







BASE - SQL:一种强大的开源文本转SQL基准方法
代码:https://github.com/CycloneBoy/base_sql
论文:https://arxiv.org/abs/2502.10739
摘要
将自然语言转换为用于查询数据库的SQL语言(文本到SQL,Text-to-SQL)具有广阔的应用前景,受到了广泛关注。目前,主流的文本到SQL方法主要分为基于上下文学习(in-context learning,ICL)的方法和基于监督微调(supervised fine-tuning,SFT)的方法。基于ICL的方法由于使用了最先进的闭源模型,能够取得相对较好的效果。然而,在实际应用场景中,需要考虑数据隐私、SQL生成效率和成本等因素,基于SFT的方法具有一定优势。目前,基于开源模型微调的方法缺乏易于实现且有效的(性价比高的)基线方法。我们提出了一种基于流水线的开源模型微调方法,称为BASE - SQL,它包括四个组件:模式链接(Schema Linking)、候选SQL生成(Candidate SQL Generate)、SQL修订(SQL Revision)和SQL合并修订(SQL Merge Revision)。实验结果表明,BASE - SQL使用开源模型Qwen2.5 - Coder - 32B - Instruct,在BIRD开发集上的准确率达到67.47%,在Spider测试集上达到 88.9 % {88.9}\% 88.9% ,显著优于其他使用开源模型的方法,甚至超过了几种使用GPT - 4o闭源模型的方法。同时,BASE - SQL易于实现且效率高(平均而言,生成一次SQL仅需调用大语言模型五次)。代码将在https://github.com/CycloneBoy/base_sql上开源。
1 引言
文本到SQL(Text-to-SQL)任务是将自然语言转换为结构化查询语言(Structured Query Language,SQL)以查询数据库,该任务受到了越来越多的关注(秦等人,2022年;卡索吉安尼斯 - 梅马拉基斯(Katsogiannis-Meimarakis)和库特里卡(Koutrika),2023年;刘等人,2024年;施等人,2024年)。它可以降低用户与数据库交互的难度,尤其在数据分析、商业智能、智能客服等领域具有广阔的应用前景。随着深度学习技术的快速发展,文本到SQL任务取得了飞速进展,从之前只能回答特定领域的单表问题,发展到能够解决跨领域多表的复杂问题SQL生成。在著名的Spider(于等人,2019年)基准测试中,其准确率达到了 90 % {90}\% 90% 。
早期的文本到SQL(Text-to-SQL)方法主要基于序列到序列(Seq2Seq)生成方法(王等人,2020年;郭等人,2019年;李等人,2023a)。当前主流方法是基于大语言模型(LLMs)的方法,大致可分为基于上下文学习(ICL)的方法和基于监督微调(SFT)的方法(刘等人,2024年)。基于上下文学习的方法(普尔雷扎和拉菲伊,2023年;高等人,2023年;李等人,2024年;普尔雷扎等人,2024年)主要使用最先进的闭源大语言模型(如:GPT - 4、GPT - 4o、Gemini - 1.5 Pro等),然后使用各种策略来提升当前最优(SOTA)性能,而不考虑SQL生成的效率和成本。得益于模型强大的推理能力,这类方法通常能取得更好的效果。基于监督微调的方法使用开源大语言模型进行微调,以提高SQL生成效果(普尔雷扎和拉菲伊,2024年;李等人,2024a;杨等人,2024b)。由于所使用的模型规模较小,其性能通常不如基于上下文学习的方法。
