







DBSCAN是一种著名的密度聚类算法,基于一组邻域参数(r,MinPts)来刻画样本的紧密程度。说的通俗点就是以某个样本点为中心,以r为半径进行画圆,在圆内的范围都是邻域范围。
基本概念:
(1)r-邻域。对任意Xi属于数据集D,其r邻域包含样本集D中与Xi的距离不大于r的样本,即N(Xi)={Xj属于D,dist(Xi,Xj)<=r}。(其实就是画了个圈子)
(2)核心对象。核心对象就是r-邻域内至少包含MinPts个样本,即|N(Xi)|>=MinPts,
那么Xi为一个核心对象。(圈子内的小弟足够多,那么就是老大,否则就不是老大)
(3)密度直达。如果Xj位于Xi的r-邻域内,并且Xi为核心对象,则称Xj由Xi密度直达。(可以理解为由老大直接领导的小弟)
(4)密度可达。对Xi与Xj,如果存在样本序列P1,P2…Pn,其中P1=Xi,Pn=Xj且P(i+1)由Pi密度直达,则称Xj由Xi密度可达。(可以理解为别人家的小弟,不在我的直接领导下,但是还是可以下点命令的吧)
(5)密度相连。对Xi与Xj,如果存在Xk使得Xi与Xj均由Xk密度可达,则称Xi与Xj密度相连。(可以理解为Xk找了两个小弟,注意Xk必须是老大,两个小弟地位等同)
这里给大家提一下,这个r-邻域中的距离怎么衡量呢?用什么指标来进行衡量?
参照之前博文讲的几种样本相似度度量的距离标准,一般用欧氏距离即可。
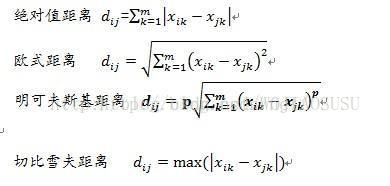
了解了这些概念之后,接下来就开始正式了解一下DBSCAN算法。

总结起来DBSCAN就是三个步骤:
(1) 先找出所有的核心对象来。
(2) 然后对所有的核心对象进行随机遍历,找出所有的密度可达点。(可达的概念还是挺重要的,其实就是核心点在中间当做桥梁,即一个核心对象的邻域内也包含其他的核心对象,这样就可以串下去了)
(3) 当所有的核心对象点遍历完之后,剩下的点就是噪声点或者是低密度区域。
理解了这三句话,DBSCAN算法基本就差不多了。接下来分析一下DBSCAN的优缺点以及改进的方向。
算法的显著优点是聚类速度快且能够有效处理噪声点和发现任意形状的空间聚类。但是由于它直接对整个数据库进行操作且进行聚类时使用了一个全局性的表征密度的参数,因此也具有比较明显的弱点:
(1)当数据量增大时,要求较大的内存支持I/O消耗也很大;
(2)当空间聚类的密度不均匀、聚类间距差相差很大时,聚类质量较差。
(3)与用户输入的邻域半径及密度域值密切相关,可能由于用户对数据特点不了解而输入不合适的参数得出不准确的结论。参数敏感
(4)算法过滤噪声点同时也是其缺点,造成了其不适用于某些领域(比如网络安全领域中恶意攻击的判断)
与K-MEANS算法相比较DBSCAN算法的优点:
(1) 不必输入聚类簇数量K。
(2) 聚类簇的形状没有任何限制。
(3) 可以在需要的时候输入过滤噪声的参数。














 2388
2388











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









