






 文章介绍了融合黄金正弦的减法优化器算法(GSABO)在BP神经网络中的应用,通过优化权值阈值提高模型精度。以股票预测和分类为例,展示了标准BP与GSABO-BP的对比,显示了GSABO在收敛速度和预测准确性上的优势。
文章介绍了融合黄金正弦的减法优化器算法(GSABO)在BP神经网络中的应用,通过优化权值阈值提高模型精度。以股票预测和分类为例,展示了标准BP与GSABO-BP的对比,显示了GSABO在收敛速度和预测准确性上的优势。
今天采用前一阵改进最为成功的智能优化算法---融合黄金正弦的减法优化器算法(GSABO)优化BP神经网络。该算法不仅是2023年较新的算法,而且改进后的收敛速度和寻优精度都是极佳!点击链接跳转GSABO算法:融合黄金正弦,十种混沌映射,搞定!把把最优值,本文思路可用于所有智能算法的改进
文章一次性讲解两种案例,回归与分类。回归案例中,作者选用了一个经典的股票数据。分类案例中,作者选用的是公用的UCI数据集。
BP神经网络初始的权值阈值都是随机生成的,因此不一定是最佳的。采用智能算法优化BP神经网络的权值阈值,使得输入与输出有更加完美的映射关系,以此来提升BP神经网络模型的精度。本文采用GSABO算法对BP神经网络的权值阈值进行优化,并应用于实际的回归和分类案例中。
01 股票预测案例
案例虽然介绍的是股票预测,但是GSABO-BP预测模型是通用的,大家根据自己的数据直接替换即可。
股票数据特征有:开盘价,盘中最高价,盘中最低价,收盘价等。预测值为股票价格。股票数据整理代码已写好,想换成自己数据的童鞋不需要理解此代码,替换数据即可。下面直接上标准BP的预测结果和GSABO-BP的预测结果。
