







文本到SQL的数据库描述自动生成
论文:https://arxiv.org/abs/2502.20657
代码:https://github.com/XGenerationLab/XiYan-DBDescGen
摘要
在文本到SQL任务的背景下,表和列的描述对于弥合自然语言和数据库模式之间的差距至关重要。本报告提出了一种在没有明确描述时自动生成有效数据库描述的方法。所提出的方法采用双过程方法:先进行从粗到细的过程,然后进行从细到粗的过程。从粗到细的方法利用大语言模型(LLM)的内在知识来引导从数据库到表,最后到列的理解过程。这种方法提供了对数据库结构的整体理解,并确保上下文一致。相反,从细到粗的方法从列级别开始,在回到表级别时提供更准确和细致的理解。在Bird基准测试上的实验结果表明,与不使用描述相比,使用所提出方法生成的描述可将SQL生成的准确率提高0.93%,并达到了人类水平性能的 37 % {37}\% 37% 。源代码可在https://github.com/XGenerationLab/XiYan-DBDescGen上公开获取。
1 引言
将自然语言查询转换为结构化查询语言(SQL)的技术,即文本到SQL(Text-to-SQL)或自然语言到SQL(NL2SQL),使非专业用户和高级用户都能轻松地从复杂数据集中提取信息[15, 5, 6]。
在自然语言到SQL(NL2SQL)任务中,表和列的描述提供了语义上下文,有助于模型理解用户查询中的各种实体与数据库模式之间的关系。这种上下文对于准确生成SQL查询至关重要。表描述提供了对每个表所代表内容的高层次理解,指导模型为用户查询选择相关的表。另一方面,列描述详细说明了每列中包含的数据,帮助模型将自然语言准确映射到特定的列。当使用同义词或不同的表达方式,或者多个字段非常相似时,这一点尤为重要。
在实际应用中,表和列的描述有时会缺失,而手动为复杂数据库编写描述通常是一项耗时费力且容易出错的任务,需要全面了解数据库的上下文。因此,自然语言到SQL(NL2SQL)系统面临冷启动问题,即此类元数据的缺失会阻碍准确生成SQL查询。所以,在没有明确描述的情况下,自动生成这些描述是弥合自然语言与数据库模式之间差距的有效方法。
为解决自然语言到结构化查询语言(NL2SQL)任务中的冷启动问题,我们提出了一种利用双过程策略自动生成表和列描述的方法:先采用从粗到细的方法,再使用从细到粗的机制。从粗到细的方法从更广泛的数据库层面开始理解过程,逐步缩小范围到表,最终聚焦到各个列。它提供了一个全面的上下文框架,使我们在关注数据库的各个元素之前,能够对数据库结构有一个整体的理解。另一方面,从细到粗的方法从细粒度的列层面开始,然后通过层次结构上升到表。它提供了详细的微观层面的见解,最终在从整体上考虑表时,有助于实现更准确、更细致的理解。通过整合这两种互补的方法,我们旨在更稳健、更有效地理解数据库结构,提高NL2SQL的性能。
