






R-CNN 作者 : Ross Girshick
FAST R-CNN 作者 : Ross Girshick
FASTER R-CNN 作者 : Jian Sun
MASK R-CNN 作者 :kaiming he
一. RCNN
RCNN的基本思想是使用不同尺度的窗口在图像上滑动来截取ROI区域,再送入分类网络中对其识别,这些不同尺度的滑动窗口被称为anchor.
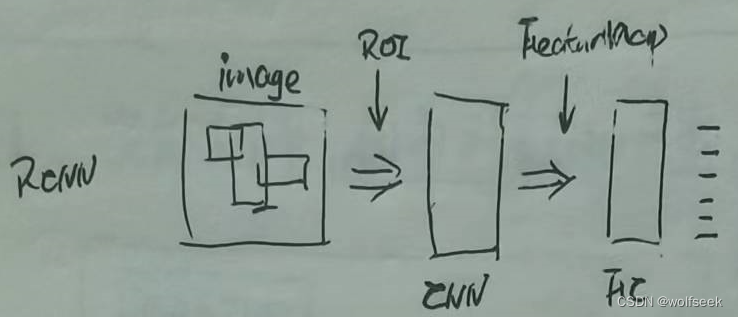
Anchor分为三个尺度和这种尺寸,也就是对图像上每个点产生9个anchor,然后对这些截取出来的图片缩放,缩放到统一尺寸后送入CNN网络。但这回引起庞大的计算量(对一张488*488尺寸的图像,将有488*488*9张anchor图像,),所以需要先对anchor区域进行初判,区分出前景和背景,只对前景评分高的部分图片送入CNN中,最初这个判断前景和背景的工作是由SVM分类器完成的。
所以RCNN需要训练两部分,前景背景分类网络和目标检测网络。
二. FAST RCNN
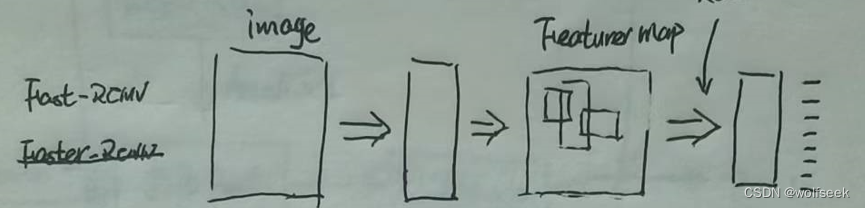
FAST RCNN是对RCNN的升级,改进点:
- RCNN对每个窗口计算一次CNN,FAST RCNN对整张图计算一次CNN,在计算中共享。即从特征图中裁剪ROI。
- RCNN是由三个网络组合而成的,需要分别训练三个网络,FAST RCNN将其整合在一个模型中,使用更为方便。
三. FASTER RCNN
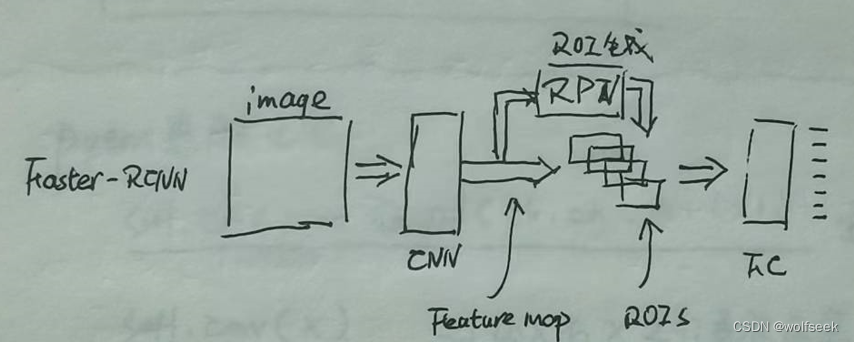
FASTER RCNN 是对FAST RCNN的优化,FAST RCNN使用滑动窗口技术实现,FASTER RCNN使用特征图生成预选窗口。使用预设的预选窗口(anchor)是存在一定缺陷的,不够紧贴目标,此处对anchor产生了一个修正值,使其使其更贴合检测目标。(它增加了一个3x3的网络和两个1x1的网络,在特征图上滑动窗口生成边界和分值,用来判断anchor的好坏,对好边界在送入后记处理)。
四. Mask RCNN
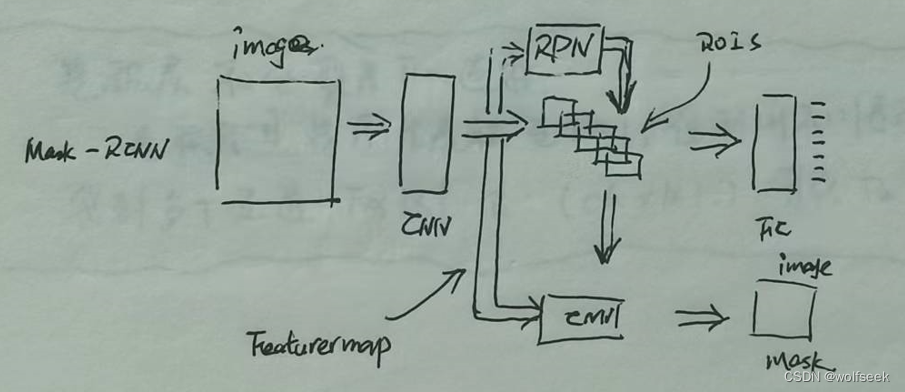
Mask RCNN是对faster RCNN的升级,在其之上增加了一个CNN网络,用于从featureMap中提取mask图像,最终应用到从像素级提取检测目标。
五. 备注
- RCNN系列网络在输入图像上都是使用固定大小的图片如244X244或488X488,对任意图片输入都是缩放到这个尺寸上之后再送入网络。
- RCNN系列它主网络是VGG或resnet。全新训练一个vgg网络本身就是一件困难的事情,我尝试在c++版本voc数据集+ libtorch + RTX2060上训练,网络规模智能到CNN网络的规模只能到256级别,上512就奔溃。陆续花费3天时间,训练了3万多次,正确率大约70%左右(没有使用预测数据集)。
- FAST RCNN和FASTER RCNN都有一个裁剪特征图,并判断前景或背景的过程,这个动作会导致产生的tensor的大小和维度不一致,无法组合成更大维度的tensor。排查FASTER RCNN的实现代码发现,它是先裁剪然后对前景分值排序,筛选出分值最高的300个或2000个。
- 从个人的体验上,裁剪原图整个网络运行速度比裁剪特征图还快不少。特征图本身数据量比原图大的多裁剪也费时,我的裁剪代码是在CPU上裁剪的,存在数据从CPU到GPU的传输。
















 6487
6487











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











