






Build Neo4j database from existing training/test/valid spilts
使用命令行语句
gradle run --args="--c Foo/config.json -l"在Run类中传参
String[] args1={"-c","Foo/config.json","-l"};if (cmd.hasOption("l")) {
GPFL system = new GPFL(config, "learn_log");
system.learn();
}在GPFL类中learn()
public void learn() {
graphFile = new File(home, "databases/graph.db");
graph = IO.loadGraph(graphFile);
trainFile = new File(home, "data/annotated_train.txt");
validFile = new File(home, "data/annotated_valid.txt");
ruleFile = IO.createEmptyFile(new File(out, "rules.txt"));
ruleIndexHome = new File(out, "index");
ruleIndexHome.mkdir();
populateTargets();
GlobalTimer.programStartTime = System.currentTimeMillis();
for (String target : targets) {
File ruleIndexFile = IO.createEmptyFile(new File(ruleIndexHome
, target.replaceAll("[:/<>]", "_") + ".txt"));
Settings.TARGET = target;
Context context = new Context();
Logger.println(MessageFormat.format("\n# ({0}\\{1}) Start Learning Rules for Target: {2}",
globalTargetCounter++, targets.size(), target), 1);
try (Transaction tx = graph.beginTx()) {
Set<Pair> trainPairs = IO.readPair(graph, trainFile, target);
Settings.TARGET_FUNCTIONAL = IO.isTargetFunctional(trainPairs);
Set<Pair> validPairs = IO.readPair(graph, validFile, target);
Logger.println(MessageFormat.format("# Train Size: {0}", trainPairs.size()), 1);
generalization(trainPairs, context);
if(Settings.ESSENTIAL_TIME != -1 && Settings.INS_DEPTH != 0)
EssentialRuleGenerator.generateEssentialRules(trainPairs, validPairs, context, graph, ruleIndexFile, ruleFile);
specialization(context, trainPairs, validPairs, ruleIndexFile);
IO.orderRuleIndexFile(ruleIndexFile);
tx.success();
}
}
IO.orderRules(out);
GlobalTimer.reportMaxMemoryUsed();
GlobalTimer.reportTime();
}在IO类中loadGraph(), 从图数据库中加载数据
graph = IO.loadGraph(graphFile); public static GraphDatabaseService loadGraph(File graphFile) {
Logger.println("\n# Load Neo4J Graph from: " + graphFile.getPath(), 1);
GraphDatabaseService graph = new GraphDatabaseFactory()
.newEmbeddedDatabase( graphFile );
Runtime.getRuntime().addShutdownHook( new Thread( graph::shutdown ));
DecimalFormat format = new DecimalFormat("####.###");
try(Transaction tx = graph.beginTx()) {
long relationshipTypes = graph.getAllRelationshipTypes().stream().count();
long relationships = graph.getAllRelationships().stream().count();
long nodes = graph.getAllNodes().stream().count();
Logger.println(MessageFormat.format("# Relationship Types: {0} | Relationships: {1} " +
"| Nodes: {2} | Instance Density: {3} | Degree: {4}",
relationshipTypes,
relationships,
nodes,
format.format((double) relationships / relationshipTypes),
format.format((double) relationships / nodes)), 1);
tx.success();
}
return graph;
}与图数据建立连接
GraphDatabaseService graph = new GraphDatabaseFactory()
.newEmbeddedDatabase( graphFile );指定文件夹路径,创建相应的文件
- trainFile :annotated_train.txt
- validFile:annotated_vaild.txt
- ruleFile:rules.txt
- ruleIndexHome:index文件夹
trainFile = new File(home, "data/annotated_train.txt");
validFile = new File(home, "data/annotated_valid.txt");
ruleFile = IO.createEmptyFile(new File(out, "rules.txt"));
ruleIndexHome = new File(out, "index");
ruleIndexHome.mkdir();在Engine类中populateTargets();选择学哪些Targets
public void populateTargets() {
if(testFile != null)
//从testFile中,获取targets有哪些类型
targets = IO.readTargets(testFile);
else {
try(Transaction tx = graph.beginTx()) {
for (RelationshipType type : graph.getAllRelationshipTypes())
targets.add(type.name());
tx.success();
}
}
//选择学些的Targets
Set<String> selectedTargets = new HashSet<>();
try {
JSONArray array = args.getJSONArray("target_relation");
if(!array.isEmpty()) {
for (Object o : array) {
String target = (String) o;
if (targets.contains(target))
selectedTargets.add(target);
else {
System.err.println("# Selected Targets do not exist in the test file.");
System.exit(-1);
}
}
targets = selectedTargets;
}
} catch (JSONException e) {
try {
int randomSelect = args.getInt("randomly_selected_relations");
if (randomSelect != 0) {
List<String> targetList = new ArrayList<>(targets);
Collections.shuffle(targetList);
targets = new HashSet<>(targetList.subList(0, Math.min(randomSelect, targetList.size())));
}
} catch (JSONException ignored) { }
}
}遍历每一个target
以第一个target,publishes为例
# (1\12) Start Learning Rules for Target: PUBLISHES

for (String target : targets) {
File ruleIndexFile = IO.createEmptyFile(new File(ruleIndexHome
, target.replaceAll("[:/<>]", "_") + ".txt"));
Settings.TARGET = target;
Context context = new Context();
Logger.println(MessageFormat.format("\n# ({0}\\{1}) Start Learning Rules for Target: {2}",
globalTargetCounter++, targets.size(), target), 1);
try (Transaction tx = graph.beginTx()) {
Set<Pair> trainPairs = IO.readPair(graph, trainFile, target);
Settings.TARGET_FUNCTIONAL = IO.isTargetFunctional(trainPairs);
Set<Pair> validPairs = IO.readPair(graph, validFile, target);
Logger.println(MessageFormat.format("# Train Size: {0}", trainPairs.size()), 1);
