







随着人工智能和大数据技术的快速发展,高效的向量数据库系统成为了许多应用的核心组件。Milvus作为一个开源的向量数据库,专为处理大规模、高维向量数据的检索而设计。在实际应用中,对Milvus进行系统监控与日志管理是确保系统稳定性和性能的关键环节。本文将详细介绍如何基于Milvus进行系统监控与日志管理,包括使用监控工具、日志管理与分析,重点关注异常情况及其处理方法。
一、系统监控
系统监控是保障数据库系统稳定运行的重要手段。通过监控,可以及时发现并解决系统中的潜在问题,确保系统高效运行。对于Milvus,系统监控主要包括CPU使用率、内存使用率、磁盘I/O、网络流量等指标的监控。
1.1 监控工具选择
为了有效监控Milvus的运行状态,我们可以选择以下几种常见的监控工具:
- Prometheus:一个开源的系统监控和报警工具,适用于高维向量数据库的监控。
- Grafana:一个开源的可视化工具,通常与Prometheus配合使用,提供丰富的图表展示功能。
- Node Exporter:一个Prometheus的导出器,用于收集机器的硬件和操作系统指标。
- Kibana:一个开源的分析和可视化平台,适用于日志分析。
安装Prometheus和Grafana
以下是安装Prometheus和Grafana的基本步骤:
# 安装Prometheus
wget https://github.com/prometheus/prometheus/releases/download/v2.29.1/prometheus-2.29.1.linux-amd64.tar.gz
tar -xvf prometheus-2.29.1.linux-amd64.tar.gz
cd prometheus-2.29.1.linux-amd64
./prometheus --config.file=prometheus.yml
# 安装Grafana
wget https://dl.grafana.com/oss/release/grafana-8.1.5.linux-amd64.tar.gz
tar -zxvf grafana-8.1.5.linux-amd64.tar.gz
cd grafana-8.1.5
./bin/grafana-server
1.2 配置Prometheus
配置Prometheus以收集Milvus的监控数据。首先,编辑Prometheus配置文件prometheus.yml:
global:
scrape_interval: 15s
scrape_configs:
- job_name: 'milvus'
static_configs:
- targets: ['localhost:19530']
1.3 配置Grafana
在Grafana中配置数据源和仪表盘,以可视化展示Prometheus收集的监控数据。步骤如下:
- 登录Grafana,点击“Configuration” -> “Data Sources” -> “Add data source”。
- 选择“Prometheus”并填写Prometheus的URL(例如
http://localhost:9090)。 - 点击“Save & Test”确认配置。
- 创建一个新的仪表盘并添加面板,选择Prometheus作为数据源,设置查询语句以获取相关指标数据。
监控指标示例
以下是一些常见的监控指标:
- CPU使用率:
rate(node_cpu_seconds_total[5m]) - 内存使用率:
node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes - 磁盘I/O:
rate(node_disk_io_time_seconds_total[5m]) - 网络流量:
rate(node_network_receive_bytes_total[5m])
1.4 设置报警规则
在Prometheus中设置报警规则,当某些指标超过预设阈值时触发报警。编辑Prometheus的报警规则配置文件alert.rules:
groups:
- name: milvus_alerts
rules:
- alert: HighCPUUsage
expr: rate(node_cpu_seconds_total[5m]) > 0.8
for: 5m
labels:
severity: critical
annotations:
summary: "High CPU usage detected"
description: "CPU usage has exceeded 80% for the past 5 minutes"
启动Prometheus并加载报警规则:
./prometheus --config.file=prometheus.yml --rule.file=alert.rules
流程图:
