比较。最后,我们还通过将真实转录文本文字传递给基线 LLM (GT → LLM)来基准测试 Oracle ASR 系统的性能。对于 KWS 任务,我们使用在 ASR 假设中进行子串搜索的关键字作为基线。对于 PSP 任务,我们训练特定任务的分类器,该分类器使用来自 WavLM Large 的最后一层表示。该分类器包含一个前馈层,接着是一个带有帧间均值池的两层门控循环单元(GRU),随后是另外两层前馈网络,最后是一个 softmax 操作符。这些模型在相同的特定任务数据上进行训练,从而允许与我们基于 WavLM 的多模态模型进行直接比较。
## 4 结果
### 4.1 SpeechVerse 模型的评估
我们在多个领域和数据集上的 11 项独特任务上评估了利用 SpeechVerse 框架的端到端训练的联合语音与语言模型(E2E-SLM)。我们首先通过 ASR 基准测试评估 SpeechVerse 的核心语音理解能力。然后,我们在表 2 和表 3 中分别评估更复杂的 SLU 任务和副语言语音任务。
### 4.1.1 ASR 和 SLU 任务的表现
首先,我们在四个公开的 ASR 基准测试数据集(libri-test-clean, libri-test-other, Voxpopuli 和 CommonVoice)上评估 SpeechVerse 模型的表现。每个数据集的 WER 数字报告在表 2 中。表中的第二行的 SpeechVerse ASR 使用的模型与第三行中的任务特化预训练 ASR 模型(Task-FT)相同。当比较我们的任务特化预训练 ASR 模型(它也是多任务微调的初始化)与 Whisper ASR 时,我们的模型平均表现稍好。然而,在两个多任务模型中,WER 都有所增加,Multitask-WLM 在四个测试集中的三个测试集中表现与 Whisper 类似。多任务 SpeechVerse 模型的较低性能可能是由于在多任务训练期间构建批次时对 ASR 数据集赋予了较低的权重,这是为了平衡所有任务的性能,因为不同任务之间的数据分布是不平衡的。
