







数位化快速发展的时代,人工智能(AI)已成为推动创新和技术进步的关键力量。市面上已经出现许多AI硬件平台,但开发者需要购买硬件才能够测试AI模型的推论速度。Qualcomm作为全球领先的无线技术创新者,近期推出Qualcomm AI Hub平台,提供开发者在未取得硬件的状况下针对AI模型优化和验证,平台会提供推论的时间及每一层执行的结果等资讯,以下就来介绍Qualcomm AI Hub平台吧。
►Qualcomm AI Hub平台介绍
Qualcomm于2024年2月发布Qualcomm AI Hub 平台,旨在为开发者提供优化和验证过的AI模型,以便在Snapdragon®和Qualcomm®设备上运行。这个平台不仅支持移动计算、汽车、物联网等多个领域,还提供一个强大的模型库,截至目前为止包括Whisper、ControlNet、Stable Diffusion和Baichuan 7B等超过109个热门AI模型,这些模型覆盖了视觉、音频和语音应用,并且已经在Qualcomm AI Hub、GitHub和Hugging Face上提供。
Qualcomm AI Hub的一大特色是其能够让开发者轻松部署这些AI模型到边缘设备上,这意味着开发者可以在几分钟内将他们的PyTorch模型部署到实际的托管设备上。这不仅大大缩短产品上市的时间,还能充分利用装置上AI带来的诸多优势,如即时性、可靠性、隐私性、个人化和成本节省等。
