







Bag of Freebies for Training Object Detection Neural Networks 论文阅读笔记

这个题目取的有点意思:用于训练目标检测神经网络的免费赠品袋
摘要
启发式训练大大提高了各种图像分类模型的准确率,而目标检测模型具有更为复杂的神经网络结构和优化目标。训练策略和管道在不同的模式中有很大的差异。在这个工作中,作者探索了适用于各种模型的训练调整,包括Faster R-CNN和YOLOv3。这些调整不会改变模型架构,因此,推理成本保持不变。然而,经验结果表明,与最先进的基线相比,这些赠品可以提高高达5%的绝对精度。
一、介绍
目标检测无疑是计算机视觉中最基本的应用之一,引起了各领域研究者的广泛关注。最新最先进的检测器,包括单级的(SSD和YOLO)或多级类似rcnn的神经网络和许多变体或扩展工作,它们都是基于图像分类骨干网络,如VGG, ResNet, Inception和MobileNet系列。尽管现代目标探测器发展迅速,取得了巨大的成功,但不同的工作通常采用不同的数据预处理和训练管道,使得不同的目标检测方法很难相互受益或在其他领域取得相应的进步。
作者致力于探索一种有效和通用的方法,可以提高所有流行的目标检测网络的性能,而不引入额外的计算成本在推理。首先探讨目标检测中的混合技术。考虑到多目标检测任务的特殊性质,它更倾向于空间保持变换。因此,提出了一种用于目标检测任务的视觉相干图像混合方法。其次,探索了详细的训练管道,包括学习率调度、标签平滑和同步BatchNorm。最后,通过逐步堆叠它们来训练单级和多级对象检测网络以验证这些调整的影响。
主要贡献:
- 系统地评价了应用于不同目标检测管道的各种训练启发式,为今后的研究提供了有价值的实践指导;
- 提出了一种用于训练目标检测网络的视觉相干图像混合方法,实证结果表明,该方法能有效提高模型的泛化能力;
- 拓展目标检测数据增强领域的研究深度,增强模型泛化能力,减少过拟合问题;
- 在不修改网络架构和增加额外的推理成本的情况下,实现了高达5%的绝对精度提升(比基线提高了15 - 20%)。

二、相关工作
2.1 由图像分类引入的启发式技术
- 引入学习率预热启发式(warmup),以克服minibath size过大的负面影响;
- 在实验中,warmup对YOLOv3至关重要;
- 有一系列的方法试图解决深层神经网络的脆弱性,从而引入了标签平滑,修正了交叉熵损失中的hard ground truth;
- Zhanget al.提出了mixup来缓解对抗性干扰;
- 针对传统的步长策略,在( Stochastic gradient descent with warm restarts)中提出了学习速率衰减的余弦退火策略。
2.2 Deep Object Detection Pipelines
目前最先进的基于深度神经网络的目标检测模型大多来自多级和单级管道,例如RCNN和YOLO。
在单级管道中,预测由单个卷积网络生成,因此保持了空间对齐(除了YOLO在最后使用了全连接层)。然而,在多个阶段的管道中,例如Fast R-CNN和Faster-RCNN,最终的预测是由在特定兴趣区域(ROIS)中采样并汇集的特征生成的。ROIS要么通过神经网络传播,要么通过确定性算法(例如选择性搜索)传播。这一主要差异导致了数据处理和网络优化方面的显著差异。例如,由于单级管道缺乏空间变化,正如SingleShot MultiBox Object Detector (SSD)所证明的那样,空间数据增强对性能至关重要。由于缺乏探索,很多训练细节都是一个系列独有的。
在这项工作中,作者系统地探索了可能有助于提高两个管道性能的互利调整和技巧。
三、Bag of Freebies
3.1 Visually Coherent Image Mixup for Object Detection(目标检测的视觉相干图像混淆)
mixup已被证明成功地缓解了分类网络中的对抗式扰动。混合图像分类任务的关键思想是通过混合像素作为训练图像对之间的插值,使神经网络规则化,以支持简单的线性行为。同时,用相同的比例将单热图像标签混合。
Rosenfeldet al进行了一系列名为“房间里的大象”的有趣实验,在这个实验中,大象被随机地放置在自然图像上,然后这个对抗图像被用来挑战现有的目标检测模型。结果表明,现有的目标检测模型对这种攻击具有一定的局限性,在检测移植对象时存在一定的不足。受Rosenfeldet等人启发式实验的启发,关注在物体检测中发挥重要作用的自然共现物体呈现。通过应用更复杂的空间变换,引入了在自然图像表示中常见的遮挡和空间信号扰动。
在实验中,继续增加混合过程中使用的混合比例,结果帧中的物体更有活力和连贯的自然表现,类似于在观看低FPS电影或监控视频时经常观察到的过渡帧。图2和图3分别展示了图像分类和这种高比率混叠的视觉对比。使用几何保持对齐的图像混合,以避免扭曲图像。


选择α和β都至少为1的beta分布,这在视觉上更连贯,而不是像图像分类中混合比的分布由beta分布b(0.2,0.2)相同的做法。

在Pascal VOC数据集上使用YOLOv3网络进行实验,测试了经验混合比分布。α和β均等于1.5的Beta分布略优于1.0(相当于均匀分布),且优于固定均匀混合。我们认识到,对于相互遮挡的目标检测,鼓励网络观察不寻常的拥挤块,无论是自然呈现的还是由对抗技术创建的。


