







论文名称: Deep High-Resolution Representation Learning for Human Pose Estimation
论文下载地址:https://arxiv.org/abs/1902.09212
 https://github.com/leoxiaobin/deep-high-resolution-net.pytorch
https://github.com/leoxiaobin/deep-high-resolution-net.pytorch在bilibili上的视频讲解:HRNet网络详解_哔哩哔哩_bilibili
这篇文章是由中国科学技术大学和亚洲微软研究院在2019年共同发表的。这篇文章中的HRNet(High-Resolution Net)是针对2D人体姿态估计(Human Pose Estimation或Keypoint Detection)任务提出的,并且该网络主要是针对单一个体的姿态评估(即输入网络的图像中应该只有一个人体目标)。人体姿态估计在现今的应用场景也比较多,比如说人体行为动作识别,人机交互(比如人作出某种动作可以触发系统执行某些任务),动画制作(比如根据人体的关键点信息生成对应卡通人物的动作)等等。
对于Human Pose Estimation任务,现在基于深度学习的方法主要有两种:
1.基于regressing的方式,即直接预测每个关键点的位置坐标。
2.基于heatmap的方式,即针对每个关键点预测一张热力图(预测出现在每个位置上的分数)。
当前检测效果最好的一些方法基本都是基于heatmap的,所以HRNet也是采用基于heatmap的方式。
1 HRNet网络结构
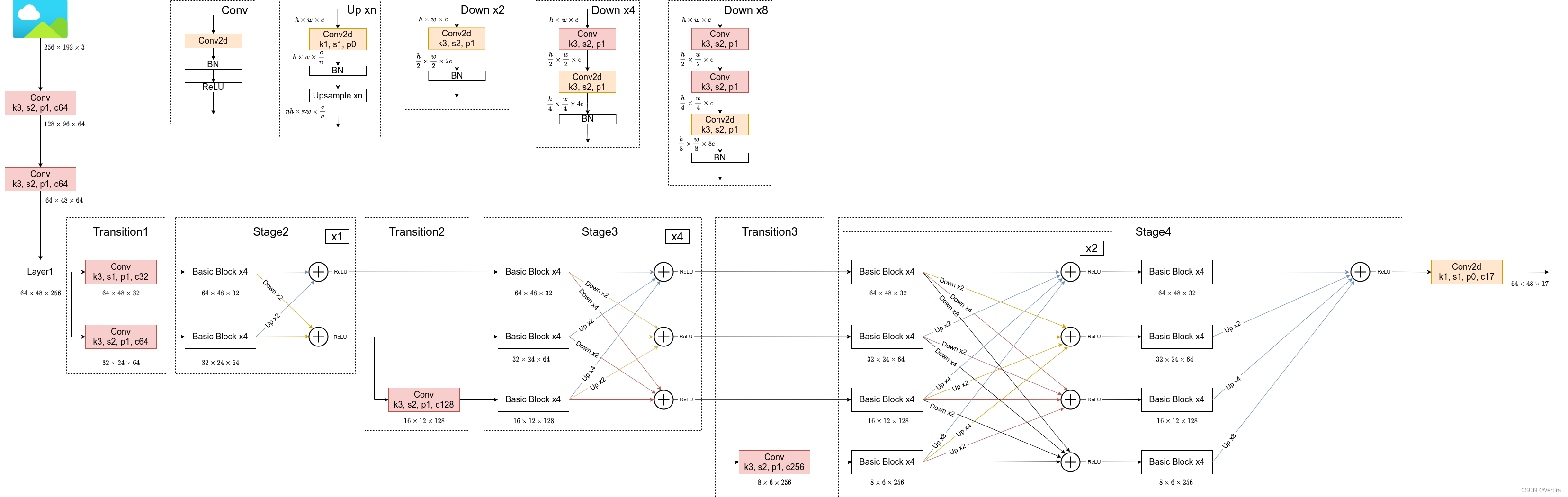
