






SCINet 论文笔记✍
📅发表时间:2022
🔢期刊会议:NIPS
🎯方向分类: TS Forecasting
⚙️ 做了什么:
对时间序列进行下采样,对每个子序列使用多个卷积核进行特征提取,之后再进行聚合。以多个时间分辨率迭代地提取交换信息,加入交互式学习来补偿下采样过程中的信息损失
🔨 解决了什么问题:
给定一个时间序列X*和长度为T的时间窗口,在时间戳t处基于前T个时间步预测τ个时间步
🔬 现状不足
传统模型方法
ARIMA和Holt-winters
更适用于单变量数据,没有深度学习方法表现好
RNNs方法
存在梯度消失和梯度爆炸的问题
Transformer-based方法
得益于其对长序列的建模能力主要用于长期预测
TCN方法(本文)casual convolution && dilated conventional
①每层共享一个卷积核,无法提取复杂的时间动态
②靠近输入的层感受野受到限制会导致时间关系丢失
✨ 创新点
考虑时间序列的独特属性:下采样之后时间序列的趋势、季节性等时间关系很大程度上得到保留
👩🏻💻 模型架构

SCI-Block
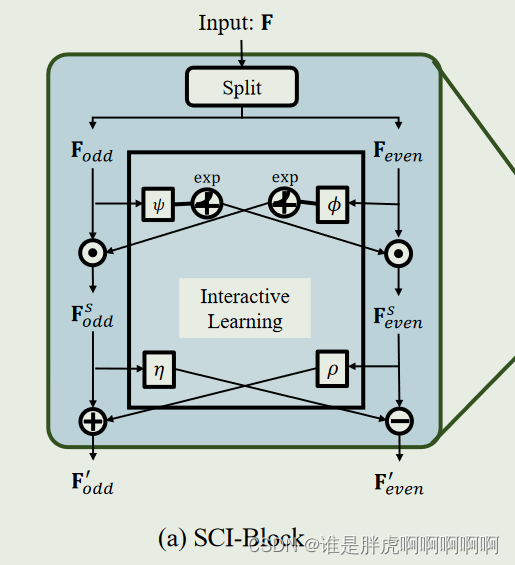