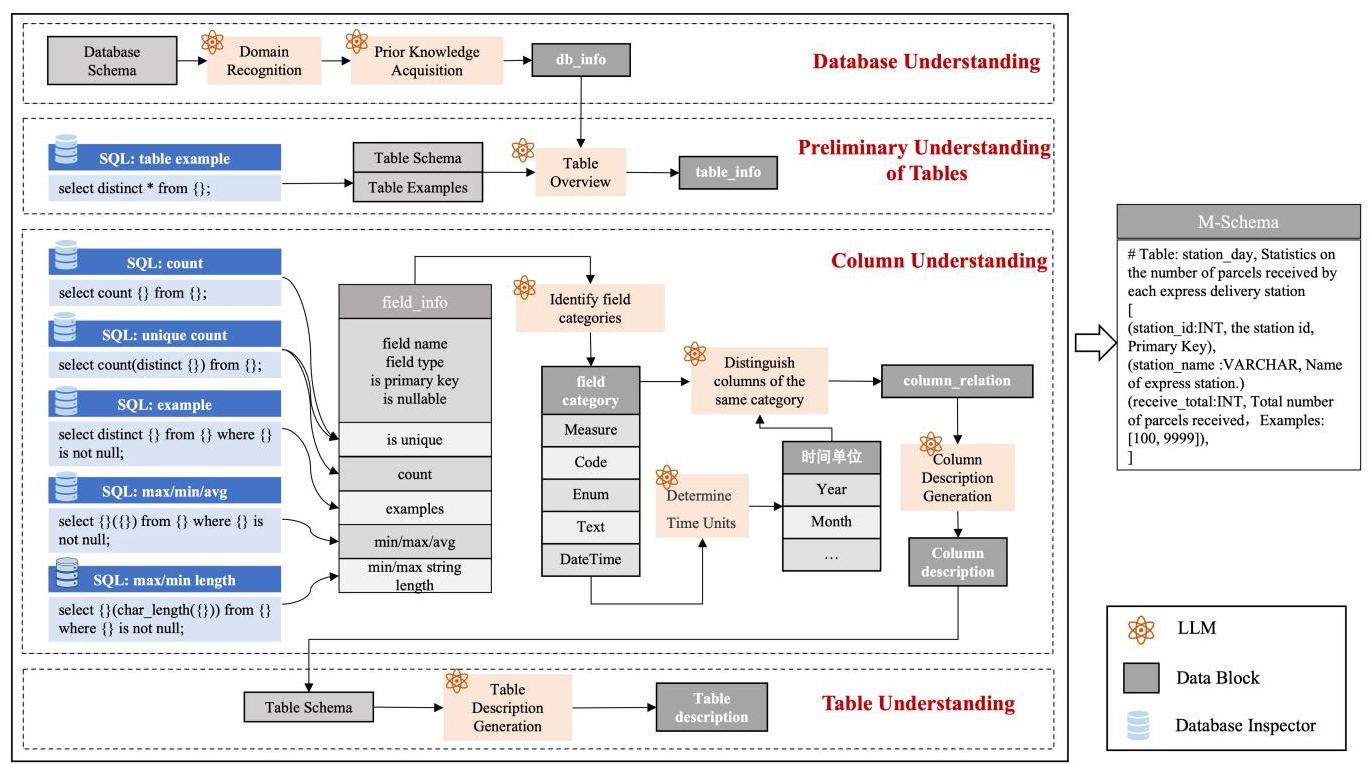
图1:所提出的数据库描述生成方法的工作流程。
为了证明所提出方法的有效性,我们在Bird [4]开发基准上进行了实验。实验结果表明,与不使用描述相比,使用我们的方法生成的描述将SQL生成准确率提高了 0.98 % {0.98}\% 0.98% 。这弥补了通常由手动注释造成的 37 % {37}\% 37% 的差距。
2 数据库描述生成
2.1 数据库理解
所提出的数据库描述生成方法始于对数据库的全面理解。通过向大语言模型(LLM)提供完整的数据库模式,可以实现以下目标:
-
领域识别:确定数据库所属的特定领域,并概述其一般内容。此步骤涉及辨别数据库的主题和功能上下文,为进一步分析提供更清晰的视角。
-
先验知识获取:利用大语言模型(LLM)在预训练阶段获得的知识,分析所确定领域内典型的感兴趣维度和指标。重点是揭示相关且有洞察力的关键属性,指导进一步的研究,并使对数据库潜在应用的理解更具针对性。
了解数据库的整体架构及其内部的相互关系,能提供基础的认知,使我们在查看特定表和列时能够获得准确且相关的见解。同时,这也确保了详细分析与上下文保持一致。我们将此阶段获得的信息表示为db_info(数据库信息),它是对表和列进行详细分析的基础。
2.2 表的初步理解
此步骤基于上一步对数据库的理解,专注于分析数据库中的每个单独的表。这包括对表的功能分析和对列的语义预测。
首先,分析该表中存储了哪些数据以及该表可能的功能是什么。然后,利用 d b _ i n f o {db}\_ {info} db_info 中的上下文信息来推测数据背后的语义含义和潜在意义。
通过综合这种对表的基础理解(表示为table_info,表信息),可以详细且连贯地描绘出每个表的内容、用途和重要性。这与前面确定的更广泛的领域目标相一致,并有助于在后续的列分析阶段进行有针对性的分析和洞察。
2.3 列的理解
2.3.1 确定字段的类别
在数据库中,字段通常分为两类:维度和度量。维度是描述数据的属性,提供了对数据进行分段、过滤或分类的方法,而度量是可以进行数学聚合或分析的数值。为了更深入地理解每个字段,我们将维度分为四类:代码、枚举、日期时间和文本。
-
代码:此类别指的是包含标识符或代码的字段,这些标识符或代码通常用于在数据库中唯一标识一个实体或对象,例如用户 ID。
-
