






目录
数据预处理
通过查看数据后我们发现数据量很庞大,每条数据中含有25个属性,这里我们只需要province、city、station、aqi、so2、no2、co、o3、pm2_5这9个属性
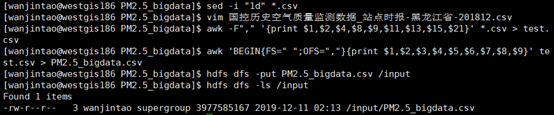
首先通过sed命令删除所有csv文件的第一行即列名
然后通过awk命令读取所有csv文件的第1、2、4、8、9、11、13、15、21列的数据写入test.csv文件
由于生成的csv文件是以空格作为分隔符,不利于创建DataFrame,通过awk命令再次将test.csv文件的分隔符转化为逗号分隔符,写入PM2.5_bigdata.csv文件
最后将数据上传至hdfs
创建DataFrame和进行一些操作
在确保hadoop和spark集群成功启动之后,进去spark安装目录,使用命令bin/spark-shell --master spark://westgis186:7077以集群形式启动spark-shell
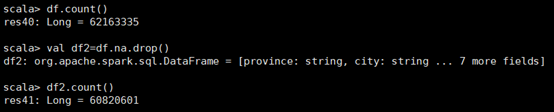
使用spark.read.csv()创建DataFrame,df1.count()后发现有62163335条数据

这里使用toDF()函数修改默认的列名,打印出df的前5行发现成功修改了列名,接着使用cash()函数的持久化机制来避免后续重复计算的开销

使用groupBy()函数可以对记录进行统计分组
通过df.groupBy("province").count().show(50)可以查看到共有31个省的记录,其中四川省的记录最多,海南省的记录最少

使用df.groupBy("city").count().collect()命令可以返回(city,count)的数组,count()后发现共有373个city的记录
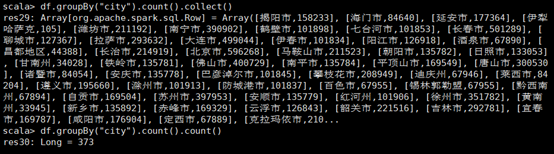
使用df.groupBy("station").count().count()可以发现共有1518个PM2.5观测站
使用df.na.drop()删除为空的行
使用sort()操作对记录进行排序
df2.sort(df("pm2_5").desc,df("so2").desc).show()表示更据pm2_5字段进行降序排序,当pm2_5值相同时,再根据so2进行降序排序

df2.orderBy(df("pm2_5").asc,df("so2").asc).show()表示更据pm2_5字段进行升序排序,当pm2_5值相同时,再根据so2进行升序排序,其中orderBy会引发全局排序,sort会进行分组排序

DataFrame利用spark ml实现线性回归
Spark ml拟合模型都是使用libsvm格式
Libsvm格式为:label index1:value1 index2:value2 ……
其中label是实例标签即因变量,index是有顺序的索引即特征编号,必须要升序排列value是特征值即要训练的数据
在这里我们使用python函数将csv数据转化为libsvm文本数据
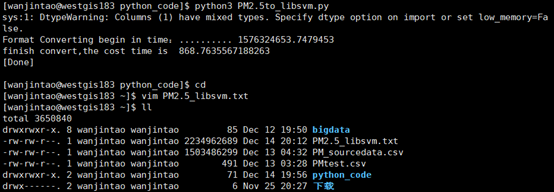
转化后的libsvm数据为:pm2_5 1:so2 2:no2 3:co 4:o3,如下图所示:

最后将PM2.5_libsvm.txt上传至HDFS,以集群方式启动spark-shell
导入spark.ml做线性回归所需相应的包,并生成DataFrame
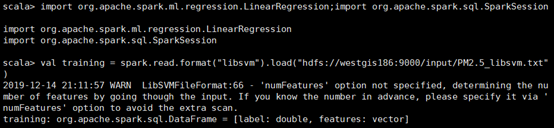
用count()函数计数,发现共有62163334条数据,使用show()函数输出前20条数据

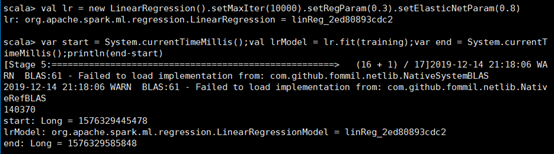
接下来就可以开始拟合模型了,其中
setMaxIter()参数设置最大迭代次数
setRegParam()参数设置正则项的参数
setElasticNetParam()参数设置弹性参数,用于调节L1和L2之间的比例,两种正则化比例加起来是1,详见后面正则化的设置,默认为0,只使用L2正则化,设置为1就是只用L1正则化,
引入System.currentTimeMillis()函数来计算拟合模型所需要的时间,执行时间为140370毫秒,即140.37秒
输出拟合模型的系数和截距,发现so2的系数为0.32343,no2的系数为0.83900,co的系数为0.23091,o3的系数为0.04647,即no2与pm2_5的线性相关程度最大

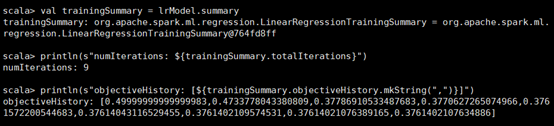
进一步输出模型信息总结:
输出模型的迭代次数、每次迭代的目标值即损失函数+正则化式
输出每个样本的误差值,即(label减去预测值)

输出均方根误差和最终的决定系数,0-1之间,值越大,拟合程度越高

最后输出训练集的预测
















 6774
6774











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









