







声明:文章是从本人公众号中复制而来,因此,想最新最快了解各类智能优化算法及其改进的朋友,可关注我的公众号:强盛机器学习,不定期会有很多免费代码分享~
目录
极光优化算法(Polar Lights Optimization, PLO)是一种新型的元启发式算法(智能优化算法),灵感来源于自然界中的极光现象。不同于以往的动物园算法,该算法清晰易懂,性能也不错,值得一试!该成果由Chong Yuan 于2024年8月发表在SCI期刊《Neurocomputing》上!

由于发表时间较短,谷歌学术上还没人引用!你先用,你就是创新!

原理简介
灵感:极光是一种美丽的自然现象,电脉冲发生在距离地平线80到500公里的高度。地球的磁场从南极到北极形成了一个强大的磁屏蔽,以一种弯曲的磁力线的形式表现出来。

一、初始化阶段
在PLO中,迭代过程将从基于伪随机数生成的初始种群开始。如Eq.(1)所述,整个种群以一个矩阵的形式表示,其大小为二进制数和𝐷列,其中二进制数表示种群中包含的候选解的大小,𝐷表示解空间的可伸缩维度。
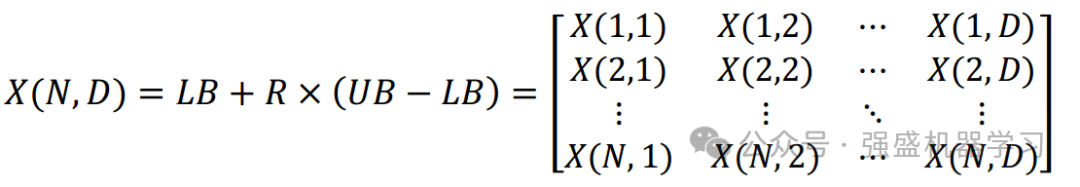
式中UB、LB为解空间的边界,𝑅为取值为[0,1]的随机数序列。在PLO中,利用求解空间中的搜索代理模拟了一群高能带电粒子绕着磁感应体飞向地球的极中心
二、回转运动
