








EM算法是一种迭代算法,用于含有隐变量(hidden variable)的概率模型参数的极大似然估计,或极大后验概率估计。
EM算法的每次迭代由两步组成:E步,求期望(expectation);M步,求极大(maximization)。所以这一算法称为期望极大算法(expectation maximization algorithm),简称EM算法。
9.1 EM算法的引入
概率模型有时既含有观测变量( observable variable),又含有隐变量或潜在变量( (latent variable)。EM算法就是含有隐变量的概率模型参数的极大似然估计法,或极大后验概率估计法。
9.1.1 EM算法
开局一个经典EM算法例子
三硬币模型 假设有 3 枚硬币, 分别记作 A , B , C \mathrm{A}, \mathrm{B}, \mathrm{C} A,B,C 。这些硬币正面出现 的概率分别是 π , p \pi, p π,p 和 q ∘ q_{\circ} q∘ 进行如下掷硬币试验: 先掷硬币 A \mathrm{A} A, 根据其结果选出硬币 B \mathrm{B} B 或硬币 C \mathrm{C} C, 正面选硬币 B, 反面选硬币 C \mathrm{C} C; 然后掷选出的硬币, 掷硬币的结果, 出现正 面记作 1 , 出现反面记作 0 ; 独立地重复 n n n 次试验 (这里, n = 10 n=10 n=10 ), 观测结果如下:
1 , 1 , 0 , 1 , 0 , 0 , 1 , 0 , 1 , 1 1,1,0,1,0,0,1,0,1,1 1,1,0,1,0,0,1,0,1,1
假设只能观测到掷硬币的结果, 不能观测掷硬币的过程。问如何估计三硬币正面出现的概率, 即三硬币模型的参数。
解 三硬币模型可以写作
P ( y ∣ θ ) = ∑ z P ( y , z ∣ θ ) = ∑ z P ( z ∣ θ ) P ( y ∣ z , θ ) = π p y ( 1 − p ) 1 − y + ( 1 − π ) q y ( 1 − q ) 1 − y \begin{aligned} P(y \mid \theta) &=\sum_{z} P(y, z \mid \theta)=\sum_{z} P(z \mid \theta) P(y \mid z, \theta) \\ &=\pi p^{y}(1-p)^{1-y}+(1-\pi) q^{y}(1-q)^{1-y} \end{aligned} P(y∣θ)=z∑P(y,z∣θ)=z∑P(z∣θ)P(y∣z,θ)=πpy(1−p)1−y+(1−π)qy(1−q)1−y
这里, 随机变量 y y y 是观测变量, 表示一次试验观测的结果是 1 或 0 ; 随机变量 z z z 是隐 变量, 表示未观测到的掷硬币 A \mathrm{A} A 的结果; θ = ( π , p , q ) \theta=(\pi, p, q) θ=(π,p,q) 是模型参数。这一模型是以上数据的生成模型。注意, 随机变量 y y y 的数据可以观测,随机变量 z z z 的数据不可观测。
将观测数据表示为
Y
=
(
Y
1
,
Y
2
,
⋯
,
Y
n
)
T
Y=\left(Y_{1}, Y_{2}, \cdots, Y_{n}\right)^{\mathrm{T}}
Y=(Y1,Y2,⋯,Yn)T, 未观测数据表示为
Z
=
(
Z
1
,
Z
2
,
⋯
,
Z
n
)
T
Z=\left(Z_{1}, Z_{2}, \cdots, Z_{n}\right)^{\mathrm{T}}
Z=(Z1,Z2,⋯,Zn)T
则观测数据的似然函数为
P ( Y ∣ θ ) = ∑ Z P ( Z ∣ θ ) P ( Y ∣ Z , θ ) P(Y \mid \theta)=\sum_{Z} P(Z \mid \theta) P(Y \mid Z, \theta) P(Y∣θ)=Z∑P(Z∣θ)P(Y∣Z,θ)
即
P ( Y ∣ θ ) = ∏ j = 1 n [ π p y j ( 1 − p ) 1 − y j + ( 1 − π ) q y j ( 1 − q ) 1 − y j ] P(Y \mid \theta)=\prod_{j=1}^{n}\left[\pi p^{y_{j}}(1-p)^{1-y_{j}}+(1-\pi) q^{y_{j}}(1-q)^{1-y_{j}}\right] P(Y∣θ)=j=1∏n[πpyj(1−p)1−yj+(1−π)qyj(1−q)1−yj]
考虑求模型参数 θ = ( π , p , q ) \theta=(\pi, p, q) θ=(π,p,q) 的极大似然估计, 即
θ ^ = arg max θ log P ( Y ∣ θ ) \hat{\theta}=\arg \max _{\theta} \log P(Y \mid \theta) θ^=argθmaxlogP(Y∣θ)
下面给出针对以上问题的 EM 算法
EM 算法首先选取参数的初值, 记作
θ
(
0
)
=
(
π
(
0
)
,
p
(
0
)
,
q
(
0
)
)
\theta^{(0)}=\left(\pi^{(0)}, p^{(0)}, q^{(0)}\right)
θ(0)=(π(0),p(0),q(0)), 然后通过下面的 步骤迭代计算参数的估计值, 直至收敛为止。第
i
i
i 次迭代参数的估计值为
θ
(
i
)
=
\theta^{(i)}=
θ(i)=
(
π
(
i
)
,
p
(
i
)
,
q
(
i
)
)
。
\left(\pi^{(i)}, p^{(i)}, q^{(i)}\right) 。
(π(i),p(i),q(i))。 EM 算法的第
i
+
1
i+1
i+1 次迭代如下。
E
\mathrm{E}
E 步: 计算在模型参数
π
(
i
)
,
p
(
i
)
,
q
(
i
)
\pi^{(i)}, p^{(i)}, q^{(i)}
π(i),p(i),q(i) 下观测数据
y
j
y_{j}
yj 来自掷硬币
B
\mathrm{B}
B 的概率
μ j ( i + 1 ) = π ( i ) ( p ( i ) ) y j ( 1 − p ( i ) ) 1 − y j π ( i ) ( p ( i ) ) y j ( 1 − p ( i ) ) 1 − y j + ( 1 − π ( i ) ) ( q ( i ) ) y j ( 1 − q ( i ) ) 1 − y j \mu_{j}^{(i+1)}=\frac{\pi^{(i)}\left(p^{(i)}\right)^{y_{j}}\left(1-p^{(i)}\right)^{1-y_{j}}}{\pi^{(i)}\left(p^{(i)}\right)^{y_{j}}\left(1-p^{(i)}\right)^{1-y_{j}}+\left(1-\pi^{(i)}\right)\left(q^{(i)}\right)^{y_{j}}\left(1-q^{(i)}\right)^{1-y_{j}}} μj(i+1)=π(i)(p(i))yj(1−p(i))1−yj+(1−π(i))(q(i))yj(1−q(i))1−yjπ(i)(p(i))yj(1−p(i))1−yj
M 步: 计算模型参数的新估计值
π ( i + 1 ) = 1 n ∑ j = 1 n μ j ( i + 1 ) \pi^{(i+1)}=\frac{1}{n} \sum_{j=1}^{n} \mu_{j}^{(i+1)} π(i+1)=n1j=1∑nμj(i+1)
p ( i + 1 ) = ∑ j = 1 n μ j ( i + 1 ) y j ∑ j = 1 n μ j ( i + 1 ) q ( i + 1 ) = ∑ j = 1 n ( 1 − μ j ( i + 1 ) ) y j ∑ j = 1 n ( 1 − μ j ( i + 1 ) ) \begin{gathered} p^{(i+1)}=\frac{\sum_{j=1}^{n} \mu_{j}^{(i+1)} y_{j}}{\sum_{j=1}^{n} \mu_{j}^{(i+1)}} \\ q^{(i+1)}=\frac{\sum_{j=1}^{n}\left(1-\mu_{j}^{(i+1)}\right) y_{j}}{\sum_{j=1}^{n}\left(1-\mu_{j}^{(i+1)}\right)} \end{gathered} p(i+1)=∑j=1nμj(i+1)∑j=1nμj(i+1)yjq(i+1)=∑j=1n(1−μj(i+1))∑j=1n(1−μj(i+1))yj
EM算法与初值的选择有关,选择不同的初值可能得到不同的参数估计值。
- 用 Y Y Y 表示观测随机变量的数据, Z Z Z 表示隐随机变量的数据。
- Y Y Y 和 Z Z Z 连 在一起称为完全数据 (complete-data), 观测数据 Y Y Y 又称为不完全数据 (incompletedata)。
- 假设给定观测数据 Y Y Y, 其概率分布是 P ( Y ∣ θ ) P(Y \mid \theta) P(Y∣θ), 其中 θ \theta θ 是需要估计的模型参数, 那么不完全数据 Y Y Y 的似然函数是 P ( Y ∣ θ ) P(Y \mid \theta) P(Y∣θ), 对数似然函数 L ( θ ) = log P ( Y ∣ θ ) ; L(\theta)=\log P(Y \mid \theta) ; L(θ)=logP(Y∣θ); 假设 Y Y Y 和 Z Z Z 的联合概率分布是 P ( Y , Z ∣ θ ) P(Y, Z \mid \theta) P(Y,Z∣θ), 那么完全数据的对数似然函数是 log P ( Y , Z ∣ θ ) \log P(Y, Z \mid \theta) logP(Y,Z∣θ) 。
-
E
M
\mathrm{EM}
EM 算法通过迭代求
L
(
θ
)
=
log
P
(
Y
∣
θ
)
L(\theta)=\log P(Y \mid \theta)
L(θ)=logP(Y∣θ) 的极大似然估计。每次迭代包含两步:
E
\mathrm{E}
E
步, 求期望; M \mathrm{M} M 步, 求极大化。
EM 算法 输入: 观测变量数据 Y Y Y, 隐变量数据 Z Z Z, 联合分布 P ( Y , Z ∣ θ ) P(Y, Z \mid \theta) P(Y,Z∣θ), 条件分布 P ( Z ∣ Y , θ ) P(Z \mid Y, \theta) P(Z∣Y,θ); 输出: 模型参数 θ \theta θ 。
-
选择参数的初值 θ ( 0 ) \theta^{(0)} θ(0), 开始迭代;
-
E \mathrm{E} E 步: 记 θ ( i ) \theta^{(i)} θ(i) 为第 i i i 次迭代参数 θ \theta θ 的估计值, 在第 i + 1 i+1 i+1 次迭代的 E \mathrm{E} E 步, 计算