分开之后各自经过1D卷积核进行指数平滑,再和原先分开后的矩阵进行对应元素相乘得到Fsodd和Fseven 之后再次加(减)上另一个通过卷积核的序列,
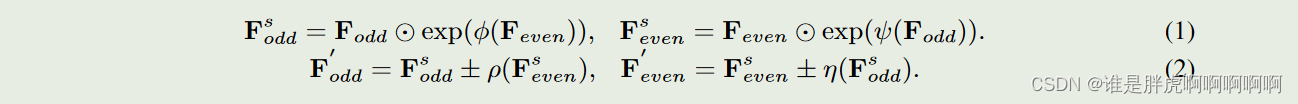
四个卷积核的结构如下:
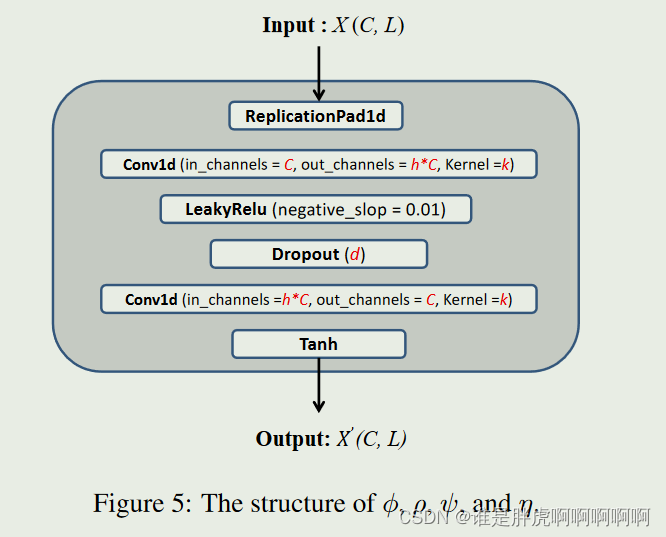
SCINet
以SCIBlock为节点的二叉树,所有的下采样-卷积-交互操作完成后,将得到的低分辨率数据反转奇偶分裂操作重排连接成为一个新的序列,并进行残差连接后送入全连接层进行解码得到最后的特征/预测(取决于SCINet在堆叠结构中的位置)
从采样频率来看,类似于做了两次有规律的下采样操作。SCINet采用树状结构来嵌套这些SCIBlock,在第L 层有 2l−1 个SCIBlock。则在经过 l 层的采样之后,共会得到 2L 个子序列。然后,由于这些序列的长度都只会有原始序列的 1/2L ,因此在采用concat操作拼接后总序列长度和原始序列是相等的。有趣的是,新序列的每个点是可以与原始序列的每个点一一对应的,因此可以采用Realign来调整新序列的拼接方式,使两者一致。