






一、大模型部署背景
所谓部署就是讲用已经训练好的模型放在特定的环境中运行的过程。
大模型部署面临的挑战
- 计算量巨大
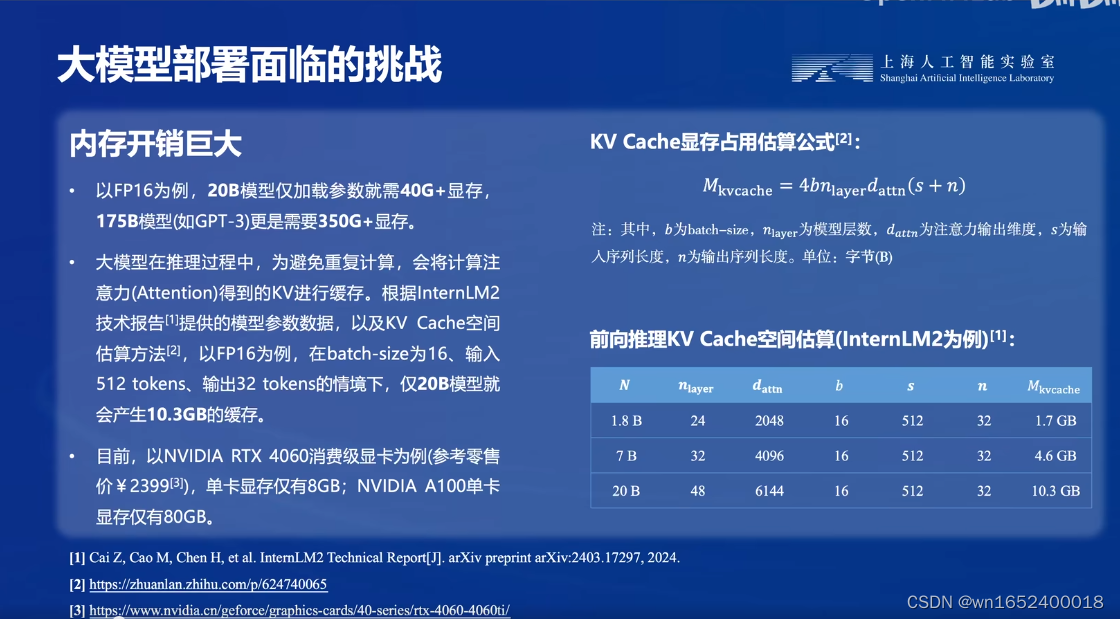
 2. 内存开销巨大
2. 内存开销巨大
图片右下角表格n表示生成token数。
 3.访存瓶颈和动态请求
3.访存瓶颈和动态请求
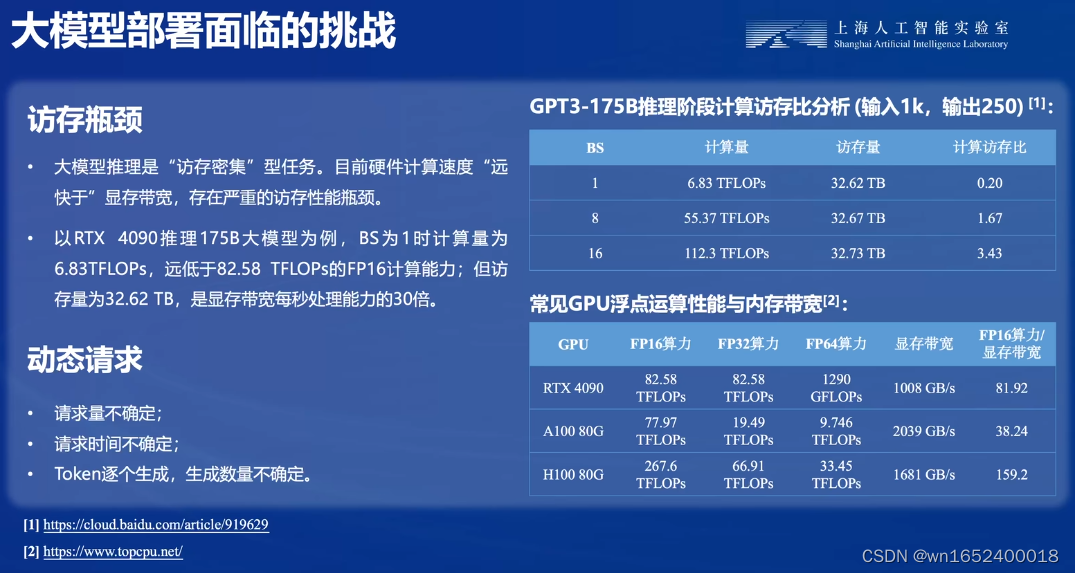 大模型的推理过程中是一个访存密集型任务,大模型的前向推力过程不光光需要计算,在计算过程中还会产生一些中间计算结果并写入显存,还需要往往访存量远大于计算能力。如4090显卡显存带宽只有1008GB/s。