根据阅读项目源码绘制的关于HRNet-W32的模型结构简图,在论文中除了提出HRNet-W32外还有一个HRNet-W48的版本,两者区别仅仅在每个模块所采用的通道个数不同,网络的整体结构都是一样的。而该论文的核心思想就是不断地去融合不同尺度上的信息,也就是论文中所说的Exchange Blocks。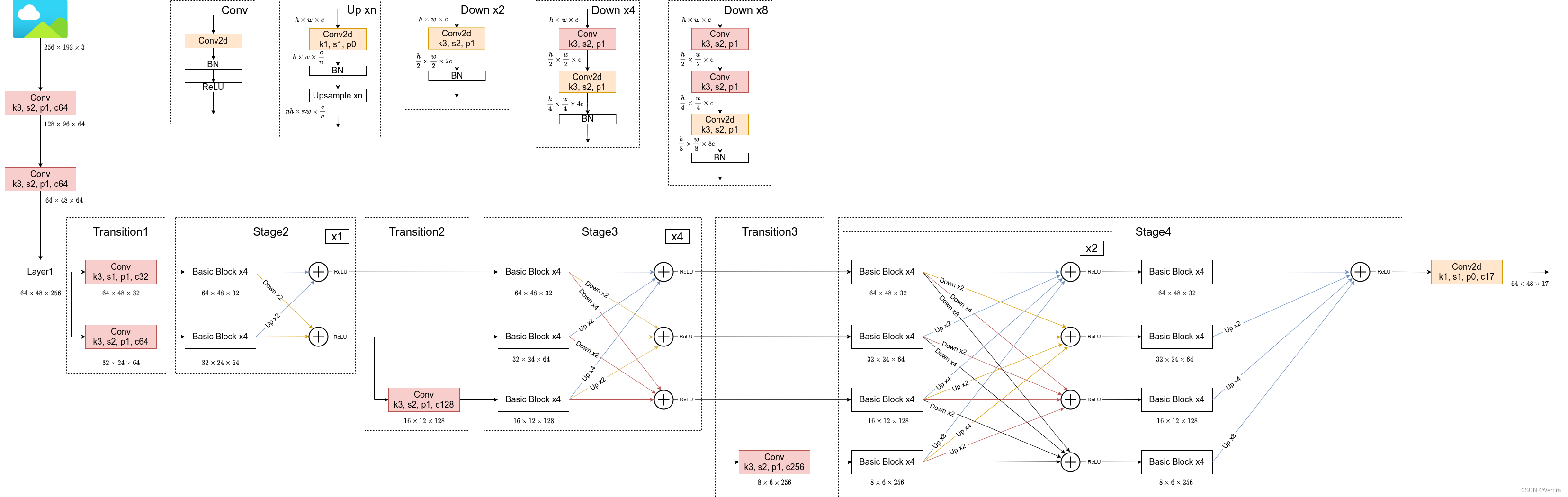
通过上图可以看出,HRNet首先通过两个卷积核大小为3x3步距为2的卷积层(后面都跟有BN以及ReLU)共下采样了4倍。然后通过Layer1模块,这里的Layer1其实和之前讲的ResNet中的Layer1类似,就是重复堆叠Bottleneck,注意这里的Layer1只会调整通道个数,并不会改变特征层大小。下面是实现Layer1时所使用的代码。
# Stage1
downsample = nn.Sequential(
nn.Conv2d(64, 256, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(256, momentum=BN_MOMENTUM)
)
self.layer1 = nn.Sequential(
Bottleneck(64, 64, downsample=downsample),
Bottleneck(256, 64),
Bottleneck(256, 64),
Bottleneck(256, 64)
)
