






R语言随机森林全流程分析
引言
再2023年6月,如果你以Random Forest为关键词在Google Scholar检索,时间降序。

你会发现这些方法用于各个领域的研究:GIS、环境、遥感(只要有大数据)
发表的期刊水平也参差不齐,有Frontiers、Remote Sensing(MDPI)、总环。
除了很少有顶尖期刊,但也不乏还不错的期刊,从一区到四区。为何这个方法一直在使用?这就引出了随机森林的几个优点。
随机森林是集成学习(Ensemble Learning),集成学习的基本思想就是将多个分类器组合,从而实现一个预测效果更好的集成分类器。
随机森林既可以胜任分类任务又可以胜任回归任务。机器学习中有两种任务,回归和分类,而随机森林可以同时胜任这两种任务。其中分类任务是对离散值进行预测(比如将一景图像中的植被,建筑,水体等地物类型分类);回归任务是对连续值进行预测(比如根据已有的数据预测明天的气温是多少度,预测明天某基金的价格)。
随机森林能评估特征的相对重要性。集成学习模型的一大特点是可以输出特征重要性,特征重要性能够在一定程度上辅助我们对特征进行筛选,从而使得模型的鲁棒性更好。在实际研究中,也能提供一定的物理意义。
代码实现
借助于R语言的高效数据分析,我们使用R的randomForest包实现这一效果
数据集载入
首先加载数据集:
library(tidyverse)
data(airquality)
airquality <- airquality %>% na.omit()
airquality
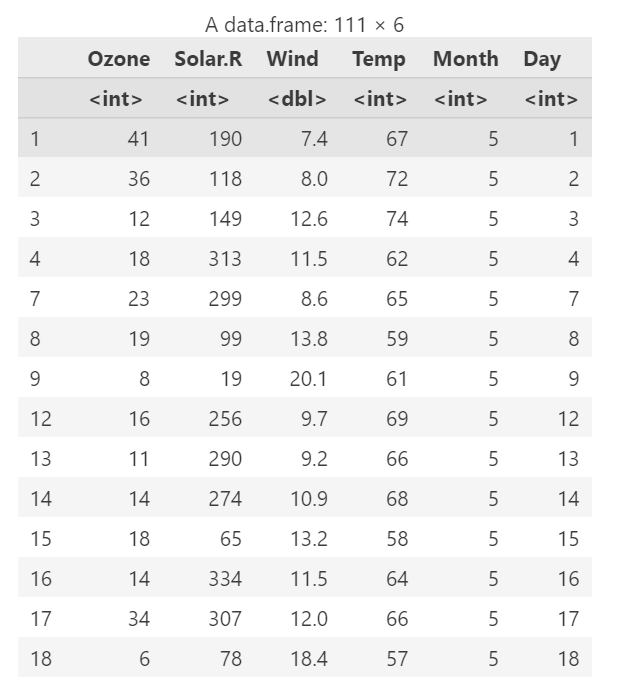
在airquality数据集中,Ozone是臭氧变量,其它太阳辐射Solar.R、风速Wind和温度Temp等等对臭氧的影响。
数据训练
这里首先把数据集划分训练集(70%)和测试集(30%)
使用randomForest开始训练,其中Ozone~代表臭氧Ozone为因变量,其它数据为自变量。
# To evaluate the performance of RF
# split traning data (70%) and validation data (30%)
set.seed(123)
train <- sample(nrow(airquality), nrow(airquality)*0.7)
ozo_train <- airquality[train, ]
ozo_test <- airquality[-train, ]
# randomForest
library(randomForest)
# Random forest calculation(default 500 tress),please see ?randomForest
set.seed(123)
ozo_train.forest <- randomForest(Ozone~., data = ozo_train, importance = TRUE)
ozo_train.forest
结果如图:

-
结果中,
% Var explained体现了预测变量(太阳辐射,温度,降水和时间变量)对响应变量(臭氧)有关方差的整体解释率。 -