二、日志管理与分析
日志管理是系统运维的重要组成部分,通过日志可以记录系统运行状态、诊断问题并进行性能分析。对于Milvus,日志管理主要包括日志的收集、存储、分析和可视化。
2.1 日志收集
Milvus默认生成日志文件,可以通过配置文件milvus.yaml进行日志级别和日志路径的设置。
logs:
level: debug
file:
path: /var/log/milvus
max_size: 300MB
max_age: 10
max_backups: 10
2.2 日志存储与管理
为了更好地管理和分析日志,我们可以使用Elasticsearch和Kibana。
安装Elasticsearch和Kibana
# 安装Elasticsearch
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.10.1-linux-x86_64.tar.gz
tar -xzf elasticsearch-7.10.1-linux-x86_64.tar.gz
cd elasticsearch-7.10.1
./bin/elasticsearch
# 安装Kibana
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.10.1-linux-x86_64.tar.gz
tar -xzf kibana-7.10.1-linux-x86_64.tar.gz
cd kibana-7.10.1
./bin/kibana
2.3 配置Filebeat
使用Filebeat将Milvus日志文件收集并发送到Elasticsearch。安装并配置Filebeat:
# 安装Filebeat
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.10.1-linux-x86_64.tar.gz
tar -xzf filebeat-7.10.1-linux-x86_64.tar.gz
cd filebeat-7.10.1
# 配置Filebeat
cat <<EOF > filebeat.yml
filebeat.inputs:
- type: log
paths:
- /var/log/milvus/*.log
output.elasticsearch:
hosts: ["localhost:9200"]
EOF
# 启动Filebeat
./filebeat -e -c filebeat.yml
2.4 日志分析与可视化
通过Kibana配置索引模式并创建仪表盘进行日志分析和可视化。
- 登录Kibana,点击“Management” -> “Index Patterns” -> “Create index pattern”。
- 输入索引名称(如
filebeat-*),设置时间字段。 - 在“Kibana”->“Dashboard”中创建新的仪表盘,添加面板以展示日志数据。
日志分析示例
以下是一些常见的日志分析场景:
- 错误日志分析:过滤并分析错误日志,找出系统运行中的问题。
- 性能分析:通过分析日志中的响应时间、查询次数等信息,评估系统性能。
- 用户行为分析:记录并分析用户的查询行为,优化系统设计。
流程图:
2.5 异常情况及处理
在日志管理和系统监控中,以下是一些需要重点关注的异常情况:
- 高CPU使用率:CPU使用率持续高于80%,可能导致系统响应变慢,需检查运行中的任务和查询优化。
- 内存泄漏:内存使用率持续增长,可能导致系统崩溃,需排查内存泄漏问题。
- 磁盘I/O瓶颈:磁盘I/O负载过高,影响数据读取和写入速度,需优化存储方案或扩展存储容量。
- 网络流量异常:网络流量异常增高或突降,可能是恶意攻击或网络故障,需检查网络配置和安全设置。
- 错误日志增加:错误日志数量异常增加,需及时排查并修复系统故障。
处理建议:
- 高CPU使用率:检查系统进程,优化查询语句,考虑扩展CPU资源。
- 内存泄漏:使用内存分析工具(如Valgrind)排查内存泄漏,优化代码。
- 磁盘I/O瓶颈:增加存储节点,优化数据存储结构,使用高速SSD。
- 网络流量异常:配置防火墙和入侵检测系统,检查网络设备和链路状态。
- 错误日志增加:定期检查和分析错误日志,快速定位并修复问题。
三、实战案例
为了更好地理解如何进行系统监控和日志管理,以下是一个完整的实战案例:
3.1 部署和配置
部署Milvus和监控工具
# 部署Milvus
docker run -d --name milvus -p 19530:19530 milvusdb/milvus:latest
# 部署Prometheus
docker run -d --name prometheus -p 9090:9090 -v /path/to/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus
