










论文地址:https://research.facebook.com/file/1574548786327032/LLaMA--Open-and-Efficient-Foundation-Language-Models.pdf
介绍
LLaMA,是Meta AI最新发布的一个从7B到65B参数的基础语言模型集合。在数以万亿计的token上训练模型,并表明有可能完全使用公开的数据集来训练最先进的模型,而不需要求助于专有的和不可获取的数据集。LLaMA-13B在大多数bechmark上超过了GPT-3(175B),而LLaMA-65B与最好的模型Chinchilla70B和PaLM-540B相比具有竞争力。
核心结论
-
LLaMA 是一个开源的基础语言模型集合,参数范围从7B到65B,完全使用公开的数据集在数万亿 Token 上训练;
-
LLaMA-13B 在大多数基准上都优于 GPT-3(175B),而模型大小却小了 10 倍以上,LLaMA-65B 与最好的模型 Chinchilla70B 和 PaLM-540B 性能相当;
-
该研究表明,通过完全在公开可用的数据上进行训练,有可能达到最先进的性能,而不需要求助于专有的数据集,这可能有助于努力提高鲁棒性和减轻已知的问题,如毒性和偏见;
-
向研究界发布LLaMA模型,可能会加速大型语言模型的开放,并促进对指令微调的进一步研究,未来的工作将包括发布在更大的预训练语料库上训练的更大的模型。
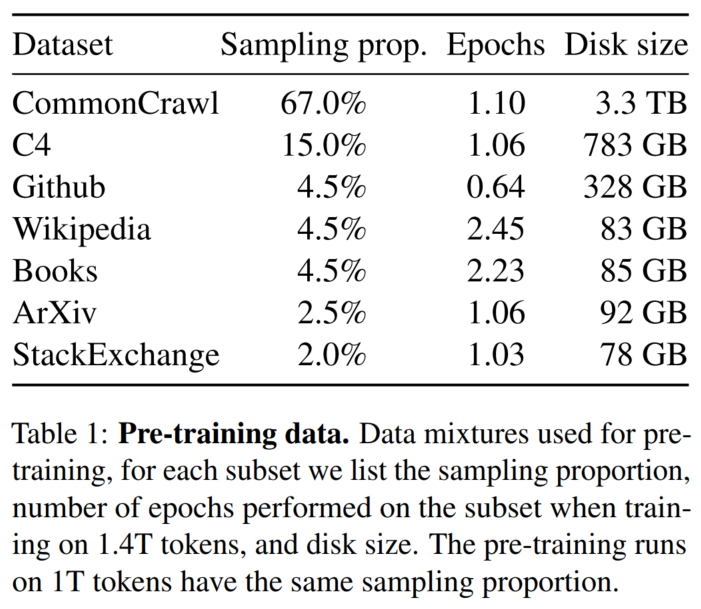
预训练数据
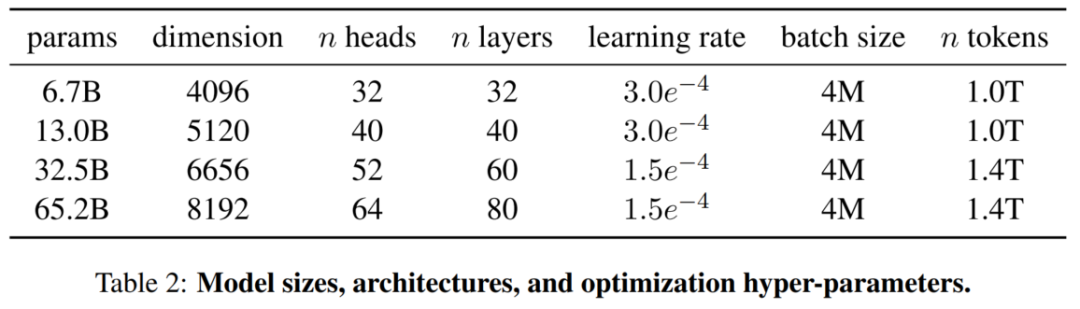
模型的架构与参数