太阳距离地球大约1.5亿公里,不断地向我们的地球发射电子和质子,我们的地球完全被它的磁场包围,从地球向外延伸大约5万到6.5万公里。当这些粒子接近地球时,它们会遇到地球磁场的阻力,并在其影响下向各个方向辐射。在这个过程中,接近地球的带电粒子与地球磁场相互作用,沿着磁场线经历旋转运动,这是一种用洛伦兹力描述的现象。用公式表示为:
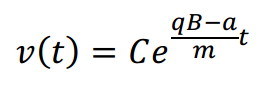
方程中,积分常数C,荷电粒子所携带的电荷q、质量m和地磁场强度B均不发生变化。为简单起见,在本策略中,C、q、B变量的值为1,且𝑚为100。阻尼因子的取值为[1,1.5]的随机值,在策略内利用算法的适应度评估过程对时间进行模拟。
三、极光椭圆步道
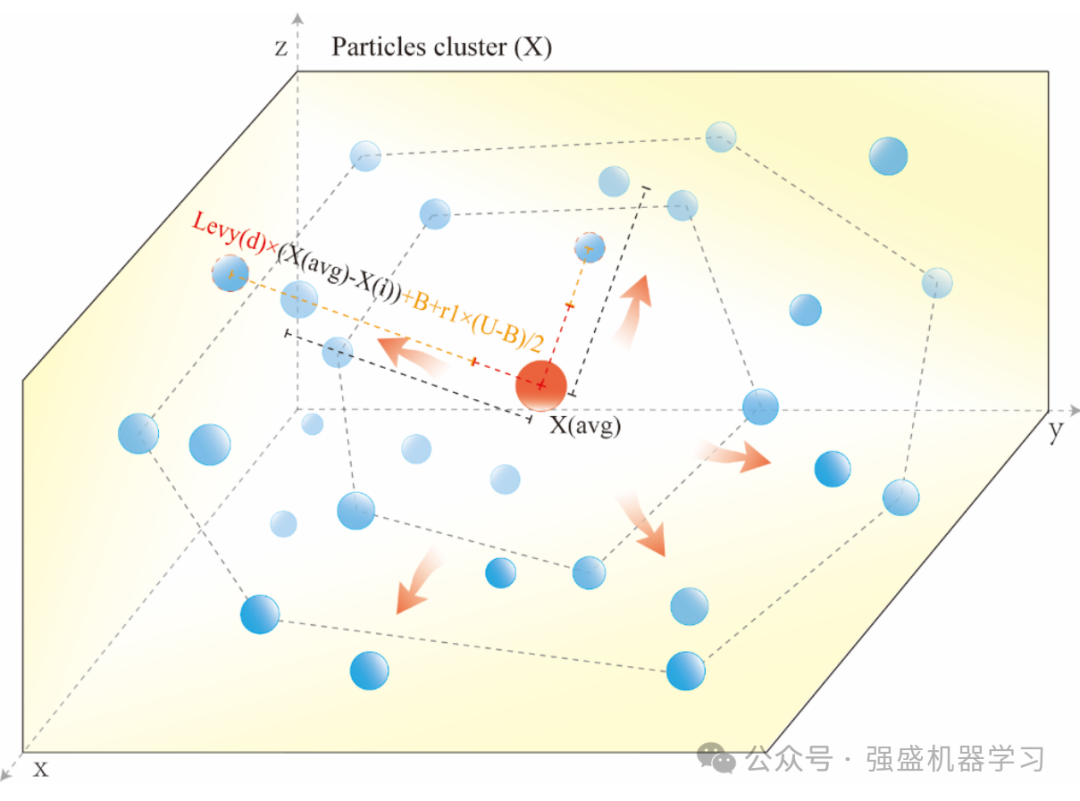
首先,旋转运动表现为粒子沿地球磁力线旋转,沿固定轨迹缓慢运动。这种运动模式强调局部开发和精细调整,旨在更深入地探索局部解空间,寻找局部最优或优化当前解的局部结构。这与局部搜索阶段一致,在该阶段,采取细微的调整和小步骤来提高解决方案的质量,使它们更接近最优解决方案。
其次,极光椭圆行走涉及围绕候选点的快速运动,以获得最佳解决方案或局部最优。这种模式强调全局探索特征,粒子以更大的步骤探索解空间,以发现更多有价值的区域。这对应于全局探索阶段,在这个阶段,解空间被用更大的步长搜索,以找到全局最优或更好的解。
因此,本文将这两种策略结合到PLO中,提出的新计算模型如下式所示。
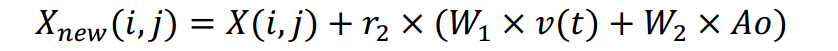