解释了约70.44%的总方差,可以理解为该回归的R2=70.44,相当可观的一个数值,表明臭氧与这些变量密切相关
可视化结果
接下来可视化随机森林的回归效果:
# Scatterplot
library(ggplot2)
library(ggExtra)
library(ggpmisc)
library(ggpubr)
g <- ggplot(train_test, aes(obs, pre)) +
geom_point() +
geom_smooth(method="lm", se=F) +
geom_abline(slope = 1,intercept = 0,lty="dashed") +
stat_poly_eq(
aes(label =paste( ..adj.rr.label.., sep = '~~')),
formula = y ~ x, parse = TRUE,
family="serif",
size = 6.4,
color="black",
label.x = 0.1, #0-1之间的比例确定位置
label.y = 1)
g1 <- ggMarginal(g, type = "histogram", fill="transparent")
g <- ggplot(predict_test, aes(obs, pre)) +
geom_point() +
geom_smooth(method="lm", se=F) +
geom_abline(slope = 1,intercept = 0,lty="dashed") +
stat_poly_eq(
aes(label =paste( ..adj.rr.label.., sep = '~~')),
formula = y ~ x, parse = TRUE,
family="serif",
size = 6.4,
color="black",
label.x = 0.1, #0-1之间的比例确定位置
label.y = 1)
g2 <- ggMarginal(g, type = "histogram", fill="transparent")
ggarrange(g1, g2, ncol = 2)
# ggMarginal(g, type = "boxplot", fill="transparent")
# ggMarginal(g, type = "density", fill="transparent")
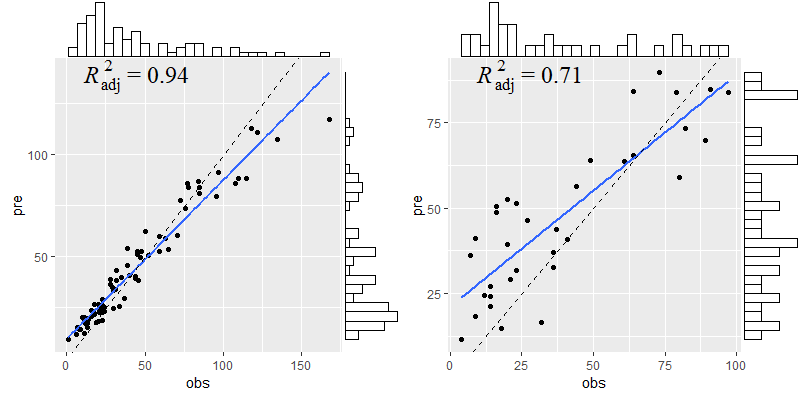
如图所示,在训练集的拟合效果很好,R2可达0.94
在测试集上表现也较好,R2可达0.71
重要性评估
接下来查看变量重要性
##Ozo 的重要性评估
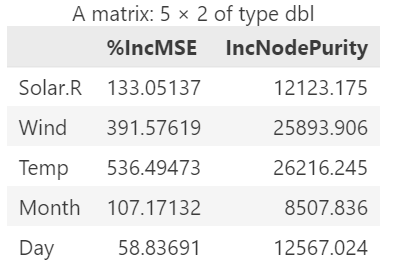
importance_ozo <- ozo_train.forest$importance
importance_ozo
importance_plot <- tibble(var = rownames(importance_ozo),
IncMSE = importance_ozo[,1],
IncNodePurity = importance_ozo[,2])
