






极光优化算法(Polar Lights Optimization, PLO)是一种受自然奇观启发的元启发式优化算法。结合了高能粒子的运动和研究物理学的基本原理,极光优化算法是一个独特的模拟粒子运动的模型。该模型结合了旋转运动和极光椭圆行走,前者有利于局部开采,后者有利于全球勘探。通过协同结合这两种策略,拟议的PLO实现了本地开发和全球勘探的平衡方法。此外,还引入了粒子碰撞策略,提高了逃避局部最优的效率。


该成果于2024年发表在计算机领域二区SCI期刊“Neurocomputing”上。PLO方法具有出色的迭代优化性能和出色的鲁棒性。
1、算法原理
(1)初始化
在PLO中,迭代过程将从基于伪随机数生成的初始种群开始。如Eq.(1)所示,整个种群以大小为N行D列的矩阵形式表示,其中N表示种群中包含的候选解的大小,D表示解空间的可扩展维度。
式中,UB和LB表示解空间的边界,R表示取值为[0,1]的随机数序列。在PLO中,用求解空间中的搜索代理模拟了一群高能带电粒子绕着磁敏感器向极中心飞向地球的过程。
(2)回转运动
本节将描述在PLO中寻找最佳解的方法,即受高能粒子向地球的广泛旅行的启发而进行的旋转运动。太阳距离地球大约1.5亿公里,不断地向地球发射电子和质子,地球完全被它的磁场包围,从地球向外延伸约5万至6.5万公里。当这些粒子接近地球时,它们会遇到来自地球磁场的阻力,并在其影响下向不同方向辐射。在这个过程中,接近地球的带电粒子与地球磁场相互作用,沿着磁场线经历旋转运动,这种现象可以用洛伦兹力来描述。数学上,假设带电粒子在地球磁场(B)内的电荷q和速度v,则洛伦兹力FL可表示如下:
FL使带电粒子受到向心力的作用,导致带电粒子在磁场中沿磁力线旋转运动。同样,带电粒子的方程可以用洛伦兹力和牛顿第二定律来描述:
其中m是带电粒子的质量。这个方程描述了带电粒子的速度随时间的变化,从而可以确定其在磁场中的轨迹。将上述两个方程合起来,可以得到一个一阶常微分方程:
这个微分方程描述了带电粒子的速度随时间的变化。通过求解这个微分方程,可以得到粒子速度随时间变化的规律,从而深入了解粒子在地球磁场中的运动,如下图所示。
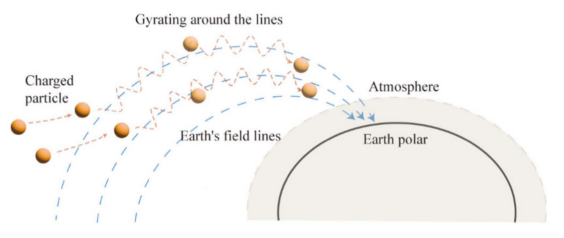
然而,这些高能粒子在大气中遇到空气分子的阻力,导致不光滑的绕圈运动。这种不平滑的绕圈运动是由于大气的阻尼作用。当带电粒子进入大气层时,与大气分子的碰撞降低了它们的动能,使它们的圆周运动半径减小。
在考虑了大气对带电粒子的阻尼效应后,可以将这种阻尼现象纳入控制粒子速度随时间变化的方程中。在这个方程中,引入了一个阻尼因子α,表示粒子速度的衰减率。因此,描述带电粒子速度随时间变化的公式:
修正得到一个非齐次一阶线性微分方程。采用常变方法,假设解v = Ceλt,其中C和λ为待定系数。代入方程,得到下式:
求解得到 ,因此方程的最终解为
其中C为积分常数,在此方程中,带电粒子携带的电荷q、质量m和地球磁场强度B不变。为简单起见,在此策略中,C、q和B取1,m取100,阻尼因子α为取[1,1.5]的随机值。
(3)极光椭圆步道
本节介绍了PLO中的极光椭圆漫步,这是一种有助于高效搜索解空间的方法。这种策略的想法源于天文观测者对极光的广泛研究。极光椭圆的大小取决于行星际磁场的南北分量,其边界随地磁活动而变化。在这种现象中,地球复杂的大气层进一步促进了各种高能粒子的运动。极光椭圆行走的复杂波动将对全球搜索产生重大影响。正是这种不可预测的混沌满足了PLO对解决方案空间快速全局搜索的需求。值得注意的是,Levy Flight (LF)在MAs中经常被用来增强全局探索,因为它本质上是一个随机的非高斯漫步。其阶跃值基于Levy稳定分布进行分散。可将LF表示为下式:
式中,β为调节稳定性的重要LF指标,d为步长。
在极光椭圆行走中,LF模拟的高能粒子受地磁活动和大气的影响,极光椭圆边界在极方向上收缩,在赤道方向上膨胀。具体变化过程如下式所示:
其中Xavg为高能粒子群的质心位置。X(i, j)为高能粒子的当前位置,Xavg(j)−X(i, j)表示粒子的运动趋势。极光是极光椭圆的一种复杂变化,由LFs的分散分布模拟而成,LFs驱动高能粒子在两极和赤道之间运动。对每个粒子的运动进行简单模拟,如图所示。
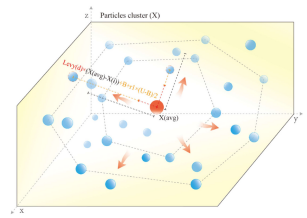
该策略增强了PLO的全球勘探能力,使其能够快速导航整个解决方案空间并搜索有价值的区域。
将两种策略结合到PLO中,所提出的新计算模型如下式所示。
式中,Xnew(i, j)为高能粒子完成更新后的位置,r2为不可控环境等因素对粒子带来的干扰,取[0,1]的值。为了最大限度地提高局部开发和全局开发的效率,引入了两个随算法每次迭代而变化的自适应权值W1和W2。由下式计算得到:
其中W1和W2控制公式中旋转运动和极光椭圆行走的权重,如图a所示,v(t)的权重随着W1的增加而增加;如图b所示,Ao W2的权重逐渐减小。随着算法的迭代,全局搜索和局部开发依靠权重的变化来达到平衡,探索最优解。

(4)粒子碰撞
鲁棒全局策略和强局部策略并不是精细算法的唯一关键组成部分。此外,一种更有效的避免收敛到局部最优或摆脱局部最优的能力是必要的。因此,本节将介绍粒子碰撞策略,以提高跳出卡住情况的能力。在太阳风中,电子和质子等带电粒子以高速从太阳飞向地球,并在撞击大气层时相互碰撞。