generalization(trainPairs, context);
if(Settings.ESSENTIAL_TIME != -1 && Settings.INS_DEPTH != 0)
EssentialRuleGenerator.generateEssentialRules(trainPairs, validPairs, context, graph, ruleIndexFile, ruleFile);
specialization(context, trainPairs, validPairs, ruleIndexFile);
IO.orderRuleIndexFile(ruleIndexFile);
tx.success();
}
}
publishes的规则,存储到该路径当中
Foo\i3c3\index\PUBLISHES.txt
File ruleIndexFile = IO.createEmptyFile(new File(ruleIndexHome
, target.replaceAll("[:/<>]", "_") + ".txt"));在IO类中的readPair()
1841条数据,其中有440条数据与Publishes相关

Set<Pair> trainPairs = IO.readPair(graph, trainFile, target);public static Set<Pair> readPair(GraphDatabaseService graph, File in, String target) {
Set<Pair> pairs = new HashSet<>();
try(Transaction tx = graph.beginTx()) {
try(LineIterator l = FileUtils.lineIterator(in)) {//它创建了一个迭代器,可以按行遍历给定的文件
while(l.hasNext()) {
String[] words = l.nextLine().split("\t");
long relationId = Long.parseLong(words[0]);//735
long headId = Long.parseLong(words[1]);//407
String type = words[2];//PUBLISHES
long tailId = Long.parseLong(words[3]);//266
if(type.equals(target)) {
if(relationId != -1) {
Relationship rel = graph.getRelationshipById(relationId);//以第一条数据为例(407)-[PUBLISHES,735]->(266)
pairs.add(new Pair(rel.getStartNodeId(), rel.getEndNodeId(), rel.getId()
, rel, rel.getType()
, (String) rel.getStartNode().getProperty(Settings.NEO4J_IDENTIFIER)
, (String) rel.getEndNode().getProperty(Settings.NEO4J_IDENTIFIER)
, rel.getType().name()));
} else {
pairs.add(new Pair(headId, tailId));
}
}
}
} catch (IOException e) {
e.printStackTrace();
System.exit(-1);
}
tx.success();
}
return pairs;
}遍历文件中的每一条数据,生成行的迭代器
按行遍历每一条数据
FileUtils使用介绍_码路编的博客-CSDN博客_fileutils
try(LineIterator l = FileUtils.lineIterator(in)) {//它创建了一个迭代器,可以按行遍历给定的文件
while(l.hasNext()) {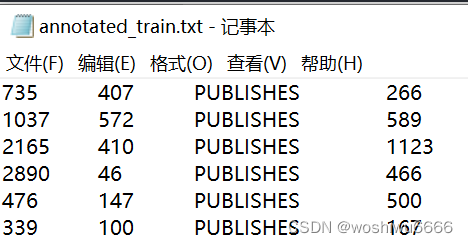
以第一条数据为例relationId 是735,headId 是407,type是PUBLISHES,tailid是266
String[] words = l.nextLine().split("\t");
long relationId = Long.parseLong(words[0]);//735
long headId = Long.parseLong(words[1]);//407
String type = words[2];//PUBLISHES
long tailId = Long.parseLong(words[3]);//266将相关信息保存到Pairs当中
if(type.equals(target)) {
if(relationId != -1) {
Relationship rel = graph.getRelationshipById(relationId);//以第一条数据为例(407)-[PUBLISHES,735]->(266)
pairs.add(new Pair(rel.getStartNodeId(), rel.getEndNodeId(), rel.getId()
, rel, rel.getType()
, (String) rel.getStartNode().getProperty(Settings.NEO4J_IDENTIFIER)
, (String) rel.getEndNode().getProperty(Settings.NEO4J_IDENTIFIER)
, rel.getType().name()));
} else {
pairs.add(new Pair(headId, tailId));
}
}通过id索引,获取用id表示的数据
Settings.NEO4J_IDENTIFIER="name"
Relationship rel = graph.getRelationshipById(relationId);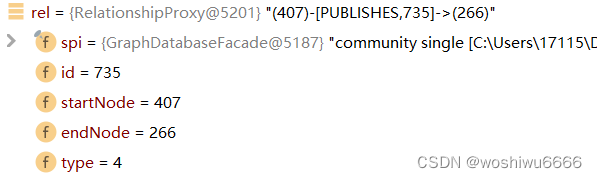
pairs.add(new Pair(rel.getStartNodeId(), rel.getEndNodeId(), rel.getId()
, rel, rel.getType()
, (String) rel.getStartNode().getProperty(Settings.NEO4J_IDENTIFIER)
, (String) rel.getEndNode().getProperty(Settings.NEO4J_IDENTIFIER)
, rel.getType().name()));将索引的信息与原数据的信息存储到pairs当中

获取原数据的信息
(String) rel.getStartNode().getProperty(Settings.NEO4J_IDENTIFIER)
, (String) rel.getEndNode().getProperty(Settings.NEO4J_IDENTIFIER)在IO类中isTargetFunctional()
Settings.TARGET_FUNCTIONAL = IO.isTargetFunctional(trainPairs); public static boolean isTargetFunctional(Set<Pair> trainPairs) {
Multimap<Long, Long> subToObjs = MultimapBuilder.hashKeys().hashSetValues().build();
for (Pair trainPair : trainPairs) {
subToObjs.put(trainPair.subId, trainPair.objId);
}
int functionalCount = 0;
for (Long sub : subToObjs.keySet()) {
if(subToObjs.get(sub).size() == 1)
functionalCount++;
}
return ((double) functionalCount / subToObjs.keySet().size()) >= 0.9d;
}subToObjs
- key:一个节点的序号
- value:关联多个节点的序号
![]()
subToObjs.put(trainPair.subId, trainPair.objId);统计有多少个节点是一对一的
functionalCount++;如果这种一对一的关系占所有的节点比例大于90%返回true,小于90%就是false
return ((double) functionalCount / subToObjs.keySet().size()) >= 0.9d;在Engine类中的generalization()
generalization(trainPairs, context); public void generalization(Set<Pair> trainPairs, Context context) {
long s = System.currentTimeMillis();
BlockingQueue<Rule> ruleQueue = new LinkedBlockingDeque<>(Settings.BATCH_SIZE * 2);
Set<Pair> visitedTrainPairs = new HashSet<>();
RuleProducer[] producers = new RuleProducer[Settings.THREAD_NUMBER];
RuleConsumer consumer = new RuleConsumer(0, ruleQueue, context);
for (int i = 0; i < producers.length; i++) {
producers[i] = new RuleProducer(i, ruleQueue, trainPairs, visitedTrainPairs, graph, consumer);
}
try {
for (RuleProducer producer : producers) {
producer.join();
}
consumer.join();
} catch (InterruptedException e) {
e.printStackTrace();
System.exit(-1);
}
Logger.println(MessageFormat.format("# Visited/Training Instances: {0}/{1} | Ratio: {2}%" +
" | Sampled Paths: {3} | Saturation: {4}%"
, visitedTrainPairs.size()
, trainPairs.size()
, new DecimalFormat("###.##").format(((double) visitedTrainPairs.size() / trainPairs.size()) * 100f)