Q ( θ , θ ( i ) ) = E Z [ log P ( Y , Z ∣ θ ) ∣ Y , θ ( i ) ] = ∑ Z log P ( Y , Z ∣ θ ) P ( Z ∣ Y , θ ( i ) ) \begin{aligned} Q\left(\theta, \theta^{(i)}\right) &=E_{Z}\left[\log P(Y, Z \mid \theta) \mid Y, \theta^{(i)}\right] \\ &=\sum_{Z} \log P(Y, Z \mid \theta) P\left(Z \mid Y, \theta^{(i)}\right) \end{aligned} Q(θ,θ(i))=EZ[logP(Y,Z∣θ)∣Y,θ(i)]=Z∑logP(Y,Z∣θ)P(Z∣Y,θ(i))这里, P ( Z ∣ Y , θ ( i ) ) P\left(Z \mid Y, \theta^{(i)}\right) P(Z∣Y,θ(i)) 是在给定观测数据 Y Y Y 和当前的参数估计 θ ( i ) \theta^{(i)} θ(i) 下隐变量数据 Z Z Z 的条 概率分布;
-
M 步: 求使 Q ( θ , θ ( i ) ) Q\left(\theta, \theta^{(i)}\right) Q(θ,θ(i)) 极大化的 θ \theta θ, 确定第 i + 1 i+1 i+1 次迭代的参数的估计值 θ ( i + 1 ) \theta^{(i+1)} θ(i+1)
θ ( i + 1 ) = arg max θ Q ( θ , θ ( i ) ) \theta^{(i+1)}=\arg \max _{\theta} Q\left(\theta, \theta^{(i)}\right) θ(i+1)=argθmaxQ(θ,θ(i)) -
重复第(2) 步和第 ( 3 ) (3) (3) 步, 直到收敛。
( Q (Q (Q 函数) 完全数据的对数似然函数 log P ( Y , Z ∣ θ ) \log P(Y, Z \mid \theta) logP(Y,Z∣θ) 关于在给定观测数 据 Y Y Y 和当前参数 θ ( i ) \theta^{(i)} θ(i) 下对未观测数据 Z Z Z 的条件概率分布 P ( Z ∣ Y , θ ( i ) ) P\left(Z \mid Y, \theta^{(i)}\right) P(Z∣Y,θ(i)) 的期望称为 Q Q Q 函数,即
Q ( θ , θ ( i ) ) = E Z [ log P ( Y , Z ∣ θ ) ∣ Y , θ ( i ) ] Q\left(\theta, \theta^{(i)}\right)=E_{Z}\left[\log P(Y, Z \mid \theta) \mid Y, \theta^{(i)}\right] Q(θ,θ(i))=EZ[logP(Y,Z∣θ)∣Y,θ(i)]
下面关于 EM 算法作几点说明:
步骤 (1)参数的初值可以任意选择, 但需注意 E M \mathrm{EM} EM 算法对初值是敏感的。
步骤 (2) E \mathrm{E} E 步求 Q ( θ , θ ( i ) ) 。 Q Q\left(\theta, \theta^{(i)}\right) 。 Q Q(θ,θ(i))。Q 函数式中 Z Z Z 是未观测数据, Y Y Y 是观测数据。注 意, Q ( θ , θ ( i ) ) Q\left(\theta, \theta^{(i)}\right) Q(θ,θ(i)) 的第 1 个变元表示要极大化的参数, 第 2 个变元表示参数的当前估计 值。每次迭代实际在求 Q Q Q 函数及其极大。
步骤 (3) M \mathrm{M} M 步求 Q ( θ , θ ( i ) ) Q\left(\theta, \theta^{(i)}\right) Q(θ,θ(i)) 的极大化, 得到 θ ( i + 1 ) \theta^{(i+1)} θ(i+1), 完成一次迭代 θ ( i ) → θ ( i + 1 ) \theta^{(i)} \rightarrow \theta^{(i+1)} θ(i)→θ(i+1) 。 后面将证明每次迭代使似然函数增大或达到局部极值。
步骤 (4) 给出停止迭代的条件, 一般是对较小的正数 ε 1 , ε 2 \varepsilon_{1}, \varepsilon_{2} ε1,ε2, 若满足∥ θ ( i + 1 ) − θ ( i ) ∥ < ε 1 或 ∥ Q ( θ ( i + 1 ) , θ ( i ) ) − Q ( θ ( i ) , θ ( i ) ) ∥ < ε 2 \left\|\theta^{(i+1)}-\theta^{(i)}\right\|<\varepsilon_{1} \quad \text { 或 }\left\|Q\left(\theta^{(i+1)}, \theta^{(i)}\right)-Q\left(\theta^{(i)}, \theta^{(i)}\right)\right\|<\varepsilon_{2} ∥∥∥θ(i+1)−θ(i)∥∥∥<ε1 或 ∥∥∥Q(θ(i+1),θ(i))−Q(θ(i),θ(i))∥∥∥<ε2
则停止迭代。备注:实际工程中可能会设置epoch迭代停止
9.1.2 E M \mathrm{EM} EM 算法的导出
通过近似求解观测数据的对数似然函数的极大化问题来导出 E M \mathrm{EM} EM 算法, 由此 可以清楚地看出 EM算法的作用。 我们面对一个含有隐变量的概率模型, 目标是极大化观测数据 (不完全数据) Y Y Y 关于参数 θ \theta θ 的对数似然函数, 即极大化
L ( θ ) = log P ( Y ∣ θ ) = log ∑ Z P ( Y , Z ∣ θ ) = log ( ∑ Z P ( Y ∣ Z , θ ) P ( Z ∣ θ ) ) \begin{aligned} L(\theta) &=\log P(Y \mid \theta)=\log \sum_{Z} P(Y, Z \mid \theta) \\ &=\log \left(\sum_{Z} P(Y \mid Z, \theta) P(Z \mid \theta)\right) \end{aligned} L(θ)=logP(Y∣θ)=logZ∑P(Y,Z∣θ)=log(Z∑P(Y∣Z,θ)P(Z∣θ))
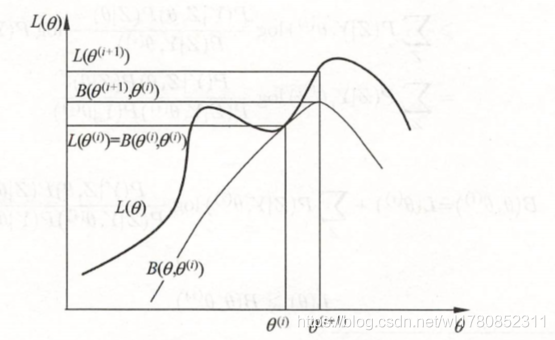
事实上, E M \mathrm{EM} EM 算法是通过迭代逐步近似极大化 L ( θ ) L(\theta) L(θ) 的。假设在第 i i i 次迭代后 θ \theta θ 的 估计值是 θ ( i ) \theta^{(i)} θ(i) 。我们希望新估计值 θ \theta θ 能使 L ( θ ) L(\theta) L(θ) 增加, 即 L ( θ ) > L ( θ ( i ) ) L(\theta)>L\left(\theta^{(i)}\right) L(θ)>L(θ(i)), 并逐步达到极 大值。为此, 考虑两者的差:
L ( θ ) − L ( θ ( i ) ) = log ( ∑ Z P ( Y ∣ Z , θ ) P ( Z ∣ θ ) ) − log P ( Y ∣ θ ( i ) ) L(\theta)-L\left(\theta^{(i)}\right)=\log \left(\sum_{Z} P(Y \mid Z, \theta) P(Z \mid \theta)\right)-\log P\left(Y \mid \theta^{(i)}\right) L(θ)−L(θ(i))=log(Z∑P(Y∣Z,θ)P(Z∣θ))−logP(Y∣θ(i))
利用 Jensen 不等式 (Jensen inequality) log ∑ j λ j y j ⩾ ∑ j λ j log y j \log \sum_{j} \lambda_{j} y_{j} \geqslant \sum_{j} \lambda_{j} \log y_{j} log∑jλjyj⩾∑jλjlogyj, 其中 λ j ⩾ 0 , ∑ j λ j = 1 \lambda_{j} \geqslant 0, \sum_{j} \lambda_{j}=1 λj⩾0,∑jλj=1 。
∑ Z P ( Z ∣ Y , θ ( i ) ) = 1 \sum_{Z} P\left(Z \mid Y, \theta^{(i)}\right)=1 ∑ZP(Z∣Y,θ(i))=1,
未观测数据 Z Z Z 的条件概率分布
L ( θ ) − L ( θ ( i ) ) = log ( ∑ Z P ( Z ∣ Y , θ ( i ) ) P ( Y ∣ Z , θ ) P ( Z ∣ θ ) P ( Z ∣ Y , θ ( i ) ) ) − log P ( Y ∣ θ ( i ) ) ⩾ ∑ Z P ( Z ∣ Y , θ ( i ) ) log P ( Y ∣ Z , θ ) P ( Z ∣ θ ) P ( Z ∣ Y , θ ( i ) ) − ∑ Z P ( Z ∣ Y , θ ( i ) ) ⋅ log P ( Y ∣ θ ( i ) ) = ∑ Z P ( Z ∣ Y , θ ( i ) ) log P ( Y ∣ Z , θ ) P ( Z ∣ θ ) P ( Z ∣ Y , θ ( i ) ) P ( Y ∣ θ ( i ) ) \begin{aligned} L(\theta)-L\left(\theta^{(i)}\right) &=\log \left(\sum_{Z} P\left(Z \mid Y, \theta^{(i)}\right) \frac{P(Y \mid Z, \theta) P(Z \mid \theta)}{P\left(Z \mid Y, \theta^{(i)}\right)}\right)-\log P\left(Y \mid \theta^{(i)}\right) \\ & \geqslant \sum_{Z} P\left(Z \mid Y, \theta^{(i)}\right) \log \frac{P(Y \mid Z, \theta) P(Z \mid \theta)}{P\left(Z \mid Y, \theta^{(i)}\right)}-\sum_{Z} P\left(Z \mid Y, \theta^{(i)}\right)\cdot \log P\left(Y \mid \theta^{(i)}\right) \\ &=\sum_{Z} P\left(Z \mid Y, \theta^{(i)}\right) \log \frac{P(Y \mid Z, \theta) P(Z \mid \theta)}{P\left(Z \mid Y, \theta^{(i)}\right) P\left(Y \mid \theta^{(i)}\right)} \end{aligned} L(θ)−L(θ(i))=log(Z∑P(Z∣Y,θ(i))P(Z∣Y,θ(i))P(Y∣Z,θ)P(Z∣θ))−logP(Y∣θ(i))⩾Z∑P(Z∣Y,θ(i))logP(Z∣Y,θ(i))P(Y∣Z,θ)P(Z∣θ)−Z∑P(Z∣Y,θ(i))⋅logP(Y∣θ(i))=Z∑P(Z∣Y,θ(i))logP(Z∣Y,θ(i))P(Y∣θ(i))P(Y∣Z,θ)P(Z∣θ)
令