对于开发者而言,Qualcomm AI Hub提供了一个无缝整合AI模型到应用程式中的机会,这不仅有助于缩短开发周期,还能提升装置性能。高通通过其AI引擎(包括NPU、CPU和GPU)的硬体加速,实现推论速度的快速提升,模型提供TFLite、Qualcomm® AI Engine Direct(QNN)、ONNX。
此外,Qualcomm AI Research也在Android手机和Windows PC上展示了其大型语言和视觉助理(LLaVA)模型的功能。这是一款具有超过70亿个参数的大型多模态模型(LMM),能够处理文字、图像等多种类型的资料输入,并能生成关于图像的多轮对话。这项技术的应用前景非常广泛,从个人助理到语言翻译,都能够提供更加个性化和高效的服务。
►页面介绍
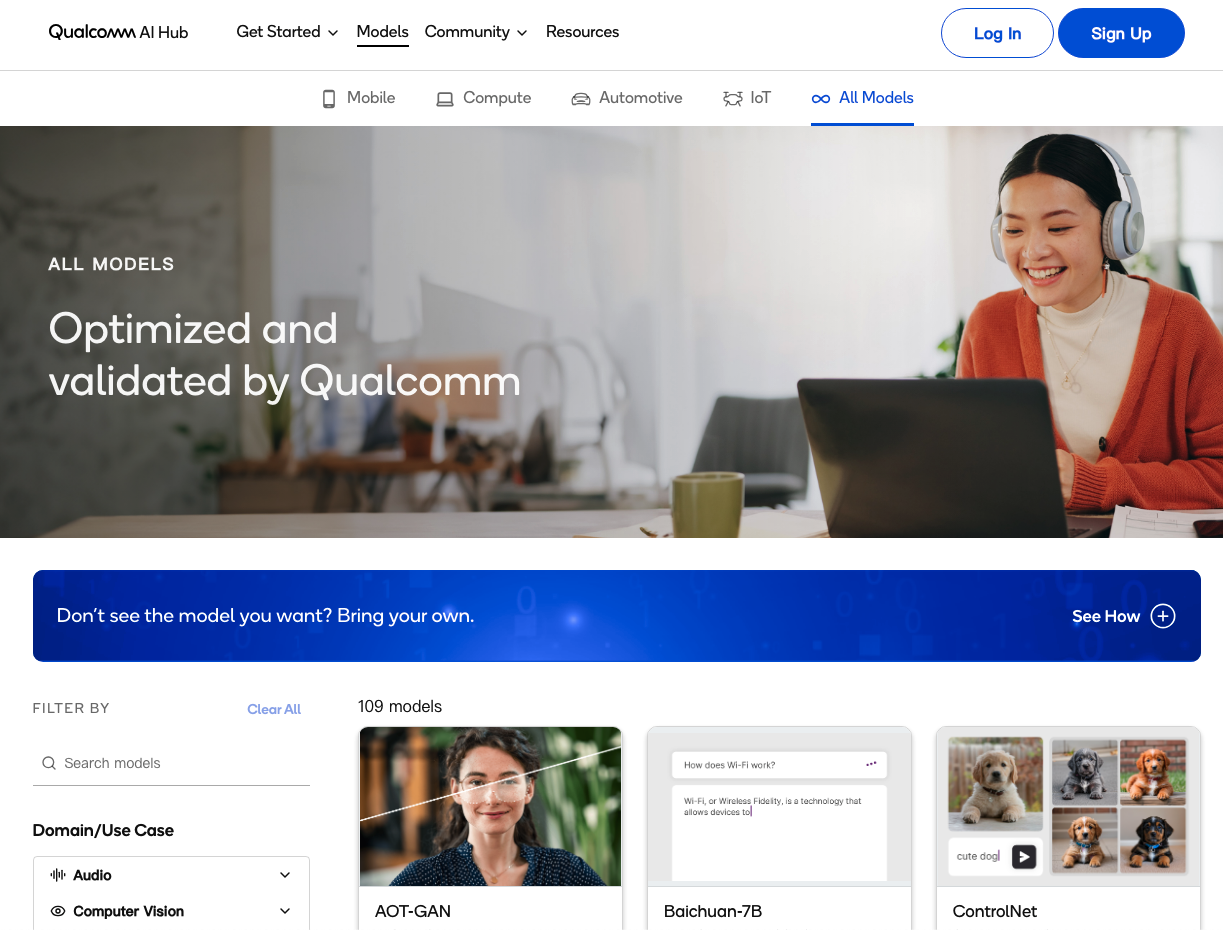
下图为主页面,目前区分4个领域的模型选单,包含Mobile、Compute、Automotive、IoT。
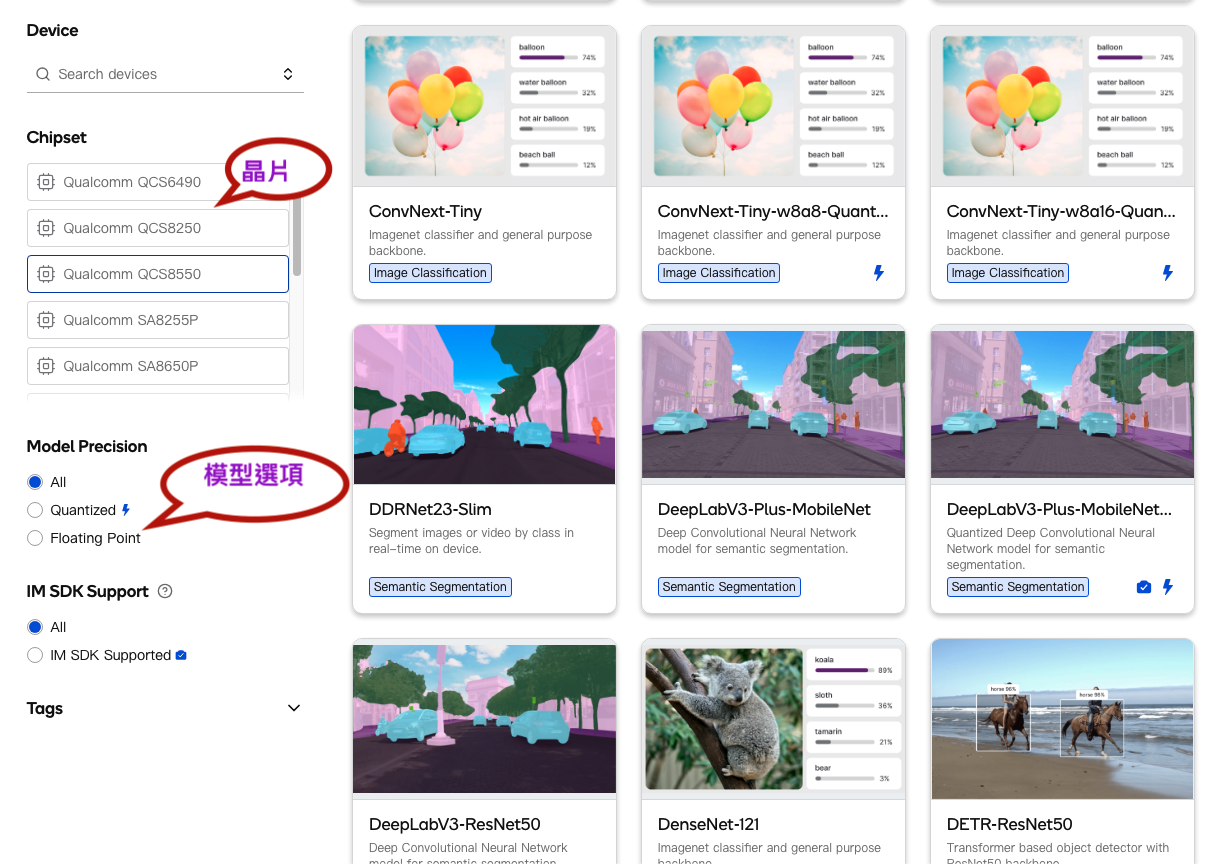
依据需求选择芯片及模型筛选,加快模型的找寻,如下图:
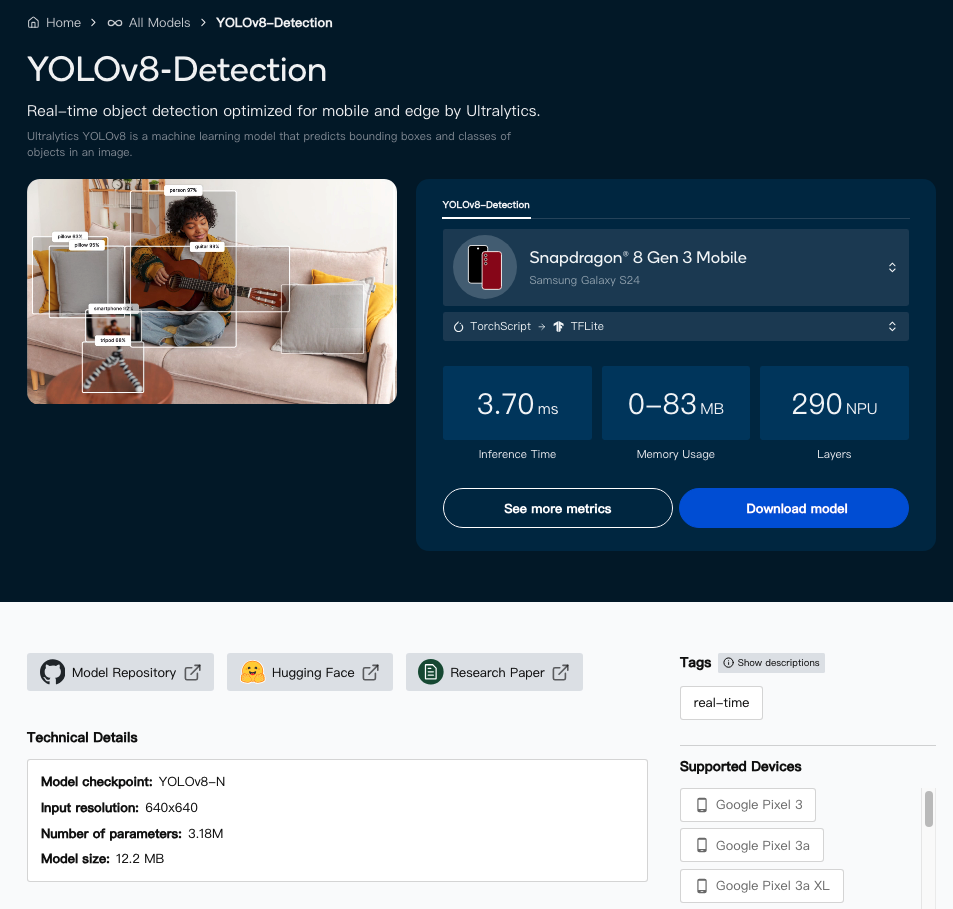