对于 SLU 任务,一个常见的问题是端到端模型能否超过通过 ASR 转录语音然后传递给语言模型的级联流水线。为了调查这个问题,我们在五个语义理解任务上使用与 SpeechVerse 相同的基础模型进行了实验。文本基础模型在五个 SLU 任务的数据上进一步微调,因为我们发现 Flan-T5 在这些基准测试集上的零射击(zero-shot)性能相当差。我们还报告了将真实转录文本文字输入微调过的 LLM 的性能,以提供上限结果。在除关键字提取外的五个任务中的四个任务中,端到端训练的模型比级联流水线表现更好。特别是像意图分类、槽标签和语音翻译等更常见的任务,比级联系统表现得更好,证明了我们利用 SpeechVerse 训练的模型的有效性。我们还观察到,SpeechVerse 模型在 KWS 任务上比级联流水线绝对高出 10% 的准确率,而在 KWE 任务上则明显落后。由于关键字搜索任务需要将注意力聚焦在特定的词上,联合建模通过克服级联流水线中的错误传播来提高准确率。我们还进行了消融研究,以确定 KWE 任务是否通过 ASR 转录和关键字的联合解码进一步受益。我们注意到性能有所提高,缩小了与级联流水线的差距。该研究的结果在小节 4.3.2 中有详细说明。相比任务特化 SpeechVerse 模型,多任务模型的性能略有下降,但差异不大。总体而言,使用 WavLM 编码器或 Best-RQ 编码器训练的多任务模型在大多数任务中都优于级联系统。
### 4.1.2 副语言任务的表现
表 3 的结果显示,相对于为每个任务独立微调 WavLM 模型,使用多任务学习在各种副语言语音处理任务上能明显提高性能。具体来说,使用 Best-RQ 音频编码器(Multitask-BRQ)进行多任务学习训练的 SpeechVerse 模型在情感识别上比基线 WavLM 模型提高了 $4.8\%$ ,音频情感分类提高了 $6.6\%$ ,口音分类提高了 $2.5\%$ 。相比之下,使用 WavLM 编码器进行多任务学习的 SpeechVerse 模型(Multitask-WLM)所取得的提升较为适中。统一表示法对所有编码层的自适应组合帮助 Multitask-BRQ 模型在不同副语言任务上的表现得到改善。总体而言,相对于基线 WavLM 模型的任务特定微调,多任务学习能显著提升模型在多种语音任务中的泛化能力和有效性。结果突显了通过多任务学习技术在相关任务中学习共享表示的优势。
