









paper: https://arxiv.org/pdf/1805.02023.pdf
code:https://github.com/jiesutd/LatticeLSTM
前言
NER(命名实体识别)是信息抽取的一个基础任务,常用的做法是character-based和word-based,其中基于字符的方法是每个字符会输出一个实体标签,它的缺点是不能利用字与字之间的信息;而基于词的方法是每个词会输出一个实体标签,会受到分词的影响,而且更容易出现OOV的情况。
而且《Chinese named entity recognition and word segmentation based on character》、《Chinese named entity recognition with a sequence labeling approach: based on characters, or based on words?》、《Comparison of the impact of word segmentation on name tagging for Chinese and japanese.》这三篇论文都说明了character-based方法要优于word-based方法,那有没有一种方法可以把这两种方法结合呢?有,最近NER模型词汇增强方法之一的LatticeLSTM就是。在介绍这个模型之前,我们先简单回顾一下之前的模型。
首先介绍一下符号,一个句子可以表示为每个字符的序列,如s = c1,c2,...,cm,同样也可以表示为每个词的序列,如s = w1,w2,...,wn,那么可以使用t(i,k)表示第i个词的第k个字符。
基于字符和基于词模型
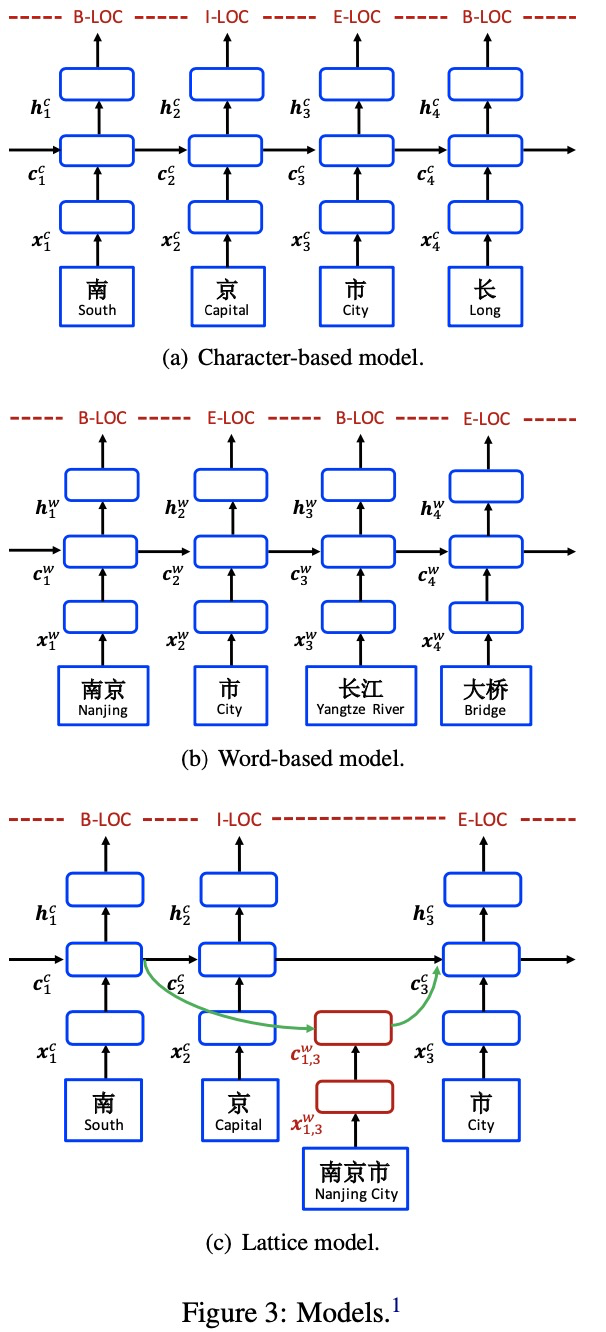
1、Character-Based Model
1)Char + bichar
xcj = [ec(cj ); eb(cj , cj+1)],把当前字符和当前字符与下一个字符的词向量拼接起来。
2)Char + softword
xcj = [ec(cj);es(seg(cj))],seg(cj)表示的label的词向量,如果一个词包括两个字符,那么这两个字符的seg(cj)应该是一样的。
2、Word-Based Model
1)Word + char LSTM
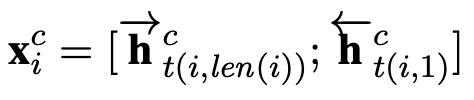
通过双向拼接词的最后一个字符的隐藏向量来表示词向量
2)Word + char LSTM′
使用标准的biLSTM进行拼接每个字符的词向量
3)Word + char CNN
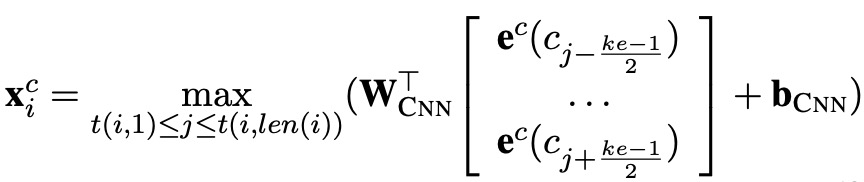
采用卷积的方式来捕获词的字符信息,比如一个词有3个字符,卷积窗口为2,那么可以进行两次卷积,了解CNN的朋友,很容易理解的,然后使用maxpooling。