假如选择YOLOv8-Detection模型,点选后会进入此画面,分别提供推论装置、模型、推论时间、记忆体使用、NPU阶层数、模型大小及详细资讯等,如下图:
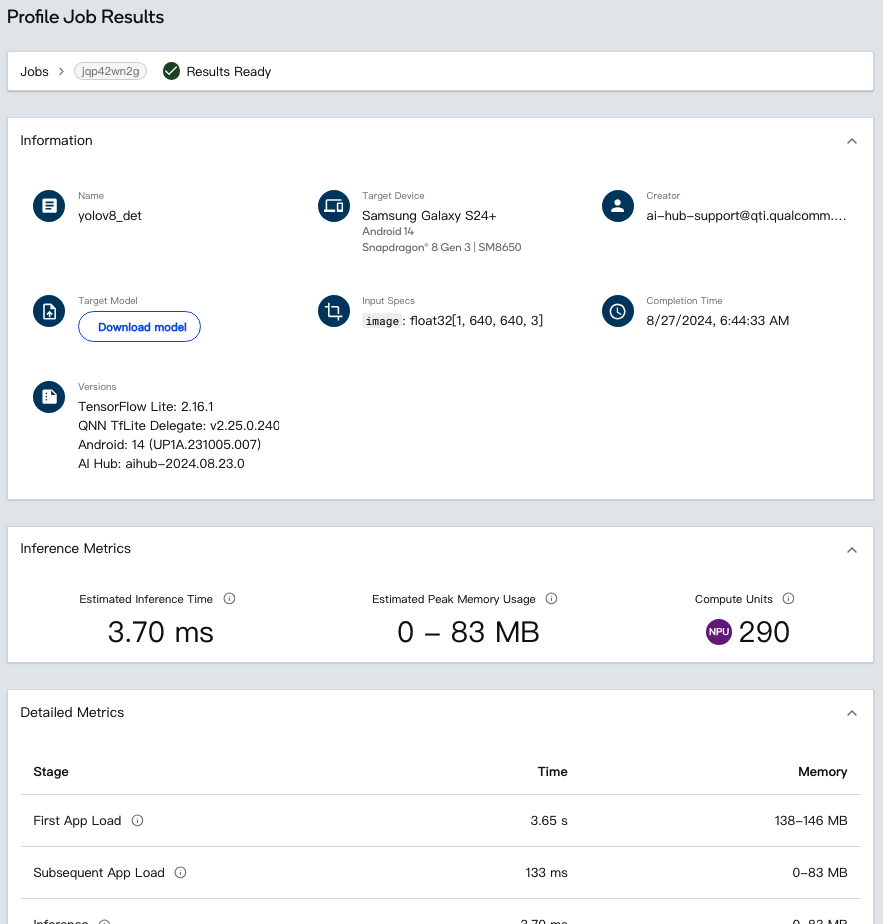
点选“See more metrics”按钮,如下图所示,该页面提供更详尽的资讯,包含详细指标、运行层分析及配置,AI模型开发者可以依照结果进行模型调整及量化,优化模型运行结果。
►Qualcomm AI Hub建立
第1步:Python环境
建议使用miniconda
Windows:安装完成后,从“开始”功能表开启 Anaconda Prompt。
macOS/Linux:安装完成后,开启一个新的 shell 视窗。
conda create python=3.8 -n qai_hub
conda activate qai_hub第2步:安装Python客户端
pip3 install qai-hub第 3 步:取得API Token
这部分需要先向高通签署NDA才能取得API Token,前往Qualcomm® AI Hub并使用您的 Qualcomm ID 登录,至Account -> Settings -> API Token。
步骤 4:设定 API 令牌
接下来,在终端机中使用以下命令使用 API 令牌配置客户端:
qai-hub configure --api_token [INSERT_API_TOKEN]透过上述的步骤,就已经安装完QAI Hub,接下来就是使用及测试:
列出可使用的装置
此Python程式码范例为过滤Samsung Galaxy S23及Android OS 13的装置:
import qai_hub as hub
devices = hub.get_devices(name="Samsung Galaxy S23 (Family)")
print(devices)
devices_os13 = hub.get_devices(os="13", attributes="os:android")
print(devices_os13)
除了使用Python程式码能查看之外,也可以使用CLI指令,而且会以列表显示,能够很清楚的查看到装置讯息,指令如下:
qai-hub list-devices --device-attr chipset:qualcomm-snapdragon-8gen2
►Qualcomm AI Hub模型编译、Profile及推论
下方为mobilenet_v2范例,需要下载mobilenet_v2.pt模型,可以使用指令或直接点选下载:
wget https://qaihub-public-assets.s3.us-west-2.amazonaws.com/apidoc/mobilenet_v2.pt范例装置使用msung Galaxy S23 (Family),当然也可以更换其他装置,需要在装置列表上找适合自己的装置做替换,透过下面的程式码范例就可以知道模型是否能够高通平台上执行,范例如下:
import qai_hub as hub
import numpy as np
# Compile a model
compile_job = hub.submit_compile_job(
model="mobilenet_v2.pt",
device=hub.Device("Samsung Galaxy S23 (Family)"),
input_specs=dict(image=(1, 3, 224, 224)),
)
assert isinstance(compile_job, hub.CompileJob)
# Profile the compiled model
profile_job = hub.submit_profile_job(
model=compile_job.get_target_model(),
device=hub.Device("Samsung Galaxy S23 (Family)"),
)
assert isinstance(profile_job, hub.ProfileJob)