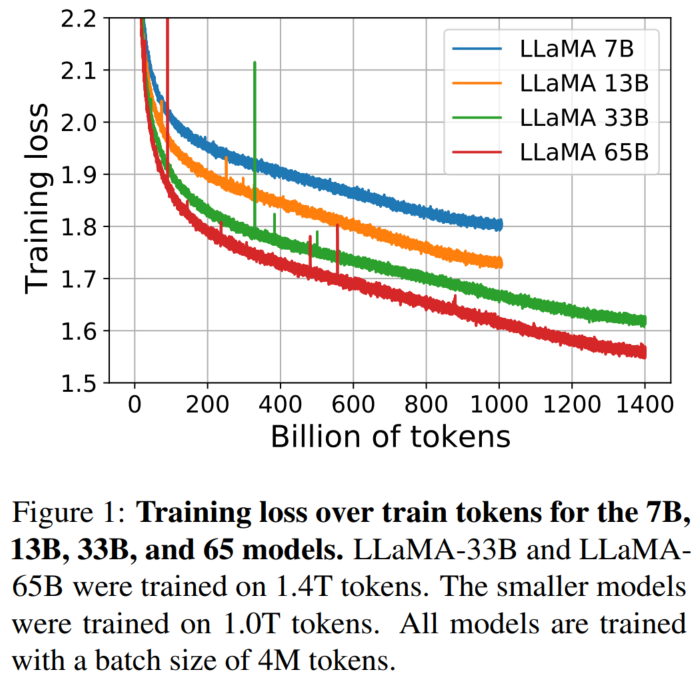
模型的性能
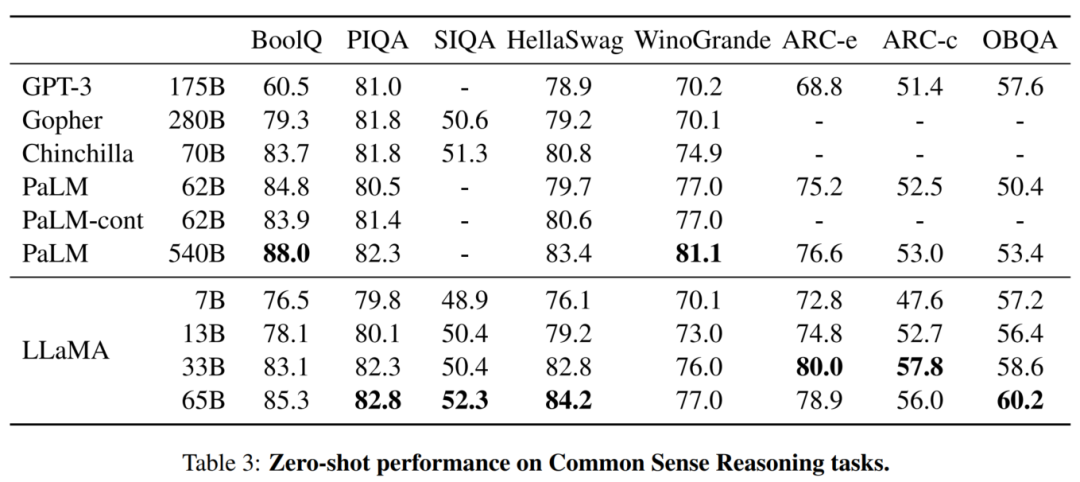
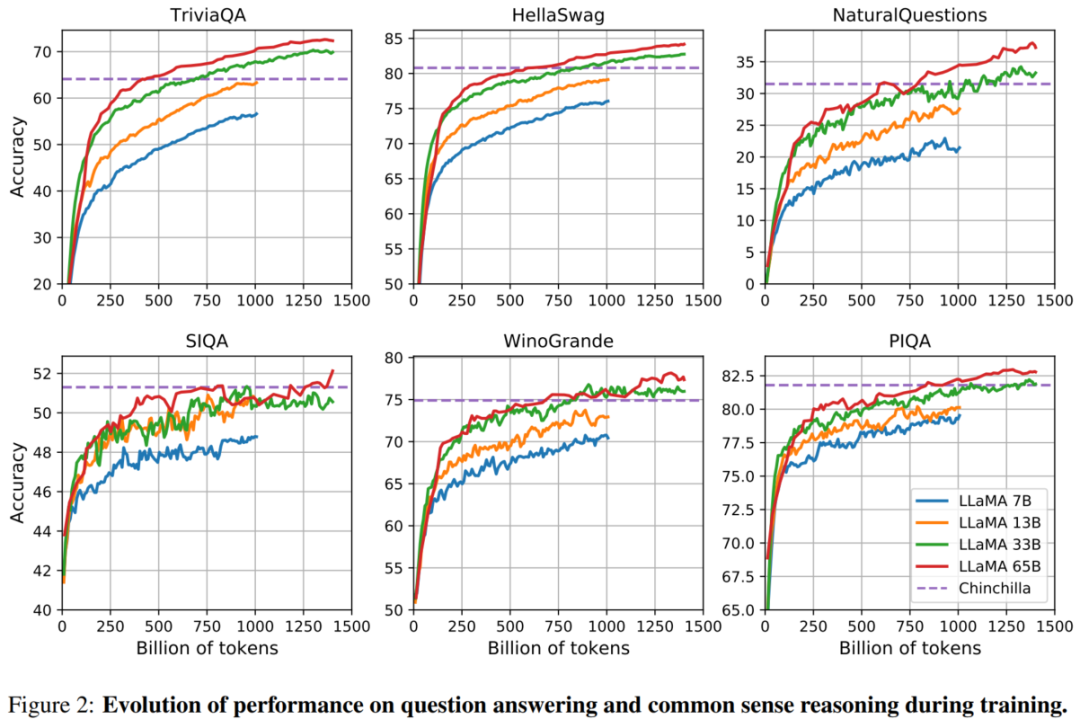
结果评估
1、在常识推理、闭卷答题和阅读理解方面,LLaMA-65B几乎在所有基准上都优于Chinchilla-70B和PaLM-540B;
2、在数学方面 ,尽管LLaMA-65B没有在任何相关的数据集上进行过微调,但它在在GSM8k上的表现依然要优于Minerva-62B。而在MATH基准上,LLaMA-65B超过了PaLM-62B,但低于Minerva-62B;
3、值得注意的是,谷歌开发的Minerva模型,是以PaLM语言模型为基础,并采用大量的数学文档和论文语料库对其进行微调。在思维链提示和自洽解码的加持下,Minerva-540B可以在各类数学推理和科学问题的评估基准上达到SOTA;
4、在代码生成基准上 ,LLaMA-62B优于cont-PaLM(62B)以及PaLM-540B。此外, Meta还尝试使用了论文「Scaling Instruction-Finetuned Language Models」中介绍的指令微调方法。由此产生的模型LLaMA-I,在MMLU上要优于Flan-PaLM-cont(62B),而且还展示了一些有趣的指令能力。
参考文献:
[1] https://hub.baai.ac.cn/view/24411


















 5433
5433

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











