






截止到本期,一共发了7篇关于机器学习预测全家桶Python代码的文章。参考往期文章如下:
2.机器学习预测全家桶-Python,一次性搞定多/单特征输入,多/单步预测!最强模板!
3.机器学习预测全家桶-Python,新增CEEMDAN结合代码,大大提升预测精度!
4.机器学习预测全家桶-Python,新增VMD结合代码,大大提升预测精度!
5.Python机器学习预测+回归全家桶,再添数十种回归模型!这次千万别再错过了!
6.Python机器学习预测+回归全家桶,新增TCN,BiTCN,TCN-GRU,BiTCN-BiGRU等组合模型预测
7.调用最新mealpy库,实现215个优化算法优化CNN-BiLSTM-Attention,电力负荷预测
今天再更新一期关于Transformer预测的代码。
一、Transformer 模型概述
Transformer 作为一种创新的神经网络结构,深受欢迎。采用 Transformer 编码器对光伏、负荷数据特征间的复杂关系以及时间序列中的长短期依赖关系进行挖掘,可以提高光伏功率、负荷预测的准确性。Transformer 编码器一般由多个编码器层堆叠而成,具体架构如图所示。每个编 码器层包括注意力子层和前馈神经网络子层,其中注意力子层包括多头自注意力机制和残差连接与层归一化,前馈神经网络子层包括前馈神经网络和残差连接与层归一化。关于Transformer模型介绍网上有很多博主都讲解的不错,本期主要为代码实现。
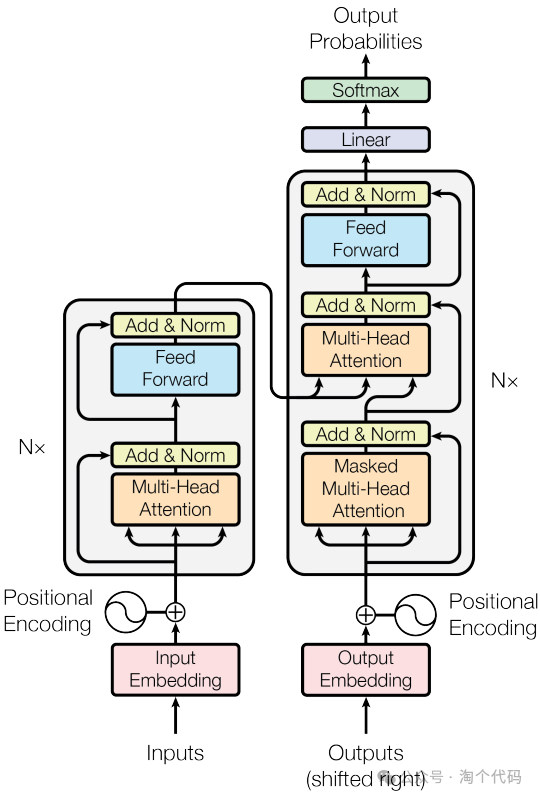
Transformer架构
本期新增模型:Transformer 模型
Transformer 模型在小数据集上往往会表现出过拟合的现象,因此本期代码训练数据较大,设置了3万个样本,其中90%作为训练集,10%作为测试集。
以《风电场功率预测.xlsx》为例进行介绍。数据格式如下:
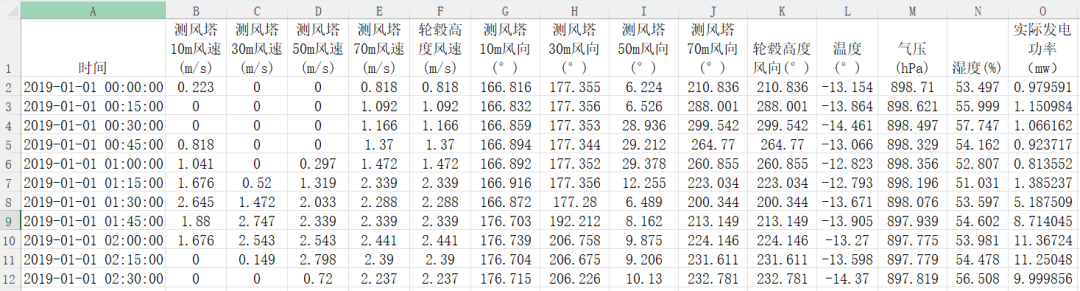
设置网络为多特征输入,多步预测。采用前10个历史时刻的特征值预测未来2天的功率值。(当然你也可以改为其他任何你想改的,比如单特征、单步预测等,不会改的参考这篇文章:一次性搞定多/单特征输入,多/单步预测!最强模板!)
二、结果展示:
采用前10个历史时刻的特征值预测未来2个时刻的功率值。
第一步预测结果:

