







(一)运动物体检测(在代码参考即书上学习过程中遇到的问题先整理下,再进行自己代码相关的介绍)
(1)points[]参数的解释 (在此处先进行内存的申请,并且在后续进行角点的存储)
最近在做基于OpenCV的点特征视频跟踪算法研究,老是出现assertion failed 问题,搞的我几乎差点放弃了,网上关于这个的帖子也比较少,但是这个最后解决了,很高兴啊。呵呵,具体来说就是指针的问题,要么指针或者数组越界、要么没有给指针或者数组申请内存。
const int MAX_COUNT = 900;
points[0] = (CvPoint2D32f*)cvAlloc(MAX_COUNT*sizeof(points[0][0]));
points[1] = (CvPoint2D32f*)cvAlloc(MAX_COUNT*sizeof(points[0][0]));
我的错误出现在这里:
for(b=size/2;b<50;b++)
for(a=size/2;a<50;a++)
{
if(CV_MAT_ELEM(*mat_corner,int,a,b)!=0)
{
points[1][q].x= a;//float
points[1][q].y= b;
q++;
}
}
当我的循环a,b的次数过于大的时候,而我申请的内存MAX_COUNT只有900时,就会出现上述错误。
解决办法:要么减小a、b的值,要么增大MAX_COUNT的值。。。。。
(2)opencv运动与跟踪
跟踪不明物体的方法是跟踪视觉上重要的关键点,并不是整个物体。局部特征可以用来进行跟踪,角点研究!!
跟踪一些独一无二的点。实际上,被选择的点或特征应该是独一无二的,或者至少接近独一无二。如果一个点在两个正交的方向上都有明显的导数,则我们认为词典更倾向是独一无二的。
最普遍的使用角点定义是Harris角点,图像灰度强度的二阶导数矩阵,即形成一幅性的hessian矩阵图像。对于Harris角点,我们使用每点周围小窗口的二阶导数图像的自相关矩阵。
故求角点准确位置的疑问转化为求使误差和S最小的点的疑问。该疑问可用迭代的要领优化求解,对式(1)两端同时乘以
可用迭代的要领优化求解
这样就得到了角点O的迭代式,通过对原始Harris角点执行 一定级数的迭代优化,可以得到其更精确的坐标位置
http://blog.sina.com.cn/s/blog_75e063c10100w7av.html
在使用opencv显示图像时会出现图像倒立的情况,IplImage的origin属性有关系。origin为0表示顶左结构,即图像的原点是左上角,如果为1为左下角。
一般从硬盘读入的图片或者通过cvCreateImage方法创建的IplImage图片默认的origin为0,即显示的时候都是正的。
而由摄像头或者视频文件获取的帧图像origin为1,此时显示的时候扫描顺序是从下到上,显示也是正的(opencv显示的时候是根据origin的值显示的,如果origin=1,则从下到上显示,否则反之)。
但是如果你自己创建了一个IplImage格式的图像img,且从帧图像中copy或者截取一部分区域进行显示的时候就会出现倒立情况。这是因为cvCreateImage方法得到的img的origin是0,而帧图像的origin为1,它会将帧图像的第i行赋值给img的第height-i行,因此就出现了倒立.解决办法是:在创建之后将origin调整为与帧图像的origin一致即可。
IplImage* face=cvCreateImage(cvSize(width,height),copy_Frame->depth,copy_Frame->nChannels);
//因为IplImage的origin=0,所以要先将face->origin改为1
face->origin=copy_Frame->origin;//1
后来在Google Book里查了一下,发现《Learning OpenCV:Computer Vision with the OpenCV Library》中有这么一段话描述的不错:
The sequence structure itself has some important elements that you should be aware of. The first, and one you will use often, is total . This is the total number of points or objects in the sequence. The next four important elements are pointers to other sequence: h_prev , h_next , v_prev and v_next . These four pointers are part of what are calledCV_TREE_NODE_FIELDS ; they are used not to indicate elements inside of the sequence but rather to connect different sequences to one another. Other objects in the OpenCV universe also contain these tree node fields.
而CvRect资料结构则是画方框 CvBox2D则是椭圆形的制作,一般感兴趣区域演算法都是用方框CvRect来做实作, CvBox2D则是在OpenCV用人脸椭圆追踪比较用的到。
cvRect()撷取感兴趣位置的座标,以及他的区块大小,前两个参数是座标,后两个是宽跟高
这两个资料结构都是OpenCV ,roi专用的资料结构,roi,全名的意思就是感兴趣的区域(感兴趣区) ,对于图形来讲,总是有一些物体或是重要的图像是我们必须要做研究,追踪或分析的,物件追踪在影像处理也是很大的一们领域,举凡是人脸追踪,汽车追踪,鸟类追踪,或是图形检索都是可以利用的roi的资料结构做实作的,而研究或分析的部份,则是对感兴趣的区域实作特殊的演算法,或是对他做纹理或特征分析,再资讯比对上面会得到很大的帮助。而CvRect资料结构则是画方框, CvBox2D则是椭圆形的制作,一般感兴趣区域演算法都是用方框CvRect来做实作, CvBox2D则是在OpenCV用人脸椭圆追踪比较用的到。