大模型的推理过程中是一个访存密集型任务,大模型的前向推力过程不光光需要计算,在计算过程中还会产生一些中间计算结果并写入显存,还需要往往访存量远大于计算能力。如4090显卡显存带宽只有1008GB/s。
二、大模型部署方法
- 模型裁剪(pruning)

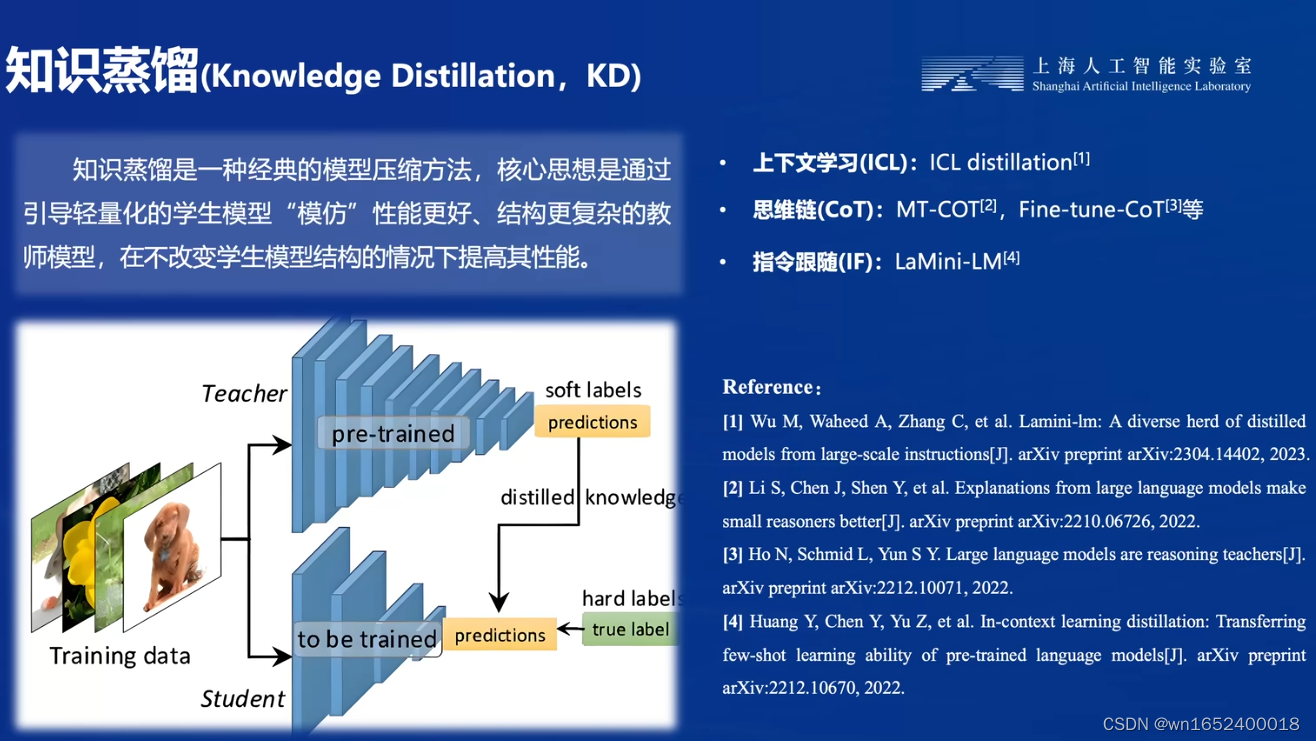
- 知识蒸馏(Knowledge Distillation)
 3)量化(Quantization)
3)量化(Quantization)