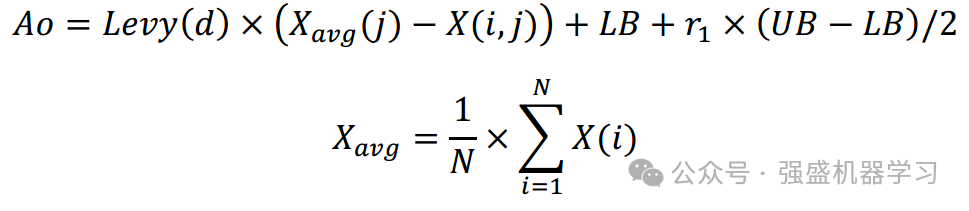
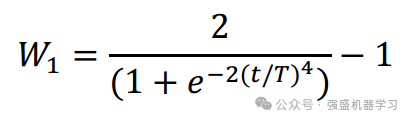
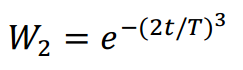
式中Xnew(i,j)为高能粒子完成更新后的位置,r2为不可控环境等因素对粒子带来的干扰,取[0,1]的值。
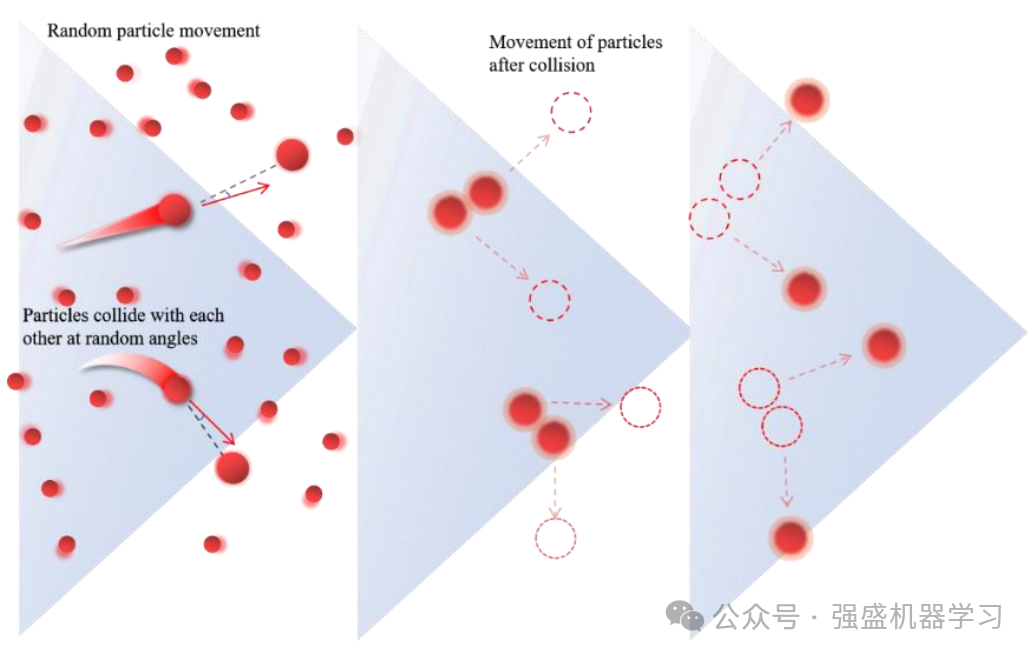
四、粒子碰撞
粒子间的混沌碰撞使得PLO能够离开局部最优。如果一个粒子是关注的焦点,它可能会随机漂移出既定的飞行轨迹,并与周围的任何粒子发生碰撞。当以即将与之碰撞的粒子为参照物时,碰撞可能发生在任何角度,就像新手台球游戏的不确定结果一样。此外,当高能粒子从太阳飞向地球时,也会发生轻微的碰撞。然而,当这些粒子进入大气和极光在椭圆形内汇合,碰撞发生更频繁,导致极光的形状不断变化。数学模型如下式所示:
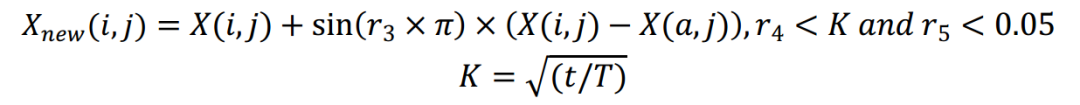
其中X(a,j)表示粒子簇中的任意粒子。随着算法的进行,粒子之间的碰撞变得越来越频繁,因此由碰撞概率𝐾控制。𝑟3和𝑟4是随机值,取值范围为[0,1]。
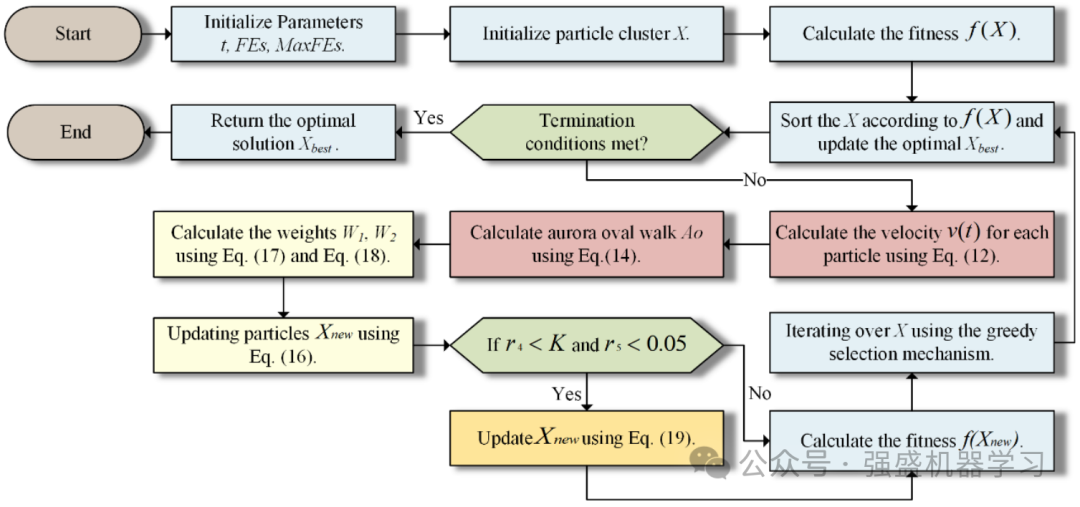
算法流程图和伪代码
为了使大家更好地理解,这边给出作者算法的流程图和伪代码,非常清晰!

