






第三章——Spark编程基础
一、创建RDD
1.从内存中读取数据创建RDD
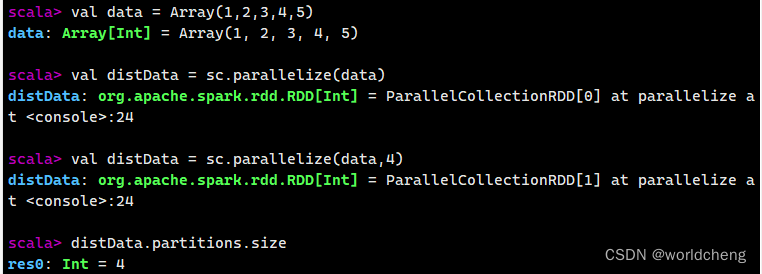
这种方式有两种常用的方法,parallelize()方法和makeRDD()方法。均利用内存中已存在的集合,复制集合的元素去创建一个可用于并行计算的RDD
(1)parallelize()方法
该方法有两个输入参数:
一是必须是Seq集合。Seq表示序列,指的是一类具有一定长度的,可迭代访问的对象,其中每个元素均带有一个从0开始的、固定的索引。
二是分区数。
(2)makeRDD()方法
该方法有两种使用方法,第一种与parallelize()方法一致;第二种是通过接收一个Seq[(T,Seq[String])]参数类型创建RDD。
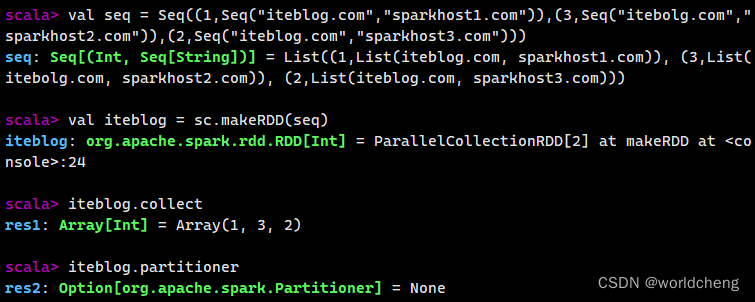
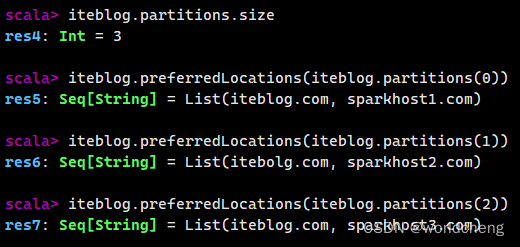
2.从外部存储系统中读取数据创建RDD
从外部存储系统中读取数据创建RDD是指直接读取存放在文件系统中的数据文件创建RDD。从内存中读取数据创建RDD的方法常用于测试,从外部存储系统中读取数据创建RDD才是用于实践的常用方法。
从外部存储系统中读取数据创建RDD,一般使用SparkContext对象的textFile()方法读取。
(1)通过HDFS文件创建RDD
这种方式是直接通过textFile()方法读取HDFS文件的位置即可。
(2)通过Linux本地文件创建RDD
这种方式也是使用textFile()方法读取,但需要在路径前面加上“file://”表示从Linux本地文件系统读取。
二、各种操作RDD方法详解
1.操作单个RDD
(1)使用map()方法转换数据
map()方法是一种基础的转换操作,可以对RDD中的每一个数据元素通过某种函数进行转换并返回新的RDD。
例如,通过map()方法对一个RDD的每一个元素进行平方运算,结果会生成一个新的RDD。

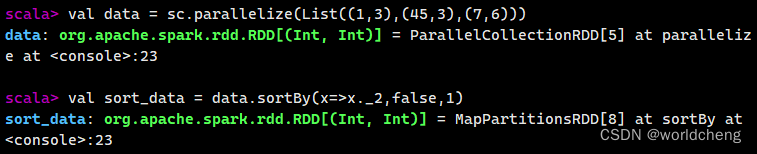
