







Paper:https://ieeexplore.ieee.org/document/9434034
数据 + 代码:https://github.com/xingchenzhao/MixDANN
创新点:
目前网络的训练数据和测试数据需要遵循相同的分布,而目前可能所获得的医学数据很多情况都是来自不同的设备或者医院等。作者认为网络应该学习到domain invariance,从而在数据分布不同的情况下,模型具备较好的表现。应该属于 Domain Generalization。
数据集:
- a multi-site public MICCAI WMH Challenge Dataset [1] from three sites (Amsterdam (A), Singapore (S), Utrecht (U)
- 作者自己构建的数据集
算法:
网络整体框架:DANN(Domain Adversarial Neural Network)+ MixUp嵌入
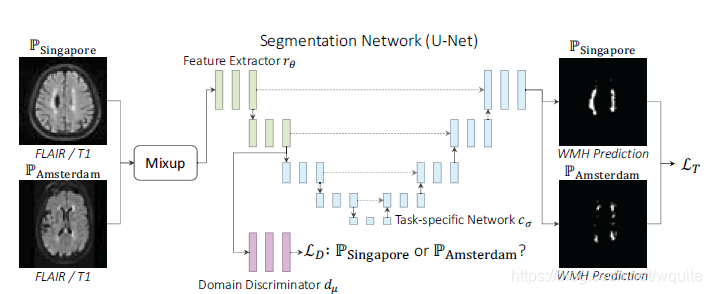
- DANN:
包括 Feature Extraction + Domain Generalization + Task-specific Network, 简单理解为UNet为backbone,加入了判别器进行domain invariance的判别。Feature Extraction为UNet的下采样部分,Task-specific Network为UNet的上采样部分。整体loss function定义,作者认为所定义的loss可以根据H-divergence来进行解释 :
-
最小化DANN的分割 loss
-
最大化Discriminator的 loss,这是由于Discriminator被设计用来对domain invariance进行判别,所以需要Discriminator不能判别出对应的domain,也就是需要max loss。
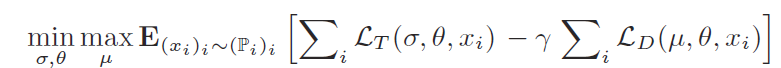 LT 作者所用为Dice Similarity Coefficient Loss
LT 作者所用为Dice Similarity Coefficient Loss -
Domain Generalization:应该是作者的核心创新点,前提是domain information是在网络刚开始的卷积层就可以被显著感知到,再借鉴于GAN的对抗生成的思想,引入判别domain invariance的Discriminator作为约束。
具体操作来说通过在UNet第二个下采样模块添加另一条路径进行全连接层(3层)(Discriminator),Discriminator 的loss function为cross entropy,定义为:
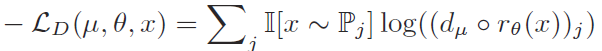
-
Discriminator利用Gradient Reversal Layer的方式进行梯度传导,简单理解为向负的梯度方向优化就是最大化目标函数
- MixUp:
数据增强操作,作者认为MixUp的操作也引入了domain invariance
- 举例来说是data augmentation包括类似添加noise 的操作,而训练带有noise的样本的目的是使得model去除noise的影响,作者认为这也是domain invariance的一部分
- 具体操作文章表述如下:
 此外,对于对应数据的标签也要做相同的mixup。
此外,对于对应数据的标签也要做相同的mixup。
个人认为,label方面有两个label,一个是分割所用的正常label,以及domain invariance所用的mixup的label














 5616
5616











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









