







 本文提出了一种名为高分辨率网络(HRNet)的新架构,用于人体姿态估计,旨在保持高分辨率表示并提高关键点定位的准确性。与传统方法不同,HRNet并行连接从高分辨率到低分辨率的子网络,通过多尺度融合实现信息交换,从而生成更精确的空间热图。在COCO、MPII和PoseTrack数据集上的实验验证了HRNet的有效性。
本文提出了一种名为高分辨率网络(HRNet)的新架构,用于人体姿态估计,旨在保持高分辨率表示并提高关键点定位的准确性。与传统方法不同,HRNet并行连接从高分辨率到低分辨率的子网络,通过多尺度融合实现信息交换,从而生成更精确的空间热图。在COCO、MPII和PoseTrack数据集上的实验验证了HRNet的有效性。
用于人体姿势估计的深度高分辨率表示学习
paper题目:Deep High-Resolution Representation Learning for Human Pose Estimation
paper是中国科学技术大学发表在CVPR 2019的工作
Abstract
在本文中,我们对人体姿势估计问题感兴趣,重点是学习可靠的高分辨率表示。大多数现有方法从高分辨率到低分辨率网络产生的低分辨率表示中恢复高分辨率表示。相反,我们提出的网络在整个过程中保持高分辨率表示。
我们从高分辨率子网络作为第一阶段开始,逐步添加从高分辨率到低分辨率的子网络以形成更多阶段,并将多分辨率子网络并行连接。我们进行重复的多尺度融合,使得每个从高到低分辨率的表示一遍又一遍地接收来自其他并行表示的信息,从而产生丰富的高分辨率表示。因此,预测的关键点热图可能更准确且空间更精确。我们通过两个基准数据集(COCO 关键点检测数据集和 MPII 人体姿势数据集)的优异姿势估计结果,凭经验证明了我们网络的有效性。此外,我们还展示了我们的网络在 PoseTrack 数据集上的姿势跟踪方面的优越性。代码和模型已在 https://github.com/leoxiaobin/deep-high-resolution-net.pytorch 上公开提供。
1. Introduction
二维人体姿态估计一直是计算机视觉中的一个基本但具有挑战性的问题。目标是定位人体解剖关键点(例如肘部、手腕等)或部位。它有很多应用,包括人体动作识别、人机交互、动画等。本文对单人姿态估计感兴趣,这是其他相关问题的基础,例如多人姿态估计[6,26,32 , 38, 46, 55, 40, 45, 17, 69],视频姿态估计和跟踪[48, 70]等。
最近的发展表明深度卷积神经网络已经实现了最先进的性能。大多数现有方法通过网络传递输入,通常由串联连接的从高分辨率到低分辨率的子网络组成,然后提高分辨率。例如,Hourglass [39]通过对称的从低到高的过程恢复高分辨率。 SimpleBaseline [70] 采用一些转置卷积层来生成高分辨率表示。此外,扩张卷积还用于放大从高到低分辨率网络的后面层(例如 VGGNet 或 ResNet)[26, 74]。
我们提出了一种新颖的架构,即高分辨率网络(HRNet),它能够在整个过程中保持高分辨率表示。我们从高分辨率子网作为第一阶段开始,逐步添加从高分辨率到低分辨率的子网以形成更多阶段,并将多分辨率子网并行连接。我们通过在整个过程中一遍又一遍地在并行多分辨率子网络之间交换信息来进行重复的多尺度融合。我们估计网络输出的高分辨率表示的关键点。生成的网络如图 1 所示。