实际上,通过对常用训练数据集的检查,并没有这样的训练图像。相比之下,由于随机生成的具有视觉欺骗性的训练图像,使用混合方法训练的模型更加健壮。此外,混合模型更谦逊,更不自信,生成的对象的平均分数更低。但是,这种行为并不影响实验结果。
同时,我们评估了模型对大象滑过假视频的性能,尽管大象在自然图像中非常罕见。混合模型能够在外来大象图像块严重遮挡下保留拥挤的家具物体。
3.2 Classification Head Label Smoothing
对于每个目标,检测网络通常使用softmax函数计算所有类的概率分布,由于softmax函数的特性,这会鼓励模型对其预测过于自信,并容易过度拟合。
标记平滑是由Szegedyet等人提出的一种正则化形式:
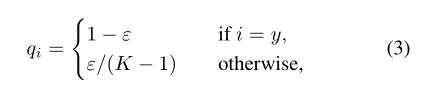
其中K是类别总数,ε是一个小常数。这种技术降低了模型的置信度,用最大对数和最小对数之间的差异来衡量。
3.3 Data Preprocessing
在图像分类领域,神经网络对图像的几何变换具有很强的容忍度。它实际上是鼓励随机扰动空间特征,例如。随机翻转、旋转和裁剪图像,以提高泛化精度和避免过拟合。然而,对于目标检测图像的预处理,我们需要格外谨慎,因为检测网络对这种变换更加敏感。
数据增强方法:
- 随机几何变换。包括随机裁剪(有约束),随机扩展,随机水平翻转和随机调整大小(有随机插值)。
- 随机色彩抖动,包括亮度、色相、饱和度和对比度。
在目标检测中,单级网络生成的检测结果与输入图像的空间形状成比例。多级网络由于基于采样的方法对特征图进行了大量的裁剪操作,它代替了随机裁剪输入图像的操作,因此这些网络在训练阶段不需要大量的几何增强。这是单阶段和多阶段目标检测数据管道的主要区别。
3.4 Training Schedule Revamping
- step schedule
步进计划是使用最广泛的学习率计划。在步进计划中,学习率在到达预定义的时点或迭代后乘以一个小于1的常数。例如,Faster-RCNN的默认步长学习率计划是将学习率降低0.1 at 60 kiterations。类似地,YOLOv3在40k and 45k iterations使用相同的比率0.1来降低学习率。步进计划有急剧的学习率转变,这可能导致优化器在接下来的几个迭代中重新稳定学习势头。 - cosine learning rate
余弦计划根据余弦函数在0到pi上的值缩放学习率。它从缓慢降低大的学习率开始,然后在半途快速降低学习率,最后以极小的斜率降低小的学习率,直到达到0。 - Warmup learning rate
预热学习率是另一个常见的策略,以避免在初始训练迭代中梯度爆炸。预热学习速率计划对于一些目标检测算法是至关重要的,例如YOLOv3,它在最开始的迭代中有一个主要的梯度,即sigmoid分类评分初始化在0.5左右,大多数预测倾向于0。
使用余弦学习计划和适当的warmup可以获得更好的验证精度,如图6所示,在训练中,使用余弦学习速率衰减获得的验证mAP在任何时候都优于step学习速率计划。由于学习率调整的频率较高,也较少出现阶跃衰减的高原现象,即验证性能会停留一段时间,直到学习率降低。

3.5 Synchronized Batch Normalization
在一些小批量的任务中,batch Normalization会影响性能(例如,单个GPU)。Peng等人证明了同步批处理归一化在目标检测中的重要性。在本工作中,我们回顾了YOLOv3同步批处理归一化的重要性,以评估相对较小的批处理大小对每个GPU的影响,因为训练图像形状明显大于图像分类任务。
3.6 Random shapes training for single-stage object detection networks
自然训练图像有各种各样的形状。为了适应记忆限制并允许更简单的批处理,许多单级目标检测网络都使用固定形状进行训练。为了减少过拟合的风险和提高网络预测的泛化,我们采用了Redmonet et al中的随机形状训练方法。更具体地说,a mini-batch of N training images被调整为N×3×H×W,其中H和W是网络stride的乘数。例如,给定feature map的stride为32,我们使用H = W∈{320,352,384,416,448,480,512,544,576,608}对YOLOv3进行训练。
四、实验
4.1 Incremental trick evaluation on Pascal VOC


4.2 Bag of Freebies on MS COCO

4.3 Impact of mixup on different phases of training detection network

五、总结
文章提出了一系列训练增强的方法,在引入零开销的推理环境的同时,显著提高了模型性能。通过对YOLOv3和Faster-RCNN在Pascal VOC和COCO数据集上的经验实验表明,该方法可以持续改进目标检测模型。通过叠加所有这些调整,没有观察到任何水平下降的迹象,这些免费赠品都是训练时间的修改,因此只影响模型权值,不会增加推理时间或改变网络结构。















 5662
5662











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