标准BP模型预测结果:
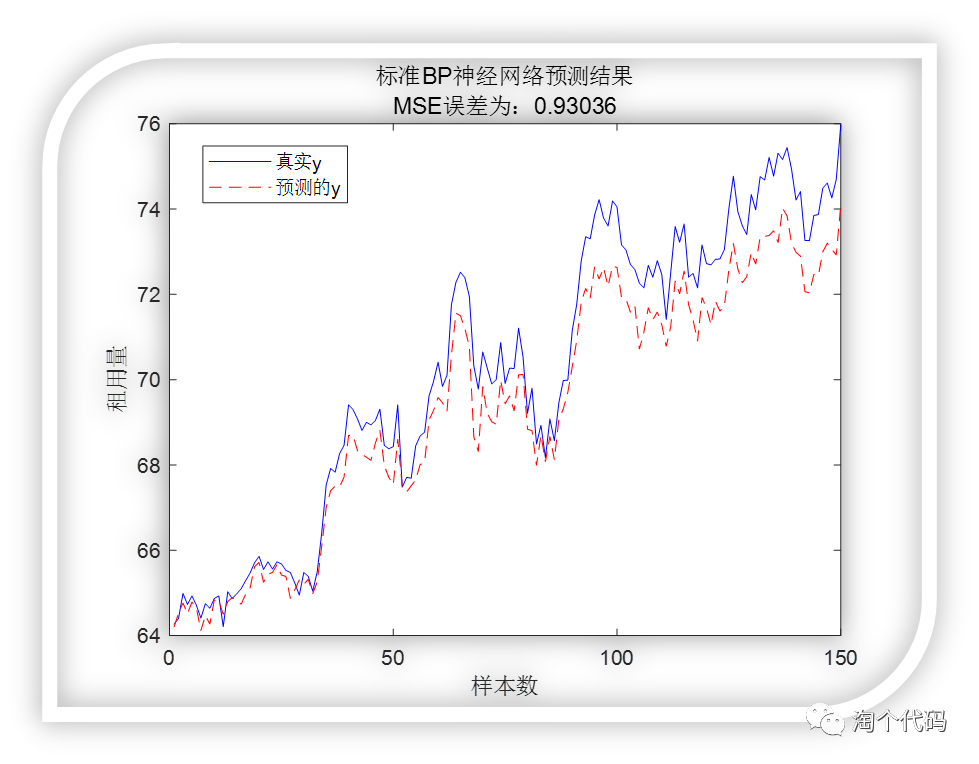
可以看到标准BP神经网络的预测效果不是很理想,无法跟踪真实值,偏差较大。
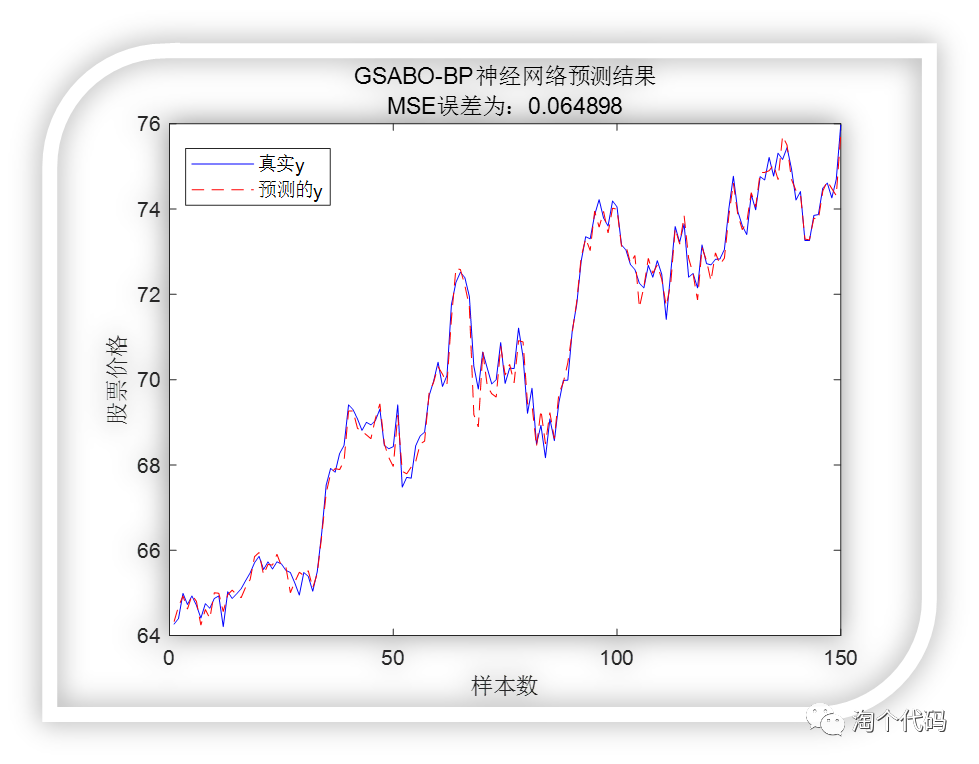
GSABO-BP预测结果:
可以看到GSABO-BP神经网络的预测值可以紧密跟随真实值,效果很好。
将真实值,BP预测值和GSABO-BP预测值放在一起,效果更加明显。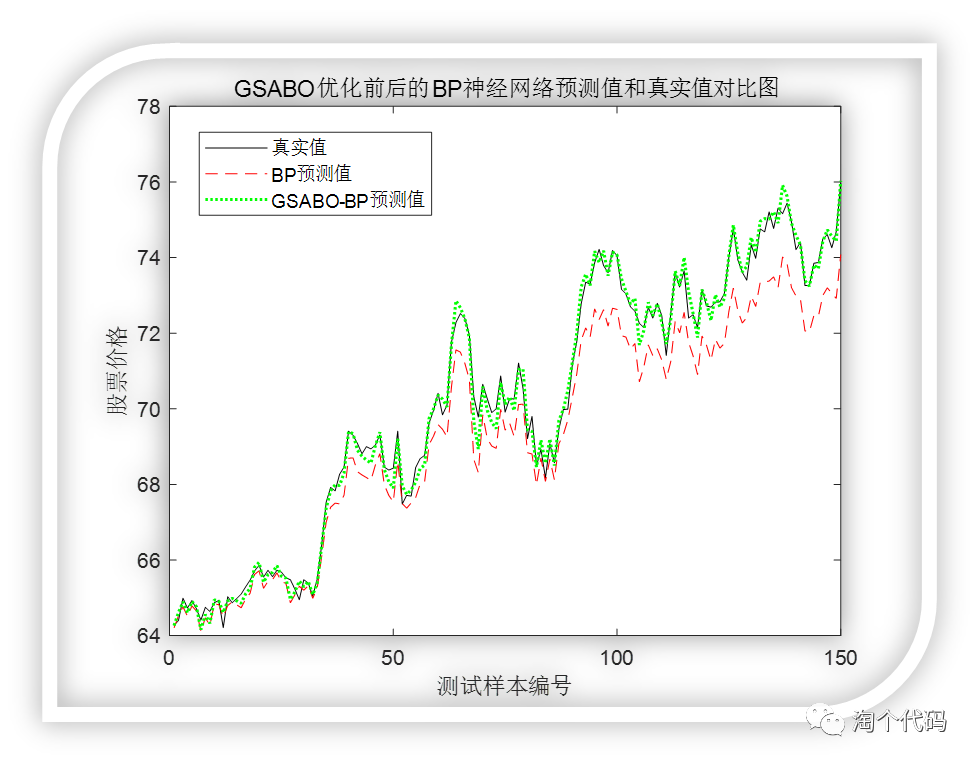
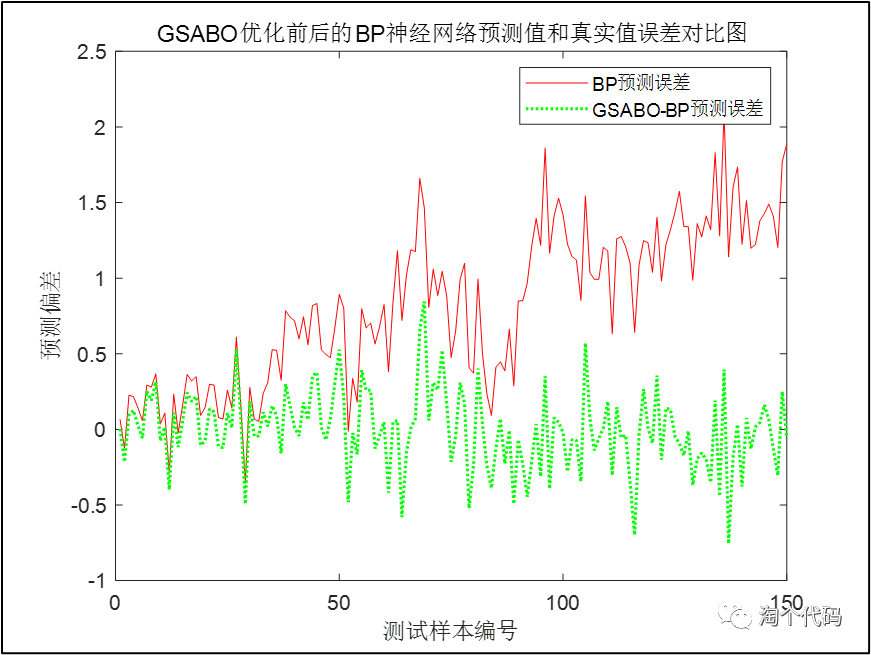
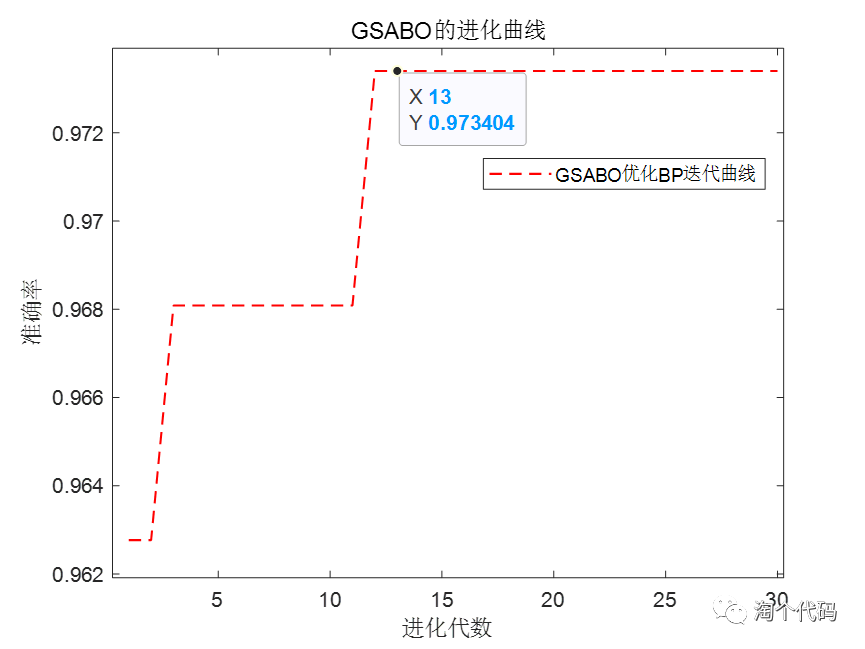