%IncMSE即increase in mean squared error,通过对每一个预测变量随机赋值,如果该预测变量更为重要,那么其值被随机替换后模型预测的误差会增大。因此,该值越大表示该变量的重要性越大;
IncNodePurity即increase in node purity,通过残差平方和来度量,代表了每个变量对分类树每个节点上观测值的异质性的影响,从而比较变量的重要性。该值越大表示该变量的重要性越大。
对于%IncMSE或IncNodePurity,二选一作为判断预测变量重要性的指标。需注意的是,二者的排名存在一定的差异。
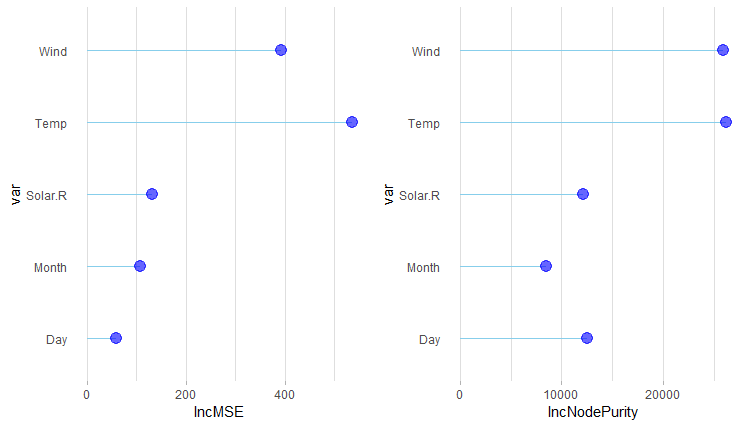
对重要性排序进行可视化:
p1 <- ggplot(importance_plot, aes(x=var, y=IncMSE)) +
geom_segment( aes(x=var, xend=var, y=0, yend=IncMSE), color="skyblue") +
geom_point( color="blue", size=4, alpha=0.6) +
theme_light() +
coord_flip() +
theme(
panel.grid.major.y = element_blank(),
panel.border = element_blank(),
axis.ticks.y = element_blank()
)
p2 <- ggplot(importance_plot, aes(x=var, y=IncNodePurity)) +
geom_segment( aes(x=var, xend=var, y=0, yend=IncNodePurity), color="skyblue") +
geom_point( color="blue", size=4, alpha=0.6) +
theme_light() +
coord_flip() +
theme(
panel.grid.major.y = element_blank(),
panel.border = element_blank(),
axis.ticks.y = element_blank()
)
ggarrange(p1, p2, ncol = 2)
可以看到,温度Temp是臭氧的一个主要因素
交叉验证
接下来进行五折交叉验证,来选取超参数(这里是变量个数):
-
replicate用于重复n次所需语句,这里进行5次五折交叉验证 -
rfcv通过嵌套交叉验证程序显示模型的交叉验证预测性能,模型的预测器数量按顺序减少(按变量重要性排序)。 -
step如果log=TRUE,则为每个步骤要删除的变量的分数,否则一次删除这么多变量 -
cv.fold为折数
#5 次重复五折交叉验证
set.seed(111)
ozo_train.cv <- replicate(5, rfcv(ozo_train[-ncol(ozo_train)], ozo_train$Ozone, cv.fold = 5, step = 0.8), simplify = FALSE)
#ozo_train.cv