这张图片则是简单的实作撷取感兴趣的区域,图中人物的头像被cvRect资料结构设定,传给IplImage资料结构而被抓到了,这只是一个简单的手动抓人物的实作.这边ROI的制作方式有很多种,这边只是其中一种的介绍,之后还会有ROI相关的函式应用,在这张图片内,利用cvRect()撷取感兴趣位置的座标,以及他的区块大小,前两个参数是座标,后两个是宽跟高,再将cvRect资料结构用cvRectToROI()转成IplROI格式,然后直接给IplImage资料结构内的ROI,而Rect2的实作也只是把IplROI结构转换成CvRect的资料结构罢了,而如果把IplImage资料结构的ROI设定成NULL,那又会回到原图影像大小了,在这边cvRectToROI()的第二个参数是COI(Color Of Interesting)感兴趣的通道颜色,而在OpenCV的cvShowImage()没有被实作出来,而它还是在其他演算法函式上被用的到.
typedef struct CvRect
{
int x; /* 方形的最左角的x-坐标 */
int y; /* 方形的最上或者最下角的y-坐标 */
int width; /* 宽 */
int height; /* 高 */
}
CvRect;
/* 构造函数*/
inline CvRect cvRect( int x, int y, int width, int height );
#include "stdafx.h"
#include "cv.h"
#include "highgui.h"
int main()
{
IplImage *Image1;
IplROI ROI;
CvRect Rect1,Rect2;
Image1=cvLoadImage("coast2.jpg",1);
Rect1=cvRect(200,50,100,100);
ROI=cvRectToROI(Rect1,0);
Image1->roi=&ROI;
Rect2=cvROIToRect(*Image1->roi);
cvNamedWindow("Coast(Region Of Interesting)",1);
cvShowImage("Coast(Region Of Interesting)",Image1);
Image1->roi=NULL;
cvNamedWindow("Coast",1);
cvShowImage("Coast",Image1);
cvWaitKey(0);
}
CvBox资料结构
#include <cv.h>
#include <highgui.h>
#include <stdio.h>
#include <stdlib.h>
int main()
{
CvPoint2D32f Point1 =cvPoint2D32f(200,200);
CvSize2D32f Size1 = cvSize2D32f(50,50);
CvBox2D Box1;
Box1.center=Point1;
Box1.size=Size1;
Box1.angle=90;
printf("Box Point is :(%.1f,%.1f)\n",Box1.center.x,Box1.center.y);
printf("Box Size is : (%.1f,%.1f)\n",Box1.size.width,Box1.size.height);
printf("Box Angle is : %.1f\n",Box1.angle);
system("pause");
}