接着通过一系列Transition结构以及Stage结构,每通过一个Transition结构都会新增一个尺度分支。比如说Transition1,它在layer1的输出基础上通过并行两个卷积核大小为3x3的卷积层得到两个不同的尺度分支,即下采样4倍的尺度以及下采样8倍的尺度。在Transition2中在原来的两个尺度分支基础上再新加一个下采样16倍的尺度,注意这里是直接在下采样8倍的尺度基础上通过一个卷积核大小为3x3步距为2的卷积层得到下采样16倍的尺度。如果有阅读过原论文的小伙伴肯定会有些疑惑,因为在论文的图1中,给出的Transition2应该是通过融合不同尺度的特征层得到的(下图用红色矩形框框出的部分)。但根据源码的实现过程确实就和我上面图中画的一样,就一个3x3的卷积层没做不同尺度的融合,包括我看其他代码仓库实现的HRNet都是如此。大家也可以自己看看源码对比一下。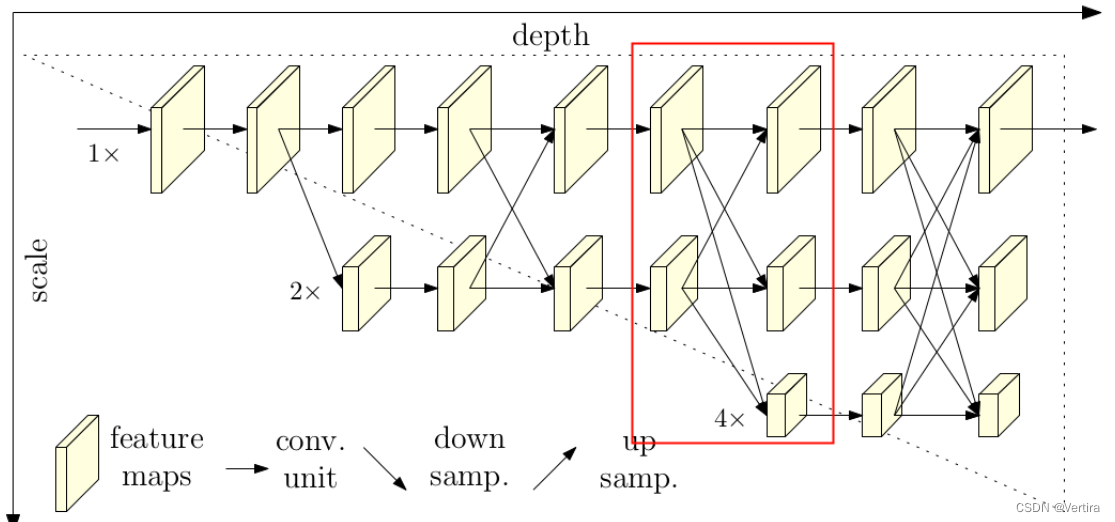
简单介绍完Transition结构后,在来说说网络中最重要的Stage结构。为了方便大家理解,这里以Stage3为例,对于每个尺度分支,首先通过4个Basic Block,没错就是ResNet里的Basic Block,然后融合不同尺度上的信息。对于每个尺度分支上的输出都是由所有分支上的输出进行融合得到的。比如说对于下采样4倍分支的输出,它是分别将下采样4倍分支的输出(不做任何处理) 、 下采样8倍分支的输出通过Up x2上采样2倍 以及下采样16倍分支的输出通过Up x4上采样4倍进行相加最后通过ReLU得到下采样4倍分支的融合输出。其他分支也是类似的,下图画的已经非常清楚了。图中右上角的x4表示该模块(Basic Block和Exchange Block)要重复堆叠4次。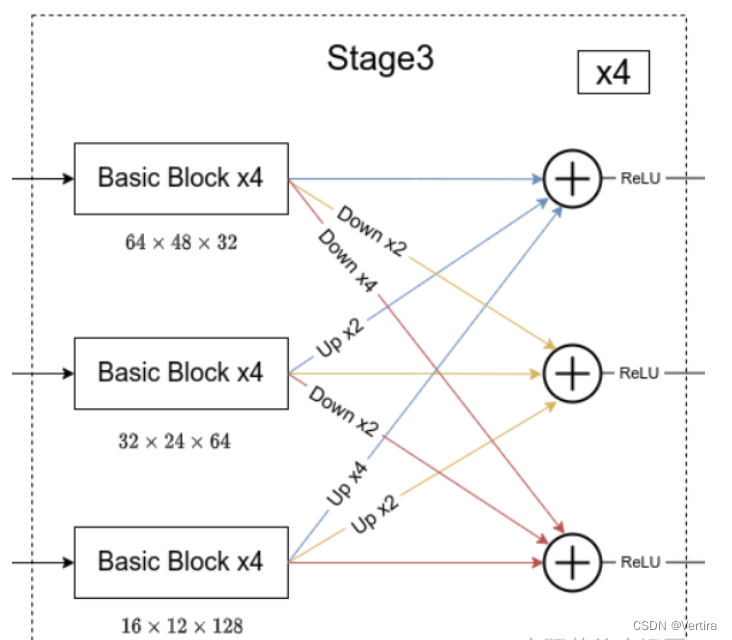