LatticeLSTM模型介绍
前面算是“开胃菜”,哈哈,主菜马上就来。
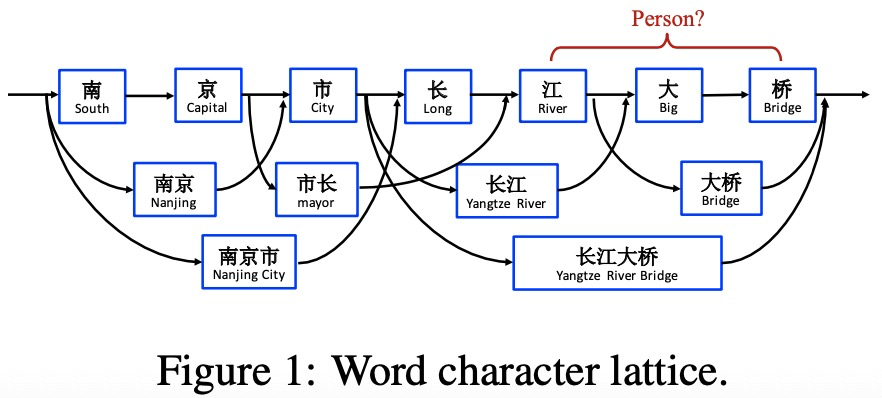
LatticeLSTM通过引入词汇的信息可以排除“江大桥”是人名所产生的歧义。序列中每个字符之间都可能会组合成相应的词汇,但是如果枚举所有的可能,这么这个是序列长度的指数级复杂度,LatticeLSTM是通过引入外部词典,并且使用门控机制来进行动态选择词汇和融入词汇信息来实现。
首先每个字符会使用下面lookup table方式使用向量表示
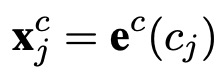
再介绍一下标准的LSTM的公式,相信很多人都非常清楚了,符合的含义我这里也不解释了。下面是基于字符的LSTM结构
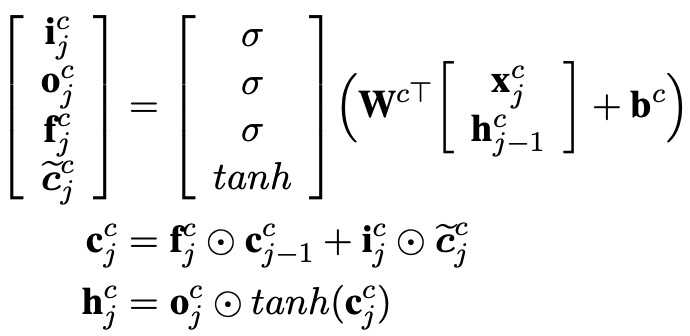
句子序列可以通过和外部词典匹配到所有可能的词,然后使用某种词向量(比如word2vec等等)方式来映射为词向量,如下图
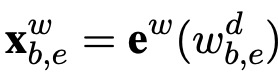
其中b和e表示词在句子中的索引。下面是基于词的LSTM结构
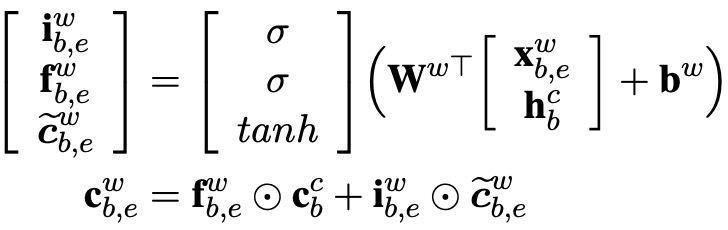
由于序列的label是字符级别的输出,所以词的LSTM是不需要输出门的。