, consumer.getPathCount()
, new DecimalFormat("###.##").format(consumer.getSaturation() * 100f))
);
GlobalTimer.updateTemplateGenStats(Helpers.timerAndMemory(s, "# Generalization"));
Logger.println(Context.analyzeRuleComposition("# Generated Templates"
, context.getAbstractRules()), 1);
}BlockingQueue
什么是BlockingQueue?一次性说清了_java令人头秃的博客-CSDN博客_blockingqueue
使用无限 BlockingQueue 设计生产者 - 消费者模型时最重要的是 消费者应该能够像生产者向队列添加消息一样快地消费消息 。
6个线程共同使用ruleQueue
BlockingQueue<Rule> ruleQueue = new LinkedBlockingDeque<>(Settings.BATCH_SIZE * 2);创建RuleProducer线程数组对象,6个生产者
RuleProducer[] producers = new RuleProducer[Settings.THREAD_NUMBER];
创建Ruleconsumer线程对象,1个消费者
RuleConsumer consumer = new RuleConsumer(0, ruleQueue, context);在Engine类RuleConsumer(),执行消费者线程的内容
RuleConsumer(int id, BlockingQueue<Rule> ruleQueue, Context context) {
super("RuleConsumer-" + id);
this.id = id;
this.ruleQueue = ruleQueue;
this.context = context;
GlobalTimer.setGenStartTime(System.currentTimeMillis());
start();
}@Override
public void run() {
Set<Rule> currentBatch = new HashSet<>();
do {
if(pathCount % Settings.BATCH_SIZE == 0) {
int overlaps = 0;
if(currentBatch.isEmpty() && pathCount != 0)
break;
for (Rule rule : currentBatch) {
if(context.getAbstractRules().contains(rule))
overlaps++;
else
context.updateFreqAndIndex(rule);
}
saturation = currentBatch.isEmpty() ? 0d : (double) overlaps / currentBatch.size();
currentBatch.clear();
}
Rule rule = ruleQueue.poll();
if(rule != null) {
if(rule.isClosed() ? rule.length() <= Settings.CAR_DEPTH : rule.length() <= Settings.INS_DEPTH)
currentBatch.add(rule);
pathCount++;
}
} while (saturation < Settings.SATURATION && !GlobalTimer.stopGen());
for (Rule rule : currentBatch) {
context.updateFreqAndIndex(rule);
}
}值的注意的是 getAbstractRules()是获取变量ruleFrequency的规则,ruleFrequency包含了abstract(closed)和instantited(非closed)
context.getAbstractRules().contains(rule)pathCount是得到的规则总数
有可能产生了相同的规则也进行累加的Settings.BATCH_SIZE =30000
相当于是pathCount<30000的时候,要检查currentbatch是否与ruleFrequency重复,再添加规则到ruleFrequency当中,currentBatch在此时是每次都只有一条规则,因为poll()是每次只吐出一条。而当pathCount>30000的时候,当currentBatch
if(pathCount % Settings.BATCH_SIZE == 0) {如果rulefrequency中包含这些rule,则overlap++
if(context.getAbstractRules().contains(rule))
overlaps++;将rule添加到ruleFrequency当中,并统计数量
值的注意的是ruleFrequency是没有限制大小的,ruleQueue才有限制大小
context.updateFreqAndIndex(rule); public synchronized void updateFreqAndIndex(Rule rule) {
if(ruleFrequency.containsKey(rule))
ruleFrequency.put(rule, ruleFrequency.get(rule) + 1);
else {
ruleFrequency.put(rule, 1);
indexRule.put(index++, rule);
}
}饱和度的计算
currentBatch是当前得到的规则集合
如果当前集合没有规则,则saturation =0,否则的话saturation =overlaps / currentBatch.size()
saturation = currentBatch.isEmpty() ? 0d : (double) overlaps / currentBatch.size();从ruleQueue中获取规则,相当于是消费者
Rule rule = ruleQueue.poll();判断规则的长度,随后执行pathCount++;
if(rule != null) {
if(rule.isClosed() ? rule.length() <= Settings.CAR_DEPTH : rule.length() <= Settings.INS_DEPTH)
currentBatch.add(rule);
pathCount++;
}如果规则是closed则用阈值Settings.CAR_DEPTH进行判断,非closed则用INS_DEPTH进行判断
值的注意的是closed在文章里也称作closed abstract rules,非closed的在文章里称作instantiated rules
if(rule.isClosed() ? rule.length() <= Settings.CAR_DEPTH : rule.length() <= Settings.INS_DEPTH)只有满足阈值才添加到 currentBatch
currentBatch.add(rule);线程执行的阈值
while (saturation < Settings.SATURATION && !GlobalTimer.stopGen());判断数量是否达到阈值
saturation < Settings.SATURATION在Global Timer类stopGen(),判断时间是否达到阈值
GlobalTimer.stopGen() public static boolean stopGen() {
if(Settings.GEN_TIME == 0)
return false;
return ((double) (System.currentTimeMillis() - genStartTime) / 1000d) > Settings.GEN_TIME;
}在Engine类RuleProducer(),启动6个RuleProducer线程,生产者的线程
for (int i = 0; i < producers.length; i++) {
producers[i] = new RuleProducer(i, ruleQueue, trainPairs, visitedTrainPairs, graph, consumer);
}RuleProducer(int id, BlockingQueue<Rule> ruleQueue, Set<Pair> trainPairs, Set<Pair> visitedTrainPairs
, GraphDatabaseService graph, Thread consumer) {
super("RuleProducer-" + id);
this.id = id;
this.ruleQueue = ruleQueue;
this.trainPairs = new ArrayList<>(trainPairs);
this.graph = graph;
this.consumer = consumer;
this.visitedTrainPairs = visitedTrainPairs;
start();
}start()执行线程的内容
@Override
public void run() {
Random rand = new Random();
try(Transaction tx = graph.beginTx()) {
while(consumer.isAlive()) {
Pair pair = trainPairs.get(rand.nextInt(trainPairs.size()));
addVisitedPair(pair);
Traverser traverser = GraphOps.buildStandardTraverser(graph, pair, Settings.RANDOM_WALKERS);
for (Path path : traverser) {
Rule rule = Context.createTemplate(path, pair);
while (consumer.isAlive()) {
if (ruleQueue.offer(rule, 100, TimeUnit.MILLISECONDS))
break;
}
if (!consumer.isAlive())
break;
}
}
tx.success();
} catch (InterruptedException e) {
e.printStackTrace();
System.exit(-1);
}
}判断线程是否存活pisAlive()方法_墨白hu的博客-CSDN博客_isalive
consumer.isAlive()随机选取一条数据
Pair pair = trainPairs.get(rand.nextInt(trainPairs.size()));将抽取过的结果保存到visitedTrainPairs