B ( θ , θ ( i ) ) = ^ L ( θ ( i ) ) + ∑ Z P ( Z ∣ Y , θ ( i ) ) log P ( Y ∣ Z , θ ) P ( Z ∣ θ ) P ( Z ∣ Y , θ ( i ) ) P ( Y ∣ θ ( i ) ) ① B\left(\theta, \theta^{(i)}\right) \hat =L\left(\theta^{(i)}\right)+\sum_{Z} P\left(Z \mid Y, \theta^{(i)}\right) \log \frac{P(Y \mid Z, \theta) P(Z \mid \theta)}{P\left(Z \mid Y, \theta^{(i)}\right) P\left(Y \mid \theta^{(i)}\right)}① B(θ,θ(i))=^L(θ(i))+Z∑P(Z∣Y,θ(i))logP(Z∣Y,θ(i))P(Y∣θ(i))P(Y∣Z,θ)P(Z∣θ)①
则
L ( θ ) ⩾ B ( θ , θ ( i ) ) L(\theta) \geqslant B\left(\theta, \theta^{(i)}\right) L(θ)⩾B(θ,θ(i))
即函数 B ( θ , θ ( i ) ) B\left(\theta, \theta^{(i)}\right) B(θ,θ(i)) 是 L ( θ ) L(\theta) L(θ) 的一个下界, 而且由式①可知,
L ( θ ( i ) ) = B ( θ ( i ) , θ ( i ) ) L\left(\theta^{(i)}\right)=B\left(\theta^{(i)}, \theta^{(i)}\right) L(θ(i))=B(θ(i),θ(i))
因此, 任何可以使 B ( θ , θ ( i ) ) B\left(\theta, \theta^{(i)}\right) B(θ,θ(i)) 增大的 θ \theta θ, 也可以使 L ( θ ) L(\theta) L(θ) 增大。为了使 L ( θ ) L(\theta) L(θ) 有尽可能大 的增长, 选择 θ ( i + 1 ) \theta^{(i+1)} θ(i+1) 使 B ( θ , θ ( i ) ) B\left(\theta, \theta^{(i)}\right) B(θ,θ(i)) 达到极大, 即
θ ( i + 1 ) = arg max θ B ( θ , θ ( i ) ) \theta^{(i+1)}=\arg \max _{\theta} B\left(\theta, \theta^{(i)}\right) θ(i+1)=argθmaxB(θ,θ(i))
现在求 θ ( i + 1 ) \theta^{(i+1)} θ(i+1) 的表达式。省去对 θ \theta θ 的极大化而訁是常数的项, 由式 θ ( i + 1 ) = arg max θ B ( θ , θ ( i ) ) \theta^{(i+1)}=\arg \max _{\theta} B\left(\theta, \theta^{(i)}\right) θ(i+1)=argmaxθB(θ,θ(i)) 、式 ①及式 θ ( i + 1 ) = arg max θ Q ( θ , θ ( i ) ) \theta^{(i+1)}=\arg \max _{\theta} Q\left(\theta, \theta^{(i)}\right) θ(i+1)=argmaxθQ(θ,θ(i)), 有
θ ( i + 1 ) = arg max θ ( L ( θ ( i ) ) + ∑ Z P ( Z ∣ Y , θ ( i ) ) log P ( Y ∣ Z , θ ) P ( Z ∣ θ ) P ( Z ∣ Y , θ ( i ) ) P ( Y ∣ θ ( i ) ) ) = arg max θ ( ∑ Z P ( Z ∣ Y , θ ( i ) ) log ( P ( Y ∣ Z , θ ) P ( Z ∣ θ ) ) ) = arg max θ ( ∑ Z P ( Z ∣ Y , θ ( i ) ) log P ( Y , Z ∣ θ ) ) = arg max θ Q ( θ , θ ( i ) ) \begin{aligned} \theta^{(i+1)} &=\arg \max _{\theta}\left(L\left(\theta^{(i)}\right)+\sum_{Z} P\left(Z \mid Y, \theta^{(i)}\right) \log \frac{P(Y \mid Z, \theta) P(Z \mid \theta)}{P\left(Z \mid Y, \theta^{(i)}\right) P\left(Y \mid \theta^{(i)}\right)}\right) \\ &=\arg \max _{\theta}\left(\sum_{Z} P\left(Z \mid Y, \theta^{(i)}\right) \log (P(Y \mid Z, \theta) P(Z \mid \theta))\right) \\ &=\arg \max _{\theta}\left(\sum_{Z} P\left(Z \mid Y, \theta^{(i)}\right) \log P(Y, Z \mid \theta)\right) \\ &=\arg \max _{\theta} Q\left(\theta, \theta^{(i)}\right) \end{aligned} θ(i+1)=argθmax(L(θ(i))+Z∑P(Z∣Y,θ(i))logP(Z∣Y,θ(i))P(Y∣θ(i))P(Y∣Z,θ)P(Z∣θ))=argθmax(Z∑P(Z∣Y,θ(i))log(P(Y∣Z,θ)P(Z∣θ)))=argθmax(Z∑P(Z∣Y,θ(i))logP(Y,Z∣θ))=argθmaxQ(θ,θ(i))
上式等价于 E M \mathrm{EM} EM 算法的一次迭代, 即求 Q Q Q 函数及其极大化。EM 算法是通过不断求解下界的极大化逼近求解对数似然函数极大化的算法。
E M \mathrm{EM} EM 算法的直观解释
9.1.3 EM 算法在无监督学习中的应用
监督学习是由训练数据
{
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
,
⋯
,
(
x
N
,
y
N
)
}
\left\{\left(x_{1}, y_{1}\right),\left(x_{2}, y_{2}\right), \cdots,\left(x_{N}, y_{N}\right)\right\}
{(x1,y1),(x2,y2),⋯,(xN,yN)} 学习条件概率分布
P
(
Y
∣
X
)
P(Y \mid X)
P(Y∣X) 或决策函数
Y
=
f
(
X
)
Y=f(X)
Y=f(X) 作为模型, 用于分类、回归、标注等任务。这时训练数据中的每个样本点由输入和输出对组成。
有时训练数据只有输入没有对应的输出
{
(
x
1
,
∙
)
,
(
x
2
,
∙
)
,
⋯
,
(
x
N
,
∙
)
}
\left\{\left(x_{1}, \bullet\right),\left(x_{2}, \bullet\right), \cdots,\left(x_{N}, \bullet\right)\right\}
{(x1,∙),(x2,∙),⋯,(xN,∙)}, 从这样的数据学习模型称为无监督学习问题。
EM 算法可以用于生成模型的无监督学习。生成模型由联合概率分布 P ( X , Y ) P(X, Y) P(X,Y) 表示, 可以认为无监督学习训练数据是联合概率分布产生的数据。 X X X 为观测数据, Y Y Y 为未观测数据。
9.2 EM算法的收敛性
设 P ( Y ∣ θ ) P(Y \mid \theta) P(Y∣θ) 为观测数据的似然函数, θ ( i ) ( i = 1 , 2 , ⋯ ) \theta^{(i)}(i=1,2, \cdots) θ(i)(i=1,2,⋯) 为 E M \mathrm{EM} EM 算法得到的参数估计序列, P ( Y ∣ θ ( i ) ) ( i = 1 , 2 , ⋯ ) P\left(Y \mid \theta^{(i)}\right)(i=1,2, \cdots) P(Y∣θ(i))(i=1,2,⋯) 为对应的似然函数序列, 则 P ( Y ∣ θ ( i ) ) P\left(Y \mid \theta^{(i)}\right) P(Y∣θ(i)) 是单调递增的,即
P ( Y ∣ θ ( i + 1 ) ) ⩾ P ( Y ∣ θ ( i ) ) P\left(Y \mid \theta^{(i+1)}\right) \geqslant P\left(Y \mid \theta^{(i)}\right) P(Y∣θ(i+1))⩾P(Y∣θ(i))
证明 由于
P ( Y ∣ θ ) = P ( Y , Z ∣ θ ) P ( Z ∣ Y , θ ) P(Y \mid \theta)=\frac{P(Y, Z \mid \theta)}{P(Z \mid Y, \theta)} P(Y∣θ)=P(Z∣Y,θ)P(Y,Z∣θ)
条件联合分布的分解
条件联合分布的分解
P ( X = a , Y = b ∣ Z = c ) = P ( X = a ∣ Y = b , Z = c ) P ( Y = b ∣ Z = c ) P(X=a, Y=b \mid Z=c)=P(X=a \mid Y=b, Z=c) P(Y=b \mid Z=c) P(X=a,Y=b∣Z=c)=P(X=a∣Y=b,Z=c)P(Y=b∣Z=c)
取对数有
log P ( Y ∣ θ ) = log P ( Y , Z ∣ θ ) − log P ( Z ∣ Y , θ ) \log P(Y \mid \theta)=\log P(Y, Z \mid \theta)-\log P(Z \mid Y, \theta) logP(Y∣θ)=logP(Y,Z∣θ)−logP(Z∣Y,θ)
由式 Q ( θ , θ ( i ) ) = E Z [ log P ( Y , Z ∣ θ ) ∣ Y , θ ( i ) ] Q\left(\theta, \theta^{(i)}\right)=E_{Z}\left[\log P(Y, Z \mid \theta) \mid Y, \theta^{(i)}\right] Q(θ,θ(i))=EZ[logP(Y,Z∣θ)∣Y,θ(i)]
Q ( θ , θ ( i ) ) = ∑ Z log P ( Y , Z ∣ θ ) P ( Z ∣ Y , θ ( i ) ) Q\left(\theta, \theta^{(i)}\right)=\sum_{Z} \log P(Y, Z \mid \theta) P\left(Z \mid Y, \theta^{(i)}\right) Q(θ,θ(i))=Z∑logP(Y,Z∣θ)P(Z∣Y,θ(i))
令
H ( θ , θ ( i ) ) = ∑ Z log P ( Z ∣ Y , θ ) P ( Z ∣ Y , θ ( i ) ) H\left(\theta, \theta^{(i)}\right)=\sum_{Z} \log P(Z \mid Y, \theta) P\left(Z \mid Y, \theta^{(i)}\right) H(θ,θ(i))=Z∑logP(Z∣Y,θ)P(Z∣Y,θ(i))
为什么?