在现实世界的文本到SQL(Text-to-SQL)应用场景中,会考虑以下因素:数据隐私、SQL生成的效率和成本。因此,基于开源模型的监督微调(SFT)方法具有一定优势。CodeS(李等人,2024a)使用专门策划的以SQL为中心的语料库进行增量预训练,并将其与双向数据增强技术相结合进行监督微调,最终超越了使用大量闭源模型的方法,但它依赖大量数据进行增量预训练。SENSE(杨等人,2024b)使用闭源模型合成的数据对小模型进行微调,证明了其合成数据的有效性,但它依赖闭源模型进行数据合成。DTS - SQL(普尔雷扎和拉菲伊,2024)通过分别对模式链接和SQL生成进行微调来简化SQL生成,但缺乏详细分析。CHESS(塔莱伊等人,2024)使用流水线方法分多个步骤生成SQL,证明了流水线方法的优越性。MSc - SQL(戈尔蒂等人,2024)通过微调多个不同模型生成候选SQL,然后使用选择模型选择最终结果。尽管这些方法与使用像GPT - 4这样的闭源模型的方法相当,但它们仍不如使用像GPT - 4o和Gemini 1.5 pro这样的最先进闭源模型的方法。同时,基于监督微调的方法缺乏高性价比的基线方法,这也阻碍了基于监督微调方法的发展。
为了解决开源模型SFT(监督微调)方法所面临的挑战,我们提出了一种基于流水线方法的新方法BASE - SQL。BASE - SQL主要由四个组件组成:模式链接(Schema Linking)、候选SQL生成(Candidate SQL Generate)、SQL修正(SQL Revision)和SQL合并修正(SQL Merge Revision)。在模式链接组件中,我们仅执行表链接,不执行列链接。表链接通过微调一个开源模型获得。候选SQL生成同样通过微调一个开源模型获得。SQL修正使用另一个结合了完整模式(Full Schema)的开源模型来执行SQL纠错。最后,SQL合并修正用于通过两轮合并修正生成最终的SQL。通过详细的实验,我们分析了不同组件在不同参数配置下的效果。最后,我们的方法BASE - SQL仅使用了两个32B的开源模型Qwen2.5 - Coder - 32B - Instruct(Hui等人,2024)和Qwen2.5 - 32B - Instruct(Yang等人,2024a),在BIRD(Li等人,2024b)开发集上达到了 67.47 % {67.47}\% 67.47% 的准确率,在Spider测试集上达到了88.9%的准确率。BASE - SQL比其他最先进的方法效率高得多。平均而言,一次生成仅需调用大模型5次。此外,复现BASE - SQL的成本也非常低。无需使用额外的数据进行增量预训练。总体而言,BASE - SQL是一种经济高效的文本到SQL(Text - to - SQL)基线方法。
综上所述,我们的主要贡献如下:
-
我们分析了当前基于监督微调(SFT)的文本到SQL方法的优缺点,并提出了一种新的基于流水线的方法BASE - SQL。
-
通过大量对比实验,我们分析了在不同参数配置下,我们方法的不同组件的SQL生成效果,为后续研究提供了一定参考。
-