### 4.1.3 与 SOTA 模型的比较
表 4 将 SpeechVerse 模型与当前最先进(SOTA)模型在五个不同任务上的表现进行比较:自动语音识别(ASR)、语音翻译(ST)、意图分类(IC)、槽填充(SF)和情感识别(ER)。在这些任务中,SpeechVerse 展现出与之前的专用模型相当或更优的性能。当对比我们的任务特定预训练 ASR 模型(也作为多任务微调的初始化)与 Whisper ASR 时,我们的模型在平均表现上稍好一些。然而,多任务模型(Multitask-WLM)在四个测试集中有三处表现与 Whisper 相似。在三个语言对的语音翻译评估中,任务特定的 SpeechVerse 模型 ${ }^{*}$ SpeechVerse Task-FT 模型包括所有意图和槽以进行比较,在两个语言对上超过了 SeamlessM4T,而多任务 SpeechVerse 模型则在平均性能上与之前的工作竞争力相当。这两个模型在英罗翻译对上表现不佳。SpeechVerse 模型在语音翻译上的整体性能受到底层语言模型 FlanT5 能力的显著限制,因为语音翻译能力不能超过 FlanT5 作为基础语言模型提供的翻译质量。为了评估 SpeechVerse 在口语理解任务上的表现,如意图分类(IC)和槽填充(SF),我们通过纳入所有 69 个意图(包括已知和未知的)以及所有槽来重新训练任务特定的 SpeechVerse 模型。这使我们能将 SpeechVerse 与之前的工作在完整的意图和槽集上进行比较。我们的 SpeechVerse 模型在槽填充任务中达到了与之前 SOTA( $P F$-hbt-large )相近的性能,但在意图分类上比分数低 $5\%$ 。然而,当在微调时冻结编码器权重时,SpeechVerse 比相同的 SOTA 模型(Frozen-hbt-large)高出 $10\%$ 。为了进一步分析与之前 SOTA 之间的差距,我们进行了一个允许在微调期间调整音频编码器权重的实验,最终达到了 $89.5\%$ 的准确率,与之前的 SOTA 一致。这表明,意图分类性能在进行全面微调时可能会过拟合到 SLURP 数据集的特定声学条件。专注于情感识别任务训练的 SpeechVerse 模型相比之前的 SOTA 模型( $w 2 v 2$-L-robust )在无权重平均召回上绝对提升 $8\%$ ;相比之下,多任务 SpeechVerse 模型仅提高了 $3\%$ 。然而,值得注意的是,之前的 SOTA 工作使用的是 MSP-Podcast 1.7 数据集,而我们使用的是 1.11 版本进行训练。两种方法的测试集版本相同。总体而言,在各种任务评估中,SpeechVerse 模型在某些情况下的表现与之前的专用模型相竞争或更优。
