







文章目录
SqueezeNet
论文:SQUEEZENET: ALEXNET-LEVEL ACCURACY WITH 50X FEWER PARAMETERS AND <0.5MB MODEL SIZE
论文的目的在于在保证模型精度的情况下,尽量减少模型的参数。本文在此目的下提出了3条设计策略:
1)用1x1的卷积核代替3x3的卷积核
2)输入到3x3卷积层的feature map的通道数,从而减少3x3卷积层的参数量
3)在网络中推迟downsampling的位置,使得feature map(文中叫做activation)比较大
文章提出了Fire Module,包括两层:
1)squeeze layer:就是用1x1的卷积核压缩维度
2)expand layer:用1x1的卷积核和3x3的卷积核提取特征,扩展维度
这里就用了前两条设计策略。
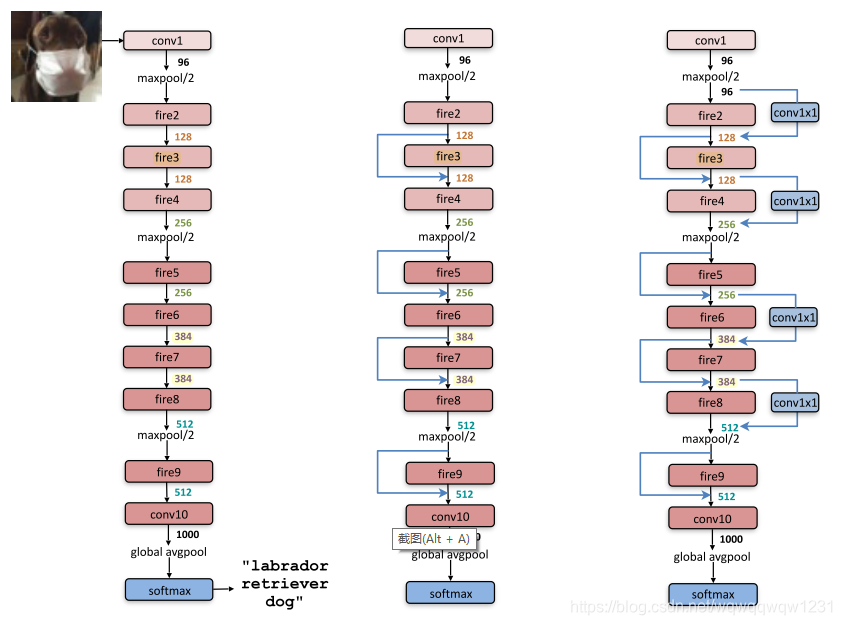
然后将Fire module堆叠起来,使用第3条策略,推迟down sampling,在feature map尺度适中的地方多加几个fire module,形成SqueezeNet,如下左图:
最后使用Deep compression的技术,将模型压缩到0.5M
在ablation study中,作者讨论了:
1)squeeze layer的kernel的数量
2)expand layer中1x1和3x3的比例
对结果的影响。
作者也做了类似于resnet的shortcut的连接,如上中图和上右图,发现隔层直接连接最好,不要加1x1的卷积核调整维度
最后,该文章的缺点,我认为这篇知乎讲的很好:

MobileNet
v1
论文:MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
相比于SqueezeNet,本文是在卷积层面进行了修改。本文提出了使用可分离卷积来代替传统卷积。可分离卷积已经有很多博客讲过了,总体思想就是:
首先对于输入的feature map的每个通道单独看待,把整个M个通道的feature map看做为M个1通道的feature map。每一个feature map配一个3x3的卷积核去处理,可以得到M个1通道的feature map。然后再使用具有N个M通道的1x1的卷积核对整个feature map改变维度,改变为N个通道。
这样子做的好处,可以减少参数量和计算量。计算量的减少比率如下:
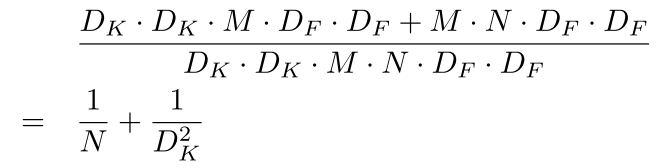
N是输出feature map的通道数,在[32,1024]变动, D k D_k Dk是卷积核的边长,就是3,所以减小的比率基本就是1/9。
文章还提出了Width Multiplier,就是每层feature map通道数变少,叫做thinner model,在ablation study中发现,thinner model要比浅层网络在差不多的计算量和参数量的情况下效果要好。
更好的是相比于SqueezeNet,计算量少,效果好。
It is also 4% better than Squeezenet [12] at about the same size and 22× less computation.
v2
贴个博客,我认为这个讲的很好。
这里记录一下我自己的想法。文章中的insight表示为下图:

低维空间中的兴趣流型先转到n维空间做relu再转回来,当n小的时候,信息丢失的就比较多。
那么,如果想要兴趣流行保持在低维空间中,本文构造module,先用1x1升维,relu;然后再用3x3做分离卷积提取特征,做relu;然后再用1x1降维到低维空间。既然relu在低维空间做会丢失信息,索性最后一个1x1之后就不用relu了。本文叫做linear bottleneck。
然后再加入ResNet的计算残差的shortcut,新module就成了Res module。但新module不同于ResNet中的输入输出tensor维度高,中间维度低,本文中形成的是中间tensor维度高,输入输出维度低。所以叫做Inverted Residuals。
然后把这些module串联起来,就形成了MobileNetv2.
ShuffleNet
v1
论文:ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
我对于ShuffleNet的理解是联系了ResNeXt和MobileNetv1的。
先说说ResNeXt和MobileNet:ResNeXt和MobileNetv1都是对3x3的那个卷积层做了计算量的缩减。ResNeXt是将3x3进行了分组卷积,而MobileNetv1则更彻底,提出了可分离卷积,实际上ResNeXt的分组,每组只有1
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1839
1839











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