如果实在看不懂,不用担心,可以看下源代码,再结合上文公式理解就一目了然了!
性能测评
原文作者在CEC2014经典测试集中的9种经典算法和8种高性能改进算法进行比较,并进一步与IEEE CEC2022最新测试集进行比较,结果证明PLO算法具有很强的竞争力。
这边为了方便大家对比与理解,采用23个标准测试函数,即CEC2005,设置种群数量为30,迭代次数为1000,和经典的灰狼优化算法GWO进行对比!这边展示其中5个测试函数的图,其余十几个测试函数大家可以自行切换尝试!
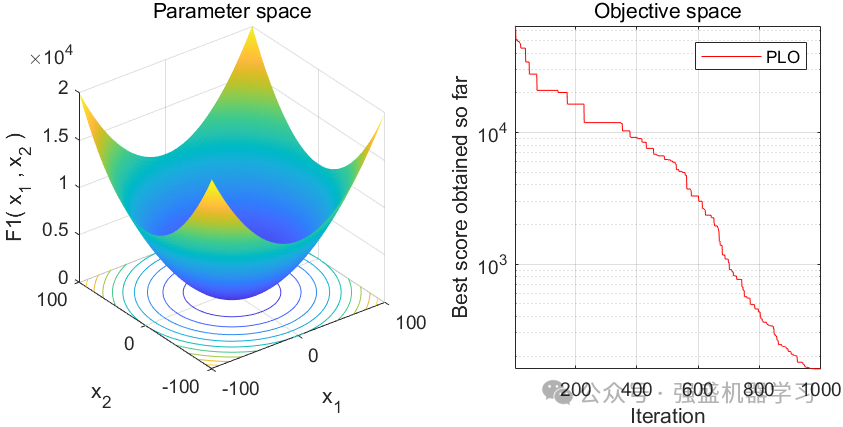
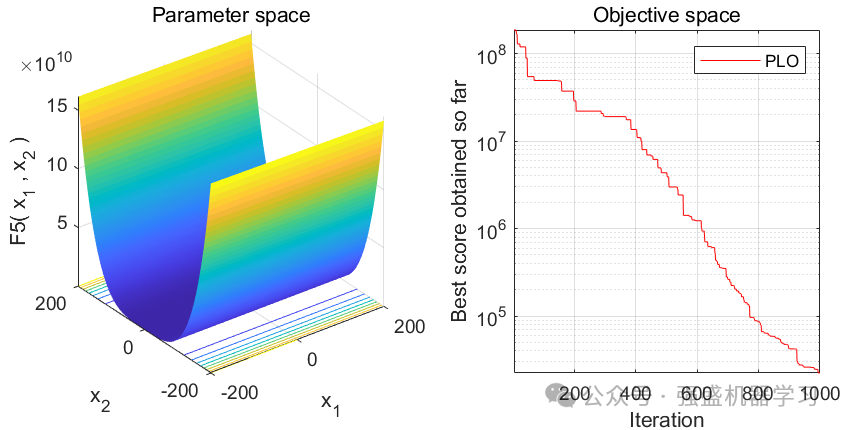
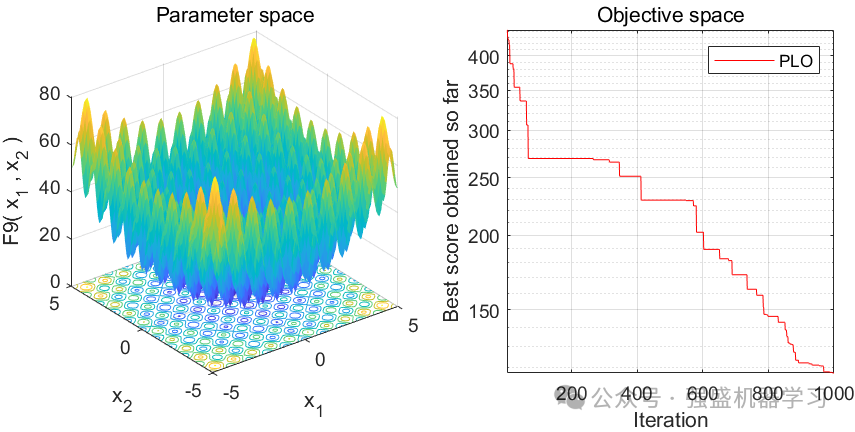
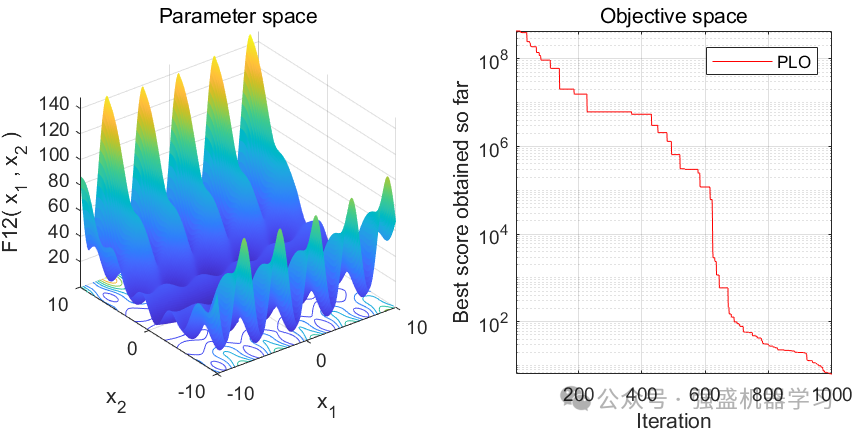
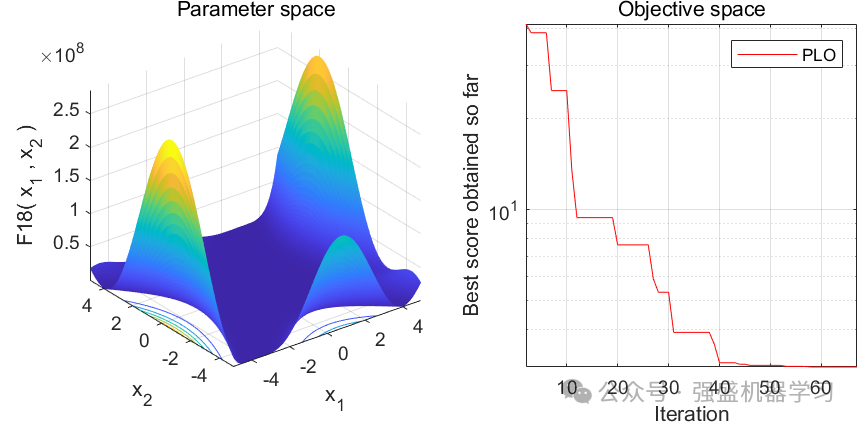
可以看到,这个算法收敛速度较快!大家应用到各类预测、优化问题中也是一个不错的选择~
参考文献
[1]Yuan C, Zhao D, Heidari A A, et al. Polar lights optimizer: Algorithm and applications in image segmentation and feature selection[J]. Neurocomputing, 2024, 607: 128427.
完整代码