表 4:SpeechVerse 模型与之前的专用 SOTA 模型在五个不同任务上的比较:自动语音识别(ASR)、语音翻译(ST)、意图分类(IC)、槽填充(SF)和情感识别(ER)。
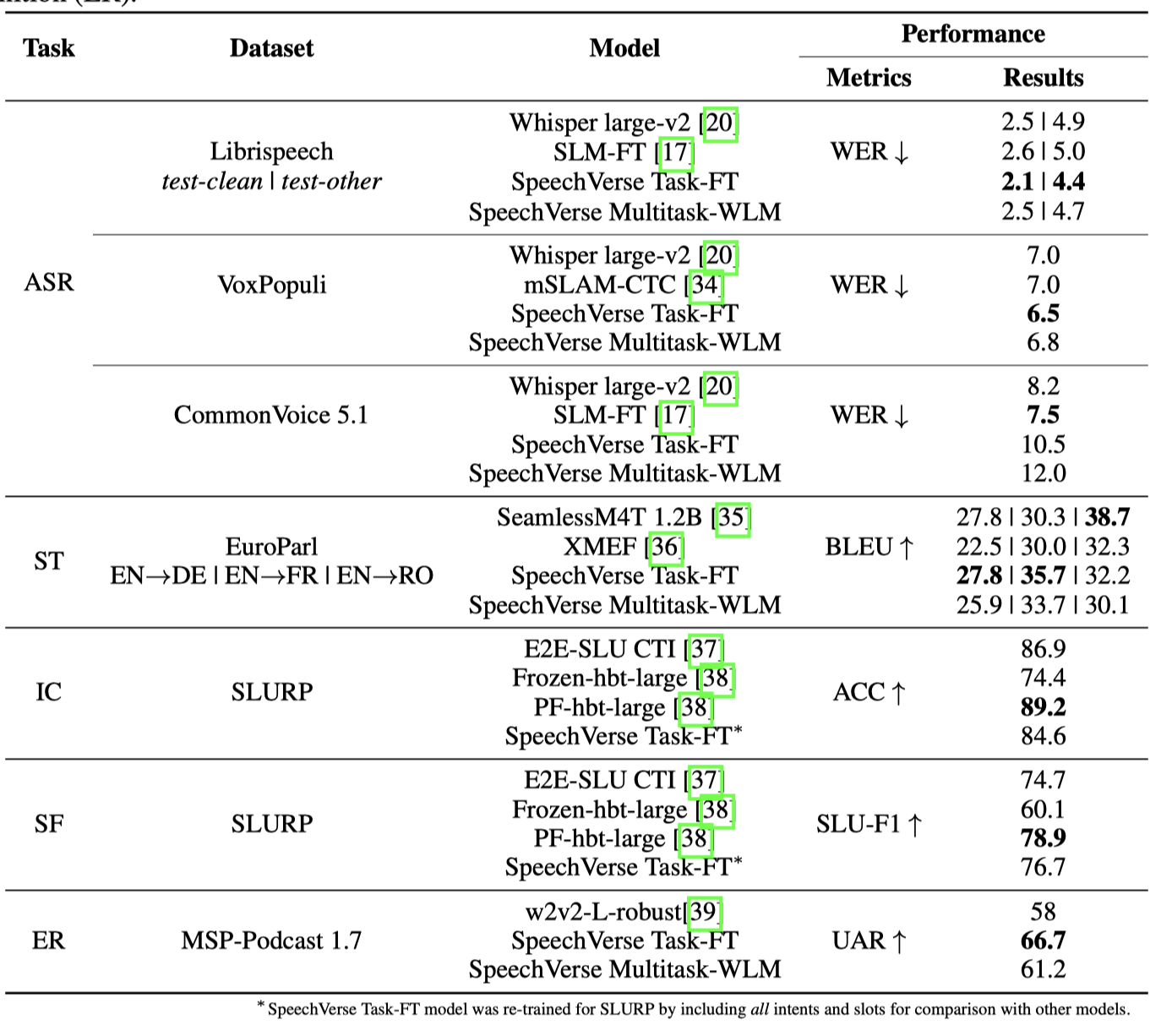
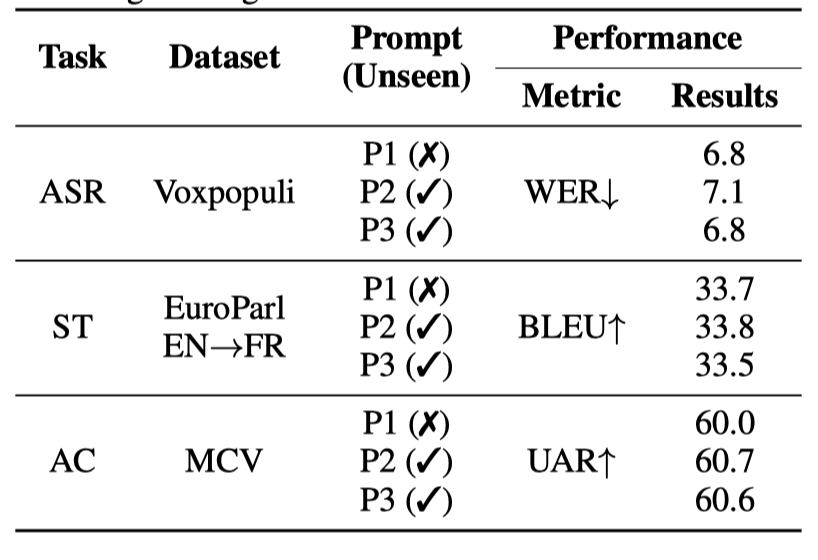
表 5:对未见提示的泛化性能:评估了每个任务在三种不同提示上的表现,其中两种是训练期间未见过的。
### 4.2 指令间的泛化性能
我们全面研究了 Multitask-WLM 模型在处理多种未见过的指令时的泛化能力。首先,我们尝试使用与训练时不同的措辞完成已见任务。我们为一些训练任务创建了新的提示,并评估了模型对提示变化的鲁棒性。接下来,我们展示了模型利用底层 LLM 的强大语言理解能力,泛化到在多模态微调期间完全未见过的新任务的潜力。
### 4.2.1 测量对提示变化的鲁棒性
为了评估不同提示对训练任务性能的影响,我们使用三个额外提示测试了 MultiTaskWLM 模型的三个不同任务:ASR、ST 和 AC。我们每个任务测试三个提示,一个直接取自训练时使用的提示集,另外两个是用不同的措辞和背景创建的新提示。如表5所示,模型在每个任务的提示间表现相似。在 ASR 任务中,我们仅看到已见提示和未见提示之间有0.3的 WER 轻微变化。同样,对于 ST 和 AC 任务,度量值随着提示的改变而变化很小。这些微小的差异表明我们的模型已经很好地泛化其核心能力,并且不强依赖于提示的具体措辞或背景。虽然提示工程对于最佳性能仍然重要,但这些结果表明模型已经学习了能够跨提示选择转移的稳健任务特定技能,至少对于训练期间见过的任务而言。对于那些超出训练期间见过的任务,我们在后续章节 4.3.1 中单独研究提示设计。