例如输入一个短序列 {x1,x2,x3,x4,x5,x6,x7,x8} ,经过两层的采样后,会得到四个子序列 {x1∗,x5∗} 、 {x3∗,x7∗} 、 {x2∗,x6∗} 和 {x4∗,x8∗} 。则重新排列后可以获得数据增强的新序列 {x1∗,x2∗,x3∗,x4∗,x5∗,x6∗,x7∗,x8∗} ,这个序列中每个数据都包含了其他数据的交互信息,会有更强的可预测性。这种一一对应的特点使所采用的残差模块更为合理
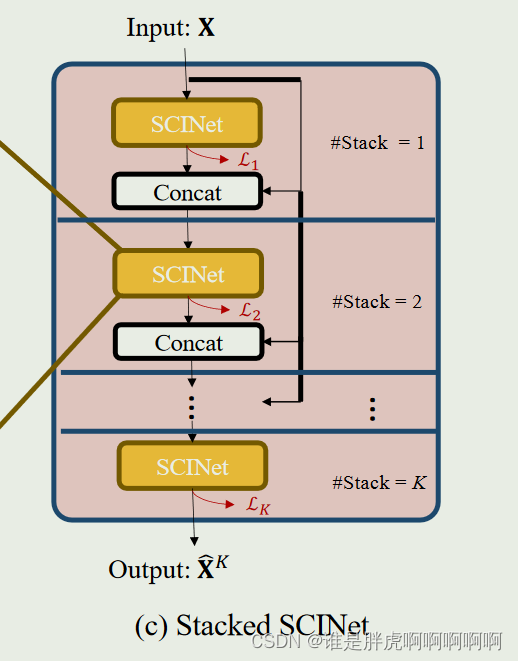
Stacked SCINet
通过中继监督对SCINet进行堆叠,能够提取复杂的时间动态。这里的concat操作是将预测长度补长至输入长度也就是时间窗口的长度。
在隐藏层中加了辅助的分类器,作为网络分支对主干网络进行监督。如果直接对整个网络进行梯度下降,输出层的误差经过多层反向传播会大幅减小出现梯度消失的问题。为了解决此问题,在每个阶段的输出上都计算损失,保证底层参数正常更新,从而解决网络随着深度增加出现的梯度消失问题。
复杂度分析
