







原文:Drone-based Object Counting by Spatially Regularized Regional Proposal Network
摘要:现有的计数方法通常采用基于回归的方法,并且不能精确定位目标对象,这妨碍了进一步的分析(例如高级理解和细粒度分类)。此外,以前的大部分工作主要集中在使用固定摄像头对静态环境中的物体进行计数。受无人驾驶飞行器(即无人驾驶飞机)出现的驱动,我们有兴趣在这种动态环境中检测和计数物体。我们提出布局建议网络(LPN)和空间内核,以同时对无人机录制的视频中的目标对象(例如汽车)进行计数和本地化。与传统的地区建议(region proposal)方法不同,我们利用空间布局信息(例如,汽车经常停车),并将这些空间正则化约束引入到我们的网络中,以提高定位精度。为了评估我们的计数方法,我们提出了一个新的大型汽车停车场数据集(CARPK),其中包含从不同停车场捕获的近9万辆汽车。据我们所知,它是支持对象计数的第一个也是最大的无人机视图数据集,并提供了边界框注释。
1、介绍
随着无人驾驶飞行器的出现,新的潜在应用出现在针对航空相机的无限制图像和视频分析中。 在这项工作中,我们解决了计算无人驾驶视频中物体(例如汽车)数量的计数问题。 用于监视停车场的现有方法[10,2,1]通常假设场景的被监视对象的位置已经预先已知并且摄像机被固定,并且投掷汽车计数作为分类问题,这使得传统汽车 计数方法不直接适用于无约束无人机视频。
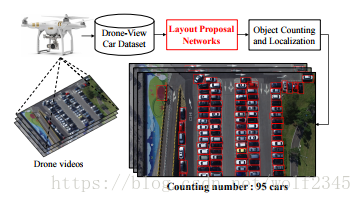
图1.我们提出了一个布局建议网络(LPN)来对无人机视频中的对象进行本地化和统计。 我们介绍了用于学习我们的网络的空间限制,以提高定位精度。 详细的网络结构如图4所示。
目前的对象计数方法经常学习一种将高维图像空间映射到非负计数的回归模型[30,18]。 然而,这些方法不能产生精确的物体位置,这限制了进一步的研究和应用(例如识别)。
我们观察到,对于一组对象实例存在某些布局模式,可以利用这些布局模式来提高对象计数的准确性。 例如,汽车常常停在一排,动物聚集在一定的布局(例如,鱼环和鸭漩涡)。 在本文中,我们介绍了一种新颖的布局建议网络(LPN),可对无人机视频中的物体进行计数和本地化(图1)。 与现有的对象提议方法不同,我们引入了一种新的空间正则化损失来学习我们的布局建议网络。 请注意,我们的方法学习对象提议之间的一般相邻关系,并不特定于某个场景。
我们的空间正则化损失是一种权重方案,它对不同的对象提议的重要性分数进行重新加权,并鼓励将区域提案放置在正确的位置。 它通常也可以嵌入任何物体检测系统中进行物体计数和检测。 通过利用空间布局信息,我们改进了公共PUCPR数据集[10](从59.9%到62.5%)的最新地区建议方法的平均召回率。
表1.鸟瞰车相关数据集的比较。 与PUCPR数据集相比,我们的数据集支持在单个场景中为所有车辆提供边界框注释的计数任务。 最重要的是,与其他汽车数据集相比,我们的CARPK是无人机场景中唯一的数据集,并且具有足够多的数量,以便为深度学习模型提供足够的训练样本。


图2.(a),(b),(c),(d)和(e)是OIRDS [28],VEDAI [20],COWC [18],PUCPR [10]和CARPK (我们的)数据集(每个数据集有两个图像)。 与(a),(b)和(c)相比,PUCPR数据集和CARPK数据集在单个场景中拥有更多的汽车数量,更适合评估计数任务。