我们仅使用两个32B的开源模型,在BIRD和Spider数据集上,我们的方法优于所有其他使用开源模型的方法,甚至超过了几种使用GPT - 4o闭源模型的方法。同时,它具有较高的推理效率和较低的复现成本,表明BASE - SQL是一种性价比高的基线方法。我们的源代码将发布在https:// github.com/CycloneBoy/base_sql。
2 相关工作
早期的文本到SQL(Text-to-SQL)方法主要基于序列到序列(Seq2Seq)方法。通过编码器对自然语言和数据库模式进行语义编码,然后通过解码器进行解码,以生成相应的SQL语句(钟等人,2017)。由于SQL语言有一定的语法规则,直接通过解码器生成SQL模型时容易出错。在此基础上,提出了基于SQL语法规则的槽填充方法(王等人,2020;郭等人,2019;余等人,2018b)和基于草图的方法(吕等人,2020;余等人,2018a)。例如,(李等人,2023a)提出了一种排序增强编码器来减轻模式链接的工作量,并提出了一种骨架感知解码器来隐式引导骨架的SQL生成。这些方法受限于基础模型的能力,模型泛化能力不强,并且对于不同领域的数据库需要大量数据进行微调。
随着从预训练语言模型到大型语言模型的快速发展,基于大语言模型(LLM)的文本到SQL(结构化查询语言)方法已成为主流。DIN - SQL(普尔雷扎(Pourreza)和拉菲伊(Rafiei),2023年)将生成问题分解为多个子问题,并使用GPT - 4进行上下文学习(ICL),最终击败了大量微调模型。DAIL - SQL(高(Gao)等人,2023年)通过大量对比实验探索了不同模式表示、示例选择和示例组织的优缺点,为后续研究提供了有效建议。MCS - SQL(李(Lee)等人,2024年)使用不同的提示来探索更广泛的搜索空间以生成多个候选SQL,然后根据置信度分数对其进行过滤,最后通过多项选择获得最终结果。(王(Wang)等人,2024年;岑(Cen)等人,2024年)使用多智能体协作框架,利用不同的智能体完成特定的子任务,最终完成SQL生成。CHASE - SQL(普尔雷扎(Pourreza)等人,2024年)发现广泛使用的自一致性策略无法从大量候选SQL池中有效选择最佳SQL,因此提出了一种基于成对比较的排序策略,并结合三种创新策略生成多样化、高质量的候选SQL,在BIRD数据集上达到了最优水平(SOTA)。由于基于上下文学习(ICL)的方法不需要额外的计算资源进行模型微调,且具有高度的灵活性和泛化性,因此它是目前广泛使用的一种方法。
由于数据隐私和效率等问题,基于监督微调(SFT)的方法具有一定优势。(Pourreza和Rafiei,2024年;Li等人,2024a;Gorti等人,2024年)选择开源大语言模型(LLM)进行微调并取得了良好效果,超越了许多使用专有闭源大语言模型的方法。CodeS(Li等人,2024a)结合了模式链接、数据增强和预训练方法,在多个数据集上取得了最优(SOTA)结果,并开源了从10亿参数到150亿参数的预训练模型。SENSE(Yang等人,2024b)使用强大的大语言模型合成弱监督数据来训练小型大语言模型。实验结果表明了其合成数据的有效性。MSc - SQL(Gorti等人,2024年)首先通过模式链接对模式进行过滤,然后使用多个小型大语言模型进行微调以生成多种候选SQL语句,最后使用选择器选择最终的SQL语句。CHESS(Talaei等人,2024年)和XiYan - SQL(Gao等人,2024年)结合了上下文学习(ICL)和模型微调的优缺点,基于流水线方法,包括实体和上下文检索、模式链接以及用于SQL生成和SQL选择的微调大语言模型,证明了上下文学习和监督微调方法相结合的有效性。