枚举:枚举字段是包含预定义可能值列表的维度。此类别通常表示分类数据,例如状态(如“活跃”、“非活跃”),或描述某个属性的任何有限且固定的选项集。
-
日期时间:日期时间字段捕获与特定时间点相关的数据。这些维度允许根据不同的粒度(如小时、天、月或年)来组织数据。此类字段对于与时间相关的分析(如测量趋势和事件时间戳)至关重要。
-
文本:此类别包含非结构化或半结构化的文本数据。这些字段可用于基于名称和描述等文本信息进行定性分析。
对于每一列,从数据库中提取列信息,其中包括:1) 基本详情:字段名称、字段类型、是否为主键、是否可为空、是否唯一以及字段示例;2) 统计信息:计数(不同值)、最大值/最小值和平均值,以及字符串的最大和最小长度。我们将字段信息提供给大语言模型(LLM),并通过一系列流程对列进行分类。由于日期时间(DateTime)维度在商业智能(BI)分析中非常重要,我们还使用大语言模型来确定日期时间列的粒度,特别是那些以整数或字符串类型存储的列。然后将这些额外信息添加到列信息中用于
2.3.2 区分同一类别的列
鉴于同一类别内的列经常表现出语义关联或相似性这一观察结果,对于每一类列,我们将整个表格以及同一类别的字段一起呈现给大语言模型(LLM),促使它分析这些字段之间的差异和相互联系。大语言模型在这一阶段的输出记为column_relation。这一过程至关重要,因为它有助于模型有效区分相似的字段,从而避免潜在的混淆。
2.3.3 列描述生成
在这一步中,我们使用大语言模型(LLM)根据表格的基本信息table_info、同一类别字段之间的关系column_relation以及字段的基本信息field_info来预测一个字段可能的语义。数据库级、表级上下文以及列间关系有助于模型准确理解每个列在表中的作用。我们发现过长的列描述会阻碍自然语言到SQL(NL2SQL)的有效性,因此我们将长度限制在少于20个单词。
2.4 表描述生成
获取每列的语义后,我们更新M-Schema。在此阶段,我们提示大语言模型(LLM)纵览整个表格,总结其内容,并分析其作为表格描述的潜在应用。通过从列级别向上整合详细信息,这有助于发现可能被忽略的模式或异常,从而完善对数据库的整体理解。表格描述的长度限制在100个单词以内。
表1:不同描述下在鸟类(Bird)基准测试中的性能比较。

2.5 实现
我们已将所提出方法的源代码发布在GitHub上,链接为https://github.com/XGenerationLab/ XiYan - DBDescGen。我们的工具支持三种广泛使用的数据库引擎:SQLite、MySQL和PostgreSQL,并且它也与M - 模式(M - Schema)兼容。
我们提供四种描述生成模式:
-
无注释:移除所有表和列的描述。
-
