







原文地址:http://blog.csdn.net/liumaolincycle/article/details/48501423
微调是基于已经学习好的模型的,通过修改结构,从已学习好的模型权重中继续训练。下面就在另一个数据集Flickr Style上面微调CaffeNet模型,来预测图像风格,而不再是目标类别。
1.说明
Flickr Style图像数据集在视觉上和训练了bvlc_reference_caffenet的ImageNet数据集很像,由于这个模型在目标分类上用得很好,我们就想把它也用在风格分类器中。因为只有80,000个图像可用于训练,所以从用了1,000,000个图像的ImageNet学到的参数开始训练,再根据需要进行微调。如果给出caffe train命令的weights参数,预训练的权重就会载入模型中,通过名字来匹配层。
因为我们现在只预测20个类而不再是1,000个,所以需要修改模型中的最后一层,把prototxt最后一层的名字由fc8改为fc8_flickr。bvlc_reference_caffenet中没有层名叫fc8_flickr,因此该层将从随机权重开始训练。同理,可以多改几个其它层的名字,被修改的层都会从随机权重开始训练。
此外,减少solver prototxt中的总体学习率base_lr,但是增加新引进层的blobs_lr。主要原因是新数据让新加的层学习很快,模型中剩下的层改变很慢,在solver中设置stepsize为更低的值,希望学习率下降快一些。我们也可以通过设置blobs_lr为0来阻止除fc8_flickr外的所有层微调。
2.步骤
数据集已经分解为带相应标签的URL列表,用一个简单Python脚本assemble_data.py下载数据的子集并将其分为训练集和验证集,先看一下用法:
- 1
- 1
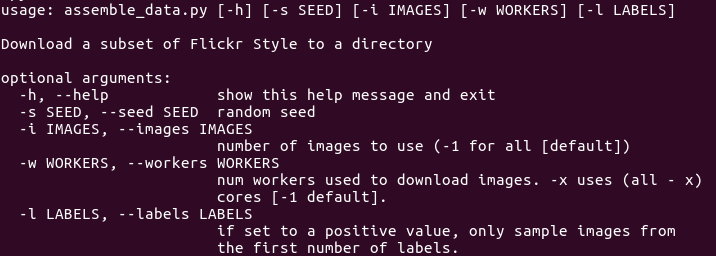
再用它下载数据集:
- 1
- 1
这个脚本下载2000个图像和相应的train/val文件到data/flickr_style中,这里感谢 鱼蛋蛋哥 和 小咸鱼_ 指出,在用自己的数据训练时,编号一定要从0开始,或者最后一层的输出类别数要大于最大的编号,否则不会收敛。
本例的prototxt还需要ImageNet的均值文件,运行:
- 1
- 1
下载在data/ilsvrc12中。
我们还需要ImageNet训练而得的模型,运行:
- 1
- 1
下载在models/bvlc_reference_caffenet中,就可以开始训练了:
- 1
- 2
- 3
- 4
- 1
- 2
- 3
- 4
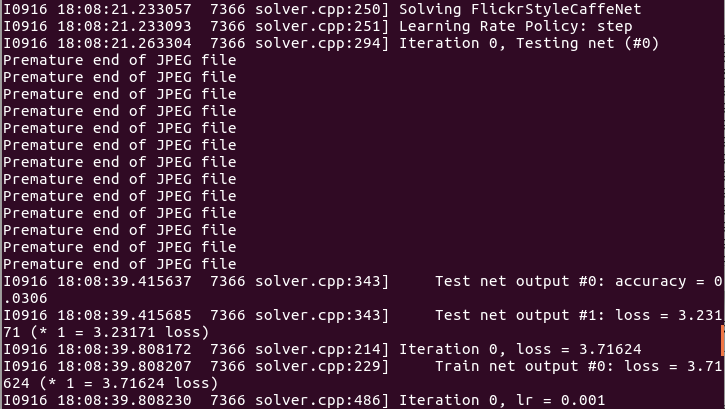
可以看一下 models/finetune_flickr_style/solver.prototxt和models/finetune_flickr_style/train_val.prototxt中的内容。
注意看损失下降的速度,尽管迭代1000次后达到的23.5%准确率不是很好,但在这么少的迭代次数就达到了,说明模型正在又快又好地学习。当模型在整个训练集上做了100,000次迭代,完全微调好,准确率是39.16%。我只迭代了10,000次,也达到了29.46%,在GTX660上用了一个半小时。

不用微调预训练模型而是直接训练时:
- 1
- 1
微调适用于时间不够或数据不够的情况,即使在CPU模式,每遍历一次训练集也只要大约100s,GPU微调显然更快,并能在数分钟或数小时内学习到有用模型,而不再需要数天或数周了。
3.训练的模型
训练完全部80K图像得到的模型最终准确率为39%,可由下面的命令得到该训练好的模型:
- 1
- 1















 4847
4847

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