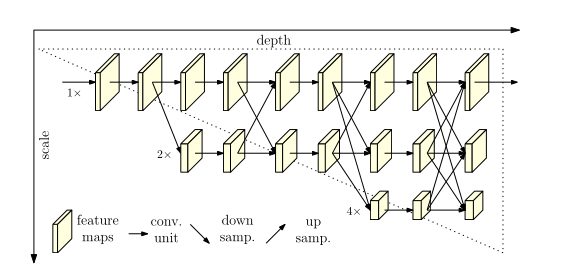
图 1. 说明了所提出的 HRNet 的架构。它由并行的高到低分辨率子网络组成,并在多分辨率子网络之间重复信息交换(多尺度融合)。水平和垂直方向分别对应于网络的深度和特征图的比例。
与现有广泛使用的姿势估计网络[39,26,74,70]相比,我们的网络有两个好处。 (i) 我们的方法并行连接高分辨率到低分辨率的子网,而不是像大多数现有解决方案那样串联连接。因此,我们的方法能够保持高分辨率,而不是通过从低到高的过程恢复分辨率,因此预测的热图在空间上可能更精确。 (ii) 大多数现有的融合方案聚合了低层和高层表示。相反,我们执行重复的多尺度融合,以借助相同深度和相似级别的低分辨率表示来增强高分辨率表示,反之亦然,从而导致高分辨率表示对于姿态估计也很丰富。因此,我们预测的热图可能更准确。
我们凭经验证明了优于两个基准数据集的关键点检测性能:COCO 关键点检测数据集 [35] 和 MPII 人体姿势数据集 [2]。此外,我们在 PoseTrack 数据集 [1] 上展示了我们的网络在视频姿势跟踪方面的优越性。
2. Related Work
大多数传统的单人姿态估计解决方案采用概率图模型或图像结构模型[76, 49],最近通过利用深度学习来改进,以更好地建模一元和成对能量[9, 63, 44]或者模仿推理过程中的迭代[13]。如今,深度卷积神经网络提供了主导解决方案[20,34,60,41,42,47,56,16]。有两种主流方法:回归关键点的位置[64,7],估计关键点热图[13,14,75],然后选择热值最高的位置作为关键点。
大多数用于关键点热图估计的卷积神经网络由类似于分类网络的主干子网络组成,它会降低分辨率,主体产生与其输入相同分辨率的表示,然后是估计关键点位置的热图的回归器。估计然后转换为全分辨率。主体主要采用从高到低、从低到高的框架,可能会增加多尺度融合和中(深)监督。
从高到低和从低到高。从高到低的过程旨在生成低分辨率和高级表示,而从低到高的过程旨在生成高分辨率表示[4,11,22,70,39,60]。这两个过程都可能重复多次以提高性能[74,39,14]。
代表性的网络设计模式包括: (i) 对称的从高到低和从低到高的过程。 Hourglass 及其后续[39,14,74,30]将从低到高的过程设计为从高到低的过程的镜像。 (ii) 从高到低重,从低到高轻。从高到低的过程是基于ImageNet分类网络,例如[11, 70]中采用的ResNet,而从低到高的过程只是一些双线性上采样[11]或转置卷积[70]层。 (iii) 与扩张卷积的组合。在[26,50,34]中,ResNet或VGGNet的最后两个阶段采用扩张卷积来消除空间分辨率损失,随后进行轻量级从低到高的处理以进一步提高分辨率,避免昂贵的计算成本仅使用扩张卷积[11,26,50]。图 2 描述了四个代表性的姿态估计网络。
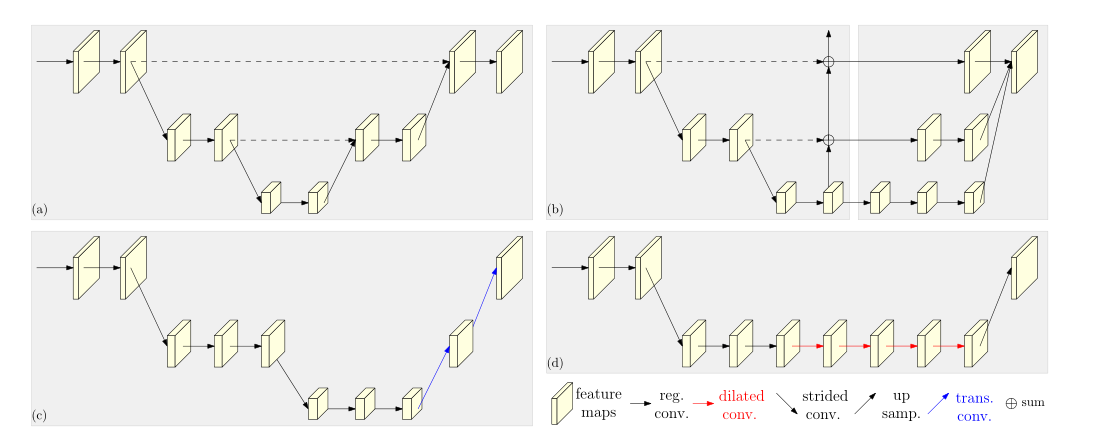
图 2.依赖于从高到低和从低到高框架的代表性姿态估计网络的图示。 (a)沙漏[39]。(b) 级联金字塔网络[11]。 © SimpleBaseline [70]:用于从低到高处理的转置卷积。 (d) 与扩张卷积的组合[26]。右下图例:reg。 = 常规卷积,扩张 = 扩张卷积,反式。 = 转置卷积、跨步 = 跨步卷积、连接。 =串联。在(a)中,从高到低和从低到高的过程是对称的。在(b)、©和(d)中,作为分类网络(ResNet或VGGNet)的一部分的从高到低的过程是重的,而从低到高的过程是轻的。在(a)和(b)中,高到低和低到高过程的相同分辨率层之间的跳跃连接(虚线)主要旨在融合低级和高级特征。在(b)中,右侧部分finenet结合了通过卷积处理的低级和高级特征。