(2)使用sortBy()方法进行排序
该方法用于对标准RDD进行排序,有三个可输入参数:
第一个参数是一个函数f:(T)=>K,左边是排序对象中的元素,右边返回的是元素中要进行排序的值。(该参数必须输入)
第二个参数是ascending,决定排序是降序还是升序,默认是true,即升序。
第三个参数是numPartitions,决定排序后的RDD分区的个数,默认分区个数与之前相等。
例如,通过一个村放了3个二元组的列表创建一个RDD,对元组的第二个值进行降序排列,分区数设置为1。
(3)使用collect()方法查询数据
collect()方法是一种行动操作,可以将RDD中所有元素转换成数组并返回到Driver端,适用于返回处理后的少量数据。有两种操作方式:
一是直接调用collect返回该RDD中的所有元素,返回类型是一个Array[T]数组。
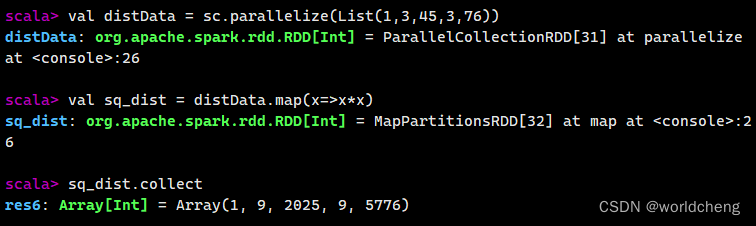
二是collect[U:ClassTag](f:PartialFunction[T,U]):RDD[U]。这种方式需要提供一个标准的偏函数,将元素保存至一个RDD中。
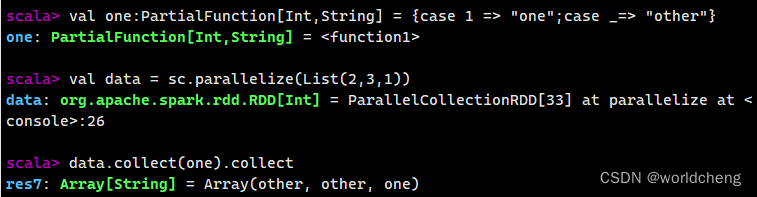
(4)使用flatMap()方法转换数据
flatMap()将函数参数应用于RDD之中的每一个元素,将返回的迭代器(数组、列表等)中的所有元素构成新的RDD。
例如:使用flatMap()方法分割字符串
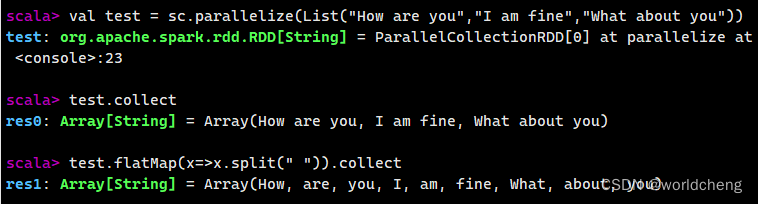
(5)使用take()方法查询某几个值
该方法用来获取指定个数的数据,返回数据为数组。
例如:

2.操作多个RDD
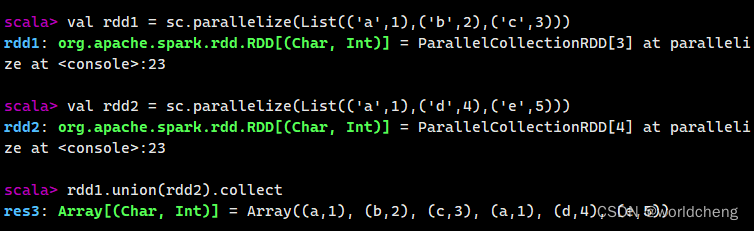
(1)使用union()方法合并多个RDD
该方法是一种转换操作,用于将两个RDD合并成一个,不进行去重操作,而且两个RDD中每个元素的值的个数、数据类型需要保持一致。
例如:
(2)使用filter()方法进行过滤
filter()方法是一种转换操作,用于过滤RDD中的元素。该方法需要传入一个用于过滤的函数作为参数,该函数的返回值为Boolean类型。该函数过滤掉返回值为false的元素。
例如:创建一个RDD,并且过滤掉每个元组第二个值<=1的元素。
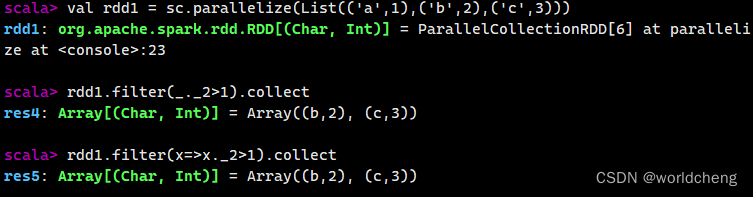
(3)使用distinct()方法进行去重
distinct()方法是一种转换操作,用于RDD的数据去重,去除两个完全相同的元素,无参数。
例:

(4)使用简单的集合操作
RDD是一个分布式的数据集合,有如求交集、并集、补集和笛卡尔积等的操作。
①intersection()方法
求两个RDD的共同元素。
例:
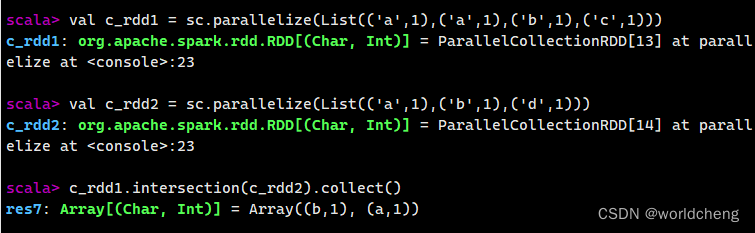
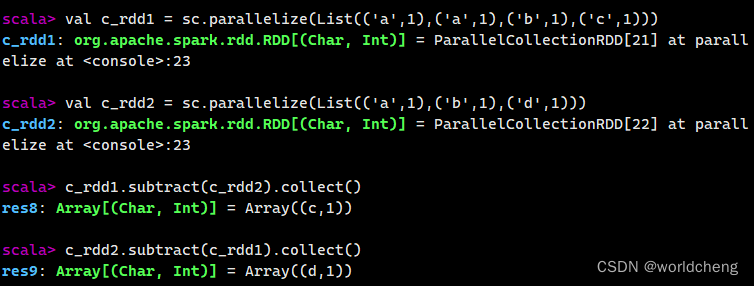
②subtract()方法
该方法用于将前一个RDD中在后一个RDD出现的元素删除,可以认为是求补集的操作。返回值是一个RDD。
例:
③cartesian()方法
该方法可将两个集合的元素两两合成一组。
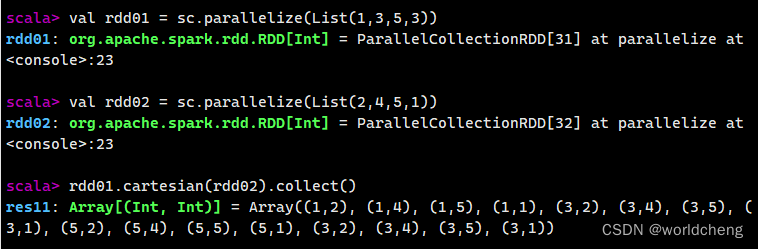
3.操作键值对RDD
(1)了解键值对RDD
键值对RDD是由一组组的键值对组成的,分为键和值,一般用来存储二元组。
(2)创建键值对RDD
将一个普通的RDD转化为一个键值对RDD,可以使用map()方法。当读取键值对类型的数据时可以直接返回一个键值对RDD。
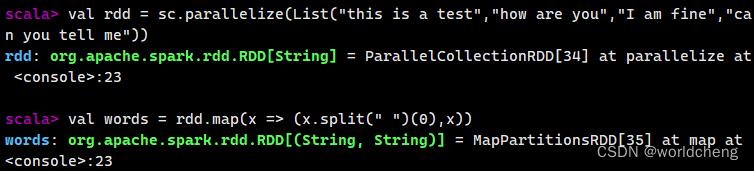
例如:以一个有英语单词组成的文本为例,提取每行的第一个单词作为键,将整个句子作为值,创建一个键值对RDD。
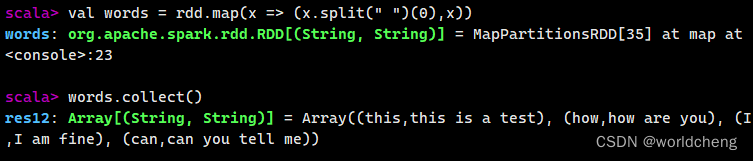
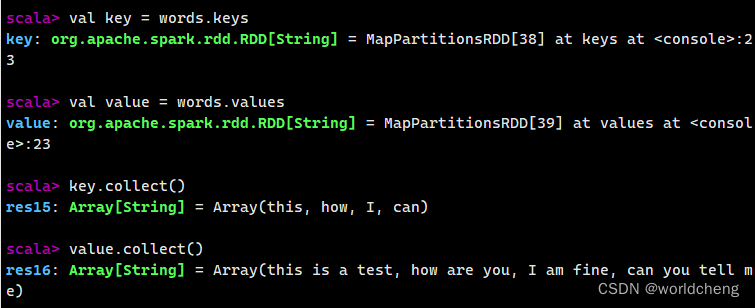
(3)使用键值对RDD的keys和values方法