接下来是一个GSABO优化前后的BP神经网络误差对比图。
GSABO-BP的迭代曲线,以预测值和真实值的MSE为目标函数。
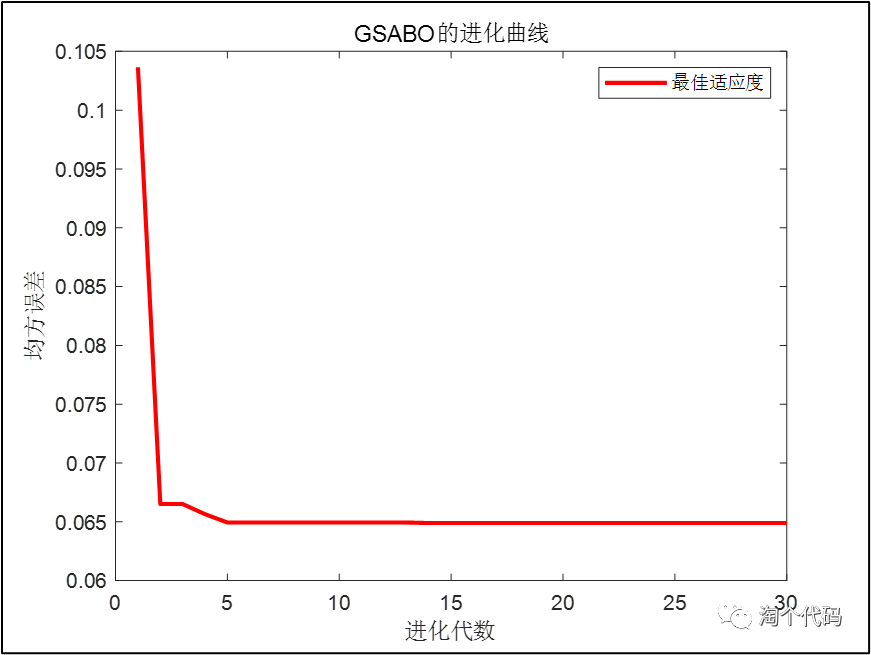

GSABO-BP预测模型的评价:可以看到,GSABO-BP方法在股票预测案例中可以很好地进行股票价格预测。
02 分类案例
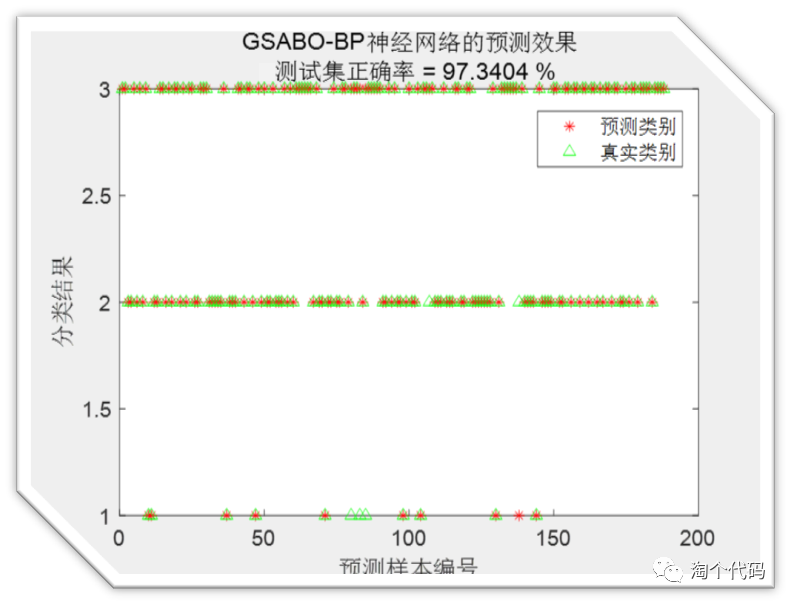
接下来是GSABO-BP的分类案例,采用的数据是UCI数据集中的Balancescale.mat数据,该数据一共分为三类。接下来看结果。
标准BP模型分类结果:
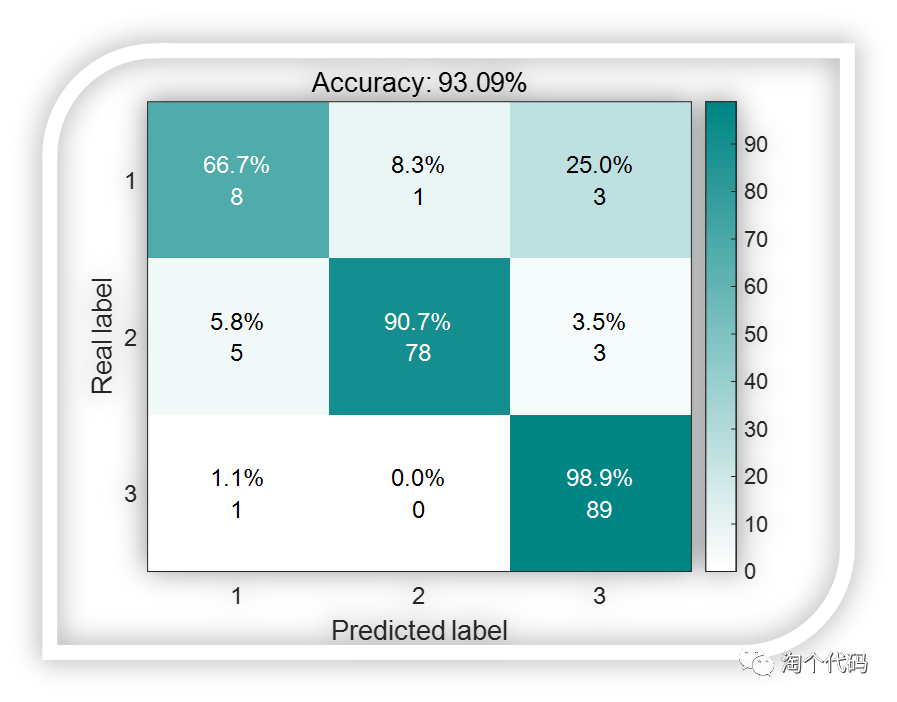
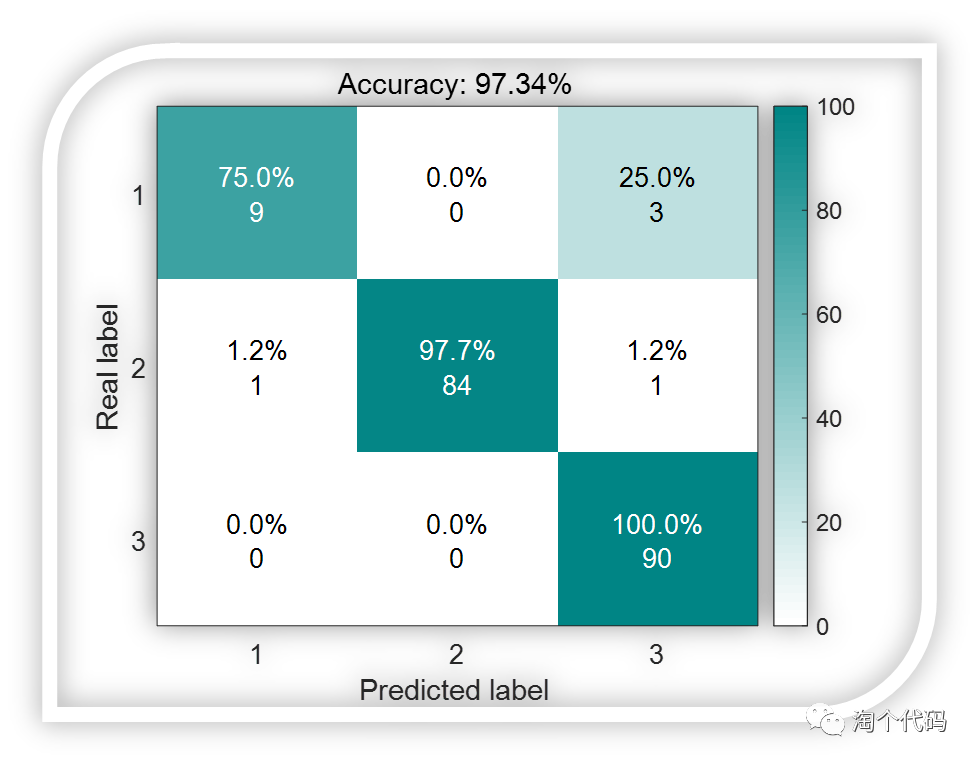