为了评估我们方法的有效性和可靠性,我们引入了一个新的大型计数数据集CARPK(表1)。 我们的数据集包含89,777辆车,并为每辆车提供边界框注释。 此外,我们考虑PKLot [10]的子数据集PUCPR,它是PKLot数据集中场景关闭到鸟瞰图的那个。 我们的新CARPK数据集提供了无约束场景中的第一个和最大规模的无人机视图停车场数据集,而不是PUCPR数据集中高层建筑的固定摄像机视图(图2)。 此外,PUCPR数据集只能与分类任务结合使用,该分类任务将预先裁剪的图像(汽车或非汽车)与给定位置分类。
此外,PUCPR数据集仅注释部分关注区域的停车区域,因此不能支持计数任务。 由于我们的任务是对图像中的对象进行计数,因此我们还为部分PUCPR数据集以单幅全图像对所有汽车进行注释。 我们的CARPK数据集的内容在4个不同停车场的各种场景中是无脚本和多样化的。 据我们所知,我们的数据集是第一个也是最大的基于无人机的数据集,它可以支持计数任务,并为完整图像中的众多汽车提供手动标注的注释。 本文的主要贡献总结如下:
1. 据我们所知,这是利用空间布局信息进行物体区域建议的第一项工作。 我们改进了公共PUCPR数据集中最新地区提案方法的平均召回率(即59.9%[22]至62.5%)。
2. .我们引入了一个新的大型停车场数据集(CARPK),其中包含近9万辆基于无人机场景的高分辨率图像记录的汽车停车场。 最重要的是,与其他停车场数据集相比,我们的CARPK数据集是支持计数的第一个也是最大的停车场数据集.
3. 我们对本区域提案方法的不同决策选择提供深入分析,并证明利用布局信息可以大大减少提案并改进计数结果。
2 相关工作
2.1 目标计数
大多数当代计数方法大致可以分为两类。 一个是通过回归方法计数,另一个是通过检测实例计数[17,14]。 回归计数器通常是高维图像空间到非负计数的映射。 有几种方法[3,6,7,8,15]试图通过使用受低级特征训练的全局回归器来预测计数。 但是,全局回归方法忽略了一些约束条件,例如人们通常在人行道上行走以及实例的大小。 还有一些基于密度回归的方法[23,16,5],它们可以通过可计数对象的密度来估计对象计数,然后在该密度上聚合。
最近,大量作品将深入学习引入人群统计任务。 Zhang等人没有将计算物体的数量计算在有限的场景中, [31]解决了过场人群统计任务的问题,这是过去的密度估计方法的弱点。 Sindagi等人 [26]结合全球和当地的背景信息,以更好地估计人群数量。 Mundhenk等人 [18]通过提取图像块的表示来估计航空图像子空间中的汽车数量,以近似物体组的外观。 Zhang等人 [32]利用FCN和LSTM联合估算车辆密度并计算城市摄像机拍摄的低分辨率视频。 然而,基于回归的方法不能产生精确的对象位置,这严重限制了进一步的研究和应用(例如,高级理解和细粒度分类)。
2.2 目标建议
近年来,地区提案发展良好,网络深厚。 由于在推断时间内在多个位置和尺度上检测对象需要计算量大的分类器,因此解决此问题的最佳方法是查看可能位置的一小部分。 最近的一些工作证明,基于深度网络的区域提案方法已经超过了以前的作品[29,4,33,9],这些作品基于低级提示,有了大幅度提高
3 数据集
由于缺乏大型标准化公共数据集,其中包含无数基于无人机的图像集合,因此很难创建用于深度学习模型的自动计数系统。例如,OIRDS [28]仅有180辆独特的汽车。最近与汽车相关的数据集VEDAI [20]拥有2,950辆汽车,但这些数据仍然太少,无法用于深度学习者。较新的数据集COWC [18]拥有32,716辆汽车,但图像分辨率仍然很低。它每辆车只有24到48个像素。此外,标注格式不是以boundingbox的形式标注,而是以汽车模型检索,汽车品牌统计,以及探索哪种类型的汽车为主的汽车的中心像素点,不能进一步调查。将在当地开车。此外,以上所有数据都是低分辨率图像,无法提供详细信息用于学习细粒度的深层模型。现有数据集的问题是:1)低分辨率图像可能损害训练模型的性能; 2)数据集中的车号较少,有可能在训练深度模型时导致过度拟合。