原始模式:直接使用从数据库的数据定义语言(Data Definition Language,DDL)中提取的原始注释。
-
生成模式:移除所有表和列的描述,然后完全使用大语言模型(Large Language Model,LLM)进行生成。
-
合并:将“原始”和“生成”模式相结合。该模型会为缺少原始注释的表和列生成描述,同时保留已有原始注释。
你可以直接连接到数据库,生成表描述并构建M-Schema,其可用于下游的自然语言到SQL(NL2SQL)任务。
3 实验
我们在Bird开发集[4]上进行实验,以验证所提出的描述生成方法的有效性。在我们的实验中未使用证据,因为证据提供的信息有助于理解表和字段。为了证明所提出的描述生成方法的泛化能力,我们使用三个广泛使用的开源模型作为SQL生成器,分别是Qwen2.5-Coder-14B [3]、Codestral-22B 2 {}^{2} 2 和Llama3 18 B 3 {18}{\mathrm{\;B}}^{3} 18B3 。数据库结构被构建为M-Schema [2]并提供给大语言模型(LLM)。我们使用执行准确率(EX)来评估生成的SQL查询的有效性。
为评估描述对自然语言到SQL(NL2SQL)性能的影响,我们比较了三种场景:不使用任何描述、使用所提出方法生成的描述以及使用人工编写的描述。结果如表1所示。平均而言,与不使用描述相比,我们生成的描述使性能提升了0.93%,达到了人工水平的 39 % {39}\% 39% 。这表明我们的描述生成方法对提高NL2SQL性能具有积极影响。
图2展示了数据库描述如何影响SQL生成。如果没有描述,大语言模型(LLM)可能会误解“isPromo”列的语义,并错误地将“promotions”一词与“promoType”列关联起来。然而,我们提出的方法通过分析整个表、与其他字段建立联系并结合大语言模型的固有知识,准确推断出“isPromo”表示“是否为促销”,最终实现了正确的模式链接。
4 结论
在本报告中,我们提出了一种用于表和列描述的自动化方法,该方法采用双过程方法:先从粗到细,再从细到粗。通过整合这两种互补的方法,我们旨在更稳健、有效地理解数据库结构,促进将自然语言查询更准确地转换为SQL语句。实验结果表明,与不使用描述相比,使用所提出的方法生成描述可使SQL生成的准确率提高0.98%。
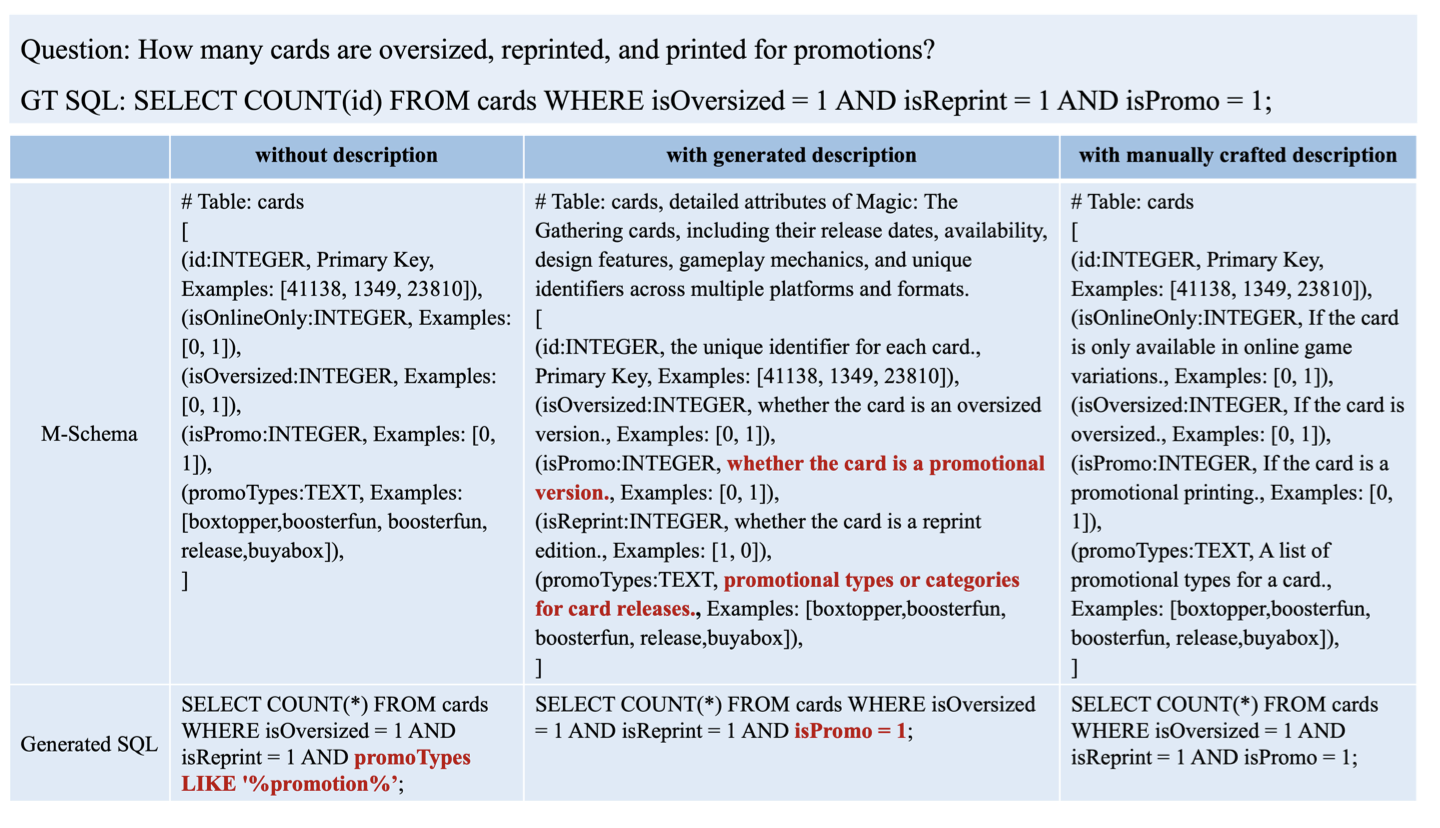
图2:不同数据库描述对SQL生成的影响。


















 805
805

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











