







缘起:
- 今天看hive库表分析的代码,里面涉及到了case when then else end语句,深究发现虽然其本身比较简单--基础用法:简单的条件判断,但有高级的用法--对列值进行分组处理,这里参照别人的经验进行总结下。
1、基础用法
- 写法一:
SELECT
s.s_id,
s.s_name,
s.s_sex,
CASE
WHEN s.s_sex = '1' THEN '男'
WHEN s.s_sex = '2' THEN '女'
ELSE '其他'
END as sex,
s.s_age,
s.class_id
FROM
t_b_student s
WHERE
1 = 1
- 写法二:
SELECT
s.s_id,
s.s_name,
s.s_sex,
CASE s.s_sex
WHEN '1' THEN '男'
WHEN '2' THEN '女'
ELSE '其他'
END as sex,
s.s_age,
s.class_id
FROM
t_b_student s
WHERE
1 = 1
运行结果:

可以发现,两种写法的区别是s.s_sex在case…when…语句的位置不同,但其功能是一样的(运行结果相同),只是方法二有时使用的场合会受到限制,如不能写判断式:不能在when后面直接写判断式形如
c
a
s
e
s
a
l
a
r
y
w
h
e
n
′
>
1
′
case\ salary\ when\ '>1'
case salary when ′>1′,只能通过方法一种的形式写判断式。
值得注意的是Case函数只返回第一个符合条件的值,剩下的Case部分将会被自动忽略。
追加方法一与方法二的细微区别:通过别人的博客(本人未验证):
- 方法二为简单case函数写法:列名,这里是sex,如果没有后面的as sex,则显示在屏幕上的列名依旧是为sex。
- 方法一为case搜索函数写法:列名,这里是sex,若是不为整个CASE WHEN语句写个别名as sex 的话,则显示在屏幕上的列名即为整个CASE WHEN语句。
2、高级用法–依据列值分组
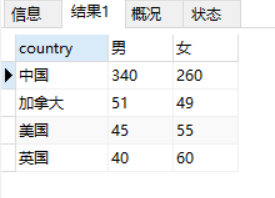
2.1 分组形式1(按照列值拆分出多列)
有数据表t_b_population如下:

以男女性别为列,分别各个国家对应性别的人数。
SELECT country,
SUM(CASE WHEN p.sex = '1' THEN p.population ELSE 0 END) AS '男',
SUM(CASE WHEN p.sex = '2' THEN p.population ELSE 0 END) AS '女'
FROM
t_b_population p
GROUP BY country;
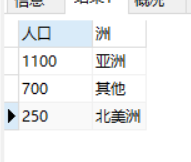
2.2 分组形式2(按照列值的范围重新分组统计)
如有以下t_b_country库表:

对country字段按照所在洲分组并统计人数。
SELECT
SUM(c.population) AS '人口',
CASE c.country
WHEN '中国' THEN '亚洲'
WHEN '印度' THEN '亚洲'
WHEN '日本' THEN '亚洲'
WHEN '美国' THEN '北美洲'
WHEN '加拿大' THEN '北美洲'
WHEN '墨西哥' THEN '北美洲'
ELSE '其他' END AS '洲'
FROM
t_b_country c
GROUP BY CASE c.country
WHEN '中国' THEN '亚洲'
WHEN '印度' THEN '亚洲'
WHEN '日本' THEN '亚洲'
WHEN '美国' THEN '北美洲'
WHEN '加拿大' THEN '北美洲'
WHEN '墨西哥' THEN '北美洲'
ELSE '其他' END;
运行结果















 4129
4129











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