受此启发,提出了一种粒子碰撞策略。粒子间的混沌碰撞使得PLO能够离开局部最优。在这种策略中,如果我们关注当前移动的粒子,它可能会与粒子群中的任何粒子发生混沌碰撞,从而在途中产生新的位置,如图所示。
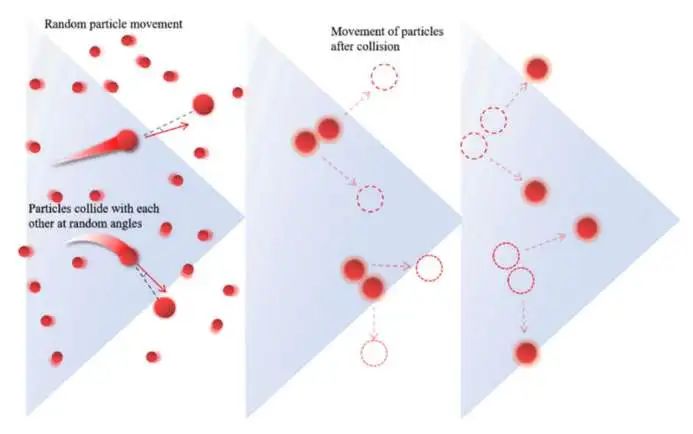
数学模型如式所示:
式中X(a, j)表示粒子簇中的任意粒子。随着算法的进行,粒子之间的碰撞变得越来越频繁,因此由公式计算的碰撞概率K来控制。r3和r4是随机值,取[0,1]中的值。
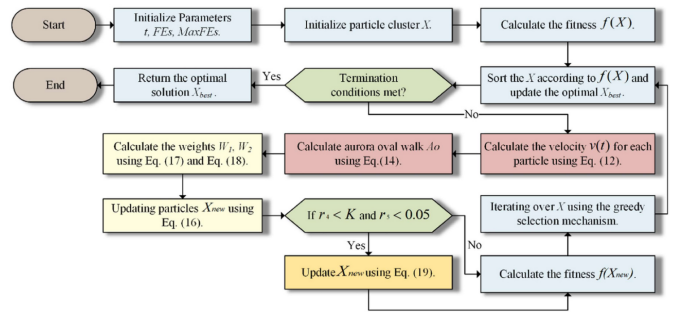
PLO所对应的算法流程图如下图所示
PLO对应的伪代码过程如下图所示

2、结果展示
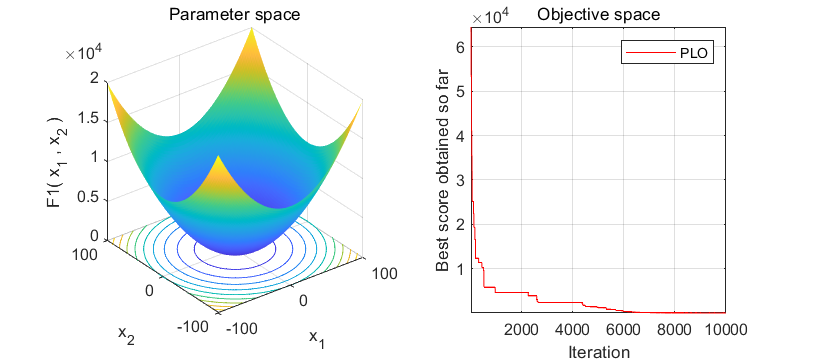
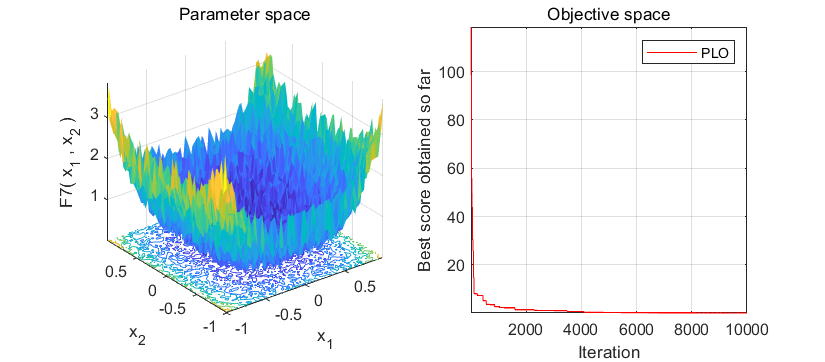
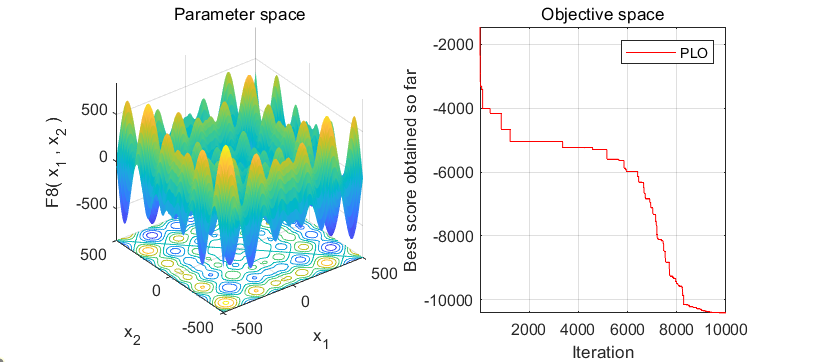
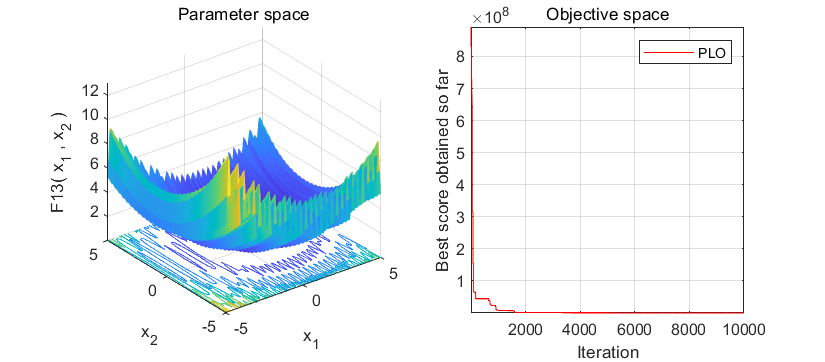
3、MATLAB核心代码
%% 淘个代码 %%
% 极光优化算法(Polar Lights Optimization, PLO)
function [Best_pos,Bestscore,Convergence_curve]=PLO(N,MaxFEs,lb,ub,dim,fobj)
tic
%% Initialization
FEs = 0;
it = 1;
fitness=inf*ones(N,1);
fitness_new=inf*ones(N,1);
X=initialization(N,dim,ub,lb);
V=ones(N,dim);
X_new=zeros(N,dim);
for i=1:N
fitness(i)=fobj(X(i,:));
FEs=FEs+1;
end
[fitness, SortOrder]=sort(fitness);
X=X(SortOrder,:);
Bestpos=X(1,:);
Bestscore=fitness(1);
Convergence_curve=[];
Convergence_curve(it)=Bestscore;
%% Main loop
while FEs <= MaxFEs
X_sum=sum(X,1);
X_mean=X_sum/N;
w1=tansig((FEs/MaxFEs)^4);
w2=exp(-(2*FEs/MaxFEs)^3);
for i=1:N
a=rand()/2+1;
V(i,:)=1*exp((1-a)/100*FEs);
LS=V(i,:);