addVisitedPair(pair); private synchronized void addVisitedPair(Pair pair) {
visitedTrainPairs.add(pair);
}在GraphOps类中buildStandardTraverser()
Traverser traverser = GraphOps.buildStandardTraverser(graph, pair, Settings.RANDOM_WALKERS); public static Traverser buildStandardTraverser(GraphDatabaseService graph, Pair pair, int randomWalkers){
Traverser traverser;
Node startNode = graph.getNodeById(pair.subId);
Node endNode = graph.getNodeById(pair.objId);
traverser = graph.traversalDescription()
.uniqueness(Uniqueness.NODE_PATH)
.order(BranchingPolicy.PreorderBFS())
.expand(standardRandomWalker(randomWalkers))
.evaluator(toDepthNoTrivial(Settings.DEPTH, pair))
.traverse(startNode, endNode);
return traverser;
}从图中获取节点
假设当前获取的数据为[413,514]
Node startNode = graph.getNodeById(pair.subId);
Node endNode = graph.getNodeById(pair.objId);
遍历与节点相关的路径
前五个相当于配置遍历时候的规则
traverser = graph.traversalDescription()
.uniqueness(Uniqueness.NODE_PATH)
.order(BranchingPolicy.PreorderBFS())
.expand(standardRandomWalker(randomWalkers))
.evaluator(toDepthNoTrivial(Settings.DEPTH, pair))
.traverse(startNode, endNode);开始配置遍历的规则
.traversalDescription()Neo4j之图数据遍历总结 - 墨天轮 (modb.pro)
Neo4j:入门基础(八)之Traversal API_Dawn_www的博客-CSDN博客
Neo4j3.5学习笔记——Traversal遍历之黑客帝国_蹦蹦恰Amy的博客-CSDN博客
被遍历过的结点可以在后续继续出现
Neo4j3.5学习笔记——Traversal遍历之在遍历查询中的唯一路径_蹦蹦恰Amy的博客-CSDN博客

.uniqueness(Uniqueness.NODE_PATH) 宽度优先
宽度优先
广度优先遍历也分先序(PreOrder)、中序和后序(PostOrder)
在循环的时候一个traverse包含了一次广搜的内容
.order(BranchingPolicy.PreorderBFS())一个BranchSelector是用来定义如何选择遍历下一个分支。这被用来实现遍历顺序。遍历框架提供了一些基本的顺序实现:
Traversal.preorderDepthFirst(): 深度优先,在访问的子节点之前访问每一个节点。Traversal.postorderDepthFirst(): 深度优先,在访问的子节点之后访问每一个节点。Traversal.preorderBreadthFirst(): 宽度优先,在访问的子节点之前访问每一个节点。Traversal.postorderBreadthFirst(): 宽度优先,在访问的子节点之后访问每一个节点。
该方法的作用是筛选路径
.expand(standardRandomWalker(randomWalkers))java - neo4j中的随机后置遍历 | Neo4j (lmlphp.com)
Neo4j中的定向路径(Directed paths in Neo4j)_电脑培训 (656463.com)
在GraphOps类中standardRandomWalker(randomWalkers)
重写了new PathExpander()中的迭代器方法
standardRandomWalker(randomWalkers)public interface PathExpander<STATE>
{
/**
* Returns relationships for a {@link Path}, most commonly from the
* {@link Path#endNode()}.
*
* @param path the path to expand (most commonly the end node).
* @param state the state of this branch in the current traversal.
* {@link BranchState#getState()} returns the state and
* {@link BranchState#setState(Object)} optionally sets the state for
* the children of this branch. If state isn't altered the children
* of this path will see the state of the parent.
* @return the relationships to return for the {@code path}.
*/
Iterable<Relationship> expand( Path path, BranchState<STATE> state );
/**
* Returns a new instance with the exact expansion logic, but reversed.
*
* @return a reversed {@link PathExpander}.
*/
PathExpander<STATE> reverse();
}在GraphOps中新生成的迭代器方法Iterable<Relationship> expand(Path path, BranchState state)
在遍历traverser的时候会先执行next()方法,再执行Iterable中的expand()方法
执行1次for循环,生成一条规则。执行完当前traverser里的遍历,多个for循环,就要重新获取startnode与endnode,生成新的traverser
for (Path path : traverser) {在BranchingPolicy类中执行next()
@Override
public TraversalBranch next( TraversalContext metadata )
{
TraversalBranch result = null;
while ( result == null )
{
TraversalBranch next = current.next( expander, metadata );
if ( next != null )
{
queue.add( next );
result = next;
}
else
{
current = queue.poll();
if ( current == null )
{
return null;
}
}
}
return result;
}在GraphOps类中执行expand()方法
public static PathExpander standardRandomWalker(int randomWalkers) {
return new PathExpander() {
@Override
public Iterable<Relationship> expand(Path path, BranchState state) {
Set<Relationship> results = Sets.newHashSet();
List<Relationship> candidates = Lists.newArrayList( path.endNode().getRelationships() );
if ( candidates.size() < randomWalkers || randomWalkers == 0 ) return candidates;
Random rand = new Random();
for ( int i = 0; i < randomWalkers; i++ ) {
int choice = rand.nextInt( candidates.size() );
results.add( candidates.get( choice ) );
candidates.remove( choice );
}
return results;
}
@Override
public PathExpander reverse() {
return null;
}
};
}获取candidates,分是否大于randomWalker,大于要执行下面的随机抽取
小于randomWalker的情况
在这里是找到包含path节点的数据,可以是头也可以是尾
第一次,是找到包含413的数据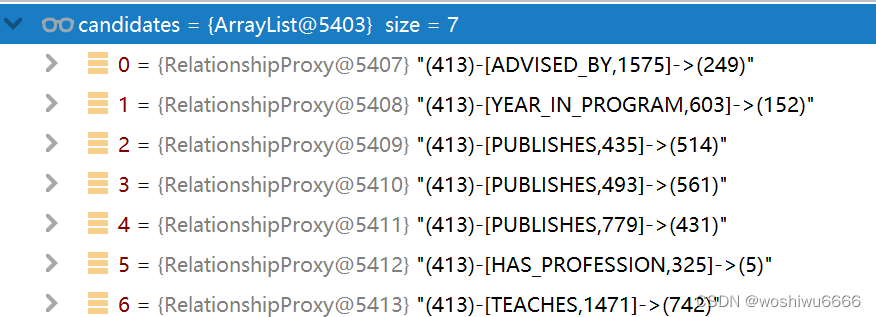
第二次,找到包含514的数据

第三次,找到包含249的数据
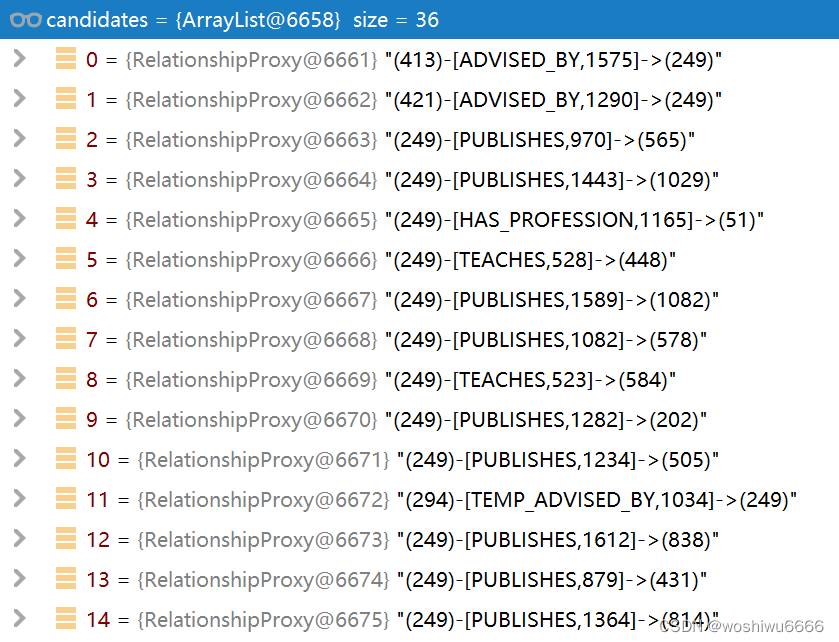
List<Relationship> candidates = Lists.newArrayList( path.endNode().getRelationships() );当candidates小于randomWalkers或者randomWalkers的值为0
直接返回candidates
if ( candidates.size() < randomWalkers || randomWalkers == 0 ) return candidates;大于randomWalker的情况,随机选择10条
Random rand = new Random();
for ( int i = 0; i < randomWalkers; i++ ) {
int choice = rand.nextInt( candidates.size() );
results.add( candidates.get( choice ) );
candidates.remove( choice );
}
return results;在GraphOps中toDepthNoTrivial()
该方法的作用控制路径长度,控制后面节点是否遍历
关于neo4j:基于关系属性的最长路径 | 码农家园 (codenong.com)
.evaluator(toDepthNoTrivial(Settings.DEPTH, pair))- depth:是限定的长度