第二步预测结果:

指标打印结果:

三、部分核心代码:
本期Transformer 模型采用torch框架构建。
# 定义 Transformer 模型
class TransformerModel(nn.Module):
def __init__(self, input_dim, output_dim, hidden_dim, num_layers, num_heads, dropout_prob):
super(TransformerModel, self).__init__()
# maxpool the input feature map/tensor to the transformer
# a rectangular kernel worked better here for the rectangular input spectrogram feature map/tensor
self.transformer_maxpool = nn.MaxPool2d(kernel_size=[1, 2], stride=[1, 2])
# 初始化一个 TransformerEncoderLayer,用于构建 Transformer 模型的编码层
self.encoder_layer = nn.TransformerEncoderLayer(
d_model=input_dim, # input feature (frequency) dim after maxpooling 128*563 -> 64*140 (freq*time)
nhead=num_heads, # self-attention layers in each multi-head self-attention layer in each encoder block
dim_feedforward=hidden_dim,# 2 linear layers in each encoder block's feedforward network
dropout=dropout_prob,
activation = 'relu' # ReLU: avoid saturation/tame gradient/reduce compute time
)
# 初始化一个 TransformerEncoder,用于构建整个 Transformer 编码器
self.transformer_encoder = nn.TransformerEncoder(self.encoder_layer, num_layers=num_layers)
self.decoder = nn.Linear(input_dim, output_dim)
self.init_weights()
# 设置超参数
input_dim = n_in*or_dim #输入维度
output_dim = n_out #输出维度
hidden_dim = 128 # Feed Forward层(Attention后面的全连接网络)的隐藏层的神经元数量。该值越大,网络参数量越多,计算量越大。
num_layers = 2 #层数
num_heads = 2 #多头注意力机制中,head的数量。注意力头数需要能被input_dim整除,否则会报错哦!
dropout_prob = 0.1 #dropout值。默认值为0.01
learning_rate = 0.001
num_epochs = 50
batch_size = 128
# seq_length = 10
# 初始化模型、损失函数和优化器
model = TransformerModel(input_dim, output_dim, hidden_dim, num_layers, num_heads, dropout_prob)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# 训练模型
X_TRAIN = torch.tensor(vp_train, dtype=torch.float32)
Y_TRAIN = torch.tensor(vt_train, dtype=torch.float32)
X_TEST = torch.tensor(vp_test, dtype=torch.float32)
Y_TEST = torch.tensor(vt_test, dtype=torch.float32)
for epoch in range(num_epochs):
for i in range(0, n_train_number, batch_size):
# zero out gradients for next pass
# pytorch accumulates gradients from backwards passes (convenient for RNNs)
optimizer.zero_grad()
# 获取当前批次的训练数据
batch_X = X_TRAIN[i:i+batch_size]
batch_y = Y_TRAIN[i:i+batch_size]
# 前向传播
output = model(batch_X)
# 计算损失
loss = criterion(output.squeeze(), batch_y)
# 反向传播及优化
loss.backward()
optimizer.step()
# 打印当前训练损失
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')后续会继续更新一些其他模型……敬请期待!
机器学习python全家桶代码获取
https://mbd.pub/o/bread/ZZqXmpty
识别此二维码也可跳转全家桶
后续有更新直接进入此链接,即可下载最新的!

或点击下方阅读原文获取此全家桶。
全家桶pip包推荐版如下:
tensorflow~=2.15.0
pandas~=2.2.0
openpyxl~=3.1.2
matplotlib~=3.8.2
numpy~=1.26.3
keras~=2.15.0
mplcyberpunk~=0.7.1
scikit-learn~=1.4.0
scipy~=1.12.0
qbstyles~=0.1.4
prettytable~=3.9.0
vmdpy~=0.2
xgboost~=2.0.3
mealpy~=3.0.1
torch~=2.3.1获取更多代码:

或者复制链接跳转:
https://docs.qq.com/sheet/DU3NjYkF5TWdFUnpu















 174
174











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