 需要注意量化的模型在推理时一般还需要反量化会浮点数再计算,但是大模型的量化还是有可能会提升推理速度的。原因就是前文中提到的大模型的推理是一种访存密集型的任务,访存瓶颈一般远大于计算瓶颈,通过量化可以降低访存量。
需要注意量化的模型在推理时一般还需要反量化会浮点数再计算,但是大模型的量化还是有可能会提升推理速度的。原因就是前文中提到的大模型的推理是一种访存密集型的任务,访存瓶颈一般远大于计算瓶颈,通过量化可以降低访存量。
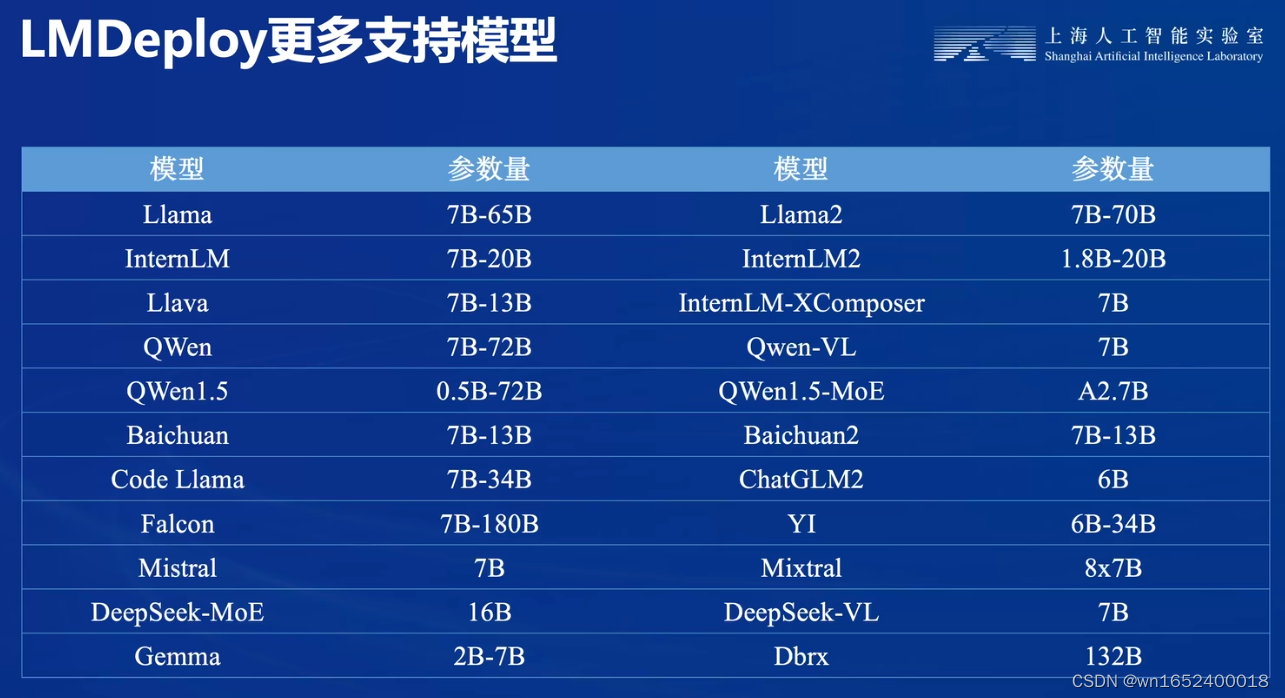
三、LMDeploy简介
 LMDeploy核心功能
LMDeploy核心功能
 其中continuous batch推理模式主要用来解决在推理过程中不同批次的生成结果不同而影响推力效率的问题。