- pair:随机获取的一个节点
- path:
public static PathEvaluator toDepthNoTrivial(final int depth, Pair pair) {
return new PathEvaluator.Adapter()
{
@Override
public Evaluation evaluate(Path path, BranchState state)
{
boolean fromSource = pair.subId == path.startNode().getId();
boolean closed = pathIsClosed( path, pair );
boolean hasTargetRelation = false;
int pathLength = path.length();
if ( path.lastRelationship() != null ) {
Relationship relation = path.lastRelationship();
hasTargetRelation = relation.getType().equals(pair.type);
if ( pathLength == 1
&& relation.getStartNodeId() == pair.objId
&& relation.getEndNodeId() == pair.subId
&& hasTargetRelation)
return Evaluation.INCLUDE_AND_PRUNE;
}
if ( pathLength == 0 )
return Evaluation.EXCLUDE_AND_CONTINUE;
if ( pathLength == 1 && hasTargetRelation && closed )
return Evaluation.EXCLUDE_AND_PRUNE;
if ( closed && fromSource )
return Evaluation.INCLUDE_AND_PRUNE;
else if ( closed )
return Evaluation.EXCLUDE_AND_PRUNE;
if (selfloop(path))
return Evaluation.EXCLUDE_AND_PRUNE;
return Evaluation.of( pathLength <= depth, pathLength < depth );
}
};
}遍历的6种情况
其中值的注意的是,hastargetrelation是判断pairs与path的target是否相同,但是只去判断一次,只判断firstatom
- INCLUDE,规则集合中包含这条结果,也就是会执行for (Path path : traverser) ,生成template
- PRUNE, 不对利用对这条规则的节点继续遍历
1. 如果是pathLength =1,并且pairs的尾与path的头相同,以及path的尾与pairs的头相同,并且target相同
if ( pathLength == 1
&& relation.getStartNodeId() == pair.objId
&& relation.getEndNodeId() == pair.subId
&& hasTargetRelation)
return Evaluation.INCLUDE_AND_PRUNE;2.执行startnode和endnode单一节点的时候
if ( pathLength == 0 )
return Evaluation.EXCLUDE_AND_CONTINUE;3.当pathlength=1,当前的path与pairs是头头,尾尾相同或者是path的头与pairs的尾相同,不纳入规则,并且不能继续遍历这些节点,要跳出不然就是死循环
if ( pathLength == 1 && hasTargetRelation && closed )
return Evaluation.EXCLUDE_AND_PRUNE;4.中间有元素,也就是path不止为1,头头尾尾相同,纳入规则,如果头尾倒序相同不能纳入为规则
if ( closed && fromSource )
return Evaluation.INCLUDE_AND_PRUNE;
else if ( closed )
return Evaluation.EXCLUDE_AND_PRUNE;
5.当该节点只有一个节点,后续没有接任何一个节点
if (selfloop(path))
return Evaluation.EXCLUDE_AND_PRUNE;private static boolean selfloop(Path path) {
return path.startNode().equals( path.endNode() ) && path.length() != 0;
}6.如果两个长度都满足 pathLength <= depth, pathLength < depth,执行INCLUDE_AND_CONTINUE
如果只满足pathLength <= depth,执行INCLUDE_AND_PRUNE,包含这条规则但不再遍历下去了
如果不满足pathLength <= depth,超过了范围不能包含这条规则,并且不对path的节点继续遍历
后一个双目实际上都是赋值EXCLUDE_AND_PRUNE
return Evaluation.of( pathLength <= depth, pathLength < depth ); public static Evaluation of( boolean includes, boolean continues )
{
return includes ? (continues ? INCLUDE_AND_CONTINUE : INCLUDE_AND_PRUNE)
: (continues ? EXCLUDE_AND_CONTINUE : EXCLUDE_AND_PRUNE);
}判断是否是closed
fromSource path的前与pair的前比较,相同则为fromSource
fromSource为true表示,前和前相同
在fromSource的基础上
如果fromSource正确,则比较path的后与pair的后是否相同,如果相同则为closed
如果fromSource错误,则比较path的后与pair的前是否相同,如果相同则为closed
closed为true表示,两个节点至少有一个节点是相同的,可以是正序相同也可以是倒序相同
private static boolean pathIsClosed(Path path, Pair pair) {
boolean fromSource = path.startNode().getId() == pair.subId;
if ( fromSource )
return path.endNode().getId() == pair.objId;
else
return path.endNode().getId() == pair.subId;
} 大量的Evaluator是用来决定在每一个位置(用一个 Path 表示):是应该继续遍历查询以及节点是否包括在结果中。 对于一个给定的 Path,它要求对遍历查询分支采用下面四个动作中的一种:
Evaluation.INCLUDE_AND_CONTINUE: 包括这个节点在结果中并且继续遍历查询。Evaluation.INCLUDE_AND_PRUNE: 包括这个节点在结果中并且继续不遍历查询。Evaluation.EXCLUDE_AND_CONTINUE: 排除这个节点在结果中并且继续遍历查询。Evaluation.EXCLUDE_AND_PRUNE: 排除这个节点在结果中并且继续不遍历查询。
指定遍历的开头节点和结束节点
.traverse(startNode, endNode);利用遍历的路径生成规则
第一条path是数据 (547)-[PUBLISHES,986]->(871)
第二条path是数据 (547)-[PUBLISHES,1649]->(1003)
for (Path path : traverser) {
Rule rule = Context.createTemplate(path, pair);在Context类中 createTemplate()更多的例子可参考平板的笔记
长度为2
第一次
- path:(547)-[PUBLISHES,986]->(871)
- pair:(547)-[PUBLISHES,1779]->(924)
第二次
- path:(547)-[PUBLISHES,1649]->(1003)
- pair:(547)-[PUBLISHES,1779]->(924)
长度为3
- path: (547)-[PUBLISHES,1649]->(1003)<-[PUBLISHES,1323]-(98)
- pair:(547)-[PUBLISHES,1779]->(924)
- 在图中都是正序(outgoing)存储,547->1003,以及98->1003
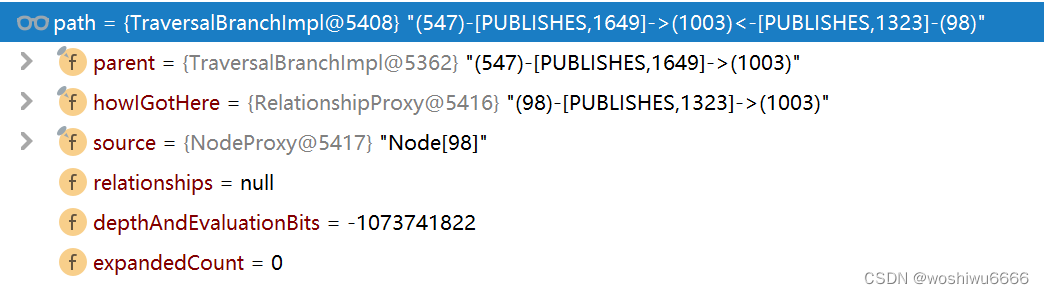
注意pair是一直保持不变的,path是会因traverse而不断的更新
public static Rule createTemplate(Path path, Pair pair) {
List<Atom> bodyAtoms = buildBodyAtoms(path);
Atom head = new Atom(pair);
return new Template(head, bodyAtoms);
}在Context类中 buildBodyAtoms()
获取原数据,生成bodyAtoms
对(547)-[PUBLISHES,1649]->(1003)<-[PUBLISHES,1323]-(98),从左到右生成bodyatoms,第一个节点是547,第二个节点是1003
得到下面的结果
注意看都是正序存储的,1003是endnode,都在后面,publishes(xxx,title91)
具体方向是在里面有表示sub到obj是从左到右,outgoing箭头是正向,incoming箭头是反向

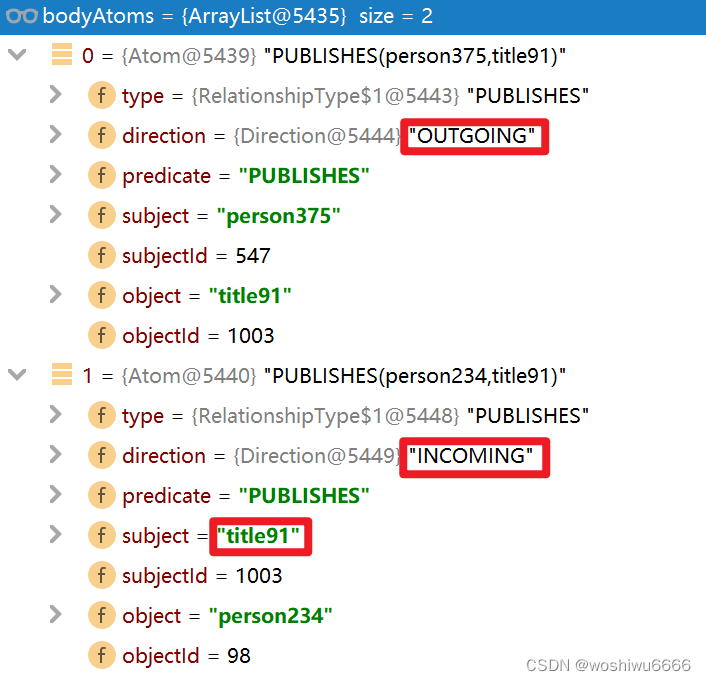
private static List<Atom> buildBodyAtoms(Path path) {
List<Atom> bodyAtoms = Lists.newArrayList();
List<Relationship> relationships = Lists.newArrayList( path.relationships() );
List<Node> nodes = Lists.newArrayList( path.nodes() );
for( int i = 0; i < relationships.size(); i++ ) {
bodyAtoms.add( new Atom( nodes.get( i ), relationships.get( i ) ) );
}
return bodyAtoms;
}处理传进来的path
List<Atom> bodyAtoms = Lists.newArrayList();