# Inference the compiled model
sample = np.random.random((1, 3, 224, 224)).astype(np.float32)
inference_job = hub.submit_inference_job(
model=compile_job.get_target_model(),
device=hub.Device("Samsung Galaxy S23 (Family)"),
inputs=dict(image=[sample]),
)
assert isinstance(inference_job, hub.InferenceJob)
inference_job.download_output_data()
执行Python程式码,如果成功会显示SUCCESS,如下图:
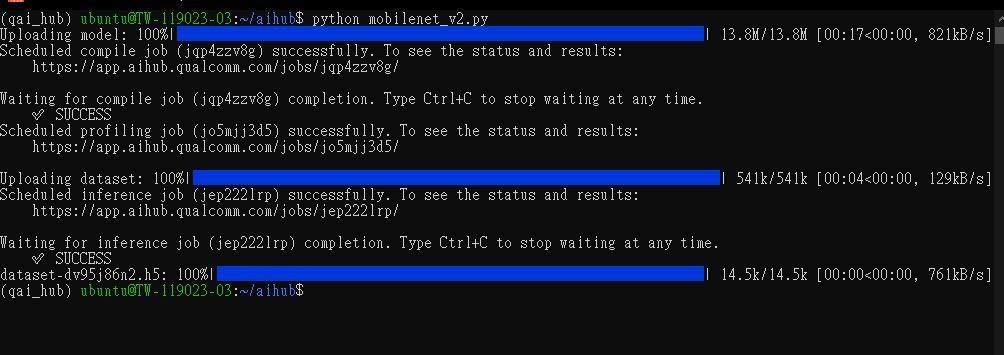
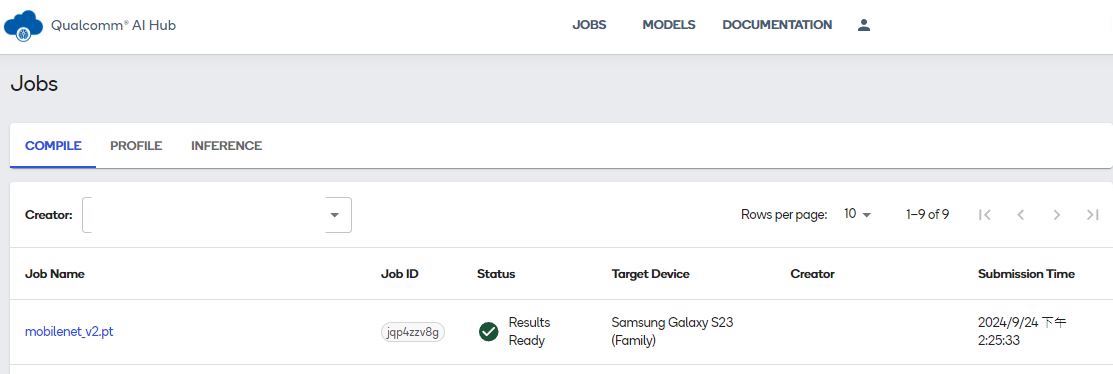
在官网上登入后台,即可看到刚刚执行的模型,包含COMPILE、PROFILE及INFERENCE,如果失败Status会显示失败的状态,如下图:
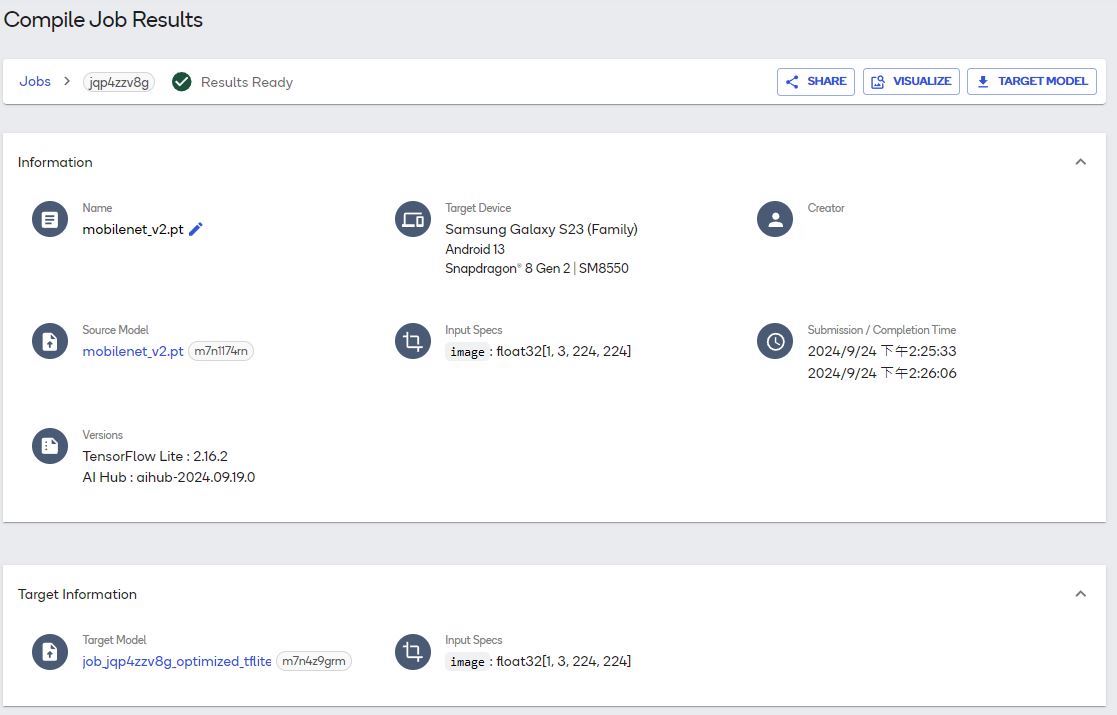
在COMPILE页面点选mobilenet_v2.pt即可查看详细资料,如下图:
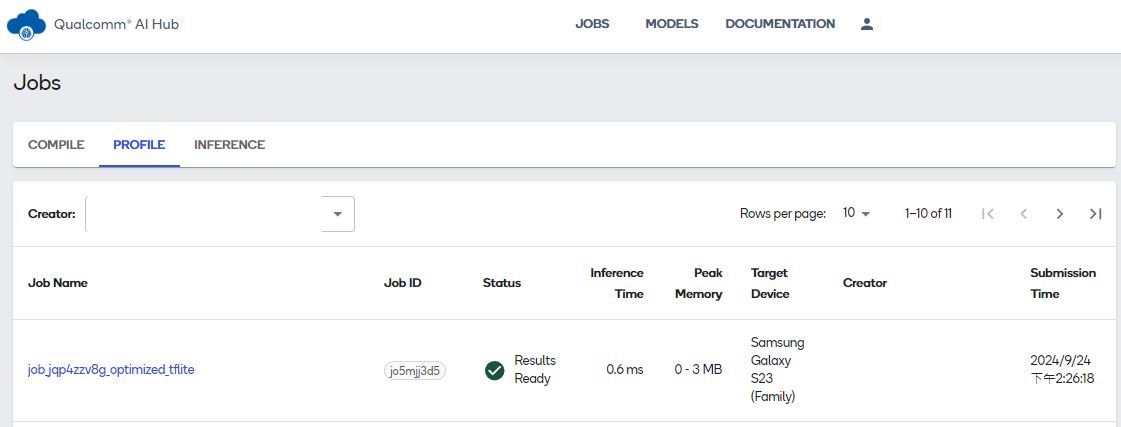
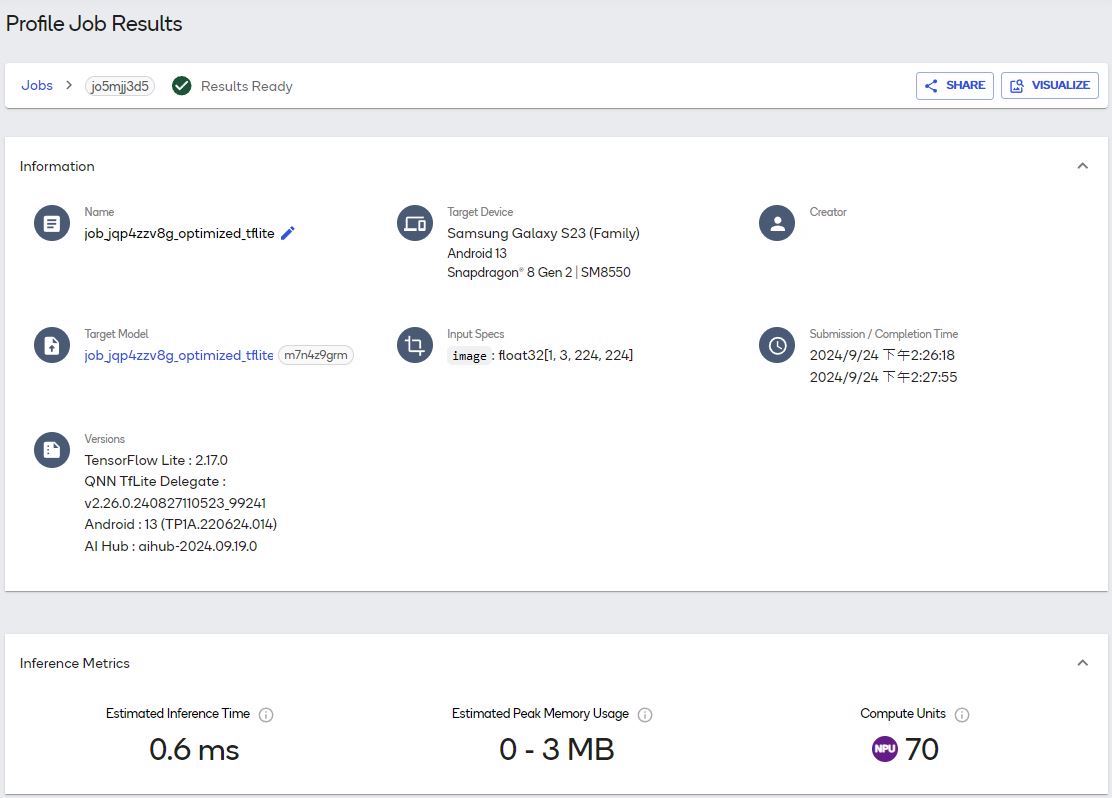
在PROFILE页面,则会看到转换完成的job.jqp4zzv8g_optimized.tflite及状态,如下图:
点选 “job.jqp4zzv8g_optimized.tflite”,即可查看详细状态,如下图:
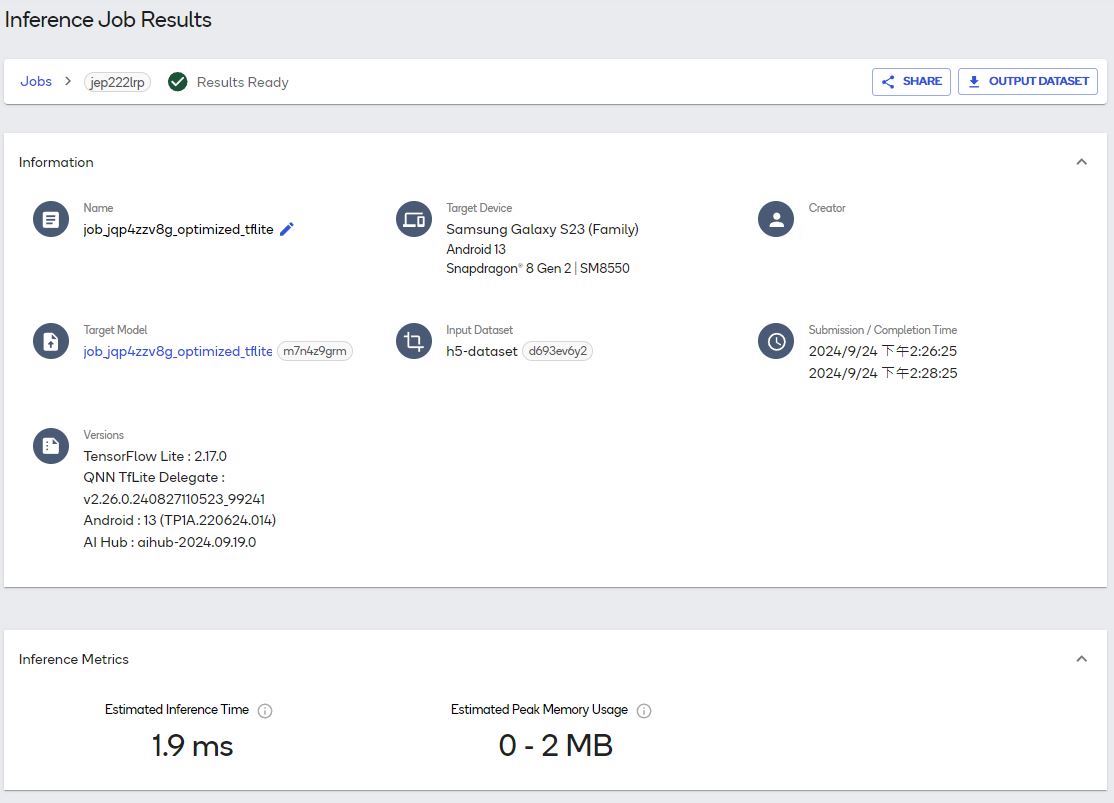
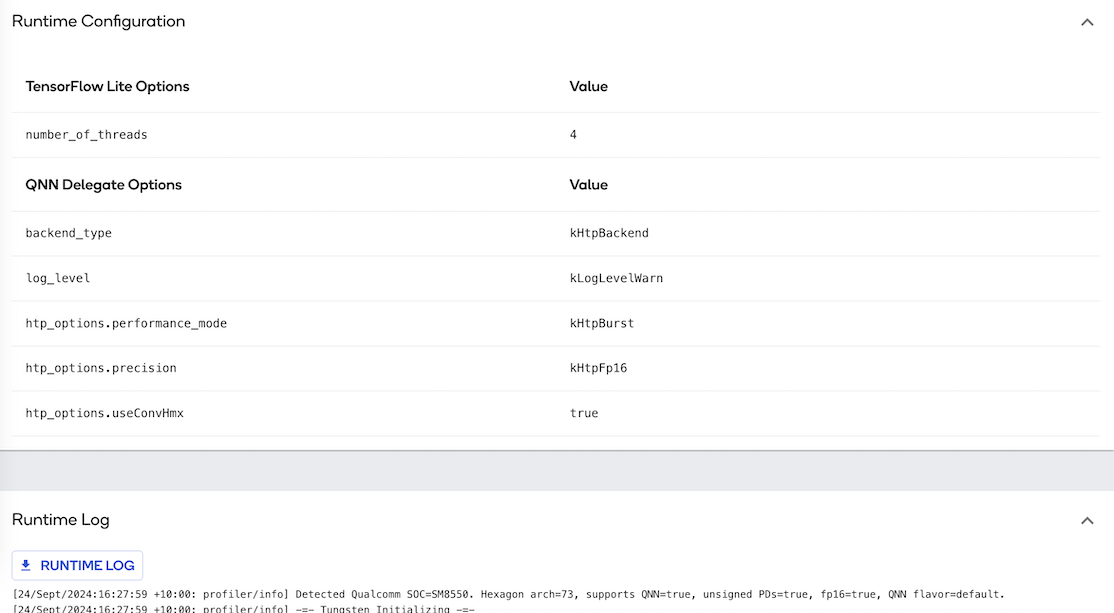
INFERENCE的主页面与PROFILE的主页面相同,但需要点进去查看详细资讯,内有推论的结果、Runtime Configuration及Runtime Log,如下图:
►小结
本篇博文就到这里,相信大家对于Qualcomm AI Hub平台有所了解,使用Qualcomm AI Hub能为开发者确认AI模型的正确性及推论速度,在未购买开发板的状况下确定AI模型是否能执行,根据实际需求选择开发板,让用户的开发专案能更贴近实际场景,高通持续优化产品及增加公开的AI模型,加速用户开发产品的时间,希望这篇博文对你有所帮助,谢谢你的阅读!。
►参考
►Q&A
问: Qualcomm AI Hub提供哪些类型的AI模型?
答: 提供多种针对视觉、音频和语音应用优化的开源AI模型,包括fp16和int8(量化)格式的模型,以支持各种装置上的即时AI体验。
问: 开发者如何使用Qualcomm AI Hub?
答: 开发者可以注册并登录Qualcomm AI Hub,从而运行、下载和部署模型。这些模型可以直接在搭载高通技术的真实设备上运行,加速上市时间并提高效率。
问: Qualcomm AI Hub如何支持装置上的AI?
答: 通过Qualcomm AI Stack支持在CPU、GPU或NPU上运行TensorFlow Lite、ONNX Runtime或Qualcomm® AI Engine Direct等工具,从而在Qualcomm设备上轻松部署优化的AI模型。
问: 开发者如何使用这些AI模型?
答: 开发者可以将这些模型无缝整合到他们的应用程式中,这有助于缩短产品上市时间,并充分利用装置上AI带来的即时性、可靠性、隐私性、个人化和成本节省等优势。
问: 开发者如何获得Qualcomm AI Hub的模型?
答: 开发者可以通过Qualcomm AI Hub、GitHub和Hugging Face等渠道获得这些模型,并可以在搭载高通平台的云端托管装置上运行这些模型。


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