把暂时不用的部分KV cache放到内存中,等需要用到时再读入显存,从而缓解显存压力。
其中continuous batch推理模式主要用来解决在推理过程中不同批次的生成结果不同而影响推力效率的问题。把暂时不用的部分KV cache放到内存中,等需要用到时再读入显存,从而缓解显存压力。
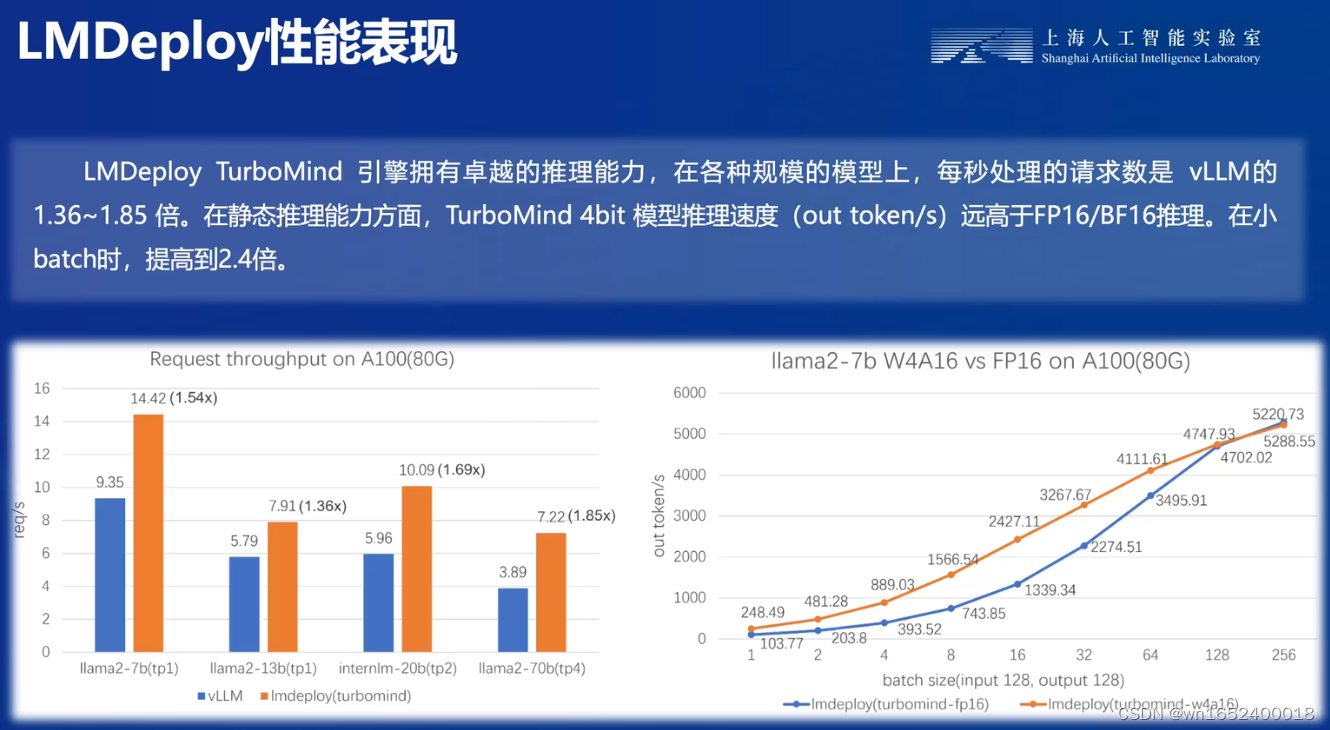
LMDeploy性能表现















 387
387

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