混淆矩阵结果图:
简单说一下这个图该怎么理解。请大家横着看,每行的数据加起来是100%,每行的数据个数加起来就是测试集中第一类数据的真实个数。以第一行为例,测试集中一共有12个数据是属于第一类的,而12个数据中,有8个预测正确,有1个预测成了第2类,3个预测成了第三类。其他行均这样理解。
下面这个图是另一种结果展现方式,在一些论文中会用这种方式展示结果。
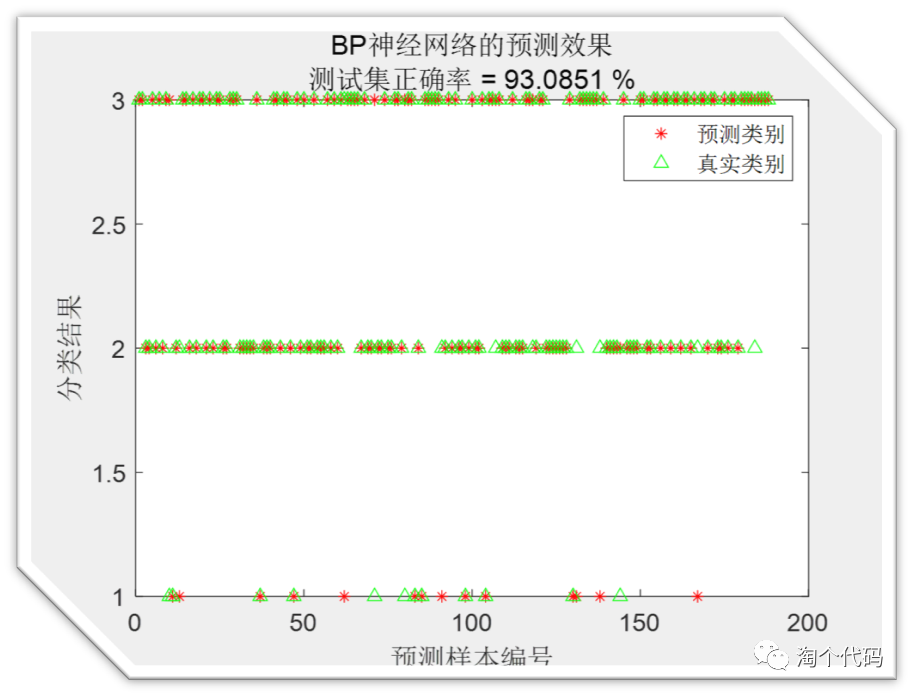
GSABO-BP分类结果:
03 代码展示
%% 初始化
clear
close all
clc
warning off
rng(0)
load data.mat %加载股票数据,这里直接替换自己的数据即可。
%% 数据归一化
[inputn,inputps]=mapminmax(input_train,0,1);
[outputn,outputps]=mapminmax(output_train);
inputn_test=mapminmax('apply',input_test,inputps);
%% 获取输入层节点、输出层节点个数
inputnum=size(input_train,1);
outputnum=size(output_train,1);
disp('/')
disp('神经网络结构...')
disp(['输入层的节点数为:',num2str(inputnum)])
disp(['输出层的节点数为:',num2str(outputnum)])
disp(' ')
disp('隐含层节点的确定过程...')