### 4.2.2 开放式指令遵循
为了研究模型理解开放式文本和语音指令的能力,我们给模型提供了若干不受限的创意请求,这些请求并不在我们的训练课程中。我们在表6中列举了几个这样的例子。在许多这些例子中,模型需要展示对书面和口头指令的深刻理解才能成功执行任务。例如,在创意 QA 任务中,模型必须理解口述请求和指令提示以生成相关响应。在摘要任务中,模型必须正确推测口述内容以生成摘要。在上下文偏差任务中,当提供提示时,我们观察到模型甚至能够自行纠正其输出。多任务模型在输入从训练数据分布上发生变化时的稳健响应展示了其核心指令遵循技能的适应性。与其过拟合训练领域,多任务学习方法使得模型能学习到更多在指令理解和执行上的多才多艺的能力,从而更好地转移到新的上下文中。我们在下一节中提供了一些关于未见任务和标签的定量结果。
表6: 开放式任务上的定性示例展示了模型的指令遵循能力。DC: 域分类;QA: 问答;ST: 语音翻译
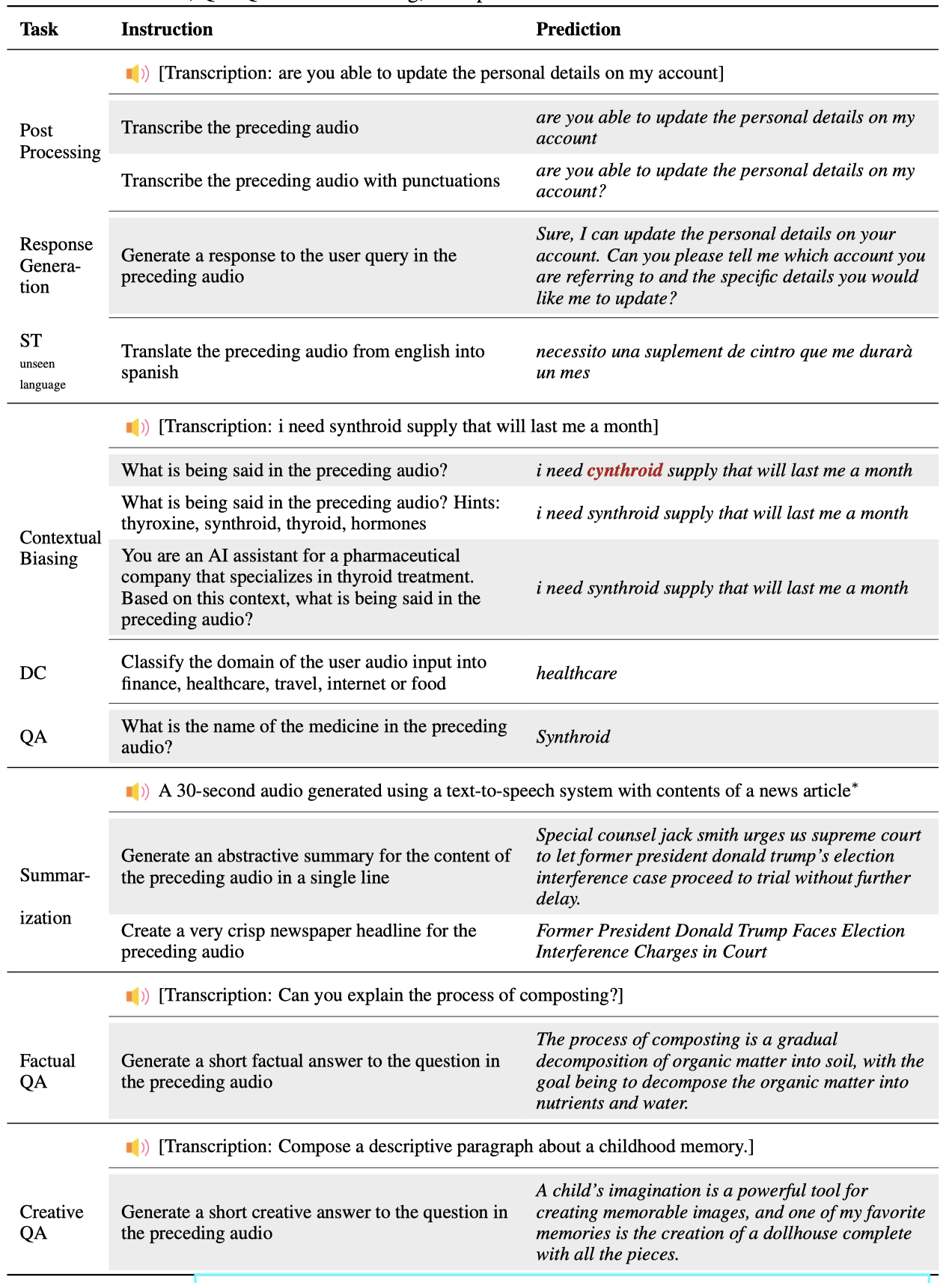
表7: 三个未见任务在有限解码(CD)和非限定解码(Non-CD)下的结果比较。我们对比了仅包含类别标签的指令提示与在提示中提供每个类别标签描述的设置。

### 4.3 提高性能的策略
我们进一步评估了一些策略来提高多任务模型在未见任务和类别标签上的性能。首先,我们利用有限解码 [40] 来处理预定义有限结果集的任务。接下来,我们还研究了在某些复杂的口语理解任务中,将任务输出与 ASR 假设同时解码的方法。
### 4.3.1 有限解码
我们在 [40] 的工作基础上,提出了一种与模型无关的方法,在文本生成过程强制实施特定领域的知识和约束。基于这一前期方法,我们探索了将解码约束应用于SpeechVerse模型,以提升其对未见过的语音分类任务的泛化能力。与其让模型自由生成响应提示的内容,不如限制解码输出只能来自预定义的类别名称词汇。例如,在意图分类任务中,模型将被限制仅生成诸如“播放电台”、“时间查询”或“烹饪食谱”等意图标签。通过限制输出空间,模型更有可能生成所需的类别标签,而非无关文本。
我们精心对模型在封闭任务(例如一组多样的分类任务)中的表现进行了基准测试,这些任务都有一组预定义的有限类别标签。为了理解指令提示的影响,我们将这项研究分为两部分:(1) 仅在提示中提供类别标签,(2) 在提示中提供每个类别标签的相关描述。我们确保这些类别标签在训练期间没有出现,因此对于模型来说都是新任务。此外,我们评估了在这两部分中使用约束解码的有效性,因为这些类别标签事先是已知的。需要注意的是,SL任务被认为是一个更难的任务,因为模型不仅需要正确分类槽标签,还要从语音中识别出相应的槽值。因此,我们报告了SLU-F1指标以及SL的SD-F1(槽标签检测)指标。该研究结果如表7所示。