SCINet 的计算成本通常与 TCN 架构的计算成本相当。最坏情况的时间复杂度为 O(T log T ),远低于基于 Transformer 的普通解决方案:O(T 2)。
损失函数
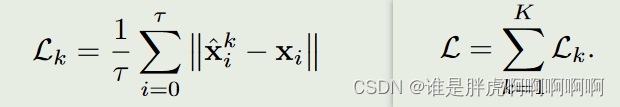
🙋♀️ Experiments
Data sets

Results && Analysis
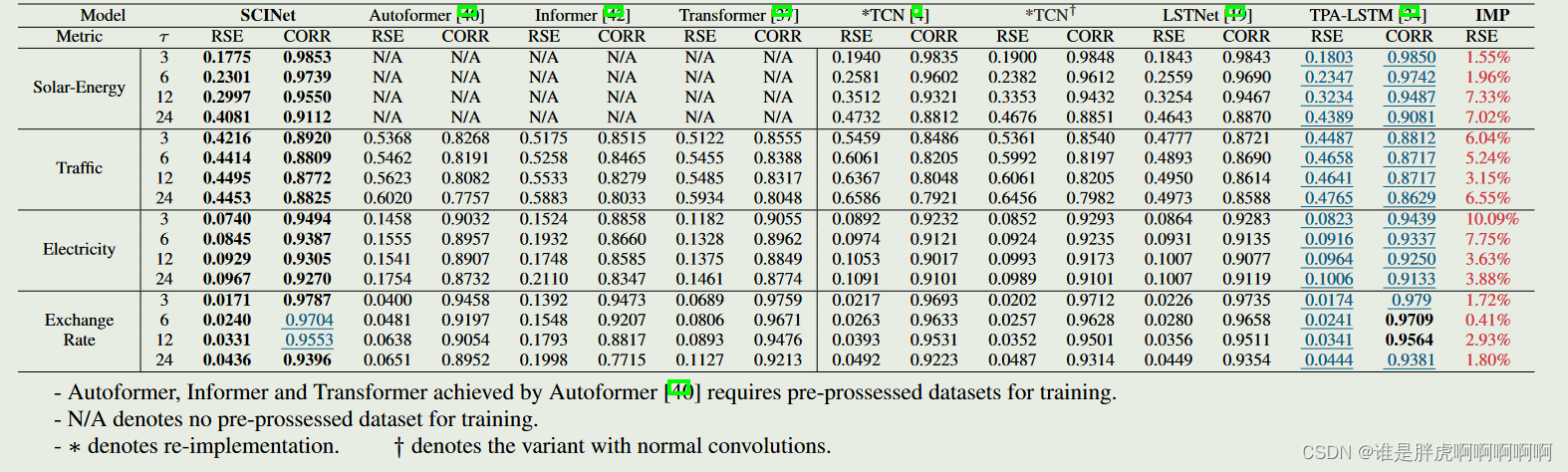
Short-term Time Series Forecasting:
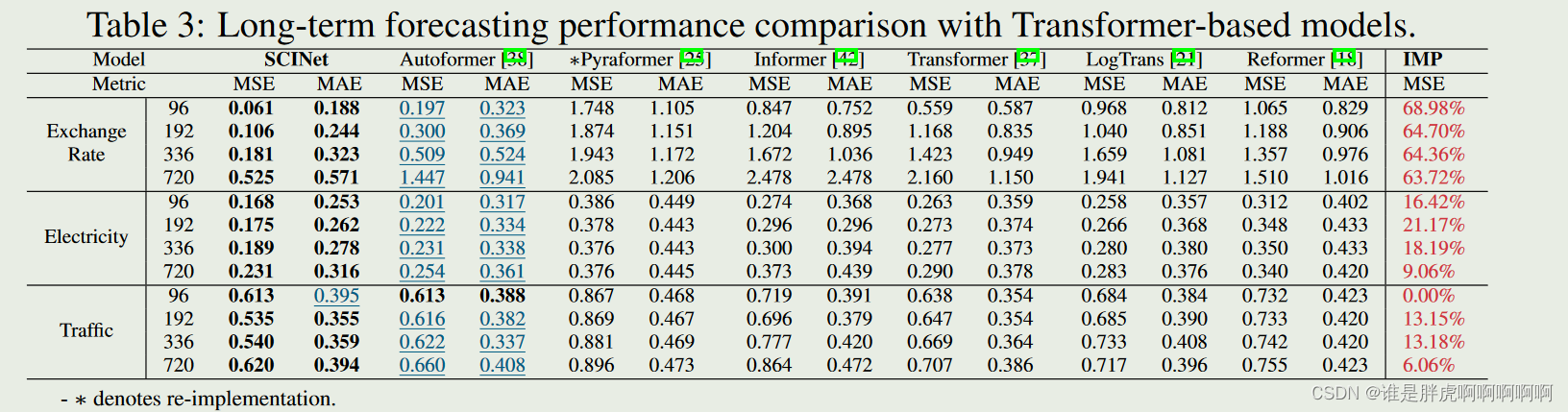
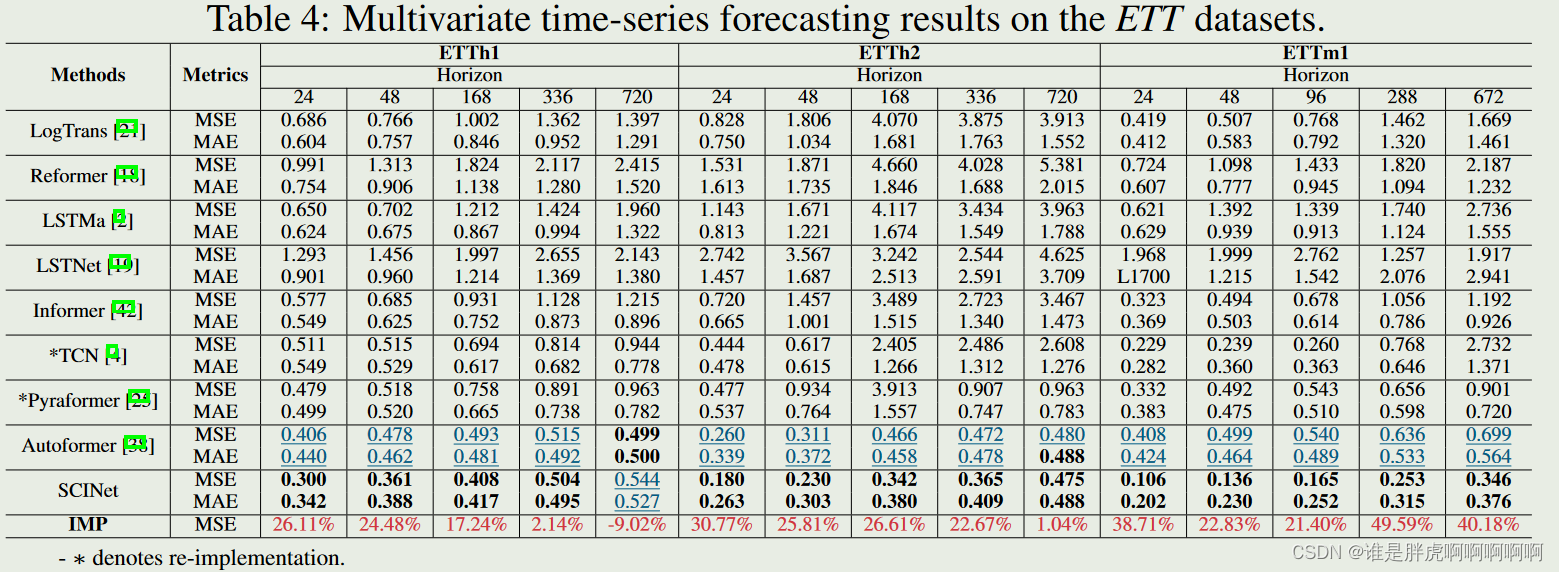
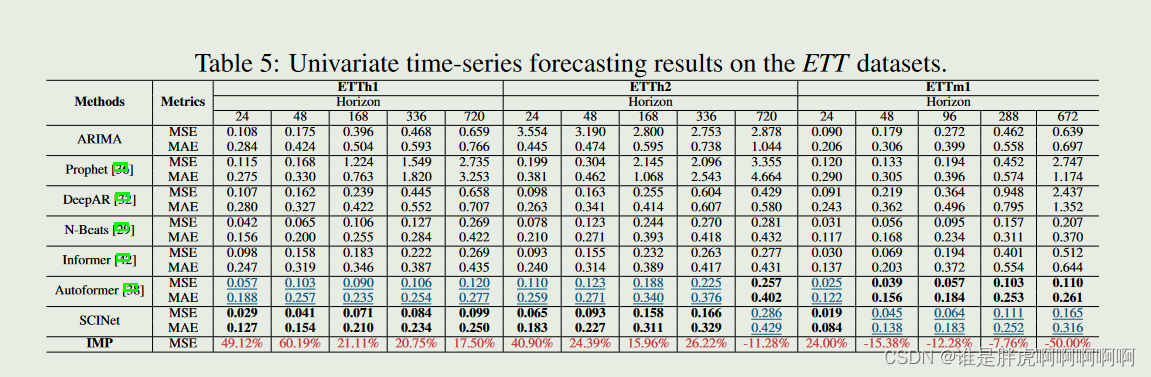
Long-term Time Series Forecasting:
Spatial-temporal Time Series Forecasting:
















 2465
2465

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