由于 : log P ( Y ∣ θ ) = log P ( Y , Z ∣ θ ) − log P ( Z ∣ Y , θ ) \log P(Y \mid \theta)=\log P(Y, Z \mid \theta)-\log P(Z \mid Y, \theta) logP(Y∣θ)=logP(Y,Z∣θ)−logP(Z∣Y,θ) 两边对Z求积分 :
log P ( Y ∣ θ ) a m p ; = ∑ z P ( Z ∣ Y , θ ( i ) ) ⋅ log P ( Y ∣ θ ) a m p ; = log P ( Y ∣ θ ) ∑ z P ( Z ∣ Y , θ ( i ) ) a m p ; = log P ( Y ∣ θ ) \begin{aligned} \log P(Y\mid \theta) &=\sum_{z} P\left(Z \mid Y, \theta^{(i)}\right) \cdot \log P(Y\mid \theta) \\ &=\log P(Y \mid \theta) \sum_{z} P\left(Z \mid Y, \theta^{(i)}\right) \\ &=\log P(Y\mid \theta) \end{aligned} logP(Y∣θ)amp;=z∑P(Z∣Y,θ(i))⋅logP(Y∣θ)amp;=logP(Y∣θ)z∑P(Z∣Y,θ(i))amp;=logP(Y∣θ)
对左边公式求积分,由于 log P ( Y ∣ θ ) \log P(Y \mid \theta) logP(Y∣θ) 无关Z的积分,后项求积分等于1
Righ t = log P ( Y , Z ∣ θ ) − log P ( Z ∣ Y , θ ) \operatorname{Righ} t=\log P(Y, Z \mid \theta)-\log P(Z \mid Y, \theta) Right=logP(Y,Z∣θ)−logP(Z∣Y,θ)
= ∑ z P ( Z ∣ Y , θ ( i ) ) log P ( Y , Z ∣ θ ) − ∑ z P ( Z ∣ Y , θ ( i ) log P ( Z ∣ Y , θ ) =\sum_{z} P\left(Z \mid Y, \theta^{(i)}\right) \log P(Y, Z \mid \theta)-\sum_{z} P\left(Z \mid Y, \theta^{(i)} \log P(Z \mid Y, \theta)\right. =∑zP(Z∣Y,θ(i))logP(Y,Z∣θ)−∑zP(Z∣Y,θ(i)logP(Z∣Y,θ)于是对数似然函数可以写成
log P ( Y ∣ θ ) = Q ( θ , θ ( i ) ) − H ( θ , θ ( i ) ) \log P(Y \mid \theta)=Q\left(\theta, \theta^{(i)}\right)-H\left(\theta, \theta^{(i)}\right) logP(Y∣θ)=Q(θ,θ(i))−H(θ,θ(i))
在上式中分别取 θ \theta θ 为 θ ( i ) \theta^{(i)} θ(i) 和 θ ( i + 1 ) \theta^{(i+1)} θ(i+1) 并相减, 有
log P ( Y ∣ θ ( i + 1 ) ) − log P ( Y ∣ θ ( i ) ) = [ Q ( θ ( i + 1 ) , θ ( i ) ) − Q ( θ ( i ) , θ ( i ) ) ] − [ H ( θ ( i + 1 ) , θ ( i ) ) − H ( θ ( i ) , θ ( i ) ) ] ① \begin{aligned} &\log P\left(Y \mid \theta^{(i+1)}\right)-\log P\left(Y \mid \theta^{(i)}\right) \\ &\quad=\left[Q\left(\theta^{(i+1)}, \theta^{(i)}\right)-Q\left(\theta^{(i)}, \theta^{(i)}\right)\right]-\left[H\left(\theta^{(i+1)}, \theta^{(i)}\right)-H\left(\theta^{(i)}, \theta^{(i)}\right)\right] \end{aligned}① logP(Y∣θ(i+1))−logP(Y∣θ(i))=[Q(θ(i+1),θ(i))−Q(θ(i),θ(i))]−[H(θ(i+1),θ(i))−H(θ(i),θ(i))]①
为证式 P ( Y ∣ θ ( i + 1 ) ) ⩾ P ( Y ∣ θ ( i ) ) P\left(Y \mid \theta^{(i+1)}\right) \geqslant P\left(Y \mid \theta^{(i)}\right) P(Y∣θ(i+1))⩾P(Y∣θ(i)), 只需证上式右端是非负的。上式右端的第 1 项, 由于 θ ( i + 1 ) \theta^{(i+1)} θ(i+1) 使 Q ( θ , θ ( i ) ) Q\left(\theta, \theta^{(i)}\right) Q(θ,θ(i)) 达到极大, 所以有
Q ( θ ( i + 1 ) , θ ( i ) ) − Q ( θ ( i ) , θ ( i ) ) ⩾ 0 Q\left(\theta^{(i+1)}, \theta^{(i)}\right)-Q\left(\theta^{(i)}, \theta^{(i)}\right) \geqslant 0 Q(θ(i+1),θ(i))−Q(θ(i),θ(i))⩾0
其第 2 项, 由式 H ( θ , θ ( i ) ) = ∑ Z log P ( Z ∣ Y , θ ) P ( Z ∣ Y , θ ( i ) ) H\left(\theta, \theta^{(i)}\right)=\sum_{Z} \log P(Z \mid Y, \theta) P\left(Z \mid Y, \theta^{(i)}\right) H(θ,θ(i))=∑ZlogP(Z∣Y,θ)P(Z∣Y,θ(i)) 可得:
H ( θ ( i + 1 ) , θ ( i ) ) − H ( θ ( i ) , θ ( i ) ) = ∑ Z ( log P ( Z ∣ Y , θ ( i + 1 ) ) P ( Z ∣ Y , θ ( i ) ) ) P ( Z ∣ Y , θ ( i ) ) ⩽ log ( ∑ Z P ( Z ∣ Y , θ ( i + 1 ) ) P ( Z ∣ Y , θ ( i ) ) P ( Z ∣ Y , θ ( i ) ) ) = log ( ∑ Z P ( Z ∣ Y , θ ( i + 1 ) ) ) = 0 ② \begin{aligned} H\left(\theta^{(i+1)}, \theta^{(i)}\right)-H\left(\theta^{(i)}, \theta^{(i)}\right) &=\sum_{Z}\left(\log \frac{P\left(Z \mid Y, \theta^{(i+1)}\right)}{P\left(Z \mid Y, \theta^{(i)}\right)}\right) P\left(Z \mid Y, \theta^{(i)}\right) \\ & \leqslant \log \left(\sum_{Z} \frac{P\left(Z \mid Y, \theta^{(i+1)}\right)}{P\left(Z \mid Y, \theta^{(i)}\right)} P\left(Z \mid Y, \theta^{(i)}\right)\right) \\ &=\log \left(\sum_{Z} P\left(Z \mid Y, \theta^{(i+1)}\right)\right)=0 \end{aligned}② H(θ(i+1),θ(i))−H(θ(i),θ(i))=Z∑(logP(Z∣Y,θ(i))P(Z∣Y,θ(i+1)))P(Z∣Y,θ(i))⩽log(Z∑P(Z∣Y,θ(i))P(Z∣Y,θ(i+1))P(Z∣Y,θ(i)))=log(Z∑P(Z∣Y,θ(i+1)))=0②
这里的不等号由 Jensen 不等式得到。
由式 Q ( θ ( i + 1 ) , θ ( i ) ) − Q ( θ ( i ) , θ ( i ) ) ⩾ 0 Q\left(\theta^{(i+1)}, \theta^{(i)}\right)-Q\left(\theta^{(i)}, \theta^{(i)}\right) \geqslant 0 Q(θ(i+1),θ(i))−Q(θ(i),θ(i))⩾0 和式②即知式①右端是非负的。
定理 设 L ( θ ) = log P ( Y ∣ θ ) L(\theta)=\log P(Y \mid \theta) L(θ)=logP(Y∣θ) 为观测数据的对数似然函数, θ ( i ) ( i = 1 , 2 , ⋯ ) \theta^{(i)}(i=1,2, \cdots) θ(i)(i=1,2,⋯)
为 E M \mathrm{EM} EM 算法得到的参数估计序列, L ( θ ( i ) ) ( i = 1 , 2 , ⋯ ) L\left(\theta^{(i)}\right)(i=1,2, \cdots) L(θ(i))(i=1,2,⋯) 为对应的对数似然函数序列。( 1 )如果 P ( Y ∣ θ ) P(Y \mid \theta) P(Y∣θ) 有上界, 则 L ( θ ( i ) ) = log P ( Y ∣ θ ( i ) ) L\left(\theta^{(i)}\right)=\log P\left(Y \mid \theta^{(i)}\right) L(θ(i))=logP(Y∣θ(i)) 收敛到某一值 L ∗ L^{*} L∗;
( 2 ) 在函数 Q ( θ , θ ′ ) Q\left(\theta, \theta^{\prime}\right) Q(θ,θ′) 与 L ( θ ) L(\theta) L(θ) 满足一定条件下, 由 E M \mathrm{EM} EM 算法得到的参数估计序列 θ ( i ) \theta^{(i)} θ(i) 的收敘值 θ ∗ \theta^{*} θ∗ 是 L ( θ ) L(\theta) L(θ) 的稳定点。证明 \quad (1) 由 L ( θ ) = log P ( Y ∣ θ ( i ) ) L(\theta)=\log P\left(Y \mid \theta^{(i)}\right) L(θ)=logP(Y∣θ(i)) 的单调性及 P ( Y ∣ θ ) P(Y \mid \theta) P(Y∣θ)的有界性立即得到。
9.3 EM算法在高斯混合模型学习中的应用
9.3.1 高斯混合模型
高斯混合模型是指具有如下形式的概率分布模型:
P ( y ∣ θ ) = ∑ k = 1 K α k ϕ ( y ∣ θ k ) P(y \mid \theta)=\sum_{k=1}^{K} \alpha_{k} \phi\left(y \mid \theta_{k}\right) P(y∣θ)=k=1∑Kαkϕ(y∣θk)
其中, α k \alpha_{k} αk 是系数, α k ⩾ 0 , ∑ k = 1 K α k = 1 ; ϕ ( y ∣ θ k ) \alpha_{k} \geqslant 0, \sum_{k=1}^{K} \alpha_{k}=1 ; \phi\left(y \mid \theta_{k}\right) αk⩾0,∑k=1Kαk=1;ϕ(y∣θk) 是高斯分布密度, θ k = ( μ k , σ k 2 ) \theta_{k}=\left(\mu_{k}, \sigma_{k}^{2}\right) θk=(μk,σk2),
ϕ ( y ∣ θ k ) = 1 2 π σ k exp ( − ( y − μ k ) 2 2 σ k 2 ) ① \phi\left(y \mid \theta_{k}\right)=\frac{1}{\sqrt{2 \pi} \sigma_{k}} \exp \left(-\frac{\left(y-\mu_{k}\right)^{2}}{2 \sigma_{k}^{2}}\right)① ϕ(y∣θk)=2πσk1exp(−2σk2(y−μk)2)①