3 方法
我们提出的BASE - SQL框架如图1所示,它包含四个组件:模式链接(Schema Linking)、候选SQL生成(Candidate SQL Generate)、SQL修订(SQL Revision)和SQL合并修订(SQL Merge Revision)。
3.1 模式表示(Schema Representation)
为了让大语言模型(LLM)生成相应的SQL语句,需要在提示上下文中包含数据库的表结构信息,以便大语言模型能够充分理解数据库模式。表示数据库表结构信息的方法有很多(高等人,2023),包括代码结构表示法(南等人,2023)、羊驼监督微调提示表示法(李等人,2024)、国际象棋表示法(塔莱伊等人,2024)、M-模式表示法(高等人,2024)等。越来越多的表示法包含列的示例值,这使得大语言模型能够理解表中的数据。希言SQL(高等人,2024)最近提出的M-模式表示法展示了数据库中每列的列名、数据类型、列描述符、主键信息和示例值,其表现优于代码结构表示法。尽管每列都包含相应的示例值,但我们的实验发现,在每个表后面添加当前表的随机查询的三列表结果,可以进一步提高大语言模型对数据库表结构的理解。图2展示了不同的表示方法。
3.2 模式链接
模式链接(Schema linking)是指识别将自然语言转换为SQL所需的数据库表和列信息,并过滤掉冗余表列带来的噪声信息。它可以显著提高SQL生成的准确性。目前,它主要包括三种方法:数据库实体链接、表链接和列链接(Liu等人,2024)。其中,列链接是最困难的,因为遗漏任何列都会导致后续的SQL生成失败。为了提高列链接的召回率,许多方法通常需要在这部分多次调用大语言模型(LLM),导致SQL生成效率低下。例如,XiYan - SQL(Gao等人,2024)和CHESS(Talaei等人,2024)都使用列选择器(Column Selector)来过滤不相关的列。这需要判断数据库中的每一列以及用户问题是否需要保留。
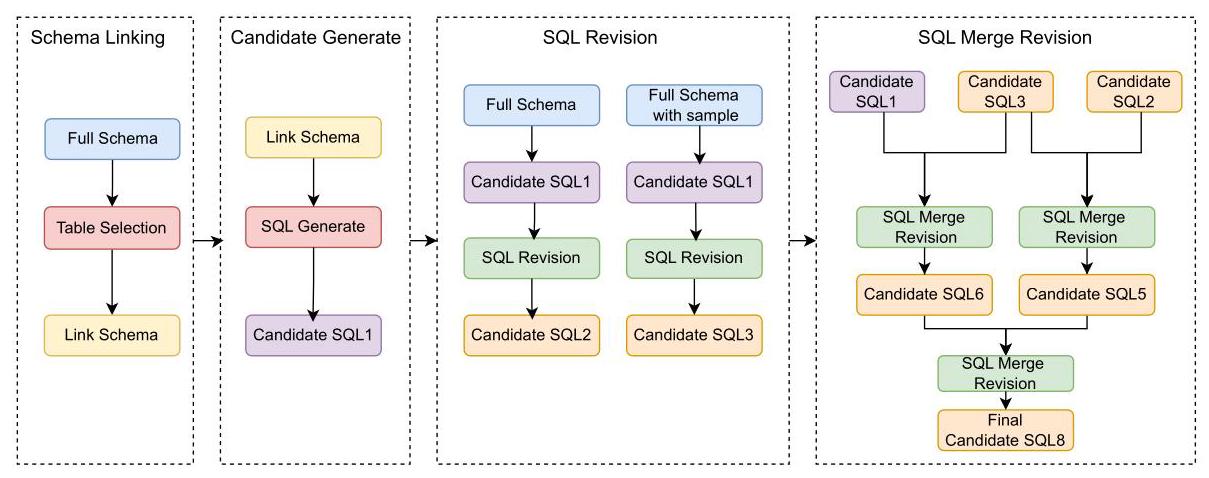
图1:所提出的BASE - SQL框架概述,该框架由四个组件组成:1) 模式链接(Schema linking):通过微调模型识别最相关的表;2) 候选生成(Candidate Generation):通过微调模型生成候选SQL1;3) SQL修订(SQL Revision):使用所有表模式、候选SQL1及其执行结果进行SQL修正,生成候选SQL2和候选SQL3;4) SQL合并修订(SQL Merge Revision):使用候选SQL1、候选SQL2和候选SQL3进行组合修正,生成最终的SQL。
与MSc - SQL(戈尔蒂等人,2024年)一样,我们仅使用表链接,通过微调模型来识别与问题相关的表名。我们不使用列链接,原因有以下三点:1) 我们使用的开源模型相对较小,列链接的识别准确率较低,会降低后续SQL生成的准确率;2) 我们通过实验发现,对于我们的模型而言,即使列链接完全准确,SQL生成准确率的提升也不显著(详见表3的实验结果)。3) 为了兼顾整体SQL生成的效率,减少对大语言模型(LLM)的调用次数。
3.3 候选生成