由于现有数据集存在上述问题,因此我们从无人机视图图像创建了大型停车场数据集,这些数据集更适合深度学习算法。它支持对象计数,对象本地化和进一步调查,通过提供boundingbox方面的注释。与我们最相似的公共数据集,也有高分辨率的汽车图像,是PKLot的子数据集PUCPR [10],它从建筑物的第10层提供视图,因此类似于无人机视图图像到一定程度上。但是,PUCPR数据集只能与分类任务一起使用,该分类任务会将给定位置的预处理图像(汽车或非汽车)分类。此外,该数据集仅从单个图像中的总共331个停车位注释了一部分汽车(100个特定停车位),使其无法支持计数和本地化任务。因此,我们从部分PUCPR数据集的单个图像中完成所有汽车的注释,称为PUCPR +数据集,现在总共拥有近17,000辆汽车。除了PUCPR的不完整标注问题之外,还有一个致命的问题,即它们的摄像机传感器被固定在同一个地方,使得数据集的图像场景完全相同 - 导致深度学习模型遇到数据集偏差问题。
出于这个原因,我们引入了一个全新的数据集CARPK,我们的数据集的内容在4个不同的停车场的各种场景中是无脚本和多样化的。我们的数据集还包含大约90,000辆无人机视角的汽车。它与PUCPR数据集中高层建筑的摄像头不同。这是一个用于在各种停车场场景中进行汽车计数的大型数据集。该图像集通过为每辆车提供边界框进行注释。所有标记的边界框都用左上角和右下角记录得很好。只要标记区域可以被识别,并且可以确定该实例是一辆汽车,就会包含位于图像边缘的汽车。据我们所知,我们的数据集是第一个也是最大的基于无人机视图的停车场数据集,可支持以全图形方式为大量汽车提供手动标记的注释计数。表1中列出了数据集的细节,图2中显示了一些示例。
4 方法
我们的物品计数系统采用了一个区域建议模块,它考虑了规则化的布局结构。 它是一个深度完全卷积网络,将任意大小的图像作为输入,并输出可能包含实例的对象不可知提议。 整个系统是一个统一的对象统一框架(图1)。 通过利用复现实例对象的空间信息,LPN模块不仅关注可能的位置,而且还建议目标检测模块在图像中应该看的方向。
4.1. Layout Proposal Network(布局建议网络LPN)
我们观察到,对于一组对象实例存在某些布局模式,可用于预测可能以相同方向或相同实例附近出现的对象。 因此,我们设计了一个新颖的地区建议模块,可以利用结构布局并从特定方向收集附近物体的置信度分数(图3)。
我们综合描述LPNs的设计网络结构(图4)如下。 类似于RPN [22],网络通过在共享卷积特征映射上滑动小网络来生成区域提议。 它将最后一个卷积层上的3×3窗口作为输入,用于减少表示维度,然后将特征馈送到两个相同的1×1卷积层,其中一个用于定位,另一个用于分类该框属于前景还是分类。 区别在于我们的损失函数为每个位置处的预测框引入空间正则化权重。 利用空间信息的权重,我们可以最大限度地减少网络中多任务对象功能的损失。 我们在每幅图像上使用的损失函数定义如下:
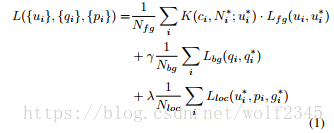