称为第
k
k
k 个分模型。
一般混合模型可以由任意概率分布密度代替式①中的高斯分布密度。
9.3.2 高斯混合模型参数估计的EM算法
观测数据 y 1 , y 2 , ⋯ , y N y_{1}, y_{2}, \cdots, y_{N} y1,y2,⋯,yN 由高斯混合模型生成,
P ( y ∣ θ ) = ∑ k = 1 K α k ϕ ( y ∣ θ k ) P(y \mid \theta)=\sum_{k=1}^{K} \alpha_{k} \phi\left(y \mid \theta_{k}\right) P(y∣θ)=k=1∑Kαkϕ(y∣θk)
其中, θ = ( α 1 , α 2 , ⋯ , α K ; θ 1 , θ 2 , ⋯ , θ K ) \theta=\left(\alpha_{1}, \alpha_{2}, \cdots, \alpha_{K} ; \theta_{1}, \theta_{2}, \cdots, \theta_{K}\right) θ=(α1,α2,⋯,αK;θ1,θ2,⋯,θK) 。用 EM算法估计高斯混合模型的参数 θ \theta θ 。
-
明确隐变量, 写出完全数据的对数似然函数
可以设想观测数据 y j , j = 1 , 2 , ⋯ , N y_{j}, j=1,2, \cdots, N yj,j=1,2,⋯,N, 是这样产生的: 首先依概率 α k \alpha_{k} αk 选择第 k k k 个高斯分布分模型 ϕ ( y ∣ θ k ) \phi\left(y \mid \theta_{k}\right) ϕ(y∣θk), 然后依第 k k k 个分模型的概率分布 ϕ ( y ∣ θ k ) \phi\left(y \mid \theta_{k}\right) ϕ(y∣θk) 生成观测数据 y j y_{j} yj 。 这时观测数据 y j , j = 1 , 2 , ⋯ , N y_{j}, j=1,2, \cdots, N yj,j=1,2,⋯,N, 是已知的; 反映观测数据 y j y_{j} yj 来自第 k k k 个分模 型的数据是未知的, k = 1 , 2 , ⋯ , K k=1,2, \cdots, K k=1,2,⋯,K, 以隐变量 γ j k \gamma_{j k} γjk 表示, 其定义如下:
γ j k = { 1 , 第 j 个观测来自第 k 个分模型 0 , 否则 j = 1 , 2 , ⋯ , N ; k = 1 , 2 , ⋯ , K \begin{aligned} &\gamma_{j k}= \begin{cases}1, & \text { 第 } j \text { 个观测来自第 } k \text { 个分模型 } \\ 0, & \text { 否则 }\end{cases} \\ &j=1,2, \cdots, & N ; \quad k=1,2, \cdots, K \end{aligned} γjk={1,0, 第 j 个观测来自第 k 个分模型 否则 j=1,2,⋯,N;k=1,2,⋯,Kγ j k \gamma_{j k} γjk 是 0-1 随机变量。
有了观测数据 y j y_{j} yj 及未观测数据 γ j k \gamma_{j k} γjk, 那么完全数据是
( y j , γ j 1 , γ j 2 , ⋯ , γ j K ) , j = 1 , 2 , ⋯ , N \left(y_{j}, \gamma_{j 1}, \gamma_{j 2}, \cdots, \gamma_{j K}\right), \quad j=1,2, \cdots, N (yj,γj1,γj2,⋯,γjK),j=1,2,⋯,N完全数据的似然函数:
P ( y , γ ∣ θ ) = ∏ j = 1 N P ( y j , γ j 1 , γ j 2 , ⋯ , γ j K ∣ θ ) = ∏ k = 1 K ∏ j = 1 N [ α k ϕ ( y j ∣ θ k ) ] γ j k = ∏ k = 1 K α k n k ∏ j = 1 N [ ϕ ( y j ∣ θ k ) ] γ j k = ∏ k = 1 K α k n k ∏ j = 1 N [ 1 2 π σ k exp ( − ( y j − μ k ) 2 2 σ k 2 ) ] γ j k 式中, n k = ∑ j = 1 N γ j k , ∑ k = 1 K n k = N \begin{aligned} P(y, \gamma \mid \theta) &=\prod_{j=1}^{N} P\left(y_{j}, \gamma_{j 1}, \gamma_{j 2}, \cdots, \gamma_{j K} \mid \theta\right) \\ &=\prod_{k=1}^{K} \prod_{j=1}^{N}\left[\alpha_{k} \phi\left(y_{j} \mid \theta_{k}\right)\right]^{\gamma_{j k}} \\ &=\prod_{k=1}^{K} \alpha_{k}^{n_{k}} \prod_{j=1}^{N}\left[\phi\left(y_{j} \mid \theta_{k}\right)\right]^{\gamma_{j k}} \\ &=\prod_{k=1}^{K} \alpha_{k}^{n_{k}} \prod_{j=1}^{N}\left[\frac{1}{\sqrt{2 \pi} \sigma_{k}} \exp \left(-\frac{\left(y_{j}-\mu_{k}\right)^{2}}{2 \sigma_{k}^{2}}\right)\right]^{\gamma_{j k}} \\ \text { 式中, } n_{k}=\sum_{j=1}^{N} \gamma_{j k}, \sum_{k=1}^{K} n_{k}=N \end{aligned} P(y,γ∣θ) 式中, nk=j=1∑Nγjk,k=1∑Knk=N=j=1∏NP(yj,γj1,γj2,⋯,γjK∣θ)=k=1∏Kj=1∏N[αkϕ(yj∣θk)]γjk=k=1∏Kαknkj=1∏N[ϕ(yj∣θk)]γjk=k=1∏Kαknkj=1∏N[2πσk1exp(−2σk2(yj−μk)2)]γjk
那么, 完全数据的对数似然函数为
log P ( y , γ ∣ θ ) = ∑ k = 1 K { n k log α k + ∑ j = 1 N γ j k [ log ( 1 2 π ) − log σ k − 1 2 σ k 2 ( y j − μ k ) 2 ] } \log P(y, \gamma \mid \theta)=\sum_{k=1}^{K}\left\{n_{k} \log \alpha_{k}+\sum_{j=1}^{N} \gamma_{j k}\left[\log \left(\frac{1}{\sqrt{2 \pi}}\right)-\log \sigma_{k}-\frac{1}{2 \sigma_{k}^{2}}\left(y_{j}-\mu_{k}\right)^{2}\right]\right\} logP(y,γ∣θ)=∑k=1K{nklogαk+∑j=1Nγjk[log(2π1)−logσk−2σk21(yj−μk)2]} -
EM 算法的 E \mathrm{E} E 步: 确定 Q Q Q 函数
Q ( θ , θ ( i ) ) = E [ log P ( y , γ ∣ θ ) ∣ y , θ ( i ) ] = E { ∑ k = 1 K { n k log α k + ∑ j = 1 N γ j k [ log ( 1 2 π ) − log σ k − 1 2 σ k 2 ( y j − μ k ) 2 ] } } = ∑ k = 1 K { ∑ j = 1 N ( E γ j k ) log α k + ∑ j = 1 N ( E γ j k ) [ log ( 1 2 π ) − log σ k − 1 2 σ k 2 ( y j − μ k ) 2 ] } ③ \begin{aligned} Q\left(\theta, \theta^{(i)}\right) &=E\left[\log P(y, \gamma \mid \theta) \mid y, \theta^{(i)}\right] \\ &=E\left\{\sum_{k=1}^{K}\left\{n_{k} \log \alpha_{k}+\sum_{j=1}^{N} \gamma_{j k}\left[\log \left(\frac{1}{\sqrt{2 \pi}}\right)-\log \sigma_{k}-\frac{1}{2 \sigma_{k}^{2}}\left(y_{j}-\mu_{k}\right)^{2}\right]\right\}\right\} \\ &=\sum_{k=1}^{K}\left\{\sum_{j=1}^{N}\left(E \gamma_{j k}\right) \log \alpha_{k}+\sum_{j=1}^{N}\left(E \gamma_{j k}\right)\left[\log \left(\frac{1}{\sqrt{2 \pi}}\right)-\log \sigma_{k}-\frac{1}{2 \sigma_{k}^{2}}\left(y_{j}-\mu_{k}\right)^{2}\right]\right\} \end{aligned}③ Q(θ,θ(i))=E[logP(y,γ∣θ)∣y,θ(i)]=E{k=1∑K{nklogαk+j=1∑Nγjk[log(2π1)−logσk−2σk21(yj−μk)2]}}=k=1∑K{j=1∑N(Eγjk)logαk+j=1∑N(Eγjk)[log(2π1)−logσk−2σk21(yj−μk)2]}③
E ( γ j k ∣ y , θ ) E\left(\gamma_{j k} \mid y, \theta\right) E(γjk∣y,θ), 记为 γ ^ i k \hat{\gamma}_{i k} γ^ik
γ ^ j k = E ( γ j k ∣ y , θ ) = P ( γ j k = 1 ∣ y , θ ) = P ( γ j k = 1 , y j ∣ θ ) ∑ k = 1 K P ( γ j k = 1 , y j ∣ θ ) = P ( y j ∣ γ j k = 1 , θ ) P ( γ j k = 1 ∣ θ ) ∑ k = 1 K P ( y j ∣ γ j k = 1 , θ ) P ( γ j k = 1 ∣ θ ) = α k ϕ ( y j ∣ θ k ) ∑ k = 1 K α k ϕ ( y j ∣ θ k ) , j = 1 , 2 , ⋯ , N ; k = 1 , 2 , ⋯ , K \begin{aligned} \hat{\gamma}_{j k}=& E\left(\gamma_{j k} \mid y, \theta\right)=P\left(\gamma_{j k}=1 \mid y, \theta\right) \\ &=\frac{P\left(\gamma_{j k}=1, y_{j} \mid \theta\right)}{\sum_{k=1}^{K} P\left(\gamma_{j k}=1, y_{j} \mid \theta\right)} \\ =& \frac{P\left(y_{j} \mid \gamma_{j k}=1, \theta\right) P\left(\gamma_{j k}=1 \mid \theta\right)}{\sum_{k=1}^{K} P\left(y_{j} \mid \gamma_{j k}=1, \theta\right) P\left(\gamma_{j k}=1 \mid \theta\right)} \\ =& \frac{\alpha_{k} \phi\left(y_{j} \mid \theta_{k}\right)}{\sum_{k=1}^{K} \alpha_{k} \phi\left(y_{j} \mid \theta_{k}\right)}, \quad j=1,2, \cdots, N ; \quad k=1,2, \cdots, K \end{aligned} γ^jk===E(γjk∣y,θ)=P(γjk=1∣y,θ)=∑k=1KP(γjk=1,yj∣θ)P(γjk=1,yj∣θ)∑k=1KP(yj∣γjk=1,θ)P(γjk=1∣θ)P(yj∣γjk=1,θ)P(γjk=1∣θ)∑k=1Kαkϕ(yj∣θk)αkϕ(yj∣θk),j=1,2,⋯,N;k=1,2,⋯,Kγ ^ j k \hat{\gamma}_{j k} γ^jk 是在当前模型参数下第 j j j 个观测数据来自第 k k k 个分模型的概率, 称为分模型 k k k 对 观测数据 y j y_{j} yj 的响应度。