我们使用强大的开源模型Qwen2.5-Coder-32B-Instruct(Hui等人,2024年)作为基础模型。它在多个与代码相关的基准测试中取得了最优(SOTA)性能。受MSc-SQL(Gorti等人,2024年)的启发,为了模拟模式链接(Schema Linking)过程中识别冗余表所产生的冗余噪声,我们根据模式链接的结果,基于训练样本中的真实表(ground-truth table)随机选择了 10 % {10}\% 10% 的样本添加噪声(从所选样本中排除真实表后,随机添加1到2个额外的表)。
得益于强大的Qwen2.5-Coder预训练模型(Hui等人,2024年),我们在实验中发现,使用LoRA(Hu等人,2021年)微调方法,仅对少量样本(1k - 4k)进行微调,该模型就能达到较高的准确率(参见图3的实验结果)。
3.4 SQL修订
生成的候选SQL可能包含逻辑和语法错误。大多数方法(塔拉伊等人,2024年;波雷扎等人,2024年;高等人,2024年)使用多轮SQL修正来提高SQL的准确性。它们通常将模式链接(Schema Linking)后的表结构、生成的候选SQL及其执行结果输入到大语言模型(LLM)中,并使用大语言模型来修正SQL中潜在的错误。通过实验,我们发现使用模式链接之前的表结构信息可以进一步提高修正的准确性,因为模式链接后会存在一些表识别错误。我们使用所有表的M-模式(M-Schema)表示和带样本的M-模式(M-Schema With Sample)表示分别进行二次独立修正,并分别生成候选SQL2和候选SQL3。
3.5 SQL合并修订
大语言模型(LLM)的生成过程是一个概率采样过程。通常很难保证一次就能生成最佳结果。因此,许多方法(高等人,2024年;波雷扎等人,2024年;戈尔蒂等人,2024年;李等人,2024年)会生成多个候选SQL语句,然后以不同方式选择最终的SQL语句。典型的方法包括:自一致性方法、重排序方法、选择方法。自一致性方法有一定的局限性,不能保证最一致的结果就是正确的结果。最近,模型选择方法受到关注,并取得了显著的性能提升。目前,选择模型需要用相应的数据进行微调。未微调的选择模型效果不理想(见表7的实验结果)。然而,目前缺乏相应的开源数据集。
因此,我们提出了一种合并修正方法,该方法结合了修正和选择的特点,通过多次合并修正生成最终的SQL语句。仅当两个候选SQL语句的执行结果不一致时,才需要进行SQL合并修正。否则,我们选择第一个候选SQL语句。首先,将两个候选SQL语句中出现的表列用作合并修正的表结构信息。然后,列出两个候选SQL语句及其对应的执行结果,由大语言模型(LLM)生成一条新的SQL语句,而不是从其中选择一条作为候选SQL语句。将SQL修正步骤得到的候选SQL2、SQL3和修正前的候选SQL1进行三次合并修正,以获得最终的候选SQL语句。
4 实验
4.1 实验设置
数据集 我们在两个广泛使用的文本转SQL数据集上评估我们的方法:Spider(Yu等人,2019年)和 BIRD \operatorname{BIRD} BIRD (Li等人,2023c)。这两个数据集的详细信息见附录A.1。
指标执行准确率(EX):通过将预测SQL执行结果与验证数据库中黄金SQL(GOLD - SQL)执行结果进行比较,来评估预测SQL的准确性。这是Spider(蜘蛛)和BIRD(伯德)排行榜使用的官方指标,也是我们实验对比的主要指标。
实现细节 实现细节见附录A.2。
4.2 主要结果