如果需要免费获得图中的完整测试代码,只需点击下方小卡片,再后台回复关键字,不区分大小写:
PLO
也可点击下方小卡片,再后台回复个人需求(比如PLO-LSTM)定制以下PLO算法优化模型(看到秒回):
1.回归/时序/分类预测类:SVM、RVM、LSSVM、ELM、KELM、HKELM、DELM、RELM、DHKELM、RF、SAE、LSTM、BiLSTM、GRU、BiGRU、PNN、CNN、BP、XGBoost、TCN、BiTCN、ESN等等均可~
2.组合预测类:CNN/TCN/BiTCN/DBN/Adaboost结合SVM、RVM、ELM、LSTM、BiLSTM、GRU、BiGRU、Attention机制类等均可(可任意搭配非常新颖)~
3.分解类:EMD、EEMD、VMD、REMD、FEEMD、TVFEMD、CEEMDAN、ICEEMDAN、SVMD、FMD等分解模型均可~
4.路径规划类:机器人路径规划、无人机三维路径规划、冷链物流路径优化、VRPTW路径优化等等~
5.优化类:光伏电池参数辨识优化、储能容量配置优化、微电网优化、PID参数整定优化、无线传感器覆盖优化、故障诊断等等均可~~
6.原创改进优化算法(适合需要创新的同学):原创改进2024年的极光优化算法PLO以及班翠鸟PKO、蜣螂DBO等任意优化算法均可,保证测试函数效果!

















 1606
1606

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