将 γ ^ j k = E γ j k \hat{\gamma}_{j k}=E \gamma_{j k} γ^jk=Eγjk 及 n k = ∑ j = 1 N E γ j k n_{k}=\sum_{j=1}^{N} E \gamma_{j k} nk=∑j=1NEγjk 代入式 ③ ③ ③, 即得
Q ( θ , θ ( i ) ) = ∑ k = 1 K { n k log α k + ∑ j = 1 N γ ^ j k [ log ( 1 2 π ) − log σ k − 1 2 σ k 2 ( y j − μ k ) 2 ] } ④ Q\left(\theta, \theta^{(i)}\right)=\sum_{k=1}^{K}\left\{n_{k} \log \alpha_{k}+\sum_{j=1}^{N} \hat{\gamma}_{j k}\left[\log \left(\frac{1}{\sqrt{2 \pi}}\right)-\log \sigma_{k}-\frac{1}{2 \sigma_{k}^{2}}\left(y_{j}-\mu_{k}\right)^{2}\right]\right\}④ Q(θ,θ(i))=k=1∑K{nklogαk+j=1∑Nγ^jk[log(2π1)−logσk−2σk21(yj−μk)2]}④ -
确定 EM 算法的 M 步
迭代的 M \mathrm{M} M 步是求函数 Q ( θ , θ ( i ) ) Q\left(\theta, \theta^{(i)}\right) Q(θ,θ(i)) 对 θ \theta θ 的极大值, 即求新一轮迭代的模型参数:
θ ( i + 1 ) = arg max θ Q ( θ , θ ( i ) ) \theta^{(i+1)}=\arg \max _{\theta} Q\left(\theta, \theta^{(i)}\right) θ(i+1)=argθmaxQ(θ,θ(i))用 μ ^ k , σ ^ k 2 \hat{\mu}_{k}, \hat{\sigma}_{k}^{2} μ^k,σ^k2 及 α ^ k , k = 1 , 2 , ⋯ , K \hat{\alpha}_{k}, k=1,2, \cdots, K α^k,k=1,2,⋯,K, 表示 θ ( i + 1 ) \theta^{(i+1)} θ(i+1) 的各参数。求 μ ^ k , σ ^ k 2 \hat{\mu}_{k}, \hat{\sigma}_{k}^{2} μ^k,σ^k2 只需将
式④分别对 μ k , σ k 2 \mu_{k}, \sigma_{k}^{2} μk,σk2 求偏导数并令其为 0, 即可得到; 求 α ^ k \hat{\alpha}_{k} α^k 是在 ∑ k = 1 K α k = 1 \sum_{k=1}^{K} \alpha_{k}=1 ∑k=1Kαk=1 条件 下求偏导数并令其为 0 得到的。结果如下:
μ ^ k = ∑ j = 1 N γ ^ j k y j ∑ j = 1 N γ ^ j k , k = 1 , 2 , ⋯ , K σ ^ k 2 = ∑ j = 1 N γ ^ j k ( y j − μ k ) 2 ∑ j = 1 N γ ^ j k , k = 1 , 2 , ⋯ , K α ^ k = n k N = ∑ j = 1 N γ ^ j k N , k = 1 , 2 , ⋯ , K \begin{array}{r} \hat{\mu}_{k}=\frac{\sum_{j=1}^{N} \hat{\gamma}_{j k} y_{j}}{\sum_{j=1}^{N} \hat{\gamma}_{j k}}, \quad k=1,2, \cdots, K \\ \hat{\sigma}_{k}^{2}=\frac{\sum_{j=1}^{N} \hat{\gamma}_{j k}\left(y_{j}-\mu_{k}\right)^{2}}{\sum_{j=1}^{N} \hat{\gamma}_{j k}}, \quad k=1,2, \cdots, K \\ \hat{\alpha}_{k}=\frac{n_{k}}{N}=\frac{\sum_{j=1}^{N} \hat{\gamma}_{j k}}{N}, \quad k=1,2, \cdots, K \end{array} μ^k=∑j=1Nγ^jk∑j=1Nγ^jkyj,k=1,2,⋯,Kσ^k2=∑j=1Nγ^jk∑j=1Nγ^jk(yj−μk)2,k=1,2,⋯,Kα^k=Nnk=N∑j=1Nγ^jk,k=1,2,⋯,K备注:对 σ k 2 \sigma_{k}^{2} σk2求导采用换元法,令 σ k 2 \sigma_{k}^{2} σk2= t t t,最后求得结果
用式 Q ( θ , θ ( i ) ) = ∑ k = 1 K { n k log α k + ∑ j = 1 N γ ^ j k [ log ( 1 2 π ) − log σ k − 1 2 σ k 2 ( y j − μ k ) 2 ] } + λ ( ∑ k = 1 K α k − 1 ) Q\left(\theta, \theta{(i)}\right)=\sum_{k=1}^{K}\left\{n_{k} \log \alpha_{k}+\sum_{j=1}^{N} \hat{\gamma}_{j k}\left[\log \left(\frac{1}{\sqrt{2 \pi}}\right)-\log \sigma_{k}-\frac{1}{2 \sigma_{k}{2}}\left(y_{j}-\mu_{k}\right)^{2}\right]\right\}+ \lambda(\sum_{k=1}^{K}\alpha_k-1) Q(θ,θ(i))=∑k=1K{nklogαk+∑j=1Nγ^jk[log(2π1)−logσk−2σk21(yj−μk)2]}+λ(∑k=1Kαk−1)对 α k \alpha_k αk求偏导,=> n k α k + λ = 0 \frac {n_k}{\alpha_k}+\lambda=0 αknk+λ=0=> α k = − n k λ \alpha_k=-\frac{n_k}{\lambda} αk=−λnk=> ∑ 1 K α k = ∑ 1 K − n k λ = 1 \sum_1^K\alpha_k=\sum_1^K-\frac{n_k}{\lambda}=1 ∑1Kαk=∑1K−λnk=1=> ∑ 1 K n k = − λ \sum_1^Kn_k=-\lambda ∑1Knk=−λ∵ ∑ k = 1 K n k = N \sum_{k=1}^{K} n_{k}=N ∑k=1Knk=N,∴ λ = − N \lambda=-N λ=−N重复以上计算, 直到对数似然函数值不再有明显的变化为止。
(高斯混合模型参数估计的EM算法)
输入: 观测数据
y
1
,
y
2
,
⋯
,
y
N
y_{1}, y_{2}, \cdots, y_{N}
y1,y2,⋯,yN, 高斯混合模型; 输出:高斯混合模型参数。
-
取参数的初始值开始迭代;
-
E \mathrm{E} E 步: 依据当前模型参数, 计算分模型 k k k 对观测数据 y j y_{j} yj 的响应度
γ ^ j k = α k ϕ ( y j ∣ θ k ) ∑ k = 1 K α k ϕ ( y j ∣ θ k ) , j = 1 , 2 , ⋯ , N ; k = 1 , 2 , ⋯ , K \hat{\gamma}_{j k}=\frac{\alpha_{k} \phi\left(y_{j} \mid \theta_{k}\right)}{\sum_{k=1}^{K} \alpha_{k} \phi\left(y_{j} \mid \theta_{k}\right)}, \quad j=1,2, \cdots, N ; \quad k=1,2, \cdots, K γ^jk=∑k=1Kαkϕ(yj∣θk)αkϕ(yj∣θk),j=1,2,⋯,N;k=1,2,⋯,K -
M \mathrm{M} M 步: 计算新一轮迭代的模型参数
μ ^ k = ∑ j = 1 N γ ^ j k y j ∑ j = 1 N γ ^ j k , k = 1 , 2 , ⋯ , K \hat{\mu}_{k}=\frac{\sum_{j=1}^{N} \hat{\gamma}_{j k} y_{j}}{\sum_{j=1}^{N} \hat{\gamma}_{j k}}, \quad k=1,2, \cdots, K μ^k=∑j=1Nγ^jk∑j=1Nγ^jkyj,k=1,2,⋯,Kσ ^ k 2 = ∑ j = 1 N γ ^ j k ( y j − μ k ) 2 ∑ j = 1 N γ ^ j k , k = 1 , 2 , ⋯ , K α ^ k = ∑ j = 1 N γ ^ j k N , k = 1 , 2 , ⋯ , K \begin{array}{r} \hat{\sigma}_{k}^{2}=\frac{\sum_{j=1}^{N} \hat{\gamma}_{j k}\left(y_{j}-\mu_{k}\right)^{2}}{\sum_{j=1}^{N} \hat{\gamma}_{j k}}, \quad k=1,2, \cdots, K \\ \hat{\alpha}_{k}=\frac{\sum_{j=1}^{N} \hat{\gamma}_{j k}}{N}, \quad k=1,2, \cdots, K \end{array} σ^k2=∑j=1Nγ^jk∑j=1Nγ^jk(yj−μk)2,k=1,2,⋯,Kα^k=N∑j=1Nγ^jk,k=1,2,⋯,K
-
重复第 2 2 2步和第 3 3 3步, 直到收敛。
9.4 EM算法的推广
9.4.1 F函数的极大-极大算法
F \boldsymbol{F} F 函数 假设隐变量数据 Z Z Z 的概率分布为 P ~ ( Z ) \tilde{P}(Z) P~(Z), 定义分布 P ~ \tilde{P} P~ 与参 数 θ \theta θ 的函数 F ( P ~ , θ ) F(\tilde{P}, \theta) F(P~,θ) 如下:
F ( P ~ , θ ) = E P ~ [ log P ( Y , Z ∣ θ ) ] + H ( P ~ ) = F ( P ~ , θ ) = ∑ Z [ P ~ ( Z ) log P ( Y , Z ∣ θ ) ] − ∑ Z [ P ~ ( Z ) log P ~ ( Z ) ] F(\tilde{P}, \theta)=E_{\tilde{P}}[\log P(Y, Z \mid \theta)]+H(\tilde{P})=F(\tilde{P}, \theta)=\sum_Z[ \tilde{P}(Z)\log P(Y, Z \mid \theta)]-\sum_Z[ \tilde{P}(Z)\log \tilde{P}(Z)] F(P~,θ)=EP~[logP(Y,Z∣θ)]+H(P~)=F(P~,θ)=Z∑[P~(Z)logP(Y,Z∣θ)]−Z∑[P~(Z)logP~(Z)]
称为 F F F 函数。式中 H ( P ~ ) = − E P ~ log P ~ ( Z ) H(\tilde{P})=-E_{\tilde{P}} \log \tilde{P}(Z) H(P~)=−EP~logP~(Z) 是分布 P ~ ( Z ) \tilde{P}(Z) P~(Z) 的熵。