BIRD结果 我们与最先进的方法进行了比较,结果如表1所示。在使用开源大语言模型(LLMs)的方法中(中间和下方的结果),我们的方法(使用通义千问2.5-代码编写器-32B-指令版(Qwen2.5-Coder-32B-Instruct))在开发集上取得了最佳成绩,比第二名的MSc-SQL(戈尔蒂等人,2024年)高1.87分,比原始的通义千问2.5-代码编写器-32B-指令版高9.07分。与使用闭源大语言模型的方法(顶部部分)相比,我们的方法具有竞争力,在开发集上超越了四种使用GPT - 4的方法和三种使用GPT - 4o的方法。BASE - SQL采用 33 B {33}\mathrm{\;B} 33B 深度求索代码编写器(DeepSeek - Coder)基础模型后,性能提升了15.84%;即使采用14B的通义千问2.5 - 代码编写器 - 32B - 指令版,性能也能提升 6.92 % {6.92}\% 6.92% ,这表明了BASE - SQL的有效性。
我们的方法仅使用两个具有320亿参数的开源大语言模型(LLM),而CHASE - SQL、惜言SQL(XiYan - SQL)和CHESS使用最先进的闭源大语言模型生成大量候选SQL,然后通过不同策略筛选出最终的SQL。总体而言,生成成本高昂且效率低下。CHASE - SQL(Pourreza等人,2024年)使用三种思维链提示技术生成21条候选SQL,然后结合一个经过微调的二元选择模型筛选出最终的SQL。惜言SQL(Gao等人,2024年)使用额外数据进行微调,并结合上下文学习(ICL)方法生成5条候选SQL,最后使用一个经过微调的二元选择器筛选出最终的SQL。CHESS(Talaei等人,2024年)生成20条候选SQL和10个测试用例来筛选出最终的SQL。其中,惜言SQL和CHESS在模式链接(Schema Linking)中使用列过滤,效率非常低。它需要对数据库的每一列和用户问题进行二元分类,以确定该列是否与用户问题相关,从而过滤掉与用户问题无关的列。总体而言,我们的方法在性能、成本和效率方面取得了一定的平衡。
Spider数据集结果:表5展示了我们的方法在Spider数据集上的结果。我们的方法在开发集上的执行准确率(EX)达到了 86.9 % {86.9}\% 86.9% ,在测试集上达到了 88.9 % {88.9}\% 88.9% ,超越了所有使用开源大语言模型(LLM)的方法,甚至在测试集上超越了CHASE - SQL(Pourreza等人,2024年)和CHESS(Talaei等人,2024年)。它仅比当前最优方法(SOTA)XiYan - SQL(Gao等人,2024年)和MCS - SQL(Lee等人,2024年)低0.8%。MCS - SQL使用上下文学习(ICL)方法生成多达20条候选SQL,然后使用多选选择方法选出最佳SQL,而我们的方法仅生成3条候选SQL。其中,我们的方法BASE - SQL的140亿参数版本极具竞争力,在开发集上仅比 32 B {32}\mathrm{\;B} 32B 版本低 0.1 % {0.1}\% 0.1% ,在测试集上低1.0%。实验结果表明,BASE - SQL具有很强的泛化能力。
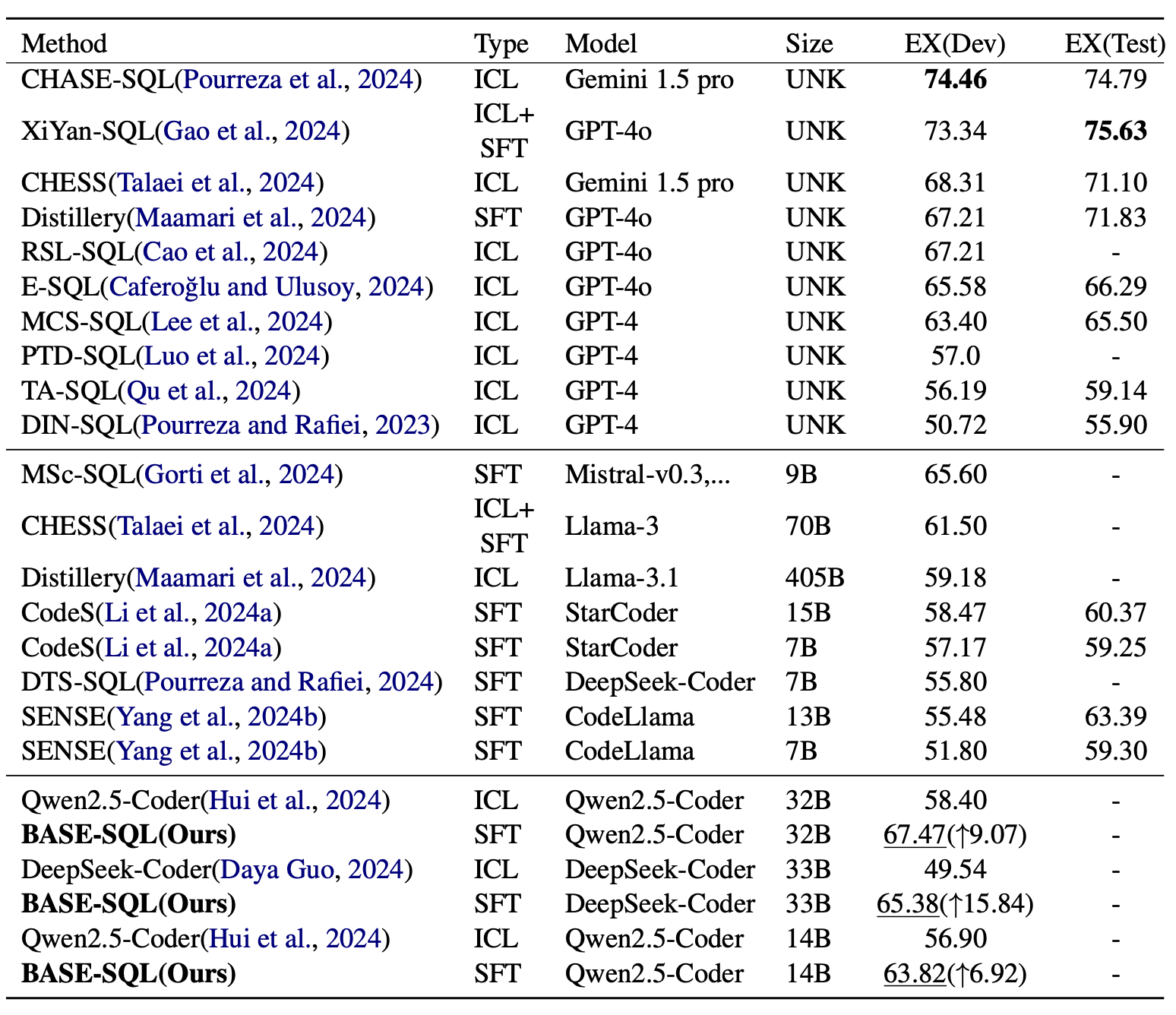
表1:不同文本转SQL方法在BIRD开发集和测试集上的性能比较。“类型”列表示方法的类型,包括:上下文学习(ICL)、有监督微调(SFT)以及ICL+SFT。“规模”列表示模型的参数数量,其中UNK表示规模未知,B表示十亿。EX表示执行准确率。下划线表示我们方法的最佳结果。