我们观察到,在提示中包含描述的结果不一致,这可以归因于提示中所提供描述的质量和主观性,尤其是这些描述在训练期间未曾出现。然而,我们看到约束解码在所有情况下都改进了结果,并且只有在提供描述并进行约束解码时才观察到最显著的提升。这表明,提供描述确实引导模型更好地理解任务语义,但只有约束解码才能客观地剔除由任何提示偏差引入的噪音。这一现象在SL任务中进一步显现,其中SLU-F1的绝对值低于SD-F1,因为SLU-F1指标包含了槽标签和槽值,而约束解码只能应用于槽标签(因此SD-F1较高)。同样地,对于完全未知的领域分类(DC)任务,即将音频内容分类为五个领域(如医疗保健、技术等),我们观察到使用约束解码的准确率强劲,达到62%。
### 4.3.2 Joint Decoding
某些SLU任务要求模型理解音频的语义或对音频内容执行操作。例如,KWE任务是从音频的ASR假设中提取重要关键字。这是模型需要多步推理的过程,我们从已有工作 [41] 中获得灵感,使用Chain-of-Thought(CoT)提示。我们训练模型首先解码音频的ASR假设,然后输出任务结果。用于同时引发ASR假设和任务输出的提示如表8所示。对于包括IC、KWE和ER在内的一组典型SLU任务,我们通过将一小部分这种多步骤示例添加到单任务示例中重新训练Task-FT模型。我们在表9中比较了是否与ASR假设联合解码的结果。
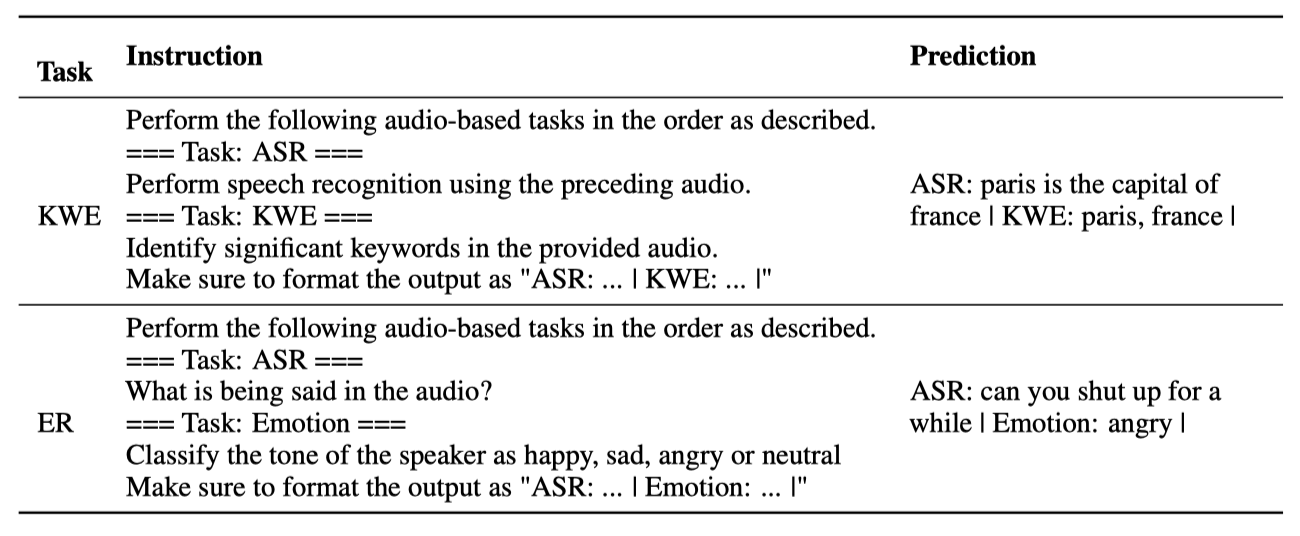
表8:用于引发KWE和ER任务复合目标的示例提示
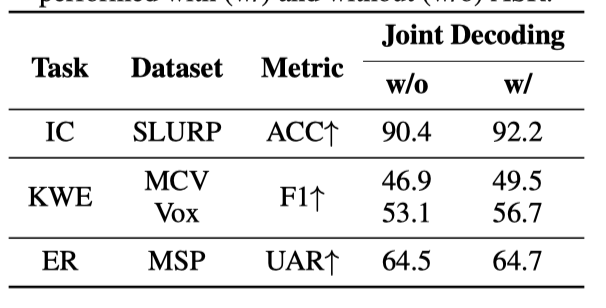
表9:在解码过程中有(w/)和无(w/o)ASR时的复合目标实验结果
表中结果显示,通过复合目标增强培训数据有助于提升所有三项任务的性能。性能提升可以归因于我们多模态模型解码器中已解码的ASR假设上的自注意力机制。此外,这种多步骤训练示例展示了模型真正的多模态能力,成功完成组合任务。进一步来说,这种模式可以通过一次调用大型多模态模型来获取转录和任务输出,从而节省宝贵的推理延迟。关于联合解码益处的更详细分析将在未来工作中进行。