%确定隐含层节点个数
%采用经验公式hiddennum=sqrt(m+n)+a,m为输入层节点个数,n为输出层节点个数,a一般取为1-10之间的整数
MSE=1e+5; %初始化最小误差
for hiddennum=fix(sqrt(inputnum+outputnum))+1:fix(sqrt(inputnum+outputnum))+5
%构建网络
net=newff(inputn,outputn,hiddennum,{'tansig','purelin'},'trainlm');% 建立模型
% 网络参数
net.trainParam.epochs=1000; % 训练次数
net.trainParam.lr=0.01; % 学习速率
net.trainParam.goal=0.000001; % 训练目标最小误差
net.trainParam.showWindow=0; %隐藏仿真界面
% 网络训练
net=train(net,inputn,outputn);
an0=sim(net,inputn); %仿真结果,依旧采用训练集进行测试
test_simu0=mapminmax('reverse',an0,outputps); %把仿真得到的数据还原为原始的数量级
mse0=mse(test_simu0,output_train); %仿真的均方误差
disp(['隐含层节点数为',num2str(hiddennum),'时,训练集的均方误差为:',num2str(mse0)])
%更新最佳的隐含层节点
if mse0<MSE
MSE=mse0;
hiddennum_best=hiddennum;
end
end
disp(['最佳的隐含层节点数为:',num2str(hiddennum_best),',训练集的均方误差为:',num2str(MSE)])
%% 构建最佳隐含层节点的BP神经网络
disp(' ')
disp('标准的BP神经网络:')
net0=newff(inputn,outputn,hiddennum_best,{'tansig','purelin'},'trainlm');% 建立模型
%网络参数配置
net0.trainParam.epochs=1000; % 训练次数,这里设置为1000次
net0.trainParam.lr=0.01; % 学习速率,这里设置为0.01
net0.trainParam.goal=0.00001; % 训练目标最小误差,这里设置为0.0001
net0.trainParam.show=25; % 显示频率,这里设置为每训练25次显示一次
net0.trainParam.mc=0.01; % 动量因子
net0.trainParam.min_grad=1e-6; % 最小性能梯度
net0.trainParam.max_fail=6; % 最高失败次数
% net0.trainParam.showWindow = false;
% net0.trainParam.showCommandLine = false; %隐藏仿真界面
%开始训练
net0=train(net0,inputn,outputn);
%预测
an0=sim(net0,inputn_test); %用训练好的模型进行仿真
%预测结果反归一化与误差计算
test_simu0=mapminmax('reverse',an0,outputps); %把仿真得到的数据还原为原始的数量级
%误差指标
mse0=mse(output_test,test_simu0);
%% 标准BP神经网络作图
figure
plot(output_test,'b-','markerfacecolor',[0.5,0.5,0.9],'MarkerSize',6)
hold on
plot(test_simu0,'r--','MarkerSize',6)
legend('真实y','预测的y')
xlabel('样本数')
ylabel('股票价格')
title(['标准BP神经网络预测结果',newline,'MSE误差为:',num2str(mse0)])
disp(['标准神经网络测试集的均方误差为:',num2str(mse0)])
%% GSABO优化算法寻最优权值阈值
disp(' ')
disp('GSABO优化BP神经网络:')
net=newff(inputn,outputn,hiddennum_best,{'tansig','purelin'},'trainlm');% 建立模型
%网络参数配置
net.trainParam.epochs=1000; % 训练次数,这里设置为1000次
net.trainParam.lr=0.01; % 学习速率,这里设置为0.01
net.trainParam.goal=0.00001; % 训练目标最小误差,这里设置为0.0001
net.trainParam.show=25; % 显示频率,这里设置为每训练25次显示一次
net.trainParam.mc=0.01; % 动量因子
net.trainParam.min_grad=1e-6; % 最小性能梯度
net.trainParam.max_fail=6; % 最高失败次数
%% 初始化GSABO参数
popsize=10; %初始种群规模
maxgen=30; %最大进化代数
lb = -2; %神经网络权值阈值的上下限
ub = 2;
numm = 2; %混沌系数
dim=inputnum*hiddennum_best+hiddennum_best+hiddennum_best*outputnum+outputnum; %自变量个数
fobj = @fitness;
[Best_score,Best_pos,GSABO_curve]=GSABOforBP(numm,popsize,maxgen,lb,ub,dim,inputnum,hiddennum_best,outputnum,net,inputn,outputn,inputn_test,outputps,output_test);
%% 绘制进化曲线
figure
plot(GSABO_curve,'r-','linewidth',2)
xlabel('进化代数')
ylabel('均方误差')
legend('最佳适应度')
title('GSABO的进化曲线')代码中注释非常详细,有对神经网络构建的注释,有对GASBO-BP代码的注释,简单易懂。
代码附带UCI常用的数据集及其解释。大家可以自行尝试别的数据进行分类。
一次性获取两种案例代码。
点击下方卡片获取更多代码!


















 1781
1781

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