引理 1 1 1 对于固定的 θ \theta θ, 存在唯一的分布 P ~ θ \tilde{P}_{\theta} P~θ 极大化 F ( P ~ , θ ) F(\tilde{P}, \theta) F(P~,θ), 这时 P ~ θ \tilde{P}_{\theta} P~θ 由下式给出:
P ~ θ ( Z ) = P ( Z ∣ Y , θ ) \tilde{P}_{\theta}(Z)=P(Z \mid Y, \theta) P~θ(Z)=P(Z∣Y,θ)
并且 P ~ θ \tilde{P}_{\theta} P~θ 随 θ \theta θ 连续变化。
证明 \quad 对于固定的 θ \theta θ, 可以求得使 F ( P ~ , θ ) F(\tilde{P}, \theta) F(P~,θ) 达到极大的分布 P ~ θ ( Z ) \tilde{P}_{\theta}(Z) P~θ(Z) 。为此, 引进拉 格朗日乘子 λ \lambda λ, 拉格朗日函数为
L = E P ~ log P ( Y , Z ∣ θ ) − E P ~ log P ~ ( Z ) + λ ( 1 − ∑ Z P ~ ( Z ) ) L=E_{\tilde{P}} \log P(Y, Z \mid \theta)-E_{\tilde{P}} \log \tilde{P}(Z)+\lambda\left(1-\sum_{Z} \tilde{P}(Z)\right) L=EP~logP(Y,Z∣θ)−EP~logP~(Z)+λ(1−Z∑P~(Z))
将其对 P Z ~ \tilde{P_Z} PZ~ 求偏导数:
∂ L ∂ P ~ ( Z ) = log P ( Y , Z ∣ θ ) − log P ~ ( Z ) − 1 − λ \frac{\partial L}{\partial \tilde{P}(Z)}=\log P(Y, Z \mid \theta)-\log \tilde{P}(Z)-1-\lambda ∂P~(Z)∂L=logP(Y,Z∣θ)−logP~(Z)−1−λ
令偏导数等于 0 , 得出
λ = log P ( Y , Z ∣ θ ) − log P ~ θ ( Z ) − 1 \lambda=\log P(Y, Z \mid \theta)-\log \tilde{P}_{\theta}(Z)-1 λ=logP(Y,Z∣θ)−logP~θ(Z)−1
由此推出 P ~ θ ( Z ) \tilde{P}_{\theta}(Z) P~θ(Z) 与 P ( Y , Z ∣ θ ) P(Y, Z \mid \theta) P(Y,Z∣θ) 成比例
P ( Y , Z ∣ θ ) P ~ θ ( Z ) = e 1 + λ \frac{P(Y, Z \mid \theta)}{\tilde{P}_{\theta}(Z)}=\mathrm{e}^{1+\lambda} P~θ(Z)P(Y,Z∣θ)=e1+λ
再从约束条件 ∑ Z P ~ θ ( Z ) = 1 \sum_{Z} \tilde{P}_{\theta}(Z)=1 ∑ZP~θ(Z)=1 ,KaTeX parse error: Expected 'EOF', got '&' at position 50: …e}^{1+\lambda}=&̲gt;P(Y \mid \th…, P ( Z ) = P ( Y , Z ∣ θ ) e 1 + λ = P ( Y , Z ∣ θ ) P ( Y ∣ θ ) = P ( Z ∣ Y , θ ) ⋅ P ( Y ∣ θ ) P ( Y ∣ θ ) = P ( Z ∣ Y , θ ) P(Z)=\frac{P(Y,Z\mid\theta)}{\mathrm{e}^{1+\lambda}}=\frac{P(Y,Z\mid\theta)}{P(Y \mid \theta)}=\frac{P(Z\mid Y,\theta)\cdot P(Y\mid\theta)}{P(Y\mid\theta)}=P(Z\mid Y,\theta) P(Z)=e1+λP(Y,Z∣θ)=P(Y∣θ)P(Y,Z∣θ)=P(Y∣θ)P(Z∣Y,θ)⋅P(Y∣θ)=P(Z∣Y,θ)
引理 2 2 2 若 P ~ θ ( Z ) = P ( Z ∣ Y , θ ) \tilde{P}_{\theta}(Z)=P(Z \mid Y, \theta) P~θ(Z)=P(Z∣Y,θ), 则 F ( P ~ , θ ) = l o g P ( Y ∣ θ ) F(\tilde{P},\theta)=logP(Y\mid\theta) F(P~,θ)=logP(Y∣θ)
F ( P ~ , θ ) = E p ~ [ l o g P ( Z ∣ Y , θ ) ⋅ P ( Y ∣ θ ) ] − E p ~ l o g P ~ ( Z ) = E p ~ [ l o g P ( Z ∣ Y , θ ) + l o g P ( Y ∣ θ ) ] − E p ~ l o g P ~ ( Z ) = E p ~ l o g P ( Z ∣ Y , θ ) + E p ~ l o g P ( Y ∣ θ ) − E p ~ l o g P ~ ( Z ) = E p ~ l o g P ~ ( Z ) + E p ~ l o g P ( Y ∣ θ ) − E p ~ l o g P ~ ( Z ) = E p ~ l o g P ( Y ∣ θ ) = ∑ Z P ( Z ) l o g P ( Y ∣ θ ) = l o g P ( Y ∣ θ ) \begin{aligned} F(\tilde{P},\theta)&=E_{\tilde{p}}[logP(Z|Y,\theta)\cdot P(Y|\theta)]-E_{\tilde{p}}log\tilde P(Z)\\ &=E_{\tilde{p}}[logP(Z|Y,\theta)+ logP(Y|\theta)]-E_{\tilde{p}}log\tilde P(Z)\\ &=E_{\tilde{p}}logP(Z|Y,\theta)+ E_{\tilde{p}}logP(Y|\theta)-E_{\tilde{p}}log\tilde P(Z)\\ &=E_{\tilde{p}}log\tilde P(Z)+ E_{\tilde{p}}logP(Y|\theta)-E_{\tilde{p}}log\tilde P(Z)\\ &=E_{\tilde{p}}logP(Y|\theta)\\ &=\sum_ZP(Z)logP(Y|\theta)\\ &=logP(Y|\theta) \end{aligned} F(P~,θ)=Ep~[logP(Z∣Y,θ)⋅P(Y∣θ)]−Ep~logP~(Z)=Ep~[logP(Z∣Y,θ)+logP(Y∣θ)]−Ep~logP~(Z)=Ep~logP(Z∣Y,θ)+Ep~logP(Y∣θ)−Ep~logP~(Z)=Ep~logP~(Z)+Ep~logP(Y∣θ)−Ep~logP~(Z)=Ep~logP(Y∣θ)=Z∑P(Z)logP(Y∣θ)=logP(Y∣θ)
定理 3设 L ( θ ) = log P ( Y ∣ θ ) L(\theta)=\log P(Y \mid \theta) L(θ)=logP(Y∣θ) 为观测数据的对数似然函数, θ ( i ) , i = 1 , 2 , ⋯ \theta^{(i)}, i=1,2, \cdots θ(i),i=1,2,⋯,为 E M \mathrm{EM} EM 算法得到的参数估计序列, 函数 F ( P ~ , θ ) F(\tilde{P}, \theta) F(P~,θ) 由式 ( 9.33 ) (9.33) (9.33) 定义。如果 F ( P ~ , θ ) F(\tilde{P}, \theta) F(P~,θ) 在 P ~ ∗ \tilde{P}^{*} P~∗ 和 θ ∗ \theta^{*} θ∗ 有局部极大值, 那么 L ( θ ) L(\theta) L(θ) 也在 θ ∗ \theta^{*} θ∗ 有局部极大值。类似地, 如果 F ( P ~ , θ ) F(\tilde{P}, \theta) F(P~,θ) 在 P ~ ∗ \tilde{P}^{*} P~∗和 θ ∗ \theta^{*} θ∗ 达到全局最大值, 那么 L ( θ ) L(\theta) L(θ) 也在 θ ∗ \theta^{*} θ∗ 达到全局最大值。
证明 由引理 1 1 1 和引理 2 2 2 可知, L ( θ ) = log P ( Y ∣ θ ) = F ( P ~ θ , θ ) L(\theta)=\log P(Y \mid \theta)=F\left(\tilde{P}_{\theta}, \theta\right) L(θ)=logP(Y∣θ)=F(P~θ,θ) 对任意 θ \theta θ 成立。
特别地, 对于使 F ( P ~ , θ ) F(\tilde{P}, \theta) F(P~,θ) 达到极大的参数 θ ∗ \theta^{*} θ∗, 有L ( θ ∗ ) = F ( P ~ θ ⋅ , θ ∗ ) = F ( P ~ ∗ , θ ∗ ) L\left(\theta^{*}\right)=F\left(\tilde{P}_{\theta} \cdot, \theta^{*}\right)=F\left(\tilde{P}^{*}, \theta^{*}\right) L(θ∗)=F(P~θ⋅,θ∗)=F(P~∗,θ∗)
为了证明 θ ∗ \theta^{*} θ∗ 是 L ( θ ) L(\theta) L(θ) 的极大点, 需要证明不存在接近 θ ∗ \theta^{*} θ∗ 的点 θ ∗ ∗ \theta^{* *} θ∗∗, 使 L ( θ ∗ ∗ ) > L ( θ ∗ ) L\left(\theta^{* *}\right)>L\left(\theta^{*}\right) L(θ∗∗)>L(θ∗) 。 假如存在这样的点 θ ∗ ∗ \theta^{* *} θ∗∗, 那么应有 F ( P ~ ∗ ∗ , θ ∗ ∗ ) > F ( P ~ ∗ , θ ∗ ) F\left(\tilde{P}^{* *}, \theta^{* *}\right)>F\left(\tilde{P}^{*}, \theta^{*}\right) F(P~∗∗,θ∗∗)>F(P~∗,θ∗), 这里 P ~ ∗ ∗ = P ~ θ ⋯ \tilde{P}^{* *}=\tilde{P}_{\theta} \cdots P~∗∗=P~θ⋯ 但因 P ~ θ \tilde{P}_{\theta} P~θ是随 θ \theta θ 连续变化的, P ~ ∗ ∗ \tilde{P}^{* *} P~∗∗ 应接近 P ~ ∗ \tilde{P}^{*} P~∗, 这与 P ~ ∗ \tilde{P}^{*} P~∗ 和 θ ∗ \theta^{*} θ∗ 是 F ( P ~ , θ ) F(\tilde{P}, \theta) F(P~,θ) 的局部极大点的假设 矛盾。
定理 4 EM 算法的一次迭代可由
F
F
F 函数的极大-极大算法实现. 设
θ
(
i
)
\theta^{(i)}
θ(i) 为第
i
i
i 次迭代参数
θ
\theta
θ 的估计,
P
~
(
i
)
\tilde{P}^{(i)}
P~(i) 为第
i
i
i 次迭代函数
P
~
\tilde{P}
P~ 的估计。在第
i
+
1
i+1
i+1
次迭代的两步为:(1) 对固定的
θ
(
i
)
\theta^{(i)}
θ(i), 求
P
~
(
i
+
1
)
\tilde{P}^{(i+1)}
P~(i+1) 使
F
(
P
~
,
θ
(
i
)
)
F\left(\tilde{P}, \theta^{(i)}\right)
F(P~,θ(i)) 极大化;( 2 ) 对固定的
P
~
(
i
+
1
)
\tilde{P}^{(i+1)}
P~(i+1), 求
θ
(
i
+
1
)
\theta^{(i+1)}
θ(i+1) 使
F
(
P
~
(
i
+
1
)
,
θ
)
F\left(\tilde{P}^{(i+1)}, \theta\right)
F(P~(i+1),θ) 极大化.
