






摘要:主成分分析(PCA)是一种常用的数据降维技术,通过保留数据集中的主要特征分量来简化模型。本文介绍了PCA的基本原理、应用场景以及在Python中的实现方法。
一、引言
在数据分析和机器学习领域,我们经常遇到高维数据集,其中包含大量的变量。这些变量可能之间存在相关性,导致数据冗余和复杂性增加。主成分分析(Principal Component Analysis,PCA)是一种有效的数据降维方法,它可以将多维数据映射到较低维度,同时保留数据集中的主要特征分量。PCA在很多领域都有广泛的应用,例如图像处理、语音识别、机器学习等。
二、PCA原理
PCA的基本思想是通过线性变换将原始数据映射到新的坐标系统中,从而简化数据集。这个变换过程涉及到以下几个步骤:
1. 数据中心化:将原始数据集减去其均值得到X,使得数据的均值为0。
2. 计算协方差矩阵:计算数据集的协方差矩阵,表示数据变量之间的相关性。
3. 特征值和特征向量:求解协方差矩阵的特征值和特征向量。特征值表示数据分布的方差,特征向量表示数据分布的方向。
4. 选择主成分:根据特征值的大小,降序排列特征值,并选择前k个最大的特征值对应的特征向量作为主成分。这些主成分能够解释数据集的大部分方差。
5. 重建数据:使用选定的主成分重建数据,得到降维后的数据集。
三、PCA应用
PCA在许多领域都有广泛的应用,以下是一些常见的应用场景:
1. 图像处理:通过PCA可以提取图像的主要特征,从而进行图像压缩、降噪等处理。
2. 语音识别:PCA可以用于语音信号处理,提取语音信号的主要成分,从而提高语音识别的准确率。
3. 机器学习:PCA可以作为预处理步骤,降低数据维度,提高机器学习模型的性能。
四、Python实现
在Python中,我们可以使用scikit-learn库来实现PCA。我们首先导入了所需的库,然后加载了iris数据集。接着,我们实例化了PCA对象,并将维度降低到2。最后,我们输出了降维后的数据和解释的方差比例。
# 导入所需库
import numpy as np
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
# 加载数据集
iris = load_iris()
X = iris.data
# 实例化PCA对象,设置降维数为2
pca = PCA(n_components=2)
X_reduced = pca.fit_transform(X)
# 输出降维后的数据
print(X_reduced)
# 输出解释的方差比例
print('Explained variance ratio:', pca.explained_variance_ratio_)结果如下:
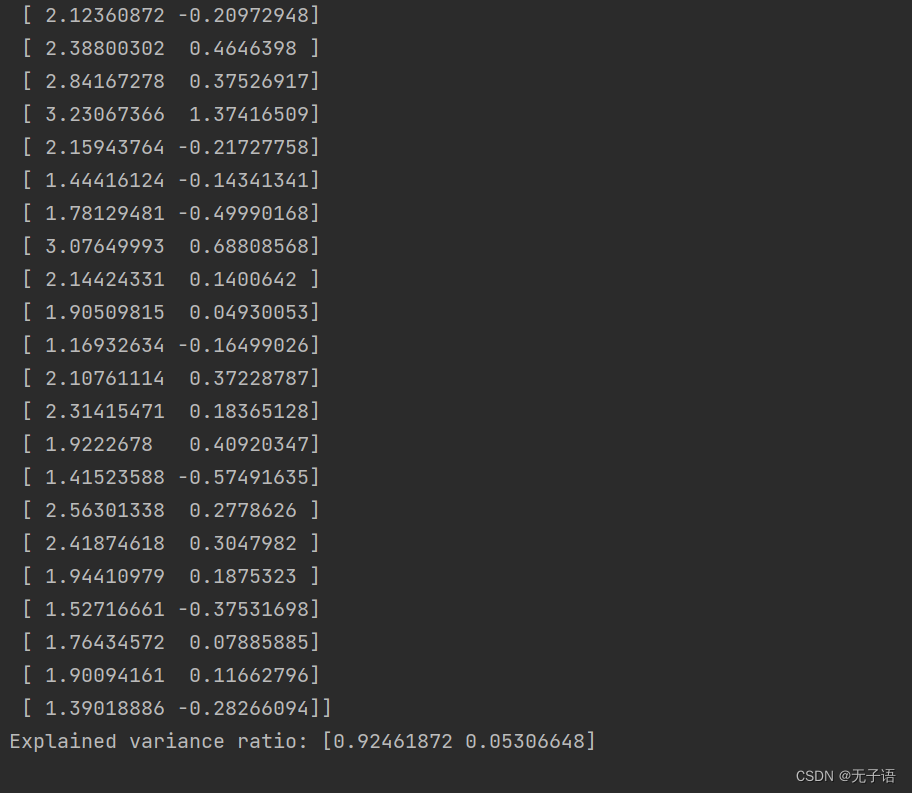















 635
635

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