CvScalar s; s=cvGet2D(img,i,j); //img就是IplImage指针了 如果图像是单通道的话就是只有s.val[0]有像素值 如果是3通道的就s.val[0]s.val[1]s.val[2]分别对应了像素的B G R这样够明了了吧?不过据说这个方法是比较慢的,但是好理解,你熟悉的话,
CvScalar定义可存放1—4个数值的数值,其结构如下。
typedef struct CvScalar
{
double val[4];
}
CvScalar;
------------------------------------------------
CvScalar pt;
如果使用的图像是1通道的,则pt.val[0]中存储数据
如果使用的图像是3通道的,则pt.val[0],pt.val[1],pt.val[2]中存储数据
==============================
cvGet2D 获得某个点的值, idx0=hight 行值, idx1=width 列值。
CVAPI(CvScalar) cvGet2D( const CvArr* arr, int idx0, int idx1 );
-----------------------------------------------
cvSet2D 给某个点赋值。
CVAPI(void) cvSet2D( CvArr* arr, int idx0, int idx1, CvScalar value );
-----------------------------------------------
由上可见,cvGet2D的返回类型和cvSet2D中value的类型都是CvScalar,这样定义一个CvScalar变量再调用函数就OK了。
cvSplit(src,dst1,dst2,dst3,0)是把三通道分离为dst1,dst2,dst3,;
cvMerge(dst1,dst2,dst3,0,dst)是把三通道dst1,dst2,dst3合为dst。
如果用cvMerge(0,0,dst3,0,dst)只是用了R通道,图像是红的。
四个通道 单通道图像是灰度图,三通道是BGR图,四通道也是BGRA图
cvAbsDiff
Calculates absolute difference between two arrays.
void cvAbsDiff(const CvArr* src1, const CvArr* src2, CvArr* dst);
src1 The first source array
src2 The second source array
dst The destination array
The function calculates absolute difference between two arrays.
dst(i)c = |src1(I)c − src2(I)c |
All the arrays must have the same data type and the same size (or ROI size).
这是文档中关于这个函数的介绍
它可以把两幅图的差的绝对值输出到另一幅图上面来
在QQ游戏里面有一款叫做"我们来找茬",就是要找两幅图的不同点
1先帧差2 之后一旦运动模板记录了不同时间的物体轮廓,3我们就用mhi图像的梯度来获取全局运动信信息,来计算出的这些梯度,由于使用cvUpdateMotionHistory()将新的轮廓引进mhi的时间步长是已知的。
mhi为运动历史图。
cvCmp和cvCmpS
- void cvCmp(
- const CvArr* src1,
- const CvArr* src2,
- CvArr* dst,
- int cmp_op
- );
- void cvCmpS(
- const CvArr* src,
- double value,
- CvArr* dst,
- int cmp_op
- );
这两个函数都是进行比较操作,比较两幅图像相应的像素值或将给定图像的像素值与某常标量值进行比较。cvCmp()和cvCmpS()的最后一个参数的比较操作符可以是表3-5所列出的任意一个。【55】
表3-5:cvCmp()和cvCmpS()使用的cmp_op值以及由此产生的比较操作
| cmp_op的值 | 比较方法 |
| CV_CMP_EQ | (src1i == src2i) |
| CV_CMP_GT | (src1i > src2i) |
| CV_CMP_GE | (src1i >= src2i) |
| CV_CMP_LT | (src1i < src2i) |
| CV_CMP_LE | (src1i <= src2i) |
| CV_CMP_NE | (src1i != src2i) |
表3-5列出的比较操作都是通过相同的函数实现的,只需传递合适的参数来说明你想怎么做,这些特殊的功能操作只能应用于单通道的图像。
这些比较功能适用于这样的应用程序,当你使用某些版本的背景减法并想对结果进行掩码处理但又只从图像中提取变化区域信息时(如从安全监控摄像机看一段视频流)。
IplImage *image;
CvSeq *cont;
image为二值图(只有黑白两色)
已找到image的cont轮廓(只有一个轮廓)
如何将轮廓内的像素点全设为RGB(255,255,255)
需要代码.
//设置一个矩形框
CvRect r = ((CvContour*)cont)->rect;
//设定颜色
CvScalar color = CV_RGB(255,255,255);
//设置感兴趣区域ROI
cvSetImageROI(image,r);
//填充
cvSet(image,color);
//取消感兴趣区域
cvResetImageROI(image);
不是填充rect,而是填充不规则的轮廓
在\samples\motempl.c有如下语句
comp_rect = ((CvConnectedComp*)cvGetSeqElem( seq, i ))->rect;
我觉得有些不解,这里的参数seq是cvSegmentMotion函数的CvSeq*型输出,cvGetSeqElem函数也应该返回指针指向CvSeq,为什么这里通过(CvConnectedComp*)类型强制转换后就会有"->rect"的成员变量?CvSeq的定义如下:
------------------------
#define CV_SEQUENCE_FIELDS() \ // 定义在cxtypes.h
int flags; /* micsellaneous flags */ \
int header_size; /* size of sequence header */ \
struct CvSeq* h_prev; /* previous sequence */ \
struct CvSeq* h_next; /* next sequence */ \
struct CvSeq* v_prev; /* 2nd previous sequence */ \
struct CvSeq* v_next; /* 2nd next sequence */ \
