









RELORA:通过低秩更新进行高秩训练
paper是马萨诸塞大学洛厄尔分校发表在ICLR 2024的工作
paper title:RELORA: HIGH-RANK TRAINING THROUGH LOW-RANK UPDATES
Code:地址
ABSTRACT
尽管扩展具有主导地位和有效性,从而产生了具有数千亿个参数的大型网络,但训练过度参数化模型的必要性仍然不太为人所知,而训练成本却呈指数级增长。在本文中,我们探索了参数高效的训练技术作为训练大型神经网络的方法。我们介绍了一种名为 ReLoRA 的新方法,该方法利用低秩更新来训练高秩网络。我们将 ReLoRA 应用于训练具有多达 13 亿个参数的 Transformer 语言模型,并表现出与常规神经网络训练相当的性能。ReLoRA 为每个 GPU 节省高达 5.5GB 的 RAM,并将训练速度提高 9-40%,具体取决于模型大小和硬件设置。我们的研究结果表明,参数高效的技术在大规模预训练中具有潜力。
1 INTRODUCTION
在过去十年中,机器学习领域一直被训练过度参数化的网络或采用“堆叠更多层”方法的趋势所主导(Krizhevsky 等人,2012 年;He 等人,2016 年;Kaplan 等人,2020 年)。大型网络的定义已经从具有 1 亿个参数的模型(Simonyan 和 Zisserman,2015 年;Radford 等人,2018 年)发展到数千亿个参数的模型(Brown 等人,2020 年;Chowdhery 等人,2022 年),这使得与训练此类网络相关的计算成本对于大多数研究小组来说难以承受。尽管如此,从理论上讲,人们对训练模型的必要性还知之甚少,因为这些模型的参数可能比训练示例多几个数量级 (Brown 等人,2020 年;Chowdhery 等人,2022 年;Fedus 等人,2022 年) (Jacot 等人,2018 年;Allen-Zhu 等人,2019 年;Zhang 等人,2021 年)。 扩展的替代方法,例如计算效率更高的扩展优化 (Hoffmann 等人,2022 年)、检索增强模型 (Khandelwal 等人,2020 年;Borgeaud 等人,2022 年),以及更长时间训练较小模型的简单方法 (Touvron 等人,2023 年),提供了新的权衡。 然而,它们并没有让我们更接近理解为什么我们需要过度参数化的模型,也很少使这些模型的训练民主化。例如,训练 RETRO (Borgeaud 等人,2022) 需要复杂的训练设置和基础设施,能够快速搜索数万亿个 token,而训练 LLaMA-7B (Touvron 等人,2023) 仍然需要数百个 GPU。 相比之下,零冗余优化器 (Rajbhandari 等人,2020)、16 位训练 (Micikevicius 等人,2018)、8 位推理 (Dettmers 等人,2022) 和参数高效微调 (PEFT) (Lialin 等人,2023) 等方法在使大型模型更易于访问方面发挥了关键作用。 具体来说,PEFT 方法已经能够在消费硬件上对十亿级语言或扩散模型进行微调。这就提出了一个问题:这些方法是否也能使预训练受益?