# 部署Grafana
docker run -d --name grafana -p 3000:3000 grafana/grafana
# 部署Elasticsearch
docker run -d --name elasticsearch -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" elasticsearch:7.10.1
# 部署Kibana
docker run -d --name kibana -p 5601:5601 --link elasticsearch:elasticsearch kibana:7.10.1
# 部署Filebeat
docker run -d --name filebeat -v /path/to/filebeat.yml:/usr/share/filebeat/filebeat.yml --link elasticsearch:elasticsearch docker.elastic.co/beats/filebeat:7.10.1
配置Prometheus和Grafana
编辑Prometheus配置文件prometheus.yml:
global:
scrape_interval: 15s
scrape_configs:
- job_name: 'milvus'
static_configs:
- targets: ['milvus:19530']
在Grafana中配置Prometheus数据源:
- 登录Grafana,点击“Configuration” -> “Data Sources” -> “Add data source”。
- 选择“Prometheus”并填写Prometheus的URL(例如
http://localhost:9090)。 - 点击“Save & Test”确认配置。
配置Filebeat
编辑Filebeat配置文件filebeat.yml:
filebeat.inputs:
- type: log
paths:
- /var/log/milvus/*.log
output.elasticsearch:
hosts: ["http://elasticsearch:9200"]
3.2 监控和日志管理
启动监控和日志管理
启动各个容器并检查状态:
docker start milvus
docker start prometheus
docker start grafana
docker start elasticsearch
docker start kibana
docker start filebeat
查看监控数据
在Grafana中创建仪表盘,添加面板显示Milvus的CPU使用率、内存使用率、磁盘I/O和网络流量等指标。
查看日志数据
在Kibana中创建索引模式,设置时间字段,创建仪表盘显示Milvus的错误日志、性能日志等。
3.3 处理异常情况
高CPU使用率
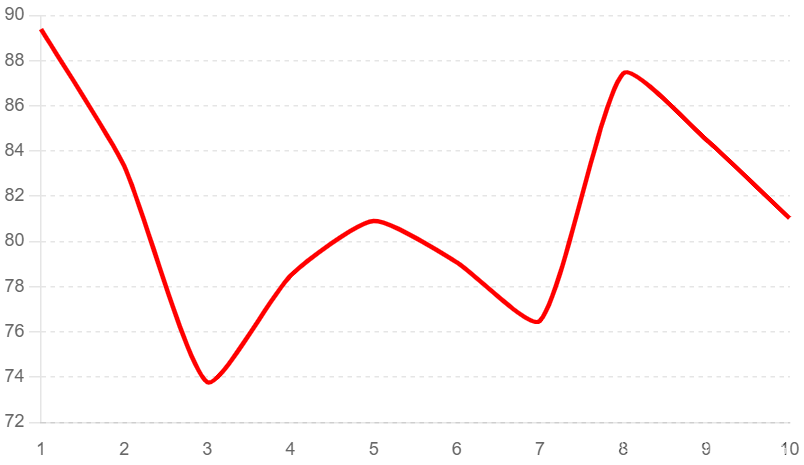
通过Grafana监控发现CPU使用率持续高于80%,需检查Milvus运行的查询任务:
- 在Milvus服务器上查看运行的查询任务和系统进程。
- 优化查询语句,减少不必要的计算。
- 考虑扩展CPU资源。
内存泄漏
通过Grafana监控发现内存使用率持续增长,可能存在内存泄漏问题:
- 使用内存分析工具(如Valgrind)排查内存泄漏。
- 优化代码,修复内存泄漏问题。
磁盘I/O瓶颈
通过Grafana监控发现磁盘I/O负载过高,影响系统性能:
- 增加存储节点,扩展存储容量。
- 优化数据存储结构,减少磁盘I/O操作。
- 使用高速SSD,提高读写速度。
网络流量异常
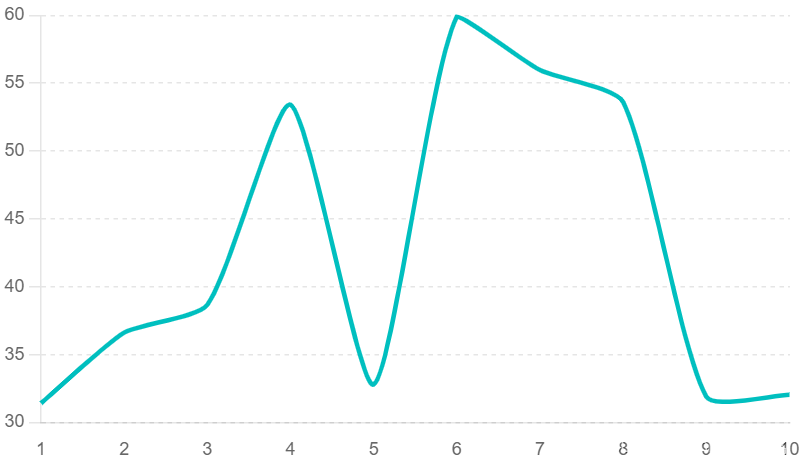
通过Grafana监控发现网络流量异常增高或突降,需检查网络配置:
- 配置防火墙和入侵检测系统,防止恶意攻击。
- 检查网络设备和链路状态,排除网络故障。
错误日志增加
通过Kibana分析发现错误日志数量异常增加,需及时排查系统故障:
- 定期检查和分析错误日志,快速定位问题。
- 优化系统设计,修复代码缺陷。
四、总结
本文详细介绍了基于Milvus的系统监控与日志管理,包括使用Prometheus和Grafana进行系统监控,使用Elasticsearch和Kibana进行日志管理与分析。通过合理的监控和日志管理,可以及时发现并处理系统中的异常情况,确保Milvus的高效稳定运行。希望本文对大家理解和实施系统监控与日志管理有所帮助。
如果你喜欢这篇文章,别忘了收藏文章、关注作者、订阅专栏,感激不尽。
















 371
371

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