List<Relationship> relationships = Lists.newArrayList( path.relationships() );
List<Node> nodes = Lists.newArrayList( path.nodes() );处理pair
(547)-[PUBLISHES,1779]->(924)
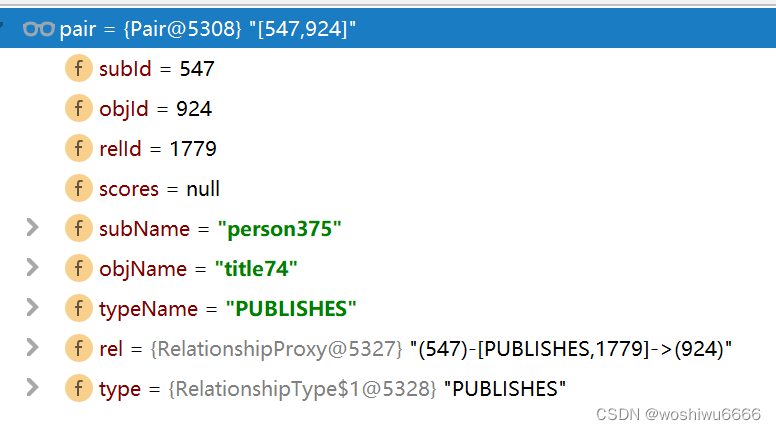
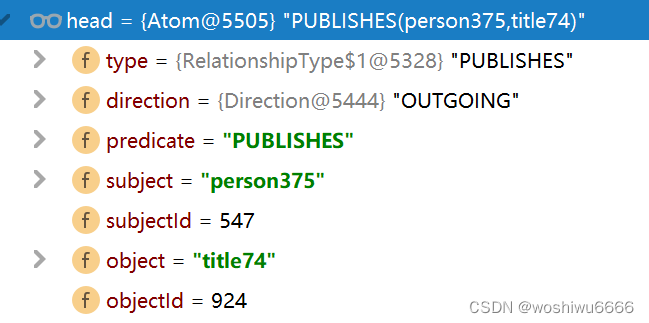
Atom head = new Atom(pair); pair的方向是outgoing的,直接从annotedtrainning.txt中读取
/**
* Init head atom with info provided by instance.
*/
public Atom(Pair pair) {
type = pair.type;
predicate = pair.type.name();
subject = pair.subName;
subjectId = pair.subId;
object = pair.objName;
objectId = pair.objId;
direction = Direction.OUTGOING;
}值得注意的是path的方向不一定是outgoing,要判断
以(924)<-[PUBLISHES,1114]-(98)为例
nodes.get(0)获得924
relationship.get(0) (98)-[PUBLISHES,1114]->(924)
bodyatom就表示为 PUB(98,924) 从左到右,sub是924,obj是98,只不过是incoming
bodyAtoms.add( new Atom( nodes.get( i ), relationships.get( i ) ) );判断此时的endnode与source值即左边的节点是否相同,如果相同则是inverse,inverse就执行Incoming
public Atom(Node source, Relationship relationship) {
// System.out.println(relationship.getEndNode());
boolean inverse = source.equals(relationship.getEndNode());
type = relationship.getType();
predicate = relationship.getType().name();
if ( inverse ) {
direction = Direction.INCOMING;
subject = (String) relationship.getEndNode().getProperty(Settings.NEO4J_IDENTIFIER);
object = (String) relationship.getStartNode().getProperty(Settings.NEO4J_IDENTIFIER);
subjectId = relationship.getEndNodeId();
objectId = relationship.getStartNodeId();
}
else {
direction = Direction.OUTGOING;
subject = (String) relationship.getStartNode().getProperty(Settings.NEO4J_IDENTIFIER);
object = (String) relationship.getEndNode().getProperty(Settings.NEO4J_IDENTIFIER);
subjectId = relationship.getStartNodeId();
objectId = relationship.getEndNodeId();
}
}在template类中Template()
return new Template(head, bodyAtoms);
public Template(Atom h, List<Atom> b) {
super( h, b );
Atom firstAtom = bodyAtoms.get( 0 );
Atom lastAtom = bodyAtoms.get( bodyAtoms.size() - 1 );
head.subject = "X";
head.object = "Y";
int variableCount = 0;
for(Atom atom : bodyAtoms) {
atom.subject = "V" + variableCount;
atom.object = "V" + ++variableCount;
}
if ( fromSubject ) firstAtom.subject = "X";
else firstAtom.subject = "Y";
if ( closed && fromSubject ) lastAtom.object = "Y";
else if ( closed ) lastAtom.object = "X";
}
在Rule类中的Rule()
super( h, b );值的注意的是bodyatom就是 提取path中的每一个关系
lastAtom 是bodyatom中的最后一个
Rule(Atom head, List<Atom> bodyAtoms) {
this.head = head;
this.bodyAtoms = new ArrayList<>(bodyAtoms);
Atom lastAtom = bodyAtoms.get(bodyAtoms.size() - 1);
closed = head.getSubjectId() == lastAtom.getObjectId() || head.getObjectId() == lastAtom.getObjectId();
Atom firstAtom = bodyAtoms.get( 0 );
fromSubject = head.getSubjectId() == firstAtom.getSubjectId();
}值的注意的是,在一次traverse当中head永远是固定的,直到遍历完这个pairs中的规则,获取新的pairs才改变这个head
相当于一个head会对应一个traverse的遍历,对应多次for循环生成规则,生成完以后,才重新获取一个head
this.head = head;
this.bodyAtoms = new ArrayList<>(bodyAtoms);判断是否是closed的
通过head的前与lastatom的后相同,或者head的后与lastatom的后相同,则是closed的
但是这种规则,都被exclude了。(head的后与lastatom的后相同)
closed = head.getSubjectId() == lastAtom.getObjectId() || head.getObjectId() == lastAtom.getObjectId();判断是否是fromSubject的
firstatom是bodyatom中的第一个
通过firstatom的前与head的前是否相同
Atom firstAtom = bodyAtoms.get( 0 );
fromSubject = head.getSubjectId() == firstAtom.getSubjectId();获取firstatom以及lastatom
Atom firstAtom = bodyAtoms.get( 0 );
Atom lastAtom = bodyAtoms.get( bodyAtoms.size() - 1 );更改head的前缀和后缀
head.subject = "X";
head.object = "Y";对所有的body atom进行转换
下面的例子都是正向的(outgoing),(数字一,数字二),数字一大于数字二
如果(数字一,数字二),数字一小于数字二,则是反向的(incoming),也就是数字二在前,箭头是<-, 数字二在后

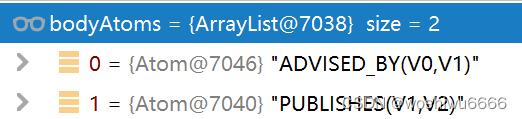
int variableCount = 0;
for(Atom atom : bodyAtoms) {
atom.subject = "V" + variableCount;
atom.object = "V" + ++variableCount;如果head和bodyatom中的第一个元素相同
firstAtom的前缀改为x,否则firstAtom的前缀改为Y
if ( fromSubject ) firstAtom.subject = "X";
else firstAtom.subject = "Y";如果head和bodyatom中的第一个元素相同,并且head的前与lastatom的后相同;或者head的后与lastatom的后相同(后面的被exclude了)
lastAtom的后缀改为Y,否则lastAtom的前缀改为X
if ( closed && fromSubject ) lastAtom.object = "Y";
else if ( closed ) lastAtom.object = "X"; 得到的rule如下图所示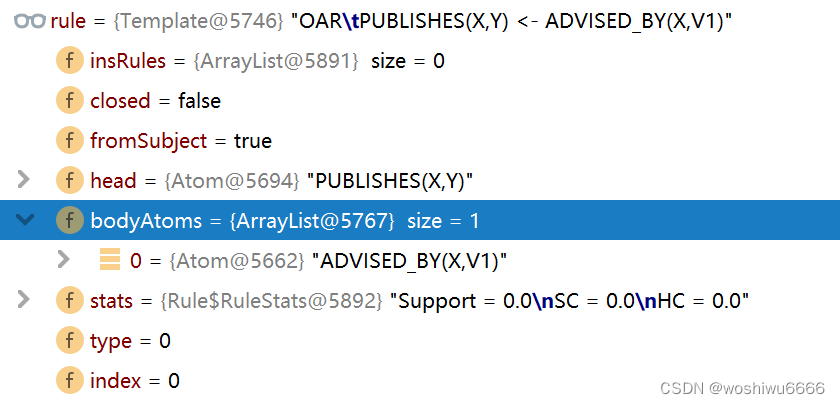
(547)-[PUBLISHES,1649]->(1003)<-[PUBLISHES,1323]-(98),得到的规则如下所示
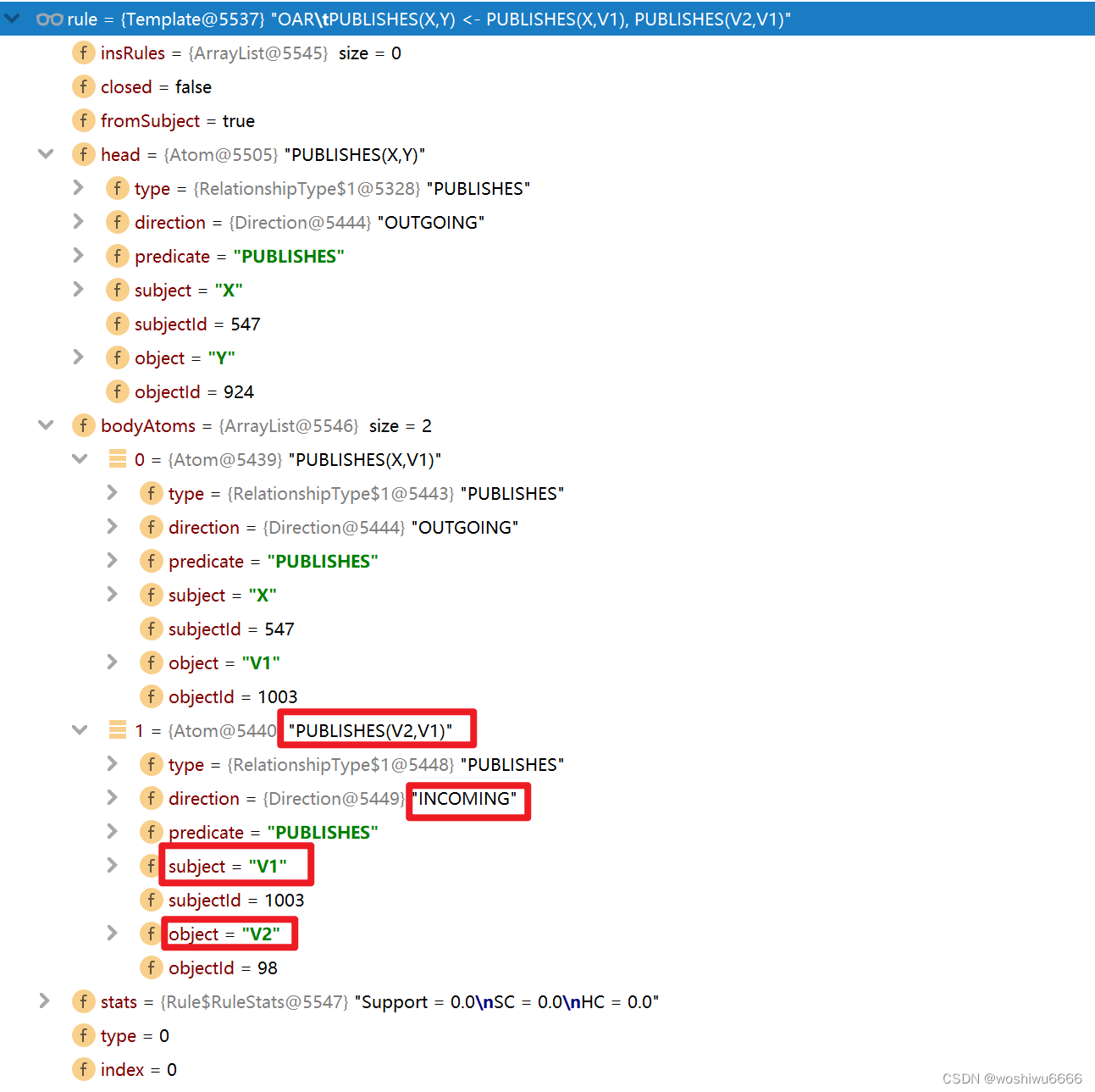
Rule rule = Context.createTemplate(path, pair);offer方法添加元素,并返回boolean,如果队列为满,阻塞一定时间,然后退出
把规则添加到队列当中
两者都是往队列尾部插入元素,不同的时候,当超出队列界限的时候,add()方法是抛出异常让你处理,而offer()方法是直接返回false
阻塞队列(BlockingQueue)是一个支持两个附加操作的队列。这两个附加的操作是:在队列为空时,获取元素的线程会等待队列变为非空。当队列满时,存储元素的线程会等待队列可用。阻塞队列常用于生产者和消费者的场景,生产者是往队列里添加元素的线程,消费者是从队列里拿元素的线程。阻塞队列就是生产者存放元素的容器,而消费者也只从容器里拿元素。
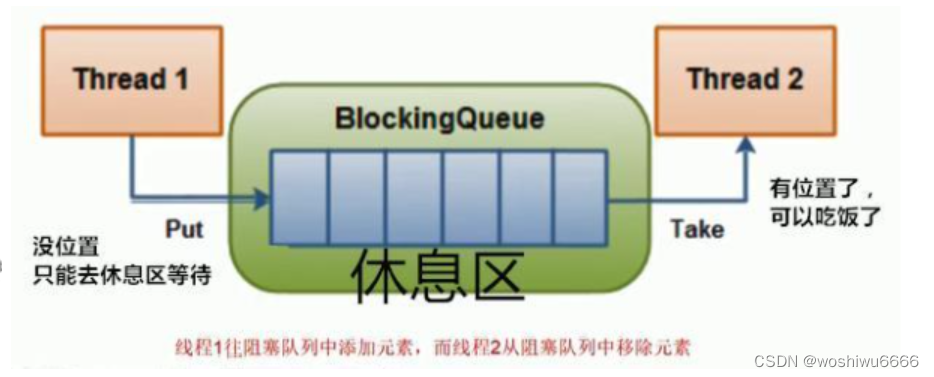
阻塞队列(BlockingQueue)_忘川丿的博客-CSDN博客_阻塞队列
阻塞队列 - 会飞的金鱼 - 博客园 (cnblogs.com)
队列的add()方法和offer()方法的区别_machihaoyu的博客-CSDN博客_offer方法
if (ruleQueue.offer(rule, 100, TimeUnit.MILLISECONDS))
break;
}public boolean offer(E e, long timeout, TimeUnit unit)
throws InterruptedException {
checkNotNull(e);
// 把超时时间转换成纳秒
long nanos = unit.toNanos(timeout);