LatticeLSTM是考虑词典中以当前字符结尾的所有可能词,那么有可能会出现多个词,比如“南京市长江大桥”中的字符“桥”,那么在字典中可能会出现“大桥”和“长江大桥”两个词,那么多个词是如何引入的呢?看下面的公式
通过上面的公式计算出每个字符以及以该字符结尾的词的权重,代入到下面的公式进行加权求和
最后使用下面的公式来更新隐藏状态(不使用标准LSTM中的
 )
)

解码就是标准的CRF,公式如下:
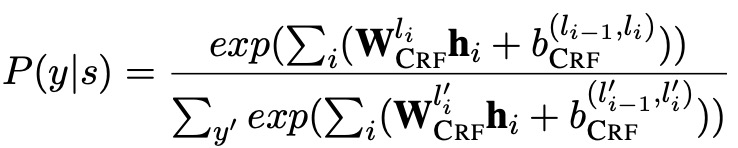
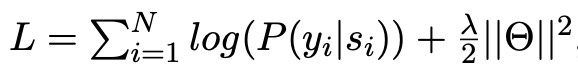
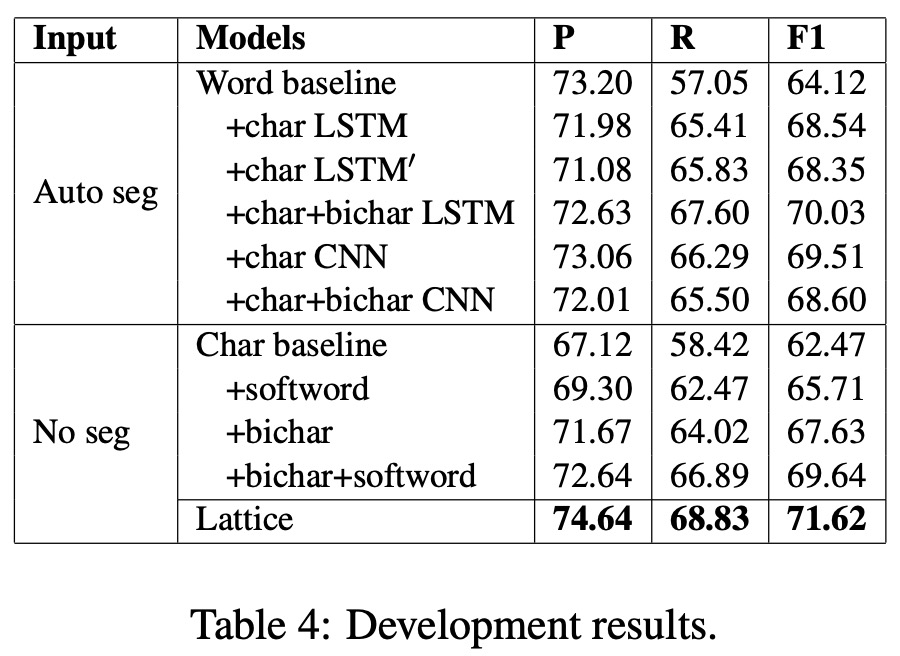
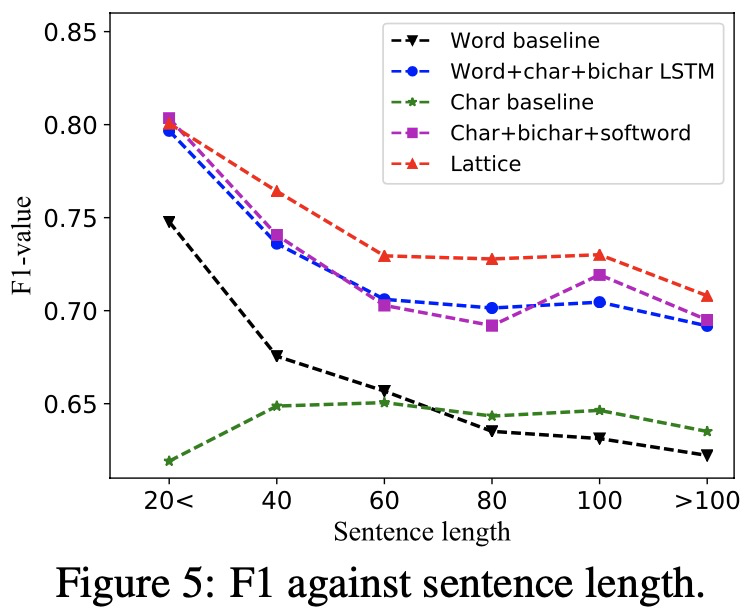
LatticeLSTM模型实验
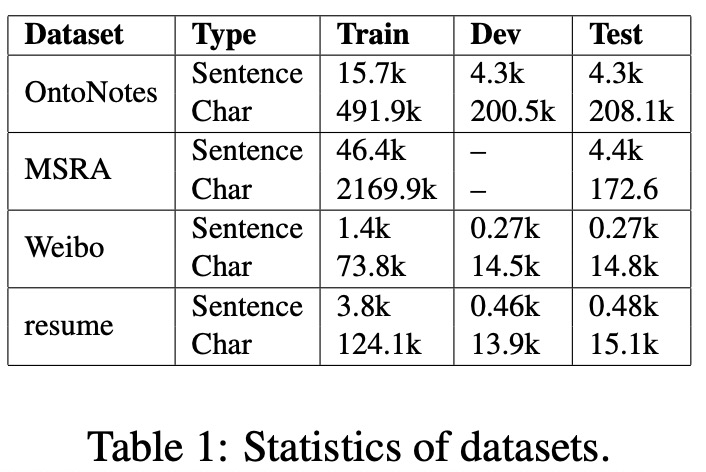
1、数据集
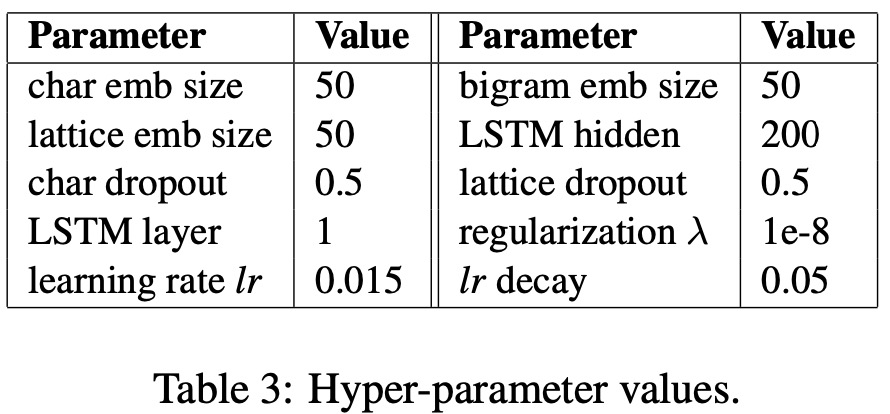
2、模型超参数
3、实验结果
LatticeLSTM不足之处
1、计算性能差,不能batch并行化(原因是每个句子中词的数量不一致);
2、存在信息损失,只能利用词结尾的信息;
3、可迁移性差,只能使用LSTM;
4、模型复杂度高,句子不能太长
















 3849
3849











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