多尺度融合。最直接的方法是将多分辨率图像分别输入多个网络并聚合输出响应图[62]。 Hourglass [39] 及其扩展 [74, 30] 通过跳跃连接逐步将从高到低过程中的低级特征组合成从低到高过程中的相同分辨率的高级特征。在级联金字塔网络[11]中,globalnet将从高到低的过程中从低到高的级别特征逐步组合到从低到高的过程中,然后细化网络将处理后的从低到高的级别特征组合起来通过卷积。我们的方法重复多尺度融合,部分受到深度融合及其扩展的启发[65,71,57,77,79]。
中级监督。早期为图像分类而开发的中间监督或深度监督[33, 59]也被用来帮助深度网络训练和提高热图估计质量,例如[67, 39, 62, 3, 11]。沙漏方法[39]和卷积姿态机方法[67]将中间热图处理为剩余子网络的输入或输入的一部分。
我们的方法。我们的网络并行连接从高到低的子网络。它在整个过程中保持高分辨率表示,以实现空间精确的热图估计。它通过重复融合从高到低的子网络产生的表示来生成可靠的高分辨率表示。我们的方法与大多数现有作品不同,后者需要单独的从低到高的上采样过程并聚合低级和高级表示。我们的方法在不使用中间热图监督的情况下,在关键点检测精度方面具有优越性,并且在计算复杂性和参数方面具有高效性。
有相关的多尺度网络用于分类和分割[5,8,72,78,29,73,53,54,23,80,53,51,18]。我们的工作部分受到其中一些[54,23,80,53]的启发,并且存在明显的差异,使得它们不适用于我们的问题。由于每个子网络(深度、批量归一化)和多尺度融合缺乏适当的设计,卷积神经结构[54]和互连的CNN[80]无法产生高质量的分割结果。网格网络[18]是许多权重共享的U-Net的组合,由两个跨多分辨率表示的独立融合过程组成:在第一阶段,信息仅从高分辨率发送到低分辨率;在第二阶段,信息仅从高分辨率发送到低分辨率;在第二阶段,信息仅从高分辨率发送到低分辨率。在第二阶段,信息仅从低分辨率发送到高分辨率,因此竞争性较差。多尺度密集网络[23]没有目标,也无法生成可靠的高分辨率表示。
3. Approach
人体姿态估计,又名关键点检测,旨在从尺寸为 W × H × 3 W \times H \times 3 W×H×3的图像 I \mathbf{I} I中检测 K K K个关键点或部位(例如肘部、手腕等)的位置。最先进的方法将这个问题转化为估计 K K K个大小为 W ′ × H ′ , { H 1 , H 2 , … , H K } W^{\prime} \times H^{\prime},\left\{\mathbf{H}_1, \mathbf{H}_2, \ldots, \mathbf{H}_K\right\} W′×H′,{ H1,H
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1491
1491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