针对键值对,spark提供了两个方法keys和values,前者返回一个仅包含键的RDD,后者返回一个仅包含值的RDD。
例如:
(4)使用键值对RDD的reduceByKey()方法
第四章
第四章又没有方法,看个鬼?直接下一章
第五章——Spark SQL
Spark SQL 是一个用于处理结构化数据的框架,可被视为一个分布式的SQL查询引擎,提供了一个抽象的可编程数据模型DataFrame。
一、创建DataFrame对象
1.通过结构化数据文件创建DataFrame
2.通过外部数据库创建DataFrame
3.通过RDD创建DataFrame
4.通过Hive中的表创建DataFrame
二、查看DataFrame数据
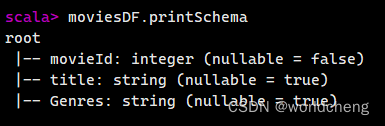
1.printSchema:输出数据模式
使用printSchema函数可以查看DataFrame数据模式,输出列的名称和类型。
2.show():查看数据
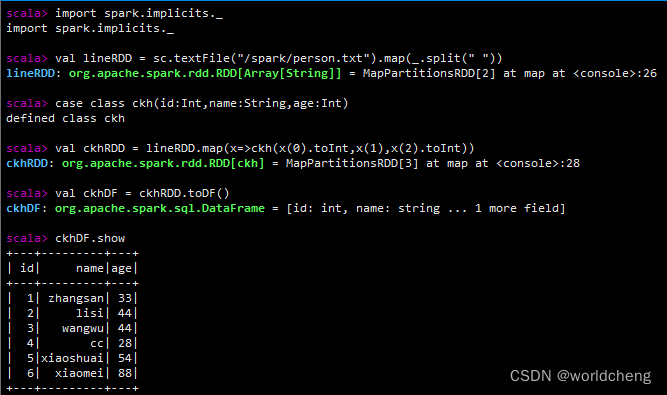
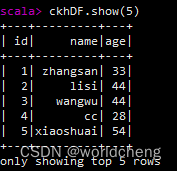
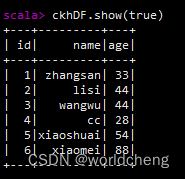
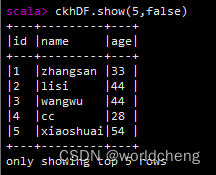
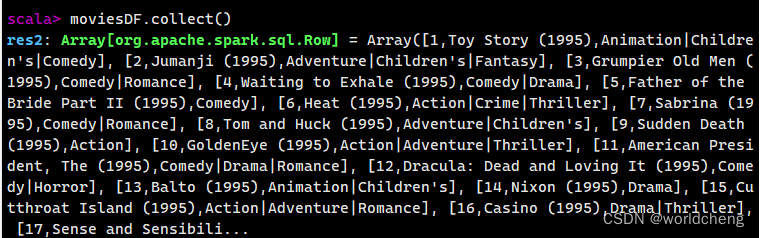
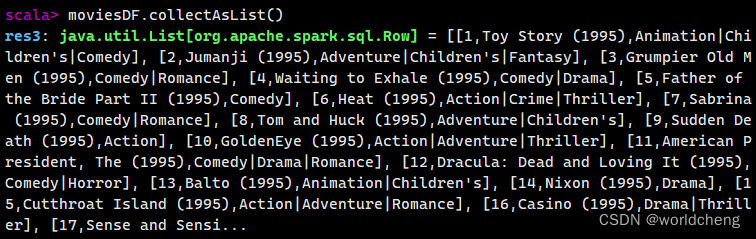
3.collect()/collectAsList():获取所有数据
collect()方法查询DataFrame中所有的数据,并返回一个数组,而collectAsList()方法,返回的是一个列表。
三、DataFrame查询操作
DataFrame查询数据有两种方法:
第一种是将DataFrame注册成临时表,在通过SQL语句查询数据。
第二种是直接在DataFrame对象上进行查询。
这里着重讲解第二种方法。