final ReentrantLock lock = this.lock;
// 获取一个可中断的互斥锁
lock.lockInterruptibly();
try {
// while循环的目的是防止在中断后没有到达传入的timeout时间,继续重试
while (count == items.length) {
if (nanos <= 0)
return false;
// 等待nanos纳秒,返回剩余的等待时间(可被中断)
nanos = notFull.awaitNanos(nanos);
}
enqueue(e);
return true;
} finally {
lock.unlock();
}
}learn完以后,得到统计的数据
只用一条数据学习的规则
generalization(trainPairs, context);pairs.subId=547&&pairs.objId=924# (1\12) Start Learning Rules for Target: PUBLISHES
# Train Size: 440
# Visited/Training Instances: 1/440 | Ratio: 0.23% | Sampled Paths: 60,001 | Saturation: 100%
# Generalization: time = 6.412s | memory = 90.109mb
# Generated Templates: 33 | ClosedRules: 1 | OpenRules: 32 | len=1: 3 | len=2: 9 | len=3: 20
统计的代码
Logger.println(MessageFormat.format("# Visited/Training Instances: {0}/{1} | Ratio: {2}%" +
" | Sampled Paths: {3} | Saturation: {4}%"
, visitedTrainPairs.size()
, trainPairs.size()
, new DecimalFormat("###.##").format(((double) visitedTrainPairs.size() / trainPairs.size()) * 100f)
, consumer.getPathCount()
, new DecimalFormat("###.##").format(consumer.getSaturation() * 100f))
);
GlobalTimer.updateTemplateGenStats(Helpers.timerAndMemory(s, "# Generalization"));
Logger.println(Context.analyzeRuleComposition("# Generated Templates"
, context.getAbstractRules()), 1);
}
具体的指标表示什么
Visited/Training Instances:表示440条publishes相关的数据一共遍历了多少条,也就是pairs的数量
通过下面这行代码随机获取进行遍历
Pair pair = trainPairs.get(rand.nextInt(trainPairs.size()));Sampled Paths:paths的数量,生成过多少条规则,生成的规则可以是重复的,统计数量时候要加上
Rule rule = ruleQueue.poll();
if(rule != null) {
if(rule.isClosed() ? rule.length() <= Settings.CAR_DEPTH : rule.length() <= Settings.INS_DEPTH)
currentBatch.add(rule);
pathCount++;
}Saturation:当前currentBatch中有多少条与ruleFrequency最终集合是重合的,占比多少
currentBatch是当前遍历回合当中满足长度条件的规则数量
saturation = currentBatch.isEmpty() ? 0d : (double) overlaps / currentBatch.size();Generated Templates:得到不重复,且满足条件的规则总数
接下来的数据统计使用的是这一段代码
public static String analyzeRuleComposition(String header, Collection<Rule> rules) {
NumberFormat f = NumberFormat.getNumberInstance(Locale.US);
int closedRules = 0;
int openRules = 0;
Map<Integer, Integer> lengthMap = new TreeMap<>();
for (Rule rule : rules) {
if(rule.isClosed())
closedRules++;
else {
openRules++;
if (lengthMap.containsKey(rule.length())) {
lengthMap.put(rule.length(), lengthMap.get(rule.length()) + 1);
} else {
lengthMap.put(rule.length(), 1);
}
}
}
String content = MessageFormat.format("{0}: {1} | ClosedRules: {2} | OpenRules: {3} | "
, header, rules.size(), closedRules, openRules);
List<String> words = new ArrayList<>();
for (Integer length : lengthMap.keySet()) {
words.add("len=" + length + ": " + f.format(lengthMap.get(length)));
}
content += String.join(" | ", words);
return content;
}ClosedRules:ClosedRules的数量
OpenRules:OpenRules的数量
3个len:Open Rules len的情况,长度1有多少条,2有多少条,3有多少条
在GPFL类当中,EssentialRuleGenerator()
筛选规则一
if(Settings.ESSENTIAL_TIME != -1 && Settings.INS_DEPTH != 0)
EssentialRuleGenerator.generateEssentialRules(trainPairs, validPairs, context, graph, ruleIndexFile, ruleFile);public static void generateEssentialRules(Set<Pair> trainPairs, Set<Pair> validPairs
, Context context, GraphDatabaseService graph
, File tempFile, File ruleFile) {
long s = System.currentTimeMillis();
NumberFormat f = NumberFormat.getNumberInstance(Locale.US);
GlobalTimer.setEssentialStartTime(System.currentTimeMillis());
Set<Rule> essentialRules = new HashSet<>();
BlockingQueue<String> tempFileContents = new LinkedBlockingDeque<>(10000000);
BlockingQueue<String> ruleFileContents = new LinkedBlockingDeque<>(10000000);
for (Rule rule : context.getAbstractRules()) {
if(!rule.isClosed() && rule.length() == 1)
essentialRules.add(rule);
}
Multimap<Long, Long> trainObjToSub = MultimapBuilder.hashKeys().hashSetValues().build();
Multimap<Long, Long> validObjToSub = MultimapBuilder.hashKeys().hashSetValues().build();
Multimap<Long, Long> trainSubToObj = MultimapBuilder.hashKeys().hashSetValues().build();
Multimap<Long, Long> validSubToObj = MultimapBuilder.hashKeys().hashSetValues().build();
for (Pair trainPair : trainPairs) {
trainObjToSub.put(trainPair.objId, trainPair.subId);
trainSubToObj.put(trainPair.subId, trainPair.objId);
}
for (Pair validPair : validPairs) {
validObjToSub.put(validPair.objId, validPair.subId);
validSubToObj.put(validPair.subId, validPair.objId);
}
ExecutorService executors = new SemaphoredThreadPool(Settings.THREAD_NUMBER);
RuleWriter tempFileWriter = new RuleWriter(0, executors, tempFile, tempFileContents, true);
RuleWriter ruleFileWriter = new RuleWriter(0, executors, ruleFile, ruleFileContents, true);
Set<Rule> specializedRules = new HashSet<>();
try {
for (Rule rule : essentialRules) {
if(GlobalTimer.stopEssential()) break;
BlockingQueue<String> contents = new LinkedBlockingDeque<>();
Set<Future<?>> futures = new HashSet<>();
context.ruleFrequency.remove(rule);
Set<Pair> groundings = generateBodyGrounding(rule, graph);