## 5 Related Work
## 5 相关工作
### 多任务学习
之前的研究显示,单个深度学习模型能够在不同领域内共同学习多个大规模任务 [42]。多任务学习的关键思想在于通过共享相关任务的表示来提高整体泛化能力和效率。遵循这种方法,T5 模型 [43] 将所有文本任务框定为文本输入到文本输出,使用统一的文本框架来促进文本任务间的共享表示。同样,SpeechNet [44] 和 SpeechT5 [19] 也利用共享的编码器-解码器框架来共同建模跨越 5 至 6 项任务的语音和文本模式,如 TTS、ASR 和语音转换 (VC)。VIOLA [15] 是单一自回归 Transformer 解码器网络,通过多任务学习将各种跨模态语音和文本任务统一为条件编解码语言模型。Whisper [20] 也采用了大规模多任务学习,针对相关语音任务(包括语言识别、语音识别和翻译)进行训练。在本工作中,SpeechVerse 利用多任务训练在多个相关任务之间传递知识,同时使用自然语言指令来执行每个任务。不像之前生成文本、语音或两者的方法,我们的方法仅关注生成文本输出,同时接受音频和文本指令。
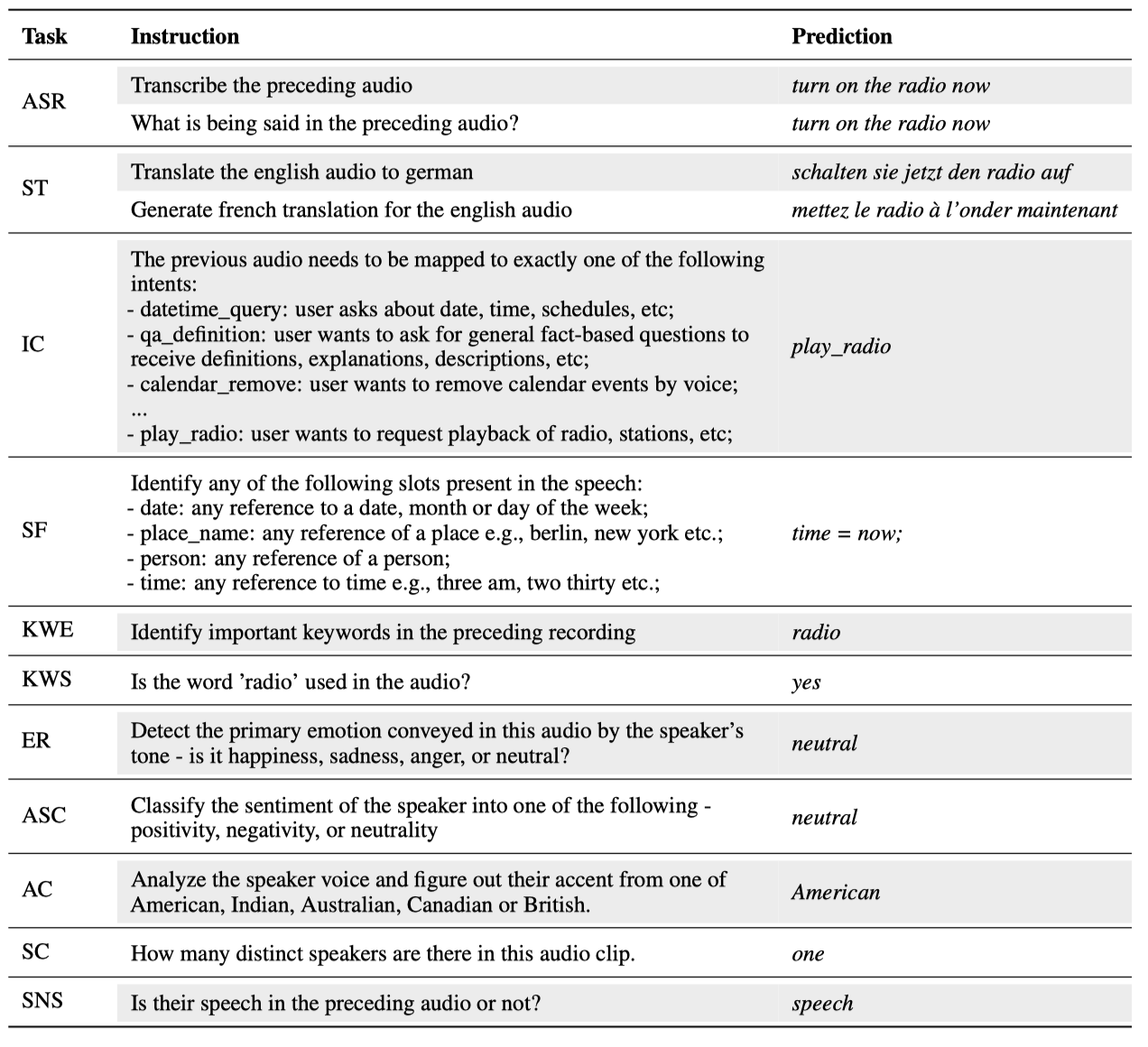
表 10:所有训练任务从一个包含转录 "turn on the radio now" 的音频文件中提取的定性示例。
### 多模态大语言模型
之前关于多模态 LLM 的工作主要集中在涉及图像的任务,如图像生成、视觉问答和图像描述 [4, 9, 45, 46]。相比之下,包含音频和语音等模态的多模态模型受到的关注相对较少 [47, 49]。然而,近年来越来越多的研究开始关注将大语言模型与音频数据结合,提出了一些新的方法 [8, 14, 17, 18, 50-52]。SpeechGPT [18] 提出了一种多模态 LLM,将 HuBERT 的离散单元与 LLM 相结合,解决如 ASR、口语问答等理解任务以及 TTS 等生成任务。[17] 引入了零样本指令跟随的新能力,适用于更多元的任务,如对话生成、语音续接和问答。最近,[16] 提出了 Qwen-Audio,这是一种大规模音频语言模型,采用多任务学习方法来处理包括人声、自然声音、音乐和歌曲在内的各种音频类型的多样任务。Qwen-Audio 使用单一音频编码器来处理各类音频,其初始化基于 Whisper-large-v2 模型 [20] 并进行完整微调。相比之下,我们的工作利用两个冻结的预训练模型,分别用于语音编码器和文本解码器,以保留它们的内在优势。此外,我们在训练过程中为每个任务利用了 30 多条指令以提高泛化能力,而[17] 只使用了单一固定指令。还要说明的是,SpeechVerse 将多任务学习与指令微调结合在一个训练阶段中。