接着再来聊聊图中的Up和Down究竟是怎么实现的,对于所有的Up模块就是通过一个卷积核大小为1x1的卷积层然后BN层最后通过Upsample直接放大n倍得到上采样后的结果(这里的上采样默认采用的是nearest最邻近插值)。Down模块相比于Up稍微麻烦点,每下采样2倍都要增加一个卷积核大小为3x3步距为2的卷积层(注意下图中Conv和Conv2d的区别,Conv2d就是普通的卷积层,而Conv包含了卷积、BN以及ReLU激活函数)。
最后,需要注意的是在Stage4中的最后一个Exchange Block只输出下采样4倍分支的输出(即只保留分辨率最高的特征层),然后接上一个卷积核大小为1x1卷积核个数为17(因为COCO数据集中对每个人标注了17个关键点)的卷积层。最终得到的特征层(64x48x17)就是针对每个关键点的heatmap(热力图)。
2 预测结果(heatmap)的可视化
关于预测得到的heatmap(热力图)听起来挺抽象的,为了方便大家理解,我画了下面这幅图。首先,左边是输入网络的预测图片,大小为256x192,为了保证原图像比例,在两侧进行了padding。右侧是我从预测结果,也就是heatmap(64x48x17)中提取出的部分关键点对应的预测信息(48x17x1)。上面有提到过,网络最终输出的heatmap分辨率是原图的1/4,所以高宽分别对应的是64和48,接着对每个关键点对应的预测信息求最大值的位置,即预测score最大的位置,作为预测关键点的位置,映射回原图就能得到原图上关键点的坐标(下图有画出每个预测关键点对应原图的位置)。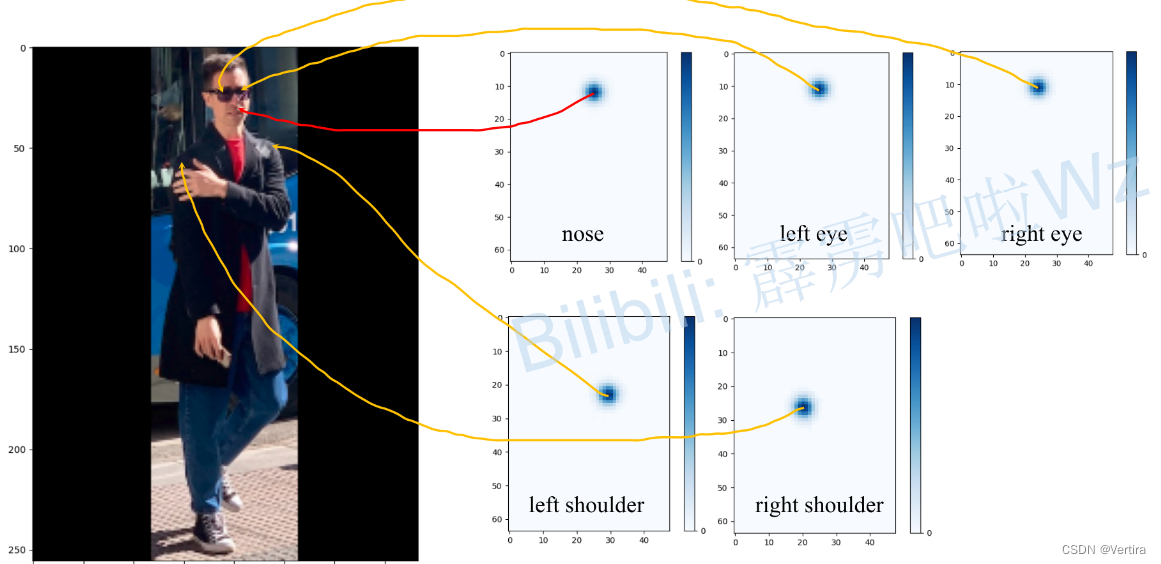
参考:
















 355
355











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









