






5.1 时间上下文信息
在进行推荐时,我们还需要考虑到用户所处的时间,季节,地点,心情等上下文信息来进行推荐(比如我们不能在冬天给用户推荐T恤等)。
5.1.1 时间效应
1.用户的兴趣是变化的:随着年龄增长,喜欢的电视剧可能会从动画片变为文艺片;喜欢的书籍也会随着自己知识的增加从入门书籍变为专业书籍等
2.物品具有生命周期,电影刚上线的时候可能被很多人关注,但是过一段时间,热度可能就降下去了
3.季节效应:反映时间本身对用户的影响,夏天吃冰淇淋,冬天吃火锅,夏天穿T恤,冬天穿棉袄等。
5.1.2 系统时间特性的分析
给定时间信息后,推荐系统由一个静态系统变为时变的系统,用三元组(u,i,t)表示用户u在时刻t对物品i产生了行为。通过以下信息研究系统的时间特性:
5.1.3 推荐系统的实时性
5.1.4 推荐算法的时间多样性
推荐系统每天推荐结果的变化程度被定义为推荐系统的时间多样性,提高时间多样性需要分两步解决:首先需要保证推荐系统能够在用户有新行为后及时调整推荐结果,其次用户没有新行为时也需要经常变化一下。
5.1.5 时间上下文推荐算法
1.最近最热门
最简单的非个性化推荐算法就是给用户推荐最近最热门的物品,给定时间T,物品i最近的流行度定义如下:
其中α是时间衰减参数。
2.时间上下文相关的ItemCF算法
回顾ItemCF算法主要由两个步骤组成:1.利用用户行为离线计算物品之间的相似度;2.根据用户的历史行为和物品相似度,给用户做在线个性化推荐。加入时间信息考虑两者均有一些变化:
物品相似度:用户在相隔很短时间内喜欢的物品具有更高的相似度,即今天和昨天看的电影比今天和一年前看的电影有更高的相似度
在线推荐:加重用户近期行为的权重,优先推荐和用户近期喜欢物品相似的物品
加入时间信息后,对ItemCF算法进行改进,计算物品相似度公式如下:
和普通的ItemCF相比,在分子中引入了和时间有关的衰减项,其中
是用户u对物品i产生行为的时间,f函数的含义是用户u对物品i产生行为的时间和对物品j产生行为的时间距离越远,f越小,即衰减函数,f可以取如下公式:
α是时间衰减参数,在不同情况下取值不同,若用户兴趣变化很快,α应取值大一点,反之则应该小一点。
时间信息不仅对相似度矩阵有影响,对预测公式也有影响,用户的行为应该和用户最近的行为关系更大,因此,我们可以通过如下公式修正预测公式:
其中为当前时刻。
3. 时间上下文相关的UserCF算法
回顾UserCF算法的基本思想:给用户推荐和他兴趣相似的其他用户喜欢的物品,可以从以下两个方面利用时间信息改进UserCF算法:
1.用户兴趣相似度:若两个用户同时喜欢相同的物品,应该有更大的兴趣相似度
2.相似用户的最近行为:应该给用户推荐相似用户最近的行为,而不是很久以前的行为
用户相似度计算公式可以改为:
相比于原来公式,在分子部分添加了一个衰减函数,u和v对i产生行为时间相隔越久则兴趣相似度越小。
推荐部分同样加入时间信息考虑,公式改为:
5.1.6 时间段图模型
时间段图模型是将时间信息建模到图模型中,也是一个二分图,其中U是用户集合,
是用户时间段节点集合,I是物品节点集合,
是物品时间段集合,E是边集合,w为边的权重,σ为顶点的权重,若用户A在时刻2对物品b产生了行为,则会在图中增加三条边,首先创建四个顶点:用户顶点A,用户时间段顶点A:2,物品顶点b,物品时间段顶点b:2。然后在图中增加3条边,(A,b)、(A:2,b)、(A,b:2)。

相关性较高的顶点一般有如下特征:
1.两个顶点之间有很多路径相连
2.两个顶点之间的路径比较少
3.两个顶点之间的路径不经过出度比较大的顶点
路径融合算法:首先提取出两个顶点之间长度小于一个阈值的所有路径,然后根据每条路径经过的顶点给每条路径赋予一定的权重,最后将两个顶点之间所有权重之和作为两个顶点之间的相关度。
假设是连接顶点
和
的一条路径,这条路径的权重取决于经过的所有顶点和边:
其中out(v)是顶点v指向顶点的集合,|out(v)|是顶点v的出度,定义了顶点的权重,
定义了边的权重,因此
,所以n越大,T(P)就会越小,且考虑了路径中顶点的出度,符合后两条。
对于顶点v和,
为两个顶点之间距离小于K的所有路径,那么顶点之间的相关度为:
对于时间段图模型所有边的权重均为1,而顶点的权重定义如下:
其中α和β为两个参数,来控制权重。
5.2 地点上下文信息
地点也是一个重要的上下文信息,例如推荐外卖时需要看用户所在的地方。在外寻找美食时,距离也是一个重要的考虑因素,
基于位置的推荐算法
LARS(Location Aware Recommender System,位置感知推荐系统)。首先将物品分为两类,一类是有空间属性的,比如餐馆、商店、旅游景点等,另一类是没有空间属性的比如电影、图书等。用户也分为两类。数据集分为3类:
1.(用户,用户位置,物品,评分)代表用户在某个地点给物品的评分
2.(用户,物品,物品位置,评分)代表用户对某个地点物品的评分
3.(用户,用户位置,物品,物品位置,评分)代表某个位置的用户对某个地点物品的评分
用户兴趣和地点具有两种特征:
1.兴趣本地化:不同国家和地区用户的兴趣存在一定差异
2.活动本地化:一个用户往往在附近的地区活动
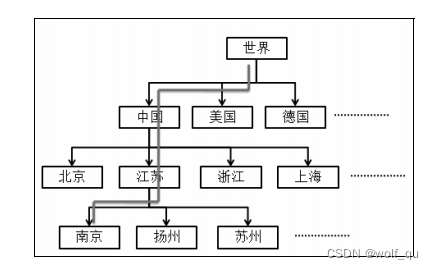
对于第一种数据集,即(用户,用户位置,物品,评分)提出LARS-U:将地区按照树状结构建模,然后从根节点出发,到叶子节点的过程中,利用每个节点上的数据都生成一个推荐列表,最终结果是推荐列表的加权。假设有一个南京的用户,就从根节点到南京节点经过四个节点,生成四个推荐结果,最后加权得到最终结果:
对于第二种数据集,即(用户,物品,物品位置,评分),首先忽略位置信息,利用ItemCF算法计算出用户u对物品i的兴趣P(u,i),但是最终物品i在用户u的推荐列表中的权重为:
其中Travelpenalty表示物品i的位置对用户u的代价,其值为对于物品i与用户u之前评分的所有物品的位置计算距离的平均值,度量距离使用的是实际的距离,为了简化算法降低复杂度,物品i取自与用户评价过的物品距离小于阈值d的所有其他物品。















 747
747











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