我们的贡献 在本研究中,我们引入了 ReLoRA,它使用在训练过程中聚合的单独低秩更新来训练高秩网络。我们通过经验证明 ReLoRA 执行高秩更新并实现与常规神经网络训练类似的性能。ReLoRA 的组成部分包括神经网络的初始全秩训练(类似于 Frankle 等人 (2019))、LoRA 训练、重启、锯齿状学习率计划和部分优化器重置。我们在多达 13 亿个参数的 Transformer 语言模型上评估了 ReLoRA。最后,我们观察到 ReLoRA 的效率随着模型大小的增加而增加,使其成为高效训练数十亿参数网络的可行选择。
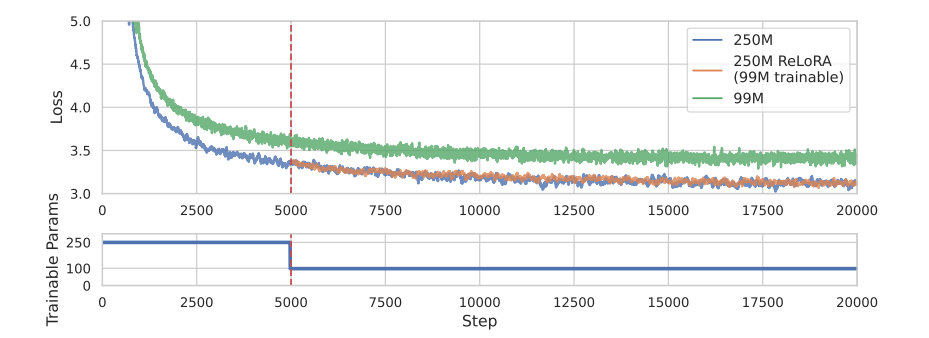
图 1:2.5 亿个模型的训练损失。ReLoRA 通过一系列低秩更新来学习高秩网络。它的表现优于具有相同可训练参数数量的网络,并且达到了与训练 1 亿以上规模的完整网络类似的性能。ReLoRA 的效率随着模型规模的增加而提高,使其成为数十亿参数训练的可行候选者。
2 METHOD
我们对两个矩阵之和的秩感兴趣: rank ( A + B ) ≤ rank ( A ) + rank ( B ) \operatorname{rank}(A+B) \leq \operatorname{rank}(A)+\operatorname{rank}(B) rank(A+B)≤rank(A)+rank(B)。我们知道,对于一个矩阵 A \mathbf{A} A,如果 rank ( A ) < dim ( A ) \operatorname{rank}(\mathbf{A})<\operatorname{dim}(\mathbf{A}) rank(A)<dim(A),则存在一个矩阵 B \mathbf{B} B,满足 rank ( B ) < dim ( B ) \operatorname{rank}(\mathbf{B})<\operatorname{dim}(\mathbf{B}) rank(B)<dim(B),使得它们的和的秩高于 A \mathbf{A} A 或 B \mathbf{B} B 中任意一个矩阵。
我们希望利用这一性质来设计一种灵活且高效的参数微调方法。我们从 LoRA (Hu et al., 2022) 开始,这是一个基于低秩更新思想的参数高效微调方法。LoRA 可应用于任何通过 W ∈ R m × n W \in \mathbb{R}^{m \times n} W∈Rm×n 参数化的线性操作。具体来说,LoRA 将权重更新 δ W \delta W δW 分解为一个秩为 r r r 的乘积 W A W B W_A W_B WAWB,如下式所示,其中 s ∈ R s \in \mathbb{R} s∈R 是一个固定的缩放因子,通常等于 1 r \frac{1}{r} r1:
δ W = s W A W B W A ∈ R in × r , W B ∈ R r × out \begin{aligned} & \delta W=s W_A W_B \\ & W_A \in \mathbb{R}^{\text {in } \times r}, W_B \in \mathbb{R}^{r \times \text {out }} \end{aligned} δW=sWAWBWA∈Rin ×r,WB∈Rr×out
在实践中,LoRA 通常通过添加新的可训练参数 W A W_A WA 和 W B W_B WB 实现,这些参数在训练后可以合并回原始参数中。因此,这些实现受到秩限制 r = max W A , W B rank ( W A W B ) r=\max _{W_A, W_B} \operatorname{rank}\left(W_A W_B\right) r=maxWA,WBrank(WAWB)。
如果我们可以重新启动 LoRA(意为在训练过程中合并 W A W_A WA 和 W B W_B WB 的值,并重置这些矩阵的值),就可以增加更新的总秩。通过多次执行这一操作,可以将神经网络的总更新表示为:
Δ W = ∑ t = 0 T 1 δ W t + ∑ t = T 1 T 2 δ W t + ⋯ + ∑ t = T N − 1 T N δ W t = s W A 1 W B 1 + s W A 2 W B 2 + ⋯ + s W A N W B N \Delta W=\sum_{t=0}^{T_1} \delta W_t+\sum_{t=T_1}^{T_2} \delta W_t+\cdots+\sum_{t=T_{N-1}}^{T_N} \delta W_t=s W_A^1 W_B^1+s W_A^2 W_B^2+\cdots+s W_A^N W_B^N ΔW=t=0∑T1δWt+t=T1∑T2δWt+⋯+t=TN−1∑TNδWt=sWA1WB1+sWA2WB2+⋯+sWANWBN
然而,在实践中实现重新启动并不简单,需要对优化过程进行多处修改。与普通的随机梯度下降(SGD)不同,Adam (Kingma and Ba, 2015) 的更新主要由梯度的一阶和二阶矩引导,这些梯度是在前几步中累积的。在实践中,Adam 的 β 1 \beta_1 β1 和 β 2 \beta_2 β2 通常非常高( 0.9 − 0.999 0.9-0.999 0.9−0.999)。这意味着,在执行“合并并重新初始化”之后,如果继续使用旧的梯度矩来更新 W A 2 W_A^2 WA2,将会引导它沿着与 W A 1 W_A^1 WA1 相同的方向优化,从而仍然聚焦于相同的子空间。
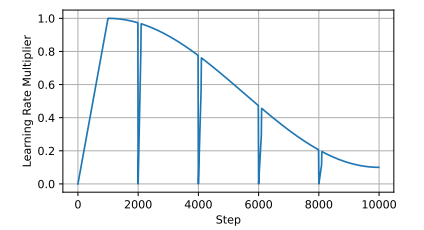
图 2:ReLoRA 中使用的锯齿状余弦调度程序。作为我们的调度程序的基础,我们遵循 Touvron 等人 (2023) 中的标准余弦衰减时间表。每次重置优化器时,我们将学习率设置为零,并快速(50-100 步)将学习率预热回余弦时间表。
为了解决这个问题,ReLoRA 在合并和重新初始化期间通过幅值修剪对优化器状态进行部分重置。为了避免优化器重置后损失发散,它还将学习率设置为 0,随后进行预热(图 2)。我们的消融研究(表 6)表明,这两项修改都是提高 LoRA 性能所必需的。最后,在我们的实验中,我们发现在从头开始训练(随机初始化)的情况下,需要进行短暂的全秩训练来“热启动”ReLoRA。所有这些使 ReLoRA 能够通过一次仅训练一小组参数来实现与全秩训练相当的性能,尤其是在大型变压器网络中。ReLoRA 在算法 1 中描述。
提高计算效率 与其他低秩训练技术(Schotthöfer 等人,2022 年;Sui 等人,2023 年;Kamalakara 等人,2022 年)不同,ReLoRA 遵循 LoRA 方法,保持原始网络的冻结权重并添加新的可训练参数。乍一看,这似乎计算效率低下;然而,冻结参数和可训练参数之间的区分在参数高效微调中起着至关重要的作用(Lialin 等人,2023 年)。 通过减少可训练参数的数量,ReLoRA 显着减少了优化器状态所花费的内存,并能够利用更大的批量大小,从而最大限度地提高硬件效率。 此外,它还降低了分布式设置中的带宽要求,这通常是大规模训练的限制因素。此外,由于冻结参数在重启之间不会更新,因此可以将它们保存为低精度量化格式(Dettmers 等人,2023 年),从而进一步减少它们对内存和计算的影响。
局部低秩训练:直觉 多项研究表明,神经网络训练要么完全低秩,要么具有多个阶段,最初是高秩,随后是低秩训练。例如,Aghajanyan 等人(2021 年)表明,随着模型变大或预训练时间延长,学习下游任务所需的更新的秩会降低。Arora 等人(2019 年)发现 SGD 偏向低秩解决方案。训练早期的彩票存在(Frankle 等人,2019 年)也部分支持了这一假设,因为训练彩票网络可以有效地看作是常规训练过程的低秩近似。 我们的实证分析(第 4 节)表明,预训练的神经网络在长轨迹上表现出高秩更新(图 4)。然而,对于足够小的轨迹,可以通过低秩更新有效地近似训练,这与 Boix-Adsera 等人 (2023) 的发现一致。鉴于上述结果,我们推测神经网络训练是局部低秩的,这直接激发了 ReLoRA。



















 1638
1638

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