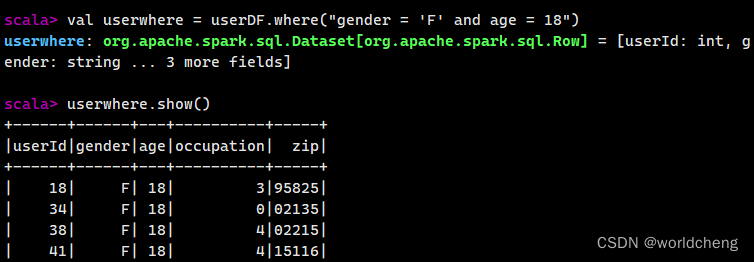
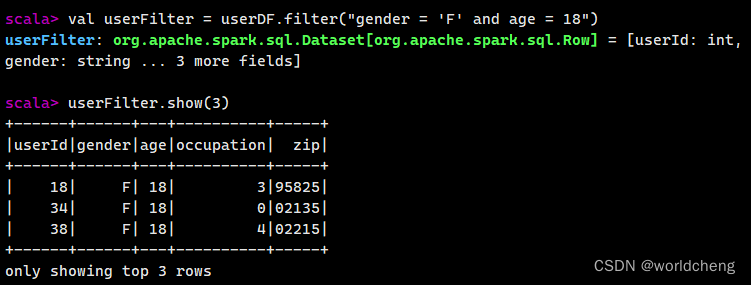
1.where()/filter()方法
使用where()和filter()方法可以查询数据中符合条件的所有字段的信息。
2.select()/selectExpr()/col()/apply()方法
它们均是查询指定字段的值的方法。
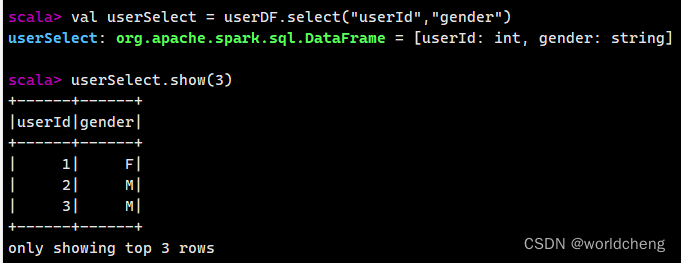
例如:select()方法:获取指定字段值
根据传入的String类型字段名获取对应的值,并返回一个DataFrame对象。
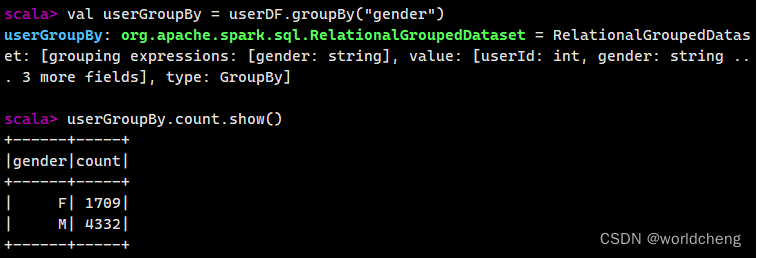
3.groupBy()方法
使用该方法可以根据指定字段对数据进行分组操作。其传入参数既可以是String类型的字段名,也可以是Column对象。
该方法返回的是一个GroupedData对象,其常用方法有:
| 方法 | 描述 |
| max(colNames:String) | 获取分组中指定字段或所有的数值类型字段的最大值 |
| min(colNames:String) | 获取分组中指定字段或所有的数值类型字段的最小值 |
| mean(colNames:String) | 获取分组中指定字段或所有的数值类型字段的平均值 |
| sum(colNames:String) | 获取分组中指定字段或所有的数值类型字段的值的和 |
| count() | 获取分组中的元素个数 |
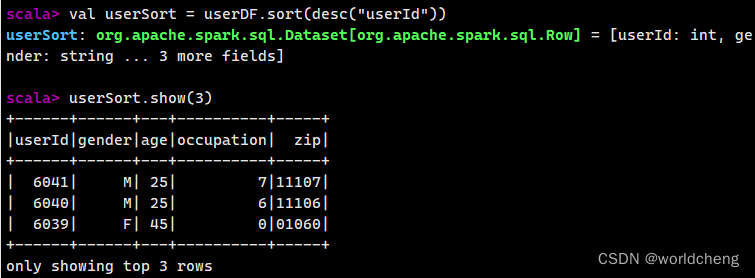
4.sort()方法
根据指定字段对数据进行排序,默认是升序排列(asc)。若要求降序排列,该方法的参数可以使用“desc("字段名称")”或“$"字段名称".desc”。















 411
411











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