ozo_train.cv <- data.frame(sapply(ozo_train.cv, '[[', 'error.cv'))
ozo_train.cv$vars <- rownames(ozo_train.cv)
ozo_train.cv <- reshape2::melt(ozo_train.cv, id = 'vars')
ozo_train.cv$vars <- as.numeric(as.character(ozo_train.cv$vars))
ozo_train.cv.mean <- aggregate(ozo_train.cv$value, by = list(ozo_train.cv$vars), FUN = mean)
ozo_train.cv.mean
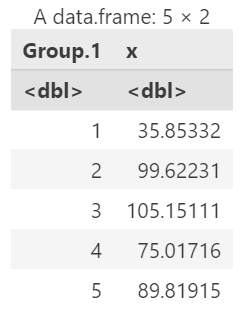
可视化误差结果
ggplot(ozo_train.cv.mean, aes(Group.1, x)) +
geom_line() +
labs(title = '',x = 'Number of vars', y = 'Cross-validation error')
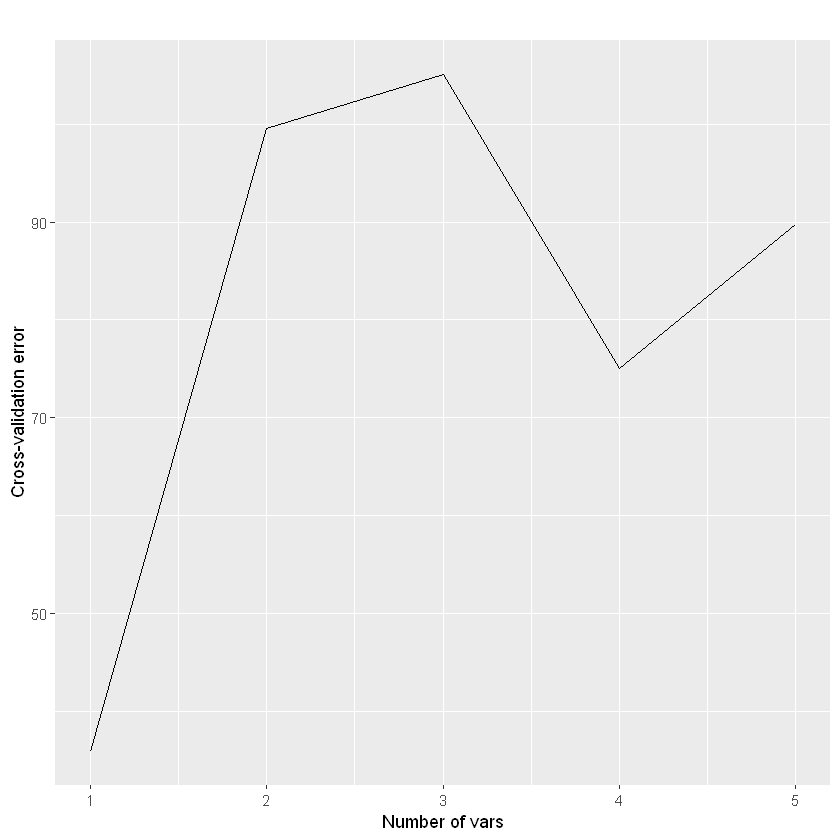
根据交叉验证曲线,提示保留1个重要的变量(或前四个重要的变量)获得理想的回归结果,因为此时的误差达到最小。
因此,根据计算得到的各ozone重要性的值(如“IncNodePurity”),将重要性由高往低排序后,最后大约选择前4个变量就可以了。
#首先根据某种重要性的高低排个序,例如根据“IncNodePurity”指标
importance_ozo <- importance_plot[order(importance_plot$IncNodePurity, decreasing = TRUE), ]
#然后取出排名靠前的因素
importance_ozo.select <- importance_ozo[1:4, ]
vars <- c(pull(importance_ozo.select, var), 'Ozone')
ozo.select <- airquality[ ,vars]
ozo.select <- reshape2::melt(ozo.select, id = 'Ozone')
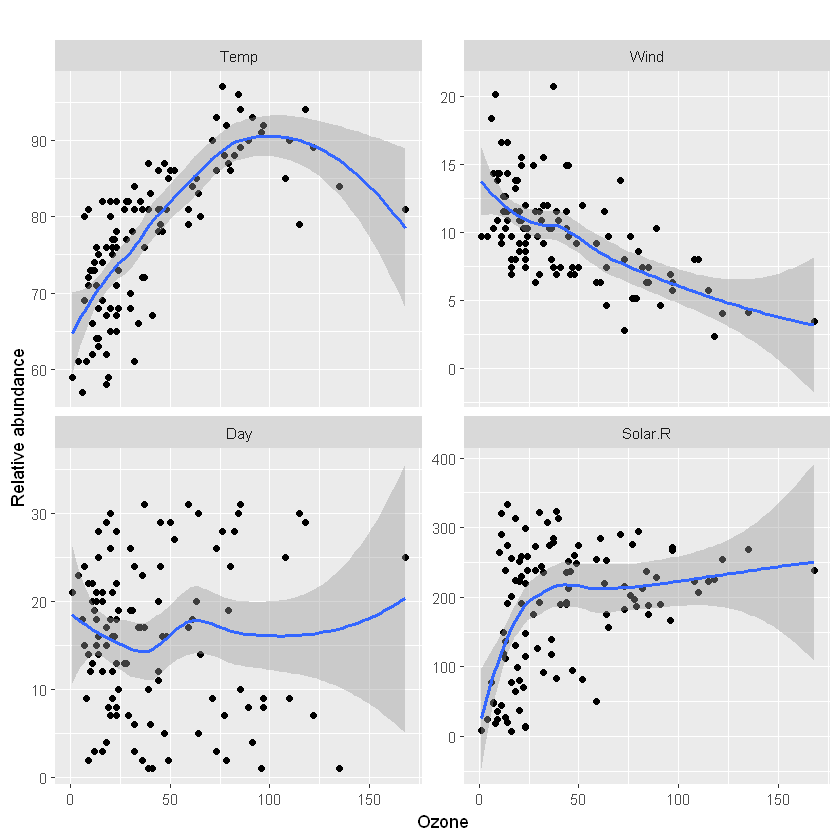
# 查看下这些重要的 vars 与Ozone的关系
ggplot(ozo.select, aes(x = Ozone, y = value)) +
geom_point() +
geom_smooth() +
facet_wrap(~variable, ncol = 2, scale = 'free_y') +
labs(title = '',x = 'Ozone', y = 'Relative abundance')
这就是R语言进行随机森林分析的全流程了,希望对大家的科研有所帮助。
本文由 mdnice 多平台发布















 308
308











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