## 6 总结
在这项工作中,我们提出了 SpeechVerse,一个多模态框架,使得 LLM 能够遵循自然语言指令来执行多样化的语音处理任务。通过监督指令微调和结合冻结的预训练语音和文本基础模型表示,SpeechVerse 在未见过的任务上实现强大的零样本泛化。广泛的基准测试表明,在 11 项任务中的 9 项上,SpeechVerse 超越了传统基线,展示了其强大的指令跟随能力。至关重要的是,SpeechVerse 在域外数据集、未见过的提示和甚至是未见过的任务上保持稳健的性能。这突显了我们提出的训练方法有效地赋予模型将文本指令映射到语音处理输出的通用技能。未来,我们计划扩展 SpeechVerse 的能力,以便遵循更复杂的指令并推广至新领域。通过将任务规范与模型设计分离,SpeechVerse 代表了一种灵活的框架,可以通过自然语言动态适应新任务而无需重新训练。
## 局限性
虽然这项工作展示了多任务 SpeechVerse 模型在各种任务中强大的指令跟随能力,但仍存在一些局限性。该研究依赖于单一的底层 LLM 架构(FlanT5),而不是探索最新的专门为指令跟随而设计的模型。此外,在未见过任务的一般化能力与原始训练任务的专业化性能之间存在权衡,这对单一的多任务模型提出了挑战。虽然该模型在处理各种未知任务方面展示了潜力,但其在广泛的可能指令范围内的局限性并未得到充分表征,且在这些未知任务上的性能未被定量测量。
## 伦理声明
我们使用的所有语音数据集中的发言者都是匿名的。我们无法访问也不尝试创建发言者的任何个人可识别信息(PII),我们的模型既不识别发言者,也不使用发言者嵌入。大部分工作使用了用于训练和测试的公共开源数据集。用于预训练 Best-RQ 编码器和 SNS 任务的内部数据集是通过第三方语音数据供应商收集的。本文开展的工作没有进行额外的数据收集。


















 3626
3626

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