int total; /* total number of elements */ \
int elem_size; /* size of sequence element in bytes */ \
char* block_max; /* maximal bound of the last block */ \
char* ptr; /* current write pointer */ \
int delta_elems; /* how many elements allocated when the sequence grows (sequence granularity) */ \
CvMemStorage* storage; /* where the sequence is stored */ \
CvSeqBlock* free_blocks; /* free blocks list */ \
CvSeqBlock* first; /* pointer to the first sequence block */
typedef struct CvSeq
{
CV_SEQUENCE_FIELDS() //调用前面的宏定义
} CvSeq;
------------------------
CvConnectedComp定义连接部件,其结构如下
------------------------
typedef struct CvConnectedComp
{
double area; /* 连通域的面积 */
float value; /* 分割域的灰度缩放值 */
CvRect rect; /* 分割域的 ROI */
} CvConnectedComp;
------------------------
我把源程序更改如下:
CvSeq *temp;
temp = cvGetSeqElem( seq, i );
comp_rect = ((CvConnectedComp*)temp)->rect;
单步调试时发现,最后comp_rect能得到正确的变量{x=0,y=0,width=640, height=352},但temp指针指向的内容中,却没有相关的内容。所以我不太明白的是,一个CvSeq的指针,强制转换为CvConnectedComp后,怎么就能提取出>rect变量?谢谢指教
解决:::1这个显然和多态有关,可知seq是CvConnectedComp的基类,在结果中将基类强制转化为派生类是允许的,因为之前函数的返回值就是派生类的,而反向则不能,因为会丢失信息,楼主可以看一下关于C++中关于多态的知识
2我回去看了一下,您说的可能有些问题,首先这两个不是类,只是结构体,其次它们之间也没有派生的关系。我仔细看了文件,可能是这个原因:
在cvSegmentMotion函数所在的Motempl.cpp中,相应函数定义如下:
{
CvSeq* components = 0;
...
CvConnectedComp comp;
...
cvSeqPush(components, &comp);
...
return components;
}
而在\samples\motempl.c如下语句
seq = cvSegmentMotion();
...
comp_rect = ((CvConnectedComp*)cvGetSeqElem( seq, i ))->rect;
cvGetSeqElem函数定义时不知道其中的element具体是什么类型的,所以返回是schar*类型的,但在这里的实际情况是CvConnectedComp类型的,所以需要强制转换
count = cvNorm( silh, 0, CV_L1, 0 ); // calculate number of points within silhouette ROI
计算各种范数!!!!参见opencv-P81
int cvRound (double value)
对一个double型的数进行四舍五入,并返回一个整型数!
在Opencv里面画箭头
在optical flow一节的例题里,看到有人利用箭头来表现flow vector,很疑惑,因为opencv本身并没有画箭头的函数,那么如何来实现呢?其实可以通过画三条线段来构成一个箭头:/*获得箭头的起点、终点坐标,两点间线段的角度和长度*/
CvPoint p,q;//新建lianggedian p,q
p.x = (int) frame1_features[i].x; //第N副image中的点x坐标
p.y = (int) frame1_features[i].y;//第N副Image中的点y坐标
q.x = (int) frame2_features[i].x;//第N+1副image中的点x坐标
q.y = (int) frame2_features[i].y;;//第N+1副image中的点y坐标
double angle; angle = atan2( (double) p.y - q.y, (double) p.x - q.x );//线段pq的坡角大小
double hypotenuse; hypotenuse = sqrt( square(p.y - q.y) + square(p.x - q.x) );//线段pq的长度
/*为了清楚直观,将箭头长度变成原长度的3倍,即减小终点坐标 */
q.x = (int) (p.x - 3 * hypotenuse * cos(angle));
q.y = (int) (p.y - 3 * hypotenuse * sin(angle));
/*绘制箭头主线. */
cvLine( frame1, p, q, line_color, line_thickness, CV_AA, 0 );/* p为线段起点,q 为终点,CV_AA 为平滑直线*/
/* 绘制箭头上下两条短线*/
p.x = (int) (q.x + 9 * cos(angle + pi / 4));//箭头上短线1,角度为pq角度上增pi/4,长度为9
p.y = (int) (q.y + 9 * sin(angle + pi / 4));//获得短线1起点x,y
cvLine( frame1, p, q, line_color, line_thickness, CV_AA, 0 );//以q为终点绘制第一条箭头短线
p.x = (int) (q.x + 9 * cos(angle - pi / 4));//箭头下短线2,角度为pq角度减少pi/4,长度为9
p.y = (int) (q.y + 9 * sin(angle - pi / 4));//获得短线2起点x,y
cvLine( frame1, p, q, line_color, line_thickness, CV_AA, 0 );//画下第二条箭头短线
}
Lucas-Kanade算法原理---光流检测
三个假设:(1)亮度恒定:被跟踪像素的灰度不随时间变化而变化
(2)时间连续
均方误差的大小在一定程度上放映了用经验公式来近似表达原来函数关系的近似程度的好坏!
多元函数的泰勒展开公式高数书的下册P119.!!!!
最小二乘法即找到的偏差的平方和最小,也即为在此点为极值点,所以分别建立偏导数为零,这样联立求出相应的系数,即得到最小二乘法,见高数书的下册P126!!!!!