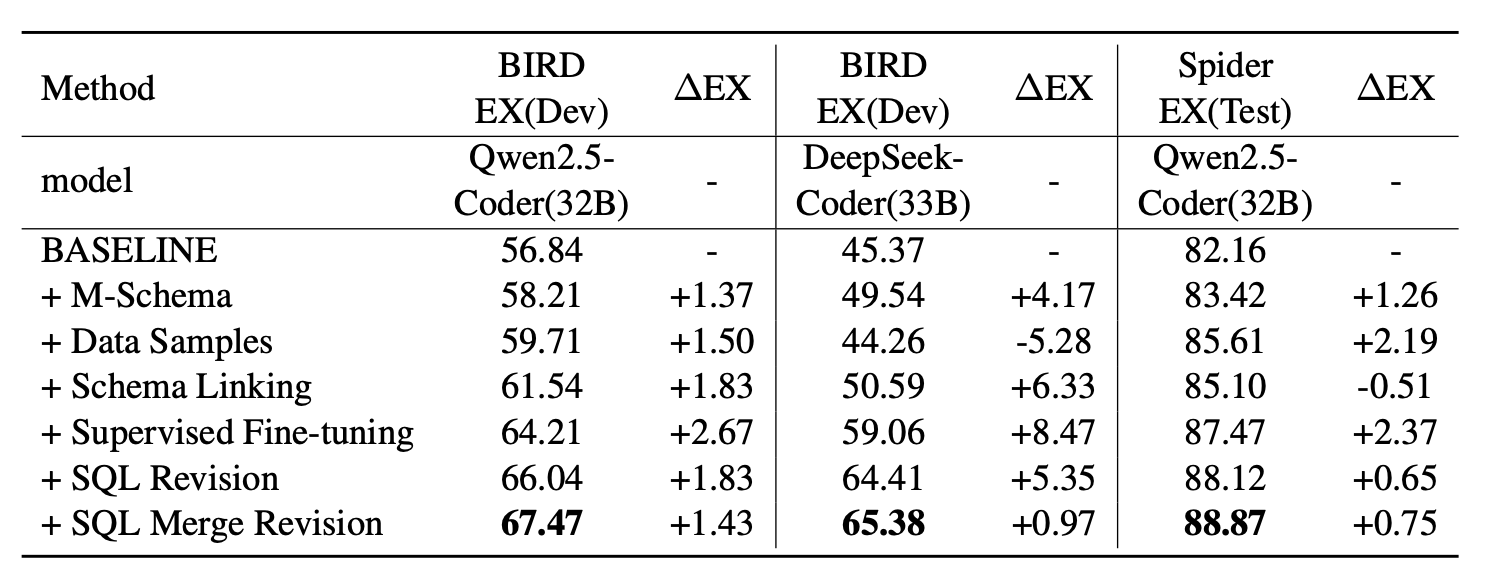
表2:我们的方法在BIRD开发数据集和Spider测试数据集上的消融实验。
4.3 消融实验研究
我们在BIRD开发集和Spider测试集上进行了消融实验,以分析不同组件对整体SQL生成的影响。实验结果如表2所示。我们的基线设置在代码表示中使用了整个模式。我们以BIRD开发集为例进行分析。用M-Schema(多模态模式)替换代码表示模式后,性能提升了1.37%,证明了M-Schema的优越性。然后我们采用带有样本表示的M-Schema,性能进一步提升了1.5%,这表明添加表内容可以进一步帮助大语言模型(LLM)从全局角度理解表结构信息,尽管M-Schema中每列的描述已经包含了当前列的几个样本值。添加模式链接(Schema-linking)后,性能提升了1.83%,这表明模式链接可以减少模式中的噪声。进行有监督微调后,获得了最大 2.67 % {2.67}\% 2.67% 的性能提升,这表明有监督微调对于大语言模型执行下游任务的重要性。进行SQL修正后,性能进一步提升了1.83%,这表明大语言模型可以利用候选SQL及其执行结果来纠正一些候选SQL中的错误。最后,进行了SQL合并修正,性能提升了 1.43 % {1.43}\% 1.43% ,这表明大语言模型可以使用多个候选SQL和相应结果,利用不同方式生成的SQL进一步提高SQL生成的准确性。
Spider测试集的性能提升情况类似,只是在添加模式链接(schema linking)后性能下降了 0.51 % {0.51}\% 0.51% ,这表明不准确的模式链接会导致后续SQL性能下降(Maamari等人,2024),因此我们使用整个模式进行SQL修订,以减少不准确的模式链接造成的性能损失影响。
4.4 分析
4.5 模式链接的影响
为了分析模式链接(Schema Linking)对SQL生成的影响,我们在BIRD开发集上进行了实验。实验结果如表3所示。黄金表模式(Gold Table Schema)方法使用所有黄金表作为模式,黄金列模式(Gold Column Schema)方法使用所有黄金列作为模式,我们的模式链接方法仅使用单个模型进行微调,模式链接一方法使用两个不同的模型进行投票,模式链接二方法使用五个不同的模型进行投票。通过比较黄金表模式和黄金列模式的结果,我们发现它们的EX指标差异不大,尤其是微调后的EX仅相差 1.04 % {1.04}\% 1.04% 。因此,我们综合考虑SQL生成的性能和效率,仅执行表链接而不执行列链接。
通过比较以下三种方法,虽然模式链接一方法(Schema Linking one method)和模式链接二方法(Schema Linking two method)通过多模型投票实现了超过 95 % {95}\% 95% 的召回率,但EX指标低于我们的模式链接方法。这表明模式链接不能过于关注召回率指标,还需要考虑表格预测的准确性。我们的模式链接方法通过单模型方法在精确率和召回率之间取得了一定的平衡。经过微调后,EX达到了 64.21 % {64.21}\% 64.21% ,仅比模式链接上限(使用黄金表格模式方法)低 3.07 % {3.07}\% 3.07% 。
4.6 不同SQL修正方法的影响