GS=Levy(dim).*(X_mean-X(i,:)+(lb+rand(1,dim)*(ub-lb))/2);
X_new(i,:)=X(i,:)+(w1*LS+w2*GS).*rand(1,dim);
end
E =sqrt(FEs/MaxFEs);
A=randperm(N);
for i=1:N
for j=1:dim
if (rand<0.05) && (rand<E)
X_new(i,j)=X(i,j)+sin(rand*pi)*(X(i,j)-X(A(i),j));
end
end
Flag4ub=X_new(i,:)>ub;
Flag4lb=X_new(i,:)<lb;
X_new(i,:)=(X_new(i,:).*(~(Flag4ub+Flag4lb)))+ub.*Flag4ub+lb.*Flag4lb;
fitness_new(i)=fobj(X_new(i,:));
FEs=FEs+1;
if fitness_new(i)<fitness(i)
X(i,:)=X_new(i,:);
fitness(i)=fitness_new(i);
end
end
[fitness, SortOrder]=sort(fitness);
X=X(SortOrder,:);
if fitness(1)<Bestscore
Bestpos=X(1,:);
Bestscore=fitness(1);
end
it = it + 1;
Convergence_curve(it)=Bestscore;
Best_pos=Bestpos;
end
toc
end
function o=Levy(d)
beta=1.5;
sigma=(gamma(1+beta)*sin(pi*beta/2)/(gamma((1+beta)/2)*beta*2^((beta-1)/2)))^(1/beta);
u=randn(1,d)*sigma;v=randn(1,d);
step=u./abs(v).^(1/beta);
o=step;
end
参考文献
[1]Yuan C, Zhao D, Heidari A A, et al. Polar lights optimizer: Algorithm and applications in image segmentation and feature selection[J]. Neurocomputing, 2024, 607: 128427.
完整代码获取
后台回复关键词:
点击下方卡片关注,获取更多代码


















 6434
6434

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