Multimap<Long, Long> originalToTails = MultimapBuilder.hashKeys().hashSetValues().build();
Multimap<Long, Long> tailToOriginals = MultimapBuilder.hashKeys().hashSetValues().build();
for (Pair grounding : groundings) {
originalToTails.put(grounding.subId, grounding.objId);
tailToOriginals.put(grounding.objId, grounding.subId);
}
Multimap<Long, Long> trainAnchoringToOriginals = rule.isFromSubject() ? trainObjToSub : trainSubToObj;
Multimap<Long, Long> validAnchoringToOriginals = rule.isFromSubject() ? validObjToSub : validSubToObj;
for (Long anchoring : trainAnchoringToOriginals.keySet()) {
if(GlobalTimer.stopEssential()) break;
Collection<Long> validOriginals = validAnchoringToOriginals.get(anchoring);
futures.add(executors.submit(new CreateHAR(rule, anchoring, trainAnchoringToOriginals.get(anchoring)
, validOriginals, originalToTails.keySet()
, graph, contents, ruleFileContents, context)));
Set<Pair> candidates = new HashSet<>();
for (Long original : trainAnchoringToOriginals.get(anchoring)) {
if(GlobalTimer.stopEssential()) break;
for (Long tail : originalToTails.get(original)) {
if(GlobalTimer.stopEssential()) break;
Pair candidate = new Pair(anchoring, tail);
if (!candidates.contains(candidate) && !trivialCheck(rule, anchoring, tail)) {
candidates.add(candidate);
futures.add(executors.submit(new CreateBAR(rule, candidate, trainAnchoringToOriginals.get(anchoring)
, validOriginals, tailToOriginals.get(tail)
, graph, contents, ruleFileContents, context)));
}
}
}
}
for (Future<?> future : futures) {
future.get();
}
if(!contents.isEmpty()) {
specializedRules.add(rule);
rule.stats.compute();
tempFileContents.put("ABS: " + context.getIndex(rule) + "\t"
+ ((Template) rule).toRuleIndexString() + "\t"
+ f.format(rule.getStandardConf()) + "\t"
+ f.format(rule.getSmoothedConf()) + "\t"
+ f.format(rule.getPcaConf()) + "\t"
+ f.format(rule.getApcaConf()) + "\t"
+ f.format(rule.getHeadCoverage()) + "\t"
+ f.format(rule.getValidPrecision()) + "\n"
+ String.join("\t", contents) + "\n");
}
}
executors.shutdown();
executors.awaitTermination(1L, TimeUnit.MINUTES);
tempFileWriter.join();
ruleFileWriter.join();
} catch (Exception e) {
e.printStackTrace();
System.exit(-1);
}
GlobalTimer.updateGenEssentialStats(Helpers.timerAndMemory(s, "# Generate Essentials"));
Logger.println("# Specialized Essential Templates: " + f.format(specializedRules.size()) + " | " +
"Generated Essential Rules: " + f.format(context.getEssentialRules()), 1);
}设置数字格式,转换为美国数字的记录方式,并且只保留三位小数
NumberFormat(数字格式化类)_小池先生的博客-CSDN博客_numberformat

NumberFormat f = NumberFormat.getNumberInstance(Locale.US);
用GlobalTimer记录起始时间
GlobalTimer.setEssentialStartTime(System.currentTimeMillis());Essentialrule只保存非closed并且length=1的规则
context变量里存储了前面ruleFrequency的规则
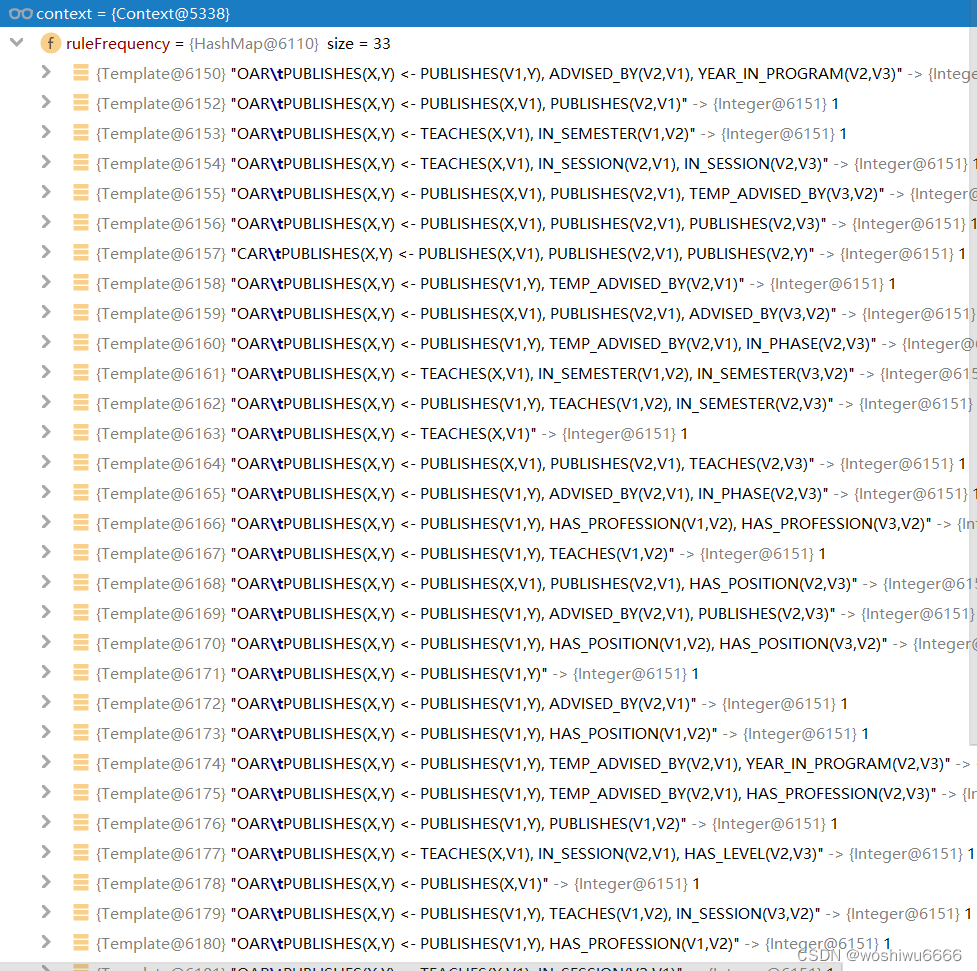
for (Rule rule : context.getAbstractRules()) {
if(!rule.isClosed() && rule.length() == 1)
essentialRules.add(rule);
}按不同的顺序存储规则
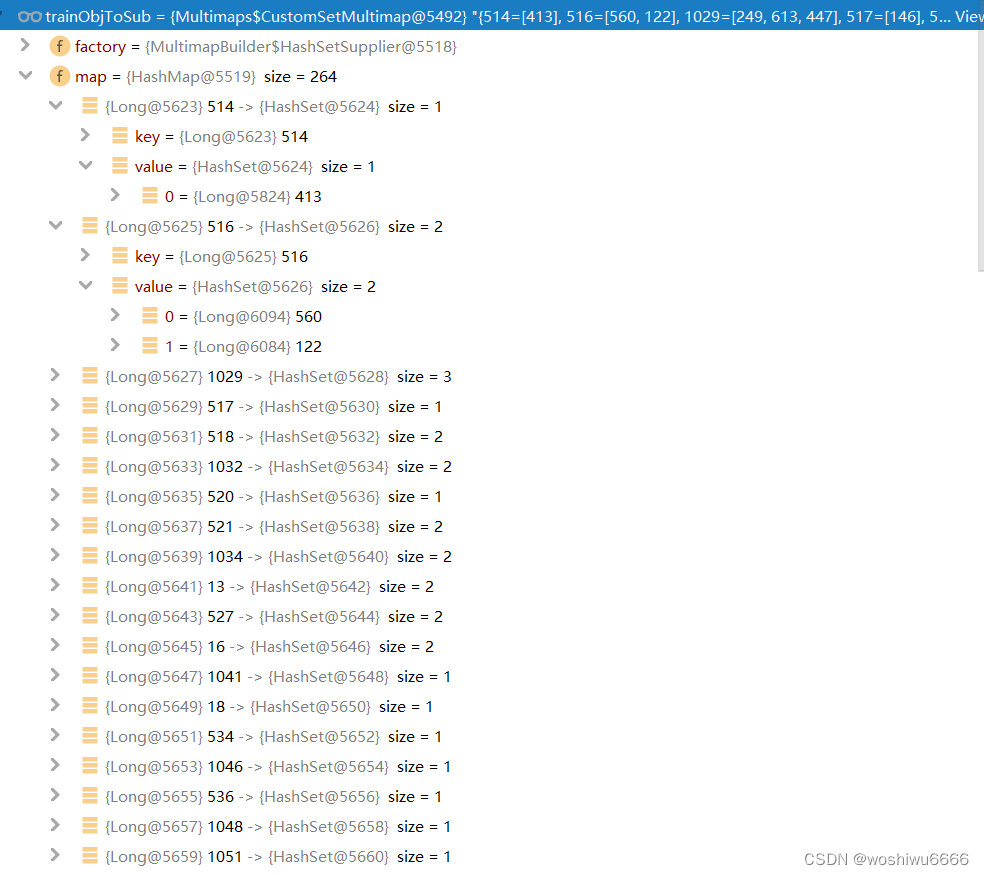
有sub左,obj右,也有sub右,obj左,其中ObjToSub与SubToObj的顺序是相反的
但值的注意的不管是ObjToSub或者是SubtoObj都包含了incoming和outgoing的规则
Multimap<Long, Long> trainObjToSub = MultimapBuilder.hashKeys().hashSetValues().build();
Multimap<Long, Long> validObjToSub = MultimapBuilder.hashKeys().hashSetValues().build();
Multimap<Long, Long> trainSubToObj = MultimapBuilder.hashKeys().hashSetValues().build();
Multimap<Long, Long> validSubToObj = MultimapBuilder.hashKeys().hashSetValues().build();
for (Pair trainPair : trainPairs) {
trainObjToSub.put(trainPair.objId, trainPair.subId);
trainSubToObj.put(trainPair.subId, trainPair.objId);
}
for (Pair validPair : validPairs) {
validObjToSub.put(validPair.objId, validPair.subId);
validSubToObj.put(validPair.subId, validPair.objId);
}
配置线程
ExecutorService executors = new SemaphoredThreadPool(Settings.THREAD_NUMBER);允许同时执行任务的最大线程数为6
Semaphore详解_JackieZhengChina的博客-CSDN博客_semaphore
并发编程 Semaphore的使用和详解_丽闪无敌的博客-CSDN博客_semaphore 使用详解
public SemaphoredThreadPool(int nThreads) {
super(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS
, new LinkedBlockingDeque<Runnable>(nThreads * 2));
semaphore = new Semaphore(nThreads);
}执行线程任务
RuleWriter tempFileWriter = new RuleWriter(0, executors, tempFile, tempFileContents, true);
RuleWriter ruleFileWriter = new RuleWriter(0, executors, ruleFile, ruleFileContents, true); RuleWriter(int id, ExecutorService service, File file, BlockingQueue<String> contents, boolean append) {
super("EssentialRule-RuleWriter-" + id);
this.id = id;
this.service = service;
this.file = file;
this.contents = contents;
this.append = append;
start();
}
@Override
public void run() {
try(PrintWriter writer = new PrintWriter(new FileWriter(file, append))) {
while(!service.isTerminated() || !contents.isEmpty()) {
String line = contents.poll();
if(line != null) {
writer.println(line);
}
}
} catch (IOException e) {
e.printStackTrace();
System.exit(-1);
}
}
}














 769
769











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