Nfg和Nbg约定俗成的前景和背景。Nloc和Nfg相同是因为它只考虑前景类的数量,如果IoU与ground trouth重叠高于0.7,或者具有最高的IoU与gruoud trouth框交叠的默认框,默认框标记为u * i = 1;如果IoU与ground trouth重叠低于0.3,默认框标记为q*i=0。Lfg(ui,ui*) = -log[ui,ui*]和Lbg(qi,qi*)=-log(1-qi)(1-qi*)是真实类别最小化的负面对数似然率。这里,i是预测框的索引。在前景损失前面,K表示我们应用空间正则化权重来重新加权每个预测框的客观分数。对于预测盒的中心位置ci,通过高斯空间核得到权重。 它将根据邻近ci的m个相邻的ground truth 中心点给出重新排列的权重。 ci的真实相邻中心被表示为N * i = {c * 1,...,c * m}∈S ci,其落入输入图像上的空间窗口像素大小S内。 我们在本文中使用S = 255来获得更大的空间范围。
Lloc是本地化损失,这是一个强大的损失函数[11]。 这个项只对前景predict box(u * i = 1)有效,否则为0.与[22]类似,我们计算前景预测盒pi与地面真值盒gi之间的偏移损失与它们的中心位置(x ,y),宽度(w)和高度(h)。

在我们的实验中,我们将γ和λ设置为1.另外,为了处理小对象,而不是conv5-3层,我们选择conv4-3图层特征以获得输入图像上更好的拼贴默认框跨度并选择 默认盒子尺寸比默认设置(128×128,256×256,512×512)小四倍(16×16,40×40,100×100)。
图4.布局建议网络的结构。 在损失层,结构权重被整合以重新加权候选人
框以获得更好的结构建议。 更多细节见第4.2节。
4.2. Spatial Pattern Score
实例的大多数对象在彼此之间呈现出一定的模式。 例如,汽车将在停车场沿着一个方向排列,船舶将定期拥抱岸边。 即使在生物学中,我们也可以找到集体动物的行为,让他们看到某种布局(例如,鱼类环面,鸭漩涡和蚂蚁厂)。 因此,我们引入了一种在培训阶段以端对端方式重新加权区域提案的方法。 所提出的方法可以减少推断阶段中用于减少计数和检测过程的计算成本的提议的数量。 对于嵌入式设备(如无人机)来说,降低功耗尤为重要,因为电池电量只能为无人机提供能量,仅能维持20分钟。
为了设计布局模式,我们在输入图像的空间上应用不同方向的二维高斯空间核K(见方程1),其中高斯核的中心是预测的方框位置ci。 我们计算所有正向预测框的置信度权重。 通过结合基础事实的布局知识,我们可以了解每个预测盒子的权重。 在方程4中,它表明预测位置ci的空间模式分数是Sci内部的地面真值位置的权重总和。 我们计算输入三元组的分数(ci,N * i,u * i):
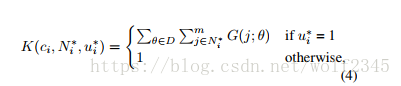
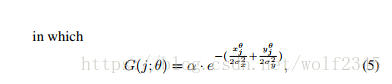
G具有不同旋转半径D = {θ1,...θr}的二维高斯空间核,其中我们使用r = 4,范围从0到π。 坐标(xj,yj)是方程5中第j个地面真值盒的中心位置,系数α是高斯函数的幅值。 所有实验使用α= 1
我们只给出标记为u * i = 1的前景预测box ci的权重。通过在不同方向核心(方程4)中聚合来自地面真值盒子N * i的权重,我们可以计算出一个总和 考虑各种布局结构的分数。 它将给物体位置提供更高的概率,物体位置的weight更大。 即,围绕它的实例越相似的对象,预测的盒子越有可能是相同类别的实例。 因此,预测盒子收集来自附近相同物体的信心(图3)。 通过利用空间正则化的权重,我们可以学习一个用于生成区域建议的模型,其中实例的对象将以其自己的布局显示。














 2002
2002











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