证明
(
1
)
\quad(1)
(1) 由引理
1
1
1, 对于固定的
θ
(
i
)
\theta^{(i)}
θ(i),
P ~ ( i + 1 ) ( Z ) = P ~ θ ( i ) ( Z ) = P ( Z ∣ Y , θ ( i ) ) \tilde{P}^{(i+1)}(Z)=\tilde{P}_{\theta^{(i)}}(Z)=P\left(Z \mid Y, \theta^{(i)}\right) P~(i+1)(Z)=P~θ(i)(Z)=P(Z∣Y,θ(i))
使 F ( P ~ , θ ( i ) ) F\left(\tilde{P}, \theta^{(i)}\right) F(P~,θ(i)) 极大化。此时,
F ( P ~ ( i + 1 ) , θ ) = E P ~ ( i + 1 ) [ log P ( Y , Z ∣ θ ) ] + H ( P ~ ( i + 1 ) ) = ∑ Z log P ( Y , Z ∣ θ ) P ( Z ∣ Y , θ ( i ) ) + H ( P ~ ( i + 1 ) ) \begin{aligned} F\left(\tilde{P}^{(i+1)}, \theta\right) &=E_{\tilde{P}^{(i+1)}}[\log P(Y, Z \mid \theta)]+H\left(\tilde{P}^{(i+1)}\right) \\ &=\sum_{Z} \log P(Y, Z \mid \theta) P\left(Z \mid Y, \theta^{(i)}\right)+H\left(\tilde{P}^{(i+1)}\right) \end{aligned} F(P~(i+1),θ)=EP~(i+1)[logP(Y,Z∣θ)]+H(P~(i+1))=Z∑logP(Y,Z∣θ)P(Z∣Y,θ(i))+H(P~(i+1))
由 Q ( θ , θ ( i ) ) Q\left(\theta, \theta^{(i)}\right) Q(θ,θ(i)) 的定义式 Q ( θ , θ ( i ) ) = E Z [ log P ( Y , Z ∣ θ ) ∣ Y , θ ( i ) ] Q\left(\theta, \theta^{(i)}\right)=E_{Z}\left[\log P(Y, Z \mid \theta) \mid Y, \theta^{(i)}\right] Q(θ,θ(i))=EZ[logP(Y,Z∣θ)∣Y,θ(i)] 有
F ( P ~ ( i + 1 ) , θ ) = Q ( θ , θ ( i ) ) + H ( P ~ ( i + 1 ) ) F\left(\tilde{P}^{(i+1)}, \theta\right)=Q\left(\theta, \theta^{(i)}\right)+H\left(\tilde{P}^{(i+1)}\right) F(P~(i+1),θ)=Q(θ,θ(i))+H(P~(i+1))
(2) 固定 P ~ ( i + 1 ) \tilde{P}^{(i+1)} P~(i+1), 求 θ ( i + 1 ) \theta^{(i+1)} θ(i+1) 使 F ( P ~ ( i + 1 ) , θ ) F\left(\tilde{P}^{(i+1)}, \theta\right) F(P~(i+1),θ) 极大化。得到
θ ( i + 1 ) = arg max θ F ( P ~ ( i + 1 ) , θ ) = arg max θ Q ( θ , θ ( i ) ) \theta^{(i+1)}=\arg \max _{\theta} F\left(\tilde{P}^{(i+1)}, \theta\right)=\arg \max _{\theta} Q\left(\theta, \theta^{(i)}\right) θ(i+1)=argθmaxF(P~(i+1),θ)=argθmaxQ(θ,θ(i))
9.4.2 GEM 算法
GEM 算法 1
输入: 观测数据,
F
F
F 函数; 输出:模型参数。
(1) 初始化参数
θ
(
0
)
\theta^{(0)}
θ(0), 开始迭代:
(2) 第
i
+
1
i+1
i+1 次迭代, 第 1 步: 记
θ
(
i
)
\theta^{(i)}
θ(i) 为参数
θ
\theta
θ 的估计值,
P
~
(
i
)
\tilde{P}^{(i)}
P~(i) 为函数
P
~
\tilde{P}
P~ 的估计,
求
P
~
(
i
+
1
)
\tilde{P}^{(i+1)}
P~(i+1) 使
P
~
\tilde{P}
P~ 极大化
F
(
P
~
,
θ
(
i
)
)
;
F\left(\tilde{P}, \theta^{(i)}\right) ;
F(P~,θ(i));
(3)第 2 步: 求
θ
(
i
+
1
)
\theta^{(i+1)}
θ(i+1) 使
F
(
P
~
(
i
+
1
)
,
θ
)
F\left(\tilde{P}^{(i+1)}, \theta\right)
F(P~(i+1),θ) 极大化;
(4) 重复
(2) 和
(
3
)
(3)
(3), 直到收敛。
在 GEM算法 1 中, 有时求
Q
(
θ
,
θ
(
i
)
)
Q\left(\theta, \theta^{(i)}\right)
Q(θ,θ(i)) 的极大化是很困难的。下面介绍的
G
E
M
\mathrm{GEM}
GEM 算
法 2 和 GEM算法 3 并不是直接求
θ
(
i
+
1
)
\theta^{(i+1)}
θ(i+1) 使
Q
(
θ
,
θ
(
i
)
)
Q\left(\theta, \theta^{(i)}\right)
Q(θ,θ(i)) 达到极大的
θ
\theta
θ, 而是找一个
θ
(
i
+
1
)
\theta^{(i+1)}
θ(i+1) 使得
Q
(
θ
(
i
+
1
)
,
θ
(
i
)
)
>
Q
(
θ
(
i
)
,
θ
(
i
)
)
.
Q\left(\theta^{(i+1)}, \theta^{(i)}\right)>Q\left(\theta^{(i)}, \theta^{(i)}\right) .
Q(θ(i+1),θ(i))>Q(θ(i),θ(i)).
GEM 算法 2
输入: 观测数据,
Q
Q
Q 函数; 输出: 模型参数。
(1) 初始化参数
θ
(
0
)
\theta^{(0)}
θ(0), 开始迭代:
(2) 第
i
+
1
i+1
i+1 次迭代, 第 1 步: 记
θ
(
i
)
\theta^{(i)}
θ(i) 为参数
θ
\theta
θ 的估计值, 计算
Q ( θ , θ ( i ) ) = E Z [ log P ( Y , Z ∣ θ ) ∣ Y , θ ( i ) ] = ∑ Z P ( Z ∣ Y , θ ( i ) ) log P ( Y , Z ∣ θ ) \begin{aligned} Q\left(\theta, \theta^{(i)}\right) &=E_{Z}\left[\log P(Y, Z \mid \theta) \mid Y, \theta^{(i)}\right] \\ &=\sum_{Z} P\left(Z \mid Y, \theta^{(i)}\right) \log P(Y, Z \mid \theta) \end{aligned} Q(θ,θ(i))=EZ[logP(Y,Z∣θ)∣Y,θ(i)]=Z∑P(Z∣Y,θ(i))logP(Y,Z∣θ)
(3) 第 2 步: 求 θ ( i + 1 ) \theta^{(i+1)} θ(i+1) 使
Q ( θ ( i + 1 ) , θ ( i ) ) > Q ( θ ( i ) , θ ( i ) ) Q\left(\theta^{(i+1)}, \theta^{(i)}\right)>Q\left(\theta^{(i)}, \theta^{(i)}\right) Q(θ(i+1),θ(i))>Q(θ(i),θ(i))
(2) 和
(
3
)
(3)
(3), 直到收敛。
(4) 重复
当参数
θ
\theta
θ 的维数为
d
(
d
⩾
2
)
d(d \geqslant 2)
d(d⩾2) 时, 可采用一种特殊的 GEM算法, 它将 EM算法的
M 步分解为
d
d
d 次条件极大化, 每次只改变参数向量的一个分量, 其余分量不改变。
GEM 算法 3
输入: 观测数据,
Q
Q
Q 函数;
输出: 模型参数。
(1)初始化参数
θ
(
0
)
=
(
θ
1
(
0
)
,
θ
2
(
0
)
,
⋯
,
θ
d
(
0
)
)
\theta^{(0)}=\left(\theta_{1}^{(0)}, \theta_{2}^{(0)}, \cdots, \theta_{d}^{(0)}\right)
θ(0)=(θ1(0),θ2(0),⋯,θd(0)), 开始迭代;
(2) 第
i
+
1
i+1
i+1 次迭代, 第 1 步: 记
θ
(
i
)
=
(
θ
1
(
i
)
,
θ
2
(
i
)
,
⋯
,
θ
d
(
i
)
)
\theta^{(i)}=\left(\theta_{1}^{(i)}, \theta_{2}^{(i)}, \cdots, \theta_{d}^{(i)}\right)
θ(i)=(θ1(i),θ2(i),⋯,θd(i)) 为参数
θ
=
(
θ
1
,
θ
2
,
⋯
,
θ
d
)
\theta=\left(\theta_{1}, \theta_{2}, \cdots, \theta_{d}\right)
θ=(θ1,θ2,⋯,θd)
的估计值, 计算
Q ( θ , θ ( i ) ) = E Z [ log P ( Y , Z ∣ θ ) ∣ Y , θ ( i ) ] = ∑ Z P ( Z ∣ y , θ ( i ) ) log P ( Y , Z ∣ θ ) \begin{aligned} Q\left(\theta, \theta^{(i)}\right) &=E_{Z}\left[\log P(Y, Z \mid \theta) \mid Y, \theta^{(i)}\right] \\ &=\sum_{Z} P\left(Z \mid y, \theta^{(i)}\right) \log P(Y, Z \mid \theta) \end{aligned} Q(θ,θ(i))=EZ[logP(Y,Z∣θ)∣Y,θ(i)]=Z∑P(Z∣y,θ(i))logP(Y,Z∣θ)
(3) 第 2 步: 进行
d
d
d 次条件极大化:
首先, 在
θ
2
(
i
)
,
⋯
,
θ
d
(
i
)
\theta_{2}^{(i)}, \cdots, \theta_{d}^{(i)}
θ2(i),⋯,θd(i) 保持不变的条件下求使
Q
(
θ
,
θ
(
i
)
)
Q\left(\theta, \theta^{(i)}\right)
Q(θ,θ(i)) 达到极大的
θ
1
(
i
+
1
)
\theta_{1}^{(i+1)}
θ1(i+1);
然后, 在
θ
1
=
θ
1
(
i
+
1
)
,
θ
j
=
θ
j
(
i
)
,
j
=
3
,
4
,
⋯
,
d
\theta_{1}=\theta_{1}^{(i+1)}, \theta_{j}=\theta_{j}^{(i)}, j=3,4, \cdots, d
θ1=θ1(i+1),θj=θj(i),j=3,4,⋯,d 的条件下求使
Q
(
θ
,
θ
(
i
)
)
Q\left(\theta, \theta^{(i)}\right)
Q(θ,θ(i)) 达到极大
的
θ
2
(
i
+
1
)
;
\theta_{2}^{(i+1)} ;
θ2(i+1);
如此继续, 经过
d
d
d 次条件极大化, 得到
θ
(
i
+
1
)
=
(
θ
1
(
i
+
1
)
,
θ
2
(
i
+
1
)
,
⋯
,
θ
d
(
i
+
1
)
)
\theta^{(i+1)}=\left(\theta_{1}^{(i+1)}, \theta_{2}^{(i+1)}, \cdots, \theta_{d}^{(i+1)}\right)
θ(i+1)=(θ1(i+1),θ2(i+1),⋯,θd(i+1)) 使得
Q ( θ ( i + 1 ) , θ ( i ) ) > Q ( θ ( i ) , θ ( i ) ) Q\left(\theta^{(i+1)}, \theta^{(i)}\right)>Q\left(\theta^{(i)}, \theta^{(i)}\right) Q(θ(i+1),θ(i))>Q(θ(i),θ(i))
(4)重复
(2) 和 ( 3 ), 直到收敛。


















 783
783

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











