







之前的两个小专题已经把划分方法聚类/层次方法聚类过了一遍,接下来就是我个人非常喜欢的一类聚类算法——密度聚类算法。
通过之前的博文,我们发现划分方法聚类算法与层次聚类算法把距离(欧氏距离,闵可夫斯基距离,曼哈顿距离等)作为两个样本或者两个簇之间相似度的评价指标,因此导致了划分方法聚类算法和层次聚类算法都旨在发现球状簇,对任意形状的聚类簇比较吃力。
如下图所示,左边的聚类簇,很明显是球状簇,那么此时我们使用划分方法聚类算法、层次聚类算法来进行聚类簇的发现。但是对于右边的簇,上面这两种方法明显就不行了。
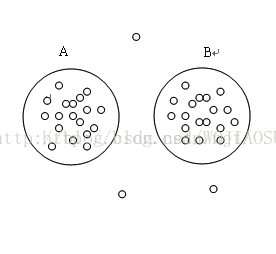

为了发现任意形状的簇,作为选择,我们可以把簇看做数据空间中被稀疏区域分开的稠密区域。
基于密度的聚类算法假设聚类结构能够通过样本分布的紧密程度确定。
通常情况下,密度聚类算法从样本密度的角度进行考察样本之间的可连接性(实际就是串联关系。),并由可连接样本不断扩展聚类簇直到获得最终的聚类结果。
基于密度聚类算法的主要特点是:
(1) 发现任意形状的簇
(2) 处理噪声
(3) 一次扫描
(4) 需要密度参数作为终止条件
主要的聚类算法有:DBSCAN,OPTICS,DENCLUE等,接下来的博文将学习以上这几种算法。














 1659
1659











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