我们对比分析了不同的SQL修正方法,实验结果如表4所示。首先,我们在相同的预修正结果(EX为64.15)下,使用三种不同的模型和四种不同的模式进行对比。实验结果显示在表中的第2、3和4列。当使用Qwen2.5 - 32B - Instruct(通义千问2.5 - 32B - 指令模型)作为SQL修正模型并采用完整模式(Full Schema)时,SQL修正效果最佳。我们推测这是因为预修正结果是通过微调相同的编码模型(Coder模型)得到的,模型能力差异不大,因此无法很好地发现错误。使用通用的Qwen2.5 - 32B - Instruct进行SQL修正,能够更好地发现SQL错误并进行纠正。然后,在相同的SQL修正模型(Qwen2.5 - 32B - Instruct)下,我们使用三种不同的预修正结果和四种不同的模式进行对比。实验结果显示在表中的第5、6和7列。实验结果表明,预修正结果越好,SQL修正后的效果越好。完整模式(Full Schema)的效果比模式链接(Schema Linking)后的模式效果更好。这表明完整模式后修正模型可以纠正一些之前被模式链接错误识别的样本。
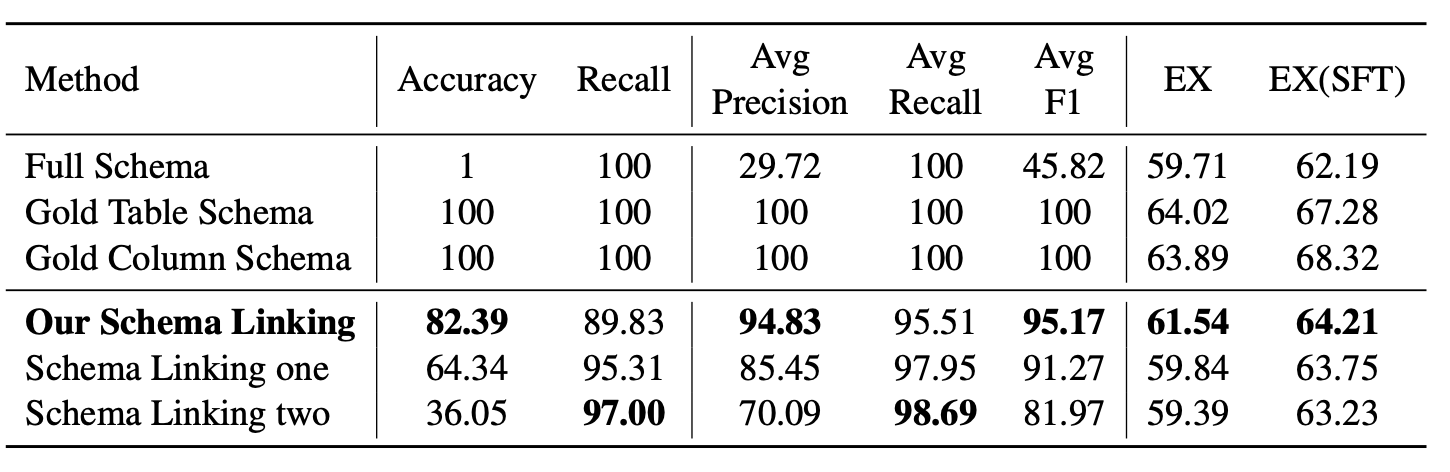
表3:使用不同模式链接方法的实验结果。准确率表示预测结果与黄金表(Gold table)完全一致的准确性。召回率表示预测结果包含所有当前黄金表的准确性。Avg是平均值(average)的缩写,它计算每个预测结果和黄金表的精确率、召回率和F1值,最后计算这三个指标的平均值。EX表示在BIRD开发集上的执行准确率。SFT表示有监督微调。
4.7 其他分析的影响
更多分析细节请参见附录B。
5 结论
在本文中,我们提出了BASE - SQL框架,这是一种基于流水线的文本到SQL(Text - to - SQL)方法,主要由模式链接(Schema Linking)、候选SQL生成(Candidate SQL Generate)、SQL修订(SQL Revision)和SQL合并修订(SQL Merge Revision)组成。我们进行了详细的实验,并分析了每个组件在不同参数配置下的影响,为后续研究提供了一定的参考。BASE - SQL仅使用两个 32 B {32}\mathrm{\;B} 32B 开源模型,在BIRD和Spider数据集上取得了具有竞争力的结果,甚至超过了大多数使用GPT - 4和GPT - 4o的方法。同时,BASE - SQL易于实现,且具有较高的SQL生成效率。它是一种适用于实际应用场景的强大基线方法。
6 局限性
尽管我们的方法在多个方面展现出了具有竞争力的结果,但本文的研究仍存在一定的局限性。首先,由于资源和时间的限制,我们无法全面验证其他开源大语言模型(如:Llama - 3.3 - 70B - Instruct、Mistral - Large - Instruct - 2411)的效果。其次,我们仅使用开源大语言模型进行实验,尚未验证闭源大语言模型(如:GPT - 4o、Gemini 1.5 pro)的BASE - SQL效果。此外,我们仅在模式链接中进行了表链接,未进行列链接。在实际应用场景中,当表中的列数量较多(数百甚至数千列)时,提示信息会特别长,这可能会影响SQL生成的效果。


















 3870
3870

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