求取一维到二维的光流,这求得的是一条运动的直线而不是一个特定的点!

牛顿迭代法:牛顿法是将非线性方程f(x) = 0逐步归结为某种线性方程来求解。
切线法:设xn是x*的摸个近似值,过曲线y=f(x)上横坐标为xk,的点pk引切线,并肩该切线与x轴交点的横坐标xn+1,作为新的近似值。
一系列的图像可以检测出运动的瞬时速度或离散图像位移。每一个时刻均有一个二维或多维的向量集合,如(x,y,t),表示指定坐标在t点的瞬时速度。设I(x,y,t)为t时刻(x,y)点的强度,在很短的时间Δt内,xy分别增加Δx, Δy ,可得:、

同时,考虑到两帧相邻图像的位移足够短,因此:

因此


最终可得出结论:
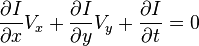
这里的  是
是 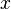 和
和  的速率,或称为
的速率,或称为 的光流。
的光流。 ,
,  和
和  是图像
是图像  在t时刻特定方向的偏导数。
在t时刻特定方向的偏导数。  ,
, 和
和  的关系可用下式表述:
的关系可用下式表述:

或
-

-
- 光流再算速度的时候,运用亮度恒定的假设,假设像素被逐帧跟踪式其亮度不发生变化
- 在这有一个问题不理解???
- 时域导数和空域导数的相除即可的到速度的方向,但是怎样得到的!!!
- 和二师兄商讨一番之后,理解了光流的方向问题,思考了一个下午.
- 对于一维的Lucas-Kanade光流跟踪首先在满足第一个假设的前提下,即亮度恒定。
- 这就是说,被跟踪的像素的灰度不随时间的变化而变化:
-

- 由这个亮度恒定的等式可以得到将亮度f(x, t)用I(x(t), t)替换, 再应用偏导数的链式规则即
-

- 其中
-

- 对于二维的即一个公式和上面的一个图
-

- 可能大家对这些公式还是比较容易理解的但是对于图像的表示,还有那个It和Ix即V得方向的判断有一些问题,其中It为时域导数,即一个点随时间的变化情况,我们考虑应该纵向考虑,即一个点在不同帧下的变化情况,即可以
-

- 是如图的O1,和O2 ,只是同一点在不同时课的曲线变化所引起的一个值的差异性即时域导数
- Ix是空域导数,即这一点的梯度方向,这个可虑的是同一帧下的情况,并非是不同帧的情况,因此可以认为是在这一条曲线上时, 该点的一个梯度的变化情况,上升或者下将。
- V而对于上面的式子只是一种推导的形式,这个V就是我们所要研究的那个图像的方向,比如我们的一维图线,我们的V方向无非就是X正半轴或者X负半轴,我们得到的像素梯度的变化方向,即沿着X的方向。 而对于二维的情况,我们考虑的那个v是我们在这一点的一个拓扑性的考虑,我们从这点进行铺开考虑空域梯度,因此我们这个方向肯定要和时域导数It相垂直的。
-
- 进而由于单维的空径问题,我们在基于第三个假设的条件下-----空间一致,考虑用5 * 5邻域的像素的亮度值来计算此像素的运动。
-

- 这里的讲义已将很详细了,因为我们的最小二乘是要求在第一个假设的情况下,亮度不变,所以此时我们要使那个绝对值得平方和最小,从而保证亮度的最小变化情况,又由于IxIx和IyIy的求和是都不为0的,因此秩数的个数2,即确定这个点处有两个较大的特征向量,因此可以得出角点的一个较好特征的依据。
-
- 接下来金字塔 Lucas-Kanade光流,连贯的运动假设可以应用。
-















 1076
1076

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









